1. Introduction
The problem of surface fitting appears repetitively in computer aided design, cultural relic representation, reverse engineering, object shape detection and many other fields during the last 20 years or so. Its essence is to build a mathematical model that approximates the object as accurately as possible from measured information. At present, 3D coordinate measuring systems are the main sources of the measured data in these fields [
1,
2], so finish surface fitting from data acquired from 3D coordinate measuring systems is significant. For now, among all these measuring systems, 3D coordinate measuring machines (CMMs) are representative and mature products which have gained widespread acceptance for their advantages of high accuracy [
3]. Besides traditional CMMs, portable 3D vision coordinate measurement machines (PCMMs) such as laser or white light scanners [
4,
5] and portable light pen 3D vision coordinate measuring systems [
6,
7], were developed in recent years in order to meet the needs of large-scale on the spot engineering metrology. Generally, the distribution of the measured data acquired from traditional CMMs and the most recently developed PCMMs are neither gridded nor completely scattered [
8]. Typically, the data points are scanning points successively sampled from iso-parametric or section curves on a surface, which makes them easily organized into rows [
1,
2]. In order to describe it clearly, we name this kind of data quasi-scattered data to distinguish it from grid data and completely scattered data in [
8].
Figure 1 is a simple sketch and it shows the difference between these three kinds of data. Grid data can easily be organized into rows and columns, and the number of points in each row and column is the same. Quasi-scattered data is scattered in space, but the points are stored according to the order of measurement, so they can easily be organized into rows, but the number of points in each row is different. Completely scattered data has no specific storage order and the points are randomly distributed. In this paper, we only assume that the initial input information is a (possibly massive) set of quasi-scattered 3D points, a typical output obtained from most of the above devices.
According to the final representation of the fitted surface, the existing related researches can be divided into three categories: fitting methods based on polygonal mesh model [
9,
10,
11,
12,
13]; fitting methods based on constructive solid geometry (CSG) model [
14]; fitting methods based on free-form parametric surface models [
15,
16,
17,
18,
19,
20,
21,
22]. Non-uniform rational B-spline (NURBS) surface, inheriting all the advantages of B-spline surface, is the most common free-form parametric surface. Most importantly, with the advantages of flexibility and versatility, it provides a good choice for a wide variety of compact and smooth shapes [
23,
24,
25,
26,
27], so NURBS surface is adopted in this paper.
The problem of NURBS surface fitting from 3D points has been analyzed from several points of view, and for grid data, there are many efficient methods, such as the works related in [
19,
21,
24,
25,
28,
29]. But for scattered data (both quasi-scattered data and completely scattered data), the fitting problem becomes much more difficult because of the limitation that the control points in NURBS surface modeling technique should be organized as a regular grid structure [
30]. In [
18], a method based on a hierarchical fitting idea is proposed, however, the merged knot vector may make the method face the problem of node redundancy, especially when the number of data points is large and the point distributions of different rows vary a lot. In [
28,
31] scattered data points are projected to base surfaces to do parameterization according to parameters of the projected points. This kind of methods are useful only when data points can be projected in an unambiguous way [
23]. In [
30] patch partitioning and polyhedral approximation are adopted to get an organized quadrilateral mesh used as the input of NURBS fitting, however the pre-processing is time consuming and the continuity between different quadrilateral patches is hard to guarantee. In [
24] a method combining a hybrid optimization algorithm and iterative scheme (HOAAI) is proposed, which converges rapidly in grid data surface fitting with high accuracy, and when used for scattered data fitting, pre-processing work also need to be done for its strong constraints on the parametrization approach. In order to solve the problem of surface fitting from scattered 3D data, a simulated annealing algorithm [
32] and some evolutionary intelligence techniques [
23,
33,
34] were introduced to enhance the robustness. However, these methods are hard to handle. When the measured object is complex or the data size is large, it is not easy to ensure practicability. Under these circumstances, these methods may become low-efficiency because the introduced artificial intelligence techniques are somewhat time-consuming. In [
35,
36], feature sensitive parameterization is conducted for point-clouds organized in the form of triangulated meshes. They use constant knot vector and allocate more parameter space to area of interest, which results in more control points in the corresponding area. In [
35], a kind of area preserving parameterization, stretch minimizing parameterization, is conducted on the image manifold of the original surface. However, the computation of image manifold is not easy and stretch minimizing parameterization requires solving a large non-linear optimization problem, which needs expensive computation. In [
36], a hybrid method that combines harmonic mapping and elastic spring is adopted to generate initial parameterization, followed by an adaptive re-parameterization procedure based on relaxation field to refine fitting result. Compared with [
35], it requires less computational cost, but the result is not as good geometrically.
In theory, the abovementioned methods provided for completely scattered data fitting are also an available choice for our problem, with no regard to their defects as stated above. If the quasi-scattered data is treated as completely scattered to finish the fitting problem, existing valuable information of measurement order is ignored and extra work must be done for the input data arranging [
24,
37,
38] or initial parameterization [
24,
28,
32,
33,
34]. For quasi-scattered data which can be easily triangulated, the methods described in [
35,
36] are applicable. However, the parameterization for quasi-scattered data doesn’t have to be so complicated, because they have already been organized into rows, which is a more efficient structure to manipulate. For now, there is no efficient and general method that can be applied to finish the problem of NURBS surface fitting from quasi-scattered data which appears frequently in reverse engineering applications (see, e.g., [
1,
2,
18]). In this paper, a new method based on resampling, hierarchical fitting and iterative projection is put forward to reconstruct a general NURBS surface from quasi-scattered 3D data. As is known, point projection and data parameterization are two essential problems when iterative projection idea is used for surface fitting. In the provided method, the projection result provides optimized result for subsequent parameterization, and in return the search space of point projection is pointed out accurately by previous parameterization result of the latest iteration. By this way, these two problems are merged together. The main contribution of this paper is that resampling is introduced in surface fitting of quasi-scattered data and a new resampling approach, which makes use of parameterization information of curve fitting and changes of curvature, is proposed. The whole method provided for quasi-scattered data fitting has the advantages of a simple principle, fast computational speed, wide application, and therefore has great utilization value. This paper is structured as follows: the basic definitions, principles and related pervious work for NURBS fitting are introduced in
Section 2. Detailed descriptions of the proposed method are provided in
Section 3, including the process of the iterative projection optimization scheme, and the implementation of resampling.
Section 4 conducts a series of numerical experiments. Finally, discussions and conclusions are provided in
Section 5.
3. New Method of Surface Fitting from Scattered Data Points
As described in the introduction, for quasi-scattered data, a set of 3D points can be regarded as the measured data of a surface , where is the number of data points in the ith row, and for any , does not have to be equal to . Assuming that points in the same row are captured from approximate iso-parametric or section curves, and each of these approximate lines never intersects with the others. Under this assumption, if curve is the curve fitting from points , and with fitting error ignored, it must be a part of S and will not intersect with other fitting curves, so in order to overcome the problem resulting from the randomness of point numbers in each row, a new method is given here: (1) first fits the points in row by row with NURBS curves, (2) resamples on the resulting curves , and ensure equivalent number of points in each row, and (3) constructs a NURBS surface based on the resampled data . Considering that no local modification is used in the proposed method, uniform weights are applied in both curve fitting and surface fitting, and for convenience of calculation, all weights are set equal to constant 1.
In the first and third part of this method, an iterative projection optimization idea is used, and it is not novel in NURBS object fitting. For example, in reference [
24], a method based on iterative projection optimization is proposed, and it is outstanding in existing methods for its high accuracy and convergence speed when it comes to grid data. In [
17], an error term called squared distance minimization (SDM) is introduced for planar curve fitting. It is defined by a curvature-based quadratic approximant of squared distances from data points to a fitting curve. A method based on this error term converges with fewer iterations comparing with methods based on point distance, but for space curves, the description of error term SDM may become too complicated. However, the curve fitted from measured points in one row of quasi-scattered data is generally a space curve, especially when the measured data is acquired by portable 3D coordinate measurement machines, so to be more general, point distance, which is widely used in practice for parametric curve and surface fitting, is selected in this paper.
In our method, new algorithms based on iterative projection optimization are given for NURBS curve and surface fitting, in which problems of data parameterization and point projection are merged together to reduce the time cost. A new resample approach which makes use of parameterization information of curve fitting and changes of curvature is proposed, which makes our method has advantages in accuracy and efficiency especially for surface fitting from quasi scattered data. The flowchart of this method is shown in
Figure 3, and concrete algorithms and implementing procedures of three major parts: NURBS curve fitting, resampling and NURBS surface fitting are introduced separately in detail in
Section 3.1,
Section 3.2 and
Section 3.3.
3.1. NURBS Curve Fitting in Our Method
As can be seen in
Figure 3, in order to construct a NURBS surface from quasi-scattered data
, a set of NURBS curves must be obtained which accurately reflect the characteristics of measured object. In this part iterative projection optimization idea is used for its obvious advantages in simplicity and generality. The curve fitting for data points in each row is an iterative process where an initial fitting curve is firstly achieved in accordance with the thought provided in
Section 2.2 and then followed by an iterative refinement based on projection. For the calculation of projection point, Newton iteration principle is used because with a good start value, it converges rapidly and stability. During one iteration of this algorithm, every
is projected onto the output of last iteration with its parameterization result in last iteration as the initial value of projection, and subsequently, reparameterize the data points based on the distribution of their corresponding projection points. With the given definitions of relevant symbols,
| , data points in lth row of the given data |
| The maximum number of iteration |
| The given fitting precision |
| Curve degree |
| The number of control points |
| , parameterization result in kth iteration |
| The knot vector in kth iteration |
| , control points in kth iteration |
| The resulting curve of kth iteration |
| The resulting parameter of point projection from point to curve |
| The average distance from any point in to its projection point on |
| The final fitting curve corresponding to |
The detail process of curve fitting for
is as follows Algorithm 1:
| Algorithm 1 |
(initial curve fitting) Do parameterization for by Equation (5), save the result as Determine the knot vector based on by Equation (6). Calculate control points according to Equations (7) and (8) with parameterization result and knot vector . Obtain the curve based on and . for do Do point projection from point to curve : let be the start value of Newton iteration, calculate the projection parameter following the way presented in Section 2.3.1. end for Calculate the average distance if do end the algorithm Update parameterization result by projection result: Determine from updated by Equation (6) Calculate control points according to Eq. (7)-(8) with and , and gain the curve for do Do point projection from point to curve by the presented way in Section 2.3.1 to get , and in this projection step is the start value of Newton iteration. end for Calculate the average distance . if or do end the algorithm go back to step 13
|
In the
kth iteration of the iterative projection optimization procedure, projection parameters gained from the (
k − 1)th iteration are used to modify the previous parameterization in order to optimize the fitted curve. The projection point is calculated using Newton iteration approach presented in
Section 2.3.1, with previous parameterization result used as the initial value. For example, in
Figure 4,
is the fitted curve of the (
k − 1)th iteration,
is the corresponding parameterization result of point
, when do point projection from
to
, parameter
is used as the initial value, and the resulting projection parameter is
. In the
kth iteration, projection parameter
is used to update the parameterization, after which corresponding parameter of point
is modified to
, and the fitted curve is updated to
. When projecting
to
,
becomes the initial value.
The time complexity of the algorithm is . Calculation of projection takes up the largest part of time cost. The authors sampled a row of 4000 data points from the model in example 1, and fit them using this algorithm. For every iteration when k > 0, more than 90% time is spent on the computation of projection. In this algorithm, parameterization result provides a good initial value for the calculation of projection point which makes Newton iteration method reach optimal projection result quickly. For the whole process, the maximum iteration number is enough for most issues.
3.2. The Resample Approach in Our Method
In this paper, resampling is applied and it plays an important role in our method, because based on it the input quasi-scattered data can be converted into grid data. It is significant for the fitting accuracy and time cost of the whole method.
Today some well-known sampling approaches are usually uniform sampling, patch size based sampling, curvature-based sampling, the equal arc length sampling and the equal parameter sampling [
43,
44,
45]. Uniform sampling first generates a straight line with sample nodes uniformly distributed on it, and then projects these nodes to the curve to get final sample points. It is not recommended when the curve is complex. Patch size-based sampling [
43,
44] divides the object into a set of ordinal units based on the knot vector. These units are ranked based on their own geometry sizes and points are distributed according to this ranking. That is, unit of the higher rank contains the more sample points, in which case, some important information in unit of very lower rank might be ignored. In curvature-based sampling, the sampling object is divided into independent units and for each unit the most critical points are first selected depending on its maximum and minimum curvature. Then more sample points are added to each unit based on the whole distribution of overall critical points, and the curvature variation can be reflected accurately by the resulting points. The equal arc length sampling, which adjusts the sampling density automatically from the curve slope, is also sensitive to curvature change. The equal parameter sampling, distributing sample points equally in parameter domain, is usually a nice choice when sample on parameter model with nonsignificant curvature changes.
As
Figure 3 shows, in order to reconstruct a surface from a given set of quasi-scattered data
, NURBS curves are obtained, and resampling is carried out on each of the resulting curves. During the process of resampling, three problems should be taken into consideration: (1) the number of sampling points is unknown, (2) guarantee that the number of resampled points in each row is the same, and (3) the resampled data should reflect the shape of surface without distortion. As mentioned above, if we just consider the first and the second problem, equal parameter sampling technique is enough and simple to realize. However, when the surface is complex in curvature, the resampling becomes troublesome through existing sample approaches.
Here a new resampling algorithm is given based on the parameterization result of curve fitting and changes of curvature. The basic idea is to sample more points in the area that curvature of curve changes rapidly and to sample less points in the area that the curve is gentle. The number of resampling points is set to be a little larger than the maximum number of original data points in each row. By this way, the resampling points not only preserve the information of original data completely but also include some important shape information acquired from the fitting curve. If the number is too large, additional resampling error may be introduced.
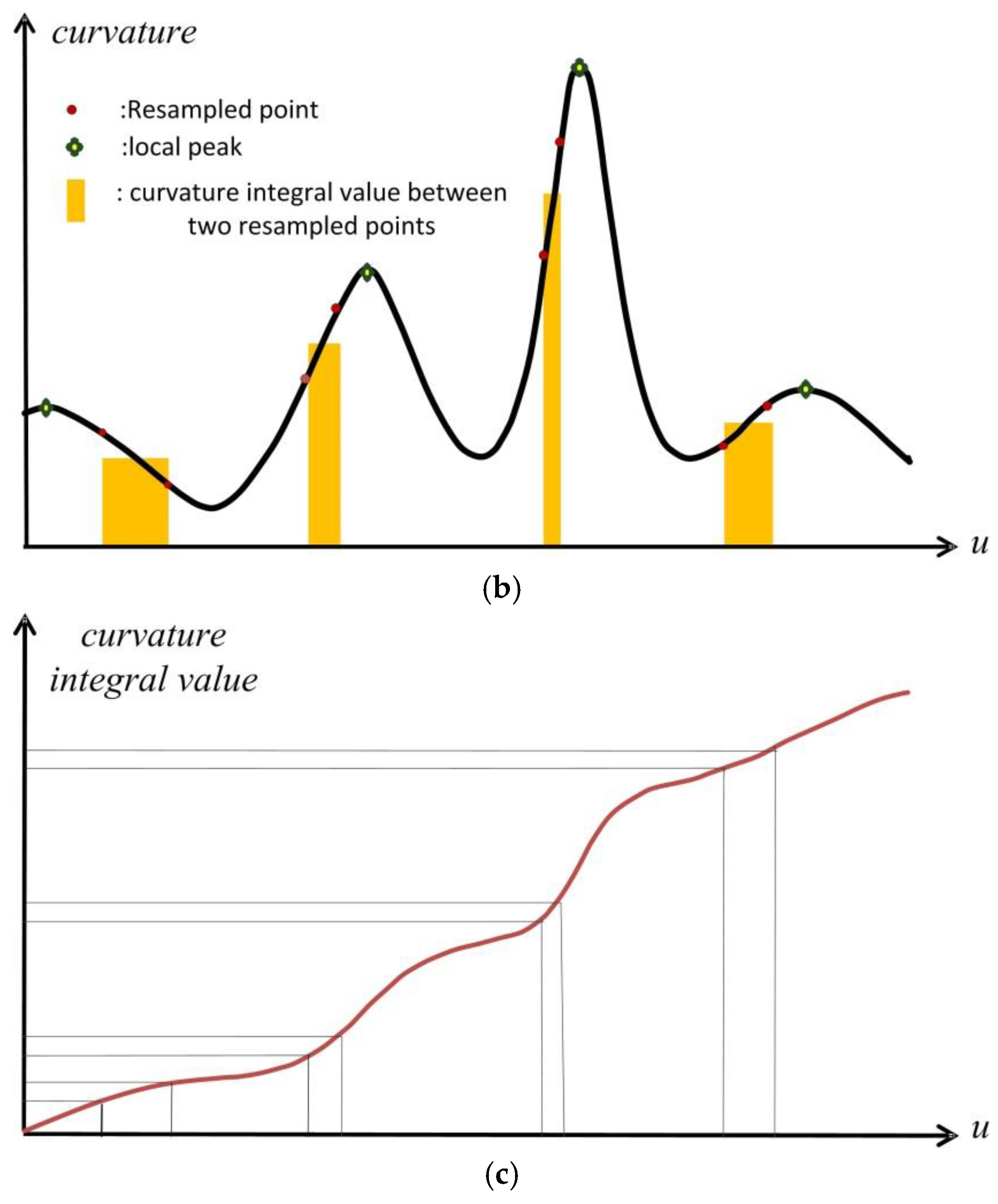
In our method, resampling is conducted on the curve fitted from each row of the measured data. When resampling on the parameter curve, the curvature variation with respect to the parameter should be gained first. In this paper, we add three more parameters between every two parameters in parameterization result, and calculate the curvature at both parameterization result and the added ones to get the curvature variation. For the reason that NURBS curve is a kind of spline curve, which means it is piecewise and segmented by knot vector, the calculated curvature has slight fluctuation in each segment. Therefore, GLPF (Gaussian low-pass filter) is adopted to smooth the curvature plot, and the parameters that achieve local maximum are saved as local peaks.
Calculate the curvature integral value between any two adjacent parameters. For two adjacent parameters and , is used as the approximate curvature integral value. Because the parameterization in initial curve fitting is based on chord-length, the geometric meaning of the curvature integral is that it is approximately proportional to the angle that the tangent vectors have rotated from parameter to . Adding the results together, we gain the whole integral value.
Next the whole integral value is divided into r parts (where r + 1 is the pre-set number of resampling point) equally, and the resulting unit controls the distribution of resampling points. That is, the curvature integral value between any two adjacent resampled parameters should be equal. By this way, it is guaranteed that there are more resampled points in the highly curved regions.
Figure 5 gives a clear explanation of the above process.
Figure 5a–d are respectively the measured data using equal parameter sampling technique, the curvature variation after GLPF, the curvature integral value, and the resample result using the provided algorithm.
When resampling on the curves
, definitions of the relevant symbols in resample are given as follows:
| The parameterization result of points in the row after curve fitting |
| The pre-set number of points resampled from each fitted curve |
| Save all the resampling points from curves , |
| Parameter corresponding to sampling point in the curve |
| Save parameters of all sampling points of curve |
The specific process of resampling is given as below Algorithm 2:
| Algorithm 2 |
for do for add parameters , , into end for Save both parameterization result and the added parameters in array A Calculate curvature at every parameter of array A Use Gaussian low-pass filter to smooth the result in step 6, and save parameters where curvature achieves local maximums (local peak) in array B Calculate the curvature integral value between any two adjacent elements in A, and gain the whole integral value. Divide the whole integral value into parts equally, denote as for Calculate the parameter where curvature integral is , and save it as the jth resampled parameter end for for if exists in do use to replace one of , the one nearer to is replaced end if end for Calculate point on at parameters in , and save the result in . end for
|
With only consideration of the preservation of geometric properties, curvature-based sampling and the equal arc length sampling are all good choices, but it is extremely difficult for them to guarantee the number equality of resampled points for each row. The proposed algorithm overcomes this problem and keeps the advantage of curvature-based sampling.
In this algorithm, parameterization result and its subdivided result (the added parameters in step 3) are used together to get the change of curvature. It is reasonable, because distribution information of the measured data is reserved in the parameterization result.
Curvature integral value in this algorithm is approximate to the included angle of tangent vectors. When resampling based on the unit integral value , for any two contiguous resampled points the included angle of tangent vectors almost keeps the same. The resulting points can reflect the curvature change of the curve and proposed algorithm keeps the advantage of curvature-based sampling. The time complexity of the algorithm is .
3.3. NURBS Surface Fitting in Our Method
In this section, the detailed algorithm of NURBS surface fitting from the resampled data
is given. In this algorithm hierarchical fitting idea, provided in
Section 2.2, is applied. The whole framework is an iterative projection optimization process. As is known, when iteration projection idea is applied, in order to improve the fitting accuracy and arithmetic speed, advisable parameterization result and high-quality start value of point projection are especially important, in our method they are ensured by fusing point projection and data parameterization into each other during iteration with the same way as
Section 3.1. Given the definitions of the relevant symbols:
| The maximum number of iteration |
| The given fitting precision |
| Surface degree in u-direction and v-direction respectively |
| , parameterization result in kth iteration |
| The u-direction knot vector in kth iteration |
| control points of u-direction in kth iteration |
| v-direction parameterization result in kth iteration |
| The v-direction knot vector in kth iteration |
| , v-direction control points in kth iteration |
| The resulting NURBS surface of kth iteration |
| The resulting parameter of point projection from to |
| The average distance from any point in to its projection point on |
| The final fitting surface corresponding to |
The details of this algorithm are as shown in the following Algorithm 3:
| Algorithm 3 |
begin iteration k = 0 while (not termination condition) do for do Do parameterization for points in lth line by Equation (5), save the result in denoted as . end for Do average operation on : . Determine the knot vector following Equation (6) with . for do Do curve approximation for points in lth line following Equations (7) and (8), and save resulting control points in , denoted as . end for for do Do parameterization for by Equation (5) and save the result in . end for Determine the knot vector based on the same as that in u-direction. For do Do curve approximation for points following the way in u-direction fitting, and get control points . end for Gain surface based on , and . for for do Do point projection from point to surface to get by the way presented in Section 2.3.2 with being the start value. end for end for Calculate the average distance . if and do , update with projection result, go back to step 7 else if or do end if end while end iteration
|
In this algorithm, the hierarchical fitting idea and iterative projection optimization are combined with each other, and during the iteration process, every point is projected onto the output of last iteration with its parameterization result in last iteration as the initial value of projection, and subsequently, re-parameterize the data points based on the distribution of their corresponding projection points. In our method uniform weights are used in the fitting process. Let N be the whole number of data points, the time complexity of this algorithm is . In iterative projection methods the calculation of point projection is the most time-consuming part, while in this algorithm, the parameterization result of last iteration provides a suitable stat value with which the projection point is reached quickly by Newton method.
4. Experiment
In order to prove the validity of the proposed method, its performance has been tested on both simulation data and real-measured data. Some test results and a comparison with other previous methods are shown in this section, and a discussion about the factors that influence the fitting result is also presented in this chapter.
4.1. Illustrative Experiment
In this section, we do experiment on six different examples: three test problems from [
24] (examples 3–5) and other three surfaces (examples 1, 2, 6). For each of example, a collection of grid data points is first fitted, and then the proposed method in
Figure 3 is tested on a set of quasi scattered points. Results including fitting error, computation time, and information about final fitted surface are provided.
Example 1. A quadric surface. This surface is given by the following equation: In this example, method for grid data fitting is tested on a collection of
data points, and a (4, 4) order fitting surface with
control points is obtained in 2.3 min, for which the average fitting error is
and the maximum error is
. We chose 97,612 points randomly from the grid data, test the proposed method in
Figure 2 on the resulting data, and a (4, 4) order NURBS surface of
control points is achieved in 3.1 min with an average fitting error of
, a maximum fitting error of
.
Figure 6 presents the randomly chosen data and its fitting surface.
Example 2. A hat surface. This surface is given as follows: In this example, a set of
data points is fitted with a (4, 4) order NURBS surface with
control points first. The average and maximum fitting error are
and
respectively, and the time cost is 1.7 min. For a collection of 53,367 scattered points chosen from the grid data, a (4, 4) order NURBS surface is obtained using the proposed method, with an average error of
and a maximum error of
in 2.4 min. The randomly chosen data and its corresponding fitting surface are displayed in
Figure 7.
Example 3. A shell surface. This parametric surface is given as follows: For this shell surface, grid data of
points is fitted, and a (4, 4) order NURBS surface is obtained in 87 s with an average error of
. We conduct our method provided in
Figure 3 on 2102 scattered points, chosen randomly from the grid one, and a (4, 4) order NURBS surface with
control points is accepted as the final result after 2.1 min, with the average error and the maximum error of
and
, respectively.
Figure 8 shows the distribution of the randomly chosen points and the corresponding fitting surface.
Example 4. A posit surface. This posit surface is given in parametric form as follows:where A = 0.655866, B = 1.03002, C = 0.74878, D = 1.40772, E = 0.868837, F = 2.43773, G = 0.495098, H = 0.377696. For this non-zero genus surface, method for grid data is applied on a set of
grid points, and the proposed method is carried out on 8725 points chosen randomly from the grid data. For the former one, the average error, the maximum error and the time cost are
,
and 3.8 min successively. And for the scattered data, an average error of
is obtained in 5.2 min, where a (4, 4) order NURBS surface with
control points is accepted as the final resulting surface, the maximum error of which is
.
Figure 9 provides the randomly chosen data and the fitted surface.
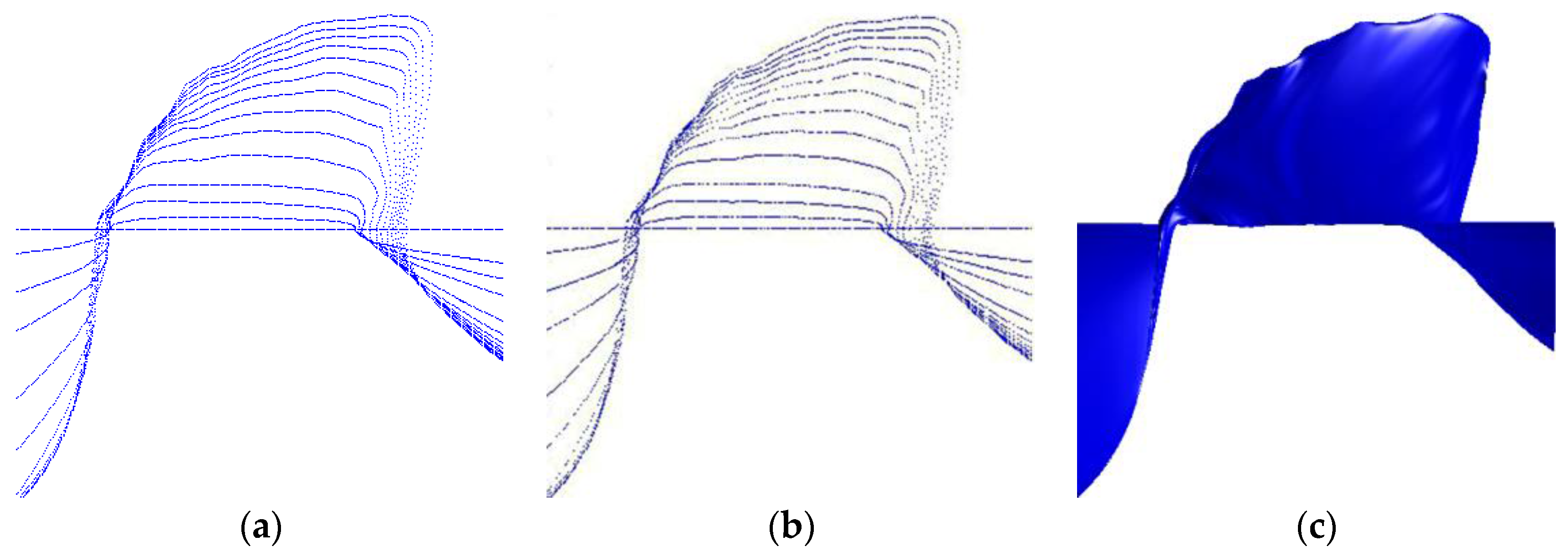
Example 5. A pump surface. For the convenience of comparison, here the real measured data points provided in [24] is adopted. It is a grid data with 14 rows and the point number of every row is 370. Every data point is consisted of three variables: rotation speed, flow and moment, measured from the Mashan Pumped Storage Power Station in China [24], and the problem is to construct a model surface which reflects the concrete mathematical relations of the three variables. For this original data, method in [24] can reach a fitting accuracy of in 1.3 min. Then for every row, we reject a part of points randomly and get a set of 4800 scattered data, from which a (5, 4) order NURBS fitted surface with control points is achieved in 1.8 min by the proposed method, where the average error is and the maximum error is . Figure 10 presents the original data, the randomly chosen data and the fitting surface. Example 6. A blade surface. In this example, data points are measured from a blade of aircraft engine by an in-situ automatic measuring machine system [46]. The left picture of Figure 11 is the scene photo (The inner room is the machining center). When the machining of one blade of the blisk is finished, the measuring machine rotates into the machining center to do measurement of the machined blade just like what is shown in right picture of Figure 11. The applied measuring probe is RSP2 probe, and it is installed on the Renscan5TM probe body. The maximum permissible error value of REVO system is no more than 1 μm, and the uncertainty of the whole measuring system is less than (10 + L/30) μm (where L is the length value of the measured object, L: mm). The measuring machine system consists of six relative motion parts, as a result, six coordinate systems from the tip center to the machine zero position are established based on the quasi-rigid-body model for building the machine coordinate system. The workpiece coordinate system is established based on the center circle of the blisk and the locating hole, as shown in the right picture of the
Figure 11. The center of the circle is used as the original point of the coordinate system. The Z-axis of the coordinate system is determined by the line that connects the centers of the circle and the locating hole. The Y-axis is determined by the vertical axis of the center circle, and then X-axis is determined by the cross product of Y-axis and Z-axis.
Twenty one sections of the blade are determined before the measuring process firstly. Because the twist angle of the blade is as much as 64° and the space between two adjacent blades is so small, one blade is divided into two surfaces (the upper surface and the lower surface). For every surface, do the measurement following these determined sections one by one. The data that used is quasi scattered data consisting of 21 rows. The maximum number of data points in a row is 118 and the minimum is 97. The whole data number is 2255. By the proposed method, a (4, 4) order NURBS surface of
control points is fitted in 17 s with an average fitting error of
, a maximum fitting error of
.
Figure 12 presents the data and its fitting surface.
According to the above fitting results, our method performs well for scattered data chosen randomly from grid data, and the fitting results of these scattered data and grid data are in the same level with regard to both fitting error and time cost. For all experiments, the computations in this paper have been performed on a PC equipped with a core processor operating at 2.7 GHz with 2 GB of RAM. Calculation of projection takes up the dominant part of time cost. The source code has been implemented in VC++, while the resulting pictures are constructed in Matlab with the obtained control points, knot vectors, and the orders.
4.2. Comparison with Other Approaches
As stated, the proposed fitting method by curvature based resampling presents a good performance for surface fitting of problems analyzed above. Compared with other methods presented in the literature, it outstands when the fitting data is scattered, especially in terms of time cost. In order to support this claim, here we do a careful comparison with five other methods found in literature [
8,
18,
23,
24,
33].
Table 1 shows the comparison results, including the average fitting error and the time cost.
The method given by Ma in [
8], projects points to a base surface created from approximate boundary points or curves to do parameterization. However, it works properly only for simple surface with no self-intersecting, and hard to get a high fitting accuracy. As shown in the comparison results, it has no advantage on time cost and fitting accuracy when used for quasi scattered data fitting.
In [
18], the rows are approximated independently of one another, and new knots are added into the knot vector during the curve fitting, then the merged knot vector is used for the fitting of the next row. This make the method face the problem of nodes redundancy. And in practice, it is often happens especially when the number of data points is large and the point distributions of different rows change a lot.
Methods in [
23], given by Gálvez, based on particle swarm optimization, can achieve perfect accuracy for examples 1–5, but its complexity and computational time are too hard to handle. Compared with it, our method has a great advantage on time cost.
For the same quasi scattered points of examples 1–5, methods provided in [
24,
33] all report reasonable fitting accuracy at the same level with ours, but they all lose the competition on time expenditure.
To summarize, when used for quasi scattered data fitting, our method reaches enough accuracy with the lowest time cost compared with previous fitting approach.
4.3. Robustness
In order to test the robustness of the proposed method, we conduct the method on several data with varying degrees of scatterness acquired from examples 1 and 5. In example 1, model surface is presented in the implicit form of , while if we let , it changes to an equivalent parametric form . To describe the experiment process on example 1 clearly, row-spacing, u-section line, v-interval, u-fluctuation and additional error introduced by resampling are introduced, and the special meanings of them are given as follows:
u-section line: Points in such a section line which have the same coordinate in u direction.
row-spacing: For two adjacent u-section lines, coordinate difference in u direction is row-spacing. If a set of section lines distribute uniformly, row-spacing is a constant value, otherwise it varies in a certain range.
v-interval and
u-fluctuation: When sampling along a
u-section line, coordinate difference in
v direction of two adjacent sample points is
v-interval and the distance in u direction from a data point to the section line is
u-fluctuation. If
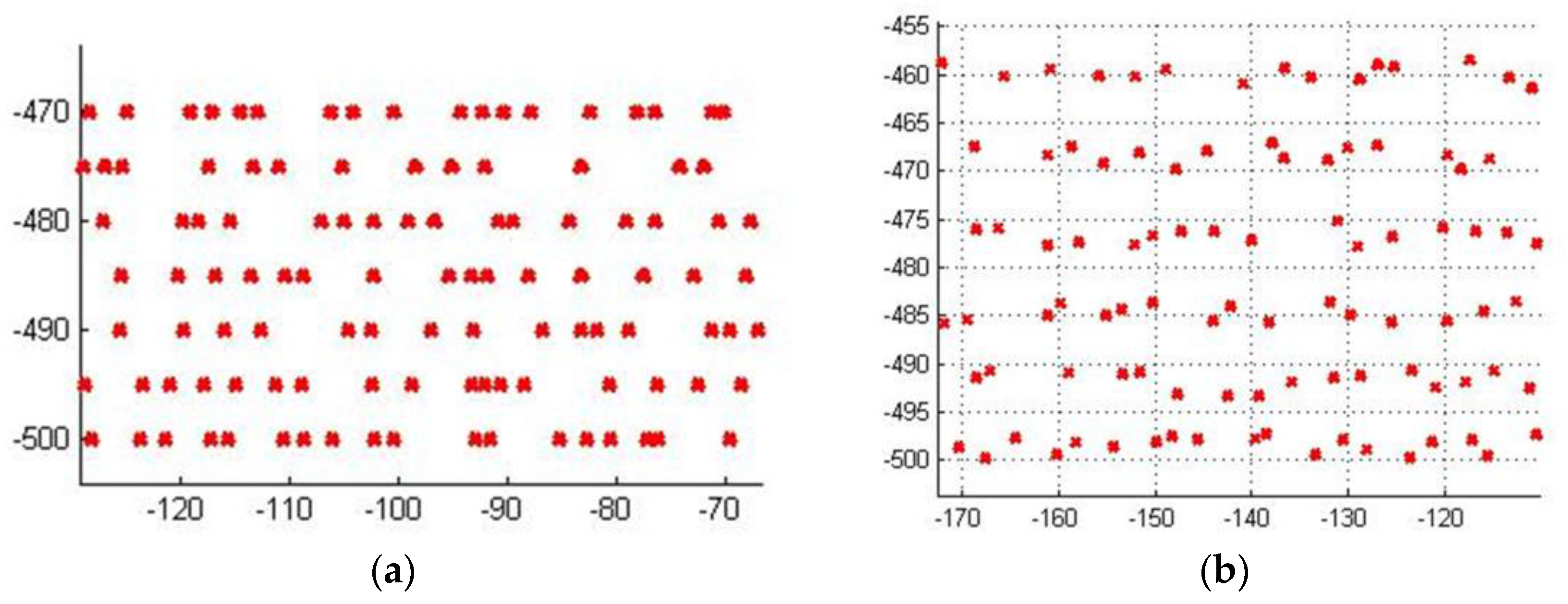
u-fluctuation is equal to zero anywhere, the sampling data points distribute as shown in
Figure 13a, otherwise as shown in
Figure 13b which is more similar to real measured data.
additional error introduced by resampling: If the average distance between measured data and the final fitting surface is denoted as called the average fitting error, and that between resampled data and is denoted as then the absolute difference is the additional error introduced by resampling.
After multiple tests on example 1, results of 12 representative experiments are listed in
Table 2.
Figure 14 gives the distribution of data points corresponding to the 11th experiment this table. In this table,
v-interval, row-spacing, and
u-fluctuation are used together to represent the scatterness of data distribution, the average error and additional error introduced by resampling are listed as the fitting results.
In example 5, the real measured data provided in [
24] is adopted as the original measured data. For this data, method in [
24] can reach a fitting accuracy of
. Here, several sets of scattered data points are acquired on the basis of the measured data. That is, each data point of the original measured data is reserved or rejected by random gating sampling, and the number of points in each row of the resulting data varies in a range randomly. Experiments are conducted on both the original measured data and the resulting scattered data to verify the robustness.
Table 3 lists experimental results of the original measured data and four sets of resulting scattered data.
By comparing the different experimental results in
Table 2, we know that the fitting precision of our method has inverse relation to the
u-fluctuation and the row-spacing. Resample is brought in to implement data transformation in our method, in order to quantify its impaction on final fitting precision, additional error brought by resample (AER) is calculated in
Table 2. And as shown in the results, it is always zero when sampling along sections strictly (the
u-fluctuation is zero), in which case resample of course has no impact on fitting precision but this is not likely to happen in actual measurement. In general, it is not zero but small enough to be ignored compared with average fitting error (AFE).
For the real-measured data points, the fitting accuracy of method provided in [
24] based on iterative projection optimization is
and our method can reach a fitting accuracy of
in few seconds, what’s more, the fitting accuracy of our method nearly unchanged after removing some of the data points randomly as listed in
Table 3, which illustrates the robustness against data missing and demonstrates that our method can be better applied in surface fitting of real-measured quasi-scattered points.
In order to test the performance in circumstance that there are areas with densely packed rows and areas with large distance between individual rows, we set rowing-spacing to be different value in different parts of the surface in example 2. When areas with densely packed rows (rowing-spacing is set to be 0.5~1) exist in the central part () where curvature change highly and areas with large distance (rowing-spacing is controlled between 10~12.5) exist in the part that the curve change gently (), the average fitting error is . While when the areas with large distance exist in the central part, the average fitting error is . So it is the distribution of measured data not the distribution of rows that affect the final fitting result.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}