Defect-Repairable Latent Feature Extraction of Driving Behavior via a Deep Sparse Autoencoder



Abstract
:1. Introduction
- We show that DSAE can extract highly correlated low-dimensional time-series of latent features by reducing various degrees of redundancy in different multi-dimensional time-series data of driving behavior.
- We verify that DSAE can reduce the negative effect of defects on the extracted time-series of latent features by repairing the defective sensor time-series data using a BP method.
- We find that the time-series of latent features extracted from the repaired time-series sensor data by DSAE have segmentation results similar to those of non-defective sensor time-series data.
2. Background
2.1. Feature Extraction for Driving Behavior Analysis
2.2. Feature Extraction by Deep Learning for Intelligent Vehicles
2.3. Defect Repair for Driving Behavior Analysis
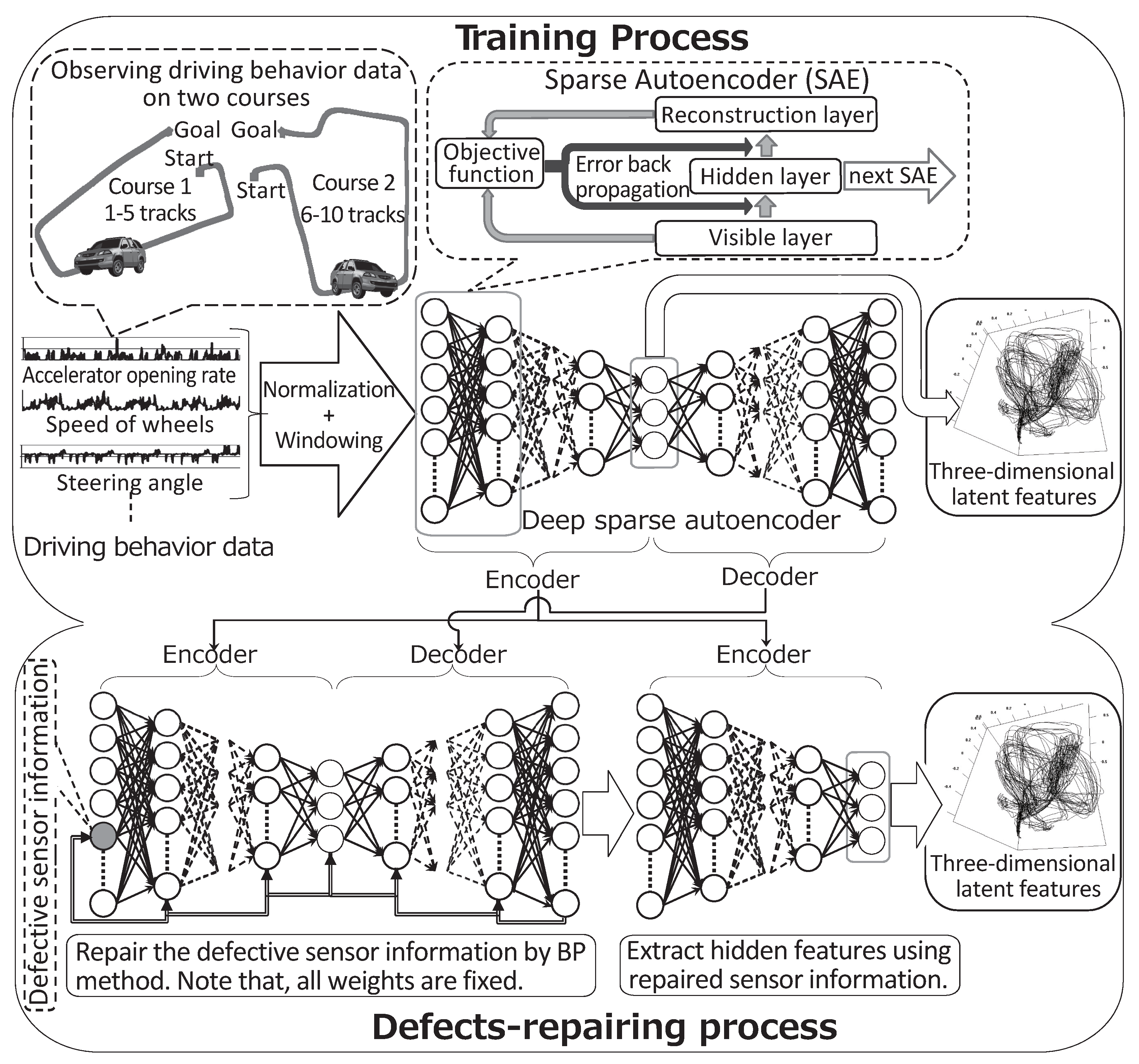
3. Proposed Method
3.1. Training Process
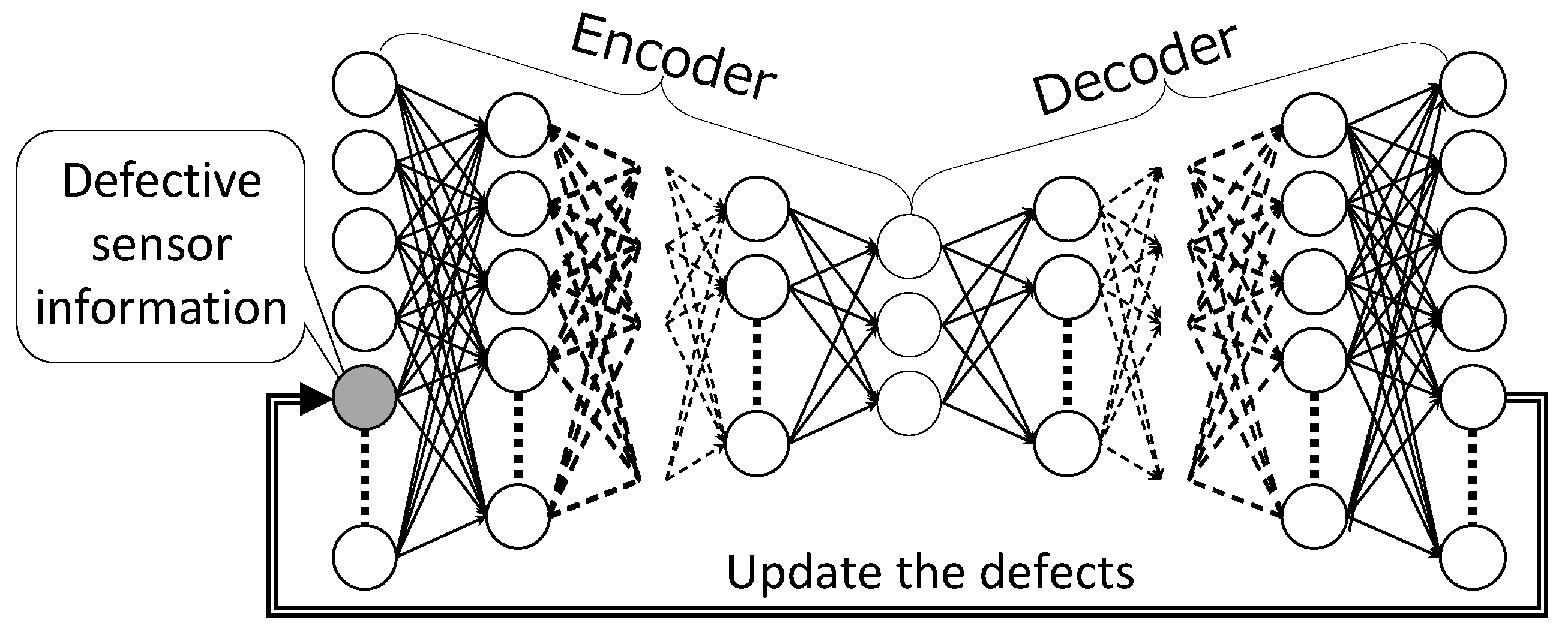
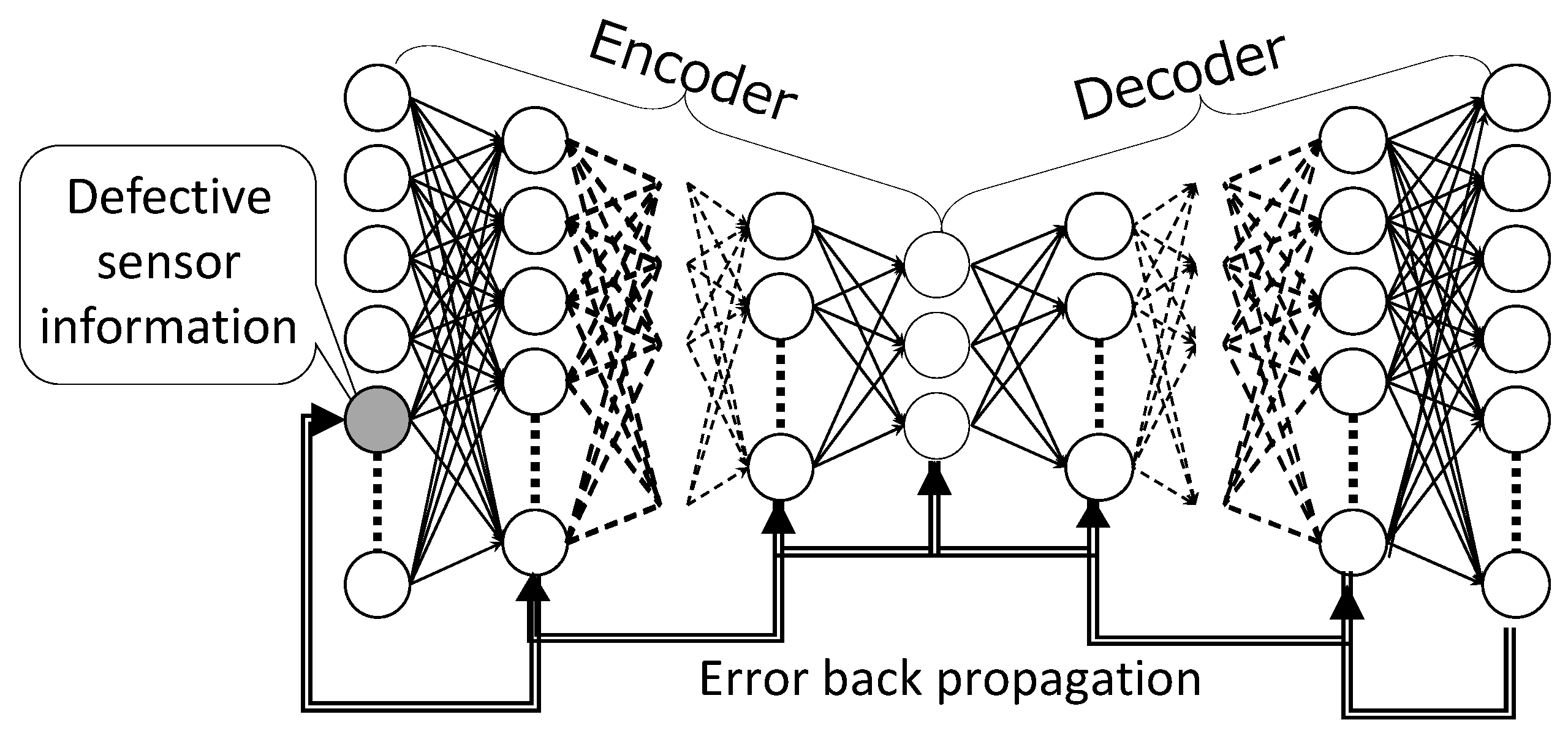
3.2. Defect-Repairing Process
3.2.1. DSAE-FP
3.2.2. DSAE-BP
4. Experiment 1: Feature Extraction
4.1. Experimental Conditions
4.2. Evaluation of Model Training via Data Reconstruction
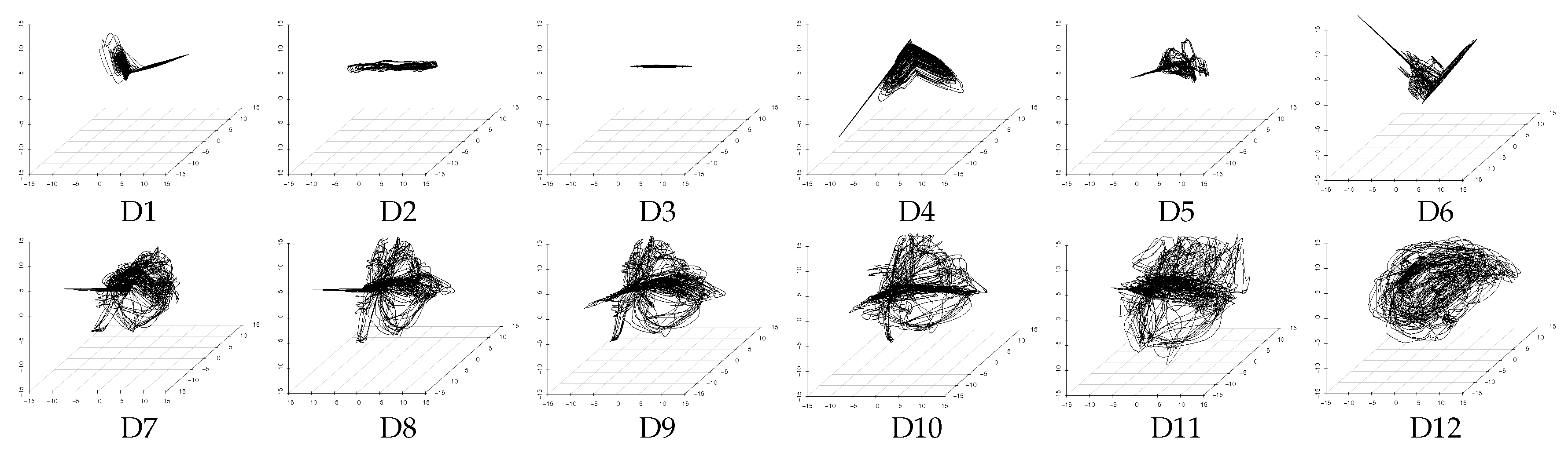
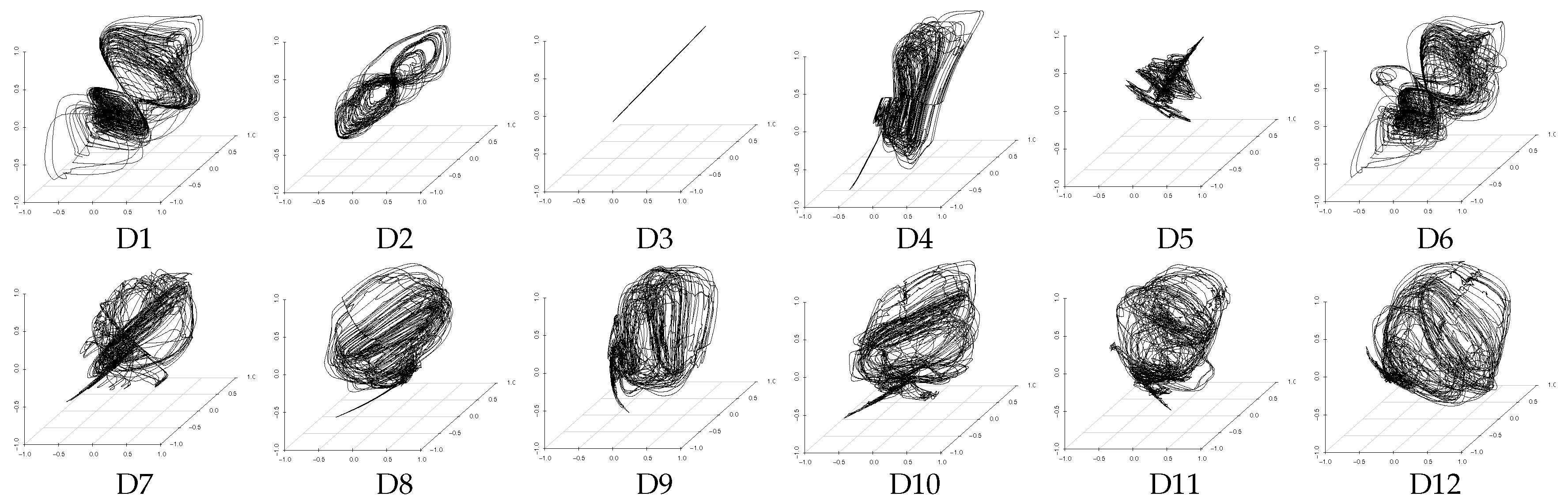
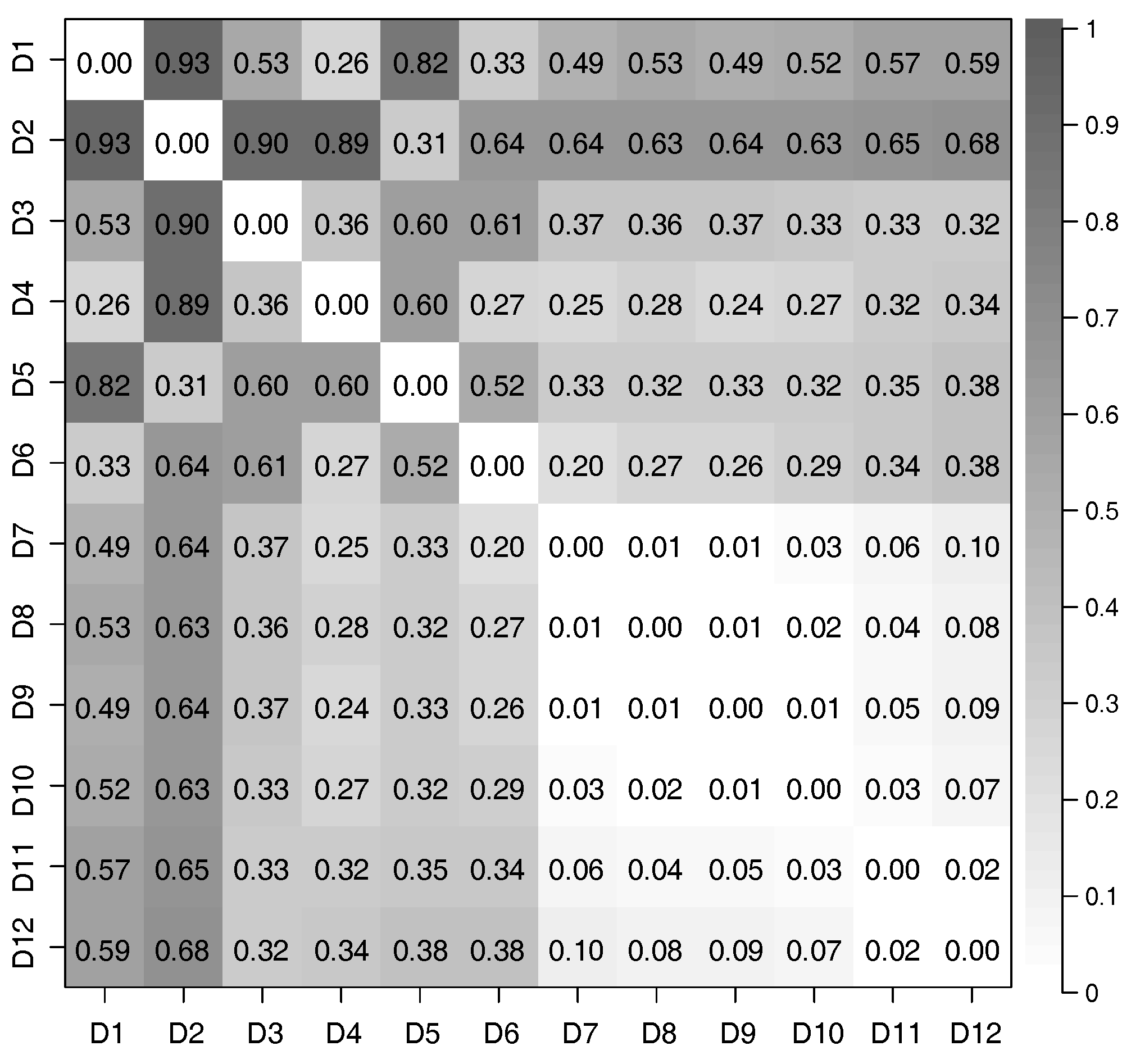
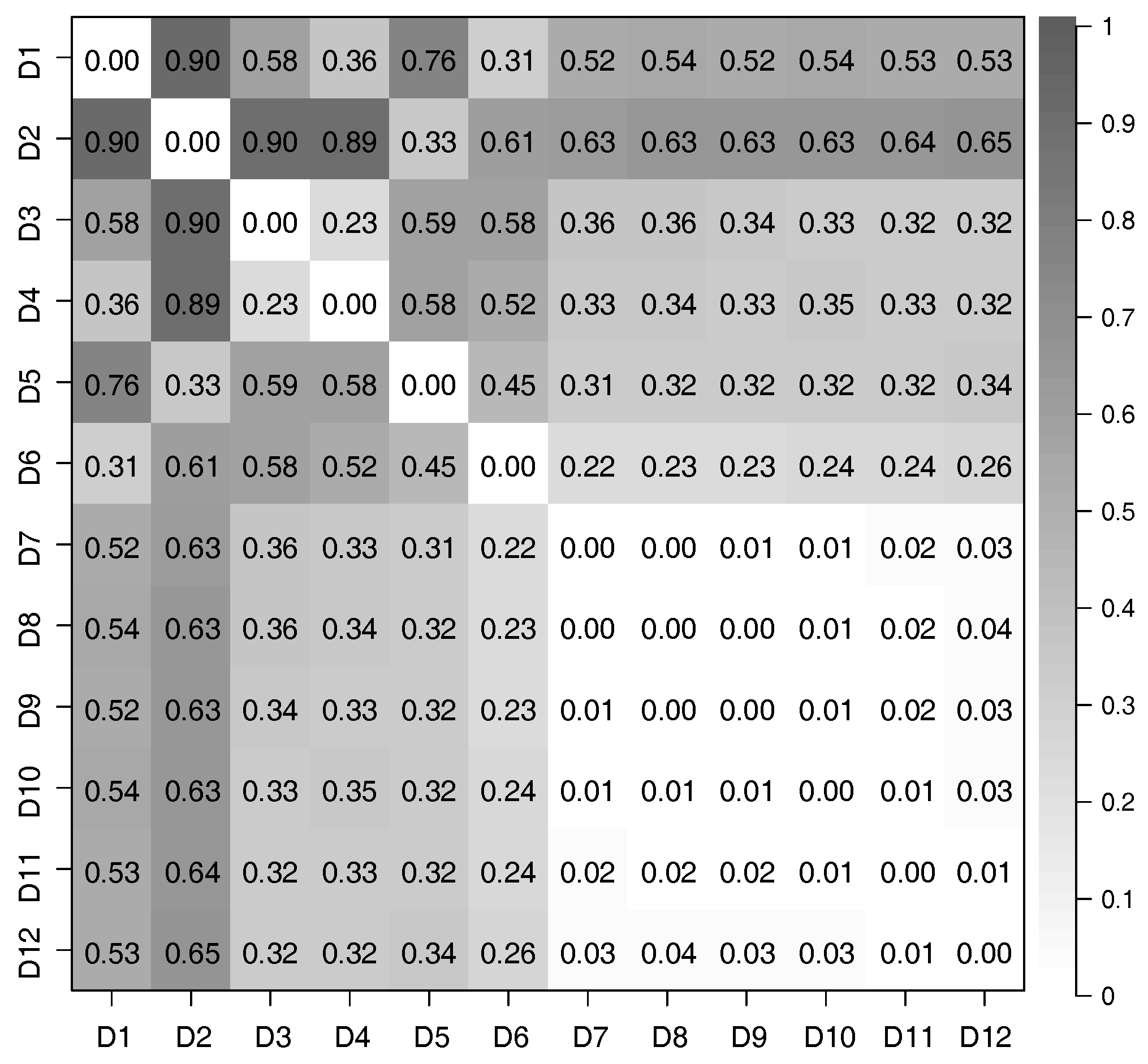
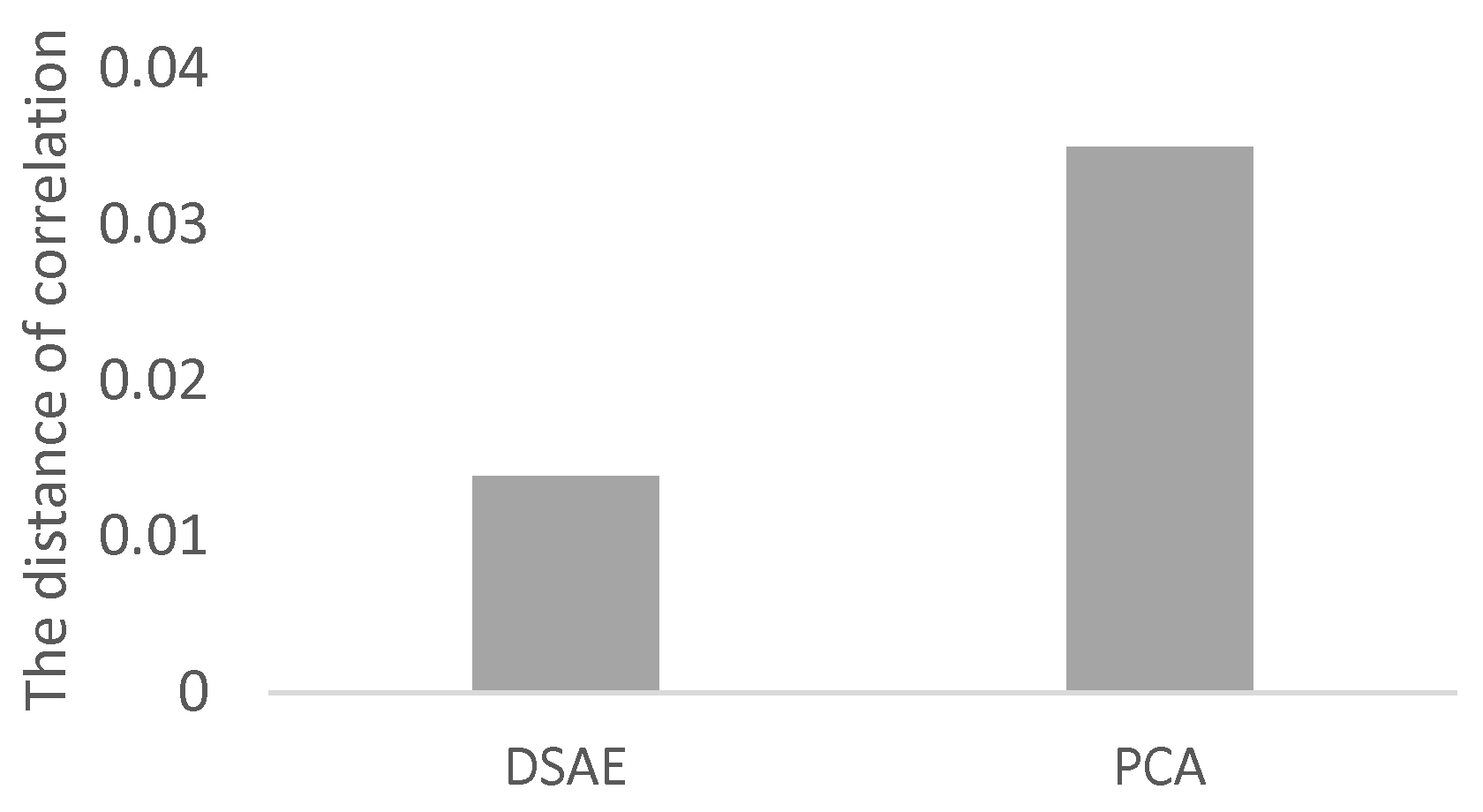
4.3. Evaluation of Latent Feature Extraction of Time-Series Using CCA
5. Experiment 2: Reducing the Negative Effect of Defects for Feature Extraction
5.1. Experimental Conditions
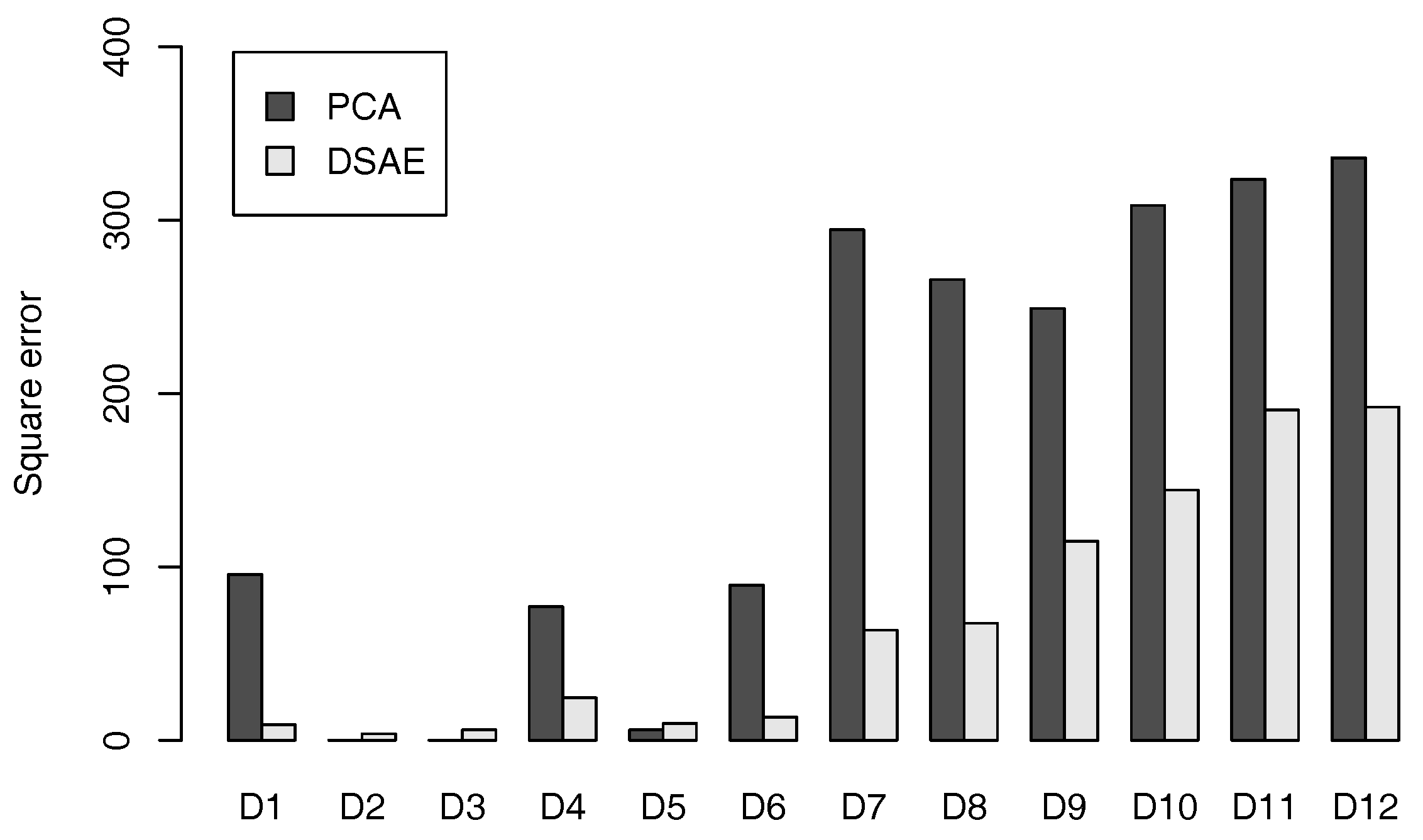
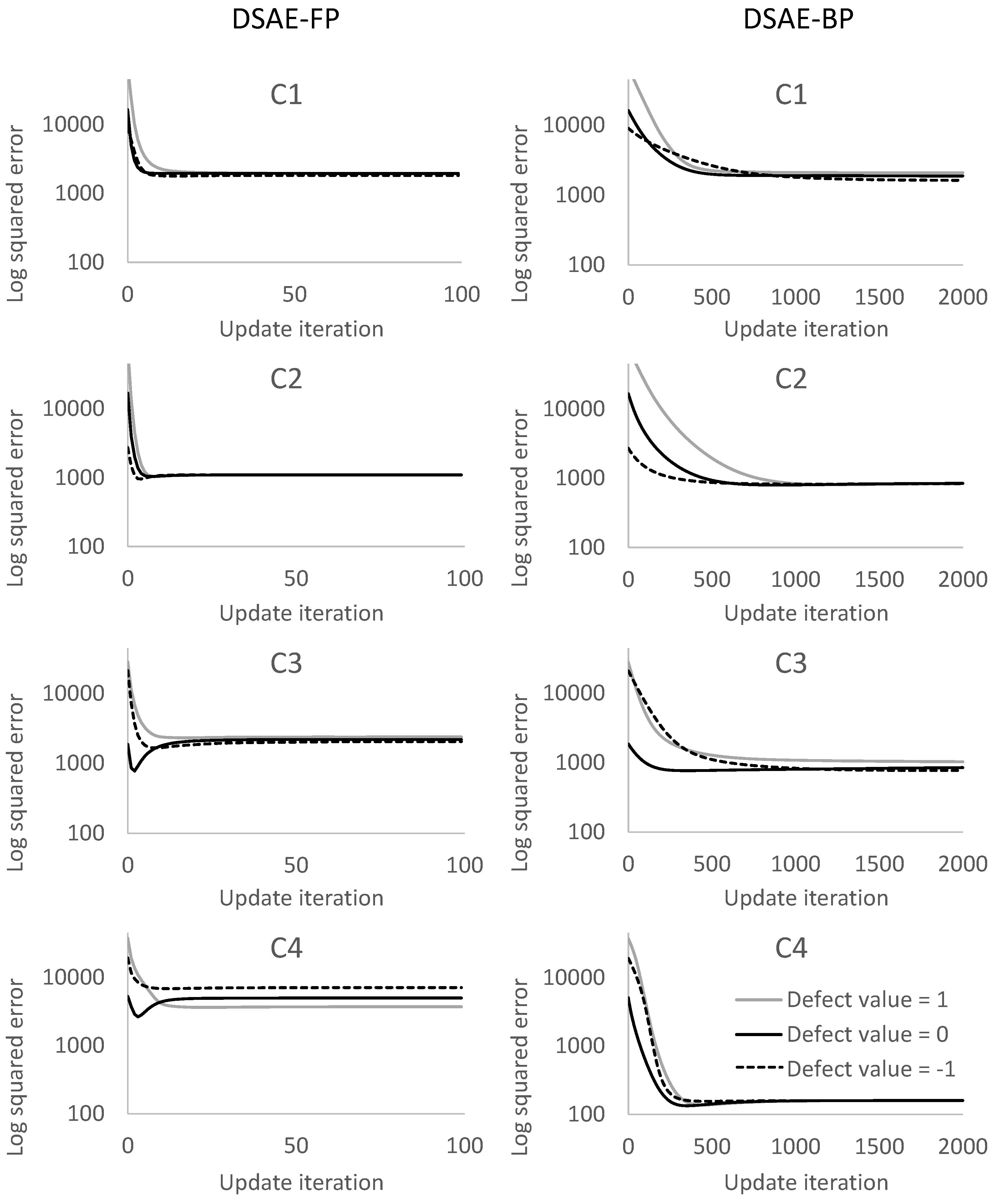
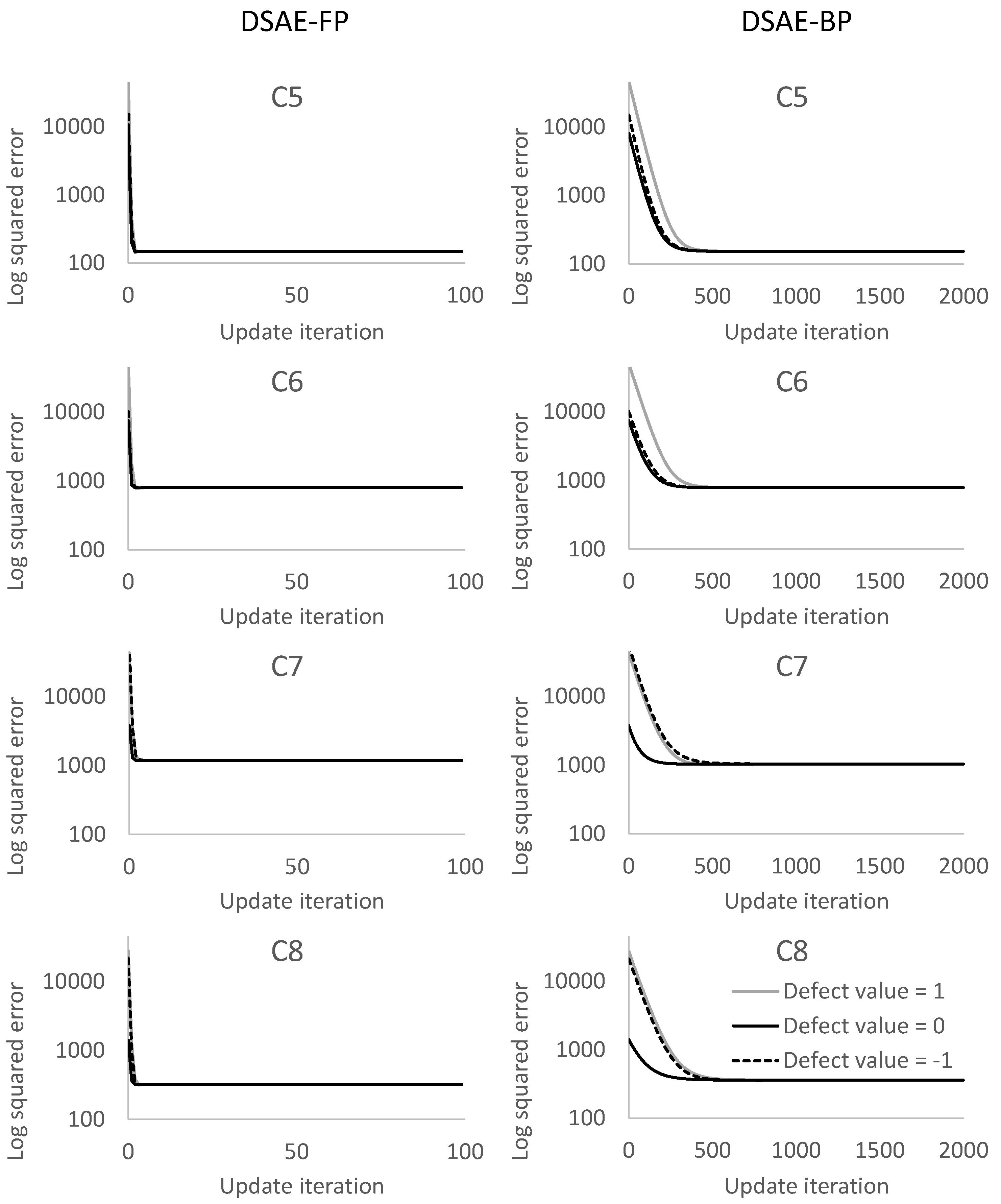
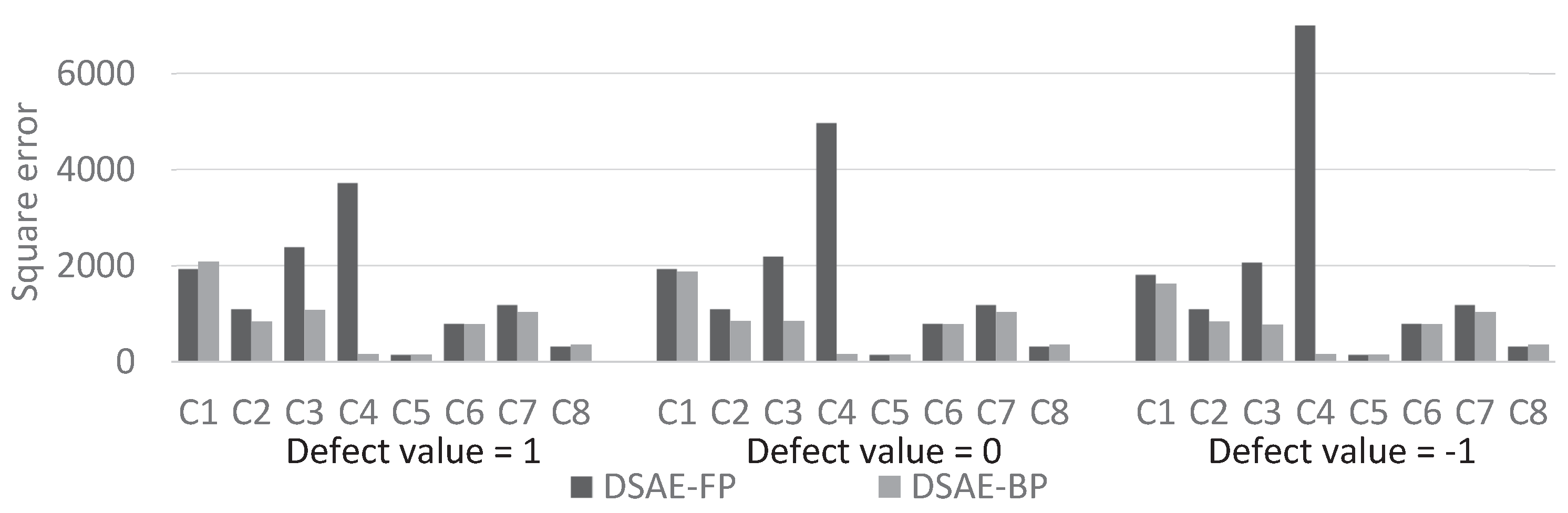
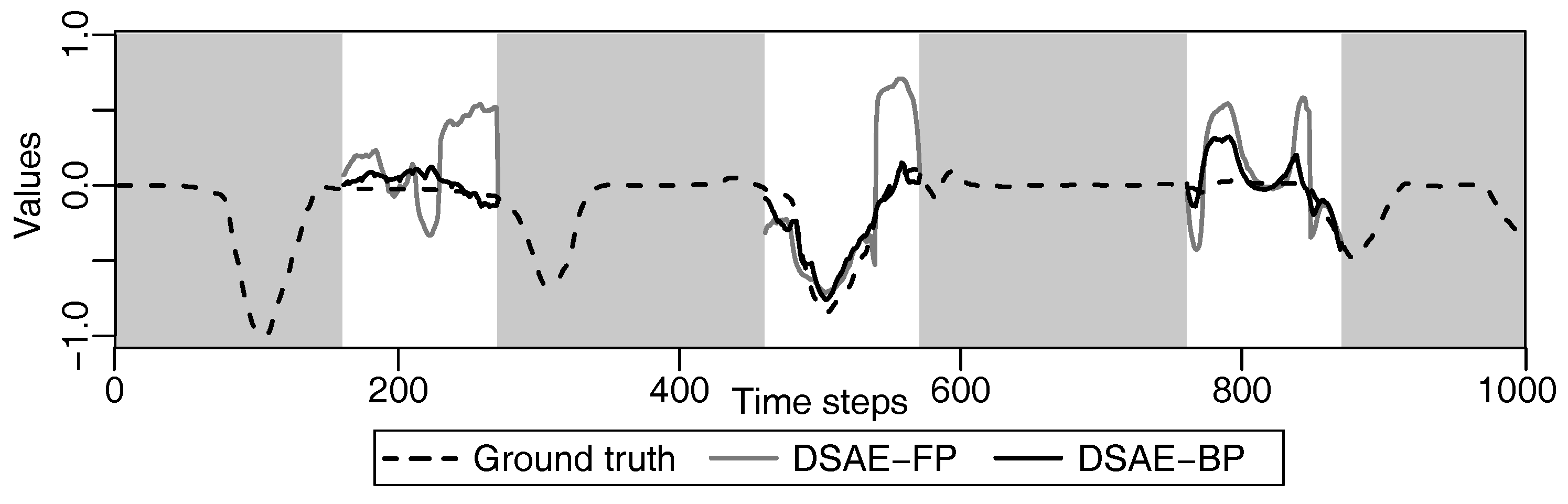
5.2. Evaluation of Data Repair of Sensor Time-Series Data
5.3. Evaluation of Feature Extraction with Defective Data
6. Application: Driving Behavior Segmentation with Defects
7. Discussion for Advantages and Limitations of Proposed Method
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Similarity between Two Extracted Time-Series of Latent Features via the Same Trained Model
Appendix B. Similarity between Two Segment Results
References
- Tagawa, T.; Tadokoro, Y.; Yairi, T. Structured denoising autoencoder for fault detection and analysis. In Proceedings of the Asian Conference on Machine Learning, Hong Kong, China, 20–22 November 2015; pp. 96–111. [Google Scholar]
- Krishnaswami, V.; Luh, G.; Rizzoni, G. Nonlinear parity equation based residual generation for diagnosis of automotive engine faults. Control Eng. Pract. 1995, 3, 1385–1392. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; pp. 89–94. [Google Scholar]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Liu, H.; Taniguchi, T.; Tanaka, Y.; Takenaka, K.; Bando, T. Essential Feature Extraction of Driving Behavior Using a Deep Learning Method. In Proceedings of the IEEE Intelligent Vehicles Symposium 2015, Seoul, Korea, 28 June–1 July 2015; pp. 1054–1060. [Google Scholar]
- Liu, H.; Taniguchi, T.; Takenaka, K.; Tanaka, Y.; Bando, T. Reducing the Negative Effect of Defective Data on Driving Behavior Segmentation via a Deep Sparse Autoencoder. In Proceedings of the 5th IEEE Global Conference on Consumer Electronics, Kyoto, Japan, 11–14 October 2016; pp. 114–118. [Google Scholar]
- Takano, W.; Matsushita, A.; Iwao, K.; Nakamura, Y. Recognition of human driving behaviors based on stochastic symbolization of time series signal. In Proceedings of the IROS 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 167–172. [Google Scholar]
- Taniguchi, T.; Nagasaka, S.; Hitomi, K.; Chandrasiri, N.P.; Bando, T. Semiotic prediction of driving behavior using unsupervised double articulation analyzer. In Proceedings of the IEEE Intelligent Vehicles Symposium 2012, Madrid, Spain, 3–7 June 2012; pp. 849–854. [Google Scholar]
- Bando, T.; Takenaka, K.; Nagasaka, S.; Taniguchi, T. Generating contextual description from driving behavioral data. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014; pp. 183–189. [Google Scholar]
- Li, Z.; Jin, X.; Zhao, X. Drunk driving detection based on classification of multivariate time series. J. Saf. Res. 2015, 54, 61–67. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Chatzigiannakis, V.; Grammatikou, M.; Papavassiliou, S. Extending driver’s horizon through comprehensive incident detection in vehicular networks. IEEE Trans. Veh. Technol. 2007, 56, 3256–3265. [Google Scholar] [CrossRef]
- Calderó-Bardají, P.; Longfei, X.; Jaschke, S.; Reermann, J.; Mideska, K.; Schmidt, G.; Deuschl, G.; Muthuraman, M. Detection of steering direction using EEG recordings based on sample entropy and time-frequency analysis. In Proceedings of the 2016 IEEE 38th Annual International Conference of the Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 833–836. [Google Scholar]
- Lin, C.T.; Liang, S.F.; Chen, Y.C.; Hsu, Y.C.; Ko, L.W. Driver’s drowsiness estimation by combining EEG signal analysis and ICA-based fuzzy neural networks. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems, Kos, Greece, 21–24 May 2006; pp. 2125–2128. [Google Scholar]
- Hyvärinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 46. [Google Scholar]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Zhao, C.; Zheng, C.; Zhao, M. Classifying driving mental fatigue based on multivariate autoregressive models and kernel learning algorithms. In Proceedings of the 2010 3rd International Conference on Biomedical Engineering and Informatics, Yantai, China, 16–18 October 2010; Volume 6, pp. 2330–2334. [Google Scholar]
- Dong, W.; Yuan, T.; Yang, K.; Li, C.; Zhang, S. Autoencoder Regularized Network For Driving Style Representation Learning. arXiv, 2017; arXiv:1701.01272. [Google Scholar]
- Hori, C.; Watanabe, S.; Hori, T.; Harsham, B.A.; Hershey, J.; Koji, Y.; Fujii, Y.; Furumoto, Y. Driver confusion status detection using recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Taniguchi, T.; Nakashima, R.; Liu, H.; Nagasaka, S. Double articulation analyzer with deep sparse autoencoder for unsupervised word discovery from speech signals. Adv. Robot. 2016, 30, 770–783. [Google Scholar] [CrossRef]
- Liu, H.; Taniguchi, T.; Tanaka, Y.; Takenaka, K.; Bando, T. Visualization of driving behavior based on hidden feature extraction by using deep learning. IEEE Trans. Intell. Transport. Syst. 2017, 18, 2477–2489. [Google Scholar] [CrossRef]
- Kaneda, Y.; Irizuki, Y.; Yamakita, M. Design method of robust Kalman filter via L1 regression and its application for vehicle control with outliers. In Proceedings of the 38th Annual Conference on IEEE Industrial Electronics Society 2012, Montreal, QC, Canada, 25–28 October 2012; pp. 2222–2227. [Google Scholar]
- Jang, J. Outlier filtering algorithm for travel time estimation using dedicated short-range communications probes on rural highways. IET Intell. Transp. Syst. 2016, 10, 453–460. [Google Scholar] [CrossRef]
- Duan, Y.; Lv, Y.; Kang, W.; Zhao, Y. A deep learning based approach for traffic data imputation. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 912–917. [Google Scholar]
- Ku, W.C.; Jagadeesh, G.R.; Prakash, A.; Srikanthan, T. A clustering-based approach for data-driven imputation of missing traffic data. In Proceedings of the IEEE Forum on Integrated and Sustainable Transportation Systems 2016, Beijing, China, 10–12 July 2016; pp. 1–6. [Google Scholar]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Ng, A. Sparse Autoencoder; CS294A Lecture Notes; Stanford University: Stanford, CA, USA, 2011; pp. 1–19. [Google Scholar]
- Rumelhart, D.E.; Hintont, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Magdon-Ismail, M.; Boutsidis, C. Optimal sparse linear auto-encoders and sparse pca. arXiv, 2015; arXiv:1502.06626. [Google Scholar]
- Hardoon, D.; Szedmak, S.; Shawe-Taylor, J. Canonical correlation analysis: An overview with application to learning methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed]
- Triacca, U.; Volodin, A. Few remarks on the geometry of the uncentered coefficient of determination. Lobachevskii J. Math. 2012, 33, 284–292. [Google Scholar] [CrossRef]
- Fox, E.B.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. A sticky HDP-HMM with application to speaker diarization. Ann. Appl. Stat. 2009, 5, 1020–1056. [Google Scholar] [CrossRef]
- Nagasaka, S.; Taniguchi, T.; Hitomi, K.; Takenaka, K.; Bando, T. Prediction of Next Contextual Changing Point of Driving Behavior Using Unsupervised Bayesian Double Articulation Analyzer. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium 2014, Dearborn, MI, USA, 8–11 June 2014; pp. 924–931. [Google Scholar]
- Mori, M.; Takenaka, K.; Bando, T.; Taniguchi, T.; Miyajima, C.; Takeda, K. Automatic lane change extraction based on temporal patterns of symbolized driving behavioral data. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 976–981. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv, 2013; arXiv:1312.6114. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measured Sensor Information | ||
| : Accelerator opening rate | : Brake master-cylinder pressure | : Steering angle |
| : Speed of wheels | : Meter readings of velocity | : Engine speed |
| : Longitudinal acceleration | : Lateral acceleration | : Yaw rate |
| Assumed latent features | ||
| V: The feature is related to the velocity | ||
| A: The feature is related to the acceleration | ||
| D: The feature is related to a change in the driving direction | ||
| Data Sets | Included Sensor Information | Assumed Latent Features | Encoder Structure of DSAE (with Window Size: 10) | The Structure of PCA (with Window Size: 10) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | √ | √ | ∘ | 2D×10=20D→10D→5D→3D | 2D×10=20D→3D | |||||||||
| D2 | √ | ∘ | 1D×10=10D→5D→3D | 1D×10=10D→3D | ||||||||||
| D3 | √ | ∘ | 1D×10=10D→5D→3D | 1D×10=10D→3D | ||||||||||
| D4 | √ | √ | √ | ∘ | ∘ | 3D×10=30D→15D→7D→3D | 3D×10=30D→3D | |||||||
| D5 | √ | √ | ∘ | ∘ | 2D×10=20D→10D→5D→3D | 2D×10=20D→3D | ||||||||
| D6 | √ | √ | √ | ∘ | ∘ | 3D×10=30D→15D→7D→3D | 3D×10=30D→3D | |||||||
| D7 | √ | √ | √ | √ | ∘ | ∘ | ∘ | 4D×10=40D→20D→10D→5D→3D | 4D×10=40D→3D | |||||
| D8 | √ | √ | √ | √ | √ | ∘ | ∘ | ∘ | 5D×10=50D→25D→12D→6D→3D | 5D×10=50D→3D | ||||
| D9 | √ | √ | √ | √ | √ | √ | ∘ | ∘ | ∘ | 6D×10=60D→30D→15D→7D→3D | 6D×10=60D→3D | |||
| D10 | √ | √ | √ | √ | √ | √ | √ | ∘ | ∘ | ∘ | 7D×10=70D→35D→17D→8D→3D | 7D×10=70D→3D | ||
| D11 | √ | √ | √ | √ | √ | √ | √ | √ | ∘ | ∘ | ∘ | 8D×10=80D→40D→20D→10D→3D | 8D×10=80D→3D | |
| D12 | √ | √ | √ | √ | √ | √ | √ | √ | √ | ∘ | ∘ | ∘ | 9D×10=90D→45D→22D→11D→3D | 9D×10=90D→3D |
| Data Sets | Included Sensor Time-Series Data | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| C1 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C2 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C3 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C4 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C5 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C6 | √ | √ | √ | √ | √ | √ | √ | √ | |
| C7 | √ | √ | √ | √ | √ | √ | √ | ||
| C8 | √ | √ | √ | √ | √ | √ | √ | √ | |
| Defect Values | Mehods | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | LI+PCA | 0.958 | 0.970 | 0.962 | 0.990 | 0.989 | 0.976 | 0.825 | 0.948 |
| 1 | LI+DSAE | 0.864 | 0.945 | 0.938 | 0.944 | 0.997 | 0.988 | 0.890 | 0.992 |
| 1 | MF+PCA | 0.950 | 0.952 | 0.957 | 0.951 | 0.945 | 0.976 | 0.893 | 0.960 |
| 1 | MF+DSAE | 0.855 | 0.916 | 0.933 | 0.725 | 0.989 | 0.990 | 0.924 | 0.995 |
| 1 | PCA | 0.581 | −0.173 | 0.520 | 0.637 | 0.595 | 0.481 | −0.269 | 0.174 |
| 1 | DSAE | −0.233 | −0.671 | 0.213 | −0.791 | 0.916 | 0.729 | 0.579 | 0.874 |
| 1 | PCA-FP | 0.832 | −1.01 | −177 | −0.858 | −0.055 | 0.337 | – | – |
| 1 | DSAE-FP | 0.968 | 0.975 | 0.906 | 0.750 | 1.00 | 0.997 | 0.987 | 0.999 |
| 1 | PCA-BP | 0.985 | 0.975 | 0.987 | 0.998 | 0.996 | 0.989 | 0.953 | 0.986 |
| 1 | DSAE-BP | 0.964 | 0.983 | 0.974 | 0.992 | 1.00 | 0.997 | 0.990 | 0.999 |
| 0 | LI+PCA | 0.958 | 0.970 | 0.962 | 0.990 | 0.989 | 0.976 | 0.825 | 0.948 |
| 0 | LI+DSAE | 0.864 | 0.945 | 0.938 | 0.944 | 0.997 | 0.988 | 0.890 | 0.992 |
| 0 | MF+PCA | 0.950 | 0.952 | 0.957 | 0.951 | 0.945 | 0.976 | 0.893 | 0.960 |
| 0 | MF+DSAE | 0.855 | 0.916 | 0.933 | 0.725 | 0.989 | 0.990 | 0.924 | 0.995 |
| 0 | PCA | 0.904 | 0.745 | 0.970 | 0.949 | 0.930 | 0.925 | 0.912 | 0.961 |
| 0 | DSAE | 0.641 | 0.553 | 0.955 | 0.692 | 0.986 | 0.960 | 0.947 | 0.995 |
| 0 | PCA-FP | 0.832 | −1.01 | −177 | −0.858 | −0.055 | 0.337 | – | – |
| 0 | DSAE-FP | 0.968 | 0.975 | 0.916 | 0.653 | 1.00 | 0.997 | 0.987 | 0.999 |
| 0 | PCA-BP | 0.985 | 0.975 | 0.987 | 0.998 | 0.996 | 0.989 | 0.953 | 0.986 |
| 0 | DSAE-BP | 0.969 | 0.983 | 0.981 | 0.992 | 1.00 | 0.997 | 0.990 | 0.999 |
| −1 | LI+PCA | 0.958 | 0.970 | 0.962 | 0.990 | 0.989 | 0.976 | 0.825 | 0.948 |
| −1 | LI+DSAE | 0.864 | 0.945 | 0.938 | 0.944 | 0.997 | 0.988 | 0.890 | 0.992 |
| −1 | MF+PCA | 0.950 | 0.952 | 0.957 | 0.951 | 0.945 | 0.976 | 0.893 | 0.960 |
| −1 | MF+DSAE | 0.855 | 0.916 | 0.933 | 0.725 | 0.989 | 0.990 | 0.924 | 0.995 |
| −1 | PCA | 0.949 | 0.961 | 0.642 | 0.814 | 0.870 | 0.901 | −0.581 | 0.351 |
| −1 | DSAE | 0.862 | 0.930 | 0.385 | −0.080 | 0.976 | 0.954 | 0.430 | 0.904 |
| −1 | PCA-FP | 0.832 | −1.01 | −177 | −0.858 | −0.055 | 0.337 | – | – |
| −1 | DSAE-FP | 0.970 | 0.975 | 0.921 | 0.489 | 1.00 | 0.997 | 0.987 | 0.999 |
| −1 | PCA-BP | 0.985 | 0.975 | 0.987 | 0.998 | 0.996 | 0.989 | 0.953 | 0.986 |
| −1 | DSAE-BP | 0.975 | 0.983 | 0.982 | 0.992 | 1.00 | 0.997 | 0.990 | 0.999 |
| Defect Value | Methods | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | RAW | 381 | 524 | 578 | 402 | 358 | 321 | 312 | 338 |
| 1 | PCA | 306 | 408 | 295 | 300 | 304 | 322 | 342 | 326 |
| 1 | DSAE | 351 | 424 | 332 | 344 | 226 | 288 | 325 | 277 |
| 1 | PCA-BP | 153 | 167 | 98.4 | 87.9 | 98.4 | 151 | 187 | 94.3 |
| 1 | DSAE-FP | 132 | 149 | 196 | 235 | 50.4 | 89.5 | 143 | 59.1 |
| 1 | DSAE-BP | 126 | 125 | 133 | 142 | 46.3 | 81.8 | 132 | 56.5 |
| 0 | RAW | 325 | 437 | 166 | 321 | 224 | 210 | 108 | 117 |
| 0 | PCA | 252 | 329 | 93.1 | 199 | 207 | 237 | 231 | 113 |
| 0 | DSAE | 310 | 352 | 126 | 281 | 137 | 213 | 196 | 72.6 |
| 0 | PCA-BP | 155 | 171 | 92.3 | 90.0 | 94.5 | 145 | 194 | 91.7 |
| 0 | DSAE-FP | 132 | 155 | 233 | 328 | 46.3 | 89.1 | 146 | 56.4 |
| 0 | DSAE-BP | 123 | 123 | 141 | 142 | 43.6 | 84.2 | 132 | 58.8 |
| −1 | RAW | 158 | 177 | 352 | 347 | 260 | 203 | 344 | 317 |
| −1 | PCA | 116 | 174 | 288 | 263 | 218 | 249 | 342 | 316 |
| −1 | DSAE | 137 | 181 | 322 | 377 | 118 | 213 | 332 | 275 |
| −1 | PCA-BP | 152 | 170 | 93.5 | 88.3 | 95.3 | 147 | 189 | 91.2 |
| −1 | DSAE-FP | 131 | 154 | 228 | 305 | 44.1 | 88.1 | 144 | 57.0 |
| −1 | DSAE-BP | 123 | 125 | 144 | 142 | 43.8 | 82.9 | 129 | 55.7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Taniguchi, T.; Takenaka, K.; Bando, T. Defect-Repairable Latent Feature Extraction of Driving Behavior via a Deep Sparse Autoencoder. Sensors 2018, 18, 608. https://doi.org/10.3390/s18020608
Liu H, Taniguchi T, Takenaka K, Bando T. Defect-Repairable Latent Feature Extraction of Driving Behavior via a Deep Sparse Autoencoder. Sensors. 2018; 18(2):608. https://doi.org/10.3390/s18020608
Chicago/Turabian StyleLiu, HaiLong, Tadahiro Taniguchi, Kazuhito Takenaka, and Takashi Bando. 2018. "Defect-Repairable Latent Feature Extraction of Driving Behavior via a Deep Sparse Autoencoder" Sensors 18, no. 2: 608. https://doi.org/10.3390/s18020608
APA StyleLiu, H., Taniguchi, T., Takenaka, K., & Bando, T. (2018). Defect-Repairable Latent Feature Extraction of Driving Behavior via a Deep Sparse Autoencoder. Sensors, 18(2), 608. https://doi.org/10.3390/s18020608