1. Introduction
The quality of tobacco is affected highly by the cultivation environment, such as the temperature, rainfall, soil and so on. Generally, tobaccos from the same region usually have the similar characteristic and fragrance style. Meanwhile, cigarettes are ranked according to the fragrance styles and the retail price is set accordingly. However, tobacco leaves from different regions may be blended together during the acquisition and shipping process intentionally or unintentionally, which makes inspection difficult before being put into production. As the manual identification of the growing region is not reliable and cannot meet the requirement, an automatic and intelligent identification approach for the tobacco growing regions is highly desirable.
With the development of spectral sensor technology, the application of the near-infrared (NIR) sensor has been widely used in many fields [
1,
2,
3,
4,
5,
6]. The spectra obtained from the NIR sensor have the potential to extract corresponding feature information for the samples. In recent years, the NIR spectral sensor technology has developed quickly as a powerful analytical method in the tobacco industry and proven its effectiveness for both qualitative and quantitative analyses due to having the characteristics of rapidity, simplicity and non-destructive measurements [
7,
8,
9], especially when it is applied to tobacco classification problems [
8,
10,
11,
12].
A lot of research works have been conducted on the classification of tobacco cultivation regions with different algorithms using near-infrared (NIR) sensors. Zhu, Gong, Li, and Yu [
13] identified the cultivation regions of tobacco with the high dimensional feature grouping method, which means they sorted all NIR spectra features according to importance scores of the features from small to large and then divided them into twelve groups, and they made the feature selection to get the optimal feature subset with different feature groups by calculating the error rate. Zhang, He, and Ye [
14] proposed the least square support vector machines (LS-SVM) to determine the tobacco producing area using the NIR sensor with the wavelength range from 1101 to 2395 nm. In their research, 4 to 12 principal components (PCs) were examined separately as the inputs of LS-SVM models and results showed that the model with 12 PCs obtained the larger correlation coefficient and smaller root mean square error. Maha Hana, McClure, Whitaker, White, and Bahler [
15] employed artificial neural networks (ANNs) with 19 points of the NIR spectra based on the multiple sensors to classify whether the burley tobacco grows in the USA or outside the USA, and obtained high prediction accuracy. Ni et al. [
10] applied improved and simplified K-nearest neighbors classification algorithm (IS-KNN) to discriminate the cultivation areas of more than 1000 Chinese flue-cured tobacco leaf samples based on the spectral sensors and they used one original method to optimize the number of significant PCs based oil analysis of error and cross-validation. It can be observed from the above studies that selecting PCs for most models is just according to the scores of the PCs.
Support vector machine (SVM), firstly proposed by Vapnik, has been proven to be a powerful technique for pattern recognition, classification, and regression in many fields [
16,
17,
18,
19,
20,
21,
22,
23]. It has attracted a lot of attention due to its remarkable advantages: (1) effective in high dimensional spaces; (2) suitable for small samples set; (3) reasonable mathematic support; and (4) efficient perform as a non-linear classifier. In recent decades, SVM has been applied widely and successfully in solving classification problems, such as recognizing bowel sound [
24], classifying vegetable pests [
25], identifying alcohol consumption [
26]. There are also some applications of SVM in the tobacco industry, such as classifying fragrant styles and evaluating the aromatic quality of flue-cured tobacco leaves [
27], classifying the producing year of tobacco [
12] and tobacco leaf grades [
28]. In our early study on discrimination of tobacco growing regions based on NIR data, it was found that the SVM model is a suitable classifier [
29].
In this study, the genetic algorithm (GA) was introduced to improve the performance of the SVM classifier. Principal component analysis (PCA) was used to extract the features from the de-noised NIR sensor data of tobacco and obtained principal components (PCs) corresponding to the score range from small to large. The first 25 PCs from PCA was chosen as the original inputs of the SVM model, and a set of the trial number of PCs from the 25 ones was examined on training to find out the most proper number of PCs for a model establishment. The input subsets with those corresponding number of PCs were tried on evaluating the performance of the SVM model and compared how many PCs can optimize the SVM classifier to the maximum extent. During the process of selecting PCs in different input subsets, GA was proposed to find the most effective PCs for the corresponding input subsets. In order to prove the availability of the proposed approach, the selection of parameters and kernel function for the SVM model were discussed in details for performance improvement. The experimental results were explained clearly with the evaluation parameters by figures and tables. This paper is based on the previous work in Reference [
30].
2. Materials and Methods
The framework of this study is shown in
Figure 1. Firstly, the Savitzky–Golay (SG) de-noising method was applied to eliminate the noise in the NIR spectra data, and PCA technology was used to extract the main features and compress the dimension of de-noised NIR spectral sensor data. Then, all dataset was divided into the training set (80%) and testing set (20%) randomly, and the former was used for optimal feature selection by GA to get the optimal input subset for establishing the SVM classifier. After that, the testing set was used for testing the performance of the SVM model.
2.1. Tobacco Database
A total of 332 tobacco samples were collected from four different regions in Guizhou Province by the Guizhou Tobacco Science Research Institute of China. Due to the suitable climate and soil condition in the local regions, tobacco cultivation is very popular there. However, it is very hard to discriminate the tobaccos from the regions. The number of tobacco samples collected from the four regions is given in
Table 1. The NIR spectra of the 332 samples were recorded with Thermo Antaris 2 with multiple sensors (Thermo Fisher Scientific Inc., Waltham, MA, USA). The spectra are with the resolution of 8 cm
−1 and 64 scans. The NIR range is from 3499 cm
−1 to 12,000 cm
−1, which is shown in
Figure 2. It shows that there are significant fluctuations from 3500 cm
−1 nm to 7000 cm
−1 and the spectra have peaks at 4004 cm
−1, 4313 cm
−1, 4727 cm
−1, and 5163 cm
−1, which are frequency doubling and sum-frequency absorption of hydrogen containing groups such as C–H, O–H, N–H, and S–H. Generally, the near-infrared band of sum frequency is located between 4000 cm
−1 and 5000 cm
−1, while the first order harmonic and second harmonic are ranged from 5556 cm
−1 to 7143 cm
−1, and the third and fourth or higher harmonic focus on the band between 11,111 cm
−1 and 12,800 cm
−1.
2.2. De-Noising for the Raw Spectra of the Samples
The NIR spectra gathered with the NIR sensor are high-dimensional. The value of absorbance is recorded at total 2084 points, so the dimension of the samples is 2084 in this study. As the spectra carry the internal information of the atomic bond of the molecule, it is very effective to do the qualitative and quantitative analysis for them.
However, unexpected noise from the NIR spectral sensor data and human operation will be introduced during the NIR sensor data acquisition. The noise may degrade the signal to noise ratio (SNR) and affect the model performance, so de-noising raw NIR spectral sensor data is very significant in the model establishment.
The SG filter is applied for the raw NIR data to eliminate the noise in the NIR spectral sensor data. The principle of the de-noising lies in replacing the contaminated NIR data with the average value that calculated from the contaminated data. A quadratic polynomial is adopted and the size of the sliding window is set to 121 in this study.
2.3. Outlier Identification and Feature Extraction
In this study, Mahalanobis distance was used to detect the outliers. The average values of all the spectra of the samples were firstly calculated and used to build an average spectrum. Then the Mahalanobis distance between each spectrum and the average spectrum was calculated, and was made as the outlier measurement of each spectrum. The spectrum with Mahalanobis distance from the average spectrum bigger than the threshold would be considered as one outlier. All the outliers were eliminated.
PCA is one of the most popular approaches to extract features from high dimensional data. It was applied for the de-noised NIR spectral sensor data with SG smoothing method. In order to keep as much information as possible, the full spectral range of the raw data from 12,000 cm
−1 to 3499 cm
−1 was adopted. There were total 2084 data points in each tobacco NIR spectrum, which tends to over-fitting easily due to the high dimension, so PCA was applied to extract the main features from the de-noised NIR spectral sensor data, which is also called reducing dimension. Each data firstly had the mean value of the corresponding columns subtracted and the covariance matrix of the new dataset was calculated. The eigenvalues and eigenvectors matrix can be calculated from the covariance matrix and the PCs from the PCA are ranked according to the value of the eigenvalues from large to small, so the PCs in the eigenvectors with larger eigenvalues contained more useful information or energy of the dataset. The number of the principal components is very significant, as too much noise and other redundant information will be carried into the data if it is too big but useful information will be lost if it is too small. Generally, a certain number of PCs are chosen simply from front to back, which means the selection is just according to the value of their eigenvalues, however, although such PCs carry the most useful information of the data, some of them may be not effective for the model to be built. In this study, the top 25 PCs from PCA algorithm were extracted as the original input for the model, as they almost occupied 100% of the information of the data, which was shown in
Figure 3.
It is very important to select the number of the PCs, since too many PCs may contain too much noise and too few PCs may lose the useful information. In this study, a series trial number of PCs (6, 8, 10, 12, 14, 16) from the 25 PCs were combined to be different input subsets for the model establishment and the most suitable input subset was selected based on the prediction accuracy of the SVM model.
2.4. Genetic Algorithm Optimized Support Vector Machine Approach
In order to feed the more effective features into the SVM model, GA was proposed to select the most model-effective PCs for the corresponding input subsets. The detailed procedure of the GA-SVM is shown in
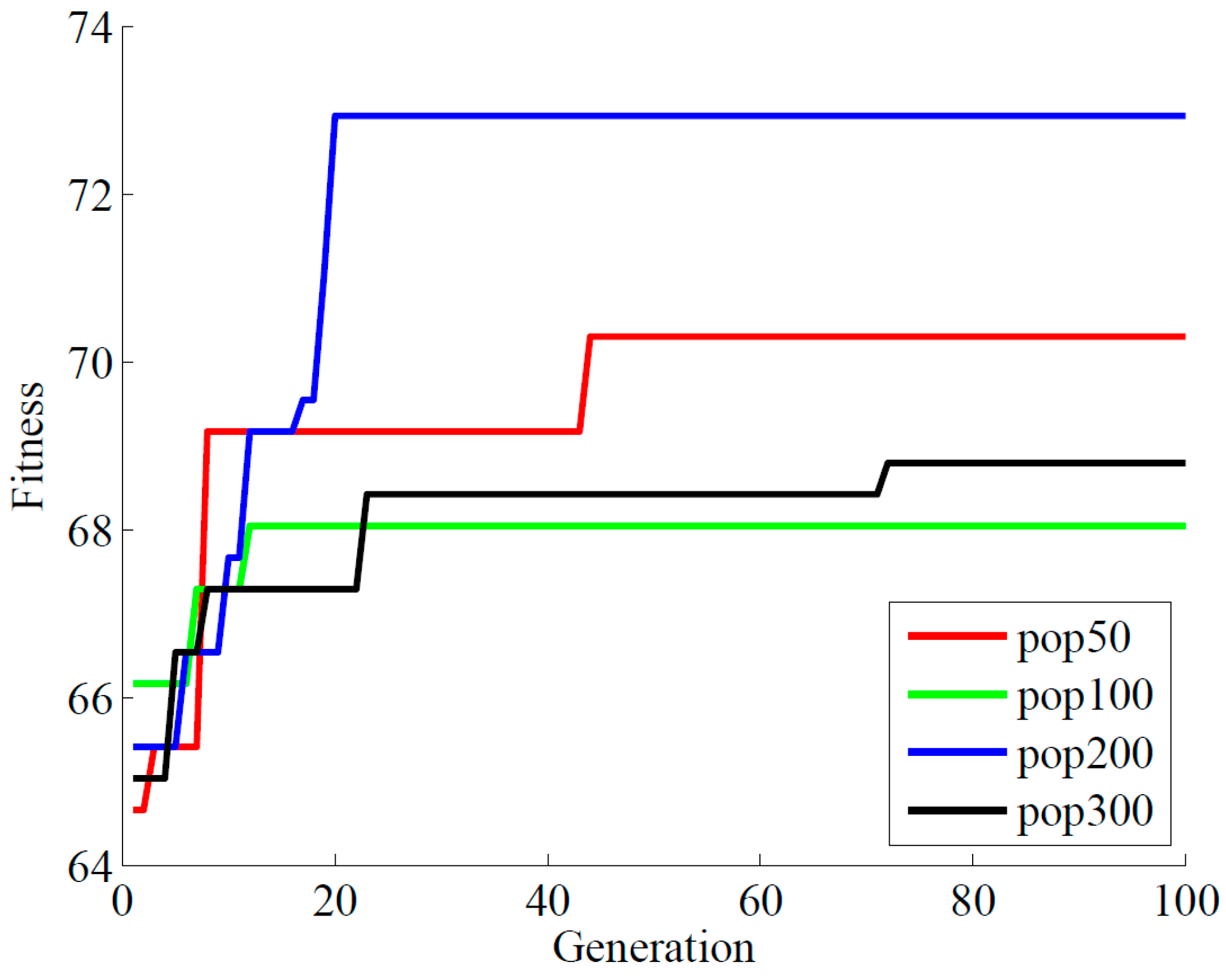
Figure 4. Firstly, the population initialization is set randomly in the first 25 PCs from the PCA algorithm. Then the optimal feature selection with GA is followed as shown in the dashed part. The prediction accuracy of the SVM classifier is used for measurement of the fitness value for each individual. The fitness value biased roulette method is used to select the suitable parents. The input subset with a larger fitness value is more likely to be selected as parents. All parents carry more effective genetic information for the SVM model. Parents are mated randomly and reproduction carries on here. Crossover and mutation, as the two main genetic operations, are functioned to produce the offspring and boost the new population. One-point crossover and uniform mutation are adopted in this study. After several generations, genes with a higher fitness value are passed on and inherited. The evolution continues until meeting the termination criteria. Finally, the optimal input subset with the best fitness is selected for the SVM classifier.
2.5. Support Vector Machine Algorithm
Although the SVM was originally designed for binary pattern recognition problems, it has been extended to solve multi-class problems. Given (
) is a set of samples,
is the vector of NIR spectral sensor data, and
= {−1,1}, which is in the case of two classes, and the linear decision hyperplane is given as
where
is the weight vector and
b is the bias, and
is the inner product operator. The separating hyperplane is
and the corresponding classifier is set to be sign of
. The Euclidean distance between any
to the separating hyperplane is given by
where
is the L2 norm. The maximize margin between
and
is equal to minimize
. In order to improve the capacity of the model, a slack variable
ε is introduced to boost the tolerance of the distance.
The goal of the classification is to find the optimal separating hyperplane (OSH) which is equal to solve the following quadratic equation,
where
i is the sample number,
C is the penalty constant,
is the slack variable. The
w and
b can be searched by solving the following equation with Lagrange multipliers method,
where
K(
) is the kernel function and plays a significant role in the SVM model. Normally, there are four kernel functions: Linear function, polynomial function, radial basis function (RBF) and sigmoid function [
30]. In this study, RBF was selected as the kernel function, and its function is given as,
Although the basic SVM is applicable to two classes, the method of SVM for multi-classification is to adopt the idea of the decision tree. It starts from the root node, divides the category contained by the node into two subclasses, and then further divides the two subclasses, and so on, until only one class is included in the subclasses. Thus one inverted binary tree is obtained in this way and the SVM classifier is trained on each decision node of binary tree to classify the samples with multi-classes.
2.6. Model Evaluation
The prediction accuracy is the significant parameter to evaluate the overall performance in the classification of the tobacco cultivation region and it is defined as
where
is the number of samples predicted rightly and
is the number of samples for prediction. In this study,
is set to be 266 and 66 in the training and testing stages, respectively.
One two-by-two confusion matrix showed in
Table 2 supports the evaluation criteria for the models. As shown in
Table 2,
n means the number of samples, and the parameters are defined according to the styles of the given label and the predicted label, where
is the number of positive samples that are labeled as positive,
is the number of negative samples labeled as negative,
is the number of positive samples labeled as negative, and
is the number of negative samples labeled as positive [
30]. The functions of the evaluation criteria are given as
where
is sensitivity rate, which is a measure of the ability to detect the positive patterns;
is specificity rate, which is means the ability to specify the negative patterns;
is the precision rate, which represents the ability to predict the positive patterns; and
is F1-score, which considers both the precision and sensitivity of the test.
4. Conclusions
In order to investigate the effective PCs from PCA for the tobacco cultivation-region classification, in this study the first 25 PCs from PCA were firstly chosen as the original input, and six input subsets with different number of PCs (6, 8, 10, 12, 14, 16) from the 25 ones were then examined for the SVM model. The genetic algorithm was proposed to select the most effective PCs for the corresponding input subsets. The setting parameters of GA were discussed in detail to find the most suitable GA parameters. A series of experiments were conducted with and without the GA. Interestingly it was found that the more effective PCs may not be the PCs that have more information in general. Comparative studies show that the SVM classifier with the optimal PCs selected by GA has a superior performance with the SVM classifier with same number of PCs from the first component. The results demonstrated the tobacco cultivation region classifier relied on the sensitivity of the PCs but not the information they possess from the raw tobacco NIR spectral sensor data, and the GA is a feasible method for feature selection in classification problems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}