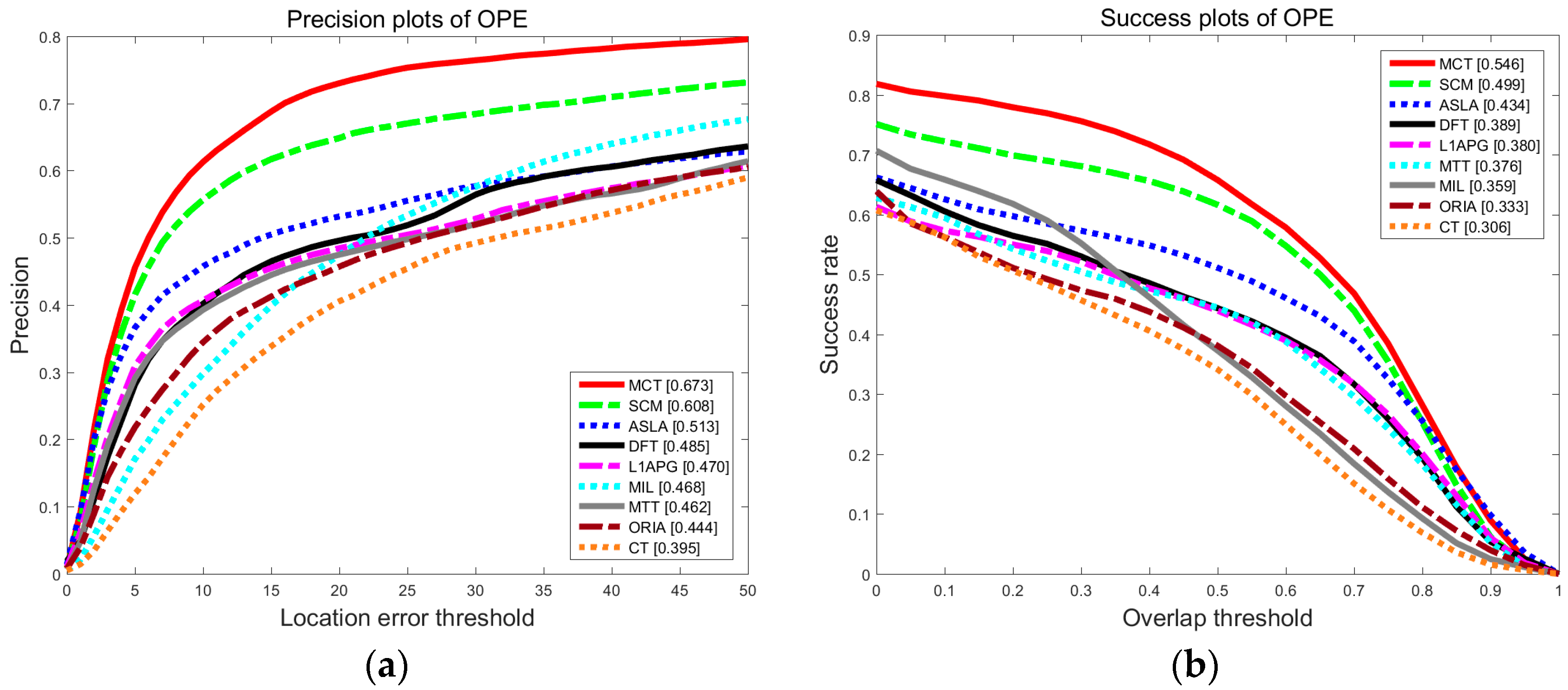
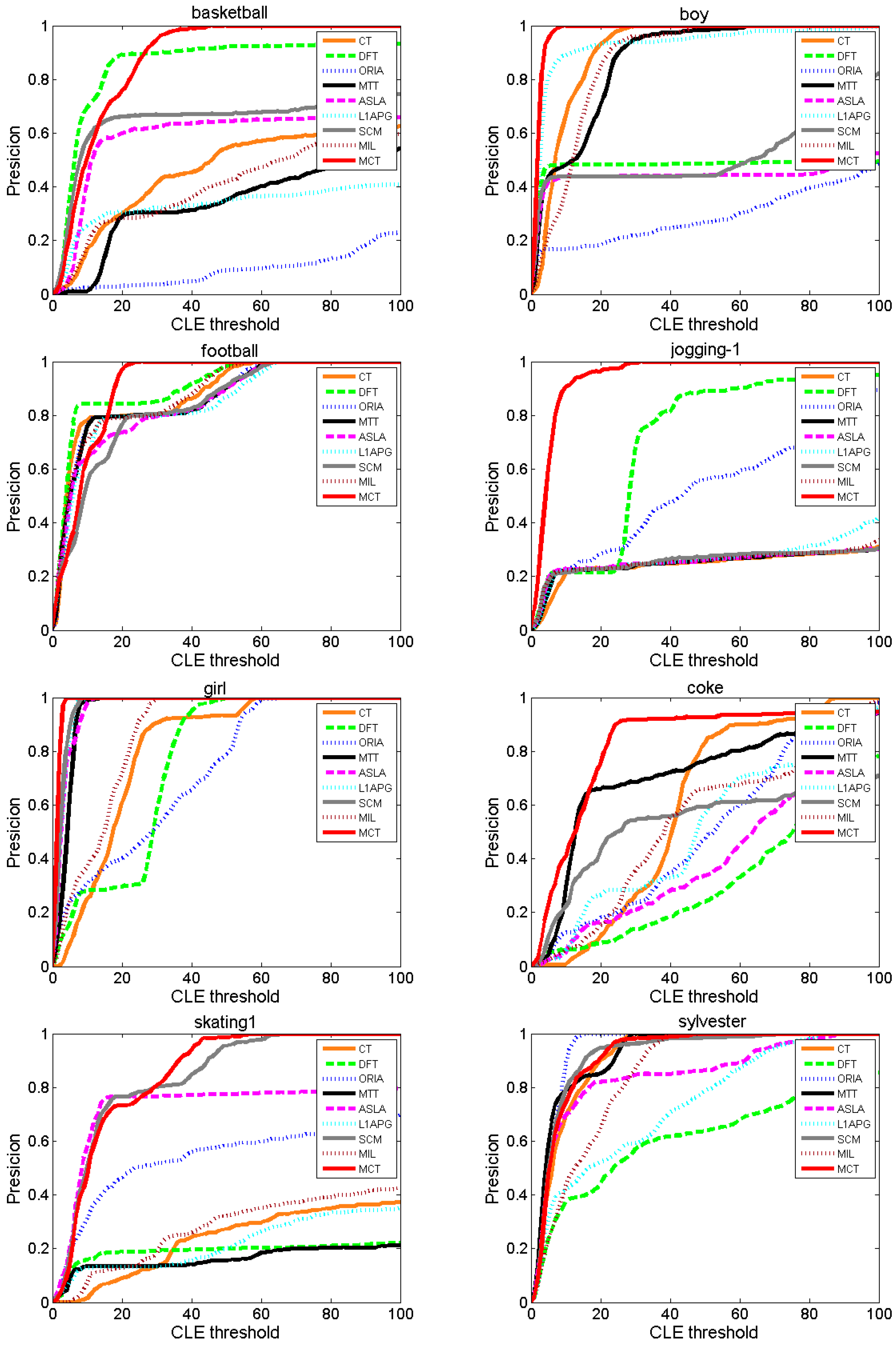
To evaluate the performance of our proposed MCT algorithm, we test our tracker on the CVPR2013 (OTB2013) dataset, which has been widely used in evaluation [
33]. OTB contains 50 video sequences, source codes for 29 trackers and their experimental results on the 50 video sequences. We compared our tracker with eight state-of-the-art tracking algorithms: the compressive tracking (CT) [
23], distribution fields for tracking (DFT) [
31], online robust image alignment (ORIA) [
20], MTT [
8], visual tracking via adaptive structural local sparse appearance model (ASLA) [
18], L1APG [
12], SCM [
2], and MIL [
22] trackers. The basic information of these trackers is listed in
Table 1. As described in related work, most algorithms ignore the temporal correlation of the target states. MTT, ASLA and SCM obtain candidates by Gaussian distribution model, MIL and CT obtain candidates by dense sampling, DFT and ORIA obtain candidates by local optimum search. Only LIAPG considers target motion speed in the previous frame and obtain candidates by constant velocity model. Besides, the competition algorithms cover all the type of appearance model, but all of the appearance models are designed from the perspective of the target’s appearance feature. We evaluate the CT, DFT, ORIA, MTT, ASLA, L1APG, SCM, and MIL trackers by using the available source codes. We conduct experiments on all 50 video sequences and perform a concrete analysis on eight specific video sequences with different problems. All the problems we concerned are covered in the video sequences, thus the effectiveness of the algorithm can be illustrated. The basic information of the eight test video sequences and primary problems are shown in
Table 2 [
33].
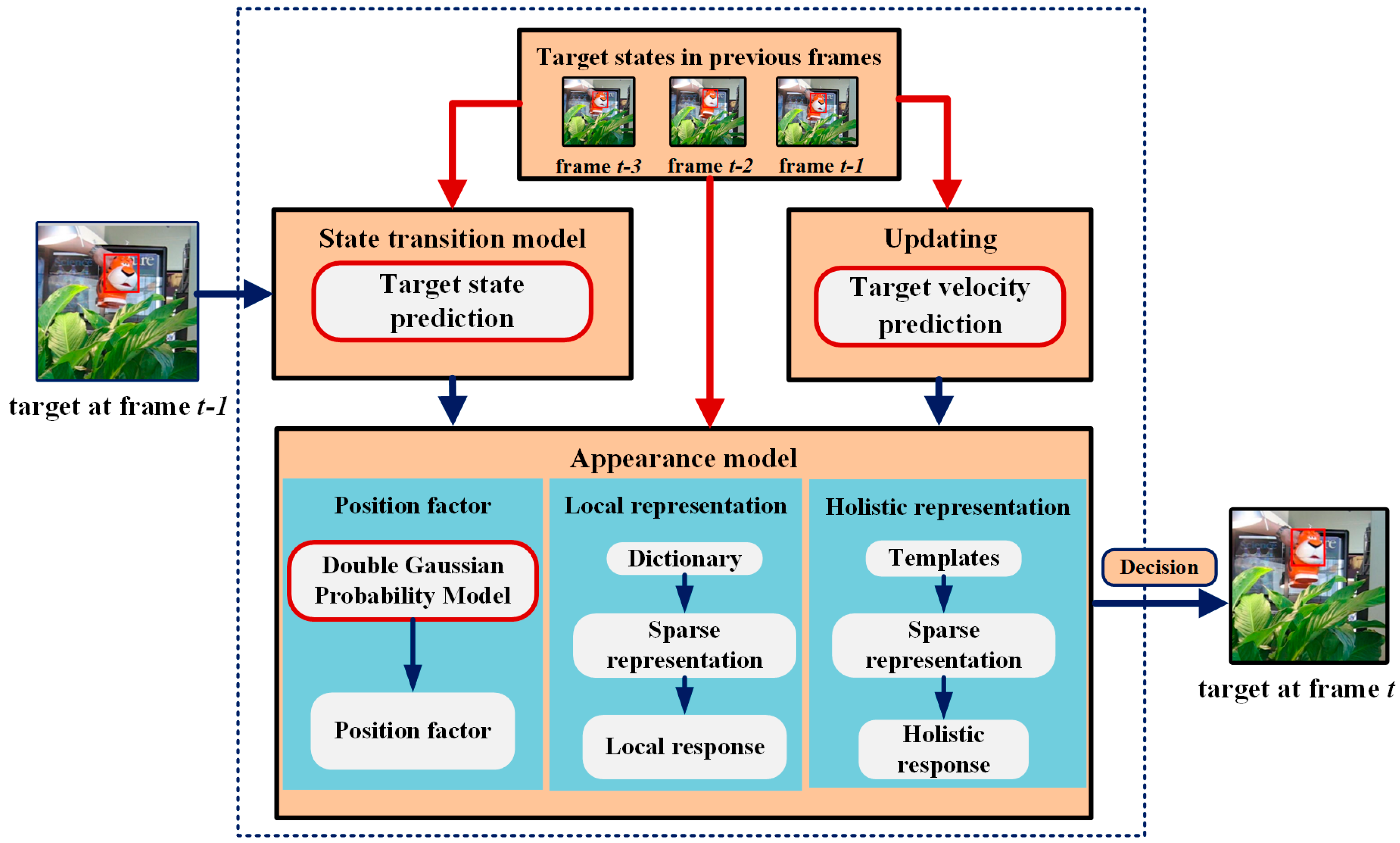
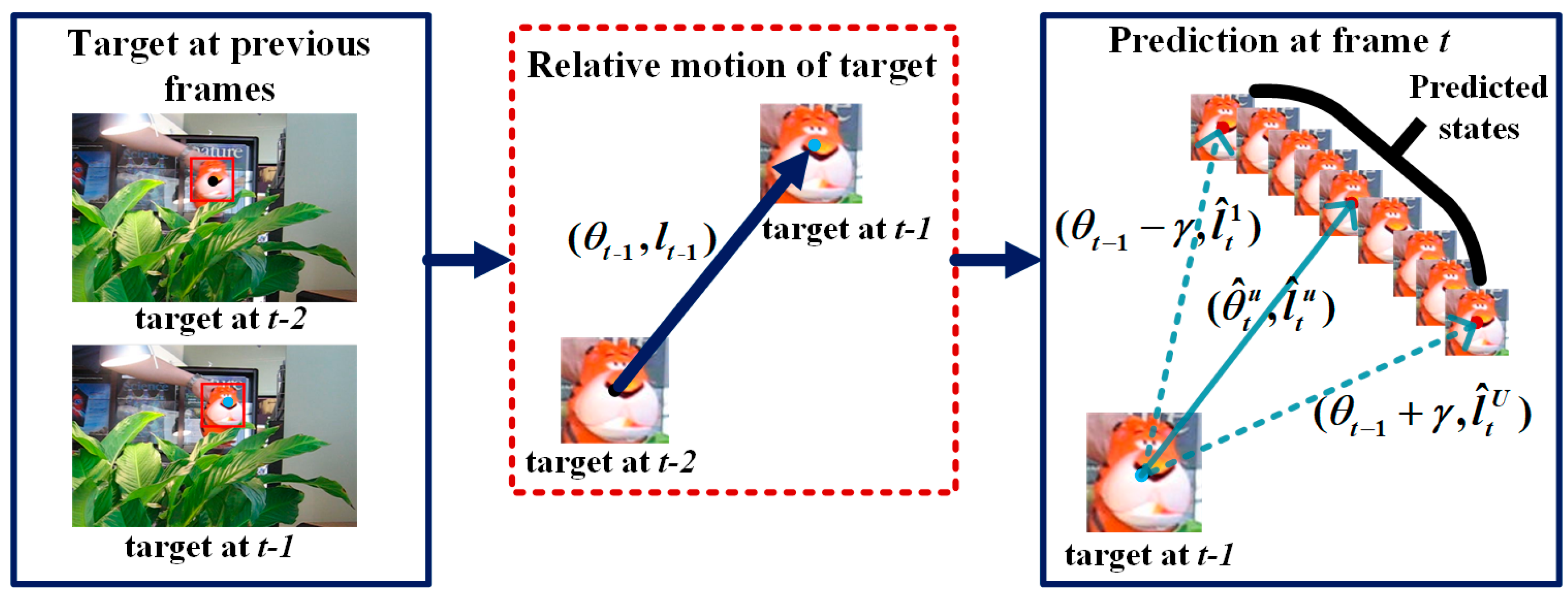
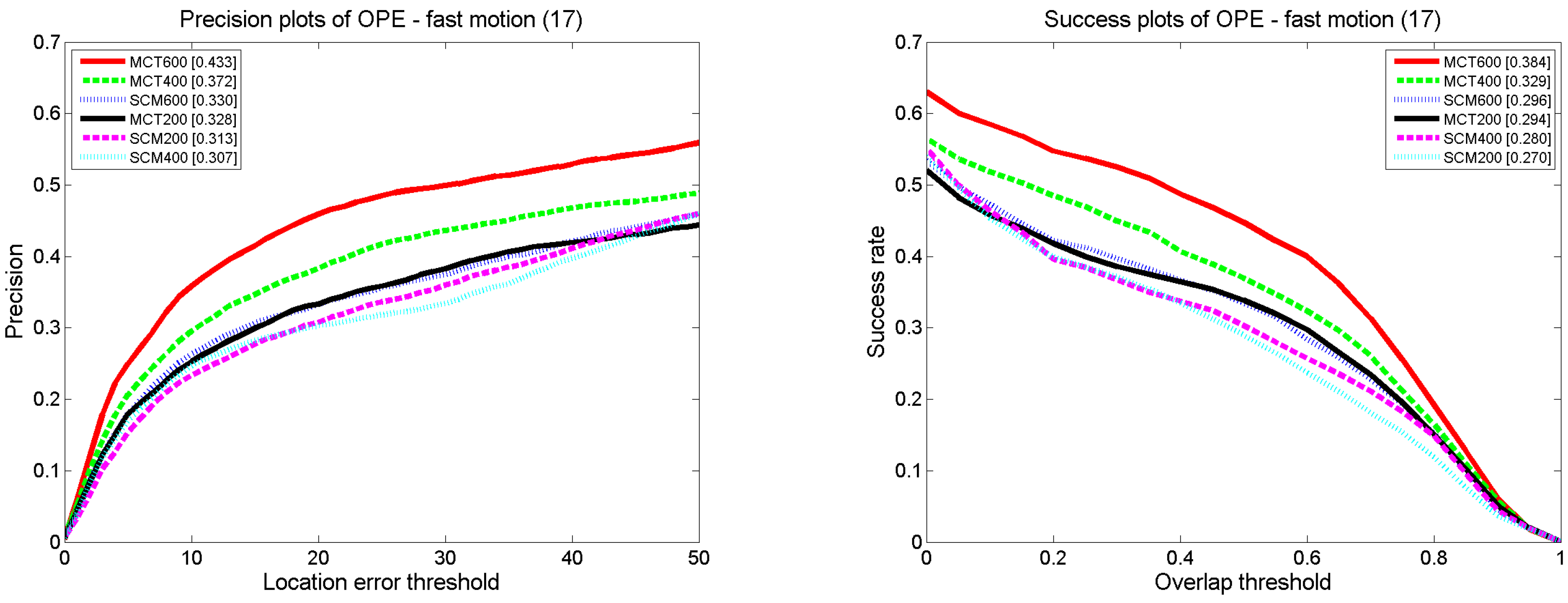
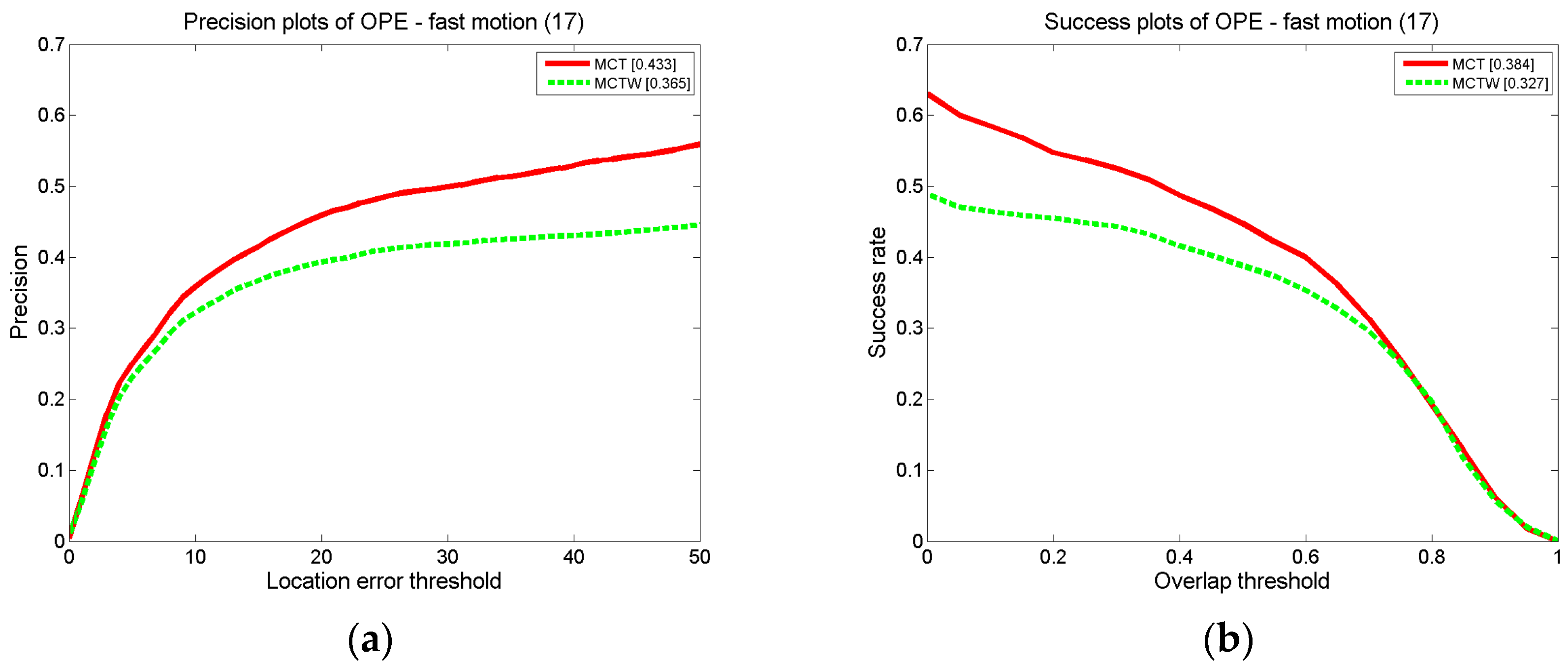
In the experiment, for each test video sequence, all information is unknown except for the initial target position of the first frame. The number of candidate samples is 600 including 250 basic candidate samples and 350 dynamic candidate samples. The number of motion directions we predicted is seven. In each direction, a total of 50 candidate samples are obtained. In the update, five of positive templates are updated every five frames from image regions away more than 20 pixels the current tracking result.
4.2. Qualitative Evaluation
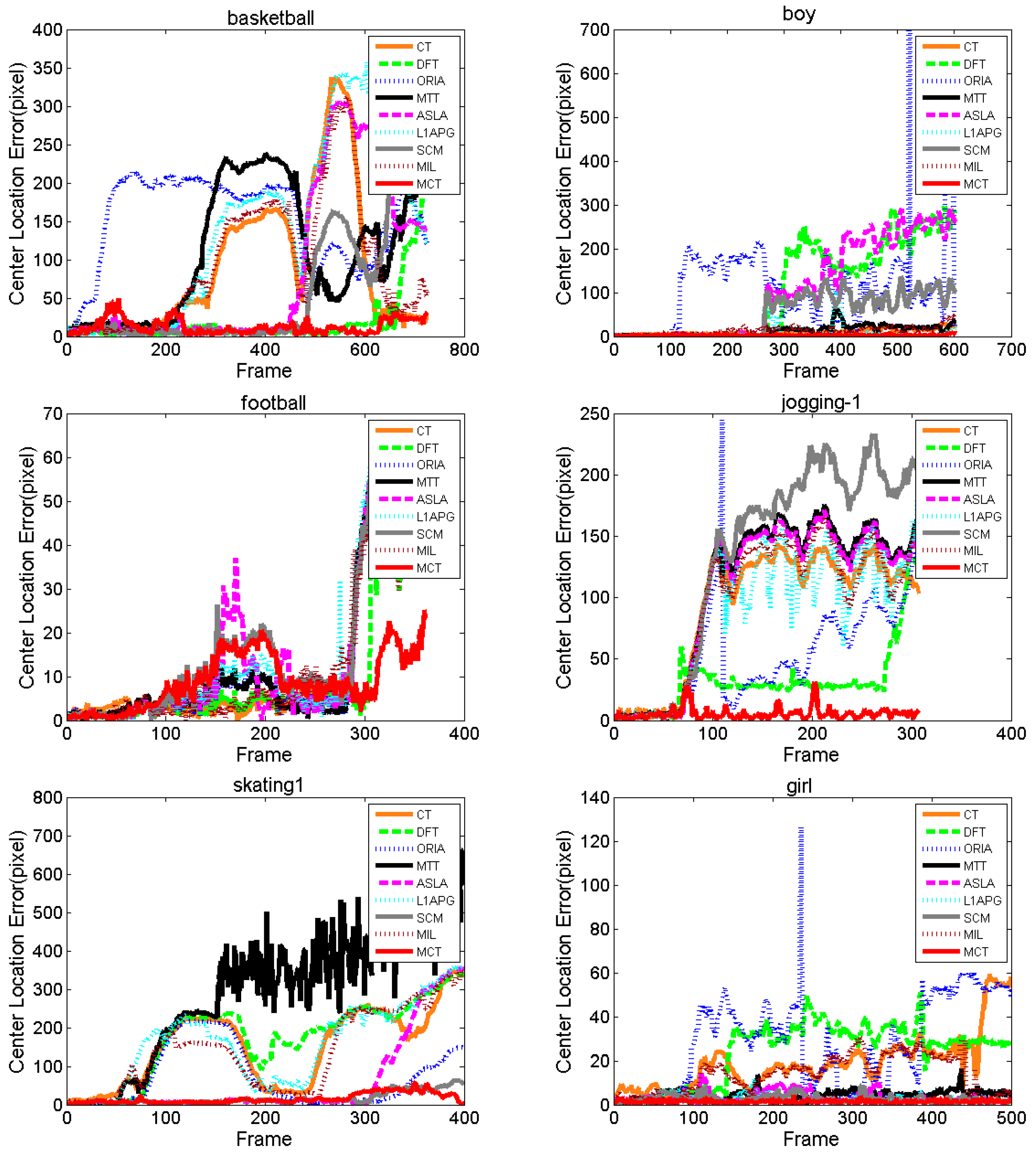
The qualitative analysis results of the algorithms on eight test videos are shown in
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16. All the problems we concerned are covered in these video sequences, fast motion and scale variation, partial or full occlusion, the deformation and illumination variation. We analyze the performance of algorithms on eight specific video sequences with different problems one by one.
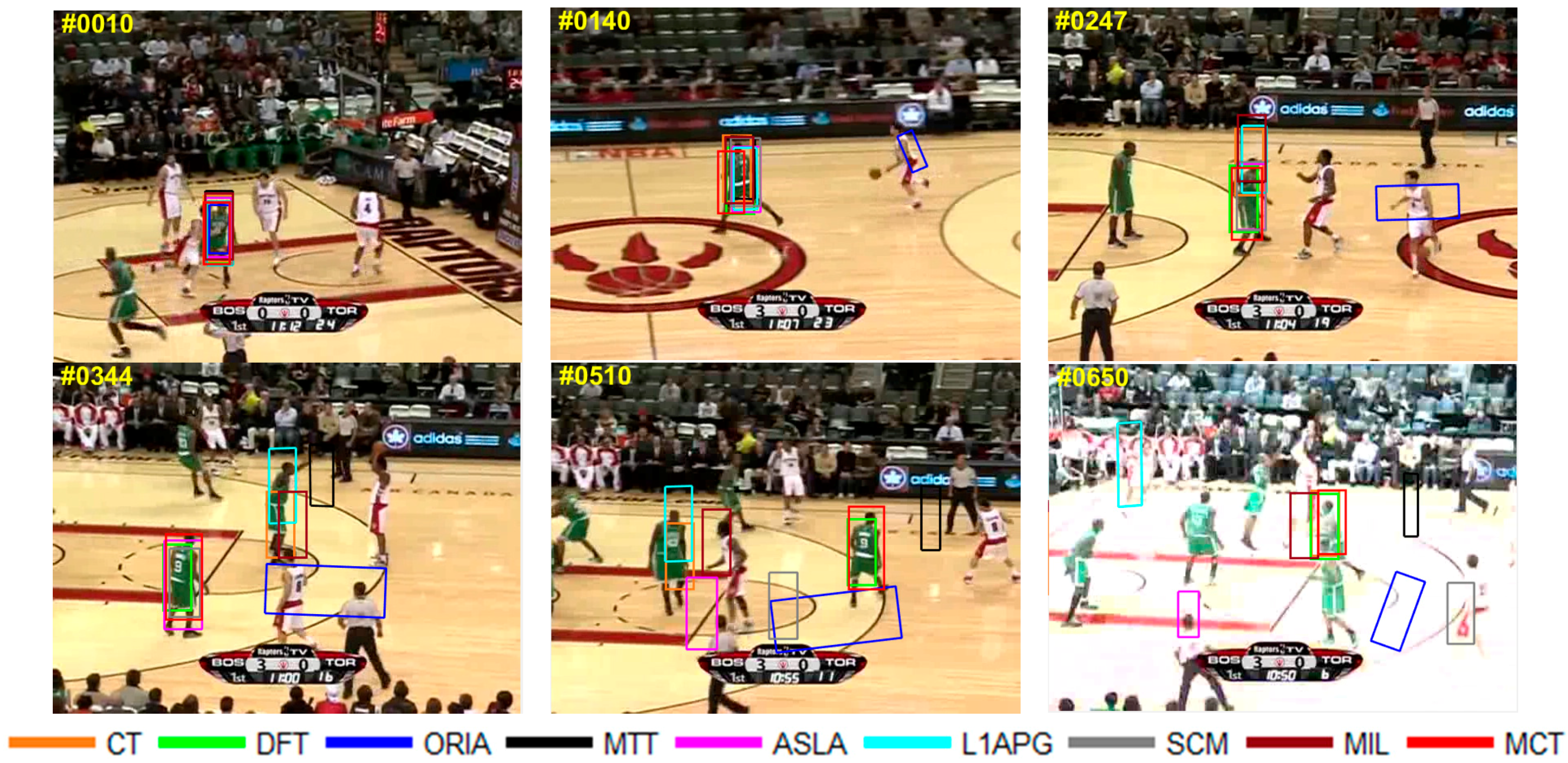
1. Fast motion
As shown in
Figure 9, the content of the video sequence
Boy is a dancing boy. In the process of dancing, the target shakes randomly with fast motion as shown from 88th to 386th. The boy’s appearance blurs during the fast motion. The tracking box of ORIA cannot keep up with the fast motion of the target and the tracking drift occurs in 108th. In the 160th frame, the target moves backwards, the tracking box of ORIA loses the target completely in 160th. In the 293rd frame, the boy is squatting down, the tracking boxes of SCM and ALSA cannot keep up with the variation of the target, which leads to tracking failure after 293rd. Besides, the tracking boxes of MTT, L1APG and MIL have tracking drift in 293rd. As tracking continues, CT, MTT, L1APG, SCM, MIL and other algorithms also cannot keep up with the target motion. Only MCT is able to properly track the target.
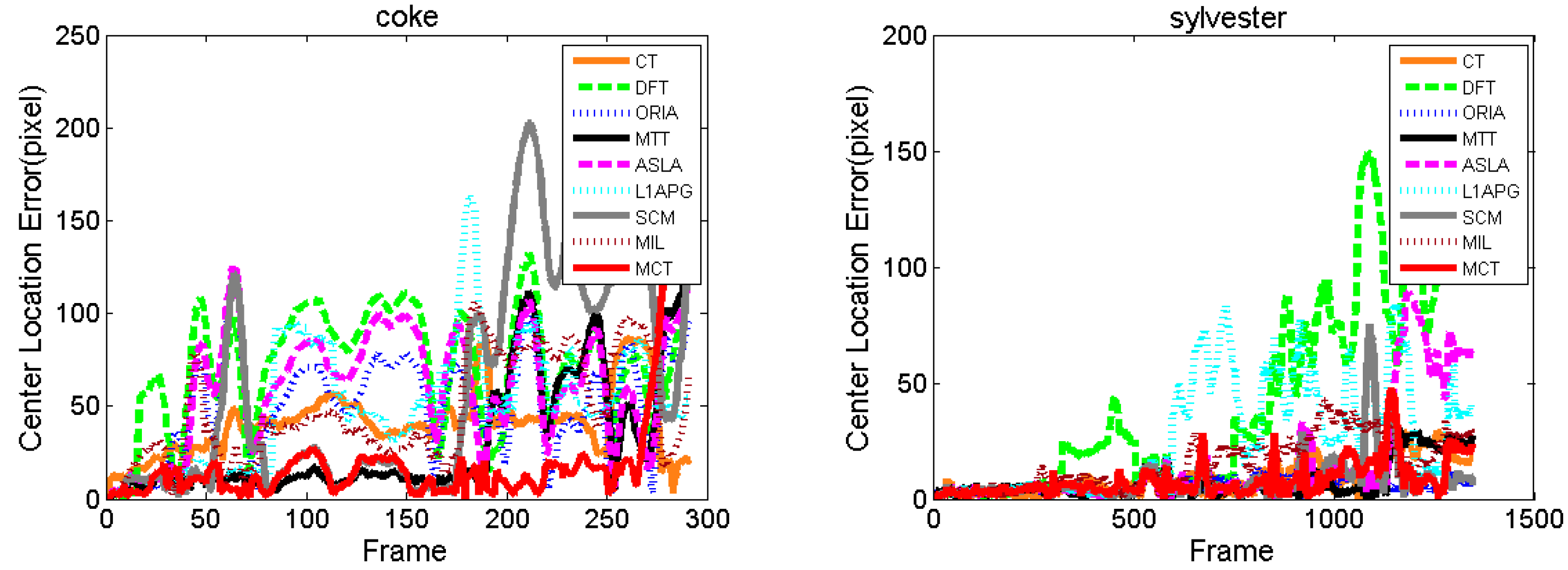
For
Coke, a can held by a man moves fast within a small area in the complex background with the dense bushes.
Figure 10 shows the tracking results on Coke. In the 42nd frame, because of occlusion by plants, the algorithms DFT, L1APG MIL and ASLA have tracking drifts to different extents, while MCT and MTT perform well. Then the target keeps moving fast from the 42nd to the 67th frame. The motion directions vary rapidly, which results in tracking drifts with the L1APG, MTT and CT algorithms in 67th. The tracking box of DFT, ORIA and ASLA lose the target completely in 67th, while the MCT and MIL algorithms can accurately track the target in the presence of fast motion. After 194th frame, all algorithms except MCT fail to track the target. Throughout the entire process of fast motion, the MCT algorithm can stably track the target.
Our algorithm, MCT, performs notably well on videos that involve fast motion. This is because the MCT algorithm takes into account motion consistency so that targeted candidate samples can be calculated after predicting the target’s possible motion state during fast motion, which can possibly cover the region where the target may appear. In addition, the position factor is proposed to decrease the influence of secondary samples, and an adaptive strategy is utilized to address the change in the target’s appearance brought about by fast motion. All of these factors guarantee highly stable and accurate tracking.
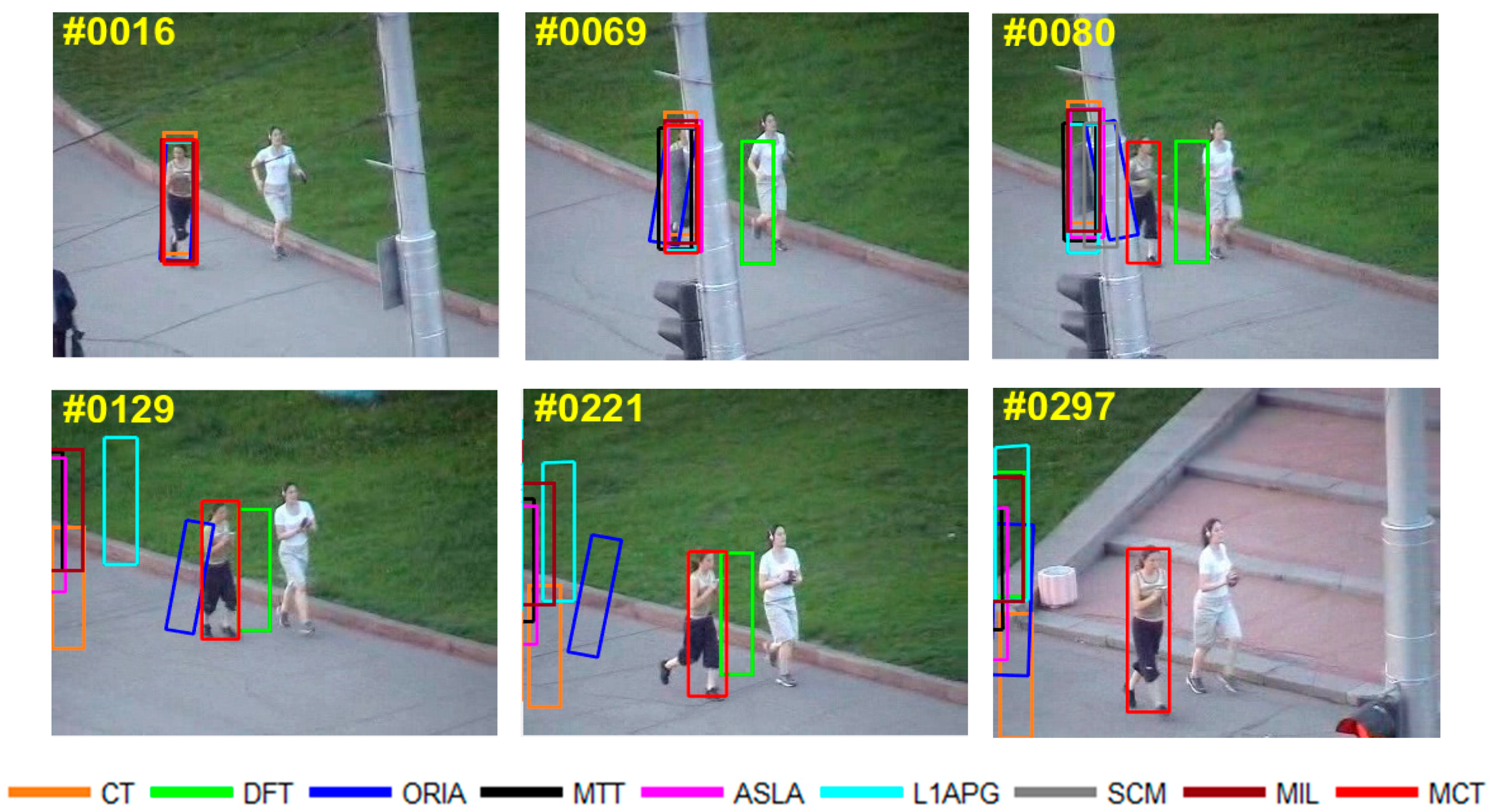
2. Partial and full occlusion
Two ladies are jogging in the video
Jogging-1. As shown in
Figure 11, partial and full occlusions are caused by the pole during the jogging from the 69th to 80th frame. In the 69th frame, the DFT algorithm fails to track the target first when partial occlusion occurs by the pole and the DFT algorithm turns to track the jogger with white shirt. In the 80th frame, after the jogger we tracked appears without partial or full occlusion, all the algorithms lose the target completely except MCT. In the following frames, while the other algorithms fail to track the target, MCT can stably track the target until the occlusion completely disappears in the 129th frame. The tracking box of DFT has tracking drift in the 221st frame. In the 297th frame, all the algorithms except MCT have no overlap with the true target.
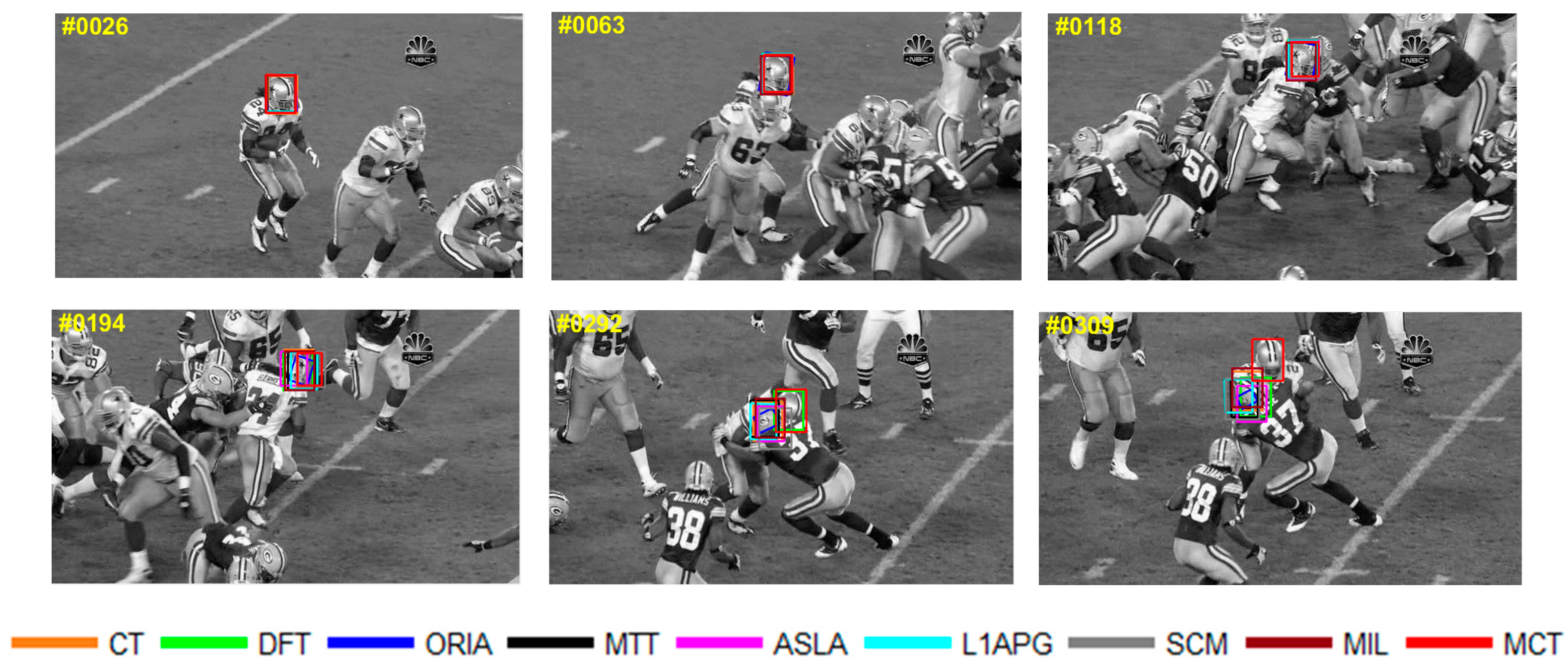
The tracking results on
Football are shown in
Figure 12. For
Football, occlusion occurs when football players compete in the game. The players are crowded in the presence of the ball robbing. And the partial or full occlusion will occur in the situation of ball robbing. In the 118th frame, the players are crowded in the same place and the target we tracked is in the middle of the crowds, then the partial occlusion occurs at the head of the target, which causes confusion of different football players. As the competition goes, the algorithms have a tracking drift in the frame 194th. In 292nd, only MCT and DFT can accurately track the target under the full occlusion. The tracking box of L1APG, ASLA, MIL and other algorithms lose the target and turn to track another player close to the target we tracked. When the occlusion disappears in the 309th frame, only MCT can still track the target.
In MCT, the occlusion factor is proposed in the local representation. When occlusion occurs, the background information of the target increases, and the occlusion factor will change correspondingly. Partial and full occlusions can be rectified based on the occlusion factor in appearance model.
3. Deformation and illumination variation
For
Basketball, the target
No.9 basketball player’s appearance varies in the game because of inconstant motion. Moreover, illumination changes because reporters take photos, especially when players are shooting. The tracking results of the nine algorithms are shown in
Figure 13. As we can see, when the player starts to run, almost all the tracking boxes have tracking drift in the frame 140th, and ORIA lose the target completely. When the deformation occurs in 247th, ORIA, MTT, L1APG, CT and MIL fail to track the target. Only DFT and MCT can track the target with a slight tracking drift. In the 344th frame, the player turns around, while MCT, SCM, DFT, and ASLA succeed and other algorithms lose the true target. In the 510th frame, when the player moves to spectator, all the algorithms fail to track except MCT and DFT. However, DFT has tracking drifts. When illumination changes in the 650th frame, only MCT and DFT can track the target.
For
Sylvester, a man shakes a toy under the light. Within the whole process, as shown in
Figure 14, illumination and deformation of the toy change, and the plane rotates inside and outside occur. The tracking boxes have drift when the toy begins to move under the light in the frame 264th. In the 467th frame, the toy is lower its head, in such a situation, the algorithm DFT almost lose the target. Then in the 613rd frame, when the toy has rotation, the algorithm L1APG fails to track the target and other algorithms have tracking drift. In the 956th frame, the toy is rotating under the light, and more algorithms such as DFT and L1APG lose the target. However, MCT performs well under the circumstances with deformation and illumination especially shows robustness within illumination decreasing between the 264th to the 467th frame.
First, MCT is based on particle filtering framework, so that to some extent diversity of candidate samples can resolve elastic deformation. Secondly, holistic representation and local representation are utilized in the appearance model, which shows great robustness by enabling holistic and local representation to capture the changes of target’s deformation and illumination variation. Finally, when models are being updated, appropriately updating positive and negative templates can also adapt to the changes of appearance and environment.
4. Scale variation and rotation
For
Skating1, a female athlete is skating on ice, and the athlete continuously slides so the relative distance to camera changes continuously, thus the athlete has a scale variation in the scene. Besides, the athlete is dancing in the process, thus the athlete also has a rotation in the scene. It can be seen in
Figure 15, from the 24th frame to the 176th frame, the size of the target becomes smaller, and the algorithms SCM, ASLA and MCT can track the target. And CT, DFT, ORIA, L1APG and MIL lose the true target in the frame 176th. From the 176th to the 371st frame, the target moves to the front of the stage and becomes larger with rotation on the stage, and almost all the algorithms fail to track except MCT and SCM. But SCM has tracking drift. In the 389th frame, SCM loses the athlete, and only MCT can track the target.
For
Girl, a woman sitting on the chair varies her position and facing direction by rotating the chair. It can be seen in
Figure 16, the size of the target changes from the 11st to the 392nd frame with rotation on the chair. Because of the chair’s rotation, the size of the target becomes smaller in the 101st frame compared with that in the 11st frame. After that, the girl turns around and becomes larger in 134th. In this process, all the algorithms have tracking drift, and ORIA loses the target completely from 101st to 487th. When the target turns around from 101st to 134th, the tracking boxes of ORI, CT and MIL lose the target. Although the appearance of the target changes promiscuously from 227th to 487th, MCT performs well under this circumstance and shows robustness and accuracy compared with other algorithms.
Based on particle filter, six affine parameters including parameters indicate scaling variation and rotation are used in MCT to represent the candidate samples. Thus, the diversity of scaling can be ensured in prediction of candidate samples, which could adapt to the scene of scale variation.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}