1. Introduction
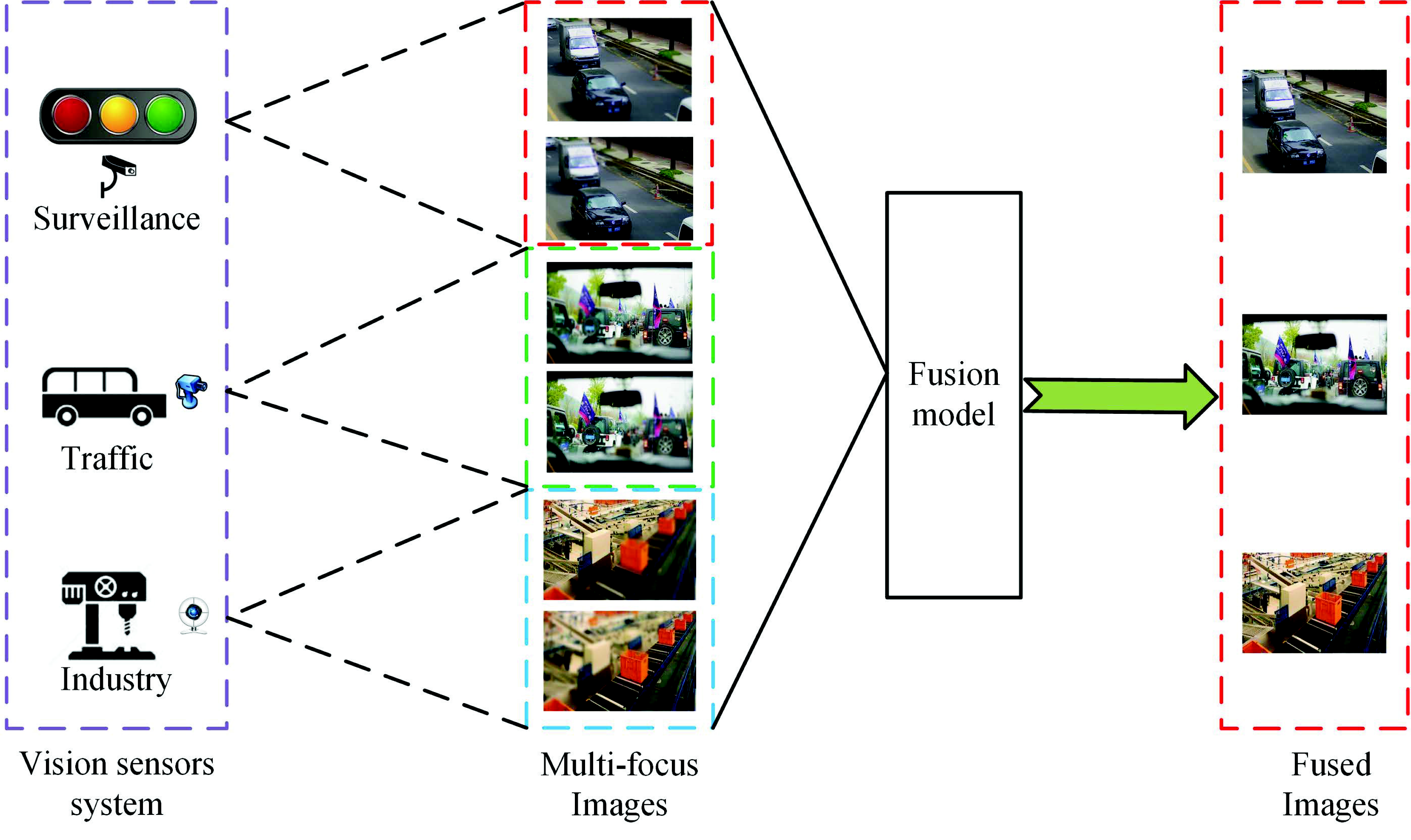
A large number of images can be obtained via vision sensor systems (VSS). These images are employed in many applications, such as surveillance, traffic and industrial, as is shown in
Figure 1. For example, these images can be used to build an urban surveillance system, as in [
1]. Besides, these images can be utilized to monitor objects and behavior in [
2]. Images with sufficient information are required to achieve these goals. However, Since the depth of field (DOF) is limited in vision sensors, it is hard to obtain an all-focused image, which can provide more information compared to the single multi-focus image. This causes difficulties for VSS in analyzing and understanding the image. In addition, it also causes redundancy in storage. To address those problems, multi-focus image fusion technology can fuse the complementary information from two or more defocused images into a single all-focused image. Compared with each defocused image, the fused image with extended DOF can provide more information and can thus better interpret the scene.
Of the popular multi-focus image fusion methods, there are two major branches [
3]: spatial domain methods and transform domain methods.
Spatial domain methods directly fuse source images via specific fusion rules. The primitive way is to calculate the mean of the source images pixel by pixel. To avoid the same treatment of pixels, Tian et al. [
4] used a normalized weighted aggregation approach. Li et al. [
5] decomposed the source image into the detail layer and base layer, then fused them by using a guided filter. However, the pixel-based fusion methods are often subject to noise and misregistration. To further enhance the fusion performance, some block- and region-based methods have been proposed. For instance, Li et al. [
6] chose the image blocks based on spatial frequency. Miao et al. [
7] measured the activity of blocks based on image gradients. Song et al. [
8] fused source images adaptively by using the weighted least squares filter. Jian et al. [
9] decomposed images into multiple scales and fused them through a rolling guidance filter. Zuo et al. [
10] fused images based on region segmentation. Besides spatial frequency and image gradients, the energy of Laplacian method is also an important method to evaluate the sharpness measures. Although the influences of noise and misregistration become smaller, those methods often suffer from block artifacts and contrast decrease.
Unlike the former, the main idea of transform domain methods is to fuse multi-focus images in the transform domain. Those methods include the Laplacian pyramid (LP) [
11], the ratio of the low-pass pyramid (RP) [
12], the gradient pyramid (GP) [
13], discrete wavelet transform (DWT) [
14], dual-tree complex wavelet transform (DTCWT) [
15] and discrete cosine harmonic wavelet transform (DCHWT) [
16]. Nowadays, some multi-scale geometry analysis tools are employed. For instance, Tessens et al. [
17] used curvelet transform (CVT) to decompose multi-focus images. Zhang et al. [
18] used nonsubsampled contourlet transform (NSCT) to decompose multi-focus images. Huang et al. [
19] fused source images in the non-subsampled shearlet transform domain. Wu et al. [
20] used the hidden Markov model to fuse multi-focus images. Besides the transform domain methods listed above, some new transform domain method such as independent component analysis (ICA) [
21] and sparse representation (SR) [
22,
23] are also used to fuse multi-focus image. To avoid block effects and undesirable artifacts, those methods often employ the sliding window technique to obtain image patches. For instance, SR-based image fusion methods divide source images into patches via a sliding window with a fixed size and transform the image patches to sparse coefficients, then apply the L1-norm to the sparse coefficients to measure the activity level.
Although some of the multi-focus fusion methods perform well, there are still some drawbacks that remain to be settled. For spatial domain methods, some of them are subject to noisy and misregistration, and block effects may be caused in the fused images. Besides, some methods also result in increased artifacts near the boundary, decreased contrast and reduced sharpness. For transform domain methods, the fusion rules are based on the relevant coefficients; thus, a small change in the coefficients would cause a huge change in pixel values, which would cause undesirable artifacts.
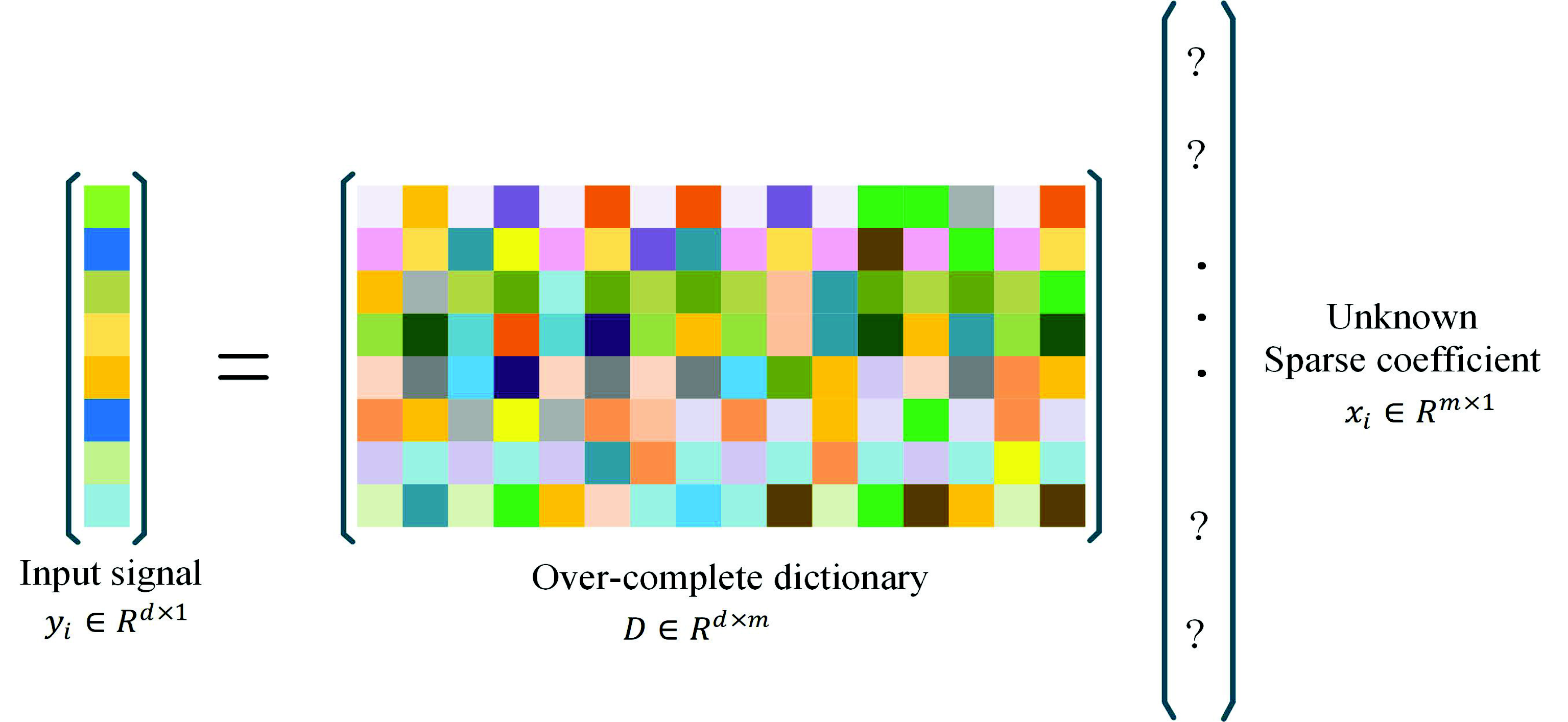
Sparse representation [
22] has drawn much attention in recent years for its outstanding ability in computer vision tasks and machine learning, such as image denoising [
24], object tracking [
25,
26], face recognition [
27] and image super-resolution [
28,
29,
30]. Similarly, sparse representation has achieved great success in the field of multi-focus image fusion [
31,
32,
33,
34,
35]. Yang et al. [
31] brought SR to multi-focus image fusion. Based on this work, Liu et al. [
32] fused the multi-focus images based on SR with adaptive sparse domain selection. In their method, different categories of images were utilized to learn multiple sub-dictionaries. However, this often leads to overfitting of the sub-dictionaries and causes obvious artificial effects. To address this problem, Liu et al. [
33] decomposed source images into multiple scale and fused them by using SR. To further improve the resolution of the fused image, Yin et al. [
34] combined image fusion and image super-resolution together based on SR. Besides, Mansour et al. [
35] proposed a novel multi-focus image fusion method based on SR with a guided filter, and the Markov random field was also utilized to refine the decision map in their method. These methods can achieve good performances. However, there are still some drawbacks that remain to be settled:
Some SR-based methods [
31,
32,
33,
34,
35] obtain the fused image by fusing the corresponding sparse coefficients directly, while a small change in the coefficients may cause a huge variation in pixel values. This would lead to undesirable effects on the fused image.
For some ambiguous areas in the multi-focus image, the sparse coefficients cannot determine if they are focused or not. This often causes spatial inconsistency problems. For example, the initial map obtained by Mansour’s method [
35] suffered from spatial inconsistency. The following process to refine the decision map requires much computational cost.
The boundary between the focused area and the unfocused area is smooth, while the final decision map obtained by Mansour’s method [
35] was sharp on the boundary. This may lead to halo effects on the boundary between the focused area and the unfocused area.
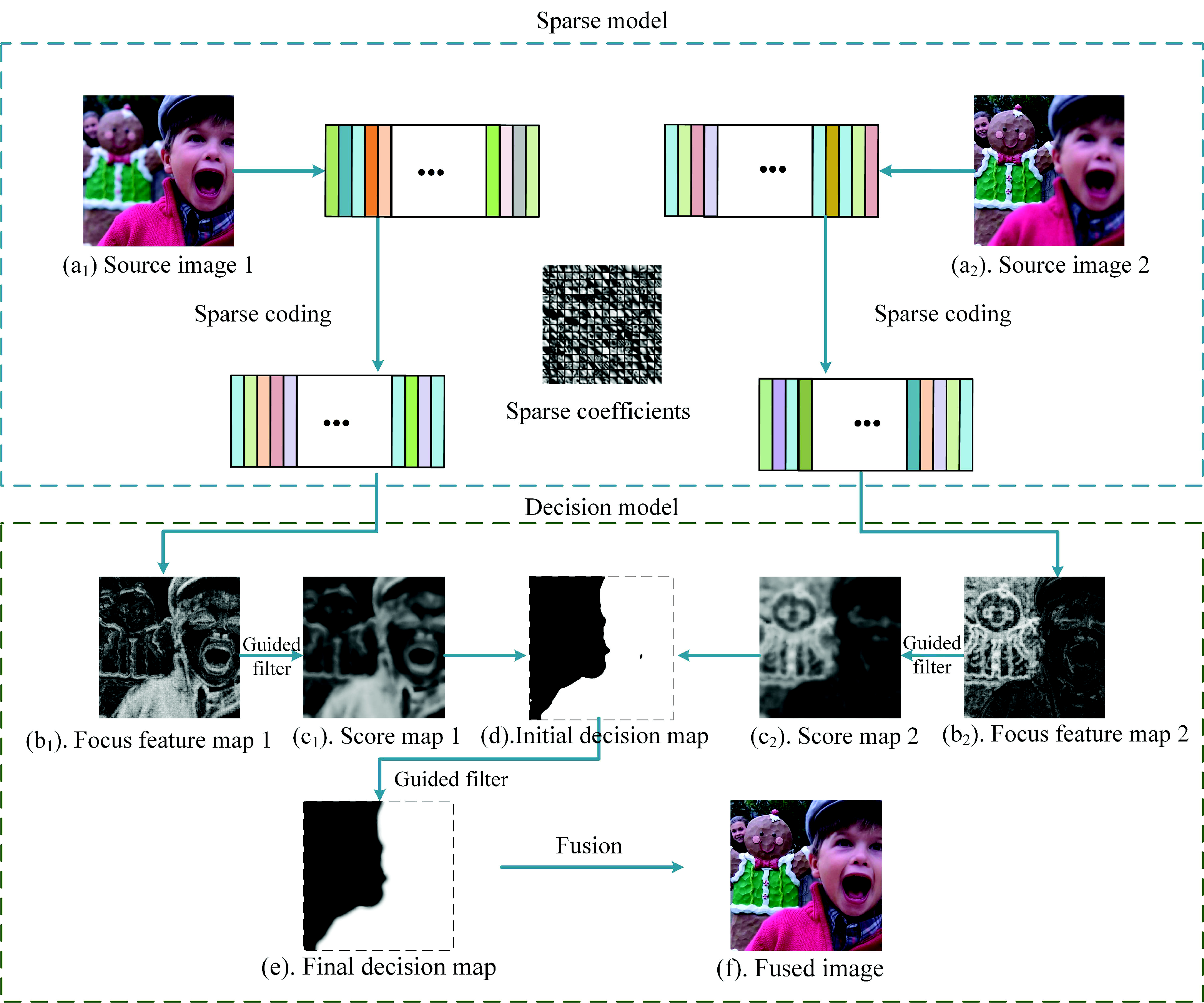
To solve these problems, we propose a novel multi-focus image fusion method (SRGF) by using sparse coding and the guided filter [
36]. The proposed method uses sparse coefficients to classify the focused regions and defocused regions to obtain the focus feature maps, as shown in
Figure 2b. Then, the guided filter is used to calculate the score maps as shown in
Figure 2c. An initial decision map as shown in
Figure 2d can be obtained via comparing the score maps. After that, consistency verification is preformed, and the initial decision map is further refined by the guided filter to obtain the final decision map, as shown in
Figure 2e. Compared with these traditional SR-based methods, there are three major contributions:
We use sparse coefficients to classify the focused regions and the unfocused regions to build an initial decision map, as shown in
Figure 2d, rather than directly fusing the sparse coefficients. The initial decision map would be optimized in the latter steps. In this way, we avoid the artifacts caused by improper selection of the sparse coefficients.
To address the spatial inconsistency problem, we use the guided filter to smooth the focus feature maps, as shown in
Figure 2b, fully considering the connection with the adjacent pixels. In this way, we effectively preserve the structure of images and avoid the spatial inconsistency problem.
To generate a decision map, which concerns the the boundary information, a guided filter is used to refine the initial decision map. By doing so, the boundary of the final decision map, as shown in
Figure 2e, is smoothed, and it has a slow transition. Thus, the halo artifact of the fused image is efficiently reduced.
To validate the proposed method, we conduct a series of experiments. By the experiments, we demonstrate that the proposed method can obtain satisfying fusion results. Moreover, it is competitive with the existing state-of-the-art fusion method.
The remainder of paper is organized as follows. In
Section 2, the SR theory and the guided filter are briefly reviewed.
Section 3 describes the proposed multi-focus image fusion method in detail.
Section 4 analyzes the experimental results. Finally,
Section 5 concludes the paper.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}