
Support Vector Data Description Model to Map Specific Land Cover with Optimal Parameters Determined from a Window-Based Validation Set


Abstract
:1. Introduction
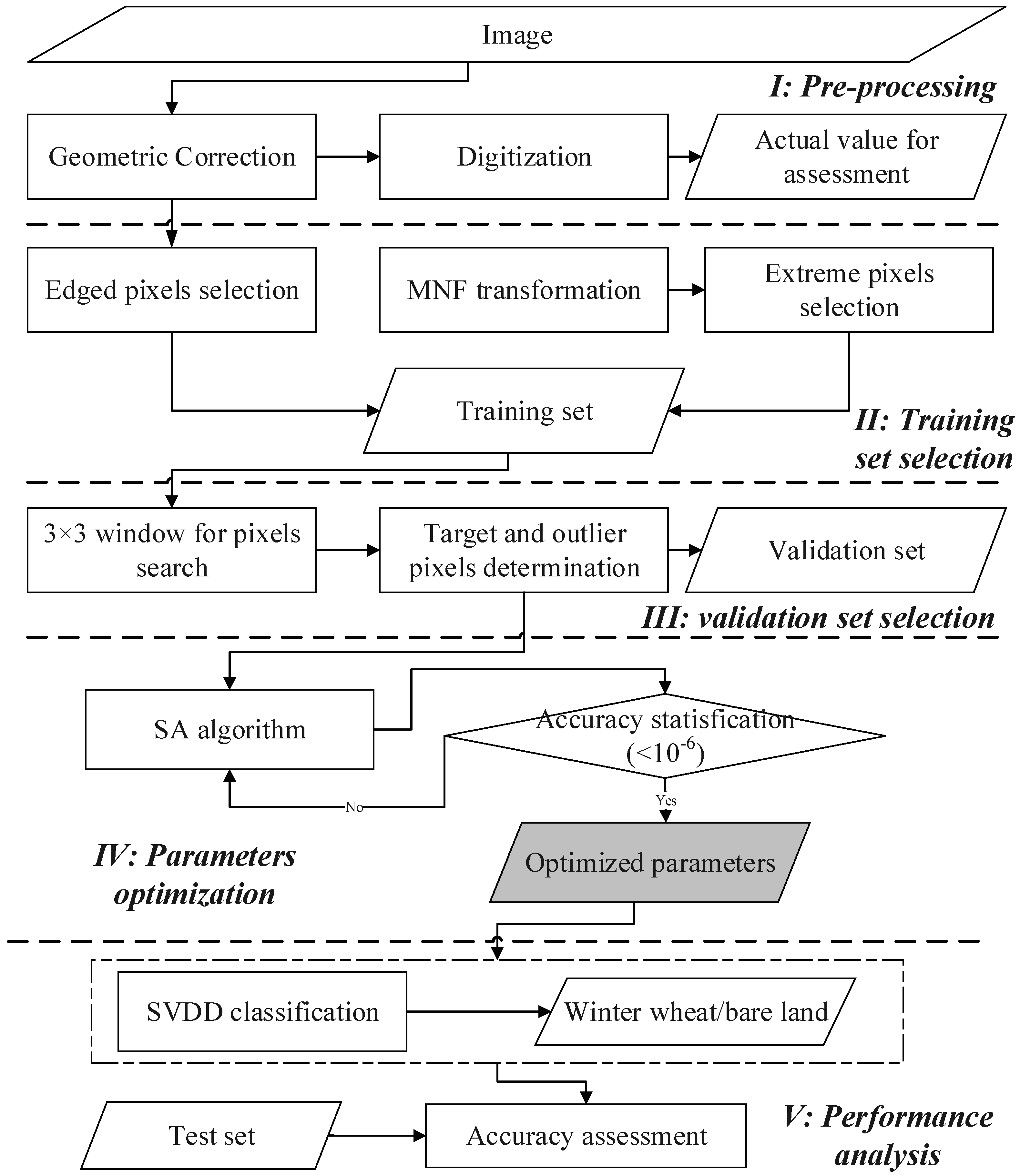
2. WVS-SVDD: Window-Based Validation Set for SVDD
2.1. Training Set Selection
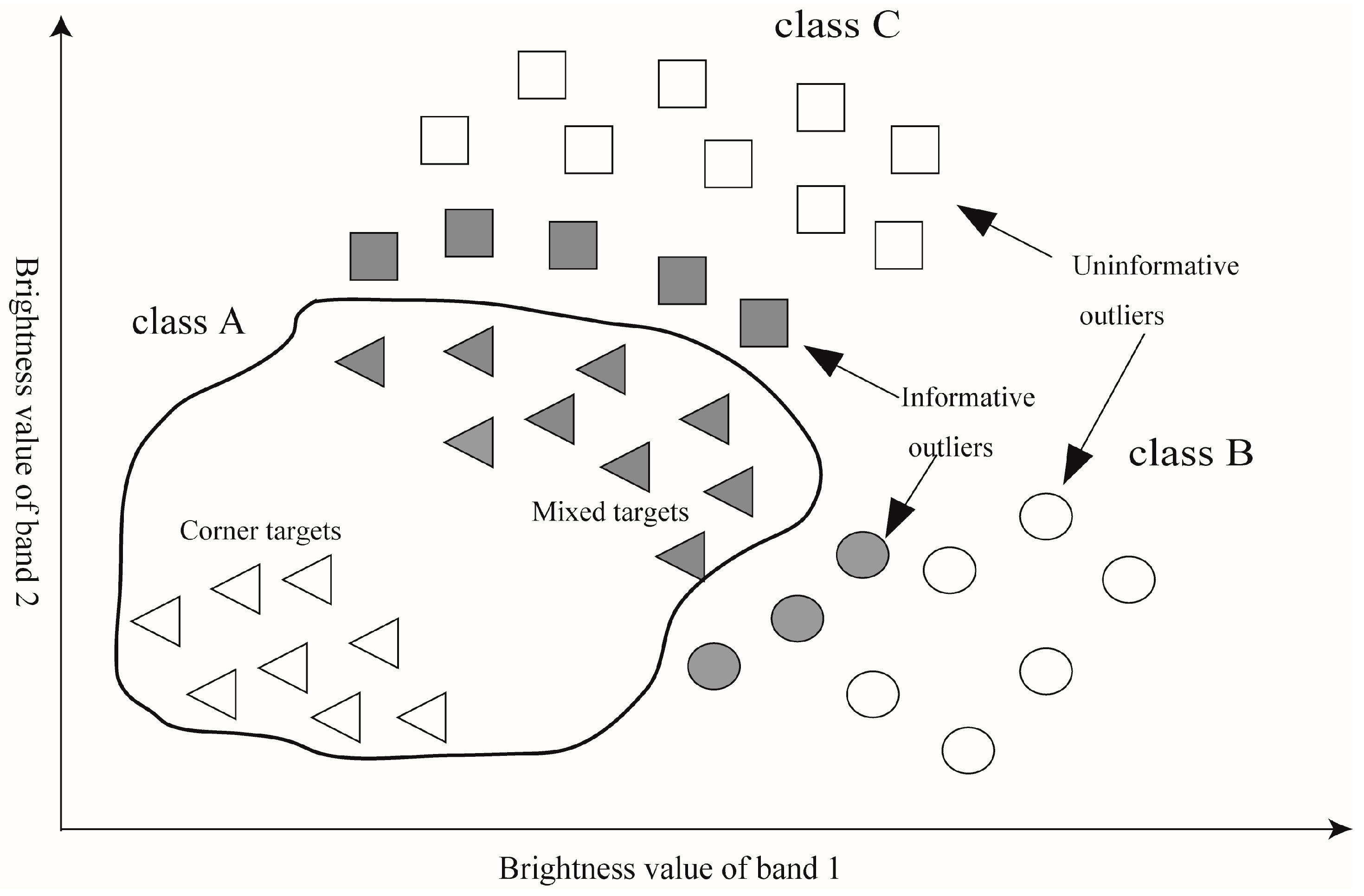
2.2. Validation Set Selection
2.3. Optimal C and s Determination Using SA Algorithm
2.4. SVDD-Based Specific Land-Cover Classification
3. Experiments
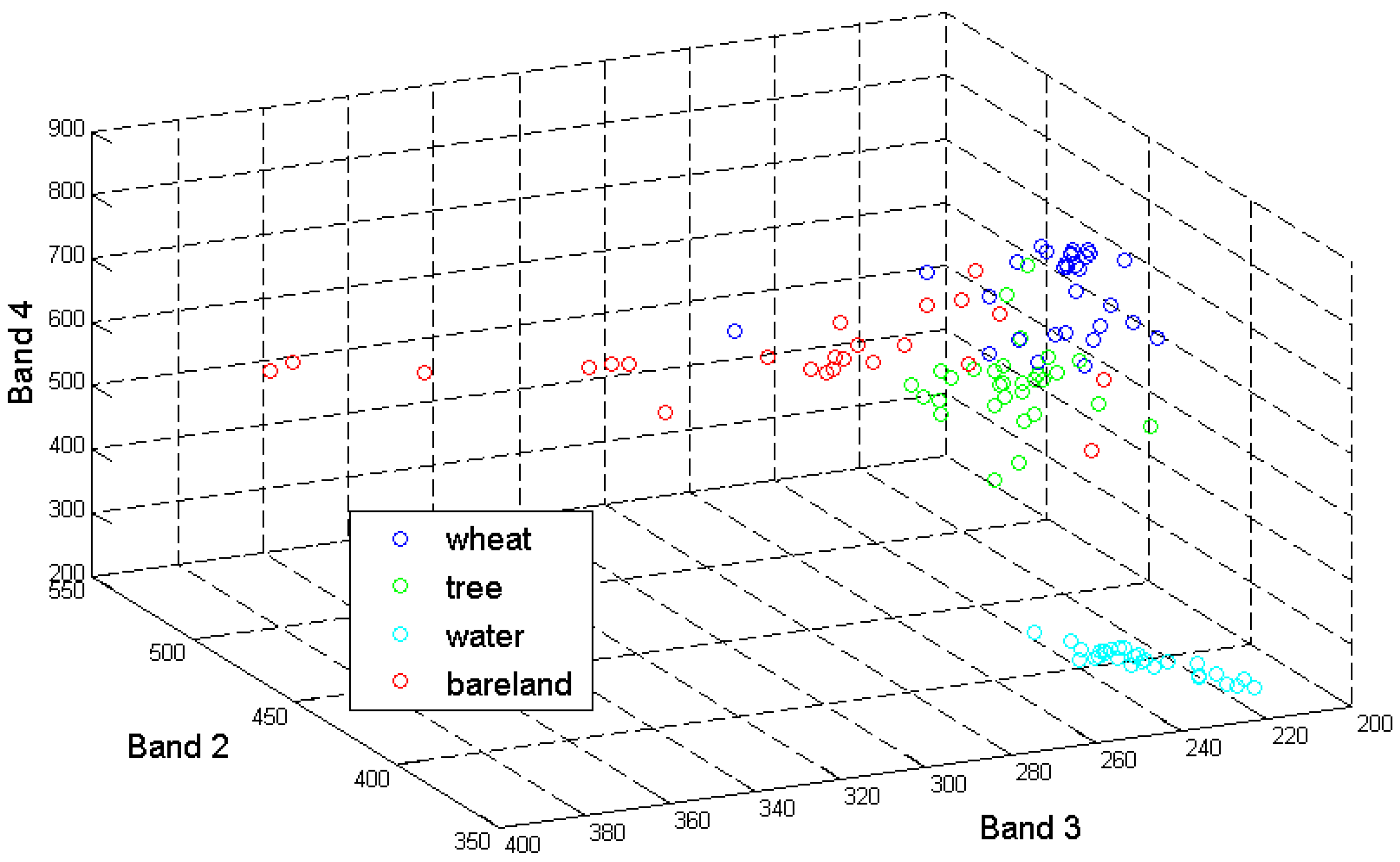
3.1. Comparison between WVS-SVDD, Conventional SVDD and SVM
3.2. Sensitivity to Window Size and Pixels’ Spatial Scale
3.3. The Effect of Untrained Classes on the Classification Accuracy
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Giri, C.; Pengra, B.; Long, J.; Loveland, T.R. Next generation of global land cover characterization, mapping, and monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 30–37. [Google Scholar] [CrossRef]
- Pouliot, D.; Latifovic, R.; Zabcic, N.; Guindon, L.; Olthof, I. Development and assessment of a 250 m spatial resolution MODIS annual land cover time series (2000–2011) for the forest region of Canada derived from change-based updating. Remote Sens. Environ. 2014, 140, 731–743. [Google Scholar] [CrossRef]
- Puertas, O.L.; Brenning, A.; Meza, F.J. Balancing misclassification errors of land cover classification maps using support vector machines and Landsat imagery in the Maipo river basin (Central Chile, 1975–2010). Remote Sens. Environ. 2013, 137, 112–123. [Google Scholar] [CrossRef]
- Foody, G.M. Hard and soft classifications by a neural network with a non-exhaustively defined set of classe. Int. J. Remote Sens. 2010, 23, 3853–3864. [Google Scholar] [CrossRef]
- Klemas, V. Remote sensing of wetlands: Case studies comparing practical techniques. J. Coast. Res. 2011, 27, 418–427. [Google Scholar] [CrossRef]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, Z. Active one-class classification of remote sensing image. In Proceedings of the International Conference on Earth Observation Data Processing and Analysis, Wuhan, China, 29 December 2008. [Google Scholar]
- Muñoz-Marí, J.; Bovolo, F.; Gómez-Chova, L.; Bruzzone, L.; Camps-Valls, G. Semisupervised one-class support vector machines for classification of remote sensing data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3188–3197. [Google Scholar] [CrossRef]
- Sanchez-Hernandez, C.; Boyd, D.S.; Foody, G.M. Mapping specific habitats from remotely sensed imagery: Support vector machine and support vector data description based classification of coastal saltmarsh habitats. Ecol. Inf. 2007, 2, 83–88. [Google Scholar] [CrossRef]
- Song, X.; Fan, G.; Rao, M. SVM-based data editing for enhanced one-class classification of remotely sensed imagery. IEEE Geosci. Remote Sens. Lett. 2008, 5, 189–193. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Muñoz-Marí, J.; Rojo-Alvarez, J.L. Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1822–1835. [Google Scholar] [CrossRef]
- Niazmardi, S.; Homayouni, S.; Safari, A. An improved FCM algorithm based on the SVDD for unsupervised hyperspectral data classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 831–839. [Google Scholar] [CrossRef]
- Marconcini, M.; Fernandez-Prieto, D.; Buchholz, T. Targeted land-cover classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4173–4193. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Sanchez-Hernandez, C.; Boyd, D.S.; Foody, G.M. One-class classification for mapping a specific land-cover class: SVDD classification of fenland. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1061–1073. [Google Scholar] [CrossRef]
- Muñoz-Marí, J.; Bruzzone, L.; Camps-Valls, G. A support vector domain description approach to supervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 2683–2692. [Google Scholar] [CrossRef]
- Uslu, F.; Binol, H.; Ilarslan, M.; Bal, A. Improving SVDD classification performance on hyperspectral images via correlation based ensemble technique. Opt. Laser Eng. 2017, 89, 169–177. [Google Scholar] [CrossRef]
- Khazai, S.; Safari, A.; Mojaradi, B.; Homayouni, S. Improving the SVDD approach to hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2012, 9, 594–598. [Google Scholar] [CrossRef]
- Piper, J. Variability and bias in experimentally measured classifier error rates. Pattern Recognit. Lett. 1992, 13, 685–692. [Google Scholar] [CrossRef]
- Mather, P.; Koch, M. Computer Processing of Remotely-Sensed Images: An Introduction, 4rd ed.; John Wiley & Sons: Chichester, UK, 2011. [Google Scholar]
- Van Niel, T.G.; McVicar, T.R.; Datt, B. On the relationship between training sample size and data dimensionality of broadband multi-temporal classification. Remote Sens. Environ. 2005, 98, 468–480. [Google Scholar] [CrossRef]
- Shuai, G.; Zhang, J.; Deng, L.; Zhu, X. Edge-pixels-based support vector data description for specific land-cover distribution mapping. J. Appl. Remote Sens. 2015, 9, 096034. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. The use of small training sets containing mixed pixels for accurate hard image classification: Training on mixed spectral responses for classification by a SVM. Remote Sens. Environ. 2006, 103, 179–189. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. Use of impervious surface in urban land-use classification. Remote Sens. Environ. 2006, 102, 146–160. [Google Scholar] [CrossRef]
- Wang, C.K.; Ting, Y.; Liu, Y.H.; Hariyanto, G. A novel approach to generate artificial outliers for support vector data description. In Proceedings of the IEEE International Symposium on Industrial Electronics, Seoul, Korea, 5–8 July 2009; pp. 2202–2207. [Google Scholar]
- Dekkers, A.; Aarts, E. Global optimization and simulated annealing. Math Program. 1991, 50, 367–393. [Google Scholar] [CrossRef]
- Lin, S.; Lee, Z.; Chen, S.; Tseng, T. Parameter determination of support vector machine and feature selection using simulated annealing approach. Appl. Soft Comput. 2008, 8, 1505–1512. [Google Scholar] [CrossRef]
- Song, C.; Woodcock, C.E.; Seto, K.C.; Lenney, M.P.; Macomber, S.A. Classification and Change Detection Using Landsat TM Data. When and how to correct for atmospheric effects? Remote Sens. Environ. 2001, 75, 230–244. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Duveiller, G.; Defourny, P. A conceptual framework to define the spatial resolution requirements for agricultural monitoring using remote sensing. Remote Sens. Environ. 2010, 114, 2637–2650. [Google Scholar] [CrossRef]
- Pan, Y.; Hu, T.; Zhu, X.; Zhang, J.; Wang, X. Mapping cropland distributions using a hard and soft classification model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4301–4312. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asner, G.P. Cropland distributions from temporal unmixing of MODIS data. Remote Sens. Environ. 2004, 93, 412–422. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Class | Classification Methods | # of Pixels in Validation Sets | Optimal Parameters | ||
|---|---|---|---|---|---|
| Target | Outlier | C | s | ||
| wheat | WVS-SVDD | 470 | 128 | 0.02 | 1.01 |
| traditional SVDD | 0.05 | 17.81 | |||
| bare land | WVS-SVDD | 449 | 68 | 0.08 | 9.98 |
| traditional SVDD | 0.02 | 18.37 | |||
| Target Class | Classification Methods | Classification Accuracy (%) | ||
|---|---|---|---|---|
| PA | UA | OA | ||
| wheat | WVS-SVDD | 71.12 | 97.36 | 89.25 |
| Traditional Method | 95.33 | 64.84 | 80.33 | |
| SVM | 94.57 | 90.37 | 94.37 | |
| bare land | WVS-SVDD | 82.49 | 81.89 | 83.65 |
| Traditional Method | 88.54 | 71.24 | 78.41 | |
| SVM | 90.85 | 91.51 | 91.96 | |
| Spatial Resolution and Window Size | # of Pixels in Validation Set | Optimal Parameters | Classification Accuracy (%) | ||||
|---|---|---|---|---|---|---|---|
| Target | Outlier | C | s | PA | UA | OA | |
| 2.4 m | |||||||
| 3 ×3 | 470 | 128 | 0.02 | 1.01 | 71.12 | 97.36 | 89.25 |
| 5 × 5 | 1056 | 367 | 0.02 | 1.02 | 79.75 | 96.22 | 91.84 |
| 7 × 7 | 1687 | 702 | 0.05 | 3.76 | 80.49 | 97.05 | 92.34 |
| 9 × 9 | 2307 | 1104 | 0.02 | 1.40 | 81.18 | 95.62 | 92.13 |
| 11 × 11 | 2926 | 1580 | 0.01 | 1.03 | 80.11 | 96.11 | 91.93 |
| 5 m | |||||||
| 3 × 3 | 338 | 123 | 0.11 | 1.12 | 81.07 | 86.27 | 88.89 |
| 5 × 5 | 697 | 383 | 0.08 | 9.76 | 85.50 | 86.31 | 90.20 |
| 7 × 7 | 1090 | 748 | 0.21 | 7.37 | 81.91 | 93.66 | 91.75 |
| 9 × 9 | 1542 | 1202 | 0.21 | 1.94 | 82.32 | 93.42 | 91.80 |
| 11 × 11 | 2026 | 1744 | 0.09 | 4.37 | 85.10 | 86.73 | 90.25 |
| 10 m | |||||||
| 3 × 3 | 385 | 136 | 0.02 | 1.40 | 93.53 | 92.32 | 95.01 |
| 5 × 5 | 822 | 317 | 0.04 | 1.57 | 91.13 | 93.87 | 94.81 |
| 7 × 7 | 1302 | 554 | 0.02 | 1.51 | 92.93 | 92.53 | 94.90 |
| 9 × 9 | 1818 | 841 | 0.11 | 1.68 | 89.44 | 97.12 | 95.37 |
| 11 × 11 | 2358 | 1163 | 0.14 | 7.65 | 90.57 | 96.72 | 95.62 |
| 15 m | |||||||
| 3 × 3 | 464 | 144 | 0.01 | 1.04 | 91.92 | 93.10 | 94.75 |
| 5 × 5 | 1013 | 363 | 0.03 | 1.06 | 90.68 | 95.09 | 95.07 |
| 7 × 7 | 1657 | 905 | 0.02 | 1.08 | 92.07 | 93.48 | 94.95 |
| 9 × 9 | 2375 | 1480 | 0.02 | 1.11 | 91.63 | 94.39 | 95.14 |
| 11 × 11 | 3179 | 2176 | 0.03 | 1.09 | 90.87 | 95.13 | 95.15 |
| 20 m | |||||||
| 3 × 3 | 538 | 106 | 0.03 | 1.52 | 93.30 | 93.40 | 95.29 |
| 5 × 5 | 1198 | 302 | 0.03 | 1.47 | 93.39 | 93.41 | 95.33 |
| 7 × 7 | 1926 | 567 | 0.01 | 1.19 | 94.71 | 92.32 | 95.33 |
| 9 × 9 | 2694 | 913 | 0.03 | 1.51 | 93.33 | 93.41 | 95.30 |
| 11 × 11 | 3461 | 1329 | 0.02 | 1.21 | 93.88 | 93.87 | 95.66 |
| Method | Untrained Class | Classification Accuracy (%) | ||
|---|---|---|---|---|
| PA | UA | OA | ||
| WVS-SVDD | None | 93.53 | 92.32 | 95.01 |
| Bare land | 94.40 | 85.93 | 92.63 | |
| Trees | 93.06 | 93.21 | 95.19 | |
| SVM | None | 95.76 | 92.77 | 95.91 |
| Bare land | 96.33 | 86.09 | 93.26 | |
| Trees | 98.81 | 81.51 | 91.73 | |
| Water | 95.17 | 93.55 | 96.01 | |
| Trees and water | 98.29 | 83.46 | 92.58 | |
| Bare land and water | 93.62 | 74.97 | 86.82 | |
| Bare land and trees | 99.98 | 59.63 | 76.28 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Yuan, Z.; Shuai, G.; Pan, Y.; Zhu, X. Support Vector Data Description Model to Map Specific Land Cover with Optimal Parameters Determined from a Window-Based Validation Set. Sensors 2017, 17, 960. https://doi.org/10.3390/s17050960
Zhang J, Yuan Z, Shuai G, Pan Y, Zhu X. Support Vector Data Description Model to Map Specific Land Cover with Optimal Parameters Determined from a Window-Based Validation Set. Sensors. 2017; 17(5):960. https://doi.org/10.3390/s17050960
Chicago/Turabian StyleZhang, Jinshui, Zhoumiqi Yuan, Guanyuan Shuai, Yaozhong Pan, and Xiufang Zhu. 2017. "Support Vector Data Description Model to Map Specific Land Cover with Optimal Parameters Determined from a Window-Based Validation Set" Sensors 17, no. 5: 960. https://doi.org/10.3390/s17050960
APA StyleZhang, J., Yuan, Z., Shuai, G., Pan, Y., & Zhu, X. (2017). Support Vector Data Description Model to Map Specific Land Cover with Optimal Parameters Determined from a Window-Based Validation Set. Sensors, 17(5), 960. https://doi.org/10.3390/s17050960