1. Introduction
An increase of road accident rates has become a source of increased casualties and deaths leading to a global road safety crisis [
1]. A total of 52,160 Road Traffic accidents (RTAs) were recorded during the year 2000 in the state of Qatar. Among them, there were 1130 injuries and 85 fatalities. The data consisted on RTAs was collected from the traffic department, Qatar. Almost 53% of the death victims were in the age 10–40 years old, and the remaining 53% who died due to RTAs were in the age of 10–19 years old [
2]. Furthermore, traffic accidents are amongst the major sources of public death in the US [
3] for individuals of age 11 and of every age from 16 through 24 in 2014. The number of motor-vehicle deaths reported in 2016 was 40,200, a 6% increase from 2015, and the first time the total annual fatality has exceeded 40,000 since 2007 [
4].
The most common reason of death in a road accident is the belated delivery or absence of first aid due to the delay of the notification of the accident reaching the nearest hospital or ambulance team. Every minute of delay to provide emergency medical aid to injured crash victims can significantly decrease their survival rate. For instance, an analysis conducted in [
5] showed that a reduction by 1 min in the response time is correlated with a six-percent difference in survival rate. A quick and timely medical response by emergency care services is, therefore, required to reach the accident spot to deliver timely care to the accident victims.
Thus, a preferred approach for reduction in road traffic death rate, is to decrease the unnecessary delays in information to reach the emergency responders [
6]. A six-percent fatality reduction would be possible if all time delays of the notification to emergency responders can be eliminated [
7]. To address this issue, traditional vehicular sensor systems, for instance OnStar, can detect car accidents by means of accelerometer and airbag control modules and notify appropriate emergency services immediately by means of built-in cellular radio sensors [
8]. Automated Crash Notification (ACN) systems exploit the telemetric data from the collided vehicles to inform the emergency services in order to reduce fatalities from car accidents [
9]. Visual sensors (surveillance cameras) are also widely used to monitor driver and vehicle behavior by tracking vehicle trajectories near traffic lights or on highways to monitor traffic flow and road disruptions [
10,
11] A robust visual monitoring system would detect the abnormal events and instantly inform the relevant authority [
12].
However, not all vehicles or roads are equipped with automated accident or damage detection sensors. Furthermore, an analysis based solely on visual data is insufficient and prone to errors [
13]. Indeed, the performance of CCTV cameras is limited under adverse weather conditions and is highly sensitive to sudden lighting changes, reflections, and shadow [
14]. Moreover, the imaging systems have a limited depth-of-field. An activity that occurs within a certain range from the camera remains in focus, while objects closer or away, out of the range appear as blurred or out-of-focus in the image [
15]. In such cases, the visual information available from CCTV cameras is not sufficient to reliably track or monitor the activities of vehicles or to accurately detect hazardous situations. Certain abnormal events, such as gunshots, squealing brakes and screaming cannot be accurately detected from visual information only but have very distinguishing acoustic signatures. Such kind of events can be efficiently detected by analyzing audio streams acquired by microphones [
16]. Furthermore, it may happen that the abnormal events occur outside the range of a camera (field of view) or occluded by obstacles, making them almost impossible to detect by visual analytics. In such scenarios, audio stream analysis can provide complementary information, which may improve the reliability and robustness of the video surveillance system [
17].
Furthermore, CCTV cameras facilitate the collection of information about individuals and thus can lead to increased risk of unintentional browsing or abuse of surveillance data [
18]. On the other hand, audio-based systems can be an alternative solution in situations where CCTV cameras are not permitted due to privacy concerns (e.g., public toilets) [
19]. Audio monitoring systems can be employed either alone or in combination with existing surveillance infrastructures [
20]. In fact, Internet protocol (IP) cameras, which are commonly used for surveillance applications, are typically equipped with embedded microphones, making them multisensory and multimodal fusion systems that are capable of utilizing both audio and visual information.
Standard video cameras are almost useless at night because of the scarce ambient illumination and glare from car headlights. By contrast, audio analysis systems are unaffected under varying lighting conditions. However, this task becomes challenging and the performance may reduce in an open and noisy environment such as a highway. An audio analysis system in such an environment faces a high level of non-stationary background noise in addition to potentially relevant sound events. The sounds of interest to be recognized are interrupted by background noises, making it hard to isolate them from the environmental noise that is often non-stationary. The energy of audio events of interest may be low compared with the unwanted non-stationary noise [
21].
This paper proposes an efficient method for audio event detection for traffic surveillance application. The proposed system performs automatic detection and classification of two types of road hazardous situations: car crashes (CC) and tire skidding (TS) in the presence of environmental noise by analyzing the audio streams captured by microphones. The TS event is considered as an abnormal event because a frequent occurrence of this event is a sign of a dangerous and busy road state, which may require attention from traffic personnel to ensure safety. The problem of audio events detection and classification such as gunshots, explosions, and screams has been addressed in several previous studies [
15,
16,
22,
23]. Although various audio surveillance system setups and additional audio features have been explored, most of the approaches proposed in the previous studies are based on the conventional methods of modeling short-term power spectrum features such as the Mel-frequency cepstral coefficient (MFCC) [
24], using either Gaussian mixture models (GMMs) or Hidden Markov models (HMMs) [
20].
The state-of-the-art approaches for audio-based surveillance can be classified into two main categories, depending upon the architecture used for classification [
16]. Methods residing in the primary category rely on frame by frame operation. The input signal is divided into small chunks of frames, from which characteristic features (MFCCs or wavelet-based coefficients) are extracted. These features are then processed by a classifier to make decisions. For example, Vacher et al. [
25] detected screams or gunshots by employing GMM-based classifiers trained on Wavelet based cepstral coefficients. Similarly, Clavel et al. [
26] did the same using 49 different sets of features. Valenzise et al. [
27] used this approach to model background sounds. In [
28], the automatic detection and recognition of impulsive sounds were proposed utilizing a median filter and linear spectral band features. Six types of impulsive events were classified using both GMM and HMM classifiers, and the results were assessed. The authors in [
26] used short time energy, MFCCs, some spectral features and their derivatives and their combination with a GMM classifier to detect abnormal audio events in continuous recordings of public places. Later a more advanced scheme was designed in [
29] to detect impulsive sounds such as gunshots and screams. In addition, this system is also able to localize the positions of such sound events in a public place. Small improvements were achieved by adding more features, i.e., temporal, spectral distribution, and correlation-based features. Similarly, a two-stage recognition schema was proposed in [
30]. The incoming audio signal is processed to classify it as either a normal sound (metro station environment) or abnormal sound (gunshot, scream or explosion) using MFCC features and an HMM classifier. In case if it is determined to be abnormal, the system can then identify the type of abnormality using maximum-likelihood classification.
In the second category of audio surveillance techniques, more complex architectures have been proposed. For instance, the authors in [
31] presented a combination of two different classification techniques: GMM and a support vector machine (SVM) classifier, to detect shout events in a public transport vehicle. A three-stage integrated system based on a GMM-classifier was proposed in [
32], in which the first stage categorizes the incoming signal as a volcanic (normal speech or a shout) or nonvolcanic (gunshot, explosion, background noise) event. In the second stage, the sounds are further classified into normal or screamed (speech) and in case if it is nonvolcanic event, classified into non-threating background sound or atypical sound event of interest. Finally, in the third stage, the system identifies the type of hazardous situation the incoming signal belongs to. In [
33], an automatic recognizer was proposed that extracts a wide set of features from input signals and classifies them into abnormal events of interest, i.e., screams, gunshot, or broken glass, using two classifiers with rejection options. Their approach consists of combining the decisions of both classifiers to reduce the false detection rate.
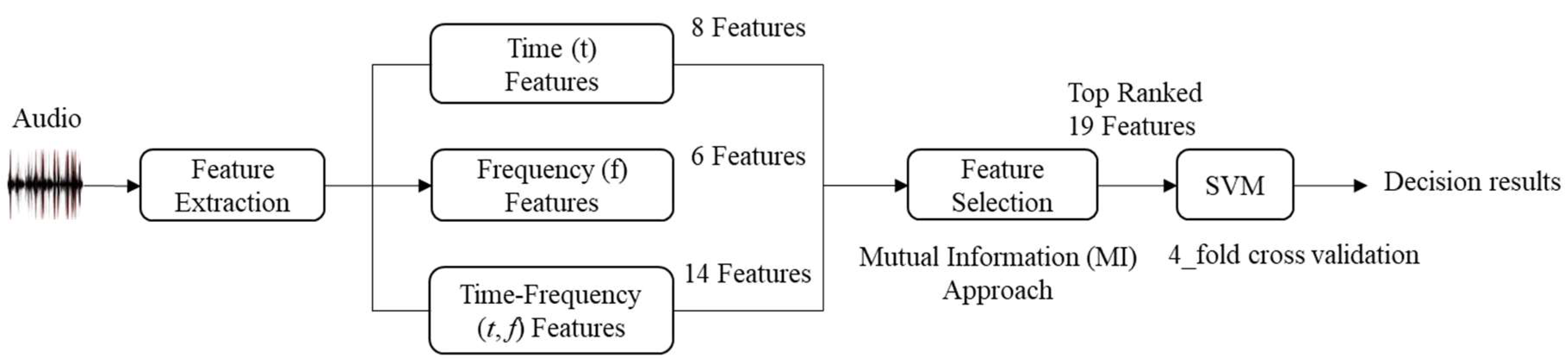
The proposed technique employs a short-time analysis based on features observed in the temporal, spectral and the joint time–frequency (
t,
f) domain, extracted from quadratic time–frequency distributions (QTFDs), for sound detection and classification. Whereas previous studies have either used a combination of temporal and spectral features [
13,
17] or (
t,
f)-based techniques [
22,
23] alone for non-stationary signal classification such as audio data, this work is novel in the sense that we have used a combination of
t-,
f- and (
t,
f)-domain features. In addition, we have extracted (
t,
f)-features from high resolution and robust QTFDs, whereas in previous studies time-frequency features are extracted from conventional spectrograms. We have initially evaluated the resolution and classification performances of different QTFDs, allowing us to select the best amongst them, i.e., the Extended modified beta distribution (EMBD). The performance of the proposed approach is evaluated on the publicly available MIVIA dataset [
13], which contains two types of hazardous events: car crashes and tire skidding. The main aim of this work is to correctly classify events of these two types in the presence of background noise on the highways. For the performance evaluation, the resulting classification results are compared with some of state-of-the-art approaches [
13,
19].
3. Results and Discussions
In order to evaluate the relevance of the set of features considered in the study, the proposed features were ranked in accordance with the criteria defined in
Section 2.
Table 3 shows all
t-,
f- and (
t,
f)-domain features as well as the set of features that were selected based on the minimum redundancy and maximum relevance criteria [
43]. The total classification accuracy is calculated using the n top-ranked features, where
. Through experiments, we observed that the best total classification accuracy was achieved using the 19 top-ranked features listed in
Table 3.
The performance of the proposed approach is evaluated using several different measures: (1) the recognition rate (RR), i.e., the rate of correctly identified events; (2) the false positive rate (FPR), i.e., rate of falsely identified abnormal events which actually belongs to background sounds; (3) the missed detection rate (MDR), i.e., the rate of undetected abnormal events; and (4) the error rate (ER), i.e., the rate of detection of abnormal events but are falsely classified. Using these measures, the classification matrix achieved using the proposed approach is illustrated in
Table 4.
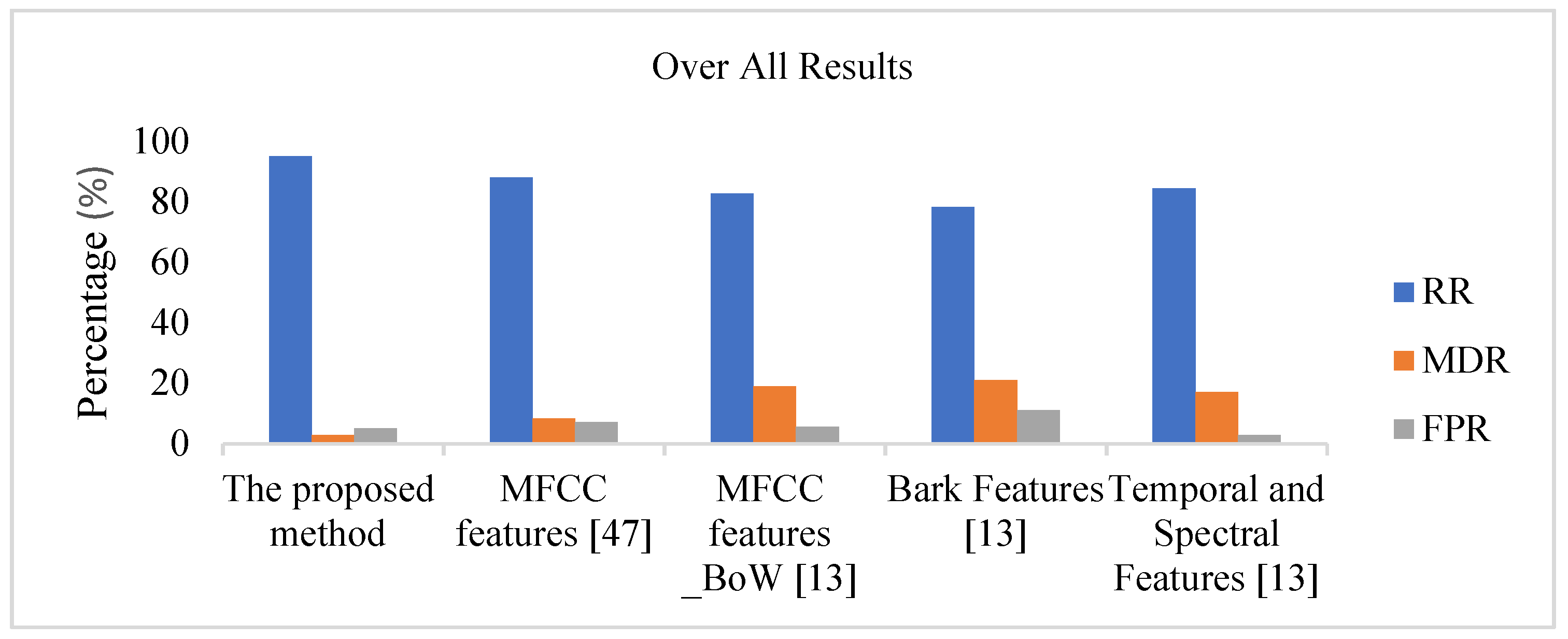
We have compared the results with those achieved using the MFCC features extracted as proposed in [
47] and the system proposed in [
13]. By considering a combination of
t-, f- and (
t,
f)-domain features, the proposed system achieved an average RR of 95% in the presence of background noise, with an MDR of 2.25%. In the case of the MFCC features extracted as proposed in [
47], the system achieved an average RR equal to 88% and an MDR of 2.5%. For comparison, an average RR of 80.25% or 82% with an MDR of 19% or 17.25%, respectively, was achieved using the bag-of-words (BoW) approach proposed in [
13] when the system was configured with
clusters (number of words) and was implemented based on MFCC features or a combination of spectral and temporal features, respectively.
A detection system is considered to be very sensitive if it has a low false negative rate (FNR), meaning that when an event occurs, it is almost certain to be detected. On the other hand, a system is considered to be very specific if it has a low FPR, meaning that when an event is reported, it has almost certainly occurred, with few false alarms. The proposed system is extremely sensitive compared with the sets of features proposed in [
13], as indicated by the MDR of 2.25%. It also has better specificity than either the Bark or the MFCC features, although its specificity is lower than that of the temporal-spectral feature set proposed in [
13], by a small margin.
We also observe that in the proposed approach, the rejection error (undetected events of interest) is less than the interclass error (wrongly classified events). By contrast, for the method proposed in [
13], we observe that the major source of classification error is the rejection error, whereas the interclass error is low. In
Table 5, we have summarized the achieved results in comparison with the features set that is proposed in [
13] for a system configuration with
clusters. We observe that the average RR and MDR for the proposed set of features are much better than those for both the MFCC features based systems proposed in [
47] and [
13], as depicted in
Figure 4.
The proposed system, with its combination with temporal, spectral, and joint (
t,
f) features, shows higher robustness to traffic noise than the Bark and MFCC features proposed in [
13,
46] but lower robustness than the bag-of-words approach when applied based on spectral and temporal features [
13]. However, further studies on the use of advanced QTFDs to extract additional (
t,
f) features could improve the robustness to noise.
Furthermore, in order to confirm the improvement in the RR caused by the combination of the three typologies of features,
Table 6 illustrates the accuracy achieved by the
t-domain features, f-domain features, and joint (
t,
f) features, in addition to their combination without feature selection and after feature selection. Refer to
Table 4, among the 19 top ranked features, 10 features are (
t,
f) features, followed by 5 f-domain features, and 4
t-domain features. This shows that the (
t,
f) features are the most relevant features for audio classification and are supported by the results depicted in
Table 6. The selection of the top 19 features significantly reduces the computation cost of our audio classification system.
The (
t,
f) variance feature amongst the top ranked features in classifying the events of interest can be justified by the fact that the CC sound is an impulsive sound with a limited time duration, whereas the TS is a sustained sound that lasts for several seconds. The variance in the CC sound appears to be higher than the TS sound, due to the high nonuniformity in it. Similarly, the same justification is valid for the coefficient of variation in the (
t,
f) plane, which is the ratio of variance over mean, and appears in the second position in the list. The spectral skewness and spectral flatness measure the spread and uniformity of signal energy distribution in the joint (
t,
f) plane. Based on the energy distribution of signals in the (
t,
f) plane, they can be discriminated. For example, as illustrated in
Figure 5, the energy of the TS sound in the (
t,
f) domain are concentrated along the IFs of the signal components, which results in lower values of the (
t,
f) spectral flatness, whereas the energy of the CC signal is more widely distributed in the (
t,
f) domain, resulting in higher values of (
t,
f) spectral flatness. Similarly, the extension of spectral entropy to (
t,
f) spectral entropy measures the randomness in the signal’s energy distribution in the (
t,
f) plane. The energy of the CC signals is more uniformly distributed in the (
t,
f) domain as compared to the TS signals, resulting in high TF entropy.
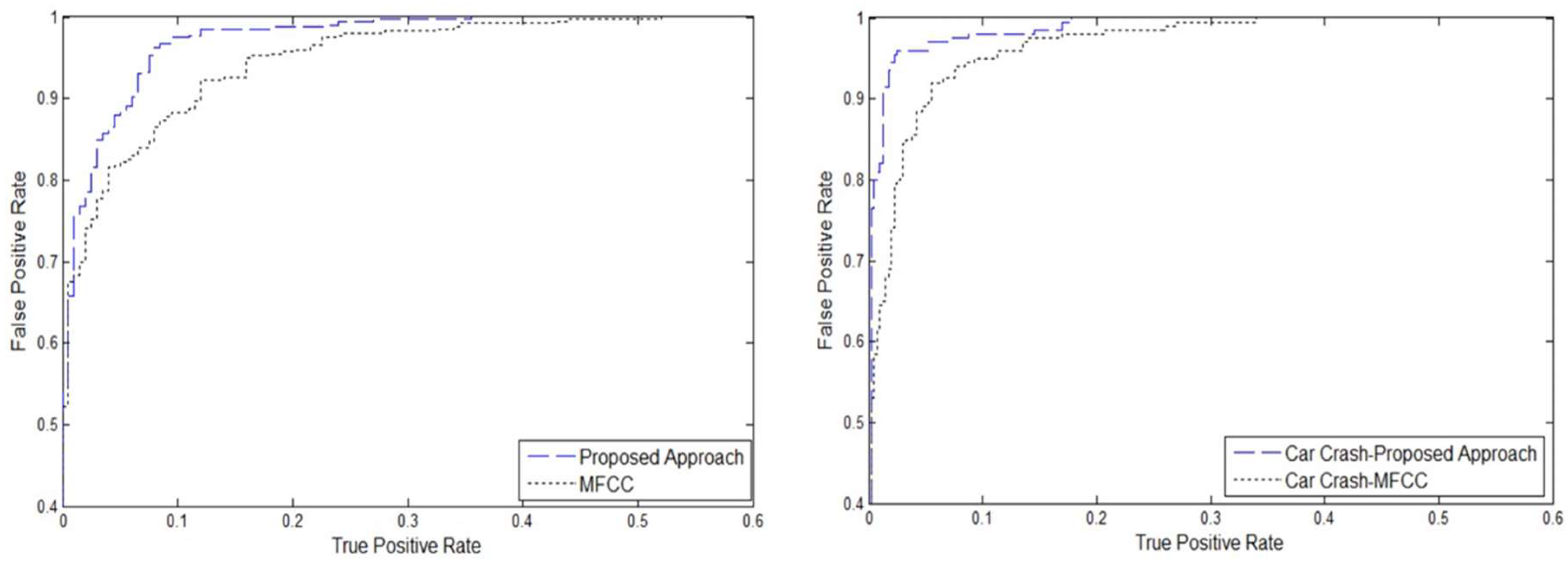
We can further compare the experimental results of our approach with that achieved using the MFCC features [
47], by considering the receiver operating characteristic (ROC) curves depicted in
Figure 6, which reflect the overall performance of the classification systems. The proposed set of features clearly outperforms the MFCC features, as the corresponding curve lies closer to the left and top borders of the quadrant. We can also consider the area under the ROC curve (AUC) as a measure of performance: the AUC results are reported in
Table 5. The closer a ROC curve is to the top-left corner of the plane, the better is the performance of the corresponding classification system. Similarly, a higher AUC value indicates better overall performance, with a value of 1 indicating perfect classification. The proposed method (dashed line) outperforms the MFCC features (dotted line), with an AUC that is approximately 2% higher regardless of whether CC and TS are both considered as positive classes or CC alone is considered as the positive class.
The proposed method detects audio events using an off-line signal analysis. However, in the future we aim to optimize the method for real-time audio signal event identification and classification. The TFDs provide a huge amount of information, which makes them computationally complex and less attractive for real-time application. However, the computational load of TFDs can be significantly reduced by using more computationally efficient algorithms for implementing TFDs [
34]. The proposed approach takes 6 s in processing the three events, i.e., CC, TS and BN of duration 0.75 s each, using a PC equipped with an Intel Core i7, 64 GB of RAM with NVIDIA graphics. The computational time of training a classifier and feature selection is not included. The GPU systems can further reduce the computational time of our algorithm.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}