Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks



Abstract
:1. Introduction
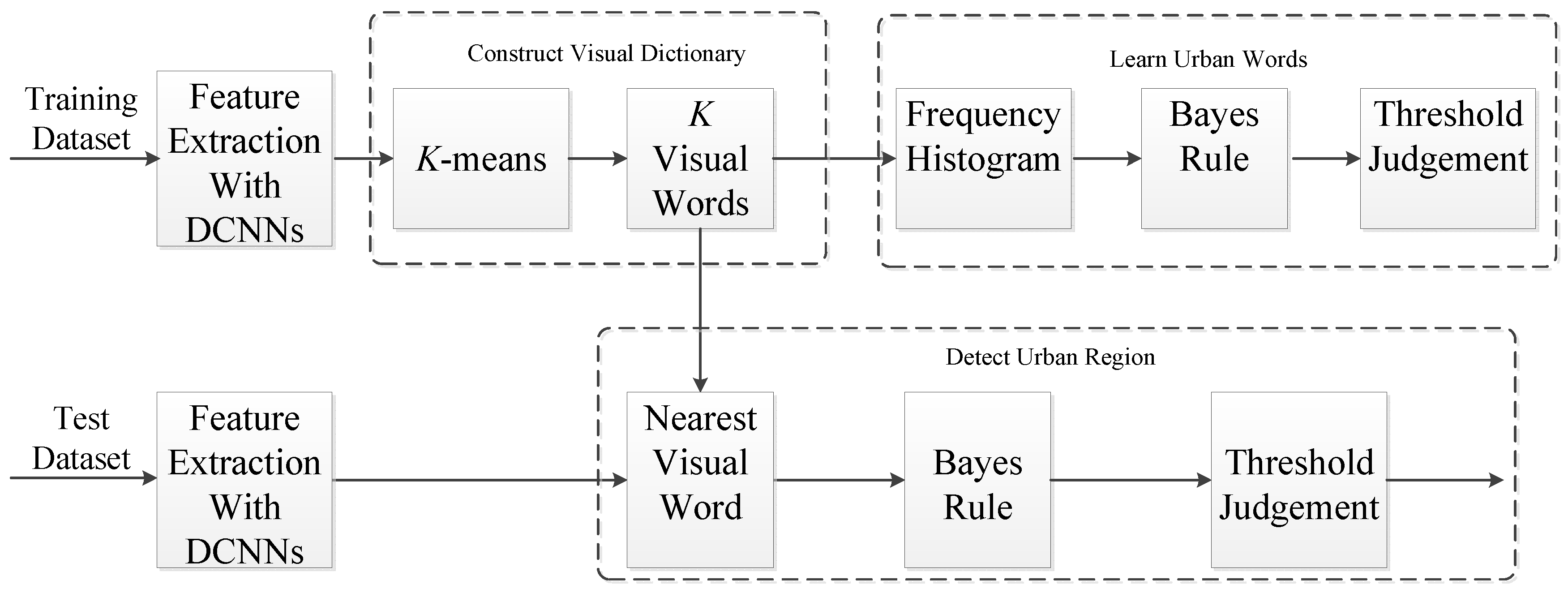
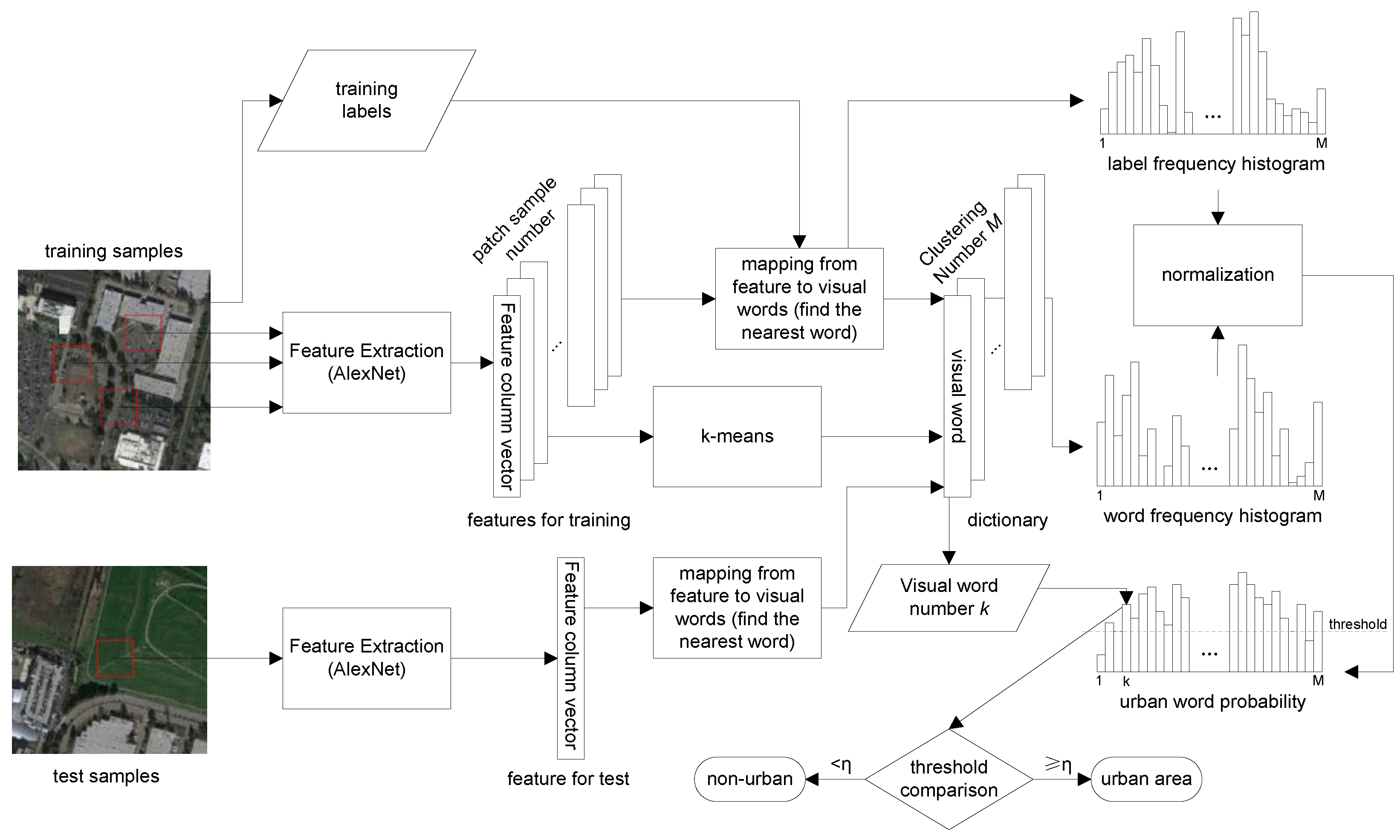
2. Proposed Method
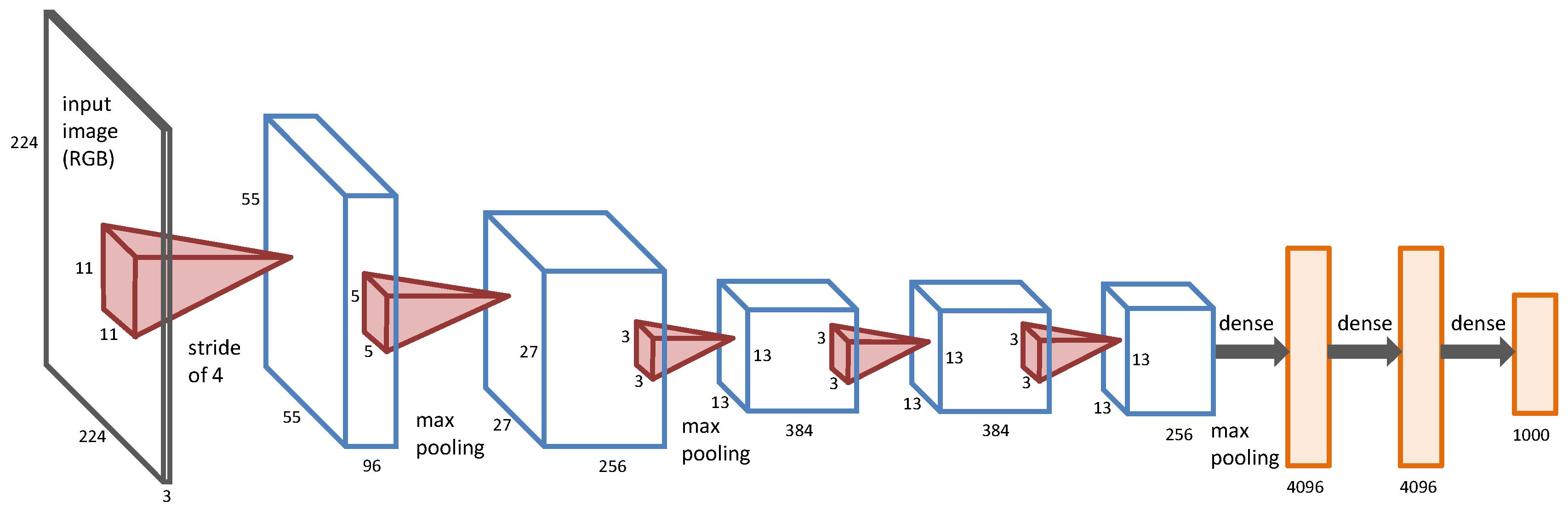
2.1. Deep Convolutional Neural Networks
2.2. Constructing a Visual Dictionary Based on DCNNs
2.3. Learning Urban Words
2.4. Detecting Urban Regions in a Test Image
3. Experiments
3.1. Datasets and Settings
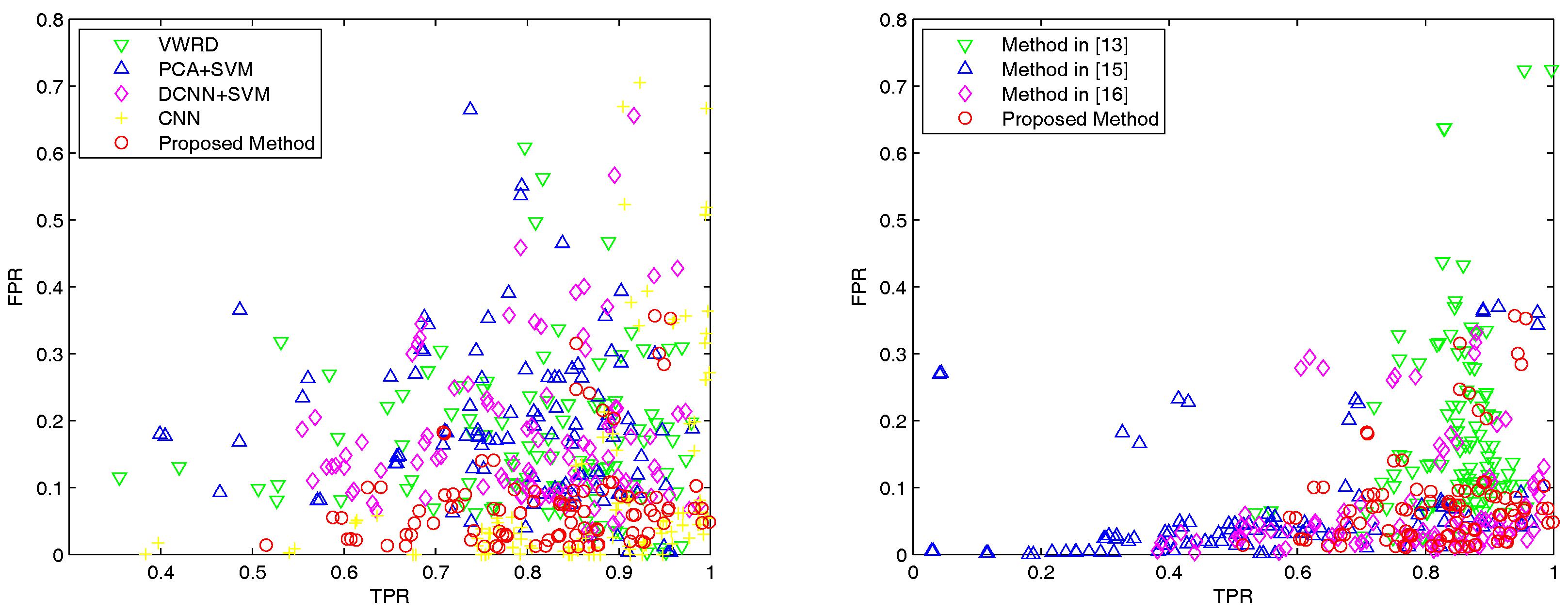
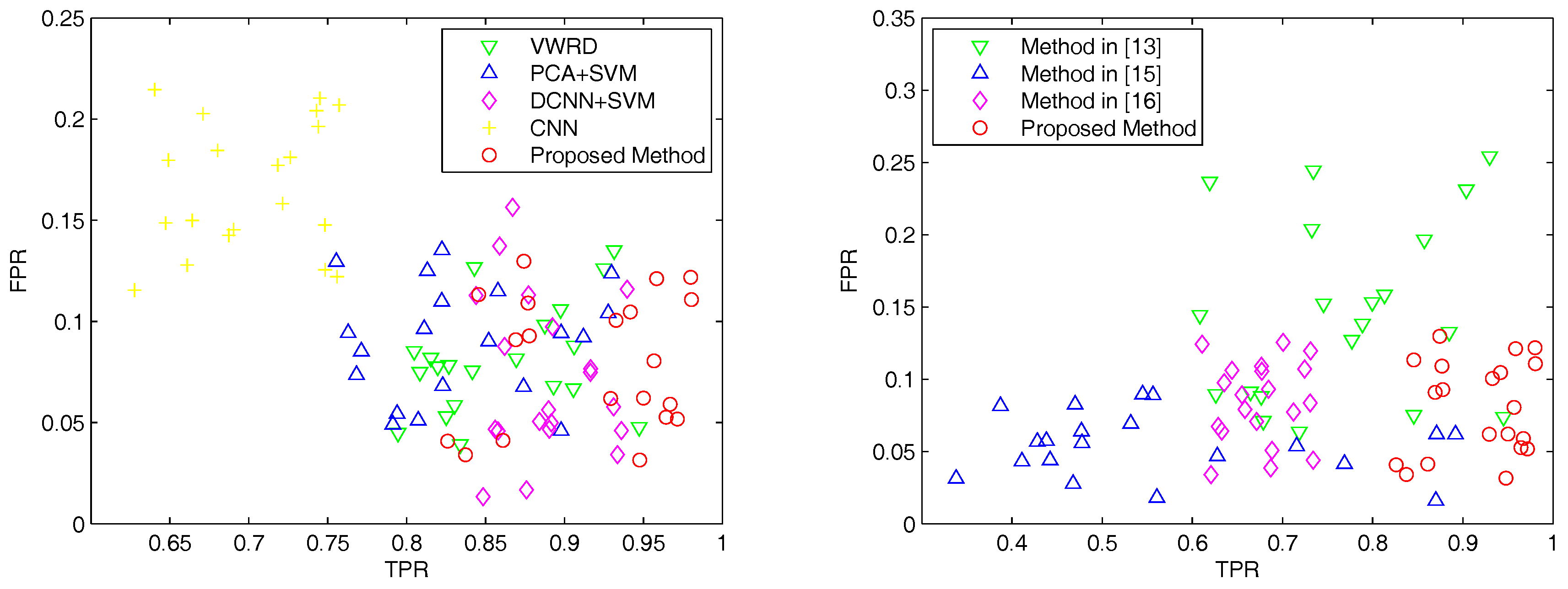
3.2. Results on the Google Earth Dataset
3.3. Results on The Digital Globe Dataset
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zheng, C.; Wang, L.; Zhao, H.; Chen, X. Urban area detection from high-spatial resolution remote sensing imagery using Markov random field-based region growing. J. Appl. Remote Sens. 2014, 8, 083566. [Google Scholar] [CrossRef]
- Shi, H.; Chen, L.; Bi, F.k.; Chen, H.; Yu, Y. Accurate Urban Area Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1948–1952. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust feature matching for remote sensing image registration via locally linear transforming. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised Multilayer Feature Learning for Satellite Image Scene Classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Li, C.; Ma, Y.; Mei, X.; Liu, C.; Ma, J. Hyperspectral Image Classification With Robust Sparse Representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 641–645. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Iannelli, G.C.; Lisini, G.; Dell’Acqua, F.; Feitosa, R.Q.; Costa, G.A.O.P.D.; Gamba, P. Urban area extent extraction in spaceborne HR and VHR data using multi-resolution features. Sensors 2014, 14, 18337–18352. [Google Scholar] [CrossRef] [PubMed]
- Tao, C.; Tan, Y.; Yu, J.G.; Tian, J. Urban area detection using multiple kernel learning and graph cut. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 83–86. [Google Scholar]
- Su, W.; Li, J.; Chen, Y.; Liu, Z.; Zhang, J.; Low, T.M.; Suppiah, I.; Hashim, S.A.M. Textural and local spatial statistics for the object-oriented classification of urban areas using high resolution imagery. Int. J. Remote Sens. 2008, 29, 3105–3117. [Google Scholar] [CrossRef]
- Manno-Kovács, A.; Ok, A.O. Building Detection From Monocular VHR Images by Integrated Urban Area Knowledge. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2140–2144. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J.; Liu, C.; Li, Y. Feature guided Gaussian mixture model with semi-supervised EM and local geometric constraint for retinal image registration. Inf. Sci. 2017, 417, 128–142. [Google Scholar] [CrossRef]
- Sirmacek, B.; Ünsalan, C. Urban-area and building detection using SIFT keypoints and graph theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar] [CrossRef]
- Sirmacek, B.; Ünsalan, C. Urban area detection using local feature points and spatial voting. IEEE Geosci. Remote Sens. Lett. 2010, 7, 146–150. [Google Scholar] [CrossRef]
- Kovacs, A.; Szirányi, T. Improved harris feature point set for orientation-sensitive urban-area detection in aerial images. IEEE Geosci. Remote Sens. Lett. 2013, 10, 796–800. [Google Scholar] [CrossRef]
- Tao, C.; Tan, Y.; Zou, Z.r.; Tian, J. Unsupervised detection of built-up areas from multiple high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1300–1304. [Google Scholar] [CrossRef]
- Li, Y.; Tan, Y.; Deng, J.; Wen, Q.; Tian, J. Cauchy graph embedding optimization for built-up areas detection from high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2078–2096. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.J.; Elvidge, C.D.; Zhao, K.; Thomson, A.; Imhoff, M. A cluster-based method to map urban area from DMSP/OLS nightlights. Remote Sens. Environ. 2014, 147, 173–185. [Google Scholar] [CrossRef]
- Estoque, R.C.; Murayama, Y. Classification and change detection of built-up lands from Landsat-7 ETM+ and Landsat-8 OLI/TIRS imageries: A comparative assessment of various spectral indices. Ecol. Indic. 2015, 56, 205–217. [Google Scholar] [CrossRef]
- Sinha, P.; Verma, N.K.; Ayele, E. Urban built-up area extraction and change detection of Adama municipal area using time-series Landsat images. Int. J. Adv. Remote Sens. GIS 2016, 5, 1886–1895. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Pesaresi, M.; Amason, K. Classification and feature extraction for remote sensing images from urban areas based on morphological transformations. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1940–1949. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Decision fusion for the classification of urban remote sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2828–2838. [Google Scholar] [CrossRef]
- Weizman, L.; Goldberger, J. Urban-area segmentation using visual words. IEEE Geosci. Remote Sens. Lett. 2009, 6, 388–392. [Google Scholar] [CrossRef]
- Li, Y.; Tan, Y.; Li, Y.; Qi, S.; Tian, J. Built-up area detection from satellite images using multikernel learning, multifield integrating, and multihypothesis voting. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1190–1194. [Google Scholar]
- Hu, Z.; Li, Q.; Zhang, Q.; Wu, G. Representation of block-based image features in a multi-scale framework for built-up area detection. Remote Sens. 2016, 8, 155. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Ding, M.; Antani, S.; Jaeger, S.; Xue, Z.; Candemir, S.; Kohli, M.; Thoma, G. Local-global classifier fusion for screening chest radiographs. SPIE Med. Imaging 2017, 10138, 101380A. [Google Scholar]
- Ding, M.; Fan, G. Articulated and generalized gaussian kernel correlation for human pose estimation. IEEE Trans. Image Process. 2016, 25, 776–789. [Google Scholar] [CrossRef] [PubMed]
- Ge, S.; Fan, G.; Ding, M. Non-rigid point set registration with global-local topology preservation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 245–251. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: LA JOLLA, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional Neural Network With Data Augmentation for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Sherrah, J. Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery. arXiv, 2016; arXiv:1606.02585. [Google Scholar]
- Wu, Y.; Zhang, R.; Li, Y. The Detection of Built-up Areas in High-Resolution SAR Images Based on Deep Neural Networks. In Proceedings of the International Conference on Image and Graphics, Solan, India, 21–23 September 2017; pp. 646–655. [Google Scholar]
- Mboga, N.; Persello, C.; Bergado, J.R.; Stein, A. Detection of Informal Settlements from VHR Images Using Convolutional Neural Networks. Remote Sens. 2017, 9, 1106. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Hara, K.; Jagadeesh, V.; Piramuthu, R. Fashion apparel detection: The role of deep convolutional neural network and pose-dependent priors. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Ma, J.; Zhao, J. Robust Topological Navigation via Convolutional Neural Network Feature and Sharpness Measure. IEEE Access 2017, 5, 20707–20715. [Google Scholar] [CrossRef]
- Ševo, I.; Avramović, A. Convolutional neural network based automatic object detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 740–744. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 950–965. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust point matching via vector field consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar]
- Ma, J.; Qiu, W.; Zhao, J.; Ma, Y.; Yuille, A.L.; Tu, Z. Robust L2E Estimation of Transformation for Non-Rigid Registration. IEEE Trans. Signal Process. 2015, 63, 1115–1129. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before P.P. | After P.P. | |||||||
|---|---|---|---|---|---|---|---|---|
| TPR | FPR | OA | Kappa | TPR | FPR | OA | Kappa | |
| 0.50 | 0.7514 | 0.1711 | 0.7971 | 0.5805 | 0.8712 | 0.1606 | 0.8524 | 0.6997 |
| 0.55 | 0.7360 | 0.1411 | 0.8085 | 0.6005 | 0.8459 | 0.1426 | 0.8527 | 0.6979 |
| 0.60 | 0.7125 | 0.1267 | 0.8073 | 0.5953 | 0.8339 | 0.1163 | 0.8633 | 0.7175 |
| 0.65 | 0.6310 | 0.0713 | 0.8066 | 0.5834 | 0.7098 | 0.0828 | 0.8321 | 0.6438 |
| 0.70 | 0.6310 | 0.0713 | 0.8066 | 0.5834 | 0.7098 | 0.0828 | 0.8321 | 0.6438 |
| 0.75 | 0.6310 | 0.0713 | 0.8066 | 0.5834 | 0.7098 | 0.0828 | 0.8321 | 0.6438 |
| 0.80 | 0.6310 | 0.0713 | 0.8066 | 0.5834 | 0.7098 | 0.0828 | 0.8321 | 0.6438 |
| 0.85 | 0.3253 | 0.0301 | 0.7055 | 0.3266 | 0.3728 | 0.0343 | 0.7225 | 0.3711 |
| 0.90 | 0.2679 | 0.0114 | 0.6930 | 0.2879 | 0.3544 | 0.0237 | 0.7212 | 0.3646 |
| Before P.P. | After P.P. | |||||||
|---|---|---|---|---|---|---|---|---|
| TPR | FPR | OA | Kappa | TPR | FPR | OA | Kappa | |
| 0.50 | 0.7654 | 0.1532 | 0.8133 | 0.6137 | 0.8576 | 0.1259 | 0.8673 | 0.7276 |
| 0.55 | 0.7143 | 0.1078 | 0.8189 | 0.6187 | 0.8267 | 0.1048 | 0.8670 | 0.7245 |
| 0.60 | 0.6709 | 0.0670 | 0.8250 | 0.6258 | 0.8067 | 0.0768 | 0.8752 | 0.7392 |
| 0.65 | 0.6756 | 0.0434 | 0.8408 | 0.6580 | 0.8092 | 0.0740 | 0.8779 | 0.7447 |
| 0.70 | 0.6193 | 0.0533 | 0.8118 | 0.5930 | 0.7411 | 0.0498 | 0.8640 | 0.7113 |
| 0.75 | 0.5171 | 0.0377 | 0.7788 | 0.5123 | 0.6275 | 0.0442 | 0.8205 | 0.6116 |
| 0.80 | 0.4882 | 0.0303 | 0.7713 | 0.4924 | 0.5887 | 0.0230 | 0.8170 | 0.5996 |
| 0.85 | 0.3263 | 0.0200 | 0.7106 | 0.3390 | 0.4563 | 0.0209 | 0.7637 | 0.4716 |
| 0.90 | 0.2507 | 0.0204 | 0.6792 | 0.2581 | 0.3374 | 0.0213 | 0.7144 | 0.3491 |
| OA | Kappa | TPR | FPR | |
|---|---|---|---|---|
| Method in [13] | 0.8141 | 0.6258 | 0.8345 | 0.2015 |
| Method in [15] | 0.7465 | 0.4571 | 0.4988 | 0.0640 |
| Method in [16] | 0.8535 | 0.6819 | 0.7538 | 0.0599 |
| VWRD [23] | 0.8223 ± 0.0014 | 0.6350 ± 0.0025 | 0.8115 ± 0.0039 | 0.1705 ± 0.0047 |
| PCA + SVM | 0.8002 ± 0.0039 | 0.5904 ± 0.0081 | 0.7891 ± 0.0098 | 0.1921 ± 0.0062 |
| DCNNs + SVM | 0.8155 ± 0.0044 | 0.6212 ± 0.0079 | 0.8024 ± 0.0021 | 0.1755 ± 0.0081 |
| CNN [36] | 0.8751 ± 0.0025 | 0.7345 ± 0.0033 | 0.8658 ± 0.0033 | 0.1074 ± 0.0053 |
| Proposed method | 0.8765 ± 0.0011 | 0.7408 ± 0.0012 | 0.8195 ± 0.0028 | 0.0778 ± 0.0019 |
| Before P.P. | After P.P. | |||||||
|---|---|---|---|---|---|---|---|---|
| TPR | FPR | OA | Kappa | TPR | FPR | OA | Kappa | |
| 0.50 | 0.7654 | 0.1532 | 0.8133 | 0.6137 | 0.8576 | 0.1259 | 0.8673 | 0.7276 |
| 0.55 | 0.7143 | 0.1078 | 0.8189 | 0.6187 | 0.8267 | 0.1048 | 0.8670 | 0.7245 |
| 0.60 | 0.6709 | 0.0670 | 0.8250 | 0.6258 | 0.8067 | 0.0768 | 0.8752 | 0.7392 |
| 0.65 | 0.6756 | 0.0434 | 0.8408 | 0.6580 | 0.8092 | 0.0740 | 0.8779 | 0.7447 |
| 0.70 | 0.6193 | 0.0533 | 0.8118 | 0.5930 | 0.7411 | 0.0498 | 0.8640 | 0.7113 |
| 0.75 | 0.5171 | 0.0377 | 0.7788 | 0.5123 | 0.6275 | 0.0442 | 0.8205 | 0.6116 |
| 0.80 | 0.4882 | 0.0303 | 0.7713 | 0.4924 | 0.5887 | 0.0230 | 0.8170 | 0.5996 |
| 0.85 | 0.3263 | 0.0200 | 0.7106 | 0.3390 | 0.4563 | 0.0209 | 0.7637 | 0.4716 |
| 0.90 | 0.2507 | 0.0204 | 0.6792 | 0.2581 | 0.3374 | 0.0213 | 0.7144 | 0.3491 |
| Before P.P. | After P.P. | |||||||
|---|---|---|---|---|---|---|---|---|
| TPR | FPR | OA | Kappa | TPR | FPR | OA | Kappa | |
| 0.50 | 0.8344 | 0.1770 | 0.8263 | 0.6082 | 0.9171 | 0.1427 | 0.8739 | 0.7110 |
| 0.55 | 0.7915 | 0.1170 | 0.8543 | 0.6660 | 0.8921 | 0.1114 | 0.8896 | 0.7444 |
| 0.60 | 0.7265 | 0.0752 | 0.8568 | 0.6721 | 0.8708 | 0.0974 | 0.8931 | 0.7518 |
| 0.65 | 0.7408 | 0.0626 | 0.8702 | 0.7015 | 0.8791 | 0.0902 | 0.9007 | 0.7686 |
| 0.70 | 0.6823 | 0.0683 | 0.8421 | 0.6416 | 0.8079 | 0.0650 | 0.8941 | 0.7539 |
| 0.75 | 0.5996 | 0.0562 | 0.8088 | 0.5753 | 0.6941 | 0.0666 | 0.8483 | 0.6547 |
| 0.80 | 0.5619 | 0.0463 | 0.7929 | 0.5465 | 0.6551 | 0.0438 | 0.8435 | 0.6466 |
| 0.85 | 0.4069 | 0.0405 | 0.6878 | 0.3698 | 0.5255 | 0.0456 | 0.7713 | 0.5066 |
| 0.90 | 0.3302 | 0.0341 | 0.6192 | 0.2783 | 0.4152 | 0.0451 | 0.6929 | 0.3758 |
| OA | Kappa | TPR | FPR | |
|---|---|---|---|---|
| Method in [13] | 0.8381 | 0.6048 | 0.8094 | 0.1522 |
| Method in [15] | 0.8264 | 0.4828 | 0.4900 | 0.0602 |
| Method in [16] | 0.8459 | 0.5944 | 0.6545 | 0.0760 |
| VWRD [23] | 0.8872 ± 0.0054 | 0.7600 ± 0.0023 | 0.8560± 0.0042 | 0.0876 ± 0.0037 |
| PCA + SVM | 0.8755 ± 0.0042 | 0.7535 ± 0.0056 | 0.8528 ± 0.0038 | 0.0901 ± 0.0053 |
| DCNNs + SVM | 0.8889 ± 0.0035 | 0.7766 ± 0.0061 | 0.8970 ± 0.0025 | 0.0845 ± 0.0036 |
| CNN-2 [36] | 0.8046 ± 0.0028 | 0.5244 ± 0.0037 | 0.7046 ± 0.0025 | 0.1648 ± 0.0033 |
| Proposed method | 0.9212 ± 0.0016 | 0.7998 ± 0.0015 | 0.9100 ± 0.0017 | 0.0751 ± 0.0026 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, T.; Li, C.; Xu, J.; Ma, J. Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors 2018, 18, 904. https://doi.org/10.3390/s18030904
Tian T, Li C, Xu J, Ma J. Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors. 2018; 18(3):904. https://doi.org/10.3390/s18030904
Chicago/Turabian StyleTian, Tian, Chang Li, Jinkang Xu, and Jiayi Ma. 2018. "Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks" Sensors 18, no. 3: 904. https://doi.org/10.3390/s18030904
APA StyleTian, T., Li, C., Xu, J., & Ma, J. (2018). Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors, 18(3), 904. https://doi.org/10.3390/s18030904