1. Introduction
Once the concept of the Cyber Physical System (CPS) was first proposed by the American National Science Foundation (NFS) in 2006, it soon became so popular that CPS is even regarded as a next revolution of technology which can rival the contribution of the Internet [
1]. CPS applications are being explored in various areas, e.g., smart transportation, smart cities, precision agriculture and entertainment. A CPS is a (large) geographically distributed, close-loop system. It closely interacts with the physical world by sensing and actuating. Roughly speaking, a CPS consists of wireless/wired sensor networks (WSNs), decision support systems (DSSs), networked control systems (NCSs) and physical systems/elements. To integrate these four kinds of subsystems, the framework/model of CPS should support both the discrete models (i.e., WSN, DSS and some NCS) and continuous models (i.e., some NCS and physical systems), and integrate them seamlessly.
In the last decades, numerous conceptual frameworks/models were proposed to explore the CPS design in different domains and improve the X-abilities of CPS. One famous proposal among them is the National Institute of Standards and Technology (NIST) reference framework, which was proposed by the CPS Public Working Group of NIST in 2014. This proposal comprehensively analyzes the requirements from various aspects and highlights research issues of
complexity,
timing,
adaptability,
safety,
reliability,
maintainability [
2]. However, these conceptual frameworks/models mainly focused on the requirements and the possible models for CPS design, few of them discussed the dependability of CPS [
3,
4]. Meanwhile, most of the current models or solutions are limited to static centralized architectures, which are incapable of analyzing the dynamic behavior in uncertain environments [
3], let alone achieve synergy between adaptability and dependability under the complex constraints.
Complexity is one key challenge to dependability engineering. To design a dependable system, one key is using simplicity to control complexity [
5]. Considering the infinite scenarios of a changeable environment, it is infeasible to do a complete testing/simulation to evaluate the decision in design period. Model@run.time is a smart solution to evaluate decision at runtime. Compared to testing/simulation in design period, Model@run.time can significantly narrow the possible testing space, which can decrease the complexity and improve the accuracy of evaluation [
6]. In some sense, modeling and evaluating at runtime is also a kind of solution for decision making. Moreover, these decisions should be transformed into executable applications. However, runtime transforming introduces extra complexity, which decreases the dependability. Thus
a systemic solution is needed to build an executable decision to avoid the runtime transforming.Rammig proposed the challenges of autonomic distributed real-time systems from: (1) modeling dynamically reconfigurable systems; (2) dynamically reconfigurable system; (3) dynamically reconfigurable target hardware [
7]. CPS suffers the same challenges, but more serious. As a CPS consists of various heterogeneous subsystems, the processing behaviors of one same decision are different in most cases, e.g., the execution duration of programs, the reliability of subsystems and the accuracy of data. Moreover, the available solutions for reconstruction are infinite. It is too heavy for Model@run.time solutions to evaluate the inconsistent behavior of these solutions in time. As Rammig argued, the only chance to cope with the challenges of autonomic distributed real-time systems is to enforce composability and compositionality (C&C) [
7]. Improving the C&C of subsystems is a promising solution for dynamic reconstruction and runtime evaluation [
8,
9]. High C&C subsystem design can also comprehensively reduce the complexity of CPSs, simplify the evaluation of decisions and improve the dependability of decision processing.
1.1. Overview of the Pattern of Self-Managed Loop
Autonomic computing (AC) is a common trend solution for complex systems [
10]. AC systems try to simplify management and improve the adaptability by applying
MAPE-K methods [
10]. In other words, an AC system tries to automatically make decisions (a.k.a. planning) and take actions (a.k.a. executing) at runtime. Self-management is a more detailed proposal for AC systems, which includes four subcategories:
self-configuring,
self-healing,
self-optimizing and
self-protecting [
11]. More and more studies try to introduce self-management (or AC) into CPS to improve the flexibility and adaptability [
12,
13], and the dependability [
14,
15]. Warriach et al. expanded the categories of self-management with a set of self-* abilities, including
self-healing,
self-protection,
self-awareness,
self-organizing,
self-synchronization and
self-configuration, and analyzed both functional and nonfunctional requirements of self-healing in smart environment applications [
16].
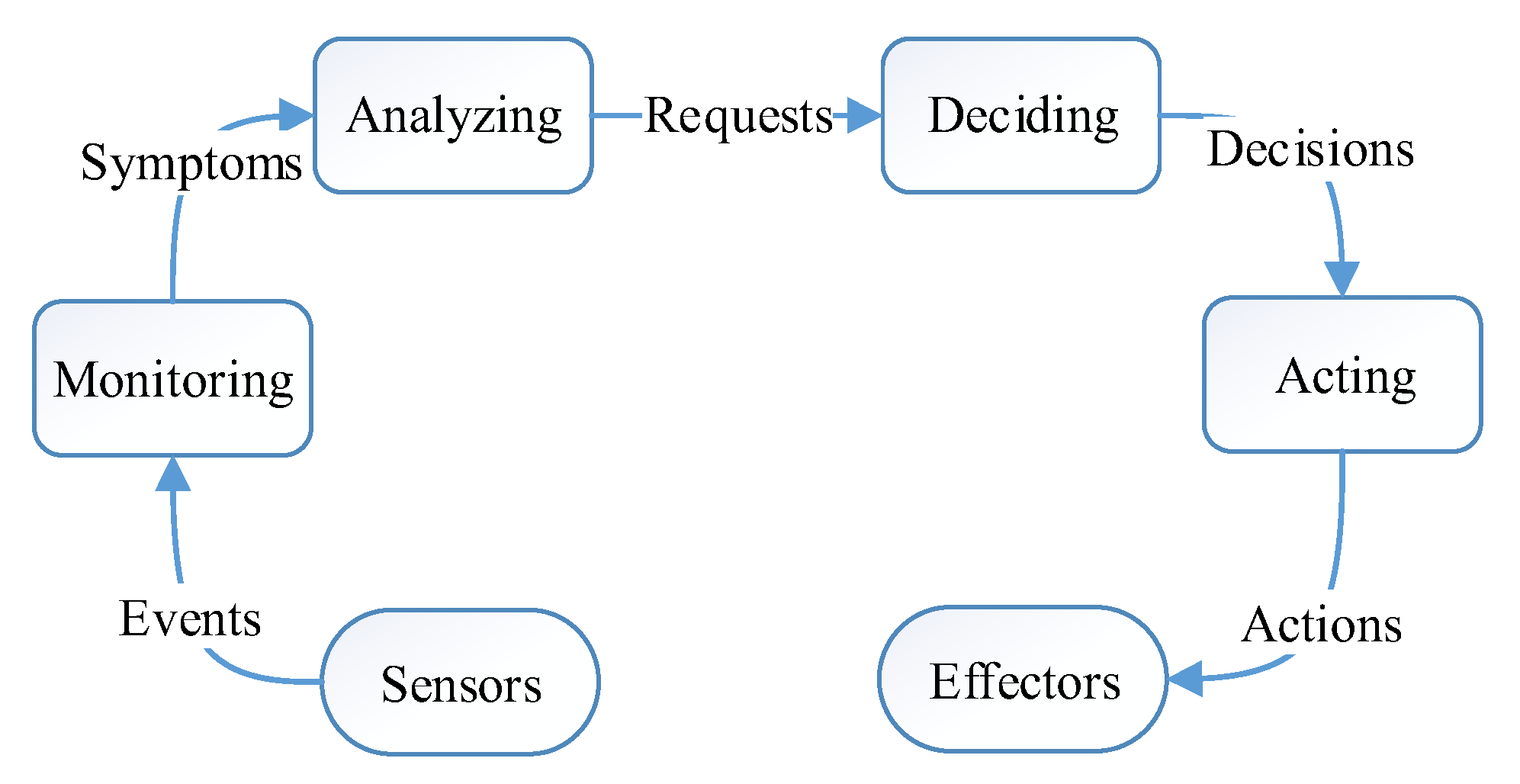
Generally, all these self-* processes of the AC system involve four main phases: monitoring, analyzing, deciding, and acting [
17], which is illustrated in
Figure 1. AC was once proposed for business computer systems, which are generally deployed in a well-protected environment (such as data centers), and rarely affected by the natural world. Hence, a general AC system doesn’t need to adapt to the changeable external environment.
The self-management for the general AC system is system-centric, which mainly focuses on the continuous improvement of system itself, such as load balance, reducing resource consumption of services, improving dependability and security of system. Indeed, it is us, human beings, who are trained to adapt to the AC systems.
Compared to general AC system, a self-managed CPS has to interact automatically with the physical world. To behave properly, it should take the right actions in the right place, at the right time, with reasonable processing speed. In other words, it should not only continuously improve the system itself, but also adapt to the variable environment. Hence, a self-managed CPS should form two types of closed loops [
13,
18,
19]. One is a self-healing loop [
19], which is similar to the schema in
Figure 1. Another is the interactive loop between the cyber world and the physical world, which is illustrated in
Figure 2. The interaction loop includes long-term loops for causal reasoning (big data driven
MAPE-K loop) and short-term loop for dependable decision process (the feedback control loop). The self-healing loop and interaction loop may influence each other, e.g., the temperature rise will trigger the cooling control loop (environment-in-loop adaptation) and also affects the reliability of hardware (system-centric self-management). In this paper, we focus on improving the consistency of event observation (the long-term loop) and improving the dependability of decision process (the short-term loop).
Centralized decision arrangement is the most common solution for AC systems. The processing flow of a decision is controlled by a (local) central system, such as DSS. The processing flow fails if the decision manager fails (a.k.a. single point of failure). The dependability of such processing solutions is limited by the central system. To overcome this issue, one generic solution is deploying redundant decision arrangement system. However, it may generate conflicting decisions because two redundant decision control systems may have the inconsistent observation results and get different events’ orders.
Even to one same centralized decision manager, the order of events may be wrong. The physical events occur in parallel and sensors are distributed in CPS. Due to various issues (e.g., errors, failures, delays, etc.) [
20,
21], the clocks of sensors may not be precisely synchronized. As a consequence, different sensors may generate inconsistent timestamps for one same event, which confuses the DSS and misguides the fault diagnosis methods. Taking precision agriculture as an example, the DSS analyzes the soil moisture with the current temperature and the status of leaves; and then makes a final decision that the plants could and should be watered. Then the nozzle starts to spray water at the timestamp
, and the event of starting to spray is denoted as
. The soil moisture sensor detects the increase of humidity at the timestamp
, and this event is denoted as
. If we hold the assumption of the global reference time, it implies that
and
are comparable. When DSS receives
before
and finds that
, the DSS will alarm that there are some things wrong with the nozzle or pipe (i.e., leaking). Whereas in a real multi-agent CPS, the timestamps
and
are not comparable because of the time synchronization deviation between the node with soil moisture sensor and the actuator with nozzle. Hence, the timing order of
and
is indistinguishable. Consequently, the information of causality between physical events is lost, and further analysis becomes impossible. The timing issue is challenging the correctness of self-managing decisions, especially to the real-time CPS.
Another challenge is guaranteeing the consistency of the dynamic behavior with simple and dependable (Model@run.time) solutions. As a kind of system of systems (SoS), a CPS is composed of numerous heterogeneous subsystems. These subsystems may also recursively consist of various other subsystems. To describe this feature, we should abstract the subsystems with a model that is closed under composition. To model the dynamic structure and dynamic behavior for self-management, the reference framework should be flexible enough to describe the runtime composition. To guarantee the quality of decisions and quantitative analyze the dynamic behavior, the properties of subsystems should be composable and the requirements of decision should be runtime decomposable. With systematic consideration of these requirements, we proposed a framework based on compositional actors.
The contributions of the paper are manifold. We introduce a relative time solution to solve the inconsistent event observation in CPS, which forms a foundation for a decentralized decision process. Moreover, we design a formal compositional framework of the decentralized decision process. A self-similar recursive actor interface is proposed to simplify self-management. We analyze the composability and compositionality of our design and provide seven composition patterns. A one-order dynamic feedback strategy is introduced to improve the reliability, scalability and stability of decision process.
1.2. Structure of Paper
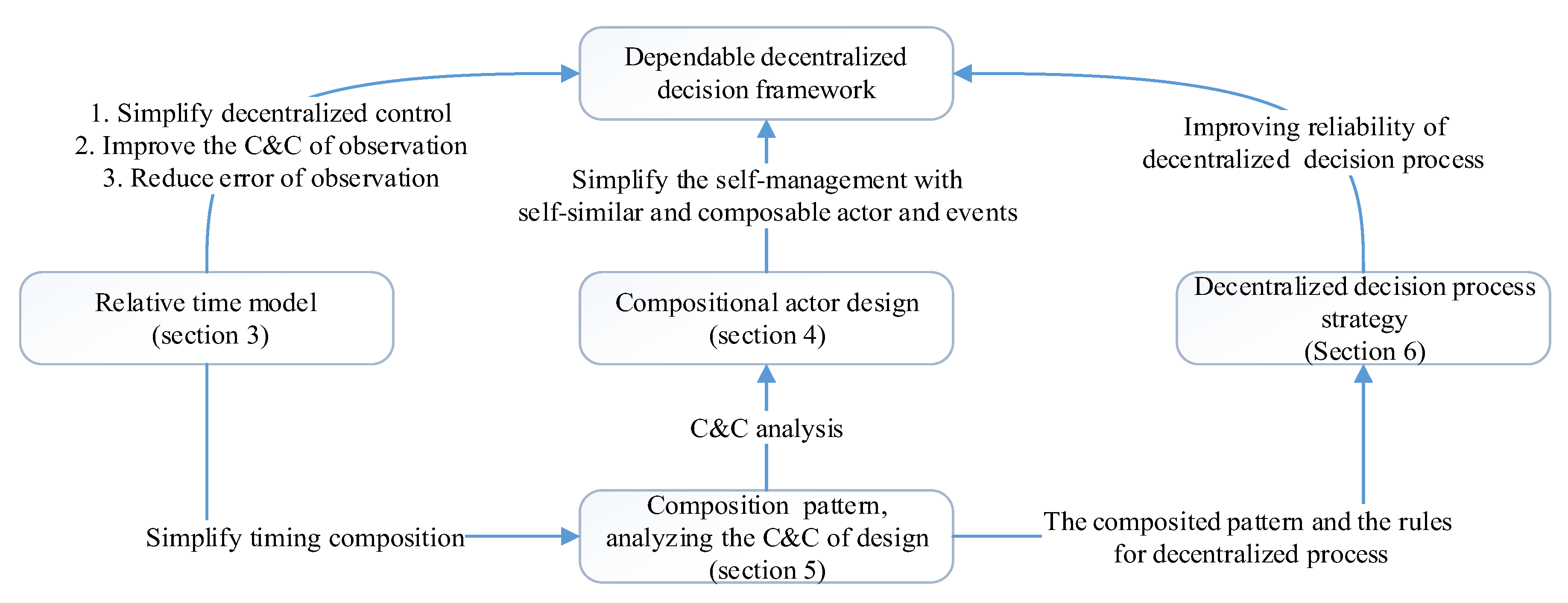
The remainder of the paper is organized as follows:
Section 2 is about the related works on self-management CPS and formalization.
Section 3 introduces the relative time model to guarantee the consistency of event observation and the qualitative contrastive analysis with the absolute time model.
Section 4 details the actor-based formal model and the interface design. We analyze the composability and compositionality of reference framework in
Section 5. We introduce a simple decentralized decision process strategy and one-order feedback decentralized dynamic decision process strategy and compare the reliability with other two strategies in
Section 6. The relationship of
Section 3,
Section 4,
Section 5 and
Section 6 is shown in
Figure 3.
Section 7 is a case study of the dependability of decentralized decision process.
Section 8 draws the conclusions.
Notations: (1) without additional notes, we use
or
to represent the absolute timestamp,
to represent the duration,
and
to represent the relative timestamp in the remainder of our paper. We use
to represent the static duration for WCET, BCET, and static requirement of advice, and
to represent the real duration or the dynamic requirement of decision; (2) the term “subsystem” is an agent with several actors. “Subsystem” to decentralized CPS is the “component” to centralized system; (3) the “decision” in this paper is a dynamical concept, which is similar to the concept of “application” and “program”. An example is introduced in
Appendix A.1 for further understanding of the decentralized decision process.
2. Related Works on Self-Management Framework for CPS
Roughly speaking, a CPS has to face two kinds of uncertainty. One is the changeable environment, another is the unpredictable process flow caused by resource competition and random failures. To behave properly under uncertainty, CPS should make and process decisions according to the context. For each self-adapting decision, CPS should select the right subsystems from various heterogeneous candidates, organize them in the right way, and coordinate the decision process on subsystems. For self-healing, each prearranged subsystem may be replaced by others at runtime, and heterogeneous redundant subsystems should cooperate together to improve the reliability. No matter self-adapting or self-healing, CPS has to dynamically reconstruct its services, structure and topology at runtime. However, dynamic reconstruction decreases the controllability and predictability of CPS behavior. It is a big challenge to achieving the consistent quality of decisions process, such as consistent timing, predictable reliability and safety. To overcome these issues, systemic solutions are need to evaluate the correctness of reconstruction and to guarantee the consistency of the dynamic behavior of decisions.
A good framework is the foundation for self-management CPS. Massive aspect oriented formal framework have been published to improve the functional performance of CPS [
22,
23], and various frameworks are proposed for self-adapting CPS. As we classified in the survey [
3], these frameworks of CPS can be classified into three types: Service Oriented Architecture (SOA)-based frameworks, Multi-Agent System (MAS)-based frameworks, and other aspect oriented frameworks. Compared to SOA-based frameworks, MAS-based frameworks are more lightweight and more scalable. As a kind of SoS, CPS shows high flexibility, but low predictability. More and more researchers are paying attention to verification and validation (V&V) of the dynamic structure and behavior of CPS with Model@run.time methods to improve their predictability. A formal framework is an alternative solution to improve the predictability and dependability without introducing too much complexity.
Unfortunately, there are relatively few studies on formal framework (architecture) and dependability evaluation [
3]. SCA-ASM is a formal SOA-based framework for modeling and validating distributed self-adaptive applications. SCA-ASM can model the behavior of monitoring and reacting to environmental changes and to internal changes, and the related operators for expressing and coordinating self-adaptive behaviors [
24,
25]. A MAS-based framework based on the logic-based modeling language called SALMA was introduced, this model focuses on the information transfer processing [
26]. In the domain of cyber-physical transportation, Mashkoor et al. built a formal model with higher-order logic [
27]. These frameworks are based on centralized decision process control solutions. The centralized decision controller is slow in reacting because of the long transmission delay, which increases the safety risk. Moreover, the centralized decision controller is a single point of failure. Decentralized control can overcome these drawbacks, and more and more studies are being published in this field. A formal framework was proposed for decentralized partially observable Markov decision process problems. Based this framework, a policy iteration algorithm is presented to improve the coordination of distributed subsystems [
28]. A decentralized control solution based on Markov decision processes is proposed for automatically constructed macro-actions in multi-robot applications [
29]. However, these solutions mainly focus on the performance and convergence speed, the dependability and timing issues are rarely discussed. Moreover, these researches are based on ideal subsystems assumption, where all subsystems are dependable and behave consistently.
In the real world CPS, numerous heterogeneous subsystems are applied. These subsystems have different properties, i.e., different performance, different precision, which complicate the control of decision process. Various kinds of solutions have been invented to hide the differences between subsystems, such as middleware and virtualization [
30,
31], interface technology [
32] and specification [
33]. These technologies simplify the self-adaptation by providing consistent interfaces. Nevertheless, it is still not enough for self-management CPS. For safety, the risk of all decisions should be evaluable, and all actions should be predictable, which implies that all services and actions have consistent, stable behavior at run-time. Specifically, a CPS should be stable in the timing behavior and the reliability of services, and the accuracy of data, etc. Otherwise, the inconsistent and uncontrollable behaviors will make the CPS unpredictable and increase the risk of safety, mislead the DSS into making wrong decisions, i.e., the reasoning failure caused by inconsistent timestamp, which was introduced earlier.
To hide the differences and guarantee the quality of services, one promising way is to improve the C&C of services. Composability is the property whereby component properties do not change by virtue of interactions with other components [
9]. It comes from the philosophy of reductionism, which highlights the consistent behavior of the component when it cooperates with other components to build a whole system. On the contrary, compositionality is originated from holism. Compositionality is that system level properties can be computed from and decomposed into component properties [
9]. It is more about the capacity of decomposition of the system level properties. It focuses on the consistency between the system level properties and its divided properties (component properties), where the system level properties can be calculated with components/subsystems properties. For more detailed discussions about composability and compositionality readers may refer to [
9]. By the way, the concepts of composability and compositionality are interchangeable in some studies.
Designing subsystems with high C&C can reduce the complexity of CPS and systematically improve the quality of services. A theory of composition for heterogeneous systems was proposed to improve the stability, which decouples stability from timing uncertainties caused by networking and computation [
34]. Nuzzo introduced a platform-based design methodology based on contracts to refine the design flow. This methodology uses contracts to specify and abstract the components, then validates contracts according to the structure of CPS in design period [
35]. An I/O automata-based compositional specification theory is proposed to abstract and refine the temporal ordering of behavior, and to improve the reasoning of the behavior of components [
36], which is useful for dynamic decision evaluation and fault diagnosis. To guarantee the timeliness of real-time operations, a formal definition of timing compositionality is introduced [
37]. However, how to guarantee in general the quality of dynamic characteristics such as timing [
37], safety [
34] and dependability is still an open issue. Both new architectures and evaluation methods are needed for guaranteeing the timing and the dependability at runtime. A contract-based requirement composition and decomposition strategy was introduced for component-based development of distributed systems [
38]. This work is a valuable reference to the solution design for Model@run.time-based decision evaluations.
To achieve dependable CPS, systematic solutions are necessary. Both traditional means and self-healing methods are useful for maintaining the dependability of CPS. These methods should be applied organically at different levels to achieve dependability without introducing too much complexity. A satellite oriented formal correctness, safety, dependability, and performance analysis method is introduced in [
39]; it comprehensively applies the traditional methods to improve a static architecture, yet the traditional means are limited to static architectures, and they become less and less efficient for CPS [
3]. Self-healing methods are the trend to manage the dependability of the dynamic structure, which generally adjusts the architecture to prevent or recover from failures with flexible strategies. A simplex reference model was proposed to limit the fault propagation in CPS that built with unreliable components [
40]. A methodology is introduced to formalize the requirements, the specification and the descriptive statements with domain knowledge, it shows a systematic solution to verify the dependability of CPS with formal models [
41].
What’s done cannot be undone, so this hardly eliminates the negative effects of a wrong physical operation, which makes great claims upon the dependability of CPS. Without maintenance of services and self-healing solutions, self-adapting CPS is still inapplicable. Considering the complex influence between self-healing actions and self-adapting actions, a good formal framework is needed to simplify the decision evaluation at run-time. To address the complexity, we need a systemic solution to apply self-management without introducing too much complexity.
3. Improving the C&C of Timing Behavior with a Relative Time-Based Model
Time is important to computing [
42], especially for feedback control and causal reasoning. As a necessary condition for causal reasoning, it is important to achieve consensus on the timing behavior of both physical and cyber events. Moreover, the precise time can improve the control and cooperation between subsystems. Both context aware-based self-adaptation and fault prevention-based self-healing can benefit from the accurate causal reasoning and precise decision control. Hence, it is necessary to eliminate the temporal difference among subsystems and improve the C&C of timing for the self-management CPS.
To improve the C&C of timing and make all events observers achieve consensus on timing behavior (the same order of observed events). One intuitive solution is to establish a global reference time with a precisely timed infrastructure and time synchronization protocol. A time-centric model has been introduced for CPS [
43]. It is a global reference time-based solution where every subsystem shares one absolute reference time. It is relatively easy to meet the assumption of global reference time for wired small scale CPS. Whereas for a large scale wireless connected CPS, such as the smart transportation CPS and the precision agriculture CPS, maintaining the consistent reference time (absolute time) is a big challenge [
20,
21].
Furthermore, even if we have a well synchronized system, it still can’t achieve consistent absolute time and reproduce the causal relationship of events in cyberspace due to the imprecise timestamp. In fact, the timestamp of an observed event is rough. The accuracy of a timestamp depends on the sensitivity of the sensor, the processing speed, the sampling period, even the distance between the target object and sensor. Imagine that a physical event occurs at timestamp and the sensor detects the event at timestamp , where and are absolute times, (because sensing takes time). To sensors (especially to the smart sensors integrated complex data analysis), is not equal on different subsystems because of the sensitivity and the processing speed. Even to one same sensor, is under stochastic volatility. Consequently, it’s impossible to get the consistent absolute time of events in distributed CPS.
As current causal analysis methods just need the order of events, absolute time is an overly restrictive conditions, e.g., for logical reasoning : if two events and occur then we must have the result (event) ; or for quantum causal analysis with probability : the probability of the observing event given that event is true/observed. Few technologies support to deduce further conclusion from the accurate time difference between the result event and the event . There are two main reasons: (1) as is affected by many factors, the acceptable range of maybe too large. It is difficult to quantitatively analyze the stochastic volatility of . For example, it takes several weeks to observe the effect of fertilization. In the meantime, various factors may changes the efficient of fertilizer; (2) meanwhile, most events are irrelevant, it wastes resources to guarantee the absolute time of these events.
In general, there are two kinds of timekeeping methods. One is absolute time, where all subsystems share the same reference time (i.e., UTC) and the timestamp of event . Another is based on local time, where all subsystems have a different local reference time . For one same event, these subsystems have different observation timestamps . Analyzing the sequence of events is the first step for mining the relationship between events. The common method to get the order is calculating the timestamp difference between two events. With absolute time, we can directly get the difference . With local time, it is relatively complex. As the base reference time is different, the common solutions of local timestamps are not directly comparable. The difference of two reference times is necessary, so the final timestamp difference of two events is .
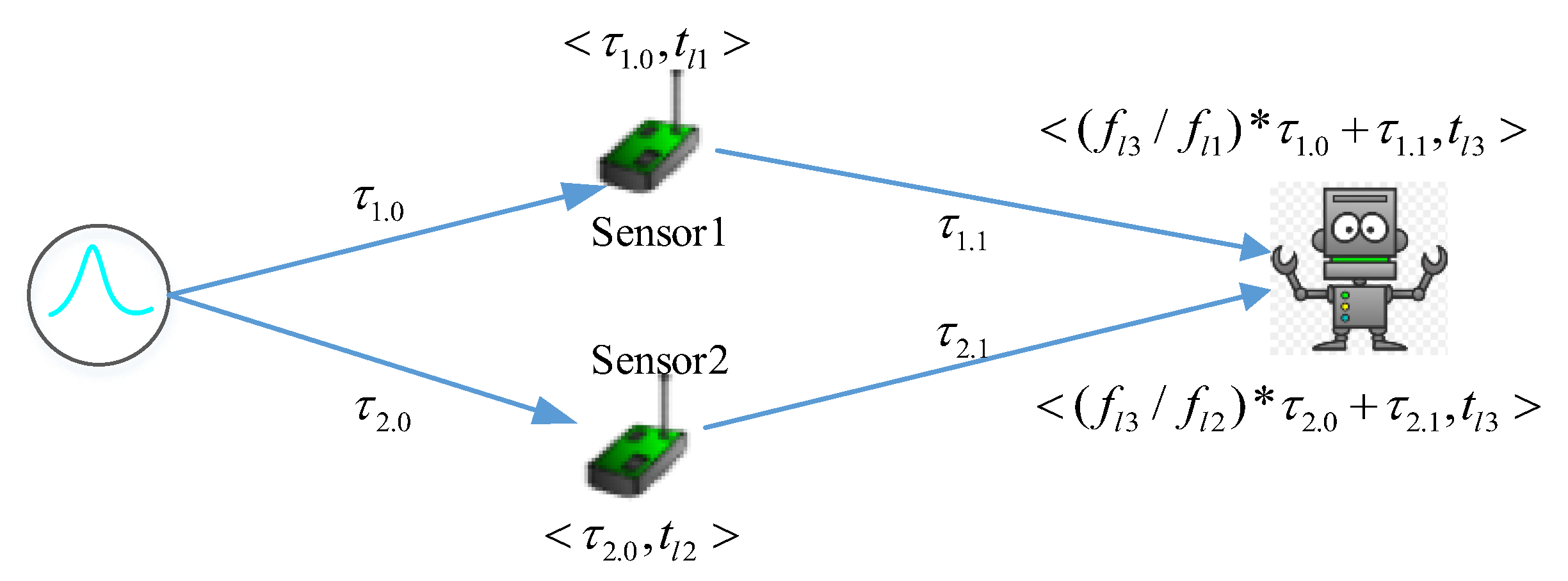
As observation is relative to each observer and each case, we propose a relative time model. Every subsystem just needs to record the duration that it takes to observe the event. The relationship of absolute time and different observers’ timestamp is depicted in
Figure 4. The tuple of timestamp is (absolute time, timestamp according to sensors’ view, timestamp according to actuator’s view). For example, a physical event occurs at the absolute time
. It takes
sensor1 to observe the physical event, and the absolute timestamp is
. The actuator observes the event from
sensor1 at
. Here, let us assume that
sensor1, sensor2 and actuator are not well synchronized, they have to record the observation based on their own local times. The timestamp in local time when
sensor1 observes the event is
, where
and
are two timestamps based on different reference times, and
. Obviously,
sensor1 can infer that the physical event occurs at
. Likewise, the actuator observes the event from
sensor1 at absolute timestamp
, and at
from sensor1s’ view, and at
from the actuator’s view. The event from
sensor2 occurs at
, where
maybe not equal to
. As mentioned earlier, we can’t figure out the order of two observations based on the timestamps
and
. To simplify the calculation of
, one intuitive solution is to select a good observer to let
. The actuator is such an observer, the actuator can infer that the event occurs at
and
. As
and
share the same local reference time, we have the difference of the timestamps
, where
and
are amount of the process time and transmission time. Currently,
the best observers are the sensors. To achieve this, we propose a dynamic decision process framework, which will be introduced in the last part of this paper.
Theoretically speaking, two observations of one same event should be identical. For timing, two observations should have the same timestamp, where
. However, it may be not true in the real world system, because the clocks on different subsystems have different speeds due to the frequency deviation of oscillators. The revised relative time model is shown in
Figure 5, where
is the system clock frequency of the respective subsystems. The tuple of timestamp is (accumulated time from the physical event is generated, local time). For example, the actuator observes the event from
sesnor1 at local time
, the accumulated time is
. From the view of the actuator, the physical event is generated at the relative time
.
So far, the remaining problem is how to automatically get the scale of the frequency
. Based on the time synchronization solutions for the symmetric network [
21] or the asymmetry network [
44], every observer can get the duration of transmission time by exchanging message methods according to its own clock, whereas compared to the absolute time model, the relative time model doesn’t need to synchronize the clocks. Instead, the neighbor subsystem just needs to check the scale of the frequency
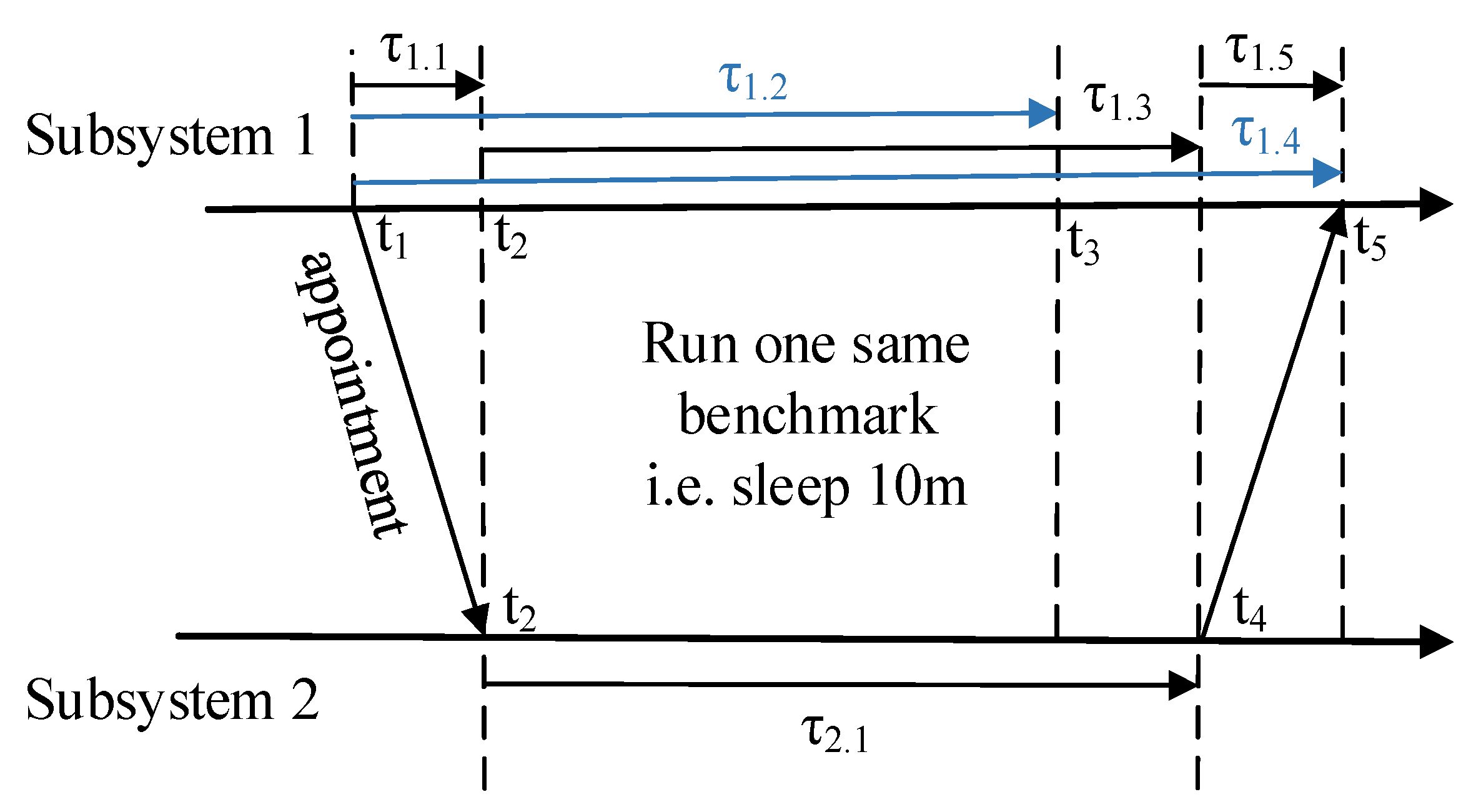
. We design an appointment and execution method to calculate
which is shown in
Figure 6. For easy understanding, all the timestamps in
Figure 6 are absolute times, and all the duration are relative. With the exchanging message method, every subsystem has already got the
and
(actually,
and
can be inaccurate because of
).
At the beginning, subsystem1 makes an appointment with subsystem2 to execute one same benchmark at the same time (the execution speed of the benchmark should be independent to the hardware architecture, i.e., the size of cache). Subsystem1 takes to finish the benchmark and takes to get the finished signal from subsystem2. From the view of subsystem1, it takes subsystem2 to finish the benchmark. Thus . We can simplify the relative time model by calibrating the clock (oscillator) of all subsystems with a base clock (oscillator) before deployment, and set for every subsystem and get an absolute duration. To simplify the formulation, we use the term absolute duration in the remainder of this paper. We can easily change the absolute duration to relative duration with formulation if it is necessary.
Considering related physical events are in geographical proximity, the observer should be as close as possible to the source of events. Thus, the accumulated error of duration of two events will not be too large that CPS can’t reproduce cause-effect relationships. As soon as the events being observed and serialized, their orders (relationships) are confirmed. Then, CPS can apply various technologies for further analysis of the relationship between these events.
The relative time model records the duration of events instead of the absolute timestamp when events occur. Ideally,
just needs to be set once. In the real world system, it may still need to be calibrated several times during the system lifetime, because oscillators are affected by temperature and aging. Anyhow, this process can decrease the frequency of synchronization significantly and has a more stable error. Furthermore, the relative time model doesn’t need a global reference time, which can improve the scalability of CPS significantly, no matter the subsystems are heterogeneous or not. Detail comparison between relative model and absolute time mode is beyond the scope of this paper, the qualitative conclusion is shown in
Table 1.
4. The Formal Reference Framework for Decision Process
As mentioned earlier, it can benefit a lot by improving the C&C of subsystems. Our solution mainly focuses on the composition of subsystems and decomposition of requirements at run-time. In this section, we introduce the formal reference framework for the dynamic decision process.
4.1. Overview of the Actor Based Framework
A self-managed CPS should automatically sense the environment and diagnose itself, then make both self-adapting and self-healing decisions, and execute these decisions. Decision making and executing are the two key parts to form the close-loop. Improving the C&C of subsystems can decrease the complexity of the process of both decision making and decision executing. Composability can simplify decision making by simplifying the evaluation of the reasonability of decisions. Otherwise, DSS has to enumerate all available combinations. Compositionality can simplify decision executing by simplifying the decomposition of the requirements at runtime, which is helpful for guaranteeing the dependability of decision execution. Composability and compositionality are two sides of the same coin, which are the necessary qualities for a good CPS framework.
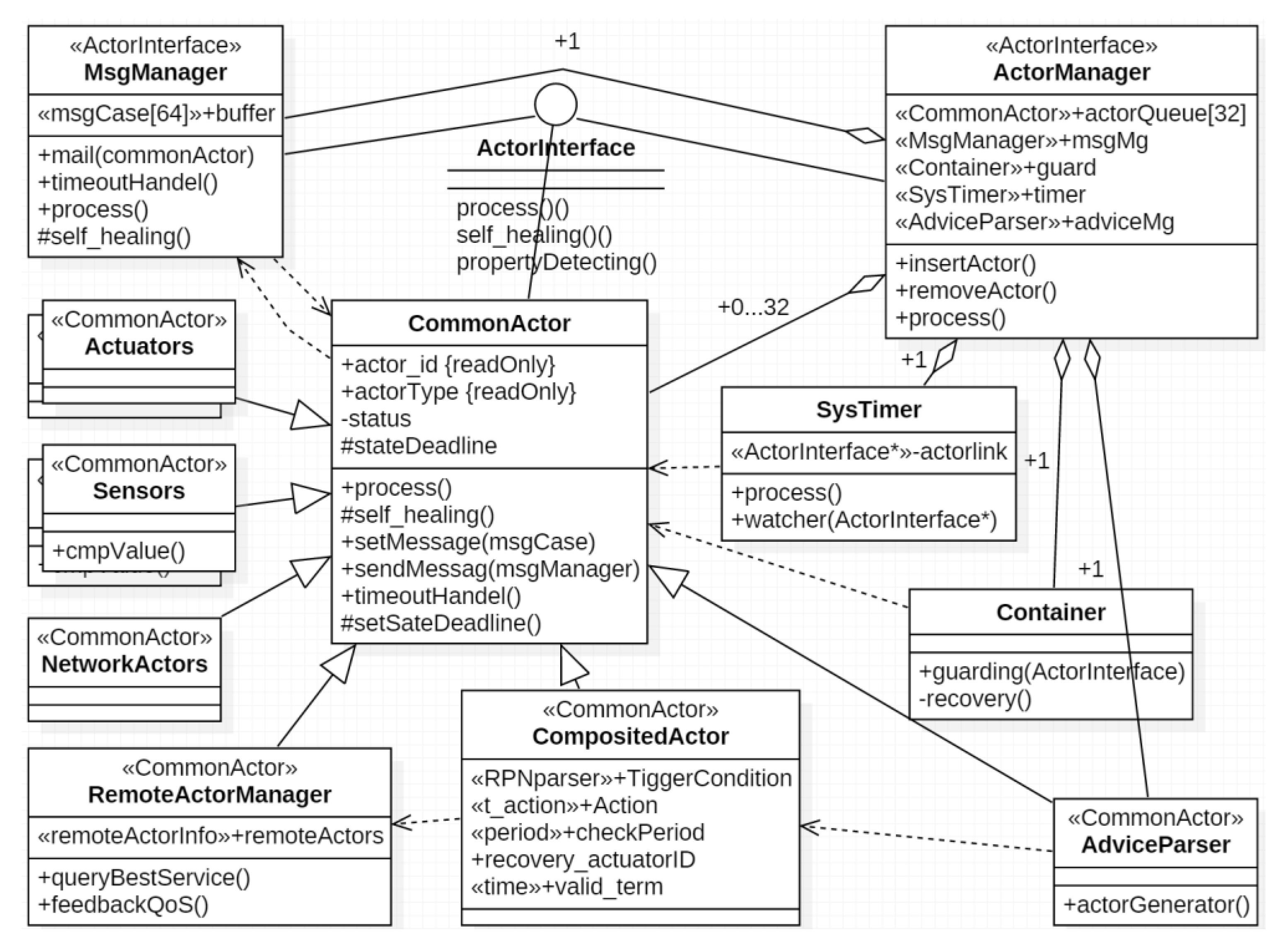
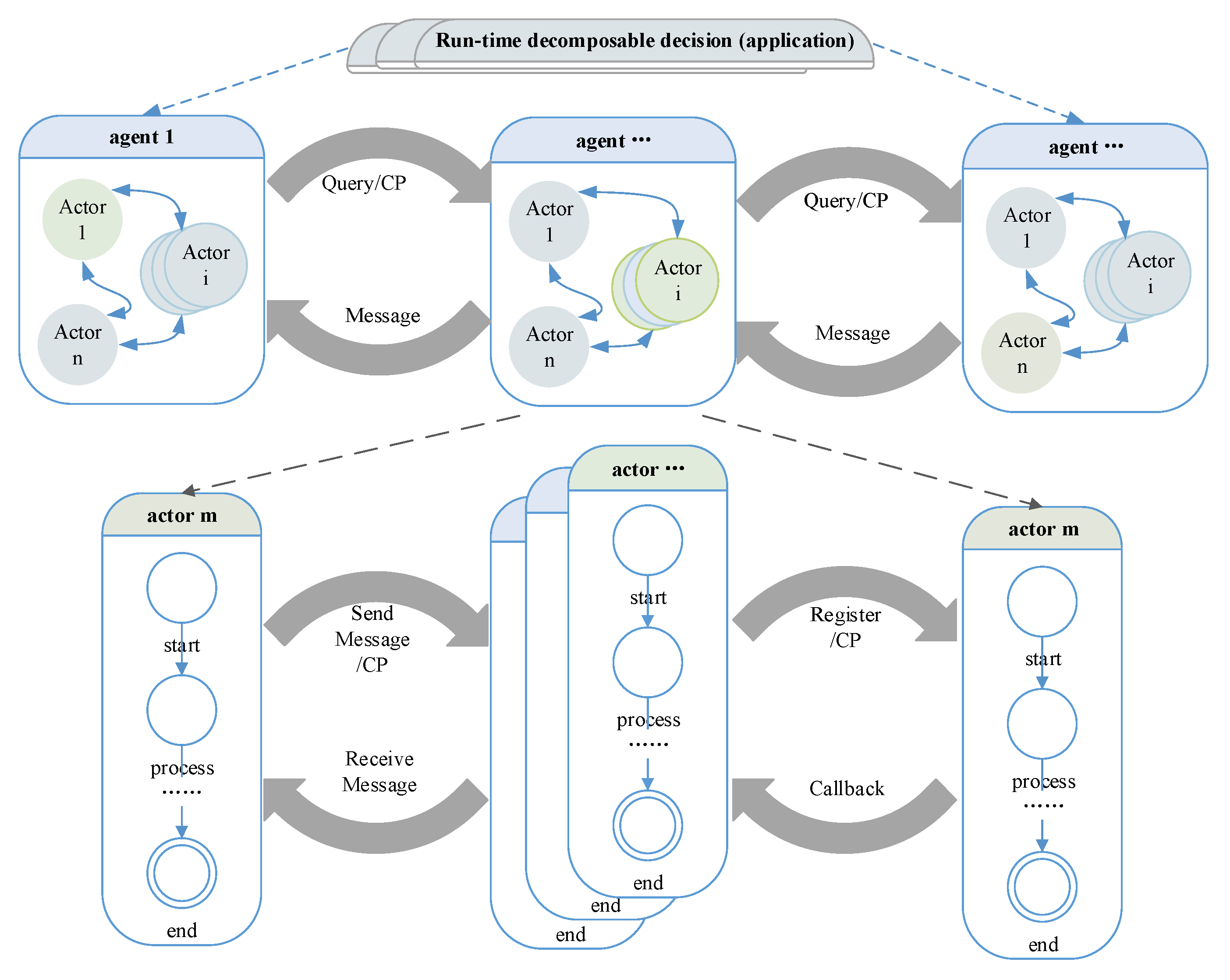
A self-management CPS includes two parts: (1) the agent platform, which includes hardware and corresponding actors; (2) the dynamic behavior management subsystem (decision subsystem). An overview of an actor-based framework for a self-management CPS is shown in
Figure 7. The actor is the atomic abstraction of subsystems in our reference model. Agents are the platform for decision execution. The behavior of a decision depends on both the properties of hardware and the properties of the actors. To simplify, we integrate the hardware properties into the properties of the actors. We assume that the decision has been made by the DSS. Here, we focus on the evaluation of advice and the dependability guaranteeing in run-time.
4.2. Actor and Decision Formalization
Definition 1 (Actors)
. An actor is a time bounded Mealy finite state machine (FSM) . Where is a finite set of events, and event should not be empty , is the timer interrupt event based on local time; is a finite set of states, where has a time bound that represents the duration that the actor stays in state , and the maximal time bound of state denotes ; is the initial state, and . is a set of transition operations, where , is the time bound of transition ; is a set of actions, where . In addition, an actor must contain one non-empty action ; otherwise, it can’t interact with other actors. is the time bound of action ; is the union set of the time bound of the state, transition and action . Here we have and because the transition in cyber space and the action with physical world are always asynchronous. is the identifier of the type of actor.
In the rest of this paper, we will simplify the notation by writing instead of trajectory (the transition sequence) , whenever the context allows doing so without introducing ambiguity. We define if and only if and produce identical output sequence for all valid input sequences , where . , just says that the two actors has the same trajectory, the two actors may be not isomorphism, and the properties of two actors can be different, i.e., the performance, the reliability etc. If , and also all the properties of and are the same, we use the notation .
Every actor has a set of properties, which we denote as . In our dependable framework, , where is the worst-case execution-time (WCET) of processing a decision, is the best-case execution-time (BCET). is the failure rate, where is the online time or the elapsed time from last recovery. We can calculate by replacing the BCET and in the formula . Likewise, we have the .
Notice
and
are not the time from
to
. For the case presented in
Figure 8,
receives output in state
, and generates a new output in state
. Thus
is the
in formula
. We also can get the
and
with the Monte Carlo method.
Definition 2 (Actor Composition)
. Let be a composition, where is a set of preorder actors of the composition, ; is a set of successor actors of the composition, and ; is the messages (special events) set for the composition communication; is the communication pair of the composition, the arrow is the direction of message.
We use the notations
to represent point-to-point communication that
sends a message
in state
with action
, and
receives
in state
with action
, and
,
.
is the one-to-many communication.
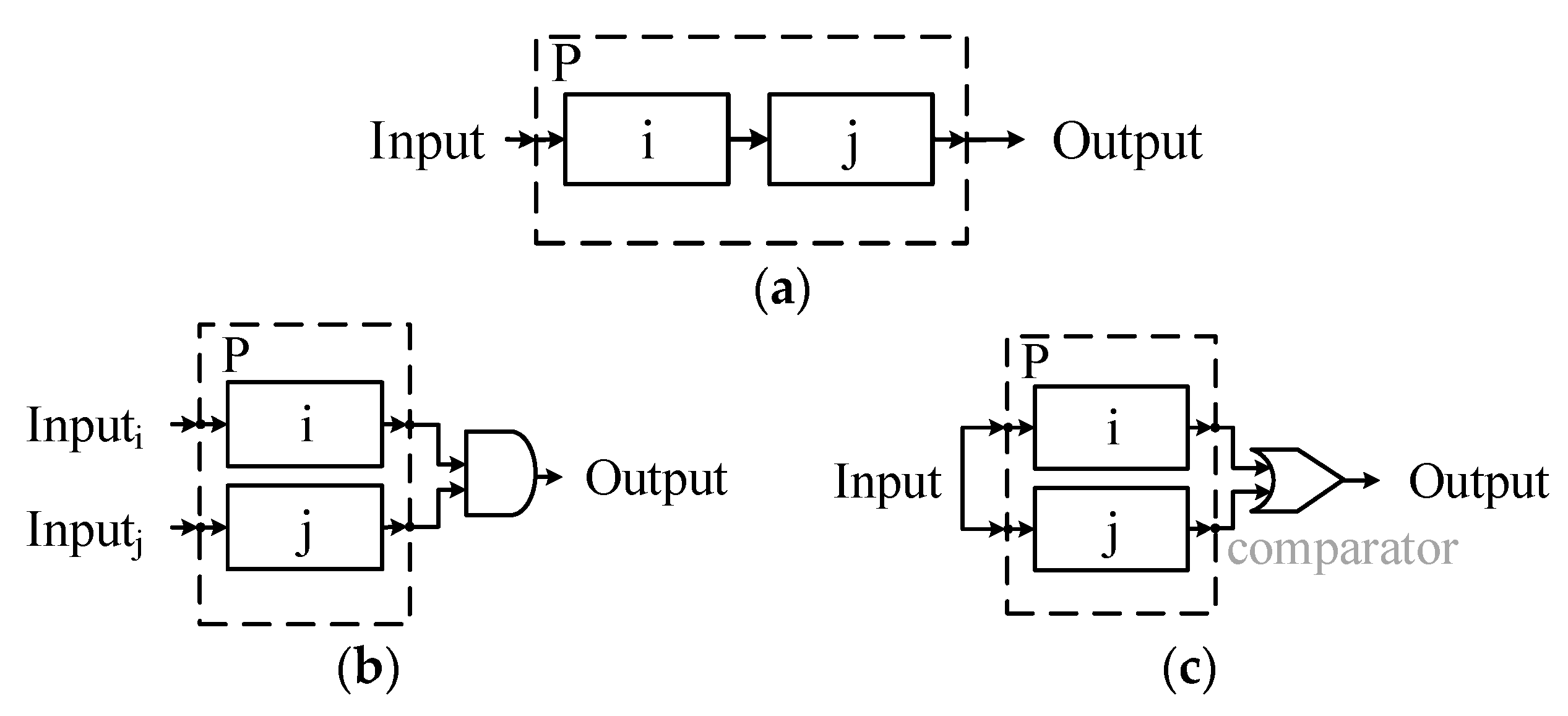
is the many-to-one communication. The three types of communication are illustrated in
Table 2.
Using message-based composition, we can decouple the actors and reduce the constraints of operation interfaces.
We will use to represent the communication in short, and to identify the message itself. Without explicit mention, also implies that the and have the same definition of the structure of the message; if not, will ignore the message. In addition, we use , where shares the same description of structure with , the context/value of message could be different. means that and have the same the structure and the context. means that and are identical, which means that and the properties (e.g., time bound etc.) of message are the same.
Notice that, according to this model, one can send a message to itself, whereas in a real system, only the composited actor can send the message to itself (the subsystem of the composited actor). It is meaningless for an atomic actor to do so. is the agent/subsystem level view of interactions. These interactions are not limited to applications’ communication, which include the interactions between agents to maintain the infrastructures, e.g., topology, QoS, etc. For advice evaluation, we ignore the communication for maintenance.
Definition 3 (Advice)
. Let be an advice, where is a set of observation event , which represents the preorder actor observes whether the target has generated event or not, , , ; is an composition which includes an operation instruction on event , . is the identifier of actuator actor to take the action, is the action triggering conditions, is the action finishing conditions, , ; is Boolean operations . A generic form of advice is defined as . Every advice has a set of constraints , is the maximal process time of the decision that generated from , is the term of validity of , is the minimum reliability requirement of the decision.
Notice that operation instructions
in the composition message for
can be a set of operations
.
For safety, one decision contains one final actuator and can only take one action, because mealy FSM (1) is on not closed status under parallel composition [
45], hence, the final action should be processed in serial order. However, it doesn’t says that actuators can’t be the target actor of
.
is an observation event, the trigger of a decision can depend on the event whether a target actuator has taken/finished an action.
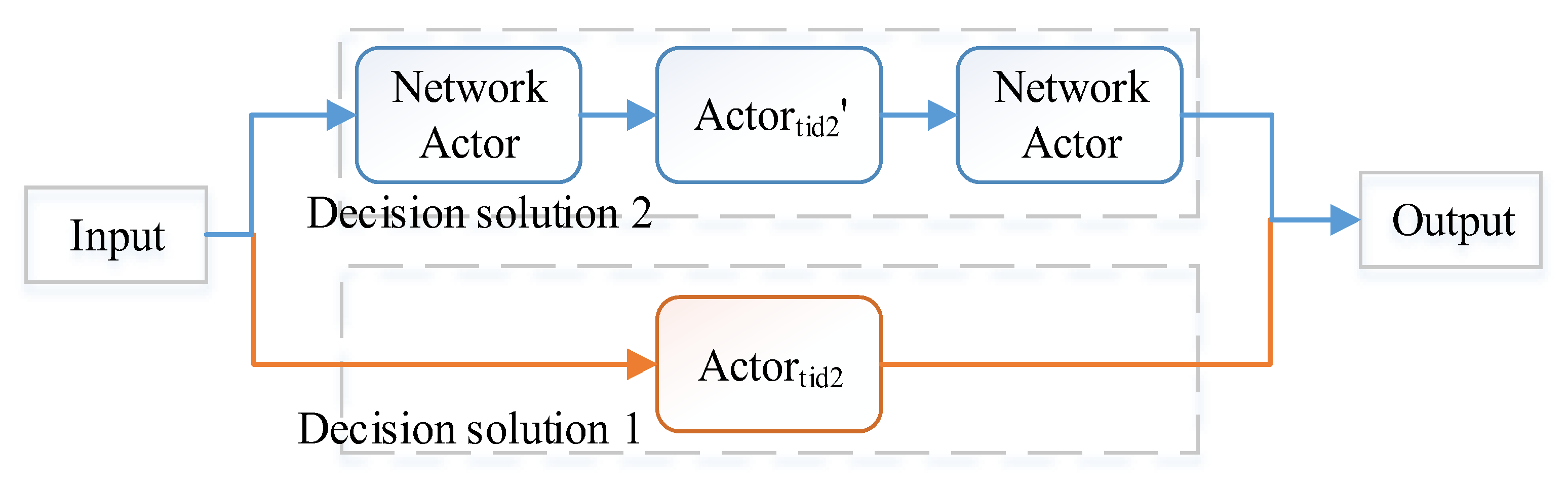
Definition 4 (Decision)
. Let be the decision instance of an advice , where and whose is defined in or is an network actor; is the universally unique identifier, has the same with the decision; is the run-time decomposed requirements of .
is the remaining processing time of the decision, where is the actual processing time of ; is the saved time; is the current reliability of decision, which will be introduced in Section 5 and Section 6.1. belongs to a composition pattern, which will be introduced in Section 5.2. And also has a time bound , first waits for time then starts to process the decision, is the reserved time for parallel composition to synchronize the processing; is the reserved time for decision process, . In summary, should wait and finish the step of decision in .
Uuid is the identification to avoid repeatedly processing one decision on the same actors, which is an important constraint to prevent duplication and maintain safety.
is for transmitting the dynamic requirement to successor actors,
is for synchronization,
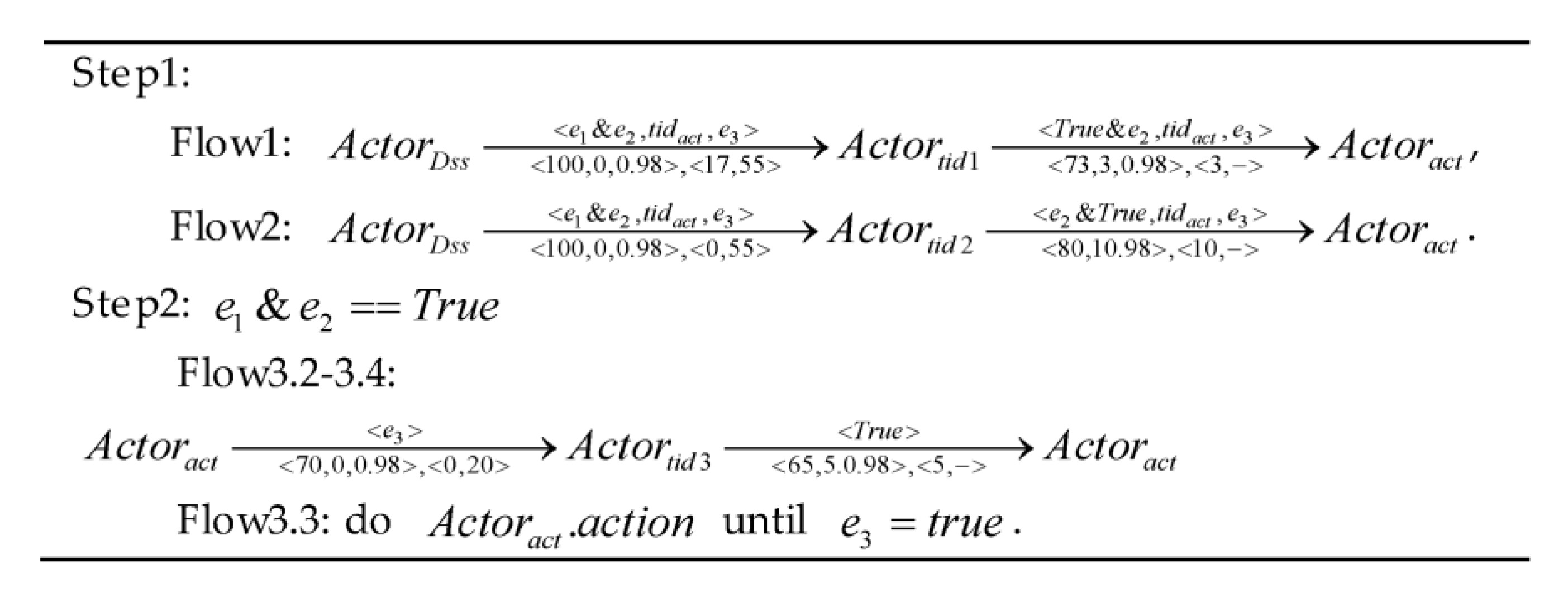
is used to control the deadline of process. The example of the formal process flow is introduced in
Appendix A.1.
4.3. Centralized and Decentralized Decision Process
According to the way of decision management, there are two kinds of decision process forms. One is centralized decision process; another is our proposal, decentralized decision process. Without loss of generality, the local DSS generates an advice with two , .
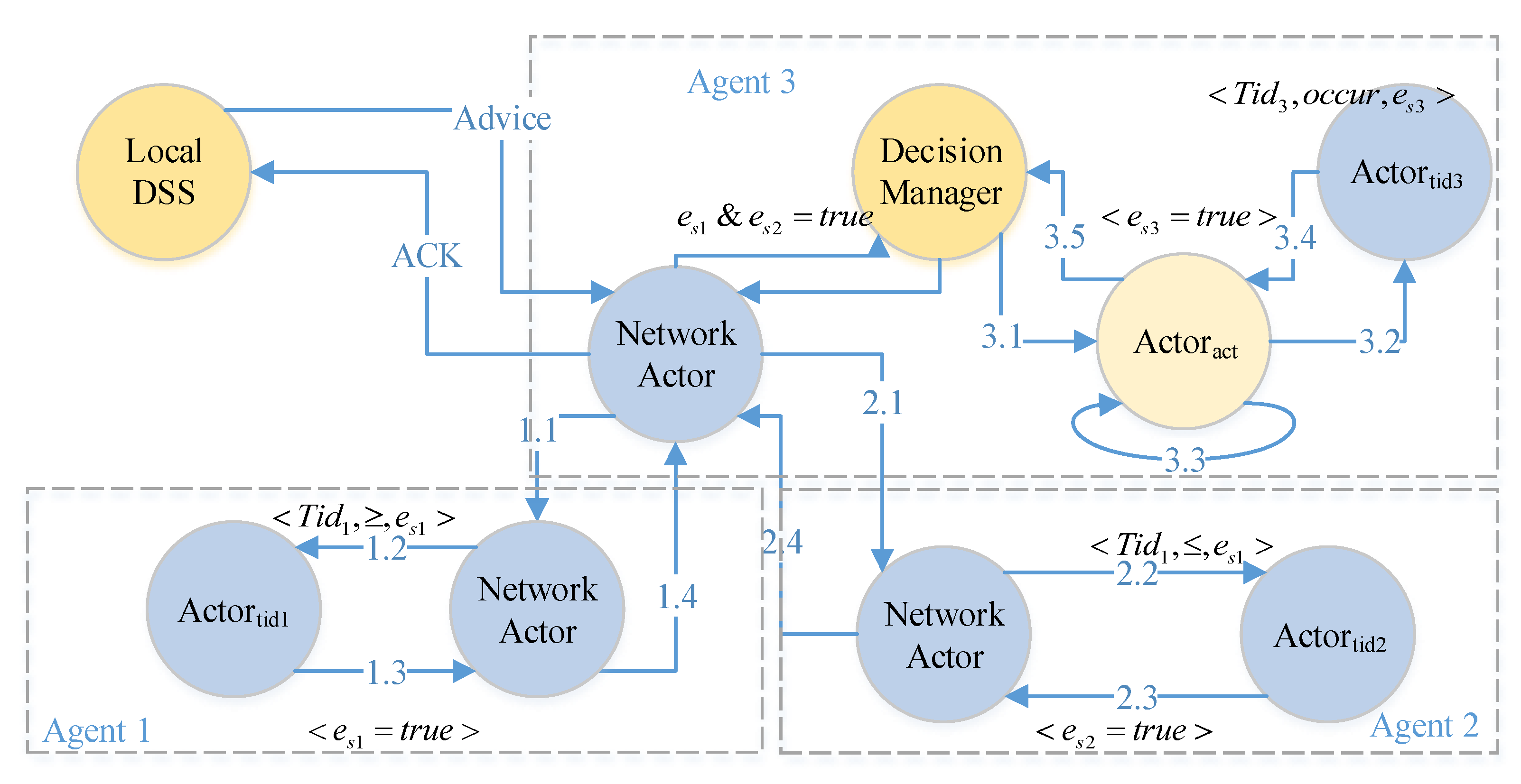
The
centralized decision process flow is illustrated in
Figure 9. The local DSS sends an advice to a decision manager and the decision manager controls the flows of a decision process. At every step (1.1 to 1.4, 2.1 to 2.4 and 3.1 to 3.5), the sensors and actuators should acknowledge to the manager, then the manager sends the command for next operation. By the way,
is also a decision manager to the process of
.
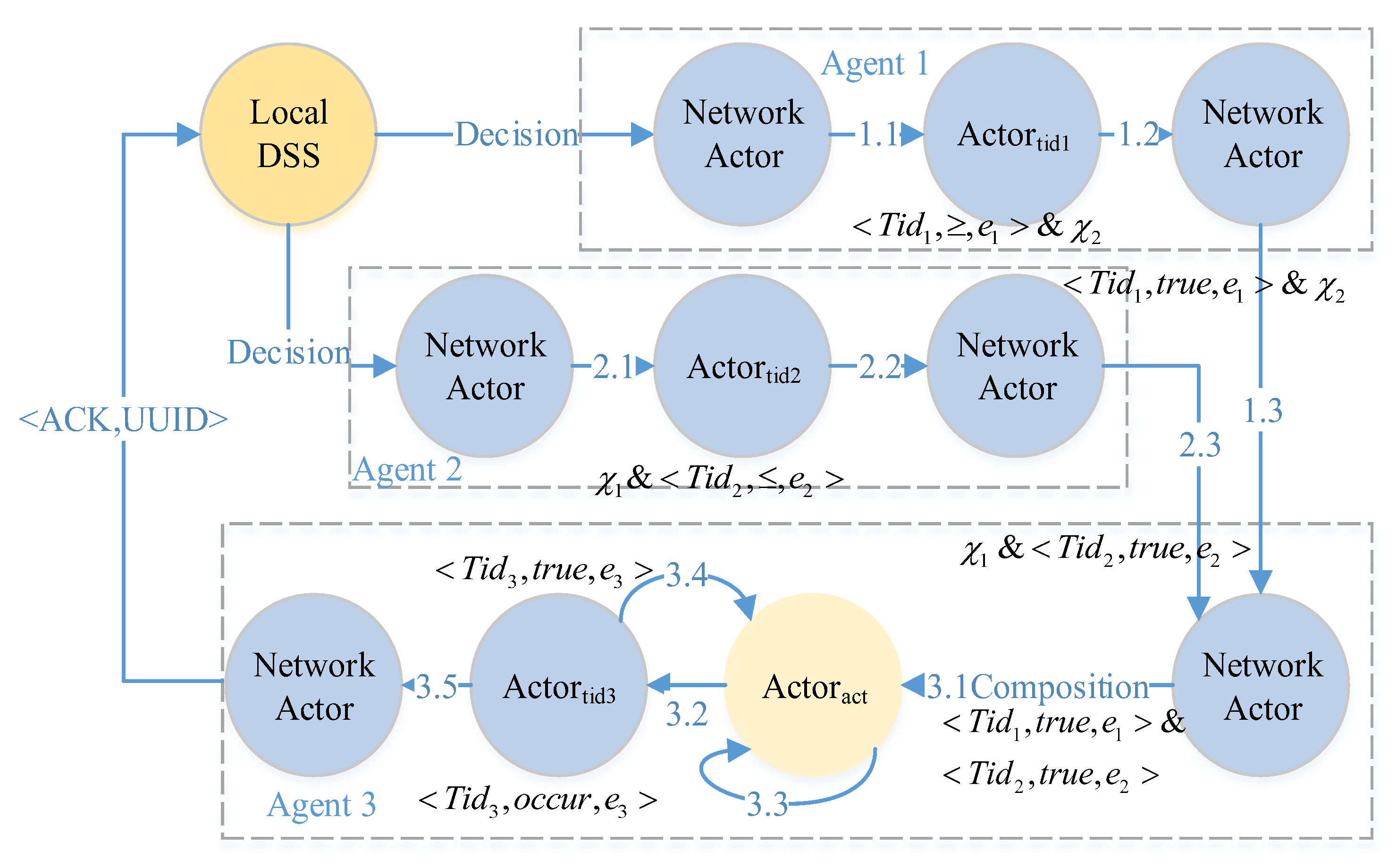
To overcome the single point of failure and to minimize the duration (time) error for event observations, we design a decision as a program solution. The
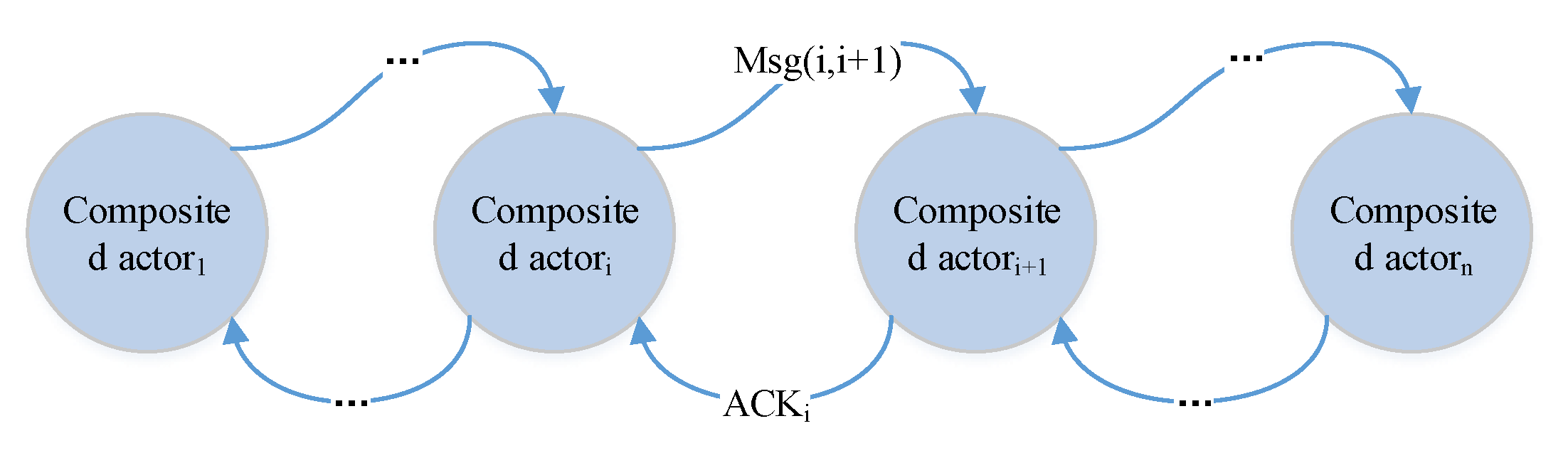
decentralized decision process flow is illustrated in
Figure 10. A decision is processed with the flow of transmission. It has no explicit decision manager. In some sense, every actor can be regarded as a decision manager for next step composition. The successor waits for all messages from its preorders according to the composition pattern (step 3.1). Based on the decentralized solution, CPS can observe the firsthand events (both physical events and cyber events).
4.4. Simplify Self-Management Strategies with Self-Similar Actor
CPSs have massive subsystems, and some of them are heterogeneous. It is impossible to specify strategies for every subsystem. In general, most of the subsystems have limited resources, it is too complex to apply enough powerful strategies to adapt to all situations. Moreover, it is also impossible to exhaust all situations. The systematic solution is need to decease the complexity of runtime decision management.
The key idea to achieve self-management without deceasing the dependability is using simplicity to control complexity [
5] and simplifying the management (control) based on self-similarity [
46]. To achieve this, we need to take full advantage of the characteristic of SoS and design a systematic framework and self-similar subsystems to enable recursive composition for CPS. Our framework includes four levels of abstraction:
CPS,
Agent,
CompositedActor and
CommonActor. The BNF (Backus Normal Form) of the composition relation is shown in Equation (1). To achieve self-similarity, we propose a well-design actor interface to simplify the self-management. These actors share a set of similar operations, the self-similar interface is shown in
Figure 11. By applying FSM based actor design, we simplify the constraints for runtime decision decomposition and actor composition. The detailed composition pattern will be discussed in
Section 5.
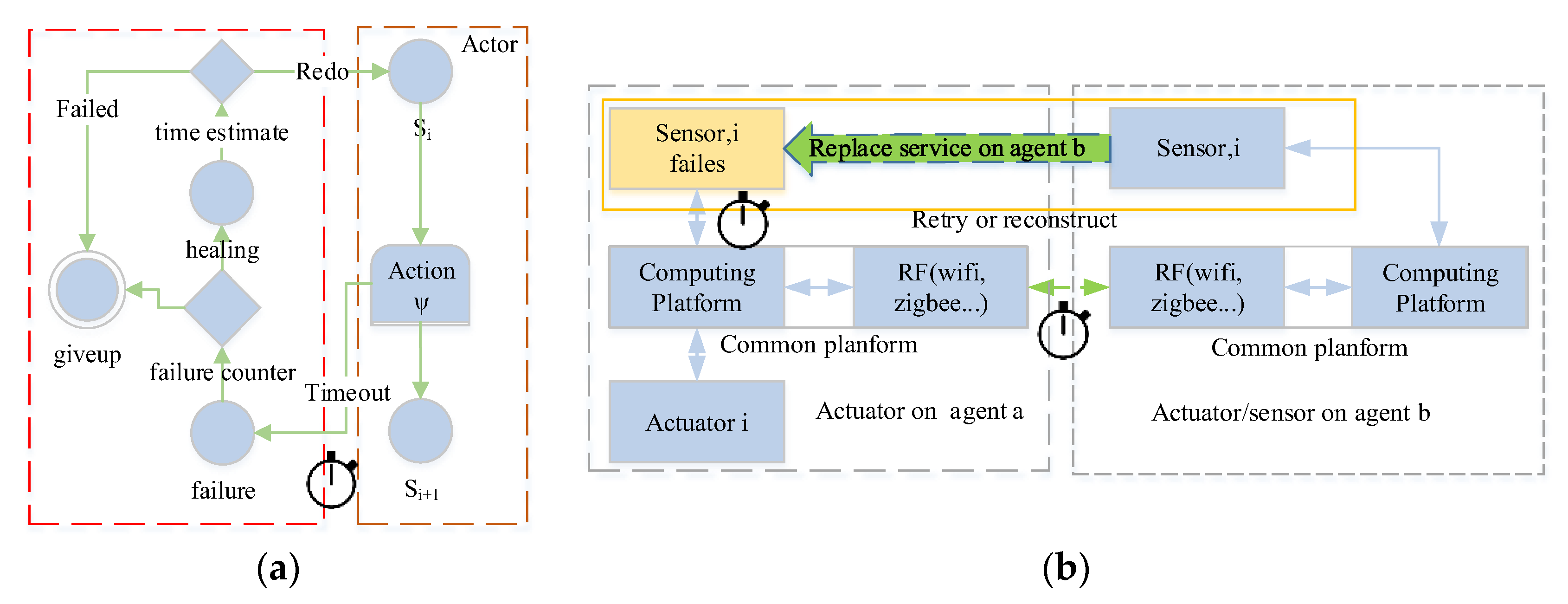
Base on the thought of everything as an actor, we can abstract the decision with compositedactor, which can be recursive decomposed at runtime. Based on the self-similar interface design, the ActorManager on different agents can manage every sub-part of decision with the same rule. And every actor supports a set of same actions self-healing() and property_detecting(). property_detecting() is dedicated to check the requirements with the actors’ properties, which include process time and reliability. A compositedactor is generated by the adviceparser according to the advice. The compositedactor just fills the Tiggerconditions if there is not on the same agent. Otherwise, the compositedactor take actions if the value of the Boolean expression of the Tiggerconditions is true.
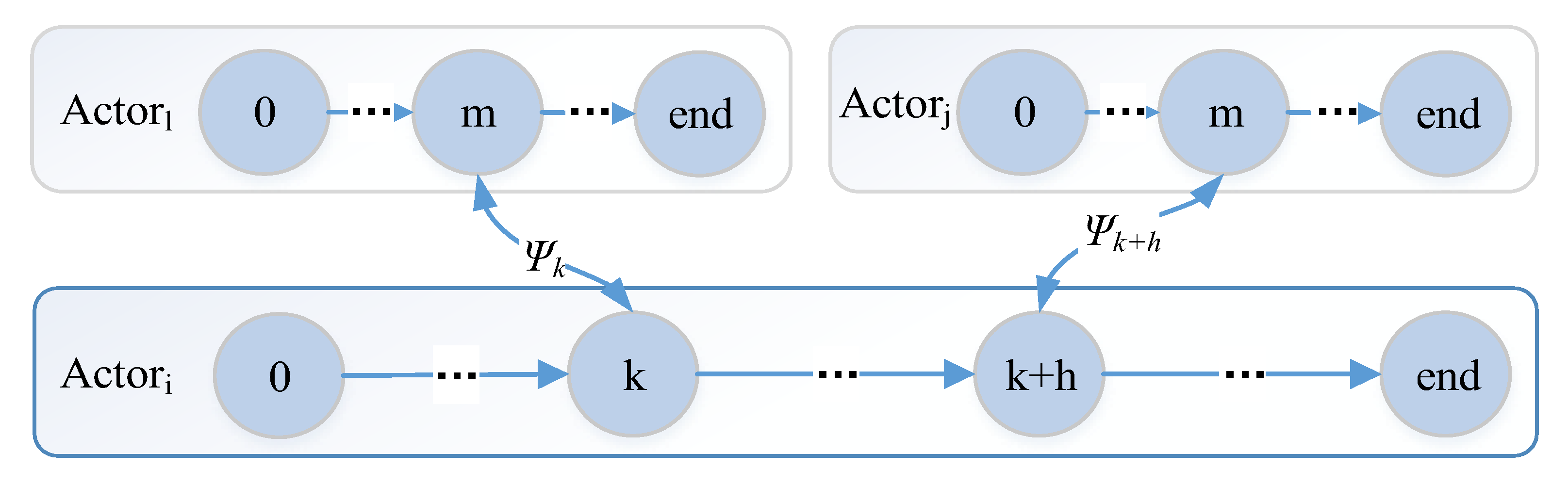
By using message-based composition, actors share the same communication pattern. Combining with the self-similar interface, actors can have a self-similar behavior, which is depicted in
Figure 12. For example, based on the observation event
and
, the observation is recursive (Boolean operation is closed); logically, any level subsystem can be an observer. The recursive decomposition of event stops when the event is an atomic event, where
. Based on the recursive design, a complex strategy/decision can be decomposed and processed by basic actors. Based on self-similar behavior, simple (self-healing) rules can be applied at all levels of CPS, which is shown in
Figure 13. The threshold for the timeout detection are the time bound
which defined in
Section 4.2.
8. Discussion
In this paper, we mainly focus on the introduction of a compositional framework and the evaluation of decentralized decision process. A CPS is an autonomic computing system which should be able to adapt to the changeable environment, prevent and recover from various failures automatically. To achieve this goal, CPS has to adjust its structure and behavior dynamically. In this paper, we introduce a systemic solution to improve the consistency of event observation (the long-term loop) and the dependability of decision process (the short-term loop). To solve the inconsistent timestamp of the events, an observer based relative time solution is proposed to guarantee the consistent event observation for causal reasoning and processing duration management. The relative time solution infers the timestamp when the events occur with process duration and the timestamp that event observed. Using the locality of events, we can select the nearest local observer to control the errors of observation. This solution doesn’t need the global reference time and periodic clock synchronization, it can increase the scalability of CPS.
To minimize the errors of observation and to overcome single point failure of centralized decision process, we design a formal reference framework based on compositional actor for self-management CPS. Base on the thought of decision as a program, actor-based decisions (advice) can be decomposed and composed at runtime. Moreover, a self-similar recursive actor interface is proposed to simplify self-management. We provide the patterns and evaluation rules and constraints for reliability and process time composition and decomposition.
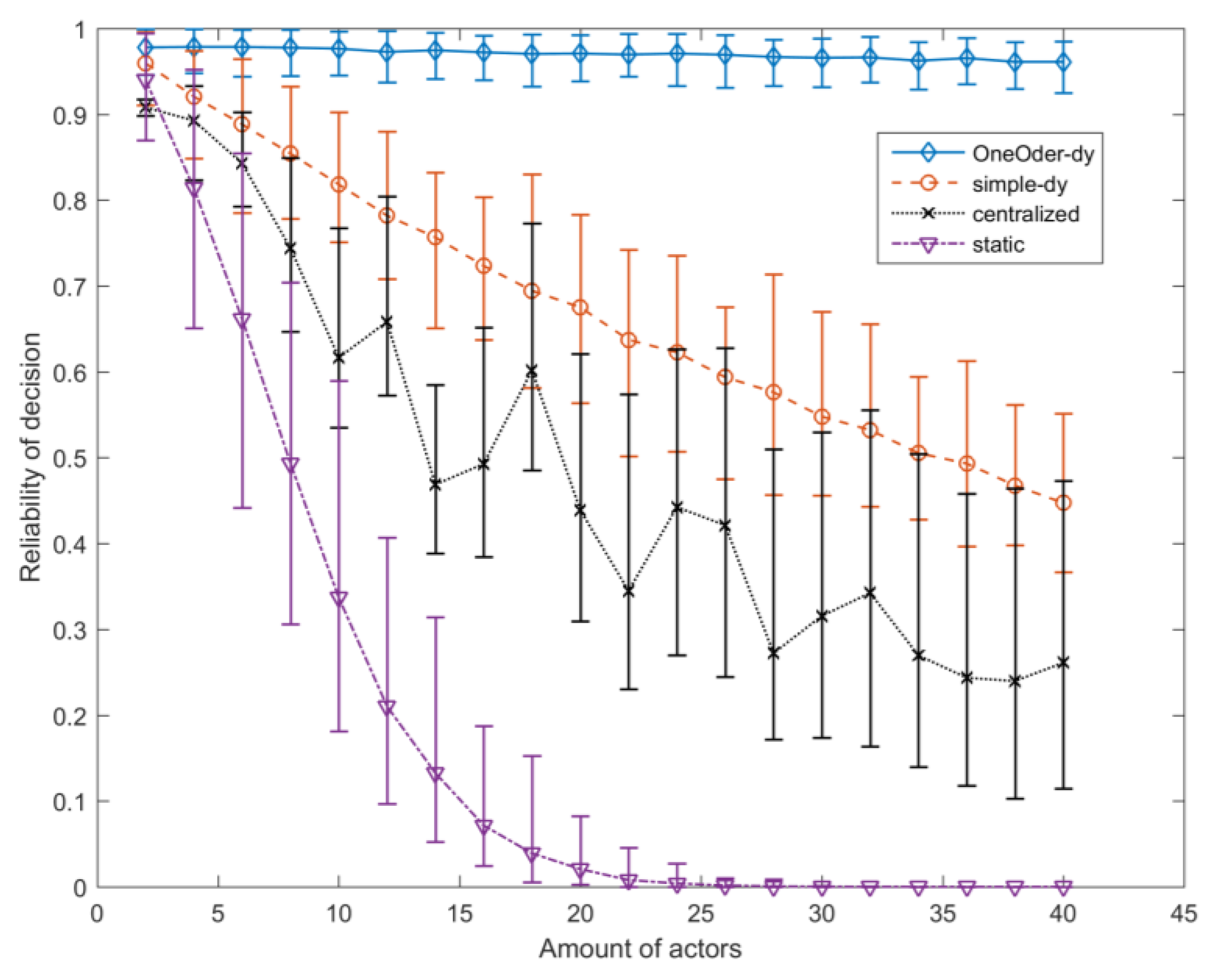
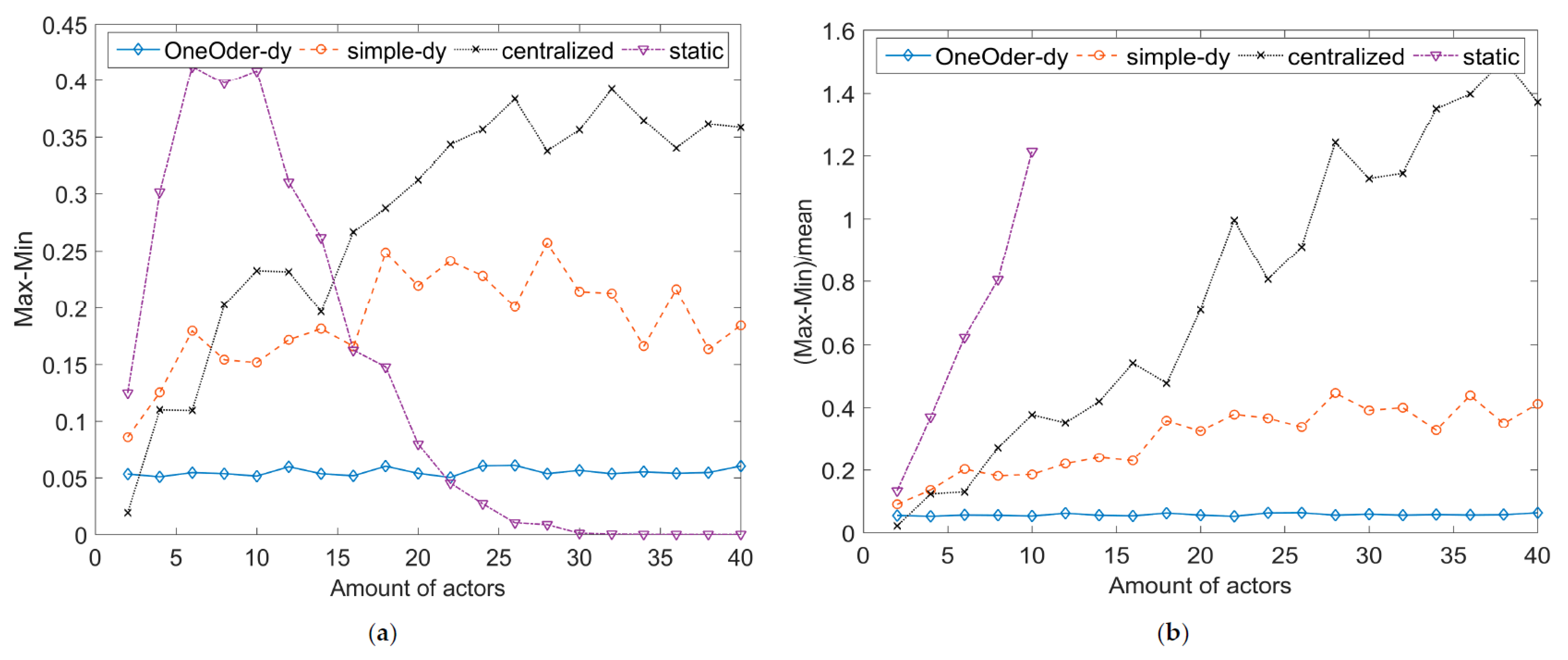
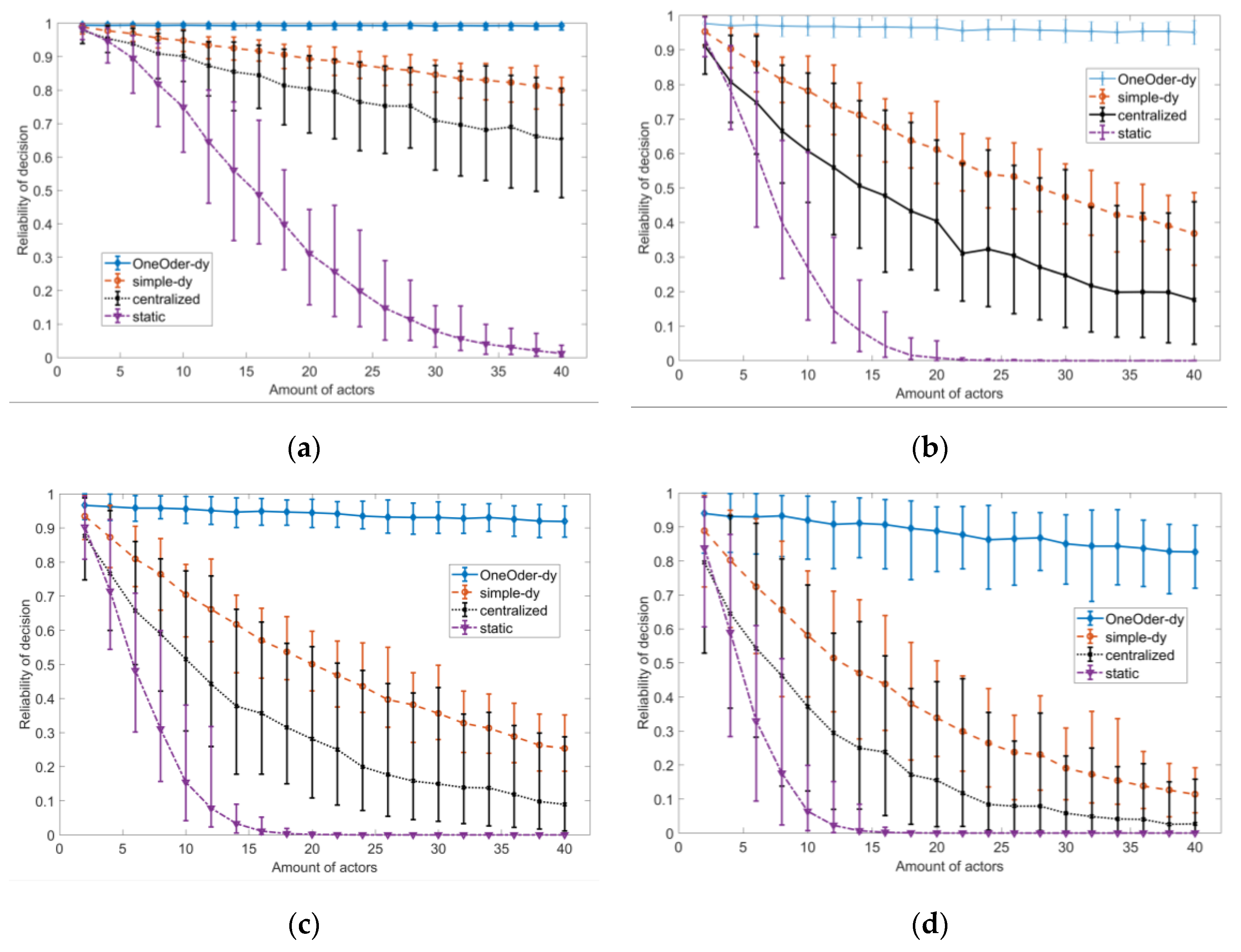
Based on this framework, we propose a simple dynamic decision process strategy and a one-order dynamic feedback decision process strategy and compare the reliability with traditional static strategy and centralized decision process strategy, the simulation results shows that the one-order dynamic feedback strategy has high reliability, scalability and stability against the complexity of decision and random failure.
The testing results of the real world system show the comprehensive improvement of dependability with our framework. Our compositional framework improves the scalability through three main solutions: (1) the relative time model is applied to remove the central reference time node; (2) the compositional framework supports decentralized decision process; (3) one-order dynamic feedback strategy improves the scalability. CPS can apply different composition patterns to achieve the balance between requirements of safety, reliability and process time.
In this paper, we show a way to simplify the dependability evaluation for dynamic systems. By improving the composability and compositionality of actors, we can evaluate the system requirements with the properties of compositional actors, and deduce the system behavior from the behavior of subsystems, which can accelerate the progress of evaluation significantly.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










