1. Introduction
As mobile healthcare systems have become widely used, users have begun to expect increasingly accurate performance with better appearance. The appearance of the mobile healthcare system relies highly on the development of sensing devices, either external or wearable. Due to many limitations of external sensing devices, wearable sensors have increasingly attracted the interest of both users and researchers. Recently, many wearable sensors have been developed for many applications, such as medical, sports, and commercial fields (see a recent review in [
1]). For researchers investigating the mobile healthcare system, it is also challenging to utilize multi-dimensional information collected from existing wearable sensors for more accurate performance.
To guarantee the performance of the mobile healthcare system, two crucial functions are required: human-activity recognition (HAR) and energy-expenditure (EE) estimation. The former, which is also called the HAR problem, has attracted many researchers since the late ‘90s (see recent reviews in [
2,
3]). With the development of computing technologies, it becomes possible to recognize human activities, especially ambulatory activities, with significantly high accuracy. Researchers have recently reported very high recognition performance, from 97 to 99%, under different approaches [
4,
5]. The latter function is also broadly implemented in the mobile healthcare service and is represented as calorie consumption. These two issues are closely related to each other in that the EE estimation is accurate assuming that the activities of the monitored person are properly recognized [
6].
The most frequently used sensor in the mobile healthcare system is the tri-axial accelerometer. Single or multiple accelerometers are broadly used for the HAR problem and EE estimation. However, as mentioned in a recent review by Lara and Labrador [
3], physiological signals such as heart rate, respiration rate, and electrocardiogram (ECG) have attracted little interest. The specific reason we pay attention to physiological signals is that the information provided by the accelerometer is insufficient for recognition of some confusing activities in terms of acceleration. Furthermore, an accelerometer has a critical drawback in cases of little or no movement but with obvious energy consumption, for example, sedentary work. One previous study has proven that heart-rate variabilities reflect qualitative differences in static and dynamic activities [
7].
Biomedical sensors for physiological signals have continuously developed. On the other hand, as reviewed by Liu and Liu, recent biomedical sensors have become wireless, portable, and wearable on the platform of mobile phone. Yet, the method of analyzing the collected physiological signals is still a challenge [
8].
Based on these considerations, we expect that such physiological signals may provide us with additional information for better recognition of human activities and prediction of EE, even for such cases. To the best of our knowledge, no study has been performed yet to solve these drawbacks for both issues (HAR and EE estimation) with an approach that exploits human physiological signals.
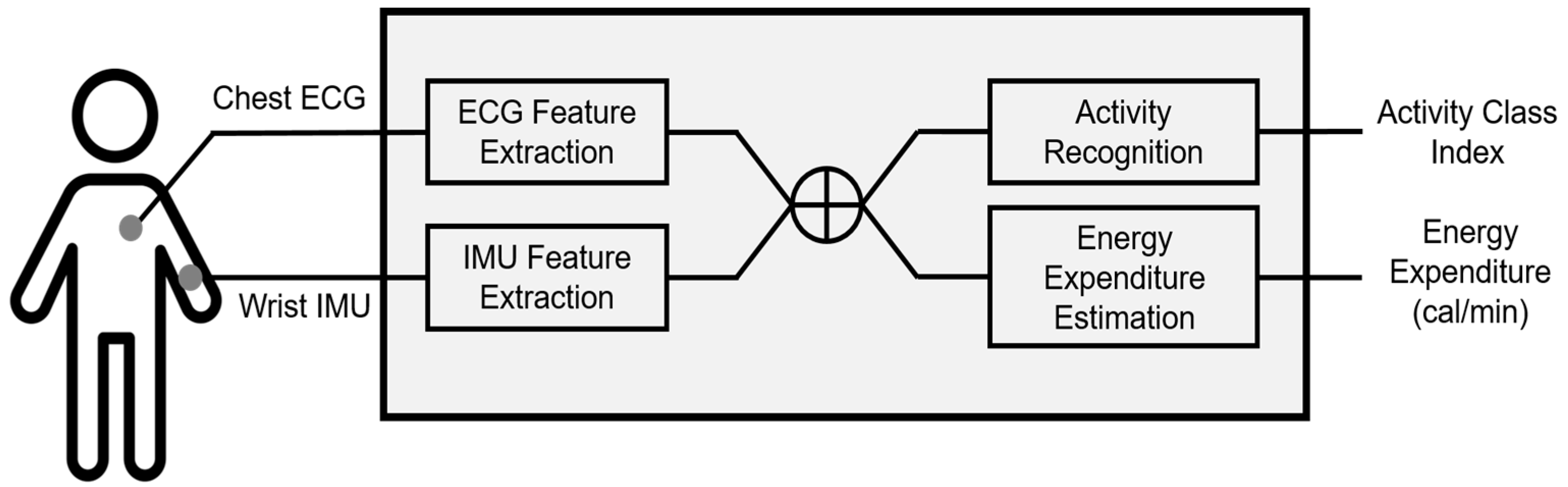
In this study, we aim to recognize human ambulatory activities and estimate EE using our database composed of accelerometer and physiological signals, collected from 13 voluntarily participating subjects in a laboratory environment. To investigate the role of physiological signals in both issues, we compare the recognition and estimation performances with and without ECG data.
The organization of the paper is as follows. We first give a brief review of some of the existing approaches for HAR and EE estimation using wearable sensors. Then, we introduce our database and the wearable sensors used in this study. Next, we describe our approaches and experimental results of HAR and EE estimation. Finally, we conclude this paper with a discussion.
4. Activity Recognition
As our first experiment, we examined the activity-recognition performance with respect to the input data compositions using support vector machines with a linear kernel (Linear SVM) and a radial basis function kernel (RBF SVM), k-nearest neighbors (kNN) and linear discriminant analysis (LDA). We set up three recognition scenarios to evaluate performance as follows and applied the four aforementioned classification methods to these scenarios: (1) IMU only: input data are composed of four time- and frequency-domain features extracted from the accelerometer data acquired from IMU sensors. (2) IMU + ECG: input data are composed of four features from IMU sensors (same as (1)) and 31 HRV parameters extracted from the ECG data. (3) IMU + selected ECG: input data are composed of four features from IMU sensors (same as (1)) and selected HRV parameters extracted from the ECG data. The selection criterion is based on the statistical significance (p-value) of the training data. We used the Mann-Whitney U test, which is a nonparametric method for data whose probability distribution is not normal, frequently used to assess the differences in HRV parameters.
To evaluate the validity of the recognition performance, we used a leave-one-subject-out cross-validation strategy. We divided the data from 13 subjects into three groups: training, validation, and testing. For each cross-validation fold, there are training data from 11 subjects, validation data from one subject, and testing data from one subject. There is no overlap of data/subject between groups. Validation data were used to select the optimal parameters for some classifiers, such as SVM (box constraint for both kernels, and gamma for the RBF kernel) and kNN (k, the number of nearest neighbors) for every scenario. Additionally, validation data were also used to find the optimal number of ECG features in the Scenario III. We used the LIBSVM toolbox for the classification [
32] and Matlab Statistics Toolbox (The MathWorks, Inc., Natick, MA, USA) for the other classification methods.
4.1. Scenario I: IMU Only
In this recognition scenario, we used four-dimensional input data, and features were extracted from IMU data only.
Figure 4 shows average feature values for each subject in time- and frequency-domains, respectively. As shown in the figure, static (SI and ST) and dynamic activities (WK, AS, and RU) are clearly distinguished. However, SI and ST of static activity, WK and AS of dynamic activity are somewhat overlapping, suggesting the difficulty of classification.
Table 2 shows the confusion table for SVM, and the overall recognition accuracy is 83.08%. On the other hand, RBF SVM achieved an accuracy of 76.92%. For kNN, the recognition accuracy is 81.15% with an optimal k of 3, as determined by the validation data. LDA obtained 72.12%. As shown in the confusion table, SI and ST are frequently confused with each other, and WK is confused with AS. This trend has also been observed in the confusion table published in [
31]. We can conclude that the information obtained from IMU sensors is insufficient to classify static activities in detail because there is not a big difference between SI and ST in the feature domain. It also shows that there is not a big difference between WK and AS in terms of acceleration.
4.2. Scenario II: IMU + ECG
In this recognition scenario, we used four-dimensional input data from IMU data and additional 31-dimensional HRV parameters from ECG data. In other words, the input-data dimension in this scenario is 35. As a result, the recognition accuracy of linear SVM improves to 91.73%, while RBF SVM outperforms it with an accuracy of 92.31%. LDA has the largest improvement with the highest accuracy of 94.81%. kNN improves to 87.50% with an optimal k as 1. The result shows that all methods experience improvement, large or small, due to the additional data. Compared to the previous scenario, the confusion table shows that WK is no longer confused with AS with ECG data, but SI and ST are still confused with each other, although this is slightly improved (see
Table 3).
4.3. Scenario III: IMU + Selected ECG
We used a statistical test to select better ECG features to solve the drawbacks observed by previous scenarios. The Mann-Whitney U test was used for the evaluation of all univariate differences in HRV parameters between the SI and ST classes, and between the WK and AS classes. To observe the effect of feature selection, we drew two scatter plots before and after feature selection using training samples with their known labels. Samples before feature selection have 31 dimensions and thus cannot be drawn in 2-D or 3-D, so we apply principal component analysis to reduce their dimensions only for the purpose of drawing the plots. Samples after feature selection are represented by two-dimensional vectors because the highest validation accuracy is obtained when two ECG features are used. Specifically, selected features are exactly the same for every 13 folds, mean R-R interval (mRRI) and mean heart rate (mHR).
Figure 5 shows the effect of feature selection, separately drawn for two class-pairs, i.e., SI/ST and WK/AS. For samples before selection, the first and second principal components were used for a scatter plot. As shown in the Figure, samples before selection overlap one another, which implies difficulty in classification. However, samples with selected features show better distinctiveness compared to the samples before selection. Moreover, sample distributions before selection in classes SI and ST are more overlapped compared to those in classes WK and AS (see
Figure 5a,c). This trend indicates that classification of SI and ST is more difficult than that of WK and AS, which is in line with the confusion table given in
Table 3. As shown in the confusion table in
Table 4, there are significant improvements in classes SI, ST, and WK, compared to the confusion table in
Table 3.
The classification accuracies for all three scenarios are summarized in
Table 5. All four methods achieved their highest performances in scenario III, and LDA obtained the highest performance overall, 96.35%.
5. Energy-Expenditure Estimation
In the second experiment, we proposed a novel approach to estimate EE during six activities (SI, ST, WK, AS, RU, and REST). As mentioned in
Section 3.1., we aim to estimate EE using data obtained from wearable sensors as closely as possible to the EE measured by the metabolic gas analysis system. To estimate the energy consumed during activities, we developed several linear-regression models using multi-sensory input features as independent variables. Generally, a linear-regression model takes the form shown in Equation (1). Assuming a total number of samples
n, the estimated energy (kcal/min) of the
i-th sample,
, is calculated as follows:
where
is a
k-th regression coefficient,
represents the
k-th input feature of the
i-th sample, and
is the error term. The elements of a
K-dimensional vector
can be simply estimated using an ordinary least-squares method by minimizing the sum of squared error
. The estimate of the regression-coefficient vector
can be obtained using following closed-form expression (Equation (2)).
where ’ denotes transpose.
Using this method, we set up four models to compare estimation performances from two perspectives: data and model types. Hereafter, we refer to them as (1) the single model with IMU data only (Model I), (2) the single model with both IMU and ECG data (Model II), (3) the activity-specific model with IMU data only (Model III), and (4) the activity-specific model with both IMU and ECG data (Model IV). For all models, anthropometric features (weight and height) and accelerometer features from IMU data (RMS, standard deviation, dominant frequency, and energy) are commonly used for the initial regression variables. Model II and IV additionally use physiological features (31 HRV parameters).
By comparison of the four models, we expected effects due to (1) the addition of physiological features in EE (data type) and (2) the methods of model construction (single or activity-specific; model type). The effect of (1) can be seen by comparing Models I and II and comparing Models III and IV. The effect of (2) can be seen by comparing Models I and III and comparing Models II and IV.
Among multi-sensory features, the selection criterion of regression variables is based on the statistical significance (p-value < 0.05) in the regression model generated by training data. To evaluate each model’s estimation performance, we used the root-mean-square error (RMSE) between the EE values (kcal/min) predicted by a model and the values actually observed by the metabolic gas analysis system.
To validate the generated regression model, we also used a leave-one-subject-out cross-validation strategy. Data from 12 subjects were used to select the optimal regression variables and compute their coefficients. Data from the remaining subject were used to test the generated model. The performance reported afterwards is the average EE or the average RMSE after 13-fold cross-validation. The average RMSE values for each activity are reported in
Table 6.
To investigate each effect on estimation performance, a two-way ANOVA was conducted to compare the main effects of types of data and model and the interaction effect between type of data and model on the EE estimation performance. Data type included two levels (IMU and IMU + ECG) and model type consisted of two levels (single and activity-specific).
5.1. Effect of Data Type
First, we investigated the effect of data type on EE performance. The models without physiological features are Models I and III, while the models with additional physiological features are Models II and IV. As mentioned above, the initial features of Models I and III are two anthropometric features and four accelerometer features, and they are used to construct least-squares fits of their models to the training data. Models II and IV used additional physiological features from ECG data, i.e., a 37-dimensional feature vector in total, to construct a least-squares fit. The EE estimation performances of Models III and IV are described in
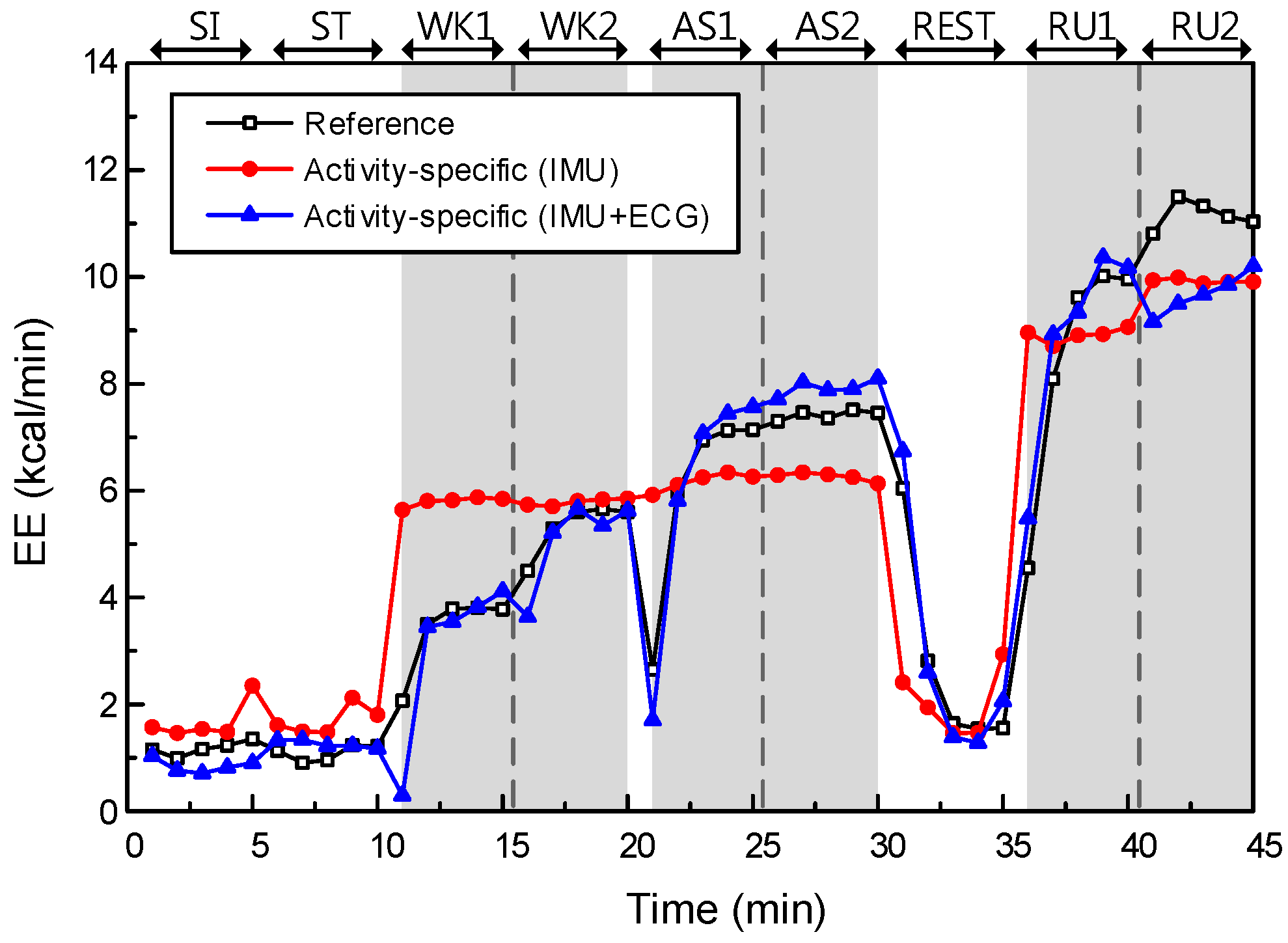
Figure 6.
The main effect of data type yielded an F ratio of F(1, 308) = 38.69, p < 0.001, indicating a significant difference in RMSEs between the models with IMU only (Models I and III; μ = 1.59, σ = 0.68) and models with IMU + ECG (Models II and IV; μ = 1.03, σ = 0.38). This result shows that the models with additional physiological features could significantly improve the estimation performance, relative to the models without physiological features.
5.2. Effect of Model Type
Next, we compared two types of models in EE estimation. In Models I and III, one single model is generated by the training data for all six activities. In Models II and IV, unlike in the single model, we generated two regression models for each activity type: static and dynamic. Static activities include SI, ST and REST, while dynamic activities are WA, AS and RU.
The main effect of model type yielded an F ratio of F(1, 308) = 8.58,
p < 0.005, indicating a significant difference in RMSEs between the single models (Models I and II; μ = 1.44, σ = 0.58) and the activity-specific models (Models III and IV; μ = 1.18, σ = 0.64). This result shows that the activity-specific model could improve the estimation performance significantly, relative to the single model. The EE estimation performance of Models II and IV are described in
Figure 7.
We confirmed that both effects are statistically significant on the EE estimation performance. In other words, the addition of physiological features and the use of an activity-specific model have significant impacts on the performance improvement. By comparing these two effects, we can see that data type has a greater impact on the EE estimation performance than the effect of model type. However, there was no significant interaction effect between data and model types (p-value = 0.90).
Consequently, Model IV generates 26 regression models computed from each cross validation fold (13-fold) and each activity (static and dynamic). Representatively,
Table 7 shows final regression models computed from 1st cross-validation fold.
6. Discussion
As mentioned earlier, HAR and EE estimation are important information provided by the mobile healthcare system. The HAR problem has been investigated for a long time by many researchers, and the reported performances of existing approaches seem to be sufficiently high, even for commercialization. The reason we tried to propose a novel approach for this widely known problem is that it is crucial to understand different characteristics of static and dynamic activities for accurate HAR and EE estimation in our daily lives. The accelerometer, as is also well known, has been a good tool for HAR and EE estimation, but we found significant drawbacks, such as the confusion of some activities (SI/ST and WK/AS) and in estimating energy expenditures for activities involving little or no movement (but obviously consuming energy). In this study, we found a significant role of human physiological signals (specifically, HRV parameters) for both problems and an impact of the activity-specific model on EE estimation.
6.1. Activity Recognition
Our findings show that selected ECG features indeed improved classification performance dramatically, especially for some labels that were confused when we used IMU features only. Moreover, the selected ECG features are the same for all 13 folds. In other words, the power of the selected ECG features is verified with different training data. Therefore, it is necessary to further consider the details of these two selected features: mRRI and mHR.
By definition, mRRI is the average interval of two successive R peaks. Differences between the mRRI values for the SI and ST classes are shown to be statistically significant by the Mann-Whitney U test (for the SI class, μ = 0.86, σ = 0.12; for the ST class, μ = 0.77, σ = 0.10, and p-value = 5.51 × 10−6). This means that the interval between R-R peaks is longer for a sitting activity than for a standing activity, and the longer RR interval indicates slower heartbeat due to that activity. We can observe a statistically significant difference in mRRI values between the WK and AS classes (for the WK class, μ = 0.61, σ = 0.08; for the AS class, μ = 0.47, σ = 0.07, p-value = 3.15 × 10−6). In the same way, the ascending activity makes the heart beat faster than walking.
Moreover, we can clearly interpret these trends with mHR, the mean heart rate. The mHR values also show such differences for both pairs of activity classes (for the SI class, μ = 71.23, σ = 9.11; for the ST class, μ = 79.89, σ = 10.29, p-value = 0; for the WK class, μ = 100.82, σ = 12.58; for the AS class, μ = 130.64, σ = 18.32, p-value = 0).
Then, the question is whether ECG features alone can classify activity classes. We additionally developed new scenarios with ECG-only features: (4) ECG-only, and (5) selected ECG-only, and tested these scenarios with LDA which yielded the highest performance in previous scenarios. As a result, we obtained 68.65% (σ = 6.74) with scenario IV, and 69.04% (σ = 7.11). Specifically, predicted labels in scenario V showed that there is no misclassification at all between the SI and ST classes, and between the WK and AS classes, as we statistically investigated above. However, low classification performance of these new scenarios was due to the confusion between static activity classes (SI and ST) and WK classes.
According to these findings, our physiological signals, especially some of HRV parameters associated with the information of the heartbeat, can help to recognize more accurately some activities for which movements are not easily recognizable with accelerometer signals only. In conclusion, the characteristics of the ECG and the IMU are complementary in terms of HAR, so that using these features together can improve performance than using each of them.
6.2. Energy Expenditure Estimation
In EE estimation, we generated four models with respect to the data and model types. The effects of data and model types on EE estimation performance were statistically significant in terms of RMSE with reference data from the metabolic gas analysis system. Moreover, the effect of data type was greater than the effect of model type. However, the effect of model type was a dramatic improvement, in static activities specifically. Comparing the RMSEs for static and dynamic activities separately, the difference between Models II and IV was statistically significant for static activities only (p-value = 9.71 × 10−7, t(1, 38) = 5.83, for Model II; μ = 1.02, σ = 0.54, for Model IV; μ = 0.55, σ = 0.26). This result indicates that the proposed model has made a significant improvement in EE estimation for activities involving little or no physical movement, as expected.
We found that the generated regression models have common variables. Common variables in Models II and IV indicate significant contributions of some features, among all 37 features we used (two anthropometric, four accelerometer, and 31 HRV features). Surprisingly, mHR, which had a great impact on activity recognition as well, was selected by all 13 folds. In other words, the additional information about heart rate is also useful in EE estimation. The crucial role of mHR in both problems means a lot in terms of system construction. By simply computing the average heart rate, we can improve EE estimation performance for static and dynamic activities that reflect daily life.
6.3. Limitations and Future Work
We proposed a novel approach to recognize human ambulatory activities and estimate EE using our database composed of IMU and ECG signals, collected from 13 subjects. We have successfully demonstrated that using additional ECG signals, especially adding specific HRV parameters, has resulted in performance improvements for both issues. However, there is obvious limitation that our database has been collected under controlled laboratory environment with subject at specific ages. For broader application of the proposed system, it should be verified with different subject groups such as age, gender, race etc. Because the characteristic of physiological signals providing useful information on heart is highly dependent on these effects. Therefore, system performance may also be enhanced with more sample numbers of the same group with the testing subject.
Considering daily life monitoring using our approach, our database may be limited to a few activities classes. However, we set up the models not for every single activity class but for each activity category (static or dynamic), even though there are other activities beyond six activity classes that we used, our system is expected to yield reasonable performance by applying either static or dynamic model. Moreover, to adapt continuously collected daily life data, system should be updated regularly with new training data. In other words, how to effectively process the vast amount of data and incorporate them into the system will be a new challenge. Future work can be done to address these issues with active learning or selective sampling to regularly update individual models.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}