1. Introduction
Remote-sensing techniques are increasingly used in geological exploration, natural disaster prevention, monitoring, etc. [
1,
2,
3,
4,
5]. They usually require very high-resolution satellite images, which are texturally-rich and may raise the running costs of systems. However, many remote-sensing satellites must rapidly respond to emergencies, such as fires and earthquakes, and quickly return the region of interest (ROI) of the emergency to the ground station [
6]. In general processing procedure, the satellite image data are downlinked to the ground station for processing and analysis. The data size of Earth’s observation satellites often exceeds 10 GB. So, the process of data downlink causes a long delay time, and it severely affects rapid response to emergencies [
7,
8,
9]. On-board processing is a way to effectively improve response speed and provide immediate products for rapid decision-making [
10,
11,
12]. After processing and sending the data about which we are most concerned, the amount of data can be reduced several times. Therefore, by processing the data on-board and downlinking the processing results only, the communication bandwidth of downlink can be reduced. At the same time, the data processing flow of the ground station can simultaneously be accelerated and simplified. Consequently, on-board processing can reduce the cost and complexity of ground processing systems and solve the delay problem in image acquisition, analysis, and application.
The acquired remote-sensing images may contain uneven radiation brightness stripes and deformation areas, due to the defects of the sensors and the relative movement between satellite platforms and the Earth [
13,
14,
15]. Therefore, the acquired raw data from sensors on satellite platforms cannot be used directly. So, image preprocessing is a necessary step to solve such crucial problems. There are several necessary steps for preprocessing within charge coupled device (CCD) camera images, such as relative radiation correction (RRC), geometric correction (GC), and multi-CCD stitching (MCCDS).
Numerous studies have been performed to satisfy the needs of on-board processing. Cong Li et al. [
16] introduced a new volume calculation formula and developed a new real-time implementation of a maximum simplex volume algorithm, which is suitable for real-time, on-board processing. Qian Du et al. [
8] employed a small portion of pixels in the evaluation of data statistics to accelerate the real-time implementation of detection and classification. This design achieved fast, real-time, on-board processing by reducing computational complexity and simplifying hardware implementation.
Scholars have also conducted related studies of architecture implementation and efficient algorithm mapping. El-Araby et al. [
10] presented a reconfigurable computing real-time cloud detection system for satellite on-board processing. Kalomiros et al. [
17] designed a hardware/software field-programmable gate array (FPGA) system for fast image processing, which can be utilized for an extensive range of custom applications. Winfried et al. [
18] designed an on-board, bispectral infrared detection system, which is based on the neural network processor NI1000, a digital signal processor (DSP), and a FPGA. The system can perform on-board radiometric correction, geometric correction, and texture extraction. Botella et al. [
19] proposed an architecture for a neuromorphic, robust optical flow based on a FPGA, which was applied in a complicated environment. Multi-core processors and graphic processing units (GPUs) for achieving real-time performance of the Harsanyi–Farrand–Chang (HFC) method for a virtual dimensionality (VD) algorithm was proposed for unmixing [
20]. Carlos et al. presented the first FPGA design for the HFC-VD algorithm to realize unmixing [
21].
The previously mentioned methods—GPU, FPGA, and DSP—are the most common processors for implementing these algorithms in real time. In a ground processing system, a GPU is the popular choice for a preprocessing system. Although a GPU can provide high computing performance, it consumes considerable energy and cannot achieve the radiation tolerance required for an on-board environment. Therefore, a GPU cannot be adapted to an on-board processing system. To satisfy the requirements of on-board processing, this system should be implemented using a FPGA, which has low power consumption and high radiation resistance [
22,
23,
24]. Considering the computational complexity of a preprocessing algorithm, the use of a DSP as a co-processor is common to perform processes that are not computationally demanding and need to be sporadically executed. Although some publications have designed GC systems based on a FPGA, these systems are not suitable for remote-sensing images [
25,
26,
27] or cannot achieve the complete process [
28]. To the best of our knowledge, no such hardware systems have been proposed for remote image preprocessing, probably because of the complex computations and data management required. However, such a preprocessing step should be executed on this platform to achieve higher performance.
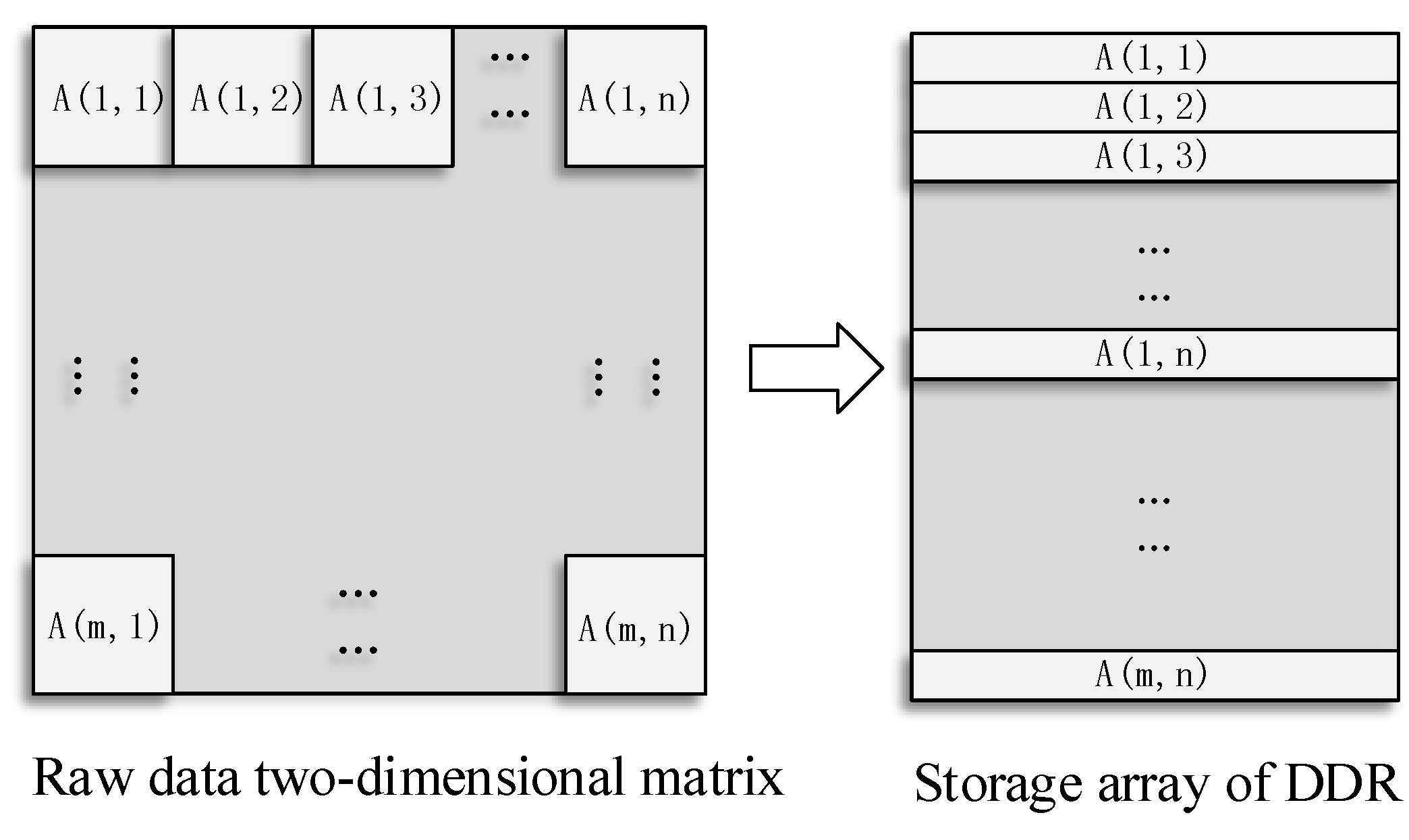
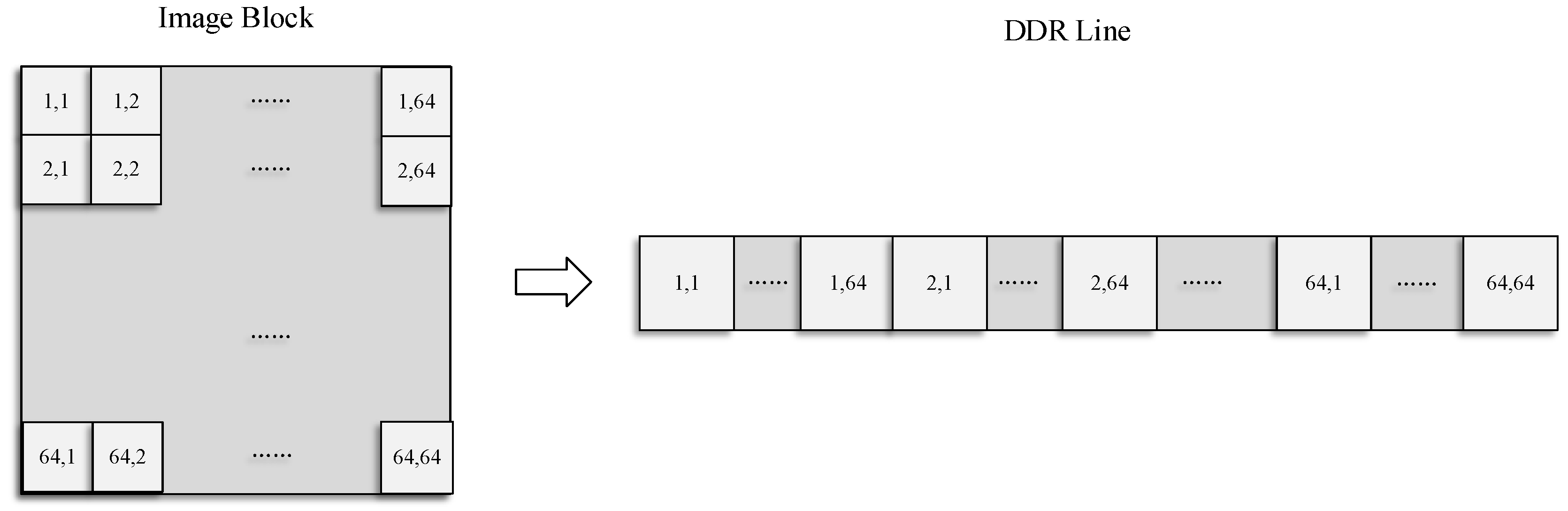
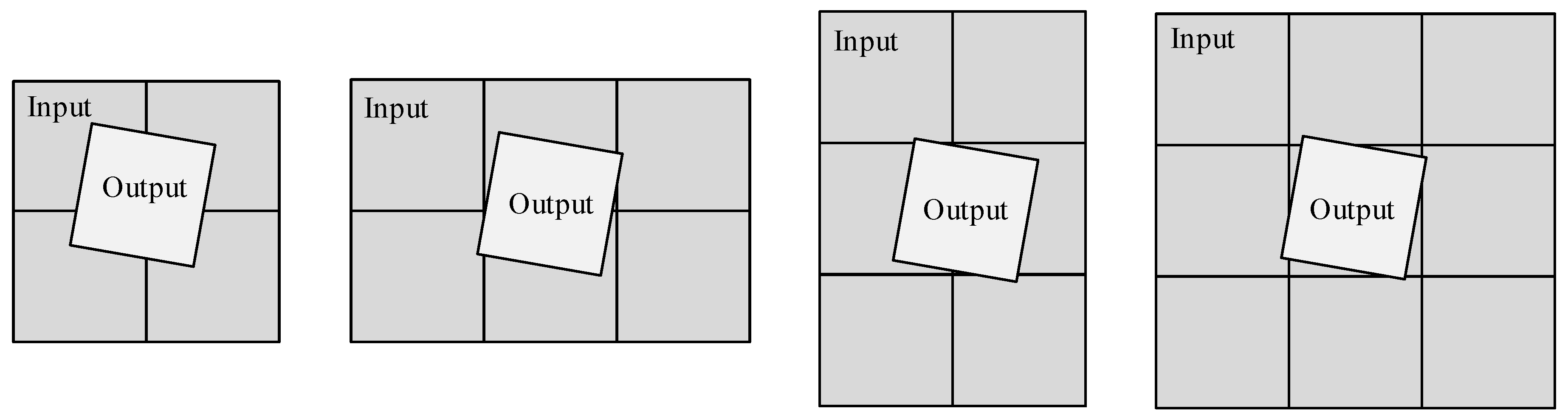
The process of image preprocessing can be decomposed into two parts. The first step calculates the model parameters. This step processes small amounts of data but involves complex calculations (such as sine and cosine functions), making it suitable for a DSP. The second step uses the model parameters to perform a pixel-by-pixel, gray-scale calculation and obtain the output image. When the pixels are calculated in this step, parallel calculations are appropriate, because the calculation forms of all the pixels are similar. However, due to the irregularity of the image deformation and other issues, there are several problems in the pixel calculation step. First, the calculation of each pixel coordinate requires many parameters and a large amount of hardware computing resources. Some parameters are involved in each pixel coordinate calculation and must be repeatedly calculated many times, thus wasting considerable time. Therefore, it is necessary to optimize the algorithm to improve computational efficiency. Second, due to the irregularity of the image deformation, the input and output data cannot be strictly correlated with each other, which makes it difficult to implement the pipeline process. Therefore, it is necessary to design the methods for reading and storing the data according to the characteristics of the geometric deformation. Third, existing algorithms use floating-point data for calculations. Compared with fixed-point calculations, floating-point calculations require more resources and more time. Because the amount of image data is large, it is very important to design a fixed-point solution to speed up the process.
Therefore, we optimized the design of the preprocessing algorithm regarding these aspects of the hardware implementation. First, a hierarchical decomposition mapping method based on coordinate transformation is proposed, which can effectively reduce the computation burden of on-board processing. Second, according to the characteristics of the data read and write irregularities, a block mapping design is implemented to avoid wasting time when reading and writing data. Finally, we design a fixed-point algorithm for the RRC and pixel resampling parts. The design can reduce resources and ensure accuracy. Using these technologies, an optical image preprocessing system based on FPGA and DSP coprocessors is designed and implemented. Because our system is designed for on-board processing, we chose processors with high radiation tolerance for space environments.
Thus, our contributions can be summarized as follows: first, we proposed a hierarchical optimization and mapping method to realize the preprocessing algorithm in a hardware structure, which can effectively reduce the computation burden of on-board processing. Second, a FPGA-DSP co-processing system based on optimization is designed to realize real-time preprocessing.
The remainder of this paper is structured as follows. The second section describes the preprocessing algorithm. The third section describes a mapping strategy and optimizing method. The fourth section describes the hardware realization and parallel accelerating design. The fifth section presents the experimental results and comparison with related studies. The last section provides conclusions and plans for future research.
2. Preprocessing Method
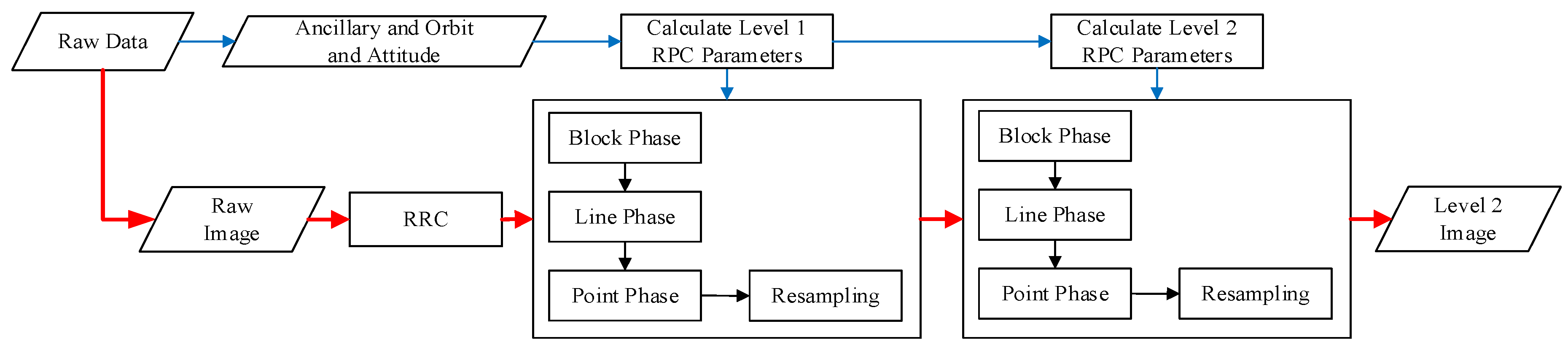
The complete process for optical remote-sensing CCD image data preprocessing is shown in
Figure 1. The process we implemented consists of three parts: RRC, MCCDS, and GC. The input of the preprocessing chain is a raw image with its corresponding ancillary information (imaging time, orbit, attitude, and other necessary information). The output of the preprocessing chain is the georeferenced image. We call the image after the RRC the Level 0 image; the image after the MCCDS is the Level 1 image, and the image after the GC is the Level 2 image.
The RRC is used to remove the systematic noise introduced by the discrepancy in the optical-electronic responses between different detectors and can be described as follows:
where
bi and
ki represent the bias and gain coefficients, respectively, of the
ith detector, which are provided by the manufacturer or calibration laboratory, and
xi and
yi correspond to the digital number value and the at-sensor radiance of the
ith detector, respectively [
29].
The MCCDS is based on the virtual CCD and rational function model (RFM). We summarize the process in two steps. First, the image coordinates of the Level 1 image corresponding to a certain number of points in the Level 0 image are solved using the rigorous imaging model and the orbit, attitude, and auxiliary information. The Level 1 image rational polynomial coefficients (RPCs) for the RFM are calculated based on these coordinate relationships. Second, for each coordinate in the required Level 1 image, the corresponding coordinate in the Level 0 image is calculated via the RPCs, and the gray value is obtained by resampling. The RFM that is employed in this process is expressed as follows:
where
a and
b are the row coordinates and column coordinates, respectively, of the Level 1 image;
s and
l are the row coordinates and column coordinates, respectively, of the Level 0 image;
x0,
x1,
x2,
x3,
y0,
y1,
y2, and
y3 are the respective polynomial coefficients;
sscale and
lscale are the scale factors; and
soff and
loff are the offsets.
The purpose of the GC is to correct the deformations that occur during imaging [
30]. GC methods are divided into parametric and non-parametric models [
31]. For on-board processing, it is more suitable to choose the parametric model, because the orbital information of the satellite platform can be obtained. The GC is based on the RFM. We summarize the process in two steps. First, the geographic coordinates in the Level 2 image that correspond to a certain number of points in the Level 1 image are solved using the rigorous imaging model, the RFM of the Level 1 image, and other information. Then, the RPCs for the RFM are solved based on the coordinate relationships. Second, for each geographic coordinate of the requested region in the Level 2 image, the corresponding image coordinate in the Level 1 image is calculated via the RPCs, and the gray value is obtained by resampling. The RFM used in this process is expressed as follows:
where
s and
l are the pixel coordinates of the Level 1 image,
x0–
x6 and
y0–
y6 are RPCs,
lon is the longitude,
lat is the latitude,
h is the elevation,
sscale and
lscale are the scale factors, and
soff and
loff are the offsets.
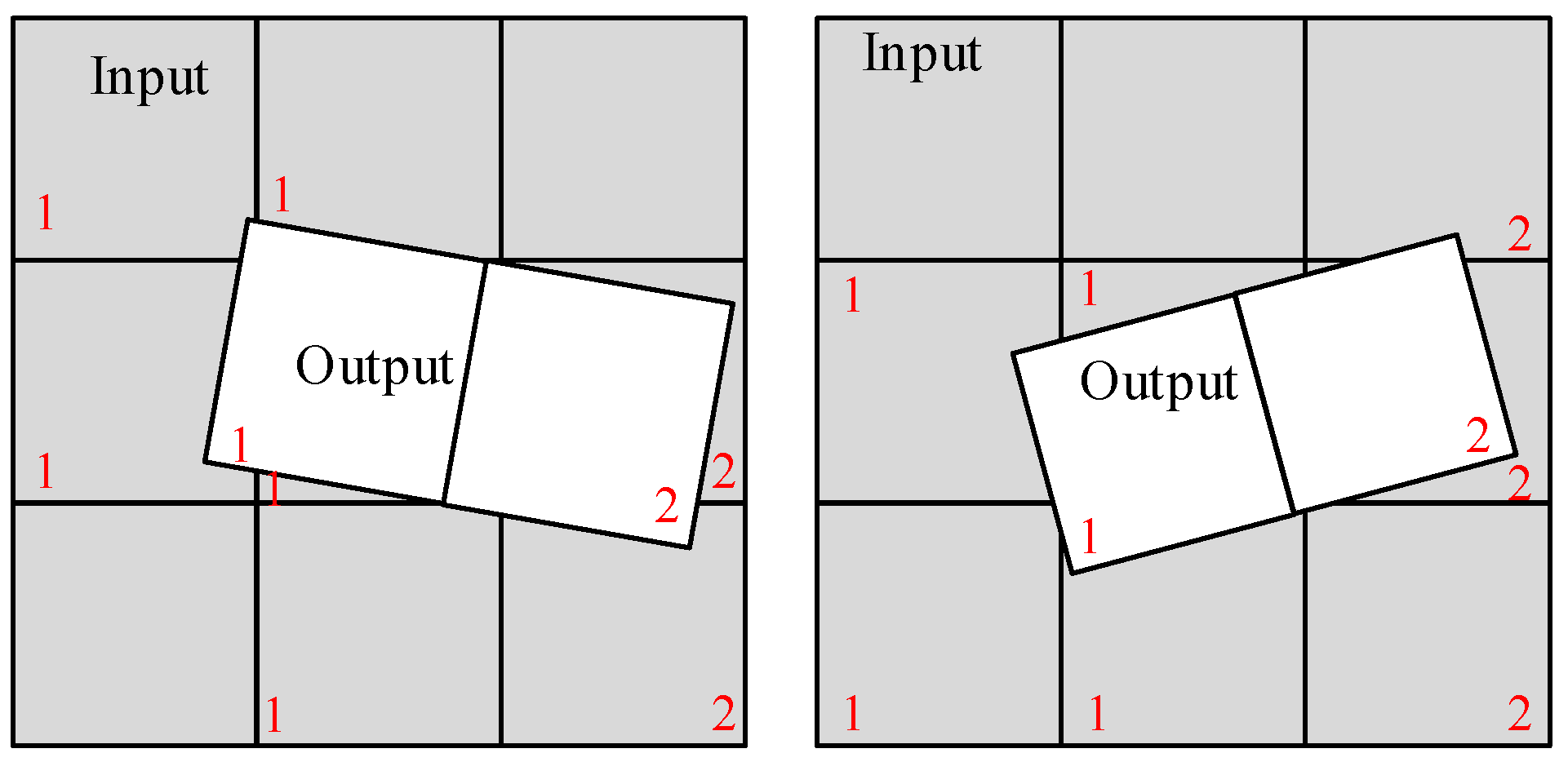
After the coordinate transformation, we obtain the coordinates (
s and
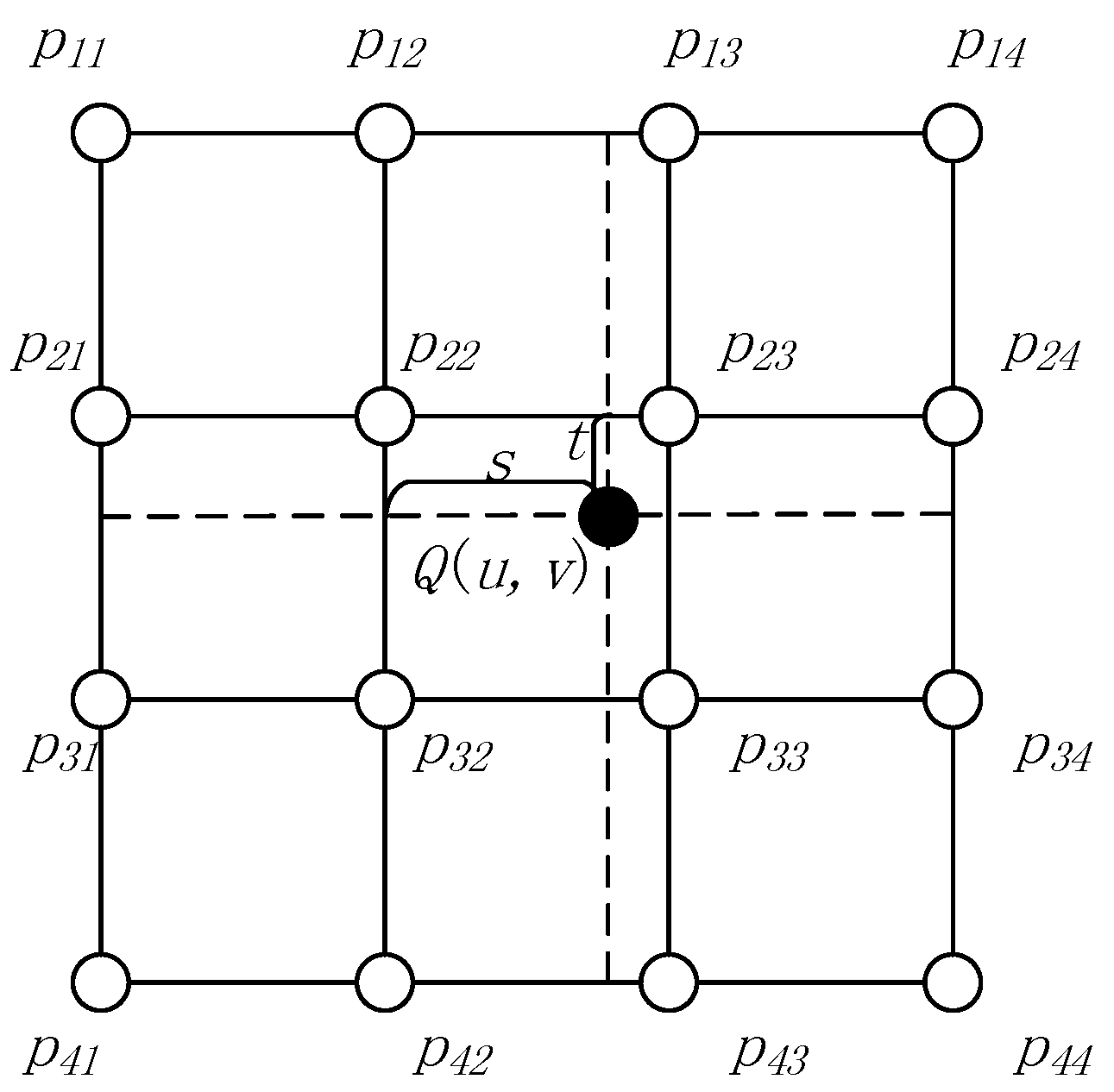
l) of the image pixels. Because the image is a discrete space grid, resampling is required to obtain the image gray values using the interpolation method. Because the bi-cubic interpolation method yields the best performance, we chose this method for our preprocessing algorithm. The bi-cubic interpolation method is shown in
Figure 2, which can be described as
where
and
Q(
u,v) is the output pixel gray value, (
u,v) is the sample position,
p11 to
p44 are the original sample pixel gray values,
, and
.
More descriptions of the image preprocessing are provided in [
32,
33,
34].
4. Realization of the FPGA-DSP Accelerating Platform
To test and verify the functionality and performance of the proposed architecture, we developed a prototype system for preprocessing and conducted a parallel processing analysis.
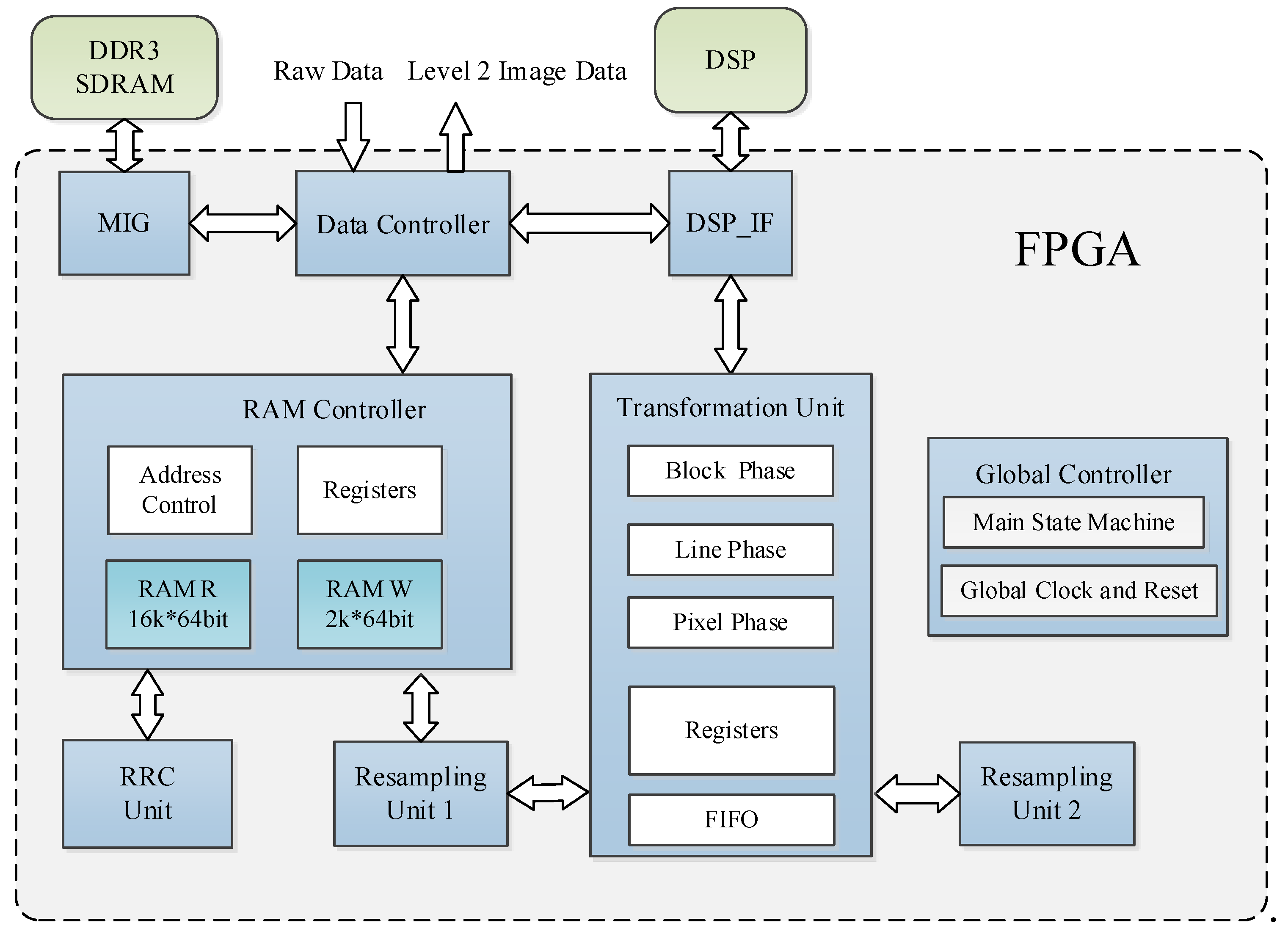
This preprocessing system is designed based on a FPGA and a DSP co-processor. The main architectural modules of this preprocessing system are shown in
Figure 11. The FPGA receives all the raw data, sends the image to the DDR for storage, and sends the remaining data to the DSP. Then, the FPGA processes the image data, whereas the DSP calculates the parameters of the two RFMs. Because the computations (such as sine and cosine functions) of the RFMs are complicated but utilize few data, the DSP is suitable for this purpose. All image data are processed by the FPGA, which ensures efficient parallelization of the algorithm.
The data controller is responsible for receiving external data and achieving data interactions among the DDR, FPGA, and DSP. The memory interface generator (MIG) is used to control the DDR SDRAM. The RAM controller caches the data that are needed for the RRC unit and resampling unit 1. The RRC unit achieves the RRC process for the entire image. The transformation unit and resampling unit 1 realize the coordinate transformation and resampling processes of the MCCDS and the GC. Resampling unit 2 is applied when a more accurate elevation is required. The DSP_IF unit is used to exchange data between the FPGA and the DSP. We set the FPGA as the main controller in the proposed system. The FPGA will send an interrupt signal to change the work state of the DSP. After receiving the interrupt signal, the DSP will first read the register of the FPGA through external buses. Then, the DSP executes the corresponding process algorithm according to the register value. During this procedure, the DSP reads data from the RAM of the FPGA and then writes the results back to the RAM of the FPGA. When finishing this procedure, the DSP modifies the register value of the FPGA, and the FPGA will perform the specific operation according to the register value, such as reading and writing data from RAM or changing the state machine. The global controller contains the main state machine, which is responsible for the phase transition, global clock, and reset. Global information is propagated to all modules in the form of broadcasts.
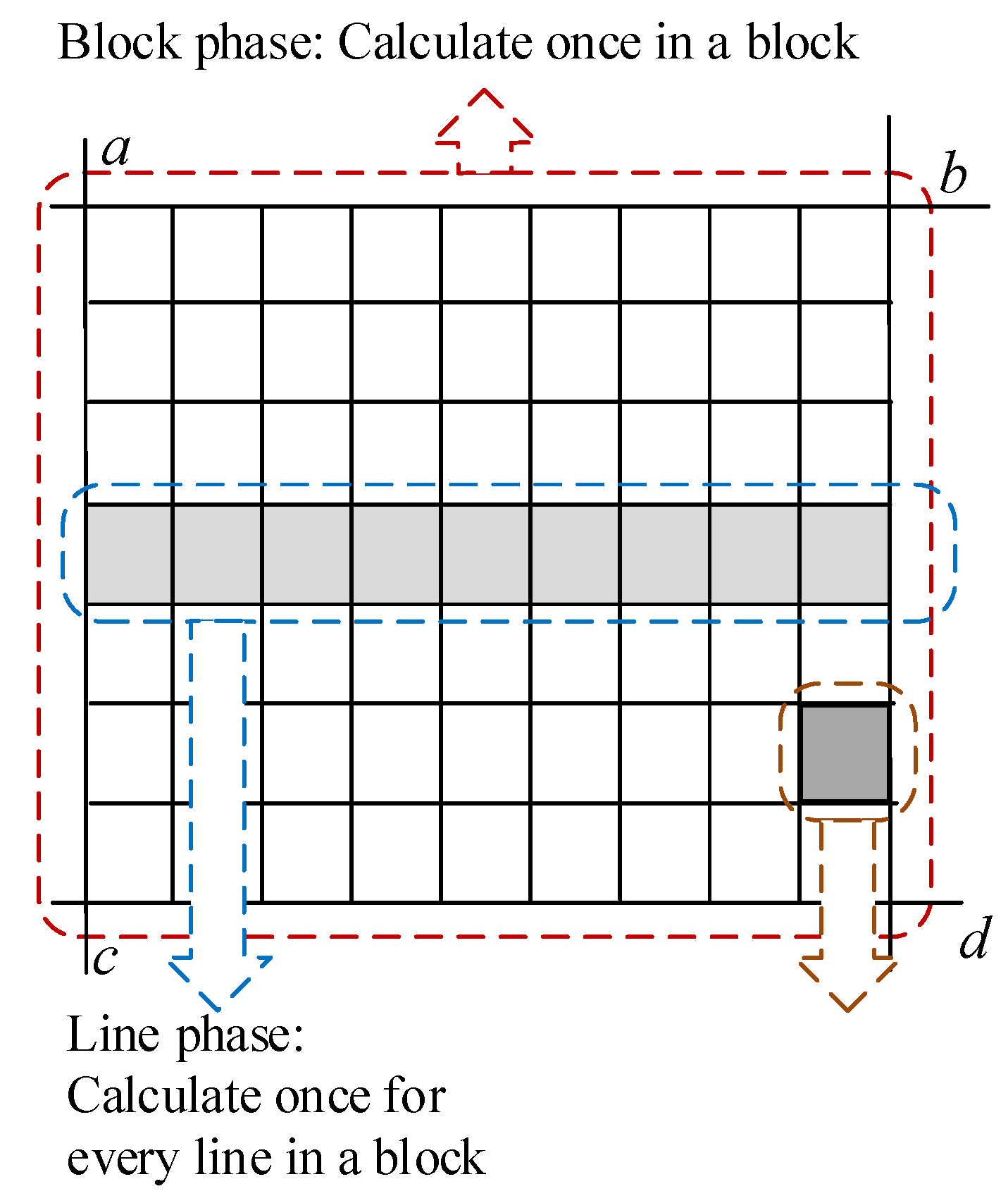
The transformation unit performs coordinate transformations based on the RPCs that are sent by the DSP_IF and then sends the coordinate transformation results to resampling unit 1. This module is designed based on the optimization algorithm of
Section 3. We designed the block phase, line phase, and point phase in this module. The block phase only needs to be run one time for each image block. The line phase runs once for each line of an image block.
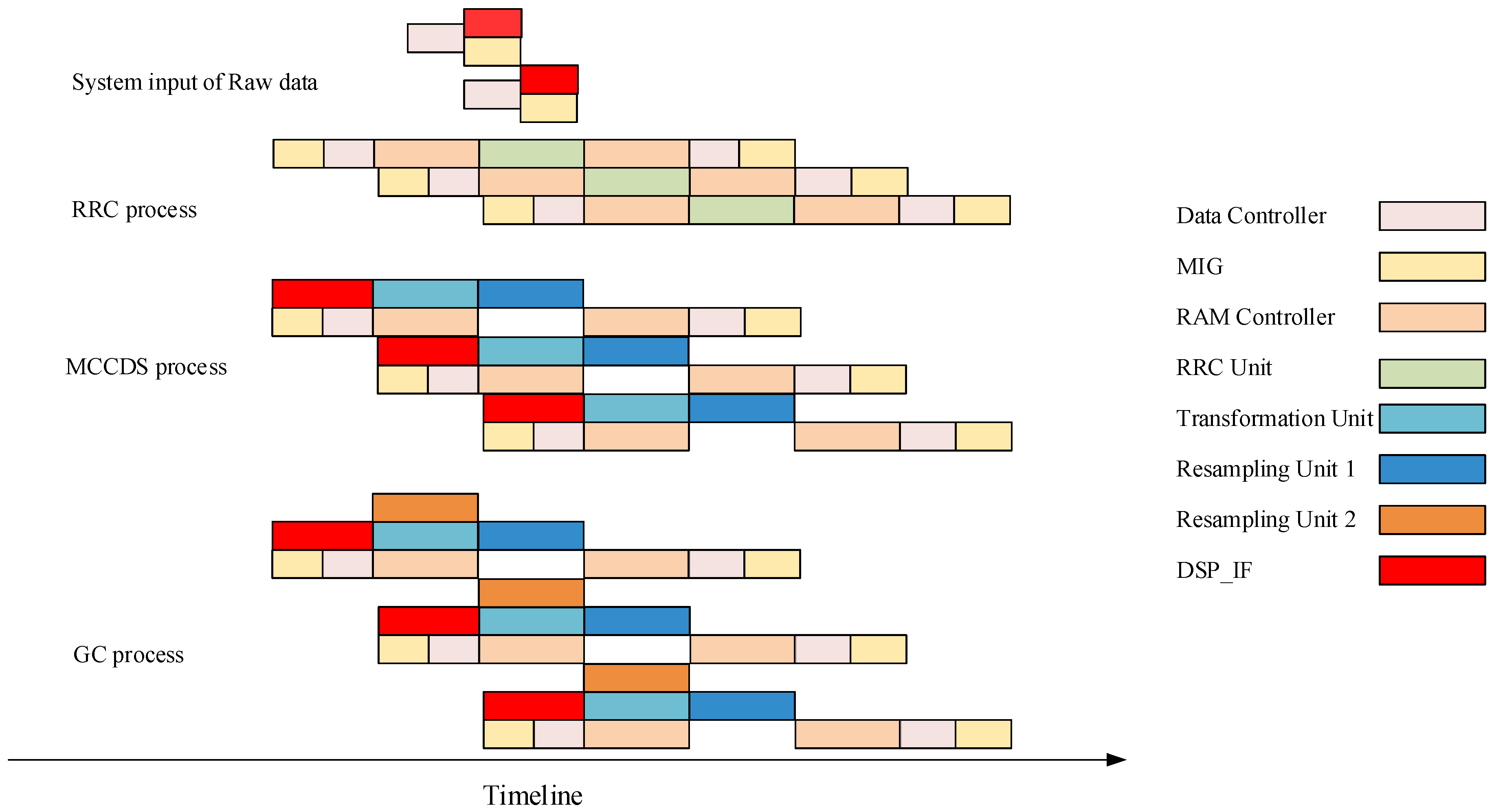
The processing timeline is shown in
Figure 12, which illustrates the working sequence of the different modules. For each procedure, after sending the data address by the DSP_IF or transformation unit, the data controller and MIG will read or store data for different purposes. Because the speed of reading is substantially higher than the speed of processing, the data controller and MIG consume less time. Because the RAM controller is designed for simultaneously reading and writing data, it can perform different functions during each procedure. As shown in
Figure 12, each processing unit (RRC unit, Transformation unit, and Resampling unit) starts working after obtaining data and does not stop until the procedure is ended. All units work on a pipeline and do not waste time waiting for other units.
5. Experimental Results
This section uses remote-sensing images to validate the preprocessing system. The verification in this section has two main goals. The first goal is to test and evaluate the effects of the system optimization methods. The second goal is to verify the function of the system and determine whether the system can realize the task of preprocessing. To address an on-board environment, the FPGA in this system was a Xilinx (San Jose, CA, United States) XC6VLX240T, and the DSP was a Texas Instruments (Dallas, TX, United States) TMS320C6701. We mainly used Verilog language to develop the system. In addition, we also used C language and a high-level synthesis tool to develop some computation units, such as the transformation unit and resampling unit. We employed synthetic and real data in our experiments. The synthetic data in this experiment consisted of three CCD push-scan images; the size of each CCD was 12,000 × 30,000 pixels. The real data in this experiment consisted of an image produced by the Gaofen-2 (GF-2) satellite. The image size was 29,200 × 27,620 pixels.
A photo of the hardware system that was employed for the preprocessing is shown in
Figure 13. In this system, there were two parallel processing units. Each processing unit contained the FPGA and DSP processors and the independent DDR and rapid data transport channel. Thus, we could easily extend the processing ability for different data volumes.
5.1. Processing Performance
This section tests the effectiveness of the algorithmic optimization approach that was employed. To evaluate the optimization of the algorithms and structures, we compared the effects of the calculation units (RRC unit, transformation unit, and resampling Unit) before and after optimization.
To ensure the comparison of identities, we designed the pipeline mode of each unit such that each unit expended the same amount of time for the same image data. The Flip-Flop (FF), Look-Up-Table (LUT), and DSP48 are the most important resources that determine the resource consumption of a FPGA. So, we verified the resource consumption before and after the calculation optimization. The comparison of the resource results is shown in
Figure 14. After algorithm optimization and fixed-point calculation design, the consumption of all the calculation resources was lower. Therefore, the design of the hierarchical mapping and fixed-point calculations can reduce the use of resources more than the design with no optimization.
Table 3 shows the FPGA resource occupation. The maximal frequency of this design is approximately 163 MHz.
To the best of our knowledge, similar hardware systems for remote image preprocessing have not been proposed; thus, we compare our system with central processing unit (CPU) based and GPU-based systems. The total system processing time for 2.01 GB of data is 11.6 s. For comparison purposes, we also processed 1.12 GB of data and recorded the time. The processing time of each processor in our system (FPGA-DSP co-processor) was compared with the processing times for other systems (CPU and GPU) [
36].
Table 4 lists the processing speeds of the different systems. The processing time of an RRC in our system is more than the processing time of a GPU; however, the processing time of a GC is less than the processing time of a GPU. The FPGA design can reach higher speeds, because the FPGA can be more flexible in implementing pipelined and parallel process. Thus, the total processing speed is faster. Due to the relatively slow processing speed of the model parameters calculation by the DSP, the acceleration of the RRC process by increasing the resource usage and waiting for the parameters is unnecessary. Although the system based on a GPU can realize rapid development, it is not suitable for an on-board environment. The power consumption of our system is about 33 W, which includes two pairs of FPGAs and DSPs and the corresponding memory and Input/Output (I/O) devices. In contrast, the power consumption of the traditional GPU-based system is about 200 W. However, NVIDIA has released the embedded GPU, such as Jetson TX2, and the power consumption of an embedded GPU is nearly 8 W per processor. In order to process the same data volume, the power consumption of an embedded GPU system is close to the power consumption of our system. But these embedded GPUs cannot be adapted for an on-board processing system, which needs radiation tolerance. So, our system is more suitable for an energy-constrained and high radiation space environment. Using the FPGA and the DSP enables greater flexibility in configuration and development at higher speeds. Therefore, the advantage of using the FPGA and DSP systems for on-board data preprocessing is irreplaceable.
5.2. Real-Time Assessment
To assess the real-time performance, we present the following formula:
where
Tin and
Tout represent the time of raw-data input and the processing result output of the processing node, respectively.
Tpro is the processing delay.
N is the number of processing nodes. When
p is less than one, the system can satisfy the real-time requirement. If
p is larger than one, the system cannot satisfy the real-time requirement. Because one processing node can process an image, the speed of all data processing is positively related to the number of nodes. For the real-time, on-board task, if we only need to obtain a determined area, then one node is sufficient. If we need to process all data that are acquired, two solutions are available. The first solution is to establish additional processing nodes. The second solution is to establish additional memory when the processing time is less than the input time. Then, the system can process the first image when the second image is inputting into the memory. Our system employs the second solution to cope with the low-speed condition. For the GF-2 satellite, the data input time of the 2 GB image data is 1 s. Our system requires 0.89 s to process and output the same data. Thus, our system can satisfy the needs of real-time processing. For actual processing, only part of the image needs to be preprocessed and downlinked. Thus, the processing time will be substantially shorter. Therefore, our system can satisfy the needs of on-board, real-time processing.
5.3. Correctness Results
To verify the correctness of our preprocessing system, we compared the results of this system with the results of the personal computer (PC) platform using the root-mean-square error (RMSE) of the output data of the two platforms as the evaluation criteria. The RMSE is expressed as
where
NDijFPGA and
DNijPC are the 16 bit integer values of the image pixels that are processed on the on-board platform and PC, respectively.
w and
h are the width and height of the Level 2 image. Because the results of the CPU calculation are floating-point data and the results of the FPGA output are fixed-point data, we first compared the RMSE between the output of the FPGA and the floating-point data of the CPU. Then, we compared the RMSE between the FPGA output and the rounding of the CPU output.
Table 5 lists the results. As we can see, the maximum RMSE is 0.2934 before the data are rounded. However, after rounding, the RMSE of both becomes zero, which means the corresponding resultant images are perfectly matched. However, the task of image preprocessing needs to obtain only integer-type image data to meet the requirements. Therefore, the fixed-point optimization method adopted by the system satisfies the precision requirements while improving the computational efficiency.
Figure 15 provides an example of the input and output of the GC processing.
6. Conclusions
This paper presents a FPGA and DSP co-processing system for an optical remote-sensing image preprocessing algorithm. The design can be applied to the rapid responses required for the on-board processing of remote-sensing images. The main contributions of this paper are as follows.
First, we optimized a mapping methodology for the preprocessing algorithm. For the linear part, hierarchical coordinate transformation optimization, a block mapping design, and fixed-point calculation are proposed. The hierarchical optimization can reduce the complexity, the block mapping can prevent the problem of geometric deformation, and the fixed-point design can reduce the time consumption and simplify the design.
Second, we designed a parallel acceleration architecture for real-time requirements. An optical image preprocessing system that is based on a FPGA and DSP coprocessor was designed and implemented. Because our system is designed for on-board processing, we chose processors with a high radiation tolerance for space environments. The experimental results of this system demonstrate that our system has the potential for application on an on-board processor, for which the resources and power consumption are limited.
Although the current system can achieve the task of preprocessing, it requires the DSP to calculate the RPCs, which limits potential applications. In future research, a preprocessing algorithm based on a full FPGA design will be investigated. By using the FPGA to implement all the processes, the computational efficiency can be further improved and wider applications can also be realized.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
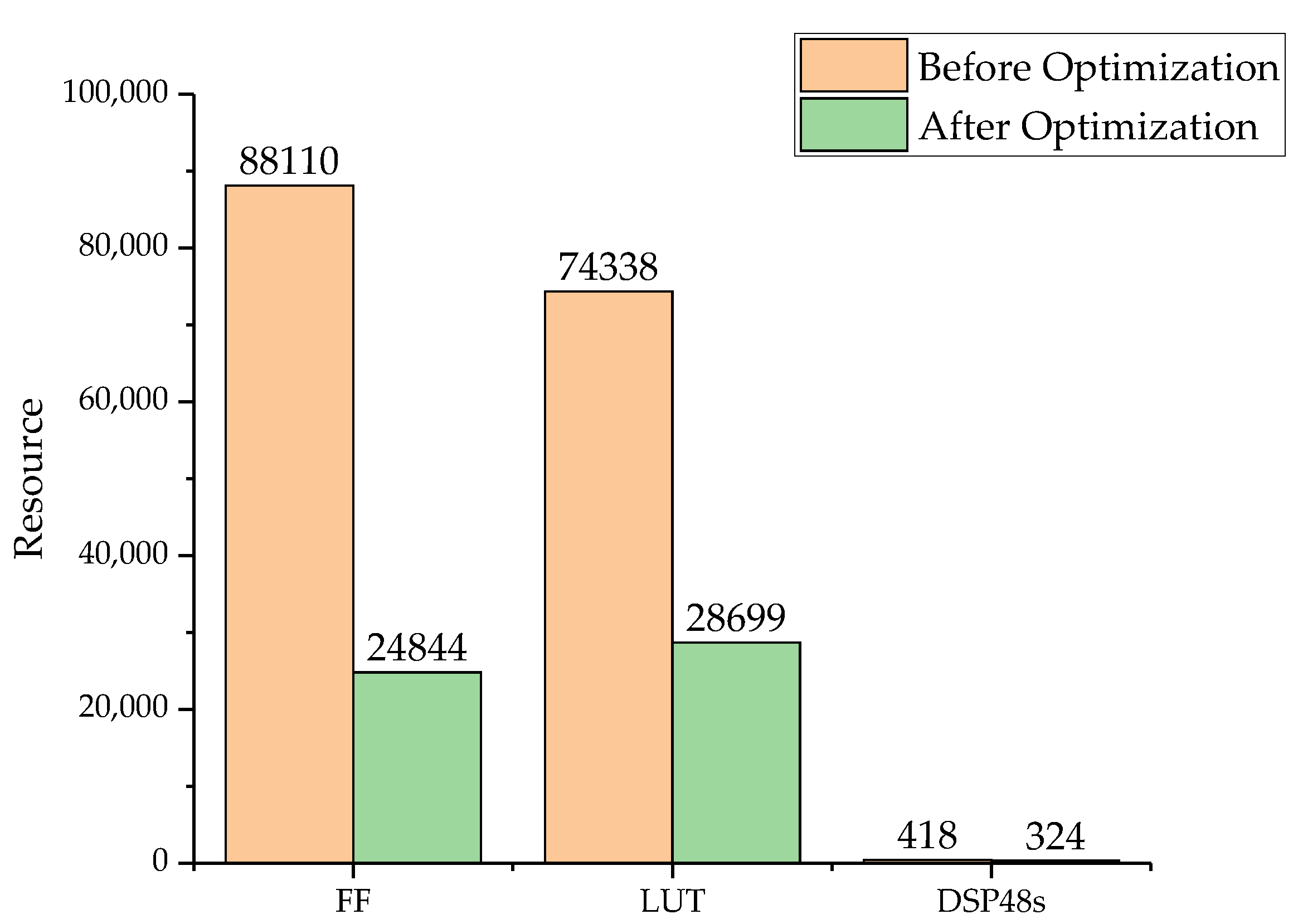{kind=link}
{kind=link}