Residual Error Based Anomaly Detection Using Auto-Encoder in SMD Machine Sound

{kind=link}
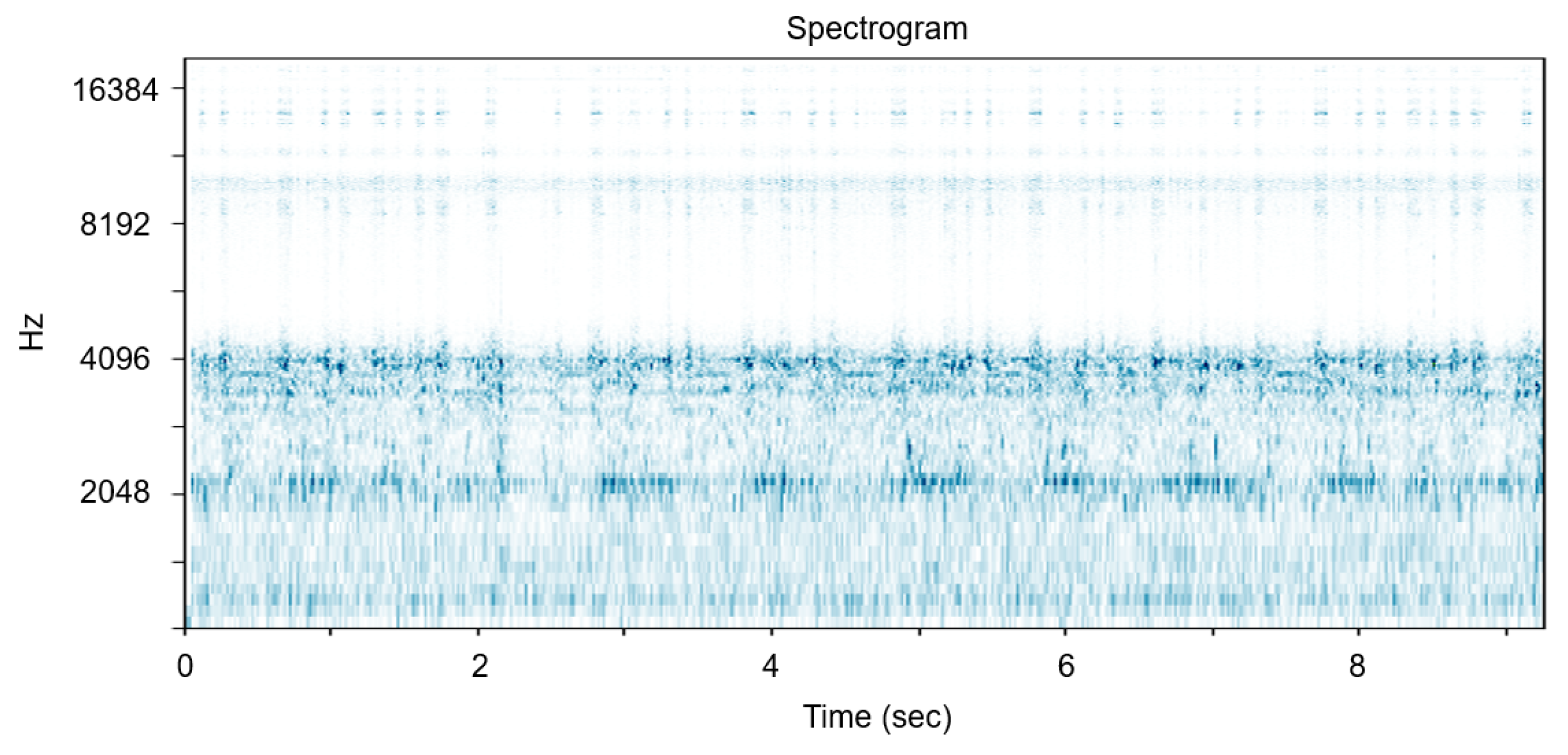{kind=link}
{kind=link}
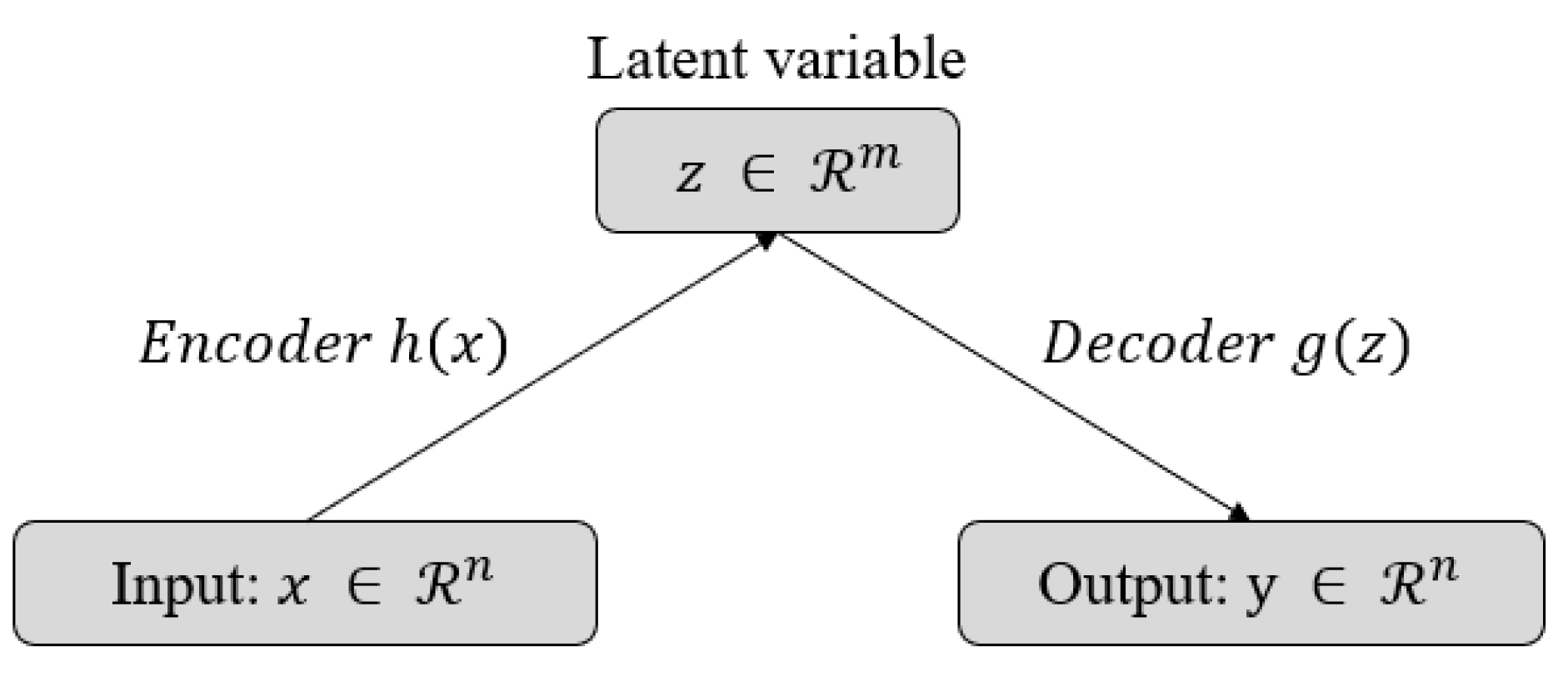{kind=link}
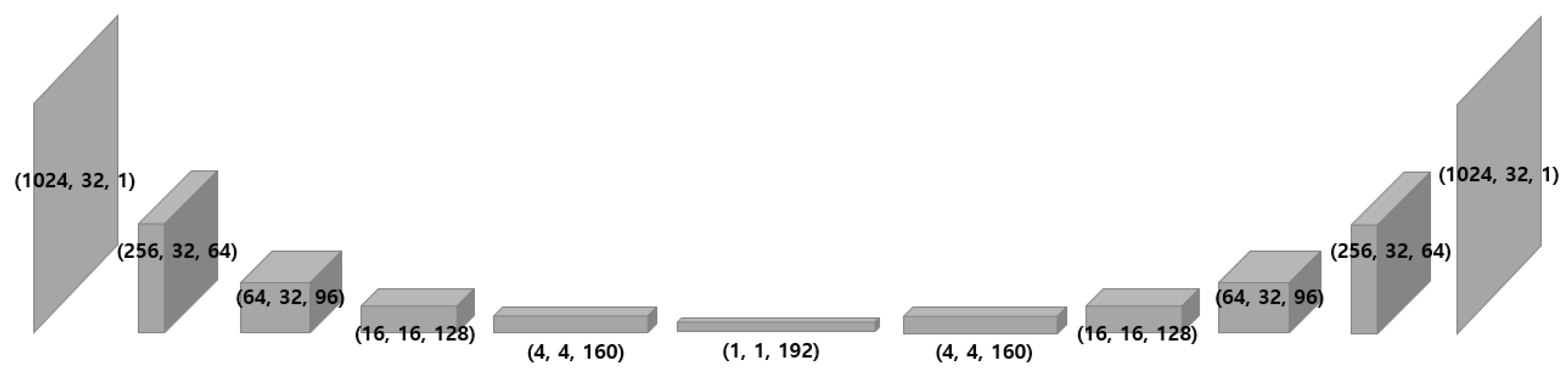{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
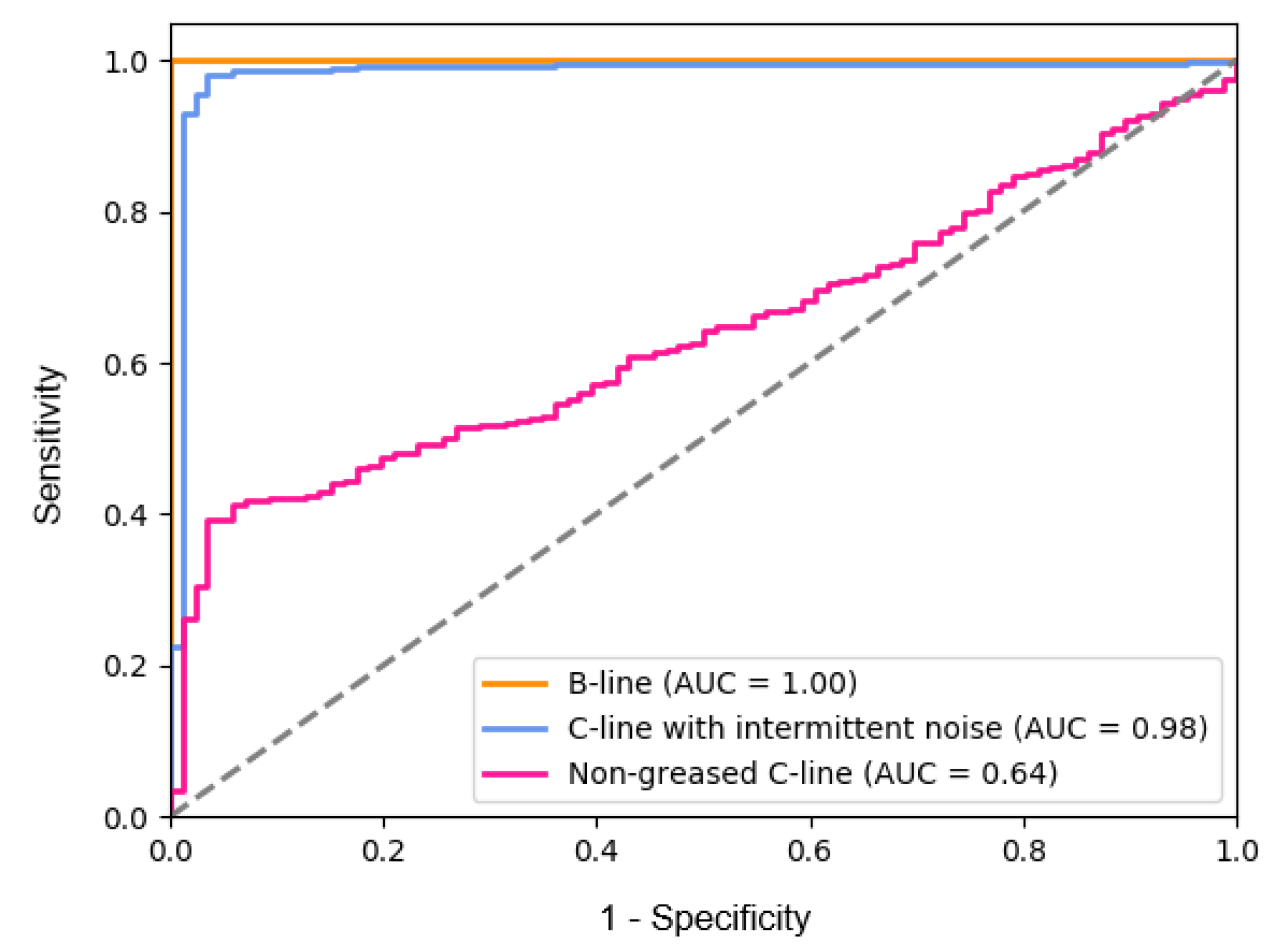{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Oh, D.Y.; Yun, I.D. Residual Error Based Anomaly Detection Using Auto-Encoder in SMD Machine Sound. Sensors 2018, 18, 1308. https://doi.org/10.3390/s18051308
Oh DY, Yun ID. Residual Error Based Anomaly Detection Using Auto-Encoder in SMD Machine Sound. Sensors. 2018; 18(5):1308. https://doi.org/10.3390/s18051308
Chicago/Turabian StyleOh, Dong Yul, and Il Dong Yun. 2018. "Residual Error Based Anomaly Detection Using Auto-Encoder in SMD Machine Sound" Sensors 18, no. 5: 1308. https://doi.org/10.3390/s18051308
APA StyleOh, D. Y., & Yun, I. D. (2018). Residual Error Based Anomaly Detection Using Auto-Encoder in SMD Machine Sound. Sensors, 18(5), 1308. https://doi.org/10.3390/s18051308