A Novel Evidence Theory and Fuzzy Preference Approach-Based Multi-Sensor Data Fusion Technique for Fault Diagnosis

Abstract
:1. Introduction
2. Preliminaries
2.1. Dempster–Shafer Evidence Theory
2.2. Distance of Pieces of Evidence
2.3. Belief Entropy
2.4. Fuzzy Preference Relations
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- for all , where and .
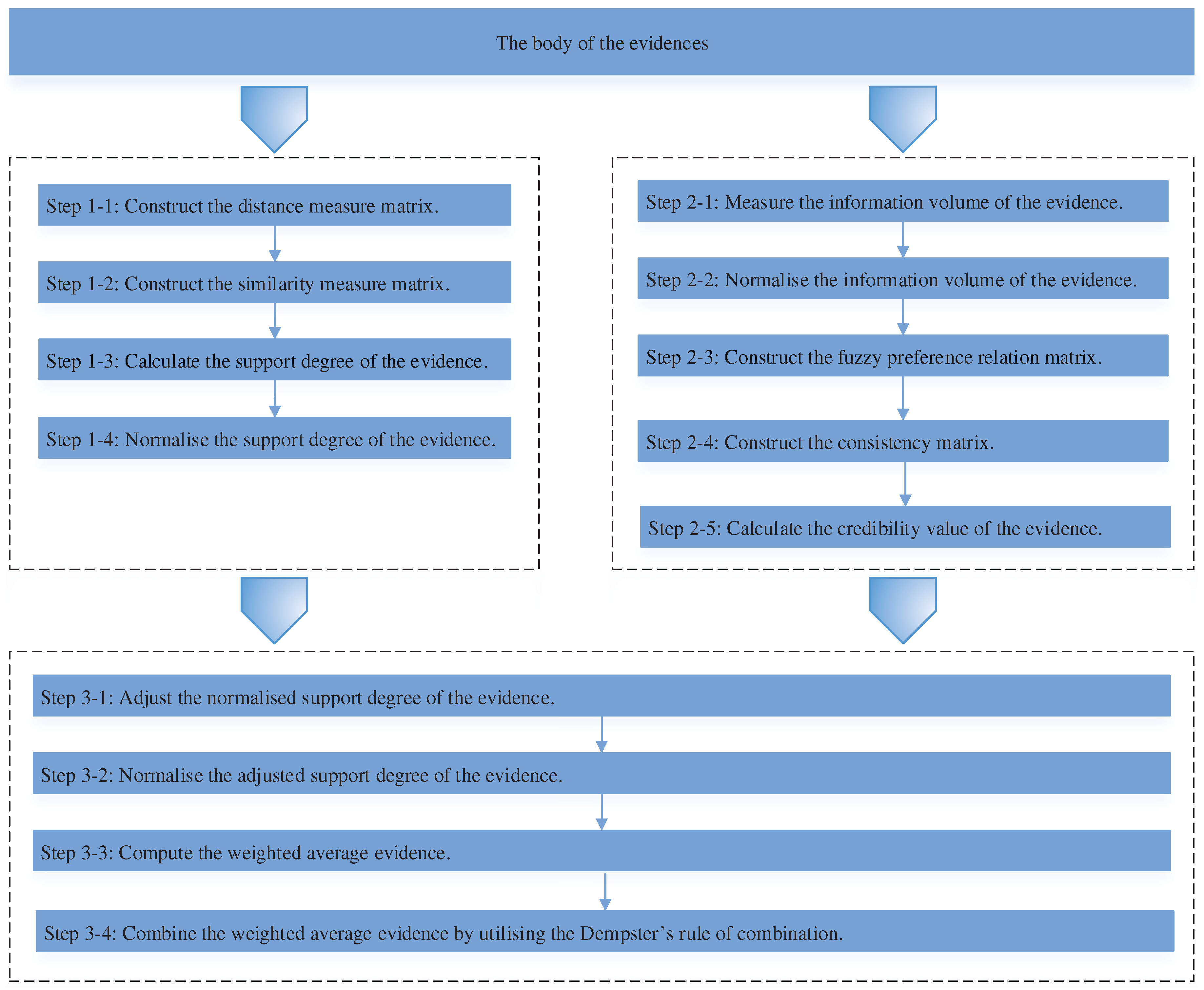
3. The Proposed Method
3.1. Calculate the Support Degree of the Evidence
- Step 1:
- Step 2:
- The similarity measure between the BPAs and can be obtained by:Then, the similarity measure matrix can be constructed as follows:
- Step 3:
- The support degree of the BPA is defined as follows:
- Step 4:
- The support degree of the BPA is normalized as below, which is denoted as :
3.2. Generate the Credibility Value of the Evidence
- Step 1:
- The belief entropy of the BPA ) is calculated by leveraging Equation (11).Because the belief entropy of the evidence may be zero in a certain case, in order to avoid allocating zero weight to such kinds of evidence, we utilize the information volume for measuring the uncertainty of the BPA as below:
- Step 2:
- The information volume of the BPA is normalized as below, which is denoted as :
- Step 3:
- The fuzzy preference relation matrix , where can be constructed by the following steps:
- Step 3-1:
- According to Definition 6, the diagonal element is assigned to 0.5.
- Step 3-2:
- If there are only two pieces of evidence, all of the off-diagonal elements and will be assigned to 0.5, because we have no sufficient evidence to detect how the pieces of evidence are preferred with respect to each other. Thus, the fuzzy preference relation matrix can be constructed by:
- Step 3-3:
- If there are more than two pieces of evidence, the variance of entropy for the BPA will be calculated as follows:
- Step 3-4:
- The smaller the value has, the more conflict the evidence has in the decision-making system, so that a small preference value is supposed to be assigned to this evidence. Otherwise, the bigger the value has, the less conflict the evidence has in the decision-making system, so that a big preference value is supposed to be assigned to this evidence. On the basis of the above variance of entropy, the off-diagonal elements and will be computed by Equations (27) and (28) introduced in [79].where and .
- Step 4:
- Based on the obtained fuzzy preference relation matrix , the consistency matrix can be constructed by Equation (16).
- Step 5:
- With the consistency matrix , the credibility value of the BPA is defined based on Equation (17):We can notice that . Hence, the credibility value of each piece of evidence is regarded as a weight that indicates the relative credibility preference in terms of the evidence.
3.3. Fuse the Weighted Average Evidence
- Step 1:
- Based on the credibility degree , the normalized support degree of the BPA will be adjusted, denoted as :
- Step 2:
- The is normalized as below, denoted as , which is considered as the final weight of the BPA .
- Step 3:
- On the basis of the final weight , the weighted average evidence can be obtained as follows:where k denotes the number of BPAs and represents the i-th BPA, which are modeled from the sensor reports.
- Step 4:
- The weighted average evidence is combined through Dempster’s combination rule, namely Equation (7), by times, if there are k number of pieces of evidence. Then, the final combination result of multiple pieces of evidence can be obtained.
4. Experiment
- Step 1:
- Construct the distance measure matrix as follows:
- Step 2:
- Construct the similarity measure matrix as follows:
- Step 3:
- Calculate the support degree of the BPA as below:
- = 2.4551,
- = 1.0716,
- = 2.7689,
- = 2.8239,
- = 2.8055.
- Step 4:
- Normalize the support degree of the BPA as follows:
- = 0.2059,
- = 0.0899,
- = 0.2322,
- = 0.2368,
- = 0.2353.
- Step 5:
- Measure the information volume of the BPA as below:
- = 4.7894,
- = 1.5984,
- = 6.1056,
- = 6.6286,
- = 5.8767.
- Step 6:
- Normalize the information volume of the BPA as follows:
- = 0.1916,
- = 0.0639,
- = 0.2442,
- = 0.2652,
- = 0.2351.
- Step 7:
- Construct the fuzzy preference relation matrix as follows:
- Step 8:
- Construct the consistency matrix as follows:
- Step 9:
- Calculate the credibility value of the BPA as below:
- = 0.2395,
- = 0.0749,
- = 0.2312,
- = 0.2198,
- = 0.2345.
- Step 10:
- Adjust the normalized support degree of the BPA based on the credibility value as below:
- = 0.0493,
- = 0.0067,
- = 0.0537,
- = 0.0521,
- = 0.0552.
- Step 11:
- Normalize the adjusted support degree of the BPA as below:
- = 0.2273,
- = 0.0310,
- = 0.2474,
- = 0.2399,
- = 0.2543.
- Step 12:
- Compute the weighted average evidence as below:
- = 0.5213,
- = 0.1606,
- = 0.0713,
- = 0.2469.
- Step 13:
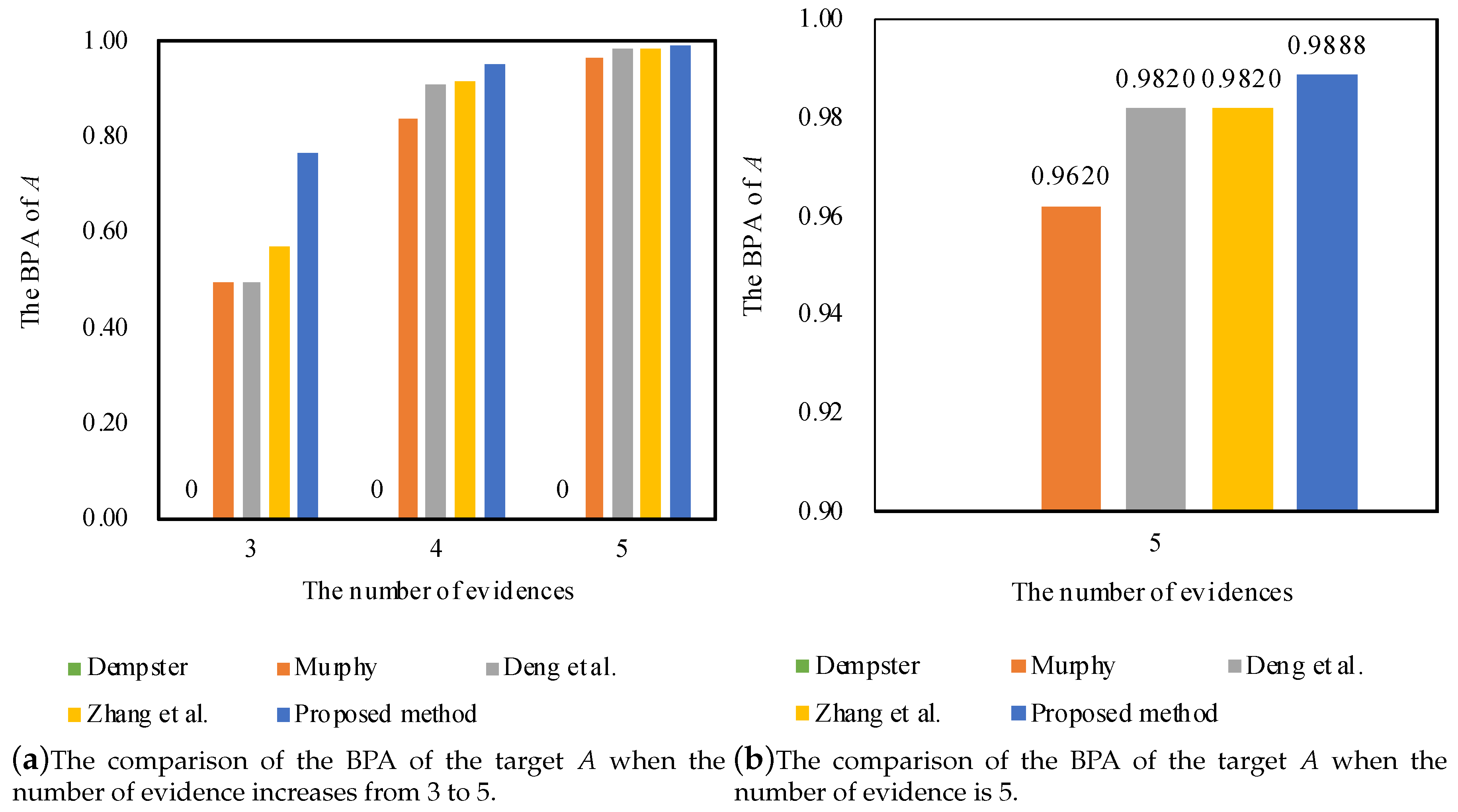
- Combine the weighted average evidence by utilizing Dempster’s rule of combination four times. The results of the combination for the first time are shown below:
- = 0.8066,
- = 0.0393,
- = 0.0614,
- = 0.0929.
For the combination for the second time, the results are listed as follows:- = 0.9239,
- = 0.0087,
- = 0.0362,
- = 0.0317.
Next, the results of the third combination are calculated as:- = 0.9701,
- = 0.0019,
- = 0.0184,
- = 0.0105.
Then, the combination results of the fourth time, namely the final fusing results, are produced as follows:- = 0.9888,
- = 0.0004,
- = 0.0087,
- = 0.0034.
5. Application
5.1. Problem Statement
5.2. Motor Rotor Fault Diagnosis Based on the Proposed Method
5.2.1. Motor Rotor Fault Diagnosis at Frequency
- = 0.5636,
- = 0.0006,
- = 0.0782,
- = 0.3576.
- = 0.8095,
- = 0.0004,
- = 0.0621,
- = 0.1280.
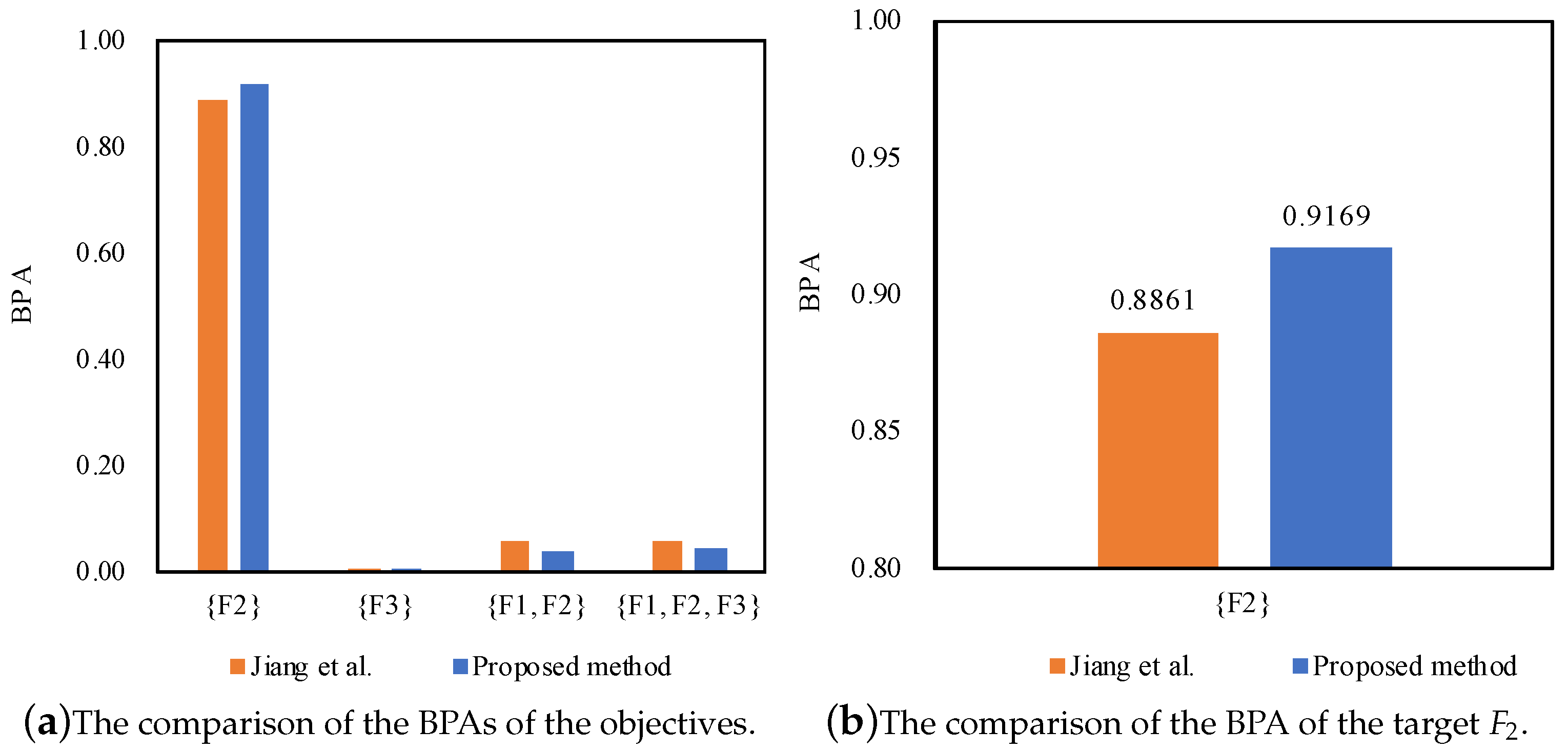
- = 0.9169,
- = 0.0002,
- = 0.0371,
- = 0.0458.
5.2.2. Motor Rotor Fault Diagnosis at Frequency
- = 0.7754,
- = 0.2246.
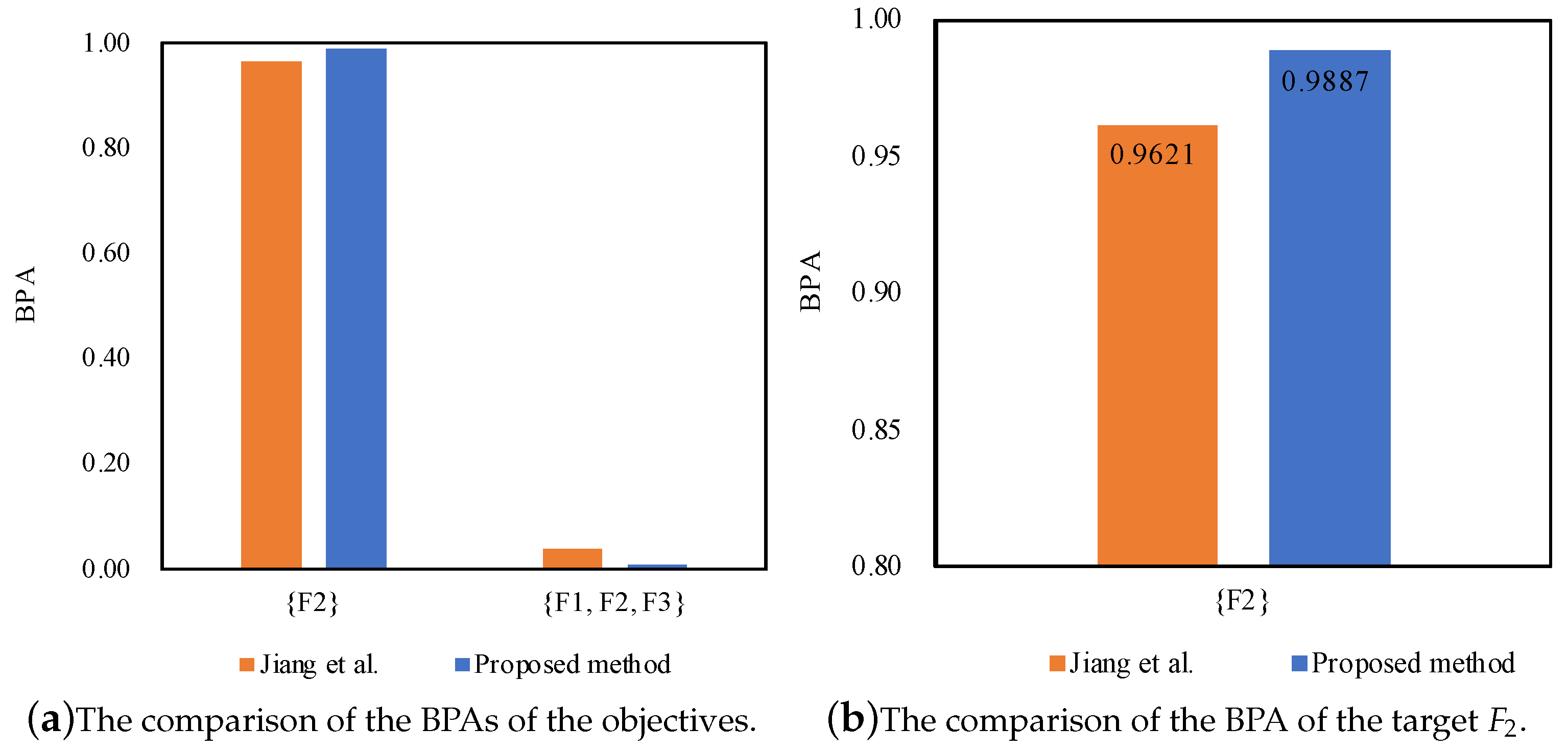
- = 0.9496,
- = 0.0504.
- = 0.9887,
- = 0.0113.
5.2.3. Motor Rotor Fault Diagnosis at Frequency
- = 0.3028,
- = 0.4323,
- = 0.2254,
- = 0.0395.
- = 0.3415,
- = 0.5634,
- = 0.0929,
- = 0.0021.
- = 0.3266,
- = 0.6365,
- = 0.0368,
- = 0.0001.
5.3. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hall, D.L.; Llinas, J. An introduction to multisensor data fusion. Proc. IEEE 1997, 85, 6–23. [Google Scholar] [CrossRef]
- Zois, E.N.; Anastassopoulos, V. Fusion of correlated decisions for writer verification. Pattern Recognit. 2001, 34, 47–61. [Google Scholar] [CrossRef]
- Dong, M.; He, D. Hidden semi-Markov model-based methodology for multi-sensor equipment health diagnosis and prognosis. Eur. J. Oper. Res. 2007, 178, 858–878. [Google Scholar] [CrossRef]
- PohlC, V. Multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef]
- Dong, J.; Zhuang, D.; Huang, Y.; Fu, J. Advances in multi-sensor data fusion: Algorithms and applications. Sensors 2009, 9, 7771–7784. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Wei, H. Fusion of infrared polarization and intensity images using support value transform and fuzzy combination rules. Infrared Phys. Technol. 2013, 60, 235–243. [Google Scholar] [CrossRef]
- Shen, X.; Varshney, P.K. Sensor selection based on generalized information gain for target tracking in large sensor networks. IEEE Trans. Signal Process. 2014, 62, 363–375. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Xie, C.; Zhou, D. An evidential sensor fusion method in fault diagnosis. Adv. Mech. Eng. 2016, 8. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Zhang, J. Zero-sum matrix game with payoffs of Dempster–Shafer belief structures and its applications on sensors. Sensors 2017, 17, 922. [Google Scholar] [CrossRef] [PubMed]
- Yunusa-Kaltungo, A.; Sinha, J.K.; Elbhbah, K. An improved data fusion technique for faults diagnosis in rotating machines. Measurement 2014, 58, 27–32. [Google Scholar] [CrossRef]
- Liu, Q.C.; Wang, H.P.B. A case study on multisensor data fusion for imbalance diagnosis of rotating machinery. Artif. Intell. Eng. Des. Anal. Manuf. 2001, 15, 203–210. [Google Scholar] [CrossRef]
- Safizadeh, M.; Latifi, S. Using multi-sensor data fusion for vibration fault diagnosis of rolling element bearings by accelerometer and load cell. Inf. Fusion 2014, 18, 1–8. [Google Scholar] [CrossRef]
- Banerjee, T.P.; Das, S. Multi-sensor data fusion using support vector machine for motor fault detection. Inf. Sci. 2012, 217, 96–107. [Google Scholar] [CrossRef]
- Niu, G.; Han, T.; Yang, B.S.; Tan, A.C.C. Multi-agent decision fusion for motor fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 1285–1299. [Google Scholar] [CrossRef] [Green Version]
- Yunusa-Kaltungo, A.; Sinha, J.K. Sensitivity analysis of higher order coherent spectra in machine faults diagnosis. Struct. Health Monit. Int. J. 2016, 15, 555–567. [Google Scholar] [CrossRef]
- Walczak, B.; Massart, D. Rough sets theory. Chemom. Intell. Lab. Syst. 1999, 47, 1–16. [Google Scholar] [CrossRef]
- Shen, L.; Tay, F.E.; Qu, L.; Shen, Y. Fault diagnosis using rough sets theory. Comput. Ind. 2000, 43, 61–72. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Chen, S.; Deng, Y.; Wu, J. Fuzzy sensor fusion based on evidence theory and its application. Appl. Artif. Intell. 2013, 27, 235–248. [Google Scholar] [CrossRef]
- Liu, H.C.; Liu, L.; Lin, Q.L. Fuzzy failure mode and effects analysis using fuzzy evidential reasoning and belief rule-based methodology. IEEE Trans. Reliab. 2013, 62, 23–36. [Google Scholar] [CrossRef]
- Mardani, A.; Jusoh, A.; Zavadskas, E.K. Fuzzy multiple criteria decision-making techniques and applications—Two decades review from 1994 to 2014. Expert Syst. Appl. 2015, 42, 4126–4148. [Google Scholar] [CrossRef]
- Zheng, H.; Deng, Y.; Hu, Y. Fuzzy evidential influence diagram and its evaluation algorithm. Knowl.-Based Syst. 2017, 131, 28–45. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 1. [Google Scholar]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017, 46, 630–640. [Google Scholar] [CrossRef]
- Zadeh, L.A. A note on Z-numbers. Inf. Sci. 2011, 181, 2923–2932. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor data fusion with Z-numbers and its application in fault diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Xiao, F. An intelligent complex event processing with D numbers under fuzzy environment. Math. Probl. Eng. 2016, 2016, 3713518. [Google Scholar] [CrossRef]
- Mo, H.; Deng, Y. A new aggregating operator for linguistic information based on D numbers. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2016, 24, 831–846. [Google Scholar] [CrossRef]
- Zhou, X.; Deng, X.; Deng, Y.; Mahadevan, S. Dependence assessment in human reliability analysis based on D numbers and AHP. Nucl. Eng. Des. 2017, 313, 243–252. [Google Scholar] [CrossRef]
- Yang, J.B.; Wang, Y.M.; Xu, D.L.; Chin, K.S.; Chatton, L. Belief rule-based methodology for mapping consumer preferences and setting product targets. Expert Syst. Appl. 2012, 39, 4749–4759. [Google Scholar] [CrossRef]
- Fu, C.; Yang, J.B.; Yang, S.L. A group evidential reasoning approach based on expert reliability. Eur. J. Oper. Res. 2015, 246, 886–893. [Google Scholar] [CrossRef]
- Yang, J.B.; Xu, D.L. Interactive minimax optimisation for integrated performance analysis and resource planning. Comput. Oper. Res. 2014, 46, 78–90. [Google Scholar] [CrossRef]
- Yang, J.B.; Xu, D.L. Evidential reasoning rule for evidence combination. Artif. Intell. 2013, 205, 1–29. [Google Scholar] [CrossRef]
- Ma, J. Qualitative approach to Bayesian networks with multiple causes. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2012, 42, 382–391. [Google Scholar] [CrossRef]
- Graziani, S.; Xibilia, M. A deep learning based soft sensor for a sour water stripping plant. In Proceedings of the 2017 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Turin, Italy, 22–25 May 2017; pp. 1–6. [Google Scholar]
- Xu, S.; Jiang, W.; Deng, X.; Shou, Y. A modified Physarum-inspired model for the user equilibrium traffic assignment problem. Appl. Math. Model. 2017. [Google Scholar] [CrossRef]
- Xibilia, M.; Gemelli, N.; Consolo, G. Input variables selection criteria for data-driven Soft Sensors design. In Proceedings of the 2017 IEEE 14th International Conference on Networking, Sensing and Control (ICNSC), Calabria, Italy, 16–18 May 2017; pp. 362–367. [Google Scholar]
- Denoeux, T. A k-nearest neighbor classification rule based on Dempster–Shafer theory. IEEE Trans. Syst. Man Cybernet. 1995, 25, 804–813. [Google Scholar] [CrossRef]
- Ma, J.; Liu, W.; Miller, P.; Zhou, H. An evidential fusion approach for gender profiling. Inf. Sci. 2016, 333, 10–20. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.-G.; Pan, Q.; Dezert, J.; Martin, A. Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognit. 2016, 52, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Fu, C.; Xu, D.L. Determining attribute weights to improve solution reliability and its application to selecting leading industries. Ann. Oper. Res. 2016, 245, 401–426. [Google Scholar] [CrossRef]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. An evidential axiomatic design approach for decision making using the evaluation of belief structure satisfaction to uncertain target values. Int. J. Intell. Syst 2017. [Google Scholar] [CrossRef]
- Rikhtegar, N.; Mansouri, N.; Ahadi Oroumieh, A.; Yazdani-Chamzini, A.; Kazimieras Zavadskas, E.; Kildienė, S. Environmental impact assessment based on group decision-making methods in mining projects. Econ. Res.-Ekonomska Istraživanja 2014, 27, 378–392. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, S.; Liu, X.; Zheng, H.; Wei, B. Evidence conflict measure based on OWA operator in open world. PLoS ONE 2017, 12, e0177828. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Wang, S. An uncertainty measure for interval-valued evidences. Int. J. Comput. Commun. Control 2017, 12, 631–644. [Google Scholar] [CrossRef]
- Zhang, X.; Deng, Y.; Chan, F.T.S.; Adamatzky, A.; Mahadevan, S. Supplier selection based on evidence theory and analytic network process. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2016, 230, 562–573. [Google Scholar] [CrossRef]
- Liu, T.; Deng, Y.; Chan, F. Evidential supplier selection based on DEMATEL and game theory. Int. J. Fuzzy Syst. 2017. [Google Scholar] [CrossRef]
- Dong, Y.; Wang, J.; Chen, F.; Hu, Y.; Deng, Y. Location of Facility Based on Simulated Annealing and “ZKW” Algorithms. Math. Probl. Eng. 2017, 2017, 4628501. [Google Scholar] [CrossRef]
- Kang, B.; Chhipi-Shrestha, G.; Deng, Y.; Mori, J.; Hewage, K.; Sadiq, R. Development of a predictive model for Clostridium difficile infection incidence in hospitals using Gaussian mixture model and Dempster-Shafer theroy. Stoch. Environ. Res. Risk Assess. 2017, 1–16. [Google Scholar] [CrossRef]
- Dutta, P. Uncertainty modeling in risk assessment based on Dempster–Shafer theory of evidence with generalized fuzzy focal elements. Fuzzy Inf. Eng. 2015, 7, 15–30. [Google Scholar] [CrossRef]
- Zheng, X.; Deng, Y. Dependence assessment in human reliability analysis based on evidence credibility decay model and IOWA operator. Ann. Nucl. Energy 2017, in press. [Google Scholar]
- Zhang, L.; Ding, L.; Wu, X.; Skibniewski, M.J. An improved Dempster–Shafer approach to construction safety risk perception. Knowl.-Based Syst. 2017, 132, 30–46. [Google Scholar] [CrossRef]
- Hang, J.; Zhang, J.; Cheng, M. Fault diagnosis of wind turbine based on multi-sensors information fusion technology. IET Renew. Power Gener. 2014, 8, 289–298. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.-H.; Shan, X.-L.; Liu, H.-G.; Zhou, C.-F. A new method of gear fault diagnosis in strong noise based on multi-sensor information fusion. J. Vib. Control 2016, 22, 1504–1515. [Google Scholar] [CrossRef]
- Yuan, K.; Xiao, F.; Fei, L.; Kang, B.; Deng, Y. Modeling sensor reliability in fault diagnosis based on evidence theory. Sensors 2016, 16, 113. [Google Scholar] [CrossRef] [PubMed]
- Sabahi, F. A novel generalized belief structure comprising unprecisiated uncertainty applied to aphasia diagnosis. J. Biomed. Inf. 2016, 62, 66–77. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Lu, X.; Su, X.; Hu, Y.; Deng, Y. New failure mode and effects analysis: An evidential downscaling method. Qual. Reliab. Eng. Int. 2016, 32, 737–746. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Tang, Y. Failure mode and effects analysis based on a novel fuzzy evidential method. Appl. Soft Comput. 2017, 57, 672–683. [Google Scholar] [CrossRef]
- Zadeh, L.A. A simple view of the Dempster–Shafer theory of evidence and its implication for the rule of combination. AI Mag. 1986, 7, 85–90. [Google Scholar]
- Deng, Y. Generalized evidence theory. Appl. Intell. 2015, 43, 530–543. [Google Scholar] [CrossRef]
- Lefevre, E.; Colot, O.; Vannoorenberghe, P. Belief function combination and conflict management. Inf. Fusion 2002, 3, 149–162. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Tang, Y.; Zhou, D. Ordered visibility graph average aggregation operator: An application in produced water management. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 023117. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Deng, Y.; Han, C.Z.; Hou, Z. Weighted evidence combination based on distance of evidence and uncertainty measure. J. Infrared Millim. Waves 2011, 30, 396–400. [Google Scholar] [CrossRef]
- Deng, X.; Xiao, F.; Deng, Y. An improved distance-based total uncertainty measure in belief function theory. Appl. Intell. 2017, 46, 898–915. [Google Scholar] [CrossRef]
- Ma, J.; Liu, W.; Benferhat, S. A belief revision framework for revising epistemic states with partial epistemic states. Int. J. Approx. Reason. 2015, 59, 20–40. [Google Scholar] [CrossRef] [Green Version]
- Smets, P. The combination of evidence in the transferable belief model. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 447–458. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Representation and combination of uncertainty with belief functions and possibility measures. Comput. Intell. 1988, 4, 244–264. [Google Scholar] [CrossRef]
- Yager, R.R. On the Dempster–Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Murphy, C.K. Combining belief functions when evidence conflicts. Decis. Support Syst. 2000, 29, 1–9. [Google Scholar] [CrossRef]
- Deng, Y.; Shi, W.; Zhu, Z.; Liu, Q. Combining belief functions based on distance of evidence. Decis. Support Syst. 2004, 38, 489–493. [Google Scholar]
- Zhang, Z.; Liu, T.; Chen, D.; Zhang, W. Novel algorithm for identifying and fusing conflicting data in wireless sensor networks. Sensors 2014, 14, 9562–9581. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P. A Generalization of Bayesian Inference; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Jousselme, A.L.; Grenier, D.; Bossé, É. A new distance between two bodies of evidence. Inf. Fusion 2001, 2, 91–101. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, M.; Deng, Y. Measure the structure similarity of nodes in complex networks based on relative entropy. Phys. A Stat. Mech. Its Appl. 2017. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Yager, R.R. Entropy and specificity in a mathematical theory of evidence. Int. J. Gen. Syst. 1983, 9, 249–260. [Google Scholar] [CrossRef]
- Tanino, T. Fuzzy preference orderings in group decision making. Fuzzy Sets Syst. 1984, 12, 117–131. [Google Scholar] [CrossRef]
- Lee, L.W. Group decision making with incomplete fuzzy preference relations based on the additive consistency and the order consistency. Expert Syst. Appl. 2012, 39, 11666–11676. [Google Scholar] [CrossRef]
- Fei, L.; Wang, H.; Chen, L.; Deng, Y. A new vector valued similarity measure for intuitionistic fuzzy sets based on OWA operators. Iran. J. Fuzzy Syst. 2017, in press. [Google Scholar]
- Fu, C.; Xu, D.L.; Yang, S.L. Distributed preference relations for multiple attribute decision analysis. J. Oper. Res. Soc. 2016, 67, 457–473. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BPA | ||||
|---|---|---|---|---|
| 0.41 | 0.29 | 0.30 | 0.00 | |
| 0.00 | 0.90 | 0.10 | 0.00 | |
| 0.58 | 0.07 | 0.00 | 0.35 | |
| 0.55 | 0.10 | 0.00 | 0.35 | |
| 0.60 | 0.10 | 0.00 | 0.30 |
| Evidence | Method | Target | ||||
|---|---|---|---|---|---|---|
| Dempster [23] | 0 | 0.6350 | 0.3650 | 0 | B | |
| Murphy [71] | 0.4939 | 0.4180 | 0.0792 | 0.0090 | A | |
| Deng et al. [72] | 0.4974 | 0.4054 | 0.0888 | 0.0084 | A | |
| Zhang et al. [73] | 0.5681 | 0.3319 | 0.0929 | 0.0084 | A | |
| Proposed method | 0.7617 | 0.1127 | 0.1176 | 0.0080 | A | |
| Dempster [23] | 0 | 0.3321 | 0.6679 | 0 | C | |
| Murphy [71] | 0.8362 | 0.1147 | 0.0410 | 0.0081 | A | |
| Deng et al. [72] | 0.9089 | 0.0444 | 0.0379 | 0.0089 | A | |
| Zhang et al. [73] | 0.9142 | 0.0395 | 0.0399 | 0.0083 | A | |
| Proposed method | 0.9507 | 0.0060 | 0.0334 | 0.0087 | A | |
| Dempster [23] | 0 | 0.1422 | 0.8578 | 0 | C | |
| Murphy [71] | 0.9620 | 0.0210 | 0.0138 | 0.0032 | A | |
| Deng et al. [72] | 0.9820 | 0.0039 | 0.0107 | 0.0034 | A | |
| Zhang et al. [73] | 0.9820 | 0.0034 | 0.0115 | 0.0032 | A | |
| Proposed method | 0.9888 | 0.0004 | 0.0087 | 0.0034 | A |
| BPA | ||||
|---|---|---|---|---|
| 0.8176 | 0.0003 | 0.1553 | 0.0268 | |
| 0.5658 | 0.0009 | 0.0646 | 0.3687 | |
| 0.2403 | 0.0004 | 0.0141 | 0.7452 |
| BPA | ||
|---|---|---|
| 0.6229 | 0.3771 | |
| 0.7660 | 0.2341 | |
| 0.8598 | 0.1402 |
| BPA | ||||
|---|---|---|---|---|
| 0.3666 | 0.4563 | 0.1185 | 0.0586 | |
| 0.2793 | 0.4151 | 0.2652 | 0.0404 | |
| 0.2897 | 0.4331 | 0.2470 | 0.0302 |
| Method | Target | ||||
|---|---|---|---|---|---|
| Jiang et al. [27] | 0.8861 | 0.0002 | 0.0582 | 0.0555 | |
| Proposed method | 0.9169 | 0.0002 | 0.0371 | 0.0458 |
| Method | Target | ||
|---|---|---|---|
| Jiang et al. [27] | 0.9621 | 0.0371 | |
| Proposed method | 0.9887 | 0.0113 |
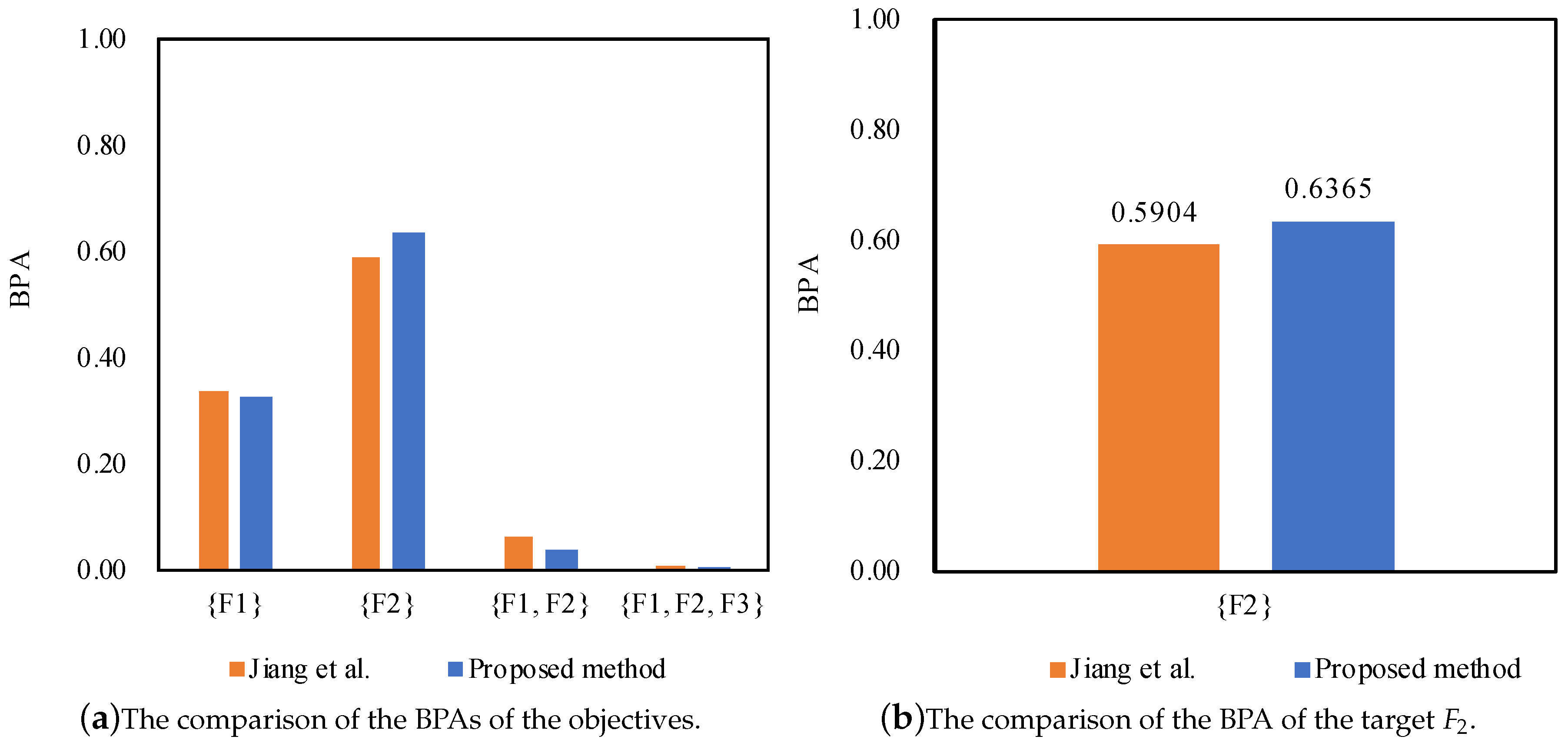
| Method | Target | ||||
|---|---|---|---|---|---|
| Jiang et al. [27] | 0.3384 | 0.5904 | 0.0651 | 0.0061 | |
| Proposed method | 0.3266 | 0.6365 | 0.0368 | 0.0001 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, F. A Novel Evidence Theory and Fuzzy Preference Approach-Based Multi-Sensor Data Fusion Technique for Fault Diagnosis. Sensors 2017, 17, 2504. https://doi.org/10.3390/s17112504
Xiao F. A Novel Evidence Theory and Fuzzy Preference Approach-Based Multi-Sensor Data Fusion Technique for Fault Diagnosis. Sensors. 2017; 17(11):2504. https://doi.org/10.3390/s17112504
Chicago/Turabian StyleXiao, Fuyuan. 2017. "A Novel Evidence Theory and Fuzzy Preference Approach-Based Multi-Sensor Data Fusion Technique for Fault Diagnosis" Sensors 17, no. 11: 2504. https://doi.org/10.3390/s17112504
APA StyleXiao, F. (2017). A Novel Evidence Theory and Fuzzy Preference Approach-Based Multi-Sensor Data Fusion Technique for Fault Diagnosis. Sensors, 17(11), 2504. https://doi.org/10.3390/s17112504