Mining Feature of Data Fusion in the Classification of Beer Flavor Information Using E-Tongue and E-Nose



Abstract
:1. Introduction
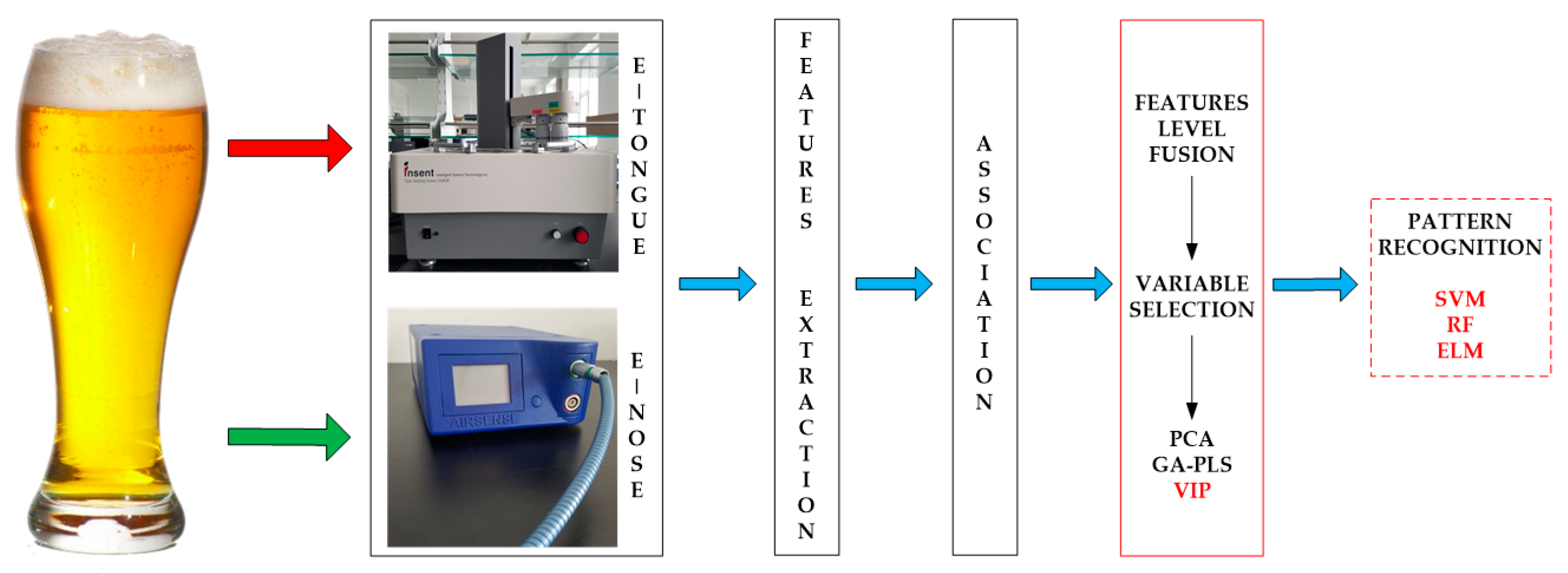
2. Materials and Methods
2.1. Beer
2.2. Data Acquisition of Intelligent Bionic Detection
2.2.1. E-Tongue Data Acquisition
2.2.2. E-Nose Data Acquisition
2.3. Variable Selection
2.4. Multivariate Analysis
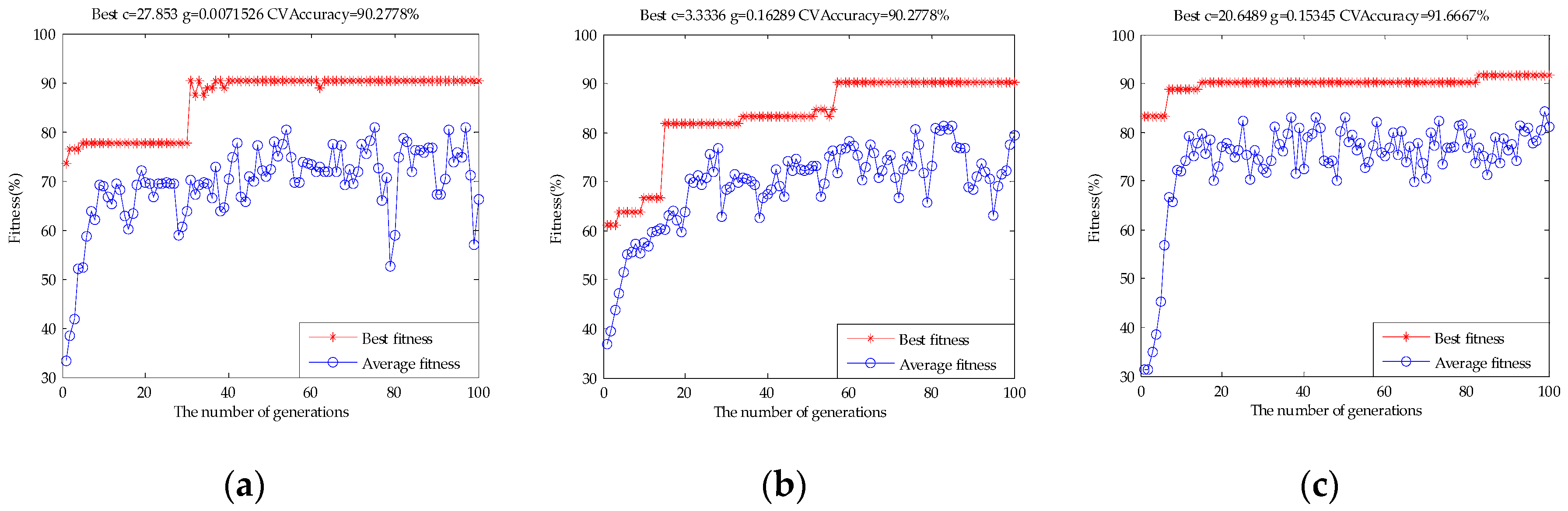
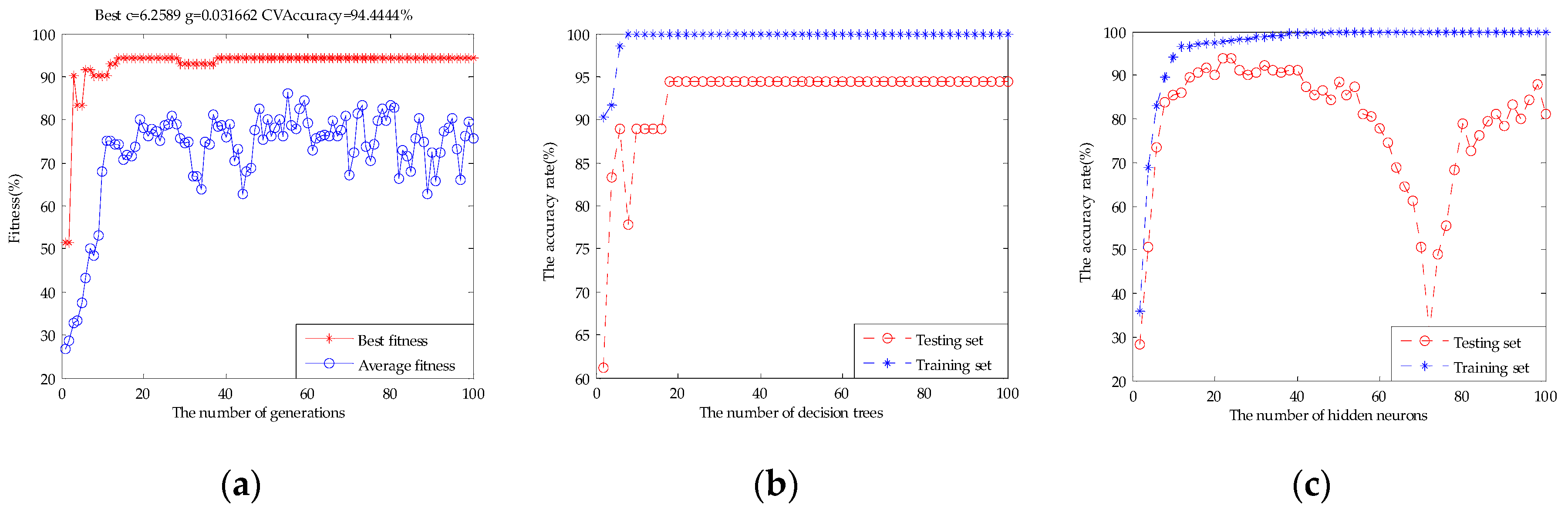
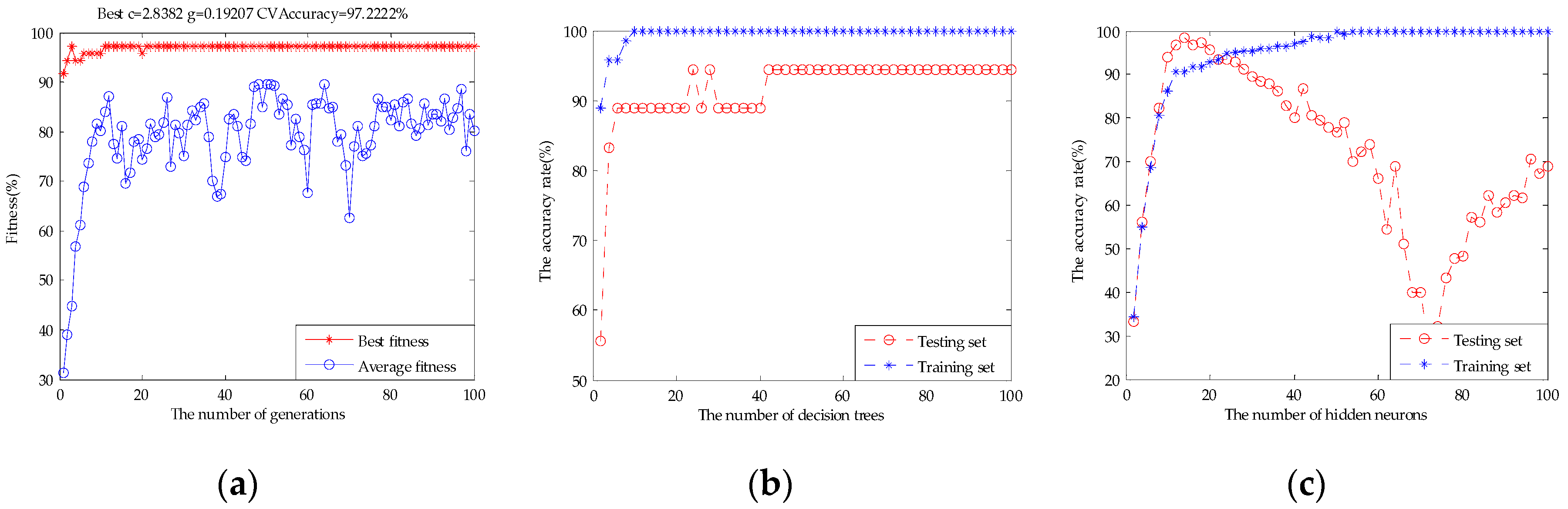
2.4.1. Support Vector Machines (SVM)
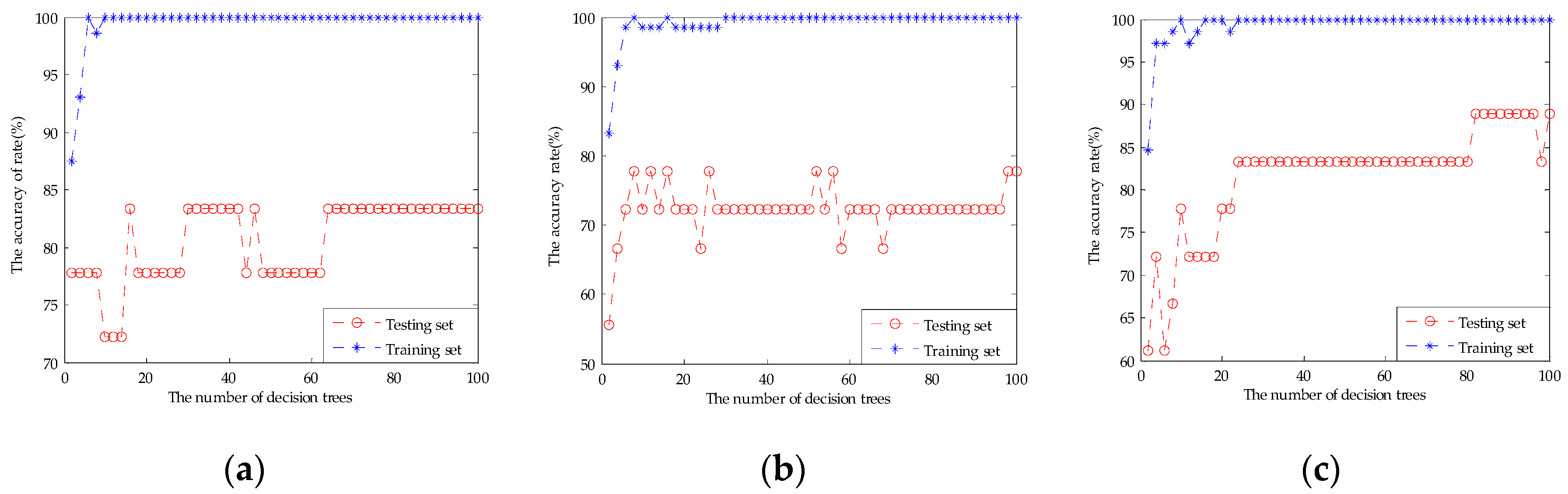
2.4.2. Random Forests (RF)
- (1)
- Using bootstrap sampling to generate training sets randomly;
- (2)
- Each training set is used to generate the decision tree . The value of the split property set for each tree is . The value is the square root of the number of input variables. In general, the value of remains stable throughout the forest development process;
- (3)
- Each tree has a complete development without taking pruning;
- (4)
- For testing set , each decision tree is used to test and obtain the category ; and
- (5)
- The category of the testing set is voted by decision trees.
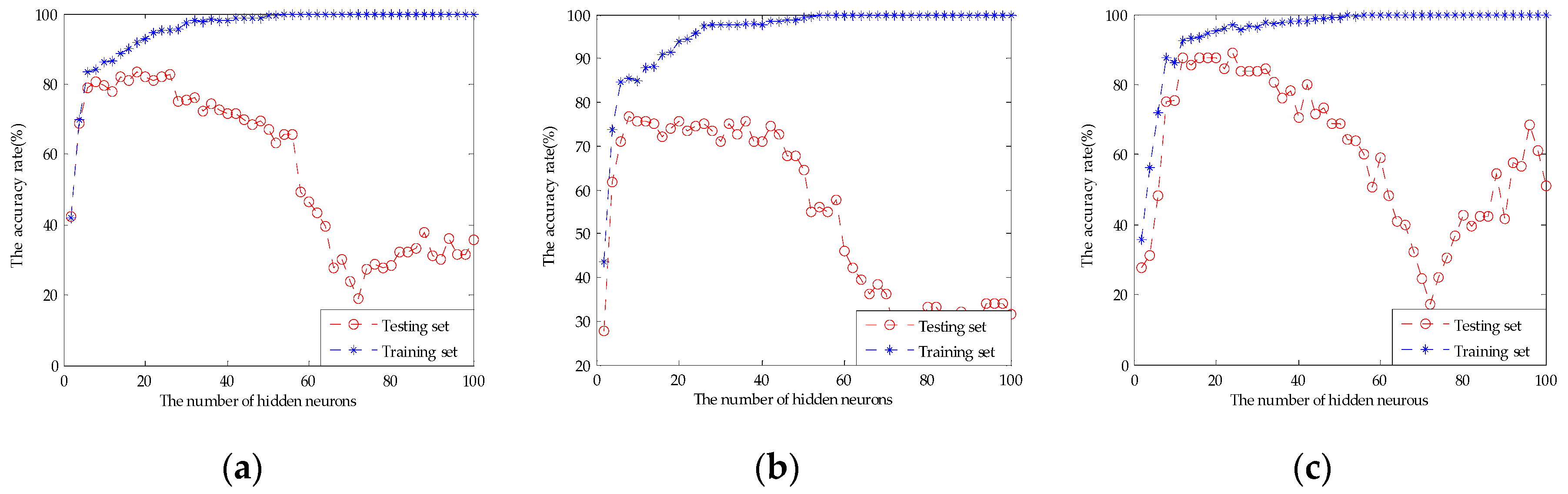
2.4.3. Extreme Learning Machine (ELM)
2.5. Allocation of Datasets and the Model Prediction Process
3. Results and Discussion
3.1. Pre-Processing
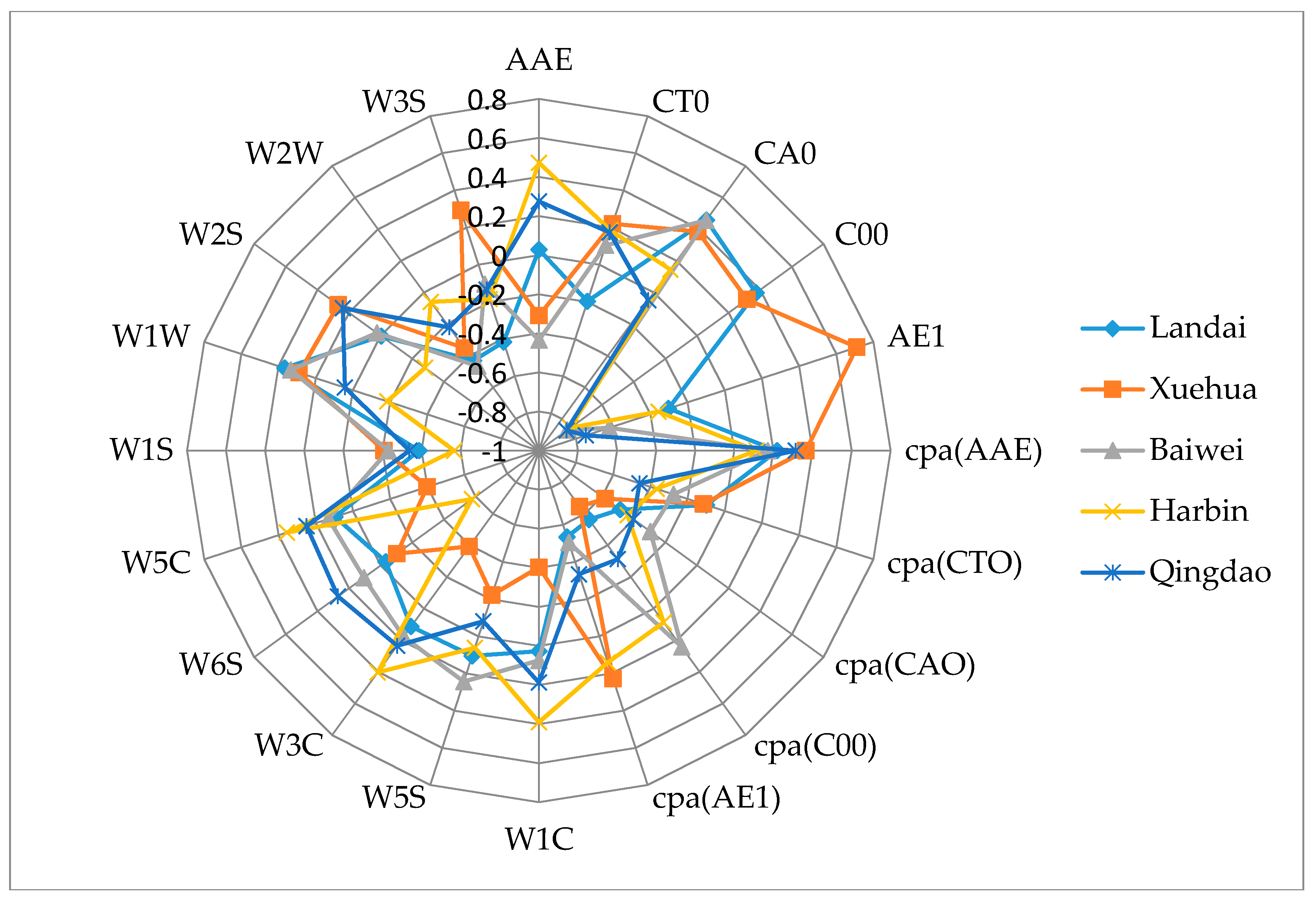
3.2. Extraction of Sensor Feature Variables
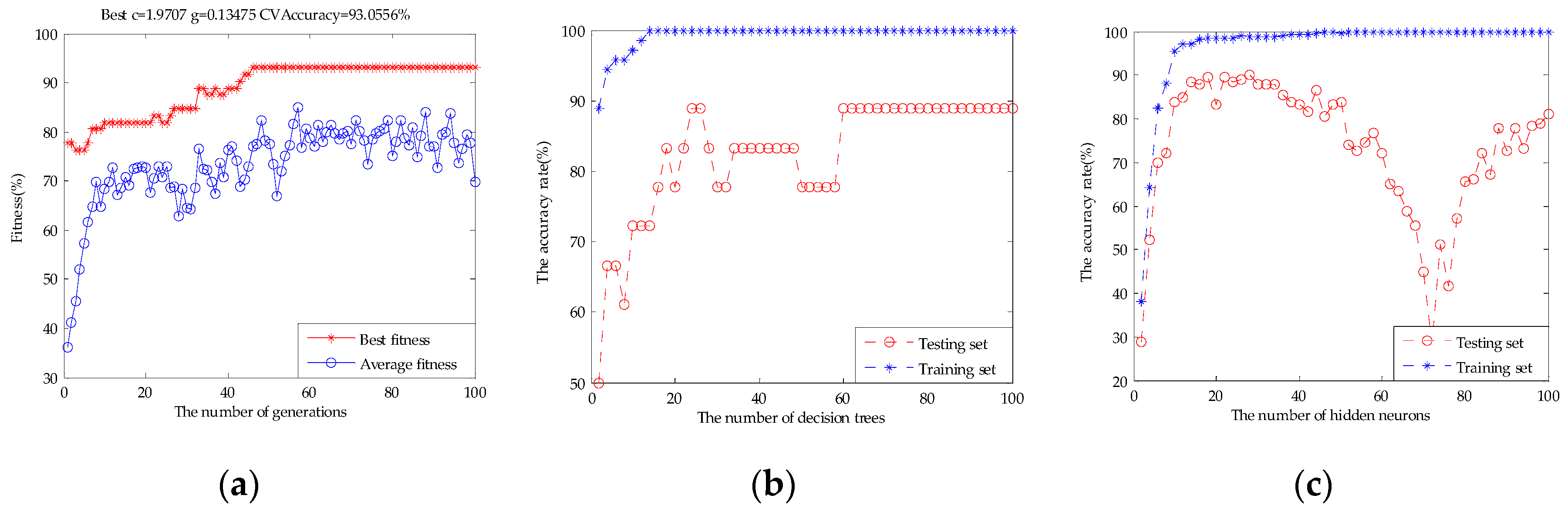
3.3. Results of the Models
4. Conclusions
- (1)
- Compared with the single e-tongue and single e-nose, the classification accuracy rate of beer flavor information was improved by using multi-sensor data fusion, and the classification accuracy rate of SVM was 88.89%, RF was 88.89%, and ELM was 88.33%;
- (2)
- The feature selection method based on PCA did not obtain the best form of beer flavor information. The feature selection method based on GA-PLS improved the beer flavor classification rate and reduced the feature dimension obviously, and SVM showed the best classification performance at 96.67%. However, it did not give the contribution behavior of each variable for the overall information; and
- (3)
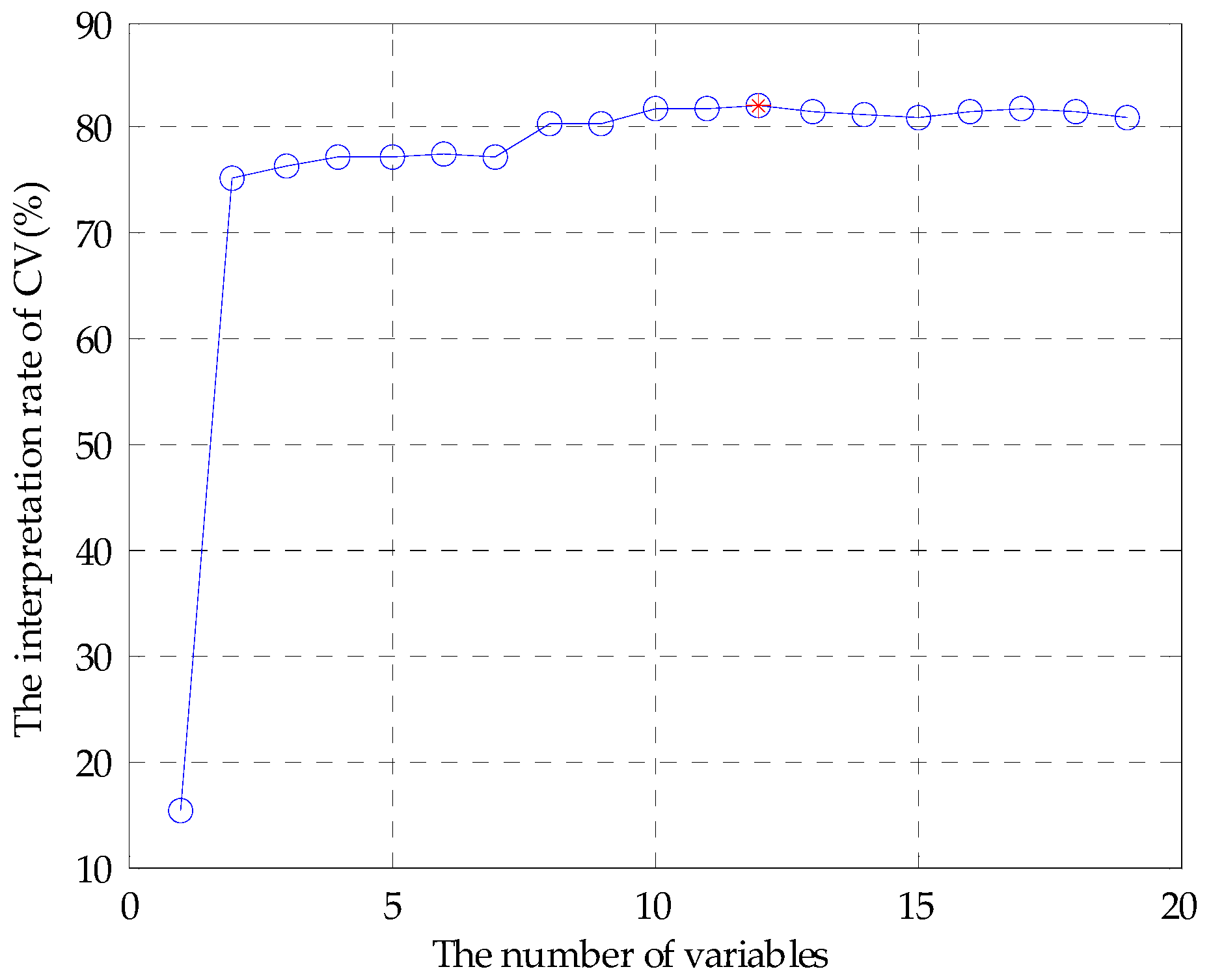
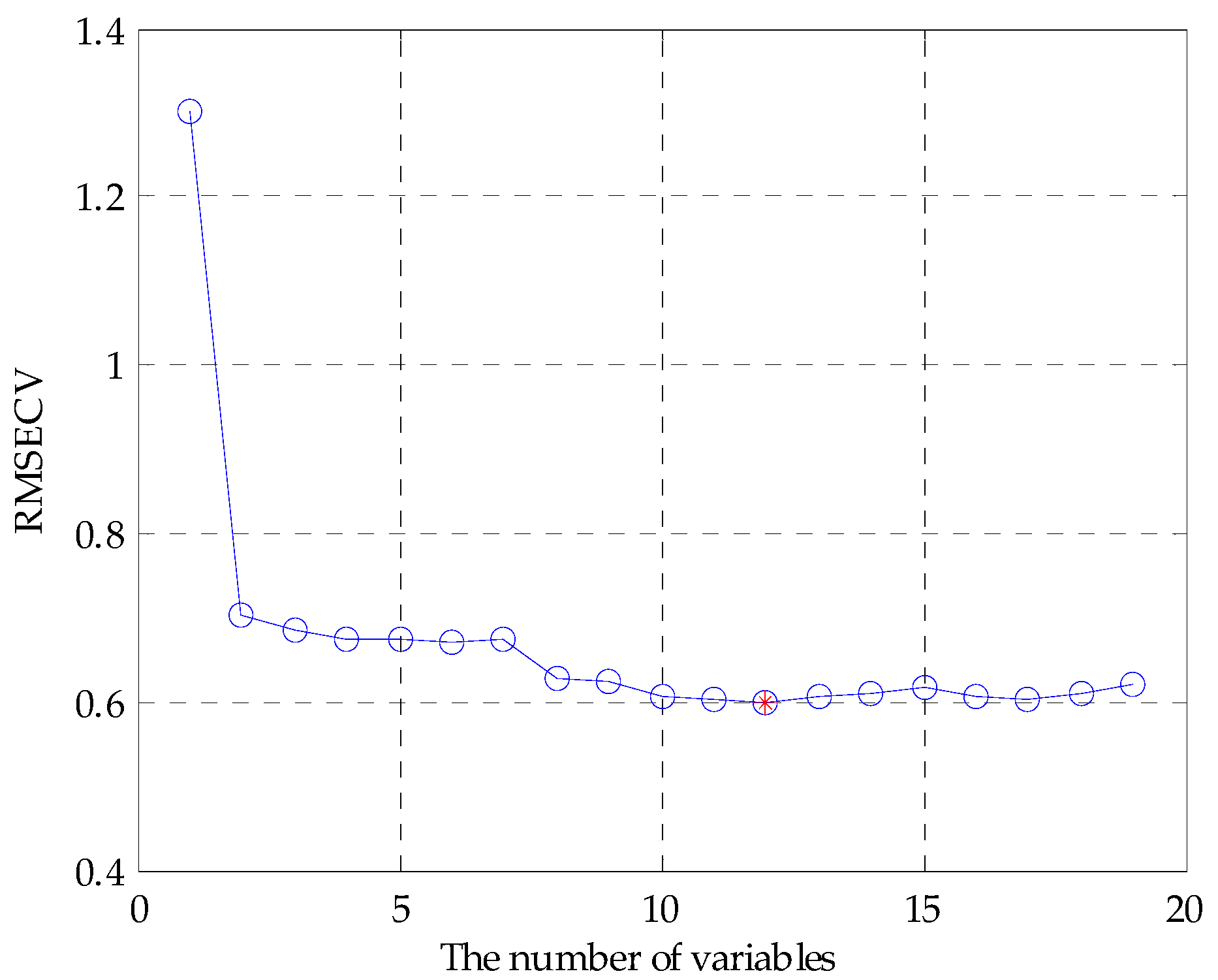
- By variable accumulation based on the best VIP score, the classification accuracy rate of SVM and ELM in subset #7 was 88.89% and 88.33%, respectively, and the classification accuracy rate of the RF in subset #9 was 88.89%, which meant that the original fusion set contained a lot of redundant information. Finally, ELM showed the best classification performance 98.33% in subset #12. Thus, C00, AE1, W1C, W3S, W3C, W5C, W1W, CA0, cpa(C00), W2S, AAE, and W1S were considered as the main features.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Denke, M.A. Nutritional and health benefits of beer. Am. J. Med. Sci. 2000, 320, 320–326. [Google Scholar] [CrossRef] [PubMed]
- Lynch, K.M.; Steffen, E.J.; Arendt, E.K. Brewers’ spent grain: A review with an emphasis on food and health. J. Inst. Brew. 2016, 122, 553–568. [Google Scholar] [CrossRef]
- Miranda, C.L.; Stevens, J.F.; Helmrich, A.; Henderson, M.C.; Rodriguez, R.J.; Yang, Y.H.; Deinzer, M.L.; Barnes, D.W.; Buhler, D.R. Antiproliferative and cytotoxic effects of prenylated flavonoids from hops (Humulus lupulus) in human cancer cell lines. Food Chem. Toxicol. 1999, 37, 271–285. [Google Scholar] [CrossRef]
- Pfeiffer, A.; Högl, B.; Kaess, H. Effect of ethanol and commonly ingested alcoholic beverages on gastric emptying and gastrointestinal transit. J. Mol. Med. 1992, 70, 487–491. [Google Scholar] [CrossRef]
- Stevens, J.F.; Ivancic, M.; Hsu, V.L.; Deinzer, M.L. Prenylflavonoids from humulus lupulus. Phytochemistry 1997, 44, 1575–1585. [Google Scholar] [CrossRef]
- Murphy, C.; Cain, W.S. Taste and olfaction: Independence vs interaction. Physiol. Behav. 1980, 24, 601–605. [Google Scholar] [CrossRef]
- Murphy, C.; Cain, W.S.; Bartoshuk, L.M. Mutual action of taste and olfaction. Sens. Process. 1977, 1, 204–211. [Google Scholar]
- Castro, L.F.; Ross, C.F. Determination of flavour compounds in beer using stir-bar sorptive extraction and solid-phase microextraction. J. Inst. Brew. 2015, 121, 197–203. [Google Scholar] [CrossRef]
- Dong, J.J.; Li, Q.L.; Yin, H.; Zhong, C.; Hao, J.G.; Yang, P.F.; Tian, Y.H.; Jia, S.R. Predictive analysis of beer quality by correlating sensory evaluation with higher alcohol and ester production using multivariate statistics methods. Food Chem. 2014, 161, 376–382. [Google Scholar] [CrossRef] [PubMed]
- Ghasemi-Varnamkhasti, M.; Mohtasebi, S.S.; Rodriguez-Mendez, M.L.; Lozano, J.; Razavi, S.H.; Ahmadi, H.; Apetrei, C. Classification of non-alcoholic beer based on aftertaste sensory evaluation by chemometric tools. Expert Syst. Appl. 2012, 39, 4315–4327. [Google Scholar] [CrossRef]
- Bacci, L.; Camilli, F.; Drago, M.S.; Magli, M.; Vagnoni, E.; Mauro, A.; Predieri, S. Sensory evaluation and instrumental measurements to determine tactile properties of wool fabrics. Text. Res. J. 2012, 82, 1430–1441. [Google Scholar] [CrossRef]
- Wang, L.; Niu, Q.; Hui, Y.; Jin, H. Discrimination of rice with different pretreatment methods by using a voltammetric electronic tongue. Sensors 2015, 15, 17767–17785. [Google Scholar] [CrossRef] [PubMed]
- Ciosek, P.; Wesoły, M.; Zabadaj, M. Towards flow-through/flow injection electronic tongue for the analysis of pharmaceuticals. Sens. Actuators B Chem. 2015, 207, 1087–1094. [Google Scholar] [CrossRef]
- Cetó, X.; González-Calabuig, A.; Crespo, N.; Pérez, S.; Capdevila, J.; Puig-Pujol, A.; Valle, M.D. Electronic tongues to assess wine sensory descriptors. Talanta 2016, 162, 218–224. [Google Scholar] [CrossRef] [PubMed]
- Romain, A.C.; Godefroid, D.; Kuske, M.; Nicolas, J. Monitoring the exhaust air of a compost pile as a process variable with an e-nose. Sens. Actuators B Chem. 2005, 106, 29–35. [Google Scholar] [CrossRef]
- Zhu, J.C.; Feng, C.; Wang, L.Y.; Niu, Y.W.; Xiao, Z.B. Evaluation of the synergism among volatile compounds in oolong tea infusion by odour threshold with sensory analysis and e-nose. Food Chem. 2017, 221, 1484–1490. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Gu, Y.; Jia, J. Classification of multiple chinese liquors by means of a QCM-based e-nose and MDS-SVM classifier. Sensors 2017, 17, 272. [Google Scholar] [CrossRef] [PubMed]
- Ghasemi-Varnamkhasti, M.; Mohtasebi, S.S.; Siadat, M.; Lozano, J.; Ahmadi, H.; Razavi, S.H.; Dicko, A. Aging fingerprint characterization of beer using electronic nose. Sens. Actuators B Chem. 2011, 159, 51–59. [Google Scholar] [CrossRef]
- Cetó, X.; Gutiérrez-Capitán, M.; Calvo, D.; Del, V.M. Beer classification by means of a potentiometric electronic tongue. Food Chem. 2013, 141, 2533–2540. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, R.; Tudu, B.; Bandyopadhyay, R.; Bhattacharyya, N. A review on combined odor and taste sensor systems. J. Food Eng. 2016, 190, 10–21. [Google Scholar] [CrossRef]
- Men, H.; Chen, D.; Zhang, X.; Liu, J.; Ning, K. Data fusion of electronic nose and electronic tongue for detection of mixed edible-oil. J. Sens. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Zakaria, A.; Shakaff, A.Y.; Masnan, M.J.; Ahmad, M.N.; Adom, A.H.; Jaafar, M.N.; Ghani, S.A.; Abdullah, A.H.; Aziz, A.H.; Kamarudin, L.M. A biomimetic sensor for the classification of honeys of different floral origin and the detection of adulteration. Sensors 2010, 11, 7799–7822. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Deng, S.; Zhu, Z.; Tian, S. Classification of rice by combining electronic tongue and nose. Food Anal. Methods 2015, 8, 1893–1902. [Google Scholar] [CrossRef]
- Han, F.; Huang, X.; Teye, E.; Gu, F.; Gu, H. Nondestructive detection of fish freshness during its preservation by combining electronic nose and electronic tongue techniques in conjunction with chemometric analysis. Anal. Methods 2014, 6, 529–536. [Google Scholar] [CrossRef]
- Pan, J.; Duan, Y.; Jiang, Y.; Lv, Y.; Zhang, H.; Zhu, Y.; Zhang, S. Evaluation of fuding white tea flavor using electronic nose and electronic tongue. Sci. Technol. Food Ind. 2017, 38, 25–43. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, J.; Gao, L. Qualification and quantisation of processed strawberry juice based on electronic nose and tongue. LWT-Food Sci. Technol. 2015, 60, 115–123. [Google Scholar] [CrossRef]
- Prieto, N.; Oliveri, P.; Leardi, R.; Gay, M.; Apetrei, C.; Rodriguez-Méndez, M.L.; Saja, J.A. Application of a GA–PLS strategy for variable reduction of electronic tongue signals. Sens. Actuators B Chem. 2013, 183, 52–57. [Google Scholar] [CrossRef]
- Zhi, R.; Zhao, L.; Zhang, D. A framework for the multi-level fusion of electronic nose and electronic nongue for tea quality assessment. Sensors 2017, 17, 1007. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Huang, C.; Xing, J.; Zheng, J. Pattern classification using an olfactory model with PCA feature selection in electronic noses: Study and application. Sensors 2012, 12, 2818–2830. [Google Scholar] [CrossRef] [PubMed]
- Hong, X.; Wang, J.; Qiu, S. Authenticating cherry tomato juices—discussion of different data standardization and fusion approaches based on electronic nose and tongue. Food Res. Int. 2014, 60, 173–179. [Google Scholar] [CrossRef]
- Cristiane, M.D.; Flavio, M.S.; Alexandra, M.; Antonio, R.J.; Maria, H.O.; Angelo, L.G.; Daniel, S.C.; Fernando, V.P. Information visualization and feature selection methods applied to detect gliadin in Gluten-Containing foodstuff with a microfluidic electronic tongue. ACS Appl. Mater. Interfaces 2017, 9, 19646–19652. [Google Scholar] [CrossRef]
- Banerjee, R.; Tudu, B.; Shaw, L.; Jana, A.; Bhattacharyya, N.; Bandyopadhyay, R. Instrumental testing of tea by combining the responses of electronic nose and tongue. J. Food Eng. 2011, 110, 356–363. [Google Scholar] [CrossRef]
- Leardi, R.; González, A.L. Genetic algorithms applied to feature selection in PLS regression: How and when to use them. Chemom. Intell. Lab. Syst. 1998, 41, 195–207. [Google Scholar] [CrossRef]
- Fassihi, A.; Sabet, R. QSAR study of p56(lck) protein tyrosine kinase inhibitory activity of flavonoid derivatives using MLR and GA-PLS. Int. J. Mol. Sci. 2008, 9, 1876–1892. [Google Scholar] [CrossRef] [PubMed]
- Galindo-Prieto, B.; Eriksson, L.; Trygg, J. Variable influence on projection (VIP) for OPLS models and its applicability in multivariate time series analysis. Chemom. Intell. Lab. Syst. 2015, 146, 297–304. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector network. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, J.; Tang, C.; Du, D. Comparison of ELM, RF, and SVM on e-nose and e-tongue to trace the quality status of mandarin (Citrus unshiu Marc.). J. Food Eng. 2015, 166, 193–203. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, W.; Wang, Y.; Wang, J. Monitoring the fermentation, post-ripeness and storage processes of set yogurt using voltammetric electronic tongue. J. Food Eng. 2017, 203, 41–52. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, J.; Li, T.; Liu, H.; Li, J.; Wang, Y. Geographical traceability of wild boletus edulis based on data fusion of FT-MIR and ICP-AES coupled with data mining methods (SVM). Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2017, 177, 20–27. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Nitze, I.; Barrett, B.; Cawkwell, F. Temporal optimisation of image acquisition for land cover classification with random forest and MODIS time-series. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 136–146. [Google Scholar] [CrossRef]
- Béjaoui, B.; Armi, Z.; Ottaviani, E.; Barelli, E.; Gargouri-Ellouz, E.; Chérif, R.; Turki, S.; Solidoro, C.; Aleya, L. Random forest model and TRIX used in combination to assess and diagnose the trophic status of Bizerte Lagoon, southern Mediterranean. Ecol. Indic. 2016, 71, 293–301. [Google Scholar] [CrossRef]
- Dubrava, S.; Mardekian, J.; Sadosky, A.; Bienen, E.J.; Parsons, B.; Hopps, M.; Markman, J. Using random forest models to identify correlates of a diabetic peripheral neuropathy diagnosis from electronic health record data. Pain Med. 2017, 18, 107–115. [Google Scholar] [CrossRef] [PubMed]
- Mao, W.; He, L.; Yan, Y.; Wang, J. Online sequential prediction of bearings imbalanced fault diagnosis by extreme learning machine. Mech. Syst. Signal Process. 2017, 83, 450–473. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Yang, W.A.; Zhou, W.; Liao, W.; Guo, Y. Identification and quantification of concurrent control chart patterns using extreme-point symmetric mode decomposition and extreme learning machines. Neurocomputing 2015, 147, 260–270. [Google Scholar] [CrossRef]
- Maione, C.; Batista, B.L.; Campiglia, A.D.; Barbosa, F.B., Jr.; Barbosa, R.M. Classification of geographic origin of rice by data mining and inductively coupled plasma mass spectrometry. Comput. Electron. Agric. 2016, 121, 101–107. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brand | Alcohol Content (% vol) | Original Wort Concentration (° P) | Raw and Auxiliary Materials |
|---|---|---|---|
| Landai | ≥4.3 | 11 | Water, malt, rice, hops |
| Xuehua | ≥3.3 | 9 | Water, malt, rice, hops |
| Baiwei | ≥3.6 | 9.7 | Water, malt, wheat, hops |
| Harbin | ≥3.6 | 9.1 | Water, malt, rice, hops |
| Qingdao | ≥4.3 | 11 | Water, malt, rice, hops |
| Dataset | Accuracy (%) | ||
|---|---|---|---|
| SVM | RF | ELM | |
| E-tongue | 83.33 | 83.33 | 82.78 |
| E-nose | 80.56 | 77.78 | 78.89 |
| E-tongue and e-nose | 88.89 | 88.89 | 88.33 |
| Dataset | Accuracy (%) | ||
|---|---|---|---|
| SVM | RF | ELM | |
| E-tongue and e-nose | 88.89 | 88.89 | 88.33 |
| PCA (e-tongue and e-nose) | 91.11 | 88.89 | 89.44 |
| GA-PLS (e-tongue and e-nose) | 96.67 | 94.44 | 94.44 |
| Subset | Variables | Accuracy (%) | ||
|---|---|---|---|---|
| SVM | RF | ELM | ||
| #1 | C00 | 37.78 | 55.56 | 43.33 |
| #2 | C00 + AE1 | 71.67 | 66.67 | 78.89 |
| #3 | C00 + AE1 + W1C | 76.11 | 66.67 | 73.89 |
| #4 | C00 + AE1 + W1C + W3S | 74.44 | 77.78 | 80.56 |
| #5 | C00 + AE1 + W1C + W3S + W3C | 77.22 | 72.22 | 78.89 |
| #6 | C00 + AE1 + W1C + W3S + W3C + W5C | 76.67 | 77.78 | 80.56 |
| #7 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W | 88.89 | 83.33 | 88.33 |
| #8 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 | 88.33 | 83.33 | 86.11 |
| #9 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) | 91.67 | 88.89 | 87.78 |
| #10 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S | 82.78 | 83.33 | 86.11 |
| #11 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE | 92.22 | 94.44 | 93.89 |
| #12 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S | 96.67 | 94.44 | 98.33 |
| #13 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W | 96.67 | 94.44 | 98.33 |
| #14 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S | 96.67 | 94.44 | 93.89 |
| #15 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 | 92.78 | 94.44 | 93.89 |
| #16 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 + cpa(CT0) | 91.67 | 88.89 | 92.78 |
| #17 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 + cpa(CT0) + W5S | 93.89 | 94.44 | 88.89 |
| #18 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 + cpa(CT0) + W5S + cpa(AE1) | 93.33 | 88.89 | 92.22 |
| #19 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 + cpa(CT0) + W5S + cpa(AE1) + cpa(CA0) | 87.78 | 88.89 | 87.78 |
| #20 | C00 + AE1 + W1C + W3S + W3C + W5C + W1W + CA0 + cpa(C00) + W2S + AAE + W1S + W2W + W6S + CT0 + cpa(CT0) + W5S + cpa(AE1) + cpa(CA0) + cpa(AAE) | 88.89 | 88.89 | 88.33 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Men, H.; Shi, Y.; Fu, S.; Jiao, Y.; Qiao, Y.; Liu, J. Mining Feature of Data Fusion in the Classification of Beer Flavor Information Using E-Tongue and E-Nose. Sensors 2017, 17, 1656. https://doi.org/10.3390/s17071656
Men H, Shi Y, Fu S, Jiao Y, Qiao Y, Liu J. Mining Feature of Data Fusion in the Classification of Beer Flavor Information Using E-Tongue and E-Nose. Sensors. 2017; 17(7):1656. https://doi.org/10.3390/s17071656
Chicago/Turabian StyleMen, Hong, Yan Shi, Songlin Fu, Yanan Jiao, Yu Qiao, and Jingjing Liu. 2017. "Mining Feature of Data Fusion in the Classification of Beer Flavor Information Using E-Tongue and E-Nose" Sensors 17, no. 7: 1656. https://doi.org/10.3390/s17071656
APA StyleMen, H., Shi, Y., Fu, S., Jiao, Y., Qiao, Y., & Liu, J. (2017). Mining Feature of Data Fusion in the Classification of Beer Flavor Information Using E-Tongue and E-Nose. Sensors, 17(7), 1656. https://doi.org/10.3390/s17071656