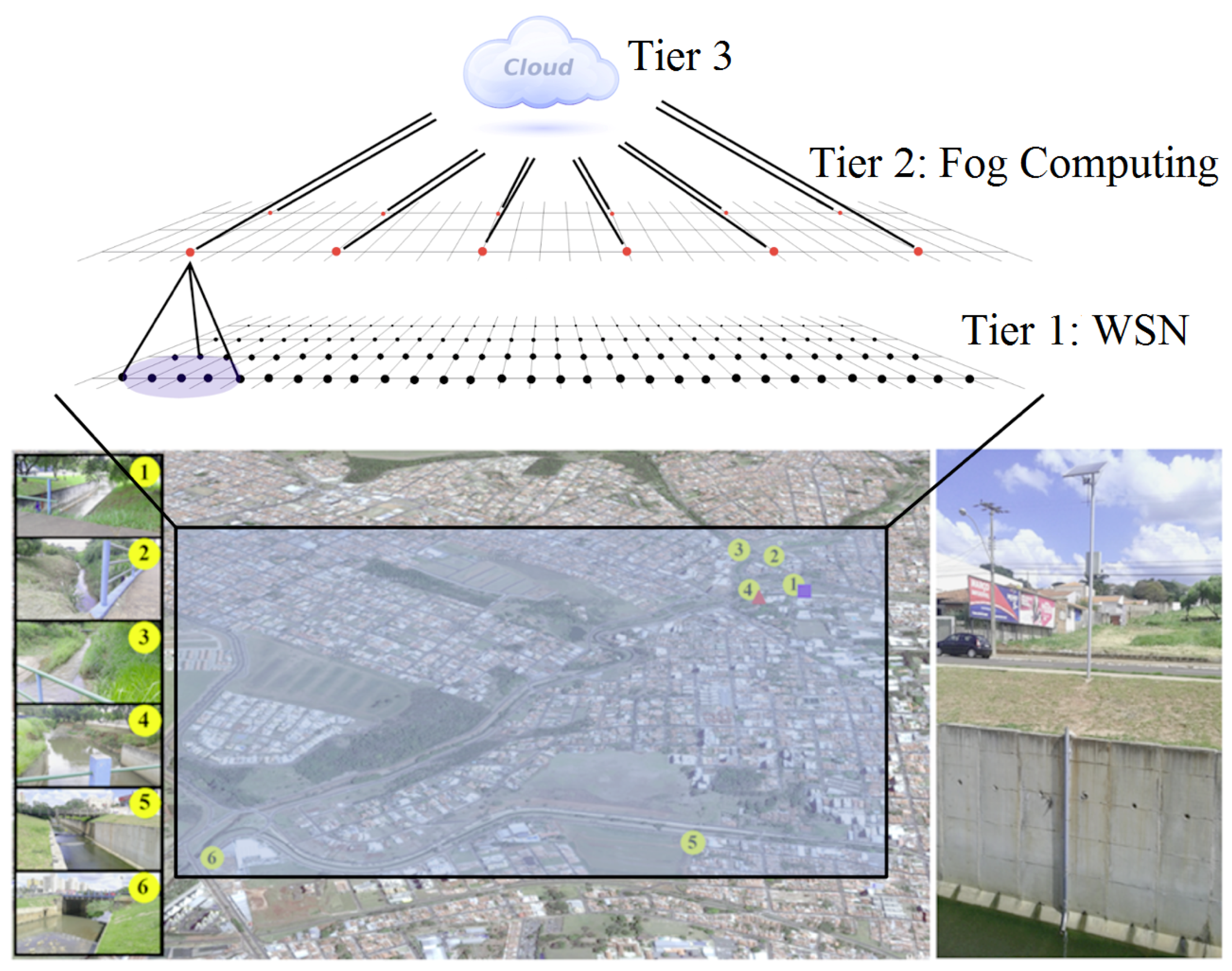
This section provides an overview of SENDI, a fault-tolerant system based on IoT and ML for the forecasting and detection of natural disasters. SENDI is formed of 3 tiers, as illustrated in
Figure 1. The first tier consists of a WSN, which is responsible for collecting and disseminating data from the monitored environment. The second tier (fog computing) is responsible for concentrating the data in the sensor nodes, as well as carrying out the distribution and processing of the data collected from the first tier. In addition, it should be noted that the second tier is based on the fog computing paradigm, which leaves the computing resources (processing and storage) closer to the end-user so that it can improve the latency of the service. Finally, the third tier consists of
Cloud where all the data of the system are concentrated and provides processing power and data storage in an abstract form. In this way, the
Cloud obtains a general view of the monitored environment and is able to combine the data gathered by the sensors with data available on the Internet and make more accurate forecasts, as well as issuing online alerts to the people in the locality.
The conception of this solution arose from the E-Noe project, which was installed in the town of São Carlos and involves flood forecasting and detection and issuing warnings of a possible flood to the residents in the region. For this reason, the main aim of SENDI is to improve the forecasting of natural disasters, while at the same time, providing a fault-tolerant scheme to the system. In the case of this last point, it is essential to ensure that the system is operating, whatever the situation.
3.1. System Architecture
The nodes of Tier 1/WSN which were modeled based on the WSN that can be found in São Carlos—SP, Brazil, form the basis of SENDI. Thus, the nodes do not possess a limited supply of energy, although they have a solar battery charger. In this tier, the basic function of the nodes is data collection. In effect, these nodes have several sensors that are able to pick up different features of the monitored environment and send these data to the Tier 2/fog computing. The nodes of this tier also have audio and visual devices (such as sirens and lights) that are able to warn the local population of the risks of a disaster occurrence.
The nodes of Tier 2/fog computing are in turn responsible for the aggregation of data collected by the sensor nodes and the dispatch of the data to Tier 3/
Cloud. It should be noted that a node from Tier 2 is only responsible for collecting data from Tier 1 when they are neighbors. Two nodes can be defined as neighbors when they are able to communicate with each other directly without the need for hops. As shown in
Figure 1, a node from Tier 2 is responsible for the nodes from Tier 1 that lie within its range of direct communication.
The nodes of Tier 2 are characterized by having a unlimited supply of energy (being that the only difference with respect to Tier 1 nodes) and help reduce the energy consumption of the sensor nodes (Tier 1/WSN) while messages are being sent to Tier 3/Cloud. Thus, like the nodes of Tier 1/WSN and for reasons of redundancy, the nodes of Tier 2/fog computing also have audio and visual devices that are able to warn the local population of the risk of a disaster incident.
Finally, Tier 3 is formed by Cloud, which provides the necessary resources for the data to be stored, combined with other online information about the monitored environment and processed by means of the forecasting models created via ML. If a risk of disaster is forecast, the Cloud also send warnings online and to the nodes of Tier 2/fog computing, which passes on these warnings to the nodes of Tier 1/WSN.
This configuration adds considerable flexibility to SENDI, since it possesses the simplest nodes that only carry out data readings, together with those that support the processing of large amounts of data and combinations of data, while at the same time making forms of energy saving available. This architecture can be easily modified depending on the monitored environment and the resources available in the locality.
3.2. Protocol Stack and Routing
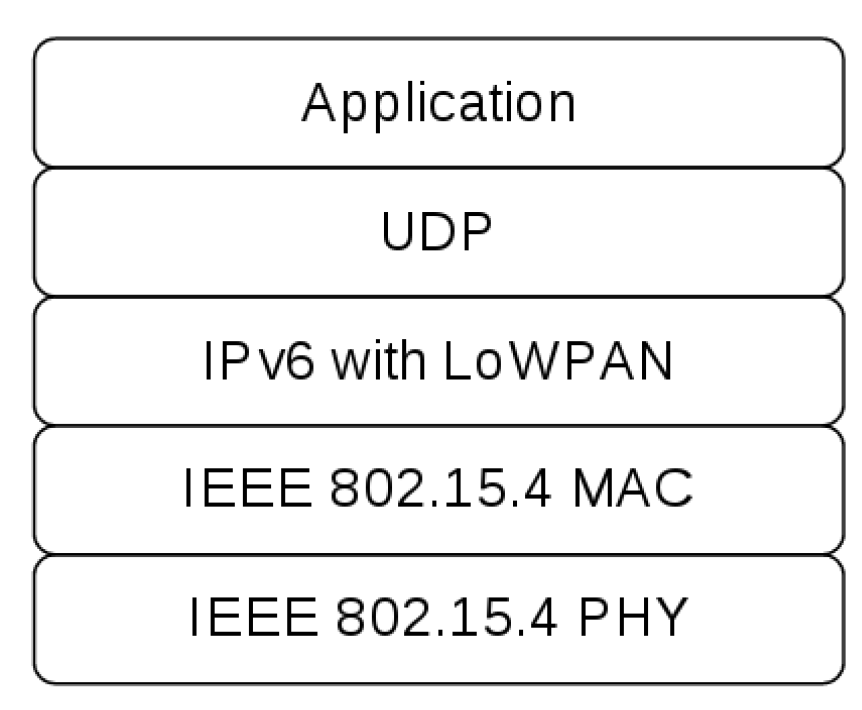
The protocol stack used by SENDI is shown in
Figure 2, where there is an IEEE 802.15.4 standard, that defines the physical layer and the media access control layer of the OSI model for LR-WPAN (Lowdata-Rate Wireless Personal Networks), and Ipv6 in the network layer. The UDP protocol was used on the transport layer because it does not require connection, and is a simple protocol, which generates less overhead in communication; in addition it does not block communication if the target node is not working. On top of the stack, there is the natural disaster monitoring and forecasting application.
As the routing protocol, RFC 6550 defines the RPL (IPv6 Routing Protocol for Low-Power and Lossy Networks) for LLNs (Low-Power and Lossy Networks). LLNs are networks which have restrictions with regard to processing power, energy and/or node memory. The nodes act as routers in these networks and usually only support low data rates, as well as having other specific features such as point-to-multipoint or multipoint-to-point communication standards. Some characteristics of these networks include high number of nodes with hardware and energy limitations, reaching thousands of nodes, all interconnected by lossy links and supporting various traffic patterns [
16]. These particular features mean that the routing in these kinds of networks can be distinguished from others and raise their own challenges and solutions [
17], as well as clearly describing the properties found in the REDE system.
The RPL protocol was initially based on widely used routing protocols and research prototypes in WSN area, being later extended and re-designed for IPv6. The main implementations of RPL found in the literature are ContikiOS and TinyOS, with TelosB being the most widely used hardware. [
16] also comments that, although it already has some years of development and research, the RPL protocol still needs to be tested more deeply in real-world applications and compared with other alternative routing protocol [
18].
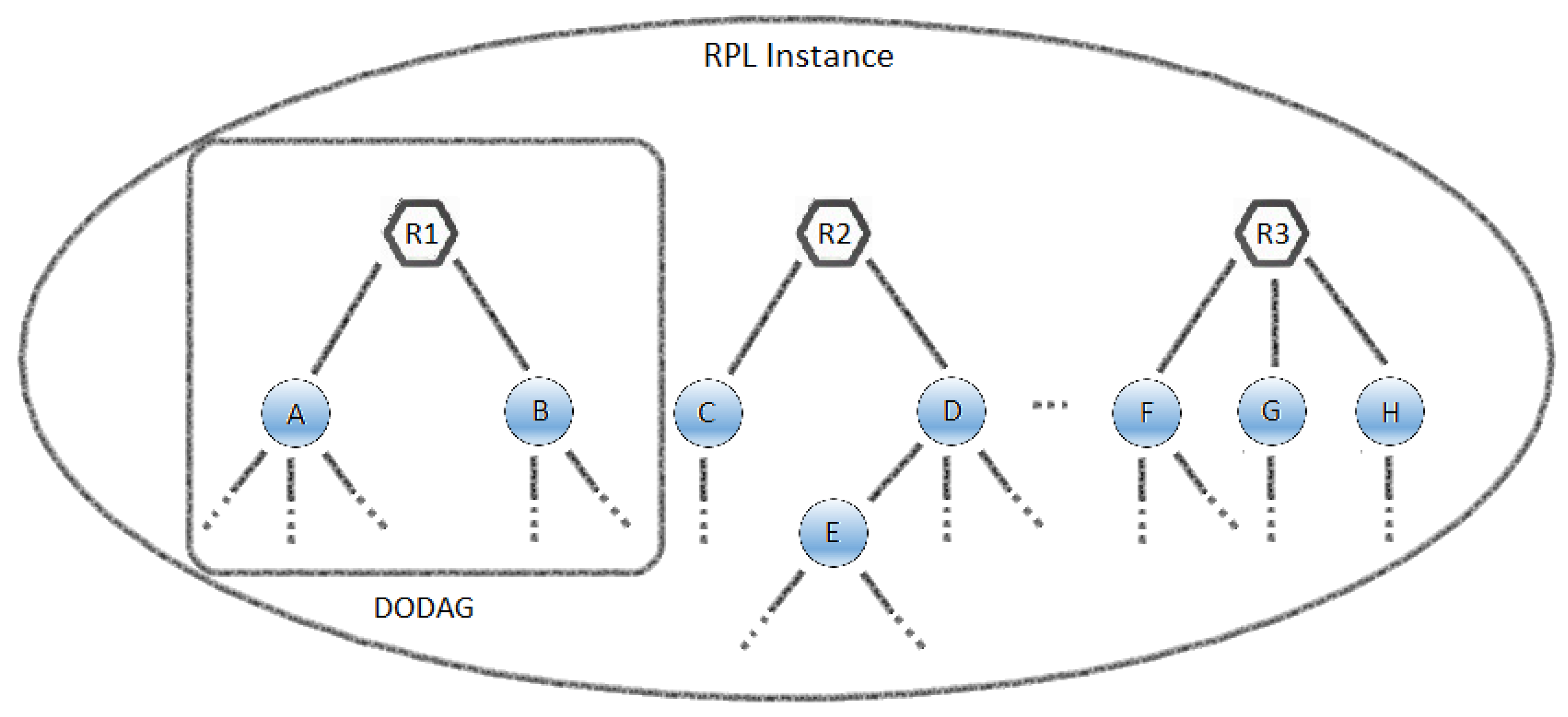
Unlike wired networks, where predefined topologies can be found because of the point-to-point, LLNs do not usually have this property which means that they have to discover the links that exist between the nodes and select them carefully. Thus, the RPL arranges the network topology as a set of either a single or several Destination Oriented DAGs (DODAG), that form a Directed Acyclic Graph (DAG), which is a DODAG formed by the sink node (root).
Figure 3 shows an example of the configuration of an RPL instance where the R1, R2 and R3 nodes are the roots of their DODAG and are, for example, interlinked with the remaining nodes in the Internet or another network. The nodes that have a direct path to the root, such as nodes A and B, are considered to be Rank 2. All the nodes which are unable to see the root directly but are able to see the Rank 2 nodes are regarded as Rank 3, such as node C from the other DODAG, and so on.
3.3. Fault Tolerance Scheme
The fault-tolerance mechanism of SENDI covers failures in the communication and transmission of data between the nodes of any of the tiers and reacts to this failure by ensuring that forecasts of disasters and the issuing of warnings do not cease to be carried out. This kind of failure can be caused either by a lack of energy or the partial or complete destruction of nodes leading to the temporary or permanent loss of their capacity to communicate. To this end, the nodes of Tiers 1 and 2 run a self-organizing algorithm so that they can be reorganized in cases such as this, as well as having embedded disaster forecasting models that are simpler than those processed by Cloud. This is because of their energy and processing capacity which allow them to carry out forecasting even if there are communication failures with Cloud or the other nodes in the system, although its accuracy is impaired.
In the case of a failure of communication with
Cloud, the nodes of Tier 2 take on the role of
Cloud, by storing the data collected by the nodes of Tier 1, distributing these data among themselves and carrying out flood forecasting by employing the forecasting models of natural disasters, as recommended in [
19]. In this study, the forecasts carried out by the nodes (similar to the nodes of Tier 2) in a particular region, are sent on to other regions in the monitored environment. In turn, the forecasts that are received, are used to carry out further forecasts in the future and increase the accuracy of the forecasts in the regions of these nodes. Against this background, this paper also extends the work undertaken in [
19], which encompasses the work carried out in a forecasting system which includes issuing fault-tolerant IoT alerts.
If failures occur in the nodes belonging to Tier 2, leading to areas being without coverage, where the nodes of Tier 1 remain without a representative in Tier 2 where readings can be sent, the nodes of Tier 1 are rearranged and certain nodes are selected from them to temporarily take the places of the defective nodes in Tier 2. This selection takes place in each round, which is regarded here as a “cycle” of reading and dispatch/distribution of data, forecasting and if necessary, the issuing of warnings. There will be selected as many nodes as needed until all the nodes in Tier 1 have a representative in Tier 2. Basically, the selected nodes play the role of the nodes in Tier 2, by aggregating data from Tier 1 (including their own), sending these data to the Cloud and if there is a failure in Cloud, carrying out the data distribution and disaster forecasting, in the monitored environment.
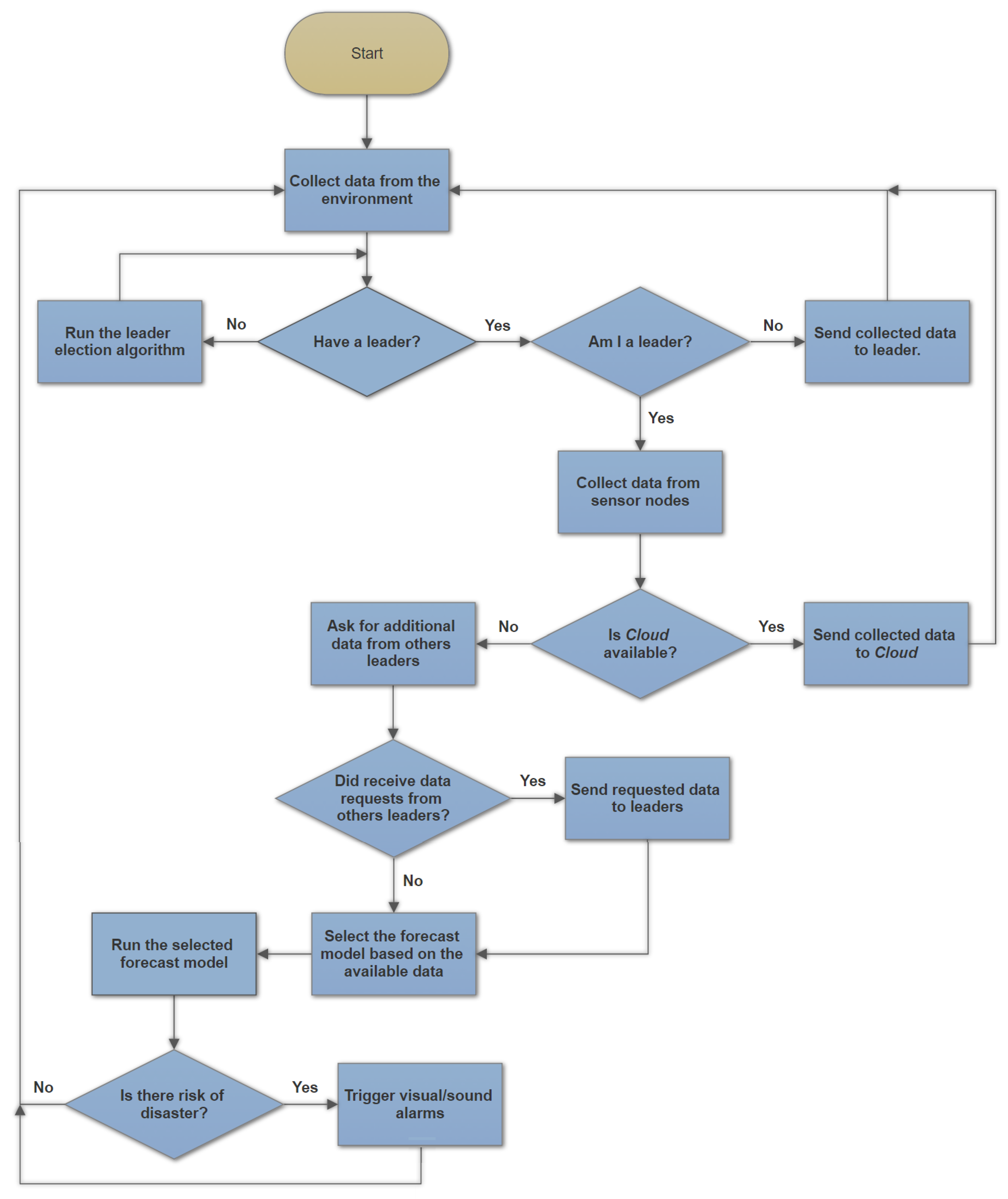
Figure 4 describes the operation of the algorithm for fault tolerance of the system performed by sensor nodes/Tier 1. The sink nodes/Tier 2 perform part of the procedure, except for the leader decision phases, since they are leaders by default.
In serious situations, where there is a loss of communication or failure affecting a large number of nodes, there can be cases where the nodes are completely isolated from others. In this case, as well as being regarded as their own leaders, they are incorporated with the models for simple forecasting that only make use of local data from the nodes themselves. Thus, although they carry out less accurate forecasting and lack the ability to issue warnings online, the nodes can still issue local warnings (such as by means of lights and sirens) and warn the population nearest to the region affected.
The leader election and cluster formation is based on the remaining energy of each node battery, as recommended in this work. It is worth highlighting that these procedures only take place when a possible disaster occurrence is detected or when all the sensing nodes (Tier 1) lose contact with the sink nodes (Tier 2). In each round, all the Tier 1 nodes must have a leader belonging to Tier 2, which groups the collected data and sends them to the
Cloud. If there is a lack of communication with the
Cloud, it processes this data and carries out the disaster forecasting. The natural leader of a sensing node in the described architecture is one of the sink nodes of Tier 2. However, if the local sink node fails, the sensing nodes are capable of selecting one of themselves as a new leader and continue the operation of the system. It should also be underlined that unlike the case in other works [
20,
21,
22], the nodes only select their leaders on the basis of their own information. They do not need to know the total amount of energy in the system or any other information about the other nodes in the system.
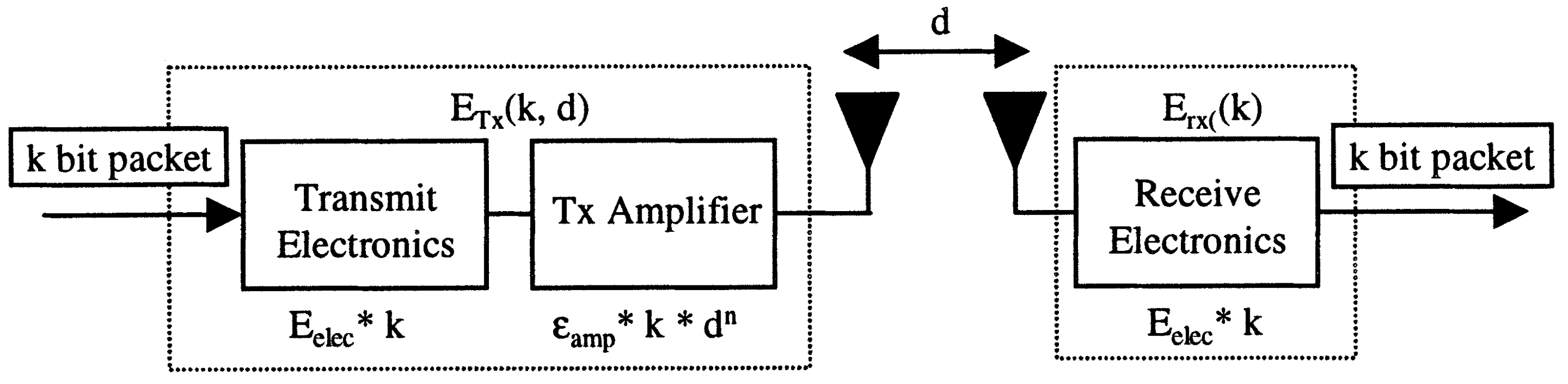
With regard to the clustering protocol based on LEACH [
23], we employ the simplified model for the radio hardware energy dissipation shown in
Figure 5 and use probability to determine whether or not a node will be a leader of a cluster and become part of Tier 2. However, unlike the case of the LEACH protocol, we suppose that: i. initially the nodes may not have the same amount of energy; ii. it is feasible for one node to be the leader on repeated occasions; iii. there is no lower or upper limit for the number of leaders; iv. the process of selection can occur many times in the same round until all the nodes have a leader; v. there is a limit for how many times the selection process can occur for a given node during a round, after this limit has been reached the node is forced to become a leader; and vi. a node can only be accepted as leader of a given node
n if it belongs to the neighborhood of the node
n, which reduces the need for hops and for communication with very distant nodes.
According to the radio energy dissipation model, energy consumption caused by the dispatch of a message containing an
l-bit to a receptor at a distance
d, for the streaming to have an acceptable Signal-to-Noise Ratio (SNR) is [
23]:
where
and
depend on the model of the transmitter amplifier for free space (
) and multipath (
) and
is the consumption of energy of each transmitted bit.
The equation used by the LEACH model to reach the optimal probability of a node and thus become the leader of a cluster, is described in Equation (
2) [
23]. This probability is used in Equation (
4) [
23], which defines a threshold. At this moment, given a node
s, a random number is generated and, if this is smaller than the calculated threshold, the node
s becomes a leader of a cluster. The details of how to get to this probability can be seen in Heinzelman [
23].
where
is the optimal probability of a node to be a leader,
n is the number of nodes and
is defined as the optimal quantity of clusters and calculated as [
23]:
As previously stated, the LEACH does not allow a node to be a leader repeatedly. For a node to be a leader again, it must be in set
G of Equation (
4) [
23]. This set only contains the nodes which had not been leaders in the most recent
rounds, where
k is the number of expected leaders and
r is the number of rounds in which the node
s was not determined as the leader.
In this work, the threshold defined by LEACH was altered to take account of the remaining energy in the node. Thus, given a node
s, its new threshold is defined as:
where
E is the current battery power of the node,
is the maximum capacity of the battery (allowing for differences in the batteries among the nodes),
is the weight given to each part of the equation, where value 1 only uses the LEACH altered/implemented in the simulation, and value 0 only uses the information about energy. After the threshold has been calculated, the procedure continues in the same way, with
s generating a random number and defining whether or not it is a leader based on a comparison between this value and the threshold. The number of rounds
r in
s is reset every time
s becomes a leader. Apart from these differences, there is no longer a limitation of
rounds, thus any node can be a leader regardless of how many times the other nodes have been leaders or the number of rounds (allowing a node with a high battery level to become the leader on repeated occasions). In a same round, this process of selection can take place several times if the first election is not enough for all the nodes to have a defined leader. The maximum number of elections in a round can be stipulated and if a node does not have a leader defined after reach this limit, the node itself becomes his own leader regardless its battery level.
The Algorithm 1 illustrates the operation for the leader election in each node. After each election attempt, if the node was not set as a leader, it waits a random time letting the other nodes in its neighborhood run the same algorithm. In case of a new leader does not appear, the election algorithm continues until it reaches the stipulated maximum limit, when the node is forced to become a leader.
| Algorithm 1 Leader Election Algorithm. |
- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
while “Node without a leader” do - 7:
- 8:
- 9:
- 10:
- 11:
if - 12:
- 13:
else - 14:
- 15:
end if - 16:
end while
|

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}