Training-Based Methods for Comparison of Object Detection Methods for Visual Object Tracking

Abstract
:1. Introduction
2. Training Based Object Detection
2.1. Aggregate Channel Features
2.2. Region-Based Convolutional Neural Network
2.3. Fast Region Based CNN
2.4. Faster Region-Based CNN
2.5. YOLO
3. Object Trackers
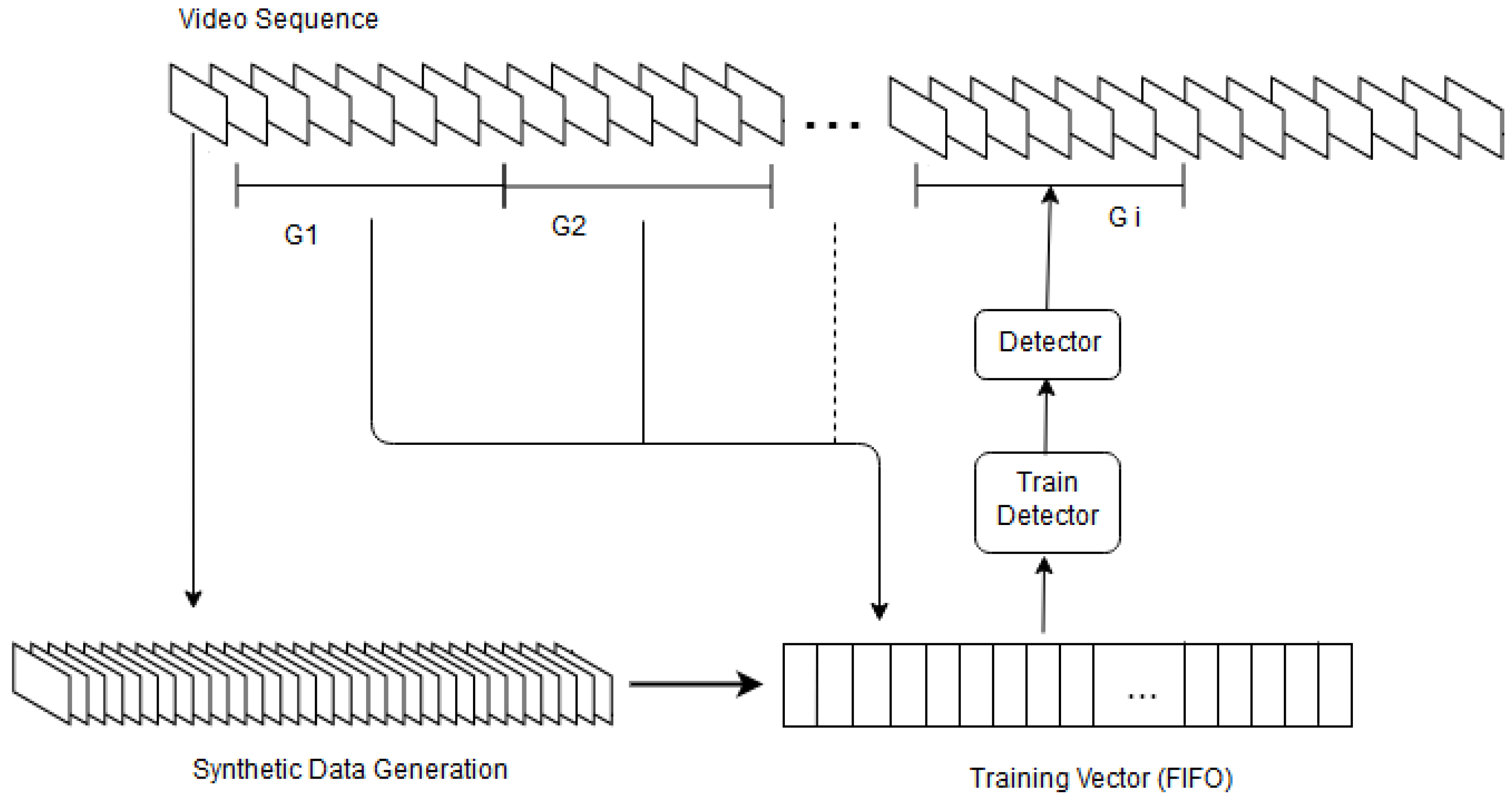
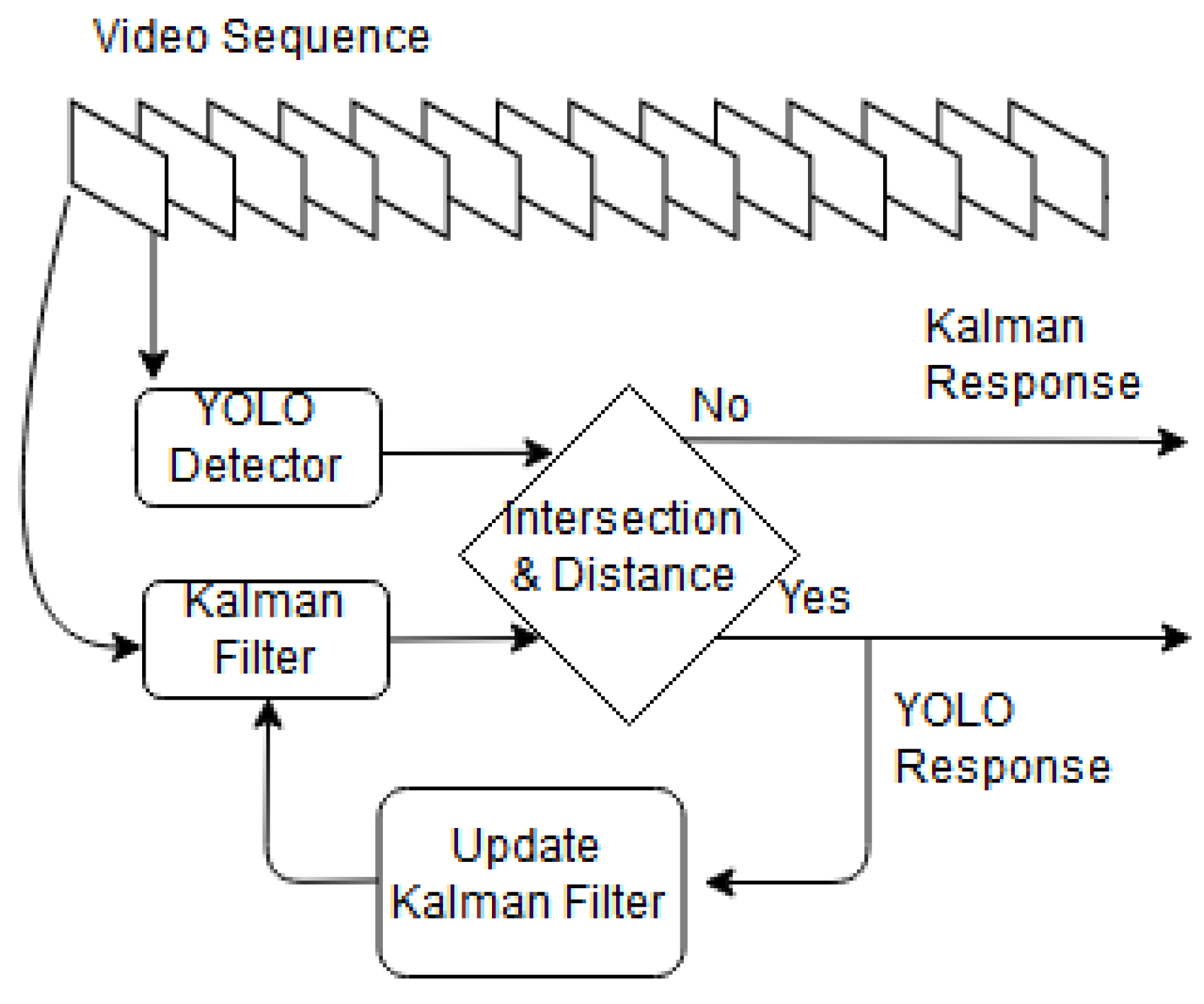
3.1. Online Tracker
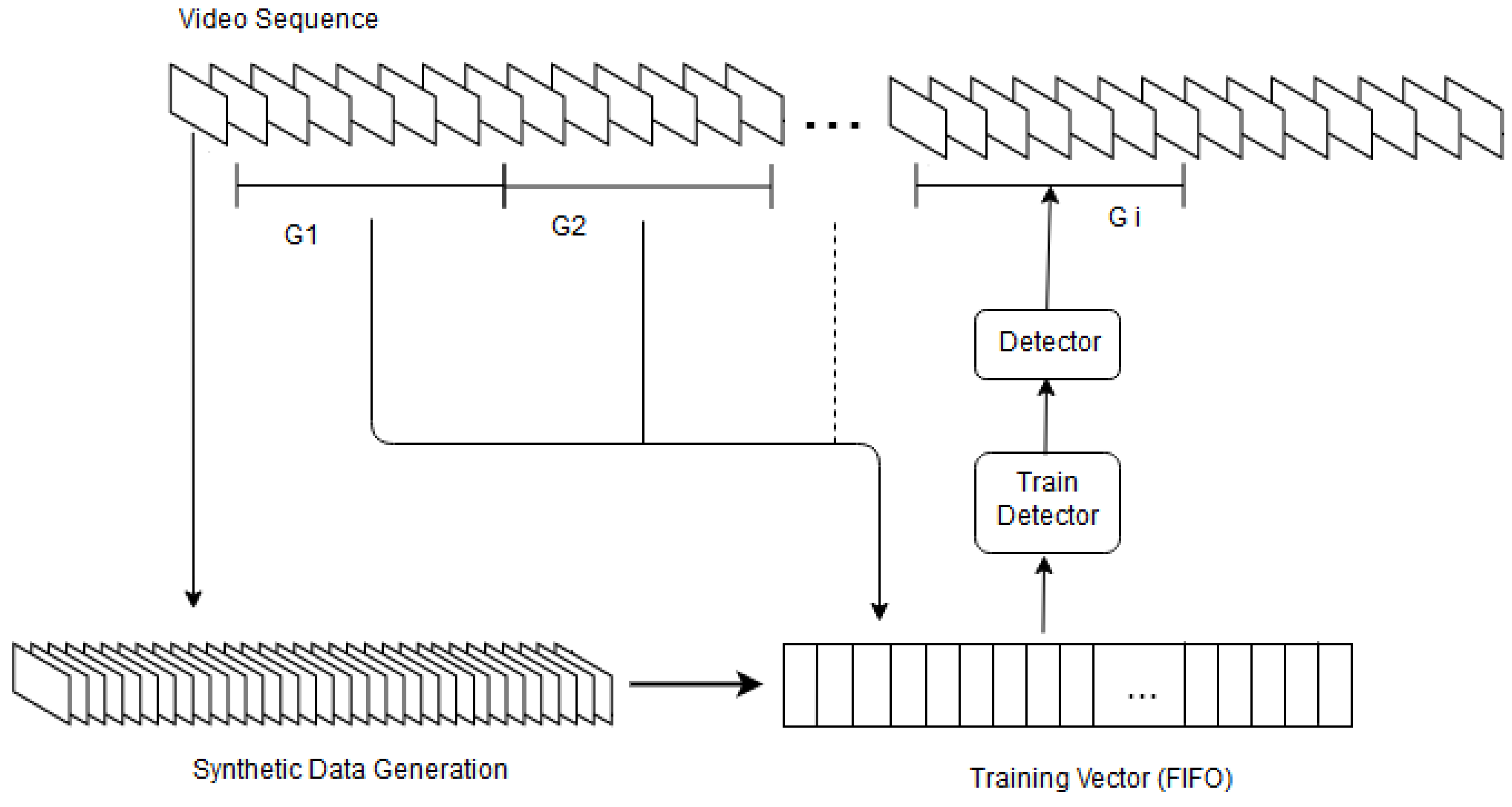
3.1.1. Synthetic Data Generation
- Rotated copies of the object of interest using the rotating angles {−10, −9.9, −9.8, ..., 0, ..., 9.9, 10}.
- Additive salt and pepper noise, with noise densities {0.001, 0.002, ..., 0.008 }.
- The enhanced version of the rotated images in item 1 using contrast adjustment .
- The enhanced version of the rotated images in item 1 using histogram equalization.
- Increasing and decreasing of image brightness with the brightness factor {0.81, 0.82, 0.83, ..., 1.29, 1.3}.
- Resized version of the object of interest using the resizing factor {0.555, 0.560, 0.565, ..., 1.55}.
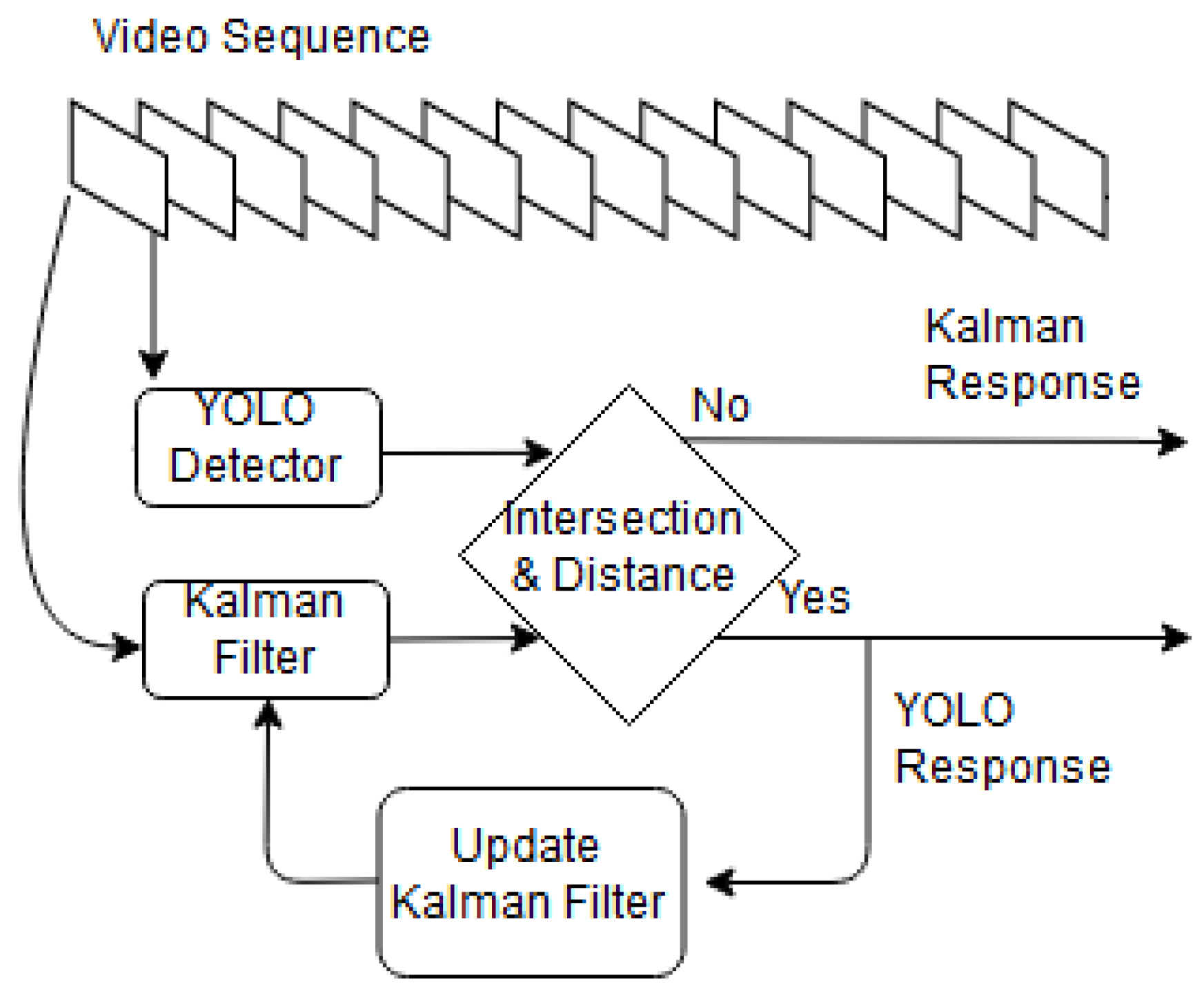
3.1.2. Tracker Updating
3.2. Offline Tracker
4. Results
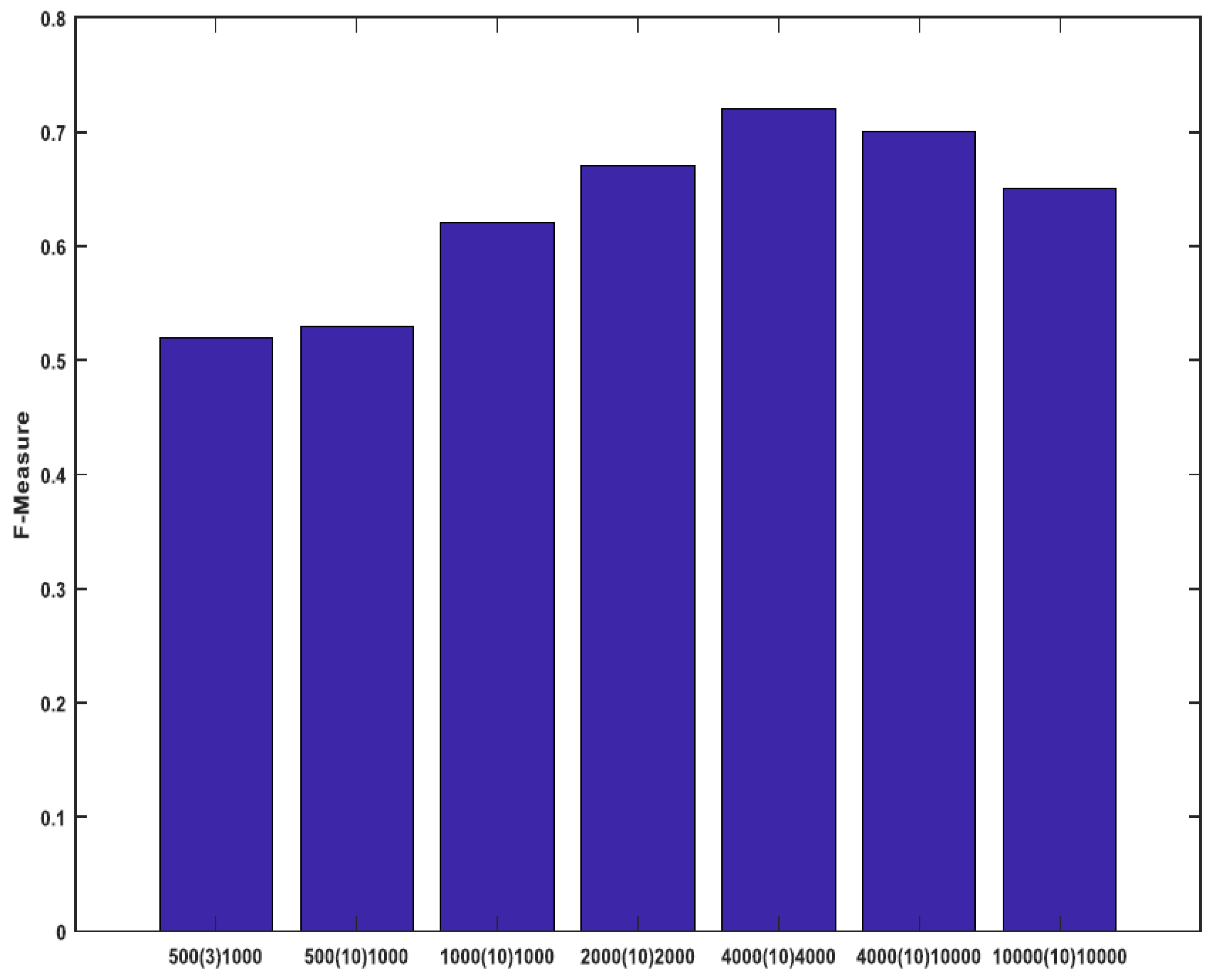
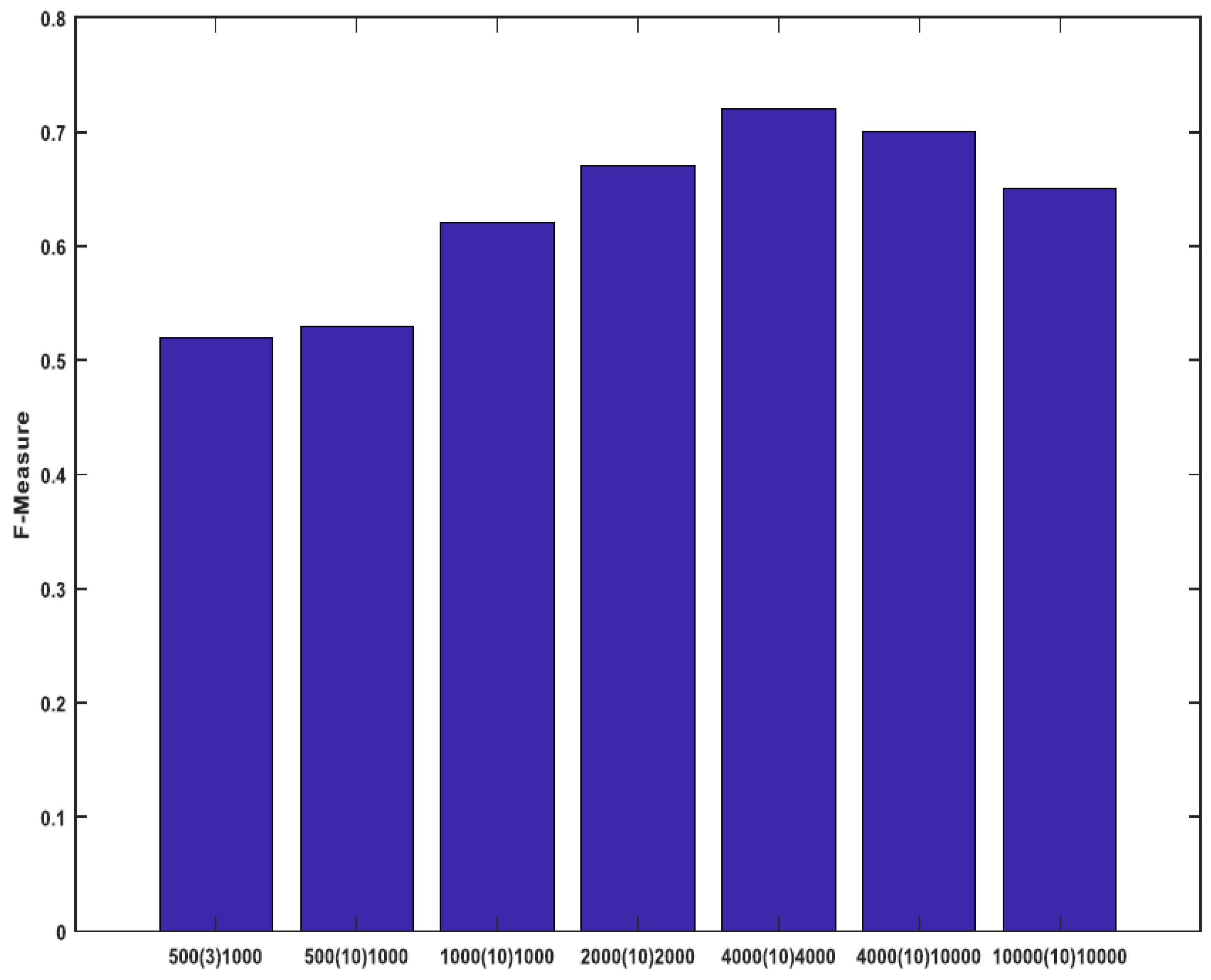
4.1. Dataset and Parameters
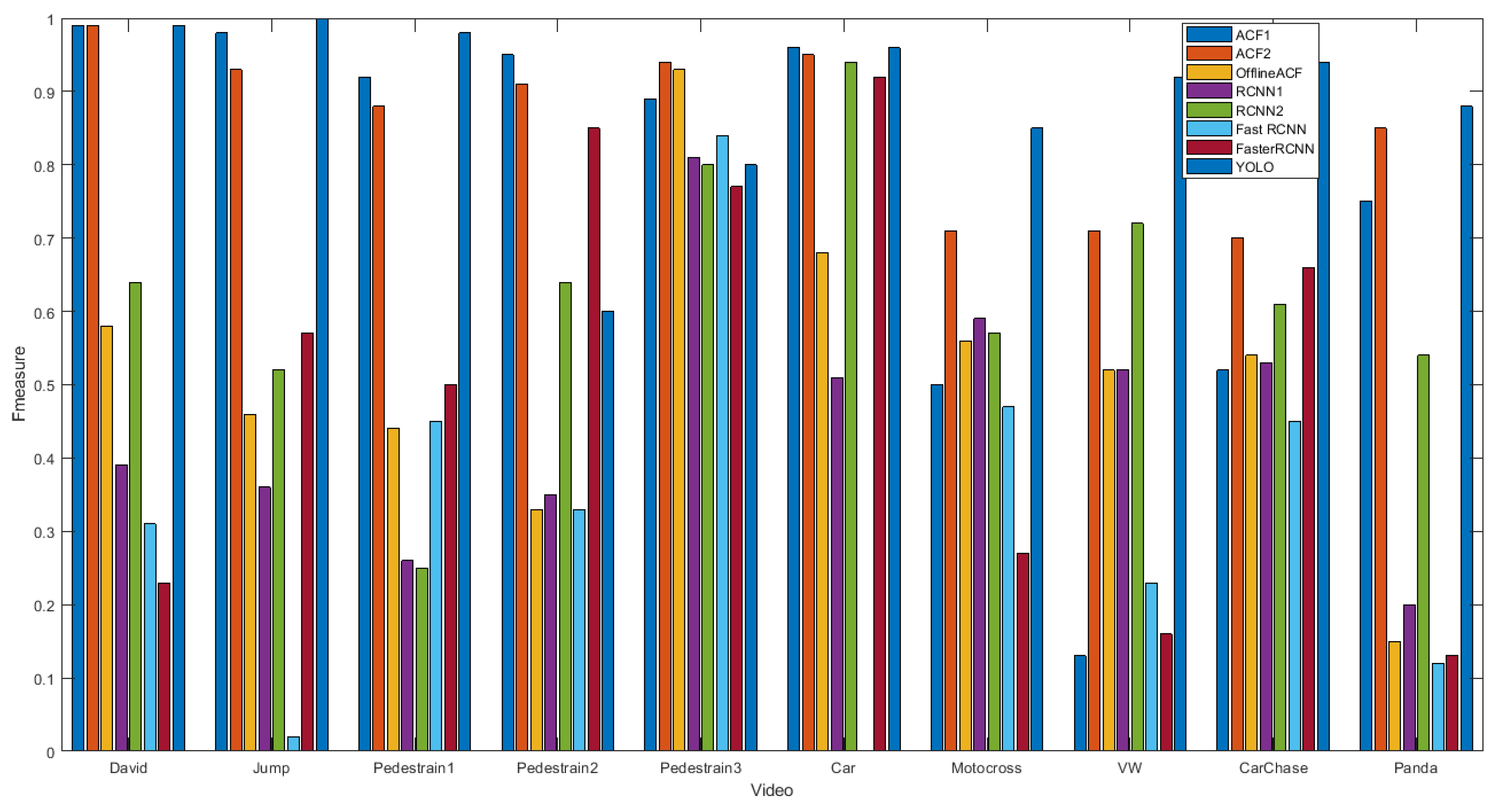
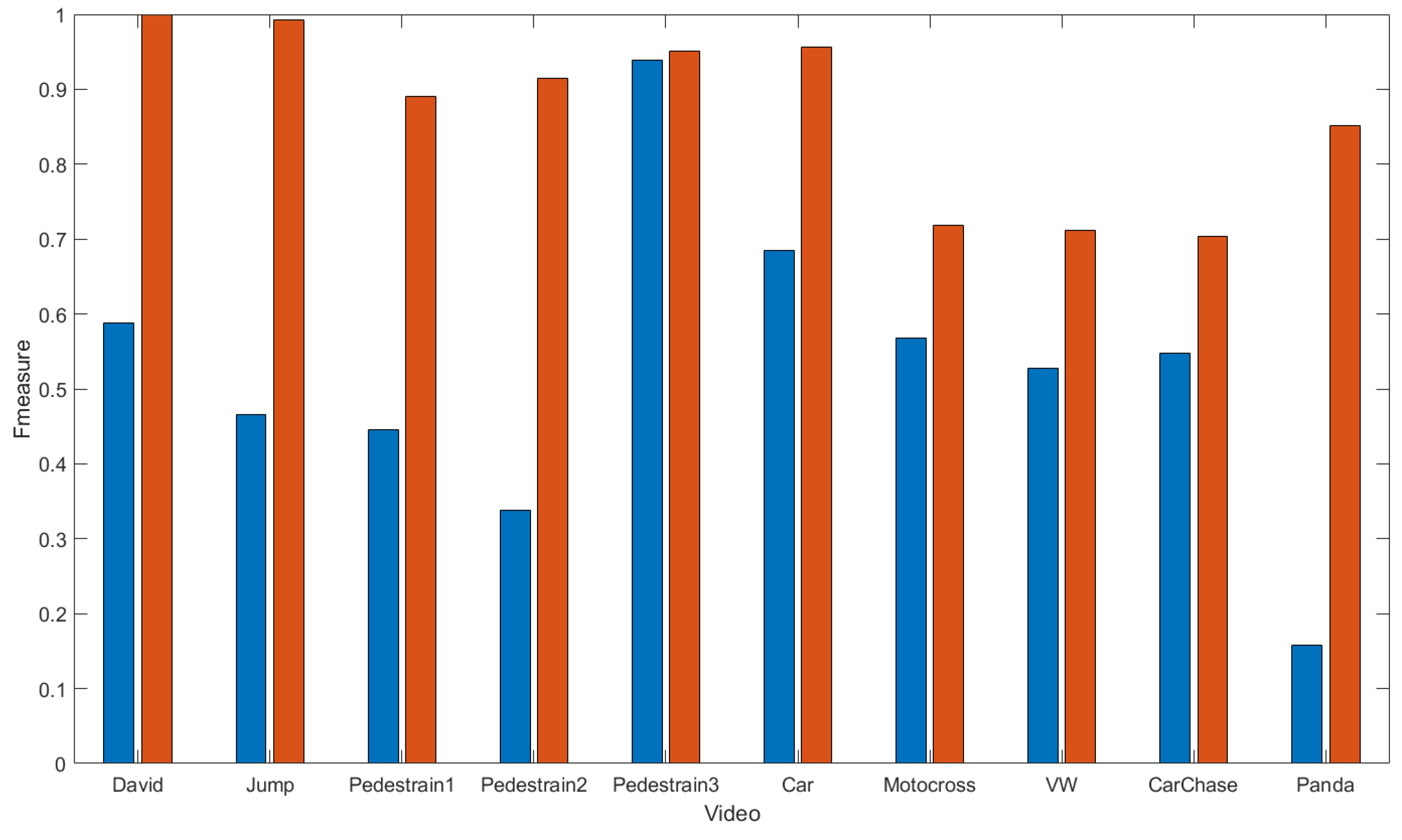
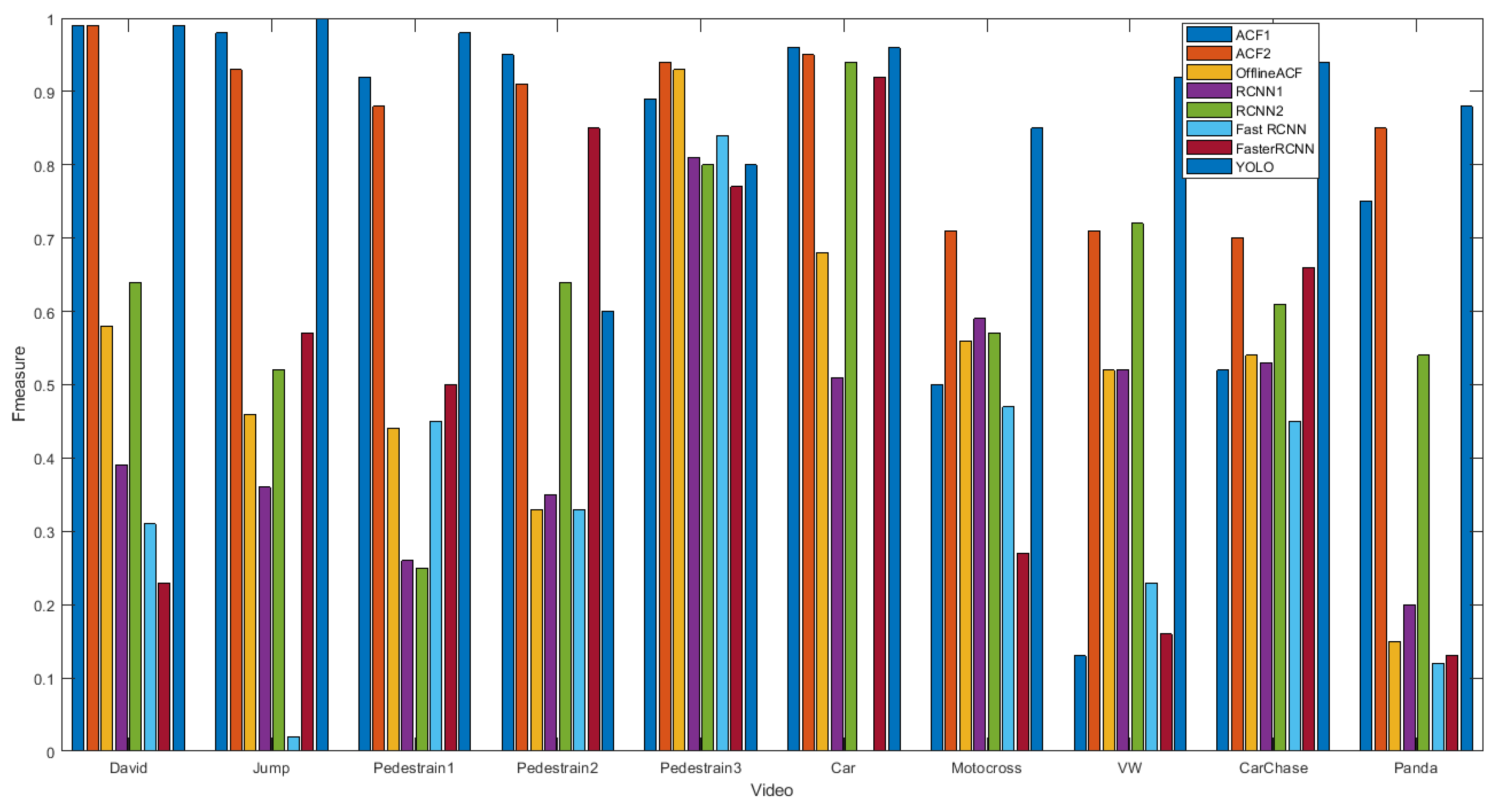
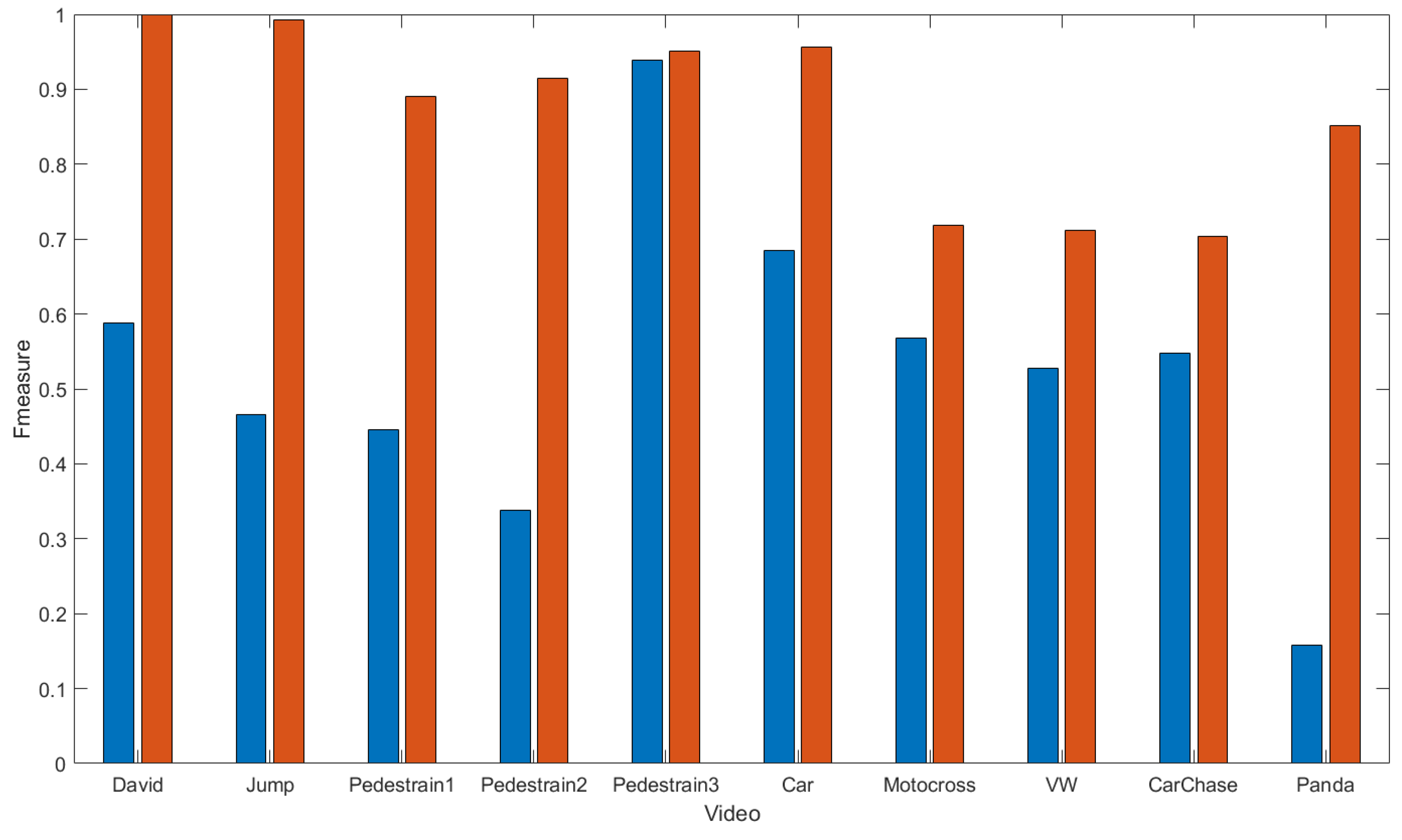
4.2. Accuracy Results
4.3. Visualization Result
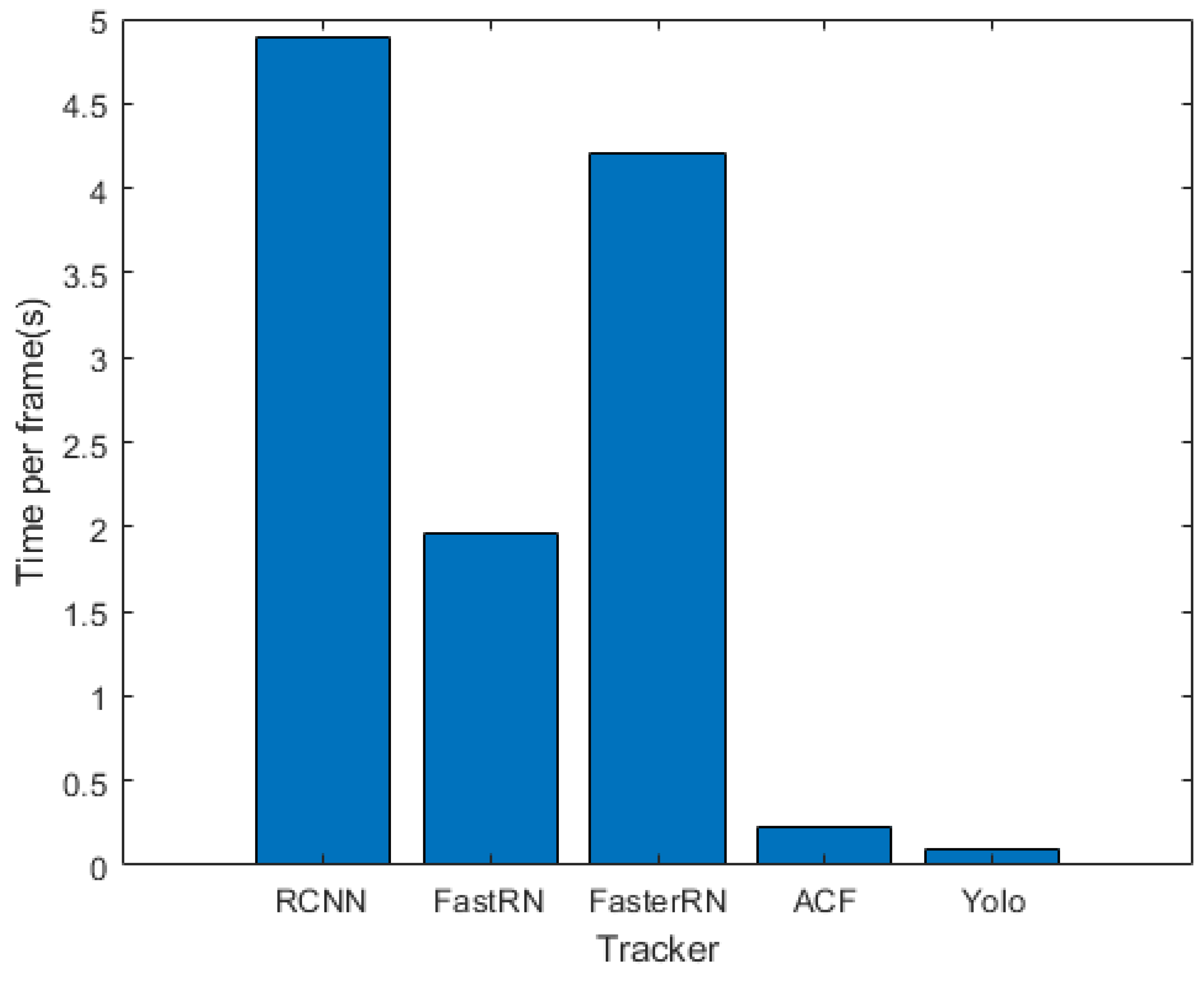
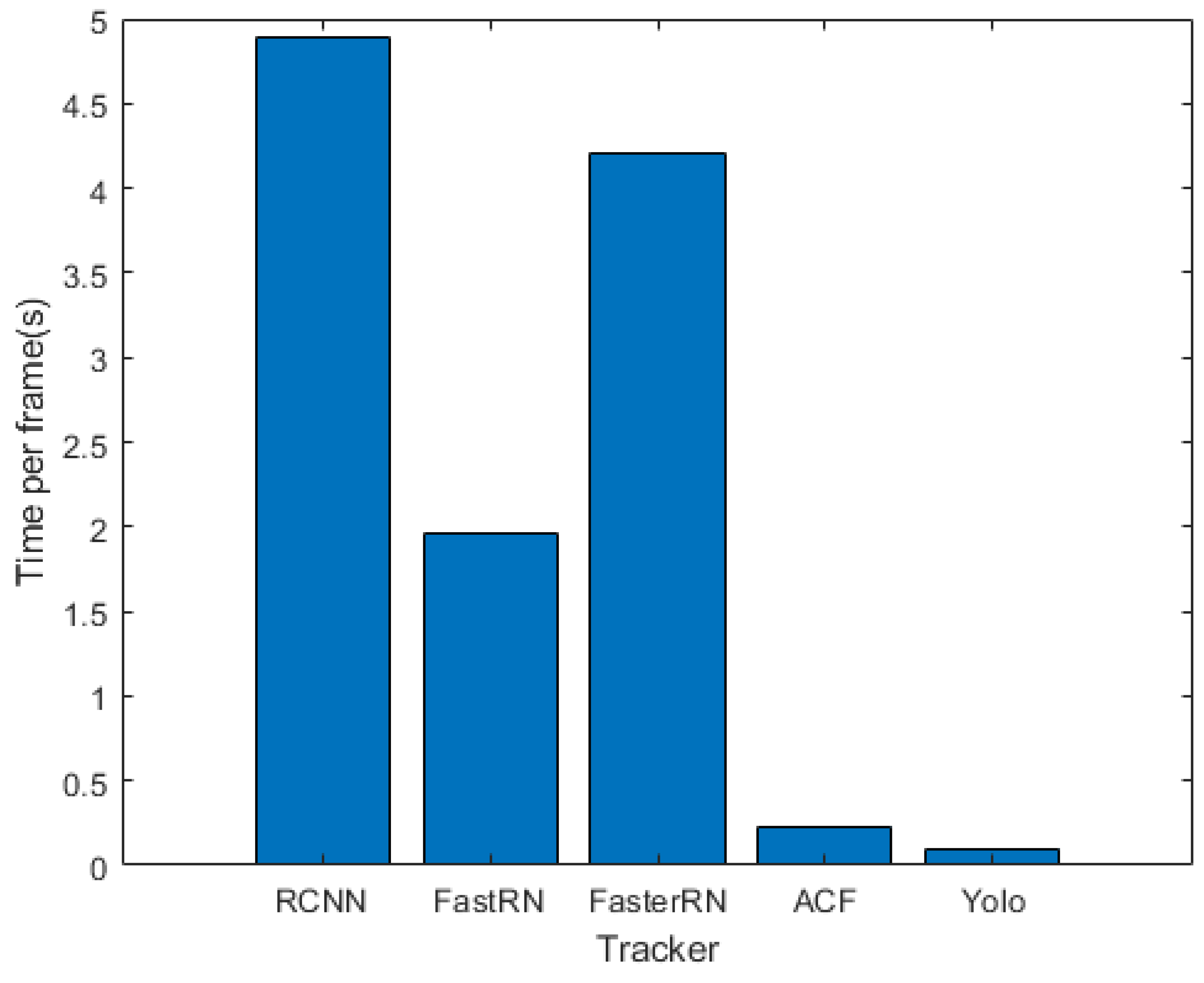
4.4. Algorithm Speed Comparison
4.5. Discussion
- The ACF tracker has the best results among the online trackers from both accuracy and speed viewpoints. ACF has effective implementation, because it runs on the CPU machine instead of GPU for the other online trackers.
- Among the RCNN-based trackers (i.e., RCNN, FastRCNN and FasterRCNN), RCNN has the best tracking accuracy. Though, FastRCNN and FasterRCNN are very fast in test phase, their tracking process is slow because they are very slow in training phase.
- Since the YOLO tracker was implemented offline, it is the fastest tracker. YOLO is not qualified for online tracking, because it is very slow in training phase.
- For human tracking from the front and side views, the combination of YOLO and Kalman filter shows the best results.
- We recommend to use the ACF tracker in unknown objects tracking because YOLO does not detect them whereas the ACF tracker does.
- Compared to YOLO and ACF, the RCNN-based trackers show less accuracy because they don’t have a very deep structure (i.e., 3 convolutional layers and 2 fully connected). By using a deeper convolutional neural network like YOLO the accuracy is dramatically increased.
- YOLO detector detects cars from the top view, but the object classification precision is low.
- For human detection, since YOLO was biased to the data from the front view, although the YOLO detection results from the view is very good the classification results is disappointing.
- Though, the object detection based on deep learning has recently improved, further improvement is still necessary. YOLO detection should be trained using a big dataset including more various views of the objects.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Milan, A.; Schindler, K.; Roth, S. Multi-Target Tracking by Discrete-Continuous Energy Minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2054–2068. [Google Scholar] [CrossRef] [PubMed]
- Milan, A.; Schindler, K.; Roth, S. Continuous Energy Minimization for Multitarget Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Yung, N.H.C.; Xu, L. Multiple-Human Tracking by Iterative Data Association and Detection Update. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1886–1899. [Google Scholar] [CrossRef]
- Bouguet, J.Y. Pyramidal Implementation of the Lucas Kanade Feature Tracker Description of the Algorithm; Intel Corporation, Microprocessor Research Labs, 1999; Available online: http://seagull.isi.edu/marbles/assets/components/workflow_portal/users/lib/opencv/share/opencv/doc/papers/algo_tracking.pdf (accessed on 15 November 2018).
- Sakai, Y.; Oda, T.; Ikeda, M.; Barolli, L. An Object Tracking System Based on SIFT and SURF Feature Extraction Methods. In Proceedings of the 18th International Conference on Network-Based Information Systems, Taipei, Taiwan, 2–4 September 2015; pp. 561–565. [Google Scholar]
- Lin, Z.; Davis, L.S.; Doermann, D.; DeMenthon, D. Hierarchical Part-Template Matching for Human Detection and Segmentation. In Proceedings of the IEEE 11th International Conference on Computer Vision, (ICCV 2007), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Wang, L.; Yung, N.H.C. Three-Dimensional Model-Based Human Detection in Crowded Scenes. IEEE Trans. Intell. Transp. Syst. 2012, 13, 691–703. [Google Scholar] [CrossRef] [Green Version]
- Leibe, B.; Seemann, E.; Schiele, B. Pedestrian Detection in Crowded Scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 878–885. [Google Scholar]
- Wu, B.; Nevatia, R. Detection and Tracking of Multiple, Partially Occluded Humans by Bayesian Combination of Edgelet based Part Detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Wang, L.; Yung, N.H.C. Extraction of Moving Objects From Their Background Based on Multiple Adaptive Thresholds and Boundary Evaluation. IEEE Trans. Intell. Transp. Syst. 2010, 11, 40–51. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Liu, S.; Muhammad, K.; Sangaiah, A.K.; Doctor, F. Object Tracking in Vary Lighting Conditions for Fog Based Intelligent Surveillance of Public Spaces. IEEE Access 2018, 6, 29283–29296. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR’10), San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; Li, Z.; Cao, X.; Ye, Q.; Chen, C.; Shen, L.; Perina, A.; Ji, R. Output Constraint Transfer for Kernelized Correlation Filter in Tracking. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 693–703. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR’16), Providence, RI, USA, 16–21 June 2016; pp. 1401–1409. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L. Speeded up robust features (Surf). J. Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Miao, Q.; Wang, G.; Shi, C.; Lin, X.; Ruan, Z. A new framework for on-line object tracking based on SURF. Pattern Recognit. Lett. 2011, 32, 1564–1571. [Google Scholar] [CrossRef]
- Shuoa, H.; Nab, W.; Huajunc, S. Object Tracking Method Based on SURF. Appl. Mech. Mater. 2012, 351–356. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.; Zhou, Z.; Guo, W.; Wang, B.; Zhao, Q. Object tracking using improved Camshift with SURF method. In Proceedings of the IEEE International Workshop on Open-Source Software for Scientific Computation, Beijing, China, 12–14 October 2011; pp. 136–141. [Google Scholar]
- Zhou, D.; Hu, D. A robust object tracking algorithm based on SURF. In Proceedings of the International Conference on Wireless Communications and Signal Processing, Hangzhou, China, 24–26 October 2013; pp. 1–5. [Google Scholar]
- Gupta, A.M.; Garg, B.S.; Kumar, C.S.; Behera, D.L. An on-line visual human tracking algorithm using SURF-based dynamic object model. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3875–3879. [Google Scholar]
- Chen, K.; Tao, W. Learning Linear Regression via Single Convolutional Layer for Visual Object Tracking. IEEE Trans. Multimed. 2018, 1–13. [Google Scholar] [CrossRef]
- Zheng, F.; Shao, L. A Winner-Take-All Strategy for Improved Object Tracking. IEEE Trans. Image Process. 2018, 27, 4302–4313. [Google Scholar] [CrossRef] [PubMed]
- Lan, L.; Wang, X.; Zhang, S.; Tao, D.; Gao, W.; Huang, T.S. Interacting Tracklets for Multi-Object Tracking. IEEE Trans. Image Process. 2018, 27, 4585–4597. [Google Scholar] [CrossRef] [PubMed]
- Zheng, F.; Shao, L.; Han, J. Robust and Long-Term Object Tracking with an Application to Vehicles. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3387–3399. [Google Scholar] [CrossRef]
- Guan, M.; Wen, C.; Shan, M.; Ng, C.L.; Zou, Y. Real-Time Event-Triggered Object Tracking in the Presence of Model Drift and Occlusion. IEEE Trans. Ind. Electron. 2018, 66, 2054–2065. [Google Scholar] [CrossRef]
- Yao, R.; Lin, G.; Shen, C.; Zhang, Y.; Shi, Q. Semantics-Aware Visual Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 1–14. [Google Scholar] [CrossRef]
- Akok, B.; Gurkan, F.; Kaplan, O.; Gunsel, B. Robust Object Tracking by Interleaving Variable Rate Color Particle Filtering and Deep Learning. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3665–3669. [Google Scholar]
- Kim, H.I.; Park, R.H. Residual LSTM Attention Network for Object Tracking. IEEE Signal Process. Lett. 2018, 25, 1029–1033. [Google Scholar] [CrossRef]
- Ding, J.; Huang, Y.; Liu, W.; Huang, K. Severely Blurred Object Tracking by Learning Deep Image Representations. IEEE Trans. Circ. Syst. Video Technol. 2016, 26, 319–331. [Google Scholar] [CrossRef]
- Yun, S.; Choi, J.; Yoo, Y.; Yun, K.; Choi, J.Y. Action-Driven Visual Object Tracking With Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2239–2252. [Google Scholar] [CrossRef] [PubMed]
- Bae, S.H.; Yoon, K.J. Confidence-Based Data Association and Discriminative Deep Appearance Learning for Robust Online Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Yeung, D.Y. Learning a Deep Compact Image Representation for Visual Tracking. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 809–817. [Google Scholar]
- Nam, H.; Han, B. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Ondruska, P.; Posner, I. Deep Tracking: Seeing Beyond Seeing Using Recurrent Neural Networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3361–3367. [Google Scholar]
- Zhang, L.; Varadarajan, J.; Suganthan, P.N.; Ahuja, N.; Moulin, P. Robust Visual Tracking Using Oblique Random Forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5825–5834. [Google Scholar]
- Wang, C.; Zhang, L.; Xie, L.; Yuan, J. Kernel Cross-Correlator. arXiv, 2018; arXiv:1709.05936. [Google Scholar]
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. RFast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Shaoqing, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Li, F.; Shirahama, K.; Nisar, M.A.; Koeping, L.; Grzegorzek, M. Comparison of Feature Learning Methods for Human Activity Recognition Using Wearable Sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv, 2015; arXiv:1511.08458. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR, San Diego, CA, USA; 7–9 May 2015. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Zorzi, M. Robust Kalman Filtering Under Model Perturbations. IEEE Trans. Autom. Control 2017, 62, 2902–2907. [Google Scholar] [CrossRef]
- Zorzi, M. Convergence analysis of a family of robust Kalman filters based on the contraction principle. SIAM J. Optim. Control 2017, 55, 3116–3131. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. YOLO. Available online: https://pjreddie.com/darknet/yolo/ (accessed on 21 June 2018).
- VOT Challenge Videos. Available online: http://www.votchallenge.net/vot2018/dataset.html (accessed on 20 September 2018).
- Fabio, C. C++ Implementation of the Kalman Filter. Available online: https://github.com/fabio-C/KalmanFilter/ (accessed on 25 June 2018).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Number of the Synthetic Data | 500 | 800 | 1000 | 2000 | 4000 | 10,000 |
|---|---|---|---|---|---|---|
| First Frame | 1 | 1 | 1 | 1 | 1 | 1 |
| Additive Noise | 2–9 | 2–9 | 2–9 | 2–9 | 2–9 | 2–9 |
| Rotation | 10–200 | 10–200 | 10–200 | 10–200 | 10–200 | 10–200 |
| Rotation + Intensity Adjustment | 201–400 | 201–599 | 201–400 | 201–400 | 201–400 | 201–400 |
| Rotation + Contrast Enhancing | 401–500 | 600–800 | 401–601 | 401–601 | 401–601 | 401–601 |
| Brightness Change | - | - | 602–1000 | 602–1000 | 602–1000 | 602–1000 |
| Brightness Change + Resizing | - | - | - | 1001–2000 | 1001–2000 | 1001–2000 |
| Rotation + Brightness Change | - | - | - | - | 2001–4000 | 2001–4000 |
| Last Row + Intensity Adjustment | - | - | - | - | - | 4001–10,000 |
| 200 | 300 | 500 | 1000 | 2000 | 5000 | 10 | 20 | 50 | 100 | 500 | 1000 | - | |
| 200 | 410 | 450 | 500 | 1000 | 2000 | 20 | 30 | 40 | 50 | 100 | 500 | 1000 |
| Methods | Length of | Length of Synthetic Data | Stage | Epoch |
|---|---|---|---|---|
| 614 | 210 | 5 | - | |
| 1000 | 500 | 3 | - | |
| , and | 1000 | 500 | - | 3 |
| 4000 | 4000 | - | 10 |
| Method | David | Jump | P1 | P2 | P3 | Car | Moto | VW | CarC | Panda |
|---|---|---|---|---|---|---|---|---|---|---|
| ACF1 | 1/0.98/0.99 | 0.96/1/0.98 | 0.96/0.88/0.92 | 0.90/1/0.95 | 0.94/0.85/0.89 | 0.97/0.95/0.96 | 0.87/0.35/0.50 | 0.14/0.13/0.13 | 0.4/0.74/0.52 | 0.83/0.69/0.75 |
| ACF2 | 0.99/0.99/0.99 | 0.87/0.99/0.93 | 0.96/0.82/0.88 | 0.84/1/0.91 | 0.93/0.96/0.94 | 0.93/0.98/0.95 | 0.97/0.56/0.71 | 0.78/0.65/0.71 | 0.78/0.64/0.70 | 0.84/0.85/0.85 |
| RCNN1 | 0.69/0.27/0.39 | 0.96/0.22/0.36 | 0.95/0.15/0.26 | 0.61/0.25/0.35 | 0.99/0.69/0.81 | 0.97/0.35/0.51 | 1/0.42/0.59 | 1/0.35/0.52 | 0.95/0.37/0.53 | 0.99/0.11/0.20 |
| RCNN2 | 0.97/0.48/0.64 | 0.96/0.36/0.52 | 0.74/0.15/0.25 | 0.75/0.56/0.64 | 0.99/0.67/0.80 | 0.99/0.90/0.94 | 0.98/0.40/0.57 | 0.96/0.57/0.72 | 0.94/0.45/0.61 | 0.99/0.37/0.54 |
| FastRCNN | 0.90/0.19/0.31 | 1/0.01/0.02 | 1/0.29/0.45 | 0.80/0.21/0.33 | 1/0.73/0.84 | 0/0/0 | 1/0.31/0.47 | 1/0.13/0.23 | 0.99/0.29/0.45 | 0.40/0.07/0.12 |
| FasterRCNN | 0.36/0.17/0.23 | 0.95/0.41/0.57 | 1/0.33/0.5 | 0.90/0.81/0.85 | 1/0.62/0.77 | 1/0.86/0.92 | 0.95/0.16/0.27 | 0.75/0.09/0.16 | 0.92/0.52/0.66 | 1/0.07/0.13 |
| Offline ACF | 0.72/0.49/0.58 | 0.30/1/0.46 | 0.40/0.49/0.44 | 0.20/1/0.33 | 0.89/0.99/0.93 | 0.59/0.81/0.68 | 1/0.39/0.56 | 0.43/0.66/0.52 | 0.45/0.68/0.54 | 0.08/0.83/0.15 |
| YOLO | 1/0.99/0.99 | 1/1/1 | 1/0.77/0.87 | 1/0.43/0.60 | 1/0.59/0.74 | 0.99/0.0.93/0.96 | 0.89/0.82/0.85 | 0.99/0.86/0.92 | 0.97/0.92/0.94 | 0.99/0.78/0.88 |
| Brand | Specification | |
|---|---|---|
| CPU | Intel | Core i7-7700K CPU @ 4.20 GHz |
| GPU | GeForce | GTX 1080 Ti/PCIe/SSE2 |
| Ram | Kingston | 15.6 GB |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delforouzi, A.; Pamarthi, B.; Grzegorzek, M. Training-Based Methods for Comparison of Object Detection Methods for Visual Object Tracking. Sensors 2018, 18, 3994. https://doi.org/10.3390/s18113994
Delforouzi A, Pamarthi B, Grzegorzek M. Training-Based Methods for Comparison of Object Detection Methods for Visual Object Tracking. Sensors. 2018; 18(11):3994. https://doi.org/10.3390/s18113994
Chicago/Turabian StyleDelforouzi, Ahmad, Bhargav Pamarthi, and Marcin Grzegorzek. 2018. "Training-Based Methods for Comparison of Object Detection Methods for Visual Object Tracking" Sensors 18, no. 11: 3994. https://doi.org/10.3390/s18113994
APA StyleDelforouzi, A., Pamarthi, B., & Grzegorzek, M. (2018). Training-Based Methods for Comparison of Object Detection Methods for Visual Object Tracking. Sensors, 18(11), 3994. https://doi.org/10.3390/s18113994