1. Introduction
In the field of machine vision and robotics research, the feature detection has attracted the attention of scholars at home and abroad. This research focuses on the robustness and the invariance to image noise, scale, translation and rotation transformations. Many feature detector methods are available in many fields [
1,
2,
3,
4], such as robot navigation, pattern recognition, image and video detection, target tracking, scene classification, texture recognition.
In recent years, many new feature description algorithms have been proposed under the premise of satisfying the invariance of rotation, scale transformation and noise, such as Scale-invariant Feature Transform (SIFT) [
5,
6], Speeded Up Robust Feature (SURF) [
7,
8], Binary Robust Independent Elementary Features (BRIEF) [
9,
10], and Binary Robust Invariant Scalable Keypoints (BRISK) [
11,
12]. The BRISK algorithm is a feature point detection and description algorithm with scale invariance and rotation invariance. It constructs the feature descriptor of the local image through the gray scale relationship of random point pairs in the neighborhood of the local image, and obtains the binary feature descriptor. Compared with the traditional algorithm, the matching speed of BRISK is faster and the storage memory is lower, but the robustness of BRISK is reduced.
In recent years, the RGB-D sensors represented by Kinect of Microsoft are spreading quickly as the RGB-D sensor can obtain the RGB image and depth image simultaneously. Compared to stereo cameras and Time-Of-Flight cameras, it has many advantages such as low price, information integrity and complex environmental adaptation. So, the RGB-D SLAM based on RGB-D images has quickly become a research focus. But algorithms only based on texture information of 2D image are widely used, such as the SURF algorithm, SIFT algorithm, BRIEF algorithm and BRISK algorithm. These don’t take the depth information of the RGB-D image into account. In this paper, the BRISK algorithm will be improved using the depth information of the RGB-D image and intensity centroid.
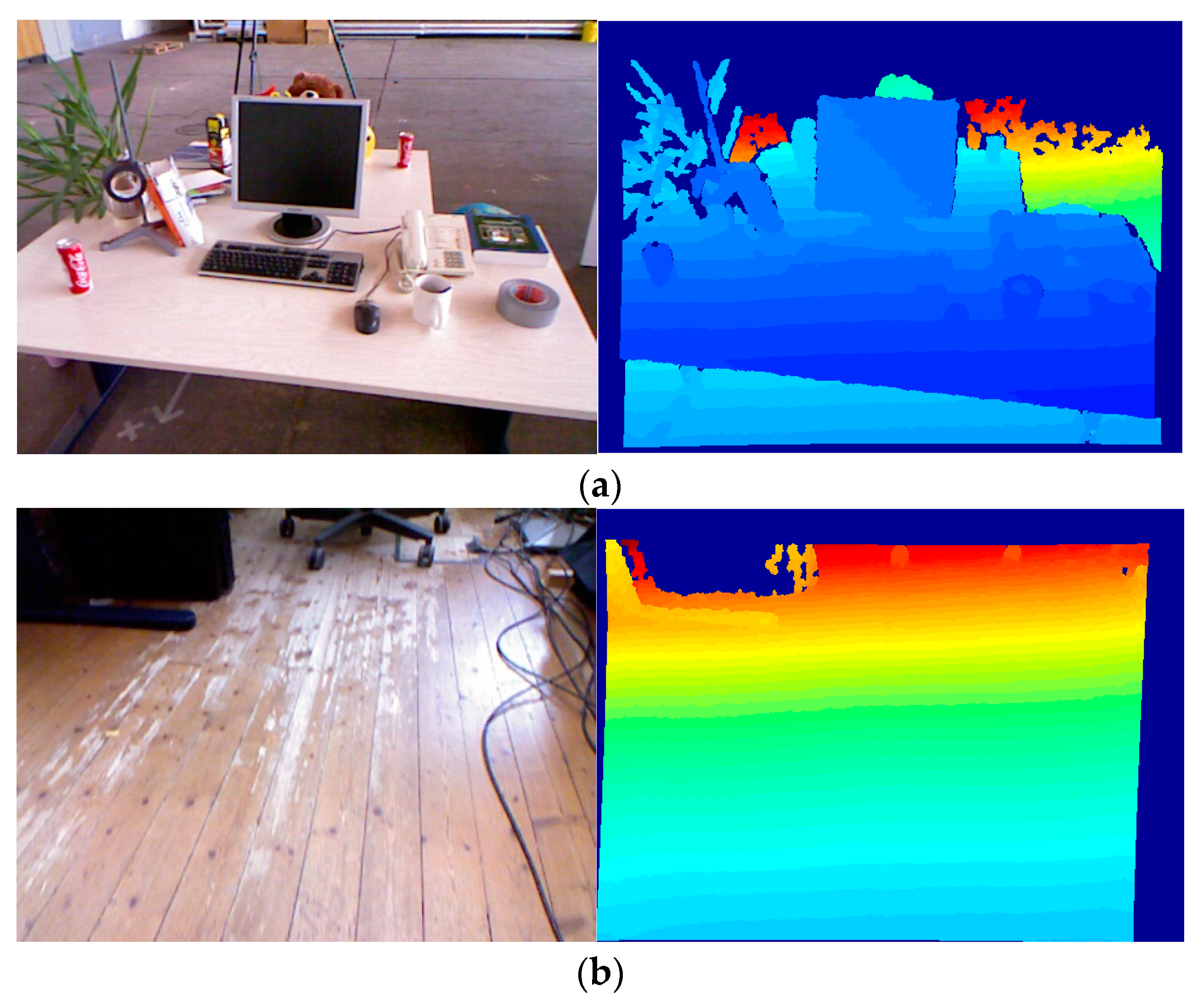
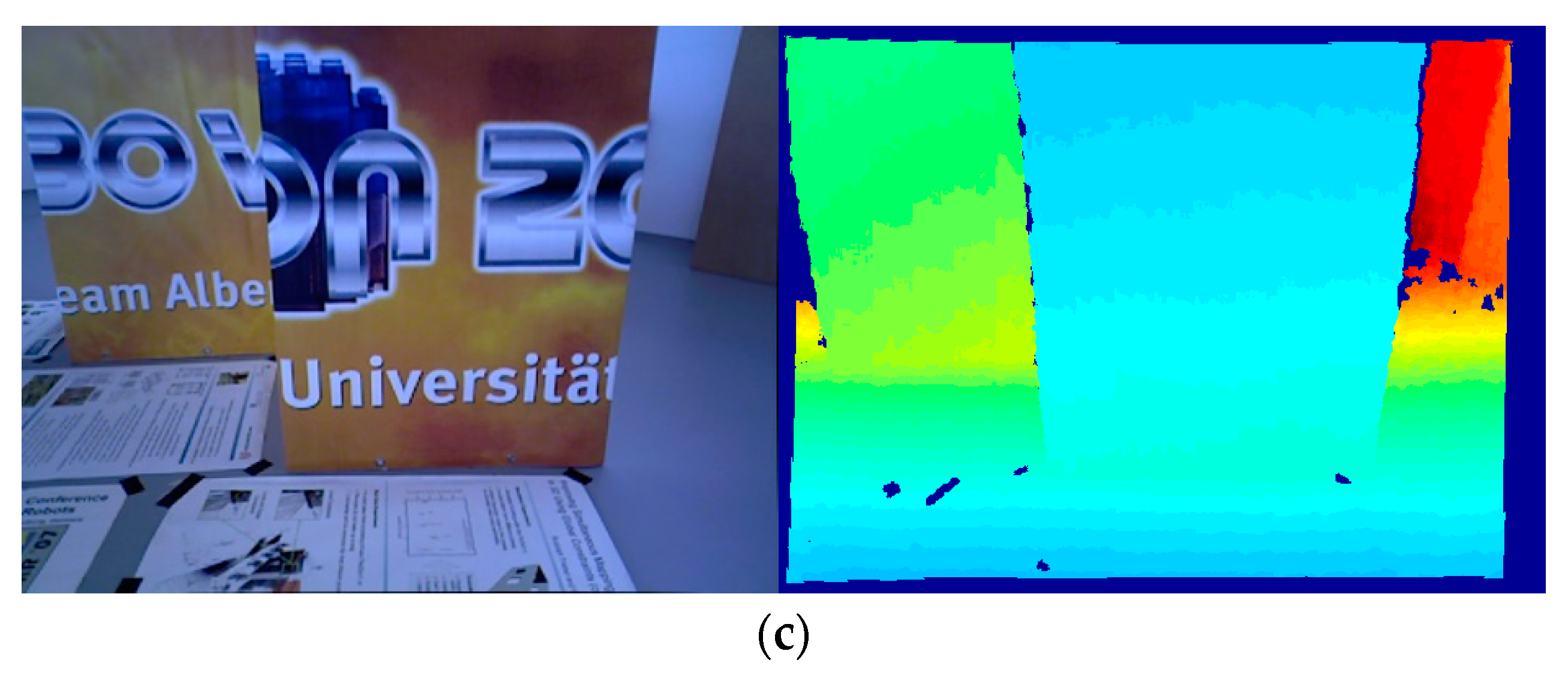
In this paper, the keypoints firstly are detected by the Features from Accelerated Segment Test (FAST) algorithm. Then, the location of the keypoint is refined in the scale and the space. Next, the scale factor of the keypoint is directly computed with the depth information of the image. And next, the intensity centroid of the circle centered on the keypoint is calculated, and the orientation of keypoint is computed by the offset from its intensity centroid. Finally, the experimental results show that, compared with the original BRISK algorithm, the improved BRISK algorithm’s robustness of rotation and scale invariance are stronger.
This paper is organized as follows. In
Section 2 a brief survey of related work is presented. Then the BRISK algorithm principle is described in
Section 3. In
Section 4, improvement of the BRISK algorithm (BRISK_D algorithm) is introduced. Some experimental results are presented in
Section 5 and, finally, we provide some conclusions and future work.
2. Related Work
Attneave et al. [
13] explains some of the problems of visual perception. From the perspective of visual behavior, people introduce information theory to quantify the data received by the visual system. From an information point of view, most of the visual information received by the human visual system is redundant, because the information received by the intricate neurons is interrelated. People can extract the main signal content by extracting information from a limited number of neurons. According to the experimental research, it is proposed to express the main visual information by pixels with large degree of variation in the uneven region of the image. However, this theory is only experimentally described, and has not been quantified.
The history of image local feature research first originates from Moravec’s point of interest [
14]. It detects interest points based on the similarity of neighborhood pixel autocorrelation functions. It is a relatively original corner detection method, which is particularly sensitive to the pixel gray noise and does not have the feature of the rotation invariance.
The Hessian detector proposed by Beaudet [
15] opens the precedent of feature point detection algorithm based on image local gradient information. The Hessian matrix is very suitable for measuring the local gradient features of images. Many well-known feature point detection algorithms based on image gradient information use Hessian matrix to calculate their corresponding feature point response functions, such as LoG [
16], SURF [
7], KAZE [
17], AKAZE [
18],and so on.
The first corner detection algorithm is the Harris corner detection method [
19]. It uses a differential operator to construct a
gradient matrix containing structural features and uses the distribution of gradient matrix eigenvalues to determine whether the local structure of the image is a corner, edge or flat region. The Shi-Tomas [
20] corner defines the corner point from the discriminability of the feature point tracking. It is essentially the same as the Harris corner, and is a development of the Harris corner. The above corner points do not have scale invariance, nor rotation invariance.
Lindeberg [
21,
22] introduces multiscale analysis in image processing, and points out that the Gauss kernel filter is the optimal scale filter. Mikolajczyk combines the multi-scale analysis and affine transformation of Lindeberg with the Harris feature points based on the gradient feature to develop the invariant features of Harris-Laplace and Harris-Affine [
23]. But the computational complexity is too large and the application is limited.
In addition to gradient-based feature points, the local invariant features appeared in 1999~2006 are more based on the patch feature. Most of the patch characteristics can provide better location, scale and direction information. Among them, the most famous feature is the SIFT feature proposed by D.G. Lowe [
5]. Although SIFT is a popular feature detection and descriptor, it has a large amount of computation and storage. SURF [
7] is another plaque-based invariant feature. In the integral operation of SURF, Bay draws on Viola’s integral graph technique in face detection [
24]. The computing speed is several times faster than that of SIFT, but its matching accuracy is somewhat lower than that of SIFT.
Bay et al. propose the Fast-Hessian feature detector based on the Hessian matrix in the SURF (Speeded Up Robust Features) [
25] algorithm and use the integral image to calculate its corresponding descriptor. Compared with the SIFT algorithm, the computational efficiency can be greatly improved. Similarly, Alcantarilla et al. also uses the Hessian matrix for feature point detection, combined with the corresponding descriptors to form KAZE [
17] and AKAZE [
18] feature detection algorithms.
Since 2006, local invariant feature detectors and descriptors based on binarization features have become the new mainstream in the field of invariant features. The originator of the detector is FAST [
26,
27], which belongs to the SUSAN [
28] operator. The SUSAN operator originates in the literature [
29]. Although the FAST operator is computationally efficient, it depends on the scene, and has no direction and scale information. It does not have scale invariance and rotation invariance. In order to overcome the dependence of FAST detector on scene, a new scene independent detector is proposed, which is the Adaptive and Generic Accelerated Segment Test (AGAST) [
30] detector. An improvement on FAST is Oriented-FAST, which is a feature detection sub module in the ORB [
31] feature generation method. The feature detection part of the BRISK [
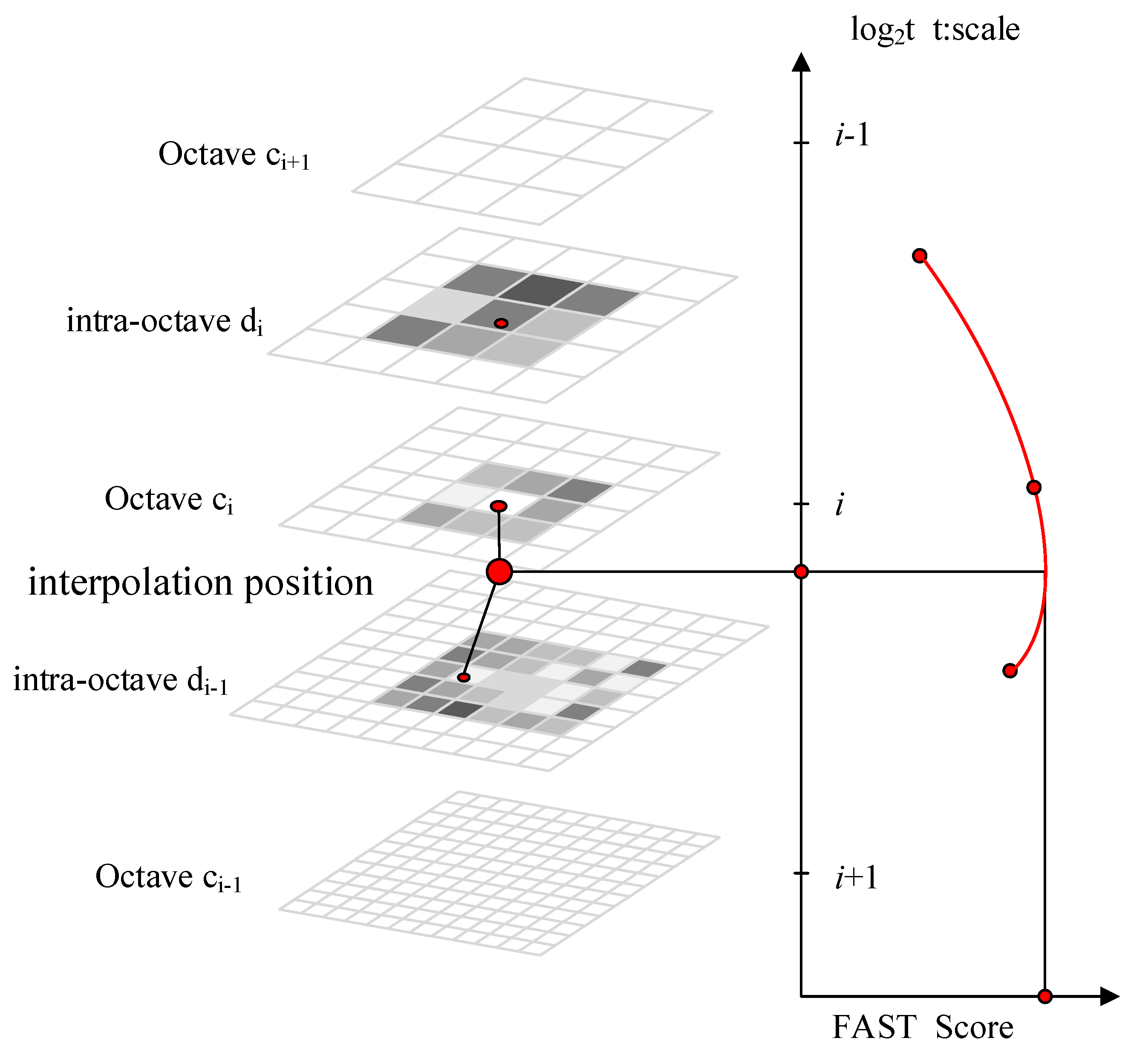
11] method is based on AGAST, which combines the advantages of SIFT on scale space search and obtains a binary invariant feature detector with scale invariance.
For the binarized feature descriptor, the most famous one is the BRIEF [
9,
32]. The binarized description feature consists of bit strings, each bit representing a gray-scale contrast between a set of pairs of points distributed at a particular position in the local neighborhood image of the feature point, all of which are used for comparison. It constitutes the constellation of the descriptor. Different feature descriptors use different constellation structures, and the pairs of points selected in the constellation for grayscale contrast to generate binarized features are also different. Since the feature is composed of two points of gray scale comparison, the feature description speed is faster, and the Euclidean distance or the Mahalanobis distance is not used in the feature matching process, and the Hamming Distance is adopted. Hamming distance can be calculated using efficient XOR operation instructions, which greatly improves the speed of feature matching. Therefore, the description and matching based on the binarized feature has higher computational efficiency than the traditional multidimensional real number feature. The improved Steered BRIEF [
9] method based on the BRIEF provides a feature orientation that is not available in the BRIEF, making the Steered BRIEF a rotation-invariant feature.
Because in the design of BRIEF, the point-to-point distribution selected in the constellation for comparison does not have a rigorous and scientific design, the binarization features have greater correlation. rBRIEF overcomes this weakness by focusing on selecting the less-relevant binary features to construct the constellation structure of the descriptor. ORB [
31] is a feature method that combines Oriented-FAST and rBRIEF. In order to avoid the strict alignment phenomenon required by the similar features and to suppress the influence of gray noise on the feature description, like DAISY [
33], BRISK also adds a gray-scale smoothing step before the point-to-scale is compared on the constellation.
The above feature description methods are divided into two categories according to the computational complexity and the storage space size: the first type is a type with large computational complexity and large storage consumption, such as SIFT, SURF, DAISY, and so on, wherein DAISY is suitable for dense matching. Due to the high-dimensional real number vector for feature description, such features are complicated to calculate and difficult to save with large amount of computation.
The second type is a binarization feature with better comprehensive performance, which has less computational complexity and requires less storage space, such as BRIEF, BRISK, ORB, and so on. They both use a binarized string feature to describe the local texture and then use the Hamming distance to describe the difference between the features. They have matching performance comparable to the first type of features, and the computational speed is significantly better than the first type of features, where BRIEF is the prototype of the second type. It has some defects, such as the need for precise alignment, and so on. ORB does not have the scale feature, but the BRISK has better comprehensive performance and has faster calculation speed than the SIFT and SURF.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}