1. Introduction
With the progress of robot-vision-system advanced technology, it is necessary to evaluate the geometric relationships among the robot, sensors, and a reference frame. This problem is usually called “robot–sensor calibration”, and it has been an active area of research for almost 40 years [
1]. As research has progressed, the applications of robot–sensor calibration have extended into many domains, such as automobile assembly, robot navigation, and endoscopic surgery. As reported previously [
2], the most widespread mathematical representations for the robot–sensor calibration problem can all be grouped into two categories:
AX =
XB and
AX =
ZB.
The first class, and the most common robot–sensor calibration problem, is hand–eye calibration
AX =
XB, which was proposed by Tsai et al. [
3] and Shiu et al. [
4]. The earliest solution strategy estimated the rotation and translation with respect to homogeneous transformation
X separately [
5,
6]. However, it was found that such a method would produce rotation error spread in the process of the translation estimation. In later strategies, both the rotation and translation with respect to homogeneous transformation
X are solved simultaneously [
7,
8,
9]. The above calibration methods solve the hand–eye relationship with different parametric approaches, such as the quaternion, dual quaternion, and Kronecker product, which are all inseparable from a known calibration object. However, there are many situations in which using an accurately-manufactured calibration object is not convenient, or is not possible at all. Indeed, due to restrictions in limited onboard weight or strictly sterile conditions, it may be inadvisable to use a calibration object in applications such as mobile robotics or endoscopy surgery. Thus, later, an approach for getting rid of the calibration object based on the structure from motion (SFM) technique was proposed by Andreff et al. [
10], and this method—also named “extended hand–eye calibration”—could handle a wider range of problems. Subsequently, a similar approach was presented in [
11], where a scale factor was included into quaternion and dual quaternion formulation. Ruland et al. [
12] proposed a branch-and-bound parameter space search method for this extended hand–eye calibration problem, which guaranteed the global optimum of rotational and translational components with respect to a cost function based on reprojection errors. In [
13,
14], Heller et al. firstly utilized second order cone programming (SOCP) to calculate the hand–eye relationship and scale factor based on the angular reprojection error, and then exploited a branch-and-bound approach to minimize an objective function based on the epipolar constraint. However, this branch-and-bound search process was very time intensive. Soon afterwards, Zhi et al. [
15] proposed an improved iterative approach to expedite the calculation speed concerning the above extended hand–eye calibration problem. Recently, with some consideration for the asynchrony of different sensors with respect to sampling rates and processing time by an online system, Li et al. [
16] presented a probabilistic approach to solve the correspondence problem of data pairs (
Ai,
Bi). However, this method has not been tested with a real robotic system. Due to the narrow range of motion allowed by the surgical instrument in minimally-invasive surgery, Pachtrachai et al. [
17] replaced planar calibration object with the CAD models of surgical tools in the process of hand–eye calibration; thus, the instrument 3D pose tracking problem has to be addressed in advance.
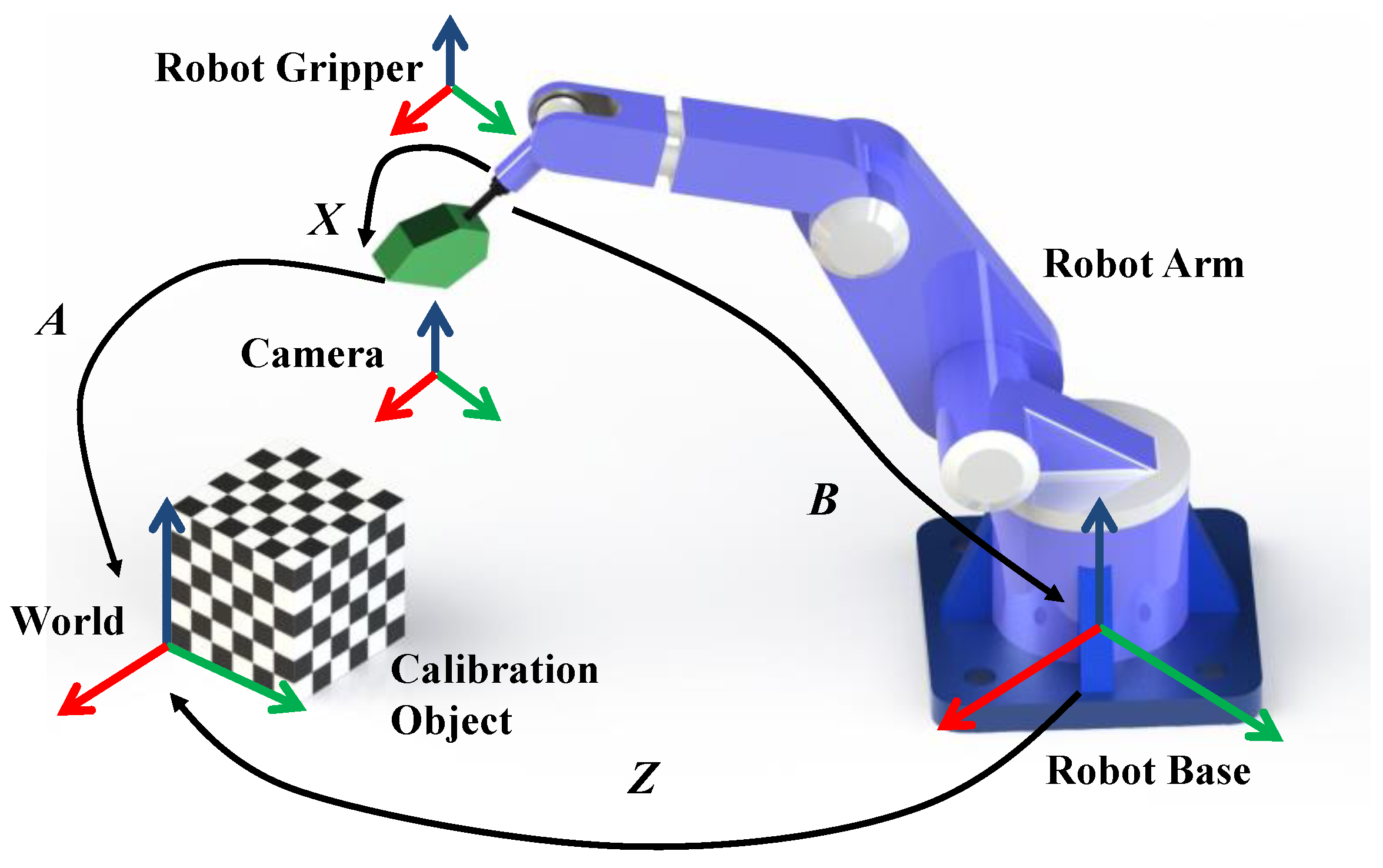
The second class of robot–sensor calibration problems is the form
AX =
ZB, which was first derived by Zhuang et al. [
18]. This equation allowed the simultaneous estimation of the transformations from the robot-base coordinates to the world frame
Z, and from the robot-gripper coordinate to the camera coordinate
X. There are also two ways to approach the robot–world and hand–eye calibration problem. In the first, the rotation and translation components associated with
X and
Z are calculated separately based on dual quaternion and Kronecker product [
19,
20]. In the second, the rotation and translation components are computed simultaneously based on the quaternion and Kronecker product [
21,
22]. Additionally, in order to obtain a globally-optimal solution, Heller et al. [
23] utilized convex linear matrix inequality (LMI) relaxations to simultaneously solve robot–world and hand–eye relationships. Very recently, in [
24,
25], Tabb et al. proposed a bundle adjustment-based approach, which is similar to the bundle adjustment partition of our algorithm. However, the main difference is that Tabb’s approach works based on a chessboard target, which our approach does not need.
To the best of the authors’ knowledge, all approaches for robot–world and hand–eye calibration are implemented with an external calibration object. However, it is necessary to further research the solving of the robot–world and hand–eye calibration problem without a calibration object, which is named “extended robot–world and hand–eye calibration” in this paper. Our work on this problem is motivated by two particular situations. The first is the use of a robot-mounted camera for multi-view, high-quality reconstruction of general objects by a rescue or endoscopic robot, where the reconstruction outcomes depend on the feature-matching accuracy instead of a 2D chessboard target. The second situation is the use of the same robot-mounted camera for large-scale digital photogrammetry under industrial conditions, such as aircraft and shipbuilding assembly sites. In this situation, in view of the limit of single measurement range, the measurement surface is segmented into several small parts. A robot with two linear guides is used to define and record the placement of the optical measurement system in front of the measurement surface. The imaging system, based on retroreflective targets (RRTs), is mounted on the robot gripper as an end effector, and non-experts can be allowed to complete the calibration and acquire the three-dimensional (3D) coordinates of the target points attached to the measurement surface from a remote location.
For these particular situations, an extended robot–world and hand–eye calibration approach without a calibration target is proposed for a robotic visual measurement system. At first, our approach improves the AX = ZB mathematical model by supposing that different camera poses comprise up to an unknown scale factor, and propose a fast linear method to give an initial estimate to the calibration equation. Then, we combine space intersection and sparse bundle adjustment to refine the robot–world and hand–eye transformation relationship, as well as 3D reconstruction, simultaneously. Finally, we demonstrate the effectiveness, correctness, and reliability of our approach with relevant synthetic and real data experiments.
3. Experiments
This section validates the proposed method for the extended robot–world and hand–eye calibration problem both on synthetic and real datasets. For the data comparison, with some considerations, one could not expect that the method without a calibration object would obtain results as accurate as the method with a calibration object. In this paper, our main purpose is that the estimation of the robot–world and hand–eye transformation is feasible without a calibration object. We refer to the means of data comparison of previous extended hand–eye calibration methods, such as those presented by Nicolas Andreff [
10], Jochen Schmidt [
11], and Jan Heller [
13]. We present an experimental evaluation of the extended robot–world and hand–eye methods, in which the estimation of rotation, translation, and scale factor can be formulated using the Kronecker product [
20], or quaternions [
21], or reprojection error [
25], and a standard robot–world and hand–eye calibration method [
25] with chessboard pattern calibration was used as an approximate truth-value, since no ground truth is available to compare accuracy between different methods. For convenience, in the following experiments, the labels “Dornaika” and “Shah” stand for the estimation of rotation, translation, and scale factor using the quaternions Equation (4) or Kronecker product Equation (5), respectively. The label “KPherwc” stands for the proposed initial calibration method based on the Kronecker product Equation (8), and the label “BAherwc” stands for the proposed optimization approach based on sparse bundle adjustment Equation (16). VisualSFM [
30]—a state-of-the-art, open-source SFM implementation—was used to obtain the camera poses for a general object in real-data experiments. All method results were obtained using a hybrid MATLAB 9.0 and C++ reference implementation, and we conducted the methods on an Intel Core i7-8750H processor running Linux.
3.1. Experiments with Synthetic Data
In order to simulate the actual process of robot motions, considering that PUMA560 is the most classic robot arm kinematics model, and that this robot has been well studied and its parameters are very well known—it has been described as the “white rat” of robotics research [
31]—referring to Zhuang [
18], we used PUMA560 robot kinematics modeling and a camera imaging model to build a synthetic scene and a virtual camera. As shown in
Figure 2, a red PUMA560 robot arm was constantly in movement with a different-colored camera attached to the end gripper. A synthetic scene consisting of 50 3D points was generated randomly into a gray cube with side length 0.5 m, and 8 different virtual camera poses set such that the cameras were faced approximately to the center of the cube were created. The intrinsic parameters of the virtual camera and Denavit–Hartenberg (DH) parameters of the PUMA 560 robot are separately listed in
Table 1 and
Table 2.
To test the performance of different methods against projection noise, the simulated data were conducted with the synthetic scene and a virtual camera. The scene 3D points were projected into the image plane after each position movement, but the projection points would be neglected if they were outside the image plane. In order to qualitatively analyze and evaluate the results of the synthetic experiment, we defined the error evaluation criteria associated with rotation and translation as follows:
where
represents the true rotation,
represents the estimated rotation,
represents the true translation, and
t represents the estimated translation. In the synthetic experiment, since the nominal value for the robot–world and hand–eye transformation can be set up in advance, there is no need to use a standard robot–world and hand–eye calibration method [
25] as an approximate truth-value. We set
= 0.1 m and
= 1 m. The entire experiment is a four-step process. Firstly, considering that real-world feature point extraction is generally expected to have accuracy within 1 pixel, projection points in the synthetic experiment were corrupted by 6 different levels of Gaussian noise in the image domain with a standard deviation
η ∈ [0, 1] pixel and a step of 0.2 pixel. Secondly, according to the synthetic scene, we defined the nominal value for the hand–eye transformation
and the robot-to-world transformation
with constant translation
and
. Thirdly, we calculated a sequence of camera positions based on space resection, and the corresponding robot motions were calculated by
B =
Z−1AX. Considering that the noise of robot motion is determined after production, we added a constant noise (σ = 0.025 mm) to robot joint offset. Finally, we performed the homogeneous transformations
X and
Z with the above four different methods and compared their rotation and translation errors in the presence of various noise levels. For each noise level, 50 repeated experiments were done with randomly generated sets of data, and the final value was the mean of all 50 errors.
Figure 3 illustrates the rotation and translation errors for each noise level using the boxplot. Clearly, our optimization method (“BAherwc”) exhibits the best behavior both in rotation and translation estimation of the transformation
X and
Z, whereas the proposed initial calibration method (“KPherwc”) performs worst under noise conditions; thus, it is extremely effective to refine the initial calibration results by follow-up sparse bundle adjustment. Meanwhile, the translation relative errors estimated by “Shah” are slightly better than those estimated by “Dornaika”. This is a result of the “Dornaika” method calculating the rotation and translation transformations regarding
X and
Z all in the same step. Due to noise, the estimated rotations may not be accurate representations of the rotation matrices, and thus, a set of nonlinear constraints have to be made for the rotation matrices; meanwhile, the estimated translations are not updated with the orthogonal restriction, which causes the larger positional errors that are illustrated in
Figure 3.
3.2. Experiments with Real Datasets
In this experiment, a Denso VS-6577GM serial 6-DOF robot arm with a Nikon D300s digital SLR camera and an AF NIKKOR 20 mm lens was used to acquire the real data. Since no ground truth gripper–camera transformation is available in the real data, it is difficult to give direct error results about the computed robot–world and hand–eye transformation, such as for the synthetic data. Therefore, it is desirable to measure the quality of the calibration results between the camera and robot device in some indirect way. In the rest of this section, we arranged two different scenes to complete the accuracy assessment: scene A, with a general object, was used to show the general applicability of the proposed method compared to the standard robot–world and hand–eye calibration approaches, and scene B, a photogrammetric retro-reflective target was used to improve the feature point-locating accuracy and decrease the false match rate for calibrating the extrinsic camera. Before the experiment, we used [
32] to calibrate the camera together with seven parameters of lens, so the images were undistorted prior to being further used in order to improve sparse bundle adjustment results.
3.2.1. Dataset A
With dataset A, our main purpose is not to prove how high the accuracy of our method is, but to demonstrate the feasibility of estimating the robot–world and hand–eye transformation without a calibration object in a general scene. Two image sets were required for the performance of the different methods in real-world conditions, as shown in
Figure 4. Some consideration for the absence of a ground truth is available in the real-data experiment. We cannot give errors between the real robot–world transformation and the computed one, just like in the synthetic experiment. Since the method with a calibration object can usually obtain more accurate results than the method without a calibration object, a chessboard pattern was firstly used for solving robot–world
Ybar and hand–eye
Xbar transformation simultaneously by the Tabb method [
25], which could be assumed to give an approximate true value for the present. Afterwards, we removed the chessboard pattern, and used books as the object instead. We used the above “Dornaika”, “Shah”, “KPherwc”, and “BAherwc” methods to calculate the homogeneous transformation
Xscene and
Yscene with the general object of books. Finally, we compared their results to the approximate true value
Xbar and
Ybar. The errors of robot–world and hand–eye relationships are defined as follows:
Figure 5a shows that the robot gripper carrying the camera took a series of photos around the center of the books. The positions of the gripper were adjusted with ten different locations, and it was ensured that the entirety of the books were in the view in every frame. The camera was set to manual mode, and images of 4288 × 2848 pixels were taken using a PC remote control. After all the photos were taken, a fast open-source SFM implementation was used to obtain the camera pose
Ai(
α), and the robot motion transformation
Bi was obtained from the known gripper-to-robot-base transformations. Then we computed robot–world and hand–eye transformation using the above four methods.
Figure 5b shows the resulting 3D model output from bundle adjustment, containing 49,352 points in space, and the poses of all the ten cameras. Due to a high number of correspondences, only every hundredth member of the set of corresponding image points was used in our experiment.
Table 3 summarize the results obtained with the two image sets mentioned above. Compared with other similar methods, it can be seen that our “BAherwc” method is nearest to the results of Tabb method [
25] based on the chessboard pattern calibration. This is because in the “BAherwc” method, it was initialized by the results from the “KPherwc” method; then, the reprojection error is directly minimized, like in Tabb reprojection [
25]. On the other hand, in the “Dornaika” and “Shah” method, the variety of the scale factor will bring instability into the solution of the robot–world and hand–eye transformation during the SFM implementation. Of course, one could not expect to obtain results as accurate as with Tabb’s standard calibration. However, depending on the different application, the advantages of the proposed extended method may outweigh this drawback. It is especially true for mobile robotics or endoscopy setups that we have in mind, where robot–world and hand–eye calibration has to be performed under specific situations, due to the restrictions in limited onboard weight or the strict sanitary conditions. In order to achieve a rough qualitative analysis, we also measured the translation from the gripper to the camera lens center by hand with the known mechanical structure of the gripper and join parts, which is approximated to [0, 58, 66] mm. The estimated translation by our “BAherwc” approach is [0.183, 57.326, 64.910] mm, which is close to the result of the previous physical measurement, showing the validity of the obtained results.
3.2.2. Dataset B
In dataset B, our main purpose is to provide a mobile benchmark for large-scale digital photogrammetry under industrial conditions, which needs a robot to move along the guide rail to complete multi-station stitching measures. In order to reduce noise disturbance caused by SFM, we used photogrammetric retro-reflective targets (RRTs) to obtain accurate feature point matching. RRTs consist of a dense arrangement of small glass beads (
Figure 6a bottom-right), as the name would suggest, which have good retro-reflective performance. The reflected light intensity in the light source direction is up to hundreds of times larger than the general diffuse reflection target. Thus, it is easy to obtain a subpixel level locating accuracy of feature points in the complex background image. As indicated in
Figure 6a, dozens of RRTs and two yellow invar alloy scale bars S
1 and S
2 constructed a photogrammetric control field, and two 6 mm diameter coded RRTs were rigidly fixed on the yellow scale bar end, for which the distance had been accurately measured by a laser interferometer. Furthermore, coded RRTs can be encoded using specific pattern of distribution, which can actualize the automatic image matching of corresponding points. Then, the robot gripper carrying the camera took a series of photos around the center of the photogrammetric field, ensuring that the entire RRTs were in the camera view in every frame. Afterwards, we used the Hartley 5-point minimal relative pose method [
33] and photogrammetry bundle adjustment to calibrate and optimize the extrinsic camera parameters.
Figure 6b shows the distribution of camera pose and RRTs. After bundle adjustment, the cameras were moved to 20 different poses faced to the RRTs and scale bars, and a Denso robot was moved in volume of 1.3 m × 1.3 m × 1.2 m. In view of photogrammetric relative orientation yields a high precision camera poses
Ai(
i = 1, …, 20), we solved hand–eye transformation
X and the robot-to-world transformation
Z by means of three methods (the “Dornaika”, “Shah”, and our “BAherwc” method) based on existing camera pose
Ai and robot motion
Bi. Then, the predictive camera poses
can be inverse-computed with Equation (1):
In this section, the discrepancy between
and
Ai is supposed to an accuracy assessment basis of robot–world and hand–eye calibration. Considering the difference of scale factor between
and
, all translations are normalized beforehand, and the mean errors of all motions (from 1 to 20) are computed in rotation and translation. The rotation and translation relative errors are described as:
Comparisons of the accuracy in rotation and translation for photogrammetric scene data set are provided in
Table 4. It can be seen that our method “BAherwc” is almost to half an order of magnitude better than the other methods with regard to both in rotation and translation estimation. The rotation error is less than 5/10,000, and translation relative error is less than 8/10,000. Our optimization method “BAherwc” outperforms the “Dornaika” and “Shah” methods, mainly because the feature extraction and matching accuracy of retroreflective targets is significantly higher than that of the general targets used by SFM; this is an expected behavior, as the “BAherwc” method, by minimizing overall reprojection error, depends on the feature extraction accuracy. This experiment might have confirmed the validity of our approach for the calibration of transformation parameters between the camera and the robot device based on the digital photogrammetric system.
Since the two invar alloy scale bars, S
1 and S
2, provided both feature correspondences and a distance measurement reference, we evaluated our “BAherwc” approach in the relative accuracy of 3D reconstruction by using distance measurement. The average distance measurement errors of the two scale bars are given in the following
Table 5. For comparison,
and
are defined as calculated values based on our “BAherwc” method as reconstruction result byproduct. The distance measurement errors are described as:
Finally, to show the iterative process of our bundle adjustment method,
Figure 7 illustrates the distance estimation error variances of the scale bars S
1 and S
2 at each iteration. One can see that although the initial reconstruction results are clearly inaccurate, the reconstruction errors after finite iteration still converge, and the final differences between the nominal value and measurement value of the two scale bars are close to 0.1 mm. Given that offline photogrammetry systems offer the highest precision and accuracy levels, the precision of feature point measurement can be as high as 1/50 of a pixel, yielding typical measurement precision on the object in the range of 1:100,000 to 1:200,000 [
34], with the former corresponding to 0.01 mm for an object of 1 m in size. The absolute accuracy of length measurements is generally 2–3 times less (e.g., about 0.025 mm for a 1-m long object) than the precision of object point coordinates, which expresses the relative accuracy of 3D shape reconstruction. The relative accuracy of reconstruction by our bundle adjustment method is also influenced by the robot arm, and it can be improved by follow-up photogrammetric network design.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}