1. Introduction
Three-dimensional (3D) lidar sensors are a key technology for navigation, localization, mapping and scene understanding in novel ground vehicle systems such as autonomous cars [
1], search and rescue robots [
2], and planetary exploration rovers [
3]. One major limitation regarding the use of lidar technology in these challenging applications is the time and computational resources required to process the dense point clouds generated by these sensors.
Classification techniques involving point clouds are used extensively and can be categorized in many ways [
4]. For instance, airborne sensors can use elevation and flatness characteristics to classify roof surfaces and urban objects [
5,
6,
7], whereas terrestrial scans are affected by obstructions and varying point density [
8]. Furthermore, algorithms have been proposed to identify particular object types, such as vehicles, buildings or trees [
9,
10], or to classify geometric primitives at point level [
11]. In this sense, while some methods segment the cloud before classifying points within the resulting clusters [
12,
13], others perform classification directly on scan points [
8]. Moreover, different machine learning descriptors have been considered (e.g., histograms [
4,
8] and conditional random fields [
14,
15]). In particular, many solutions rely on supervised learning classifiers such as Support Vector Machines (SVM) [
12,
16,
17,
18], Gaussian Processes (GP) [
19,
20], or Gaussian Mixture Models (GMM) [
11,
21,
22,
23].
This work focuses on improving the effectiveness, both in computational load and accuracy, of supervised learning classification of spatial shape features (i.e., tubular, planar or scatter shapes) obtained from covariance analysis [
11]. This is very relevant because classification of primitive geometric features is largely used as a fundamental step towards higher level scene understanding problems [
9]. For instance, classifying points into coarse geometric categories such as vertical or horizontal has been proposed as the first layer of a hierarchical methodology to process complex urban scenes [
24]. Furthermore, classification of scan points prior to segmentation is useful to process objects with unclear boundaries, such as ground, vegetation and tree crowns [
8]. In this sense, spatial shape features can describe the shape of objects for later contextual classification [
15]. Thus, classification of spatial shape features based on principal component analysis (PCA) is a constituent process in recent scene processing methods [
4,
13,
18,
23,
25].
Many classification techniques are point-wise in that they compute features for every point in a cloud by using the points within its local neighborhood, the support region. The
k-Nearest Neighbors (KNN) algorithm can produce irregular support regions whose volume depends on the varying sampling density of objects and surfaces from terrestrial scans [
8]. For example, KNN has been used to compare the performance between several classifiers [
12] and to classify into planar or non-planar surfaces [
18]. The KNN support volume can be limited by setting a fix-bound radius [
26]. Furthermore, ellipsoidal support regions of adaptive sizes, denoted as super-voxels, can be built iteratively based on point characteristics [
14,
27]. Other point-wise classification techniques adopt regular support regions by searching for all neighbors within a given radius [
8,
9,
11,
20]. In general, point-wise techniques imply a high computational load. This is why some authors have proposed oversampling techniques to reduce the amount of data in the raw point cloud [
14,
28].
Grid representations and voxels have also been considered to speed up point cloud classification. In some solutions, grids serve to segment points prior to point-wise classification. For instance, the method proposed in [
26] computes segmentation by projecting non ground points on a 2D grid and [
29] uses voxels for defining groups of points that are later classified with a Neural Network (NN) supervised learning method. Some authors have proposed computing features for points in a voxel by considering support regions defined by neighboring voxels. The authors in [
4] compute PCA for each voxel with a support region defined by the 26-neighbors. Descriptors are used both for segmentation (i.e., voxel clusters) and for later classification of the set of points within a cluster. Furthermore, in [
13], the feature vector for each voxel is obtained from a support region that includes a number of surrounding voxels. In this case, features are not employed for classification but for mapping voxels to a color space used for segmentation. Neither [
4] nor [
13] compute features to classify points within a voxel.
In a previous work [
30], we proposed an NN supervised learning formalism for classification of spatial shape features in lidar point clouds. Our interest was to use this classification method for object segmentation [
31] and construction of 2D occupancy grids for autonomous navigation [
32]. In order to reduce the computational load of the NN classifier in [
30], we implemented a computationally simple voxel-based neighborhood approach where all points in each non-overlapping voxel in a regular grid were assigned to the same class by considering features within a support region defined only by the voxel itself. This work advanced promising classification results in a natural environment according to visual validation by a human expert. These preliminary results demand further analysis of the NN method with performance metrics and considering other types of environments and sensors. More importantly, it would be interesting to generalize voxel-based neighborhood so that it can be used with other supervised classifiers.
This paper extends [
30] by addressing these questions. In particular, we analyze the NN classification method by proposing a new general framework for implementing and comparing different supervised learning classifiers that develops the voxel-based neighborhood concept. This original contribution defines offline training and online classification procedures as well as five alternative PCA-based feature vector definitions. We focus on spatial shape classes usually found in literature: scatter, tubular, and planar. In addition, we evaluate the feasibility of the voxel-based neighborhood concept for classification of terrestrial scene scans by implementing our NN method and three other classifiers commonly found in scene classification applications: SVM, GP, and GMM. A comparative performance analysis has been carried out with experimental datasets from both natural and urban environments and two different 3D rangefinders (a tilting Hokuyo and a Riegl). Classification performance metrics and processing time measurements confirm the benefits of the NN classifier and the feasibility of voxel-based neighborhood.
The rest of the paper is organized as follows. The next section reviews supervised learning methods that will be considered in the comparative analysis. Then,
Section 3 proposes a general voxel-based neighborhood approach for supervised learning classification of spatial shape features.
Section 4 describes the experimental setup and methodology for performance analysis offered in
Section 5, which discusses results for different classifiers and feature vector definitions. The paper closes with the conclusions section.
3. General Voxel-Based Neighborhood Framework for Geometric Pattern Classification
This section proposes a voxel-based geometric pattern classification approach which can be generally used by supervised learning methods. General offline training and online classification procedures are detailed. Moreover, five alternative feature vector definitions are given to classify voxels as three spatial shape classes: scatter, tubular, and planar. Furthermore, data structures are proposed for the implementation of the point cloud and the input dataset.
3.1. Definitions
In general, classifiers produce a score to indicate the degree to which a pattern is a member of a class. For an input space with N patterns, the input dataset is defined as , where is the ith input pattern and represents one of the target classes, with . The components of are computed according to a feature vector definition . Supervised learning needs a training dataset whose have been previously labeled with their corresponding .
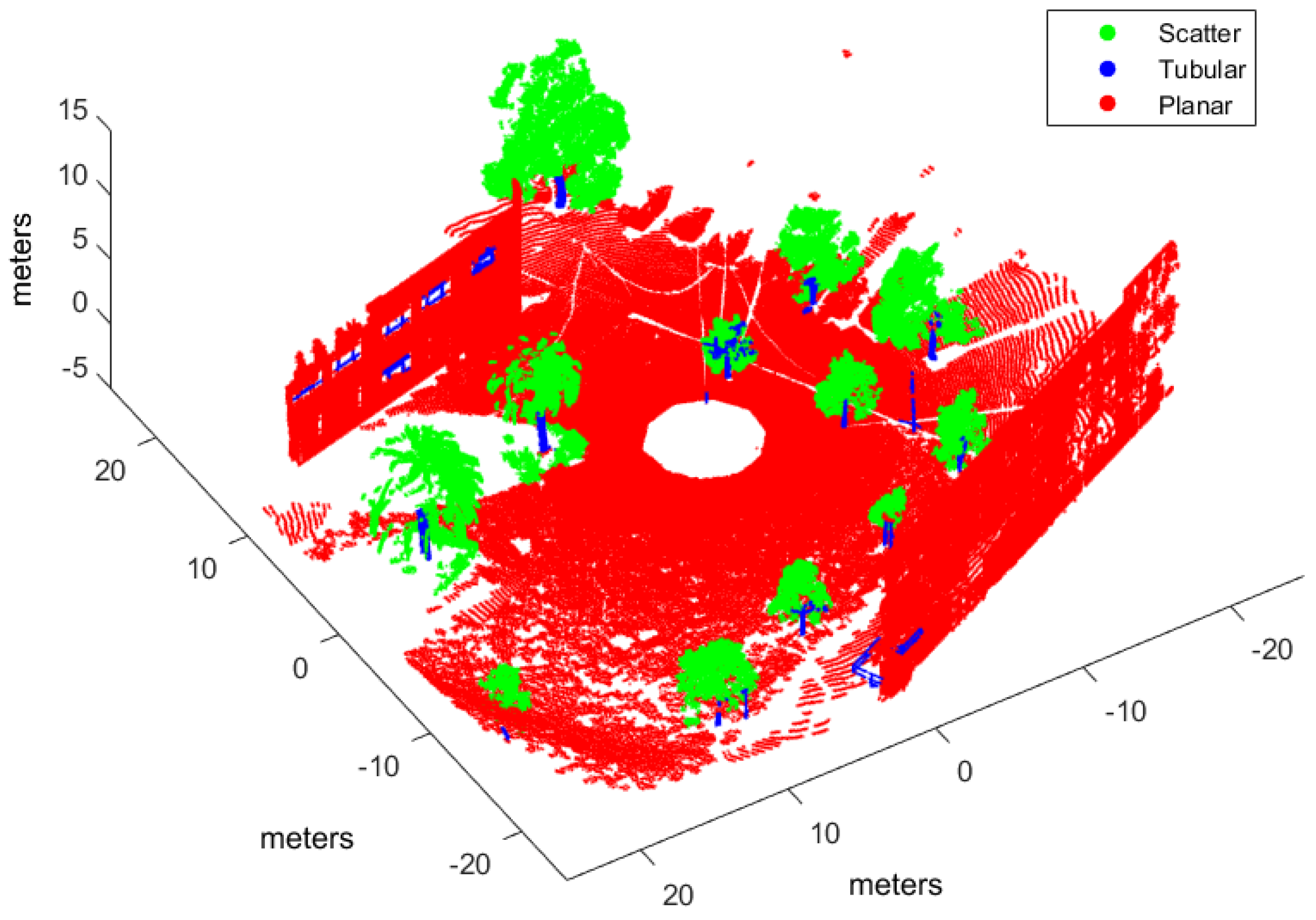
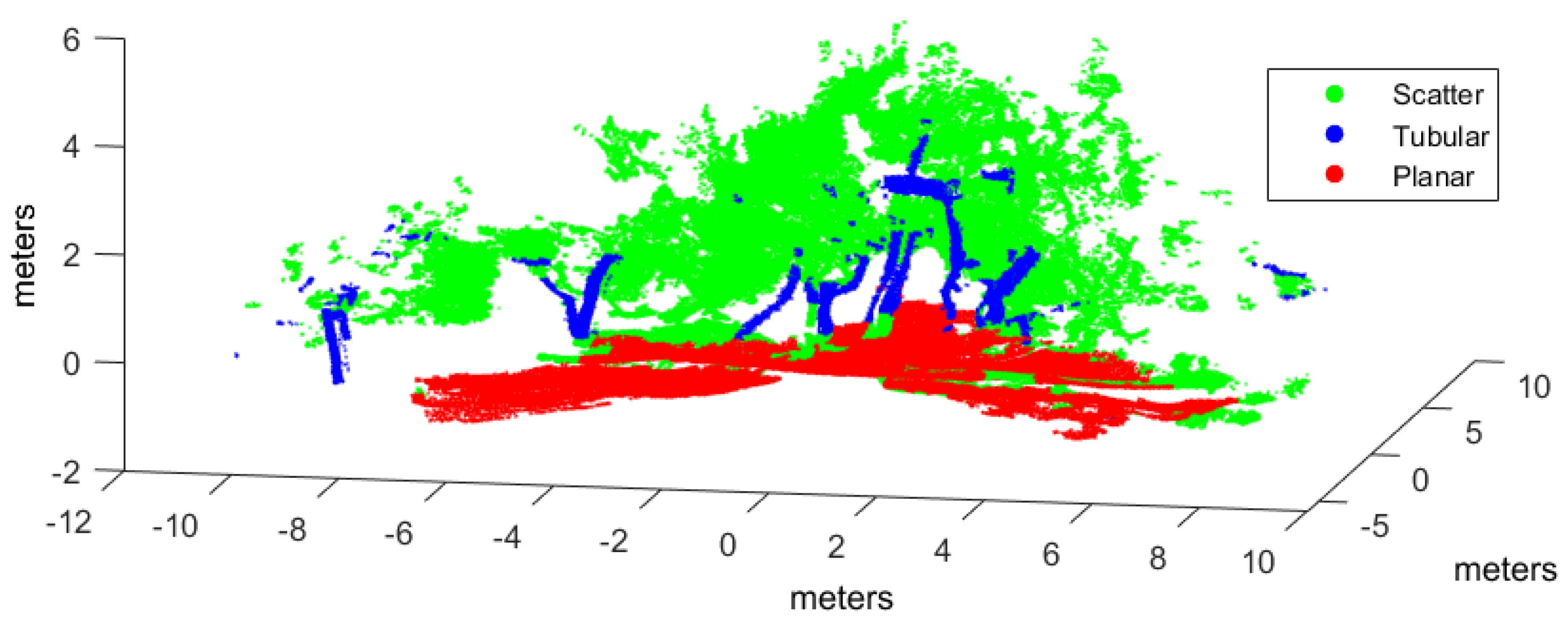
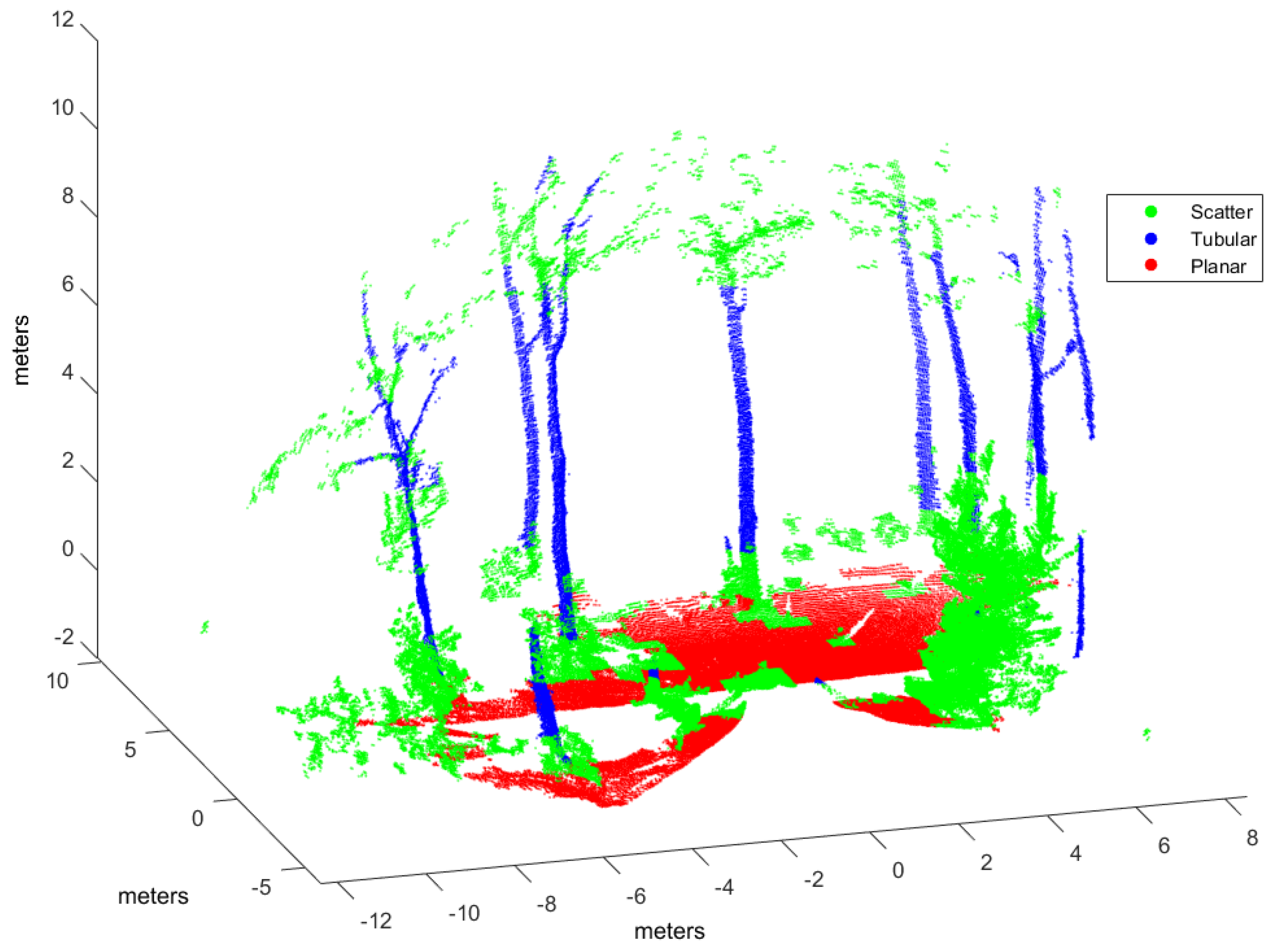
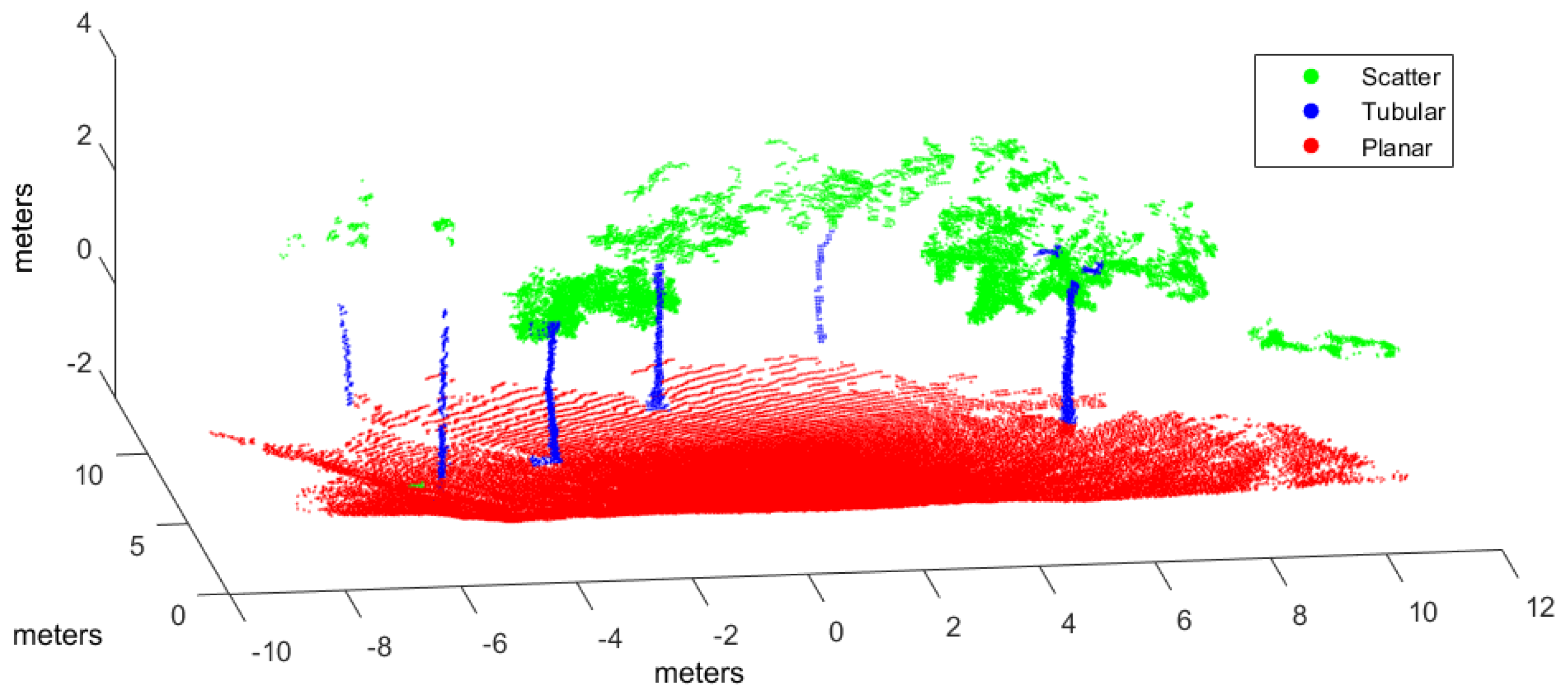
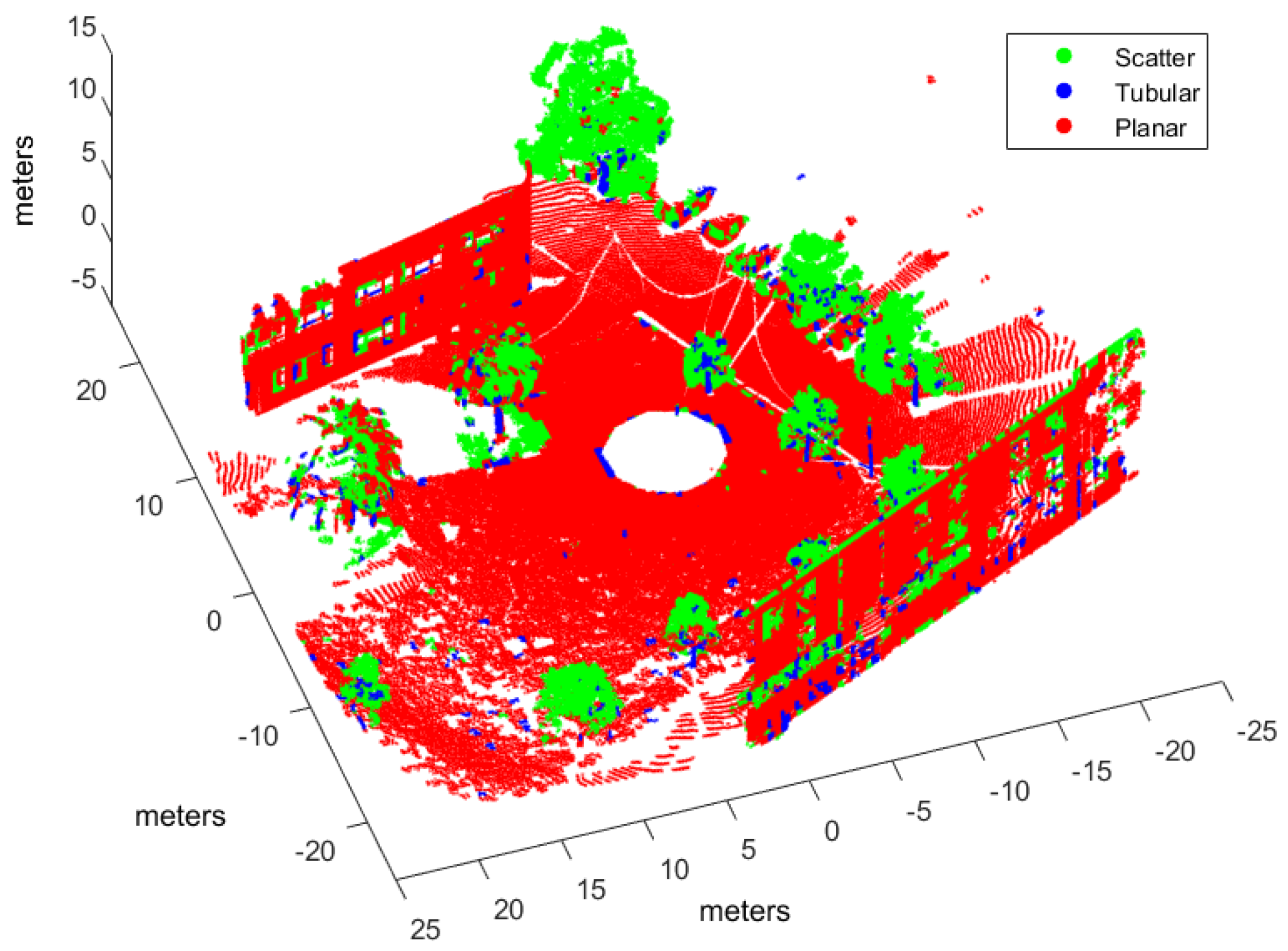
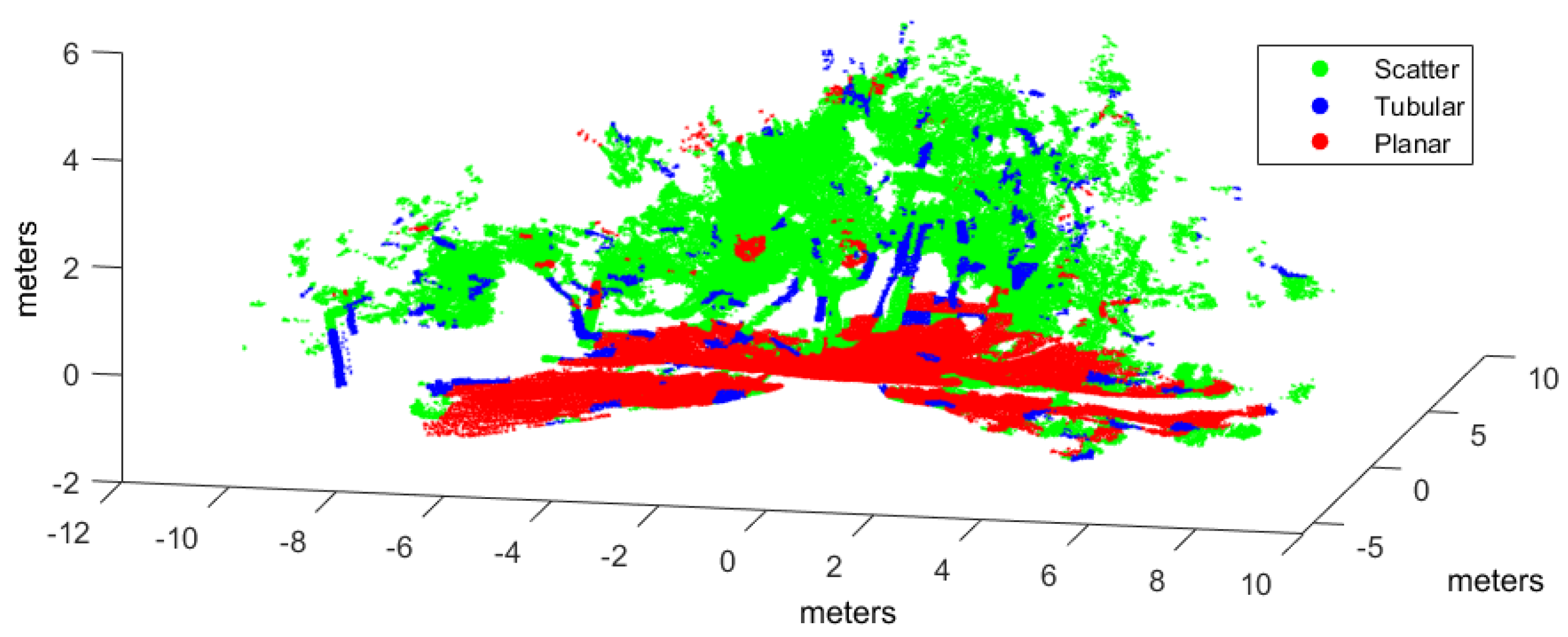
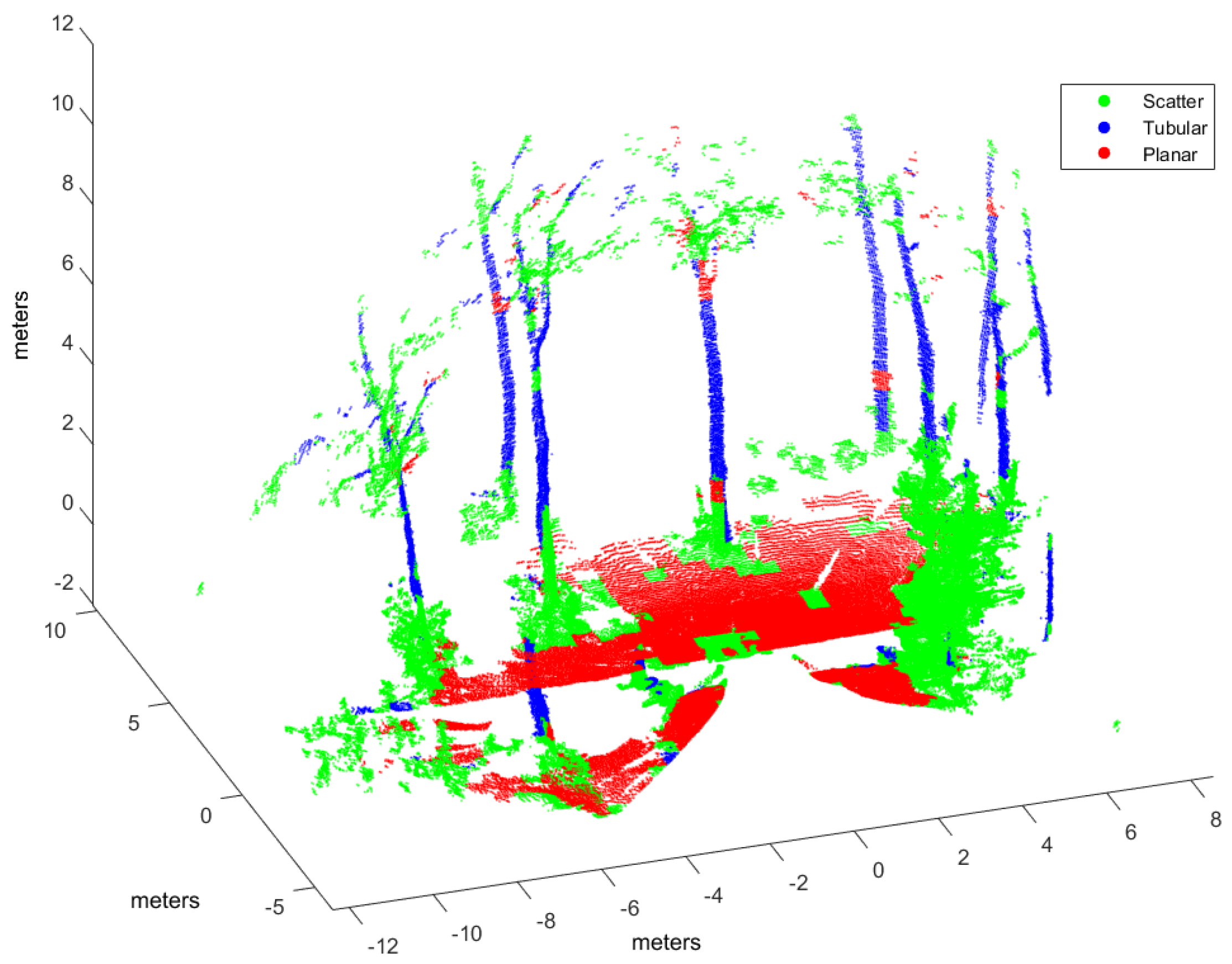
In this work, the goal is to classify scene points into three classes (i.e., ): , where , , and , correspond to scatter, tubular and planar shapes, respectively. By using voxel-based neighborhood, all points within a voxel are assigned to the same class. With this aim, the point cloud in Cartesian coordinates is voxelized into a 3D grid of regular cubic voxels of edge E. Edge size depends on the scale of the spatial shapes to be detected in the point cloud. Only those voxels containing more points than a threshold ρ are considered to be significant for classification. Thus, the size N of the input dataset is the number of significant voxels.
3.2. Training and Classification Procedures
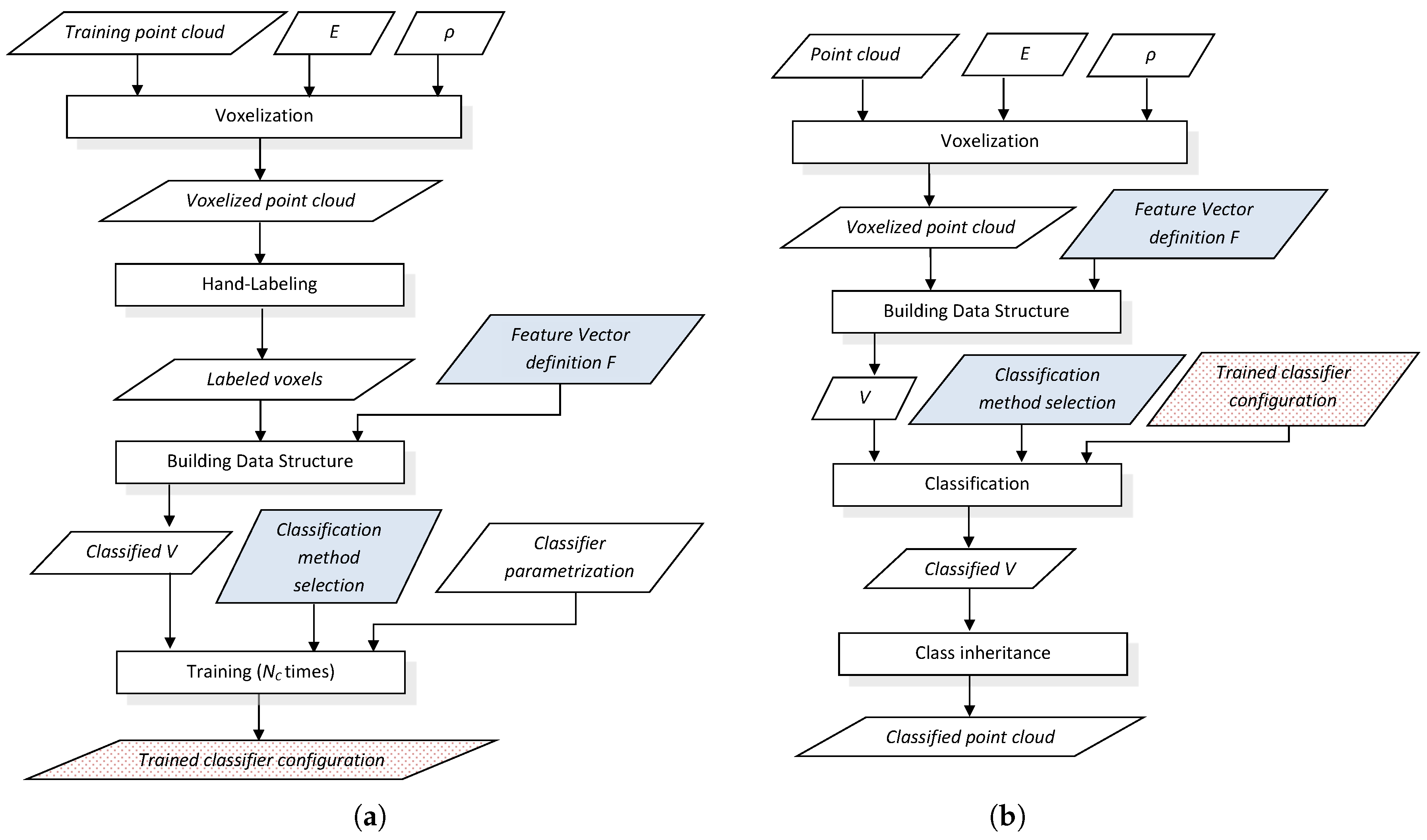
General training and classification procedures particularized for voxel-based neighborhood are shown in
Figure 1. Training is an offline process that has to be done once for a given classifier, whereas classification is performed online for each new point cloud. The training procedure produces a multi-class classifier configuration consisting on a set of
classifiers that will be used in the classification procedure. Moreover, the choice of a feature vector definition and a particular classification method must be the same for the training and classification procedures.
A data structure
V is defined to contain the input dataset
. When all
values in
V have been set, either manually or automatically, this is considered a “classified
V”. An implementation of
V is described in
Section 3.4.
The training procedure (see
Figure 1a) uses a point cloud in Cartesian coordinates where the
geometric classes must be represented and discernible. After voxelization, the
N significant voxels in the 3D grid are manually labeled with their corresponding class (
) by a human supervisor. Then, a classified
V data structure is built from the labeled voxels by computing
for a particular choice of feature vector definition
(e.g., one of the definitions proposed in
Section 3.3). Training is performed for a given classification method with its particular parameters, where a different configuration is inferred for each class. The output of the training procedure is the trained classifier configuration.
The goal of the online classification procedure (see
Figure 1b) is to classify a new point cloud. The voxelized point cloud is used to create the
V data structure with
values computed with the same feature vector definition as in the training procedure. In the classification step, the trained classifier configuration given by the training procedure completes the classified
V by appending
values computed by considering the highest score of the
classifiers. With voxel-based neighborhood, the classification for each voxel is inherited by all points within its limits.
3.3. Extracting Spatial Shape Features from Voxels
The local spatial distribution of all the points within a voxel is obtained as a decomposition in the principal components of the covariance matrix from point Cartesian coordinates. These principal components or eigenvalues are sorted in ascending order as
[
11].
A feature vector
consisting on a linear combination of the eigenvalues [
11] and
is generally considered in the literature [
13,
17]:
This definition takes into account that scatterness has no dominant direction (
), tubularness shows alignment in one dominant direction (
), and planarness has two dominant directions (
).
Nevertheless, classifier convergence and performance can be affected by the definition and scaling of
[
40]. Thus, variants of Equation (
1) based on the normalization and linear combination of eigenvalues could improve the performance of a particular classifier. Particularly, five feature vector definitions are considered in this work:
: eigenvalues from the covariance matrix.
: linear combination of the eigenvalues, as in Equation (
1).
: normalized eigenvalues.
: normalization of the linear combination.
: linear combination of normalized eigenvalues.
In
,
, and
, the overline over a value
c denotes normalization of this value in [0, 1] with respect to a 95% confidence interval. This normalization is computed as follows:
where
represents the rounded integer number of the 95% significant voxels in the middle of the distribution of
c.
The input patterns in are computed by using the selected definition with the eigenvalues given by the covariance matrix corresponding to the points within the ith significant voxel.
3.4. Data Structures
In order to represent , the classification data structure V must be related to a list of Cartesian point cloud coordinates C. Particularly, efficient access to the list of points within each voxel is required both to compute the input patterns and to inherit classification by scan points. With this purpose, this section proposes two data structures that implement the point cloud C and V, respectively.
Then,
C is defined as a sorted list of all scan points, where the
jth element has the following data:
, the Cartesian point coordinates.
, a scalar index of the voxel that contains the point. Assuming that a spatial 3D grid with
voxels includes all scan points, then a unique natural number
can be associated to each voxel [
41]. This index is associated to the point in the voxelization process.
, a natural number representing the target class. This value is hand labeled in the training process and is the resulting class in the classification process.
The structure
V that implements
is defined as a list of
N elements, where the
ith element corresponds to a significant voxel and contains:
, the scalar index associated to the voxel,
, feature vector values to be used as input pattern,
, a natural number representing the target class.
The computation of these data structures is as follows. First, all scan points in C are indexed with their corresponding voxel index, which is also used to sort the list. After that, if there are more than ρ consecutive elements in C with the same index number, then a new entry for that voxel is created in V. After voxel classification, points in C with the same voxel index inherit the target class of the corresponding voxel in V. Points in non-significant voxels will remain unclassified (i.e., with a null value in the target class field).
6. Conclusions
Many point cloud classification problems targeting real-time applications such as autonomous vehicles and terrestrial robots have received attention in recent years. Among these problems, improving the effectiveness of spatial shape features classification from 3D lidar data remains a relevant challenge because it is largely used as a fundamental step towards higher level scene understanding solutions. In particular, searching for neighboring points in dense scans introduces a computational overhead for both training and classification.
In this paper, we have extended our previous work [
30], where we devised a computationally simple voxel-based neighborhood approach for preliminary experimentation with a new a neural network (NN) classification model. Promising results demanded deeper analysis of the NN method (using performance metrics and different environments and sensors) as well as generalizing voxel-based neighborhood that could be implemented and tested with other supervised classifiers.
The originality of this work is a new general framework for supervised learning classifiers to reduce the computational load based on a simple voxel-based neighborhood definition where points in each non-overlapping voxel of a regular grid are assigned to the same class by considering features within a support region defined by the voxel itself. The contribution comprises offline training and online classification procedures as well as five alternative feature vector definitions based on principal component analysis for scatter, tubular and planar shapes.
Moreover, the feasibility of this approach has been evaluated by implementing four types of supervised learning classifiers found in scene processing methods: our NN model, support vector machines (SVM), Gaussian processes (GP), and Gaussian mixture models (GMM). An experimental performance analysis has been carried out using real scans from both natural and urban environments and two different 3D rangefinders: a tilting Hokuyo and a Riegl. The major conclusion from this analysis is that voxel-based neighborhood classification greatly improves computation time with respect to point-wise neighborhood, while no relevant differences in scene classification accuracy have been appreciated. Results have also shown that the choice of suitable features can have a dramatic effect on the performance of classification approaches. All in all, classification performance metrics and processing time measurements have confirmed the benefits of the NN classifier and the feasibility of the voxel-based neighborhood approach for terrestrial lidar scenes.
One additional advantage of processing each non-overlapping cell by using points from only that same cell is that this favors parallelization [
47]. Developing a parallel version of the proposed method to improve online classification time with multi-core computers will be addressed in future work. Furthermore, it will be also interesting to adapt the method for incremental update of classification results with consecutive scans.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}