1. Introduction
In response to an increasing threat of terrorism, personnel surveillance at security checkpoints is becoming increasingly important [
1,
2]. Typical detection systems such as metal detectors for personnel and X-ray systems for hand-carried items are effective but also have a lot of shortcomings. Metal detectors can only detect metal targets, such as handguns and knives and cannot discriminate similar items. X-ray imaging systems can penetrate clothing barriers to image items concealed by common clothing. The disadvantages of X-ray systems are that their radiation is very high and they are very damaging to the human body. As a result of that, X-ray systems are only used to detect hand-carried items. The terahertz systems are also a typical imaging systems for personnel surveillance. Working at 30–300-GHz frequency band, terahertz system can also be called the millimeter wave system [
3,
4,
5]. Terahertz systems are nonionizing and pose no known health hazard at moderate power levels. Higher frequency represents shorter wavelength (1–10 mm), which leads to higher resolution of terahertz image [
4,
5,
6]. The current terahertz security imaging system can be divided into two categories: passive imaging and active imaging. Similar to the synthetic aperture radar (SAR), by synthesizing the real aperture into a larger virtual aperture [
7,
8,
9,
10], terahertz active imaging system could obtain clear human images which reveals the reflection characteristics of the concealed objects carried on human body. After getting the human image, it’s very important and meaningful to decide whether dangerous objects are carried or determine corresponding categories of these objects automatically. This paper focuses on terahertz active imaging for security applications and aims to realize the high-speed and high-accuracy detection of concealed items in terahertz images.
Constant false alarm rate (CFAR) is a commonly used detection method in SAR image detection [
11]. In order to distinguish backgrounds and different targets, it mainly concentrates on analyzing the distribution characteristics of targets and clutters in the image by sliding windows [
12]. Because of higher resolution and lower dimension, terahertz human images suggest more geometric features of the target than SAR images, as a result of that, CAFR detection method which focuses on target’s statistical characteristics makes no sense in terahertz image detection. Therefore, an effective method of feature extraction is very essential for terahertz detection. If the extracted abstract features contain sufficient information of the geometric structure and statistical characteristics of targets, the irrelevance between different targets, or the independence between backgrounds and targets can be maximized. For optical images, traditional image feature extraction methods can be divided into the following categories: Fourier transform [
13], window Fourier transform (Gabor) [
14], wavelet transform [
15], least squares [
16], boundary direction histogram [
17], texture feature extraction based on Tamura texture feature [
18] and so forth. Especially, over the last decade, great progress has been made in various visual identification tasks, largely based on the use of scale invariant feature transform (SIFT) [
19] and histogram of oriented gradient (HOG) [
20]. Although these feature extraction methods have many advantages, such as suppressing the effects of translation, rotation and illumination-changing for image, however, some factors like slow speed, high complexity and the need for artificial participation limit their application scopes [
21,
22].
With the development of these traditional methods, the artificial neural network (ANN) has gradually attracted peoples’ attention [
23,
24,
25]. Extending from ANN, convolutional neural networks (CNN) were first proposed by LeCun et al. [
26] in the 1990s, meanwhile they applied the stochastic gradient descent via back-propagation to train the CNN availably and achieved good recognition results but then it fell out of fashion with the rise in support of vector machine (SVM) [
27]. SVM maps low dimensional data to higher dimensions and constructs a hyperplane based on nonlinear transformation of kernel function to achieve effective data classification in high-dimensional space. Compared with neural network, SVM method has a more solid mathematical theory foundation. It can effectively solve the problem of constructing high-dimensional data models under limited sample conditions and has the advantages of high generalization ability, easy to converge and dimension insensitivity. As a result, SVM has occupied the field of data classification and regression for a long time until a paper [
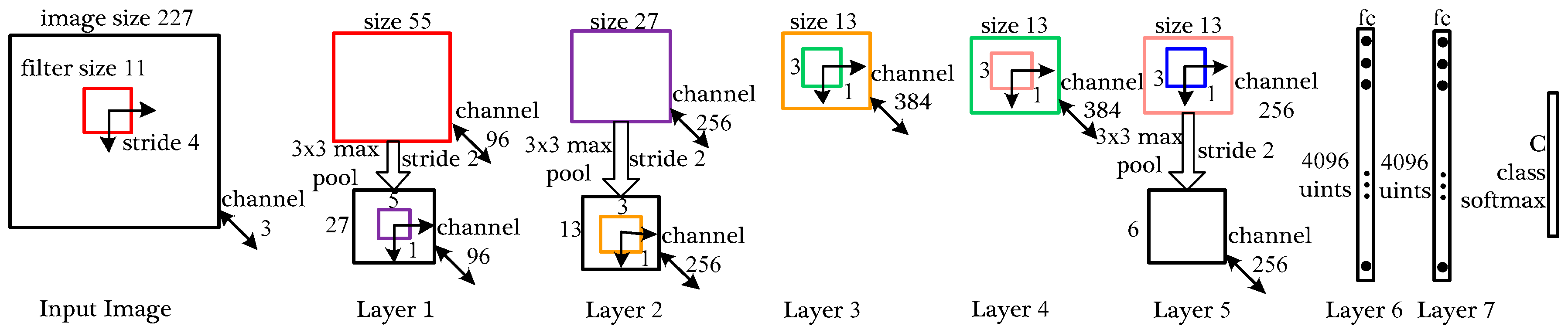
28] published in 2012 broke the silence of neural network. Krizhevsky et al. trained a large, deep CNN (Alexnet) to classify 1.2 million high-resolution optical images into 1000 different classes, which attained the highest classification accuracy at that time [
28]. CNN have lots of prior knowledge to compensate for all data and their generalization ability could be improved by adjusting the model’s depth and width. The Alexnet is made up of 5 convolutional layers and 3 fully connected layers and contains a number of unusual features which reduces its training time and improve its classification performance. The most critical parts of this network are rectified linear units (ReLUs) and dropout strategy. ReLUs improve the nonlinear mapping ability of this network and avoid the problem of vanishing gradient. Dropout reduces complex co-adaptations, as a result of that, Alexnet could learn more robustness features. At the same time, the enhancement of GPU computing power also provides a hardware foundation for such a large network and so many parameters. Since the Alexnet was proposed, there has emerged a large number of papers to expose deeper and more adaptable networks (e.g., [
29,
30]). Nowadays, classifying optical or natural images with CNN has also been matured gradually, as a matter of course, if these deep learning methods can be applied to terahertz images, the detection performance for concealed items will be greatly improved.
When training a new neural network with different data or different tasks, it’s an expensive operation to begin training with a group of random weights, for example, long training time or not well convergence. Considering that most data or tasks are related, we can speed up the model’s learning efficiency by fine-tuning with a well-trained model and this sensible optimization strategy could be called transfer learning. A scientific survey [
31] (by Pan et al., 2009) divided transfer learning into the following aspects: unsupervised transfer learning, transductive transfer learning and domain adaptation/generalization and so forth. Donahue et al. studied a semi-supervised deep convolution method for multitask learning which is the first application of transfer learning in CNN. The trained model associated with this learning method can also be considered as a supervised pre-training phase and the feature extracted from this model is called the caffe feature. Nowadays, caffe has become a very widely used open source framework for deep learning with its excellent GPU acceleration capability and simple training process. In this paper, we also adopt this training framework to train an effective classification network, at the same time, the training strategy of transfer learning has also been used in view of structural similarity between the optical image and the terahertz human image.
It is noteworthy that we have been discussing the application of deep learning in image classification till now. Compared with identifying target’s category, object detection is also a very challenging and difficult task since the detection task doesn’t only need to identify a variety of goals for different categories in the same image but also need to obtain the accurate ground truth of corresponding targets. The traditional object detection method for optical images can be summarized as the following steps: (i) getting a rough detection box by sliding multi scale and different size window in the image; (ii) extracting features from images based on a classic feature extractor, for example, SIFT, HOG, LBP et al.; (iii) identifying targets’ categories in the detection box by importing the extracted features into a trained feature classifier, for example, SVM. As we mentioned above, these object detection methods may not work very well when backgrounds are complex or different from each other and the reason can be explained as that these image features extracted by traditional methods have a poor generalization ability, result in negative adaption to actual conditions. However, for that the brain neurons can extract more advanced and more essential characteristics of objects, humans can identify different objects accurately even under bad environmental conditions. Analogously, the convolution neural network based on bionics also has good feature representation ability which is why it has developed so quickly in recent years.
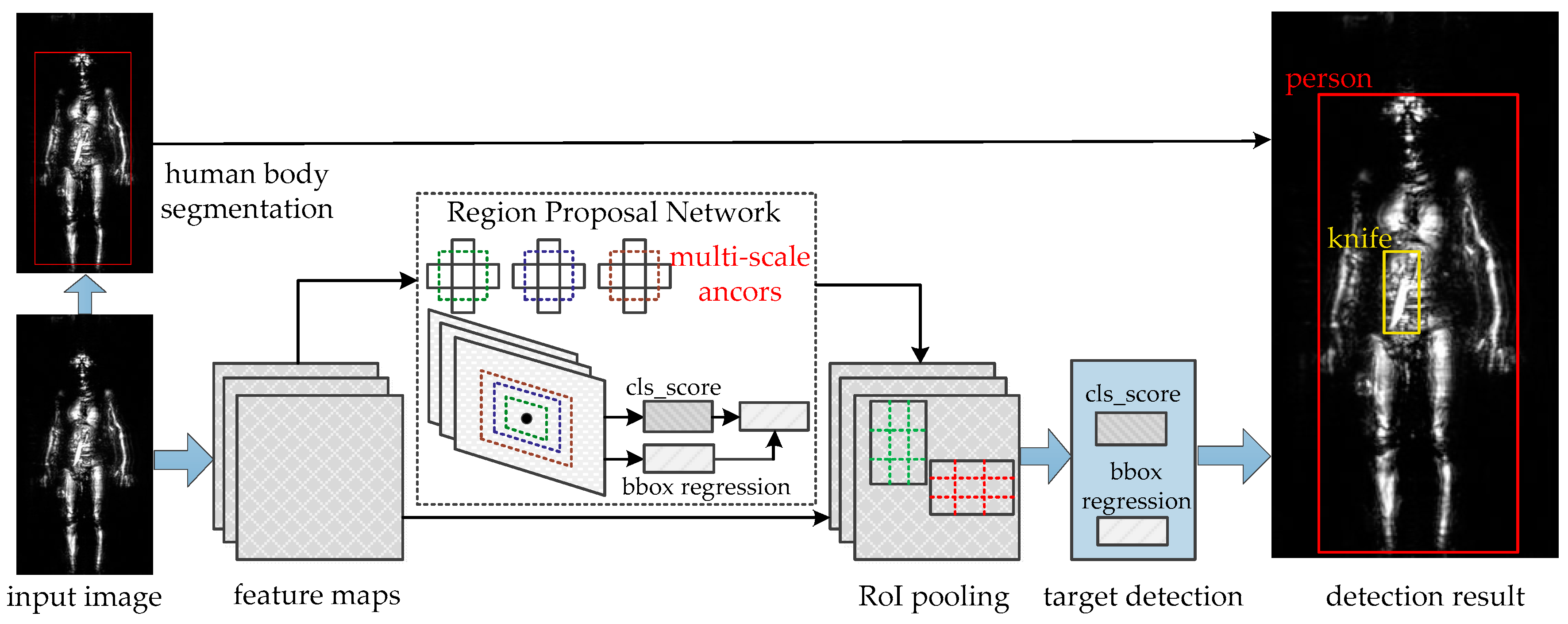
Since the CNN has shown excellent ability in image classification, extending it to image detection also becomes one of the pop problems in the field of image processing. There are two main problems with image detection: localizing objects accurately and training a high-capacity classification model with small-sample labeled data; fortunately, Girshick et al. gave out a satisfactory answer of named regions with CNN features (R-CNN) [
32] by bridging the gap between image classification and object detection. When processing an image, R-CNN first generates around 2000 different region proposals, extracts a fixed-length feature vector from each proposal with well-trained feature-extracted model, then classifies each region with category-specific linear SVMs. The Region-based CNN achieves excellent object detection accuracy; however, this method has notable drawbacks: 1. using multi-stage pipeline to train a model; 2. sacrificing a lot of time and space resources; 3. the detection speed is too slow. Considering the reduction of the training and testing time, spatial pyramid pooling networks (SPPnet) [
33] were proposed to speed up R-CNN by sharing computation and convolutional features. Although SPPnet accelerates R-CNN by 10 to 100 times at test time, it’s still a multi-stage pipeline like R-CNN. Therefore, an improved R-CNN (Fast R-CNN) was proposed by Girshick et al. which is a single-stage training algorithm that jointly learns to classify object proposals and refine their locations and this method nearly achieves real-time detection when ignoring the time spent on region proposals. Based on the Fast R-CNN, Ren et al. [
34] replaced traditional region proposal methods with a fully convolutional network named region proposal network (RPN) and the RPN can simultaneously predict object bounds and object probability. Merging RPN and Fast R-CNN into a single network, Faster R-CNN has a frame rate of 5 fps on a GPU and there is no doubt that is a great progress for object detection. Besides that, YOLO [
35], SSD [
36] and R-FCN [
37] et al., are all the most popular method for image detection.
However, these mentioned methods are designed for optical image datasets for example, PASCAL VOC 2007 [
38] and MS COCO [
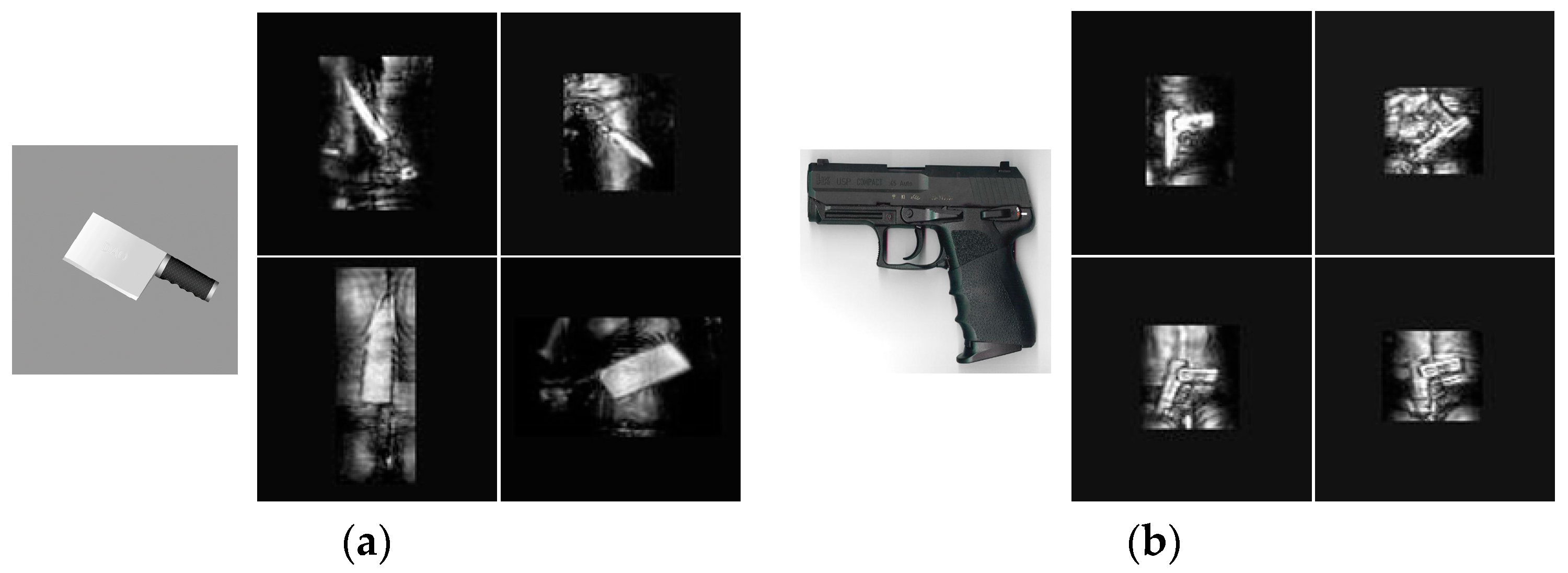
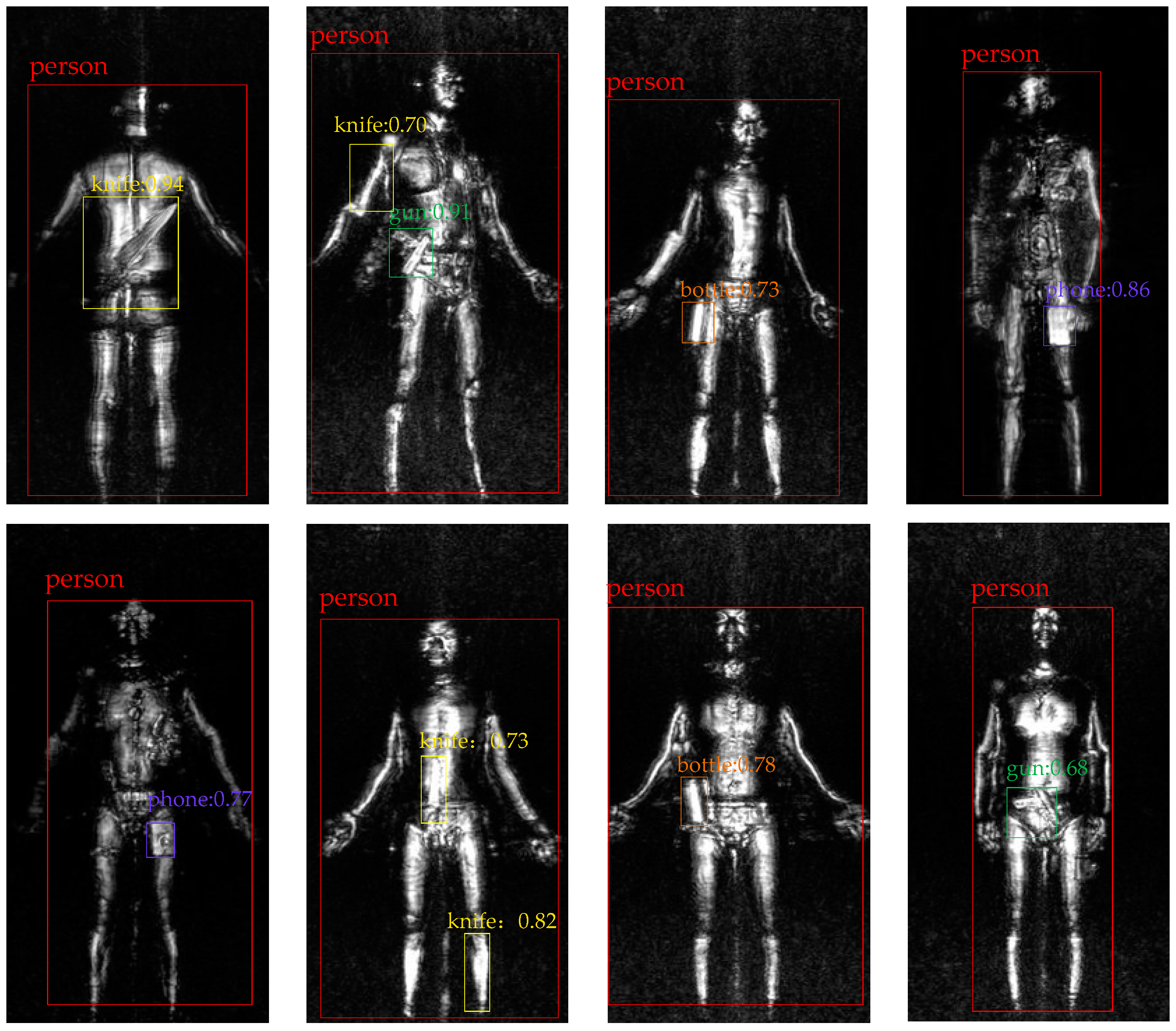
39] and terahertz images are different from these open datasets since radar images and optical images have different imaging mechanisms. Specifically, terahertz image reflects object’s electromagnetic characteristics and these characteristics vary with observation angle, target structure and material factors. Fortunately, the high working frequency of the imaging system is much closer to the optical spectrum, as a result, terahertz images of security inspection still have a lot of similar geometric features to optical images. For example, the large areas of knives’ metal materials are all represented as a series of regular bright blocks and the brightness of a knife-handle is very low in the terahertz and optical images. In this paper, we attempt to transfer these classification methods and detection methods of optical images to terahertz images. Dataset plays a very important role in deep learning. In other words, the more data, the better performance. So, we collect lots of terahertz images and label these images as the standard data format of VOC2007. Then, we establish the Terahertz Classification Dataset and discriminate a few objects in terahertz image with the classification method based on transfer learning of optical features. After solving the classification problem, considering the particularity of terahertz images, we propose an improved Faster R-CNN method based on threshold segmentation for the human body and other objects' detection.
This paper begins in
Section 2 with the showing results of terahertz imaging and the introduction of Terahertz Human Dataset. In
Section 3, the classification method and detection method of concealed items are explained. The experimental results and corresponding analysis are also descripted in this section.
Section 4 discusses some problems and
Section 5 concludes this paper.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}