1. Introduction
With the rapid advances in the digital explosion of data and connectivity, service and intelligence are growing in importance in the cyber-physical integrated hyperworld [
1]. The amount of data created by this advance is sufficient to make a model of an integrated human individual feasible, enabling services more finely tailored to individual users. As one example, Cyber-I (cyber individual), a digital clone for a real individual (Real-I) featured with a unique and comprehensive personal description, has become an ideal framework for pervasive intelligence to better encompass the corresponding Real-I [
2]. However, due to the dazzling yet unstructured abundance of information available, approaching Cyber-I by simply mining personal data is challenging, as a consequence of the lack of mature structure and high level of difficulty in computing a person’s mental state. Although a growth mechanism for Cyber-I modeling has been built in the laboratory [
3,
4], i.e., a Cyber-I model containing three growth mechanisms, namely Bigger, Higher and Closer, with a specially designed management system [
5], Cyber-I modeling is still at the theoretical stage without any actual result. Because of the difficulty in ascertaining an individual’s mental state, the development of Cyber-I modeling is still at a vestigial stage. As using measuring aspects of personality to describe an individual’s mental make-up is mainstream in the field of Psychology, a mature theoretical system to do so exists within that discipline. Thus, the computing of personality based on insights achieved within that field has become a preferential aim for better Cyber-I modeling.
Personality is a psychological construct aimed at describing the wide range of humans’ habitual behaviors, cognitions and emotional patterns that evolve from biological and environment factors [
6]. Currently, a lot of research is focused on or related to personality computing. In particular, the Big-Five (BF) personality trait theory, which contains a five-factor model (FFM), has been adopted as a theoretical foundation in leading research into personality computing, due to its long standing and widely validated research findings. According to the survey of Vinciarelli, personality computing can be classified into three areas based on three different approaches, namely Automatic Personality Recognition (APR), Automatic Personality Perception (APP) and Automatic Personality Synthesis (APS) [
7]. APR aims at inferring traits through self-assessment, i.e., through a questionnaire. In contrast, APP focuses particularly on inferring the personality observers attribute to a given individual from proximal cues, i.e., through the judgment based on others’ perception. In addition, APS is in relation to the task of automatically generating distal cues aimed at eliciting the attribution of desired personality traits. This research has applied the Automatic Personality Recognition into personality computing due to its emphasis on inferring emotional and social phenomena from machine detectable behavioural evidence, which, in this case, refers to the emotional data gathered from surrounding devices. Thus, the personal data collection carried out in our previous work by a context-aware scheduling mechanism is highly suitable as a resource for Automatic Personality Recognition [
8]. However, according to the survey mentioned above, current personality computing still relies on finding a correlation between a specific personal datum and the corresponding personality trait described in the five-factor model (FFM). These personality traits indicate broad features in terms of behavior, cognition and emotion. For example, people high in openness are motivated to seek new experiences and to engage in self-examination. Structurally, they have a fluid style of consciousness that allows them to make novel associations between remotely connected ideas. It is evident that this revelation of a person with high openness trait is too inaccurate to describe a specific human in different situations. For example, a person may show a poor ability of seeking new experiences when he feels nervous. Therefore, the comprehensive modeling of personality is urgently needed to achieve a more precise description of a human.
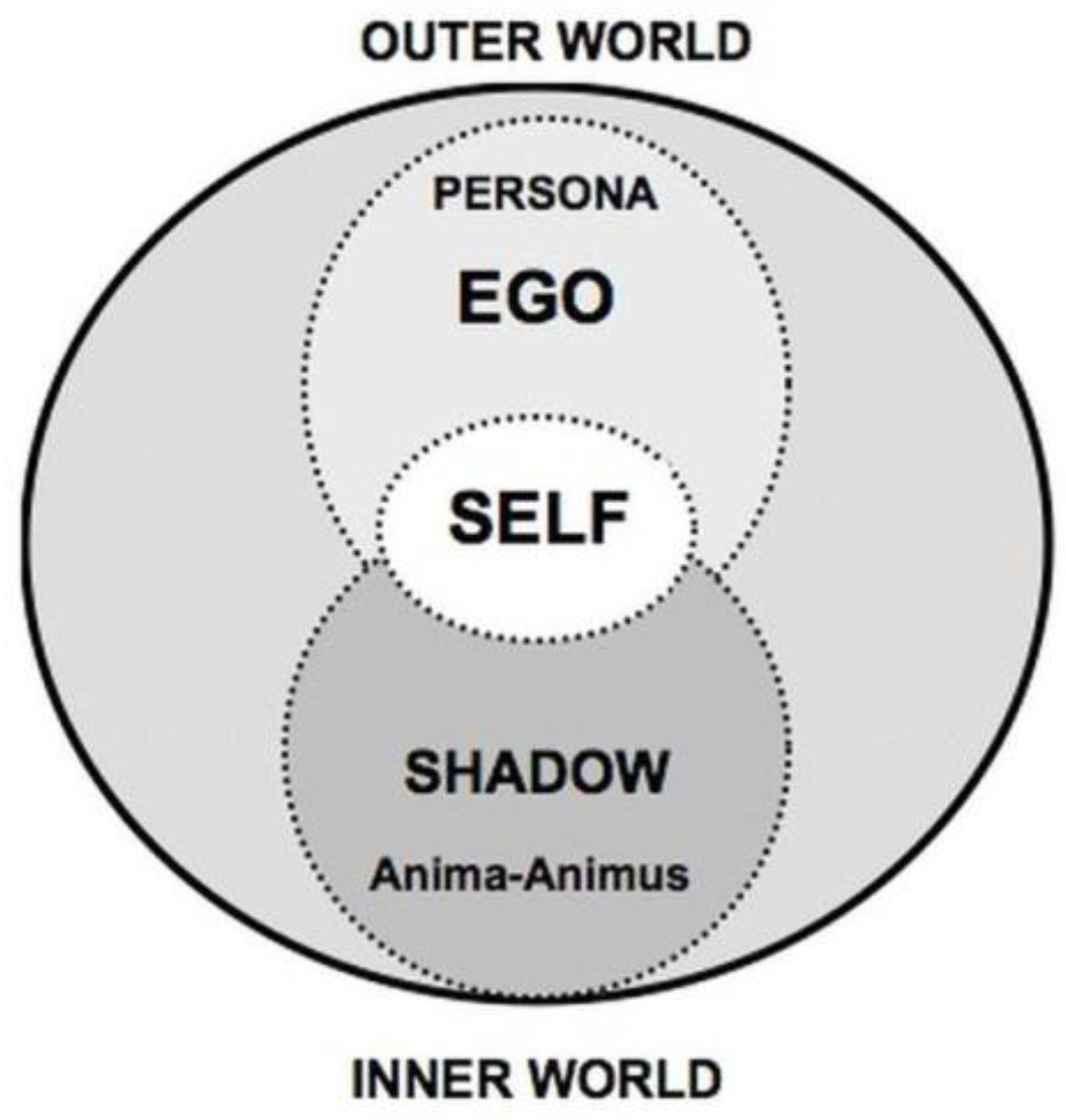
According to the theories of Carl Gustav Jung (1875-1961), the concept of
persona, as a kind of mask or social role, represents a compromise a person makes with the society concerning how he/she should appear to be [
9] with an aim to conceal the true nature of the individual [
10]. A person’s mental structure involves the persona and, as showed in
Figure 1, the model that indicates the “self” can be described as consisting of three layers. As the outer layer of this structure, persona refers to the set of a human’s mental state in different situations or scenarios. The persona is also the connection between the external physical world and the inner mental world. In order to delve into a person’s inner world, the modeling of persona is therefore needed. Furthermore, the persona makes it possible to construct a digital personality model. In view of this, this research is aimed at achieving a comprehensive personality model from the modeling of persona.
As we know, diverse personae exist in any human’s social interaction. The modeling of sufficient personae for common situations is required to accurately describe a person. The heterogeneous data sources are selected accordingly, to provide the plenty of personal data (also named
Personal Big Data). This personal big data covers all the personal data that could be gathered from daily life for human modeling, i.e., physiological data, the data from the Internet or the daily activity data. Such plentiful data provide the solid foundation for future persona modeling. In addition, the physiological data like emotion states that timely reflecting a person’s responses of activities would have high priority for the construction of persona, due to the warning from Jungians’ perspective that the researchers of persona should pay attention to hidden elements that may erupt if not made conscious [
11].
Although the personal data is more than sufficient, it seems hard to construct a person’s persona without any persona forms. Fortunately, a prototype persona could be derived from the twelve typical human types, or
archetypes, as outlined in Jungian psychological theory. The concept of an archetype was conceived by Carl Jung [
12] in his work on the collective unconscious as a typical character to whom an observer might emotionally resonate. Collective unconscious embraced impersonal, universally shared, fundamental characteristics of humanity that he referred to as primordial images or archetypes [
13]. Based on myths, legends and esoteric teachings, archetypes form part of the individual’s unconscious mind [
14]. That is to say, a specific persona in a certain scenario would take on the aspect of one or more archetypes. Such archetypes could be detected from different scenarios. For example, when playing card games, a person may exist as the archetype Hero, referring to his desire to win the game. However, the person could also show the archetype Lover, as he/she may want to help a partner in certain games. Hence, the first target of this research is to create a persona derived in one specific diverse scenario existing as a combination of different archetypes.
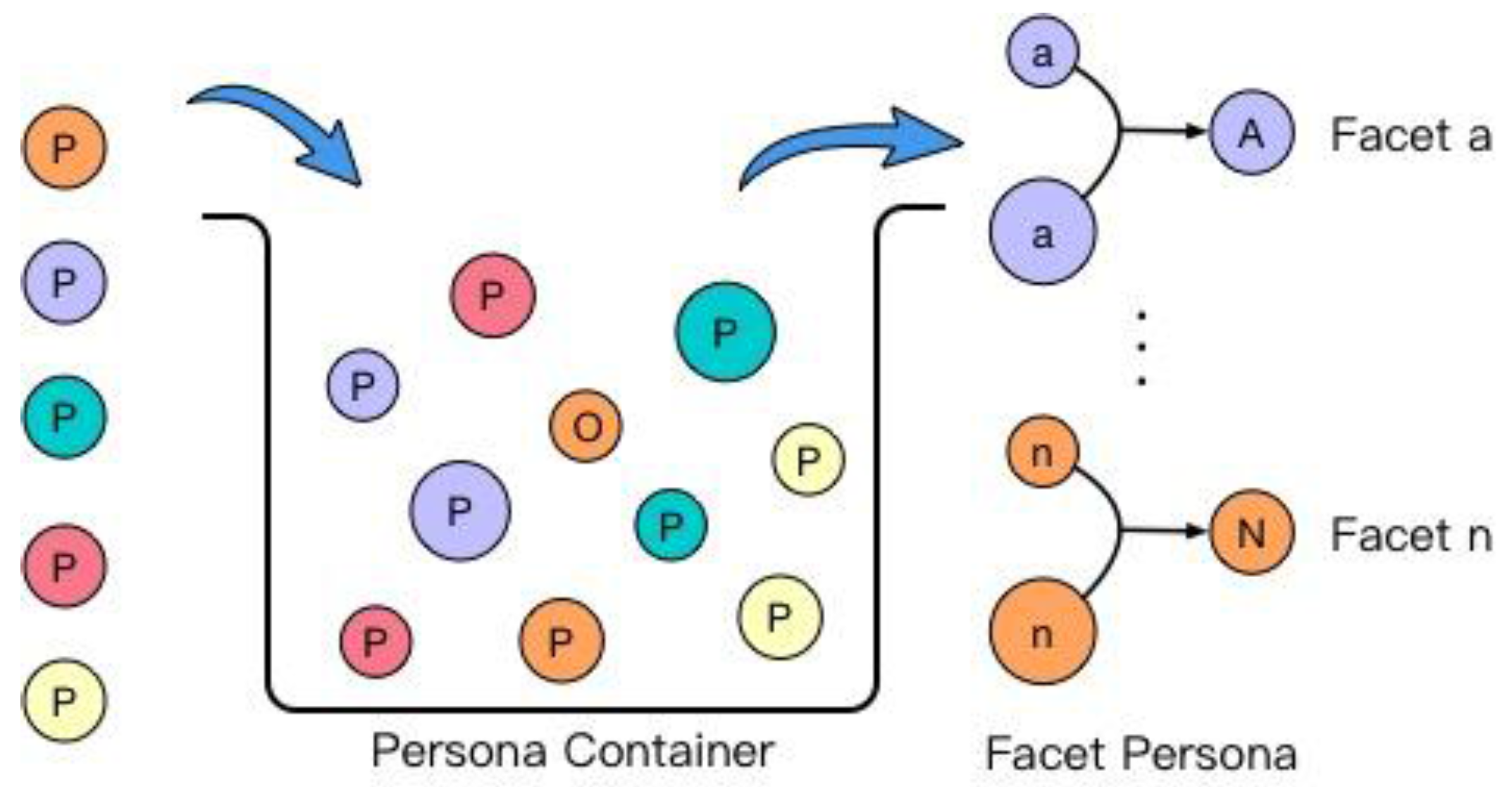
In order to acquire a comprehensive description of a human, the second objective of this research is to model a series of personae representing a comprehensive description of a certain person, or personality. One of the groupings of personae is called
facet persona (FP), in which the term ‘facet’ in the psychological field refers to a specific and unique aspect of a person’s mental state or boarder personality trait, such as the mental state demonstrated on the Internet [
15]. Specifically, each person could be modeled to one special description called a
primary persona (PP), denoting the primary personality state in which a person presents themselves.
The remainder of this paper is organized as follows: the following section introduces related studies and their relevance to this research.
Section 3 provides an overview of each function for personality modeling. The personal data collection from heterogeneous data sources is explained in
Section 4. Scenario detection from event location, contact person to user behavior is given in
Section 5.
Section 6 describes the method for the characterization of the twelve archetypes. Subsequently, the archetype-based modeling of persona is given in
Section 7. As the proposed personality model, the computing of facet persona and personality are explained in
Section 8. Experiments and discussion are presented in
Section 9. Conclusions and future work are outlined in the last section.
2. Related Works
Over a brief period of time, computing has come to focus on personal life through the increasing prevalence of smart devices. Subsequently, a great deal of research is being conducted into collecting personal data. Chittaranjan et al., investigated behavioral characteristics derived from rich automatically extracted smartphone data [
16]. Daniel et al., developed a wearable sensing platform to automatically capture individual and collective patterns of behavior, which is able to be used to predict further user behavior [
17]. In addition, context-awareness techniques have become applicable to personal data collection. One salient example of this is our previous research into context data detection and data collection scheduling in a smartphone-based client-server system. A systematic wearable data collection schedule was implemented with a corresponding context-aware engine to handle different contextual information. Accordingly, in this research a scenario and a persona are detected separately, based on previously collected wearable data, including GPS data, acceleration data, and sleep data, in order to collect information in terms of user behavior, location, and even communication.
With the increasing usage of the Internet, there is a pressing urgency to depicting user behavior in social networking, which has led to the creation of user models derived from those users.
User Persona as one user modeling technique to be used in product design and Human Computer Interaction (HCI), was first put forward by Cooper in 1999 [
18]. Different from the description of persona in psychology, “personae used for the product design refer to fictional detailed archetypical characters that represent distinct groups of behaviors, goals and motivations observed and identified during the research phase”, as defined by Goodwin [
19]. To create a fictional typical user in possession of rich detail for specific requirements, Wu, et al., proposed a method that could swiftly transform a customer’s needs into a persona based on analysis of typical product utility [
20]. To accurately create a persona, Fakinlede, et al. designed a well-defined robust psychometric model for defining and effecting a persona and depicting its functional role [
21]. AlMaliki, Ncube and Ali tried to build personae by adopting feedback from generated personae instead of from real users to improve software. Analysis or estimation may become another issue for research into persona [
22]. What’s more, taking ontology as a conceptual vocabulary, Salma et al., modelled and stored personae with a Resource Description Framework (RDF), a descriptive language [
23]. Similar to the research above into persona modeling, in this research the prevalent persona model is also applied, especially in its elements. In addition to the research focusing on persona modeling, Phuong, et al., estimated the motivation and learning strategy of students for the improvement of an educational course [
24]. Additionally, Friess explored incorporating personae into the heuristic evaluation of websites [
25]. Tu et al. have used cluster analysis to examine the persona development [
26]. Specifically, the Persona Creation and Usage Toolkit is adopted to cluster nine categories in terms of the user’s biographic background, user goals, knowledge, emotional characteristics of usage and etc. Similarly, this research selects two of the Big Five personality traits, the
Emotion Stability and the
Extroversion/Introversion to represent the calculated personality. Taking advantage of persona in online health communities, Huh et al, annotate four personae from the clustering of the usage behavior pattern of online communities based on a large amount of survey [
27]. Nevertheless, these four personae in Jina’s research, namely the Caretakers, Opportunists, Scientists and Adventurers, are only suitable for clustering the users belonging to a certain group with a specific purpose. In contrast, this research aims at a series of stable personae from different scenarios. To ensure the general applicability for universal situations, each persona is comprised of one or more of Jungian’s archetypes. In conclusion, the related modeling of persona by Cooper just regards the persona as a fictional user upon its application. The resulting persona is analogous to the relationship between a brief resume and an actual person. In contrast to the persona research described above, one feature of persona modeling in this research is the creation of a persona based on twelve human archetypes. The digitalization of a persona based on Jungian psychological theory makes it possible to construct a persona that describes a person accurately and comprehensively. Another feature differentiating this research from previous research is the application of the modeling through facet personae. This research mainly aims to mine personal traits for comprehensive personae sufficient for Automatic Personality Recognition.
Jungian’s twelve archetypes have been used by many other studies as they involve the universal goals, motivations and desires in an individual’s daily life. Bechter et al. have identified the correlation between Jungian’s archetypes and personality traits based on the statistics of 102 executive MBA students [
28], suggesting the usability of the archetypes. Similarly, on the basis of these fundamental archetypes, our research builds the persona modeling after conducting a timely questionnaire with the testers’. In addition, Munteanu et al. have found the correlation between archetypes and Myers-Briggs Personality features [
29]. Besides, Pera, Viglia and Furlan have calculated the correlation among several variable characters including the archetypes, phases and covariates [
30]. Research in relation to Jungian’s archetypes has indicated the application possibility of archetypes for human modeling.
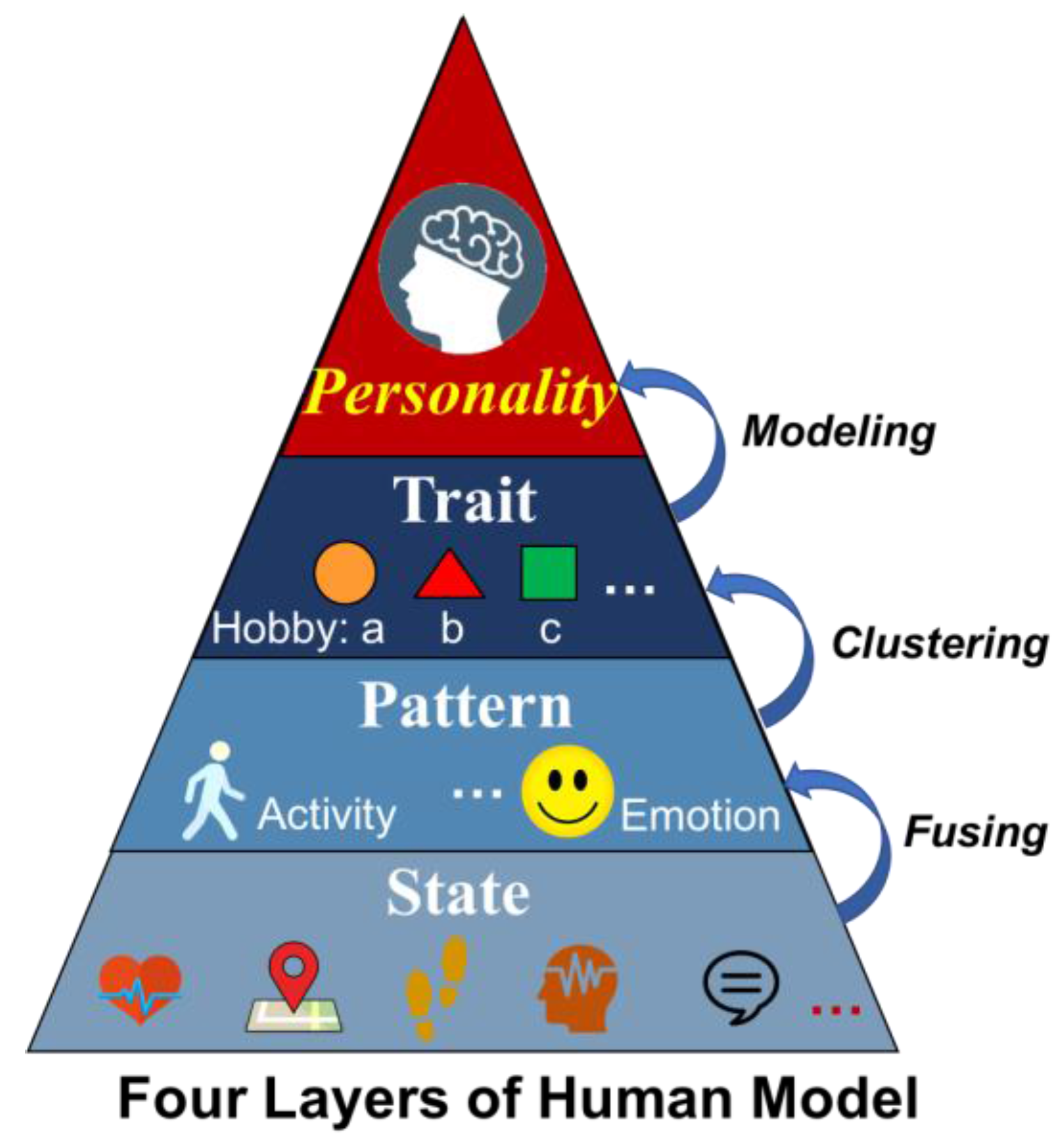
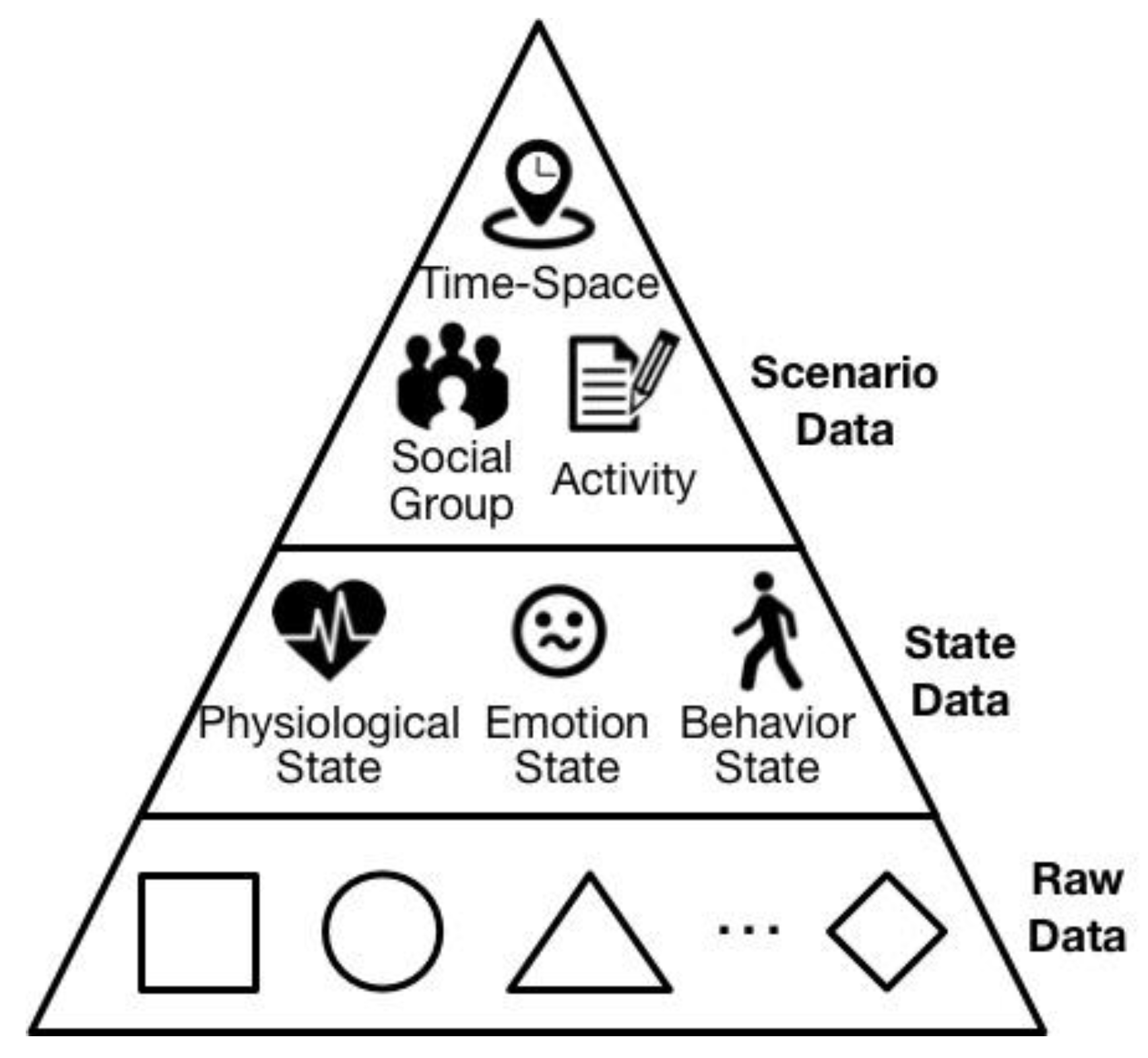
One issue for Cyber-I modeling is the accurate and comprehensive computation of an individual’s personality. Generally, the human model can be classified into four layers, as shown in
Figure 2. The bottom layer of human model involves various human states, such as the physiological state, i.e., heartrate and brain activity, or the behavior state, i.e., running, walking, or talking, etc. For the second layer, the person’s pattern such as their activity pattern or emotion pattern are described. More abstractly, the third layer shows the person’s traits in different aspects, for example taking part in a hobby such as watching movies, or their working style. These three layers covers the aspects of a human from the concrete to the abstract. However, the top layer is the modeling of a human’s psychological state, namely personality. To the present day, there has been a great deal of research into personality computing based on the widely used “Big Five” personality trait theory depicting users’ features from five different aspects. Guntuku et al, create a personality model from the perspective of user favorites [
31]. Vinciarelli surveyed personality computing in terms of measuring, perception and evaluation [
32,
33]. According to this survey, Mohammadi and Vinciarelli attempted Automatic Personality Recognition based on users’ prosodic features [
34]. In this research, the research methods of personality recognition have also been adopted as one aspect of personality computing. The difference lies in perception being based on personae for the general depiction of an individual’s pattern in all aspects of daily life, instead of merely being derived from a single or limited number of certain situations.
3. System Overview
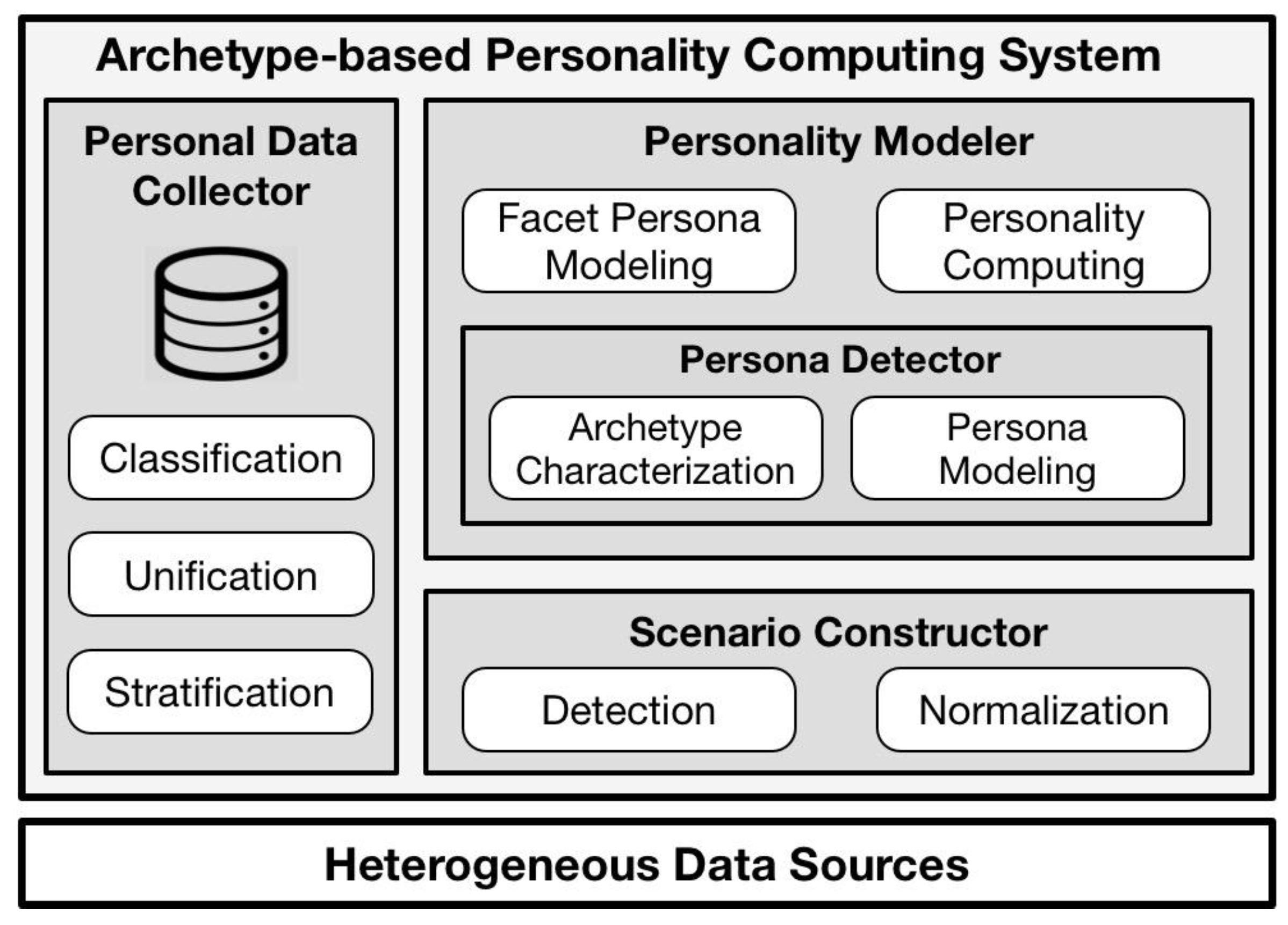
In our previous work, a conceptual model was provided to show the main steps of personality computing, and to provide evidence for the utility of persona. However, such a model was unable to provide enough stability in long-term running from data collection to personae generation. To achieve a comprehensive and stable approach to personality computing, an
archetype-based personality computing system (ABPC system) has been built accordingly, as shown in
Figure 3. The ABPC system consists of a personal data collector, a scenario detector, and a personality modeler. The details of the heterogeneous data sources and the personal data collector are introduced in sub-section one, and the function of the scenario detector is shown in sub-section two. As the core part of the personae modeler, the persona generator is demonstrated, particularly in sub-section three. Finally, sub-section four illustrates the function of the personae modeler.
3.1. Personal Data Collector
Personal Data is the foundation of human modeling. As mentioned in
Section 2, personal data refers to the kind of data which relates to or is generated by a real person. For example, GPS data from a smartphone shows a person’s location, heartbeat rate data from an iWatch reveals a person’s health condition, and the browser data from Chrome can not only tell us a person’s favorite website types, but also shows the exact time of his/her activity surfing the internet. To describe a person’s condition and activity as accurately as possible, it is necessary to choose data sources that can provide diverse personal data. Therefore,
heterogeneous data sources are selected correspondingly, which comprise of a social network, wearable devices, a smartphone and ambient devices to provide the raw data that can cover the major aspects of a person’s daily life.
As shown on the left in
Figure 3, the personal data collector contains three functions;
data stratification,
data unification and
data classification. As raw data collected from data sources is heterogeneous and can be used directly for further modeling, this data should first be classified. For example, the GPS data from the smartphone and the breath data from smart watch are collected at the same time. Clearly, the GPS data can only indicate a person’s location, and can’t be used for emotion detection. Therefore, the data stratification function is in charge of such data usage classification.
Due to the heterogeneity of raw data, data types vary from source to source. One key problem is that there is no unique method to handle the processing of all the various types of data. Actually, some kinds of data may involve deeper-level information that needs to be further excavated. For example, variation in heartbeat rate could also indicate a person’s mental state, i.e., if they are relaxed or nervous. Thus, the data unification function is intended to mine the extra information from the raw data for further processing, i.e., scenario construction and persona modeling. As the last function, the classification function inside the personal data collector is intended to bind the different types of data with the same time section. The detailed explanation of the functions from personal data collector is drawn in the next section.
3.2. Scenario Constructor
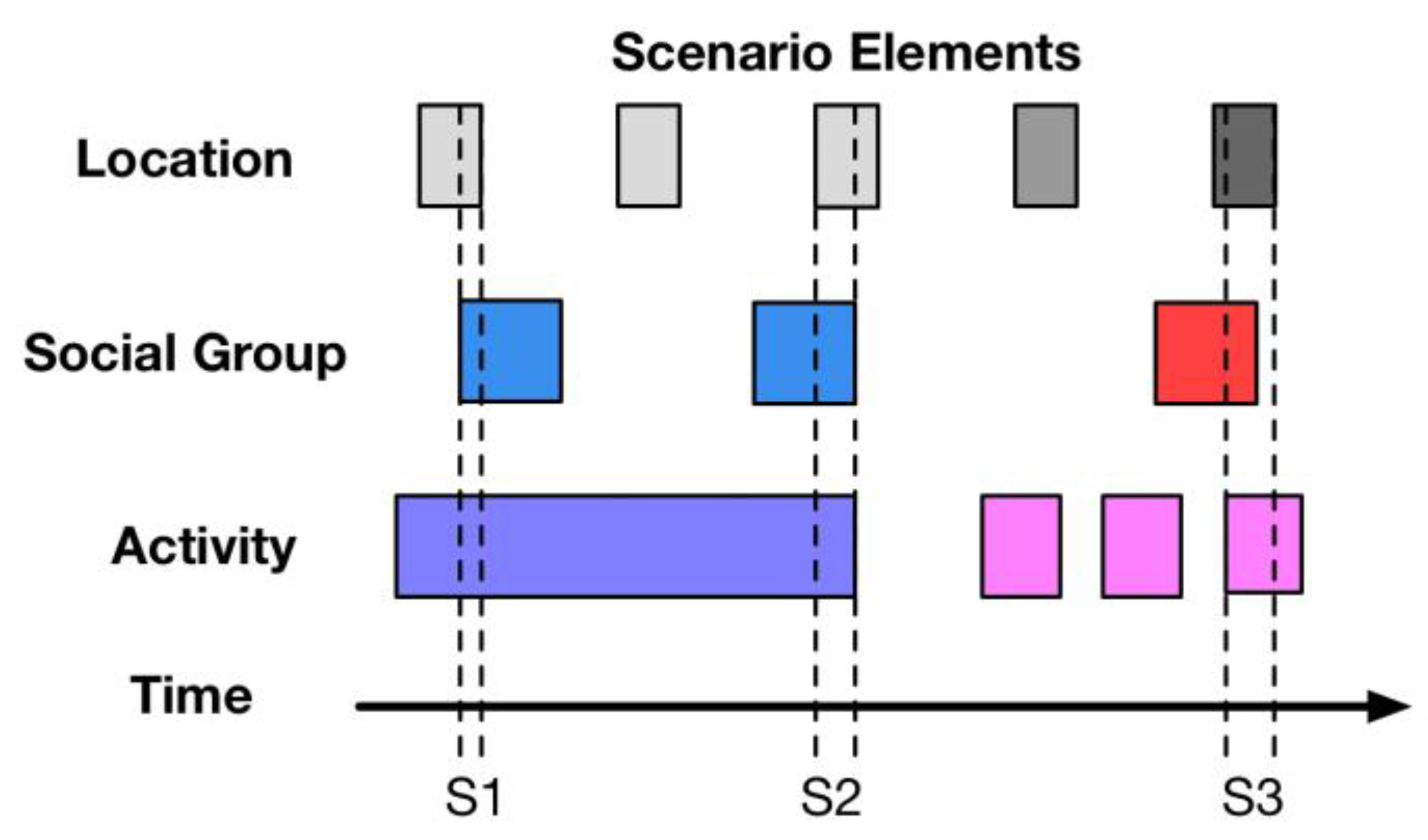
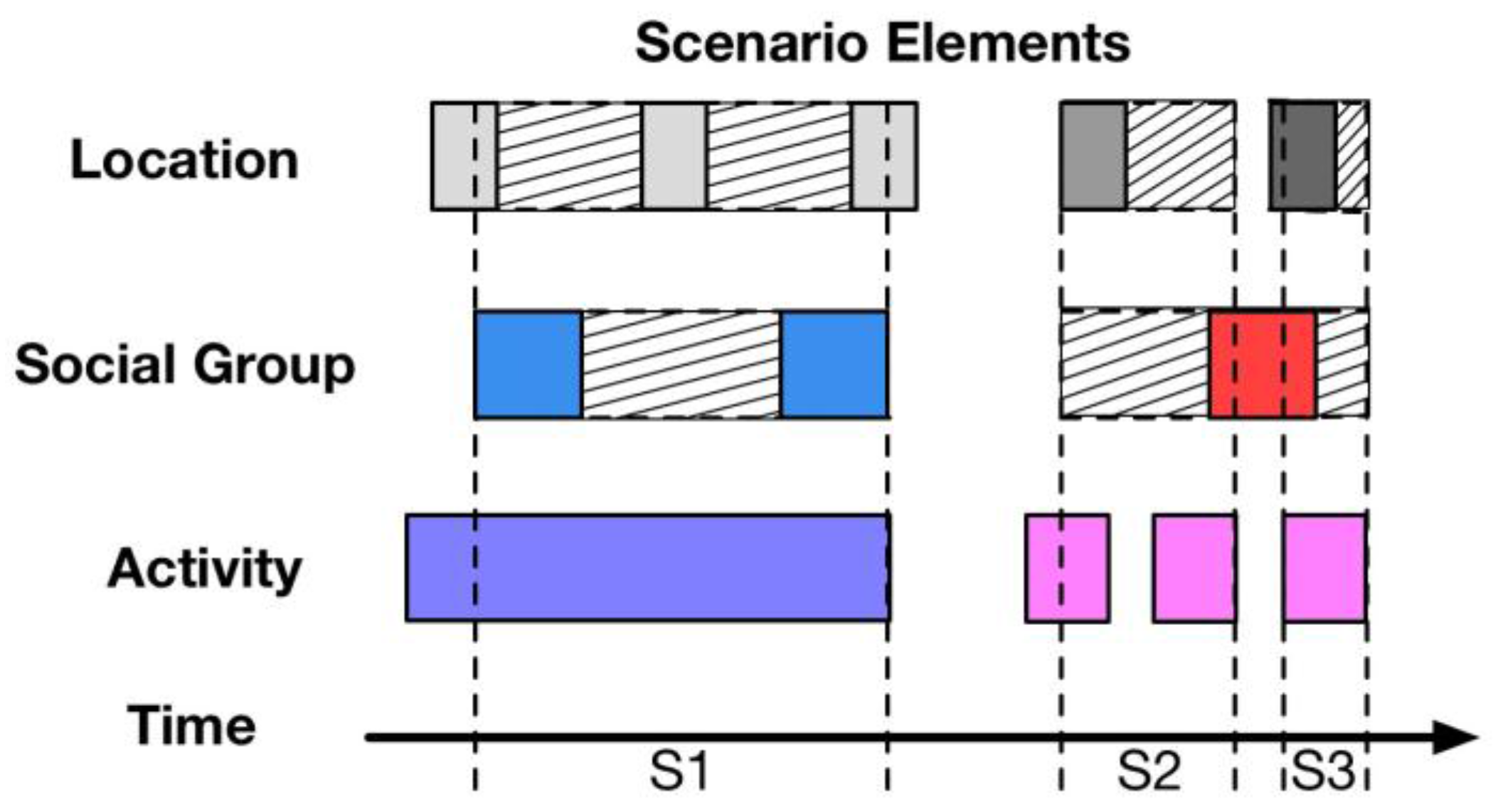
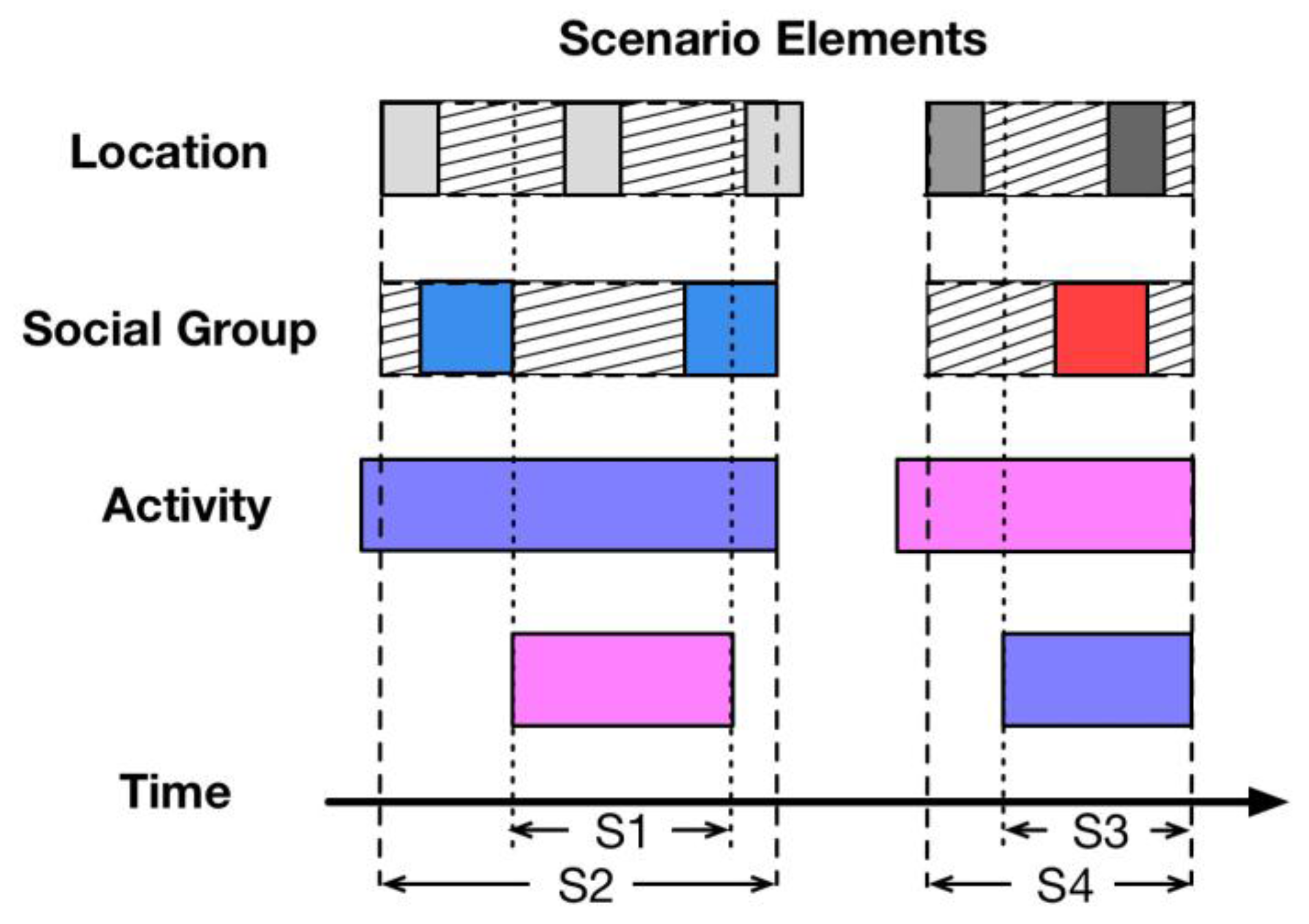
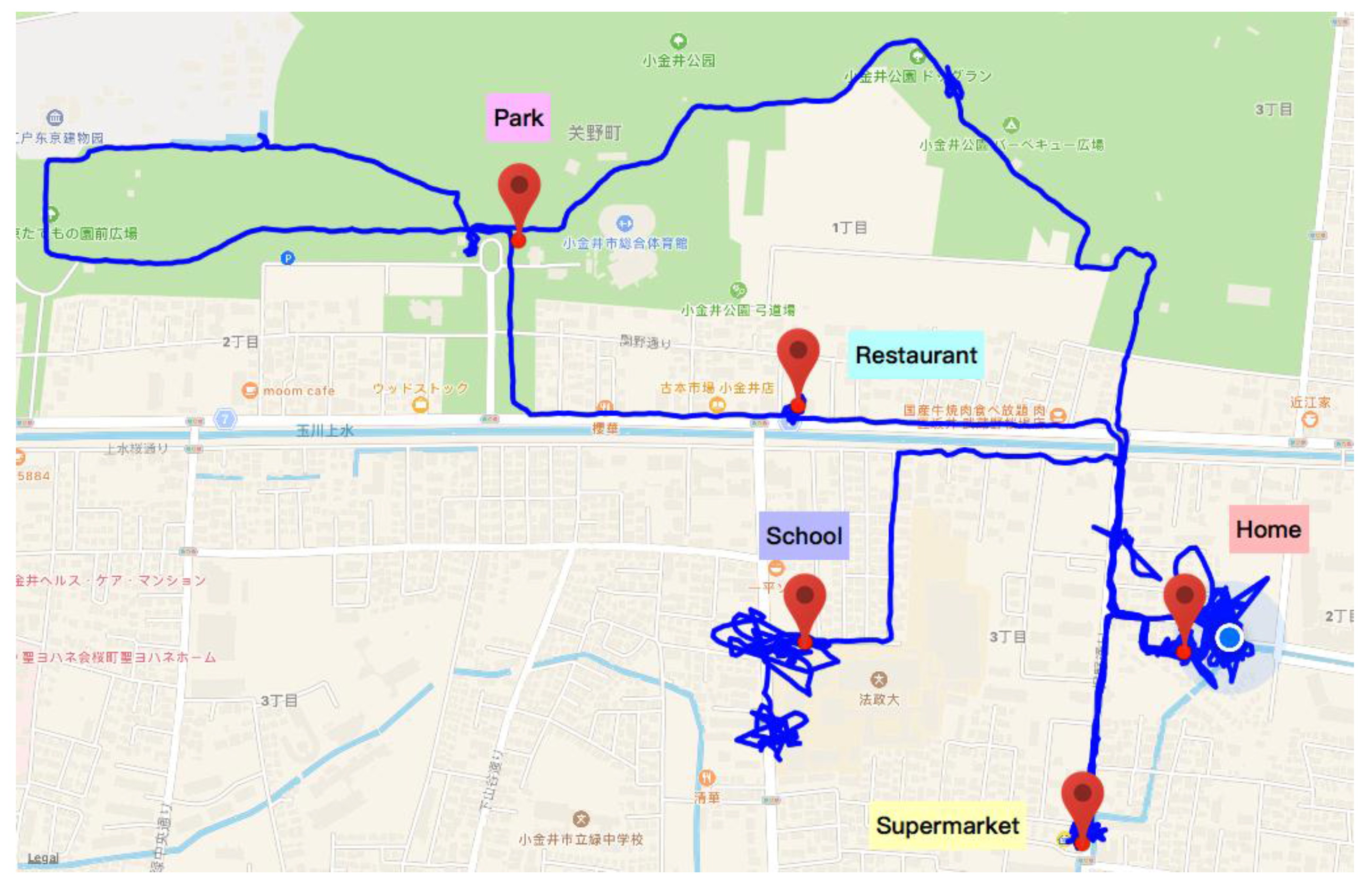
In Human-Computer Interaction (HCI), scenario refers to the context of an activity so that it can be discussed for system refinement. For example, chatting with friends on WeChat or sharing something on Moments could be regarded as two different scenarios in terms of WeChat APP. Obviously, the scenario used for HCI, also named an application-oriented scenario, could separate the user activities on a certain application into several situations. However, the scenario in terms of personality computing mainly has two features. Firstly, the heterogeneous data sources in this research guarantee that data is gathered in diverse ways, i.e., from wearables, smartphones or the internet, so that the scenario is able to involve the human state in all aspects of life but not exclusively as activities on a single HCI system. Therefore, the function
scenario construction inside the scenario detector is to gather all the possible data according to the person’s activity. The key point is how to ensure the data highly related to a specific scenario. Secondly, the main goal of the scenario construction in this research is to categorize the environment for the mental state modeling of a specific subject. Such a scenario is named the personality-oriented scenario. Thus, the
scenario normalization function inside the scenario detector is to normalize the personal data into several aspects, i.e., time, location and activity, for further personality computing. The process of scenario detection and key methods for scenario normalization are discussed in
Section 5.
3.3. Persona Detector
As defined by Swiss psychiatrist Carl Jung, a persona was the stable social face the individual presented to the world. Persona is similar to a role, which describes each human’s psychological status in in terms of the person’s interaction with society. For example, a person may present different personae when interacting with different people, i.e., chatting with parents, going out with friends, or working with their boss. We normalized the interaction with others into several kinds of scenarios. Therefore, such mental variation is the unconscious performance by our inner mind in different scenarios. To research deep into a person’s inner mind, one straightforward way is to research his/her persona. However, the persona currently is simply a psychological description and hasn’t been digitally modelized yet. The persona as understood in psychology is difficult to use in personality computing. Therefore, the main target of persona detector is to digitalize the psychological persona into a computable digital persona form.
As we know, humans are complex and may present a different persona in each different scenario. Hence, to digitalize the persona, the core issue is to seize on the invariable features present in a human’s social activity. According to the Jung’s theory of personality, archetypes, which consist of twelve different aspects act as the prototype of a human’s psychological pattern and exist within the human mind. Actually, a human may present different archetypes in different scenarios. Hence, the
archetype characterization function inside the persona generator is needed for the further
persona modeling. A detailed explanation of archetype characterization and persona construction is explained in
Section 6 and
Section 7, respectively.
3.4. Personality Modeler
Although a person may present different personae in the different scenarios, for a mature individual, his/her persona in various scenarios is relatively stable. The
Personality modeler is to depict a person according to all his personae present in different scenarios. Firstly, to describe a particular person, the characterization of personae with different aspects is necessary. For example, when together with friends, a person could be summarized as an honest person who is willing to help others but also wants to be a hero. Hence, the
facet personae modeling function inside the personality modeler is to characterize a person’s persona due to some universal facet, i.e., people, activity, etc. Secondly, the
personality computing is to give a summary of a person according to all his facet personae. The detail of modeling of personality modeler is explained in
Section 8.
4. Personal Data Collection
In this section, heterogeneous data sources with two features are discussed in the first sub-section. Due to such duality of features, the main step of data collection is proposed accordingly, and is explained in the second sub-section. As the steps of data collection, personal data stratification, personal data unification, and personal data classification are clarified in the last three sub-sections.
4.1. Heterogeneous Data Sources
With the popularity of the Internet and Internet of Things (IoT), more and more personal data is accessible. In this research, the smartphone, wearable devices, ambient devices, and the Internet are selected to provide plenty of data for personality computing, and
Table S1 shows all the personal data types and their sources. Due to their heterogeneity, three features of these data sources hindered scenario construction and persona modeling. These three features of heterogeneous data sources are shown below.
Dynamic Data Availability: For a particular type of personal data, the availability is limited by the user’s behavior, user’s location, and the device battery. Therefore, the scenario construction and persona modeling function are facing the limitations of dynamic data sources.
Multiple Data Sources: For a particular type of personal data, the data is provided by multiple sources, such as the smartphone and smartwatch both providing GPS data. Therefore, the selection of the appropriate data source is needed.
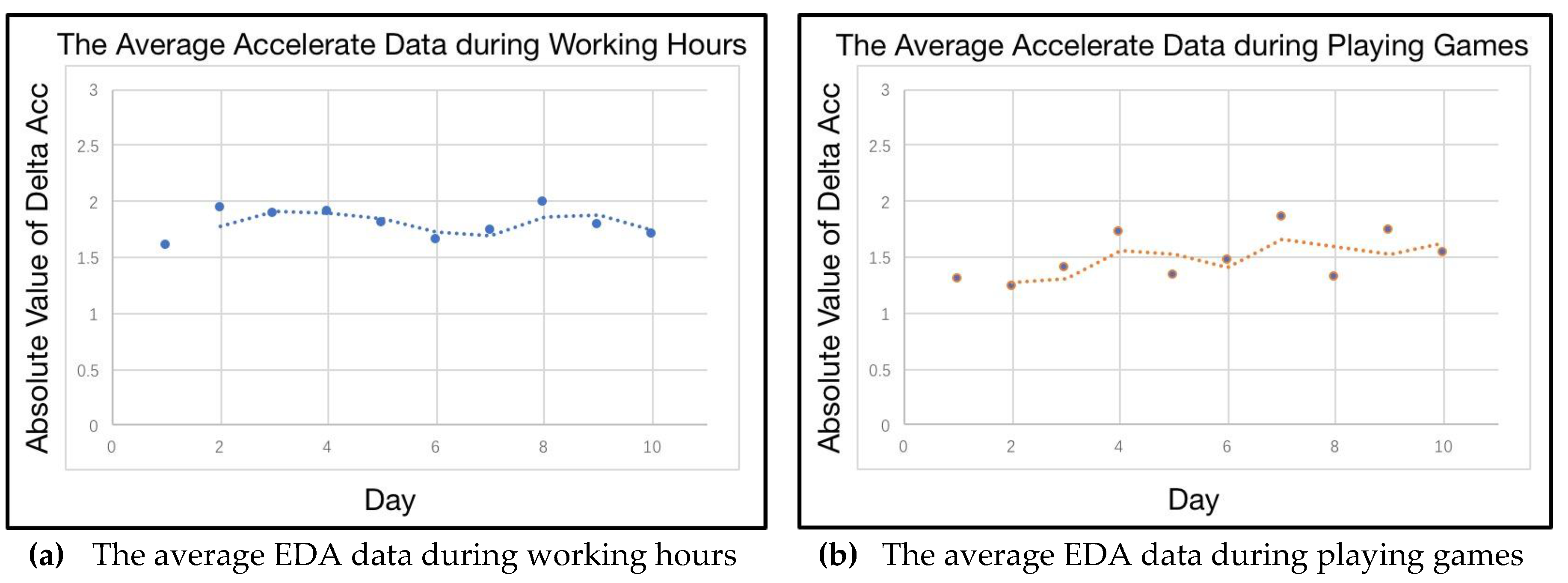
Multilevel Data Sources: The data level varies from type to type. For example, the smartwatch could provide heart rate data every minute, and such data could provide an accurate personal emotion recognition. However, the sleep data provided by a smartphone which just indicates the users’ sleep condition hourly can only be used for approximate personal activity recognition. Hence, only part of the data is prepared for scenario construction, and other parts for persona modeling.
4.2. Flow of Personal Data Collection
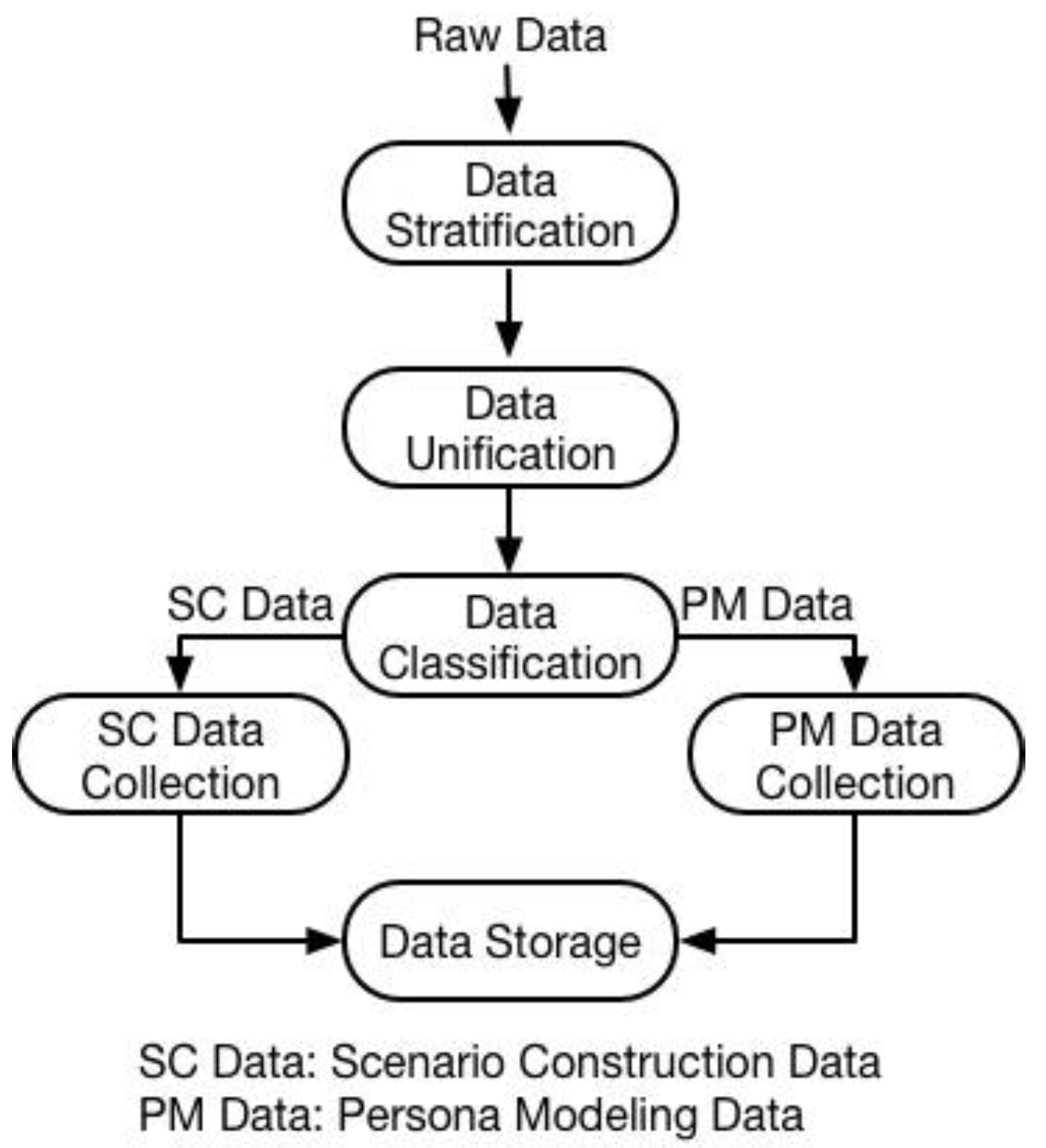
Due to data sources dynamically changing, collected raw data should be processed frequently when used for further scenario construction and persona modeling. The data collection flow is shown in
Figure 4.
The data collection mainly consists of three sub-functions. They are data stratification, data unification, and data classification. Due to the dynamic change involved in the data sources and also the diversity of data types, the ABPC system is unable to categorize the exact type and quantity of collected personal data in advance. Taking advantage of such raw data for further modeling without any processing may lead to inadequate or even incorrect data utilization. For example, the step data provided by smart shoes could easily describe a person’s walking speed and the step frequency of their gait thanks to the high quality of the data and a sufficient data sampling frequency. However, the data quality will deteriorate, and such step data only indicate that a user is moving or not during periods of time when the smart shoes are not available, and the only data source is a smartphone.
To reduce incorrect data utilization, an initial data classification is necessary. Hence, the data stratification is to separate the data into three layers according to the temporal raw data type, so that different data utilization functions, i.e., scenario construction and persona modeling, can use different layer of data. To reduce inadequate data utilization, data unification is developed accordingly. The main purpose of data unification is to first mine one layer of data, and then generate new data in different layers. Such a process is named the second data collection. Finally, the data classification will classify the data into two groups for scenario construction (SC) and persona modeling (PM) separately. The detail of three sub-functions is explained in the following three sub-sections, respectively.
4.3. Personal Data Stratification
Being the first process of data collection, the data stratification function classifies the data into three layers, and its demonstration is shown in
Figure 5.
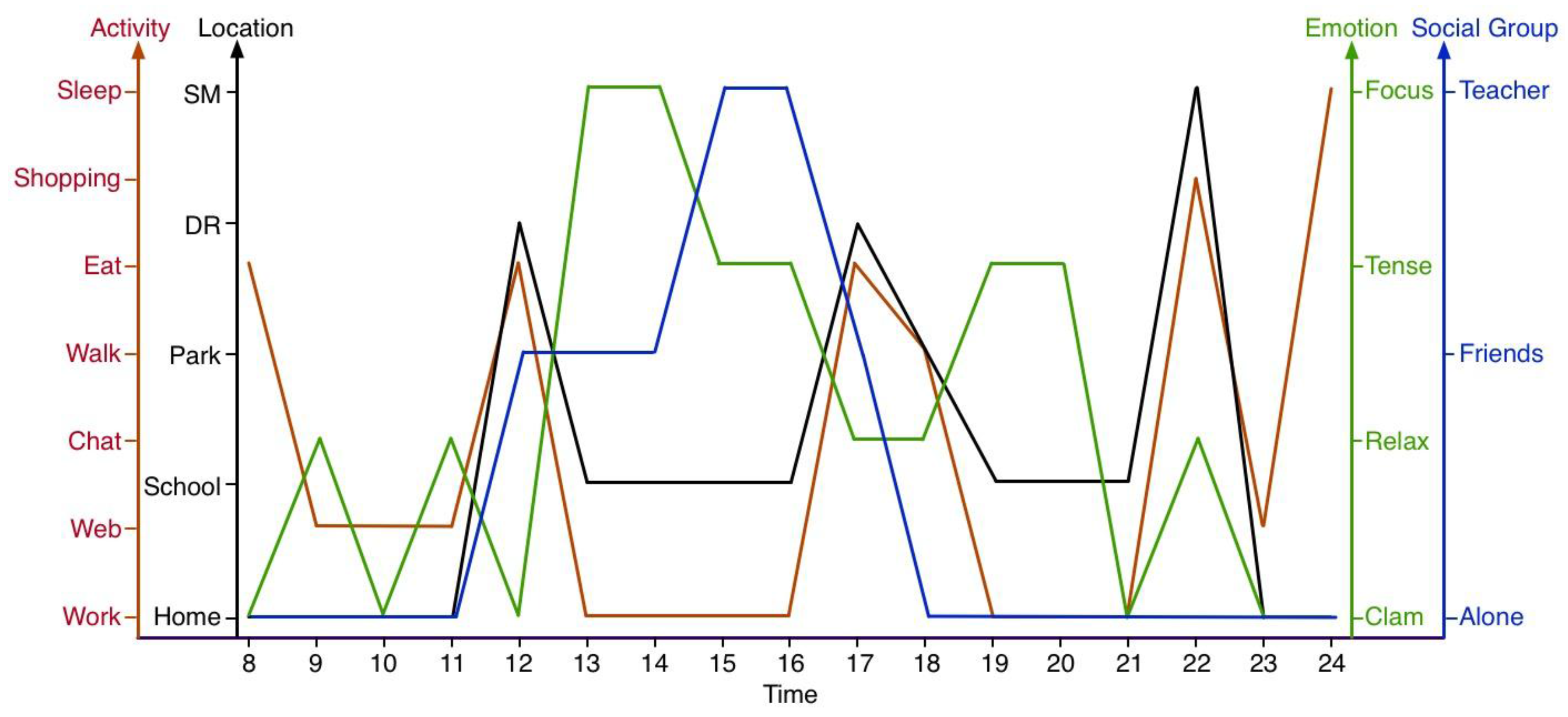
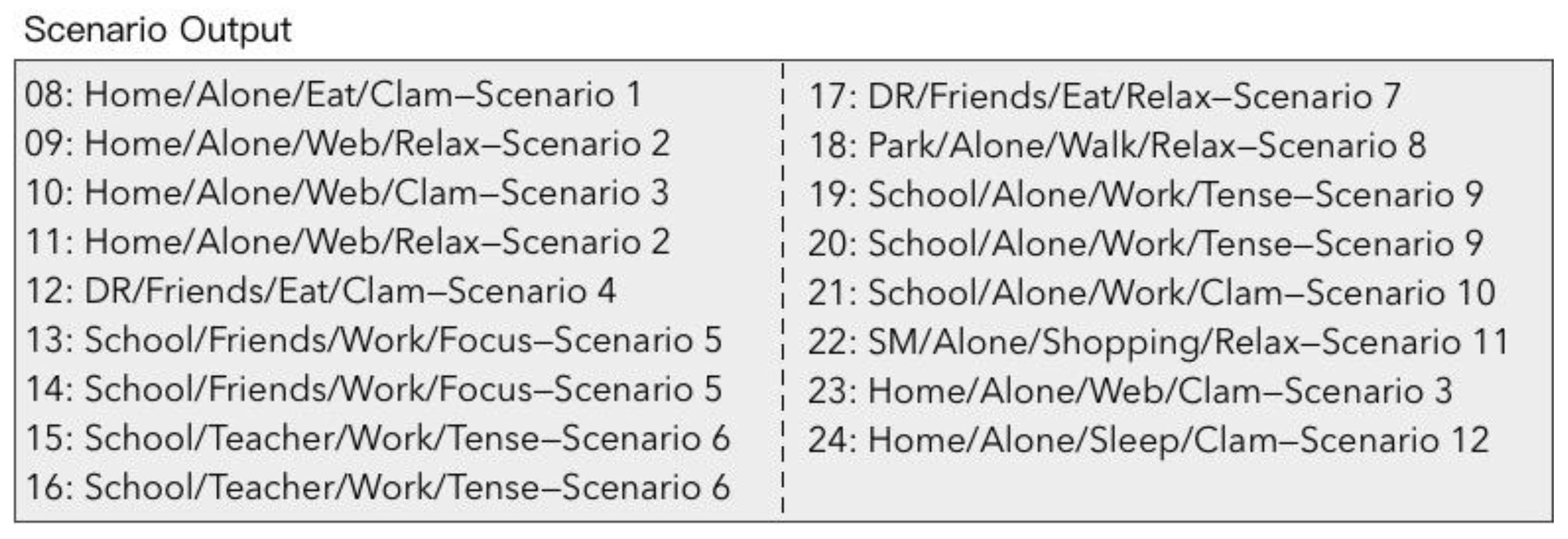
The main use of collected personal data is for further scenario construction and persona modeling. Due to the differences in the elemental composition of scenario and persona, their requirements for personal data are correspondingly different. Concretely, scenario construction needs data that indicates the basic elements of a scenario, i.e., time, location, type of activity and who is involved. Hence, such data, named scenario data, consists of the top layer of personal data. In contrast to the scenario data, the state data is for the comprehensive description of a person’s state within a concrete scenario, as shown in the center of
Figure 5. Because scenario data is limited to showing the rough activity type, i.e., walking, playing, or chatting with others, such data is not rich enough to provide description of a personal state. Hence, state data contains a person’s records of all of the states and its variations in terms of physiology, emotion, and behavior. Consequently, during the same scenario, the differences in state data from person to person reflect the uniqueness of the individual. Aside from the two kinds of data above, other kinds of data are classified into the raw data, as is shown in the bottom layer of
Figure 5. Raw data is data that cannot obviously indicate the scenario elements or human state. However, by further digging, such data may indicate some hidden information which contributes to the scenario data and state data. For example, the voice records on a person’s smartphone may be detected by machine-learning, and may identify a person or people in the immediate vicinity of the smartphone carrier. The process of obtaining the scenario data and state data by mining this raw data is called personal data unification. The details of personal data unification are explained in the next sub-section.
4.4. Personal Data Unification
During the data collection, the majority of collected data is regarded as raw data, and only a few data that contain the apparent scenario data or human state data can be classified into the top layer and second layer in
Figure 5. Hence, as mentioned in the last sub-section, personal data unification mines the hidden information from the raw data as thoroughly as possible and unifies the data with the requirements of scenario construction and persona modeling. Two different methods are provided for personal data unification, namely scenario data unification and state data unification. The core method of these two unifications relies on calculating the correlation between the specific personal part of raw data and the target data. Then such chunks of raw data can be used for target data verification, or even for data mining. One thing that should be clarified is that the correlation between raw data and target data varies from person to person. Therefore, the correlation will be calculated specifically to ensure accurate results and full usage of the raw data in each subject’s case.
4.5. Personal Data Classification
Although the data is separated into three layers by the data stratification function, to analyze a person’s state in a certain scenario, an association between scenario data and state data is necessary. Concretely, the state data should be weighted according to the scenario a person is involved in. Therefore, the personal data classification as the final part of data collection binds the scenario data and state data according to the scenario elements. For example, the state data would be classified according to different time and location. One thing that should be emphasized is that the time factor is indispensable. For example, the personal data would be classified according to linked factors such as time and location, or time and activity.
1.0. Conclusions and Future Work
10.1. Conclusions
In this paper, we have proposed an archetype-based modeling of persona to achieve three main objectives. The first objective was to detect scenarios according to user behavior effectively and swiftly. To that end, we implemented a specific scenario model with a classification algorithm for each corresponding scenario element. Each of the three fundamental elements, comprising location, social group and user activity, are described in the situation along with its essential information during an event. Therefore, this essential information is properly prepared for analysis of a user’s mental state. However, due to the difficulty of modeling in the analysis of the user’s mental state, the second objective was to achieve a model with a comprehensive individual description, based on a scenario generated previously. To reach a more detailed level of description, a conceptual model called persona was applied in this research accordingly, taking into account the fact that the persona model merely depicts the user model from one certain aspect, for example, the behavior trait used in Facebook. Hence, the second objective was to rebuild the persona based on psychological theory, i.e., Jung’s theory of personality. According to this theory, twelve archetypes common to all human beings are selected for the construction of a persona. Meanwhile, taking the personal physiological state, emotion state and behavior state into consideration, the presented archetypes of a person involved in a certain scenario were detected. The persona modeling mainly focused on determining the proportion each archetype presented in a given scenario.
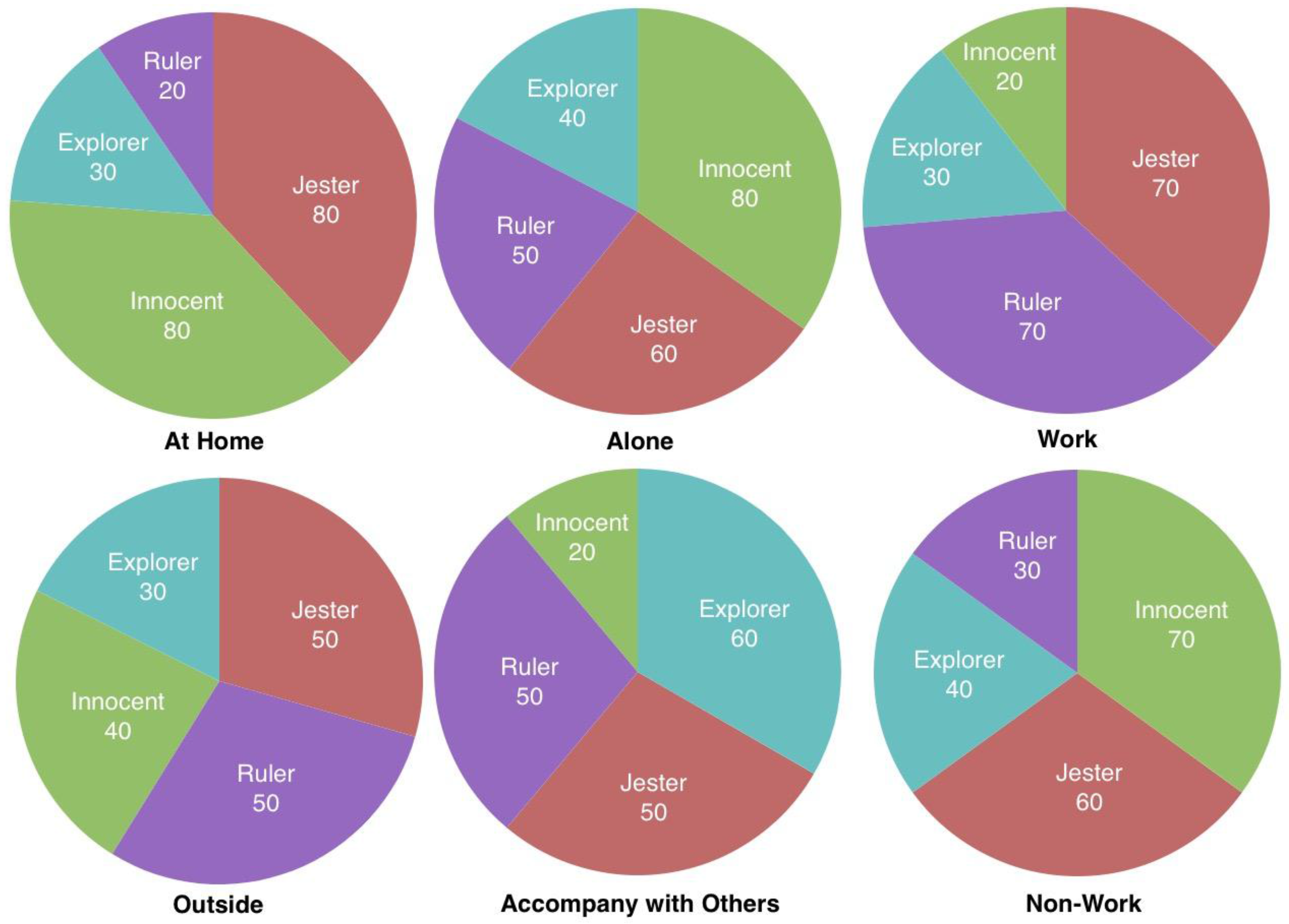
The third objective was to create a set of personae called facet personae to generate a complete individual description under different circumstances. The facet personae are a set of personae indicating the user’s states in different facets, i.e., alone or accompanied by others. In addition to this conceptual model of persona, a modeling mechanism was illustrated to depict the appropriate process generating personality from those facet personae.
10.2. Future Work
However, there are three kinds of work that remain to be done in future studies. Firstly, more elements in scenario detection need to be taken into consideration for the construction of facet personae modeling. Secondly, the facet personae modeling function needs to be further improved to serve the development of mature modeling mechanisms. Third, a wide range of experiments, especially the normalization of several common scenarios applicable to a variety of people and the facet personae modeling based on such scenarios, need to be carried out for further analysis and evaluation.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}