1. Introduction
Simultaneous localization and mapping (SLAM) is used to incrementally estimate the pose of a moving platform and simultaneously build a map of the surrounding environment [
1,
2,
3]. Owing to its ability of autonomous localization and environmental perception, SLAM has become a key prerequisite for robots to operate autonomously in an unknown environment [
4]. Visual SLAM, a system that uses a camera as its data input sensor, is widely used in platforms moving in indoor environments. Compared with radar and other range-finding instruments, a visual sensor has the advantages of low power consumption and small volume, and it can provide more abundant environmental texture information for a moving platform. Consequently, visual SLAM has drawn increasing attention in the research community [
5]. As a unique example, integration of visual odometry (VO) with these strategies has been applied successfully to planet rover localization of many planetary exploration missions [
6,
7,
8,
9], and has assisted the rovers to travel through challenging planetary surfaces by providing high-precision visual positioning results. Subsequently, many researchers attempted to improve the efficiency and robustness of SLAM methods. In terms of improving efficiency, some feature extraction algorithms such as Speeded-Up Robust Features (SURF) [
10], Binary Robust Invariant Scalable Keypoints (BRISK) [
11], and oriented FAST and rotated BRIEF (ORB) [
12] were proposed. Further, some systems introduced parallel computing to improve efficiency, such as Parallel Tracking and Mapping (PTAM) for small Augmented Reality (AR) workspaces [
13]. This is the first SLAM system to separate feature tacking and mapping as two threads, realizing real-time SLAM. As for improving accuracy and robustness, some SLAM systems have introduced the bag-of-words model [
14] for the detection of loop closure. Once a loop closure is detected, the closure error is greatly reduced. In recent years, the ability of autonomous localization and environmental perception has rendered visual SLAM an important method, especially in global navigation satellite system (GNSS) denied environments such as indoor scenes [
15,
16].
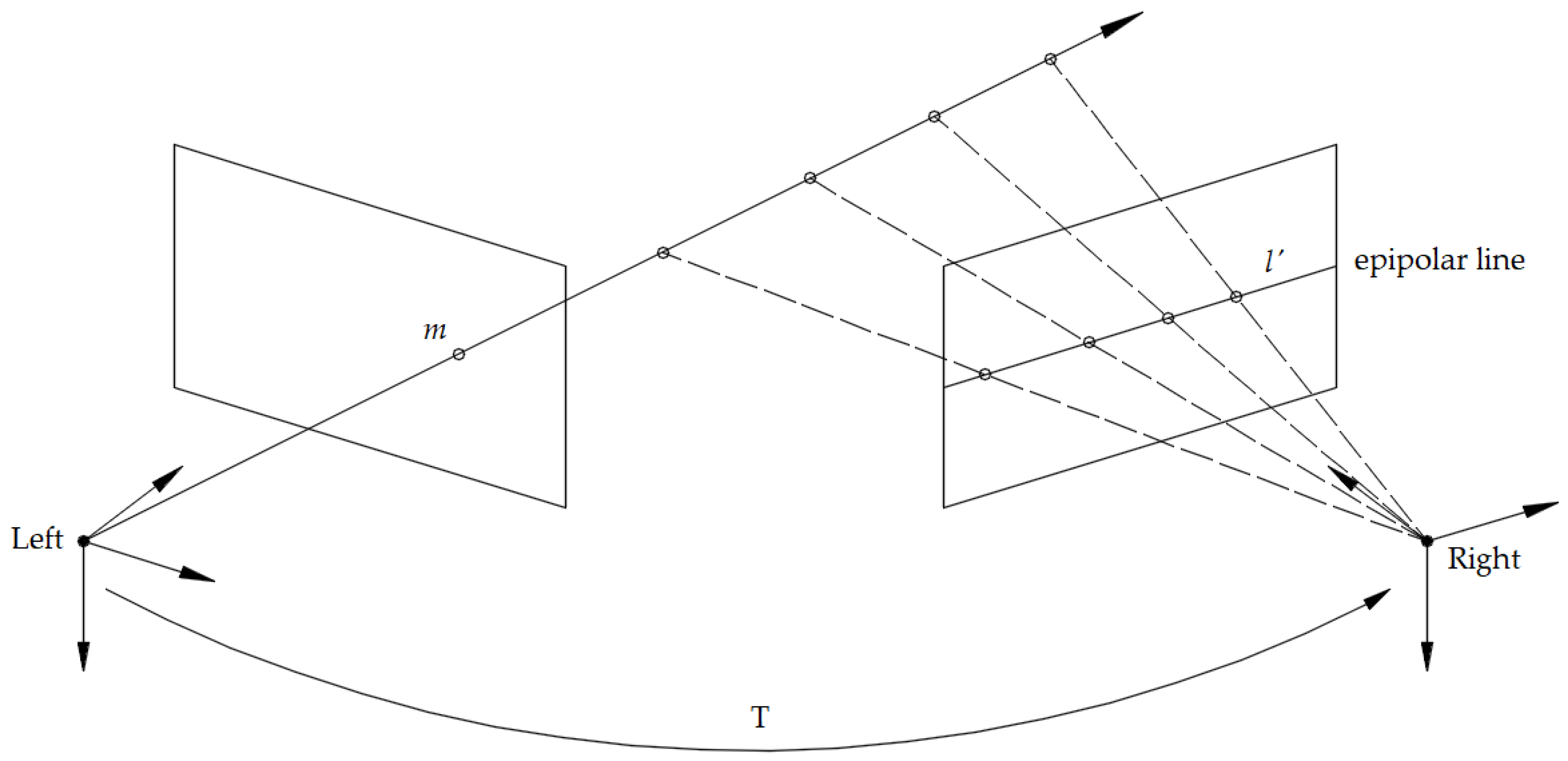
Visual SLAM can be implemented using a monocular camera [
17,
18,
19,
20], multi-camera [
21,
22,
23], and RGB-D camera [
24,
25,
26] setups. The iterative closet point (ICP) algorithm is used in motion estimation from consecutive frames containing dense point clouds and has been applied effectively in RGB-D-based SLAM [
27,
28]. However, dense point clouds, produced by dense matching and triangulation of stereo or multi-camera, have uncertainties and invalid regions in environments of low texture and illumination change [
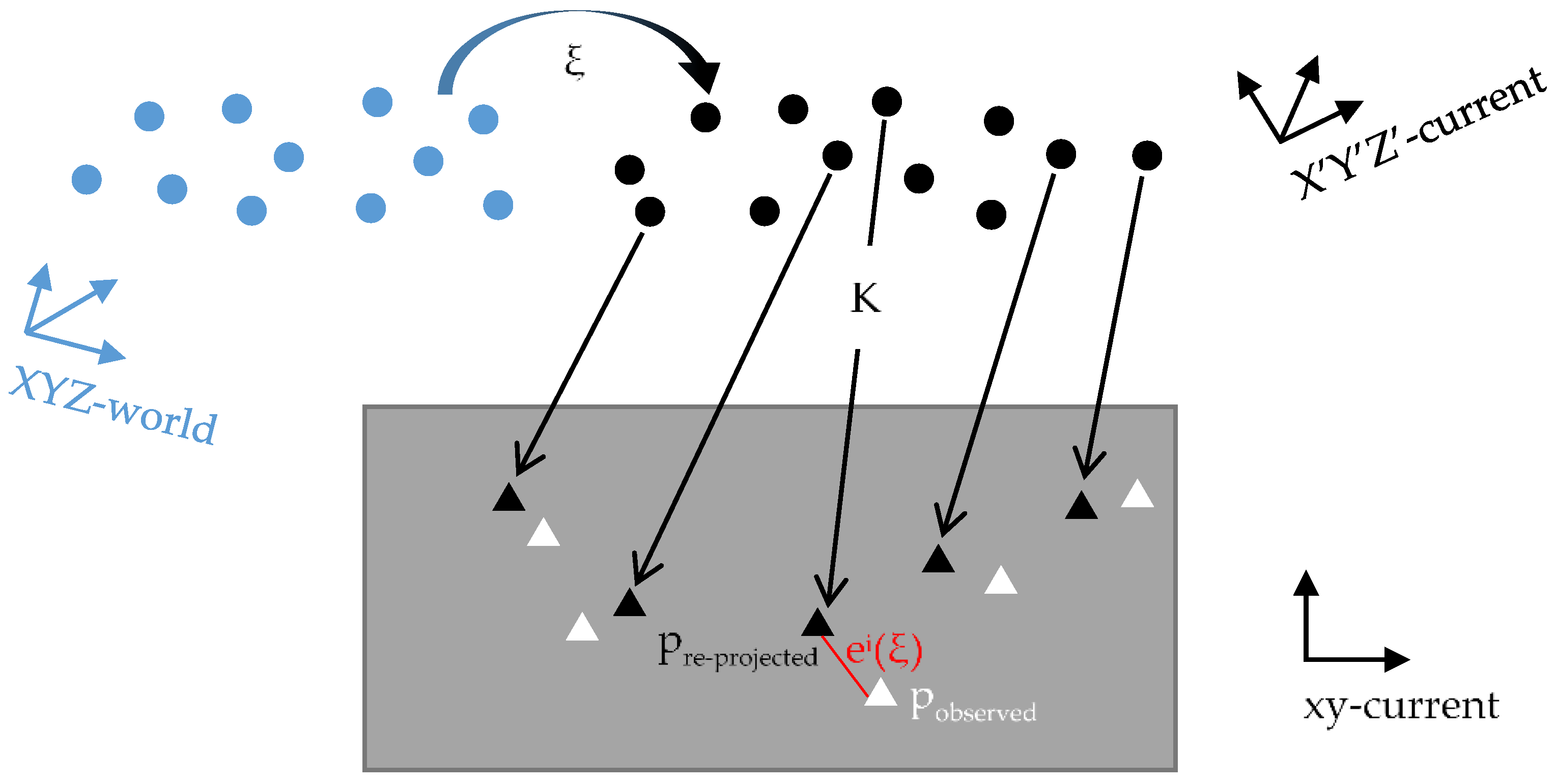
29], so in most of the visual SLAM methods, sparse feature extraction and matching are employed to calculate pose of the moving platform. Point and line segments are the two types of primary features used in visual SLAM. Point features have been predominantly used because of their convenient parameterization and implementation in feature tracking between consecutive frames. The visual SLAM systems based on point features estimate camera pose and build an environmental map by minimizing the reprojection error of the observed and corresponding reprojected point features. Furthermore, this optimization process is often solved using the general graph optimization algorithm [
30]. ORB-SLAM2 is a representative state-of-the-art visual SLAM method based on point feature [
31]; it supports monocular cameras, stereo cameras, and RGB-D cameras, and can produce high-precision results in real time.
In addition to point feature-based visual SLAM systems, line feature-based SLAM systems have been developed recently. Although a line feature is not as easily parameterized as a point feature, as a higher-dimensional feature than a point feature, it can express more environmental information in indoor scenes. Zhang et al. built a graph-based visual SLAM system using 3D straight lines instead of a point feature for localization and mapping [
32]. StructSLAM used structure lines of buildings and demonstrated the advantage of a line feature in an indoor scene with many artificial objects [
33]. Although the line features can provide more structural information, their endpoints are instable. This problem has been tackled in [
34] by utilizing relaxed constraints on their positions.
The above systems use point and line features separately. Some visual SLAM methods combine point and line features. For example, a semi-direct monocular VO, named PL-SVO [
35], can obtain more robust results in low-textured scenes by combining points and line segments. The PL-SVO uses the photometric difference between pixels of the same 3D line segment point to estimate the pose increment. The authors of PL-SVO also proposed a robust point-line feature-based stereo VO [
36]. In this stereo system, the camera motion is recovered through non-linear minimization of the projection errors of two kinds of features. Based on the work of [
35,
36], the authors extended [
36] with loop closure detection algorithm, and developed a stereo SLAM system named PL-SLAM [
37]. Note that there is also a real-time monocular visual SLAM [
38], which combines point and line features for localization and mapping, and the nonlinear least square optimization model of point and line features is similar to [
37]. The major difference between them is that the former uses a monocular camera and the latter uses a stereo camera. In literature [
39], the authors proposed a tightly-coupled monocular visual-inertial odometry (VIO) system exploiting both point-line features and inertial measurement units (IMUs) to estimate the state of camera. In those point-line feature based VO or SLAM systems, the distances from the two re-projected endpoints to the observed line segments are often used as the values to be optimized. However, the structural information of line segments, such as the angle between the re-projected and observed line segments, is not considered in the process of optimization. Furthermore, only the VO system in [
36] weighted the errors of different features according to their covariance matrices, and other reported systems do not consider the distribution of weight among different features. Di et al. obtained the inverse of the error as the weights of different data sources in RGB-D SLAM and achieved good results [
40], but the motion information of the camera was not considered.
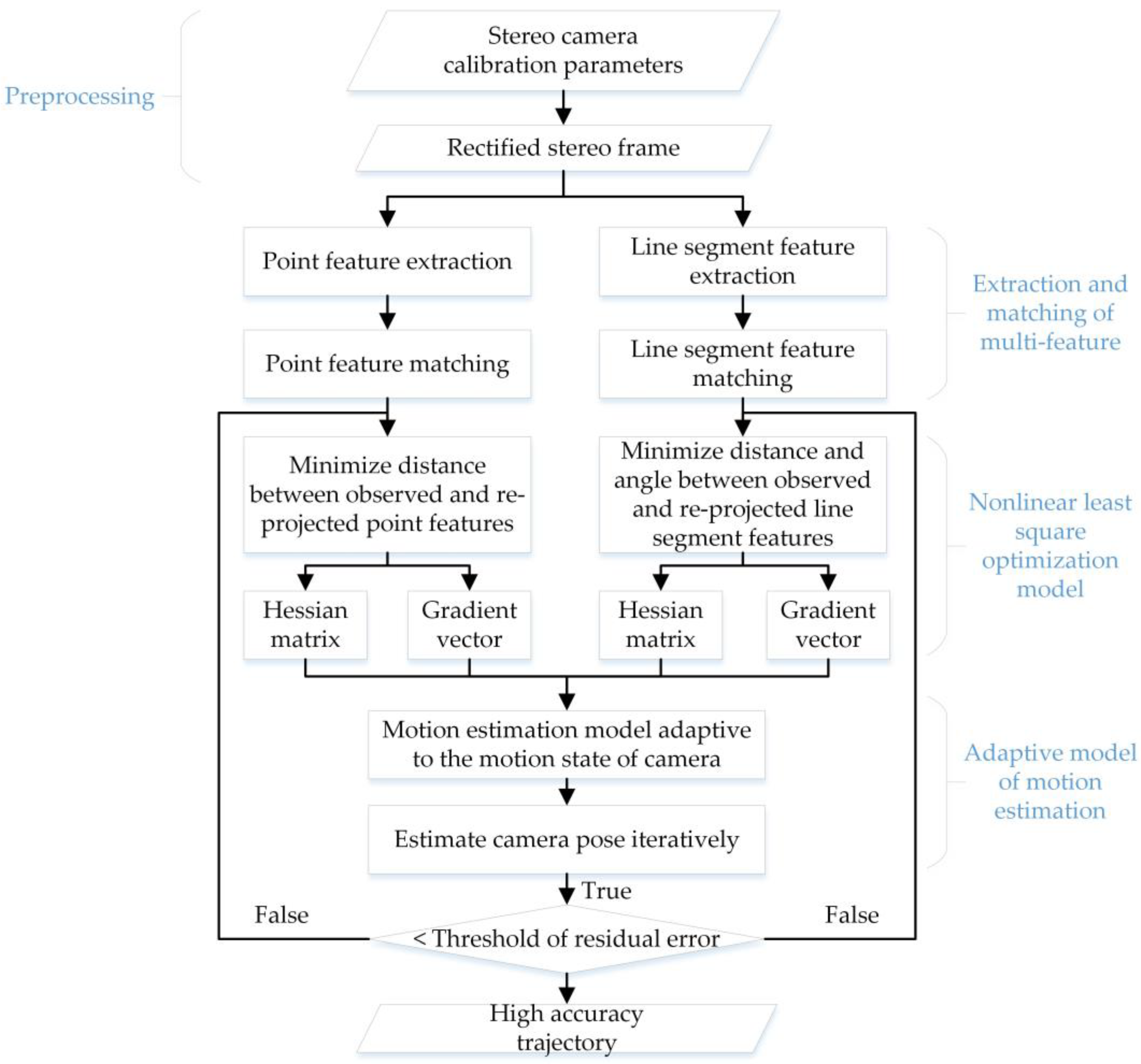
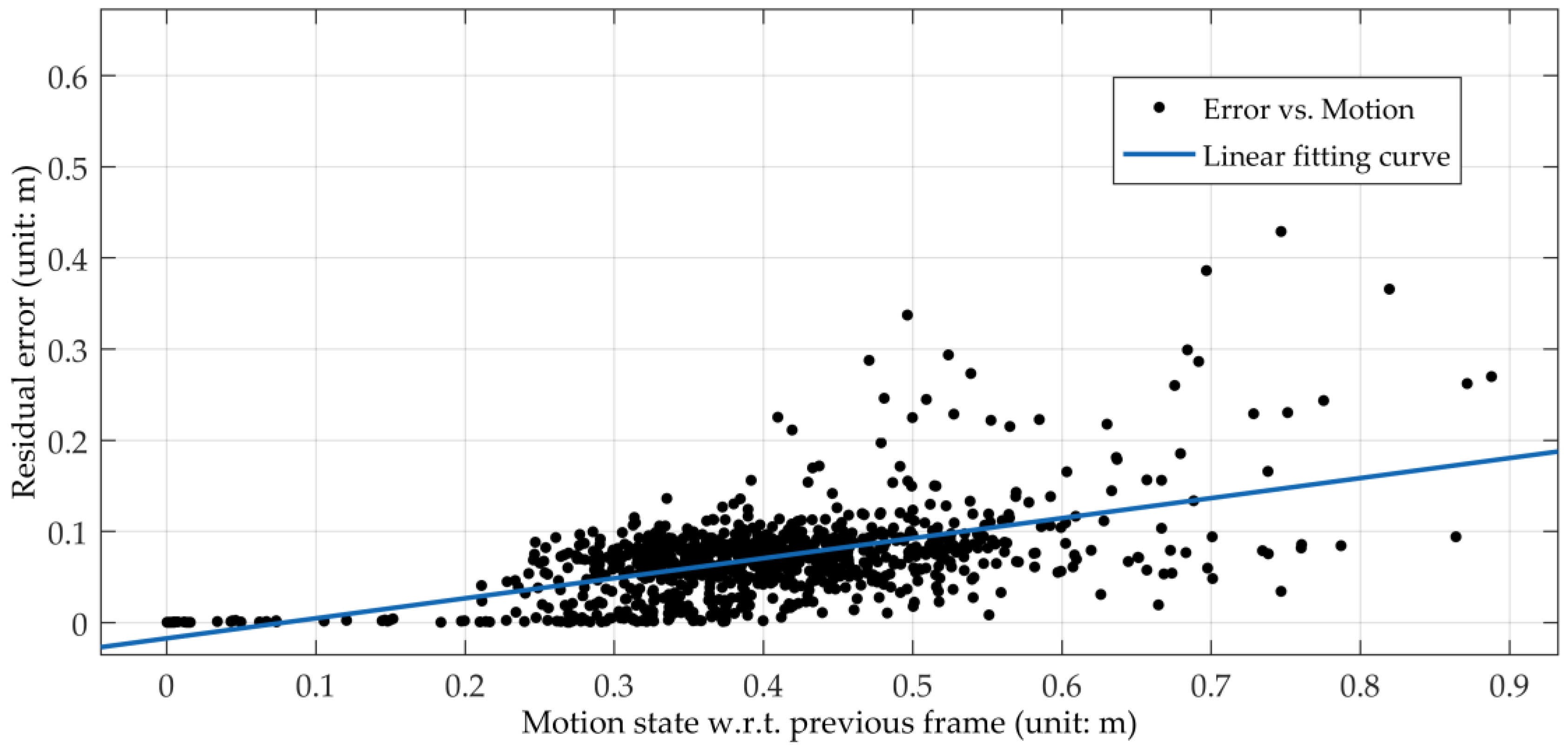
In this paper, an improved point-line feature based visual SLAM method in indoor scenes is proposed. First, unlike the traditional nonlinear least square optimization model of line segment features, an improvement of our method is the addition of the minimization of angle observation, which should be close to zero between the line segments of observation and re-projection. Compared with the traditional nonlinear least square optimization model, which includes distances between the re-projected endpoints and the observed line segment, our method combines angle observation and distance observation and shows a better performance at large turns. Second, our visual SLAM method builds an adaptive model in motion estimation so that the pose estimation model is adaptive to the motion state of a camera. With these two improvements, our visual SLAM can fully utilize point and line segment features irrespective of whether the camera is moving or turning sharply. Experimental results on EuRoC MAV datasets and sequence images captured with our stereo camera are presented to verify the accuracy and effectiveness of this improved point-line feature-based visual SLAM method in indoor scenes.
4. Conclusions
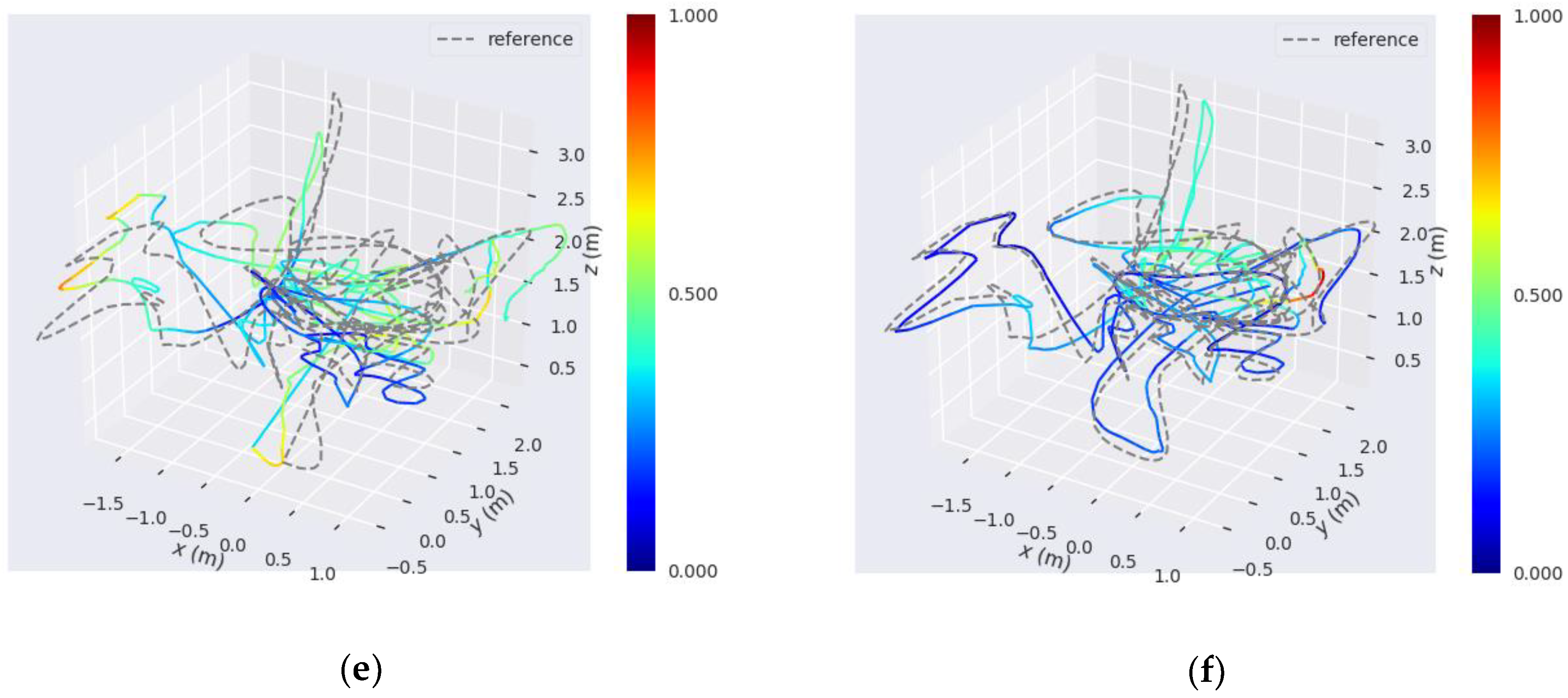
In this paper, we have presented an improved point-line feature-based visual SLAM method for indoor scenes. The proposed SLAM method has two main innovations: the angular error function added in the optimization process of line segment features, and the adaptive weighting model in iterative pose estimation. Line segment feature is a higher-dimensional feature than point features and has more structural characteristics and geometric constraints. Our optimization model of line segment features with added angular error functions can better utilize this advantage than the traditional optimization model. Furthermore, after the Hessian matrices and gradient vectors of the two kinds of features are established, our model of motion estimation, which is adaptive to the motion state of camera, is applied to build a new recombined Hessian matrix and gradient vector for iterative pose estimation.
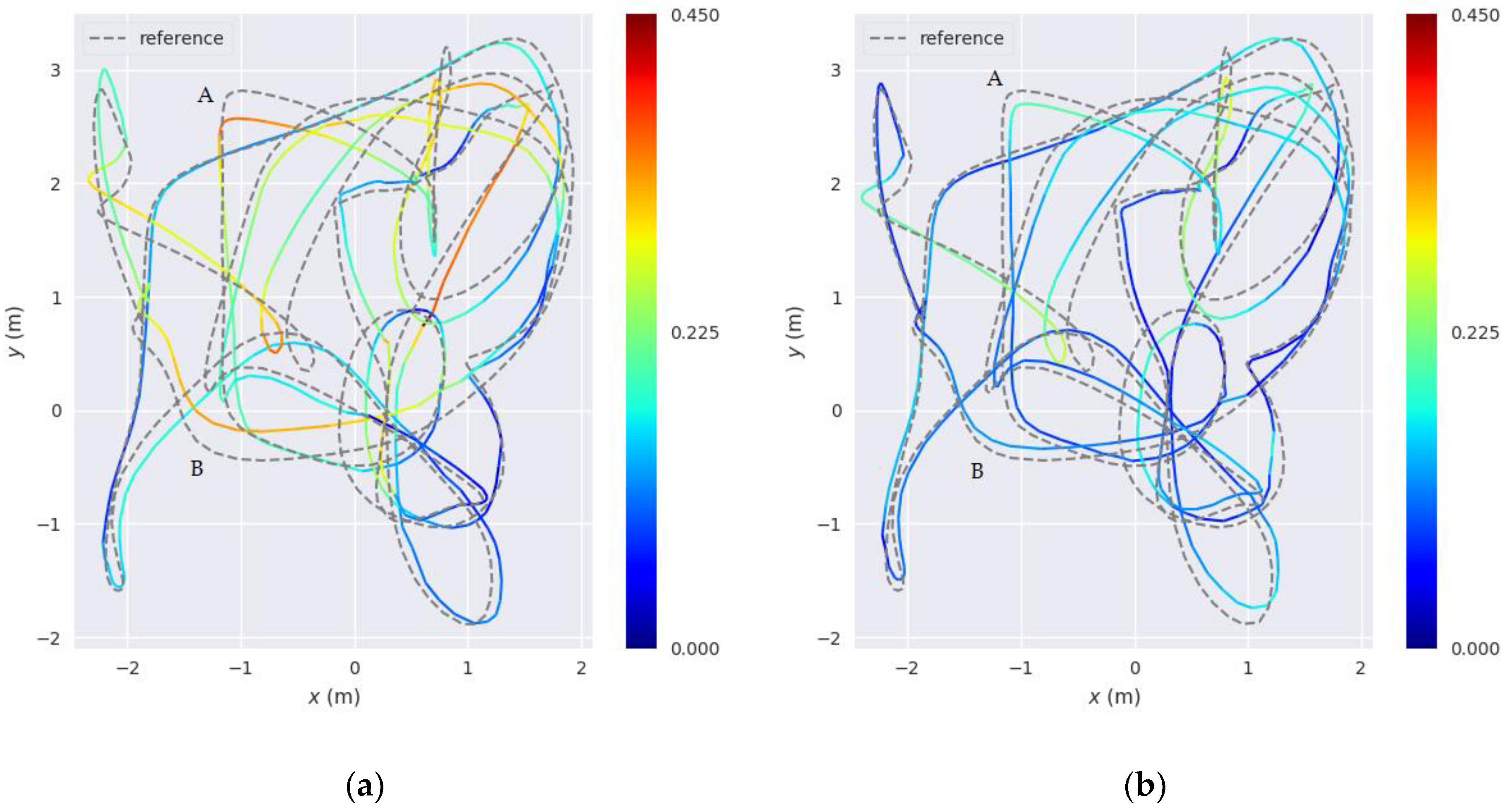
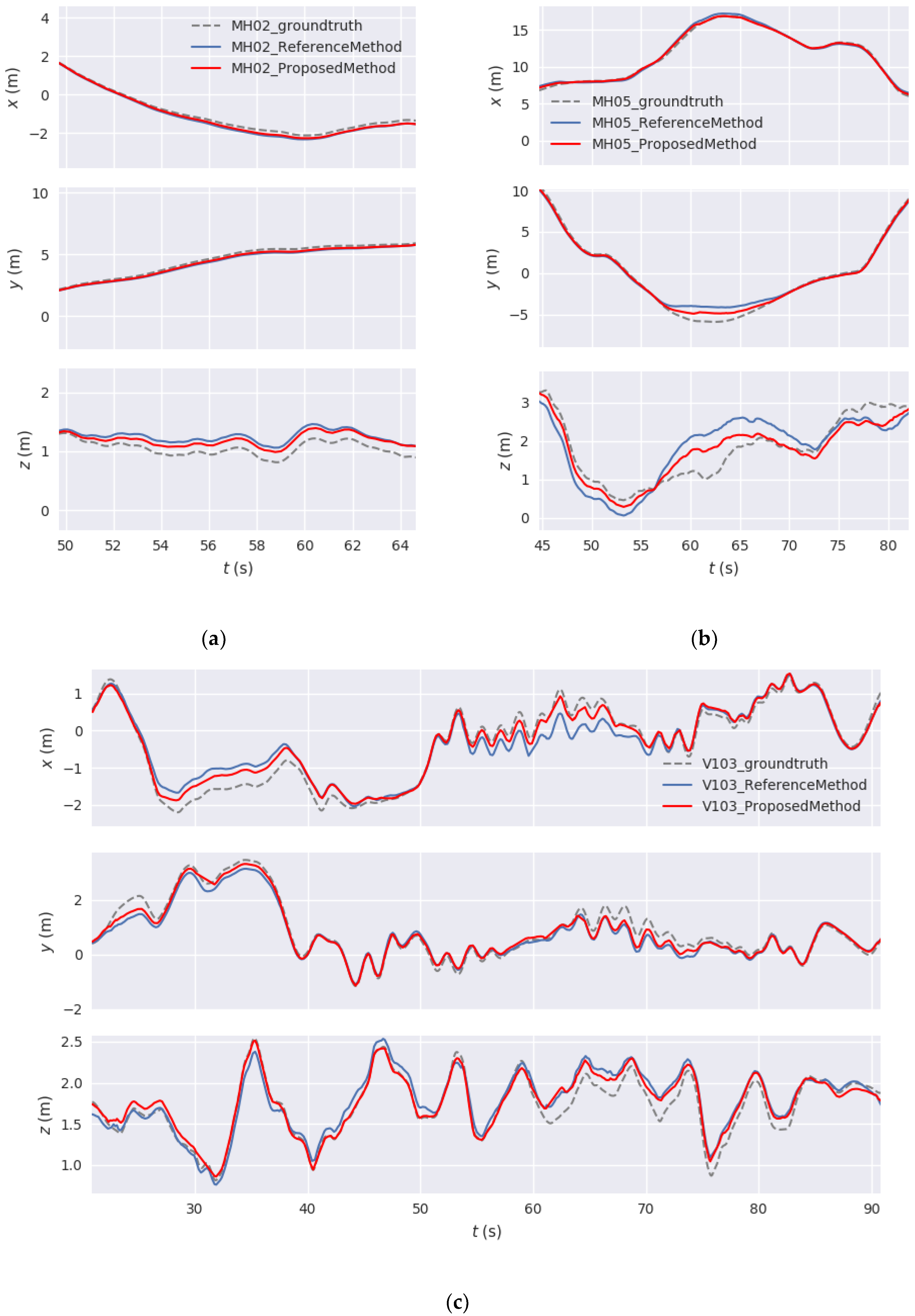
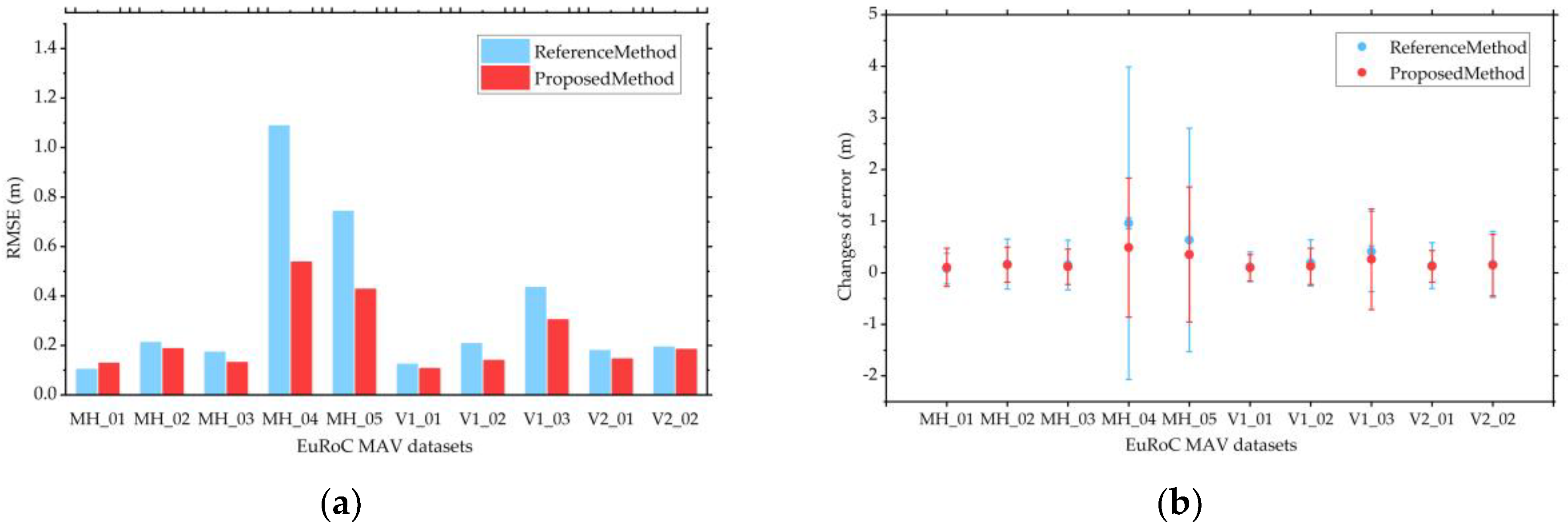
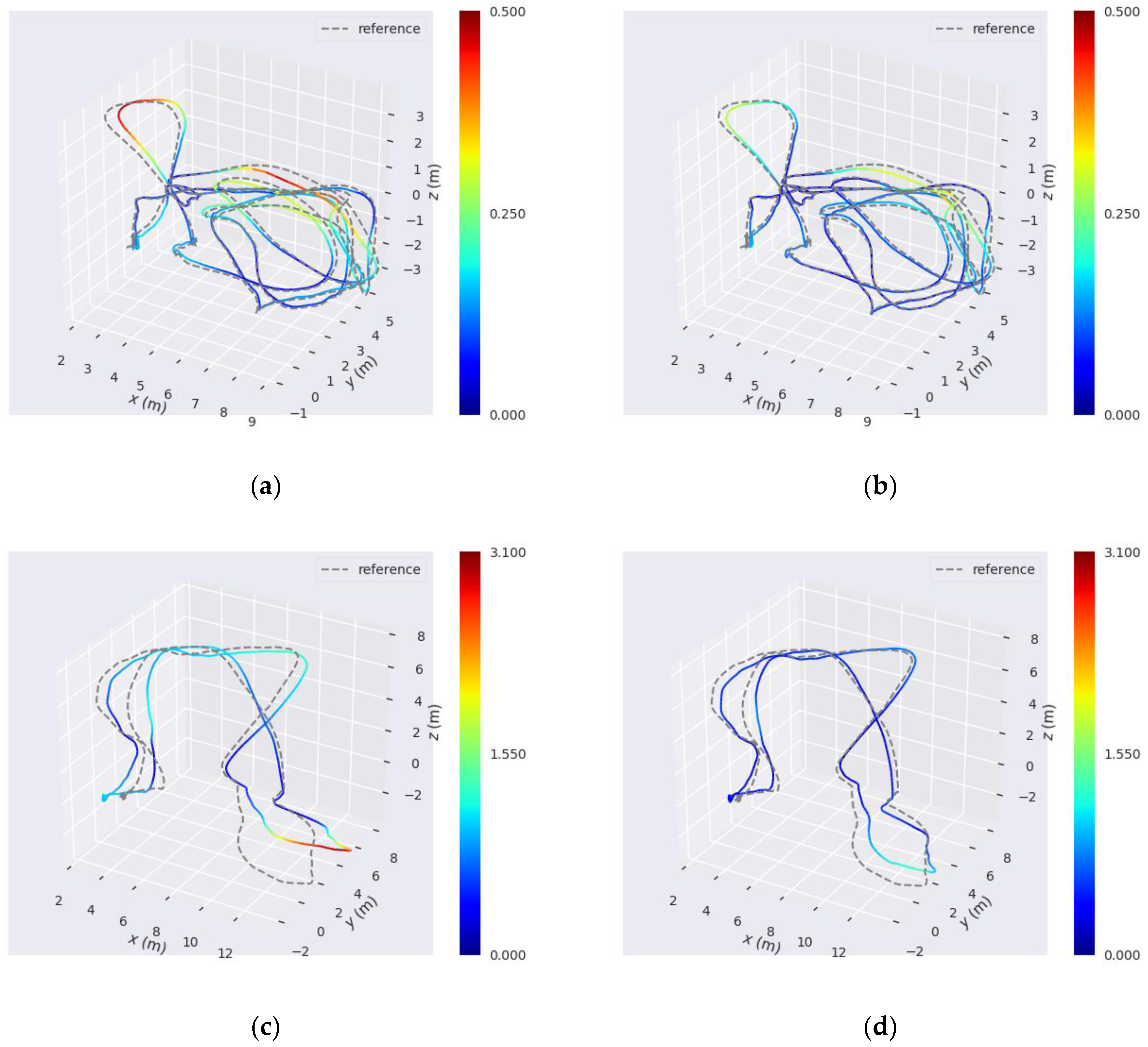
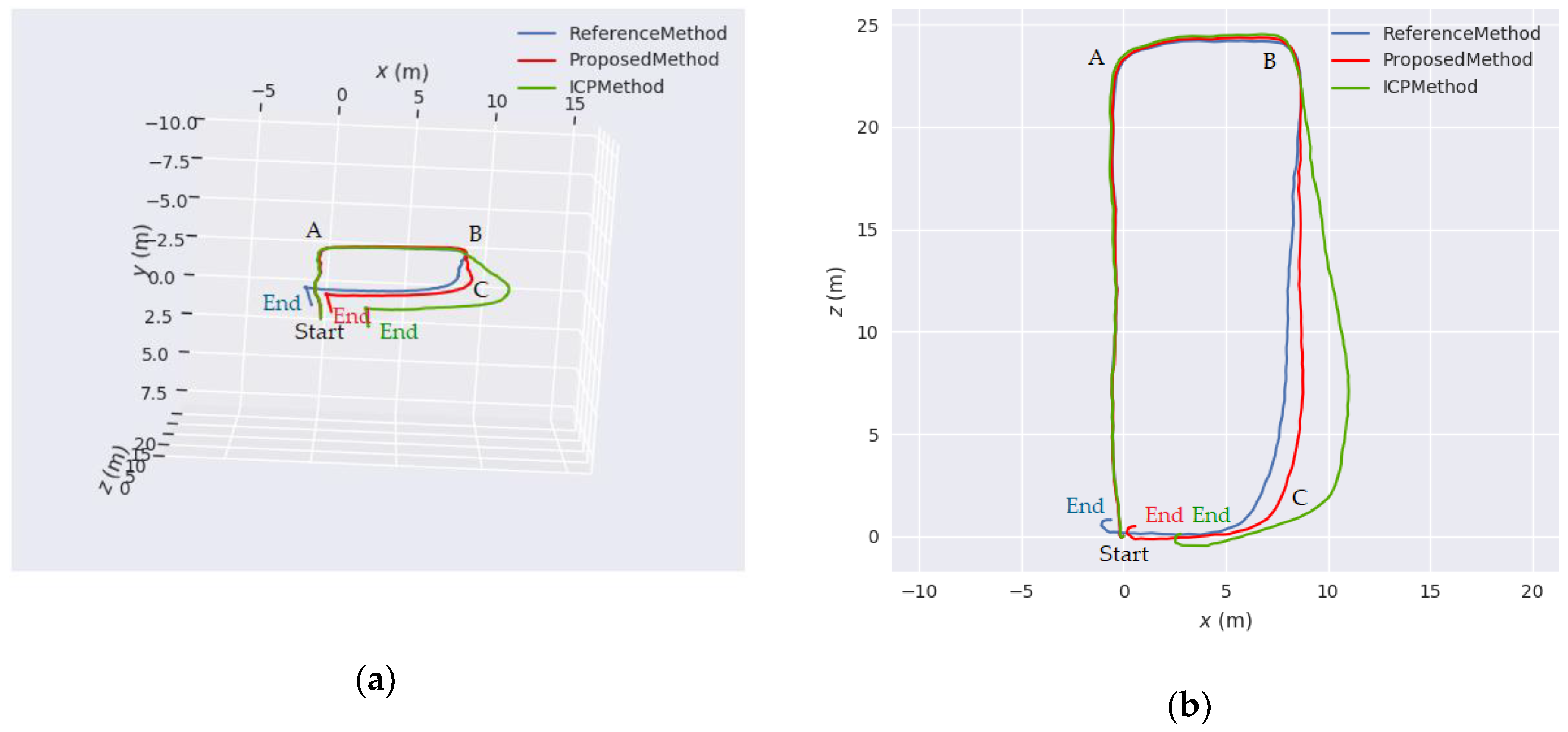
We also presented the evaluation results of the proposed SLAM method as compared with the point-line SLAM method developed in [
38,
39], which uses the traditional error model of line feature and its weighting model is based on residual errors, on both the EuRoC MAV datasets and the sequence images captured with our stereo camera. We also compared the point-to-point ICP method [
45] using the sequence images from our stereo camera. According to the experimental results, we arrive at two conclusions. First, the proposed SLAM method has more geometric constraints than the traditional point-line SLAM method and classic ICP method, because the angular error function is added to the optimization model of line segment features. Furthermore, it has good robustness and positioning accuracy at large turns. This is particularly useful for robot navigation in indoor scenes as they include many corners. Second, the adaptive weighting model for motion estimation can better utilize the advantages of point and line segment features in different motion states. Thus, it can improve the system accuracy when the camera moves with rapid rotation or severe fluctuation.
At present, we mainly used the 2D structural constraints of line segment features. In the future, we plan to further improve our SLAM method by introducing the 3D structural constraints of spatial line segment features. Furthermore, topological relations between point features and line segment features will also be considered in our method in the future, so as to better match point and line segment features in indoor environments with repeated textures.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}