NCA-Net for Tracking Multiple Objects across Multiple Cameras


Abstract
:1. Introduction
- (1)
- NCA-Net is developed by combining deep feature learning and metric learning is constructed to acquire the high-level representation of pedestrian, aiming at improving the performance of multiple objects tracking across multiple cameras.
- (2)
- A new loss function for NCA-Net is derived, which is more suitable for object tracking application and can resolve the convergence problem of network training.
- (3)
- The proposed NCA-Net is applied to extract feature in two detection-based tracking system and demonstrates the favorable performance.
2. Related Work
2.1. Tracking Framework
2.2. Deep Metric Learning
3. NCA-Net for Multi-Object Tracking
3.1. Motivation
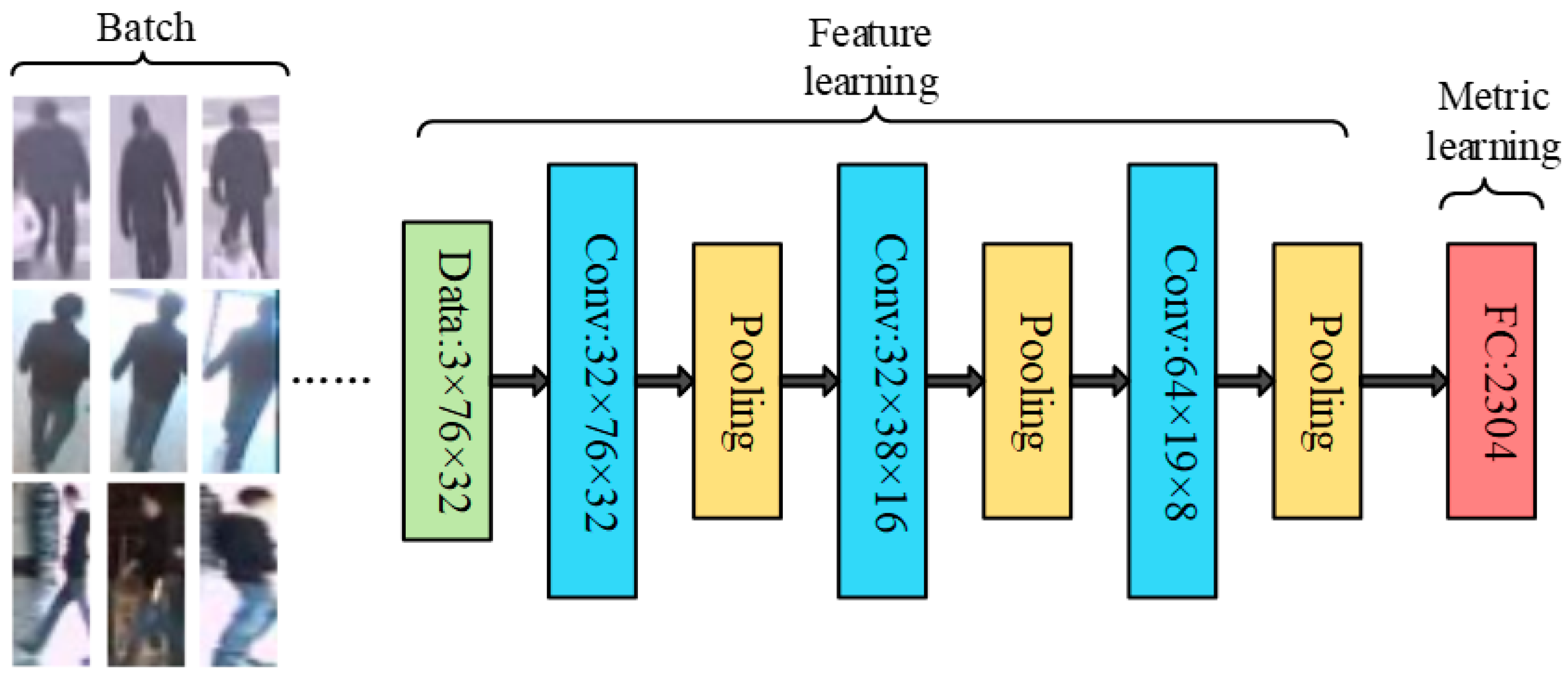
3.2. The Structure of NCA-Net
3.3. Loss Function of NCA-Net
3.4. Training of NCA-Net
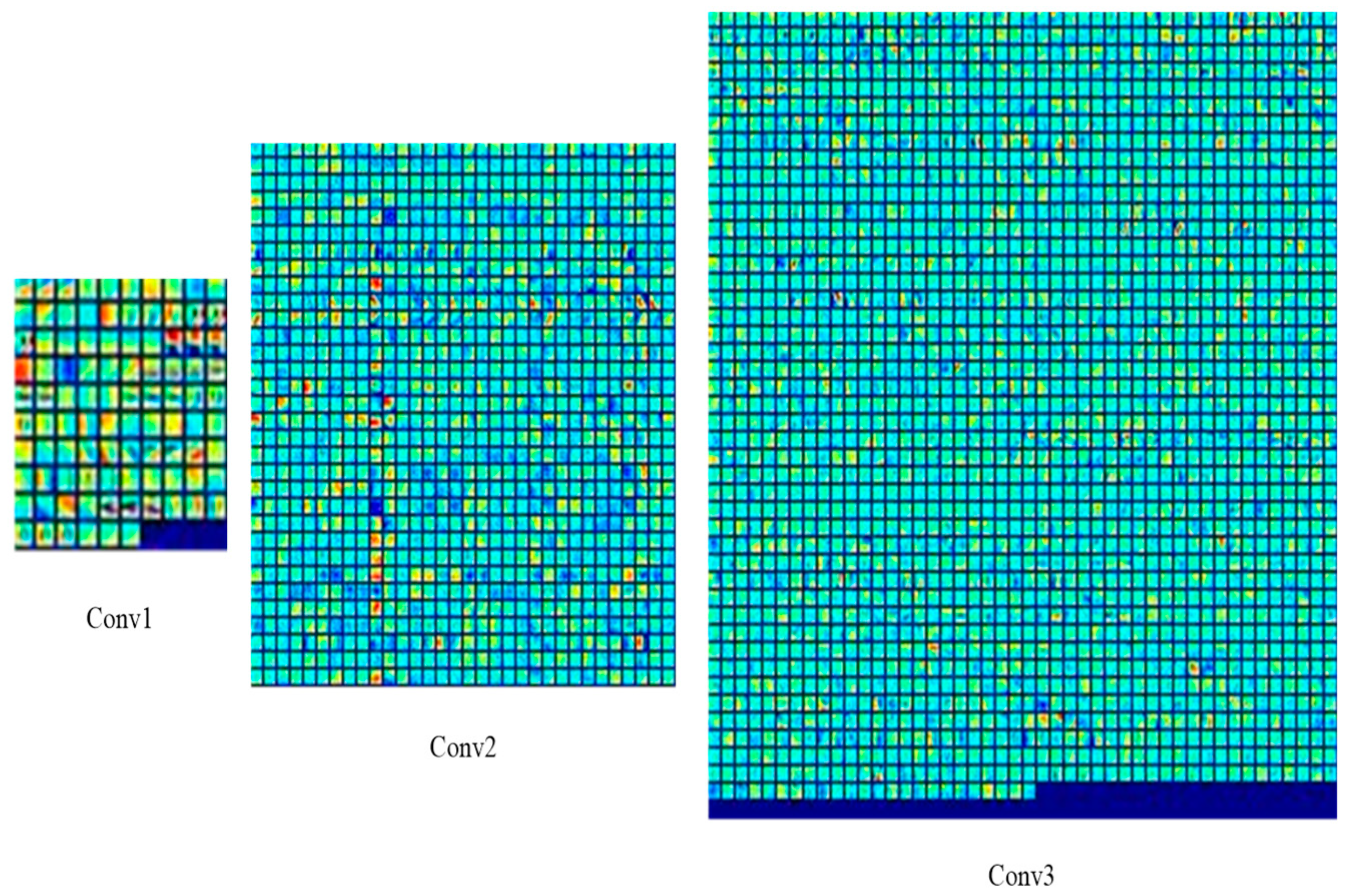
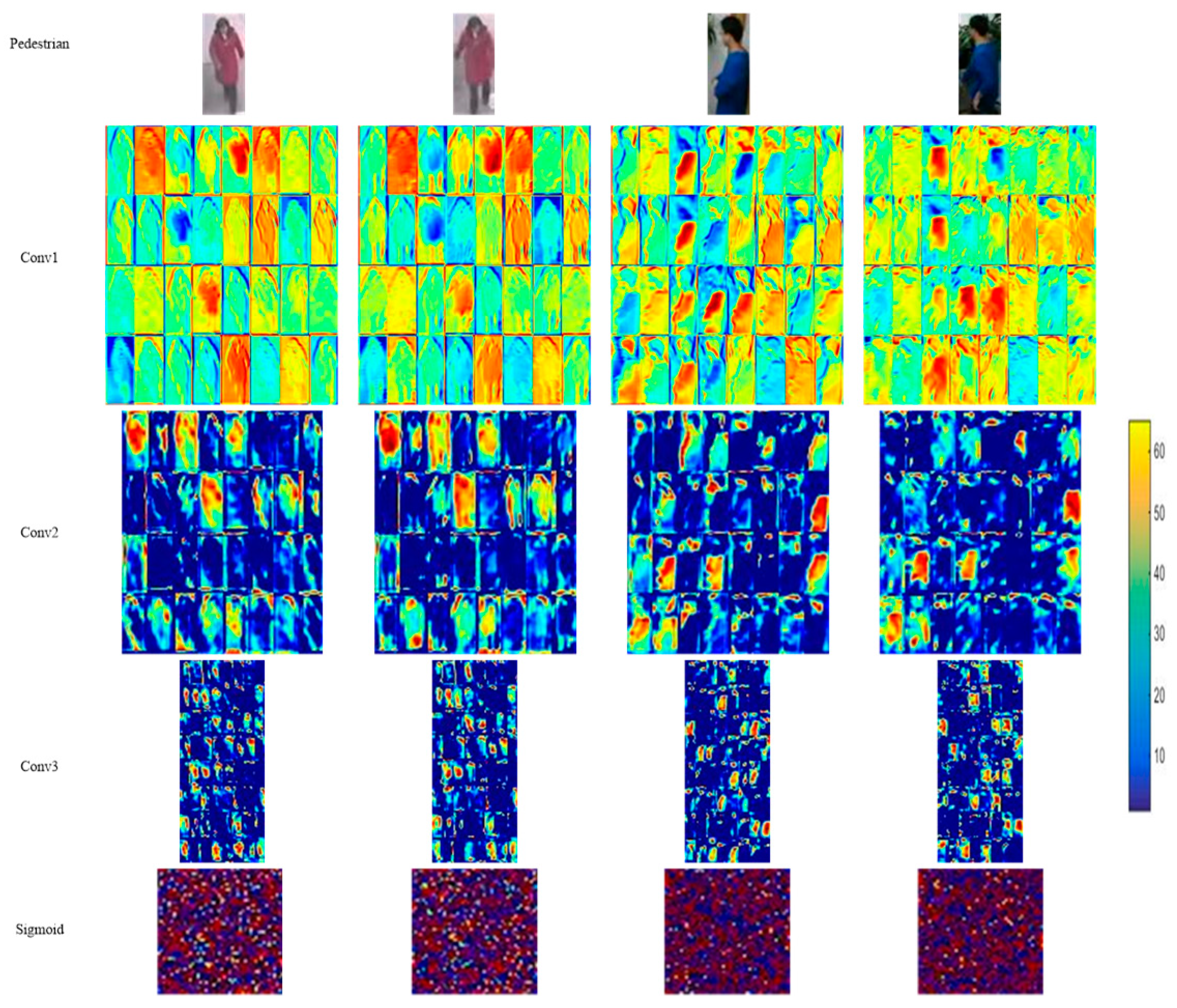
3.5. Visualization of Features Extracted from NCA-Net
3.6. Comparison of Normalized Feature and Original Feature Extracted by NCA-Net
4. Multiple Objects Tracking Algorithm across Multi-Camera
4.1. Simple Match Algorithm for MCT
4.1.1. Single Camera Case
- (1)
- ;
- (2)
- Taking the video’s resolution and frame rate into consideration, space distance needs to satisfy that ;
- (3)
- After we finish the matching between two adjacent frames, we must avoid one pedestrian appearing twice in the same frame.
4.1.2. Tracklets Association
- (1)
- ;
- (2)
- The spatial positions of two tracklets satisfy the view field distribution of two cameras;
- (3)
- Two tracklets do not overlap in the same time;
- (4)
- Two tracklets do not have a time interval more than one minute because the adjacent cameras do not distribute far away;
- (5)
- One tracklet can match no more than one tracklet.
- (1)
- ;
- (2)
- The connection points of two tracklets have small spatial distance, such as ;
- (3)
- Two tracklets do not overlap in the same time;
- (4)
- Two tracklets do not have a time interval more than five second, because occlusion always keep a short time;
- (5)
- One tracklet can match no more than two tracklets, one before it with another after.
4.2. EGTracker Using Metric Learnt by NCA-Net
5. Experimental Results
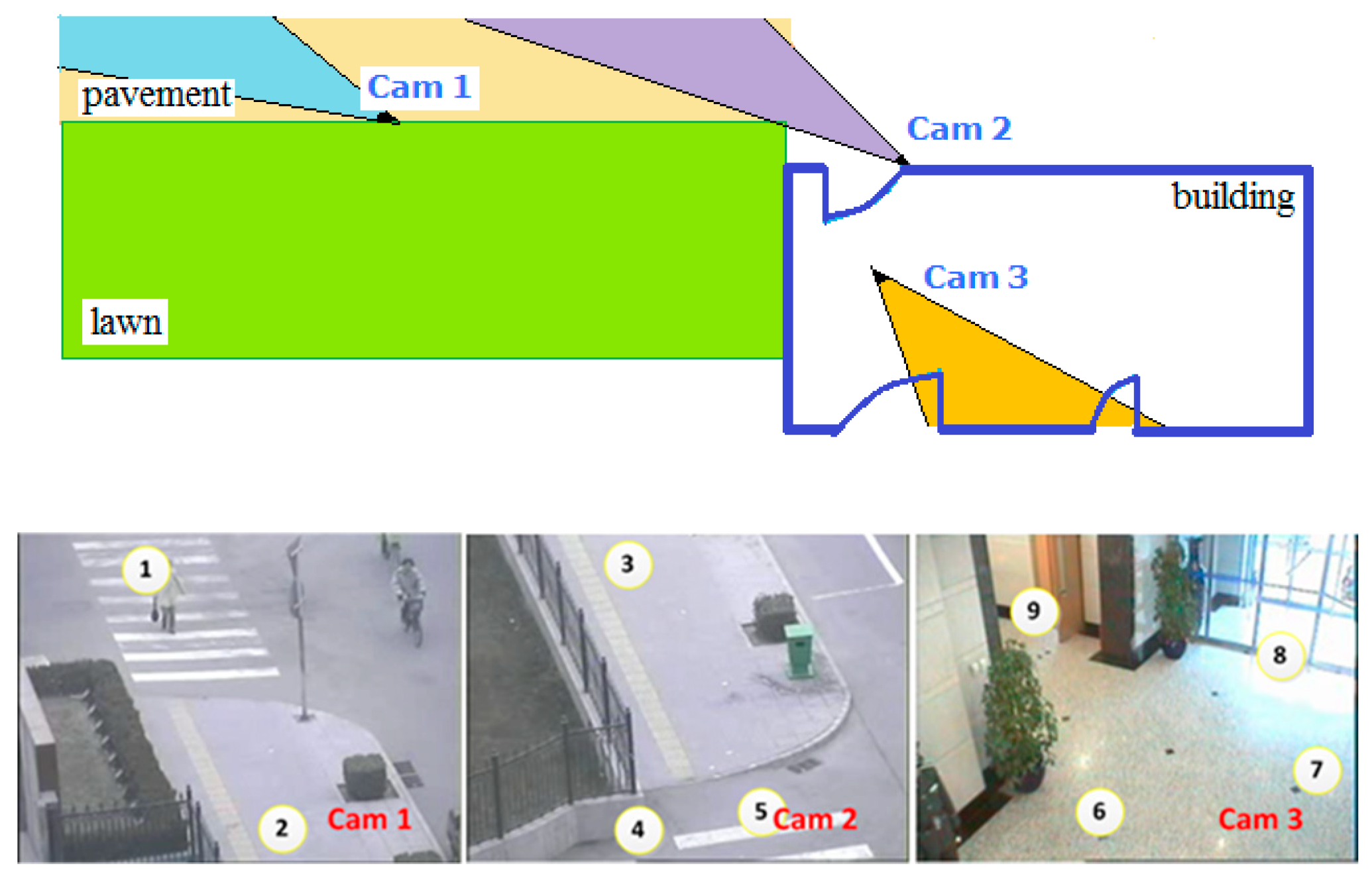
5.1. Experiment on NLPR_MCT Dataset
5.2. Extended Experiment on DukeMTMC Dataset
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Song, H.; Srinivasan, R.; Sookoor, T.; Jeschke, S. Smart Cities: Foundations, Principles and Applications; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Yang, J.; Xu, R.; Lv, Z.; Song, H. Analysis of camera arrays applicable to the internet of things. Sensors 2016, 16, 421. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Jiang, B.; Song, H. A distributed image-retrieval method in multi-camera system of smart city based on cloud computing. Future Gener. Comput. Syst. 2018, 81, 244–251. [Google Scholar] [CrossRef]
- Gary, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance, Rio de Janeiro, Brazil, 14 October 2007; pp. 41–47. [Google Scholar]
- Athira, N.; Matteo, T.; Dario, F.; Jacinto, C.N.; Alexandre, B. A multi-camera video dataset for research on high-definition surveillance. Int. J. Mach. Intell. Sens. Signal Process. 2014, 1, 267–286. [Google Scholar]
- Fleuret, F.; Berclaz, J.; Lengagne, R.; Fua, P. Multicamera People Tracking with a Probabilistic Occupancy Map. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 267–282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple Object Tracking Using K-Shortest Paths Optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shitrit, H.B.; Berclaz, J.; Fleuret, F.; Fua, P. Multi-Commodity Network Flow for Tracking Multiple People. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1614–1627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Turetken, E.; Fleuret, F.; Fua, P. Tracking Interacting Objects Using Intertwined Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2312–2326. [Google Scholar] [CrossRef] [PubMed]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. Mot16: A benchmark for multi-object tracking. arXiv, 2016; arXiv:1603.00831. [Google Scholar]
- Chen, W.; Cao, L.; Chen, X.; Huang, K. An equalized global graph model-based approach for multicamera object tracking. IEEE Trans. Circuits Syst. 2017, 27, 2367–2381. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar]
- Bose, B.; Wang, X.; Grimson, E. Multi-class object tracking algorithm that handles fragmentation and grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007. [Google Scholar]
- Song, B.; Jeng, Ti.; Staudt, E.; Roy-Chowdhury, A.K. A stochastic graph evolution framework for robust multi-target tracking. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 605–619. [Google Scholar]
- Bae, S.; Yoon, K. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4705–4713. [Google Scholar]
- Hu, W.; Li, X.; Luo, W.; Zhang, X.; Maybank, A.; Zhang, Z. Single and multiple object tracking using log-Euclidean Riemannian subspace and block-division appearance model. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2420–2440. [Google Scholar] [PubMed]
- Zhang, L.; Maaten, L.V.D. Structure preserving object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1838–1845. [Google Scholar]
- Zhang, J.; Presti, L.L.; Sclaroff, S. Online multi-person tracking by tracker hierarchy. In Proceedings of the 9th IEEE International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; pp. 379–385. [Google Scholar]
- Yoon, J.H.; Yang, M.; Lim, J.; Yoon, K. Bayesian multi-object tracking using motion context from multiple objects. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 33–40. [Google Scholar]
- Khalili, A.; Soliman, A.A.; Asaduzzaman, M. Quantum particle filter: A multiple mode method for low delay abrupt pedestrian motion tracking. Electron. Lett. 2015, 51, 1251–1253. [Google Scholar] [CrossRef]
- Sugimura, D.; Kitani, K.M.; Okabe, T.; Sato, Y.; Sugimoto, A. Using individuality to track individuals: Clustering individual trajectories in crowds using local appearance and frequency trait. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1467–1474. [Google Scholar]
- Mitzel, D.; Leibe, B. Real-time multi-person tracking with detector assisted structure propagation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 974–981. [Google Scholar]
- Mitzel, D.; Horbert, E.; Ess, A.; Leibe, B. Multi-person tracking with sparse detection and continuous segmentation. In Proceedings of the Computer Vision 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 397–410. [Google Scholar]
- Okuma, K.; Taleghani, A.; Freitas, D.N.; Lowe, D. A boosted particle filter: Multitarget detection and tracking. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 28–39. [Google Scholar]
- Führ, G.; Jung, C.R. Combining patch matching and detection for robust pedestrian tracking in monocular calibrated cameras. Pattern Recognit. Lett. 2014, 39, 11–20. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, X.; Chen, G. Pedestrian detection and tracking using HOG and oriented-LBP features. In Proceedings of the 8th IFIP International Conference on Network and Parallel Computing, Changsha, China, 21–23 October 2011; pp. 176–184. [Google Scholar]
- Tsuduki, Y.; Fujiyoshi, H. A method for visualizing pedestrian traffic flow using sift feature point tracking. In Proceedings of the Third Pacific Rim Symposium on Advances in Image and Video Technology, Tokyo, Japan, 13–16 January 2009; pp. 25–36. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, J.; Liu, T.; Jiang, B.; Song, H.; Lu, W. 3D panoramic virtual reality video quality assessment based on 3D convolutional neural networks. IEEE Access 2018, 6, 38669–38682. [Google Scholar] [CrossRef]
- Rodriguez, M.; Sivic, J.; Laptev, I.; Audibert, J. Data-driven crowd analysis in videos. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1235–1242. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Robust tracking-by-detection using a detector confidence particle filter. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1515–1522. [Google Scholar]
- Le, N.; Heili, A.; Odobez, J. Long-term time-sensitive costs for crf-based tracking by detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 43–51. [Google Scholar]
- Li, S.; Qin, Z.; Song, H. A temporal-spatial method for group detection, locating and tracking. IEEE Access 2016, 4, 4484–4494. [Google Scholar] [CrossRef]
- Guo, J.; Xu, T.; Shi, G.; Rao, Z.; Li, X. Multi-View Structural Local Subspace Tracking. Sensors 2017, 17, 666. [Google Scholar] [CrossRef] [PubMed]
- Li, D.Q.; Xu, T.F.; Chen, S.Y.; Zhang, J.Z.; Jiang, S.W. Real-Time Tracking Framework with Adaptive Features and Constrained Labels. Sensors 2016, 16, 1449. [Google Scholar] [CrossRef] [PubMed]
- Ding, S.; Lin, L.; Wang, G.; Chao, H. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognit. 2015, 48, 2993–3003. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A deep quadruplet network for person reidentification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1320–1329. [Google Scholar]
- Batchelor, O.; Green, R. Object recognition by stochastic metric learning. In Proceedings of the 10th Inter-national Conference on Simulated Evolution and Learning, Dunedin, New Zealand, 15–18 December 2014; pp. 798–809. [Google Scholar]
- Goldberger, J.; Roweis, S.; Hinton, G.; Salakhutdinov, R. Neighbourhood components analysis. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 513–520. [Google Scholar]
- Jia, Y.; Shellhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Keni, B.; Rainer, S. Evaluating multiple object tracking performance: The clear mot metrics. R. J. Image Video Process. 2008, 2008, 246309. [Google Scholar]
- Huang, C.; Wu, B.; Nevatia, R. Robust object tracking by hierarchical association of detection responses. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 761–768. [Google Scholar]
- Cai, Y.; Medioni, G. Exploring context information for inter-camera multiple target tracking. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Chen, W.; Cao, L.; Chen, X.; Huang, K. A novel solution for multi-camera object tracking. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset1 | Dataset2 | ||
| TrackingSCT | TrackingICT | TrackingSCT | TrackingICT |
| 71,853 | 334 | 88,419 | 408 |
| Dataset3 | Dataset4 | ||
| TrackingSCT | TrackingICT | TrackingSCT | TrackingICT |
| 18,187 | 152 | 42,615 | 256 |
| SMA | EGTracker | |||
|---|---|---|---|---|
| Data | SPMI | MPSI | SPMI | MPSI |
| dataset1 | 66 | 6 | 94 | 42 |
| dataset2 | 111 | 10 | 144 | 97 |
| dataset3 | 171 | 34 | 78 | 67 |
| dataset4 | 212 | 43 | 195 | 126 |
| SMA | EGTracker | USC_Vision | hfutdspmct | CRIPAC_MCT | ||
|---|---|---|---|---|---|---|
| 1 | 44 | 66 | 63 | 77 | 135 | |
| 24 | 49 | 35 | 84 | 103 | ||
| MCTA | 0.9276 | 0.8525 | 0.8831 | 0.7477 | 0.6903 | |
| 2 | 66 | 93 | 61 | 109 | 230 | |
| 49 | 107 | 59 | 140 | 153 | ||
| MCTA | 0.8792 | 0.7370 | 0.8397 | 0.6561 | 0.6234 | |
| 3 | 93 | 51 | 93 | 105 | 147 | |
| 89 | 80 | 111 | 121 | 139 | ||
| MCTA | 0.4124 | 0.4724 | 0.2427 | 0.2028 | 0.0848 | |
| 4 | 73 | 128 | 70 | 97 | 140 | |
| 152 | 159 | 141 | 188 | 209 | ||
| MCTA | 0.4056 | 0.3778 | 0.4357 | 0.2650 | 0.1830 | |
| Average MCTA | 0.6562 | 0.6099 | 0.6003 | 0.4679 | 0.3954 | |
| EGTracker | SMA | Ours+EGTracker | ||
|---|---|---|---|---|
| Dataset1 | 66 | 44 | 64 | |
| 49 | 24 | 21 | ||
| MCTA | 0.8525 | 0.9276 | 0.9363 | |
| Dataset2 | 93 | 66 | 93 | |
| 107 | 49 | 51 | ||
| MCTA | 0.7370 | 0.8792 | 0.8741 | |
| Dataset3 | 51 | 93 | 80 | |
| 80 | 89 | 83 | ||
| MCTA | 0.4724 | 0.4124 | 0.452 | |
| Dataset4 | 128 | 73 | 140 | |
| 159 | 152 | 138 | ||
| MCTA | 0.3778 | 0.4056 | 0.4594 | |
| Average MCTA | 0.6099 | 0.6562 | 0.6805 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Y.; Tai, Y.; Xiong, S. NCA-Net for Tracking Multiple Objects across Multiple Cameras. Sensors 2018, 18, 3400. https://doi.org/10.3390/s18103400
Tan Y, Tai Y, Xiong S. NCA-Net for Tracking Multiple Objects across Multiple Cameras. Sensors. 2018; 18(10):3400. https://doi.org/10.3390/s18103400
Chicago/Turabian StyleTan, Yihua, Yuan Tai, and Shengzhou Xiong. 2018. "NCA-Net for Tracking Multiple Objects across Multiple Cameras" Sensors 18, no. 10: 3400. https://doi.org/10.3390/s18103400
APA StyleTan, Y., Tai, Y., & Xiong, S. (2018). NCA-Net for Tracking Multiple Objects across Multiple Cameras. Sensors, 18(10), 3400. https://doi.org/10.3390/s18103400