1. Introduction
The Internet of Things (IoT) is a domain that represents the next most exciting technological revolution since the Internet. IoT will bring endless opportunities and impact every corner of our planet. In the healthcare domain, IoT promises to bring personalized health tracking and monitoring ever closer to the consumers. This phenomenon is evidenced in a recent Wall Street Journal article entitled “Staying Connected is Crucial to Staying Healthy” (WSJ, June 29, 2015). Modern smartphones and related devices now contain more sensors than ever before. Data from sensors can be collected more easily and more accurately. In 2014, it is estimated that 46 million people are using IoT-based health and fitness applications. Currently, the predominant IoT-based health applications are in sports and fitness. However, disease management or preventive care health applications are becoming more prevalent. The urgency for investment in health monitoring IoT technology is also echoed by a recent Wall Street Journal article (July 21, 2018) entitled “United States is Running Out of CareGivers”. By 2020, there will be 56 million people aged 65 and above as compared with 40 million in 2010. In [
1], a system called VitalRadio is reported to be able to monitor health metrics such as breathing, heart rate, walking patterns, gait, and emotional state of a person from a distance. Recently, there is a surge in the number of the real-time preventive care applications such as those for detecting falls in elderly patients due to the aging population [
2]. Previous work in fall detection required specialized hardware and software which is expensive to maintain. In [
3], the authors reviewed 57 projects that used wearable devices to detect falls in elderly. However, only 7.1% of the projects reported testing their models in a real-world setting. The same paper also pointed out that a wearable wristwatch for fall detection has the added benefit of being non-intrusive and not incurring any additional injuries during a fall. Indeed, the main challenge for fall detection is the ability to create a highly accurate detection model that can run on unobtrusive and inexpensive devices. Sensors attached to the torso of the monitored subject have shown the ability to achieve higher detection accuracy; however, often in real life the elderly refuse to wear such sensors both for practical and psychological reasons.
We investigated both traditional (Support Vector Machine and Naive Bayes) and non-traditional (Deep Learning) machine learning techniques for the creation of fall models using three different datasets. Two of the datasets were collected by our team using a Microsoft Band 2 smartwatch [
4], and a Notch [
5] sensor. The dataset contains different simulated fall events and activities of daily living (ADLs) performed by a group of volunteer test subjects. The third dataset contains data coming from the Farseeing real-world fall repository [
6]. The Smartwatch dataset is clearly needed since we are using a smartwatch device. Knowing the performance of our model on this dataset helps with the creation of a model that can be used in real life. The Farseeing dataset was the only one containing real falls from elderly people. While this dataset is not collected using smartwatch devices, it is still useful to compare how the Deep Learning model performs and compares against the traditional models. Evaluation of the models on Farseeing also helps to gain the insight on how the models deal with activity data that would realistically be seen with elderly people. The Notch dataset contains a much wider variety of ADLs collected by a wrist-mounted Notch sensor. Performance metrics for this dataset gives us a better idea of how the models perform and compare on a more complex wrist dataset. Notch also allows for a more precise labeling mechanism. Using the application provided to record Notch data, a user can visualize the data after it is recorded and set labels where falls happened at specific times. This helps examine the possibility that the model is being restricted by inaccurate labeling on the other two datasets. More information about each dataset is provided in
Section 4.1.
In both the offline and online/real-time tests, Naive Bayes (NB) achieved a higher recall as compared with Support Vector Machine (SVM) under the traditional machine learning technique across the three datasets. Among the two traditional models, SVM is better in classifying ADLs, but it misses many critical falls. To the best of our knowledge, this is the first effort to conduct an in-depth study on using the Deep Learning (Deep) model, a non-traditional machine learning technique for fall detection using a wrist-worn watch. Our results show that a Deep Learning model for fall detection generally outperforms more traditional models across the three datasets.
As noted in the literature, a significant danger with falling in elderly adults is the inability to get up after the fall, which is reported to occur in 30% of the time. Currently, there are around eight million adults aged 65 and over that use medical alert systems like LifeLine, Medical Guardian and Life Alert [
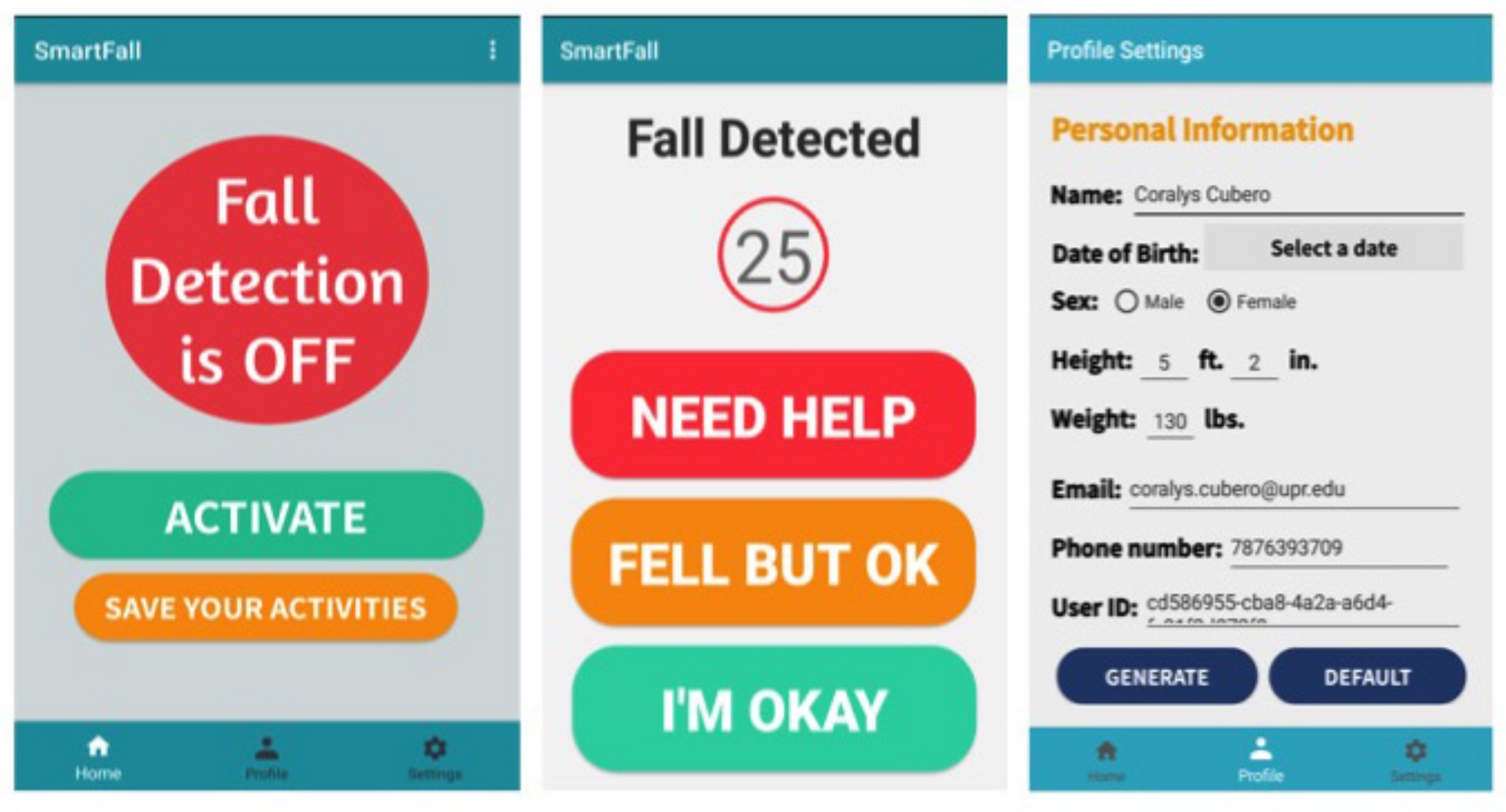
7]. The average cost of using such a system is 25 dollars per month. Our system is developed as an open source project and SmartFall will be offered as a free app. Another major problem in using these medical alert system is that, there is the danger that the person might not be conscious to press the Life Alert’s emergency button after a bad fall. With our SmartFall system, the detection of the fall in real time and the ability of sending a text message and a GPS location to a trusted family member, friend, or call 911 in real time ensure a better survival or improved care for the subject after a fall. The main contributions of the paper are:
An in-depth study of both traditional and non-traditional machine learning algorithms for fall detection on three different fall datasets.
A demonstration that the fall detection model trained using deep learning has better accuracy than models trained using either SVM or NB in predicting falls based on live wrist-worn acceleration data tested in both offline and online/real-time experiments.
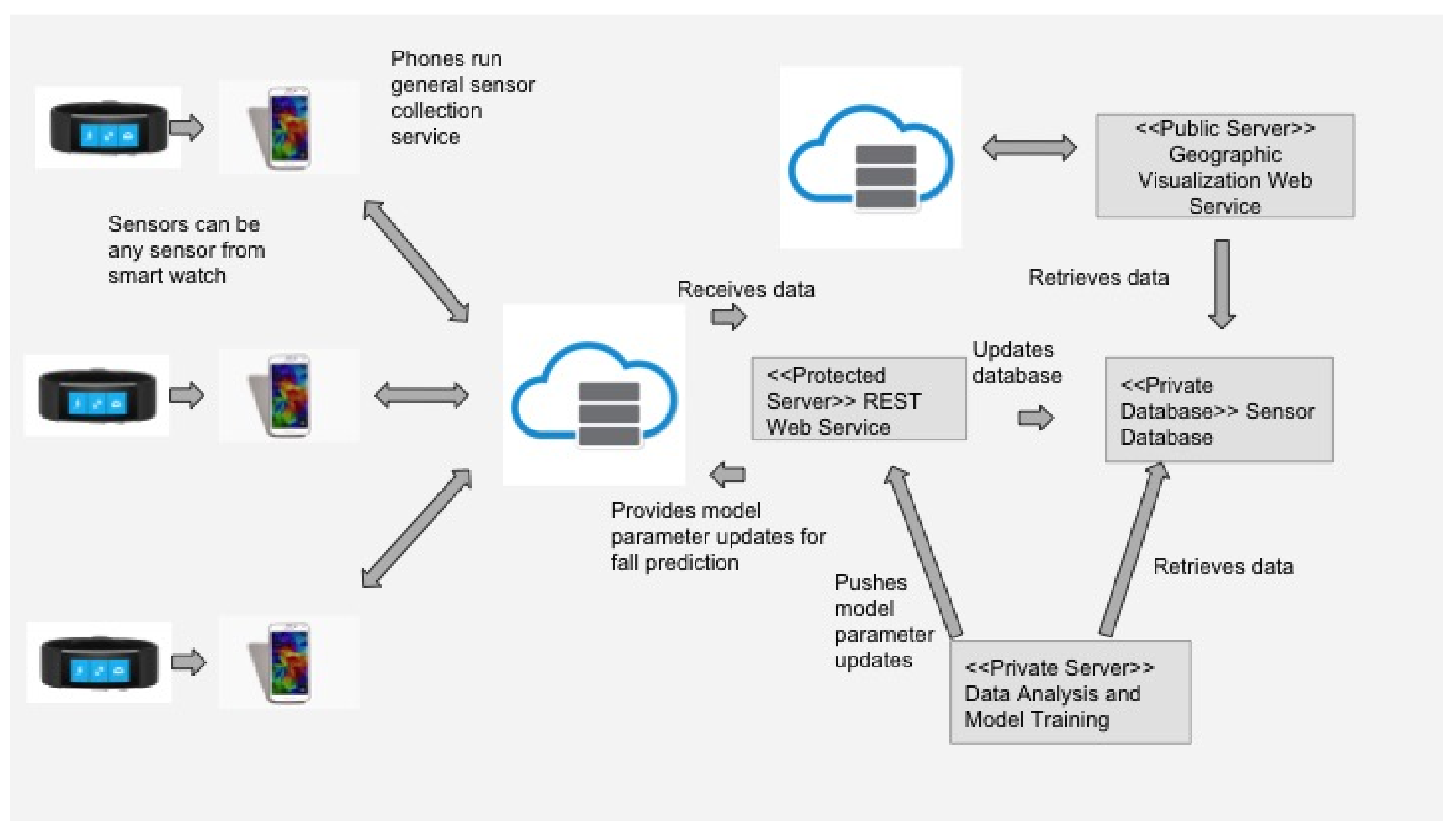
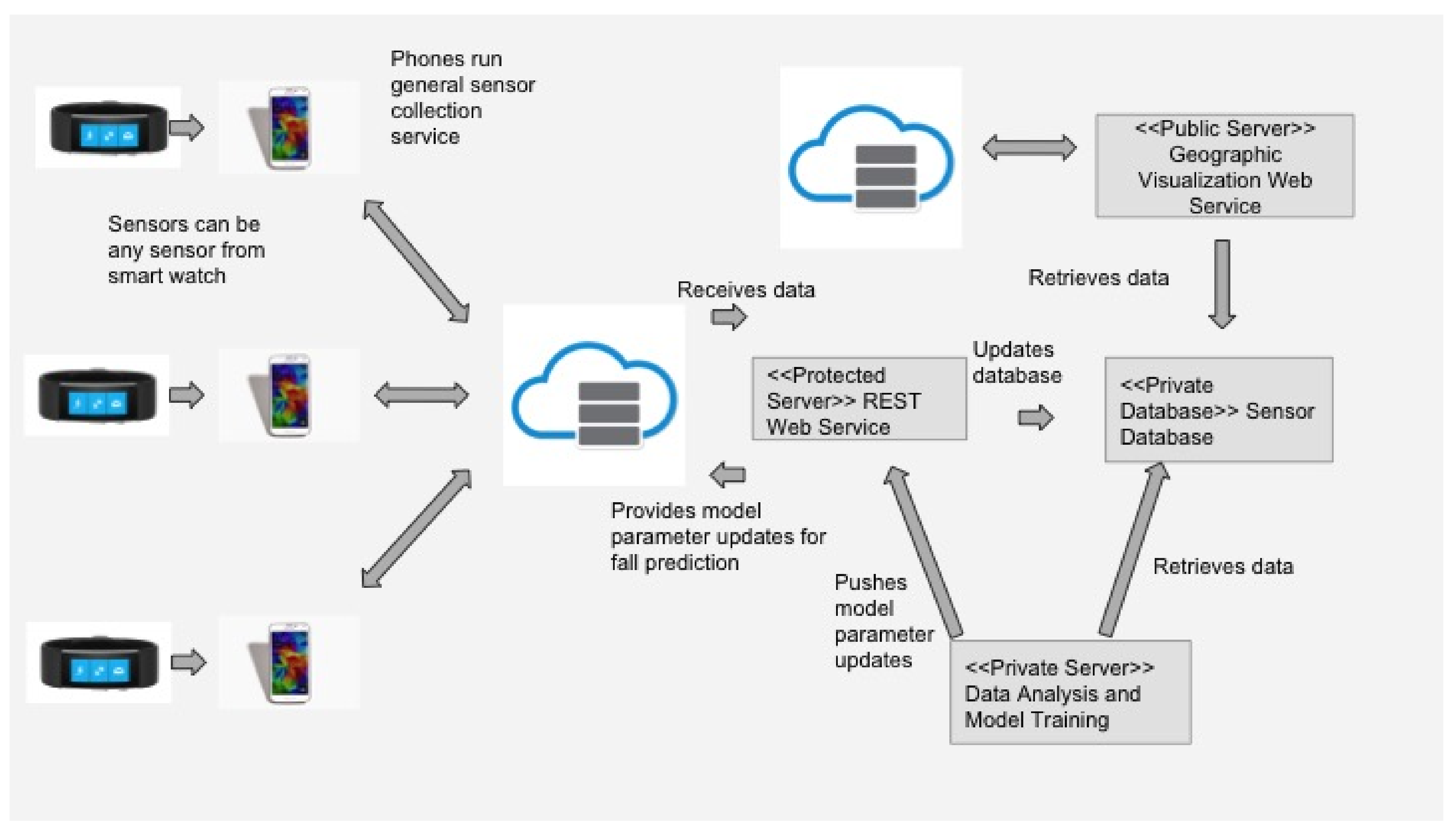
A three-layer open IoT system architecture and a real-time fall detection app that is privacy preserving and has an intuitive user interface (UI) for use by the elderly.
The remainder of this paper is organized as follows. In
Section 2, we review the existing work on fall detection and emphasize on research works that specifically address fall detection using wearable devices. In
Section 3, we provide a detailed description of the system architecture of our fall detection framework and the design of the UI. In
Section 4, we describe the three fall datasets we used for fall detection and present our fall detection methods. In
Section 5, we present the evaluation of the SVM, NB and Deep Learning models in both online and offline experiments, and finally in
Section 6, we present our conclusion and future work.
2. Related Work
The World Health Organization (WHO) reported that 28–35% of people aged 65 and above fall each year. This rate increases to 32–42% for those over 70 years of age. Thus, a great deal of research has been conducted on fall detection and prevention. The early works in this area were concentrated on specially built hardware that a person could wear or installed in a specific facility. The fall detection devices in general try to detect a change in body orientation from upright to lying that occurs immediately after a large negative acceleration to signal a fall. Those early wearable devices are not well-accepted by elderly people because of their obtrusiveness and limited mobility. However, modern smartphones and related devices now contain more sensors than ever before. Data from those devices can be collected more easily and more accurately with the increase in the computing power of those devices. Smartphones are also widespread and widely used daily by people of all ages. There is thus a dramatic increase in the research on smartphone-based fall detection and prevention in the last few years. This is highlighted in the survey paper [
8]. The smartphone-based fall detection solutions in general collect accelerometer, gyroscope and magnetometer data for fall detection. Among the collected sensor data, the accelerometer is the most widely used. The collected sensor data were analyzed using two broad types of algorithms. The first is the threshold-based algorithm which is less complex and requires less computation power. The second is the machine learning-based fall detection solutions. We will review both type of works below.
A threshold-based algorithm using a trunk-mounted bi-axial gyroscope sensor is described in [
9]. Ten young healthy male subjects performed simulated falls and the bi-axial gyroscope signals were recorded during each simulated fall. Each subject performed three identical sets of 8 different falls. Eight elderly persons were also recruited to perform ADLs that could be mistaken for falls such as sitting down, standing up, walking, getting in and out of the car, lying down and standing up from bed. The paper showed that by setting three thresholds that relate to the resultant angular velocity, angular acceleration, and change in trunk angle signals, a 100% specificity was obtained. However, there was no discussion on the practicality of attaching a trunk-mounted sensor on a person for a prolonged period. The restriction on the mobility of people and the privacy issue of data storage were not discussed as well. There is also research work utilizing a thresholding technique set to only detect falls resulting in acceleration greater than 6 G (Gravity). While this will work very well for “hard” falls, we find that many of our falls were far below 6 G, producing around 3.5 G. A wrist-mounted device may encounter even smaller acceleration than 3.5 G if the subject does not use their hands to stop their fall. This type of fall is of special importance because an injury is more likely as the fall was not “caught” by the faller’s hands. This is one of the reasons machine learning approaches are considered more robust than thresholding techniques. Even though in controlled conditions thresholding techniques may appear to be superior, they often do not perform well on anomalous data, such as falls that only reach a maximum force of 3.5 G.
A promising use of machine learning algorithms is recently presented by Guirry in [
10] for classifying ADLs with 93.45% accuracy using SVM and 94.6% accuracy using C4.5 decision trees. These ADLs include: running, walking, going up and down stairs, sitting and standing up. Their setup includes a Samsung Nexus Galaxy smartphone and the Motorola MOTOACTV smartwatch. Data were collected from the accelerometer, magnetometer, gyroscope, barometer, GPS, and light sensors. They synthesized a total of 21 features from all the sensors. They did not specifically address the fall detection problem.
The SVM learning algorithm has also been used for fall detection by other scholars in [
11]. These scholars used a trunk-mounted tri-axial sensor (a specialized hardware) to collect data. They were able to achieve 99.14% accuracy with four features using only high-pass and low-pass accelerometer data. They used a 0.1 s sliding window to record minimum and maximum directional acceleration in that time period for a feature. We drew inspiration from this approach as it allowed us to access temporal data within each sampling point rather than having to choose a generalized feature for the whole duration which might not reflect a true fall. Other work in fall detection has focused on using multiple sensors attached to the subject. For instance, sensors can be placed on the lapel, trunk, ankle, pocket, and wrist. These systems typically show marvelous results of 100% accuracy but lack convenience, portability, and are more computationally intense for a smartphone due to more data being collected and processed.
In [
12], a fall detection system architecture using multiple sensors with four traditional machine learning algorithms (SVM, NB, Decision Tree and KNN) was studied. The paper is the first to propose using ANOVA analysis to evaluate the statistical significant of differences observed by varying the number of sensors and the choice of a particular machine learning algorithm. The main conclusion from this paper is that sensors placed close to the gravity center of the human body (i.e., chest and waist) are the most effective. A similar paper in [
13] conducted a study on the effect of the sensor location on the accuracy of fall detection. They experimented with six different traditional machine learning algorithms including dynamic time warping and artificial neural network. They showed that 99.96% sensitivity can be achieved with a waist sensor location using the KNN algorithm. Our work is focused on using a wrist-worn watch as the only sensor and thus cannot leverage these research results on other sensor locations.
A recent paper [
14] on fall detection using on-wrist wearable accelerometer data concluded that threshold-based fall detection system is a promising direction because of the above 90% accuracy in fall detection with the added bonus of reduced computation cost. We disagree with this because the dynamic of fall cannot be captured in any rule-based or threshold-based system. The paper also pointed out the lack of real-world validation of majority of fall detection systems which we want to address in this paper.
There has also been some work on using Recurrent Neural Networks (RNNs) to detect falls; however, to our knowledge, no such work uses accelerometer data collected by a smartwatch to detect falls. In [
15], the authors describe an RNN architecture in which accelerometer signal is fed into 2 Long Short-Term Memory (LSTM) layers, and the output of these layers is passed through 2 feed-forward neural networks. The second of these networks produces a probability that a fall has occurred. The model is trained and evaluated on the URFD dataset [
16], which contains accelerometer data taken from a sensor placed on the pelvis, and produces a
% accuracy. The authors also describe a method to obtain additional training data by performing random rotations on the acceleration signal; training a model with this data gives an accuracy of
%.
The authors in [
17] also propose an RNN to detect falls using accelerometer data. The core of their neural network architecture consists of a fully connected layer, which processes the raw data, followed by 2 LSTM layers, and ending with another fully connected layer. They also have some normalization and dropout layers in their architecture. The authors train and test their model with the SisFall dataset [
18], which contains accelerometer data sampled at 200 Hz collected from a sensor attached to the belt buckle. In order to deal with a large imbalance in training data, of which ADLs form the vast majority, the authors define a weighted-cross entropy loss function, based on the frequency of each class in the dataset, that they use to train their model. In the end, their model attains a
% accuracy on falls and a
% accuracy on ADLs.
Our work differs primarily from these two papers in that we seek to develop a fall detection model that obtains accelerometer data from an off the shelf smartwatch rather than specialized equipment placed near the center of the body. This presents several challenges not addressed in these papers’ methodology. Because of its placement on the wrist, a smartwatch will naturally show more fluctuation in its measurements than a sensor placed on the pelvis or belt buckle. The scholars in [
18] also use accelerometer data sampled at a 200 Hz frequency obtained by specialized equipment; this is a significantly higher than the frequency used by our smartwatch, which samples at 31.25 Hz. We also have the additional restriction that the model we develop should not consume so many computational resources that it cannot be run on a smartphone. Thus, while there has been some work done on deep learning for fall detection, we have additional constraints that make these works not directly relevant for our purposes.
In summary, many different machine learning algorithms such as the SVM, NB, KNN, Decision Trees, and Neural Networks have been applied to fall detection with some success. However, very few of those models have been tested in real time and on a wrist watch. Recently, an Android Wear-based commercial fall detection application called RightMinder [
19] was released on Google Play. While the goal of RightMinder is very similar to ours, no technical details are available on the accuracy of the fall detection model and the management of the collected sensor data. We installed RightMinder and tried with 10 different simulated falls, it only detected 5 out of the 10 falls.
5. Evaluation
Our goal is to be able to detect accurately whether someone has fallen in real time based on the motion sensed by a smartwatch that a person is wearing on their wrist. We do not want to miss a fall, which implies a fall detection model with a high Recall or Sensitivity. A missed fall is represented in our evaluation experiments as a false negative (FN). We also do not want to have too many false alarms, which in our evaluation as represented as false positives (FPs), and thus, we want to achieve a high precision. In particular recall, precision, and overall accuracy are calculated as:
where true positives (TP) is the number of correctly detected falls. The number of True Negatives (TN) is not of particular interest to this application as negative instances represent non-falls and, in practice, they greatly outnumber the number of positive instances.
In this section, we first present our method for evaluating a model on the three datasets described in
Section 4. We then present the results of training and evaluating three models—NB, SVM, and Deep Learning—on the datasets. We also discuss the results of running these three models in real time with volunteers wearing smartwatches. We conclude with a comparison of the three models, and what this means for our Deep Learning model.
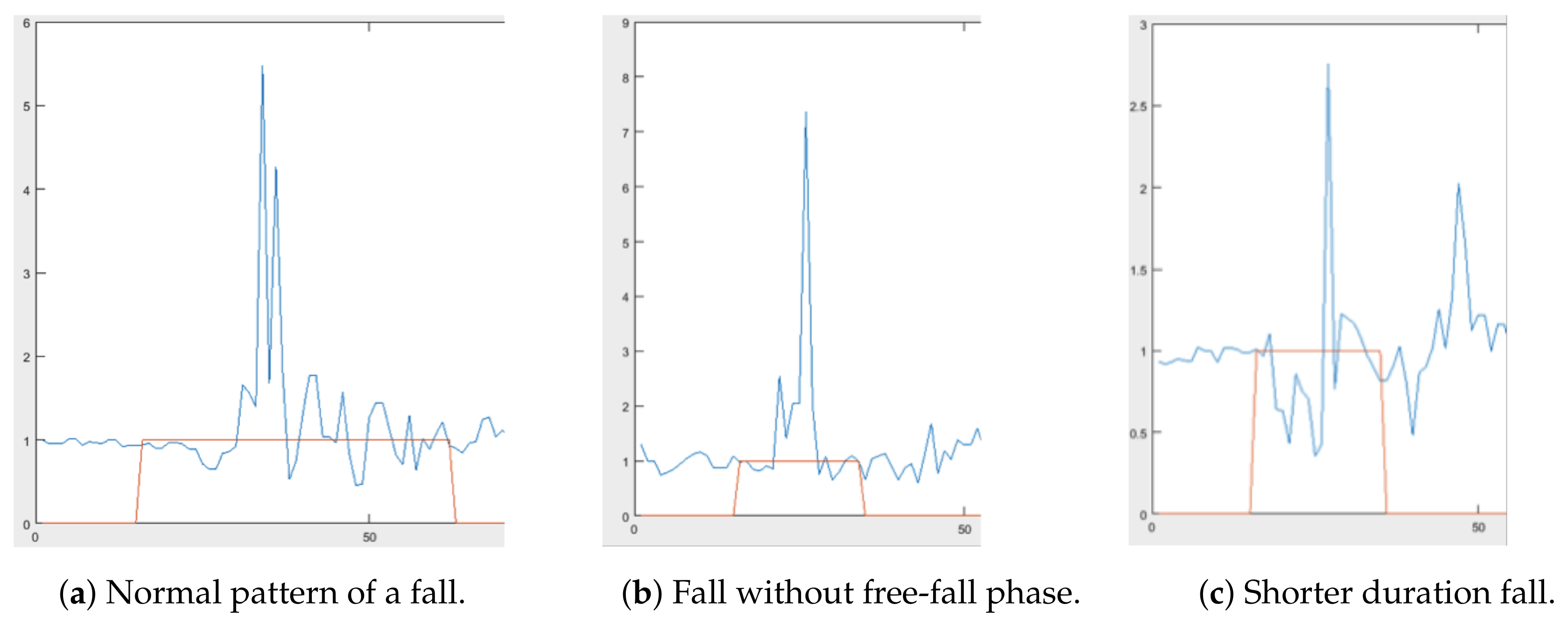
The three datasets on which we train and evaluate the three models are the Farseeing, Smartwatch, and Notch datasets, described in
Section 4. Each dataset contains continuous accelerometer data, and each data point is marked with “Fall” or “NotFall”. For our purposes, a “Fall” instance is a series of consecutive data points marked “Fall”—this corresponds to the interval of time in which a person is falling. The Smartwatch dataset is also labeled with ADL information, which makes it easy to tell where each “ADL” instance starts and stops. The Notch and Farseeing datasets, however, are not labeled with ADL intervals; they have only continuous accelerometer data marked with “NotFall”. Thus, it is harder to determine intervals in which a single ADL occurs, since ADLs typically appear back-to-back. Therefore, for these datasets, we will consider an “ADL” instance to be a 1-s interval of consecutive data points marked “NotFall”. Because there are many more data points marked “NotFall” than “Fall” in the Notch and Farseeing datasets, this formulation will produce far more ADL activities than falls. The number of falls and ADLs in each dataset is given in
Table 1.
As described in
Section 4.2.1, a NB or SVM model makes a final fall prediction when the algorithm outputs between 3 and 50 consecutive data points predicted as fall. We determine if this prediction is correct by checking if any of the predicted consecutive falls match the label on the corresponding row of the dataset. We do a similar process to determine if a Deep Learning model’s fall prediction is correct. As described in
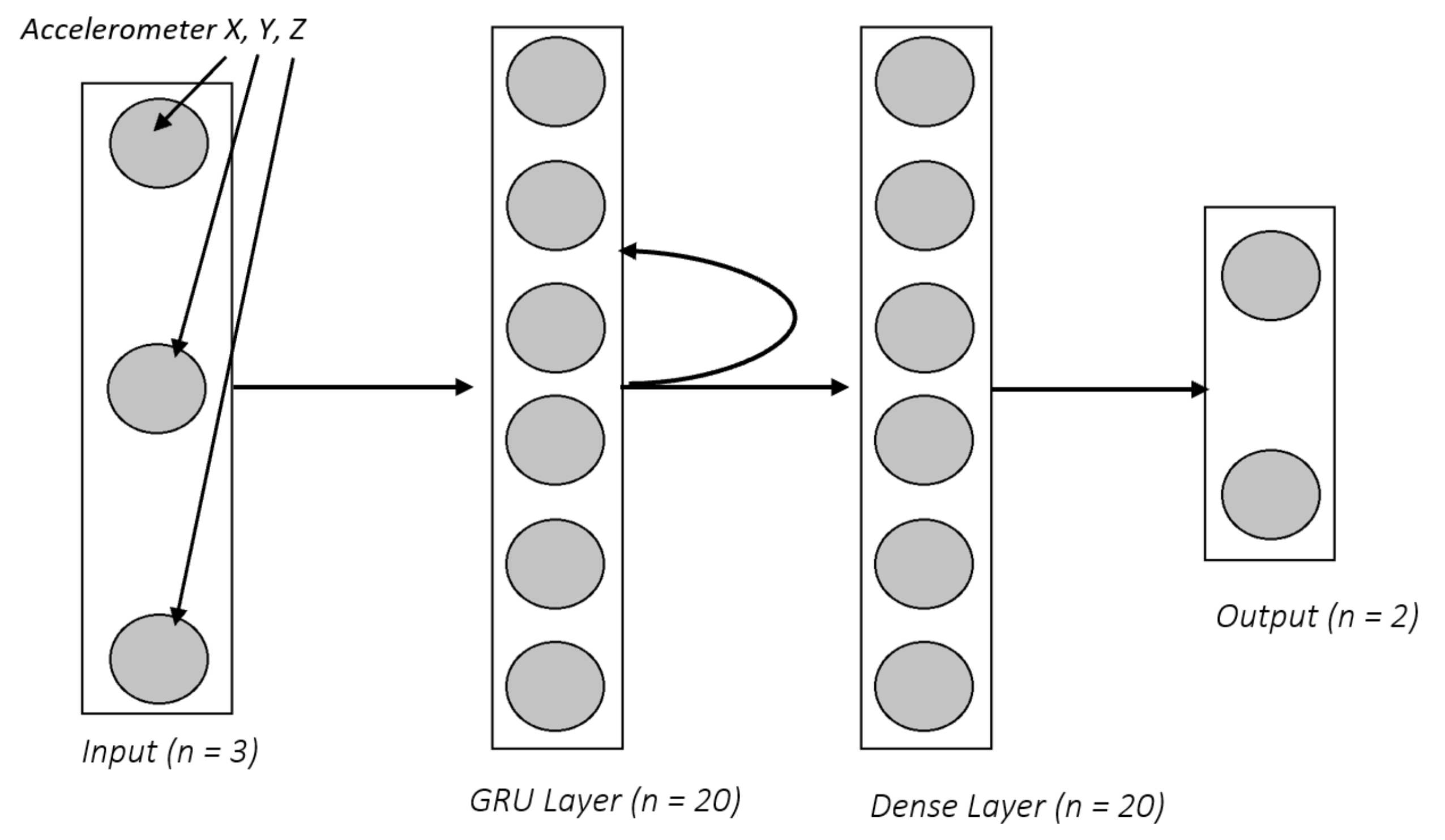
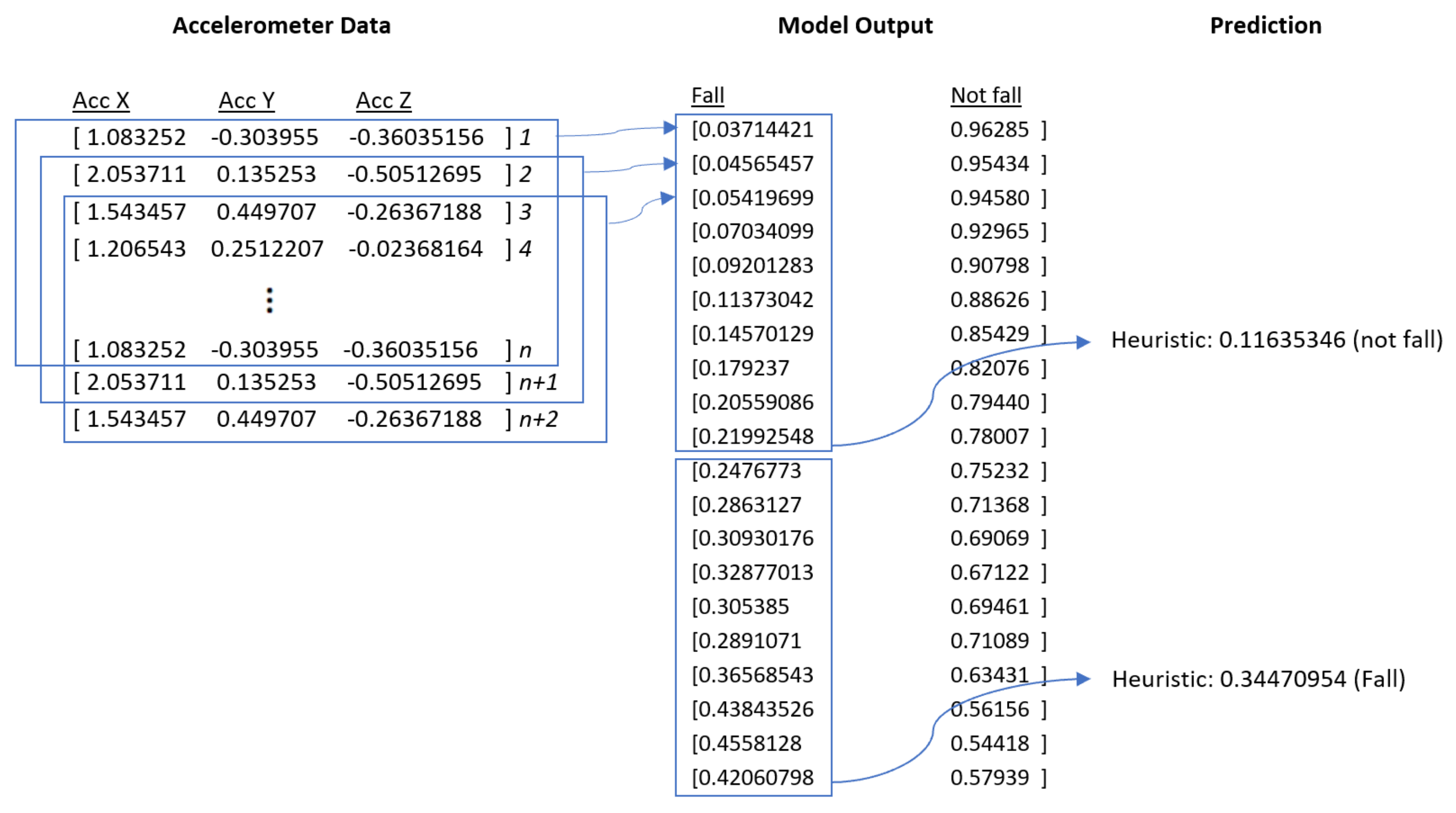
Section 4.3, a Deep Learning model produces a prediction after computing the heuristic, which is the average of probabilities generated by the neural network architecture over 10 windows of
n steps, after comparing this heuristic to a pre-defined threshold. When a Deep Learning model makes a fall prediction, we determine if that prediction is correct by checking the labels in the dataset corresponding to the final row of each of the 10 windows. If any of these labels is a “Fall”, the prediction is deemed to be correct.
The results of training and evaluating a NB, SVM, and Deep Learning model on the three datasets are presented in
Table 2. For the Smartwatch dataset, each model is trained on two-thirds of the data and is tested on the remaining third. The Notch and Farseeing datasets are analyzed using a leave-one-out strategy where the models are trained on all user files but one. Even though the data in these datasets is pre-recorded, we simulate an online environment by processing the data as if it were being received live from a smartwatch. This effectively allows us to test various models in a real-world situation without the expense of constantly recruiting volunteers.
The NB model demonstrates a recall greater than on all three datasets—this demonstrates that the model does well predicting falls. However, the model has a considerably lower precision on each dataset, indicating a lot of FPs. In particular, the precision on the Farseeing dataset is ; this especially low number is a result of poor performance in the face of imbalanced data. In the Farseeing dataset, there are over 1000 ADLs for each fall; in the Notch dataset, which is also imbalanced, there are only 23 ADLs for each fall—this increase in imbalance is enough to substantially lower the precision value between the two datasets despite only slightly lower accuracies on falls and ADLs. It is also worth noting that the imbalance in fall and ADL data in the Notch and Farseeing datasets causes the overall accuracy to be dominated by the ADL accuracy on all three models.
The SVM model demonstrates a similar pattern to the NB model in that it generally has a high recall and a lower precision. With the exception of the Farseeing dataset, the SVM model has a recall greater than or equal to , indicating that it does pretty well on falls. The low recall of on the Farseeing dataset challenges this; this may suggest that the model has a hard time identifying a rare class in the midst of extremely imbalanced data. Like the NB model, the SVM also demonstrates a lower precision value on every dataset, suggesting there are a lot of FPs. We believe that the primary cause of this in both the NB and SVM models is that these models use derived acceleration features rather than raw accelerometer data. This fundamentally limits the models, as they cannot discern between certain directional characteristics of ADLs and falls that may only be accessible through raw accelerometer data.
The Deep Learning model outperforms the NB and SVM model on every metric except for precision on the Farseeing dataset, which is lower than the SVM precision. On the Smartwatch and Farseeing dataset, the deep model has perfect recall, and it has a recall on the Notch dataset. This demonstrates that it does a very good job in identifying falls. Like the NB and SVM models, the precision values for the deep model are comparatively lower than the corresponding recall values, suggesting that it also struggles with FPs. However, with the exception of a slightly lower precision than the SVM on the Farseeing data, the deep model’s precision is higher than both NB and SVM; we believe that this is because the deep model is trained on the raw accelerometer data, which allows it to extract helpful signals of ADLs that are not present in the derived acceleration features given to the NB and SVM models. Also, like the NB model but unlike the SVM model, the deep model has a substantially lower precision on the Farseeing dataset than the other two datasets; we believe that the high level of imbalance in the Farseeing dataset may be behind this anomaly, especially as both the fall accuracy and the ADL accuracy are considerably greater on the Farseeing dataset than either the Smartwatch or Notch datasets.
In addition, we evaluated the same three models in real time by recruiting five volunteers of various heights and weights who recorded each model’s predictions on various falls and ADLs. In this case, each model was trained on the entire Smartwatch dataset described in
Section 4 and tested on the volunteers, who each wore a smartwatch paired with the smartphone app. Each volunteer placed the smartwatch on his or her left wrist, and was asked to do five each of front, back, left, and right falls. To see how the model performs on non-fall data, each volunteer also performed five each of sitting, waving (3 s), jogging (10+ s), and walking (10+ s) ADLs. Testing in this way lets us evaluate the model’s capabilities in a true online situation as well as seeing how each model performs on specific kinds of falls and ADLs. The other datasets are only labeled as “Fall” or “NotFall”, so it is not possible to analyze which types of falls and ADLs the model detects. The real-time results can be found in
Table 3.
Our NB model detects falls at a reasonable rate. Its detection rate, however, varies across the different types of falls. Front and left falls are both detected by the NB model at a rate above 80%. Back fall accuracy drops to 60%, and right falls are the lowest at 40%. The fact that the model performs much better on left falls than right falls suggests that the model may be sensitive to the wrist the smartwatch is placed on. Furthermore, the model’s poorer performance on back falls suggests that it performs like a threshold-based algorithm, since the wrist movement in back falls is not as intense. Another threshold-like behavior for this model is the tendency to perform well on light ADLs like sitting and walking (obtaining over 93% accuracy on these activities), but poorly on more motion-intensive ADLs like waving and jogging (obtaining less than 50% accuracy on these).
Our SVM model obtained much different results than the other two models. It scores the best on nearly every ADL category, while performing quite poorly on falls themselves. We prioritize obtaining TPs over not obtaining FPs, and so we consider our SVM model to have the worst performance by a wide margin. Like the NB model, the SVM model behaves like a threshold-based algorithm; however, it is far less sensitive than NB. This can be seen when looking at the ADL accuracies. While the SVM performs the best of the three models on jogging and waving, it still performs worse on these activities than it does on sitting and walking. The biggest difference between SVM and NB is the fall results: the SVM performed the same on right falls and left falls, while NB performed better on left falls. This suggests that our SVM model adapts better to different wrist placement, despite its overall poor performance.
Our Deep Learning model performs the best on detecting falls. It is far better than the other models at detecting falls with more unique wrist movements, such as back falls. Whereas both the SVM and NB do quite poorly on back falls, the Deep Learning model detected back falls as well as the other fall types. However, the Deep Learning model is not very accurate on ADLs. In ADLs that contained quick and abrupt motion, such as jogging and waving, the Deep Learning model performed slightly worse than the SVM. Unlike the SVM and NB models, however, the Deep Learning model struggles more with lighter activities such as sitting and walking. For this reason, the Deep Learning model can quickly be separated from threshold-based algorithms: it distinguishes well between quick intense movements (falling) and intense movements over a period of time (jogging/waving), but does not distinguish lighter movements (sitting/walking) from the intense movements well. Along with the good fall detection results, this is a strong indicator that the Deep Learning model does not rely on just high acceleration values for its predictions. Feature extraction is a likely contributor to this limitation for the NB and SVM models. The features that these models are trained with are all a direct function of the resultant acceleration. We believe that the use of raw accelerometer data for our Deep Learning model creates a much wider range of correlations that the model can pick up on. These additional correlations can help the model avoid regressing on a single feature, such as just a high acceleration value.
The Deep Learning, SVM, and NB models performed better overall on the offline Smartwatch dataset than on the real-time experiments. One possible explanation for this is that many of the participants in the Smartwatch dataset were included in both the training and testing of the models, making it easier for the models to recognize patterns in the falls. The real-time experiments, however, were tested on volunteers, whose data was not used to train the model. Thus, it is natural that the models do not perform as well in the online setting.
It is also important to notice that the Deep Learning model generalizes much better to new volunteers than the NB and SVM models. The SVM detected 85.7% of falls on the Smartwatch dataset, dropping to 26% in real time, while NB detected 92.3% of falls on the Smartwatch data, dropping to 66% in real time; the Deep Learning model, however, dropped from a 100% detection rate to an 86% rate. A potential cause for this is feature extraction. Both models that use extracted features showed a significant performance drop in falls detected. This may indicate the extracted features are removing important patterns in the raw data, thus oversimplifying the prediction and causing it to generalize poorly. The Deep Learning model, which uses raw data, has the opportunity to learn patterns that may help it to generalize.
In summary, our results show that a Deep Learning model for fall detection generally outperforms more traditional models such as NB and SVM. Offline and online results indicate that our deep model has both higher precision and higher recall than the NB and SVM models. We believe that this is due to the deep model’s ability to learn subtle features from the raw accelerometer data that are not available to NB and SVM, which are restricted to learning from a small set of extracted features. Furthermore, the deep model exhibits a better ability to generalize to new users when predicting falls, an important quality of any model that is to be successful in the real world. Despite the overall success of the Deep Learning model, it still has challenges, primarily in its failure to properly classify ADLs, particularly lighter ones such as sitting and walking. We believe that with further adjustments to the deep learning architecture and parameters, it will be able to detect these motions at least as well as its NB and SVM counterparts.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}