1. Introduction
The terminology “quality of life” has been continuously discussed in the literature, so as to lay a foundation to serve the subsequent quantification of Urban Environmental Quality (UEQ). Szalai [
1] emphasized that quality of life represents the degree of satisfaction with life and the feeling of well-being, which can be measured by exogenous and endogenous factors. Diener and Suh [
2] concluded the meaning of the quality of life by the satisfaction of life. Raphael et al. [
3] further echoed and agreed that quality of life tends more to be the enjoyable degree of a person toward the important responsibilities of his/her life. However, Kamp et al. [
4] described the quality of life by physical and immaterial equipment, such as health, education, justice, work, family, etc.
UEQ is the consequence of the combination of environmental parameters, including nature, open space, infrastructure, built environment, physical environment amenities and natural resources, and each parameter has its own characteristics and partial quality. Kamp et al. [
4] addressed that UEQ is an essential part of the quality of life, which has basic concepts, such as health, safety and education, in addition to the physical and environmental parameters. Designing a theoretical framework of UEQ linking to the quality of life is an essential step to understand urban sustainability and human well-being. Such a framework may help to choose the parameters and the integration techniques to evaluate the multidimensional aspects of UEQ. These integration techniques are able to assess the current and predict/estimate the future UEQ, which are modelled by the municipal and city planners [
4]. Thus, the assessment of UEQ can be an efficient tool to provide effective information of urban conditions, sustainable development and regional planning [
5]. UEQ can be modelled using satellite remote sensing techniques through analysing multi-temporal and multi-resolution data, which are able to give a clear vision for visualizing and understanding the land cover, Land Surface Temperature (LST), water conditions and vegetation in urban areas [
6,
7]. Consequently, several studies in the literatures demonstrated the use of multi-source data to model and assess the UEQ [
8,
9,
10].
Moore et al. [
11] conducted a research study in three U.K. city centre areas, including Clerkenwell in London, Devonshire Quarter in Sheffield and the city centre of Manchester. The main goal of the study was to investigate and understand the UEQ in both subjective and objective bases, which mainly represent the city in mind and the city physically in reality, respectively. The case study divided the project into three sections: (1) outdoor environmental quality, which represents the physical, environmental conditions in the city; (2) perceived environmental quality, which represents the experiences of city residents; and (3) indoor environmental quality, which represents the physical and environmental conditions of residential buildings. Noise levels, carbon monoxide and air temperature were observed over a summer and winter period for the outdoor environmental quality assessment. For the perceived environmental quality, residents from each city were hired to conduct a photo survey and a semi-structured interview to assess residents’ experiences within each case study. The levels of carbon dioxide (CO
), carbon monoxide (CO), thermal conditions (
C) and light intensity were measured for the indoor environmental monitoring. The findings of this case study illustrated the local environmental quality maps and spatial urban environmental factors that represent the environmental quality within the city. The combination of subjective and objective approaches enabled encouraging people to think about how they understand the environment. The proposed method can provide an efficient way for residents worldwide to highlight their concerns, wishes and positive aspects of their local area to support decision makers.
Fobil et al. [
12] presented a case study of UEQ in the City of Accra, Ghana. The primary goal of the study was to investigate the relationship between the urban environmental quality and death locations, which was commonly caused by malaria and infectious diarrhoea in low-income countries. First, a total of 65 environmental parameters, such as population and waste generation, water supply and sanitation, hygiene conditions and building structure material, were obtained from the Ghana Census 2000 database. The births and deaths registry in Accra provided the mortality data over the period 1998–2002. Second, Principal Component Analysis (PCA) was used to integrate the environmental parameters’ data and the mortality data of the study area. PCA was used to first compute the correlation among all pairwise parameters. Data reduction was subsequently conducted to reduce the environmental parameters. The results showed that all of the zones were labelled with good, bad or terrible environmental conditions. Third, analysis of variance was used to compare the differences in malaria and diarrhoea mortality levels in the three environmental zones. Fourth, a linear association was conducted between the environmental parameters and malaria and diarrhoea mortalities by using Generalized Linear Models (GLMs). The result demonstrated a strong relationship between environmental parameters and the mortality of malaria. However, there was no strong correlation found between environmental parameters and mortality from diarrhoea. The study illustrated that urban environmental management can be used to reduce the risk of infectious disease in low-income countries.
Lo [
13] introduced the Landsat Thematic Mapper (TM) and social data to assess the quality of life in the city of Athens. The Landsat TM image was first obtained to generate the land use/land cover map and to extract biophysical information from it, including the Normalize Difference Vegetation Index (NDVI) and LST. Socio-economic data were obtained from U.S. census, including population density, per capita income, median home value and percent of college graduates. The maximum likelihood classification was implemented to extract low and high density residential areas, commercial and industrial areas, water, roads, forests and agriculture areas. Principal Component Analysis (PCA) and GIS overlay were used to integrate the land use/land cover, biophysical and socio-economic data. The results showed that NDVI has a strong correlation with per capita income, median home value and percent of college graduates. However, it indicates that NDVI has relatively low correlation with population density, land surface temperature, high density of residential areas, commercial areas and industrial areas. The study showed that the integration of land use/land cover, biophysical and social data can aid in predicting a realistic UEQ for the city.
Another representative study was found in U.S. counties, conducted by Shoff et al. [
14]. The main goal of this case study was to investigate the place-specific risk factors for prenatal care utilization in the U.S. using Spatially-Lagged Geographically-Weighted Regression (GWR-SL). The dependent variable, including late or no prenatal care, was first extracted from the Women’s Health Quick Health Data Online from 1999–2001. The late or no prenatal care mainly represents the percentage of women who received prenatal care during their second or third period of pregnancy or did not receive prenatal care at all. The racial composition variables, including the percentage of black females of childbearing age, the percentage of American Indian/Alaskan Native (AIAN) females of childbearing age, the percentage of Asian females of childbearing age and the percentage of Hispanic females of childbearing age were obtained from the above mentioned health data to be included in the analysis. Additionally, the nativity status composition, including the percentage foreign-born, was obtained for the same period and included in the analysis. GWR-SL was implemented in this case study to model the spatial location of prenatal care utilization in U.S. counties. The results of the GWR-SL approach were compared with some of the existing methods, including ordinary least squares and the spatial lag regression model, and the GWR-SL approach showed a better understanding of prenatal care utilization in U.S. counties than the previously mentioned existing approaches. That is mainly because the GWR-SL approach takes into consideration the spatial nature of the data. The findings of this case study help to better estimate and understand the spatial prenatal care utilization in the U.S.
Despite the above successful attempts, the majority of the scholars mainly utilized PCA, GIS analysis or MCEtechniques to integrate UEQ parameters [
12,
13,
15,
16]. The PCA analytical technique has several potential disadvantages: (1) it produces unweighted components, which may not highlight those important parameters; (2) PCA does not work properly in nonlinear relationships; and finally, (3) the minimum number of components is indeterminable [
5]. The GIS overlay method does not consider correlation among parameters, nor give weight to the parameters. MCE is a weighting process that allows decision makers to modify attribute values of the variables, which may lead to biased opinions. Numerous researchers [
15,
16,
17,
18] attempted to validate the UEQ results using e-mail questionnaire, field-based questionnaire, interviews with experts and factor analysis. However, these methods can be inaccurate to test the outcomes of UEQ; as a result, it may cause tendentious results. In this research, we attempt to fill several gaps in UEQ research by: (1) utilizing a new method to normalize the UEQ parameters; (2) introducing a new method to weight urban, environmental and socio-economic variables obtained from diversity data; and (3) proposing a new method to validate urban and environmental variables with socio-economic variables for UEQ assessment in two cities in Ontario, Canada.
2. Datasets
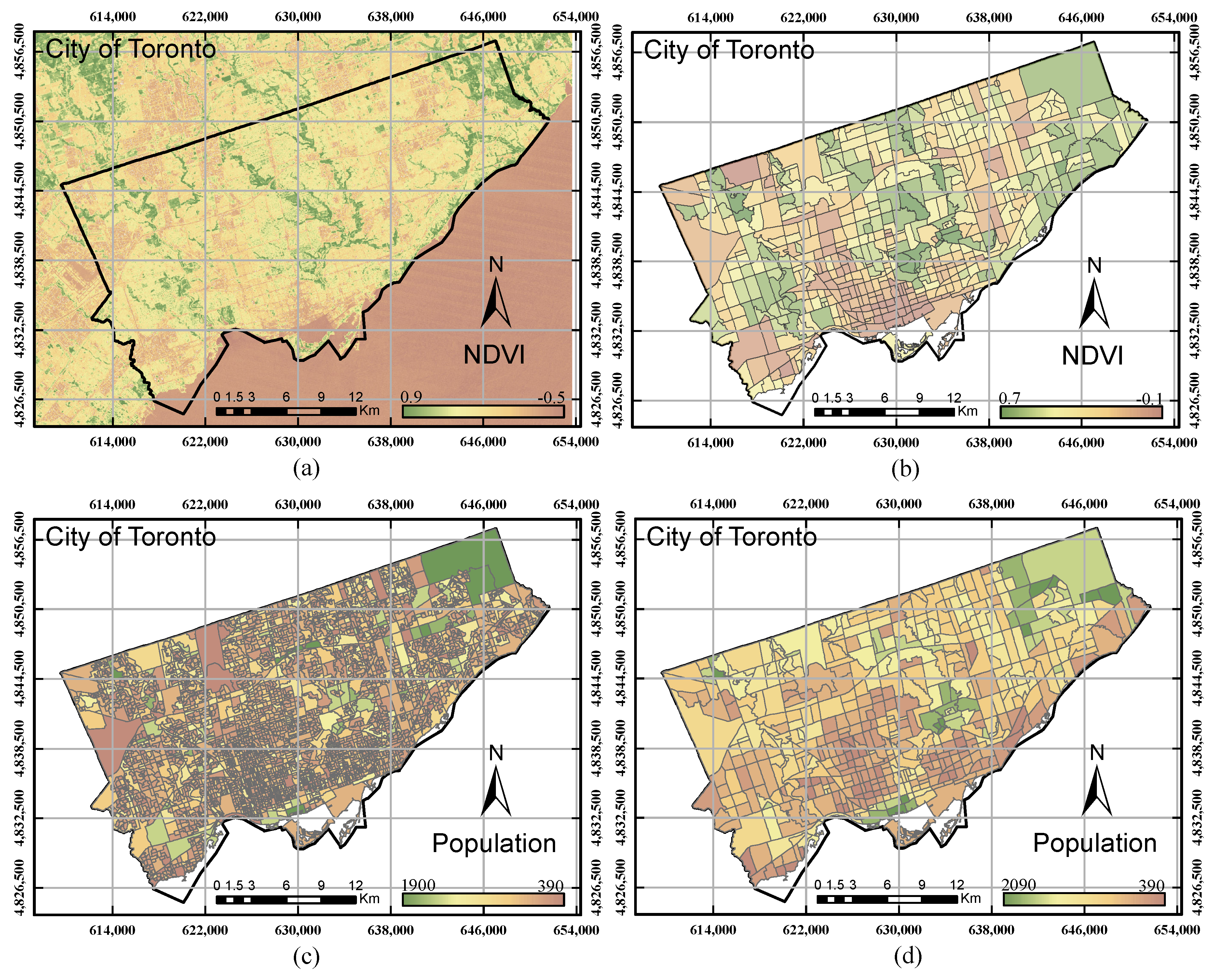
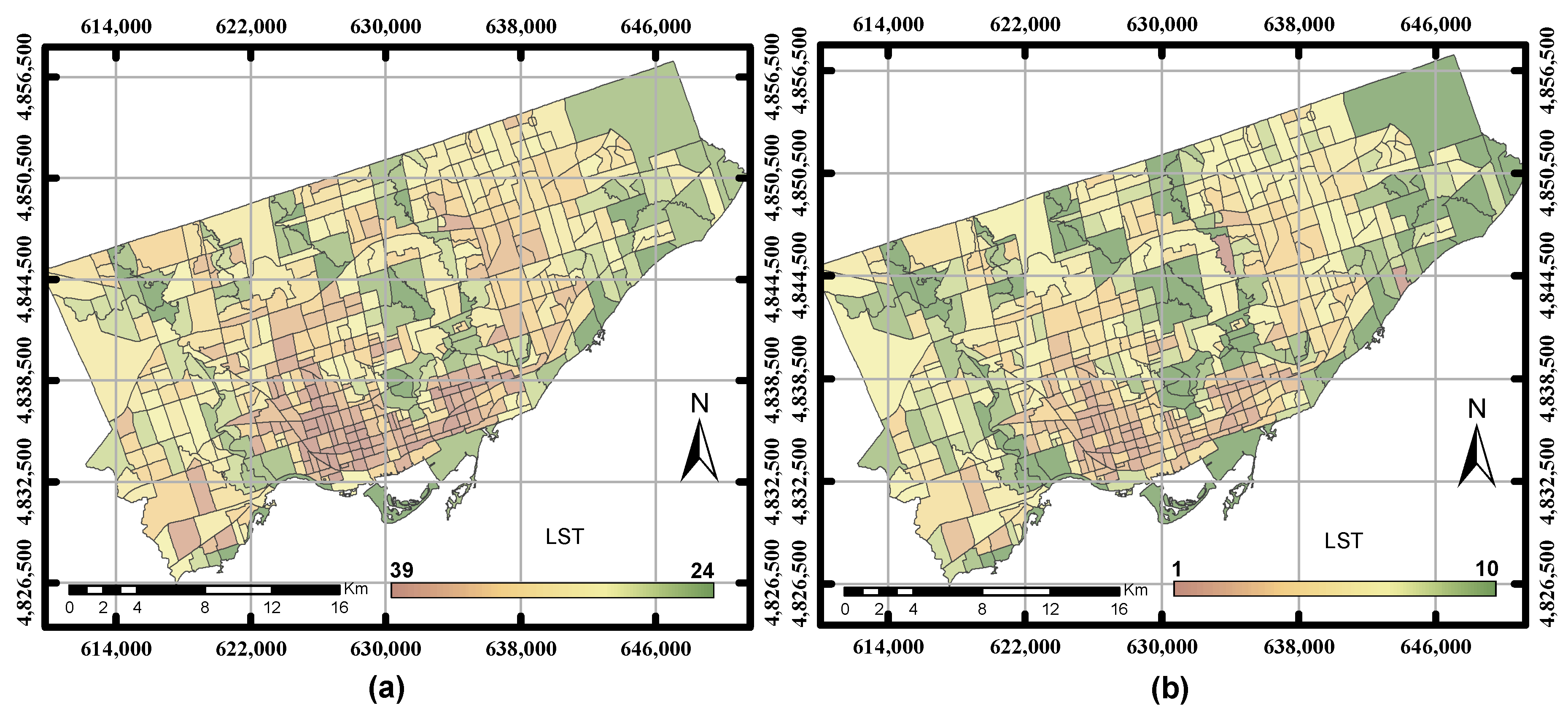
In this research, the City of Toronto and the City of Ottawa were intentionally selected as case studies due to the data availability and the rapid population growth in these two cities. The datasets used in this study include three broad categories: (1) Landsat TM satellite images; (2) GIS data layers; and (3) socio-economic data. All of the data were collected between the years 2010 and 2011 since GIS data and socio-economic are not consistently available to support the two case studies. A Landsat TM image was downloaded from the USGS Earth Explorer [
19]. The spatial resolution of the Landsat images is 30 m for the multi-spectral bands and 120 m for the thermal band. However, the thermal bands were resampled to a 30-m pixel size from the source of data predominantly to align the thermal band with the multi-spectral bands [
20]. The image was acquired during the summer season (July) to avoid the appearance of clouds and snow cover. On the other hand, a total of 14 GIS data layers were acquired from the Scholars GeoPortal [
21] for both cities during the same duration of time. The GIS layer data include land use, population density, building density, vegetation and parks, public transportation, historical areas, Central Business District (CBD), sports area, religious and cultural zone, shopping centres, education institution, entertainment zones, crime rate and health condition. These layers were imported into the ArcGIS platform (ArcGIS, Esri, Redlands, CA, USA) for further analysis. Similar to the remote sensing data, all of the data were projected to the UTM 17 N coordinate system for the City of Toronto and the UTM 18 N coordinate system for the City of Ottawa. Lastly, the socio-economic parameters were derived based on the used census data that were obtained from the census bureau. The census bureau archives hundreds of parameters/information related to socio-economic conditions. In this research, socio-economic parameters, including education (university certificate, diploma or degree), family income and land values, were also obtained for the result validation.
Table 1 summarizes the data sources being used in this study.
3. Methodology
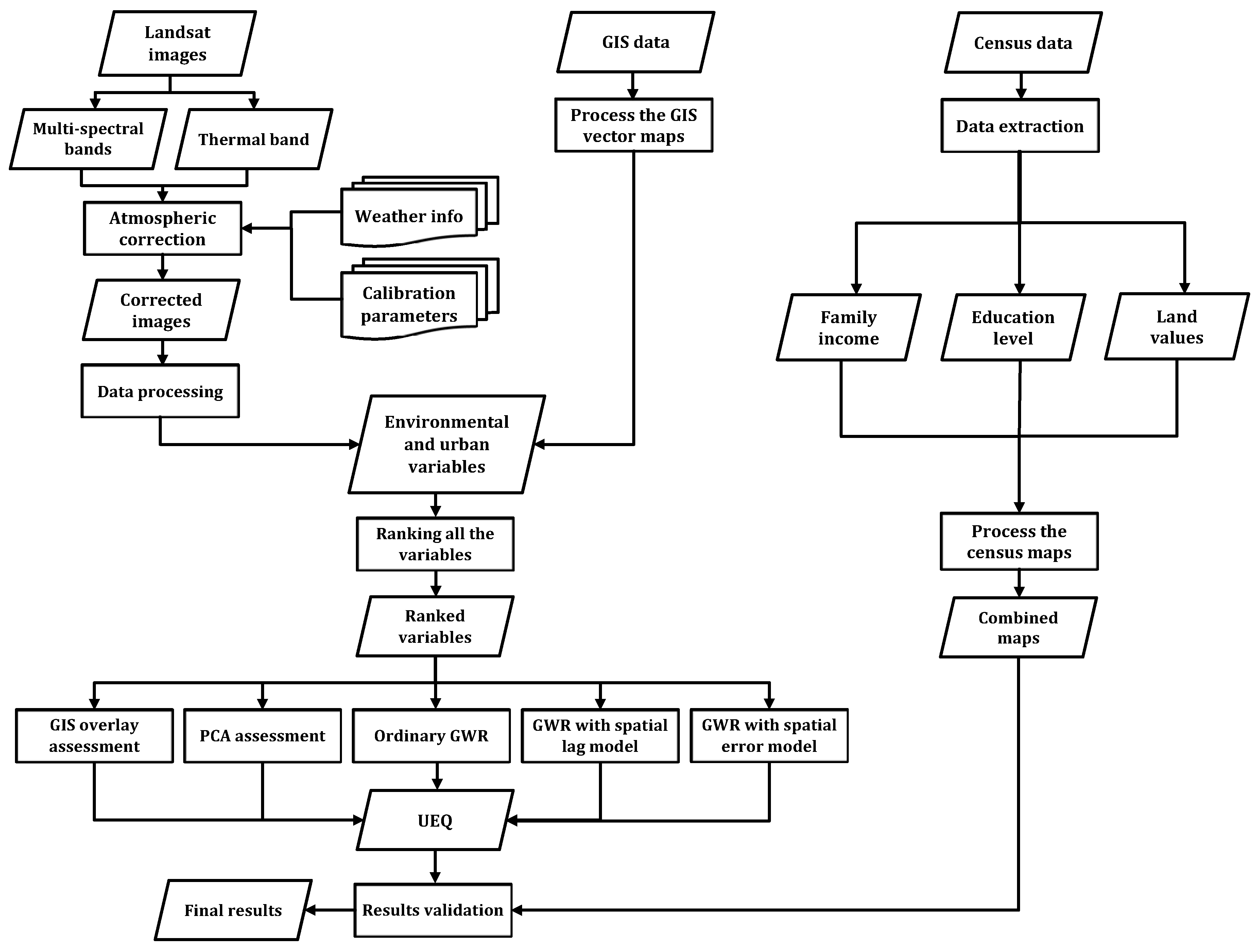
Figure 1 shows the overall workflow for the two case studies (the City of Toronto and the City of Ottawa), which can be summarized by the following steps. The Landsat images were imported into PCI Geomatics V10.1(
Geomatica, version 10.1, PCI Geomatics, Markham, ON, Canada, 2007), clipped and then projected into the UTM coordinate system. The absolute atmospheric correction model, ATCOR2 (Atmospheric Correction and Haze Reduction), built-in PCI Geomatics software was used to compute the results for several bio-physical parameters (NDVI, NDWI, built-up index and LST) [
22]. ATCOR2 was utilized to first perform radiometric calibration and to remove the effects that change the spectral characteristics of the land features [
23]. Sensor parameters, including sensor type, acquisition date, Sun elevation, Sun zenith and pixel size, were obtained in addition to weather conditions (air temperature and visibility) to conduct the subsequent atmospheric correction. The calibration parameters for Landsat TM sensor (biases and gains) were also incorporated into the atmospheric correction, as is described in [
24]. In this research, biophysical parameters, including NDVI, NDWI, built-up index and LST, were derived from the Landsat images. Urban, environmental and socio-economic parameters were all derived from GIS and census data to combine all of the parameters together for further analysis. The methodological contribution of this research work is to implement the GIS overlay, PCA and GWR (ordinary GWR, GWR with spatial error model and the GWR with spatial lag model) to integrate all urban, environmental and socio-economic parameters. Then, socio-economic parameters, including family income, higher education level and land values, were investigated to validate the final outcomes from the integration methods. The evaluation of the binary classifiers algorithm was performed to assess the precision and accuracy of each integration method. Based on the precision and accuracy of the integration methods, the optimal integrated method can be determined to estimate the best UEQ location in the two case studies.
3.1. Ranking the Parameters
Since the parameters as mentioned earlier were extracted from different data sources, they may have different scale levels and cannot be combined into a particular unit. Therefore, all of the obtained data (parameters), including raster, census and GIS data, were first transformed into one scale (sub-neighbour), as shown in
Figure 2. To standardize the parameters and represent the significant level of each polygon in the parameter, the Z-score method was performed for all of the parameters. The Z-score model is a statistical measurement that is able to standardize a wide range of data to represent the significant changes across data [
25].
The following Equation (
1) shows the first step to normalize the parameters using the Z-score:
where
x is the observation values (polygons),
i is the parameter,
μ is the mean value of the parameter and
σ is the standard derivation of the parameter. The second step is to use linear interpolation to rank the parameters from 1–10. The polygon within the parameter that has a high Z-score number will represent high values, for example 10. The polygon that has a low Z-score will result in a value of 1. However, for those parameters having negative relationships with respect to UEQ, such as crime rate, industrial areas, LST, etc., these parameters are inversely presented (e.g., the highest LST will take a value of 1, and the lowest LST value will get 10), as shown in
Figure 3. The following Equation (
2) shows how linear interpolation was calculated:
where
is the current observation value,
is the maximum observation value,
is the minimum observation value,
is the maximum ranking value,
is the determined ranking value and
is the minimum ranking value.
3.2. Data Integration of Multiple Environmental and Urban Parameters
Integration techniques can be used to combine remote sensing and GIS data for urban modelling and analysis [
26]. Previous studies demonstrated two integration methods, mainly PCA and GIS overlay, which are able to combine various parameters from a diverse source of data. In this research work, three approaches were demonstrated to integrate the aforementioned environmental and urban parameters. These two existing approaches (PCA and GIS overlay) were first implemented, and subsequently, we investigated the use of GWR techniques (ordinary GWR, the GWR with spatial lag model and the GWR with spatial error model) to integrate all of the aforementioned parameters, which can lead to an improved estimation of UEQ.
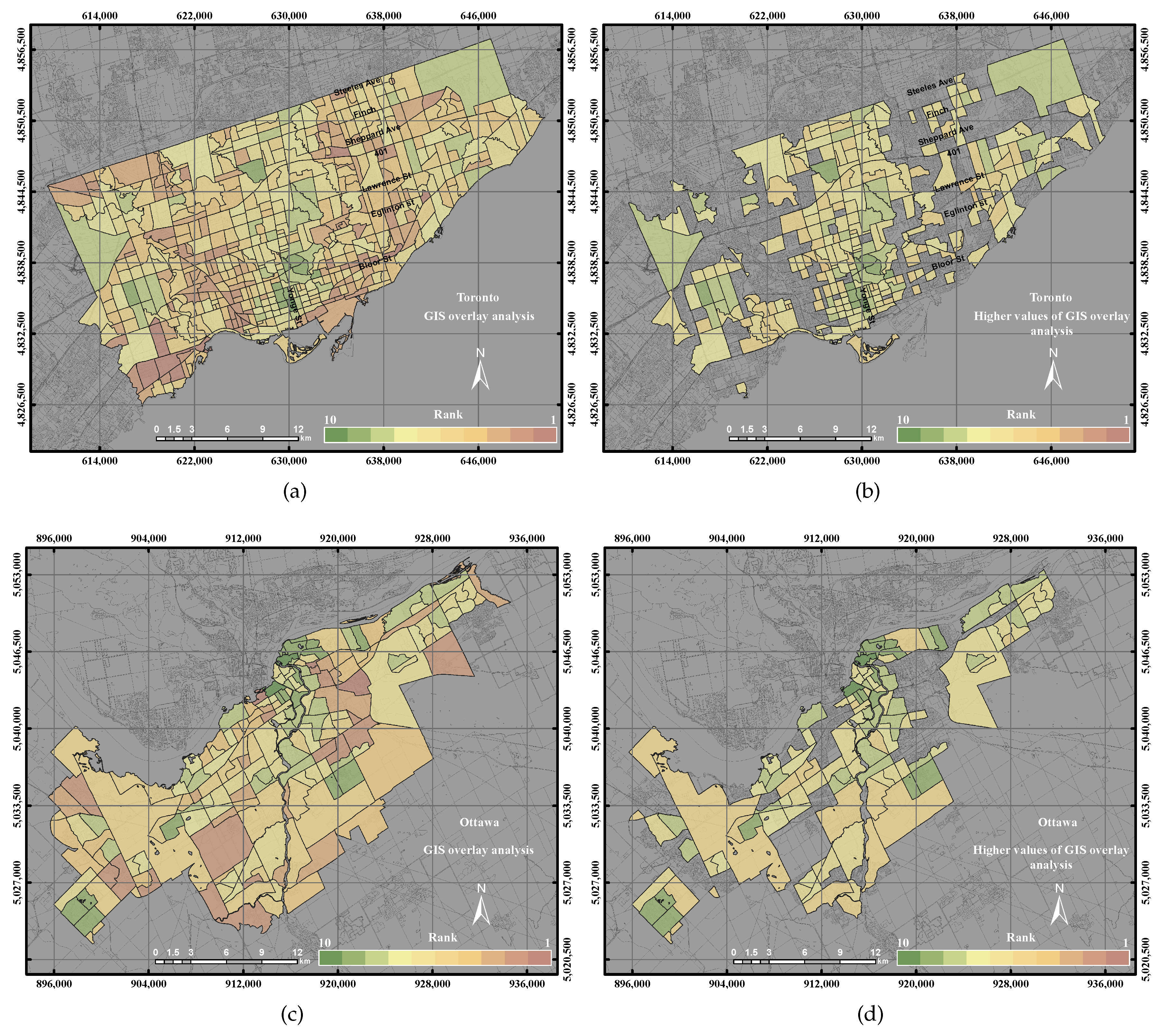
3.2.1. Geographic Information System Overlay
GIS overlay is a multi-criteria application that uses data layers for specific environmental thresholds. Remote sensing data are commonly presented as digital data in raster format. However, census data are usually stored in GIS vector format. Remote sensing data can thus be integrated with socio-economic data by converting remote sensing data from raster to vector data [
27]. In this research work, the GIS overlay integration method was used to combine the urban and environmental parameters to serve for the UEQ assessment. After, we transform all of the obtained data into sub-neighbours and rank the parameters from 1–10 using Equations (
1) and (
2). The sum of the data layers can thus illustrate the result of UEQ.
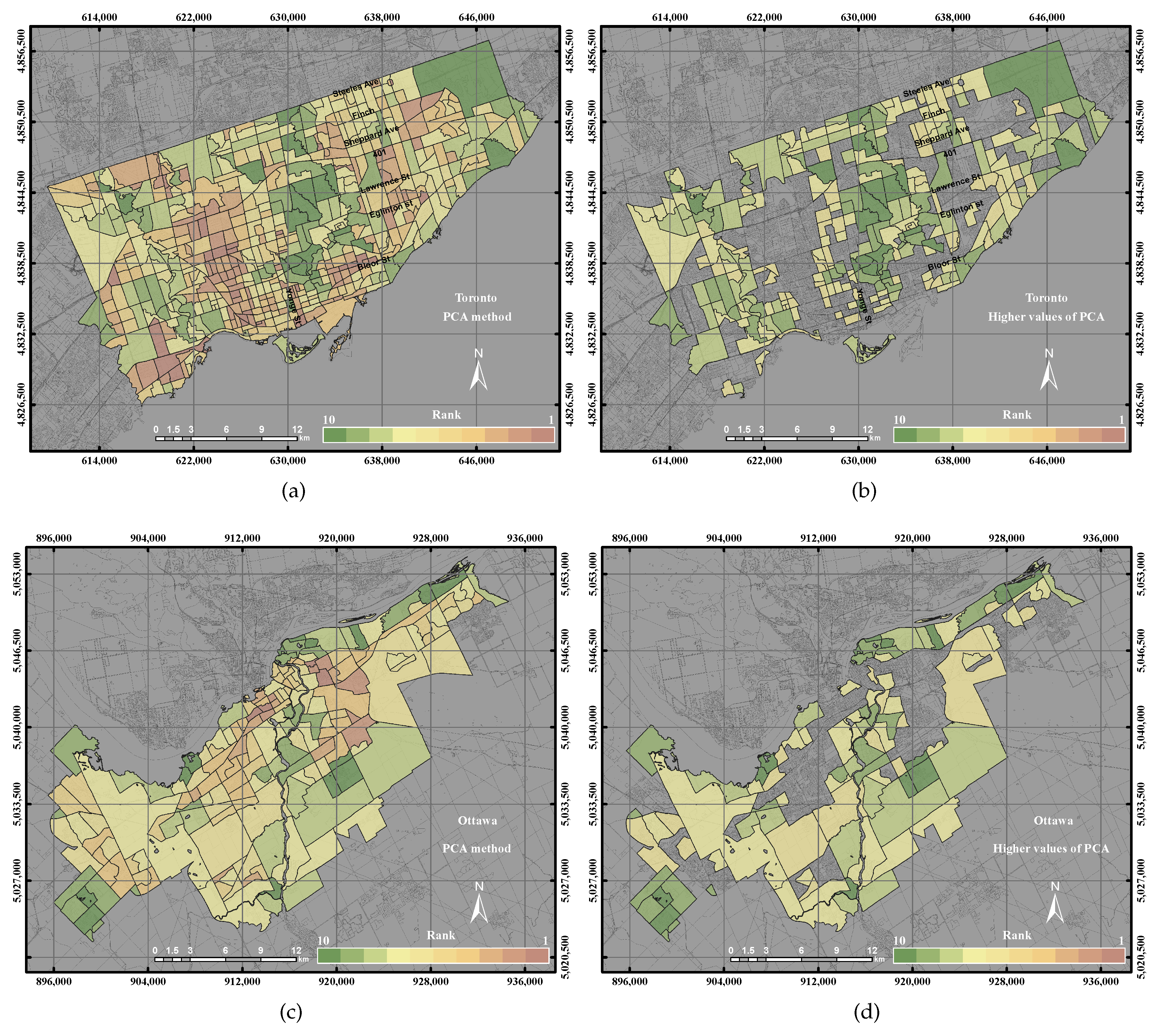
3.2.2. Principal Component Analysis
PCA is an analysis technique that compresses high dimensional data into a small size of data and retains most of the variance of the data [
28]. PCA is commonly used in many remote sensing applications. The covariance matrix of standard PCA may not be the best option for data that have different measurement units. The correlation matrix can be used instead of the covariance matrix to standardize each parameter to the variance unit or zero means. In this research work, two case studies were conducted to assess the UEQ in the City of Toronto and the City of Ottawa, respectively. The observation values of the GIS polygons of each parameter were employed in the PCA model to determine the UEQ, as shown in
Figure 4.
PCA can be computed by determining the eigenvectors and eigenvalues of the correlation matrix. The first step to compute PCA is to calculate the correlation matrix. The correlation of two random variables can be computed by using the following Equation (
3):
where
r is the correlation matrix for parameters
and
, respectively,
and
are the covariance matrix for parameter
and
, respectively, and
and
are the standard deviation for parameter
and
, respectively, at location
i.
The second step is to calculate the eigenvalues of the correlation matrix. The eigenvalue measures the scale of the data. The parameters that have eigenvalues greater than one will be a good rule of thumb to represent most of the variance of the data [
29]. Eigenvalues can be computed by using the following Equation (
4):
where
A is the correlation,
λ is the eigenvalues and
I is an
N by
N identity matrix.
The third step is to calculate the eigenvector of the correlation matrix. The eigenvector measures the direction of the data. Eigenvectors can be computed by using the following Equation (
5):
where
A is the correlation matrix,
λ is the eigenvalues and
X is the eigenvector.
The new
(observation number) for the new image can be determined using the following Equation (
6) [
28]:
where
is the eigenvector for parameter
k component
p and
is the observation number in polygon
i.
3.2.3. Ordinary Geographically-Weighted Regression
One of the limitations of using PCA is that it produces unweighted components. GWR can be used to weight the spatial location of each parameter. The dependent parameter indicates the UEQ outcome, which was derived from GIS overlay method. That is mainly because the GIS overlay was found to be more emblematic for UEQ in some previous studies and one of our parallel studies [
5,
15]. The independent parameters are the urban and environmental parameters, which were derived from the remote sensing and GIS data, such as population density, building density, NDVI, public transportation, etc. The weight can be given to some location based on the nearness and similarity of the estimated parameters at some location. Thus, the observations that are located nearer to the estimated location would have a higher weight. However, the observations that are located far from the estimated location would have a lower weight. Assume we have a dataset that consists of a dependent variable
y and a set of independent variables
, and for each of the
i observations in the dataset, a measurement of its position is available in a suitable coordinate system [
30]. Equation (
7) shows the ordinary GWR model:
where
refer to the coefficients that define a spatial relationship with respect to its surroundings at location
i. The outcomes of
indicates a new dependent variable if we have the dataset of the independent variables
x at location
i. The GWR mathematical model thus considers the weights with respect to the surroundings at location
i to estimate coefficients
that define a spatial relationship with respect to its surroundings at location
i. The following form (
8) represents the coefficients
at location
i:
where
is a square matrix of weights relative to the position of
i in the study area;
is the independent variables matrix; and
is the dependent variable. The
matrix captures dependency relations between the observations, which represent the geographical weights in the diagonal and 0 in its off diagonal matrix [
31].
In this research work, the distance-based weights algorithm was implemented to create the diagonal weighted matrix. This method can be used to avoid non-weighted isolated polygons and polygons that are located inside other polygons. An optimum bandwidth can be defined through using certain techniques, including the Cross-Validation (CV) and Akaike Information Criterion (AIC), to derive the goodness of fit [
32]. However, numerous researchers suggested different kernel functions to derive the bandwidth, such as the distance based on the taxicab geometry [
33], the chamfer distance designed for a lattice or grid space [
34,
35], the shortest path distance [
36] and the qualitative distance by translating an absolute distance metric to linguistic terms [
37,
38]. In this study, the first step to compute the weighted matrix is to determine the neighbours, mainly based on the k-nearest neighbour weighted method. For instance, we could generate centre points of a 10 × 10 lattice as a mean point location or regression point to measure the distances, as shown in
Figure 5a. In addition, the polygons can be computed based on a weighting scheme known as a kernel, and in this study, we used the Gaussian shape kernel, as shown in
Figure 5b. The following form (
9) represents the weighting scheme for the distance-based method [
32,
39].
where
is the spatial weight between observation point
j and regression point
i,
is the distance between observation point
j and regression point
i and
h is the kernel bandwidth defined by the distance between the regression location and the
k-th nearest observation.
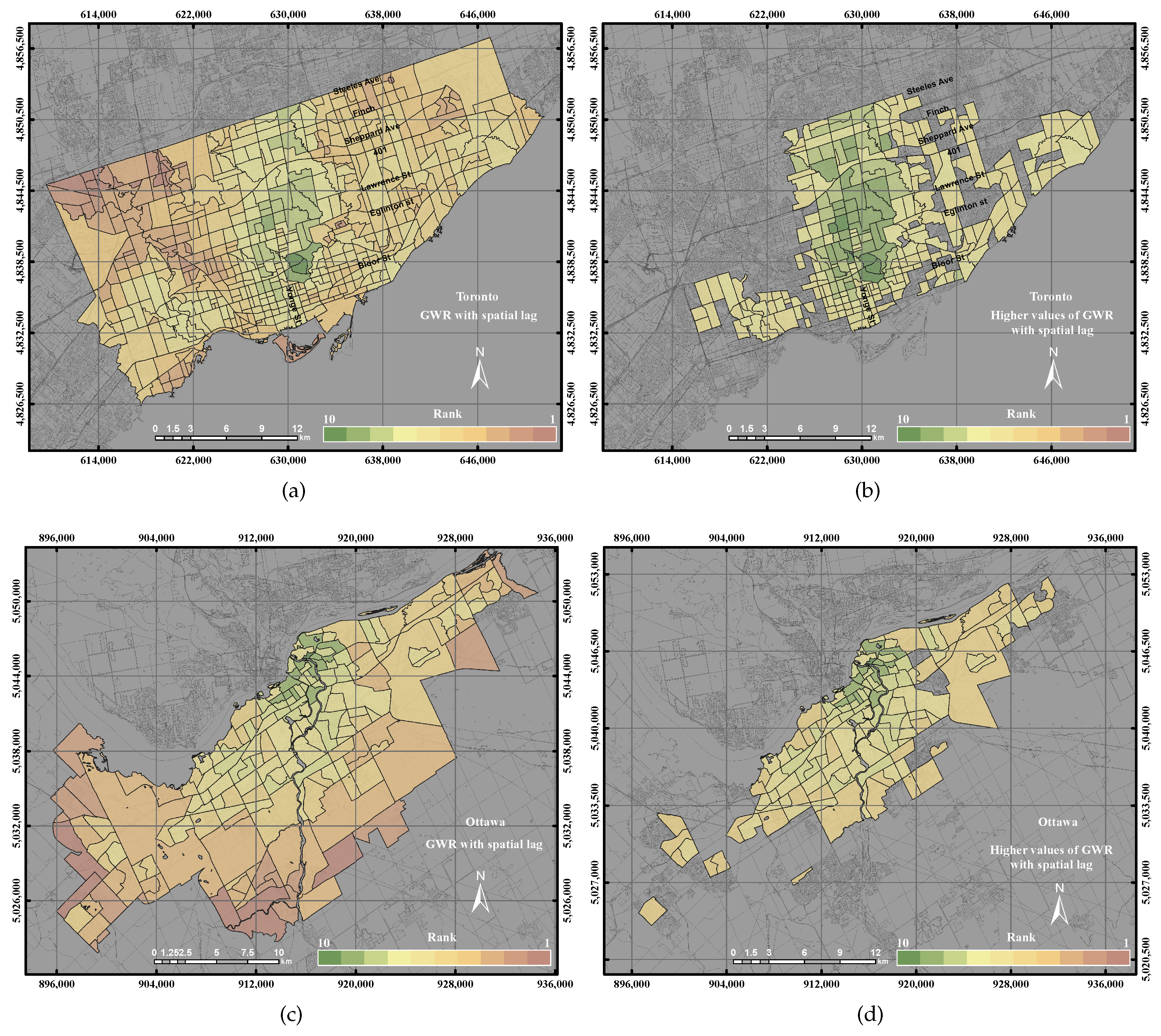
3.2.4. Geographically-Weighted Regression with Spatial Lag Model
The spatial lag model is one of the dominant spatial autoregressive regression models that has been used in many research studies [
40,
41]. Shoff et al. [
42] used the GWR with spatial lag approach to model and predict the U.S. prenatal care utilization at the county level dataset. The spatial lag model essentially heals spatial heterogeneity by including an autocorrelation coefficient and spatial weight matrix in the weighted regression model. The SLM is expressed as the following Equation (
10):
where
is an
N by 1 vector of observations on the dependent variable,
i is the location coordinates (centroid of the county),
is an
N by
N specifying spatial weights matrix, which indicates the distance relationship between locations
i and
j, and
is the spatial lag dependence between county level percentages of UEQ at location
i. For a given location, say
j,
ρ indicates the relationship between
j’s dependent variable (UEQ) and the dependent variable of
j’s neighbours defined by the distance weight matrix. Positive
ρ refers to a positive spatial autocorrelation; and if
ρ is negative, then negative spatial autocorrelation is determined.
is a
K by 1 vector of regression coefficients associated with
at location
i.
ϵ is an
N by 1 vector of the error term.
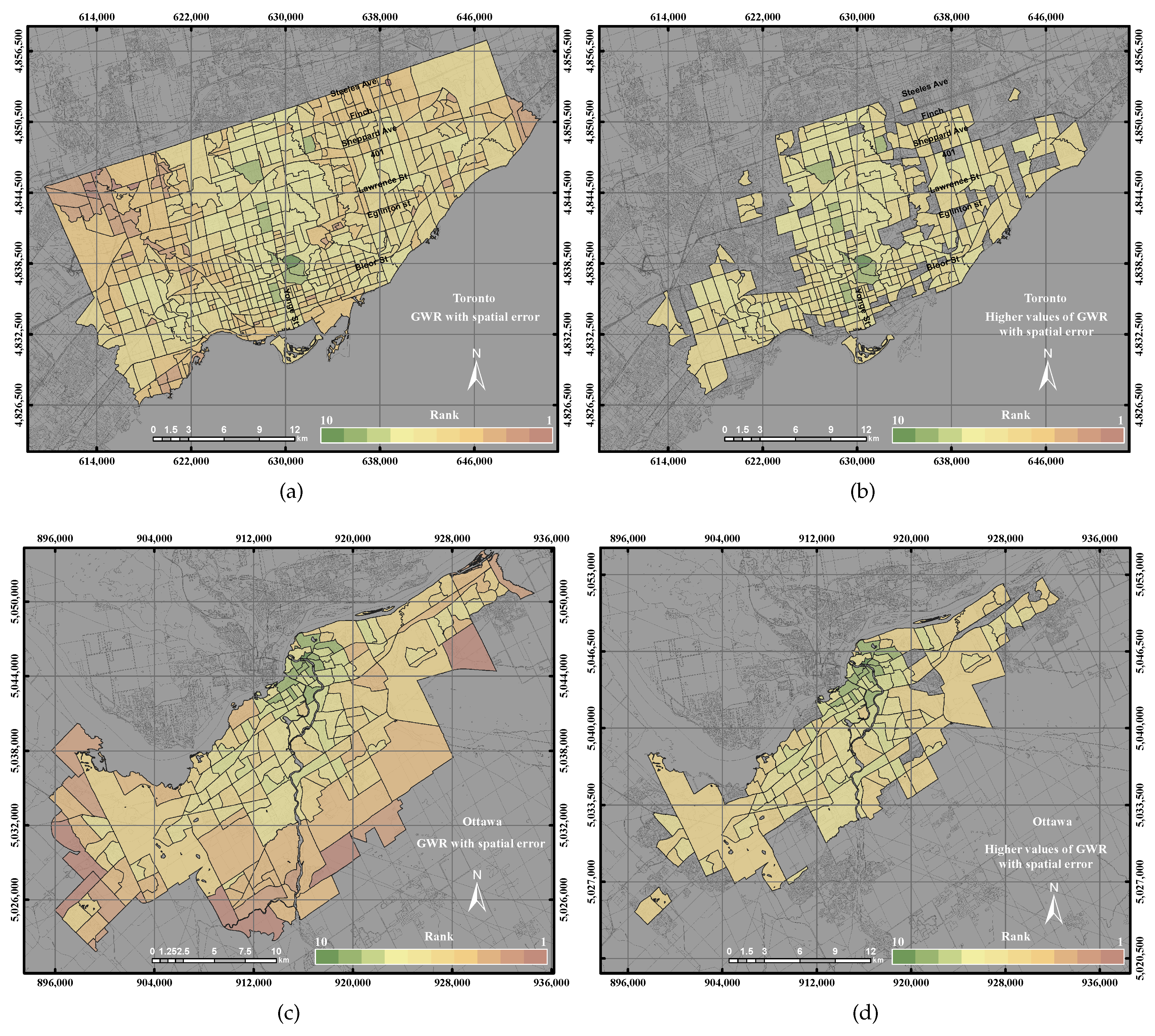
3.2.5. Geographically-Weighted Regression with Spatial Error Model
The GWR with spatial error model is appropriate when we are interested in correcting spatial autocorrelation due to the use of spatial data. In this case, the structure or spatial heterogeneity of the spatial relationship is missing. Therefore, we include the spatial autoregressive error term due to unobservable features or omitted variables that are related to locations [
43]. The GWR with spatial error model is expressed as the following Equations (
11) and (
12):
where
is the spatial autoregressive coefficient for the error lag
and
ζ is a vector of independent identically distributed errors.
3.2.6. Accuracy Assessment
Data validation is one of the major concerns in UEQ research work. Several researchers attempted to assess the accuracy of the UEQ results using different methods, including e-mail questionnaire, field-based questionnaire, asking experts and factor analysis. Regardless of the considerable amount of e-mail surveys or field-based questionnaires, both approaches are time consuming and budget dependent. Besides, factor analysis used in the previous work was performed using the same parameters that have been incorporated to compute the UEQ, which make it unreliable and biased. Numerous UEQ studies did not perform any field survey or even results validation [
11,
12,
13]. On the other hand, some of the literatures highlighted a high correlation between socio-economic parameters including (university certificate or diploma, family income and land values) and the quality of living [
44,
45,
46,
47]. Since there is a lack of ground reference to validate the results in this study, we propose to use these socio-economic parameters for data validation and to assess the UEQ results. All observed data of the three socio-economic parameters were normalized to be in the same scale from 1–10. Then, the sum of the socio-economic parameters can thus present the result of the reference, as shown in
Table 2.
The first step to validate the results is to extract the observation’s values that are higher than the mean in each parameter and reference layer. That is mainly because in this study, we need to highlight the higher UEQ areas. Second, the evaluation of binary classifiers approach was used to evaluate the UEQ based on the following two performance measures through data interpretation:
and
[
48].
is a measure that evaluates the probability that a positive outcome is correct using Equation (
13):
evaluates the effectiveness of the classifier by its percentage of correct predictions using Equation (
14):
where
refers to “True Positive”, which means the above mean polygons derived from the proposed method are being matched physically in the reference layer;
refers to “True Negative”, which represents the above mean polygons that are not detected in the proposed method and the reference layer;
refers to “False Positive”, which means the above mean polygon derived from the proposed method does not really exist in the reference layer; and
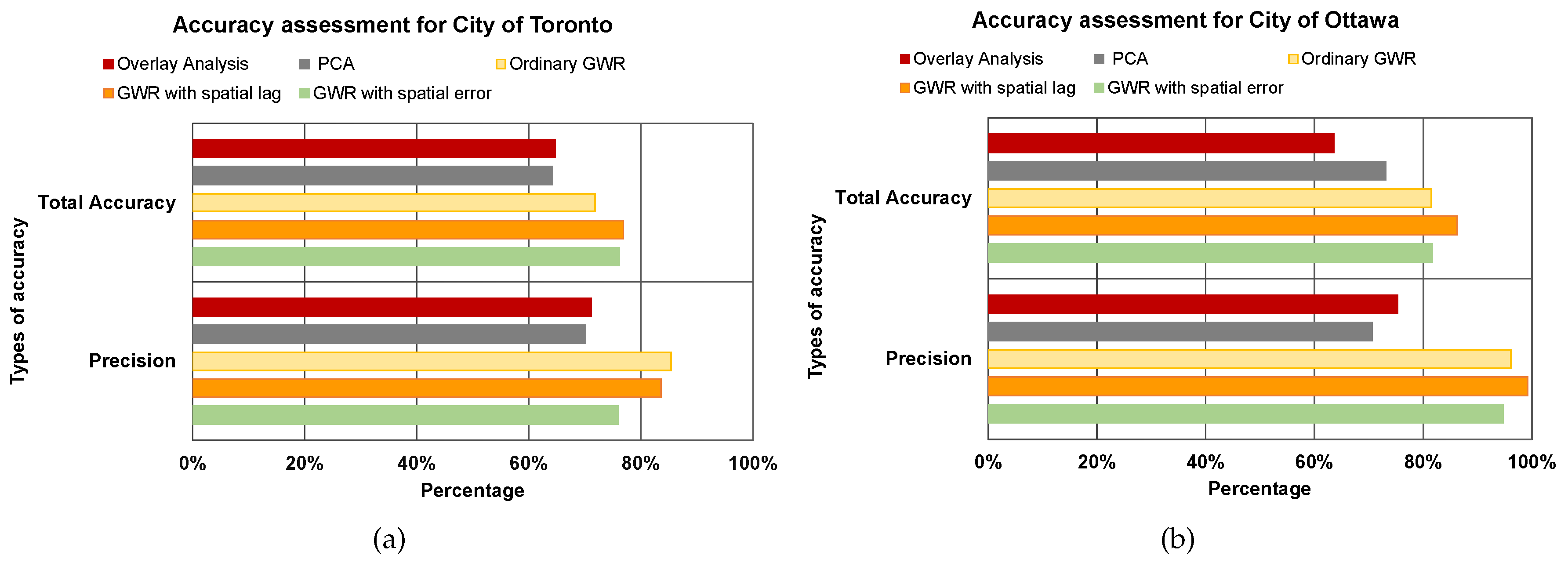
refers to “False Negative”, which means the above mean reference polygons do not exist in the proposed method. With these three indicators, we assessed the UEQ layer from the results of each proposed method, including GIS overlay, and PCA assessed the best method for our datasets.
5. Conclusions
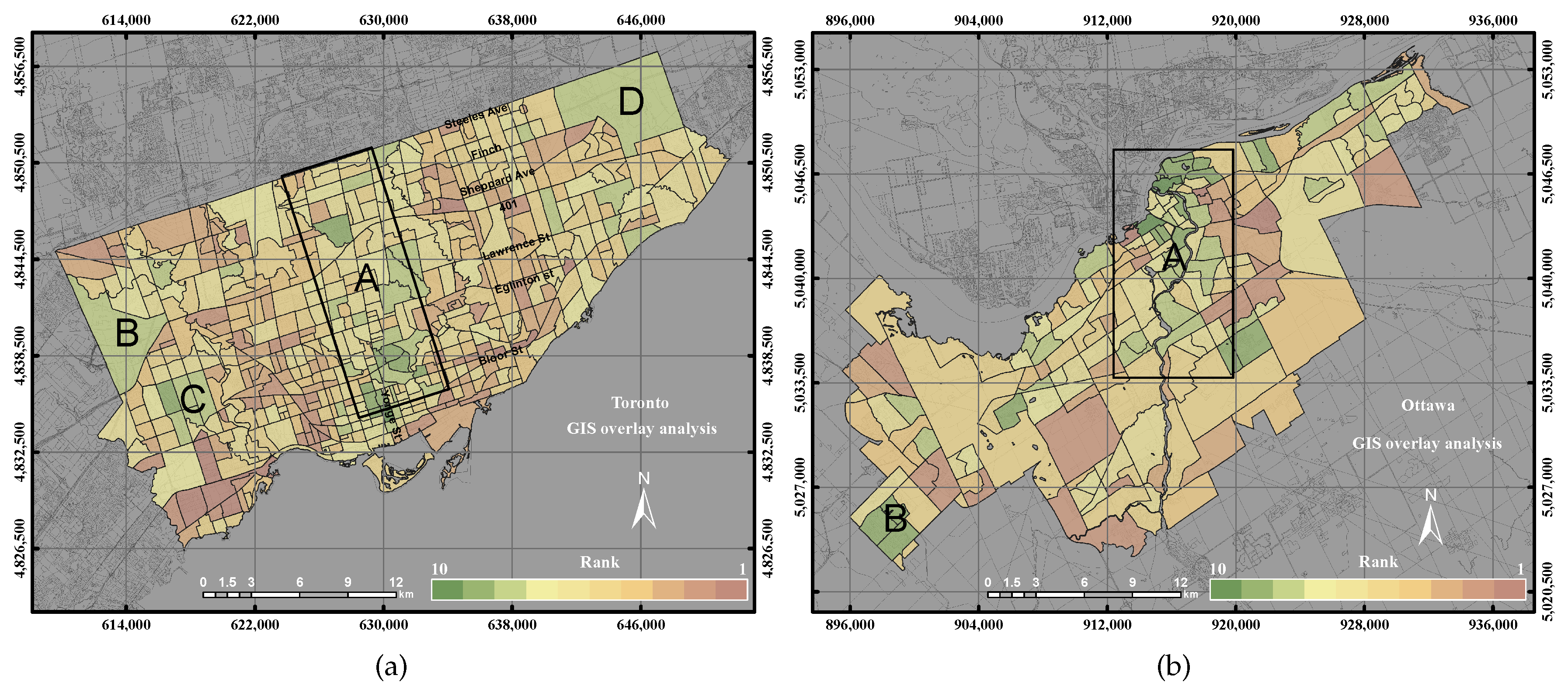
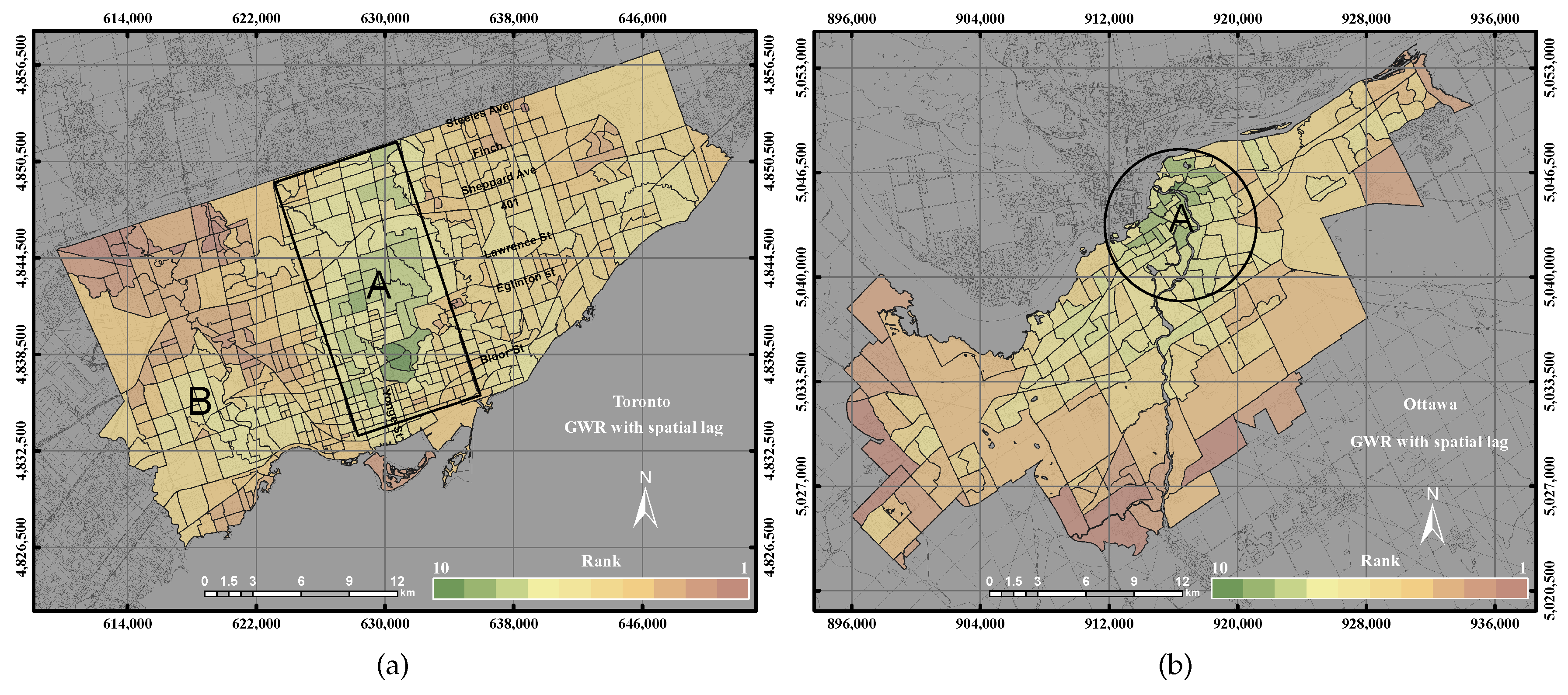
This paper epitomizes the use of the GIS overlay, PCA and GWR techniques to assess UEQ with two case studies in Ontario, Canada. The main contribution of this research work is to investigate a new method to normalize various data derived from remote sensing, GIS and census data. New approaches of GWR techniques, including the GWR with spatial lag model and the GWR with spatial error model, were tested to assess the UEQ. The new approach was evaluated to validate the final outcomes derived from the above-mentioned methods. GWR is an intellectual framework that considers the spatial relationship among the polygons in each parameter. The GWR with spatial lag model was mainly used to provide homogeneous results by incorporating the spatial lag of the dependent variable into the GWR. Therefore, the GWR with spatial lag model is capable of producing better outcomes than other unweighted integration techniques. The GWR with spatial error model was used in this study to correct the spatial autocorrelation in the spatial data. It was found that the middle of town, north of town and southwest areas have high UEQ in the City of Toronto. However, higher UEQ was found in the city centre and middle of town within the City of Ottawa. The results illustrated that the GWR with spatial lag model significantly improved the final outcomes with respect to unweighted methods, including GIS overlay and PCA up to 15% (precision) and 8% (accuracy) in the City of Toronto and 15% (precision) and 20% (accuracy) in the City of Ottawa. Moreover, the GWR with spatial lag model also improved the final outcomes with respect to weighted methods, including ordinary GWR and GWR with spatial error model up to 1% (precision) to 5% (accuracy) in the City of Toronto and 5% (precision and accuracy) in the City of Ottawa. Thus, the GWR with spatial lag model can be used to integrate multiple parameters for UEQ purposes more accurately than the unweighted integration techniques.
Besides the success of the attempted methods used in this research work, there are several potential draw backs: (1) the lack of data is always an issue that may influence the final results; (2) census socioeconomic data are usually related to administrative units and can be changed in a short period, which makes it difficult to have them available worldwide; (3) remote sensing, GIS and socioeconomic data need data transformation from raster to vector or from vector to raster, which could cause an individual loss of spatial information; (4) the distance-based weighted algorithm is more applicable to a flat surface, so all of the polygons need to be projected in advance for the output to be correct; (5) the authors have previously investigated the use of linear and nonlinear regression to run the relationship between the derived UEQ with respect to the socio-economic data (reference data). However, there is no meaningful trend found in the two cities that thus reveals the inappropriate use of a linear or non-linear model in this particular case study.
Municipalities and decision makers can consider the proposed approach to derive the UEQ for sustainable planning in many countries. However, there is always a need for new improvement to derive better precision and accuracy in the future. Therefore, updated remote sensing and GIS data are important for better results; also, integration between weighted and GWR can be a promising method to enhance the final outcomes of UEQ; future work can be focused on modelling UEQ for an arid or cold region environment/country since there are some parameters that may not be applicable in those areas. In conclusion, remote sensing and GIS techniques are useful tools to model UEQ. Spatial weighting methods further can enhance the capability to estimate UEQ in a more accurate manner.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}