A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier



Abstract
1. Introduction
2. Ensemble Empirical Mode Decomposition
3. Weighted Permutation Entropy
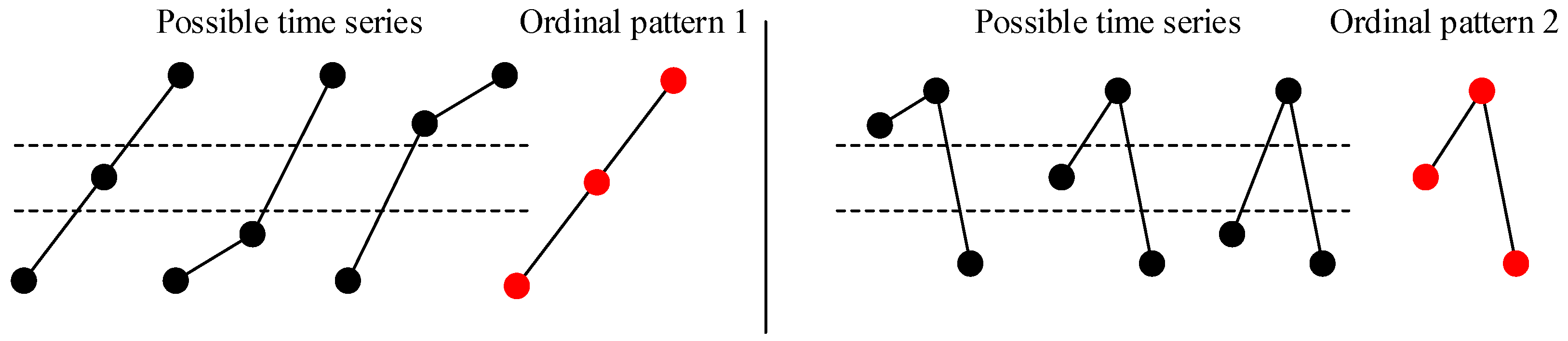
3.1. Permutation Entropy and Weighted Permutation Entropy
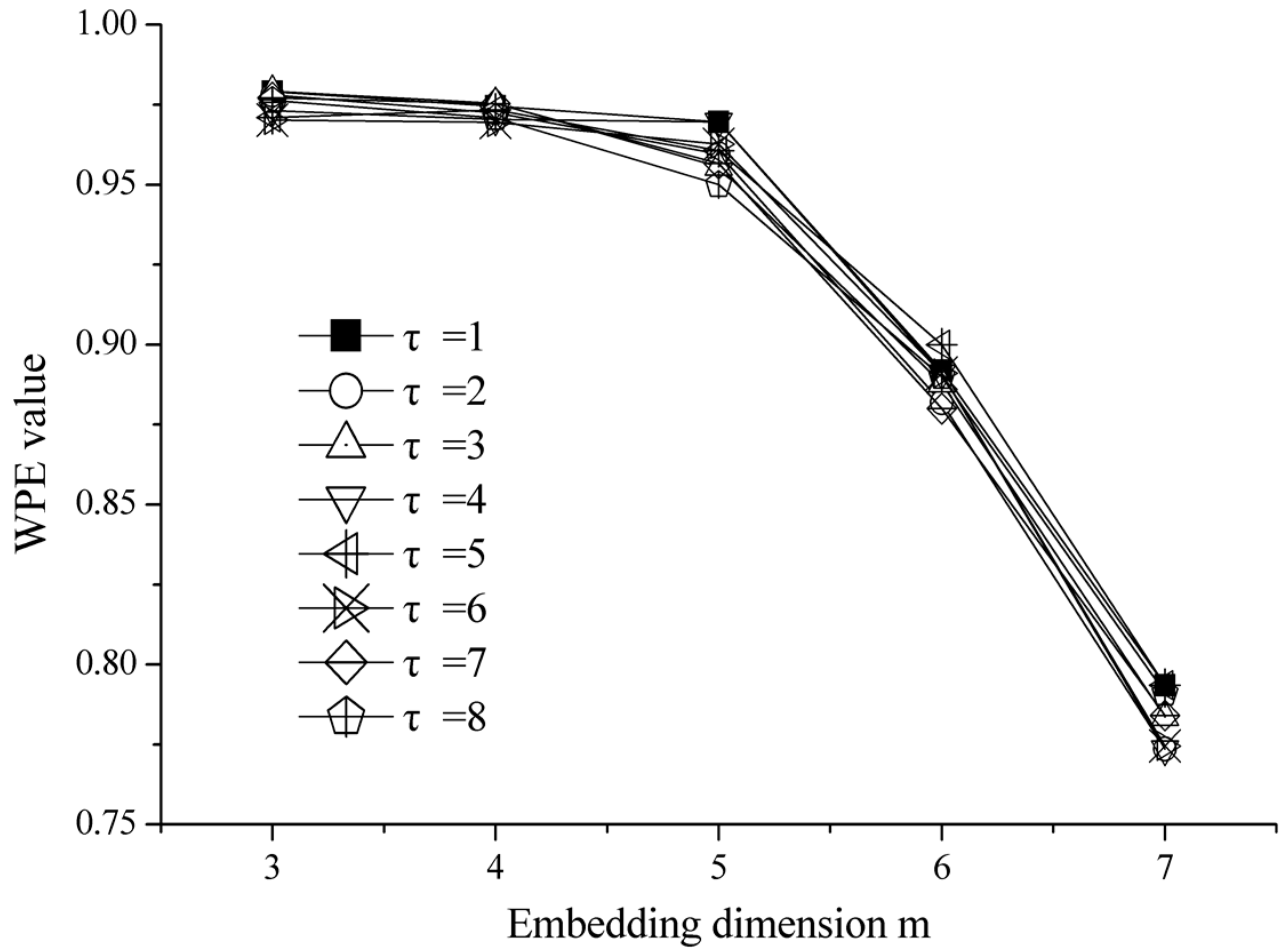
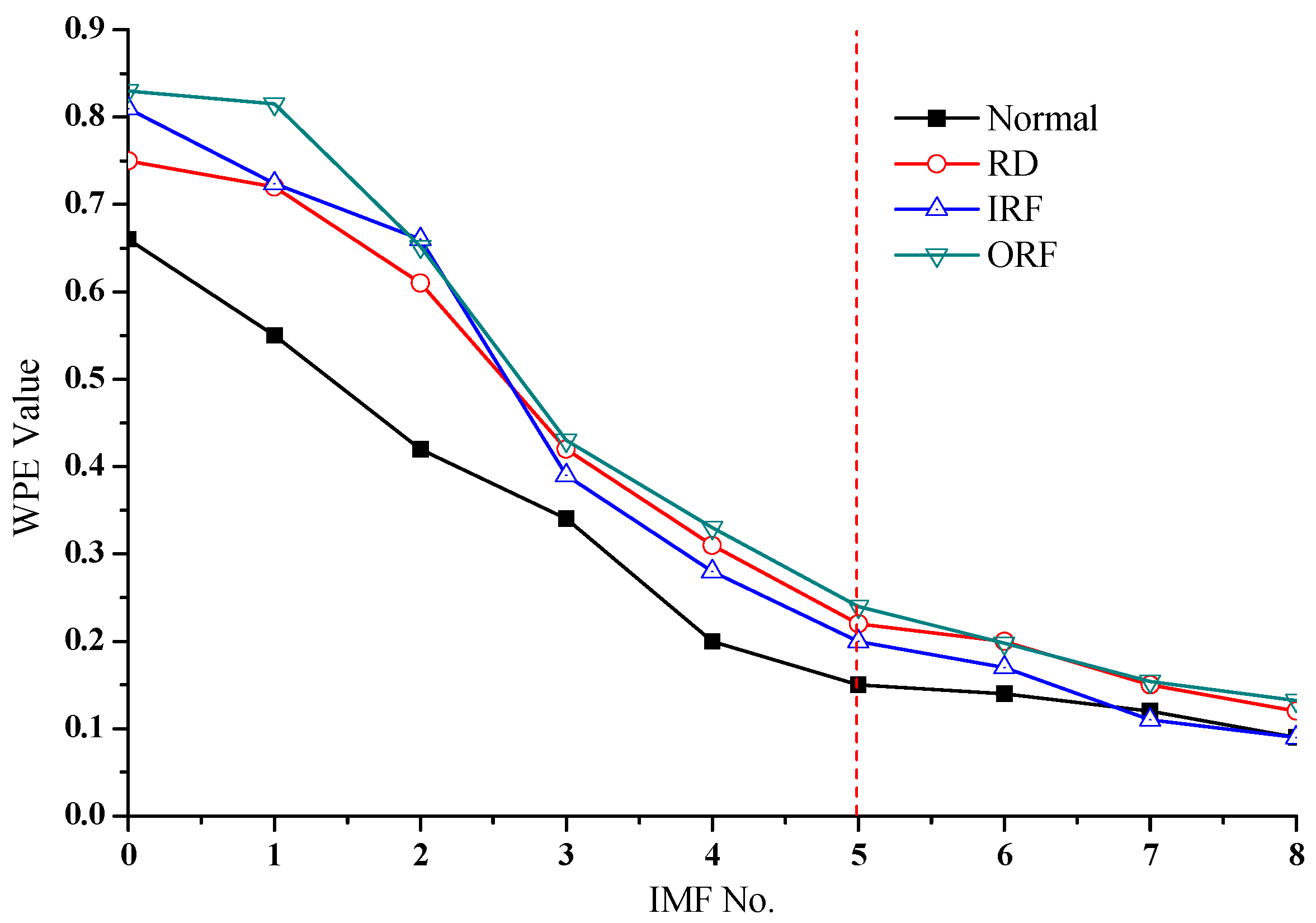
3.2. Parameter Settings for WPE
4. SVM Ensemble Classifier
4.1. Brief Introduction of SVM
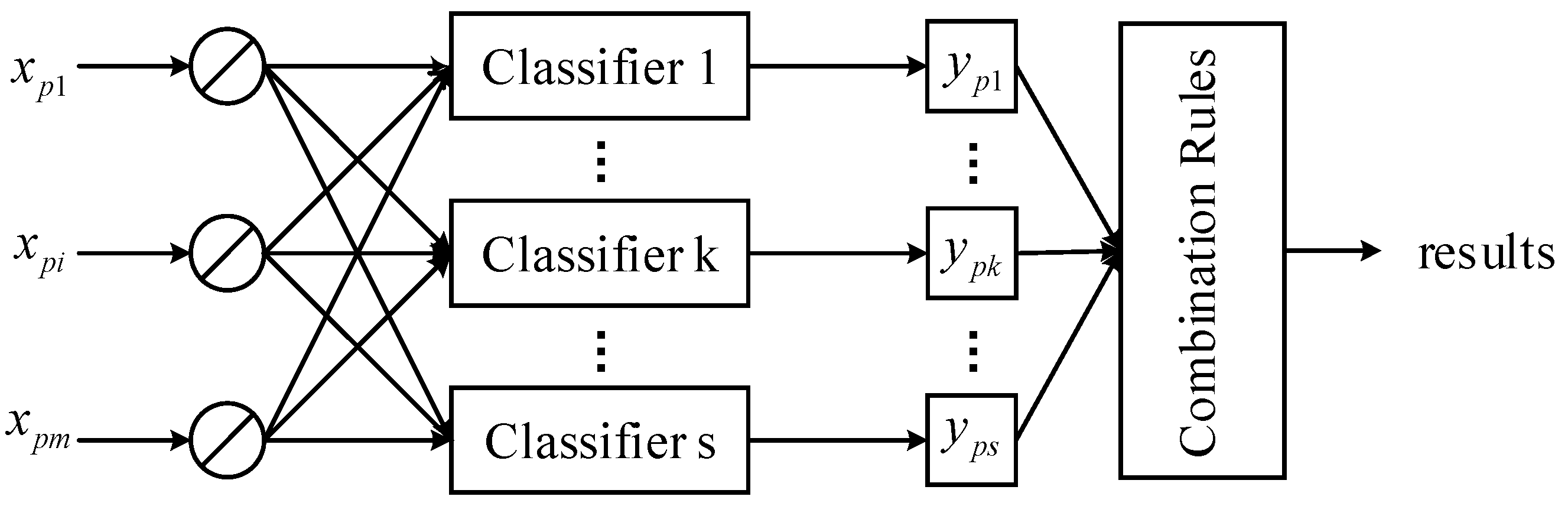
4.2. Multi-Class SVM and Ensemble Classifiers
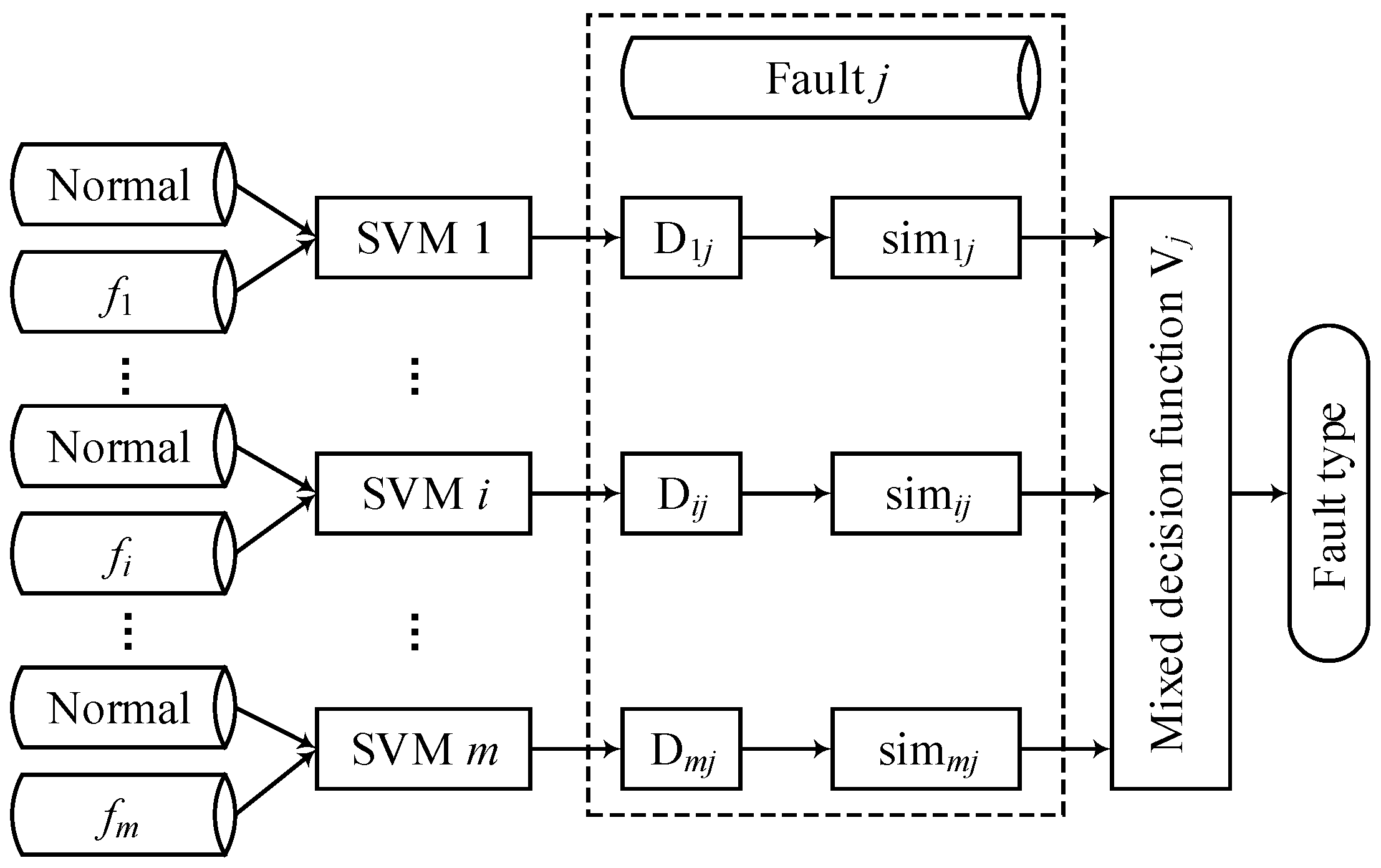
4.3. Multi-Fault Classification Based on an SVM Ensemble Classifier
- (1)
- Standardization of the training sample set (x1, x2, …, xi, …, xn, y).
- (2)
- Use RBF as the kernel function of the SVM and optimize the SVM parameters with cross-validation method (CV) [34].
- (3)
- Calculate the Lagrange coefficient .
- (4)
- Obtain the support vector sv().
- (5)
- Calculate the threshold b.
- (6)
- Establish an optimal classification hyperplane f(x) for training samples.
- (1)
- Generate a single model f(i) for each fault fi using related data.
- (2)
- Use Formula (17) to determine the weight of each model f(i).
- (3)
- Calculate the decision functions Dij of the j-th fault data using model f(i).
- (4)
- The final classification results of the j-th fault data are determined by SVM ensemble classifier with maximizing Vj.
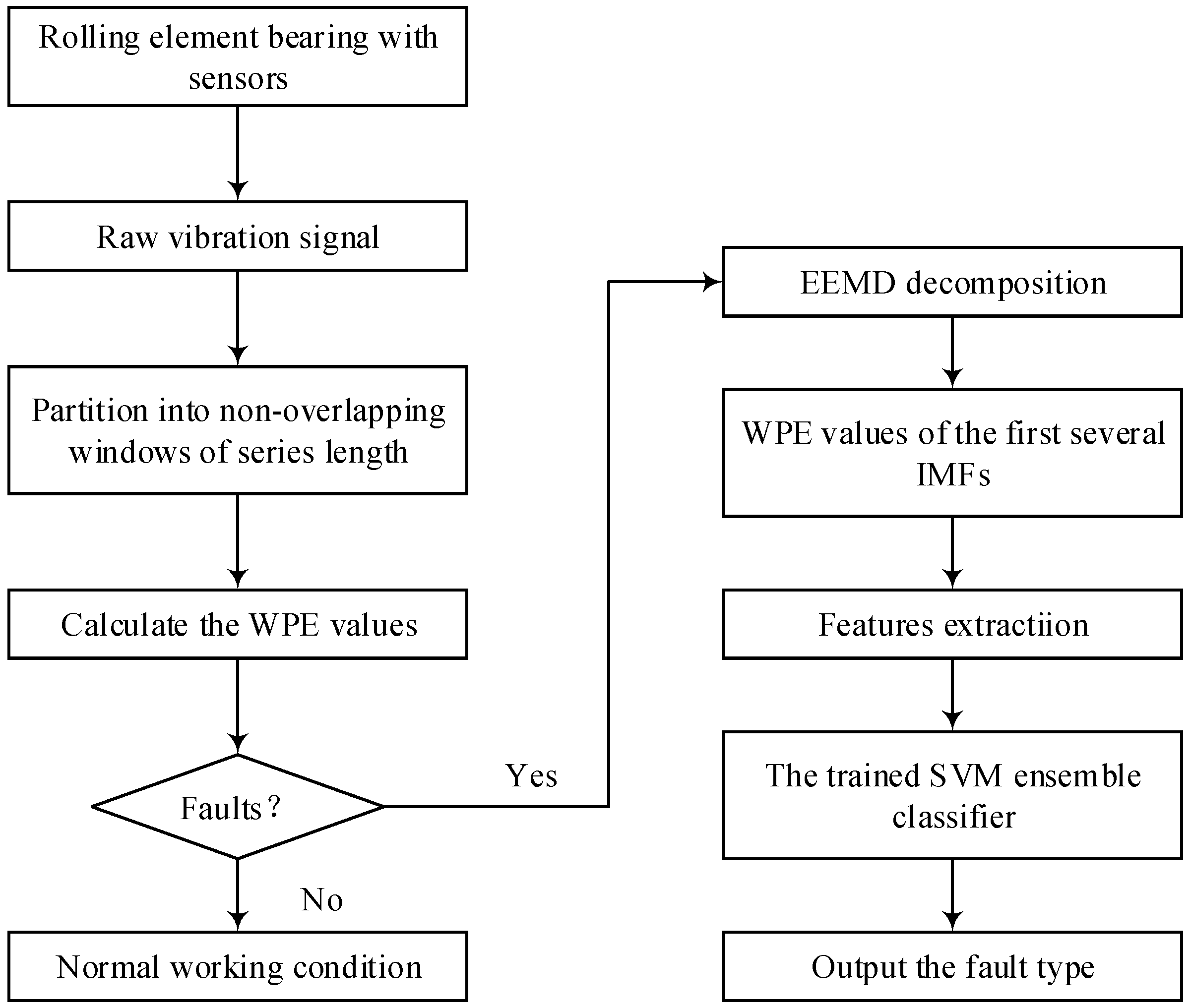
5. Proposed Fault Diagnosis Method
- (1)
- Collect the running time vibration signals of the rolling element bearing.
- (2)
- Decompose the vibration signal into the non-overlapping windows of the series length N.
- (3)
- Use Formulae (11) and (14) to calculate the WPE values for the vibration signal.
- (4)
- Fault detection is realized according to the WPE value of the vibration signal, which determines whether the bearing is faulty. If there is no fault, output the fault diagnosis result that the bearing operation is normal and end the diagnosis process. If there is a fault, go to the next step.
- (5)
- The collected vibration signal is decomposed into a series of IMFs using the EEMD method, and the WPE values of the first several IMFs are calculated as feature vectors using Equations (11) and (14).
- (6)
- Input the feature vectors to the trained SVM ensemble classifier to get the fault classification result and output the fault type.
6. Experimental Validation and Results
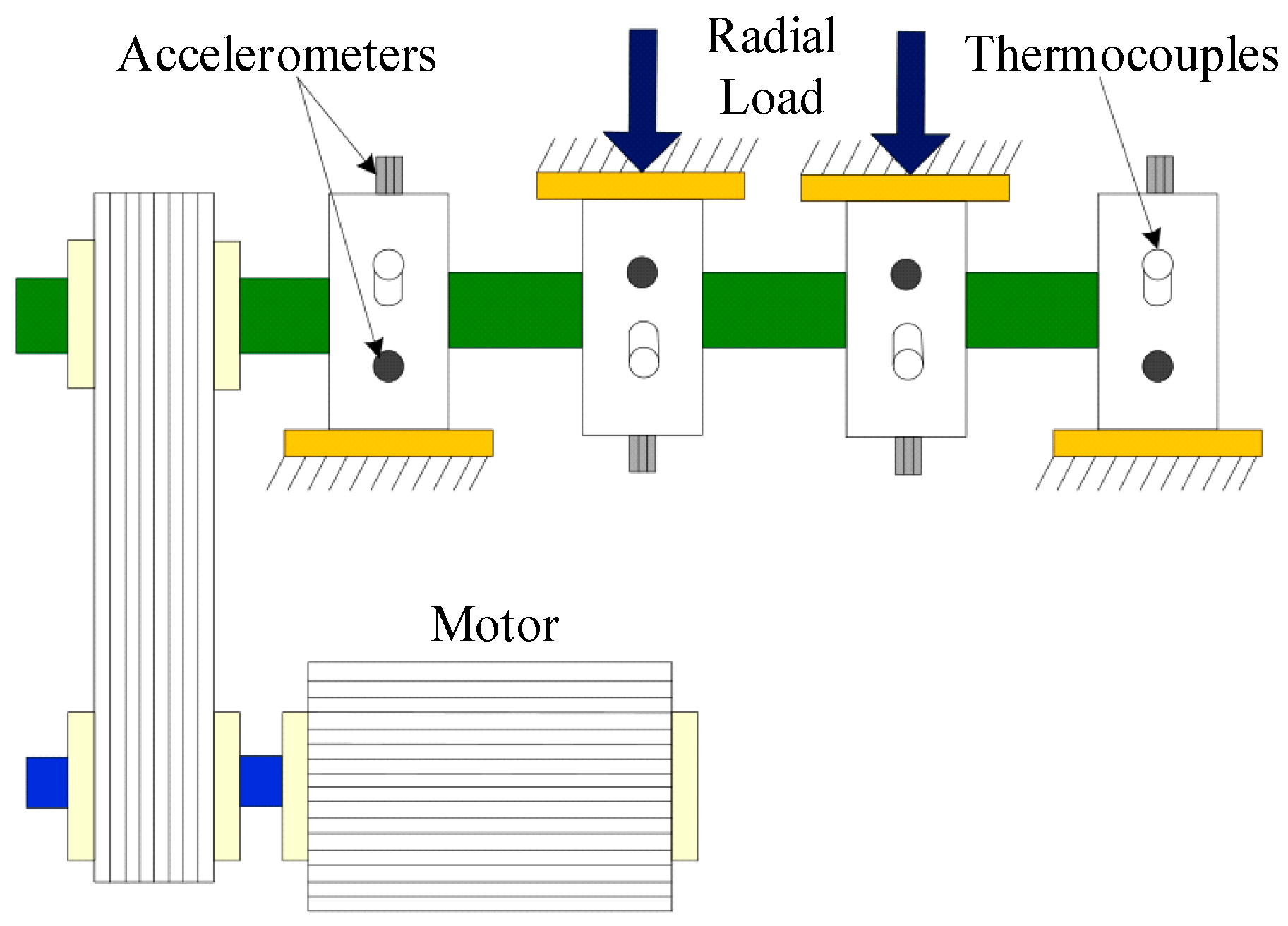
6.1. Experimental Device and Data Acquisition
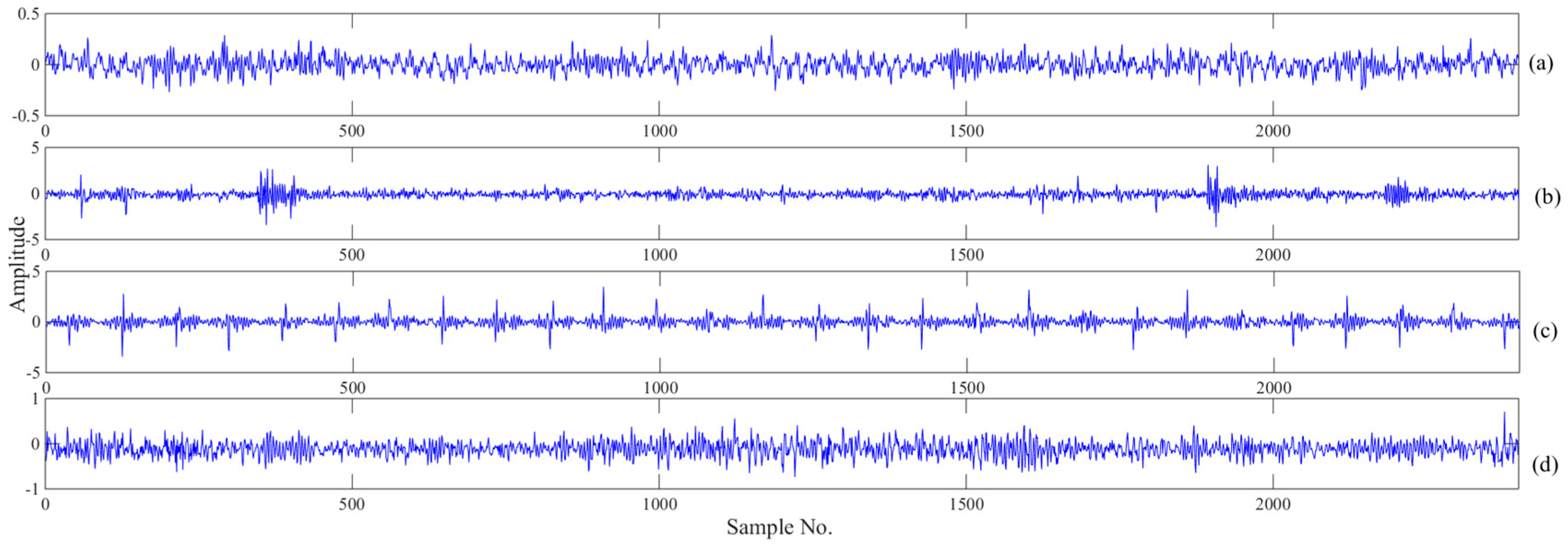
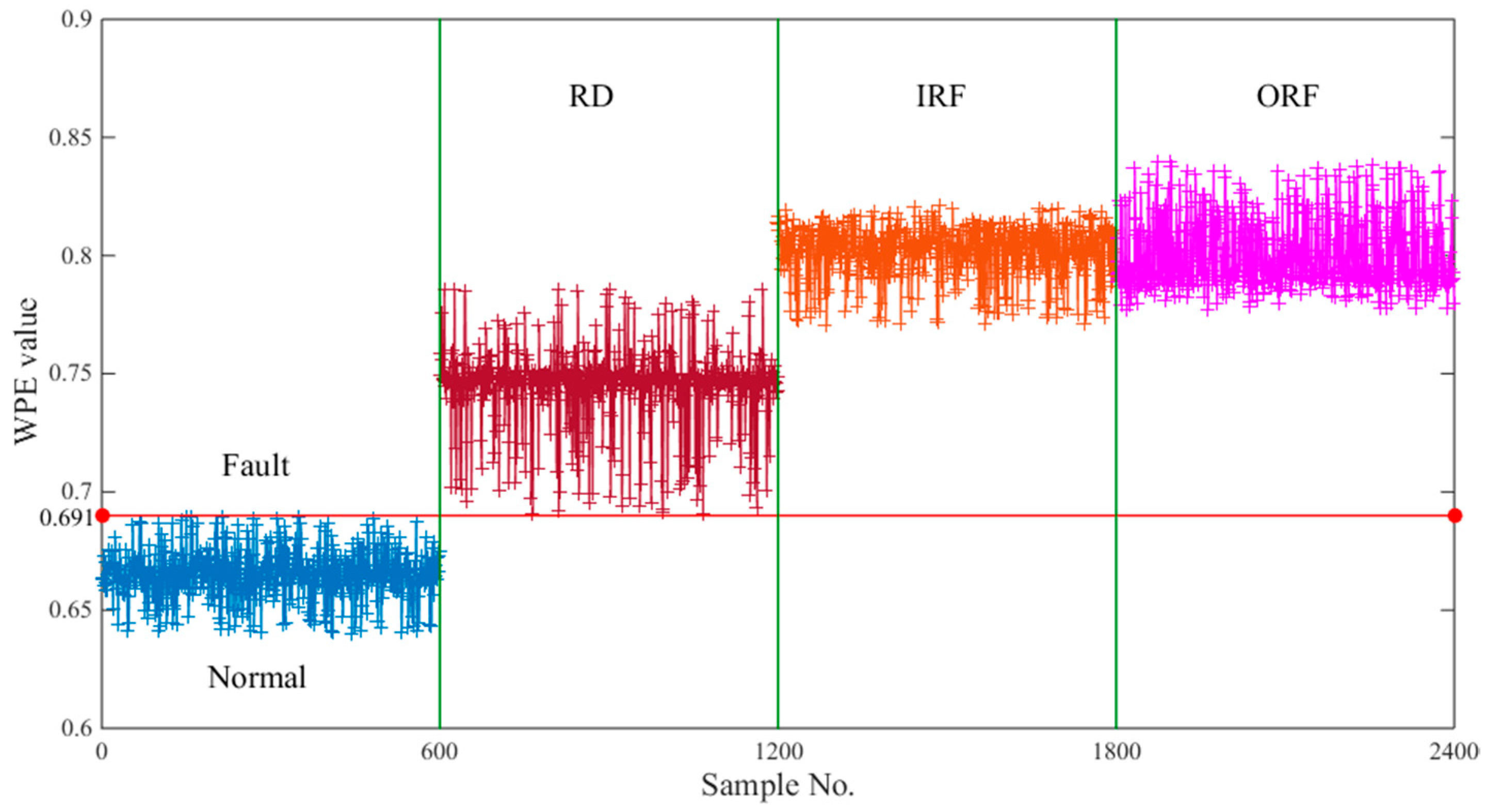
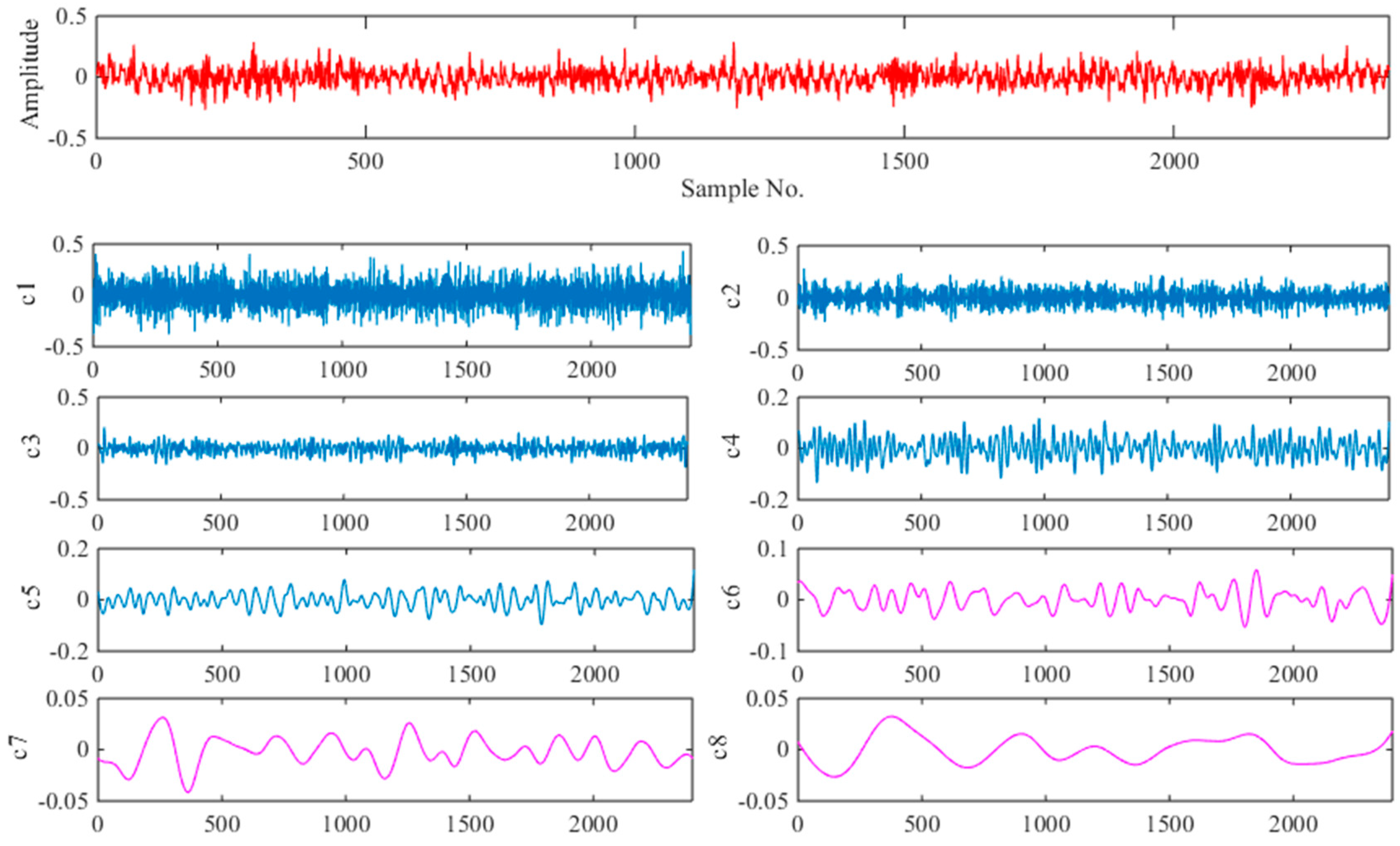
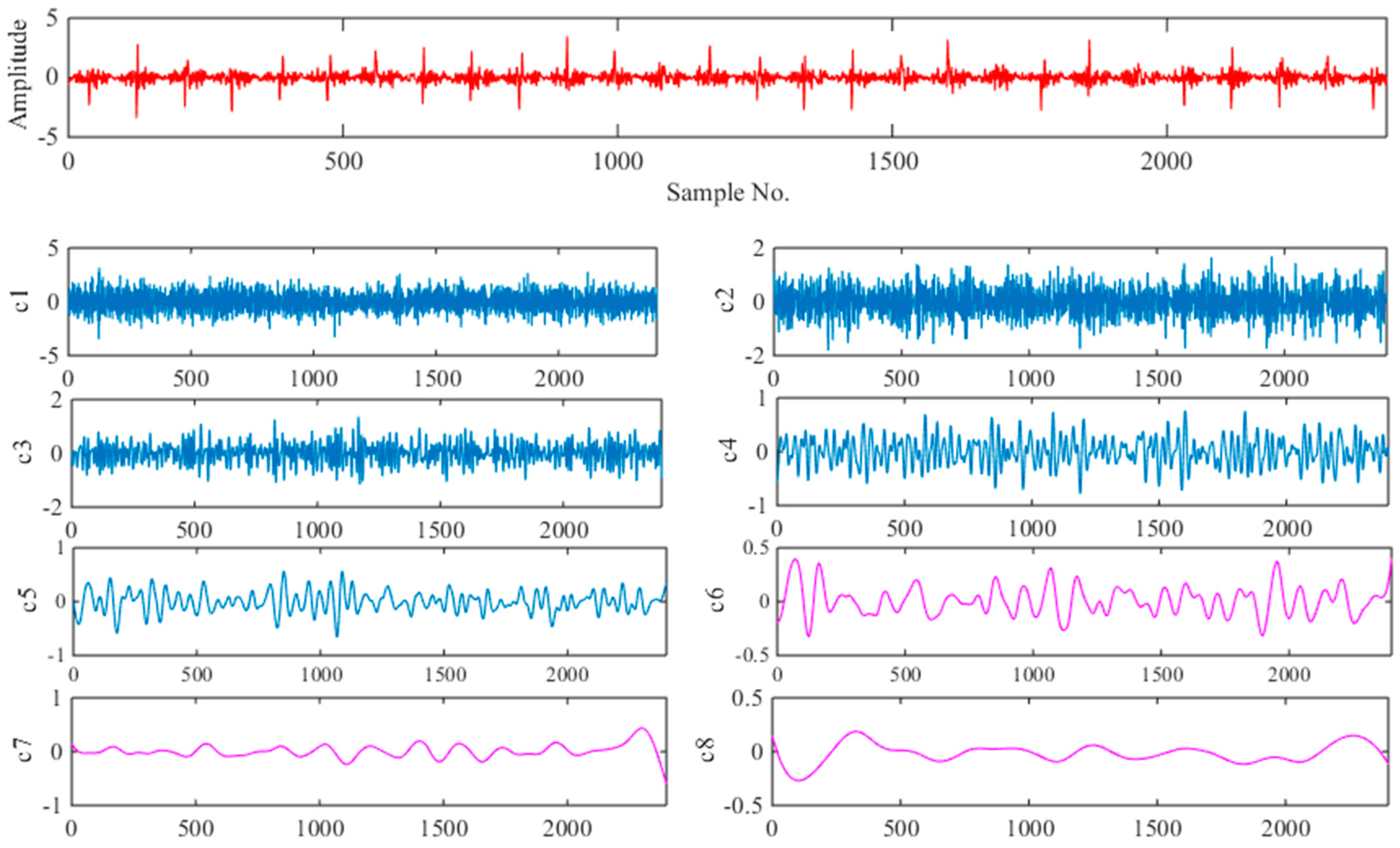
6.2. Fault Detection
6.3. Fault Identification
7. Discussion
7.1. Comparison of Different Decision Rules
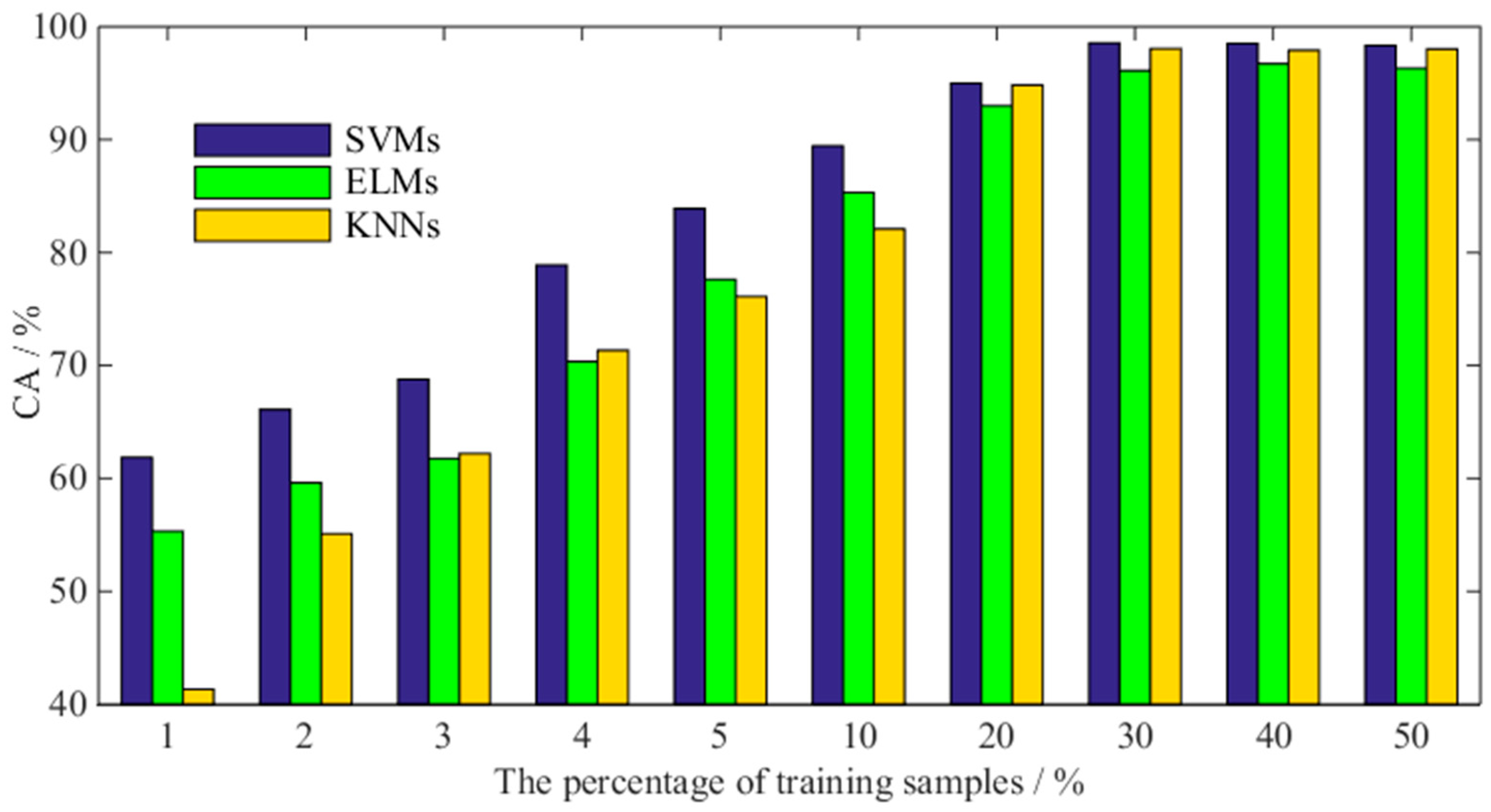
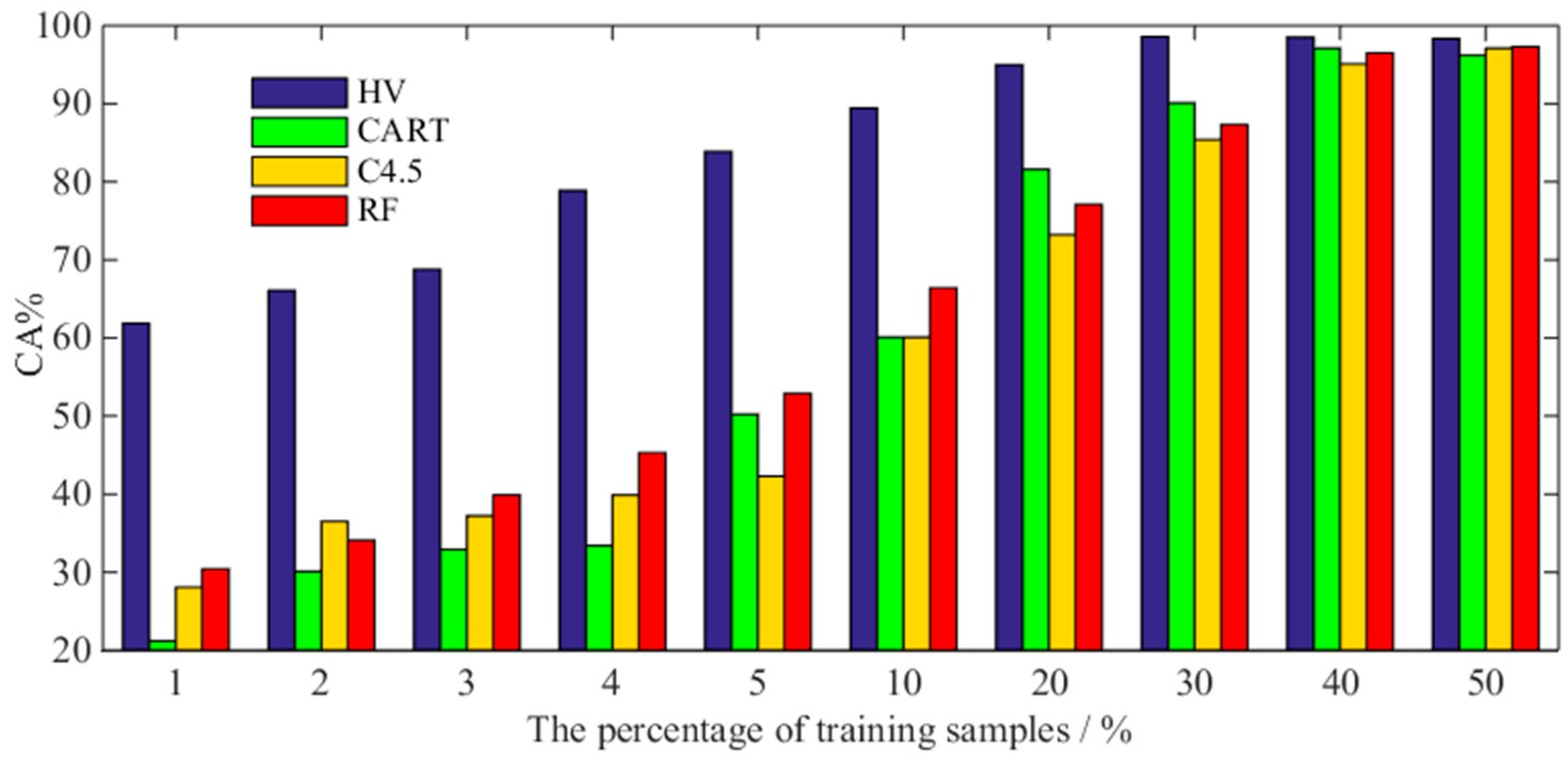
7.2. Comparison with Conventional Ensemble Classifiers
7.3. Comparison with Previous Works
7.4. Limitations and Future Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- William, P.E.; Hoffman, M.W. Identification of bearing faults using time domain zero-crossings. Mech. Syst. Signal Process. 2011, 25, 3078–3088. [Google Scholar]
- Zhang, X.; Liang, Y.; Zhou, J.; Zang, Y. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized svm. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]
- Jiang, L.; Yin, H.; Li, X.; Tang, S. Fault diagnosis of rotating machinery based on multisensor information fusion using svm and time-domain features. Shock Vib. 2014, 2014, 1–8. [Google Scholar]
- Yuan, R.; Lv, Y.; Song, G. Multi-fault diagnosis of rolling bearings via adaptive projection intrinsically transformed multivariate empirical mode decomposition and high order singular value decomposition. Sensors 2018, 18, 1210. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, R.; Gupta, V.K.; Kankar, P.K. Bearing fault diagnosis based on multi-scale permutation entropy and adaptive neuro fuzzy classifier. J. Vib. Control 2013, 21, 461–467. [Google Scholar] [CrossRef]
- Gao, H.; Liang, L.; Chen, X.; Xu, G. Feature extraction and recognition for rolling element bearing fault utilizing short-time fourier transform and non-negative matrix factorization. Chin. J. Mech. Eng. 2015, 28, 96–105. [Google Scholar] [CrossRef]
- Cao, H.; Fan, F.; Zhou, K.; He, Z. Wheel-bearing fault diagnosis of trains using empirical wavelet transform. Measurement 2016, 82, 439–449. [Google Scholar] [CrossRef]
- Wang, H.; Chen, J.; Dong, G. Feature extraction of rolling bearing’s early weak fault based on eemd and tunable q-factor wavelet transform. Mech. Syst. Signal Process. 2014, 48, 103–119. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- He, Y.; Huang, J.; Zhang, B. Approximate entropy as a nonlinear feature parameter for fault diagnosis in rotating machinery. Meas. Sci. Technol. 2012, 23, 45603–45616. [Google Scholar] [CrossRef]
- Widodo, A.; Shim, M.C.; Caesarendra, W.; Yang, B.S. Intelligent prognostics for battery health monitoring based on sample entropy. Expert Syst. Appl. Int. J. 2011, 38, 11763–11769. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y. A rolling bearing fault diagnosis approach based on lcd and fuzzy entropy. Mech. Mach. Theory 2013, 70, 441–453. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, J. Multi-fault diagnosis for rolling element bearings based on ensemble empirical mode decomposition and optimized support vector machines. Mech. Syst. Signal Process. 2013, 41, 127–140. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88. [Google Scholar] [CrossRef] [PubMed]
- Deng, B.; Liang, L.; Li, S.; Wang, R.; Yu, H.; Wang, J.; Wei, X. Complexity extraction of electroencephalograms in alzheimer’s disease with weighted-permutation entropy. Chaos 2015, 25. [Google Scholar] [CrossRef] [PubMed]
- Fadlallah, B.; Chen, B.; Keil, A.; Príncipe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Shang, P. Weighted permutation entropy based on different symbolic approaches for financial time series. Phys. A Stat. Mech. Appl. 2016, 443, 137–148. [Google Scholar] [CrossRef]
- Nair, U.; Krishna, B.M.; Namboothiri, V.N.N.; Nampoori, V.P.N. Permutation entropy based real-time chatter detection using audio signal in turning process. Int. J. Adv. Manuf. Technol. 2010, 46, 61–68. [Google Scholar] [CrossRef]
- Kuai, M.; Cheng, G.; Pang, Y.; Li, Y. Research of planetary gear fault diagnosis based on permutation entropy of ceemdan and anfis. Sensors 2018, 18, 782. [Google Scholar] [CrossRef] [PubMed]
- Yan, R.; Liu, Y.; Gao, R.X. Permutation entropy: A nonlinear statistical measure for status characterization of rotary machines. Mech. Syst. Signal Process. 2012, 29, 474–484. [Google Scholar] [CrossRef]
- Yin, H.; Yang, S.; Zhu, X.; Jin, S.; Wang, X. Satellite fault diagnosis using support vector machines based on a hybrid voting mechanism. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Vapnik; Vladimir, N. The nature of statistical learning theory. IEEE Trans. Neural Netw. 1997, 38, 409. [Google Scholar]
- Bououden, S.; Chadli, M.; Karimi, H.R. An ant colony optimization-based fuzzy predictive control approach for nonlinear processes. Inf. Sci. 2015, 299, 143–158. [Google Scholar] [CrossRef]
- Bououden, S.; Chadli, M.; Allouani, F.; Filali, S. A new approach for fuzzy predictive adaptive controller design using particle swarm optimization algorithm. Int. J. Innovative Comput. Inf. Control 2013, 9, 3741–3758. [Google Scholar]
- Li, L.; Chadli, M.; Ding, S.X.; Qiu, J.; Yang, Y. Diagnostic observer design for t–s fuzzy systems: Application to real-time-weighted fault-detection approach. IEEE Trans. Fuzzy Syst. 2018, 26, 805–816. [Google Scholar]
- Youssef, T.; Chadli, M.; Karimi, H.R.; Wang, R. Actuator and sensor faults estimation based on proportional integral observer for ts fuzzy model. J. Franklin Inst. 2017, 354, 2524–2542. [Google Scholar]
- Yang, X.; Yu, Q.; He, L.; Guo, T. The one-against-all partition based binary tree support vector machine algorithms for multi-class classification. Neurocomputing 2013, 113, 1–7. [Google Scholar] [CrossRef]
- Monroy, I.; Benitez, R.; Escudero, G.; Graells, M. A semi-supervised approach to fault diagnosis for chemical processes. Comput. Chem. Eng. 2010, 34, 631–642. [Google Scholar] [CrossRef]
- Zhong, J.; Yang, Z.; Wong, S.F. Machine condition monitoring and fault diagnosis based on support vector machine. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Macao, China, 7–10 December 2010. [Google Scholar]
- Gupta, S. A regression modeling technique on data mining. Int. J. Comput. Appl. 2015, 116, 27–29. [Google Scholar] [CrossRef]
- Han, L.; Li, C.; Shen, L. Application in feature extraction of ae signal for rolling bearing in eemd and cloud similarity measurement. Shock Vib. 2015, 2015, 1–8. [Google Scholar] [CrossRef]
- Xia, J.; Shang, P.; Wang, J.; Shi, W. Permutation and weighted-permutation entropy analysis for the complexity of nonlinear time series. Commun. Nonlinear Sci. Numer. Simul. 2016, 31, 60–68. [Google Scholar] [CrossRef]
- Cao, Y.; Tung, W.-W.; Gao, J.; Protopopescu, V.A.; Hively, L.M. Detecting dynamical changes in time series using the permutation entropy. Phys. Rev. E 2004, 70. [Google Scholar] [CrossRef] [PubMed]
- Saidi, L.; Ben Ali, J.; Friaiech, F. Application of higher order spectral features and support vector machines for bearing faults classification. ISA Trans. 2015, 54, 193–206. [Google Scholar] [CrossRef] [PubMed]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Sun, J.; Fujita, H.; Chen, P.; Li, H. Dynamic financial distress prediction with concept drift based on time weighting combined with adaboost support vector machine ensemble. Knowl. Based Syst. 2017, 120, 4–14. [Google Scholar] [CrossRef]
- Li, W.; Qiu, M.; Zhu, Z.; Wu, B.; Zhou, G. Bearing fault diagnosis based on spectrum images of vibration signals. Meas. Sci. Technol. 2015, 27. [Google Scholar] [CrossRef]
- Lam, K. Rexnord technical services. In Bearing Data Set, Nasa Ames Prognostics Data Repository; NASA Ames: Moffett Field, CA, USA, 2017. [Google Scholar]
- Kolter, J.Z.; Maloof, M.A. Dynamic weighted majority: An ensemble method for drifting concepts. J. Mach. Learn. Res. 2007, 8, 2755–2790. [Google Scholar]
- Wu, X.D.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Zhang, R.; Peng, Z.; Wu, L.; Yao, B.; Guan, Y. Fault diagnosis from raw sensor data using deep neural networks considering temporal coherence. Sensors 2017, 17, 549. [Google Scholar] [CrossRef] [PubMed]
- Yao, B.; Su, J.; Wu, L.; Guan, Y. Modified local linear embedding algorithm for rolling element bearing fault diagnosis. Appl. Sci. 2017, 7, 1178. [Google Scholar] [CrossRef]
- Zimroz, R.; Bartelmus, W. Application of adaptive filtering for weak impulsive signal recovery for bearings local damage detection in complex mining mechanical systems working under condition of varying load. Solid State Phenom. 2012, 180, 250–257. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bearing Condition | Number of Training Data | Number of Testing Data |
|---|---|---|
| Normal | 400 | 200 |
| IRF | 400 | 200 |
| ORF | 400 | 200 |
| RD | 400 | 200 |
| Actual Classes | Predicted Classes | ||
|---|---|---|---|
| RD | IRF | ORF | |
| RD | 600 | 0 | 0 |
| IRF | 3 | 583 | 14 |
| ORF | 2 | 21 | 577 |
| Fault Type | Average CA | Variance |
|---|---|---|
| RD | 100% | 0 |
| IRF | 97.17% | 1.02 |
| ORF | 96.16% | 0.37 |
| Total | 97.78% | 0.12 |
| Decision Rule | Average CA | Variance |
|---|---|---|
| MV | 72.94% | 1.13 |
| SWV | 78.56% | 2.21 |
| DWV | 85.22% | 2.45 |
| HV | 97.78% | 0.12 |
| Reference | Characteristic Features | Classifier | Number of Classified States | Construction Strategy of Training Data Set | CA (%) |
|---|---|---|---|---|---|
| Zhang et al. [42] | Divide time series data into segmentations | Deep Neural Networks (DNN) | 4 | Random selection | 94.9 |
| Yao et al. [43] | Modified local linear embedding | K-Nearest Neighbor (KNN) | 4 | Random selection | 100 |
| Saidi et al. [34] | Higher order statistics (HOS) of vibration signals + PCA | SVM-OAA | 4 | Random selection | 96.98 |
| Tiwari et al. [5] | Multi-scale permutation entropy (MPE) | Adaptive neuro fuzzy classifier | 4 | Random selection +10-fold cross validation | 92.5 |
| Zhang et al. [13] | Singular value decomposition | Multi class SVM optimized by inter cluster distance | 3 | Random selection | 98.54 |
| Present work | Weighted permutation entropy of IMFs decomposed by EEMD | SVM ensemble classifier + Decision function | 3 | Random selection | 97.78 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Qian, S.; Chang, W.; Xiao, Y.; Cheng, Y. A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier. Sensors 2018, 18, 1934. https://doi.org/10.3390/s18061934
Zhou S, Qian S, Chang W, Xiao Y, Cheng Y. A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier. Sensors. 2018; 18(6):1934. https://doi.org/10.3390/s18061934
Chicago/Turabian StyleZhou, Shenghan, Silin Qian, Wenbing Chang, Yiyong Xiao, and Yang Cheng. 2018. "A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier" Sensors 18, no. 6: 1934. https://doi.org/10.3390/s18061934
APA StyleZhou, S., Qian, S., Chang, W., Xiao, Y., & Cheng, Y. (2018). A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier. Sensors, 18(6), 1934. https://doi.org/10.3390/s18061934