Headgear Accessories Classification Using an Overhead Depth Sensor

 , , ,
, , ,
Abstract
:1. Introduction
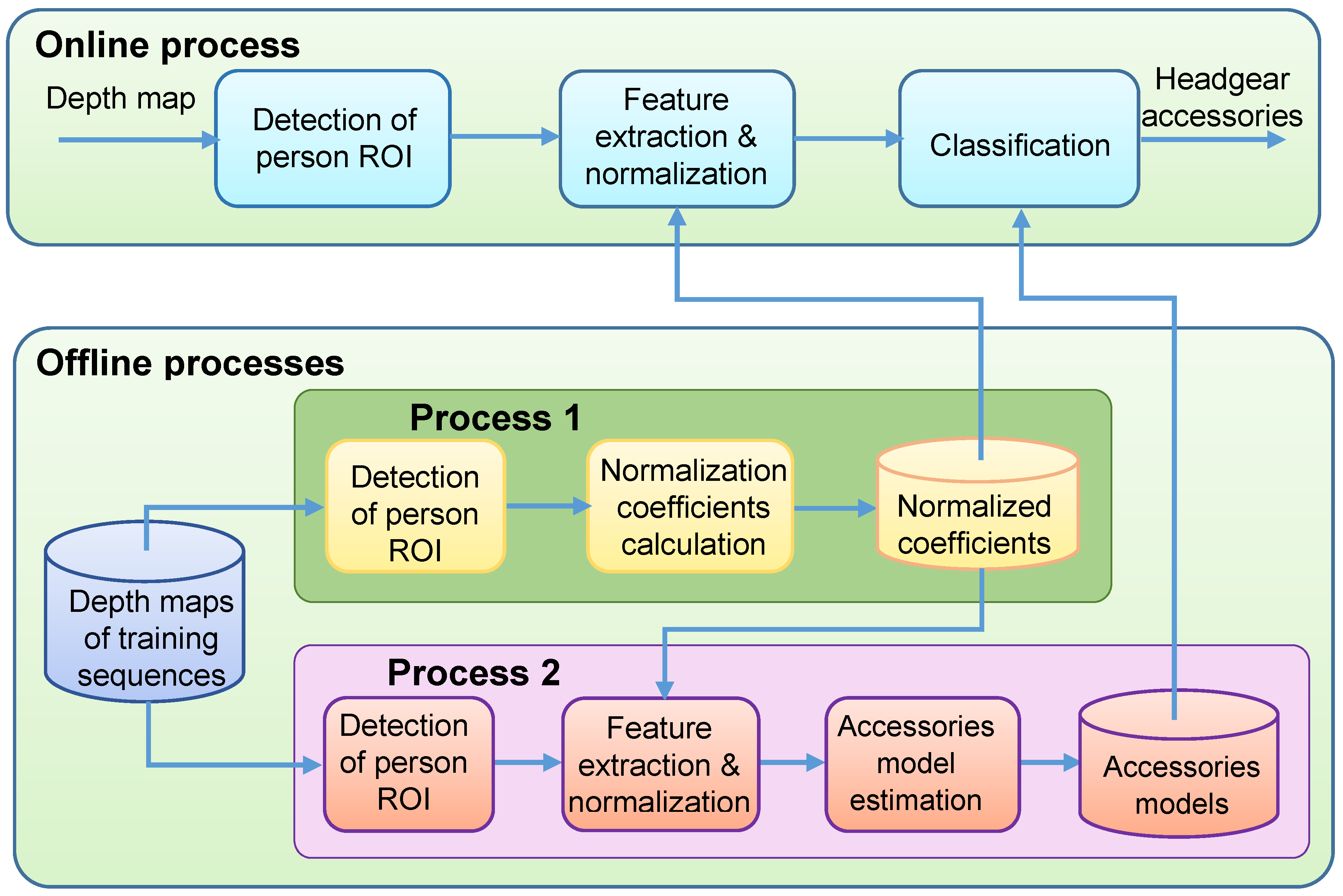
2. Accessories Classification Algorithm
2.1. Preprocessing of Depth Maps
2.2. Detection of a Person ROI
2.3. Feature Extration and Normalization
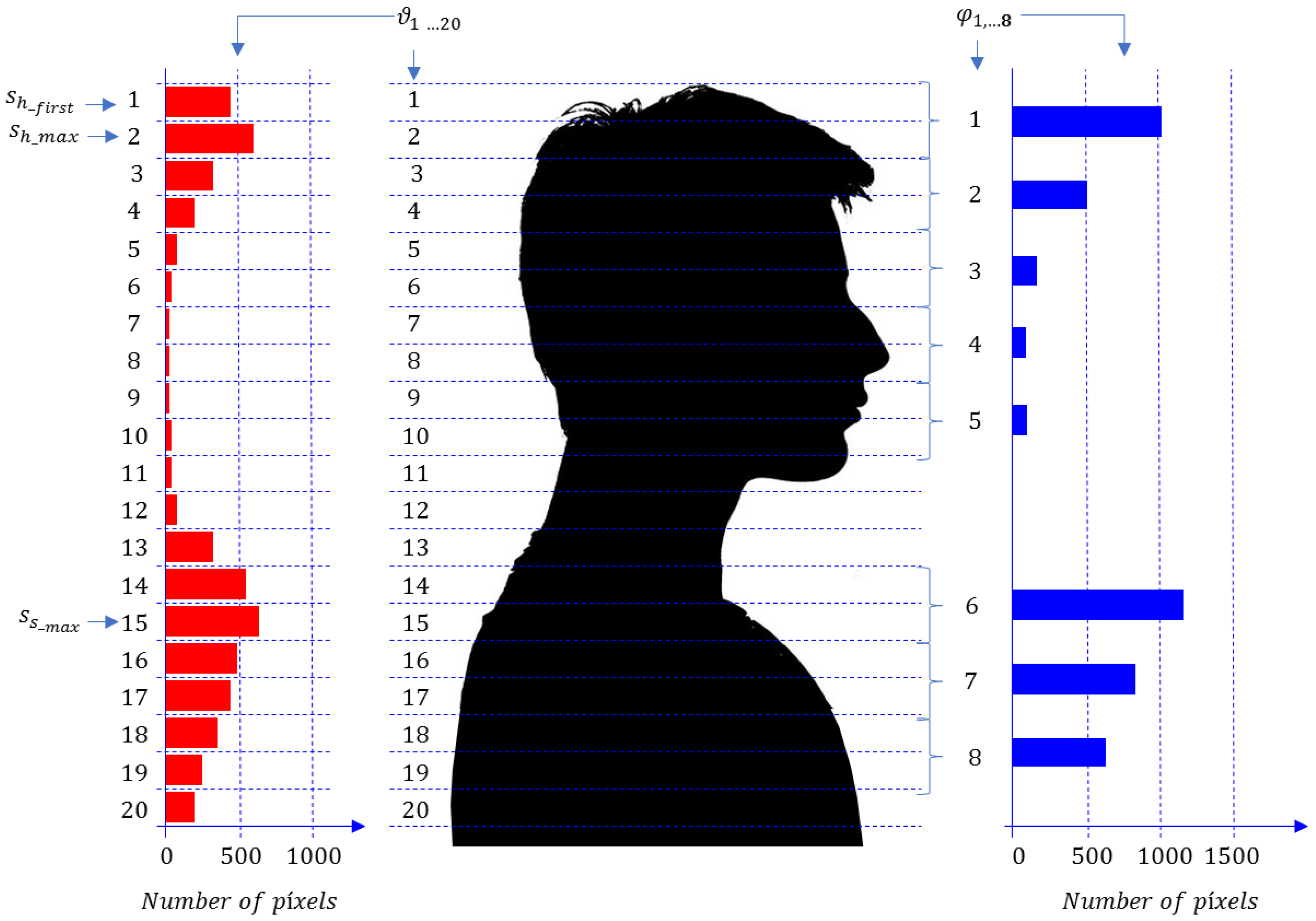
- Calculate the histogram of pixels (depth measurements) along the heights of interest (between and ), with a high enough number of intervals. In this work, 20 intervals were used, as proposed in [21], taking into account geometrical considerations (Figure 2 shows this division in 20 slices). That is, we count the number of pixels in 20 slices of 2 cm of height, obtaining a vector , where is the number of pixels in section s (being s = 1, 2, …, 20). The highest section of a given person corresponds to s = 1, as shown in Figure 2.
- Estimate the first top section of the head, . To do this, we first find the section of the head with the maximum number of pixels in the first three elements of : . Then, we assume that:where is the number of times that the numbers of pixel in section must be higher than the number of pixels in section to assume that the top section is . This step is necessary to reduce the error in the person height estimation, due to the noise in the depth maps, and for the use of small accessories or specific hair configurations (such as tied in a tail). The value of NT has been obtained empirically, and it was determined that, with values of between 10 and 20, similar results were obtained. The estimated value of the person height without noise, , will be obtained as:
- Find the five components of the feature vector () that describe the head structure. Each component is composed of two consecutive elements of organized as follows:
- Estimate the maximum section of the shoulders, . Taking into account the human morphology, we assume that can be found starting at 22 cm from the top of the head, i.e.:
- Find the three components of the feature vector () that describe the shoulders’ structure. Each component is composed of two consecutive elements of organized as follows:Each component corresponds to the number of pixels of a section of 4 cm, so that it depends on the person’s height, thus it is necessary to normalize them.
- Determine the normalized feature vector () that will be obtained dividing the components of the feature vector (), by the estimated value of its first component ():
2.4. Calculation of Normalization Coefficients
2.5. Attribute Model Estimation
2.6. Classification
| Algorithm 1 Classification | |
| 1: | Input: feature vector , average vector , scatter matrix , transformation matrix , number of classes . |
| 2: | For to do |
| 3: | // Difference between the feature vector and the average vector // |
| 4: | // Projection of in the transformed space// |
| 5: | // Recovery of in the original space // |
| 6: | // Difference between the vector and its recovery // |
| 7: | // Recovery error = Mahalanobis distance between and // |
| 8: | If then |
| 9: | and // Class has now the smallest recovery error // |
| 10: | End If |
| 11: | End For |
| 12: | Output: //Class with the smallest recovery error// |
3. Experimental Work
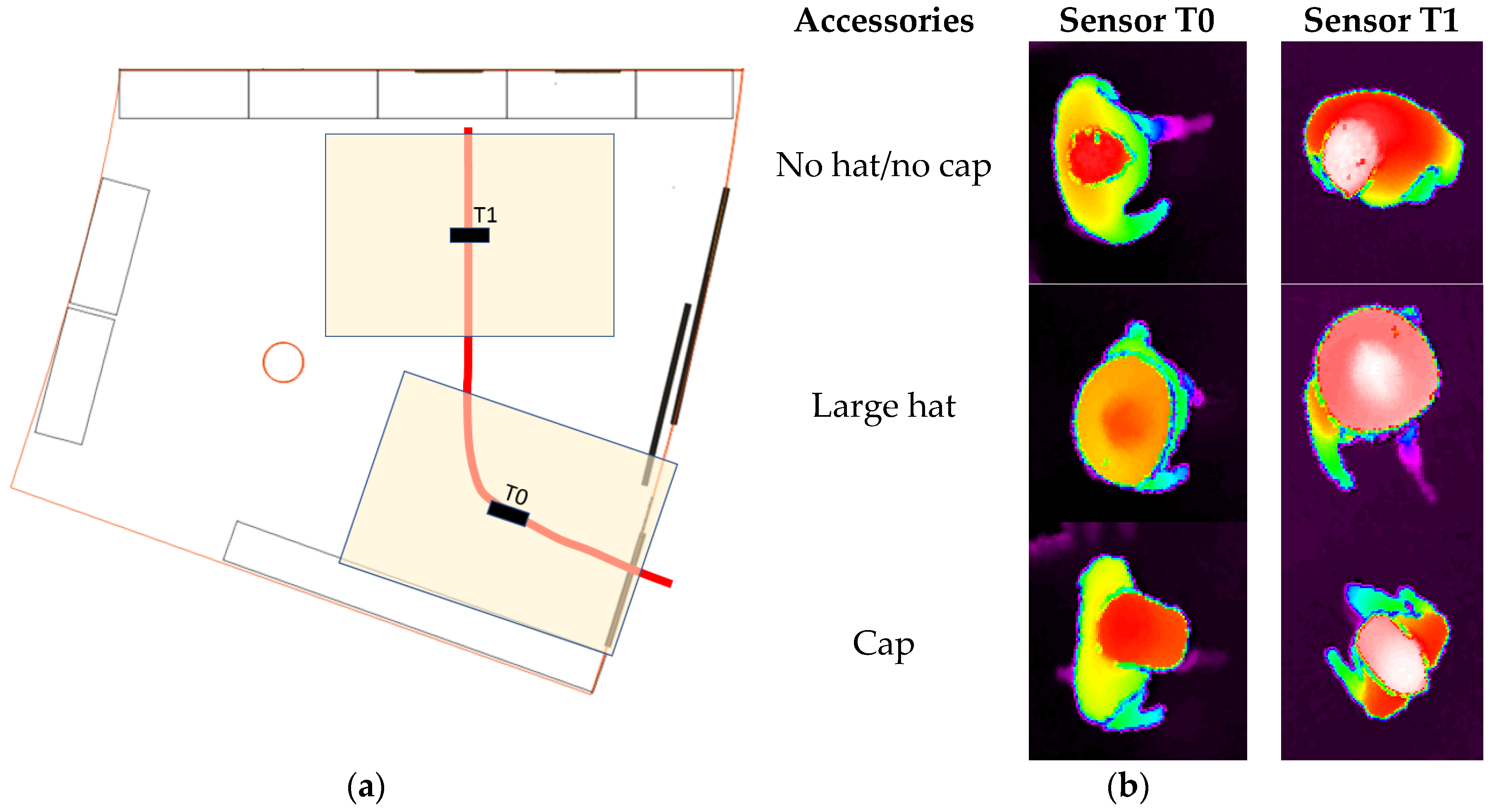
3.1. Experimental Setup
- Single people scenarios, as the target is the classification of head style/accessories configuration, with a total of 25 different persons involved.
- People without accessories (no hat nor cap) and different hairstyle configurations (short, long and with/without ponytail).
3.2. Performance Metrics
3.3. Results and Discussion
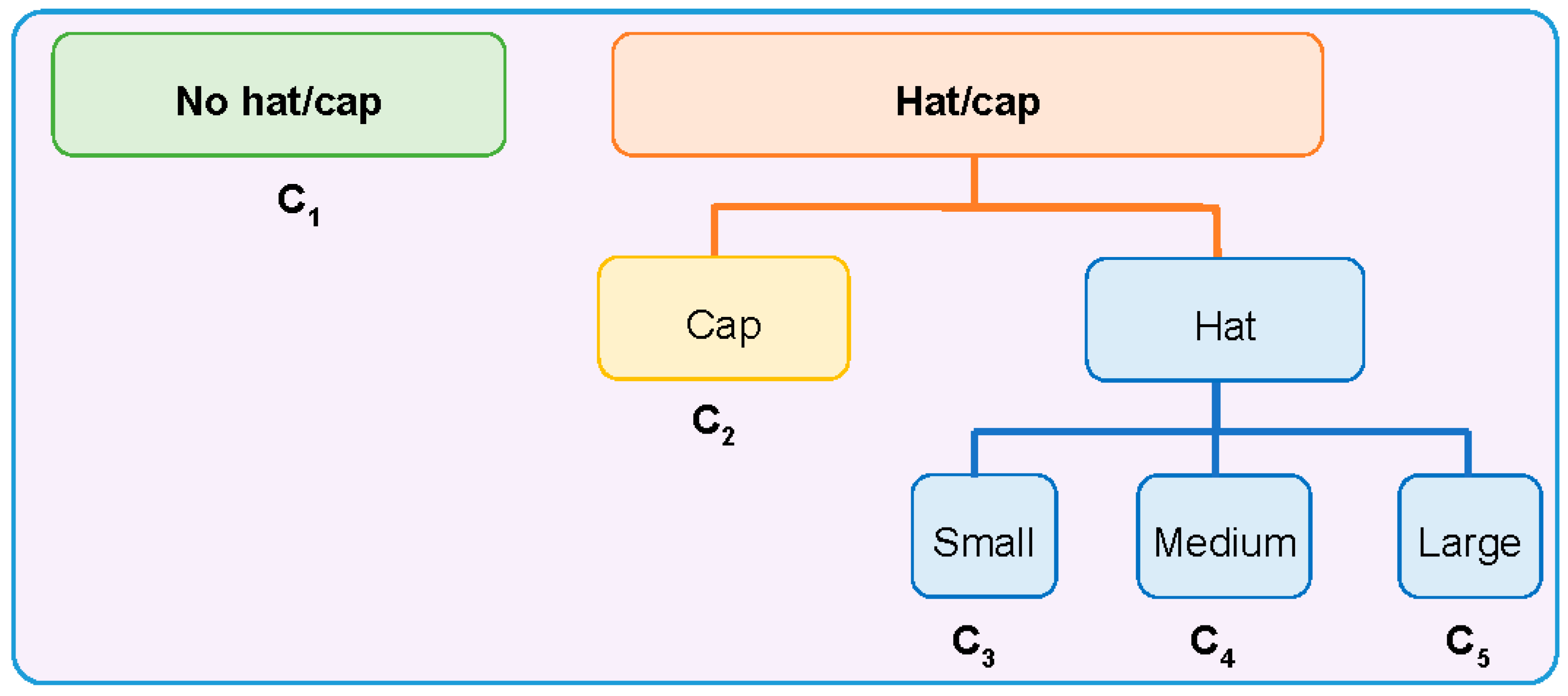
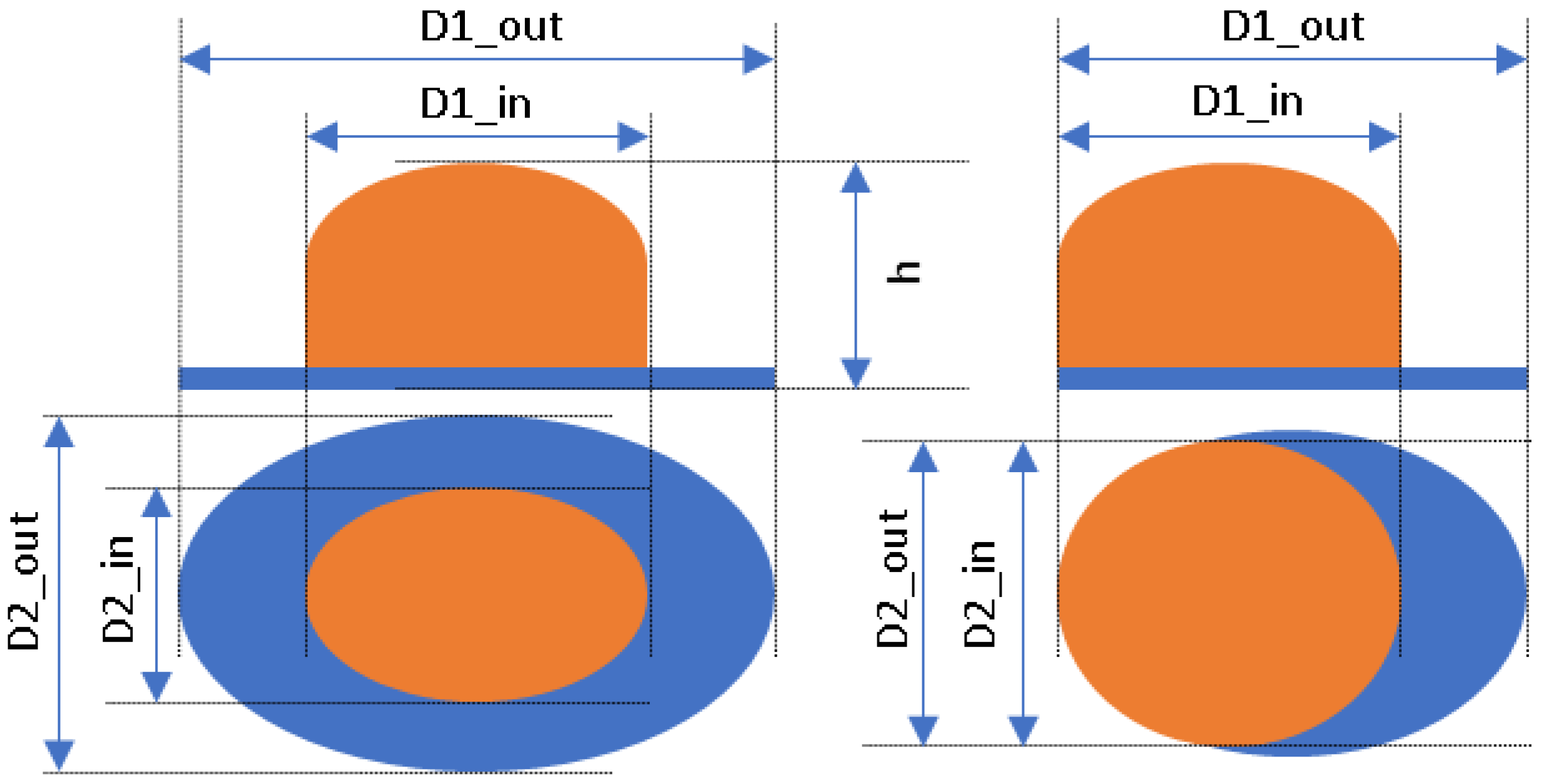
- Level 2 classification grouping: in which five classes were considered, i.e., large size hat, medium size hat, small size hat, cap and no hat/cap.
- Level 1 classification grouping: in which three classes were considered, i.e., hat, cap and no hat/cap.
- Accessory–no accessory classification: in which two classes were considered, i.e., hat/cap, and no hat/cap.
3.4. Computational Cost
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lange, R.; Seitz, P. Solid-state Time-of-Flight range camera. IEEE J. Quantum Electron. 2001, 37, 390–397. [Google Scholar] [CrossRef]
- Sell, J.; O’Connor, P. The Xbox one system on a chip and kinect sensor. IEEE Micro 2014, 34, 44–53. [Google Scholar] [CrossRef]
- Kerker, D.; Jenkins, M.P.; Gross, G.A.; Bisantz, A.M.; Nagi, R. Visual estimation of human attributes: An empirical study of context-dependent human observation capabilities. In Proceedings of the 2014 IEEE International Inter-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision Support (CogSIMA), San Antonio, TX, USA, 3–6 March 2014; Volume 1, pp. 40–46. [Google Scholar]
- Saranya, M.; Cyril, G.L.I.; Santhosh, R.R. An approach towards ear feature extraction for human identification. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; Volume 86, pp. 4824–4828. [Google Scholar]
- Kim, S.T.; Kim, D.H.; Ro, Y.M. Spatio-temporal representation for face authentication by using multi-task learning with human attributes. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2996–3000. [Google Scholar]
- Wang, H.-J.; Lin, Y.-L.; Huang, C.-Y.; Hou, Y.-L.; Hsu, W. Full body human attribute detection in indoor surveillance environment using color-depth information. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 383–388. [Google Scholar]
- Linder, T.; Arras, K.O. Real-time full-body human attribute classification in RGB-D using a tessellation boosting approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1335–1341. [Google Scholar]
- Chen, H.; Gallagher, A.; Girod, B. Describing clothing by semantic attributes. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 609–623. [Google Scholar]
- Bourdev, L.; Maji, S.; Malik, J. Describing people: A poselet-based approach to attribute classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1543–1550. [Google Scholar]
- Wang, N.; Ai, H. Hair style retrieval by semantic mapping on informative patches. In Proceedings of the First Asian Conference on Pattern Recognition, Beijing, China, 28 November 2011; pp. 110–114. [Google Scholar]
- Linder, T.; Wehner, S.; Arras, K.O. Real-time full-body human gender recognition in (RGB)-D data. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3039–3045. [Google Scholar]
- Yamasaki, T.; Matsunami, T.; Chen, T. Human attribute analysis using a top-view camera based on two-stage classification. IEICE Trans. Inf. Syst. 2013, E96-D, 993–996. [Google Scholar] [CrossRef]
- Bevilacqua, A.; Di Stefano, L.; Azzari, P. People tracking using a time-of-flight depth sensor. In Proceedings of the 2006 IEEE International Conference on Video and Signal Based Surveillance, Sydney, Australia, 22–24 November 2006; p. 89. [Google Scholar]
- Stahlschmidt, C.; Gavriilidis, A.; Velten, J.; Kummert, A. People detection and tracking from a top-view position using a Time-of-Flight camera. In Communications in Computer and Information Science, Proceedings of the International Conference on Multimedia Communications, Services and Security, Kraków, Poland, 6–7 June 2013; Dziech, A., Czyazwski, A., Eds.; Springer: Berlin/Heidelberg, Germay, 2013; Volume 368, pp. 213–223. [Google Scholar]
- Jia, L.; Radke, R.J. Using Time-of-Flight measurements for privacy-preserving tracking in a smart room. IEEE Trans. Ind. Inform. 2014, 10, 689–696. [Google Scholar] [CrossRef]
- Cai, Z.; Yu, Z.L.; Liu, H.; Zhang, K. Counting people in crowded scenes by video analyzing. In Proceedings of the 2014 9th IEEE Conference on Industrial Electronics and Applications, Hangzhou, China, 9–11 June 2014; pp. 1841–1845. [Google Scholar]
- Galčík, F.; Gargalík, R. Real-time depth map based people counting. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Poznań, Poland, 28–31 October 2013; pp. 330–341. [Google Scholar]
- Rauter, M. Reliable human detection and tracking in top-view depth images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 529–534. [Google Scholar]
- Del Pizzo, L.; Foggia, P.; Greco, A.; Percannella, G.; Vento, M. Counting people by RGB or depth overhead cameras. Pattern Recognit. Lett. 2016, 81, 41–50. [Google Scholar] [CrossRef]
- Vera, P.; Monjaraz, S.; Salas, J. Counting pedestrians with a zenithal arrangement of depth cameras. Mach. Vis. Appl. 2016, 27, 303–315. [Google Scholar] [CrossRef]
- Luna, C.A.; Losada, C.; Fuentes-Jimenez, D.; Fernandez-Rincon, A.; Mazo, M.; Macias-Guarasa, J. Robust people detection using depth information from an overhead Time-of-Flight camera. Expert Syst. Appl. 2016, 71, 240–256. [Google Scholar] [CrossRef]
- Jimenez, D.; Pizarro, D.; Mazo, M.; Palazuelos, S. Modelling and correction of multipath interference in Time of Flight cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 893–900. [Google Scholar]
- Jimenez, D.; Pizarro, D.; Mazo, M. Single frame correction of motion artifacts in PMD-based Time of Flight cameras. Image Vis. Comput. 2014, 32, 1127–1143. [Google Scholar] [CrossRef]
- He, Y.; Liang, B.; Zou, Y.; He, J.; Yang, J. Depth errors analysis and correction for Time-of-Flight (ToF) cameras. Sensors 2017, 17, 92. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Wong, K.-H. Human tracking and counting using the kinect range sensor based on adaboost and kalman filter. In Proceedings of the International Symposium on Visual Computing, Rethymnon, Greece, 29–31 July 2013; pp. 582–591. [Google Scholar]
- Matzner, S.; Heredia-Langner, A.; Amidan, B.; Boettcher, E.J.; Lochtefeld, D.; Webb, T. Standoff human identification using body shape. In Proceedings of the 2015 IEEE International Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 14–16 April 2015; pp. 1–6. [Google Scholar]
- Bushby, K.M.; Cole, T.; Matthews, J.N.; Goodship, J.A. Centiles for adult head circumference. Arch. Dis. Child. 1992, 67, 1286–1287. [Google Scholar] [CrossRef] [PubMed]
- Seidenari, L.; Varano, V.; Berretti, S.; Del Bimbo, A.; Pala, P. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 479–485. [Google Scholar]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette analysis-based gait recognition for human identification. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Luna, C.A.; Jiménez, J.A.; Pizarro, D.; Losada, C.; Rodriguez, J.M. GPCA vs. PCA in recognition and 3-D localization of ultrasound reflectors. Sensors 2010, 10, 4825–4837. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Rincon, A.; Fuentes-Jimenez, D.; Losada-Gutierrez, C.; Marron-Romera, M.; Luna, C.A.; Macias-Guarasa, J.; Mazo, M. Robust people detection and tracking from an overhead Time-of-Flight camera. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Porto, Portugal, 27 February–1 March 2017; pp. 556–564. [Google Scholar]
- Macias-Guarasa, J.; Losada-Gutierrez, C.; Fuentes-Jimenez, D.; Garcia-Jimenez, R.; Luna, C.A.; Fernandez-Rincon, A.; Mazo, M. GEINTRA Overhead ToF People Detection (GOTPD1) Database. 2016. Available online: http://www.geintra-uah.org/datasets/gotpd1 (accessed on 31 July 2017).
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed]
- Sahani, M.; Nanda, C.; Sahu, A.K.; Pattnaik, B. Web-based online embedded door access control and home security system based on face recognition. In Proceedings of the 2015 International Conference on Circuits, Power and Computing Technologies [ICCPCT], Nagercoil, India, 19–20 March 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training Accessories | Testing Accessories | |||
|---|---|---|---|---|---|
| Caps |  19 × 18, 27 × 18 2 |  18 × 15, 25 × 15 |  18 × 18, 27 × 18 |  20 × 17, 27 × 17 | |
| Large size hats 1 |  16 × 16, 38 × 38, 11 |  18 × 13, 38 × 35, 12 |  14 × 14, 34 × 34, 13 |  18 × 13, 36 × 31,14 |  18 × 13, 35 × 32, 13 |
| Medium size hats |  18 × 13, 29 × 26, 12 |  18 × 12, 32 × 26, 12 |  13 × 13, 24 × 31, 9 |  17 × 13, 32 × 27, 8 |  18 × 13, 32 × 30, 11 |
| Small size hats |  17 × 12, 27 × 23, 11 |  17 × 13, 26 × 24, 13 |  16 × 11, 15 × 20, 10 |  16 × 14, 26 × 23, 9 |  17 × 14, 28 × 24, 13 |
 18 × 15, 28 × 25, 10 |  18 × 13, 27 × 25, 14 | ||||
| #Sequences | #Frames | Level 2 Grouping | Level 1 Grouping | #Grouping1 Frames |
|---|---|---|---|---|
| 14 | 492 | Short hair | no hat/cap | 684 |
| 6 | 192 | Long hair | ||
| 6 | 399 | caps | cap | 399 |
| 3 | 384 | Large size hat | hat | 1064 |
| 6 | 289 | Medium size hat | ||
| 3 | 391 | Small size hat | ||
| 38 | 2147 | 2147 |
| #Sequences (T0 + T1) | #Frames (T0 + T1) | Level 2 Grouping | Level 1 Grouping | #Group1 Frames (T0 + T1) |
|---|---|---|---|---|
| 17 + 16 = 33 | 678 + 460 = 1138 | no hat/cap | no hat/cap | 678 + 460 = 1138 |
| 34 + 37 = 71 | 1369 + 752 = 2121 | cap | cap | 1369 + 752 = 2121 |
| 31 + 37 = 68 | 1205 + 1320 = 2525 | Large size hat | hats | 4442 + 4708 = 9150 |
| 48 + 38 = 96 | 2563 + 1829 = 4392 | Medium size hat | ||
| 34 + 49 = 83 | 674 + 1559 = 2233 | Small size hat | ||
| 164 + 177 = 351 | 6489 + 5920 = 12,409 | 6489 + 5920 = 12,409 |
| Type | Large Hat | Medium Hat | Small Hat | Cap | No Hat/Cap | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| large hat | 93.74% | ±0.94% | 6.14% | ±0.94% | 0.12% | ±0.13% | 0.00% | ±0.00% | 0.00% | ±0.00% |
| medium hat | 14.73% | ±1.05% | 69.49% | ±1.36% | 12.68% | ±0.98% | 0.00% | ±0.00% | 3.10% | ±0.51% |
| small hat | 0.00% | ±0.00% | 0.63% | ±0.33% | 82.98% | ±1.56% | 9.85% | ±1.24% | 6.54% | ±1.03% |
| cap | 0.00% | ±0.00% | 0.00% | ±0.00% | 6.69% | ±1.06% | 81.19% | ±1.66% | 12.12% | ±1.39% |
| no hat/cap | 0.00% | 0.00% | 0.00% | ±0.00% | 0.09% | ±0.17% | 4.31% | ±1.18% | 95.61% | ±1.19% |
| Type | #Frames | Hat | Cap | No Hat/Cap | |||
|---|---|---|---|---|---|---|---|
| hat | 9150 | 94.51% | ±0.47% | 2.40% | ±0.31% | 3.08% | ±0.35% |
| cap | 2121 | 6.69% | ±1.06% | 81.19% | ±1.66% | 12.12% | ±1.39% |
| no hat/cap | 1138 | 0.09% | ±0.17% | 4.31% | ±1.18% | 95.61% | ±1.19% |
| Frames | 12,409 | ||||||
| Type | #Frames | Hat/Cap | No Hat/Cap | ||
|---|---|---|---|---|---|
| hat/cap | 11,271 | 95.22% | ±0.39% | 4.78% | ±0.39% |
| no hat/cap | 1138 | 4.39% | ±1.19% | 95.61% | ±1.19% |
| #Frames | 12,409 | ||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luna, C.A.; Macias-Guarasa, J.; Losada-Gutierrez, C.; Marron-Romera, M.; Mazo, M.; Luengo-Sanchez, S.; Macho-Pedroso, R. Headgear Accessories Classification Using an Overhead Depth Sensor. Sensors 2017, 17, 1845. https://doi.org/10.3390/s17081845
Luna CA, Macias-Guarasa J, Losada-Gutierrez C, Marron-Romera M, Mazo M, Luengo-Sanchez S, Macho-Pedroso R. Headgear Accessories Classification Using an Overhead Depth Sensor. Sensors. 2017; 17(8):1845. https://doi.org/10.3390/s17081845
Chicago/Turabian StyleLuna, Carlos A., Javier Macias-Guarasa, Cristina Losada-Gutierrez, Marta Marron-Romera, Manuel Mazo, Sara Luengo-Sanchez, and Roberto Macho-Pedroso. 2017. "Headgear Accessories Classification Using an Overhead Depth Sensor" Sensors 17, no. 8: 1845. https://doi.org/10.3390/s17081845
APA StyleLuna, C. A., Macias-Guarasa, J., Losada-Gutierrez, C., Marron-Romera, M., Mazo, M., Luengo-Sanchez, S., & Macho-Pedroso, R. (2017). Headgear Accessories Classification Using an Overhead Depth Sensor. Sensors, 17(8), 1845. https://doi.org/10.3390/s17081845