The idea for the device and its operation was not modeled on any similar device. The device is not an electronic substitute for a white rod, but something like its complement and extension, because it is an imaging device, so it should be used as an addition to a white stick. Whereas neuroplasticity of the cerebral cortex there is a chance to develop the habit of using this device as a substitute for the eye, that will be reflective and will not require much attention. The device should help to “see” the obstacles (more their presence at larger distances than shape), passages or room shapes. It ought to also help to detection of the presence and location of other people without touch, so as to avoid being hit by a white cane.
All elements of the device were mounted on a bicycle helmet. In this way you can avoid uncomfortably running wires that are easy to hook and pull.
5.1. The Principle of Device Operation
As point out before, the device task is to provide a depth map read by the sensor. The map is transmitted to a user using stereo headphones and several sounds (tones with exact frequencies). Sound management is done with software installed and software written right on the Raspberry Pi. The computer links with the sensor via the USB port, and with the headphones using a built-in sound card and a 3.5 mm jack socket.
5.1.1. Depth Values Returned by the Kinect Sensor
The depth value is given by the sensor as 11 bit non-negative number, which gives us values in the range 0–2047, but it is not quite so. In fact, the zero value does not occur. The sensor at the perpendicular position of the optical axis relative to the horizontal surface of the obstacle, “sees” it only at a shortest distance of 57 cm and returns the value 488. If the object surface is set at an angle it is likely to slightly reduce the distance. The supreme value (2047) occurs when the object was detected, but no reading correct distance. This means that the value of 2047 always occurs when the distance rate could not be retrieved. This take place when the object was too close, too far away, when the lighting conditions were unsatisfactory at some point, or when the light has been noised by ambient light.
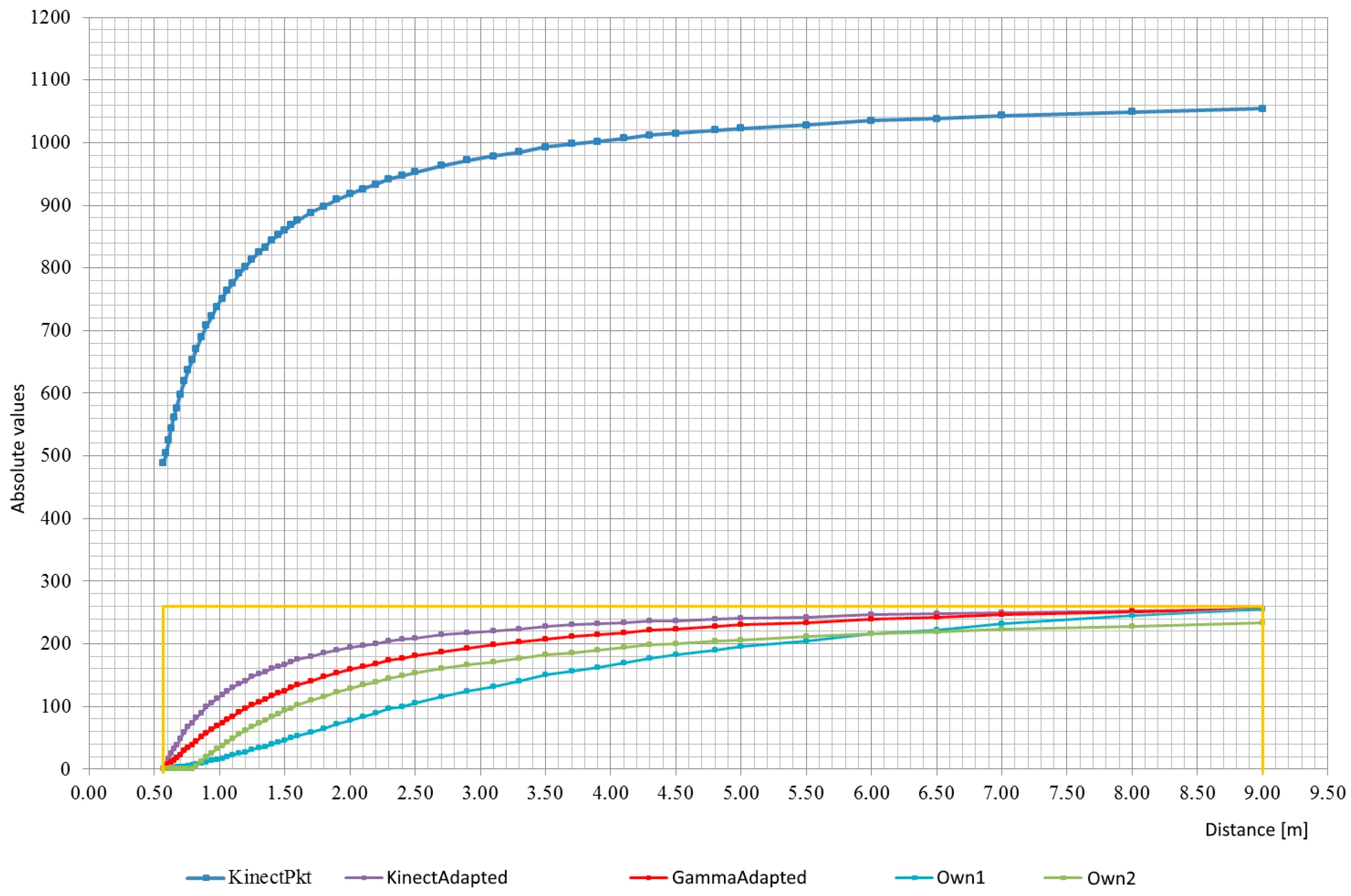
As part of the prototype preparation, measurements of the values returned by the device were made and comparison to the real distance. The program based on the presentation from the OpenKinect website was written for the measurements. The program shows on the screen the distance value read by the sensor in the center of the area of view. For easier pointing, a view of the whole depth map captured was left. Using a measuring cup, the distance between the sensor and the obstacle was measured, which after reading and writing the value was moved away by a reasonable distance. Though the measurements were not very precise, but rather demonstrative, they were precise enough to create characteristics of the sensor. It later helped performing transforming functions that adjust the loudness of the sound to the returned distance (more detailed information on these functions is given below; the way of transmitting the depth map using sounds is given below). You can see that the characteristic is non-linear—
Figure 3 blue line.
You can clearly see the high precision and large changes in raw data gather by the sensor with a small variations in distance if the object is nearby. At larger distances, changes in raw values are much minor. However, it is possible to practice such a wide measuring range for the reason that the sampling is stable. Weak precision at more distances is not an obstacle in the use of the sensor on which this article focuses.
Because the Mix_SetPosition (…) function of the SDL_mixer library as the volume/distance value takes the 8-bit parameter (so the max value is 255—silence). It was required, therefore, to process raw values into a functioning range and a slight more linear characteristic using appropriate functions.
Figure 3 presents charts of functions converting raw distance values, 11-bit to 8-bit values. Different version of the transformation functions turn out possibility to adapt the device to a wide open space or a tight like rooms. Rather, changes in the transforming function (and use the most universal) should be avoided, due to the chance that the brain of the person using the device will get accustomed to one function and will be able to recognize correct distance (to make it easier to add a fixed reference sound) volume, described later in this chapter). The mechanism described is not certain but plausible. You can also try to make the selection of the transformation function dependent on some variable component, for instance, on whether the person is in the building or outside.
The chart labeled KinectPkt shows the raw values returned by the sensor. Orange lines limit the field of the graph in which the useful range of the actual distance is located and the distance between the range 0–255 is returned by the sensor.
The graph marked as
KinectAdapted is a graph showing the values of the function relative to the actual distance values:
The function scales only raw values so that they are within the desired range. It is suitable for very tight spaces (for which the Kinect sensor is not suitable).
The graph marked as
GammaAdapted is a graph presenting the values of the function relative to the actual distance values:
This function is based on the function—Gamma, which is placed in the demonstrative source code of the libfreenect library. The function has been converted in such way that the returned values are within the preferred range.
A graph marked
Own1 shows the values of the function relative to the actual distance values:
It is an empirical function. It is more appropriate for use in the open air than Function (2) or Function (3).
The chart labeled
Own2 shows the values of the function relative to the actual distance values:
It is an empirical function. For the largest real distance to be read, it does not give you total silence. It also “skips” a part of the smallest distances detected by the sensor, in which the volume is maximum. Negative values must be set to zero (possible with conditional instructions).
The functions described above ought to be limited in the program from the top and the bottom by means of conditional instructions so that they do not exceed the range of 0–255. These functions are only proposals that do not close the pool of available functions, but only open it. The usability of the device depends on the transformation function. The key is to create a function that works well under different conditions and ensures the best possible hearing of even small differences in the distance in the entire available range.
5.1.2. Transmission of the Depth Map with Sounds
The depth map is transmitted to the user using sounds—fixed-frequency tones. Higher volume means shorter distance to the obstacle. The loudness distribution depending on the distance provides the above-described transforming functions.
The entire depth map given back by the sensor (640 × 480 px) is split into smaller blocks, which in this work will be called small fields. The operation have to be made due to the fact that it would not be possible or very difficult to transmit such a large amount of information. An additional argument for the division of the image are quite often occurring areas in which the sensor could not be able read the distance and such situation would introduce a confusion in the signal and could build an incorrect map of depth in the user’s mind.
The number of small fields fixes the final resolution of the transmitted depth map. In the prototype made, the depth map forwarded is 5 columns in 6 rows (5 × 6 small fields). This gives 30 small fields (
Figure 4). In comparison with the resolution of 640 × 480 px, which gives 307,200 px is not much. There is a good chance to increase the resolution. High resolution has been used in The vOICe program, which by default transmits a map of brightness or depth in 320 × 64 dots resolution.
In the prototype made, the coordinates of the depth point conveyed point depend on the lateralization of the sound signal and the pitch. The depth map is transmitted in the form of a “scan” of five columns from left to right and from right to left (the information in these two “scans” is not the same—this is explained further). Each transmitted column lasts a certain length of time, 200 ms, allowing quite a good listening to the tones. There are 6 small fields in one column (6 rows of depth maps), but not all are transmitted in parallel.
The pitch of individual tones determines at what height there are small fields represented by them—the higher tone is a small field located higher, the lower tone is a small field below. The tones are played in parallel (3 tones, not 6), and the volume of each matches to the distance transmitted by the small field. The scan from left to right is responsible for passing the three upper lines (three higher notes). The scan from right to left is responsible for the transmission of the three bottom lines (three lower tones). A graphic explanation of the above descriptions is given in
Figure 5.
Each deep depth map cycle starts with a short tone, always at the same volume, duration 300 ms and frequency 100 Hz, not included in the map. Its purpose is to provide reference volume when a person is once in a quieter, once louder environment.
The sound signal of the transmitted depth map is also appended with pauses for easier identification of particular phases of the message. In the transmission cycle, one can distinguish: phase 1 reference sound with a duration of 300 ms; phase 2 pause (silence) with a duration of 200 ms; phase 3 transmission of 5 columns from three upper rows with a duration of 200 ms (one column) times 5, or 1000 ms; phase 4 pause (silence) with a duration of 200 ms; phase 5 transmission of 5 columns from the three bottom rows with a duration of 200 ms (one column) times 5, or 1000 ms; phase 6 pause (silence) with a duration of 200 ms.
From the described values it is easy to calculate a total cycle time of 2900 ms. This results in a low transmission frequency of around 0.345 Hz. However, it should be noted that before the tone from the next column is reproduced, the depth map values are updated. It can be said that there is a partial refresh rate of 5 Hz (excluding gaps between individual “scans”).
The above times are determined in such a way that the beginner can hear all the sounds and learn what they mean. The next steps in learning how to use the device can be a gradual shortening of the length of individual phases until the minimum times are reached. It is likely that hardware limitations—Raspberry Pi 1 Model B+—would not allow for very short times. This problem is solved with the newer versions of the Raspberry Pi computer, with more computing power. The number of rows (sounds) can be increased. A greater increase in the number of columns results in possibly large, favorable values.
The values of fields are determined as follows: 1—The value of each of the pixels in a small field is computed using a transition table, which stores converted (using one of the transformation functions) at the start of the program distance values. This method was used in the freenect library demo code. 2—The values of all correctly read pixels are added together and their number is calculated. Pixels with too large values are discarded. These data serve to average the value later. In addition, the smallest indicated distance value is found among the pixels. 3—If the minimum specified distance value among all pixels in the small area is larger than the defined limit (currently 1.2 m) and if there is at least one pixel with a correctly read value, then the small field is described by means of correctly read pixels. 4—If the above condition was not met (i.e., if a nearby obstacle was detected), the small field is assigned the value of the minimum read distance occurring in the small field area.
You can also use the alternative method of the above algorithm, but it is probably less beneficial to use it. In this method, part of point 2 and point 3 are omitted—the values are not means, and the small field is always assigned the minimum value appearing in its area.
5.1.3. Learning Mode
Since it is not natural to make the view of the height of the view from the height of the sound, it is necessary to give the user the chance to learn this skill. For this purpose, a special program (operating directly on the device) has been made, which should help to learn reflexively depending on the height of the view from the height of the sound. In addition to the program, the person can also learn to recognize the sounds, but this is most likely a much harder learning method.
In order to enable the learning mode, after starting the normal mode, disconnect and immediately connect the Kinect sensor power plug (plug marked with a strip of insulating tape). If the plug-in is connected later than after about seven seconds, the program will not start. The device should then be restarted.
The learning mode works in an analogous way to an ordinary obstacle indicator. Device detects an obstacle situated exactly in the middle area of the sensor’s field of view and signals the smallest distance read in this area from the obstacle using a single tone, which increases in intensity as you approach an obstacle (use the same conversion function, which in normal mode). The height of the tone signaling the obstacle is selected based on the inclination of the sensor. The inclination of the sensor is read using its built-in accelerometer.
If the person bends his head forward (down), then the distance from the obstacle is signaled lower and lower (depending on the angle of inclination). If it tilts the head up, the distance is signaled with ever higher tones. No sound is reproduced if the tilt angle exceeds the field of view angle of the sensor in normal mode, which is 43°, 21.5° down or 21.5° up. It is easy to calculate that for one row (and therefore the tone) it is about 7.17°. Accelerometer readings returned by the libfreenect library are returned with a resolution of 0.5°.
The distance refresh rate here is much higher than in normal mode and is 20 Hz (refreshing every 50 ms). The reference sound is played every 80 readings, so every 4 s. It lasts the same as in normal mode—300 ms, and pauses surrounding it after 200 ms.
5.1.4. Selection and Generation of Sounds
In order for the depth map message not to be unpleasant, tones based on the C7 (divided into many octaves) tones shifted by 50 cents up (1/4 tone) were used.
In the selection of sounds, the limitations of human hearing were guided, and so they tried to keep the greatest distances between tones in one “scan”. In addition, two identical sounds could not be heard in a single “scan”.
The basic frequencies of the tones belonging to the C7 token were obtained from the website [
26]. Then, the tone frequencies were multiplied by a further power of two to get the frequency of the tones in the higher octaves, and the low frequencies of the tones were divided by successive powers of two to get the frequency of the tones in the lower octaves. The tone frequencies thus obtained have been raised by 50 cents. Of the obtained sounds, 6 frequencies were selected. Selected sounds are presented in
Table 1.
The reference tone is in no way associated with the above sounds and has a frequency of 100 Hz, which can be freely changed.
The tones were generated using the Audacity program. The amplitude of the generated sounds has been set to 0.2. The sounds have been matched to each other using the boost slider (slider on the left side of each track). The gain for f = 67.32 Hz was set to +8 dB. For f = 169.63 Hz + 5 dB. For f = 403.49 Hz − 4 dB. For f = 479.86 Hz − 4 dB. For f = 806.97 − 2 dB. For f = 2154.33 − 9 dB.
The tones have been exported to WAV files with a sampling frequency of 44100 Hz, although for the device it can be 22050 Hz, which should not cause any problems.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}