1. Introduction
Navigation is a process of monitoring and controlling the movement of an agent from one place to another. Many navigation systems have their goal positions that the agent is supposed to reach. Recent navigation studies show diverse forms of moving vehicles from simple wheeled robots [
1] to a wide range of underwater vehicles [
2], unmanned aerial vehicles [
3] and spacecraft [
4] with various sensors [
5,
6]. Furthermore, there have been techniques using various sensors like vision [
7], inertia [
8] and RFID [
9], which represent a great deal of engineering achievement.
Different from the above engineering approaches, various animals demonstrate remarkable homing capacity, and their navigation system robustly works in real environments. Local visual homing based on a snapshot model [
10] is inspired by insect navigation. An agent is supposed to return to the nest using visual cues or landmarks. The snapshot model uses only a pair of snapshot images at the nest and at the current position. The difference of landmark positions in the two images can be used to derive information about the relative location difference or homing direction. The angular difference in landmark position can greatly contribute to decisions about homing. Honeybees can find the homing direction by reducing the differences of the angular distribution of visual landmarks observed in a pair of snapshots [
10].
Desert ants (
) are known to use odometry and visual information for their navigation. The path integration with odometry information is related to calculating the accurate home location [
11,
12,
13,
14,
15]. Cumulative errors in path integration can be compensated by visual cues including the skyline and polarized information, as well as the surrounding landmark information [
16,
17,
18]. There are many other examples with visual cues [
19,
20,
21,
22], and also, their navigation involves many types of sensors including vision, olfactory, auditory, odometry and magnetic sensors. [
23,
24,
25,
26]
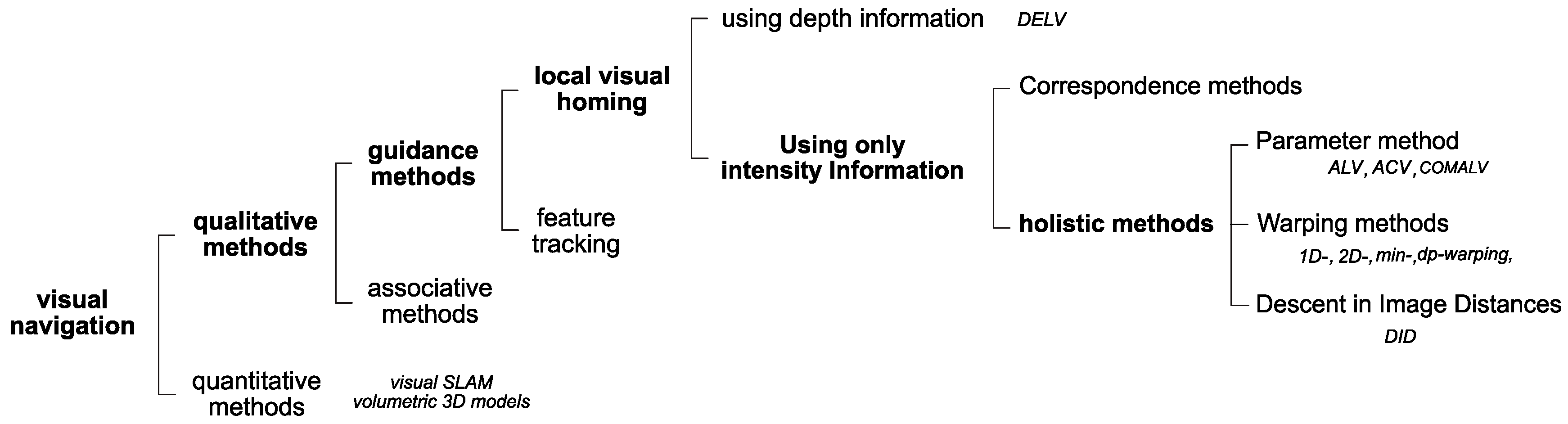
There have been many local visual homing techniques. We can largely divide these into two parts using depth or intensity information [
27] as shown in
Figure 1. Furthermore, intensity-based approaches can be divided into holistic methods and correspondence methods. Correspondence methods match extracted features in the images and thus need a complex algorithm to process feature extraction and feature matching. If there is a reference compass available, the one-to-one correspondence matching can be omitted. Holistic methods try to match the whole pixel information in the two images without extracting landmark features or classifying the features. Holistic methods have relatively low complexity.
Landmark vector models to represent the surrounding environment have been studied, and the models often use angular positions of landmarks without landmark matching, if a reference compass such as a light or magnetic compass is available and the two snapshots can be aligned with the reference coordinate. The Average Landmark Vector (ALV) model [
28] is a typical example of the landmark vector model covering the omnidirectional view. Even if it is assumed that all the landmarks on the retinal image have equal distances, the whole distribution of landmarks can be simply represented as the average landmark vector, each of which has a unit length with its angular position. According to the snapshot model [
10], the model compares two ALVs obtained from the home snapshot and the current view. The difference between the two vectors can estimate the homing direction from the current position. The ALV model can be combined with visual feature detection [
29]. The Average Correctional Vector (ACV) [
30,
31] is a variation of the ALV model. This model uses the amount of angular differences as the length of the landmark vector. Another method, the Distance Estimated Landmark Vector (DELV) model [
32,
33], suggests encoding distance in the landmark vectors and provides better estimation of the homing vector at the current position by localizing the current position in a reference map. The snapshot matching method can be combined with optic flow [
34], and it has been applied to aircraft trying to estimate the current location.
In the holistic methods, there have been two ways to handle the whole image pixels, the image distance model and the warping model. The Descent in Image Distance (DID) method [
35] uses the all pixels in a pair of images to calculate the image distance. The pixel difference between the snapshot image at a given position and the home snapshot can roughly estimate the relative distance between the two positions. If a snapshot among candidate snapshots at different positions is close to the home snapshot in terms of the image distance, it is assumed that the direction to the snapshot is close to the homing direction. More advanced models following the idea have been studied [
36,
37]. Homing in scale space [
38] uses correspondences between SIFT features and analyzes the resulting flow field to determine the movement direction. It is mathematically justified by another study [
39]. Another view-based homing method based on the Image Coordinates Extrapolation (ICE) algorithm has been tested [
40].
In contrast to the above image distance models, there have been warping methods to calculate all possible matchings between all pixels in a pair of images as another holistic approach. In the one-dimensional warping model [
41,
42,
43], all possible changes of pixels along the horizontal line are calculated under the assumption that landmarks have equal distances. The homing direction can be estimated by searching for the smallest difference in a particular angle between the candidate image and the home reference image. There are also advanced warping models including the 2D-warping and min-warping model [
44,
45,
46] that apply a variation of alignment angle estimation for the environment without a reference compass. There have been other variations of the warping model [
47,
48]. Recently, a method with various visual features like SURF has been compared with the holistic approach for robotic experiment [
49]. Generally, the holistic methods show robust performance, but need high computing time.
The image warping methods normally have an equal distance assumption for landmarks. However, the visual information is easily changed by position, distance, luminous sources, shades or other environmental factors. They can produce large homing error depending on the environmental situation. The distance information has been very often neglected in the holistic approaches, as well as landmark vector models, although it can contribute to reading the surrounding environmental information. Recently, it was shown that the depth information greatly improves the homing performance [
33,
50]. In this paper, we suggest a moment model to combine the distance information with visual features or image pixel information.
Another issue in local visual homing is related to an alignment problem of two snapshot images. If there is no reference compass, the orientations of the current view and the home need to be aligned together. That is, one visual feature in the current view should correspond to a visual feature in the home snapshot, since the visual feature points to the same landmark object. A solution to match the two different orientations is to calculate the image differences between the home snapshot and the rotated image of the current snapshot and find the rotation angle of the current view with the minimal image difference, which is called the visual compass approach [
35]. Another approach is the landmark arrangement method [
51] in which a set of visual landmarks in the current view are re-mapped to visual landmarks one by one in the reference coordinate, and a circular shift of the landmarks is applied repeatedly to find the best matching of the visual landmarks in the two orientations by checking if a set of the resultant homing vectors starting from each landmark has converged into one point with small variance. In our experiments, we will test the above two approaches for the alignment of the two snapshot images, if there is no reference compass.
In the complex cluttered environment, the Simultaneous Localization and Mapping (SLAM) method has been popular. SLAM often uses a laser sensor for distance information to build a map for the environment. Interestingly, a moment model called Elevation Moment of Inertia (EMOI) has been suggested to imitate a physical quantity, moment of inertia [
52]. The model characterizes the environmental landscape, the surrounding range value and height information as a scalar value called EMOI. Inspired by the model, we suggest a new type of moment function to cover various environmental information, which can read the landmark distribution from the environment with two components, the distance to landmarks and the visual feature of landmarks.
The main contribution of our work is to suggest a new type of moment potential to guide homing navigation and prove the convergence of the moment model to a unique reference point. The homing navigation follows the snapshot theory to compare two snapshots to determine the homing direction. We provide a homing vector estimation based on the reference point in the moment model for a pair of snapshots. Furthermore, it is shown that the moment model can encode the landmark distribution and features. Our approach can be extended to a moment model with multiple features, which can produce multiple reference points for robust homing performance. The combinational model with distance and visual features shows better homing performance than the distance information alone or the visual features alone. We demonstrate robotic homing experiments with the moment model and various methods.
2. Method
2.1. Robot Platform and the Environment
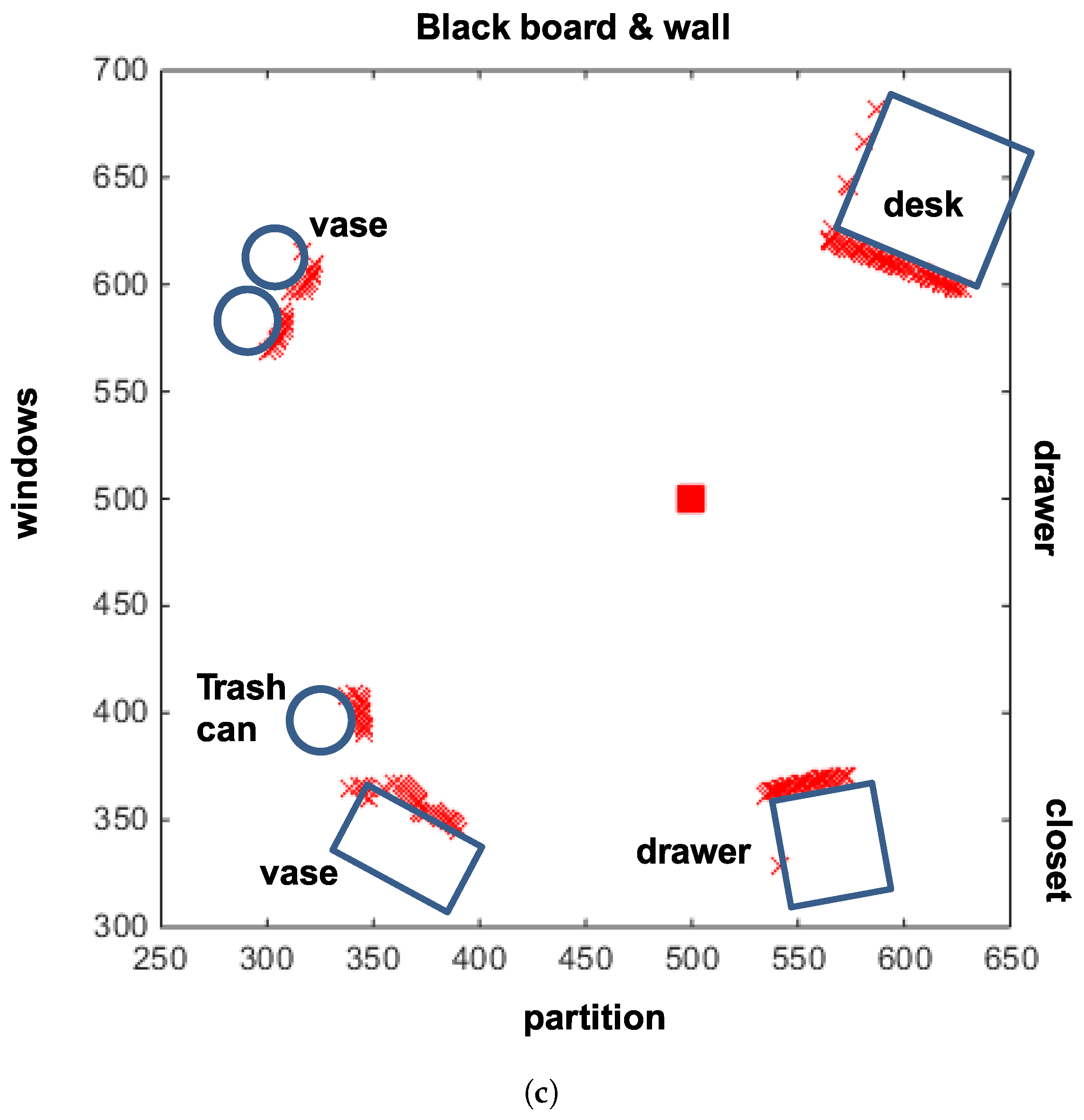
We test robotic experiments in a 6 m × 6 m room with several objects including dresser, drawers, a trash can, a plant, windows and walls. We use i-Robot Roomba for a mobile robot with two wheels, which is connected to a laptop computer for control. Here, the robot platform can read a panoramic image of the surrounding environment through an omnidirectional camera in
Figure 2, which consists of a Logitech Webcam E3500, a metal ball for a reflection mirror and the acryl support for mounting. The robot can also be mounted with a HOKUYO laser sensor URG-04 LX model shown in
Figure 2. The laser sensor can cover a range of 240 degrees in angular space with 0.36 degree resolution. To obtain an omnidirectional distance image, two shots from the laser sensor are needed. In this way, we can collect both an omnidirectional color image and depth information.
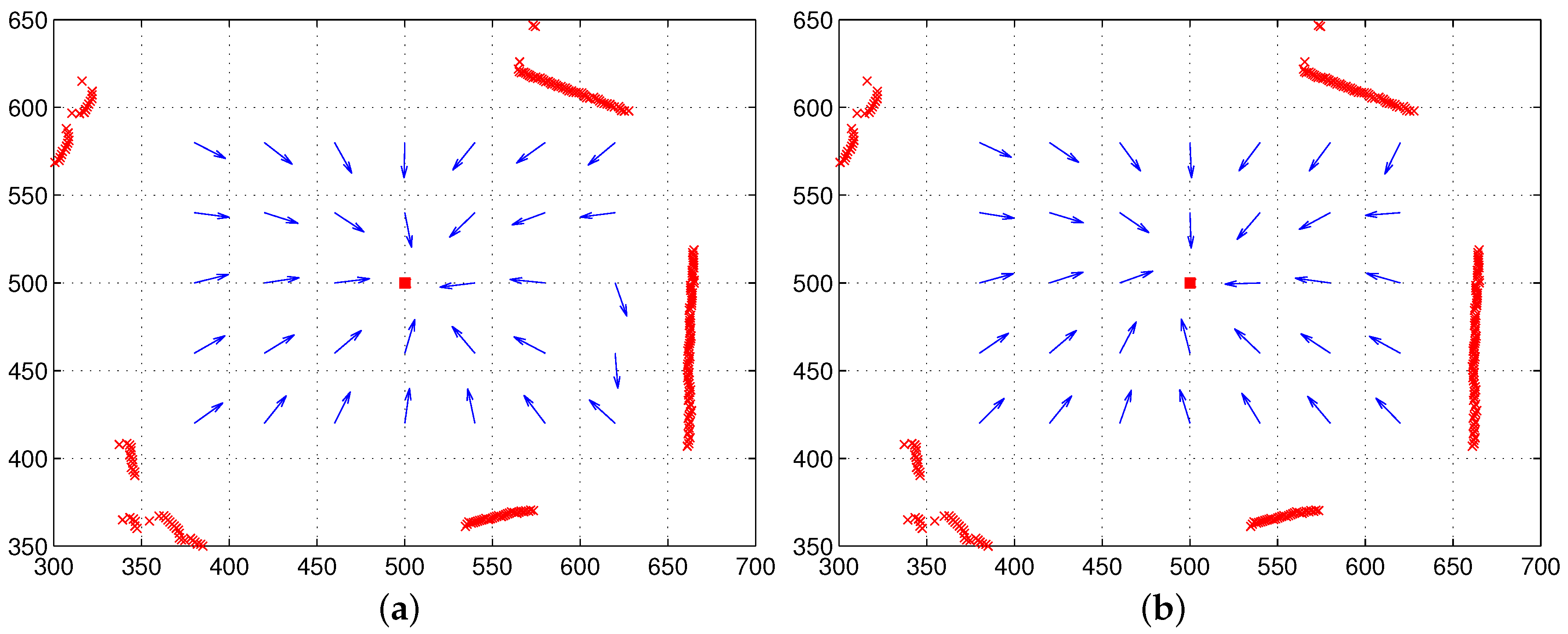
Figure 3 shows an example of the reconstructed image and depth map for the surrounding environment (red × marks show sensor readings from the laser sensor).
An omni-directional image that the robot takes has 640 × 480 RGB pixels. It is converted into a panoramic image, 720 × 120 pixels (with 0.5 degree angular resolution), with a uniform size of pixels for each angular position, while the omnidirectional image has a relatively small number of pixels near the observation point. The panoramic form can easily access the pixel in terms of the angular position and distance, the angular position in the
x-axis and distance from the center of the image in the
y-axis.
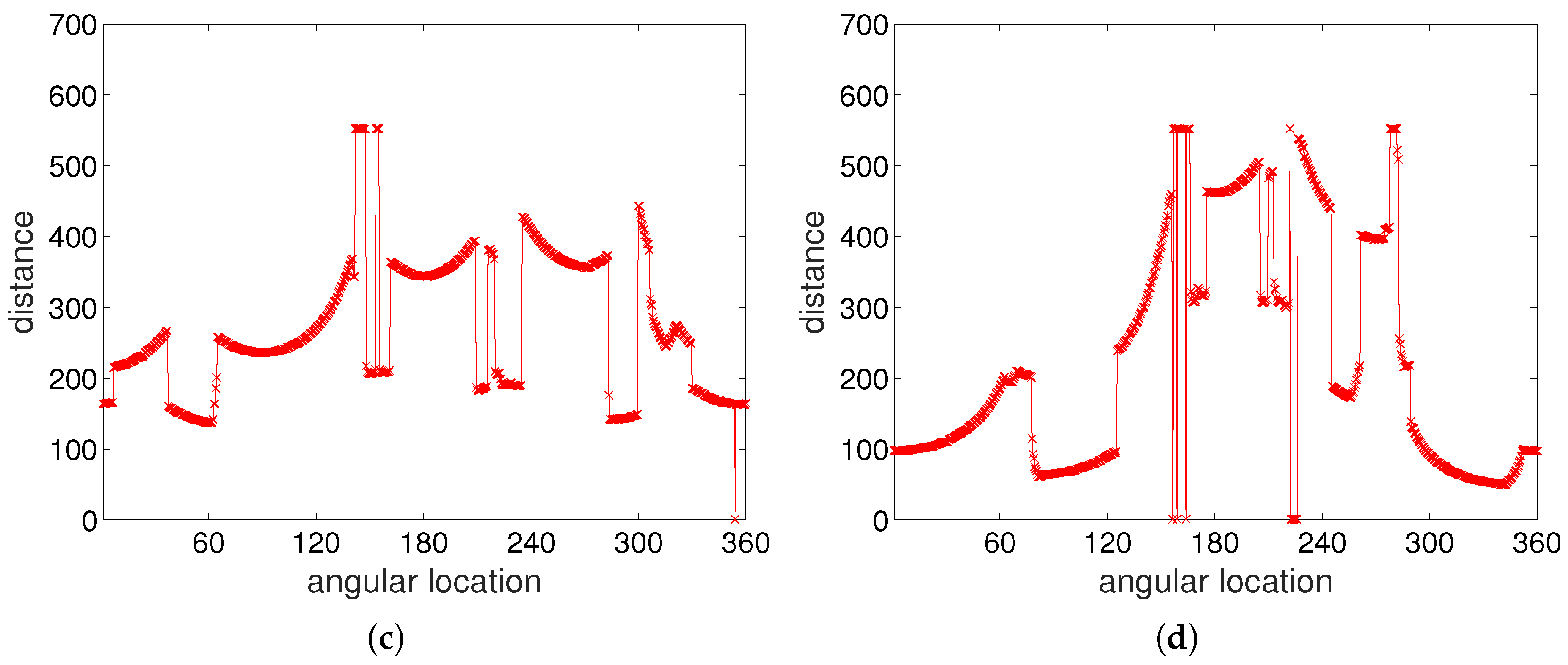
Figure 4a,b shows examples of panoramic images obtained at two different positions.
Figure 4c,d shows range data from laser sensor readings corresponding to the panoramic images. The snapshot images or snapshot distance maps have a similar landscape, but they are distorted depending on the position.
2.2. Moment Model for Landmark Distribution
In physics, the moment of inertia is a property of an area that reflects how its points are distributed. By analogy, the moment is defined as a distribution of point measurements in our navigation model.
For a given set of landmarks in the environment, we analyze the landmark distribution as a combination of their positions and features. The color intensity or height of landmarks can be feature candidates. A landmark is defined as a natural feature in the world environment, which is observable even at a far distance. All the landmarks are projected into the image plane, and the snapshot view includes a collection of landmarks. Often, an object is represented with a cluster of pixels in the image through the image segmentation process. Without any object feature extraction, each pixel in the image view can be regarded as a landmark, and then, the feature extraction process can be omitted. In real environments, the color pixels in the surrounding view (omnidirectional view) are regarded as landmarks with the color intensity, as well as the range information. Even the background at a far distance is represented as a set of landmarks. If salient landmarks are identified from the background, only those landmarks may be used in our moment model.
The color of the visual cue is the feature used in this paper. We define the moment measure
M as follows:
where there are
N landmarks,
is the range value of the
i-th landmark, that is the distance from the current location
to the landmark location
, and
is the feature value, for example the color intensity of the
i-th landmark.
The above measure is similar to the moment of inertia in physics,
. We can also see this measure as a potential function built with a set of landmarks. From that, we can find the gradient as the first derivative of the potential function as follows:
where this gradient vector indicates the change of the potential function corresponding to the current position
. To find the minimum convergence point with the gradient, we calculate the determinant of the Hessian matrix given below:
where this Hessian matrix is produced from the second-order differential of the moment equation.
is a second-order differential with respect to
x and
with respect to
y.
is equal to
, and they are zero.
The determinant of the Hessian matrix is calculated as:
We assume that each feature value (
) is positive. The sign of the second derivatives of potential function is positive as shown below:
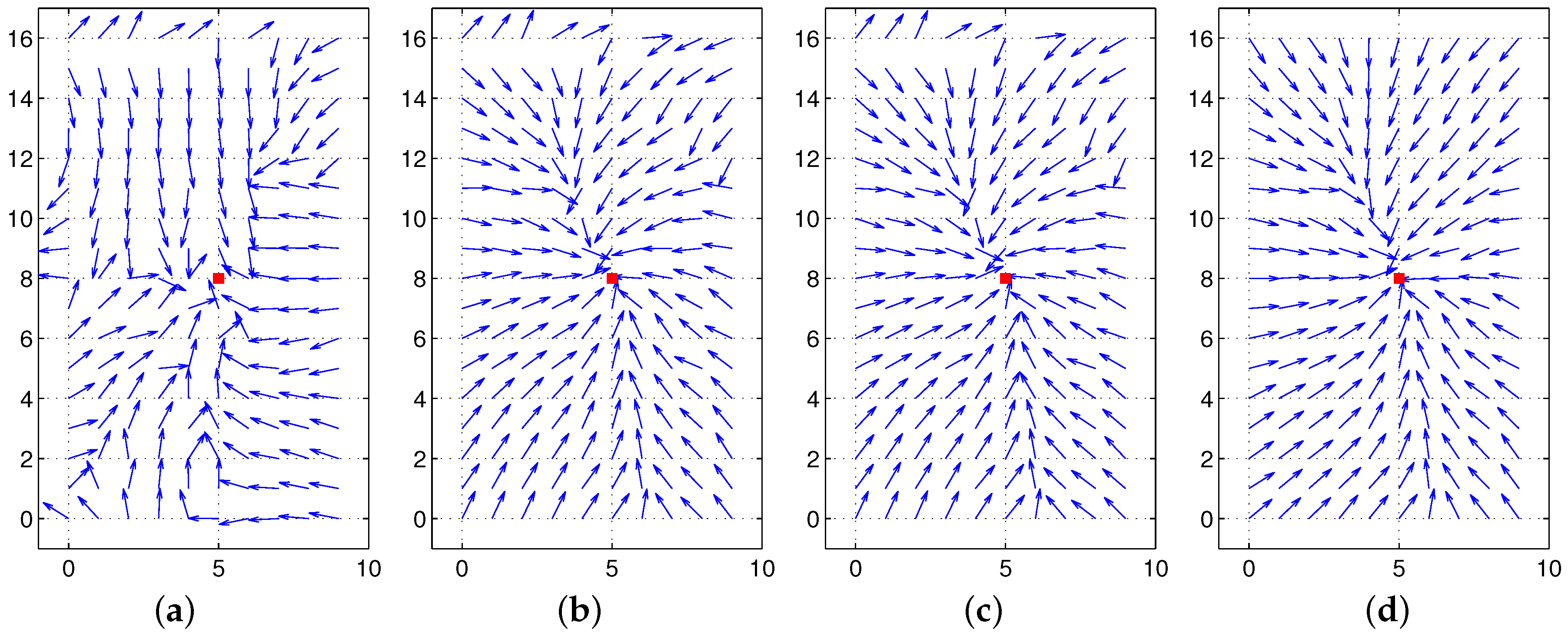
From the above property, there is only one global convergence (minimum potential) point with its gradient zero, and the determinant of the Hessian matrix is positive. Let
be the convergence point. Then:
The position
is calculated as:
where the convergence point
is the weighted average of landmark positions with respect to the landmark features, that is the center of the landmark distribution. The moment measure based on features of landmarks has unique convergence point
, regardless of any current position
.
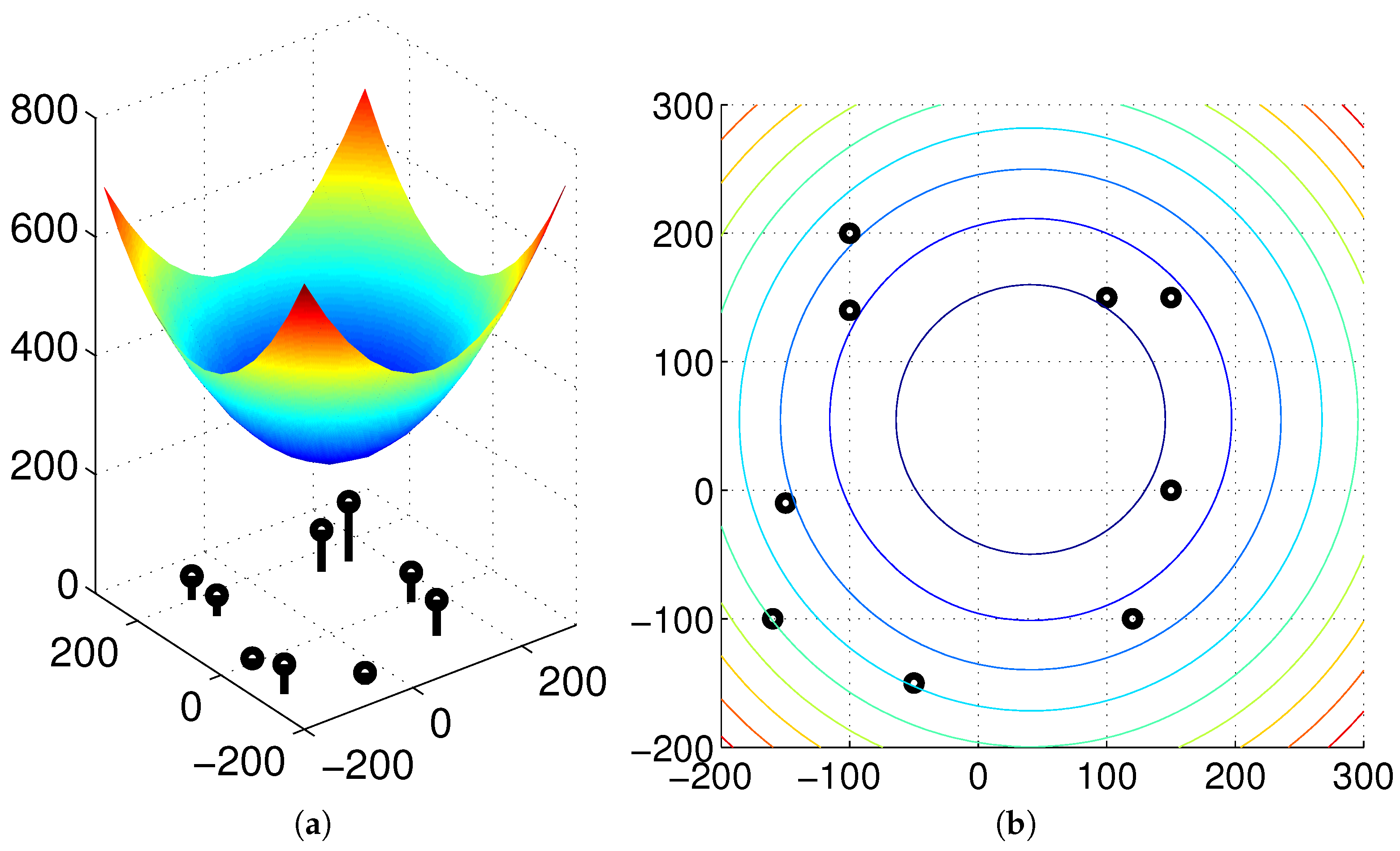
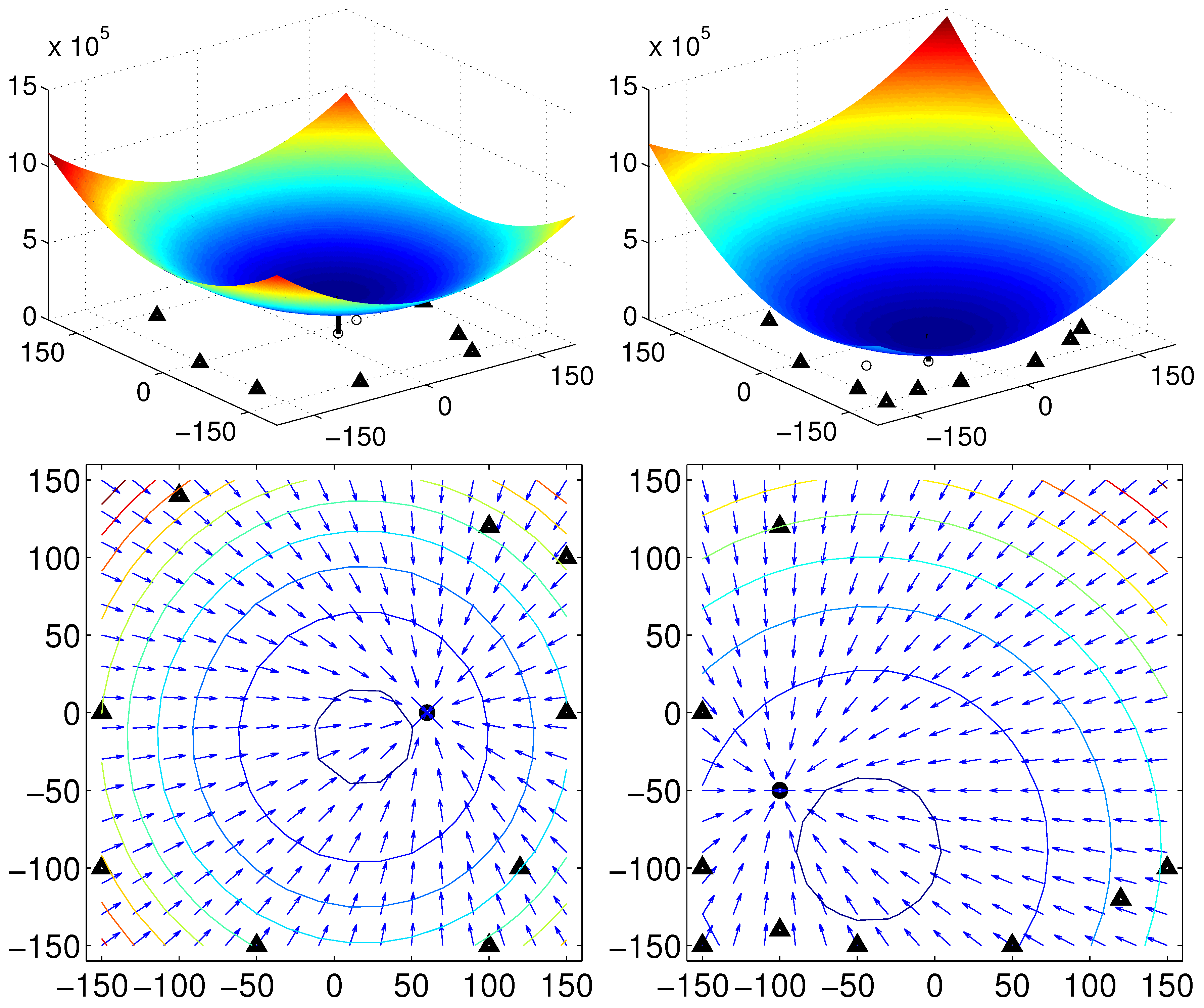
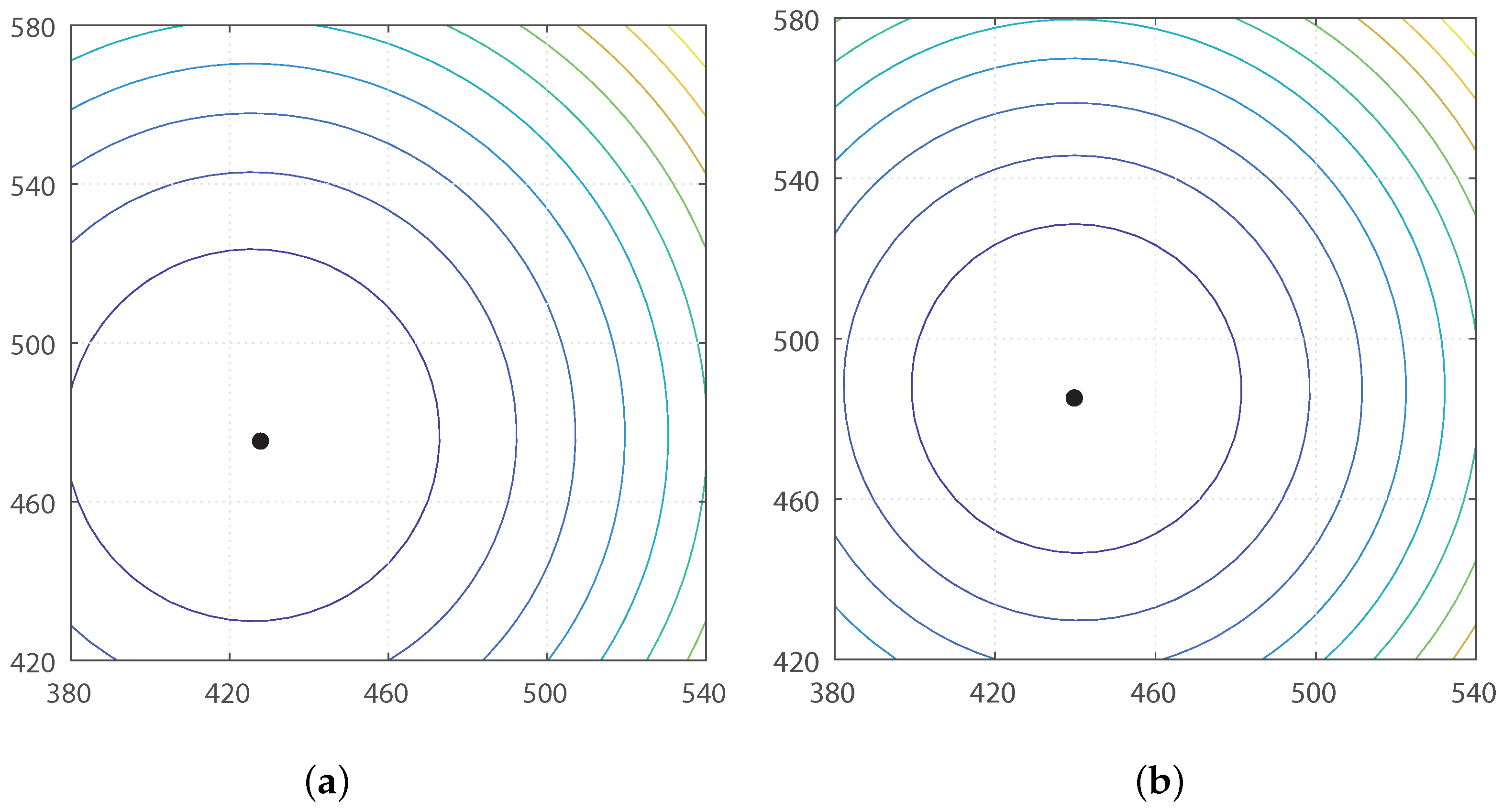
Thus, we argue that if there is no environmental change or no occlusion observed as the robot moves, then we can find the same convergence point in spite of any movement or any change in angular position. To guarantee the unique convergence point, the feature value should be positive. In our experiments, the landmark characteristics are defined as the height of landmarks or color intensity, which is positive. The moment measure is an index of landmark distribution, and its center of distribution can easily be estimated as an invariant feature, which will be useful in homing navigation. In
Figure 5, the surface of the potential function is convex-shaped, and the unique convergence point is available. Various types of feature (
) values are available, and the convergence point can change depending on the features.
2.3. Homing Vector Using the Moment Model
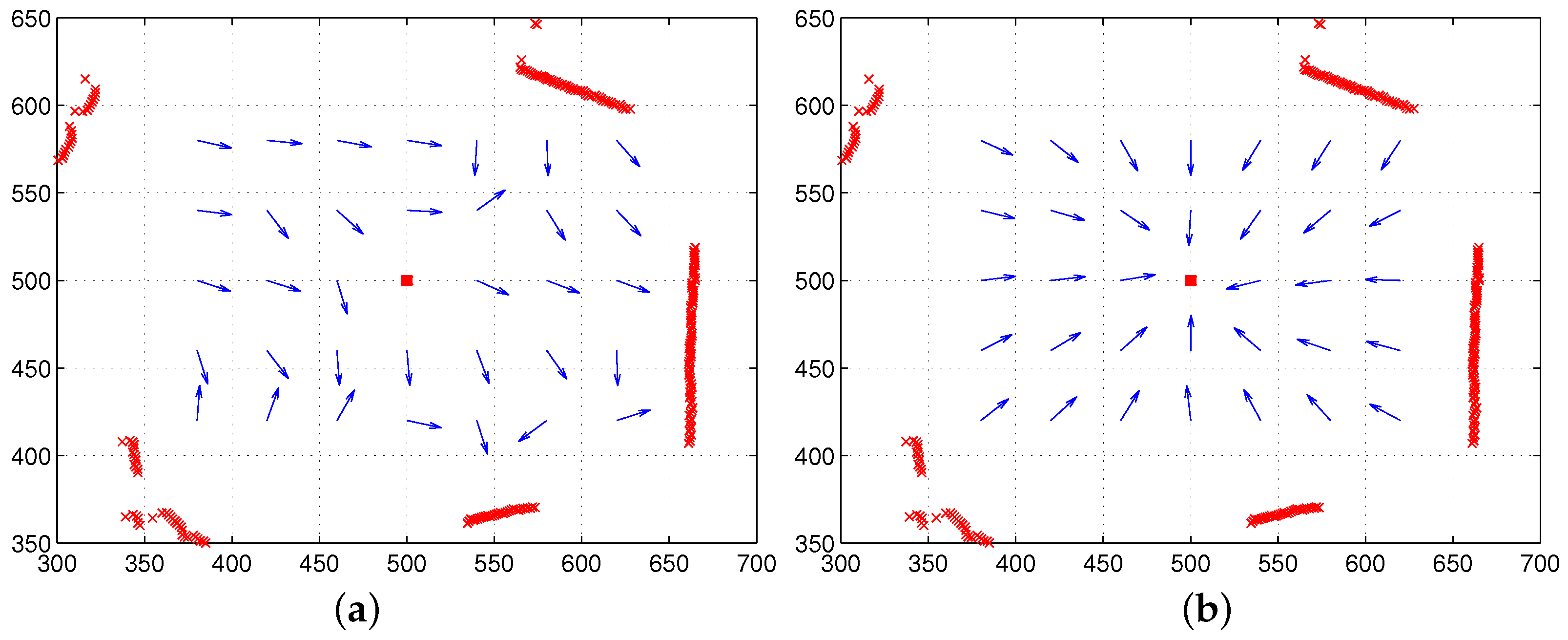
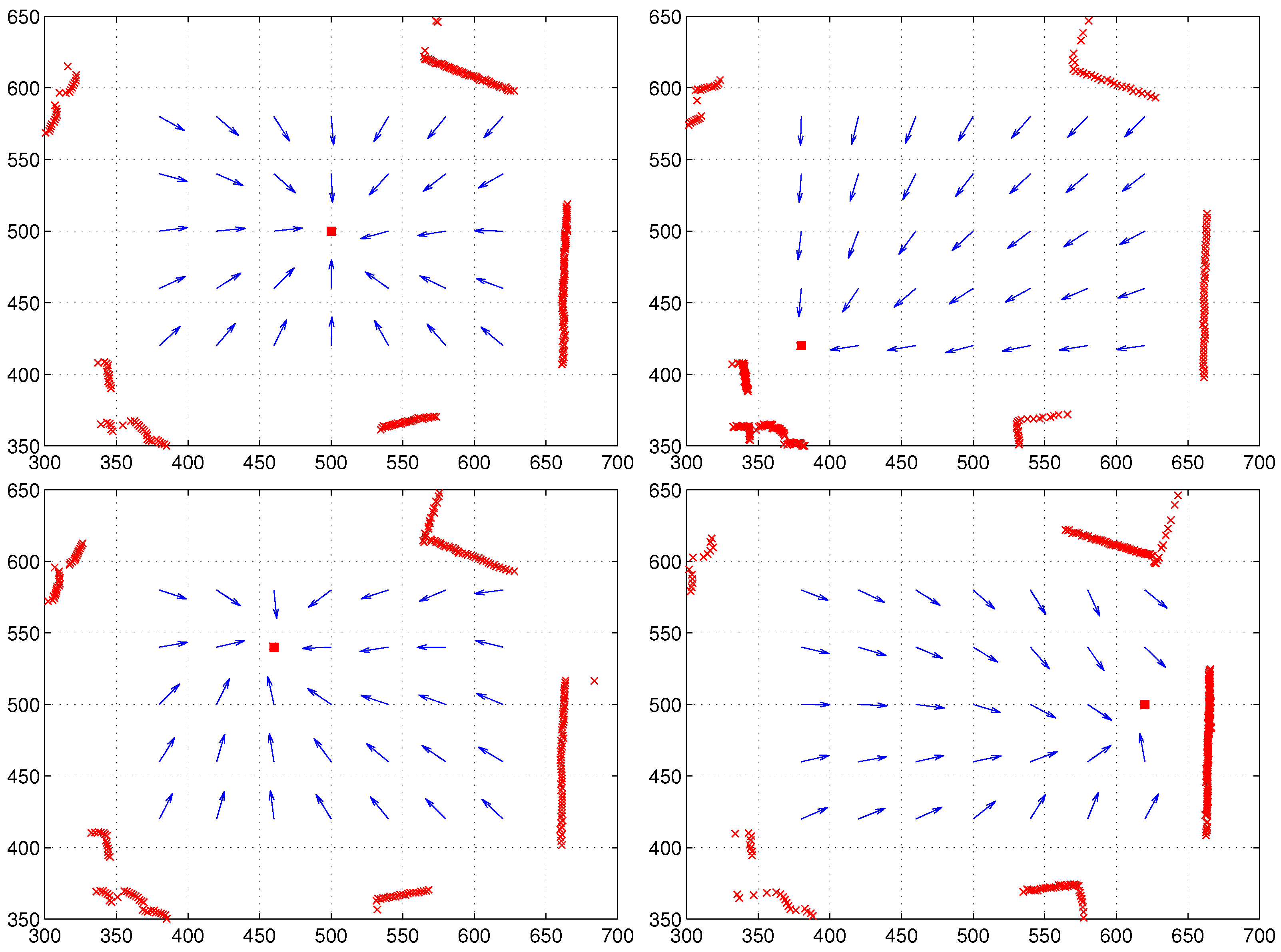
We introduce how to estimate the homing vector using the moment function. We assume there is a reference compass available. Each landmark has the feature value and range information. An agent can observe a distribution of landmarks at a given position. Assume the same landmarks are observed at any position in the environment. We take the above global convergence point as the reference point to estimate the homing vector.
If there are
N landmarks observed at the current position
, their relative distance
and the feature value
are measured for
, where
is the estimated landmark position in the coordinate with origin at the current position. The reference point vector
can be calculated by Equation (
7). In a similar way,
N landmarks are observed at the home position
. Their relative distance
and the feature value
are measured for
, where
is the estimated landmark position with origin at the home position
. The reference point vector
can be calculated by Equation (
7) again at the home position.
Then, we find the relation for homing vector
:
since we assume that the same reference point is estimated irrespective of any observation point, that is the two vectors
R and
should end at the same reference point, starting from the different positions, the current position and the home location (a little deviation of the reference points may be observed by noisy sensor readings or landmark occlusions).
At an arbitrary position
, a mobile robot has information of the relative distance and the visual features with a laser sensor and a vision camera. Equation (
7) has absolute coordinate representation, and so, we evaluate the convergence point in the coordinate with origin at the observation point.
where
is the current observation point and
is the relative distance of the
i-th landmark in the current view. Similarly, the convergence point can be evaluated in the home coordinate as follows:
where
is the home location. Then, the difference of the two reference points measured at two observation points (the home location and the current position) is given by:
where it is assumed that the same landmarks and the same visual features are observed at any position,
,
for
. Hence, the homing vector
can be estimated by the above property,
Each position defines its own reference map, but there exists a unique convergence point that is the same position regardless of any coordinate. By the convexity of the moment potential function, the minimal potential point can be reached from any position. We provided a proof that the homing vector calculated by the above model can reach the home position from any position, if the environment is isotropic, that is all landmarks and their features are invariantly observed at any position.
2.4. Moment Model with Multiple Features
If there are multiple features available for landmarks, then we can build a separate moment model for each feature. The set of moment models will lead to independent reference points, but we can assume that the distribution of each feature in the environment will be almost equal for any measured position if the environment is isotropic, that is the majority of landmarks are commonly observed in the environment. The homing vector for each feature can be voted together, which can help estimate homing direction more accurately.
We can test the moment model with RGB color intensities, three visual features for each pixel. The image colors provide three different features, red, green and blue color intensity for each pixel. The landmark feature
can thus have three components. The moment measure for each feature, red, blue and green intensity, respectively, is defined as follows:
where
for
are the landmark position with respect to the current position
and
are the color intensity for the
i-th landmark.
Then, the above three measures lead to three reference points at a given position
, using Equation (
9).
Three reference points can be determined both at the current position and at the home location. The difference of the reference points can estimate the homing direction.
The home vector
via the three reference points using the color intensities can be derived as a combinational form,
where
is calculated with red color intensity,
with green and
with blue, using Equation (
16).
As shown above, the color intensity of pixels can be applied to the moment model with multiple features. We can extend the moment measure into that with various visual features. The visual feature
allows any characteristics of landmarks, and also, multiple features can derive multiple homing vectors. The sum of the homing vector for each feature can be effective on noisy feature readings. RGB color space can be converted into another space, for example HSV space, and each feature can make separate homing vectors. Furthermore, to handle noisy sensor readings, we can allow a cut-off threshold for a feature value, and some feature can be set to
. This has the effect of choosing a set of landmarks in the omnidirectional view, instead of using the whole pixels. If
or
with the range value
, the moment model becomes similar to the ALV model [
28]. If
or
with continuous range value
, the model is similar to the DELV model [
33].
2.5. Comparison with Other Methods
To compare our moment model with other conventional approaches, we consider possible combinations of the process components. The components are related to what kind of features will be used, whether the range sensor is available or the distance can be estimated in the visual image and what kind of coordinate alignment process will be applied.
In the moment model, we can allow variable features in . In our experiments, we will mostly use the RGB color intensity as the feature value. To compare variable visual features and no visual feature, we can test for equal color intensity. In addition, the moment model requires the distance information to calculate the centroid. Since there is no distance information of landmarks in the image set, we estimated the distance using the ground line in the image, which was used for the moment model. The ground line is the boundary line between the floor and an object in the panoramic image. After blurring the whole image, a moving mask (4 × 2 pixels) to detect the horizontal edge was applied, and the number of pixels between the horizontal line and the detected ground line was counted to estimate the distance; more pixels counted indicate a larger distance to the ground or the landmark. We discriminate the methods with the ground-distance estimation in the visual image and those with the laser sensor readings for distance.
Without a reference compass, the snapshot images at two positions are not aligned. Their image coordinates may be different. We need to make an effort to find the rotation angle of a given coordinate to be matched to another coordinate. One of the well-known algorithms for alignment is the visual compass [
35]. The home snapshot is taken as a reference image, and the current view is shifted a step angle until the home image and the shifted image have the minimum difference. The shifted angle is the right angle in the coordinate alignment.
Another alignment algorithm called landmark rearrangement is available [
51]. A set of landmarks observed in the home coordinate should match another set of landmarks observed at the current position, if it is assumed that the environment is isotropic. That is, two sets of landmarks at the home location and at the current position should correspond to each other. If two coordinates (orientations) are not aligned, then the two sets of landmarks should be compared for one-to-one correspondence by a rotating shift of one landmark at a time until they closely match each other. The landmark rearrangement method first draws landmark vectors from the home location to each landmark and then adds the opposite of landmark vectors from the current position to each landmark by one-to-one mapping. Then, the sum of the resulting vectors can be converged to a point, if there is no matching error. If the two coordinates are not aligned and landmarks have a mismatch, the end points of the resulting vectors have a large variance. We use this variance criterion to make the two coordinates aligned by following the landmark rearrangement [
51]. We need to apply a rotational shift of landmarks in a given coordinate to update a series of landmarks.
For visual homing navigation, the Descent in Image Distance (DID) method [
35] can be applied to calculate homing direction, which uses snapshots near the current position and the home snapshot. We take a variation of the DID with multiple (three) images as reference images and the snapshot at the current location in order to determine the homing direction. Using the property that the absolute image difference between a pair of snapshots is proportional to the distance, the snapshot at the current position is compared with three snapshots (including the home snapshot) near the home location, and then, the image differences can determine the homing direction by the relative ratio of the image distance between each of the three snapshots and the current image. This DID method uses only visual images, and the relative difference of the in-between images can guide the homing direction without any depth sensor.
Table 1 shows various methods classified by the feature selection, the range sensor or distance estimation and the alignment process. With the reference compass, no alignment process is required, and six methods are available. Without a reference compass, eight methods are listed (for
, no visual feature is observed and only landmark rearrangement will be tested, since the visual compass is not applicable).
4. Discussion
In the current approach, we used a holistic approach to take all the pixels as landmarks. Each pixel produces a landmark vector with its own angular position, instead of an object in the real environment. If an object is close to the observer, it creates many vectors, while a small number of vectors is assigned for an object far away from the observer. Summing these landmark vectors may be different from an object representation in the real environment. It is possible that the image segmentation or clustering process can help with identifying objects from the image. Then, the corresponding object features and the distances of objects in the environment can be encoded with the moment model. In other words, a sophisticated feature extraction algorithm can be combined with the suggested moment model. We need further work to check if this feature extraction approach will be better than the holistic approach. A basic assumption in this moment model is that invariant features can be observed at any position, and a collection of the features can represent the environment well, while its centroid can be localized as a reference point.
In our experiments, the RGB color intensity in the image view can be changed depending on the observation point. The visual images can be affected by the illumination, the angle and position of the light source, as well as glint on the floor. If these changes are intense, then the mobile robot cannot estimate the homing direction accurately. Thus, the robust features available or a good measurement apparatus will be helpful for homing accuracy. We believe that the range sensor has high accuracy of measuring the distance, but the visual image has relatively noisy sensor readings for pixel-wise landmarks. An ensemble of the two measurements seems to compensate one for the other. Possibly alternative features would be helpful to improve the homing performance. An invariant feature such as landmark height rather than the color intensity can be supportive to read the environmental information better, which can play the role of a milestone to guide homing.
The suggested moment function models a distribution of landmarks with their landmark characteristics. If we take a model with , the potential has a high peak at the landmark position, which can be used as a collision avoidance model or landmark search model. The potential value will rapidly decay to zero, if the measuring position becomes far from the landmark. If a mobile robot senses a potential value greater than a threshold, then it can take the behavior of avoiding the landmark or moving towards the landmark. This is another possible application of the moment model.
In our local homing navigation, we assume that landmarks are commonly observed at any position. The suggested moment approach is based on the snapshot model, which works only in the isotropic environment, and an agent can search for the target position as the home position, starting from the current position. Our local navigation approach can be extended to a wide range of navigation in complex cluttered environments with many occlusions of landmarks. Multiple reference images as milestones can guide the right direction to the goal position [
37], even if the goal position is far way. That is, local homing navigation can be applied to each waypoint. A sequence of waypoint searches may lead to the final goal position. For future work, we will test this approach in cluttered environments to require complex homing paths.
5. Conclusions
In this paper, we suggest a new navigation method based on the moment model to characterize the landmark distribution and features. The moment model is inspired by the moment of inertia in physics, and it sees how the landmarks and their features are distributed in a given environment. Here, the landmark features and the relative distance are encoded in the moment function. The moment model allows multiple features, which can help estimate the homing direction more robustly. We proved that the landmark distribution has a unique minimum peak of moment potential, and it can be a reference point as an invariant feature at any position, which corresponds to the center of mass in physics. In the moment model, the homing vector is calculated based on this reference point.
In the experiments, we used the RGB color intensity in visual images as the features in the moment model. The distance was measured by a laser sensor, but without the depth sensor, the ground-line distance estimated in the panoramic image was tested as alternative distance information. The two components, the depth information and the features, highly contribute to successful homing performance, which is distinguished from other approaches’ results based on vision images. Especially, the depth information cannot be neglected for good homing performance.
Our approach is a holistic approach to use all the pixels as landmarks. We assumed that the environment is isotropic, that is the majority of landmarks is commonly observed in view at any position in the arena. If the mobile robot moves far away from the home location, the environment landscape will change greatly, and many occlusions occur, which may violate the isotropic assumption. In that case, the homing performance may degrade to a great extent, since the centroid of the moment value greatly migrates to another point. Thus, the moment model is appropriate for local homing navigation. We need further study to handle the problem or to cover a long-range path problem.
In the moment model, we simply applied the RGB color intensity as the visual feature. However, more sophisticated features, such as invariant features, can be developed in the image, which will further improve the homing performance. For future work, we will find what kind of visual features or other features will be useful in the moment model. Our model can be extended to various characteristics that are not easily changeable by the change of measuring positions. If the invariant property of the feature is preserved, the feature can be encoded in the moment model. Thus, various forms of the moment model can be produced.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}