Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
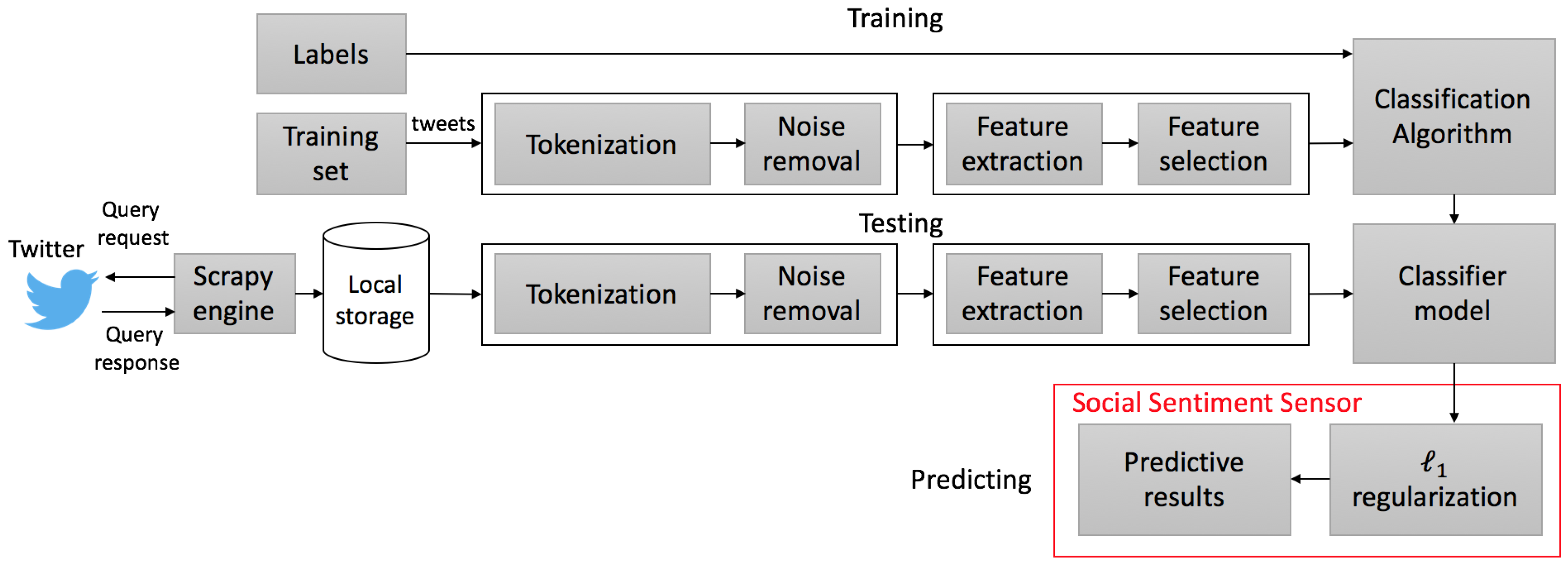
3. Proposed Methodology
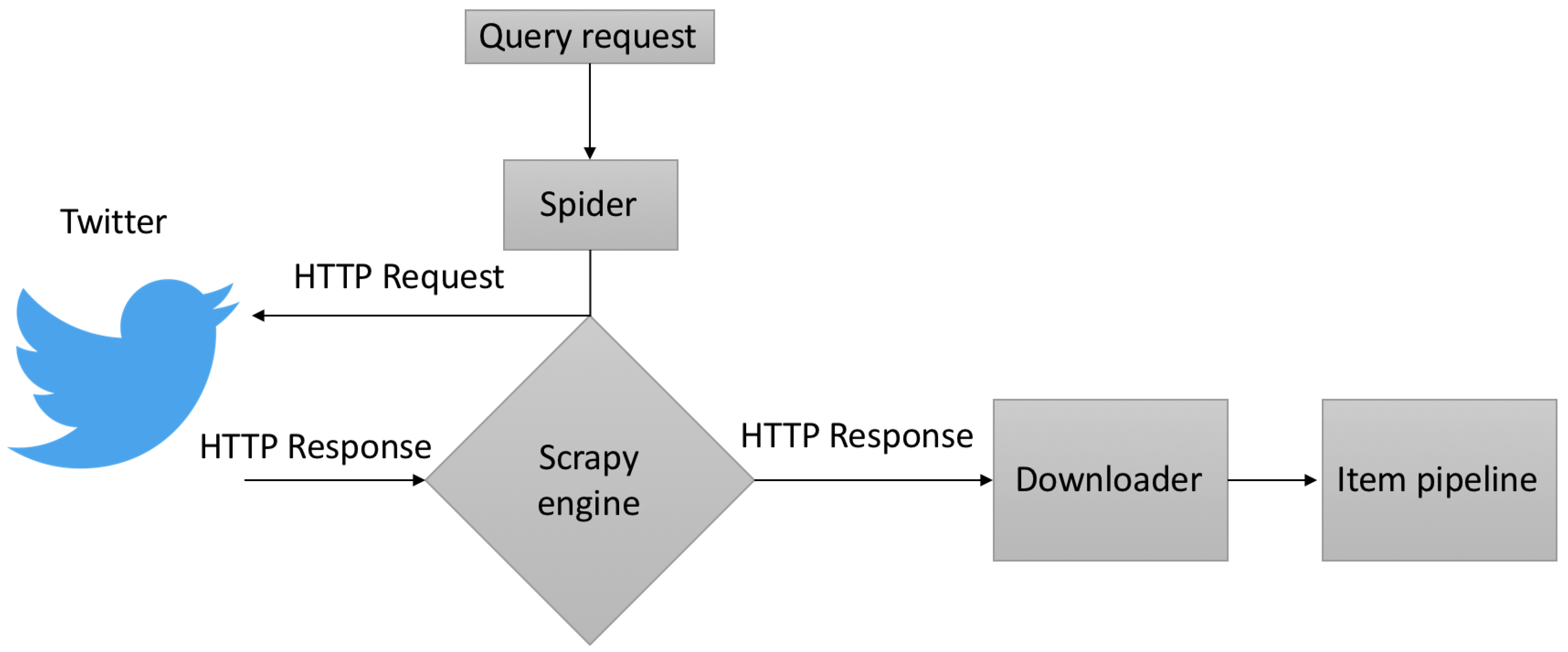
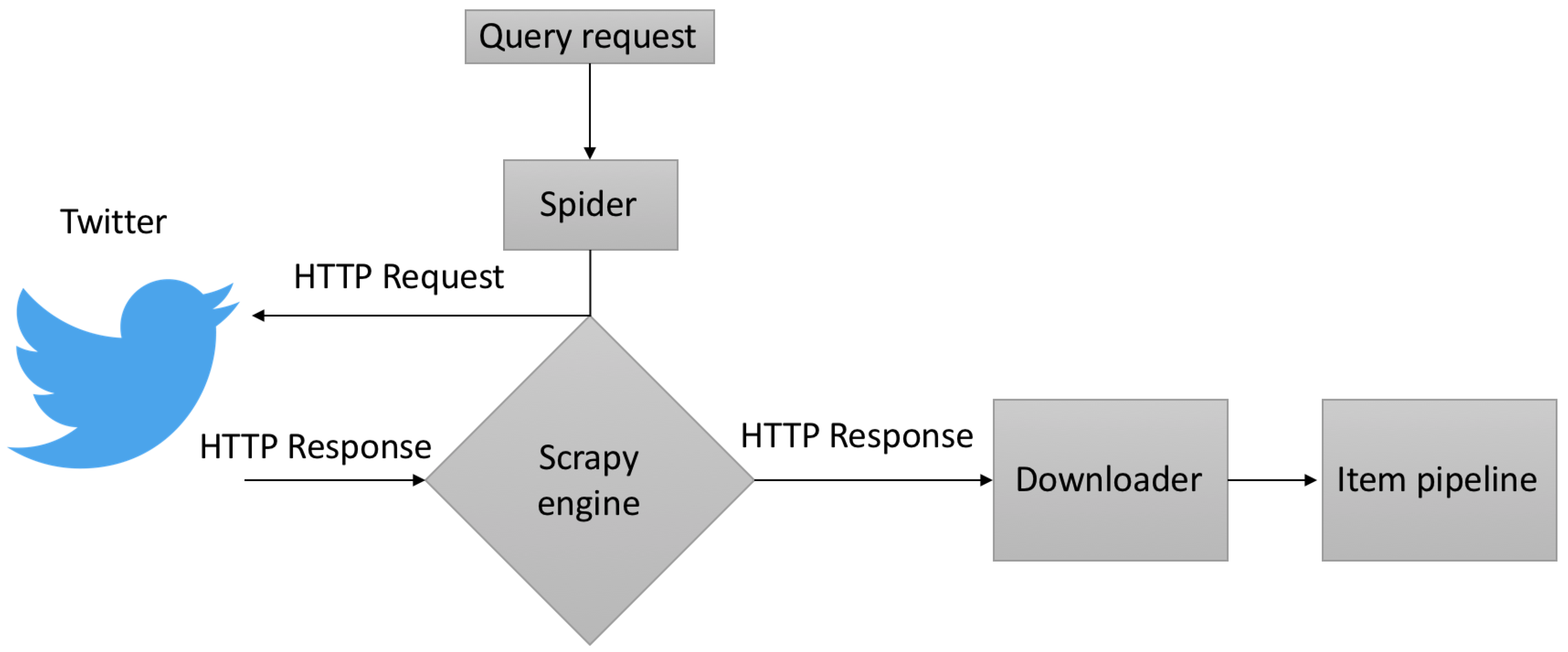
4. Data Gathering and Pre-Processing
4.1. Data Acquisition
4.2. Tokenization and Noise Removal
4.3. Lexical Derivations
5. Pre-Classification and Class Labeling
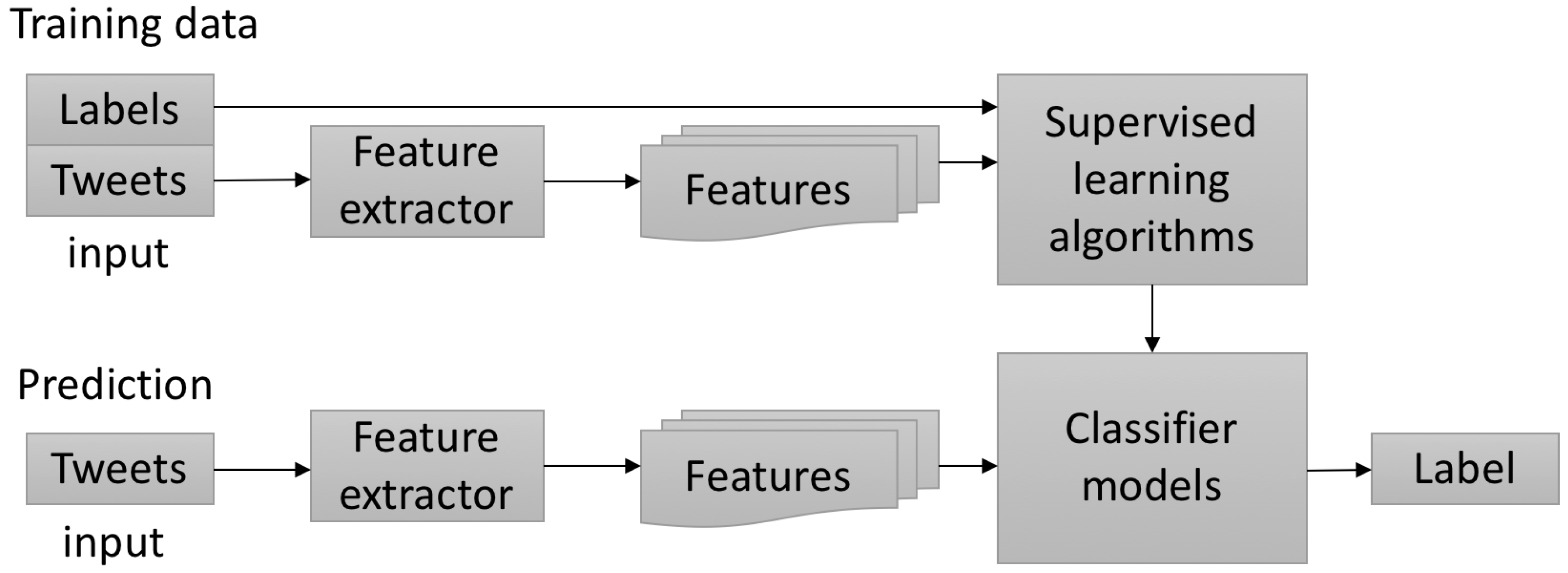
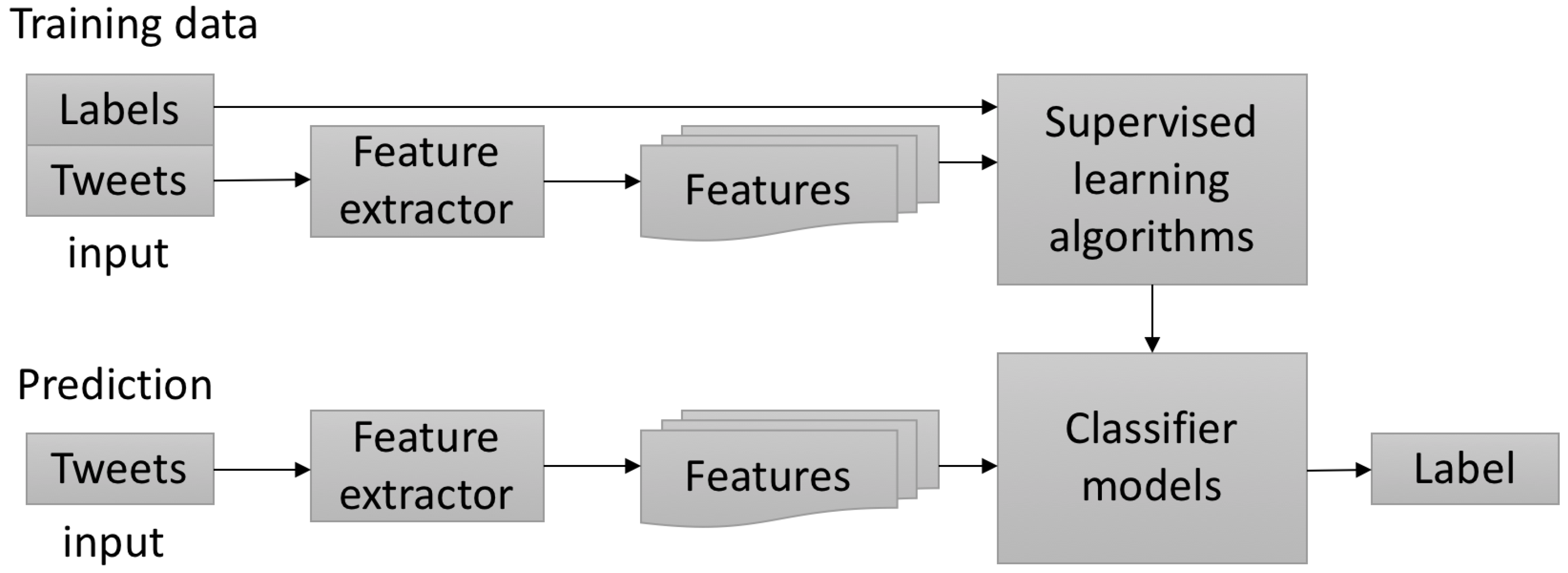
6. Supervised Classifier
Feature Extraction and Selection
7. Classification Baseline
7.1. Naive Bayes Classifier
7.2. Support Vector Machines
7.3. Maximum Entropy Classifier
8. Prediction—Statistical Analysis
Regularized Regression
- is the observation matrix of all classified tweets from corpus
- and are the observations with positive and negative scores, respectively,
- (a)
- (b)
- is the fitted security-oriented response from regression coefficients extracted from .
| Algorithm 1: Training Samples |
 |
| Algorithm 2: Testing Samples |
 |
| Algorithm 3: Computing the ℓ1 solution by Forward Stagewise |
 |
| Algorithm 4: Predictions with regularized coefficients |
| 1: function Predict() |
| 2: β ← [β0, β1, β2]; |
| 3: ; |
| return |
| 4: end function |
9. Experimental Results
9.1. A Case Study
9.2. Regularized Regression
- Mean Squared Error (): shows the difference or loss of the predicted scores with the inputs, i.e., between the actual scores, , and the predictions, .
- p-value (probability value): determines how well the observations (, ) are adjusted in the predictive model, thus rejecting the null hypothesis that relates to the low effectiveness of the samples. The lower the probability value (p-value ≈ 0), the greater the adjustment in the model.
- (coefficient of determination): explains the proportion of adjustment from the observations, (, ), with respect to the outputs, .
- Detected Attacks : the total number of cyber-attacks detected.
10. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Twitter. Available online: https://twitter.com/ (accessed on 11 March 2018).
- Twitter Company. Available online: https://about.twitter.com/en_us/company.html (accessed on 11 March 2018).
- Pak, A.; Paroubek, P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. LREc 2010, 10, 19–21. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Beyond Trending Topics: Real-World Event Identification on Twitter. In Proceedings of the International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 438–441. [Google Scholar]
- Zubiaga, A.; Liakata, M.; Procter, R.; Hoi, G.W.S.; Tolmie, P. Analysing how people orient to and spread rumours in social media by looking at conversational threads. PLoS ONE 2016, 11, e0150989. [Google Scholar] [CrossRef] [PubMed]
- Cuenca-Jara, J.; Terroso-Saenz, F.; Valdes-Vela, M.; Skarmeta, A.F. Fuzzy Modelling for Human Dynamics Based on Online Social Networks. Sensors 2017, 11, 1949. [Google Scholar] [CrossRef] [PubMed]
- Haustein, S.; Bowman, T.D.; Holmberg, K.; Tsou, A.; Sugimoto, C.R.; Larivière, V. Tweets as impact indicators: Examining the implications of automated “bot” accounts on Twitter. J. Assoc. Inf. Sci. Technol. 2016, 67, 232–238. [Google Scholar] [CrossRef]
- Ashktorab, Z.; Brown, C.; Nandi, M.; Culotta, A. Tweedr: Mining twitter to inform disaster response. In Proceedings of the Eleventh International Conference on Information Systems for Crisis Response and Management, University Park, PA, USA, 18–21 May 2014; pp. 354–358. [Google Scholar]
- Barnaghi, P.; Ghaffari, P.; Breslin, J.G. Opinion Mining and Sentiment Polarity on Twitter and Correlation Between Events and Sentiment. In Proceedings of the International Conference on Big Data Computing Service and Applications, Oxford, UK, 29 March–1 April 2016; pp. 52–57. [Google Scholar]
- Amato, F.; Cozzolino, G.; Mazzeo, A.; Romano, S. Detecting anomalies in Twitter stream for Public Security Issues. In Proceedings of the 2nd International Forum in Research and Technologies for Society and Industry Leveraging a Better Tomorrow, Bologna, Italy, 17–21 September 2016; pp. 1–4. [Google Scholar]
- Hernández, A.; Sanchez, V.; Sánchez, G.; Pérez, H.; Olivares, J.; Toscano, K.; Nakano, M.; Martinez, V. Security attack prediction based on user sentiment analysis of Twitter data. In Proceedings of the International Conference on Industrial Technology, Taipei, Taiwan, 14–17 March 2016; pp. 610–617. [Google Scholar]
- Zhang, Y.; Ruan, X.; Wang, H.; Wang, H.; He, S. Twitter Trends Manipulation: A First Look Inside the Security of Twitter Trending. IEEE Trans. Inf. Forensics Secur. 2017, 12, 144–156. [Google Scholar] [CrossRef]
- Bifet, A.; Frank, E. Sentiment knowledge discovery in twitter streaming data. In Proceedings of the International Conference on Discovery Science, Canberra, Australia, 6–8 October 2010; pp. 1–15. [Google Scholar]
- Prasad, S. Micro-Blogging Sentiment Analysis Using Bayesian Classification Methods; Technical Report; Stanford University: Stanford, CA, USA, 2010. [Google Scholar]
- Christianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Nigam, K.; Lafferty, J.; McCallum, A. Using maximum entropy for text classification. In Proceedings of the IJCAI-99 Workshop on Machine Learning for Information Filtering, Stockholm, Sweden, 1 August 1999; Volume 1, pp. 61–67. [Google Scholar]
- Indra, S.T.; Wikarsa, L.; Turang, R. Using logistic regression method to classify tweets into the selected topics. In Proceedings of the International Conference on Advanced Computer Science and Information Systems, Malang, Indonesia, 15–16 October 2016; pp. 385–390. [Google Scholar]
- Gai, K.; Qiu, M.; Sun, X. A survey on FinTech. J. Netw. Comput. Appl. 2018, 103, 262–273. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M. Blend arithmetic operations on tensor-based fully homomorphic encryption over real numbers. IEEE Trans Ind. Informat. 2017. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M.; Ming, Z.; Zhao, H.; Qiu, L. Spoofing-jamming attack strategy using optimal power distributions in wireless smart grid networks. IEEE Trans. Smart Grid 2017, 8, 2431–2439. [Google Scholar] [CrossRef]
- Kirichenko, L.; Radivilova, T.; Carlsson, A. Detecting Cyber Threats Through Social Network Analysis: Short Survey; SocioEconomic Challenges: Sumy, Ukraine, 2017. [Google Scholar]
- Lau, R.Y.; Xia, Y.; Li, C. Social media analytics for cyber attack forensic. Int. Res. J. Eng. Technol. 2012, 1, 217–220. [Google Scholar]
- Samtani, S.; Chen, H. Using social network analysis to identify key hackers for keylogging tools in hacker forums. In Proceedings of the Conference on Intelligence and Security Informatics, Tucson, AZ, USA, 27–30 September 2016; pp. 319–321. [Google Scholar]
- Gharibi, W.; Shaabi, M. Cyber threats in social networking websites. arXiv, 2012; arXiv:1202.2420. [Google Scholar]
- Kumar, S.; Carley, K.M. Understanding DDoS cyber-attacks using social media analytics. In Proceedings of the Conference on Intelligence and Security Informatics, Tucson, AZ, USA, 28–30 September 2016; pp. 231–236. [Google Scholar]
- Gayo-Avello, D. A meta-analysis of state-of-the-art electoral prediction from Twitter data. Soc. Sci. Comput. Rev. 2013, 31, 649–679. [Google Scholar] [CrossRef]
- Schoen, H.; Gayo-Avello, D.; Takis Metaxas, P.; Mustafaraj, E.; Strohmaier, M.; Gloor, P. The power of prediction with social media. Intern. Res. 2013, 23, 528–543. [Google Scholar] [CrossRef]
- Lampos, V.; De Bie, T.; Cristianini, N. Flu detector-tracking epidemics on Twitter. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 599–602. [Google Scholar]
- Yin, J.; Karimi, S.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using social media to enhance emergency situation awareness. IEEE Intell. Syst. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.H.; Liu, B. Predicting flu trends using twitter data. In Proceedings of the Computer Communications Workshops, Shangai, China, 10–15 April 2011; pp. 702–707. [Google Scholar]
- Asur, S.; Huberman, B.A. Predicting the future with social media. In Proceedings of the International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010; pp. 492–499. [Google Scholar]
- API Reference—Twitter Developers. Available online: https://developer.twitter.com/en/docs/tweets/search/api-reference (accessed on 11 March 2018).
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Sanchez, V.; Perez-Meana, H. A Web Scraping Methodology for Bypassing Twitter API Restrictions. arXiv, 2018; arXiv:1803.09875. [Google Scholar]
- Godfrey, D.; Johns, C.; Sadek, C. Interpreting Clusters of World Cup Tweets. arXiv, 2014; arXiv:1408.5427. [Google Scholar]
- Ranks, N.L. Stop Words. Available online: http://www.ranks.nl/stopwords (accessed on 11 March 2018).
- Saini, J.R.; Rakholia, R.M. On Continent and Script-Wise Divisions-Based Statistical Measures for Stop-words Lists of International Languages. Procedia Comput. Sci. 2016, 89, 313–319. [Google Scholar] [CrossRef]
- Porter, M.F. A Language for Stemming Algorithms. 2001. Available online: https://snowball.tartarus.org/texts/introduction.html (accessed on 11 March 2018).
- Balakrishnan, V.; Lloyd-Yemoh, E. Stemming and lemmatization: A comparison of retrieval performances. Lect. Notes Softw. Eng. 2014, 2, 262. [Google Scholar] [CrossRef]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision; CS224N Project Report; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- A Glossary of Common Cybersecurity Terminology. Available online: https://niccs.us-cert.gov/glossary (accessed on 11 March 2018).
- Rogers, M.K. The psyche of cybercriminals: A psycho-social perspective. In Cybercrimes: A Multidisciplinary Analysis; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Rogers, M.K. A two-dimensional circumplex approach to the development of a hacker taxonomy. Digit. Investig. 2006, 3, 97–102. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Feng, L.; Zhu, X. Novel feature selection method based on harmony search for email classification. Knowl. Based Syst. 2015, 73, 311–323. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent twitter sentiment classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 151–160. [Google Scholar]
- Collier, N.; Doan, S. Syndromic classification of twitter messages. In International Conference on Electronic Healthcare; Springer: Berlin/Heidelberg, Germany, 2011; pp. 186–195. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Madison, WI, USA, 26–27 July 1998; pp. 41–48. [Google Scholar]
- Böhme, R.; Moore, T. How do consumers react to cybercrime? In Crime Researchers Summit (eCrime); IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Hastie, T.; Efron, B. Lars: Least Angle Regression. Ann. Stat. 2007, 32, 407–499. [Google Scholar]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gold. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), At Turin, Italy, 3 December 2013. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar]
- Singhal, A.; Buckley, C.; Mitra, M. Pivoted document length normalization. In Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Zurich, Switzerland, 18–22 August 1996; pp. 21–29. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description |
|---|---|
| id | the integer representation of the unique identifier for this Tweet |
| created_at | UTC time when a tweet was created |
| text | The actual UTF-8 text of the status update |
| Prefix | Root | Sufix |
|---|---|---|
| none | corrput | tion |
| none | corrupt | ed |
| none | incorrupt | ibility |
| Account Type | Identified Accounts |
|---|---|
| hacktivism | anonymouspress, youranonglobal, wapoanon, werallanonymous, observingsentin, theanonmovement, freeanons, global_hackers, anonymousvideo, anonrrd |
| cyber-security feeds and sensors | nitdefender, malwarebytes, oinionid, moixec, uscert_gov, nakedsecurity, kaspersky, fsecure, nortononline, nsc |
| researchers and enthusiasts | peerlyst, cyber, mikko, briankrebs, nieljrubenking, dangoodin001, gcluley, campuscodi, peterkruse, e_kaspersky, troyhunt, swiftonsecurity, icheylus |
| Classifier | Class | Precision | Recall | Score |
|---|---|---|---|---|
| NB | negative | 0.77 | 0.80 | 0.79 |
| positive | 0.76 | 0.76 | 0.76 | |
| security-oriented | 0.94 | 0.91 | 0.93 | |
| SVM | negative | 0.80 | 0.80 | 0.80 |
| positive | 0.78 | 0.80 | 0.79 | |
| security-oriented | 0.95 | 0.94 | 0.95 | |
| ME | negative | 0.81 | 0.80 | 0.80 |
| positive | 0.78 | 0.80 | 0.79 | |
| security-oriented | 0.96 | 0.94 | 0.95 |
| Dates | Classifier | pos | neg | sec |
|---|---|---|---|---|
| 9 January 2016 to 23 March 2016 | NB | 1,858,329 | 2,143,213 | 535,449 |
| ME | 26,451,360 | 2,920,311 | 450,793 | |
| SVM | 2,792,088 | 2,346,357 | 540,059 | |
| 24 March 2016 to 12 June 2016 | NB | 1,909,028 | 1,969,211 | 1,969,211 |
| ME | 24,294,780 | 2,384,148 | 569,337 | |
| SVM | 2,564,449 | 2,347,377 | 682,077 | |
| 13 June 2016 to 1 September 2016 | NB | 1,957,351 | 2,428,557 | 1,208,306 |
| ME | 24,017,220 | 27,840,39 | 1,013,131 | |
| SVM | 2,535,151 | 2,740,485 | 1,213,509 | |
| 2 September 2016 to 21 November 2016 | NB | 2,290,596 | 2,966,951 | 951,907 |
| ME | 28,019,700 | 3,308,982 | 802,142 | |
| SVM | 2,957,635 | 3,257,319 | 961,466 | |
| 22 November 2016 to 10 February 2017 | NB | 2,456,003 | 3,217,832 | 985,666 |
| ME | 30,309,120 | 3,480,291 | 827,089 | |
| SVM | 3,199,296 | 3,420,468 | 923,691 | |
| 11 February 2017 to 1 May 2017 | NB | 2,436,753 | 3,464,375 | 237,160 |
| ME | 29,392,200 | 3,703,008 | 198,667 | |
| SVM | 3,102,510 | 3,626,100 | 238,128 |
| Months | MSE | p-Value | Detected Attacks | |||||
|---|---|---|---|---|---|---|---|---|
| January (2016) | 0.00243 | 1609.36 | 845.54 | 0.0 | 0.61 | 116,910 | 70,146 | 2 |
| February (2016) | 0.00223 | 1609.36 | 845.54 | 0.0 | 0.63 | 210,874 | 132,850 | 1 |
| March (2016) | 0.00001 | 1609.36 | 845.54 | 0.0 | 0.81 | 317,625 | 257,276 | 6 |
| April (2016) | 0.00314 | 1609.36 | 845.54 | 0.0 | 0.54 | 372,438 | 249,533 | 2 |
| May (2016) | 0.00141 | 1609.36 | 845.54 | 0.0 | 0.67 | 122,674 | 83,531 | 2 |
| June (2016) | 0.00002 | 1609.36 | 845.54 | 0.0 | 0.89 | 223,674 | 199,069 | 6 |
| July (2016) | 0.00008 | 1609.36 | 845.54 | 0.0 | 0.86 | 230,655 | 198,363 | 1 |
| August (2016) | 0.00009 | 1609.36 | 845.54 | 0.0 | 0.85 | 410,874 | 349,242 | 3 |
| September (2016) | 0.00015 | 1609.36 | 845.54 | 0.0 | 0.77 | 291,643 | 224,565 | 2 |
| October (2016) | 0.0004 | 1609.36 | 845.54 | 0.0 | 0.71 | 241,438 | 188,321 | 2 |
| November (2016) | 0.00054 | 1609.36 | 845.54 | 0.0 | 0.79 | 230,123 | 181,797 | 2 |
| December (2016) | 0.00312 | 1609.36 | 845.54 | 0.0 | 0.53 | 229,451 | 121,609 | 2 |
| January (2017) | 0.00144 | 1609.36 | 845.54 | 0.0 | 0.69 | 378,286 | 261,017 | 1 |
| February (2017) | 0.00334 | 1609.36 | 845.54 | 0.0 | 0.52 | 107,933 | 56,125 | 1 |
| March (2017) | 0.00339 | 1609.36 | 845.54 | 0.0 | 0.51 | 96,973 | 49,456 | 1 |
| April (2017) | 0.00330 | 1609.36 | 845.54 | 0.0 | 0.56 | 94,961 | 53,178 | 1 |
| Index | Date | News | Source | Negative Sample | Security-Oriented Sample |
|---|---|---|---|---|---|
| 1 | 2 January 2016 | ’Anti-IS group’ claims BBC website attack | BBC News | 56,712 | 1573 |
| 2 | 2 January 2016 | Hackers Shut Down Donald Trump Election Campaign Website | Hack Read | 56,712 | 1573 |
| 3 | 29 February 2016 | US Cyber Command launches hacking offensive against Islamic State | Washington Times | 24,378 | 5929 |
| 4 | 4 March 2016 | Donald Trump’s voicemails hacked by Anonymous | The Independent | 30,141 | 7744 |
| 5 | 15 March 2016 | Anonymous Declares ‘Total War’ On Donald Trump With Cyber Attacks Planned For 1 April | Huffington Post UK | 31,977 | 16,940 |
| 6 | 15 March 2016 | Anonymous Just Declared War on Donald Trump With a Massive Cyberattack | MIC | 31,977 | 16,940 |
| 7 | 17 March 2016 | ANONYMOUS OPTRUMP: HACKERS LAUNCH ‘TOTAL WAR’ ON DONALD TRUMP IN REVENGE FOR ‘HATEFUL’ CAMPAIGN | The Independent | 43,401 | 29,282 |
| 8 | 18 March 2016 | Trump Under Attack: The Donald Is Hacked by Anonymous and Son Eric Receives Threatening Letter Containing White Powder | People Magazine | 45,594 | 14,762 |
| 9 | 23 March 2016 | Anti-Trump campaign sparks civil war among Anonymous hackers | The Guardian | 41,922 | 8107 |
| 10 | 1 April 2016 | Anonymous Will Begin Latest War on Donald Trump Friday, April Fools’ Day | Inverse | 40,188 | 7623 |
| 11 | 5 April 2016 | Donald Trump’s hotel chain HACKED for second time in six months | Mirror.co.uk | 35,547 | 16,577 |
| 12 | 8 May 2016 | Presidential candidates may be vulnerable to foreign hackers, US says | The Guardian | 26,469 | 6534 |
| 13 | 31 May 2016 | Hacked construction signs call Trump a ‘shape shifting lizard’ | FOX 4 News | 26,979 | 6538 |
| 14 | 14 June 2016 | Russian Spies Hacked Into the DNC’s Donald Trump files | CNN | 23,358 | 13,794 |
| 15 | 14 June 2016 | Russian Gov Hacks DNC, Steal Trump Oppo | The Weekly Standard | 23,358 | 13,794 |
| 16 | 15 June 2016 | Donald Trump Lone Hacker Claim Responsability for Stealing Democratic Party’s Data | ABC | 34,221 | 14,762 |
| 17 | 21 June 2016 | Russian hackers reportedly access Clinton Foundation | The Sidney Morning Herald | 33,609 | 17,908 |
| 18 | 23 June 2016 | Russian Hackers Targeted Hillary Clinton Campaign Google Accounts | Forbes | 31,467 | 16,456 |
| 19 | 30 June 2016 | Hacker Reveals New Trove of DNC Documents and Answers a Few Personal Questions | Mother Jones | 32,487 | 18,388 |
| 20 | 25 July 2016 | FBI Suspects Russia Hacked DNC; U.S. Officials Say It Was to Elect Donald Trump | Daily Beast | 29,427 | 12,826 |
| 21 | 4 August 2016 | Hackers for Hillary: event attendance ‘through the roof’ after Trump remarks | The Guardian | 38,505 | 8954 |
| 22 | 18 August 2016 | Is Russia hacking the US election? | BBC News | 40,494 | 9075 |
| 23 | 24 August 2016 | No proof, but ‘Russian hackers’: CNN blunders with report on ‘breach’ at NYT–not even asking NYT | International RT | 44,013 | 8833 |
| 24 | 2 September 2016 | Putin on DNC hack: Let’s talk content, not hackers’ identity | International RT | 28,560 | 9438 |
| 25 | 6 September 2016 | Hillary Clinton Suggests Alleged Russian Hacking Is Designed to Help Trump | NBCNews.com | 35,394 | 10,890 |
| 26 | 11 September 2016 | CIA Director John Brennan warns of Russian hacking | NewsHour | 33,762 | 9075 |
| 27 | 14 September 2016 | Trump a ‘National Disgrace,’ Colin Powell Wrote in Hacked Emails | ABC News | 36,465 | 7865 |
| 28 | 17 October 2016 | Could Russian hackers change the U.S. election result? | Aljazeera | 50,184 | 11,374 |
| 29 | 31 October 2016 | Was a Trump Server Communicating With Russia? | Slate Magazine | 53,193 | 11,253 |
| 30 | 10 November 2016 | Russian hackers throw Trump victory party with new spear phishing campaign | Ars Technica | 45,849 | 11,011 |
| 31 | 11 November 2016 | Russia-linked DNC hackers launched wave of cyberattacks hours after Trump victory | Ars Technica | 34,170 | 11,737 |
| 33 | 2 December 2016 | Trump condemns CIA Russia hacking report | BBC News | 31,977 | 12,463 |
| 32 | 9 December 2016 | Russian Hackers Acted to Aid Trump in Election, U.S. Says | New York Times | 41,055 | 12,705 |
| 34 | 9 January 2017 | Surprise! WikiLeaks’ Assange Backs Trump on Russia Hacking Report | NY Times | 36,771 | 11,132 |
| 35 | 22 February 2017 | U.S. CyberCorps, ROTC For Hackers, In Disarray in Trump Admin | Vocativ | 50,082 | 5929 |
| 36 | 5 March 2017 | DeepStateGate: Democrats’ ‘Russian Hacking’ Conspiracy Theory Backfires | Big Government | 43,605 | 13,331 |
| 37 | 10 March 2017 | Trump adviser admits to contact with DNC hacker | The Hill | 42,891 | 1089 |
| 38 | 4 April 2017 | Russian Hackers Are Working To Amplify Donald Trump’s Wiretapping Claim, Expert Warns | HuffPost | 47,481 | 1089 |
| 39 | 10 April 2017 | Russian hacker arrested in Spain over ‘links to Trump victory’ | The Local | 50,898 | 3388 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Perez-Meana, H.; Olivares-Mercado, J.; Sanchez, V. Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors 2018, 18, 1380. https://doi.org/10.3390/s18051380
Hernandez-Suarez A, Sanchez-Perez G, Toscano-Medina K, Martinez-Hernandez V, Perez-Meana H, Olivares-Mercado J, Sanchez V. Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors. 2018; 18(5):1380. https://doi.org/10.3390/s18051380
Chicago/Turabian StyleHernandez-Suarez, Aldo, Gabriel Sanchez-Perez, Karina Toscano-Medina, Victor Martinez-Hernandez, Hector Perez-Meana, Jesus Olivares-Mercado, and Victor Sanchez. 2018. "Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization" Sensors 18, no. 5: 1380. https://doi.org/10.3390/s18051380
APA StyleHernandez-Suarez, A., Sanchez-Perez, G., Toscano-Medina, K., Martinez-Hernandez, V., Perez-Meana, H., Olivares-Mercado, J., & Sanchez, V. (2018). Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors, 18(5), 1380. https://doi.org/10.3390/s18051380