Abstract
With the rapid spread of built-in GPS handheld smart devices, the trajectory data from GPS sensors has grown explosively. Trajectory data has spatio-temporal characteristics and rich information. Using trajectory data processing techniques can mine the patterns of human activities and the moving patterns of vehicles in the intelligent transportation systems. A trajectory similarity measure is one of the most important issues in trajectory data mining (clustering, classification, frequent pattern mining, etc.). Unfortunately, the main similarity measure algorithms with the trajectory data have been found to be inaccurate, highly sensitive of sampling methods, and have low robustness for the noise data. To solve the above problems, three distances and their corresponding computation methods are proposed in this paper. The point-segment distance can decrease the sensitivity of the point sampling methods. The prediction distance optimizes the temporal distance with the features of trajectory data. The segment-segment distance introduces the trajectory shape factor into the similarity measurement to improve the accuracy. The three kinds of distance are integrated with the traditional dynamic time warping algorithm (DTW) algorithm to propose a new segment–based dynamic time warping algorithm (SDTW). The experimental results show that the SDTW algorithm can exhibit about 57%, 86%, and 31% better accuracy than the longest common subsequence algorithm (LCSS), and edit distance on real sequence algorithm (EDR) , and DTW, respectively, and that the sensitivity to the noise data is lower than that those algorithms.
1. Introduction
With the rapid development of sensors technology and the popularization of personal smart devices, GPS sensors are widely used to track moving objects, such as people, cars, and animals. A large number of trajectory data emerges every day. The trajectory data from GPS sensors are the spatio-temporal data sequences of mobile objects with the space-time variation. With the development of the Internet of Things, urban computing, and other research fields, the analysis of spatio-temporal data-based transportation systems have become a hot topic in the fields of machine learning. The trajectory data analysis can be a great driving force for all of the fields, for example, through applying the trajectory similarity measure algorithm, the distance matrix can be computed, which can be used to cluster the trajectory of peoples’ activities for finding the popular routes and hot spots and visualizing in OpenStreetMap [1,2]. In the intelligent transportation systems, it is of great practical value to measure the similarity of the trajectories of moving objects in a real-time, accurate, and reliable way. Intelligent trajectory measurement cannot only provide accurate location-based services, but also monitor and estimate traffic jams [3].
In trajectory data mining, one of the most important and fundamental works is to compute the similarity between different trajectories. Based on the similarity measurement of trajectory data, the trajectories can be clustered, classified, and retrieved [4]. The accuracy of the similarity measurement significantly affects the accuracy of the trajectory data mining. In recent years, some mainstream algorithms for trajectory similarity measurement have been proposed, such as the dynamic time warping algorithm (DTW) [5], longest common subsequence algorithm (LCSS) [6], and edit distance on real sequence algorithm (EDR) [7]. Those algorithms can obtain the results of similarity measurement through computing spatial point-to-point distances or temporal distances. However, there are common drawbacks resulting in the low accuracy. For example, the DTW algorithm just directly calculates the point-point distance, ignoring the influence of the different trajectory sampling methods on the generated trajectory sequence. The LCSS algorithm neglects optimizing the temporal distance of the trajectory data. The EDR algorithm does not consider the trajectory shape factor. In order to improve the accuracy, a segment-based dynamic time warping algorithm (SDTW) is proposed to measure the trajectory similarity. First, the proposed SDTW adopts the point-segment distance to reduce the sensitivity influence from the trajectory sampling methods. Then, considering the temporal distance factor, SDTW introduces the prediction distance to convert the temporal distance into the spatial distance. Finally, SDTW introduces the segment-segment distance to improve the computation accuracy by adjusting the parameters of shape factors.
The remainder of this paper is organized as follows. Section 2 discusses the related work and analyzes their drawbacks. Some definitions and problem statements are described in Section 3. Section 4 presents the proposed SDTW algorithm, and the performance evaluations are given in Section 5. Discussion and conclusions are given in Section 6.
2. Related Work
Trajectory sequence data can be regarded as time sequence data. Many approaches to the trajectory similarity measurement are introduced from the similarity measurement to the time sequence data. The simplest trajectory similarity measurement is the Euclidean distance, but it cannot obtain better accuracy when the local time shifts or when those trajectories lack the same length [8]. In order to improve the accuracy of similarity measurement, the dynamic time warping algorithm (DTW), longest common subsequence algorithm (LCSS), and edit distance on real sequence algorithm were proposed and widely applied.
Based on the idea of dynamic programming to find the optimal match point pairs between the trajectory points, the DTW can effectively solve the problem of local time shifting and various trajectory lengths [5]. The DTW algorithm was firstly introduced for speech recognition, then applied to the time sequence analysis later. The LCSS adopted a threshold to identify the match point pairs [6], but it is a similarity measurement in rough granularity without considering non-match pairs of points. The EDR is an edit distance-based algorithm, which uses a threshold to identify the match point pairs and the non-match points, different from the LCSS. Those similarity measurement algorithms can be divided into two types [8]: the one based on L1 and L2 paradigms, such as the DTW; and the other computing similarity scores based on the matching threshold, such as the LCSS and the EDR.
Wang et al. have evaluated the performance on the accuracy of main similarity measurement algorithms, DTW, LCSS, ERP [9], EDR, and SpaDe [10], in the different time sequence datasets [11]. The experimental results demonstrate that the DTW algorithm can obtain the most accurate results of the similarity measurement in the majority of datasets although its computation speed is slow. Based on the evaluation results, many similarity measurement algorithms, such as Kim [12], Keogh [13], and Improved [14], have been proposed to reduce the computation complexity at the same measurement accuracy as the DTW algorithm.
From the above analysis, it can be found that those algorithms have common drawbacks affecting the accuracy of similarity measurement.
- (1)
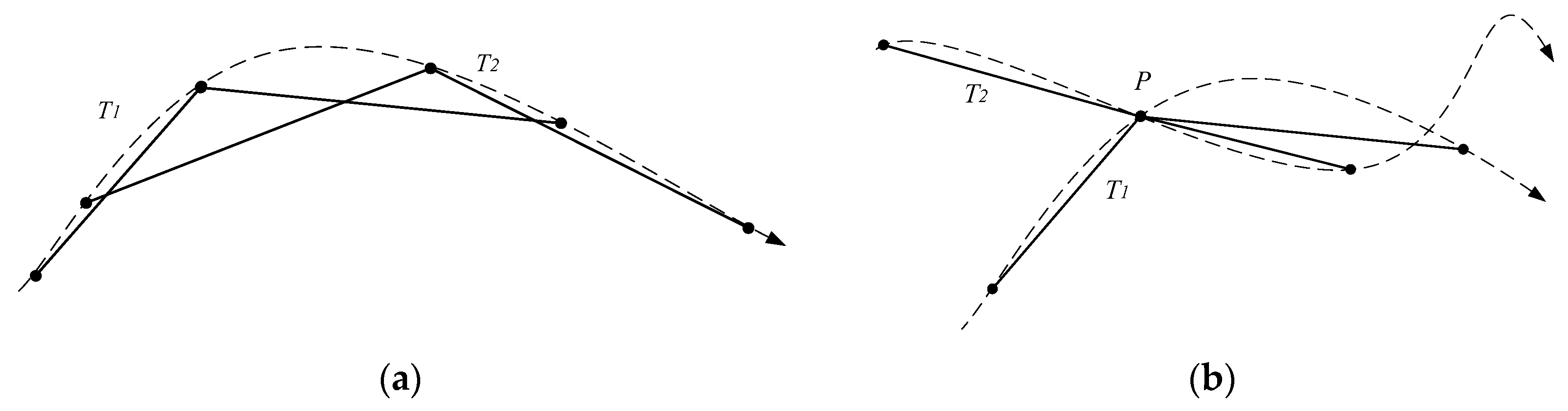
- The DTW, LCSS, and EDR algorithms only consider the comparison of two individual points. In fact, different sampling methods can form different trajectory sequences, which results in a significant negative impact on the final measurement results [15]. As shown in Figure 1a, the trajectory sequence data of a curve trajectory with an arrow may have two-point sampling methods T1 and T2. Two original trajectories are essentially identical, but their trajectory sequences are quite different. In Figure 1b, two trajectories intersect at point P, and their trajectory sequences and sample the point P. An obvious difference between the two trajectories is produced, but the difference is weakened due to the intersection point P. Thus, computing the trajectory similarity completely based on the discrete trajectory points will cause the loss of the details of the trajectories. It is necessary to find a way to keep the details to a certain extent.
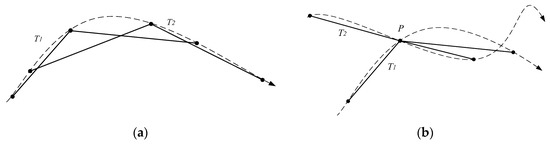 Figure 1. Various point sampling methods of the same trajectory. (a) A trajectory of two sampling methods; and (b) two trajectories take the same point.
Figure 1. Various point sampling methods of the same trajectory. (a) A trajectory of two sampling methods; and (b) two trajectories take the same point. - (2)
- Only considering the distances between the pairs of points, the mentioned algorithms cannot take shape factors into account [16]. However, shape factor is an important feature of a natural trajectory. It may result in the loss of computation accuracy when the shape factors are ignored.
- (3)
- Most algorithms of similarity measurement are derived from the time sequence similarity computation without considering the temporal distance computation between two trajectory points. Since the time measurement is different from the space measurement, it makes no sense just to simply add two weights. To solve that problem, Lee et al. proposed a trajectory distance measurement method with the weighted addition of the parallel distance, the perpendicular distance, and the angle distance [1]. Unfortunately, the proposed measurement method by Lee et al. cannot solve problems (1) and (2).
To solve the above three problems, a segment-based trajectory similarity measurement algorithm is proposed to improve the accuracy.
3. Problems and Definitions
Mobile objects generally have time and space attributes, respectively. Space attributes can be three-dimensional or two-dimensional. Two-dimension is the most widely used, so all of the words “space” refers to two-dimension space in this paper. A trajectory records a continuous movement trace of a mobile object. Due to the limitations of the GPS sensors, a trajectory T consists of a series of points , where is the spatial recorded point, t is the recorded time. For convenience, a natural trajectory and a trajectory sequence are strictly distinct.
Definition 1 (natural trajectory).
A continuous trajectory of a mobile object.
Definition 2 (trajectory sequence).
With a given Euclidean space, a natural trajectory can be expressed as , where the discrete trajectory points are ordered by time, refers to the trajectory point , , and n represents the number of points in the trajectory. T is the recorded trajectory sequence from the natural trajectory.
Definition 3 (sub-trajectory segment).
Two adjacent discrete trajectory points and are connected to form a trajectory segment , which is a sub-trajectory segment.
Definition 4 (natural sub-trajectory segment).
A part of the natural trajectory between two adjacent discrete trajectory points is constructed as a natural sub-trajectory segment.
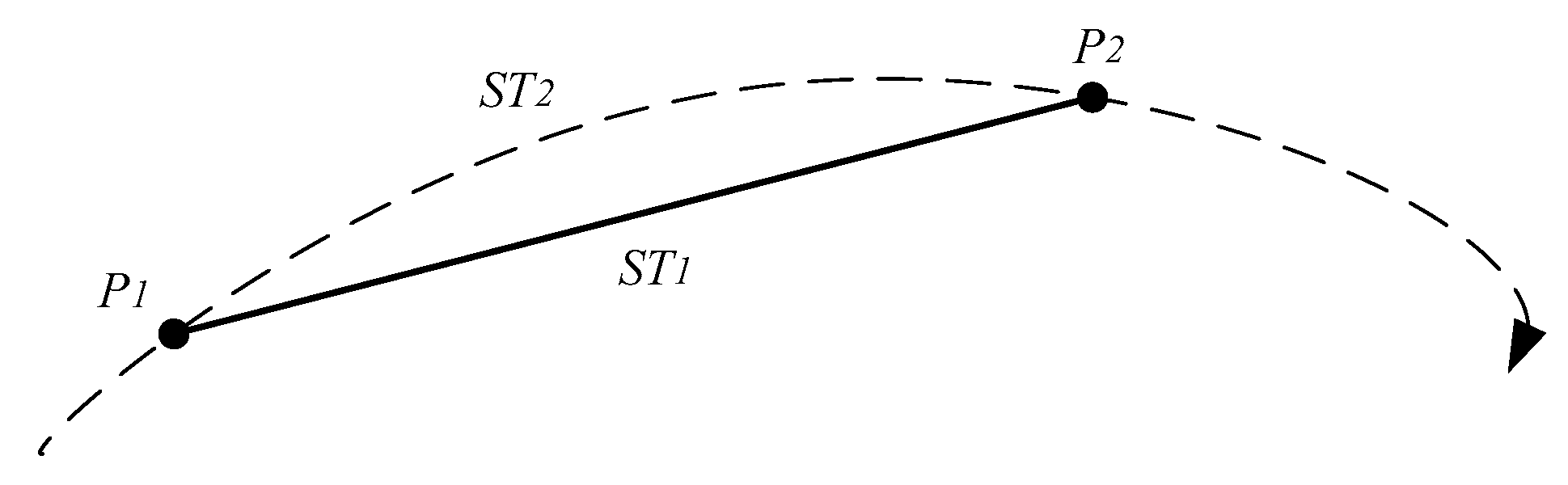
A trajectory sequence consists of a series of discrete points. Two adjacent discrete points are connected to form a sub-trajectory segment. Moreover, a real trajectory segment must exist between two adjacent discrete points. In Figure 2, and are a sub-trajectory segment and a natural sub-trajectory segment, respectively.
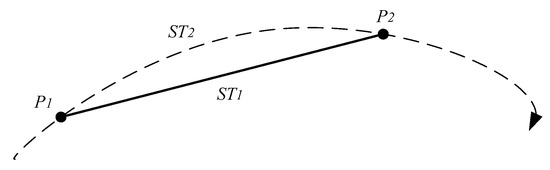
Figure 2.
A sub-trajectory segment and a natural sub-trajectory segment.
Definition 5 (proxy natural sub-trajectory segment).
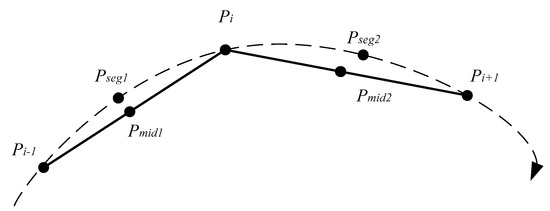
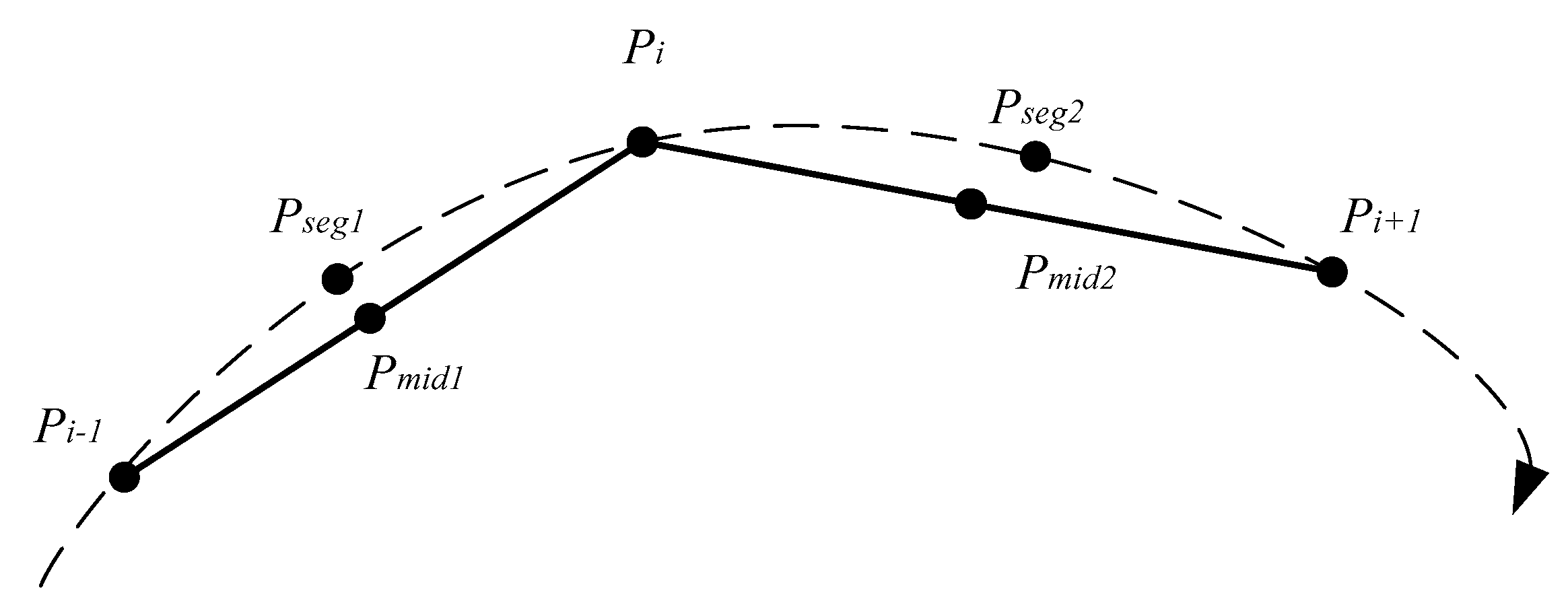
In Figure 3, is denoted as a medium point of the natural sub-trajectory segment between and . is denoted as the medium point of the natural sub-trajectory segment between and . The proxy natural sub-trajectory segment of trajectory point is the natural sub-trajectory segment between and .
Figure 3.
A Proxy of a natural sub-trajectory.
Definition 6 (proxy sub-trajectory).
is marked as a midpoint of the sub-trajectory segment of and , and is marked as the midpoint of the sub-trajectory segment of and . The sub-trajectory formed by and is the proxy sub-trajectory of .
A discrete trajectory sequence represents a whole natural trajectory. A trajectory point on its sequence represents a part of the natural trajectory, called as the proxy natural sub-trajectory of the point. A natural trajectory can only be stored as a trajectory sequence; thus, the proxy natural sub-trajectory segment cannot be obtained. It can only obtain the proxy sub-trajectory of the trajectory points.
The problem to be solved in this paper is to compute the distance between two given trajectory sequences R and S, where and . The longer the distance, the less similarity .
4. SDTW Algorithm
Due to ignoring the relationship between a trajectory sequence and a natural trajectory, the current trajectory similarity measurement algorithms are sensitive to the sampling methods. To reduce the sensitivity of the points sampling methods, a point-point distance can be converted to a distance from a point to a specific segment, which is defined as a point-segment distance. There is a fundamental difference between the temporal distance and the spatial distance of trajectory points. In this paper, the time difference and trajectory’ shape are integrated to convert a temporal distance into a spatial distance and the prediction distance is presented. The DTW algorithm only uses the point-point distance, without considering the trajectory’s important characteristic—shape—which results in the low accuracy of the DTW algorithm. If the shape factors are included, the accuracy of the similarity measurement can be improved. A trajectory sequence is regarded as multiple continuous trajectory segments, the shape lies in the difference of an angle between trajectory segments. An included angle can be considered into the similarity calculation, and its result is the segment-segment distance.
The above three distances are integrated with the traditional DTW algorithm to propose a new segment–based dynamic time warping algorithm (SDTW). SDTW adopts the point-segment distance, prediction distance, and segment-segment distance to compute the accumulative distance of two trajectory sequences, which can improve the accuracy.
4.1. Point-Segment Distance
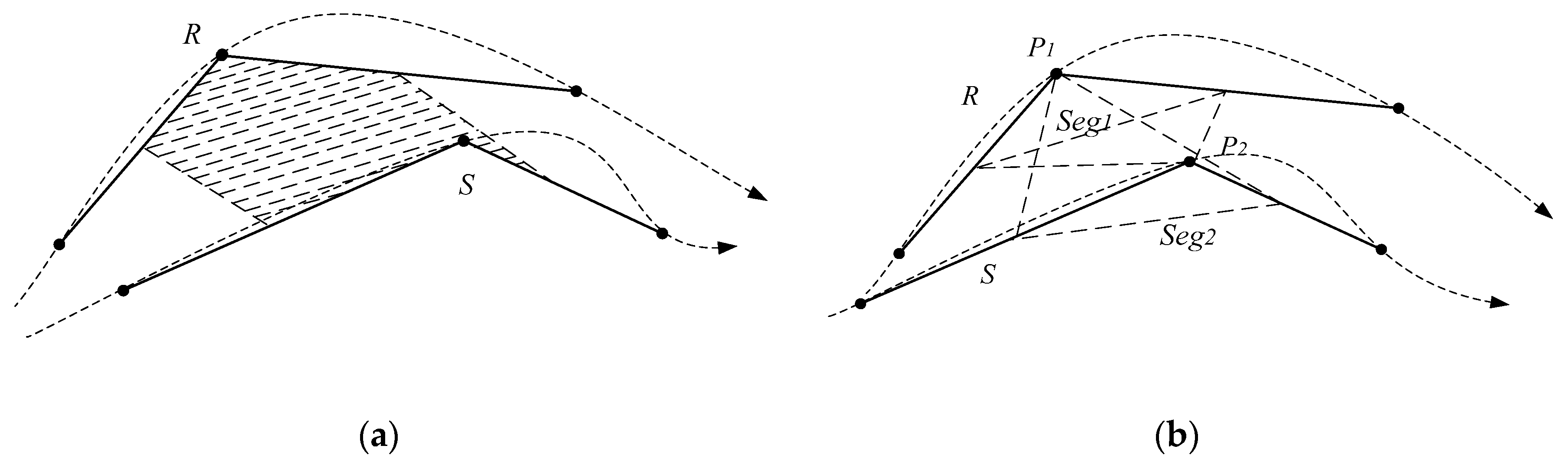
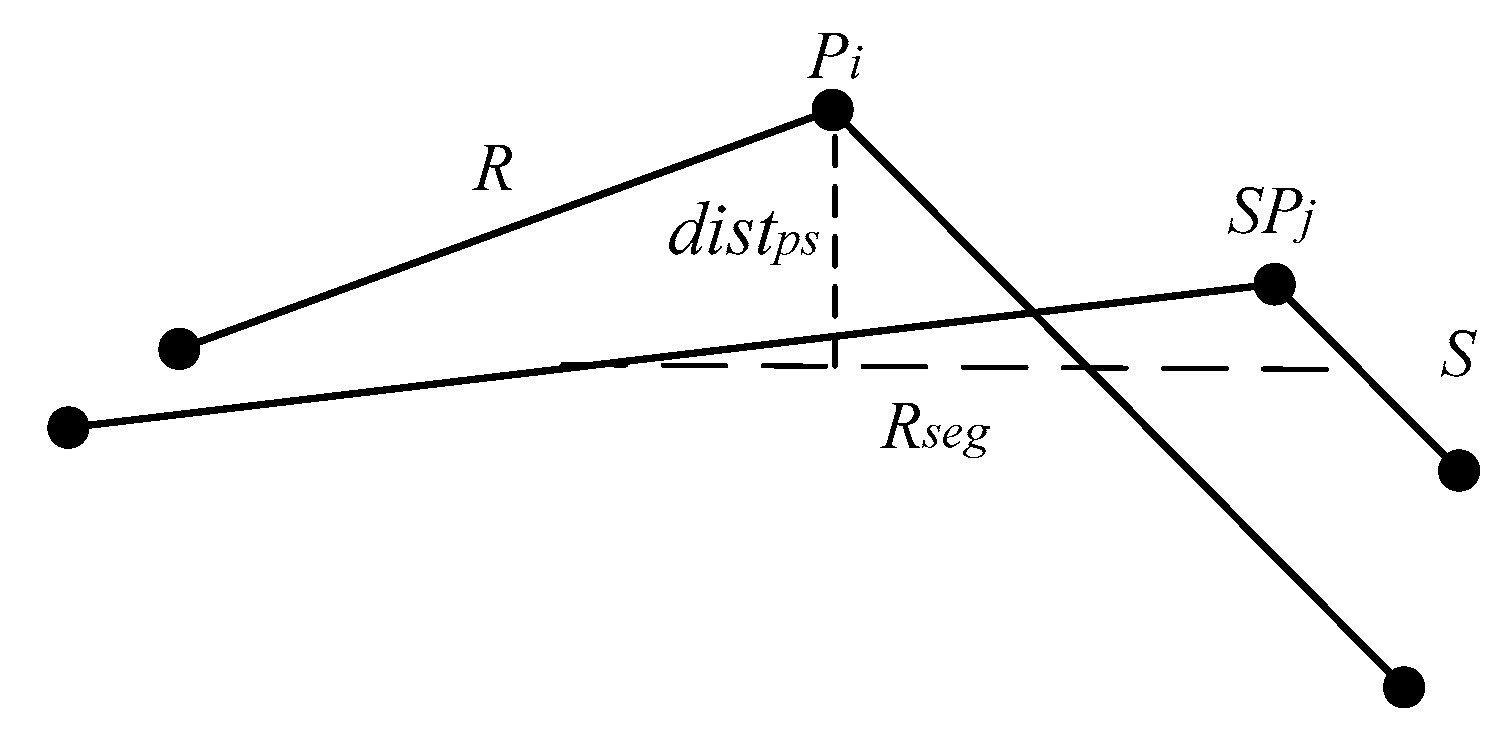
The spatial distance of two trajectory points can be converted to the spatial distance of their proxy trajectories. In fact, the point-segment distance is the spatial distance of the pair of two trajectory points. The distance of the two proxy trajectories, is the area enclosed by them (Figure 4a). The plane is an irregular polygon area, the computation is difficult. The sum of enclosed by and and enclosed by and (Figure 4b) shows a positive correlation with . That is, when the relative displacement of the two proxy trajectories occurs, the trend of + is the same as that of . So, can be replaced with the sum of and .
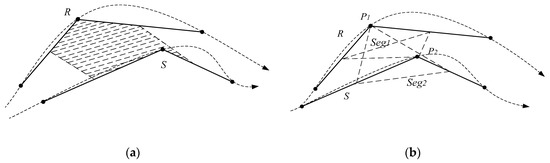
Figure 4.
Two computation methods of the proxy sub-trajectory distance. (a) The area enclosed by the two proxy trajectories; and (b) a simplified calculation method.
It is obvious that the distance calculation method based on the area is not an effective approach, especially for a trajectory point with a long proxy sub-trajectory, which results in a larger sum enclosed by it and other proxy trajectories. From the above analysis, the length of and shows a positive correlation with the condition of a trajectory point with a long proxy sub-trajectory. The longer a trajectory is, the worse the result is. It can adopt to convert the spatial distance between and into the sum of the distance from and , and the distance from and . That is, is the sum of point-segment distances.
Assume that is trajectory point i on the trajectory sequence R, and is trajectory point j on the trajectory sequence S. Define as the point-segment distance of and . Define as the point-segment distance of and , and . Figure 5 illustrates the point-segment distance computation.
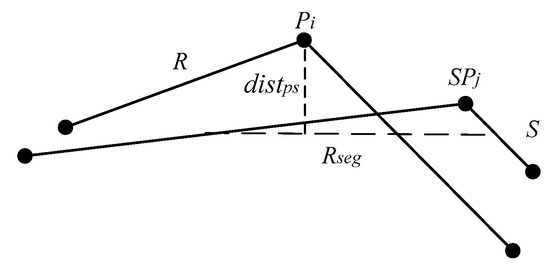
Figure 5.
Point-segment distance.
To compute , it is first to compute the midpoint of and , and the midpoint of and . and can computed as follows Equation (1):
Then it computes the shortest distance between and . is [17]:
where ; is the length of the derivation segment, :.
The formula for is the same as , and the spatial distance between and with the SDTW is as shown in Equation (3):
4.2. Prediction Distance
Most of the trajectory similarity measurement algorithms are introduced from the time sequence similarity algorithms without considering to optimize the trajectory data. However, the time series data measurement and space measurement of the trajectory are essentially different, so it is necessary to figure out a solution to calculate the temporal distance integrated with spatial distance.
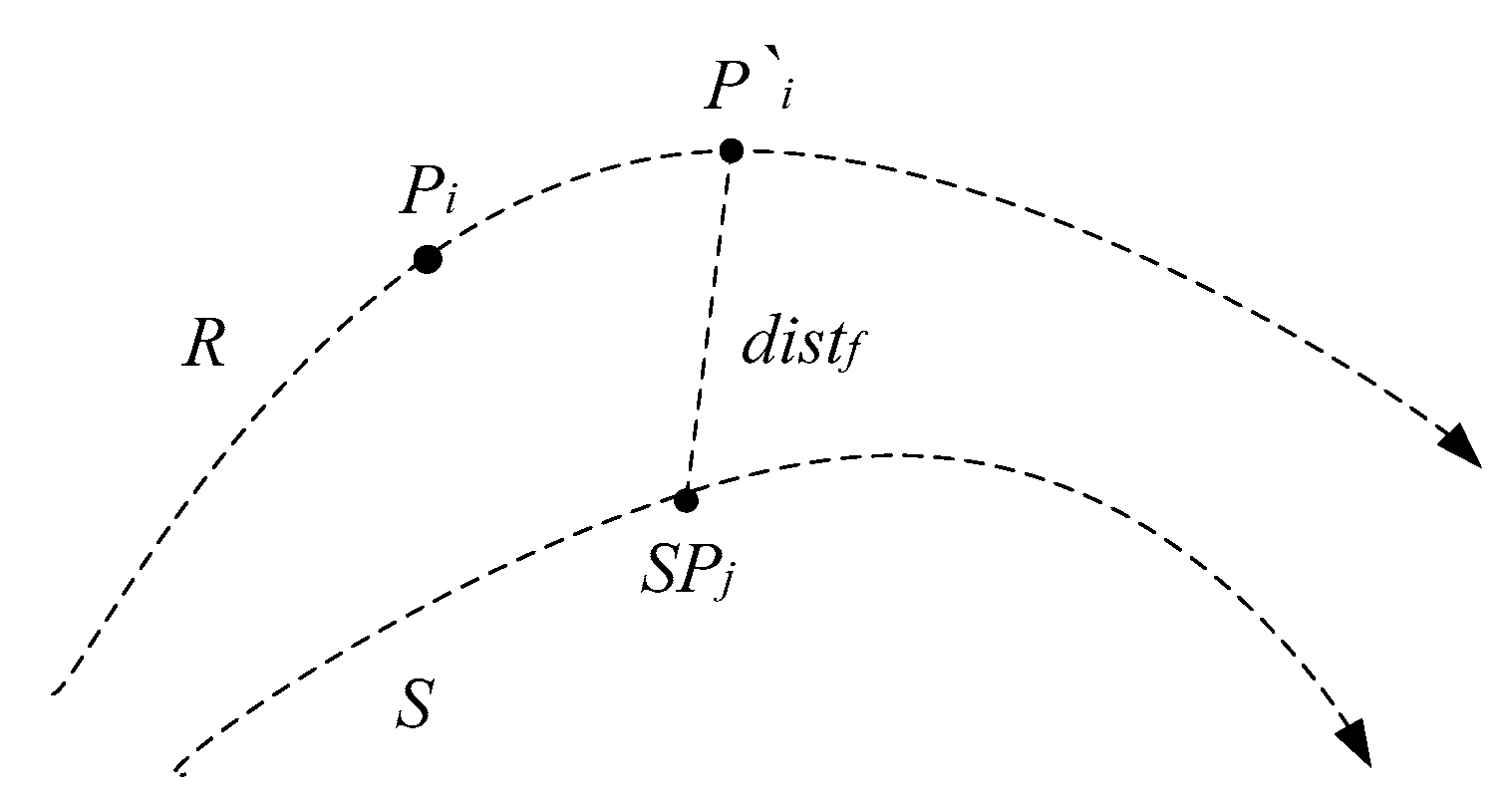
In Figure 6, the time distance between on trajectory R and on trajectory S is computed. The timestamp of is , the timestamp of is . The difference between and can actually be reflected on a specific trajectory. Assume that is regarded as a mobile object. When < , its space location after the time interval is the space location of R at the timestamp , known as a prediction position of , denoted as .
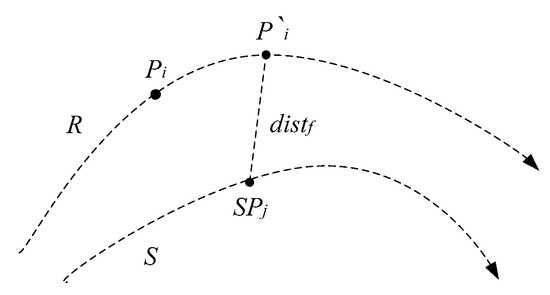
Figure 6.
Prediction distance.
The temporal distance between and is converted into the spatial distance between the prediction location of and , known as the prediction distance. It can convert a temporal distance into a spatial distance, and reflect the time distance of trajectory points on the trajectory. It can be seen that he prediction distance has good interpretability. It can effectively improve the accuracy of similarity measurements. Therefore, the natural trajectory cannot be recorded, so the similarity measurement should be based on the trajectory sequence data.
Assume that represents a trajectory point i on trajectory R and is a trajectory point j on trajectory S. To compute the prediction distance between and , one first compares the timestamps of and . The point with an earlier timestamp is set as A, and the other with the later timestamp as B. Their time difference is .
The next step is to compute the prediction location of point B with the later timestamp, named as . Since the information stored in the trajectory sequence is limited and the positions of the moving object cannot be obtained at any time, the prediction location is only an approximate position of point B. Then, it traverses the timestamp for each trajectory point to search the track range of point B at the timestamp . Suppose at the timestamp , point B is located between point and i. The spatial coordinates of the prediction position can be calculated as follows:
Suppose that it is a uniform linear motion between any two points on the trajectory, it can compute the velocity between two points as follows:
If there does exist the corresponding recorded trajectory point B at the timestamp , the can be estimated as follows:
where N is the total number of the points on the trajectory, on which point B is located.
The prediction distance between A and B is calculated as follows:
where is the Euclidean distance between A and in the coordination.
The prediction distance between A and B also presents the point-segment distance between point A and segment BB’.
4.3. Segment-Segment Distance
Suppose that is one segment i on the trajectory R, and is one segment j on the trajectory S. Suppose that ’s two endpoints are and , and ’s two endpoints are and , respectively. The segment-segment distance is can be calculated as follows.
The point-point distance includes the spatial distance and the temporal distance. The spatial-temporal distance between and is calculated as shown in Equation (8):
where t is the time sensitivity parameter. The larger parameter t is, the more sensitive the distance to the time dimension is. When parameter t = 0, the time dimension cannot be neglected.
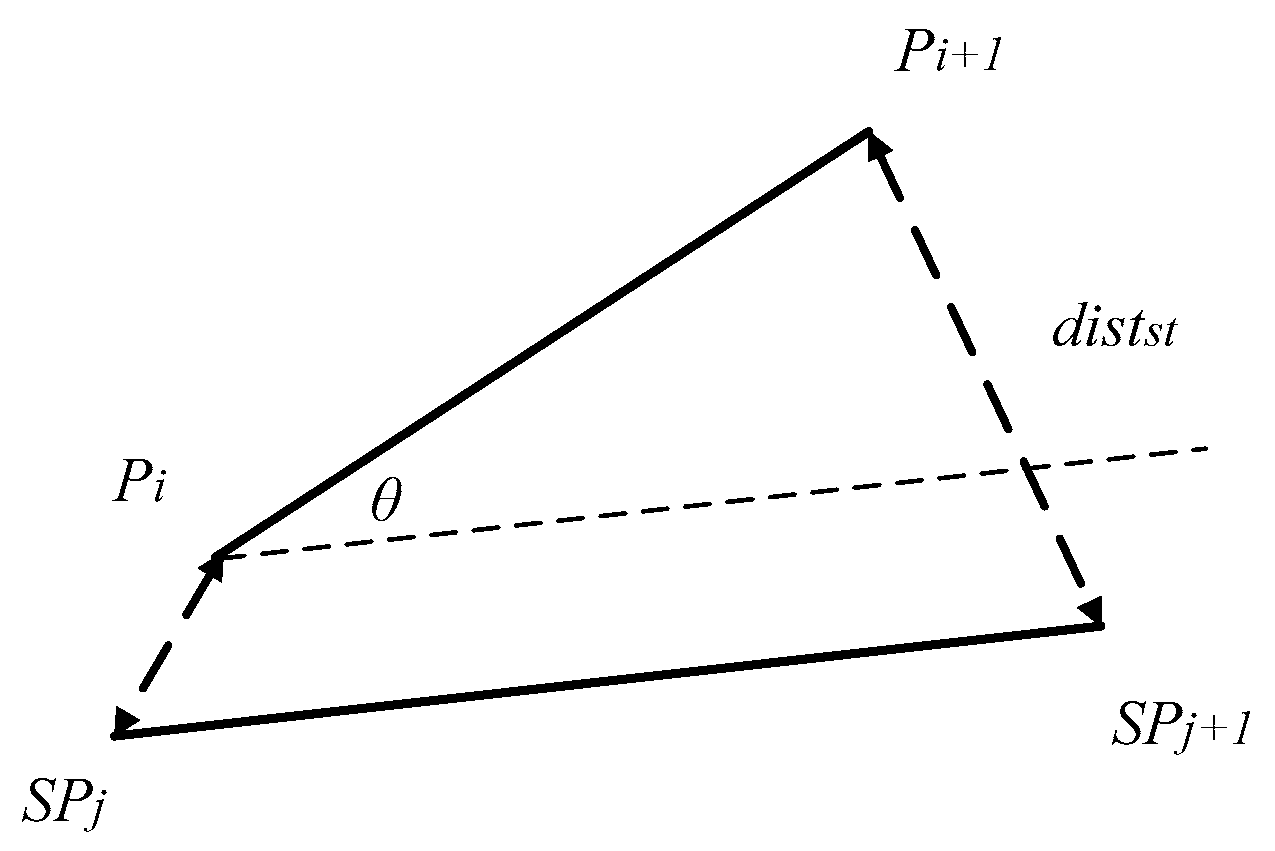
The segment-segment spatial-temporal distance is the sum of spatial-temporal distances between the two ends of the segments. represents the segment-segment spatial-temporal distance of and , as shown in Figure 7. can be calculated as follows:
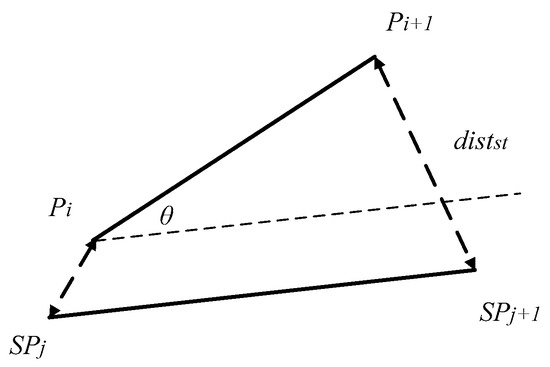
Figure 7.
Segment-Segment Distance.
Then, and the angle distance can be combined to calculate the segment-segment distance. It computes the included angle between and in Equation (10), denoted as :
Under the same condition, if the included angle increases, should be multiplied with a certain time for the computation. Thus, should be integrated with :
where can be computed in Equation (12):
where is an adjustable parameter and the shape negative factor. The greater , the less sensitive the distance to the shape factor. If there are no special requirements, let . is the spatial-temporal distance between midpoints and . is the maximum temporal distance between any two points of trajectory sequences R and S. Furthermore, it makes no sense to compare the shapes of two trajectory sequences with a long distance. The shorter the distance, the more important the shape factor. Thus, is used to dynamically adjust the weight of the shape factor.
4.4. SDTW Computation
After all of the segment-segment distances between trajectory sequences R and S have been calculated, the accumulative distance is computed derived from the idea of the DTW algorithm. Similar to the DTW algorithm, the similarity measurement of the SDTW is as follows:
where n is the number of line segments on the trajectory sequence R, m is the number of line segments on the trajectory sequence S, and indicates the first trajectory sequence , and is the new trajectory sequence after R eliminated . That is to say, represents the segment-segment distance between and .
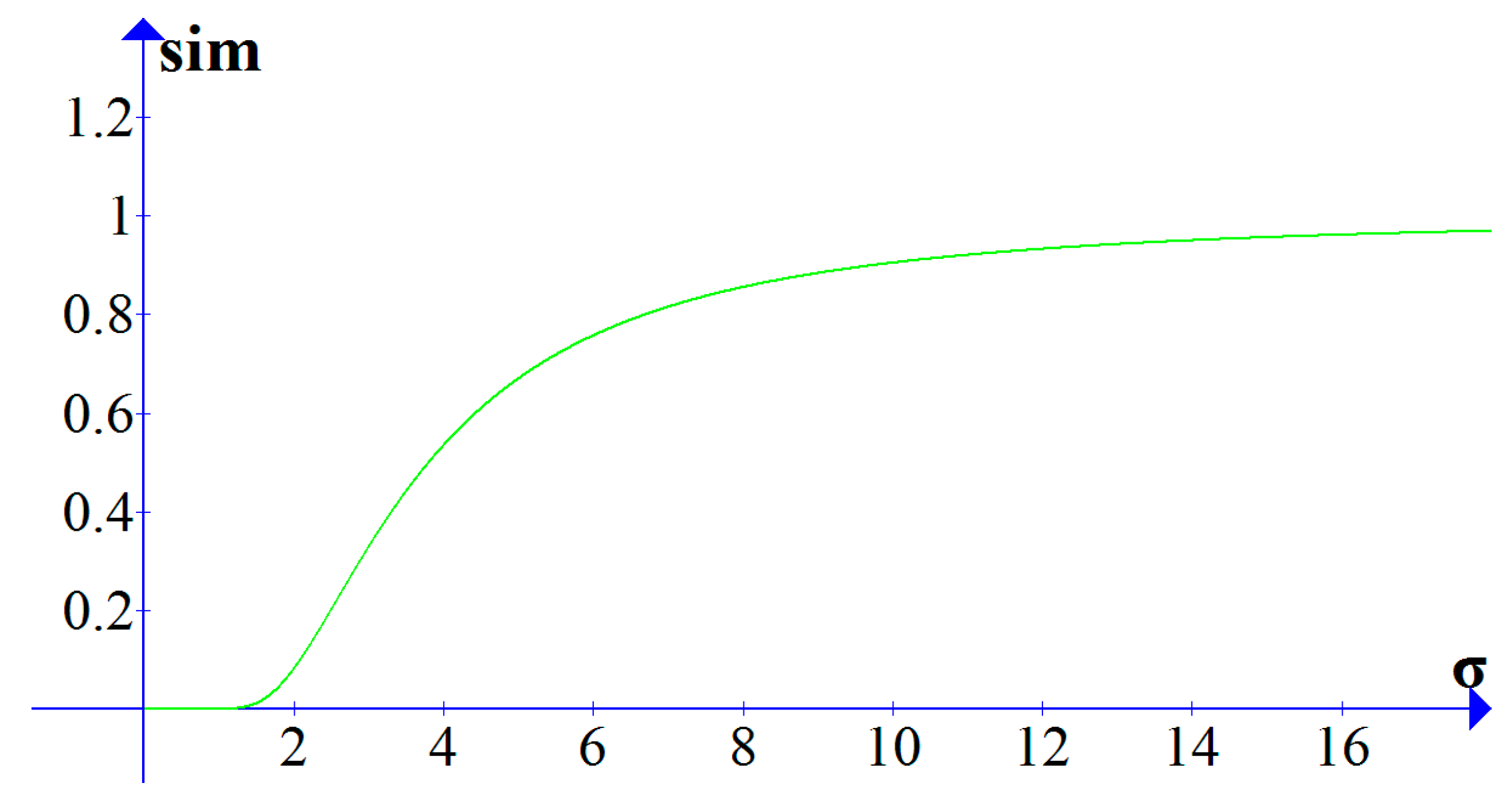
The computed accumulative distance is negative correlation with the similarity between the trajectory sequences. The accumulative distances of different two trajectories will be quite different, thus, it cannot directly compare the accumulative distances. It is necessary to convert the accumulative distance into the range [0, 1], where 0 means the two trajectories are irrelevant and 1 means the two trajectories are the same. The conversion function uses the Gaussian kernel function. The conversion function is shown as Equation (14):
where D represents the accumulative distance of R and S, is used to describe the sensitivity of the similarity to the accumulative distance. With the same D, the similarity is higher when is larger, and the similarity is lower when is small. In Figure 8, when , with the increase of , the value of sim grows slowly within the range from 0 to 1.5. When is in the range from 1.5 to 6, the value of sim grows rapidly. When is greater than 6, sim grows slowly and approaches 1.
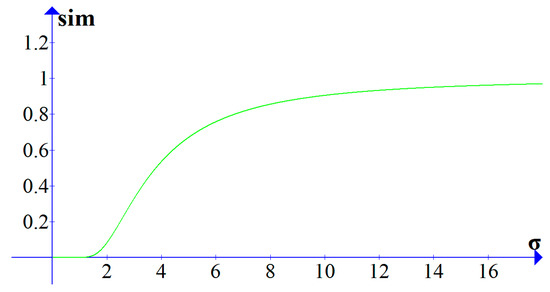
Figure 8.
The sensitivity analysis about the value of .
To sum up, the pseudocode of the SDTW algorithm proposed in the paper for the similarity computation for the two trajectory sequences is as follows:
As described in Algorithm 1, it first calculates the point-segment distance between each track point in the two trajectories according to Equation (3). If there is a temporal attribute in the trajectory data, it also needs to use Equation (7) to calculate the prediction distance. The segment-segment distance between each segment is then calculated using Equations (11) and (12). The subsequent calculation is the same as the DTW, and the final result is calculated using Equations (13) and (14) after initializing the accumulation distance matrix.
| Algorithm 1. SDTW |
| Input: Two trajectory sequences and Output: Sim, the similarity between R and S 1: for i = 0 to n //Calculate all point-segment distance 2: for j = 0 to m 3: psDist[i][j] = caclPSDistance (p[i], sp[j]) 4: for i = 0 to n //Calculate all prediction distance 5: for j = 0 to m 6: tDist[i][j] = caclTDistance (p[i], sp[j]) 7: for i = 0 to n − 1 //Calculate all segment-segment distance 8: for j = 0 to m − 1 9: sDist[i][j] = caclSDistance (s[i], ss[j], psDist, tDist) 10: init(matrix) //Initial accumulation matrix 11: for i = 1 to n − 1 //Calculate accumulation distance 12: for j = 1 to m − 1 13: matrix[i][j] = sDist[i][j]+min (matrix[I − 1][j − 1], matrix[I − 1][j], matrix[i][j − 1]) 14: return gaussianKernel (matrix[n − 2][m − 2]) |
SDTW needs to traverse every trajectory point of the two trajectories when calculating the point-segment distance, the prediction distance and the segment-segment distance. caclPSDistance( ) is used to calculate the point-segment distance of two points in the two different trajectory sequences based on Equation (3). caclTDistance is used to calculate the prediction distance of two points in the two different trajectory sequences based on Equation (7). caclSDistance is to calculate the segment-segment distance based on Equation (11). caclPSDistance and caclSDistance only involve the calculated points or segments, without considering the other points or segments. The computational complexity of function caclPSDistance and caclSDistance is constant order . In Equation (7), the dichotomy is used to find the trajectory point interval where the predicted point is located. The computational complexity of caclTDistance is . The computational complexity of DTW is also . The computational complexity of SDTW is for the trajectory data without the timestamp attribute, otherwise the computational complexity of SDTW is for the data with the time-stamp attribute.
In this paper, the SDTW algorithm does not change the core concept of the DTW, and just replaces the DTW distance computation method with three types of distance. The SDTW can also use the lower limit of the DTW distance algorithm to improve the execution efficiency. Moreover, the point-segment distance, prediction distance and segment-segment distance can be integrated with the LCSS, EDR, and other algorithms to propose new approaches to the similarity measurement.
5. Performance Evaluation
5.1. Experimental Dataset and Metrics
The dataset used in the experiments are the GPS GeoLife Trajectories dataset from Microsoft Research [18] and CVRR Trajectory Analysis Dataset [19].
The experiments use the GeoLife dataset to compare DTW and SDTW. The dataset consists of GPS trajectory data of 182 users over five years, for a total length of 1,292,951 km, but the single trajectory sequence is too long, leading to rare trajectories with a high similarity, so the trajectory sequences in the dataset is split into about 500,000 shorter ones indexed with an R* tree. The dataset does not give the trajectory sequence relationship, so the experiment results can be evaluated through visual analysis.
The experiment uses the CVRR dataset to quantitatively analyze the accuracy, the robustness of the measurement algorithms, and the effects of the parameters. The dataset is specifically for assessing the trajectory analysis algorithm, and it mainly includes three types of trajectory data: the I5 dataset, the driving trajectory of a car on a two-way highway; the Labomni dataset, the data of people walking in the laboratory (Figure 9a); and the Cross dataset, the simulation of vehicles driving straight and turning at crossroads (Figure 9b). All of these datasets mark the clusters of each trajectory. These datasets can be clustered based on the trajectory similarity measure algorithm. The obtained clustering results can be compared with the correct clusters, which have been marked in the dataset, and give the accuracy analysis of the proposed SDTW algorithm. It should be noted that the I5 dataset is comprised of mainly linear trajectories, and most algorithms can obtain good results. Therefore, the experiments only use the Cross dataset and Labomni dataset.

Figure 9.
Labomni dataset (a) and Cross dataset (b).
In the experiments, the error rate is included as one of metrics to evaluate the performance.
Definition 7 (error rate).
The error rate (ER) is the rate of wrongly-clustered trajectory sequences, which is different from CCR [20]. The lower the value, the higher the accuracy of the algorithm. Suppose the number of the known trajectory sequences is N, the total number of clusters is k, and the correct number of the sequence belonging to the class c is . The error rate is defined as follows:
5.2. Search Similar Trajectory
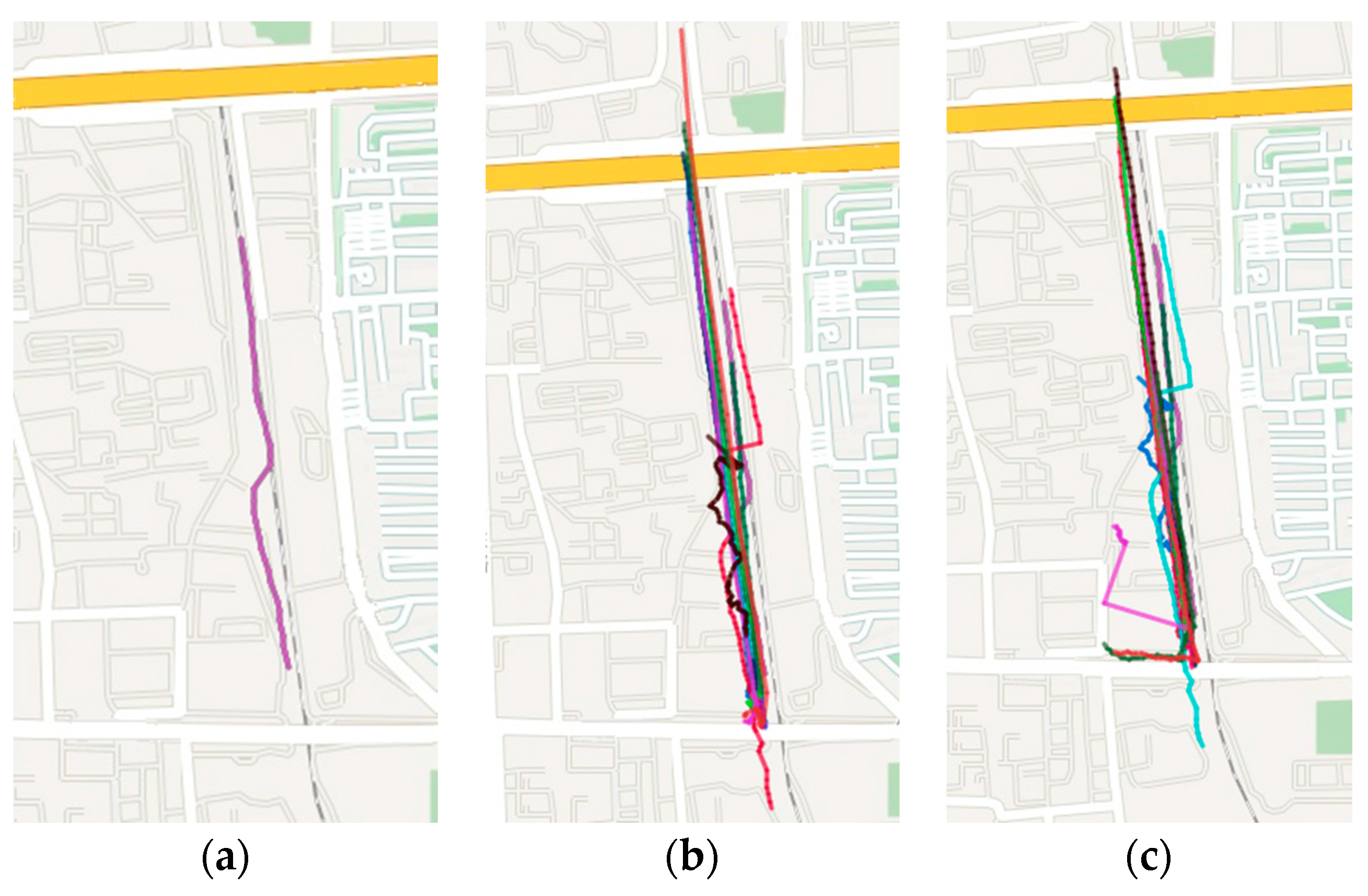
The experiments use the same dataset of trajectory sequences for the trajectory queries. It can compute and obtain the top 15 most similar trajectory sequences with the original query trajectory in the dataset, through executing the SDTW and DTW algorithm, respectively. The computational results are visually displayed on the map. The original query trajectory is shown in Figure 10a, and the query results of the SDTW algorithm and DTW algorithm are shown in Figure 10b,c, respectively.
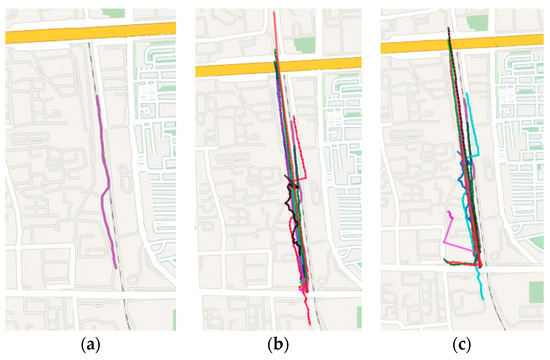
Figure 10.
Query results of trajectory sequences with the SDTW and DTW algorithms. (a) The original query trajectory; (b) Query results of trajectory sequences with the SDTW; (c) Query results of trajectory sequences with the DTW algorithms.
In Figure 10b, most of the query results of the trajectory sequence are close to the original query trajectory, and have high similarity in shape. In Figure 10c, many query results have low similarity in shape, compared with the original query trajectory. The reason is that the SDTW algorithm considers the shape factor of the natural trajectory and uses the point-segment distance to reduce the loss of the sampling method on the accuracy, so the SDTW algorithm is more accurate than the DTW algorithm.
5.3. Clustering Error Rate Comparison
The experiment is based on the CVRR dataset with cluto [21] as a clustering tool. cluto is a low-dimensional clustering and high-dimensional data software package for the analysis of the characteristics of various categories. cluto can provide a variety of optimized clustering algorithms, and support the trajectory clustering based on the similarity matrix.
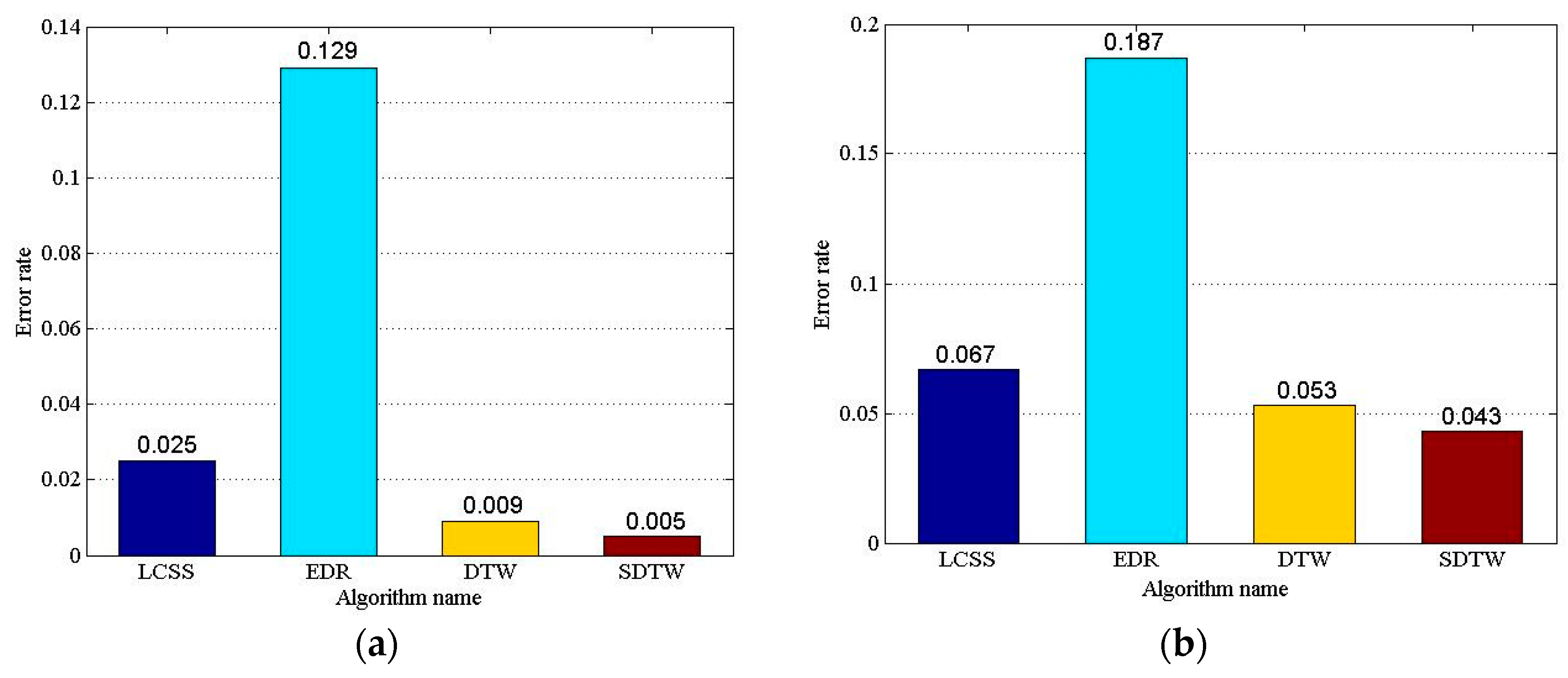
In order to evaluate the accuracy of similarity measurement, four algorithms, LCSS, EDR, DTW, and SDTW are selected to cluster the trajectory sequences. First, the trajectory similarity matrix of two datasets are generated with the similarity measurement algorithm. Then, it is clustered with agglomerative hierarchical clustering (AHC) and rbr with global optimization. Finally, the maximum ER of each dataset is regarded as the final result of clustering error rate. As to the LCSS and EDR algorithms, it is necessary to specify a threshold . In the experiments, LCSS and EDR algorithms should calculate the maximum ER with the threshold varying in range from 1 to 5, when the step is set to 1.0. As to the SDTW algorithm, it is necessary to specify the parameter . The SDTW algorithm should calculate the maximum ER with parameter varying from 1 to 10, when the step set to 1.0. It should be noted that letting the parameter in Gaussian kernel function can produce very good clustering results [22]. Figure 11 illustrates the compared results of the clustering error rate with the four algorithms.
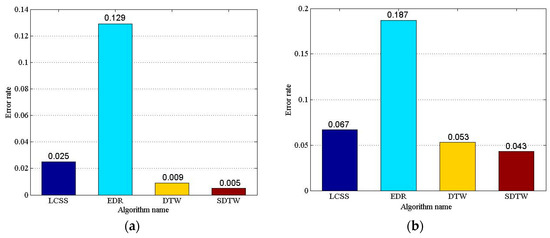
Figure 11.
Comparison of Clustering Error rates. (a) Clustering error rates based on the Cross dataset; and (b) clustering error rates based on the Labomni dataset.
As shown in Figure 11, the algorithms with various datasets lead to various error rates, but the order of the error rate is the same. The LCSS, DTW, and SDTW can obtain good clustering results, and the EDR’s clustering effect is poor. The error rate of the SDTW is the lowest, and the error rate of LCSS is higher than that of the DTW. The error rate of the SDTW is 80%, 96.12%, and 44% lower than the LCSS, EDR, and DTW with the Cross dataset, respectively; and 35.82%, 77.01%, and 18.87% lower with the Labomni dataset, respectively. To sum up, the SDTW algorithm can obtain better accuracy than that of the DTW, LCSS, and EDR. The reason is that the SDTW algorithm introduces the prediction distance to convert the temporal distance into the spatial distance, considering the temporal distance factor. Additionally, SDTW introduces the segment-segment distance to improve the computation accuracy by adjusting the parameters of shape factors.
5.4. Noise Effect Analysis
To evaluate the robustness of various algorithm, noisy data at different levels is superimposed into the original trajectory sequence data. The noise rate reflects the deviation points ratio in the trajectory sequence. When the noise rate is (0 ≤ ≤ 1), it indicates that the trajectory points of in the original data have been deviated to a certain extent. It is noted that due to noise randomness, the experiments are repeated 20 times and the average value is taken to ensure the accuracy of the results.
In the experiment, the variation of is in the range [0.1, 1] with the step 0.1. The deviation degree uses a random number. The deviation degrees of most deviation points are greater than the maximum threshold in the LCSS and EDR. The other parameters are set to the same value, as in the Section 5.3.
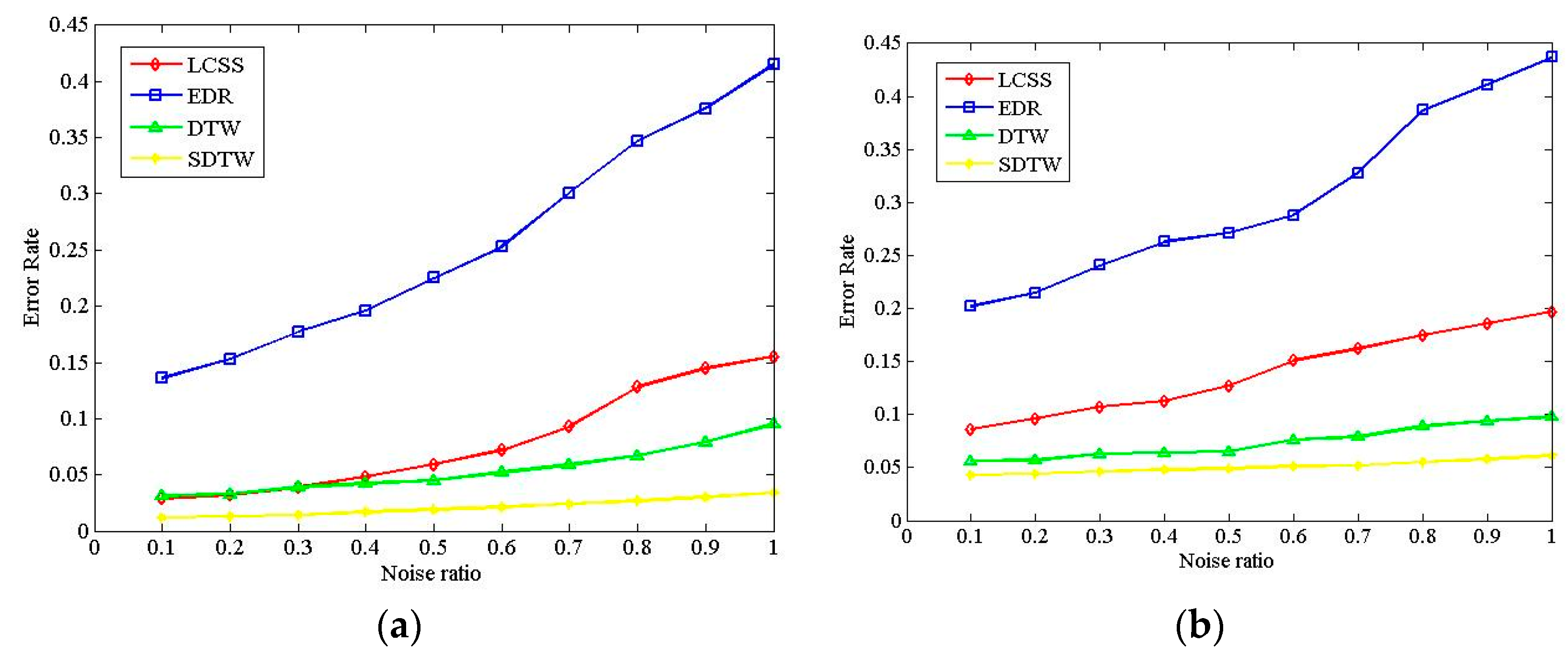
Figure 12a,b illustrates the experiment results with the Cross and Labomni datasets, respectively. The results of the clustering error rate are roughly consistent with the results in Section 5.3. It can be seen that the LCSS, DTW, and SDTW exhibit better accuracy than EDR, even in the case of noisy data. On the other hand, with the increase of the amount of noisy data, the clustering error rates of all algorithms increase gradually. From Figure 12, the maximum error rate of the LCSS, DTW, and SDTW is below 0.15 when the noise ratio varies from 0.1 to 1.0, which indicates good robustness to the noisy data for the above three algorithms. However, EDR exhibits poor performance on the robustness during the increase of noisy data.
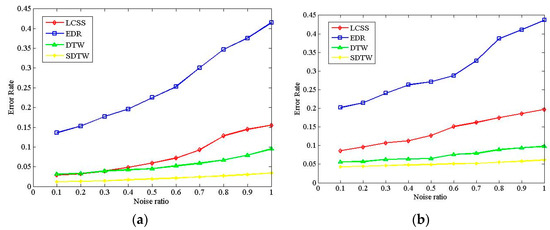
Figure 12.
Comparison of noise effect on the algorithms. (a) Clustering error rates based on the Cross dataset; and (b) clustering error rates based on the Labomni dataset.
On the other hand, In the Cross dataset, the average change ratio of ER in the LCSS, EDR, DTW, and SDTW is 23.35%, 14.88%, 14.15%, and 13.64%, respectively. In the Labomni dataset, that is 11.1%, 9.38%, 6.71%, and 4.21%, respectively. EDR and LCSS present poorer robustness than the DTW and SDTW. The conclusion that the robustness of the LCSS and EDR algorithms is better than the DTW when the deviation degree is greater than from [4] is not correct. The above conclusion is similar with [23]. The SDTW algorithm exhibits the best performance in terms of robustness, which benefits from the point-segment distance, which decreases the effect of sampling methods on the accuracy and also improves the robustness to noise.
5.5. Parameter Effect Analysis
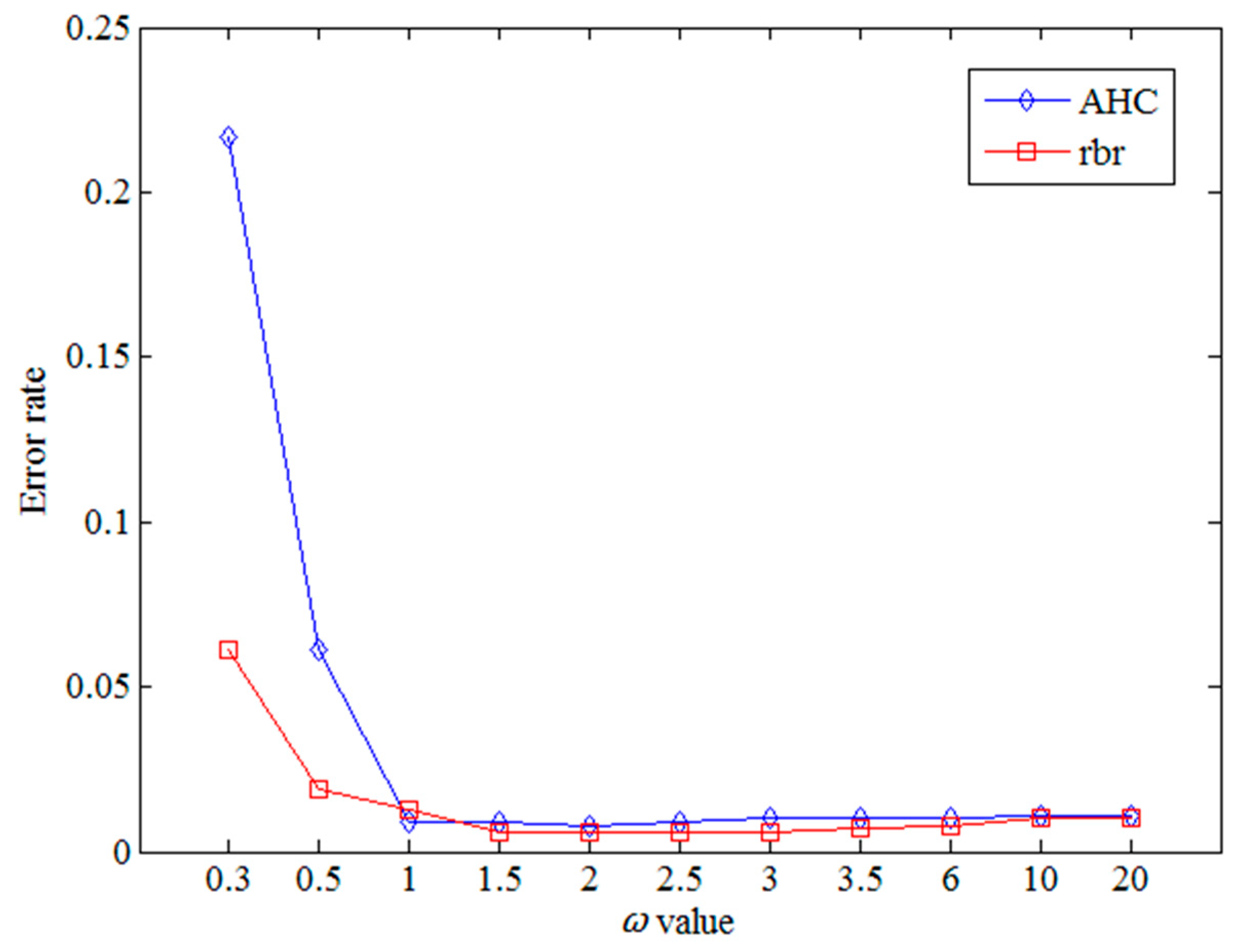
In the SDTW algorithm, is an important parameter and determines the weight of the shape factor in the similarity computation. The experiments evaluate the effect of parameter varying from 0.3 to 20, as listed in Table 1. The experiment dataset is based on Labomni dataset. Two metrics are used to compute the error rate, AHC and rbr, respectively.

Table 1.
Error rate with various values.
From Table 1 and Figure 13, when the value is relatively small, the weight of the shape factor is quite large, which results in the high error rate. When the value lies in the range below 1.0, its small change will cause a great change in the error rate. When the value is larger than 1.0, its change will make little effect on the results. The results show no large difference with the optimal results. From the experimental results, the SDTW algorithm can obtain the optimal results with the appropriate value of parameter . Furthermore, the shape factors should be properly optimized, otherwise, the improper weights of the shape factors may result in poor performance on the error rate, as shown in Figure 13.
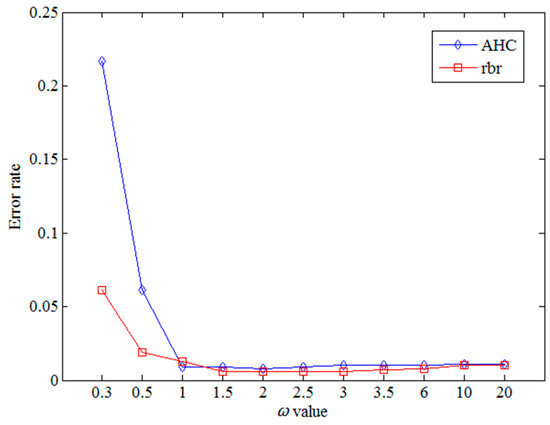
Figure 13.
ER with various values.
6. Conclusions
With the rapid development of sensor technology and the popularization of personal smart devices, GPS sensors are widely used to track moving objects. A trajectory similarity measure is one of the most important steps in trajectory data mining of human activity and vehicle moving patterns. Unfortunately, the main similarity measure algorithms with the trajectory data have been found to be inaccurate, highly sensitive to sampling methods, and have low robustness to the noise data. In order to solve the above problem, a segment-based dynamic time warping algorithm (SDTW) is proposed to measure the trajectory similarity. First, the proposed SDTW adopts the point-segment distance to reduce the sensitivity influence of the trajectory sampling method. Then, considering the temporal distance factor, SDTW introduces the prediction distance to convert the temporal distance into the spatial distance. Finally, SDTW introduces the segment-segment distance to improve the computation accuracy by adjusting the parameters of the shape factors. The experimental results indicate that the SDTW algorithm can obtain about 57%, 86%, and 31% better accuracy than the LCSS, EDR, and DTW, respectively. Meanwhile, the SDTW algorithm exhibits better robustness to the noise than that of the other algorithms.
Acknowledgments
This study was supported by the National Key Technology Research and Development Program of the Ministry of Science and Technology of China under Grant No. 2013BAB06B04, 2016YFC0400910; Key Technology Project of China Huaneng Group under Grant No. HNKJ13_H17_04; Science and Technology Program of Yunnan Province under Grant No. 2014GA007; the Fundamental Research Funds for the Central Universities under Grant No. 2015B22214; NSF-China and Guangdong Province Joint Project: U1301252; the NSF of Changzhou Institute of Technology under Grant No. YN1303, the NSF of Colleges and Universities in Jiangsu Province under Grant No. 14KJB520003 and the Qing Lan Project of Jiangsu Province. The authors are grateful to the viewers for their comments which greatly improved the quality of the paper.
Author Contributions
All four authors have contributed to the work presented in this paper. Yingchi Mao, Haishi Zhong, and Xiaofang Li formed the initial idea. Yingchi Mao, Haishi Zhong, and Xianjian Xiao developed the overall theoretical structure of the research. Yingchi Mao and Haishi Zhong conceived and designed the experiments. Haishi Zhong performed the experiments; Yingchi Mao and Haishi Zhong analyzed the data. Xianjian Xiao and Xiaofang Li provided the experiment dataset. All authors worked collaboratively on writing main text paragraph.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604.
- Das, R.D.; Winter, S. Automated urban travel interpretation: A bottom-up approach for trajectory segmentation. Sensors 2016, 16, 1962. [Google Scholar] [CrossRef] [PubMed]
- Basiri, A.; Amirian, P.; Mooney, P. Using crowdsourced trajectories for automated OSM data entry approach. Sensors 2016, 9, E1510. [Google Scholar] [CrossRef] [PubMed]
- Magdy, N.; Sakr, M.A.; Mostafa, T.; El-Bahnasy, K. Review on trajectory similarity measures. In Proceedings of the 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems, Cairo, Egypt, 12–14 December 2015; pp. 613–619.
- Kruskal, J.B. An Overview of Sequence Comparison: Time Warps, String Edits, and Macromolecules. SIAM Rev. 1983, 25, 201–237. [Google Scholar] [CrossRef]
- Kearney, J.K.; Hansen, S. Stream Editing for Animation; Department of Computer Science, Iowa University: Iowa City, IA, USA, 1990. [Google Scholar]
- Chen, L.; Zsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 491–502.
- Morse, M.D.; Patel, J.M. An efficient and accurate method for evaluating time series similarity. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 12–14 June 2007; pp. 569–580.
- Chen, L.; Ng, R. On the marriage of Lp-norms and edit distance. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 792–803.
- Chen, Y.; Nascimento, M.A.; Ooi, B.C.; Tung, A.K.H. Spade: On shape-based pattern detection in streaming time series. In Proceedings of the IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 11–15 April 2007; pp. 786–795.
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental comparison of representation methods and distance measures for time series data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef]
- Kim, S.W.; Park, S.; Chu, W.W. An Index-Based Approach for Similarity Search Supporting Time Warping in Large Sequence Databases. In Proceedings of the International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 607–614.
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Lemire, D. Faster retrieval with a two-pass dynamic-time-warping lower bound. Pattern Recognit. 2009, 42, 2169–2180. [Google Scholar] [CrossRef]
- Su, H.; Zheng, K.; Huang, J.; Wang, H.; Zhou, X. Calibrating trajectory data for spatio-temporal similarity analysis. VLDB J. 2015, 24, 93–116. [Google Scholar] [CrossRef]
- Nakamura, T.; Taki, K.; Nomiya, H.; Seki, K.; Uehara, K. A shape-based similarity measure for time series data with ensemble learning. Pattern Anal. Appl. 2013, 16, 535–548. [Google Scholar] [CrossRef]
- Wang, H. Two concise proofs of the formula of point to space linear distance. Stud. Coll. Math. 2006, 9, 38–40. [Google Scholar]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. Bull. Tech. Comm. Data Eng. 2010, 33, 32–39. [Google Scholar]
- Morris, B.T.; Trivedi, M.M. Trajectory learning for activity understanding: Unsupervised, multilevel, and long-term adaptive approach. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2287–2301. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Huang, K.; Tan, T. Comparison of Similarity Measures for Trajectory Clustering in Outdoor Surveillance Scenes. In Proceedings of the International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 1135–1138.
- Data Clustering Software| Karypis Lab. Available online: http://glaros.dtc.umn.edu/gkhome/views/cluto (accessed on 21 September 2016).
- Morris, B.; Trivedi, M. Learning trajectory patterns by clustering: Experimental studies and comparative evaluation. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 312–319.
- Wang, H.; Su, H.; Zheng, K.; Sadiq, S.; Zhou, X. An effectiveness study on trajectory similarity measures. In Proceedings of the Twenty-Fourth Australasian Database Conference, Adelaide, Australia, 29 January–1 February 2013; pp. 13–22.

© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).