An Adaptive Parallel Processing Strategy for Complex Event Processing Systems over Data Streams in Wireless Sensor Networks


Abstract
:1. Introduction
2. Related Work
3. Preliminaries
3.1. Event Model
3.2. Nested Pattern Query Language
- PATTERN (event expression: composite event expressed by the nesting of SEQ and AND, which can have negative event type(s), and their combination operators)
- WHERE (qualification: value constraint)
- WITHIN (window: time constraint)
3.3. Pattern Operators and Their Formal Semantics
4. System Model
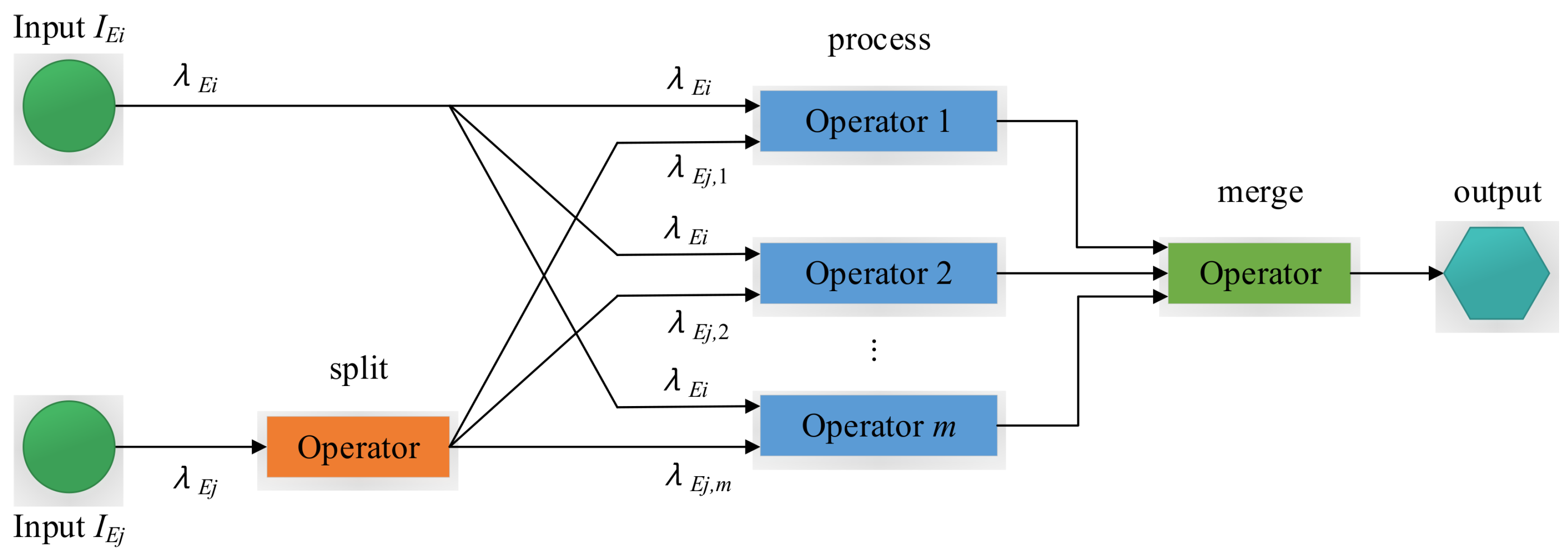
4.1. Parallelization Model
- Split: The split operator is to split an input stream into parallel sub-streams. The split operator outputs the incoming events to a number of back-end pattern operators by one of the event splitting policies from Section 4.2, where this selected event splitting policy is estimated by the adaptive parallel processing strategy that will be explained in Section 5.
- Process: The process operator performs the events from the output of the front-end operators. The multiple process operators with the same function can be executed in parallel.
- Merge: The merge operator consumes the output events from the process operators to generate the final output events. The merge operator by default simply forwards the output events to its output port.
4.2. Event Splitting Policies
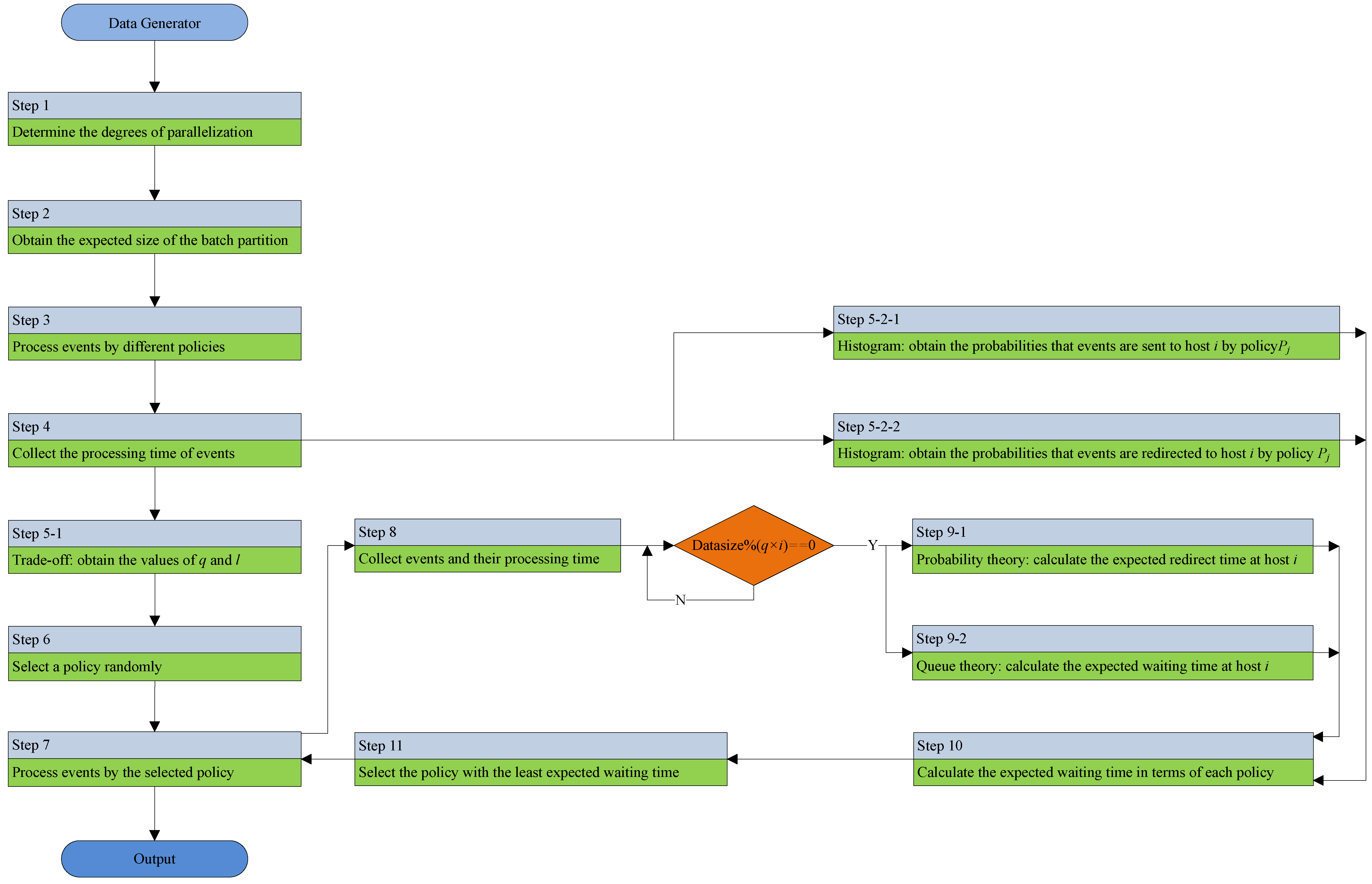
5. Adaptive Parallel Processing Strategy
5.1. Degrees of Parallelization
5.2. Expected Size of the Batch Partition
5.3. Event Processing Time Collection
5.4. Trade-Off between the Estimation Accuracy and the Processing Time
5.5. On-Line Selection of Event Splitting Policies
6. Experimental Evaluation
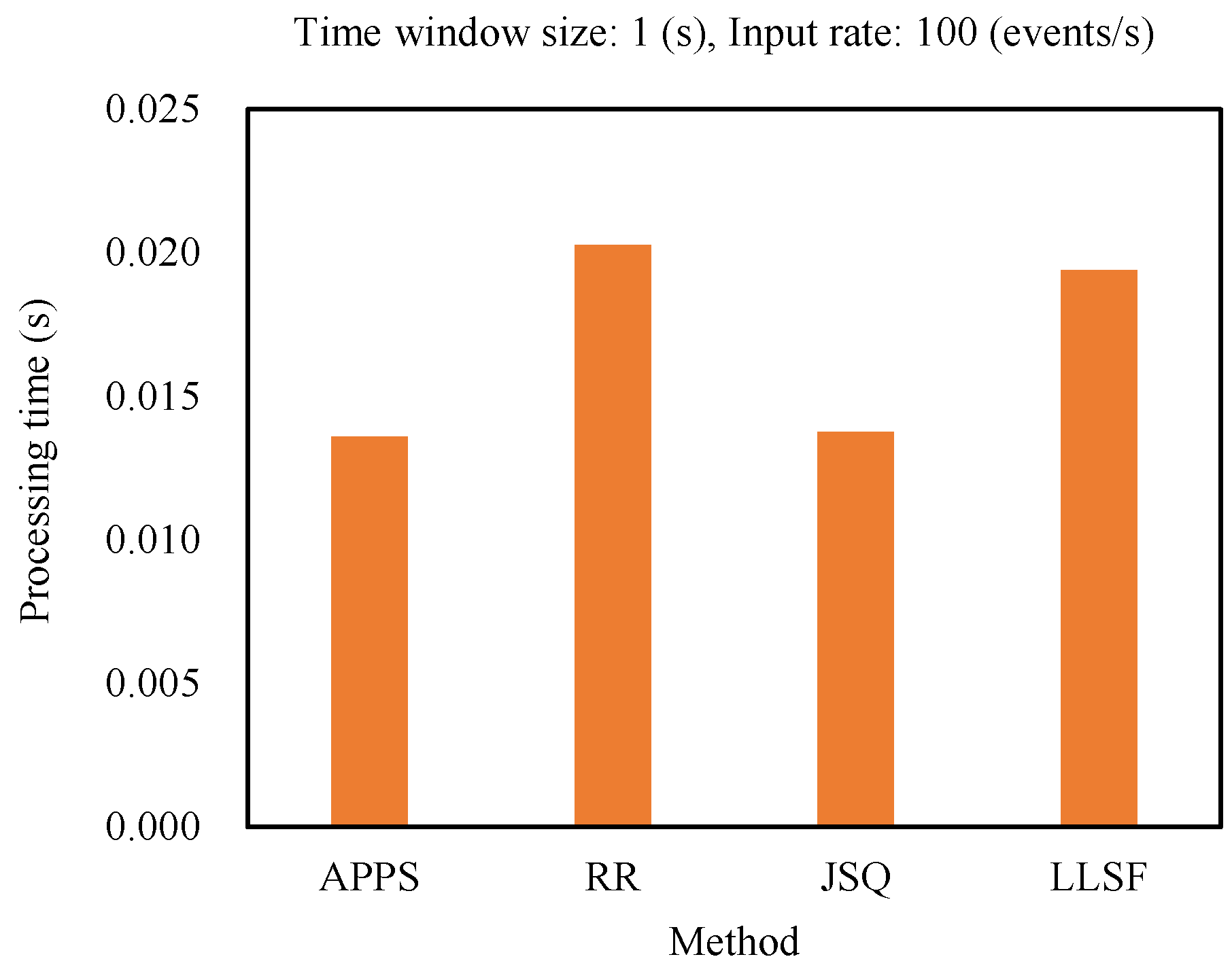
6.1. Comparing the Processing Time of the Methods
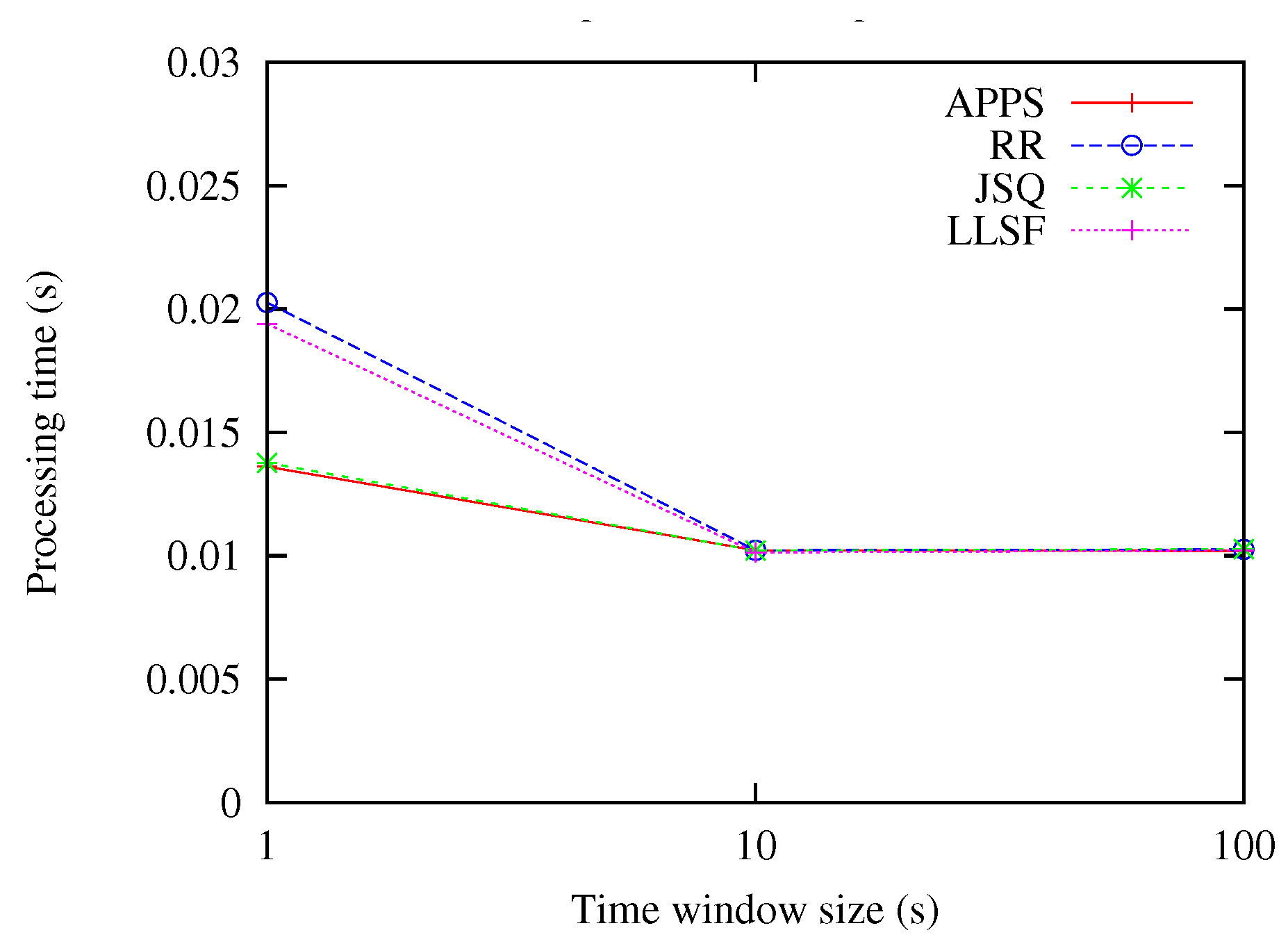
6.2. Varying the Time Window Sizes of Operators
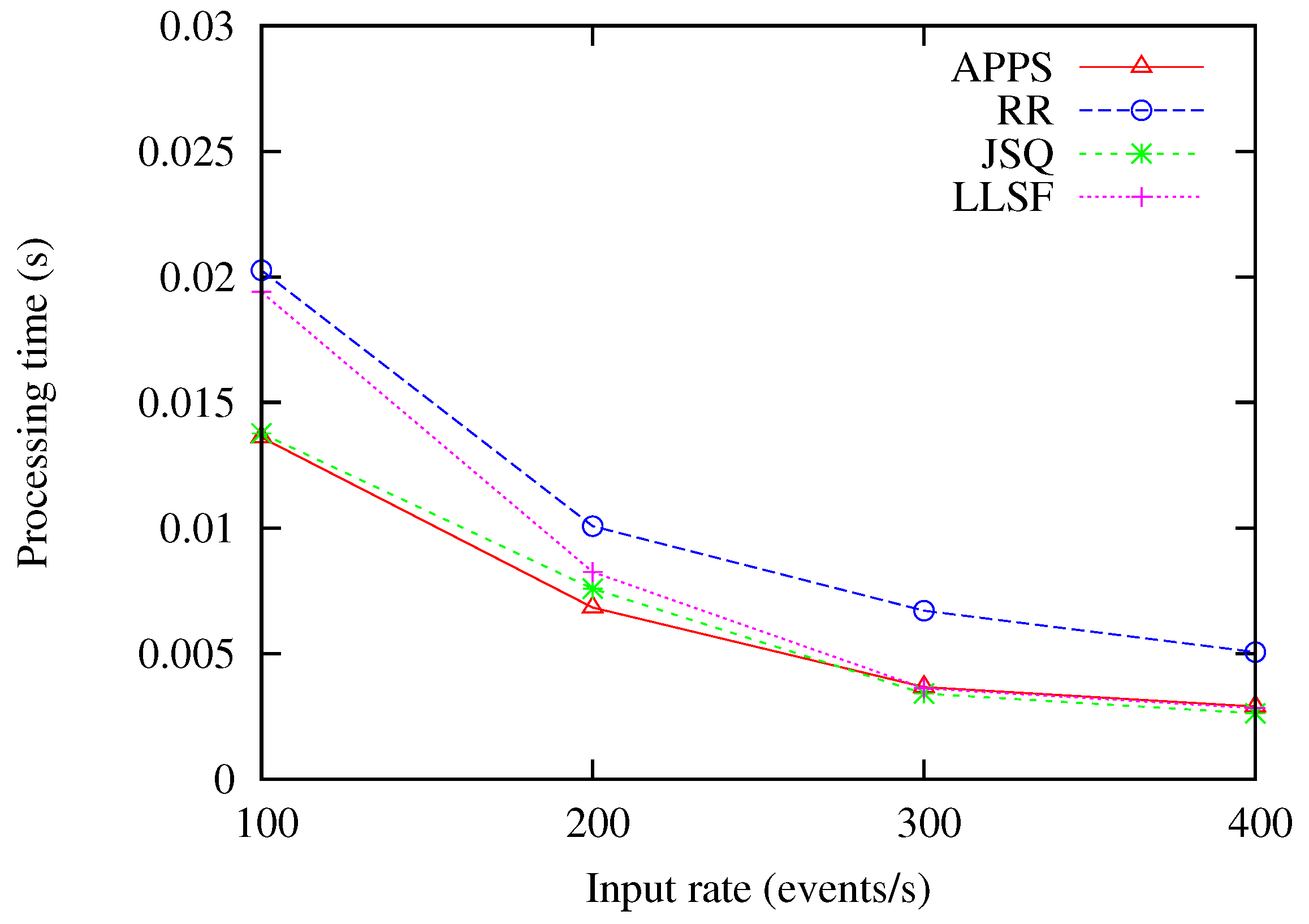
6.3. Varying the Input Rates of Streams
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, I.; Park, J.H. A scalable and adaptive video streaming framework over multiple paths. Multimed. Tools Appl. 2010, 47, 207–224. [Google Scholar] [CrossRef]
- Ding, J.W.; Deng, D.J.; Lo, Y.K.; Park, J.H. Perceptual quality based error control for scalable on-demand streaming in next-generation wireless networks. Telecommun. Syst. 2013, 52, 445–459. [Google Scholar] [CrossRef]
- Jang, J.; Jung, I.Y.; Park, J.H. An effective handling of secure data stream in IoT. Appl. Soft Comput. 2018, 68, 811–820. [Google Scholar] [CrossRef]
- Chen, M.Y.; Wu, M.N.; Chen, C.C.; Chen, Y.L.; Lin, H.E. Recommendation-aware smartphone sensing system. J. Appl. Res. Technol. 2014, 12, 1040–1050. [Google Scholar] [CrossRef]
- Boubeta-Puig, J.; Ortiz, G.; Medina-Bulo, I. A model-driven approach for facilitating user-friendly design of complex event patterns. Expert Syst. Appl. 2014, 41, 445–456. [Google Scholar] [CrossRef] [Green Version]
- Macià, H.; Valero, V.; Díaz, G.; Boubeta-Puig, J.; Ortiz, G. Complex event processing modeling by prioritized colored Petri nets. IEEE Access 2016, 4, 7425–7439. [Google Scholar] [CrossRef]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. (CSUR) 2012, 44, 15. [Google Scholar] [CrossRef]
- SASE. Available online: http://avid.cs.umass.edu/sase/ (accessed on 12 September 2017).
- Cayuga. Available online: http://www.cs.cornell.edu/bigreddata/cayuga/ (accessed on 12 September 2017).
- PIPES. Available online: http://dbs.mathematik.uni-marburg.de/Home/Research/Projects/PIPES/ (accessed on 12 September 2017).
- Coral8. Available online: http://www.complexevents.com/coral8-inc/ (accessed on 12 September 2017).
- Streambase. Available online: https://www.tibco.com/products/tibco-streambase (accessed on 12 September 2017).
- Oracle CEP. Available online: https://www.oracle.com/technetwork/middleware/complex-event-processing/overview/index.html (accessed on 12 September 2017).
- CEP for Hospital. Available online: https://stanfordhealthcare.org/search-results.clinics.html (accessed on 12 September 2017).
- Boubeta-Puig, J.; Ortiz, G.; Medina-Bulo, I. ModeL4CEP: Graphical domain-specific modeling languages for CEP domains and event patterns. Expert Syst. Appl. 2015, 42, 8095–8110. [Google Scholar] [CrossRef]
- Kim, K.; Kim, H.; Kim, S.K.; Jung, J.Y. i-RM: An intelligent risk management framework for context-aware ubiquitous cold chain logistics. Expert Syst. Appl. 2016, 46, 463–473. [Google Scholar] [CrossRef]
- Xiao, F.; Aritsugi, M.; Wang, Q.; Zhang, R. Efficient processing of multiple nested event pattern queries over multi-dimensional event streams based on a triaxial hierarchical model. Artif. Intell. Med. 2016, 72, 56–71. [Google Scholar] [CrossRef] [PubMed]
- Safaei, A.A.; Haghjoo, M.S. Parallel processing of continuous queries over data streams. Distrib. Parallel Databases 2010, 28, 93–118. [Google Scholar] [CrossRef]
- Han, W.S.; Kwak, W.; Lee, J.; Lohman, G.M.; Markl, V. Parallelizing query optimization. Proc. VLDB Endow. 2008, 1, 188–200. [Google Scholar] [CrossRef] [Green Version]
- Hirzel, M. Partition and compose: Parallel complex event processing. In Proceedings of the 6th ACM International Conference on Distributed Event-Based Systems, Berlin, Germany, 16–20 July 2012; pp. 191–200. [Google Scholar]
- Johnson, T.; Muthukrishnan, M.S.; Shkapenyuk, V.; Spatscheck, O. Query-aware partitioning for monitoring massive network data streams. In Proceedings of the 24th International Conference on Data Engineering, Vancouver, BC, Canada, 9–12 June 2008; pp. 1135–1146. [Google Scholar]
- Liu, B.; Rundensteiner, E.A. Revisiting pipelined parallelism in multi-join query processing. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 829–840. [Google Scholar]
- Chaiken, R.; Jenkins, B.; Larson, P.Å.; Ramsey, B.; Shakib, D.; Weaver, S.; Zhou, J. SCOPE: Easy and efficient parallel processing of massive data sets. Proc. VLDB Endow. 2008, 1, 1265–1276. [Google Scholar] [CrossRef]
- Upadhyaya, P.; Kwon, Y.; Balazinska, M. A latency and fault-tolerance optimizer for online parallel query plans. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 241–252. [Google Scholar]
- Safaei, A.A.; Haghjoo, M.S. Dispatching stream operators in parallel execution of continuous queries. J. Supercomput. 2012, 61, 619–641. [Google Scholar] [CrossRef]
- Brenna, L.; Gehrke, J.; Hong, M.; Johansen, D. Distributed event stream processing with non-deterministic finite automata. In Proceedings of the Third ACM International Conference on Distributed Event-Based Systems, Nashville, TN, USA, 6–9 July 2009; p. 3. [Google Scholar]
- Akdere, M.; Çetintemel, U.; Tatbul, N. Plan-based complex event detection across distributed sources. Proc. VLDB Endow. 2008, 1, 66–77. [Google Scholar] [CrossRef] [Green Version]
- Xiao, F.; Aritsugi, M. Nested pattern queries processing optimization over multi-dimensional event streams. In Proceedings of the 37th Annual Computer Software and Applications Conference, Kyoto, Japan, 22–26 July 2013; pp. 74–83. [Google Scholar]
- Carney, D.; Çetintemel, U.; Cherniack, M.; Convey, C.; Lee, S.; Seidman, G.; Stonebraker, M.; Tatbul, N.; Zdonik, S. Monitoring streams: A new class of data management applications. In Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23August 2002; pp. 215–226. [Google Scholar]
- Xiao, F.; Kitasuka, T.; Aritsugi, M. Economical and fault-tolerant load balancing in distributed stream processing systems. IEICE Trans. Inf. Syst. 2012, 95, 1062–1073. [Google Scholar] [CrossRef]
- Suhothayan, S.; Gajasinghe, K.; Loku Narangoda, I.; Chaturanga, S.; Perera, S.; Nanayakkara, V. Siddhi: A second look at complex event processing architectures. In Proceedings of the 2011 ACM Workshop on Gateway Computing Environments, Seattle, WA, USA, 18 November 2011; pp. 43–50. [Google Scholar]
- Wu, S.; Kumar, V.; Wu, K.L.; Ooi, B.C. Parallelizing stateful operators in a distributed stream processing system: How, should you and how much? In Proceedings of the 6th ACM International Conference on Distributed Event-Based Systems, Berlin, Germany, 16–20 July 2012; pp. 278–289. [Google Scholar]
- Balkesen, C.; Dindar, N.; Wetter, M.; Tatbul, N. RIP: Run-based intra-query parallelism for scalable complex event processing. In Proceedings of the 7th ACM International Conference on Distributed Event-based Systems, Arlington, TX, USA, 29 June–3 July 2013; pp. 3–14. [Google Scholar]
- Brito, A.; Martin, A.; Knauth, T.; Creutz, S.; Becker, D.; Weigert, S.; Fetzer, C. Scalable and low-latency data processing with stream mapreduce. In Proceedings of the IEEE Third International Conference on Cloud Computing Technology and Science (CloudCom), Athens, Greece, 29 November–1 December 2011; pp. 48–58. [Google Scholar]
- Schneider, S.; Hirzel, M.; Gedik, B.; Wu, K.L. Auto-parallelizing stateful distributed streaming applications. In Proceedings of the 21st international conference on Parallel Architectures and Compilation Techniques, Minneapolis, MN, USA, 19–23 September 2012; pp. 53–64. [Google Scholar]
- De Matteis, T.; Mencagli, G. Parallel patterns for window-based stateful operators on data streams: An algorithmic skeleton approach. Int. J. Parallel Program. 2017, 45, 382–401. [Google Scholar] [CrossRef]
- Liu, M.; Rundensteiner, E.; Greenfield, K.; Gupta, C.; Wang, S.; Ari, I.; Mehta, A. E-Cube: Multi-dimensional event sequence analysis using hierarchical pattern query sharing. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 889–900. [Google Scholar]
- Liu, M.; Rundensteiner, E.; Dougherty, D.; Gupta, C.; Wang, S.; Ari, I.; Mehta, A. High-performance nested CEP query processing over event streams. In Proceedings of the 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 123–134. [Google Scholar]
- Dattatreya, G.R. Performance Analysis of Queuing and Computer Networks; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Newell, C. Applications of Queueing Theory; Springer Science & Business Media: Berlin, Germany, 2013; Volume 4. [Google Scholar]
- Saaty, T.L. Elements of Queueing Theory: With Applications; McGraw-Hill: New York, NY, USA, 1961; Volume 34203. [Google Scholar]
- Ficco, M.; Esposito, C.; Palmieri, F.; Castiglione, A. A coral-reefs and game theory-based approach for optimizing elastic cloud resource allocation. Future Gen. Comput. Syst. 2018, 78, 343–352. [Google Scholar] [CrossRef]
- Ficco, M.; Pietrantuono, R.; Russo, S. Aging-related performance anomalies in the apache storm stream processing system. Future Gen. Comput. Syst. 2018, 86, 975–994. [Google Scholar] [CrossRef]
- Yin, L.; Deng, X.; Deng, Y. The negation of a basic probability assignment. IEEE Trans. Fuzzy Syst. 2018. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Hewage, K.; Sadiq, R. Generating Z-number based on OWA weights using maximum entropy. Int. J. Intell. Syst. 2018, 33, 1745–1755. [Google Scholar] [CrossRef]
- Fei, L.; Deng, Y. A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int. J. Intell. Syst. 2018. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2018. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| event splitting policy j | |
| the expected server utilization | |
| threshold of the expected server utilization | |
| m | degree of parallelization of servers |
| number of events served per unit time | |
| input rate of input stream | |
| the segment of input stream | |
| the batch partition of a segment | |
| i | number of events of a batch partition |
| q | number of batch partitions of a segment |
| average time devoted to processing i number of events | |
| average time devoted to re-directing the event | |
| among servers | |
| average time devoted to processing segments | |
| average estimation time devoted for i number of events | |
| estimation time devoted to obtaining optimal for | |
| expected redirect time for the events at host i | |
| expected waiting time for the events at host i | |
| expected waiting time for policy |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, F.; Aritsugi, M. An Adaptive Parallel Processing Strategy for Complex Event Processing Systems over Data Streams in Wireless Sensor Networks. Sensors 2018, 18, 3732. https://doi.org/10.3390/s18113732
Xiao F, Aritsugi M. An Adaptive Parallel Processing Strategy for Complex Event Processing Systems over Data Streams in Wireless Sensor Networks. Sensors. 2018; 18(11):3732. https://doi.org/10.3390/s18113732
Chicago/Turabian StyleXiao, Fuyuan, and Masayoshi Aritsugi. 2018. "An Adaptive Parallel Processing Strategy for Complex Event Processing Systems over Data Streams in Wireless Sensor Networks" Sensors 18, no. 11: 3732. https://doi.org/10.3390/s18113732
APA StyleXiao, F., & Aritsugi, M. (2018). An Adaptive Parallel Processing Strategy for Complex Event Processing Systems over Data Streams in Wireless Sensor Networks. Sensors, 18(11), 3732. https://doi.org/10.3390/s18113732