1. Introduction
Remote sensing technology is a non-contact and long distance detection technology. With the development of Internet of Things (IoT) technology [
1,
2], the field of remote sensing also shows new vitality, more and more remote sensing information can be obtained, such as low-resolution remote sensing images, hyperspectral remote sensing images and so on. IoT technology plays an important role in the process of remote sensing data acquisition. Abundant remote sensing information can also greatly improve the accuracy of remote sensing image classification, as well as people’s in-depth study of remote sensing images. The acquisition of ground image information by remote sensing technology is becoming more and more fine. Hyperspectral remote sensing images have been obtained by the way of the airborne instrument on the IoT [
3,
4,
5]. The classification of hyperspectral remote sensing images has also become a hot topic for many scholars. The classification is a method to distinguish the property and distribution of ground objects according to the information characteristics of remote sensing image. It is an area worth exploring.In the field of remote sensing, the emergence of hyperspectral remote sensing image data classification technology is a revolution [
6]. Generally, an algorithm is used for the classification of remote sensing image, such as decision tree, using the data of dimensionality reduction as input signals. These algorithms have proven their advantages in a lot of experiments, but it still exists some shortages. Firstly, single classifier has its limitations, and it cannot often get better classification accuracy for a single classifier. Secondly, hyperspectral remote sensing data has a great connection with adjacent bands, so all bands are not guaranteed high accuracy at the same time [
7,
8]. According to these limitations, some new methods are needed to improve the algorithm performance. On the basis of summarizing hyperspectral remote sensing classification technology and ensemble algorithm, this paper discusses the classification problem of hyperspectral image data based on ensemble method. Some researchers have proposed that an ensemble algorithm can deal with this issue. Chi et al. [
9] proposed that an ensemble algorithm is used to deal with remote sensing image classification, and it has stability.
With the continuous development of IoT [
10], remote sensing technology is constantly updated, and remote sensing image classification methods are also improving. The method of improving the classification effect of the integrated classifier is basically carried out in two aspects: the precision of the base classifier and the diversity between the base classifiers. So a key point needs to be solved, which is how to improve the diversity. To this point, Garcia-Pedrajas [
11] set each base classifier the weights of each training phase. This method is affected by false index data and can lead to overfit. Rodriguez et al. [
12] proposed an ensemble algorithm called Rotation Forest based on Random Forest. It is to improve the diversity of members and the precision of base classifier. Rotation Forest uses the decision tree method as each independent structure classifier, and the rotation of the principal component analysis (PCA) transform in the feature space for the training of the training sample. The most important point of the collection method is the selection of base classifier. The decision tree has been used to rotate tasks because of its sensitivity to the rotation of the characteristic axis. Lee et al. [
13] demonstrated an algorithm for non-negative matrix factorization (NMF). For non-negative data, NMF achieves better results than PCA algorithm.
To deal with the issue of classification efficiency and accuracy, Huang et al. [
14] proposed extreme learning machine(ELM) neural network. ELM is a new neural network training paradigm, where a non-iteration learning method is performed. ELM randomly generates the hidden layer parameters, and are independent of training error and output power. It has better generalization performance, and has a unified analytical solution for binary, multi-class and regression problems. ELM algorithm involves least squares which is extended to kernel learning framework [
15]. Because of its excellent performance, ELM has been applied in various fields. In hyperspectral image processing field, Pal et al. [
16] applied ELM based on kernel to classify remote sensing image, and it gives a better result than support vector machine (SVM) and some other neural network frameworks [
17]. However, ELM execution speed is far less than SVM. Bazi et al. [
18] selected different algorithm for the optimal classification parameters of ELM based on kernel function.
The main contributions of this paper are as follows:
To solve the problem of hyperspectral remote sensing images data classification, this paper proposes a classification algorithm based on improved Rotation Forest, namely ROF-KELM.
To get effective remote sensing data characteristics, the proposed algorithm uses NMF to do feature extraction due to the non-negative characteristics of remote sensing image data.
To get high diversity among the base classifiers, the proposed algorithm uses Q-statistic to select base classifiers.
This paper uses AVIRIS image data, ROSIS image data and UCI data sets to do experiment to evaluate the performance of ROF-KELM, and compares with some existing neural network ensemble algorithms. The proposed algorithm has higher classification accuracy and stronger generalization performance.
The aforementioned facts motivated us to develop a novel hyperspectral remote sensing images classification method. The rest of this paper is organized as follows.
Section 2 briefly surveys related work.
Section 3 presents a brief review of several related algorithms and gives the details of the proposed ROF-KELM algorithm.
Section 4 illustrates two examples, including hyperspectral remote sensing image data and UCI data classification, to show the excellent performance of proposed ROF-KELM algorithm. Finally, discussions and conclusions are given in
Section 5.
2. Related Work
The development of IoT plays a vital role in remote sensing image classification technology [
19]. Several ensemble techniques for classification in the remote sensing imagery have been proposed till now. Borja et al. [
20] proposed a new semisupervised segmentation algorithm for hyperspectral image segmentation. Du et al. [
21] had applied firstly Rotation Forest to the classification of hyperspectral remote sensing image. At the same time, to overcome the shortage of ELM, Du et al. [
22] proposed Bagging-based and AdaBoost-based ELMs. Bao et al. [
23] proposed a new rotation forest algorithm based on weight for the classification of hyperspectral remote sensing image. Li et al. [
24] gave a brief overview of typical deep learning models, and it shows a systematic review of pixel-wise and scene-wise remote sensing image classification approaches that are based on use of deep learning.
Zhou et al. [
25] proposed a new NMF algorithm based on region structure to explore consistent data distribution in the same region while distinguishing different data structures across regions in the no-mixed data. Tsinos et al. [
26] proposed a novel unmixing method that is based on a simultaneously spare and low-rank constrained NMF. To linear hyperspectral unmixing, Wang et al. [
27] proposed a novel Group NMF method based on group low-rank constrain, combining the low rank prior of hyperspectral data with semantic information. Karoui et al. [
28] proposed two new methods, related to linear spectral unmixing techniques, and based on NMF, optimizing a new joint NMF method. Zhang et al. [
29] proposed a new algorithm about dimension reduction of hyperspectral data based on non-negative discriminative manifold learning, which yields a discriminative and low dimensional feature representation.
Mujica et al. [
30] explored the use of principal component analysis and
and Q-statistic measures to detect and distinguish damages in structures. Ansari et al. [
31] reported about Q-statistic concept to improve the performance of generalized differences algorithm based on intensity histogram for imaging functional blood vessel structures in a rodent window chamber of a mice. Rabal et al. [
32] introduced Q-statistic concepts to improve the performance of some methods based on the histogram to estimate dynamic speckle activity.
Wu et al. [
33] proposed a novel multiple features fusion method for remote sensing image classification based on ELM. Weng et al. [
34] proposed a classification method based on deep learning, which combines convolutional neural networks and ELM to improve classification performance. Han et al. [
35] proposed a remote sensing image classification algorithm using stacked autoencoder and ensemble of ELM named SAE-ELM.
3. Proposed Learning Algorithm
In this section, we describe the basic algorithm, include Rotation Forest, NMF, ELM, KELM, Q-statistic and the proposed algorithm.
3.1. Rotation Forest
Let be a training sample characterized by n features and X as the training sample data of an matrix. Let be as the class labels. Denote by the classifier in the ensemble, and F is the feature set. The steps for training classifier are handled in the following.
F is split into
K feature sets and each subset contains
number of features. Let
be the
jth,
subset of features for
, and
be the features in
frame.
is denoted as a new training set which is selected from
randomly using bootstrap algorithm. Then, we transform
to get the coefficients
, the size of
is
. A spare rotation matrix
is organized with the above coefficients
where
is rearranged to
with respect to the original feature set. Then, the training set will become
. In this case, all classifiers will be trained in parallel style. For a given test sample
, the confidence is calculated for each class by the average combination method
where
is the probability generated by the classifier
, suppose that
belongs to class
k.
Finally, is the class with the largest confidence. It selects the sample size bigger than , and aims at two aspects as follows:
3.2. Non-Negative Matrix Factorization
Remote sensing image data has non-negative characteristics. When we deal with these data in a linear notation, the decomposition must be non-negative. In this case, if we adopt a method PCA in the Rotation Forest system, some physical properties are lost which leads to the result negative. So it is effective to avoid this problem by using non-negative matrix factorization.
As a matrix decomposition algorithm, NMF gives non-negative constraints to every value in the processing matrix. Set
Q be a
matrix. Then decompose
Q into
W and
H,
W and
H are non-negative:
where
W is a
matrix as basic matrix and
H is a
matrix as coefficient matrix. When
M is bigger than
T, to get the dimension reduction, the coefficient matrix can be selected instead of the original data matrix. At the same time, due to the non-negative constrains of every value during the decomposition, there are additive joints.After decomposition,
W and
H make the feature information of the original matrix
Q well.
3.3. Extreme Learning Machine
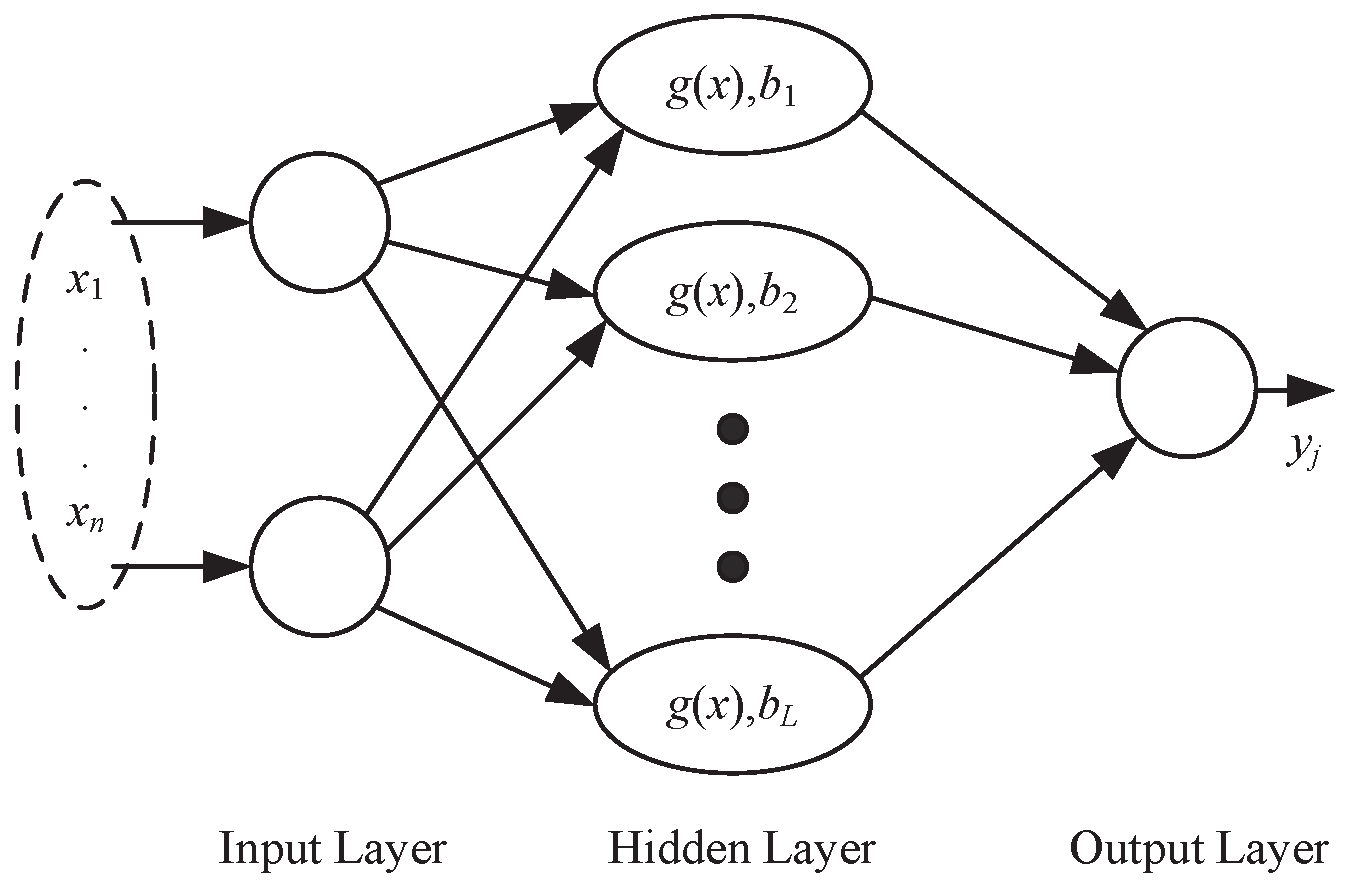
Extreme learning machine (ELM) is a new feedforward neural network training paradigm, where a non-iteration learning method is performed. Commonly, ELM consists of input layer, hidden layer, and output layer.
Figure 1 illustrated the single-hidden-layer structure of ELM. The hidden layer building process is the most different between ELM and traditional neural networks. There are usually much more nodes in ELM’s hidden layer than in traditional neural networks. Meanwhile, the beginning of training, the input weights and hidden layer biases of ELM are determined randomly and keep fixed during training process. The output weights of ELM are the only tunable weights and simple linear regression can get satisfying results. The mathematic equation of ELM is summarized as follows:
where
L is the size of the hidden neurons,
denotes the input vector,
denotes the output (only scalar case is considered in this equation),
is the input weights vector responding to the
ith hidden node,
denotes the inner product of
and
,
denotes the bias value of the
ith hidden neuron,
denotes the activation function (sigmoid function is usually used),
denotes the output weight value corresponding to the
ith hidden node and
N denotes the size of the training samples. At the very beginning, the input weights
and the bias
b are randomly valued and keep fixed in the learning procedure.
Equation (
4) can be rewritten compactly as follows:
where
,
denotes the output of ELM,
denotes the sigmoid activation function,
denotes the bias value of the
ith hidden neuron and
H is named the hidden layer output matrix.
Suppose the ELM consisting of
L nonlinear processing hidden nodes can learn the training dataset (the size is
N) correctly, so that there are
to make the following Equation (
6) hold.
where
is the target value, and
N is the number of training samples.
To simplify computation, Equation (
6) can be written as follows:
where
is the target vector. Since the input weights
and the bias
b have been randomly determined before the learning process, Equation (
7) essentially can be seen as a linear regression problem, and the smallest norm least squares solution of Equation (
7) is
where
denotes the Moore-Penrose generalized inverse of the hidden layer output matrix
H.
The hyperparameter of ELM that should be determined empirically is the number of the hidden nodes.
3.4. Kernel Extreme Learning Machine
When the feature mappings of ELM are unknown to users, that is a kernel trick is conducted, kernel extreme learning machine (KELM) is developed, and the simulation results indicate that KELM can achieve similar or better generalization performance with much faster learning speed than traditional SVR. Using Equation (
8), the output weights of ELM can be calculated one shot, avoiding the iteration of gradient decent. Nevertheless, the structure of ELM, namely the size of hidden layer that is a hyper-parameter that has very important effect on the learning performance, is very hard to choose the optimal value in a specific learning environment. Furthermore, support vector regression (SVR), as the representative of kernel methods, where kernel tricks are applied to do the inner product, are widespread used in many date processing fields. Generally speaking, ELM and SVR both are variants of single-hidden-layer feedforward network. As a result, some researchers have been studying the relationships between ELM and SVR. Without structure determination, Kernel Extreme Learning Machine (KELM) is proposed. Hereafter, we employ the expression
in place of
to explicitly indicate that the hidden layer mapping can be unknown.Consequentially, the kernel matrix of ELM is written as:
The output function
of KELM is formulated as:
where
C is regularization coefficient.
The unknown hidden layer mapping of KELM is very similar to that of SVR, and the same as SVR, the kernel should be declared. As a result, the structure of ELM is no longer need to determine. It is assumed to have the training set , where , and .
The corresponding Lagrangian dual optimization problem of Equation (
10) is:
where
is the
ith Lagrangian multiplier. The optimality conditions of Equation (
10) can be formulated as:
By substituting Equations (11) and (12) into Equation (
13), we can get
where
,
. Hence, the corresponding output function is:
Equation (
10) can be transformed to the following expression:
The same as kernel method, the type of kernel function and the corresponding kernel parameters of KELM should be carefully determined and there are no theoretical guides. Simultaneously, the hyperspectral image has complex spatial and spectral information, the represented capacity of a single kernel may not enough.
3.5. Q-Statistic
Given
N training samples, suppose there are two classifiers
,
and
are the number of samples with correct classification and wrong classification of
and
respectively,
is the number of samples with
correct classification and
wrong classification,
is the number of samples with
correct classification and
wrong classification. The Q-statistic of
and
as
is defined as:
It can be seen from Equation (
9) that the value of
is between
and 1. If the two classifiers are independent of each other, the value of
is 0. If the two classifiers tend to divide one target correctly into the same class, the value of
is positive. If two classifiers tend to divide a target into the same class, the value of
is negative. If there are
k classifiers, the Q-statistic mean of the pair classifier as
is shown in Equation (
10):
Q-statistic can better measure the differences between the base classifiers in the integration algorithm, and the calculation is simple. Therefore, the proposed algorithm selects the Q-statistic as a measure index to obtain better classification results when selecting a large difference base classifier.
3.6. ROF-KELM Algorithm
KELM as base classifier is used in Rotation Forest algorithm and then using NMF to replace PCA for extraction and become a new ensemble algorithm, which is called ROF-KELM. It improves diversity to get better classification result. The structure of ROF-KELM is show in
Figure 2.
Set be sample points described by n features. Set P be sample points set containing the training data as a matrix. Set be a vector with class labels, where takes a value from the set of class labels and c is the number of labels. Denote by base classifier number, ROF-KELM is described as belows:
Step (1) Divide the sample into two parts, 80% of the sample as training data P, 20% as test data.
Step (2) Select a bootstrap sample from P.
Step (3) Apply NMF on the training data in order to obtain the coefficient matrix.
Step (4) Arrange and re-order the NMF resulted coefficient matrix to obtain the rotation matrix, according to the sequence of Q.
Step (5) Calculate the hidden layer output matrix H using the initial kernels.
Step (6) Calculate the output weight , where .
Step (7) Use the kernel function to train ELM.
Step (8) Calculate Q-statistic through Equation (
18), selected base classifiers are the final base classifier sets, which number is
.
Step (9) Use majority voting method for final base classifiers to obtain the final classification results.
4. Simulation Results
In this section, we will give two examples to substantiate the proposed ROF-KELM for hyperspectral image classification. First, ROF-KELM is used to classify a hyperspectral image and the result is compared with some state-of-the-art classification methods. Then, ROF-KELM is tested on UCI data classification example to demonstrate the superior performance.
4.1. Simulation Results for AVIRIS Data Set
To verify the performance of ROF-KELM algorithm, we did an experiment using hyperspectral remote sensing data called AVIRIS obtained from the airborne visible infrared imaging spectroradiometer of NASA. It is from an Indian Pines forest test site in northwestern Indiana, USA. The image contains
pixels, with 200 spectral bands (104–108, 150–163, and 220). The spatial resolution is 20 m/pixel. The classification data of AVIRIS is shown in
Table 1. The schematic diagram of AVIRIS image is shown in
Figure 3.
The kernel function of KELM uses Gauss kernel . The kernel width is set to 10. The regularization parameter is also set to 10. 80% of training samples are used for training models, and the remaining 20% are used as test samples. They are used to determine the number of ensemble KELM, it generates 20 base classifiers each time for selective ensemble. Based on Q-statistic, it is determined that the number of base classifiers is 8, and gets maximum diversity. The simulation of the all algorithms on the dataset is carried out using MATLAB 2016a on a machine with an Intel Core i7, 2.26 GHz, 4 Cores CPU and 4 GB RAM.
In these experiments, the classification accuracies for the proposed algorithm are obtained and evaluated as shown in
Table 2. The overall classification accuracy(OA) is the ratio of the number of pixel categories to the total number of categories. The Kappa coefficient (Kappa) is the ratio of error reduction produced by classification and completely random classification. The value of OA and Kappa from the proposed ROF-KELM algorithm have reached 0.9457 and 0.9322, better than the comparing algorithms of Bagging [
36], Random Forest [
37], Rotation Forest [
13], SVM [
22] and KELM [
16]. Similarly, the high overall classification accuracy indicates that the algorithm has good effects in classifying AVIRIS images, and the high Kappa coefficient indicates good stability of the algorithm. Therefore, the proposed ROF-KELM algorithm performs well in the classification processing of AVIRIS images.
Eighty percent of all sample data was used as training data to classify the whole image. The classification figure is shown in
Figure 4. From the classification results of 6 algorithms, it can be seen that ROF-KELM algorithm has obvious advantages over the other 5 algorithms in classifying class 10 and class 11. In contrast to class 10, it can be seen that ROF-KELM classification result has the least wrong sample points. Rotation Forest classification result has the most wrong sample points. In contrast to class 11, it can be seen that the classification result of Bagging, Random Forest and ROF-KELM are relatively sparse, and the error sample points of the classification result of KELM are denser in the small area. From the number of error sample point, the error rate of ROF-KELM algorithm is the lowest. The advantages of the other categories are not particularly obvious. From the result analysis, the spatial information of class 10 and class 11 is more suitable for ROF-KELM algorithm.
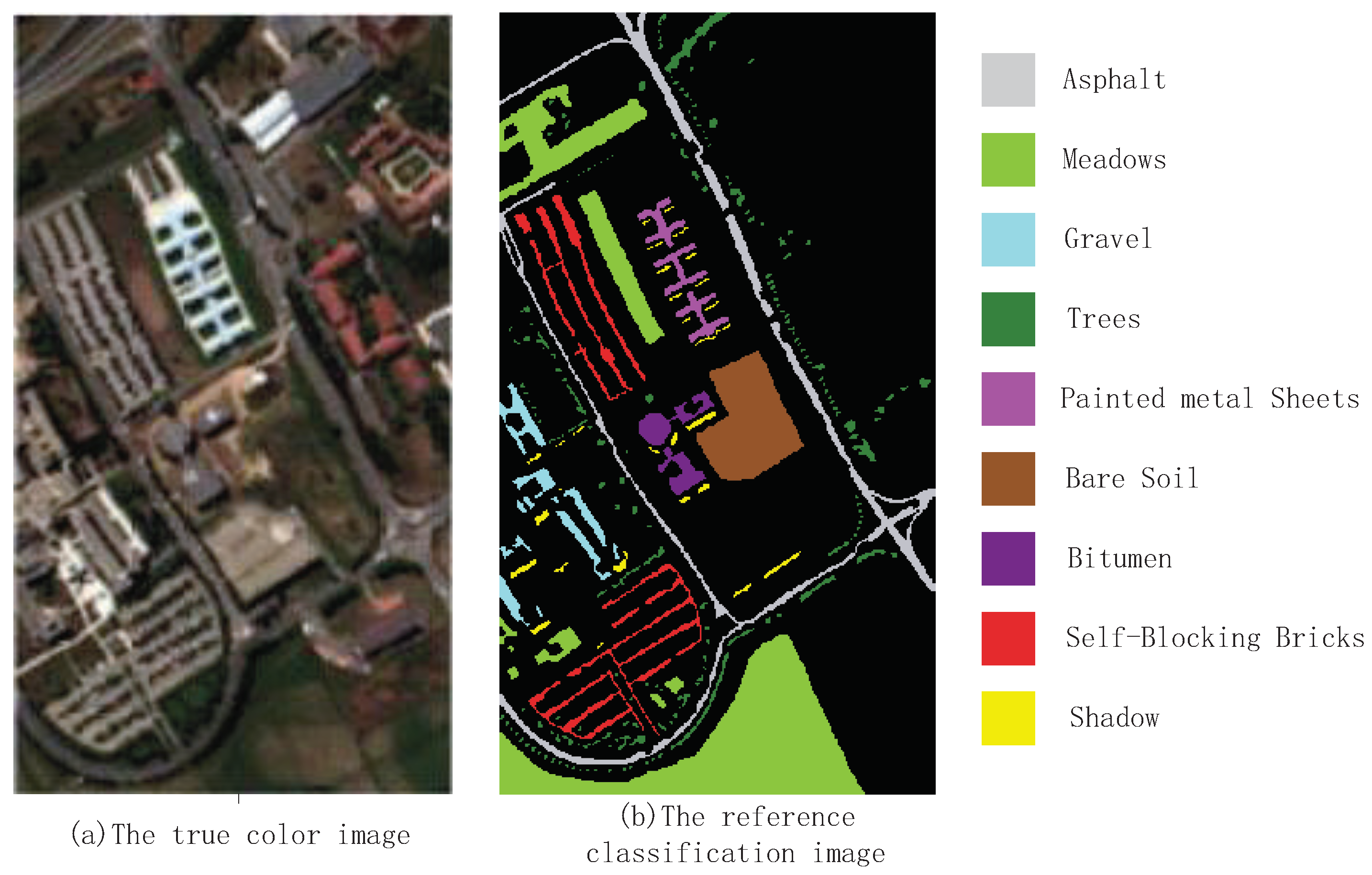
4.2. Simulation Results for ROSIS Data Sets
The second hyperspectral remote sensing image is about the University of Pavia remote sensed by Reflective Optices System Imaging Spectrometer(ROSIS). It exists 115 spectral bands across 0.43 to 0.86
m spectral range in the original hyperspectral remote sensing image. After preprocessing, 12 bad bands are removed and 103 bands are remained in this simulation. The University of Pavia image consists of pixels and the spatial resolution of is 1.3 m per pixel. There are 9 ground-truth classes in the University of Pavia image, and 42776 samples are labeled. The details of the University of Pavia image labeled samples are shown in
Table 3. From
Table 3, There are about more than 1000 samples for every class of the University of Pavia image. The schematic diagram of ROSIS image is shown in
Figure 5.
In these experiments, the classification accuracies for the proposed algorithm are obtained and evaluated as shown in
Table 4. The classification overall accuracy and Kappa coefficient from the proposed ROF-KELM algorithm have reached 0.9524 and 0.9351, better than the comparing algorithms of Bagging, Random Forest, Rotation Forest, SVM, and KELM. The high overall classification accuracy indicates that the algorithm has good effects in classifying ROSIS images, and the high Kappa coefficient indicates good stability of the algorithm. Therefore, the proposed ROF-KELM algorithm performs well in the classification processing of ROSIS images.
As it can be seen from
Figure 6, compared to class 2, the KELM algorithm has a large density of local error data points. It can be seen that the classification effect of KELM algorithm to class 2 data is not as good as the other 5 algorithms. Compared to class 6, it can be seen that KELM and SVM algorithms have a large range of data points wrong into class 2 data, and the over fitting is serious and does not get good expected results, while KELM and ROF-KELM algorithm also have local error, and the error rate is low, and the comparison can be seen that the classificaiton efficiency of ROF-KELM to class 6 is better than the other algorithms. From the whole sample classification, compared with the other 5 algorithms, ROF-KELM algorithm is more robust in the data processing in each class, and is more adaptable to different types of data, and the result of higher precision are obtained.
4.3. Simulation Results for UCI Data Sets
To further verify the effectiveness of the proposed algorithm ROF-KELM, which is compared to the UCI databases [
38], and 4 sets of UCI data are selected. The properties of each group are shown in
Table 5. In the experiment, ROF-KELM is compared with the classical algorithm Bagging [
36], Adaboost [
12] and Rotation Forest [
13] respectively, the parameter selection is the same as the experiment A, the results are shown as
Table 6.
As can be seen from
Table 6, the overall accuracy of the proposed algorithm reaches respectively 0.9239, 0.8952, 0.8325, 0.7891. It has the highest accuracy in the 4 sets of UCI data. It shows that the generalization performance of the proposed algorithm is stronger. It not only has good classification results for hyperspectral remote sensing data, but also has good classification results for many data with many dimensions and classes.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}