1. Introduction
We are entering an era of Precision Medicine [
1] and mobile health, where personalized assessments at the clinic are combined with follow up assessments on the go. In the areas of mental health, this new platform is bound to revolutionize basic research and clinical practices [
2], particularly if current subjective behavioral evaluations begin to be complemented with more objective and automated behavioral analyses [
3]. Along those lines, wearable sensing technologies are destined to help accelerate the transformation of medical and scientific practices, particularly in the areas of mental health.
Wearable sensors listening to the activities that are self-generated by the person’s nervous systems can help harness such biorhythmic activities in non-invasive ways. In this sense, such “biosensors” have become ubiquitous in our lives and can be found embedded in smart devices and activity trackers that we commonly carry with us. The time series of signals they output can help us self-monitor the various levels of functionality of our nervous systems. When paired with proper analytics, these biosensors’ activity can help us ascertain levels of volition and autonomy of the brain over the body in motion [
4].
Yet how do we take full advantage of such time series data and produce verifiable and reproducible results that maximize objectivity and automate statistical inference?
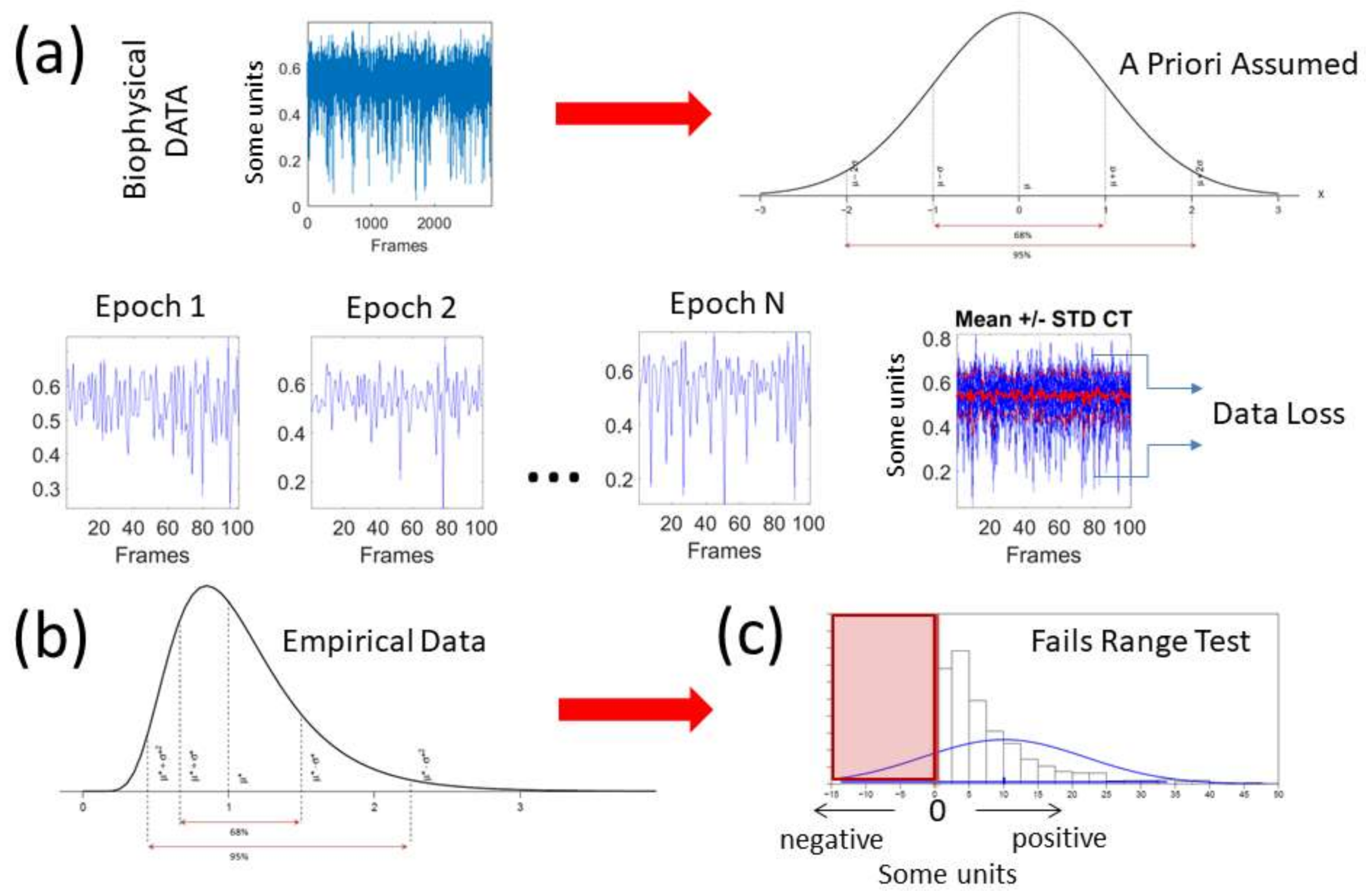
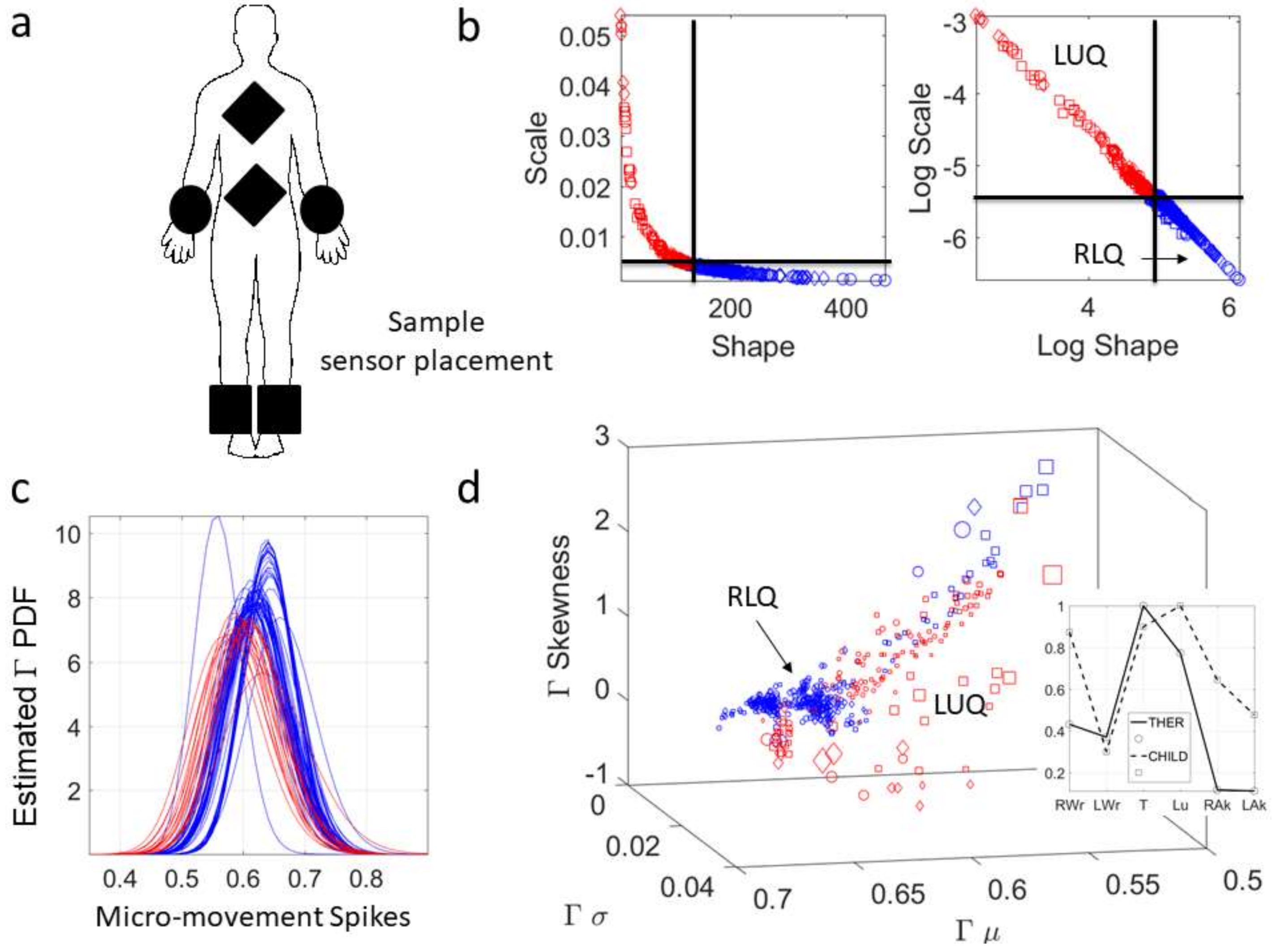
The deluge of data throughput that biosensors produce when continuously monitoring activities of the nervous systems over months and years can be challenging to analyze, interpret and decide upon. Part of the problem is the “one size fits all model” approach to the analyses (
Figure 1a). Traditionally, several assumptions are made about the data that are not empirically informed. Often, common biophysical signals (e.g., from the amplitudes of speed, acceleration, heart rate, electroencephalography (EEG), electromyography (EMG)) reveal peaks and valleys that convey information about fluctuations in the activity of the nervous systems. Under the Gaussian theoretical assumptions, these fluctuations are smoothed out through grand averages and treated as noise. Consequently, the very information we are seeking to read out from the nervous systems can be lost. Statistical inferences from such theoretical treatment of the biophysical data are incongruent with the skewness found in empirical data [
5] (
Figure 1b). The data of interest may even fail the range test under such pre-imposed (symmetric) theoretical assumptions (
Figure 1c). One may end up inferring and interpreting data that falls out of the actual range of values of the empirical data. For instance, consider speed peaks frequently used as a feature of a parameter of interest. Under some experimental task, the linear speed under consideration may have amplitudes ranging from near zero (no movement) to some value, say 50 cm/s. Under repetitions of the task, the researcher finds that the assumed theoretical Gaussian mean (µ) yields 10 cm/s and the standard deviation from the mean (σ) comes out high to 7 cm/s (perhaps this task requires adaptation and gives rise to high variability in its initial stages). When one takes μ ± 2σ, there are (assumed) variations in the non-existent negative range of that empirical data (i.e., negative speed does not make physical sense). The researcher may go on to make many inferences and further interpretations of the data under assumptions that were not empirically justified. This hypothetical situation is in fact very common in the scientific arena.
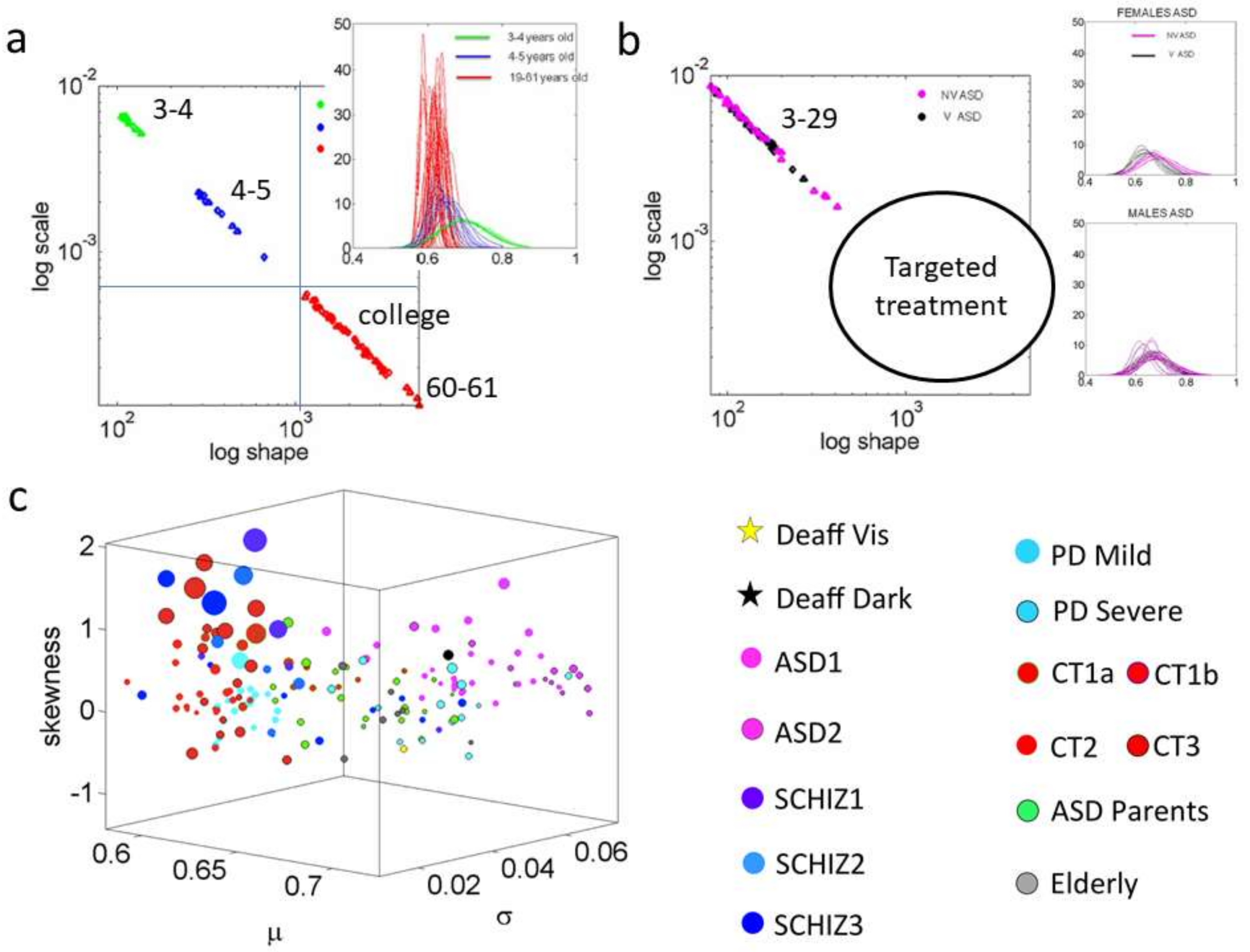
Another problem preventing us from making full use of the richness of biophysical data is the lack of a standardized metric scale. Such a scale would permit proper comparison across heterogeneous populations suffering from a common nervous system disorder. For example, motion parameters such as linear and angular speed depend on the anatomical dimensions of the person (because speed is distance traveled per unit time). Measurements of speed taken at a fixed unit time will be affected by anatomical proportions (bone length). If a study participant has longer limbs than another participant, the speed amplitude values will be higher and the range of values may also be affected by such allometric issues. Neurodevelopmental data is particularly sensitive to this problem, as physical growth occurs within days at early neonatal stages. The underlying peripheral nerves, carrying efferent and afferent flows of information, change at irregular and accelerated rates [
6]. During early stages of neurodevelopment speed-dependent data is particularly susceptible to non-uniform and non-linear changes in the stochastic signatures capturing the inherent variability of the data. The shape and dispersion of the probability distributions empirically characterizing such data shift rather fast and irregularly. Yet, often the data are examined using a static, linear framework under assumptions of normality. Such data will have to undergo some form of standardization [
3,
7] to allow for comparisons across different ages (e.g., young babies vs. four- to five-year-old children).
Nervous systems with different pathologies adapt and cope with the problems as the person develops and ages. This biological process takes place at rates of change that are unique to each person. How is the nervous system of a person coping with a disorder changing in relation to that of other people with a similar diagnosis? Diagnoses are based on expert clinical opinion derived from observation. As such, the symptom-based classification results in highly heterogeneous phenotypes [
8]. Given a clinical intervention then, what does it mean to converge towards a normal level? Once again, the current methods that rely on grand averages and a one size fits all model cannot address such complex non-linear dynamically-changing phenomena. Whether building normative data sets or analyzing data from individuals with complex pathologies of the nervous system, it will be critical to empirically inform our methods, particularly those relying on machine learning (ML) algorithms, so commonly used to examine time series of biophysical data from wearable sensing devices.
The medical field has shifted gears towards a paradigm that complements clinical expertise from humans with methods used in artificial intelligence (AI). The latter is aimed at compiling large amounts of data and efficiently integrating information from multiple layers of the knowledge network, ranging from patient self-reports to clinical scores from subjective behavioral observations to genomic data. Often the goals are to aid the process of decision-making during treatment selection and patient care that may potentially lead to better quality of life. Along those lines, the combination of open access big-data sets with ML techniques has been instrumental in parameter identification and identification of features that maximize information inherently present in the time series data, with the potential to detect patterns of relevance to a disease or its progression.
One active site that has contributed tremendously to this mission of uncovering analytics to make biosensing data analyses automated and objective is Kaggle.com. This site maintains several repositories of human activity data and makes all aspects of the data acquisition specs available to the public. Such initiatives permit the development and testing of new methods, along with their dissemination for reproducibility and improvement across the research and clinical communities.
In this paper we employ one such data set to re-analyze it, using a heuristics-free objective method that (1) provides a new standardized data type amenable to build proper statistical scales for personalized and population analyses; (2) automatically uncovers clusters of activity types; (3) provides methods to build maps of general population features.
The first part of the paper describes the results of applying our methods to the Kaggle.com activity set [
9] as an alternative to other approaches (e.g., [
10,
11,
12], etc.) that use ML methods. The second part of the paper then illustrates the methods using commercially available wearable sensors to underscore the empirically-informed statistical inferential properties of our statistical platform that remain invariant to sensor type, data parameter, or features extracted from the data. We highlight the utility of the methods to produce a standardized scale amenable to profile the general population. We also provide (upon request [
4]) libraries in Matlab (The MathWorks, Inc., Natick, MA, USA) and Python Programming Language (Wilmington, DE, USA) for use by the general community and aimed at promoting reproducibility of results.
2. Materials and Methods
The methods described in this paper have been previously published. See illustrative examples of the use of this platform in
Appendix A. For simplicity, we summarize them here in two steps: (1) the definition of the standardized data type and (2) the description of the analytics. The data sets used to illustrate the methods are from (1) Kaggle.com (
https://www.kaggle.com/uciml/human-activity-recognition-with-smartphones) containing the set of “Human Activity Recognition with Smartphones”. (2) Our Sensory Motor Integration Lab (SMIL) at Rutgers University (Piscataway, NJ, USA). The human data was collected under the protocol approved by the Institutional Review Board of Rutgers University in compliance with the Helsinki Act.
2.1. Data from Kaggle.com
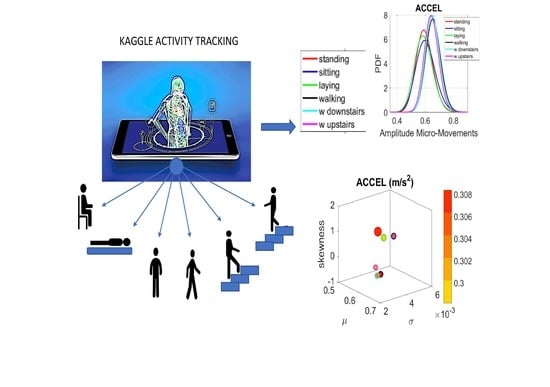
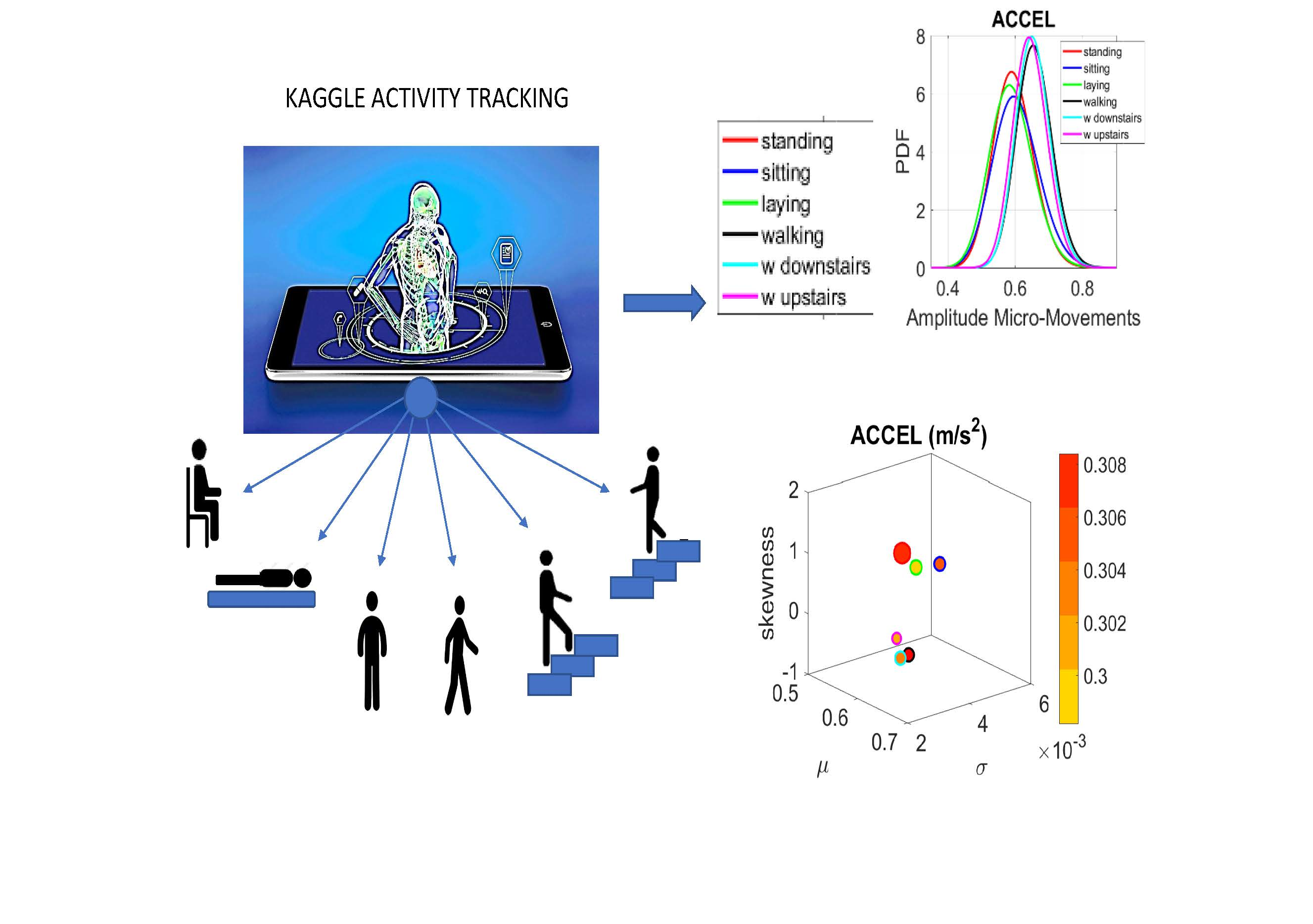
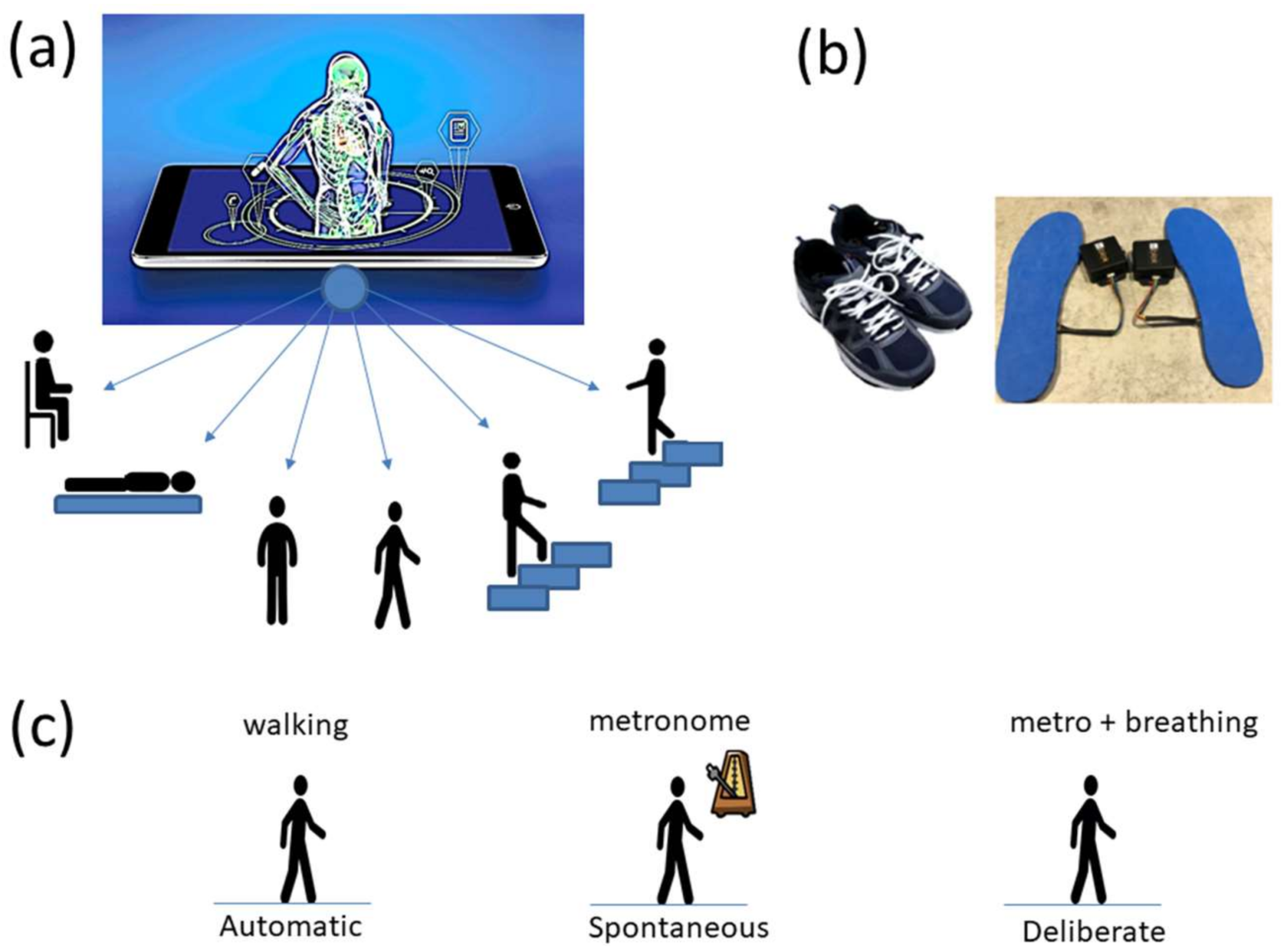
The following description of experiments are taken from the Kaggle website and are illustrated in
Figure 2a. We quote:
“The experiments have been carried out with a group of 30 volunteers within an age bracket of 19–48 years. Each person performed six activities (WALKING, WALKING_UPSTAIRS, WALKING_DOWNSTAIRS, SITTING, STANDING, LAYING) wearing a smartphone (Samsung Galaxy S II) on the waist. Using its embedded accelerometer and gyroscope, we captured 3-axial linear acceleration and 3-axial angular velocity at a constant rate of 50 Hz. The experiments have been video-recorded to label the data manually. The obtained dataset has been randomly partitioned into two sets, where 70% of the volunteers was selected for generating the training data and 30% the test data.
The sensor signals (accelerometer and gyroscope) were pre-processed by applying noise filters and then sampled in fixed-width sliding windows of 2.56 s and 50% overlap (128 readings/window). The sensor acceleration signal, which has gravitational and body motion components, was separated using a Butterworth low-pass filter into body acceleration and gravity. The gravitational force is assumed to have only low frequency components, therefore a filter with 0.3 Hz cutoff frequency was used. From each window, a vector of features was obtained by calculating variables from the time and frequency domain.”
We analyze the data from all 30 participants (accelerometer and gyroscope) and also the summary data (mean acceleration and angular speed). We take the peaks detected by the accelerometers at the corresponding sampling rate. For example, at 50 Hz, 30 s worth of data provide 1500 frames with well over 100 peaks necessary for robust estimation. In this sense, our criteria for number of peaks in a segment is that they yield tight confidence intervals for the estimated parameters generating the probability density function (PDF) curve to fit the frequency histogram. Our methods do not require the training/testing partition that ML methods employ to analyze these data. We mixed all data from all participants into a full data set. Further, we only use the acceleration and angular velocity data with a focus on fluctuations of peak amplitude and peak timing. We do not use other features in the Kaggle.com set including frequency domain parameters or information theoretical parameters.
2.2. Data from Rutgers SMIL
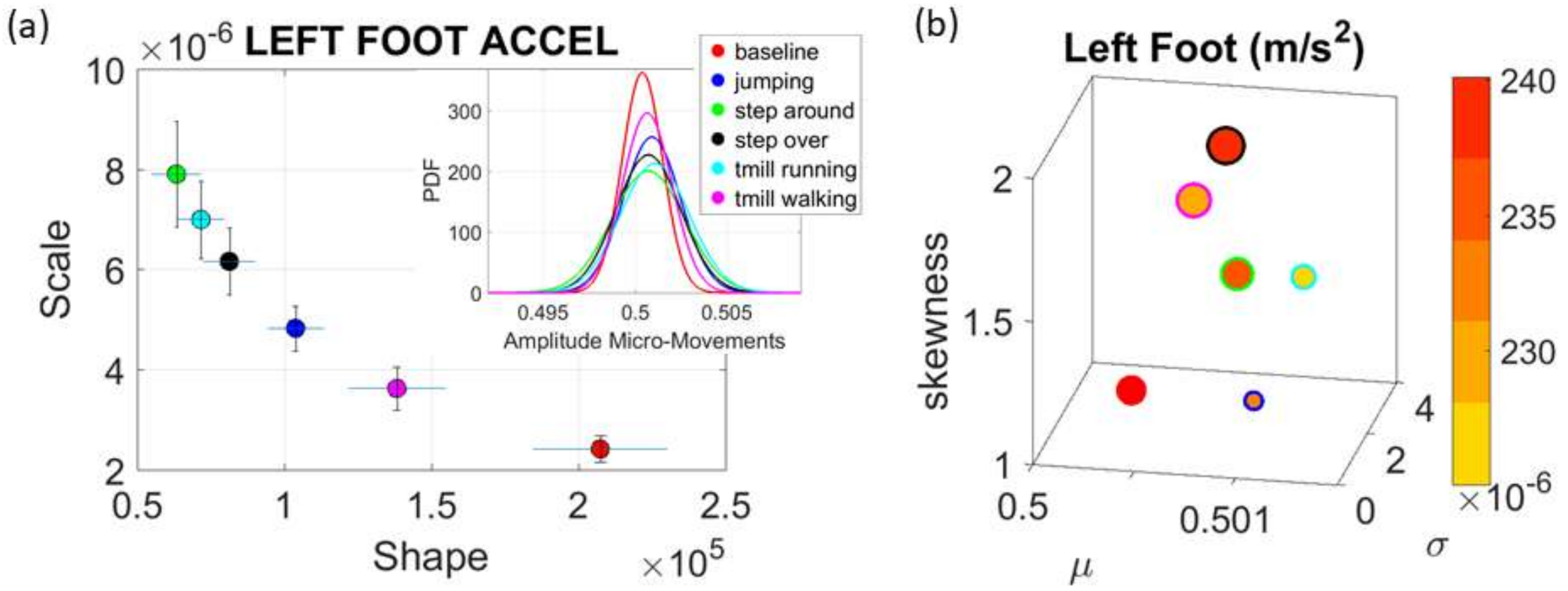
Commercial Sensors (Zeblok, Ridgefield, NJ, USA, smart shoes): One data set from one participant consists of 6 activities (WALKING, JUMPING, STEPPING AROUND OBSTACLE, STEPPING OVER OBSTACLE, WALKING ON A TREADMILL and RUNNING ON A TREADMILL.) Another data set from the same participant consists of three variants of the walking task. The participant in these sets wore Zeblok smart shoes which are commercially available. The shoes have IMU (inertial measurement unit) that collect data at 150 Hz (specs can be found here
http://www.zeblok.com/).
Figure 2b shows the insoles the participant wore inside regular tennis shoes (removing the original insole and replacing it with the Zeblok one.)
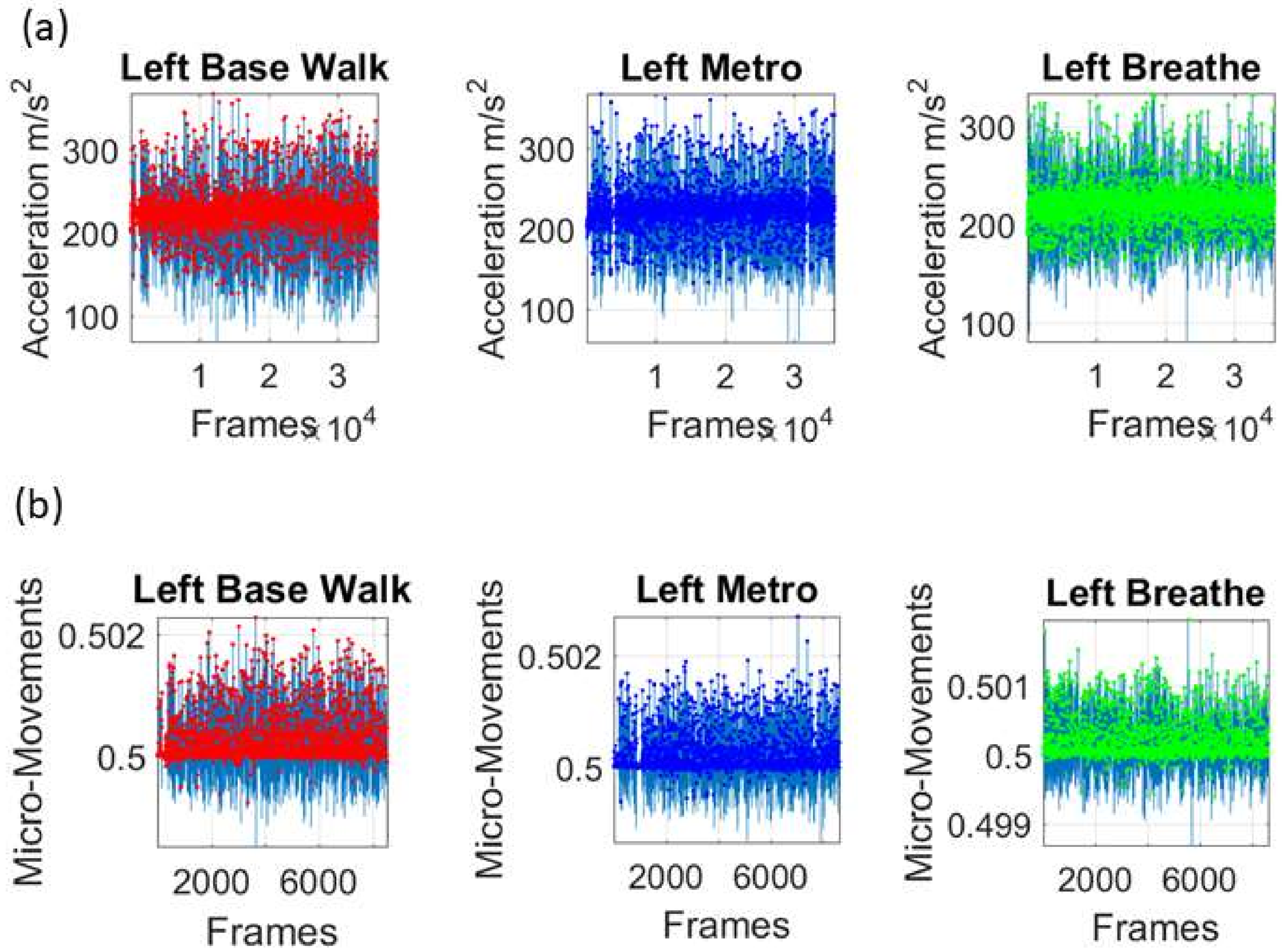
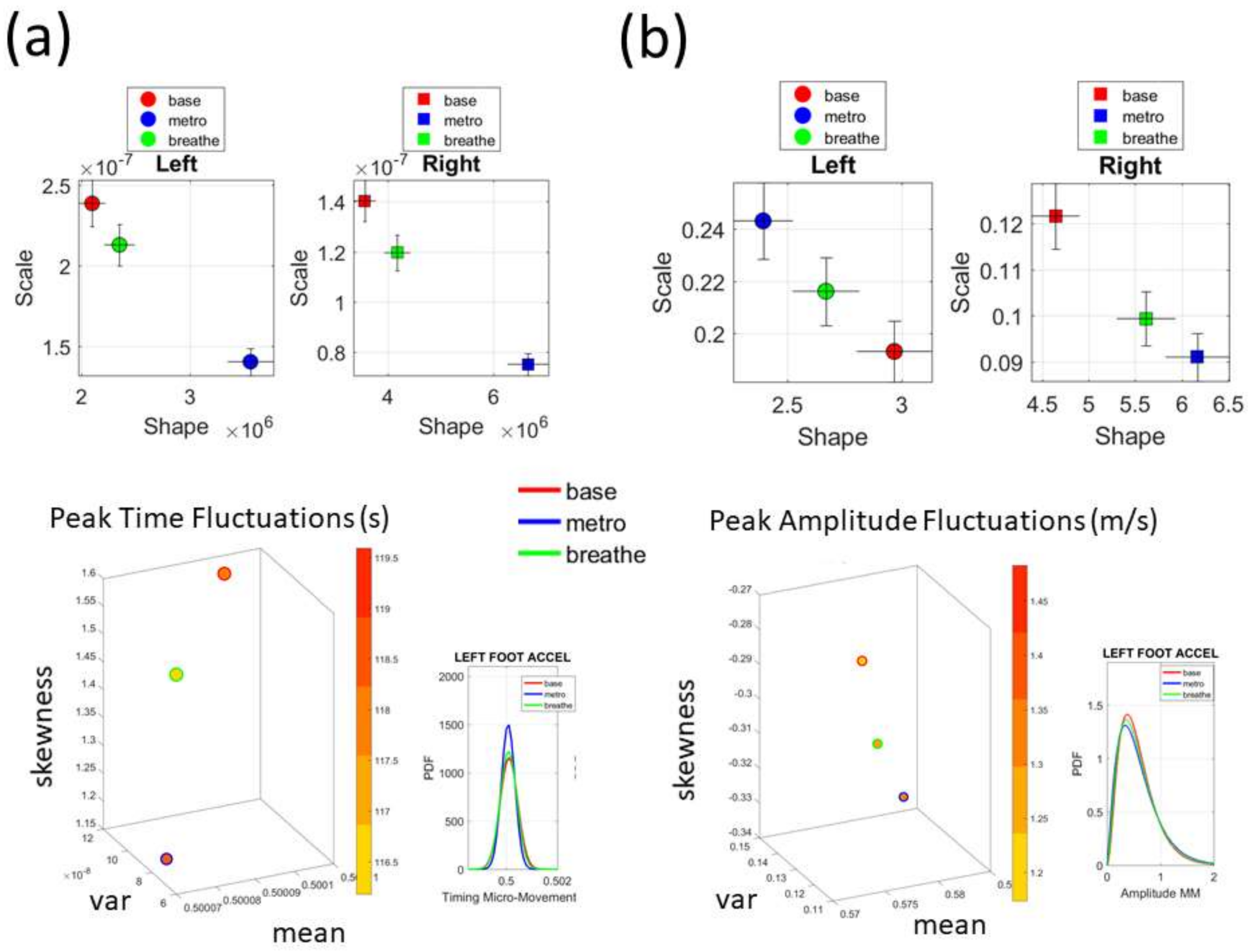
Figure 2c shows the schematics of another set of tasks previously described [
13], designed to probe the levels of control of the nervous systems: (1) natural walking (baseline) to probe ‘automatic control’; (2) metronome condition whereby a metronome is set in the background to probe ‘spontaneous control’, i.e., test if the biorhythms of the person spontaneously entrain with the metronome’s rhythm and to test if the brain is capable of spontaneously adapting to the new tempo; (3) breathing condition where the person is instructed to deliberately breathe to the metronome’s beat and we test the level of ‘volitional control’ of the person over their gait motions.
Note here that the use of one participant and set of tasks to test these sensors was not meant to compare the outcome with that of the Kaggle.com set. These are independent tasks registered with different sensor types (Kaggle set sampled at 50 Hz whereas Zeblok sampled at 150 Hz). The purpose of adding the one subject tasks was to test if the analytics could extract differences in fluctuations even when the tasks involved subtle variations of a basic activity such as walking.
Walking was present in all sets of tasks and sensor types. In the Kaggle.com set, there are two main families of tasks. One requiring motor control during overt motions of variable dynamics: walking, walking upstairs and walking downstairs. In contrast, the other set required covert motions: sitting, standing and laying down. Such tasks require motor control to keep the body in place. The natural walking task common to both sets (Kaggle.com and SMIL-collected with Zeblok insoles) posed the main goal to test if the analytics could differentiate the cases where subtle variations in breathing and external audible rhythms were present. In the Kaggle.com it was somewhat obvious that the overt vs. covert motion tasks differed. As such, it would not be as surprising if the analytics could distinguish variations in each activity class. Would these analytics be able to distinguish subtle variations within the natural walking task? Metronome induced variations and variations induced by deliberately breathing to the rhythms of the metronome are rather subtle. It was not obvious that these analytics would distinguish among such variations of the natural walking task.
2.3. Spike Trains Extracted from Behavioral Data (the Micro-Movements)
The time series data of triaxial acceleration and gyroscope vectors were converted to scalar time series data using the Euclidean norm to obtain the magnitude of each vector in the time series. This produced a time series of peaks and valleys characterizing the acceleration and angular speed. Two features of interest in each time series were the fluctuations in peak amplitude and the fluctuations in the times these peaks occurred. The peaks (and times of the peaks) were gathered into a frequency histogram to estimate the overall mean of the data set for each activity. To that end, we estimated the best continuous family of probability distributions fitting the data (using maximum likelihood estimation (MLE)). This turned out to be the continuous
Gamma family of probability distributions (confirming prior work on movement-based biometrics [
4,
5]).
The Gamma distribution has two parameters, the shape (a) describing the shape of the distribution (e.g., symmetric, skewed, etc.) and the scale (b) describing the dispersion. We estimate each of these parameters with 95% confidence intervals using MLE.
A random variable
X that is
Gamma distributed with shape
a and scale
b is denoted by
with probability density function:
The Gamma mean and the variance with the noise to signal ratio , the scale parameter that we will refer to as the noise.
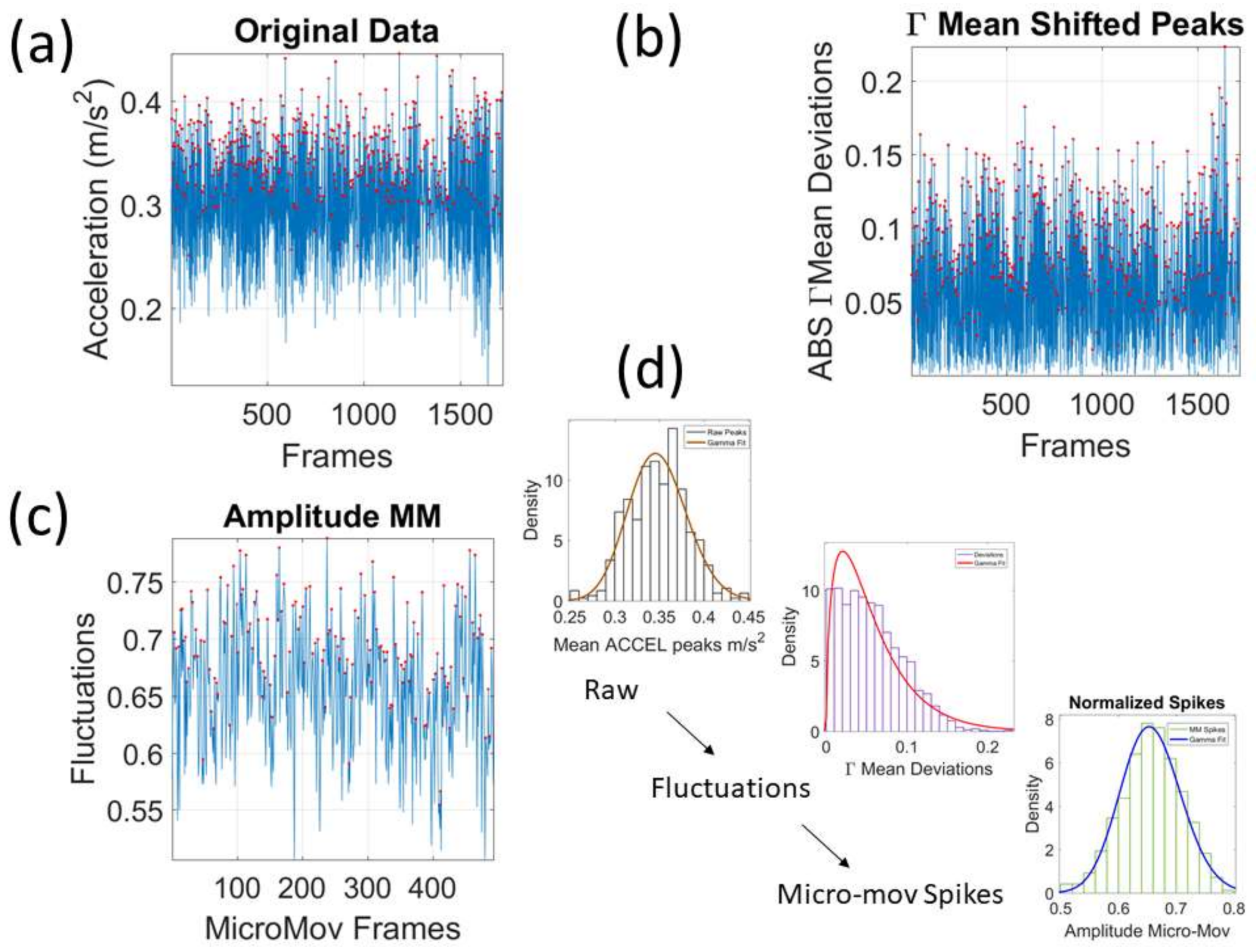
We mean-shift the original data (shown in
Figure 3a, e.g., for walking condition) to center it at the mean value and obtain the absolute deviations from the estimated
Gamma mean (
Figure 3b). Then, for each local peak fluctuation in amplitude (or timing) away from the original series estimated-
Gamma mean across all frames of the acceleration (or angular speed) profile of each routine segment, we scale it and produce a normalized value of the peak:
where the peaks and the local average values computed between the local minima surrounding the peaks are
Gamma distributed. The frequency histogram of the average acceleration (m/s
2) (or angular speed rad/s) produces a unitless quantity, which we coined the micro-movement spikes. The unitless micro-movements (MM) representing the real-numbered spike trains with values in
then provide a standardized waveform that we adopt as our data type, as shown in
Figure 3c. This Figure shows the pipeline of data processing described above with sample waveforms for each step using the acceleration signal and focusing on the peak amplitude information.
The micro-movement spikes data type accounts for possible allometric effects given by the different anatomical features of the participants [
14] and for minute fluctuations that grand-averaging methods smooth out as noise; so we can compare individualized movement-related variations across different participants without incurring in gross data loss.
2.4. Micro-Movements Spike Trains as a Gamma Process
The normalized peak amplitude and peak timing fluctuations represented by real-valued spike trains ranging from 0 to 1, are treated as events in a continuous random process. They are studied under the general rubric of Poisson random processes. Specifically, we use them as input to a
Gamma process and estimate the
Gamma parameters. We then plot the estimated
Gamma parameters with 95% confidence intervals on the
Gamma parameter plane (
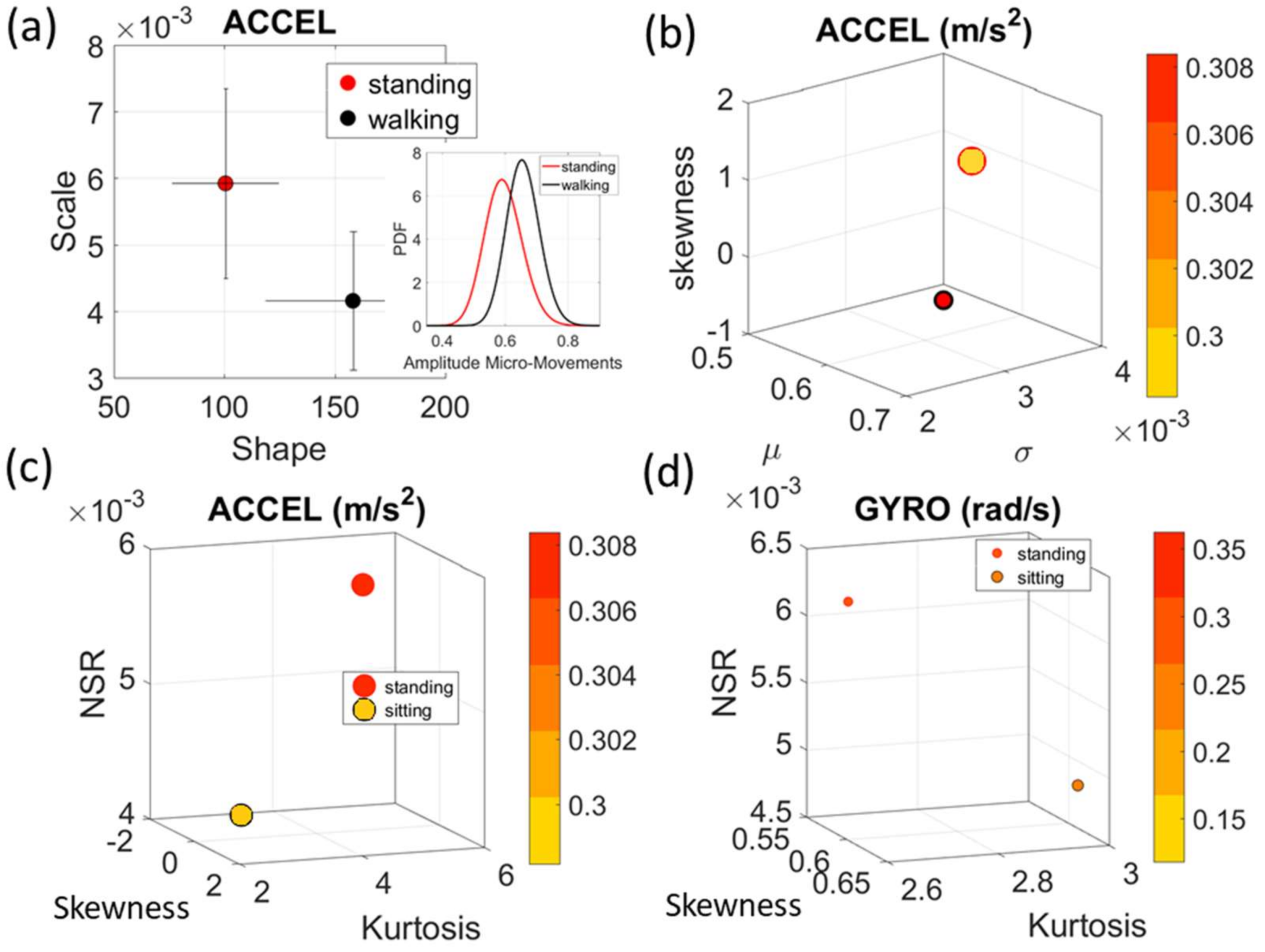
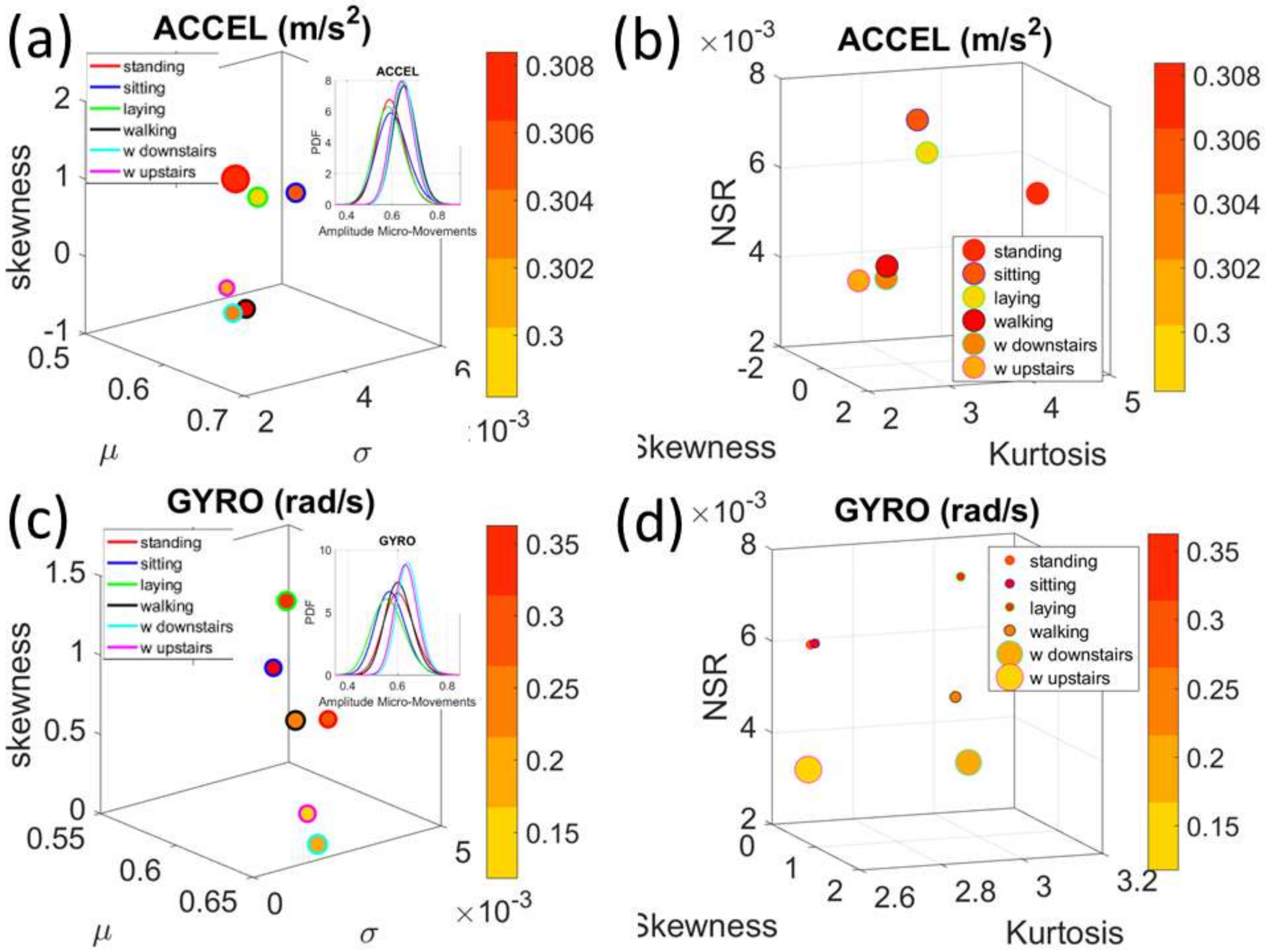
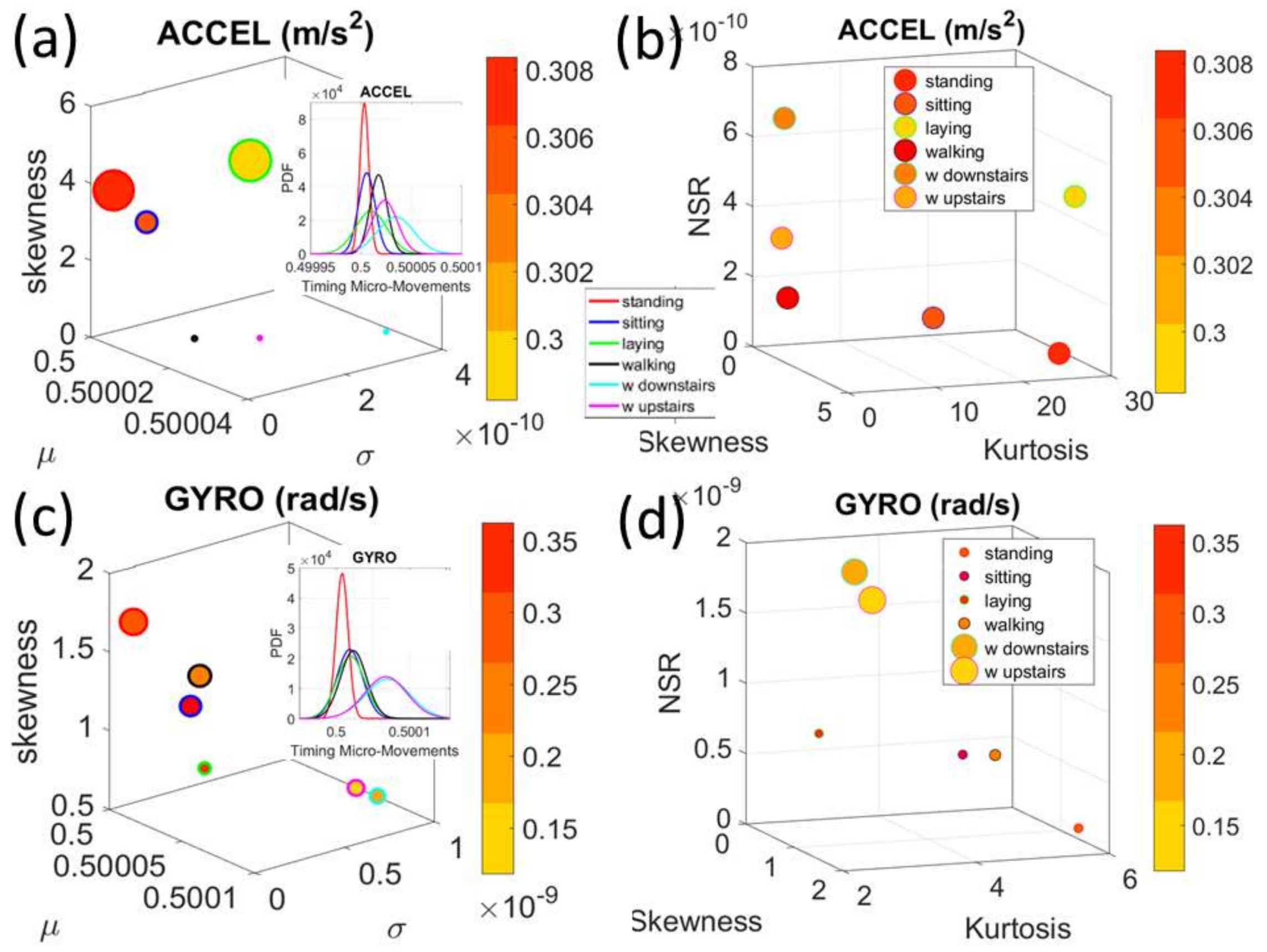
Figure 4a). There we see, for example, that the noise to signa ratio (NSR) is higher for standing than walking and that the walking activity gives rise to more symmetric PDF, also shown in the inset with the corresponding PDFs. We also estimated the
Gamma moments and plotted them on a space spanned by the
Gamma mean along the
x-axis; the
Gamma variance along the
y-axis; the skewness along the
z-axis and represented in the marker size the value of the kurtosis. Since these estimations are performed using the normalized fluctuations in peak amplitudes and timings (independent of the sensor type or participant anatomical features) they span real values from 0 to 1. We retain the physical ranges (m/s
2 or rad/s, or seconds) to color code the marker’s face and provide a color-coded gradient showing the range of parameter value (peak amplitude or peak timing) for each participant across each cohort. The color of the marker edge represents the median value of the parameter for activity type or task condition.
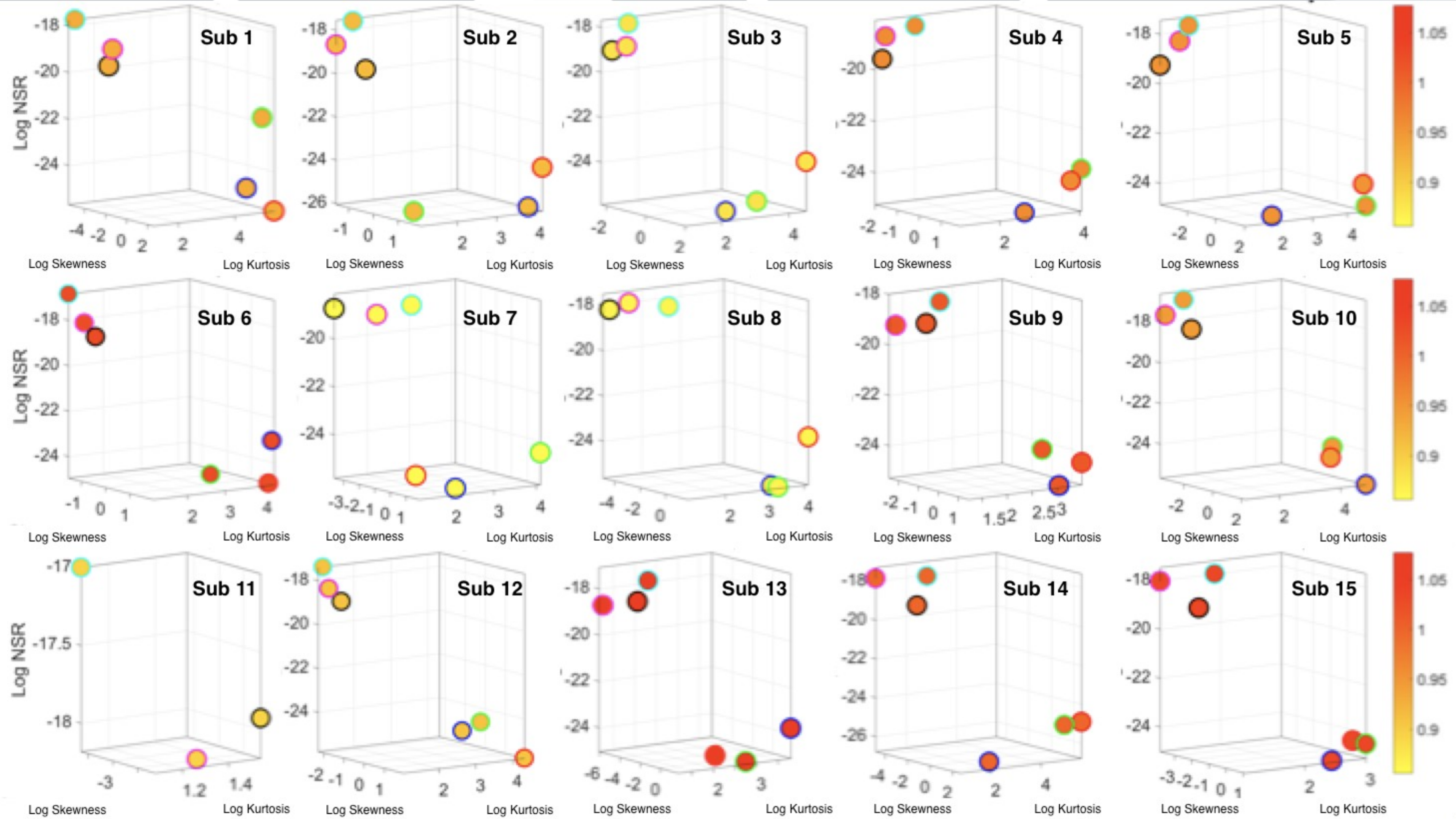
Figure 4a–d shows the sample graphs for the data in
Figure 3.
Figure 4c,d identify higher moments of the data to build a parameter space further confirming the separation of the activities along the skewness–kurtosis–NSR dimensions. These types of plots will be used in the rest of the paper to provide instances of methods of parameter identification and data visualization.
4. Discussion
The present work presented a new standardized data type (micro-movements spikes) and statistical platform for individualized behavioral analyses (SPIBA) in combination with data from Kaggle.com to illustrate the use of the methods. Further, to illustrate their general use with other commercially available sensors, we provided a task designed in our lab [
13] to probe levels of autonomous control. This task examines the interplay between deliberate and spontaneous autonomy in relation to fully automatic behaviors under natural conditions. In this case, the general behavior is walking at one’s regular pace. In the spontaneous condition, the task probes self-emerging entrainment between the internally self-generated biorhythms and the external tempo of a metronome that the person is not instructed to follow. In the deliberate condition, the person is instructed to breathe at the pace set by the metronome. Both tasks evoked changes in the peak timings and the peak amplitudes such that their accumulation over the span of minutes, shifted the probability distribution function, best describing the process in an MLE sense. Using a
Gamma process to characterize the micro-movement spike trains, these shifts were detectable. Their changes were tracked within the time span of minutes in each of the data sets we examined. The methods can provide a stochastic trajectory amenable to determine the rates of change of the signatures, a feature that is unique to the person’s nervous systems. In this sense, we have used these methods in the past to track a clinical trial in young children with SHANK3 deletion syndrome [
15,
16] and identified the pharmacodynamics of each participant to tailor the treatment and apply concepts from personalized medicine. Here we wanted to use the methods to examine other activities and ascertain whether the data type and analytics could automatically distinguish one task from another, even in cases where the differences may not be apparent.
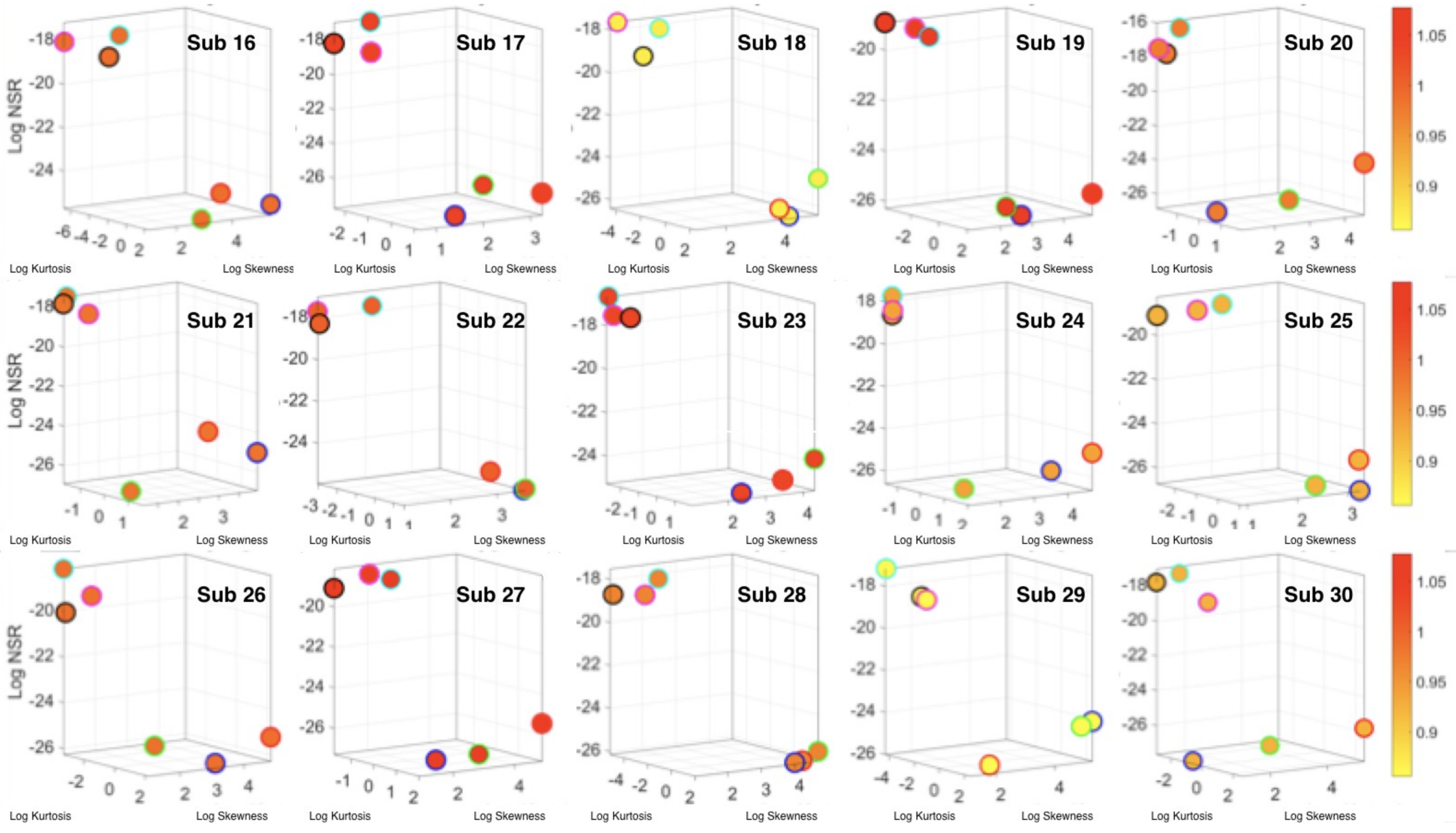
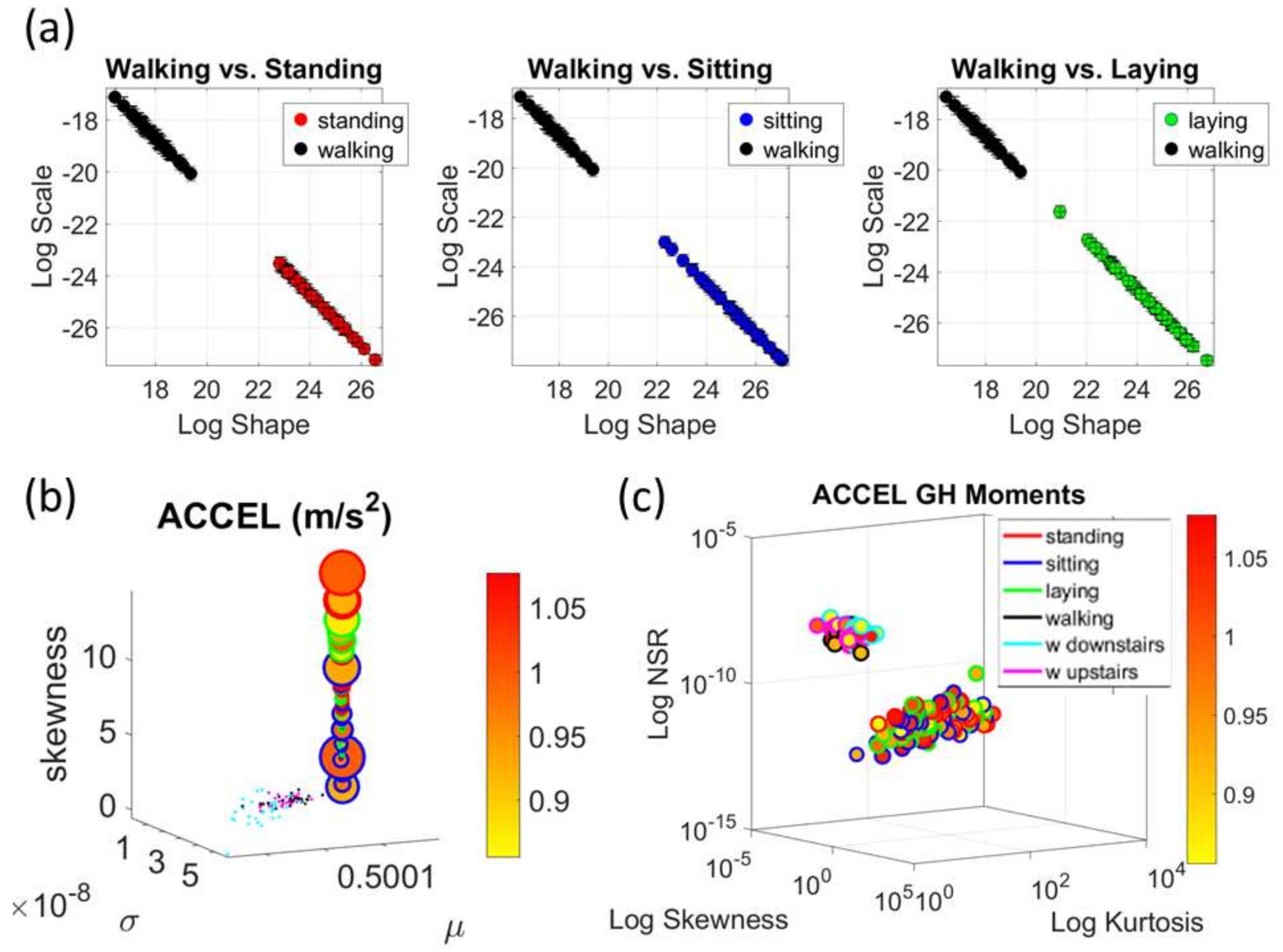
The Kaggle data set provided us with two different types of tasks requiring fundamentally different motor control strategies. The tasks involving large, overt movements within the realm of walking allowed us to probe differences in the linear acceleration and angular speed domains owing to variations involving going up or down stairs in relation to natural walking. The methods picked up those subtle variations and systematically separated for each participant the three different versions of the walking task. The other set of tasks involving covert, small movements required keeping the body in a postural position (standing up against gravity, laying or sitting). These activities demanded a different type of motor control aimed at maintaining a posture, rather than dynamically changing it. As in the overt movements, using our methods, each participant data was automatically distinguishable by the activity type. Furthermore, for each participant, the two classes of tasks lied on different locations of the Gamma parameter plane and on extreme locations of the Gamma moments space. They could be unambiguously separated for each person and for the group. The summary data involving mean activity in another Kaggle version of this data set, also yielded automatic separation by activity type within each movement class. Several parameter spaces were presented where the variability inherently present in the data systematically separated the motor control features of these tasks.
We underscore that the clusters we found spontaneously self-emerged and were not required a priori (e.g., as with
K-means.) Furthermore, we did not preset a testing and training set as ML methods do. Instead, we utilized the full data set from Kaggle without any pre-defined subsets or any additional features (e.g., the Kaggle set has 561 features and treats them as vectors, but it is not clear they are supported by a vector space, or provide a metric space, or that it is possible to extract similarity metrics, or what they should be, etc. The present approach provides a distribution-free type of analysis and rather empirically informs the stochastic model of inherent features present in the data variability (see also
Appendix A Figure A1,
Figure A2 and
Figure A3). As such, the clustering of the activities self-emerges based on the types of neuro-motor control required by these tasks. In this sense, the results are congruent with the previously proposed notion of different movement classes in motor control that map well onto different levels of variability [
5]. Movement variability is important in separating levels of autonomy that self-emerge during neonatal stages [
6] and manifest throughout life, as the person acquires the type of volitional control [
17] that is conducive of the development of the sense of agency [
18,
19].
In our previous research we had explored the present methods using smart phone data from a Kaggle set concerning patients with Parkinson’s disease and age- and sex-matched controls [
20]. Here we extend the results to refine the classification of specific tasks. Within different activity types, we can further distinguish the statistical variations that subtle changes in a highly practiced motion such as walking, produce when performing it with deliberateness, vs. when evoking spontaneous entrainment with external biorhythms in the environment. In this sense, the task that we propose here can be used in combination with the tasks in the Kaggle set to provide a comprehensive profiling of the levels of autonomy of the nervous systems. As previously introduced by our group, these can go from entirely autonomic to entirely voluntary [
5] and serve as markers of adequate neuro-motor control. These types of biometrics can complement clinical inventories like the Universal Parkinson’s Disease Rating Scale (the UPDRS) or the Autism Diagnosis Observational Schedule (ADOS) used to ascertain neurodegenerative or neurodevelopmental issues (respectively). Such inventories currently lack a component that assesses changes in data from waveforms self-generated by the nervous systems under consideration. In this sense we submit that nervous systems disorders at any stage of the human lifespan need to be physically measured. The types of biometrics this work offers are among those which would enable to track change in nervous systems activities along with detection of the shift in their stochastic signatures owing to treatments and/or disease progression. They can be considered as part of the ubiquitous computing (UBICOM) effort to connect research and technology to the service of unmet clinical needs.
Although the Kaggle set and the additional tasks that we introduced to test the methods and standardized data type take place in open loop settings, the promise of the present methods lies in the context of closed loop settings. In closed loop settings, the motor output activity is used as re-entrant input to influence the self-generated rhythms of the nervous systems. In such settings, we have parameterized the output, combined it with external sources such as audio-visual media and re-parameterized it as input to selectively steer various levels of autonomy in the system. These have ranged from spontaneous autonomy to deliberate autonomy [
21], where we have been able to use the micro-movement spike trains and
Gamma process to extract the preferred sensory input from the motor stream [
22] and re-played it back in precisely re-parameterized ways, even beneath the person’s awareness. Utilizing these methods and data type have allowed us to explore each person’s capabilities for autonomous control. In turn, this heuristics-free approach to the motor control problem has provided us with new means to begin the path of defining objective indexes of autonomy and self-independence. These types of outcome measures are fundamental to help the person ascertain his/her sense of agency during activities of daily living, social encounters and life in general, as it dynamically unfolds from day to day. Future research using these new technological advances in the medical field will facilitate the development of objective criteria to define formal metrics of quality of life. Any treatment, clinical trial or basic science study will ultimately have to ascertain such criteria to help the person improve their existence and realize the full potential of his/her life.
Potential Contribution to Behavioral Neuroscience
The analytics and data types introduced by this work may also be of use to researchers in behavioral neuroscience. Among other areas of basic scientific research, this field develops animal models for pre-clinical trials and at present lacks objective, heuristics-free methods to track the animal’s behaviors and to examine nervous systems activity at the periphery. Part of the potential benefit of adopting these analytics and data type is that they are derived with the cortical spikes in mind. As in the field of Computational Neuroscience focusing on (binary) cortical spikes trains, here we too define spikes from the behavioral kinematics data. In our case however, we provide a continuous real-valued way to describe the peak data and build a continuous scale between 0 and 1 to use continuous random processes for statistical inference. Our methods of objective and personalized behavioral analyses can thus be combined with the methods currently using continuous Poisson processes for the analyses of cortical spikes. In this way one could go beyond a “disembodied brain” approach to neuroscience and bring in this computational machinery adapted to the analyses of naturalistic continuous behaviors to redefine animal models for preclinical trials and animal research in general.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














