1. Introduction
Wireless Sensor Networks (WSNs) consist of a large amount of small, low-cost, and wirelessly connected sensor nodes, which have one or more sensed modules, deployed in an unattended natural environment. They have extensive applications, one of which is target tracking [
1]. In this application, the user is only interested in the occurrence of a certain event, like movement of an intruder or enemy tanks in battle. These events don’t happen frequently and they commonly have long intervals of inactivity. Specifically, the target tracking scenario can be divided into two stages, namely, surveillance and tracking. During the surveillance state, there is no target of interest in the sensing field, but sensor nodes are ready to detect any possible occurrences. While in tracking stage, the network reacts in response to any moving targets, and collectively tracks and records the roaming path of a moving target.
Since the sensor nodes are usually battery-powered and it is infeasible to replenish energy via replacing their battery after deployment. Therefore, optimization of energy consumption is essential in all aspects of WSN to prolong the network lifetime. In order to save energy, a smaller number of nodes are dynamically chosen for tracking task to balance the energy consumption or reduce the number of work nodes. Hence, it is crucial to select the optimization set of sensor nodes with the minimum cost and quality tracking performance. To solve the node selection problem, the distance-based methods (such as [
2,
3,
4]) are proposed, and they need less computation but cannot reach competitive tracking accuracy. To improve the tracking accuracy, the entropy-based methods (such as [
5,
6,
7]) and the optimal theory-based methods (such as [
8,
9,
10]) are proposed. Although they achieve good tracking accuracy, these methods are computationally expensive. Unfortunately, few works involve the management and selection of the sensed modules for sensor nodes which have several multi-mode sensed modules.
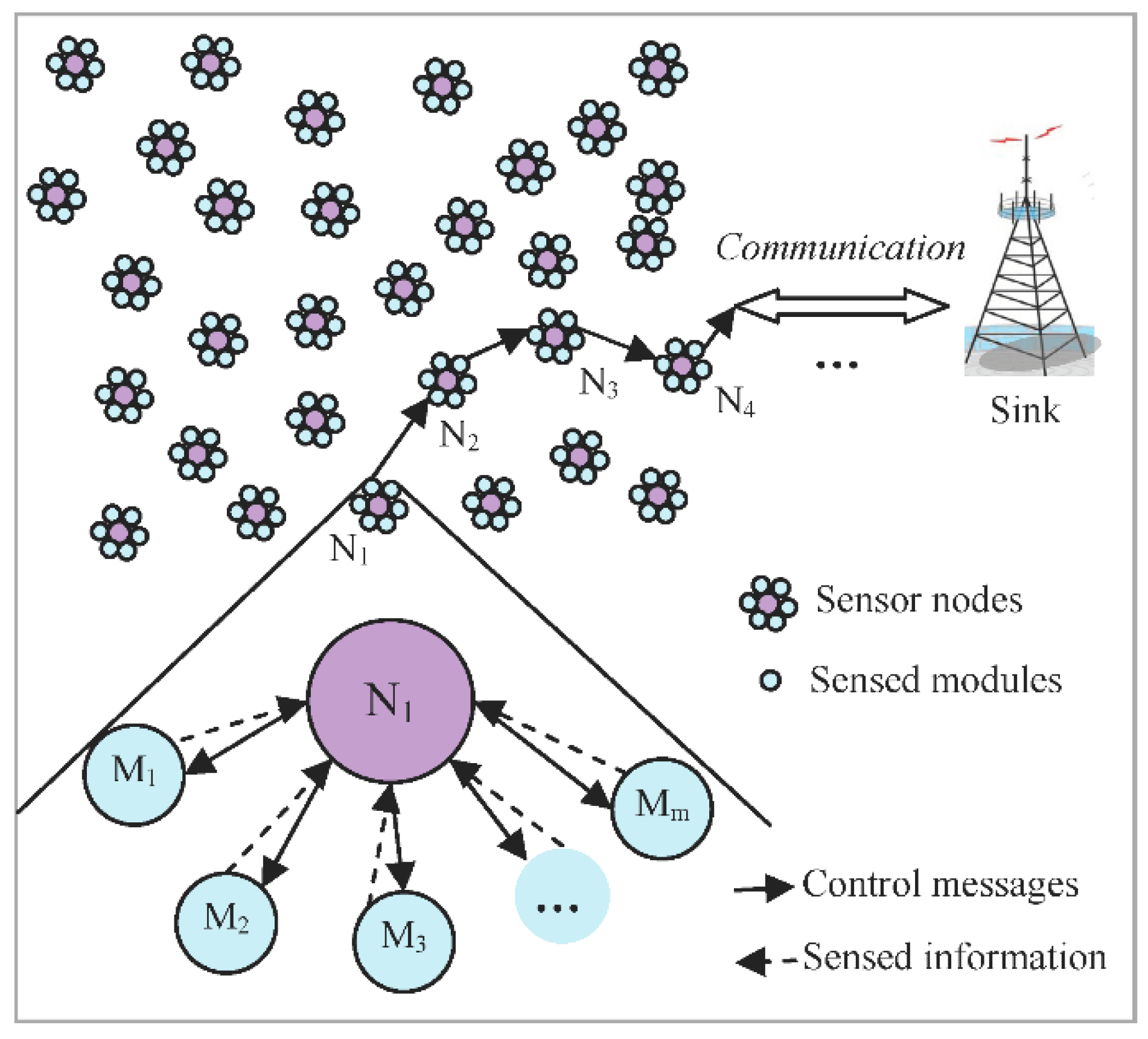
Currently, the researches on the node selection for target tracking are mainly focused on the sensor nodes with a single sensed module. In the existing works, communication module is considered to be the most power-consuming module in a node. The node management mainly refers to turn on all the modules of the selected nodes for target tracking and turn off the communication module or the other modules of the unselected nodes. However, with the development of sensor technology, more and more sensor nodes carry many different types of sensed modules at present, and each sensed module can generate the different sensed signal, such as sound, magnetic, infrared, video and so on [
11]. Using multi-mode information to cooperatively complete target tracking tasks is a trend of development in the future, and it can achieve better results than single mode information. For example, the scientists from Intel research team and the University of California, Berkeley, want to track the movements and monitor the habitat of seabirds on Duck Island. Since the seabirds are alert and the environment on Duck Island is very bad, the researchers cannot observe and track the seabirds in a usual way. Therefore, to do this, they apply a self-organizing wireless sensor network, which contains hundreds of sensor nodes equipped with multiple sensed modules, such as light, humidity, acoustic, infrared, camera sensors and so on. These nodes transmit the sensed data to base station computers 300 feet away, via satellite to California servers. However, some of the sensed modules consume a lot of energy. For example, the power consumption of the general video sensor is 20 mW–100 mW, which is larger than the power consumption of the communication module sometimes in sensor nodes. Therefore, it consumes a lot of energy to active all the modules of the sensor nodes. Generally, due to the high density of the sensor nodes, a target always is sensed by many sensor nodes, it is not necessary to collect so much video information. Furthermore, video information generated by video sensed module needs more storage space and larger transmission bandwidth, which leads to consume more energy. Therefore, the selection of sensed modules and the management of their sleep and active state must be taken into consideration.
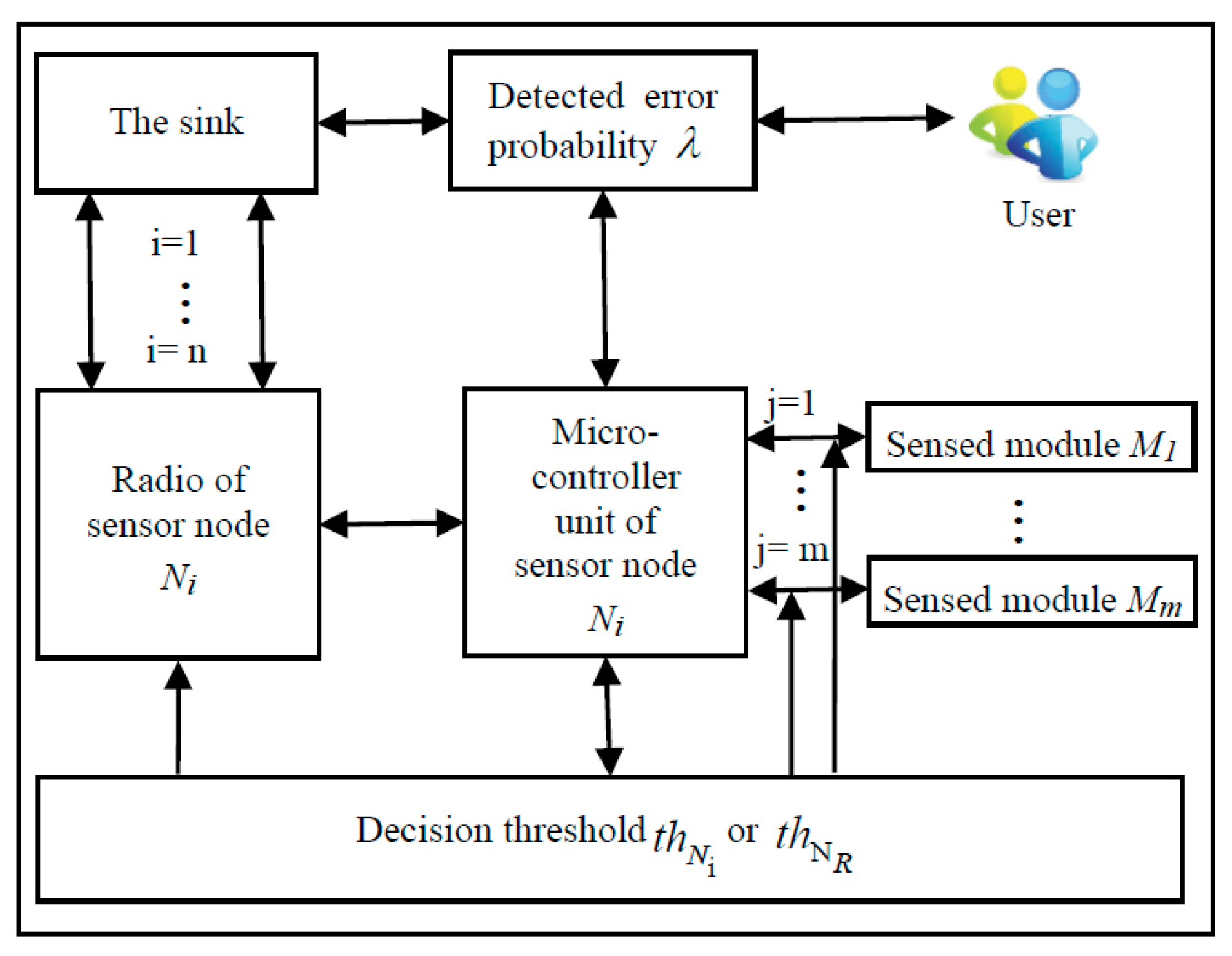
With these motivations, we propose an efficient node and sensed module management strategy, called ENSMM, for multisensory WSNs. ENSMM dynamically selects the appropriate set of sensed modules and the corresponding nodes to perform tracking tasks, and then the power consumption of nodes is managed according to the selection results. This paper considers the node management in the two different stages, surveillance and tracking. The major objective of ENSMM is to select the best subset of nodes and their sensed modules for the detecting and tracking task with minimum energy consumption. In ENSMM, the models of sensor nodes and sensed modules are more realistic than that in the traditional node management approaches which assume the sensed modules of nodes as one whole module. Furthermore, in ENSMM, each node has multiple sensed modules which have different power consumption and angular diversity of sensor’s sight line. Thus, the sensing ranges of sensors are more realistic than that in the traditional approaches which assume the sensing range of a node as a circle centred on the node. More precisely, the main contributions of this paper include:
This paper proposes an efficient and adaptive node management strategy, which considers not only node selection, but also the selection of the sensed modules for each node. In the paper, each node has multiple sensed modules and each sensed module has different power consumption and angular diversity of sensor’s sight line. Thus, the nodes can be managed efficiently and the sensor model of the nodes is more reliable and realistic in ENSMM.
ENSMM selects the node with more residual energy to turn on the sensed module which has higher power consumption. Conversely, the node with less residual energy can be in sleep state or just turn on the lower power consumption sensed modules. Consequently, ENSMM can balance energy consumption with the optimal set of nodes and the corresponding sensed modules so as to prolong the network lifetime.
This paper proposes an efficient sensed module and node selection algorithm based on a fused decision and detection probability in surveillance stage. Furthermore, in tracking stage, we propose an adaptive sensed modules selection algorithm according to the joint weighted information utility. Therefore, the target can be timely detected and the tracking reliability also is guaranteed with less and balanced energy consumption.
This paper proposes a joint weighted information utility measurement for multiple sensed modules in different nodes. The joint information utility can be expressed as the overlap area of the sight lines of sensed modules and the covariance-related ellipses. As a result, the complex entropy and the posteriori distribution estimation can be transfer into the simple area calculation to reduce the computational complexity.
2. Related Works
Recently, the problem of node management for target tracking in WSNs has been attracting much research attentions. The existing methods are mainly divided into the following three categories: distance-based methods, entropy-based methods and optimal theory-based methods.
For the distance-based methods, the simplest node management strategy is waking up the nodes which are nearest to a target to perform tracking tasks, and let the other nodes in sleep state, such as the method in literature [
2,
3]. Besides, the authors in [
4] propose a weighted distance method based on information measurement. The nodes with minimum weighted distance are chosen to perform the tracking tasks. Although the algorithm also has less computation complexity, it selects only one node each time and does not consider the spatial correlations of nodes. These kinds of methods are simple and easy to implement, but they have low tracking accuracy. To improve tracking accuracy, a combination of distance and utility function is proposed in [
12], in which each node extracts a priority value based on its utility function, which is related to the distance between the node and target. The nodes with less priority reduce their sensing range before their neighbors. Then, the nodes that cannot cover any target are not assigned the task and they are turned off. However, the approach requires the location information of all the nodes.
To improve tracking accuracy, the entropy-based node management methods have been proposed. They select the appropriate nodes for tracking tasks depending on the observation information utility of sensor nodes. The authors in [
5] propose a heuristic node selection algorithm based on information entropy and implemented by a Bayesian filter. The main idea of the method is to optimize an information utility function using the defined metrics. In [
6], the authors propose a mutual-information based sensor selection (MISS) algorithm, which allows the sensor nodes with the highest mutual information about the target state to transfer data first, and the other nodes no longer send their sensed data when the sink received enough data to estimate the target state with the required accuracy. In [
7], the authors propose a sensor selection approach based on maximum entropy fuzzy clustering to address the target tracking problem in large-scale sensor networks. They deal with this problem at two levels, sensor-level tracking and global-level fusion. Only a subset of reliable nodes is chosen for track-to-track fusion. In addition, an improved sensor selection approach is proposed for data fusion in both sparse and dense target environments. Although the entropy-based approaches achieve good tracking accuracy, they involve a lot of computations about information entropy and mutual information entropy, and have high computational complexity, especially in the case of a larger number of nodes. In addition, node selections based on information utility function are similar to the entropy-based methods such as those described in [
13,
14,
15]. The main steps of the methods are: (1) building information utility function first according to some specified parameters; (2) and then, selecting nodes to achieve the optimization information utility function. Unfortunately, this kind of methods also has a higher computational complexity.
For the optimal theory-based methods such as [
8,
10], they establish a linear system of equations whose independent variables are the selected nodes and the constraints are the number of nodes, the energy or the observation range of nodes and so on. The object is to obtain the minimum difference between the observation and actual value so as to get the optimal observation. In [
9], the authors propose a novel energy-balanced task-scheduling method for collaborative target tracking using an unscented Kalman filter. At each step of the tracking task, the head node selects active nodes from all nodes within the sensing range to minimize residual energy variations. It is shown a subset selection problem which is NP-hard (non-deterministic polynomial hard), and several energy-balanced scheduling heuristic algorithms are proposed to solve the problem. In [
16], the authors propose a probabilistic sensor management scheme based on compressive sensing and probability theory. In the proposed scheme, each node sends its sensing data with a certain probability, the sensor management can be cast as the problem of finding a suitable transmission probability at each node so that a given performance metric is optimized. This method takes the number of selected nodes into account, but it does not consider the residual energy of each node. Also, there are large computational burden. In [
17], the authors propose a Fixed-Tree Relaxation-Based Algorithm (FTRA) and a very efficient Iterative Distributed Algorithm (IDA) to obtain the best possible estimation performance at a given querying node. In FTRA, both sensor selection and routing structure are jointly optimized. However, the method selects one sensor node for the tasks at each step and does not consider the locations correlations of the sensing nodes. Literature [
18,
19] adopt an alternative conditional posterior Cramér-Rao lower bound (C-PCRLB) as the optimization criterion for node selection. Although the total number of participating nodes is limited by a time window, nodes are selected independently without considering the correlation among the observation values of nodes.
In [
20], the authors propose an efficient scheduling method based on learning automata, in which a large number of sensor nodes are dispersed randomly in close proximity of a set of targets and the objective of the scheduling mechanism is to select a subset of sensor nodes as active nodes, which can cover all of the targets. And each node is equipped with a learning automaton, which helps the node to select its proper state at any given time. In [
21], the authors propose a prolong-stable election protocol (P-SEP) for cluster head elections in the energy-limited heterogeneous fog-supported wireless sensor networks. P-SEP enables uniform nodes distribution, new cluster head selecting policy, and prolongs the time interval of the system, especially before the failure of the first node. Moreover, P-SEP considers two-level nodes’ heterogeneities: advanced and normal nodes, which have the opportunity to become cluster heads. In [
22], the authors propose a new method to improve channel assignment and decrease interference in multi-channel wireless mesh networks. The proposed method assigns a channel to each of the links subject to the interface constrains such as minimum amount of network interferences, dynamics of traffic selection for the mesh routers and numbers of hops for assignment so that the implemented channel assignment algorithms are able to adapt themselves to their underlying environment based on their functionalities.
From the above analysis, in the existing work, the node management and selection for target tracking are only for the node which has one sensed module, and if a node is selected, all its modules are simply turned on. Moreover, the existing selection algorithms often have high computational complexity. However, for sensor nodes which have several multi-mode sensed modules, few works involve the management and selection of the sensed modules and how to select the tracking nodes and their corresponding sensed modules.
5. The Sensor Node Management Algorithm in Tracking Stage
When a target occurs in the sensing area, the status of the network is changed from surveillance to tracking. All the nodes whose sensed ranges include the target are regarded as candidate nodes and the corresponding area where the candidate nodes are located forms a tracking area. In tracking stage, the nodes who detect the target report the detected information to the sink, which predicts the position of the target at the next instant and selects some sensor nodes and their sensed modules from the candidate nodes in the tracking area to execute the tracking tasks. When the sink finishes the node and sensed module selections, it will inform the related nodes to change work states. Since the residual energy and the joint weighted information utility of the nodes are considered in our selection procedure, the energy consumption of the network is significantly improved and balanced. Later, when the target moves out of the sensing field, the sink will send message to inform all the nodes to go back to surveillance stage.
5.1. Predicting Target Position in View of Particle Filter
In the target tracking application scenarios, due to the sink can obtain the collaborative sensed information of a target, it can efficiently predict the target position in the next sensing instant using PF (particle filter) algorithm, which is a very effective algorithm because it’s potential of coping with difficult nonlinear or non-Gaussian problems. PF with parallel structure bases on Monte Carlo simulation and Bayesian sampling estimation theories [
13]. And it is a sequential importance sampling method which is flexible and easy to be implemented.
The steps of PF are outlined as follows:
Assuming the initial target position probability distribution is
, the particle set is shown as follows:
where
Qs is the number of particles.
X (0) is the target position estimation in the initial sensing instant. Thus,
is the estimated target position by particle
l. In addition, the initial importance weight of particle
l is set as:
- (2)
Iterations
The importance weight of
k + 1 time instant is calculated as follows:
where
Zk+1 is the observation of target position in the
t + 1 sensing instant.
- (3)
Resampling
When the variance of the importance weights becomes excessive, the particle needs to be re-sampled. The effective sample size is defined as:
where
Var is the variance function. When
Qeff drops below a threshold
Qth, resample
Qs samples according to
and set importance weight of particle
l as:
Thus, the state of target position is updated as:
In each sensing instant, the sink node can obtain a prior state of target position for the next sensing instant.
5.2. Adaptive Node and Sensed Module Selection
For multi-mode sensor networks, dynamically selecting the best set of sensor nodes and their sensed modules for tracking tasks can reduce the energy consumption of the network and improve tracking accuracy. Furthermore, selecting some of the sensed modules to work and making the others sleep can reduce the amount of sensed information transmitted in the network so that the network energy consumption is further reduced and the network congestion will also be significantly improved. When a target enters into the sensing area, there are many sensor nodes around the target, and one node has multiple sensed modules. However, it is not necessary to track a target with so many sensor nodes and their sensed modules. Generally, we should select sensor nodes and their sensed modules which can bring more information among the candidate nodes until the tracking accuracy reaches the requirements of the user. In addition, the different sensed modules have different performance parameters and power consumption values. To balance the energy consumption, we consider the residual energy of sensor nodes during the sensed modules selection, and choose the nodes that have more residual energy to execute the energy intensive sensory tasks. The sink or the cluster head are responsible for selecting the sensor nodes and their sensed modules.
In the entropy-based method, the entropy is used as information utility measure. The information utility of node
Ni is calculated by:
where
is the posterior distribution of the target’s state, more details of entropy-based information utility measure can be found in [
5].
However, the information utility of one multi-sensor node consists of all the sensed information utilities come from each sensed module. The total information utility value of a multi-sensor node is not a simple sum of the information utility value of each single sensed module. In this section, the joint weighted information utility of the sensed modules is calculated in order to select nodes and their sensed module for tracking tasks. To obtain the joint weighted information utility, the information utility of one sensed module is first calculated in more detail below.
The target state predicted by PF algorithm as mentioned in section
A, from that, we can obtain the predicted location of the target as
and a covariance matrix as:
where
and
are deviations along axes
and
, respectively, and
r is the correlation coefficient. Then a new coordinate system, whose origin is at
and whose axes are along the direction of the eigenvectors of
, can be established. In the new coordinate system, the predicted belief is represented by zero-mean Gaussian density function with covariance:
where
and
are the largest and smallest eigenvalue of
, respectively. Then, the state uncertainty of the target can be represented by an ellipse whose major axis and minor axis are
and
, respectively as
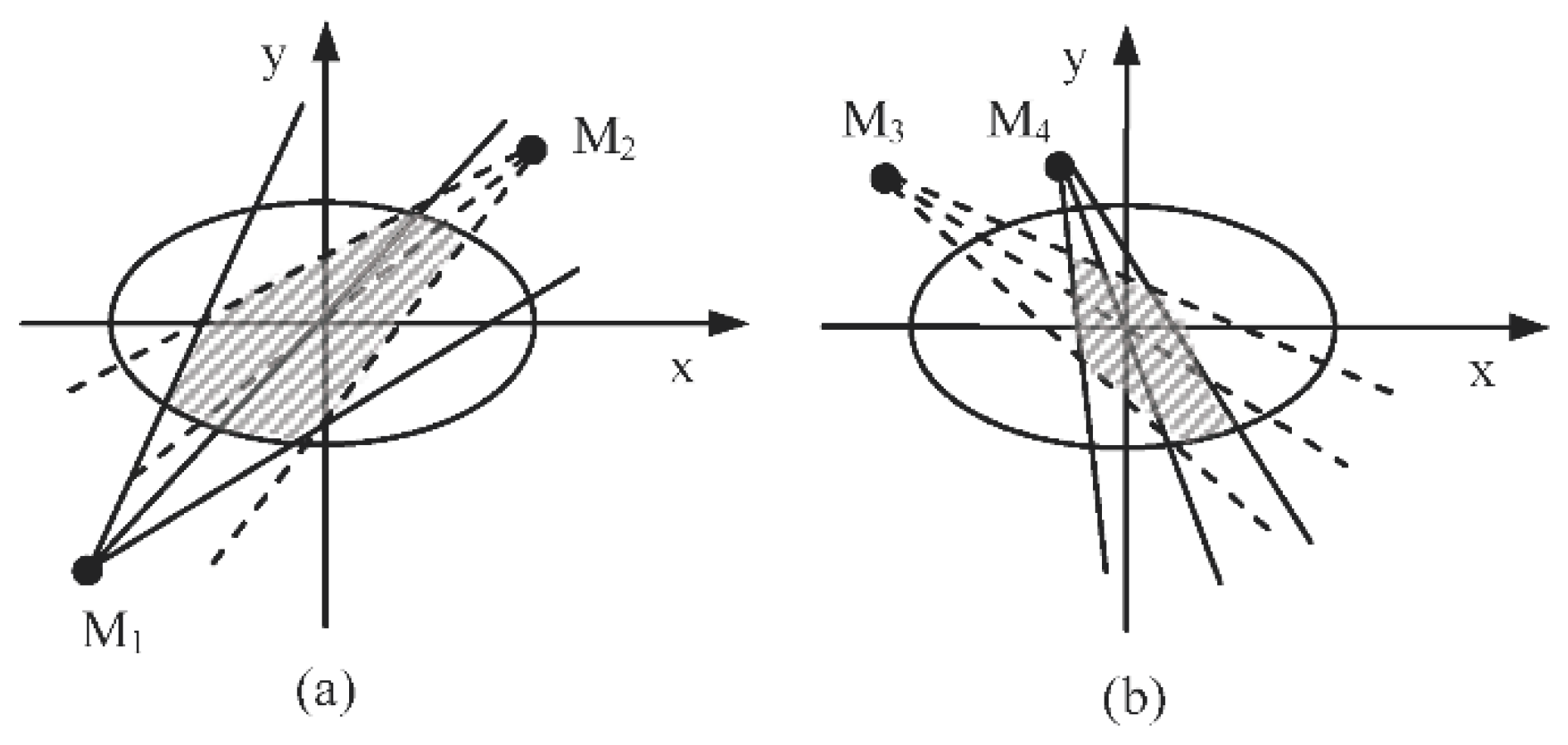
Figure 4 shows. The reason of choosing 3 sigmas is that the state of the target follows a Gaussian distribution within the region covered by a
ellipse and it will appear by the chance of 98.89% [
4].
Assuming the measurement error
is known, and the location
of node
can be denoted by the polar coordinates
. Then, the information utility of its sensed module
Mj is defined as:
In this way, the information utility of the sensed module
Mj in node
Ni can be approximated as the intersecting area of the sight lines of the sensed module and the ellipse, as shown in
Figure 4, where the angle of sight lines of sensed module
Mj is
. The smaller the area is, the more information is provided by the sensed module, and the less state uncertainty of the target is obtained. The equation of the uncertainty ellipse is described as:
The joint weighted information utility of two or more sensed modules are always affected by the position of nodes and the sight line of sensed modules. And the relative position of a target and a senor node affects the information utility of the node. Obviously, when sensor nodes and their sensed modules are selected for tracking tasks, it is inexact to consider the single sensed module each time or to view the joint information utility as a simple sum of the information utility of each module. Taking
Figure 5 as an example, the dots
M1,
M2,
M3 and
M4 are four different sensed modules in the different candidate sensing nodes. The joint information utility of
M1 and
M2 are represented as the intersecting area enclosed by the sight lines of
M1,
M2 and the ellipse (the dashed area in
Figure 5a). Analogously, the joint information utility of
M3 and
M4 are shown as the dashed area in
Figure 5b. To all appearances, the dashed area in
Figure 5a is larger than that in
Figure 5b. Accordingly, the combination of module
M3 and
M4 can obtain more sensing information utility than that of the module
M1 and
M2. That is to say, choosing module
M3 and
M4 to execute the tracking tasks can obtain more certainty of the target’s state. Therefore, we propose an adaptive node and their sensed modules selection strategy for target tracking based on the joint weighted information utility of some nodes and their sensed modules. That can be calculated as follows:
where
Joint U(
Ni) denotes the joint weighted information utility of node
Ni,
CA(
Mj) denotes the certainty area enclosed by the sight lines of module
Mj and the ellipse.
is the weighted overlapped area of the certainty area of module
M1 and
M2. The smaller the area
is, the more certainty by using the sensing information of module
M1 and
M2 there will be.
represents the weight of the module
Mj and is calculated as follows:
where
stj = 1/0 denotes the state of
Mj work/sleep,
is the detection probability of
Mj. Furthermore, the joint weighted information utility of more candidate sensing nodes can be calculated as follows:
where
t represents the number of the candidate sensing nodes,
is the jointed sensing information utility of node
N1 and
N2.
To calculate the joint weighted information utility of simply, we assume that Qp points are generated in the ellipse evenly and randomly, then the points fallen in the area of are called valid points. The joint weighted information utility of can be approximately calculated as the number of the valid points. Similarly, this method can be used to calculate the joint weighted information utility of or and so on. In general, we only need to compare the value of two joint weighted information utility without calculating the exactly values in the node selection algorithm. Using the way, the complex entropy calculation is converted to the simple comparing operation. Moreover, we can control the computational complexity and accuracy by choosing proper Qp.
In our adaptive nodes and their sensed modules selection strategy, the joint weighted information utility measurement is used to effectively select sensor nodes and their sensed modules for tracking tasks. In addition, the residual energy and location of the nodes are considered in the selecting algorithm. The nearest node from the target is preferred and the nodes that have more residual energy are selected to execute the energy intensive sensory tasks. The steps of the sensed modules selection in tracking stage are detailed as follows:
- (1)
First, each candidate node in the tracking area sorts its sensed modules from the smallest power consumption module to the biggest one and calculates the residual energy level using the same method as Algorithm 1.
- (2)
Second, each candidate node chooses one of its sensed modules as a candidate tracking module according to its residual energy level and the power consumption of corresponding module. If a node has lower residual energy than residual energy threshold, its candidate tracking module can be withdrawn temporarily and restored in the next round. The residual energy threshold is set as the coefficient ξ multiplied by the averaged residual energy of candidate nodes.
- (3)
Then, the nearest node Nest from the target is selected first and jointed into the tracking tasks. The joint weighted information utility of Nest and each remaining candidate node is calculated separately. The node which has the biggest joint weighted information utility with Nest is selected to join into the tracking tasks.
- (4)
Then, the target state uncertainty probability Pun is calculated. If the detected target state uncertainty meets the requirements of the user, the procedure of the selection algorithm is finished, or else, it goes to the step (3).
- (5)
Finally, if every candidate tracking module has been selected and the detected accuracy does not meet the requirements. It goes to the step (2) and each candidate node chooses another candidate tracking module from its sensed modules which has smaller power consumption than last one.
The nodes and their sensed modules which are selected to execute the tracking tasks send their sensed data toward the sink by multi-hop routings. When the sink obtains the data and estimates the position of the target , then it needs to select and awake the sensor nodes and their sensed modules to track the target for the next time instant. This procedure is continued until the target leaves the deployed sensing area. It can be depicted in Algorithm 2.
| Algorithm 2. Adaptive nodes and sensed modules selection in tracking stage. |
input set of candidate nodes CDD = {N1…Nd}, input the biggest tolerance target state uncertainty = θ set of selected nodes SLN set of selected sensed modules SLM set of candidates tracking modules CDM set of the nodes included candidate tracking modules NIM TH_residual_energy = ξAVE(CDD) for each sorting the sensed modules by their power PC(Mj) PC (Mj) ≤ PC(Mj+1) if (residual_energy(Ni)>TH_residual_energy) select a candidate tracking module MC add (MC) to CDM add (Ni) to NIM end if end for add (Nest) to SLN add (the candidate tracking module of Nest) to SLM for each (Ns ) calculate if (, && ) add (Ns) to SLN add (the candidate tracking module of Ns) to SLM end if calculate the target state uncertainty Pun if (Pun > θ), goto line 20 end for calculate the target state uncertainty Pun if (Pun > θ), goto line 8 outputSLN and SLM
|
Suppose the number of the candidate nodes in the tracking area is Nc, and each node has M sensed modules. Then the computation complexity of ENSMM consists of two parts: (1) selecting sensed modules according to the residual energy of the node, and (2) selecting tracking nodes according to the joint weighted information utility. It is easy to know that the computation complexity of the part 1 is O(Nc) + O(M2), as selecting sensed modules contains a sort and comparison algorithm. Part 2 can be described as follows: in each iteration, one node is selected from the candidate nodes list such that the joint weighted information utility is optimal, until the target state uncertainty reaches the requirement. The computation complexity of the part 2 is O(Nc2). Since the value of M is small, O(M2) has less complexity. Thus, the computation complexity of ENSMM is O(Nc2). In comparison, the computation complexity of the entropy based method is O(Nc4).
6. Performance Evaluation
In this section, we illustrate the performance of the proposed node and sensed module management algorithm ENSMM by numerical examples. The simulation is implemented many times in order to find the average results, also the distribution of sensor nodes and the target trajectories are different for each time so that it can avoid the influence of occasionality in one time simulation. The average results of the multiple times are more reliable. However, if the number of simulation times is more than 15, the average results of the simulations tend to stabilize. If we increase the number of simulation times again, there is a little influence on the average value. Therefore, in order to fully compare and verify our proposed algorithms, we conduct experiments under some different network environments, and for each simulation, we run at least 20 times with different random node distributions and the average results are shown. We also compare our simulation results with the distance-based method in [
4], the entropy-based method in [
6] and the optimal theory-based method in [
19] in terms of mean square error, execution time and energy cost and so on.
We consider a WSN, consisting of 200 sensors nodes randomly deployed in a 150 m × 150 m area, and assume each node has an initial energy of 1 J (Joules). The coordinate of the sink is fixed at (0, 0). Each sensor node has three sensed modules, and each sensed module has two statuses, active and sleep, and its energy consumption consists of three parts, working status, transition from active to sleep and transition from sleep to active. The details can be shown as follows:
where
H denotes the number of sensed module turned on or turned off,
Psens and
Tsens are the power and working time of the sensed module in active status respectively. Moreover, the measurement error of each sensor follows a Gaussian distribution whose standard deviation is 3 degree, and the other parameters and their values of the sensed modules are summarized in
Table 3.
The energy consumption model of the communication module used in this paper is a very widely used model, and described as in Equation (28):
where
ETx−elec and
ERx−elec are the energy consumption of the transmitter and receiver electronics.
εamp [
Joule/(
bit·
mα)] is a constant that represents the energy needed to transmit one bit to achieve an acceptable signal to noise ratio over a distance
d, and
is the path loss exponent (
) which depends on channel quality. We can assume
ETx−elec =
ERx−elec =
Eelec and set parameters
= 50 nJ/b,
= 100 pJ/(
) and
. The bandwidth of wireless channel is 1 Mbps and we adopted the MAC model of IEEE 802.15.4. In PF algorithm, the particle number
Ns is set as 500 and the re-sampling threshold
Nth = 0.2
Ns. The sampling period is 1 s. In our work, we set
Qp = 10
3. The coefficient of the residual energy threshold is set as
ξ = 0.5. The default value of the biggest detected error probability and the biggest tolerance target state uncertainty are set as
λ =
θ = 2%.
The dynamical and state transition model of a target is given as follows:
where
is the state of the moving target at
k time instant,
T is the sampling time interval,
T = 1 s.
and
are the position and velocity of the target in the direction of
x axis respectively.
and
are the position and velocity of the target in the direction of y axis respectively.
is the state transition noise of the target,
, and
. The target in the sensing area moves randomly with a maximum acceleration
amax = 2 m/s
2 and a maximum velocity
vmax = 8 m/s. In addition, the observation model is:
where
H is the observation matrix,
is the measurement noise which is assumed to be white Gaussian noise sequence with zero means and the variance
.
Table 4 lists the average energy cost of the nodes, average detected delay and failed detection percentage under different node management algorithms in surveillance stage. In this paper, the average detected delay is defined as the time period between the time when a target enters the deployed area and the time when the sink receives the target information. And the failed detection percentage is defined as the ratio of the number of time which the target was not detected in time to the number of time which the target appeared. We see that ENSMM can obtain lower average detected delay and failed detection percentage with less energy consumption and ENSMM can conserve at least 23% and 28% energy than that in distance-based and entropy-based approaches in the surveillance stage. This is because, both sensor nodes and their sensed modules are selected and managed, and turning off some of the sensing modules not only saves energy but also reduces the number of data stored and transmitted in the network, and then the total energy consumption is less. Besides, the sensed modules are selected based on its detected error probability so as to guarantee the detecting performance. However, as all the sensed modules of a node are managed as an integral unit in the other three methods, so that the energy consumption is higher than that in ENSMM. Although the entropy-based method achieves the lowest failed detection percentage, but it has the longest average detected delay since its node selection algorithm has high computational complexity. In contrast, the distance-based method reduces the computational complexity, which results in a bigger failed detection percentage. Compared with ENSMM, the optimal theory-based method just selects nodes according to the part of the optimal parameters without considering the spatial correlation between the selected nodes, so that it has higher failed detection percentage.
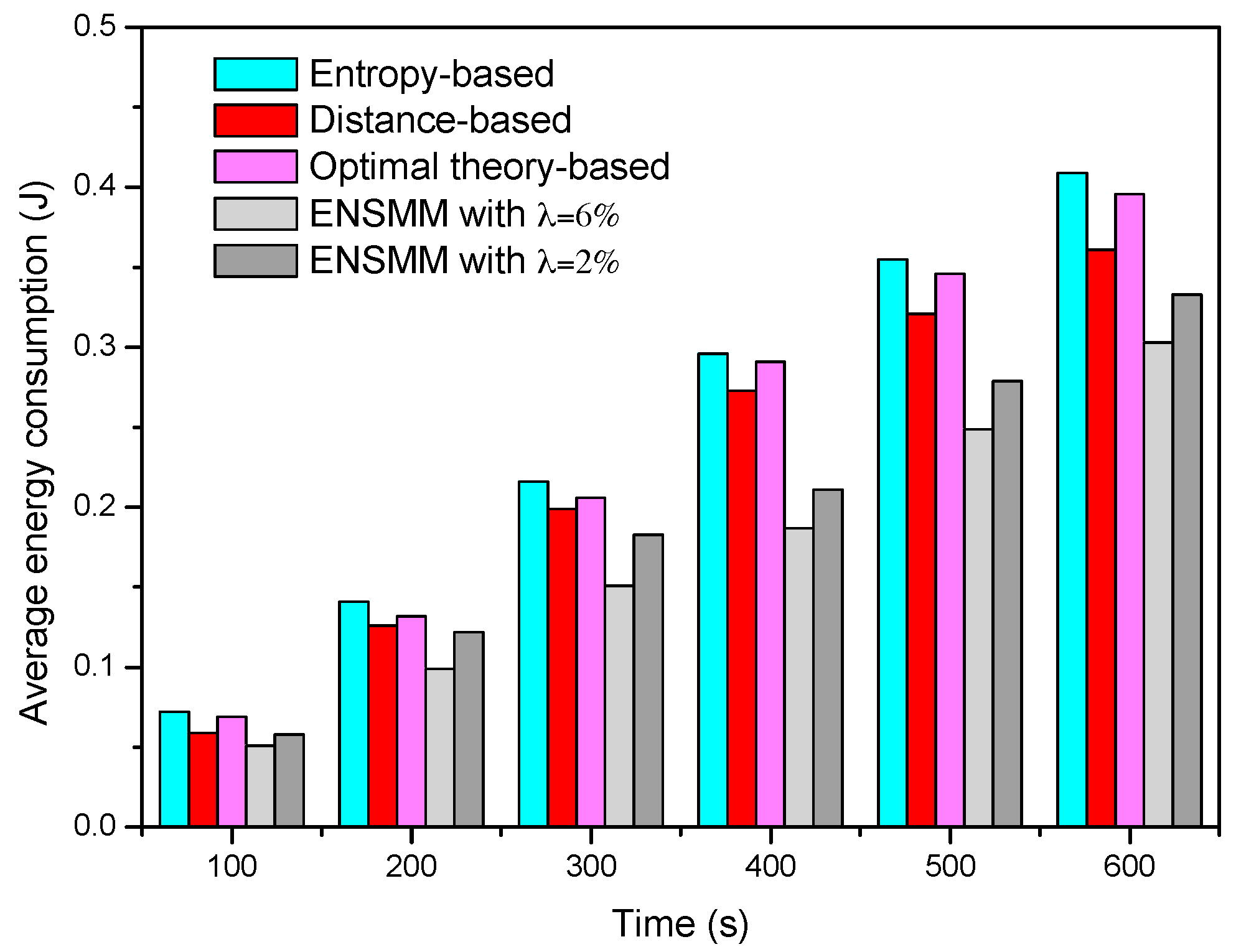
Figure 6 shows the average energy consumption of each node in surveillance stage under different node management algorithms. We can see that the average energy consumption in ENSMM is lower than that in the other methods. This is because, ENSMM carries out the power management on the sensed modules of each node, and some of sensed modules which have high power consumptions are turned off when no target appears in the deployed area. In addition, the smaller the detected error probability is, the more nodes and sensed modules are required to work, so that the average energy consumption when
λ = 2% is higher than that in
λ = 6%. Compared with ENSMM, as all the sensed modules are active when the node is work, the other three methods have higher energy consumption. In the entropy-based method, due to a great deal of calculation on mutual information, it has the highest energy consumption. The optimal theory-based method reduces the computational complexity so as to have lower energy consumption. Nevertheless, the distance-based method has the simplest computation and small computational burden so as to have lower energy consumption than the entropy-based and optimal theory-based method.
In
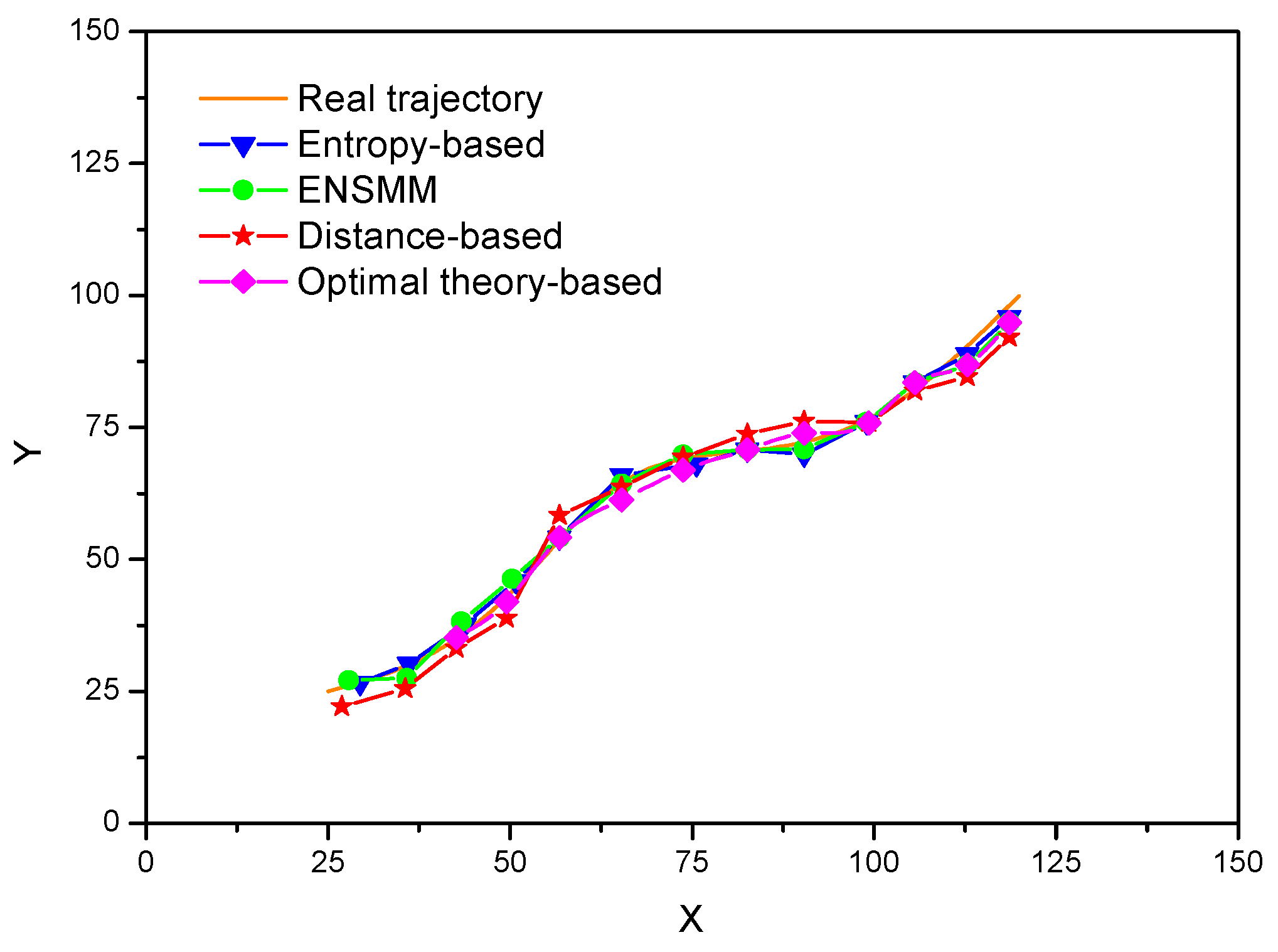
Figure 7, tracking a target with sensor nodes under the energy constraint is illustrated. Both the true target trajectory and estimated target trajectory are plotted when all the nodes send their measurements to the sink. It is observed that the proposed ENSMM shows similar performance as that of the entropy-based method. This is because the nodes and their sensed modules which can bring the maximum increment of the information utility are selected to meet the tracking accuracy. For the distance-based method, the nodes near to the target are selected by the sink with probability, and without considering the information utility and the correlation of the observations of the nodes, thus the estimated target trajectory has bigger differences with the real trajectory and it is expected to give worse tracking performance compared to the other node management methods.
In
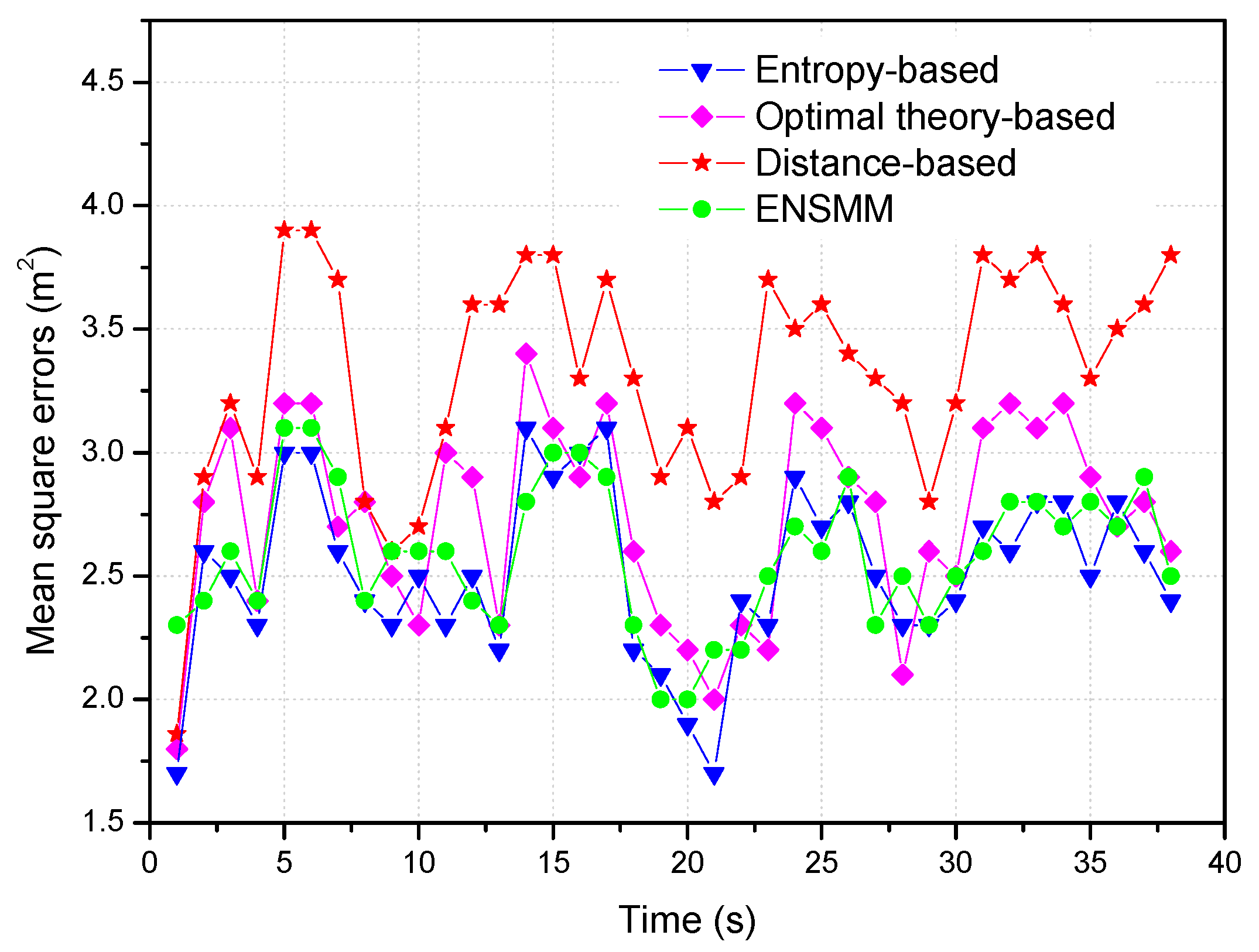
Figure 8, we show the tracking performance for different node management methods when 3 nodes are selected for tracking. From
Figure 8, we can see that ENSMM and the entropy-based method can almost obtain the same performance on the mean square positioning errors. This is because, ENSMM adopts the joint weighted information utility measurement considering the spatial correlation of nodes and their sensed modules, and then it has better chance to activate even more informative nodes and sensed modules for tracking. Likewise, since the entropy-based method executes a lot of probability predictions and intensive entropy calculations to select the appropriate nodes for tracking, so that it has the most accurate results. The optimal theory-based method has less positioning accuracy than ENSMM and entropy-based method because it selects one node each time just to optimize one of the parameters without considering the correlations among the observations of the nodes. For the distance-based method, since it just chooses the nearest sensor nodes from the target to execute the tracking tasks without considering the moving trend of the target and the effect of the angular diversities of sensor nodes, so that it obtains the least positioning accuracy.
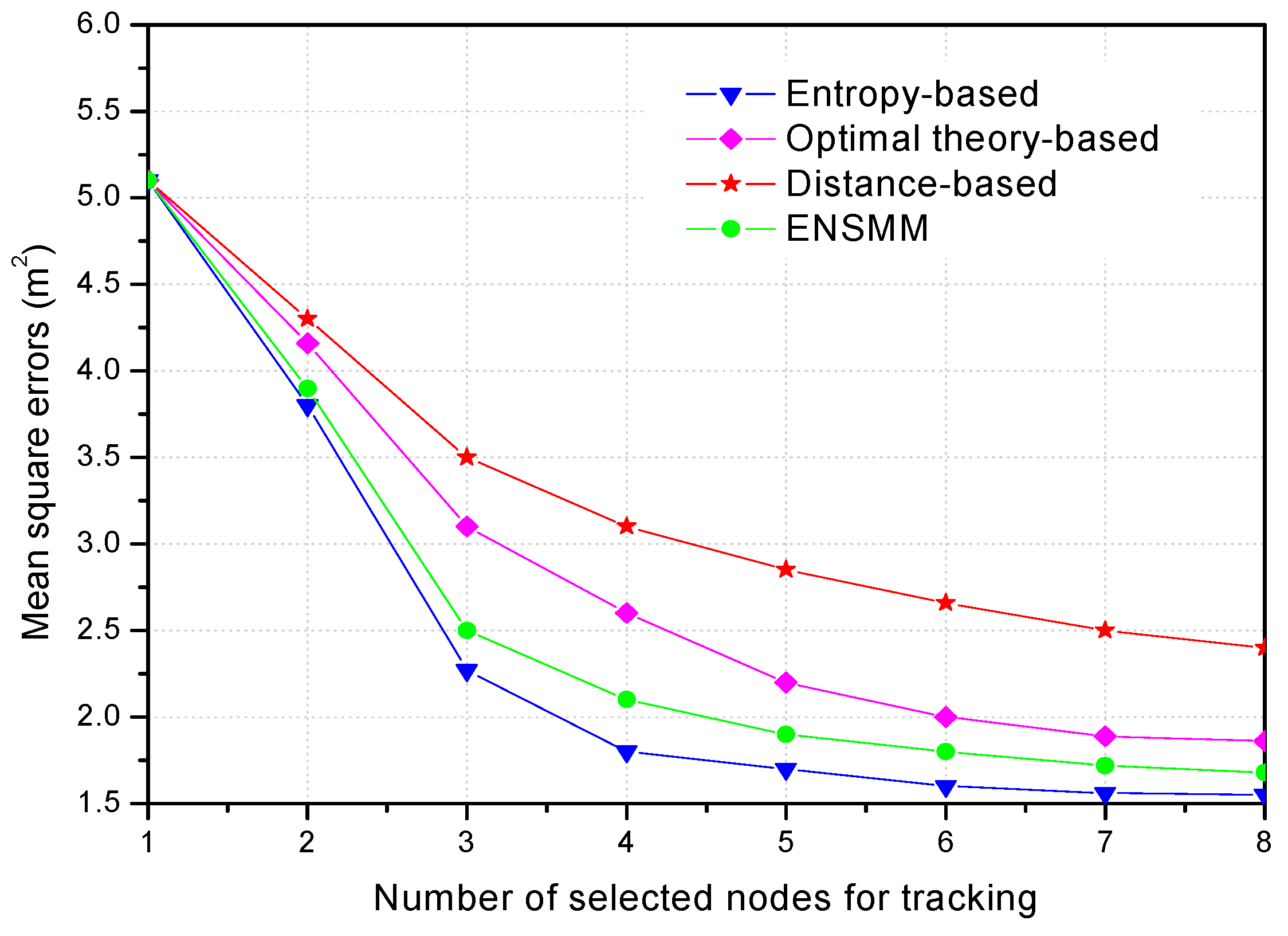
In
Figure 9, we show the tracking performance with the different number of selected sensor nodes. Obviously, the more nodes are selected for tracking, the less mean square positioning errors can be obtained, but the network energy consumption is going to increase. When the number of the selected nodes is in the range of 1 to 5, the mean square positioning errors decrease significantly as the number of nodes increases. When the number of the selected nodes is large enough, the tracking performance tends to saturate as shown in
Figure 9, and the positioning accuracy increases slowly and inconspicuously because some selected nodes bring the repetitive and useless information. Although the positioning accuracy of the distance-based method rises with the increasing number of selected nodes, it has the worst results because the selected nodes cannot provide informative observations. Besides, ENSMM selects the more informative nodes and sensed modules according to the joint weighted information utility, thus the tracking performance of ENSMM increases substantially when the number of tracking nodes grows from 1 to 5. The optimal theory-based method has worse performance than ENSMM because the correlations of the selected nodes are not considered. Comparing the results of ENSMM with other methods, it is seen that using a fewer nodes and sensed modules, ENSMM can achieve the accuracy which is obtained by selecting more nodes in the optimal theory-based and distance-based methods. Therefore, ENSMM can reduce the number of the active nodes for tracking so as to saving energy and guarantee the tracking performance.
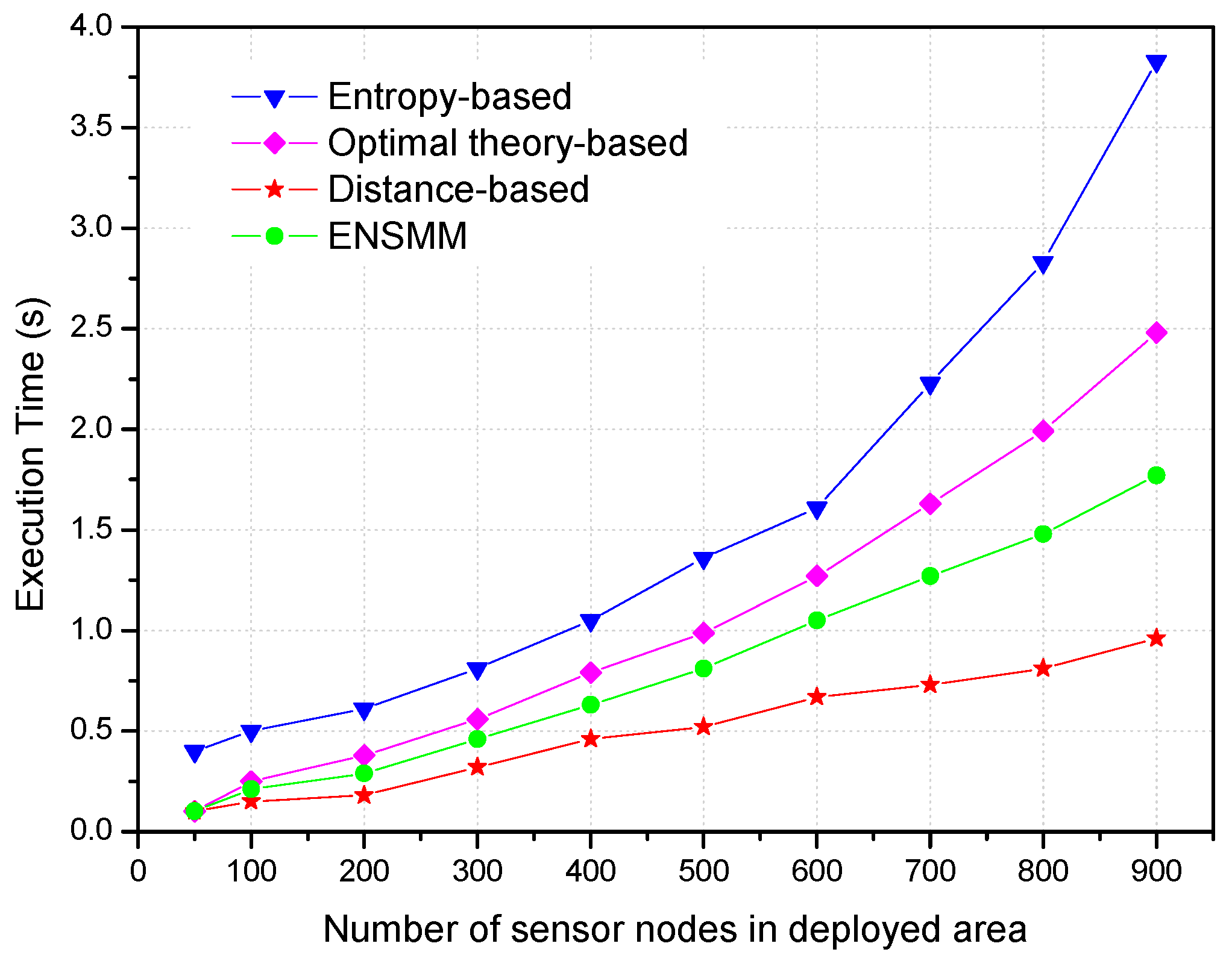
In order to investigate that node density in the network affects the computational complexities of these algorithms, the experiments were carried out keeping the other parameters fixed and progressively increasing the number of nodes in the deployed area. Specifically, the number of nodes increases from 50 to 900. We show the effect of the number of nodes on the execution time of the different algorithms in
Figure 10. Not surprisingly, all the algorithms use more execution time with the increasing the number of nodes. It is because that there are more candidate nodes in the tracking area, and then more computations are needed for node selection. The execution time of the entropy-based approach quickly rises in pace with the increasing nodes and it is the largest among these methods because more computations of mutual information utilities are needed and it is more complexity with a large number of sensor nodes. The distance-based method uses the shortest execution time compared with the others due to its simple computation. The execution time of ENSMM is shorter than that in the entropy-based and optimal theory-based methods because the complex entropy calculation is converted to the simple area comparing using the proposed joint weighted information utility measurement. From
Figure 6 and
Figure 7, we can see that ENSMM has relative lower computational complexity to achieve more tracking accuracy.
Moreover, sometimes sensed modules are available with a variable sensing range. If sensing ranges of sensors are changed, the number of candidate nodes within the tracking area is also changed. In a similar way, the longer sensing ranges the sensors have, the more candidate nodes are within the tracking area, and then node selection algorithms need to more computation. Therefore, changing the sensing range of sensors and changing the number of nodes have the similar results.
Now we study the effect of the different algorithms on the energy consumption of each node and the network lifetime.
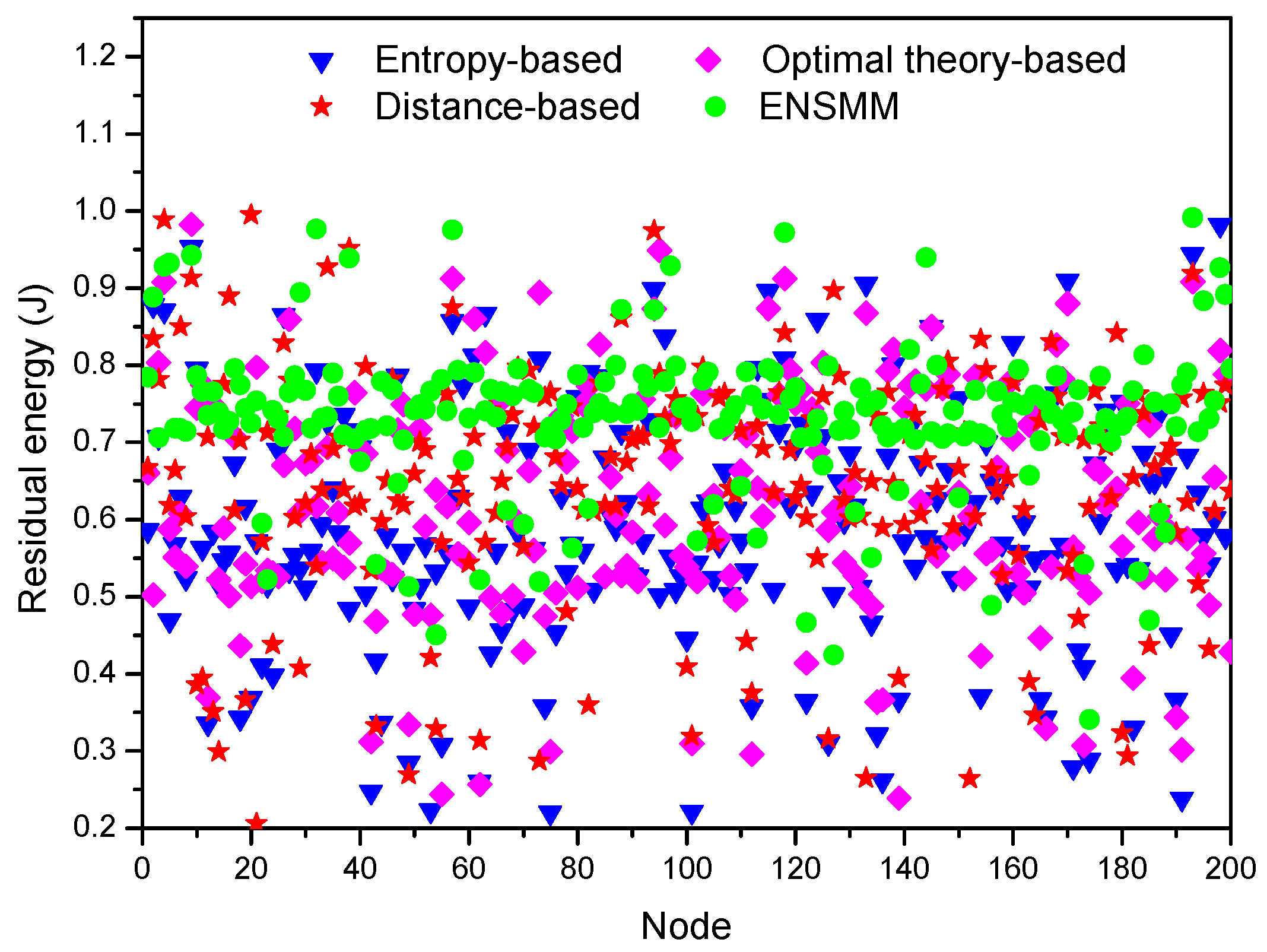
Figure 11 shows the residual energy of each node in the network under different node management algorithms after 300 s simulation time. In all the algorithms, since the nodes close to the target are active and transmitting data frequently so that their energy is quickly depleted and their residual energy is less. However, comparing with the other three algorithms, the residual energy of each node in ENSMM has a concentrated and balanced distribution as shown in
Figure 11. This is because the residual energy and power consumption of the sensed modules are considered in ENSMM node and sensed module selection procedure, and then the nodes which have more residual energy are selected to execute the energy intensive sensory tasks, so as to balance the energy consumption. In contrast, the energy consumption of each node is unbalanced in the other three algorithms, and some of the nodes near to the target have a little residual energy and will be exhausted soon.
Figure 12 shows the average energy consumption of each node in tracking stage under different node management algorithms. We can see that the average energy consumption is the highest in the entropy-based method. This is because it has the highest computational complexity and when a node is in work status all its sensed modules are active. Although the distance-based and optimal theory-based methods have lower computational complexity, they have not yet managed sleep/work status for sensed modules, so that they also have higher energy consumption. In contrast, the advantages of the proposed ENSMM are even more obvious and the average energy consumption in ENSMM is lower than that in the other methods in the tracking stage. We see that ENSMM can conserve at least 16% and 21% energy than that in distance-based and entropy-based approaches in tracking stage. This is because, ENSMM carries out the power management on the sensed modules of each node, and then not only the sleeping sensed modules can save energy but also the sleeping modules do not transmit sensed data in the network, which will reduce the number of the transmission data and further save energy.
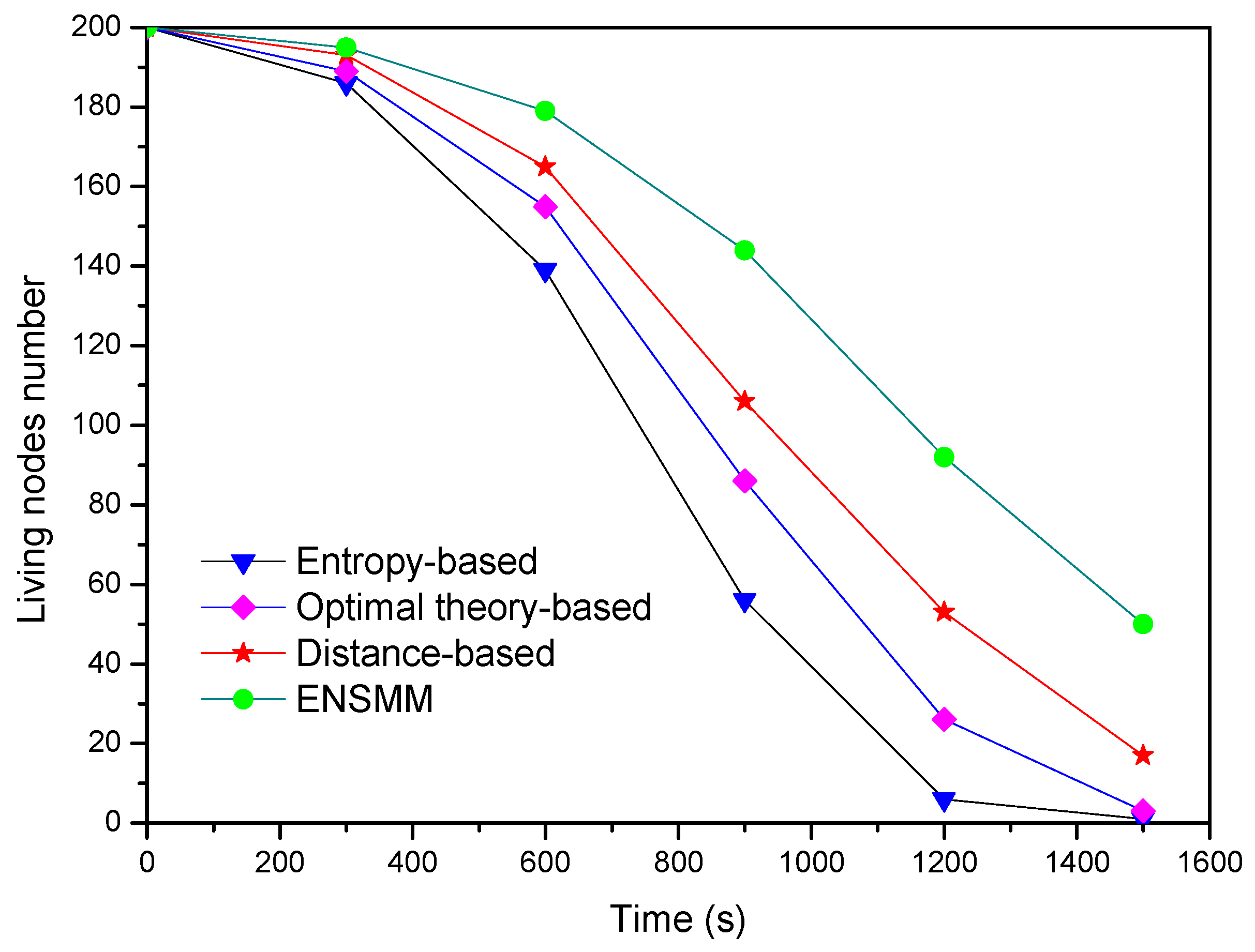
Finally,
Figure 13 shows the living node number changes with the simulation time under the different methods. We can see ENSMM has the most living nodes number among these approaches at each time step and the network lifespan in ENSMM is also extended. The main reasons are as following: (1) ENSMM has efficient power management for the nodes and the corresponding sensed modules, so that the idle nodes or sensed modules can be in sleep status to save energy; (2) It has relative less computational complexity. Meanwhile it balances the energy consumption in the network by executing the energy intensive sensory tasks on the nodes which have more residual energy; (3) It reduces the number of the transmitted data by turning off the active sensed modules.
In contrast, the other three methods have unbalanced energy consumption on each sensor node and have not an efficient way to control the sleep/active status for sensed modules. Although the closest approach has the simplest calculations, it needs more active nodes to guarantee the tracking accuracy. The entropy-based approach costs more energy because it has massive calculating works. To sum up, ENSMM achieves more energy efficiency and less computational complexity with degrading the tracking performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}