1. Introduction
Advances in 3D terrestrial laser scanning technology and its various applications have increased the size of 3D point clouds enormously. Unlike elements stored in conventional spatial database management systems (SDBMS), a 3D point cloud has even more entities—points, up to billions in number, however, each entity is not topologically related to the others. Thus, it is necessary to use relevant methods to handle the data. The methods can be categorized into two: lossy compression or abbreviation, and lossless indexing. The former category eliminates less meaningful points from the 3D point cloud. Several relevant approaches have reported that the reduced data still exhibits consistent results with half or even less point density [
1,
2,
3]. The latter category retains and uses the original coordinate information of all points, and then uses special data structures to store and retrieve the data efficiently. For example, as a dynamic partitioning algorithm, R-tree is commonly utilized in SDBMS with its derivatives, and might be applicable for this purpose. However, R-tree is based on minimum bounding rectangles (MBR) and points are apt to be enclosed by overlapping nodes, making it a poor solution [
4]. K-d tree, which is also a dynamic partitioning algorithm is more efficient and has been officially implemented in the point cloud library (PCL) [
5]. However, in the worst case, all of the child nodes should be retrieved to traverse from a node to its child node where the 3D boundary satisfies a positional query [
6]. Thus, a large 3D point cloud necessitates proper methods to re-organize or index itself efficiently. Among the known methods, octree is popular for its memory efficiency, query speed and structural simplicity [
7]. In octree, only one child node in each depth is traversed because the 3D boundary of each node is implicitly known by positional query. Thus, a leaf node can be advantageously retrieved in this approach. Octree is now being exploited by a number of applications for segmentation and visualization of 3D point clouds [
8,
9,
10,
11,
12,
13,
14], and also in PCL. However, octree, as a static partitioning algorithm, has a potential weakness, that is, memory waste because eight child nodes are always declared, even when not all of them bear point(s) within themselves. To address this weakness, a schema was presented to avoid declaration of child nodes that bear no points, and to terminate subdivision if the number of points goes below a threshold after further subdivision [
15,
16]. A memory efficient encoding method was also employed to minimize the size of a node in octree.
The present study uses a native octree, which means that derivations of octree, as introduced in the relevant approaches [
15,
16] are not considered. Instead, it deals with other issues that influence the performance of octree. These include how to make a compact node in a native octree, how to design functions (methods) applicable to the node, where to store and retrieve the 3D point cloud itself (main memory or HDD), and what the shape of octree should be. From preliminary tests, several influencing factors were found: 1) the size of a node is very flexible but does not have much influence on query speed, and 2) dynamic declaration of nodes in the octree construction process claims more memory than expected, thus, array declaration is preferable after a pseudo octree construction [
17]. The present study is based on the array-based approach and this will not be further mentioned in this paper. The paper is structured as follows: implementation of a compact node and relevant methods are outlined in
Section 2.1.1, implementation of a file-based octree to reduce main memory usage is described in
Section 2.1.2, more efforts to enhance the performance of octree are discussed in
Section 2.1.3 and
Section 2.1.4, and its application is shown in
Section 2.2. Results along with the discussion and conclusions follow in
Section 3 and
Section 4.
3. Results and Discussion
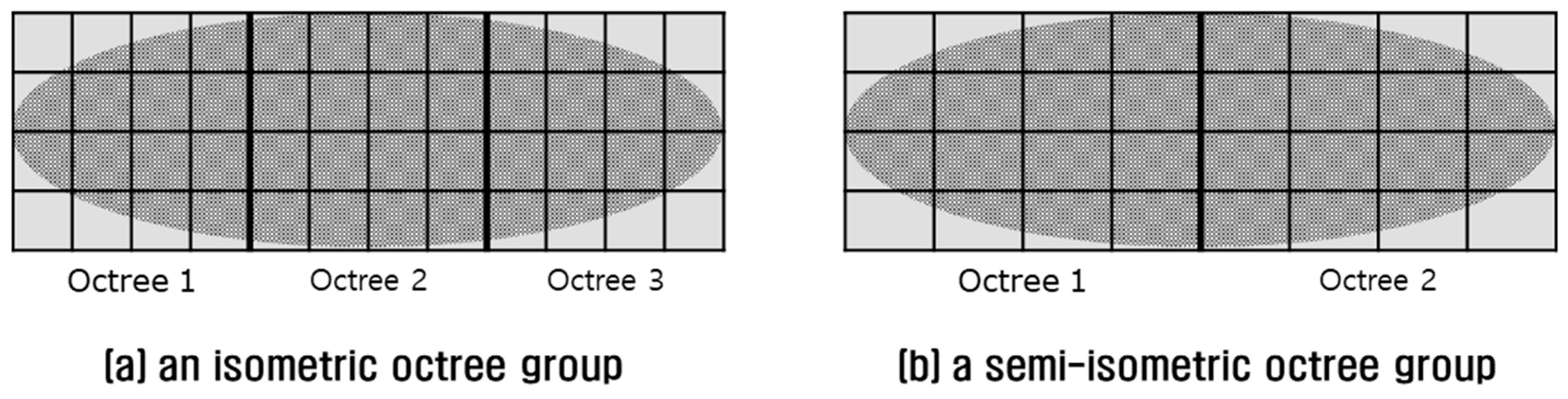
As the long tunnel (Data 1) is 1.5 km long horizontally and only 19 m long vertically, the lengths of the MBH are seriously unequal in the
x-,
y- and z-directions (
Table 1). Memory-based and file-based octrees were constructed in single octrees. The lengths in the x- and y-directions of a leaf node were 29.87 and 69.97 times larger than in the z-direction (
Table 3). A semi-isometric octree group was implemented using three thresholds. The group was composed of 171 (= 9 × 19 × 1, threshold = 3) to 1711 (= 29 × 59 × 1, threshold = 1) octrees, where the ratio of the
x- to
z-direction ranged from 3.32 (threshold = 3) to 1.03 (threshold = 1) (
Table 3). On the contrary, the lengths of the MBH of the short tunnel (Data 2) were 56 m and 26 m horizontally and 12 m vertically, which are not seriously unequal (
Table 1). The length in the
x- and
y-directions of a leaf node were only 4.68 and 2.13 times larger, respectively, than the length in the z-direction (
Table 4). A semi-isometric octree group was implemented using three thresholds and the group was composed of 1 (= 1 × 2 × 1, threshold = 3) to 8 (= 4 × 2 × 1, threshold = 1) octrees (
Table 4). The lengths of the MBH of the urban area (Data 3) are 10.7 km and 3.4 km horizontally and 0.3 km vertically, which are very unequal (
Table 1). The lengths in the x- and y-directions of a leaf node were 36.89 and 11.65 times larger than the length in the z-direction (
Table 5). A semi-isometric octree group was implemented using three thresholds and the group was composed of 36 (= 12 × 3 × 1, threshold = 3) to 396 (= 36 × 11 × 1, threshold = 1) octrees (
Table 5).
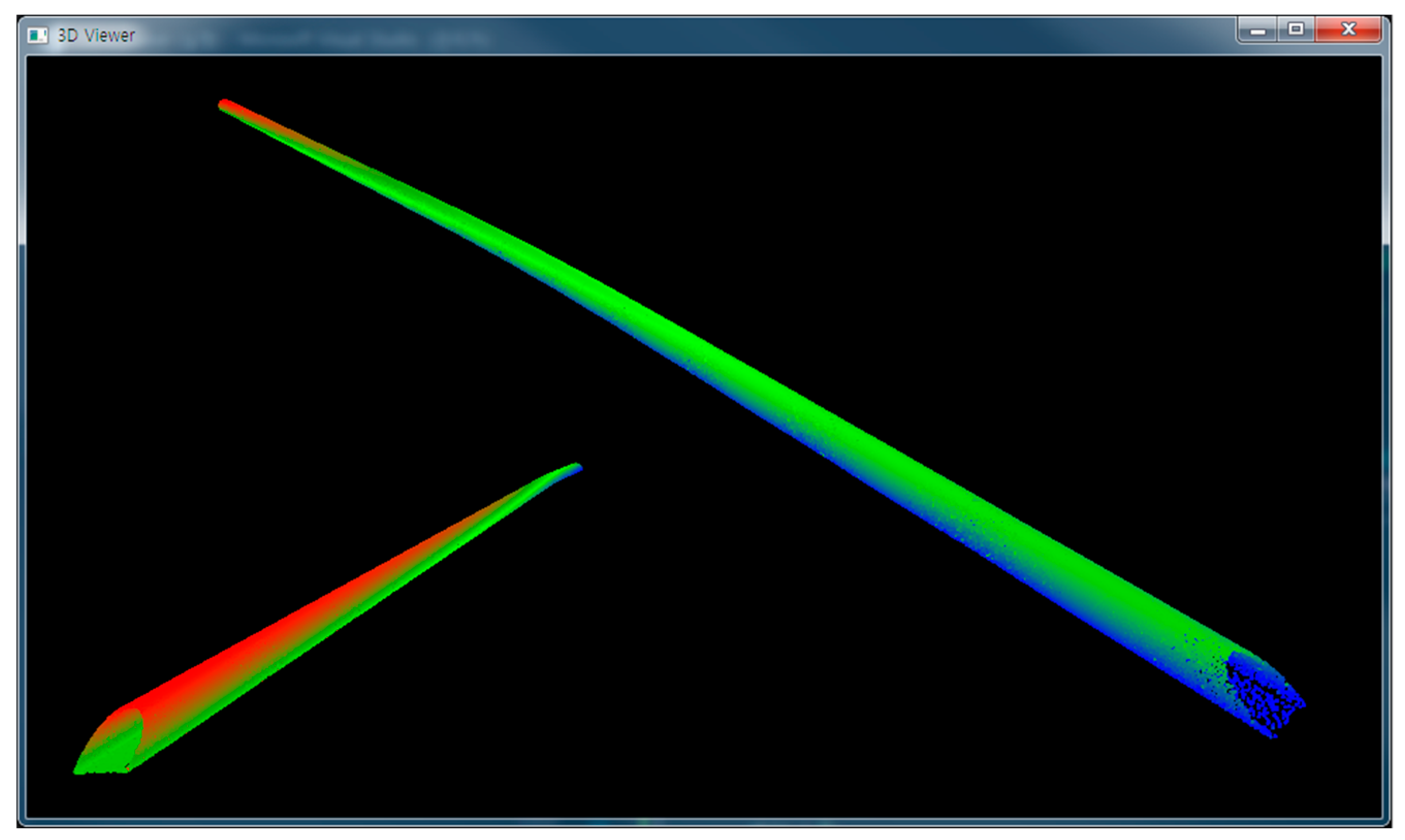
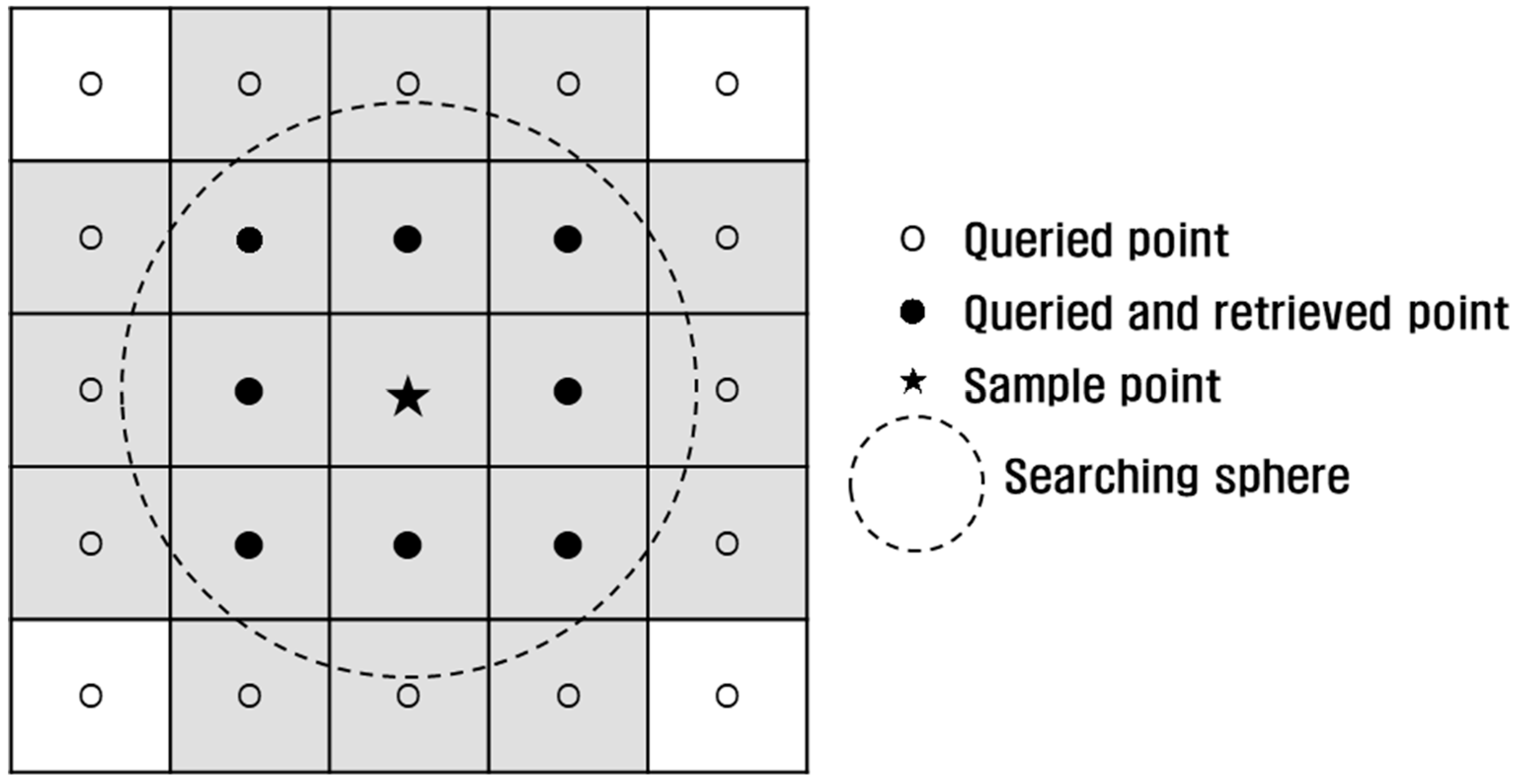
The main memory occupancy and time duration were measured during octree construction. To evaluate the performance, a proximity operation was conducted as introduced in [
6]. This operation aims to query and retrieve neighboring points within a searching sphere from the sample points (
Figure 12). Such an operation is known as fixed distance neighbors (FDN) [
19] and can be applied to k-NN [
20] if supplemented by distance sorting. The operation is necessary in normal estimation and noise filtering [
19,
21]. A total of 3005 sample points, or 1/100,000 of the data, were selected from Data 1 and neighboring points within a 5 cm (radius of the searching sphere) were queried. In all methods, the same 1,735,755 points were retrieved, and thus, no faults were detected in the proximity operation. Likewise, the same operation was conducted using Data 2 and Data 3 (
Table 6).
Octrees were constructed in Depth 8 to 13 for the memory-based approach and in Depth 8 to 9~11 for the file-based and semi-isometric approaches to avoid memory occupancy exceeding any of the memory-based approach (
Table 7,
Table 8 and
Table 9). Memory usage, along with construction time increased accordingly. As is the precondition, main memory occupancy includes the size of the 3D point cloud itself in the memory-based approach (for example, 6878 MB for Data 1). The memory-based approach exhibited enormous speed in the proximity operation. The result is credible because the performance of the main memory can never be exceeded by a file-based operation, even using SSD. Nevertheless, the semi-isometric approach using Data 1 resulted in a performance that was a little better than the memory-based approach, and quite a lot better than the file-based one. The semi-isometric approach in Depth 8 was defeated once by a file-based one in Depth 13, but the main memory occupancy was almost half. A little more memory occupancy quickly enabled enough performance improvement in the semi-isometric approach in Depth 9. Similar results were observed using Data 2 and Data 3. However, the semi-isometric approach using Data 2 did not result in dramatically better performance than the file-based one because the lengths of the MBH are not seriously unequal in the
x-,
y- and
z-directions.
The best performance for the semi-isometric approach using Data 1 was achieved in Depth 10 with threshold = 1 (
Table 10). In this case, the main memory occupancy was 72.76% that of the memory-based approach in Depth 8, but performance increased to 81.82%. In the grey-highlighted cases, the semi-isometric approach achieved better performance than the file-based approach in the same Depth. In the green-highlighted cases, the semi-isometric approach achieved better performance than the best of the file-based approach with less memory occupancy. In the yellow-highlighted cases, the semi-isometric approach resulted in even better performance. The results in the cases of threshold = 3 using Data 3 were almost the same as the file-based approach (
Table 8 and
Table 11). This can be easily understood by the fact that the two approaches share the same leaf node dimensions (
Table 4). Nevertheless, it is clear that the performance of the semi-isometric approach is better than the file-based one in the same Depth in all cases. Thus, it can be said that the semi-isometric approach is a good alternative compared to the other approaches.
Theoretically, a better performance of the semi-isometric approach should be achieved with a smaller threshold
and a larger Depth. This is because query candidate points are more delicately selected if a leaf node gets more cubic-shaped and smaller. Accordingly, all results using Data 1 meet the expectation (
Table 10). However, the best performance was achieved in Depth 9 with threshold = 1 using Data 2, and in Depth 8 with threshold = 2 using Data 3 (
Table 11 and
Table 12). This is because of over-subdivision of the octree, in which a route to reach a leaf node is so long that it overwhelms the effect of the more delicate selection of query candidate points. For this reason, an optimal parameter is hard to determine before an experiment, and thus, several configurations should be investigated to find the best one.
4. Conclusions
In the present study, a basic algorithm to construct an octree for a 3D point cloud is introduced. The algorithm can be improved in terms of memory efficiency by using a compact form of node and revised parameter passing methods, and even further by using a file-based approach. However, the query speed of a file-based approach is very poor and becomes even worse when dealing with very longish 3D point clouds scanned in tunnels and corridors. The defects can be somewhat addressed by avoiding point concentration on fewer nodes using an anisometric approach, but this also brings about the problem of query overhead increment. Finally, the semi-isometric approach was introduced to improve query performance by implementing several semi-isometric octrees in a group. In the experiments, query performance and memory efficiency could be significantly improved in the case of a 3D point cloud captured in a long tunnel. When applied on a 3D point cloud captured in a short tunnel, the semi-isometric approach resulted in better performance (though not dramatically improved) than the file-based approach. Airborne laser scanning data was also tested and the semi-isometric approach resulted in acceptable enhancement of performance. By using media such as HDD of SDD, known to be much slower than main memory, a file-based approach and its derivations can never exceed the performance of a memory-based approach. Therefore, given enough main memory and using a moderately sized 3D point cloud, the memory-based approach is the best choice. When a 3D point cloud is larger than the main memory, as is quite common today, a file-based approach is the inevitable choice. In this case, however, the semi-isometric approach is a better choice no matter whether the 3D point cloud is longish or not.
In all of the above approaches, however, every insertion of a point to a leaf node increases the main memory usage because a pointer to the point is pushed back to a vector archive of the leaf node. Eventually, the maximum number of points is limited to the size of the main memory. In future work, a more advanced approach is being planned to address this limitation.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}