2. Related Works
Studies on banknote fitness classification with regard to various paper currencies have been reported. According to the research by the Dutch central bank, De Nederlandsche Bank (DNB), based on the evaluation using color imaging, soiling was the predominant reason that degrades the quality of a banknote, and the mechanical defects appeared after the banknote was stained [
2,
3,
4]. Therefore, several previous studies use the soiling level as the criterion for judging the fitness for further circulation of a banknote [
5]. Based on the method of using banknote images captured by single or multiple sensors, these approaches can be divided into two categories: the methods using the whole banknote image and those that use certain regions of interest (ROIs) on the banknote image for the classification of banknote fitness. In the method proposed by Sun and Li [
6], they considered that the banknotes with different levels of old and new have different gray histograms. Therefore, they used the characteristics of the banknote images’ histogram as the features, dynamic time warp (DTW) for histogram alignment, and support vector machine (SVM) for classifying the banknotes’ age. Histogram features were also used in the research of He et al. [
7], in which they used a neural network (NN) as the classifier. A NN was also used in the Euro banknote recognition system proposed by Aoba et al. [
8]. In this study, the whole banknote images captured by visible and infrared (IR) sensors were converted to multiresolutional input values and subsequently fed to the classification part using a three-layered perceptron and the validation part uses the radial basis function (RBF) networks [
8]. In this system, the new and dirty Euro banknotes are classified in the RBF network-based validation part. Recently, Lee et al. [
9] proposed a soiled banknote determination based on morphological operations and Otsu’s thresholding on contact image sensor (CIS) images of banknotes.
In ROI-based approaches, certain areas on the banknote images where the degradation can be frequently detected or visualized are selected for evaluating the fitness of the banknote. In the studies of Geusebroek et al. [
3] and Balke et al. [
10], from overlapping rectangular regions on the color images of Euro banknotes, the mean and standard deviation of the channels’ intensity values were calculated and selected as the features for assessing the soiling values of banknotes using the AdaBoost algorithm [
3,
10]. Mean and standard deviation values of the wavelet-transformed ROIs were also the classification features in the method proposed by Pham el al. [
11]. In this study, these features were extracted from the little textures containing areas on the banknote images using discrete wavelet transform (DWT) and selected based on a correlation with the densitometer data and subsequently used for fitness classification by the SVM [
11]. The regions with the least amount of textures are also selected for feature extraction in the study proposed by Kwon et al. [
12], in which they used both the features extracted from visible-light reflection (VR) and near-infrared light transmission (NIRT) images of the banknotes, and the fuzzy-based classifier for the fitness classification system.
The methods that are based on certain regions on the banknotes for evaluating the fitness of banknotes have advantages of reduced input data size and processing time. However, the selection of ROIs in the previous fitness classification studies is mostly manual, and the degradation and damage of banknote can occur on the unselected areas. The global-feature-based banknote images could help to solve this problem, but since the input features are mostly based on the brightness characteristic of the banknote images, it is much affected by illumination change, wavelength of sensors, and variation in patterns of different banknote types. Moreover, in fitness classifications, most studies assumed that the input banknote’s type, denomination, and input direction are known [
1].
To overcome these shortcomings, we considered a method for classification of banknote fitness based on the convolutional neural network (CNN). This NN structure was first introduced by LeCun et al. in their studies about handwritten character recognition [
13,
14], and have recently been emerging and attracting research interest [
15], especially for the image classification of the ImageNet large-scale visual recognition challenge (ILSVRC) contest [
16,
17,
18,
19]. However, little research has been conducted on the automatic sorting of banknotes using CNNs. Ke et al. proposed a banknote image defect detection method using a CNN [
20]; however, this study had only focused on the recognition of ink dots in banknote image defects, and did not specify the type of experimental banknote image dataset or judge the fitness for recirculation of the examined banknotes. Another recent CNN-based method proposed by Pham et al. [
21] aiming to classify banknote type, denomination, and input direction showed good performance even with the mixed dataset from multiple national currencies. On the evaluation of a state-of-the-art method, we proposed a deep learning-based banknote fitness-classification method using a CNN on the gray-scale banknote images captured by visible-light one-dimensional line image sensor. Our proposed system is designed to classify the fitness of banknote into two or three levels including: (i) fit and unfit, and (ii) fit, normal and unfit for recirculation, depending on the banknote’s country of origin, and regardless of the denomination and input direction of the banknote. Compared to previous studies, our proposed method is novel in the following aspects:
- (1)
This is the first CNN-based approach for banknote fitness classification. We performed training and testing of a CNN on banknote image databases of three national currencies that consist of 12 denominations, by which the performance of our proposed method is confirmed to be robust to a variety of banknote types.
- (2)
Our study carried out fitness determination on the United States dollar (USD), the Korean won (KRW), and the Indian rupee (INR), in which three levels of fitness of banknote, namely fit, normal, and unfit cases for recirculation, are considered with the KRW and INR, whereas two levels of fit and unfit cases are considered with the USD.
- (3)
Our fitness recognition system can classify the fitness of banknote regardless of the denomination and direction of the input banknote. As a result, the pre-classification of banknote image in the denomination and input direction is not required, and there is only one trained fitness-classification model for each national currency.
- (4)
We made our trained CNN model with databases publicly available by other researchers for the fair comparisons with our method and databases.
Table 1 gives a comparison between our research and previous studies. The details of the proposed banknote fitness-classification method are presented in
Section 3. Experimental results and conclusions are given in
Section 4 and
Section 5 of this paper, respectively.
4. Experimental Results
We used banknote fitness databases from three national currencies, which are the KRW, INR, and USD, for the experiments using our proposed method. The KRW banknote image database is composed of banknotes in two denominations, 1000 and 5000 wons. The denominations of banknotes in the INR database are 10, 20, 50,100, 500, and 1000 rupees. Those for the case of the USD are 5, 10, 50, and 100 dollars. Three levels of fitness, which are fit, normal, and unfit for recirculation, are assigned for the banknotes of each denomination in the cases of the KRW and INR, and two levels including fit and unfit are defined for the USD banknotes in the experimental dataset. Examples of banknotes assigned to each fitness level are shown in
Figure 4,
Figure 5 and
Figure 6.
The number of banknotes in each fitness level of three national currency databases is given in
Table 3. We made our trained CNN model with databases publicly available by other researchers through [
28] for the fair comparisons with our method and databases.
We conducted the experiments using the two-fold cross-validation method. Therefore, the dataset of banknote images from each national currency was randomly divided into two parts. In the first trial, one of the two parts was used for training, and the other was used for testing. The process was repeated with these parts of the dataset swapped in the second trial. With the obtained results from two trials, we calculated the overall performance by averaging two accuracies.
In this research, we trained the network models separately for each national currency dataset without pre-classifying the denomination and input direction of the banknote images in the dataset. In each dataset, we performed data augmentation for expanding the number or image for training. This process helps to generalize the training data and reduce overfitting [
21]. For data augmentation, we randomly cropped the boundaries of the original image in the dataset in the range of 1 to 7 pixels. The number of images in the datasets of the KRW and INR were increased by multiplication factors of 3 and 6 times, respectively. In the case of the USD, the numbers of fit and unfit banknote images were multiplied by 21 and 71 times. Consequently, the total number of images for training in each national currency dataset was approximately 100,000 images. We also listed the number of images in each dataset and each class after augmentation in
Table 3.
In the first experiments of the CNN training, we trained three network models for fitness classification in each of the national currency dataset, and repeated it twice for two-fold cross-validation. Training and testing experiments were performed using the MATLAB implementation of the CNN [
29] on a desktop computer equipped with an Intel
® Core™ i7-3770K CPU @ 3.50 GHz [
30], 16-GB memory, and an NVIDIA GeForce GTX 1070 graphics card with 1920 CUDA cores, and 8-GB GDDR5 memory [
31]. The training method is stochastic gradient descent (SGD), also known as sequential gradient descent, in which the network parameters are updated based on the batch of data points at a time [
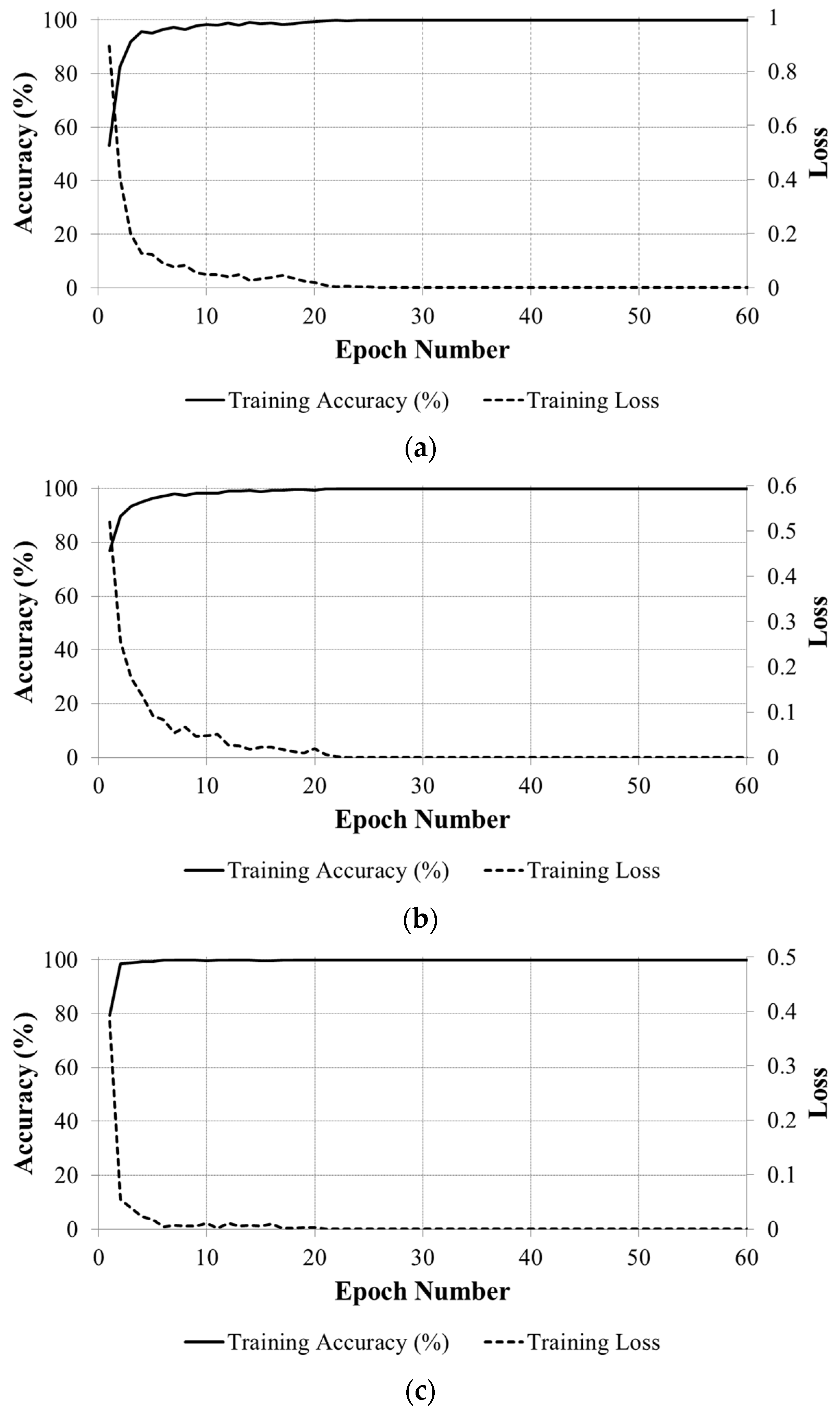
27]. The CNN training parameters were set as follows: the number of iterations for training is 60 epochs, with the initial learning rate of 0.01 and reduced by 10% at every 20 epochs. The convergence graphs of the average batch loss and accuracy according to the epoch number of the training process on the two subsets of training data in the two-fold cross-validation are shown in
Figure 7 for each country’s banknote dataset.
Figure 7 shows that the accuracy values increased to 100% and the loss curves approach zero with the increment of epoch number in all cases.
In
Figure 8, we show the 96 trained filters in the first convolutional layers of the trained CNN models for each national currency dataset using two-fold cross-validation. For visualization, the original 7 × 7 × 1 pixel filters were resized by a factor of 5 and the weight values were scaled to the range of unsigned integer number from 0 to 255, corresponding to the gray-scale image intensity values.
With the trained CNN models, we conducted the testing experiments on the datasets of each national currency, in a combination of all the denominations and input directions of the banknote images. The experimental results of the two-fold cross-validation using CNN for each dataset are shown in
Table 4,
Table 5 and
Table 6, and expressed as the confusion matrices between the desired and predicted outputs, namely the actual fitness levels of the banknotes and the fitness-classification results using the trained CNN models. From the testing results on two subsets, we calculated the average accuracy based on the number of accurately classified cases of each subset as the following formula [
32]:
with
Avr_Acc the average testing accuracy of the total
N samples in the dataset, and
GA1 and
GA2 are the number of accurately classified samples (genuine acceptance cases) from the 1st and 2nd fold cross validations, respectively.
Table 4,
Table 5 and
Table 6 show that the proposed CNN-based method yields good performance with the average testing accuracy of the two-fold cross-validation of approximately 97% in the cases of the KRW and USD, and more than 99% in the case of the INR, even with the merged denominations and input directions of banknote images in each dataset.
In
Figure 9, we show the examples of correctly classified cases in the testing results using our proposed method on the KRW, INR, and USD datasets.
Figure 9 shows that the degradation degrees in the INR banknotes are clearer to be distinguished among fitness classes of fit, normal, and unfit than that in the case of the KRW. Furthermore, the visible-light banknote images captured in the case of the USD have slightly lower brightness than those of the KRW and INR. This resulted in the highest average classification accuracy in the testing results using our proposed method on the INR dataset compared to that of the KRW and USD.
Examples of error cases are also given in
Figure 10,
Figure 11 and
Figure 12 for each of the national currency datasets. As shown in these figures, there were some cases where the input banknotes were incorrectly segmented from the background, as shown in
Figure 10a and
Figure 11d. This resulted in the banknotes being classified as the classes of lower fitness level.
Figure 10c and
Figure 11c show that the stained and soiled areas occurred sparsely on the banknotes and occasionally could not be recognized by using only visible-light images as in our method. Banknote images in
Figure 11a,b are from the fit and normal classes, respectively; however, besides the similar brightness, both of the banknotes were slightly folded on the upper parts, which affected the classification results. The fit USD banknote in
Figure 12a has hand-written marks, whereas the degradation on the unfit banknote in
Figure 12b is the fading of texture in the middle of the banknote rather than staining or soiling. These reasons caused the misclassification of fitness level in these cases. In addition, the average classification accuracy of the normal banknotes was the least among the three fitness levels in the case of INR and KRW. This is because of the fact that, the normal banknotes have the middle quality levels, which consist of stained or partly damaged more than fit banknotes but not enough to be replaces by the new ones as the cases of unfit banknotes. This resulted in the largest confusions occurring between normal class and either the fit or unfit classes, and the average classification accuracies in the cases of normal classes in both INR and KRW datasets were the least.
In the subsequent experiments, we compared the performance of the proposed method with that of the previous studies reported in [
7,
11]. As both of the previous methods required training, we also performed the two-fold cross-validation in the comparative experiments. Referring to [
7], we extracted the features from the gray-level histogram of the banknote image and used the multilayered perceptron (MLP) network as the classifiers, with 95 network nodes in the input and hidden layers. In the case of the comparative experiments using the method in [
11], we selected the areas that contain less texture on the banknote images as ROIs, and calculated the means and standard deviation values of the ROIs’ Daubechies wavelet decomposition. Because the fitness classifiers in [
11] are the SVM, in the case of the KRW and INR datasets that have three fitness levels, we trained the SVM models using the one-against-all strategy [
33]. The experiments with previous methods were implemented using MATLAB toolboxes [
34,
35].
A comparison of the experimental results between our proposed method and those in previous studies are shown in
Table 7,
Table 8 and
Table 9, in which the fitness-classification accuracies are calculated separately according to denominations and input directions of the banknote images in each national currency. This is because in the previous studies, the fitness-classification models were trained with these manually separated type banknote images. Therefore, although our proposed method does not require the pre-classification of denominations and input directions of the banknote images, we showed the accuracies separately according to these categories for comparison.
Table 7,
Table 8 and
Table 9 show that the proposed CNN-based fitness classification method outperformed the previous methods in terms of higher average classification accuracy for all the national currency datasets. This can be explained by the disadvantages of each method: the histogram-based method used only the overall brightness characteristic of the banknote images for the classification of fitness levels. This feature was strongly affected by the capturing condition of the sensors. Moreover, degradation might occur sparsely on the banknote, therefore it cannot be easily recognized by the brightness histogram only. The ROI-based method in [
11] relied only on the less textured areas on the banknote images. Consequently, if the degradation or damage of the banknote occurs on other areas, it will not be as effective as the proposed method. The CNN-based method has the advantage of the ability to train not only the classifier in the fully connected layer parts but also the filter weights in the convolutional layers, which can be considered as the feature extraction part. As a result, both the feature extraction and classification stages were intensively trained by the training datasets. Moreover, when the whole banknote image is inputted to the CNN architecture, we can make use of all of the available optical characteristics of the banknote for feature extraction. Consequently, owning to the advantages in the feature extraction procedure, the proposed fitness-classification method gave better performance compared to previous methods in terms of higher average accuracy using two-fold cross-validation.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}