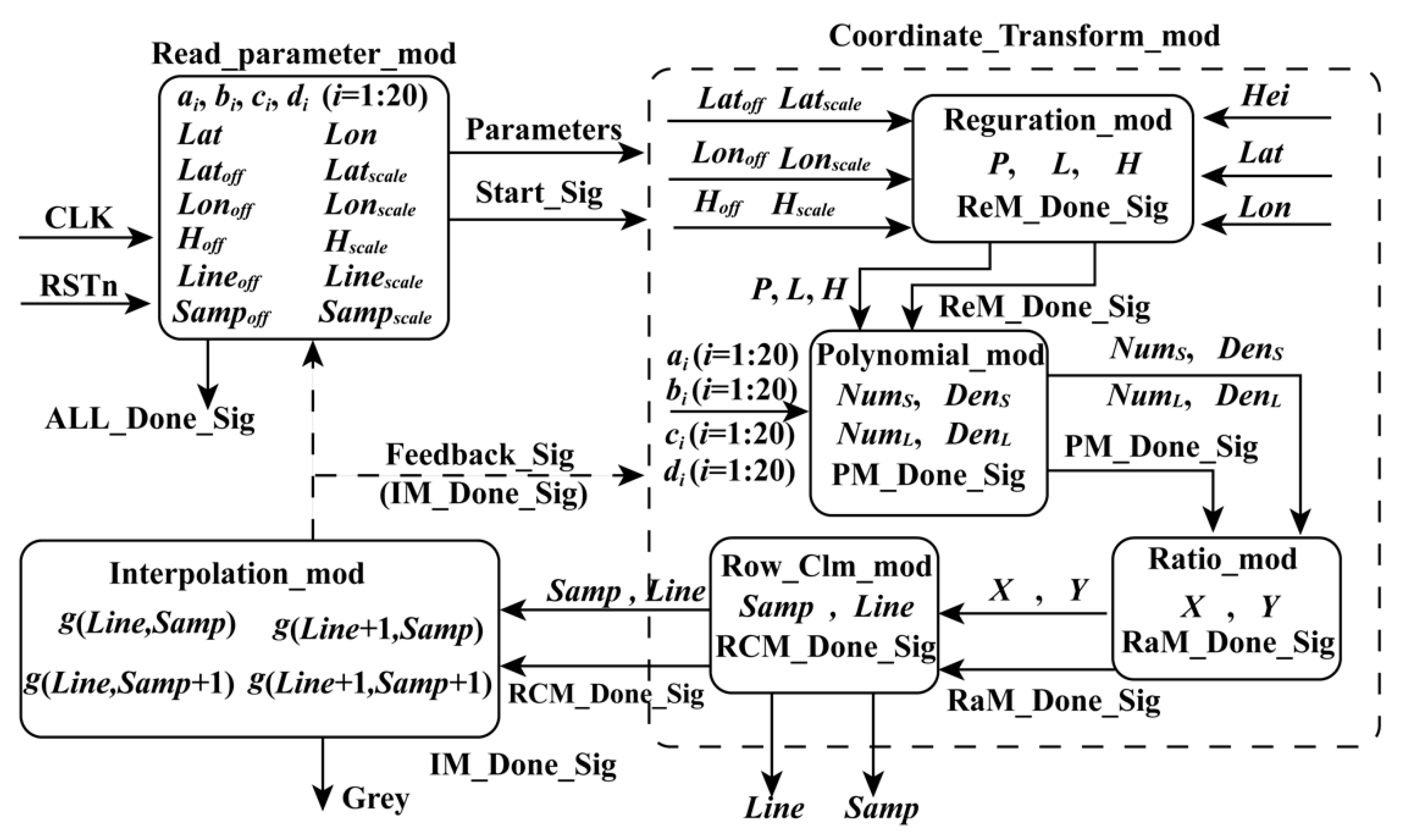
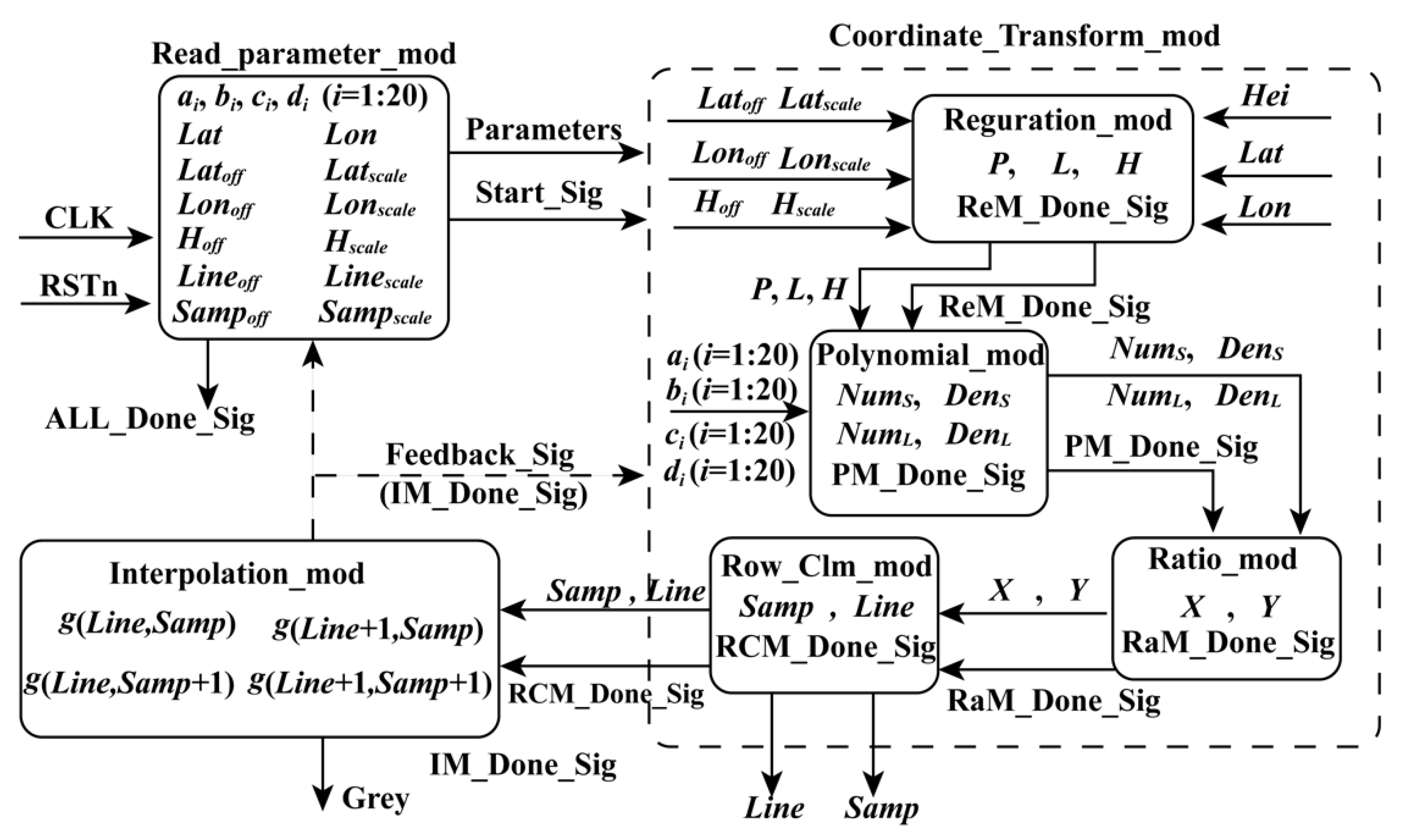
Many factors affect the computation speed when an FPGA is adopted, such as the optimal design of algorithms and the logical resource of the utilized FPGA. By analyzing the structure of the FP-RPC algorithm and optimizing it, an FPGA-based hardware architecture for FP-RPC-based orthorectification is designed, as shown in
Figure 1. As described in Equations (2)–(9), their structures are similar. It is convenient for FPGAs to be implemented in parallel. As shown in
Figure 1, the FPGA-based FP-RPC module can be divided into three submodules, that is, Read_parameter_mod (RPM), which is used to send parameters to other modules; Coordinate_Transform_mod (CTM), which is applied to transform geodetic coordinates to image coordinates; and Interpolation_mod (IM), which is utilized to perform bilinear interpolation. The details of these modules are given as follows.
2.2.1. Read Parameter Module
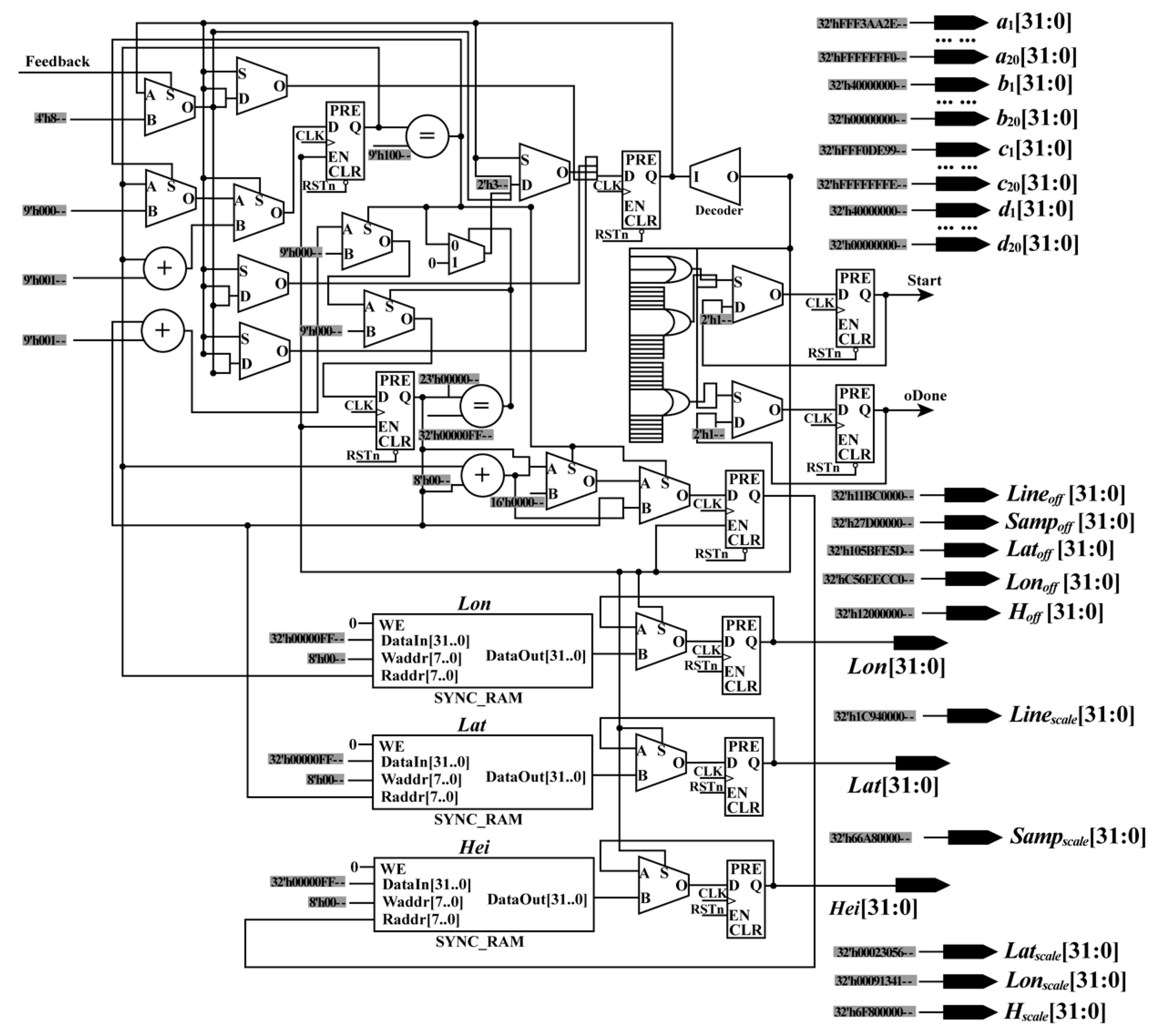
To ensure that the constants, geodetic coordinates, and the start signal (Start_Sig) are sent in the same clock cycle, a parallel module (i.e., the RPM) is designed (see
Figure 2). In the RPM, the constants are assigned corresponding values, while the geodetic coordinates are stored in RAM. In this design, all values are expressed using a fixed point of 32 bits to ensure computational accuracy.
In the RPM, the geodetic coordinates are sent to the next module according to the order of the column. First, the address of RAM is initialized as 0. When the enable signal is detected, the first group of geodetic coordinates (Lat0, Lon0, Hei0) is read from the RAM and sent to the next module with the constants and the Start_Sig in the same clock cycle. Starting from the second group of geodetic coordinates, the rules for reading and sending geodetic coordinates are changed. In other words, after the second group of geodetic coordinates (Lat1, Lon1, Hei1), the geodetic coordinates will be read and sent unless the enable signal and the feedback signal (Feedback_Sig), which are sent by the interpolation module, are detected at the same time. After the final group of geodetic coordinates are read and sent, if the Feedback_Sig is received, the done signal (ALL_Done_Sig) of orthorectification is produced. When the ALL_Done_Sig is detected, the process of orthorectification is stopped.
2.2.2. Coordinate Transformation Module
As shown in
Figure 1, for the CTM, the inputs contain the constants, the geodetic coordinates, and the Start_Sig, while the outputs include image coordinates and the done signal of this module. The CTM can be divided into four submodules, namely ReM, PM, RaM, and RCM. Details regarding these four submodules are as follows.
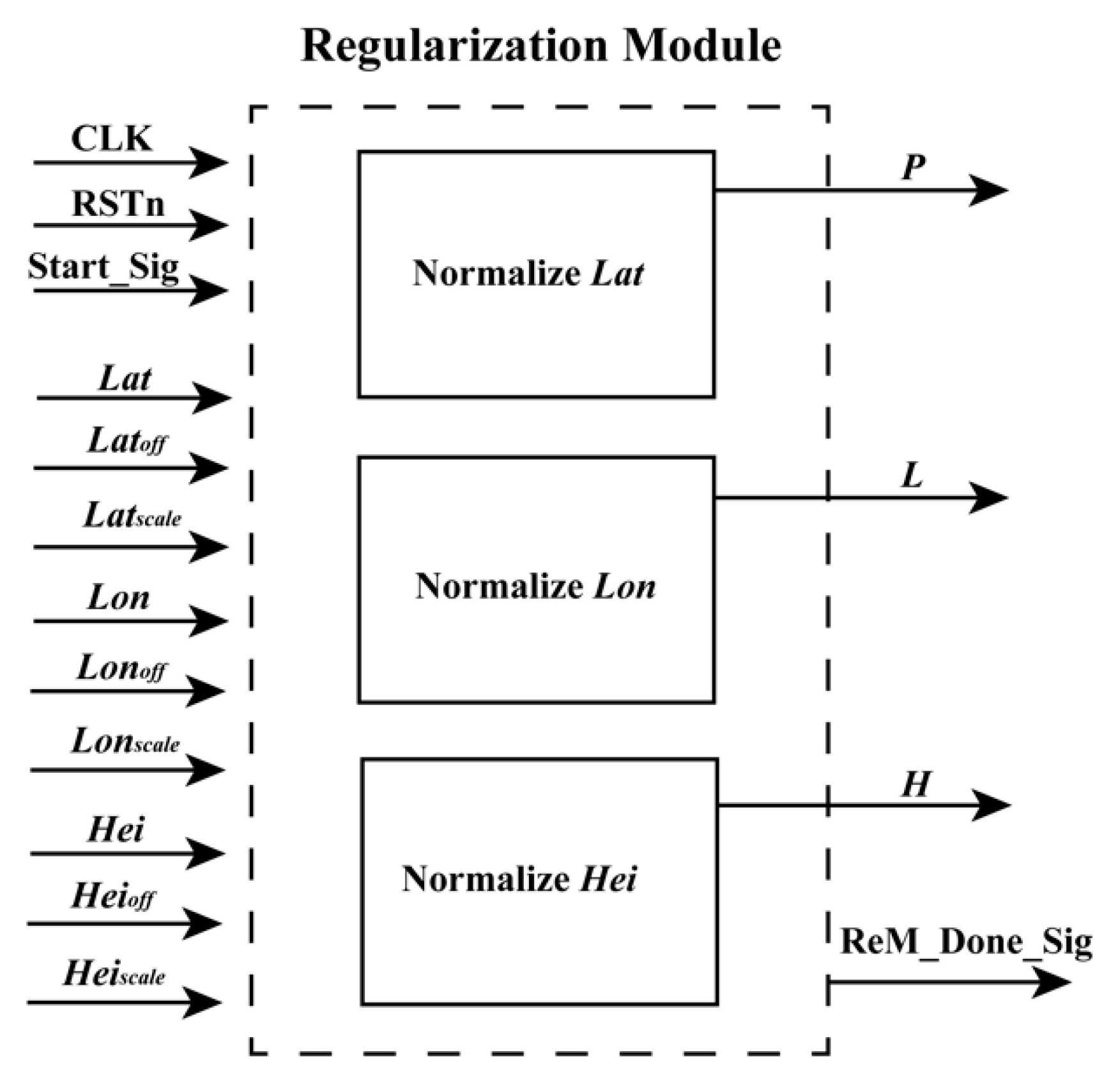
• Regulation Module
According to
Section 2.1, the geodetic coordinates (
Lat,
Lon,
Hei) should be first transformed as the normalized coordinates (
L,
P,
H) based on Equation (2) because this operation can minimize the introduction of errors during the computation of the numerical stability of equations [
13]. As shown in Equation (2), the forms of these equations are uniform. In other words, they are suitable for implementation using FPGA. To obtain the normalized coordinates (
L,
P,
H) of the geodetic coordinates (
Lat,
Lon,
Hei) using an FPGA chip, a parallel computation architecture is presented in
Figure 3. In
Figure 3, the structures of “Normalize
Lat”, “Normalize
Lon”, and “Normalize
Hei” are similar. Thus, only the schematic diagram of “Normalize
Lat” is presented (see
Figure 4).
As shown in
Figure 4, during the computation process, 1 divider, 10 adders, 10 flipflops, and 16 multiplexer units are mainly used to normalize the
Lat. In this design, the relationship among “Normalize
Lat”, “Normalize
Lon”, and “Normalize
Hei” is parallel. The normalized coordinates (
L,
P,
H) are obtained in the same clock cycle as the done signal.
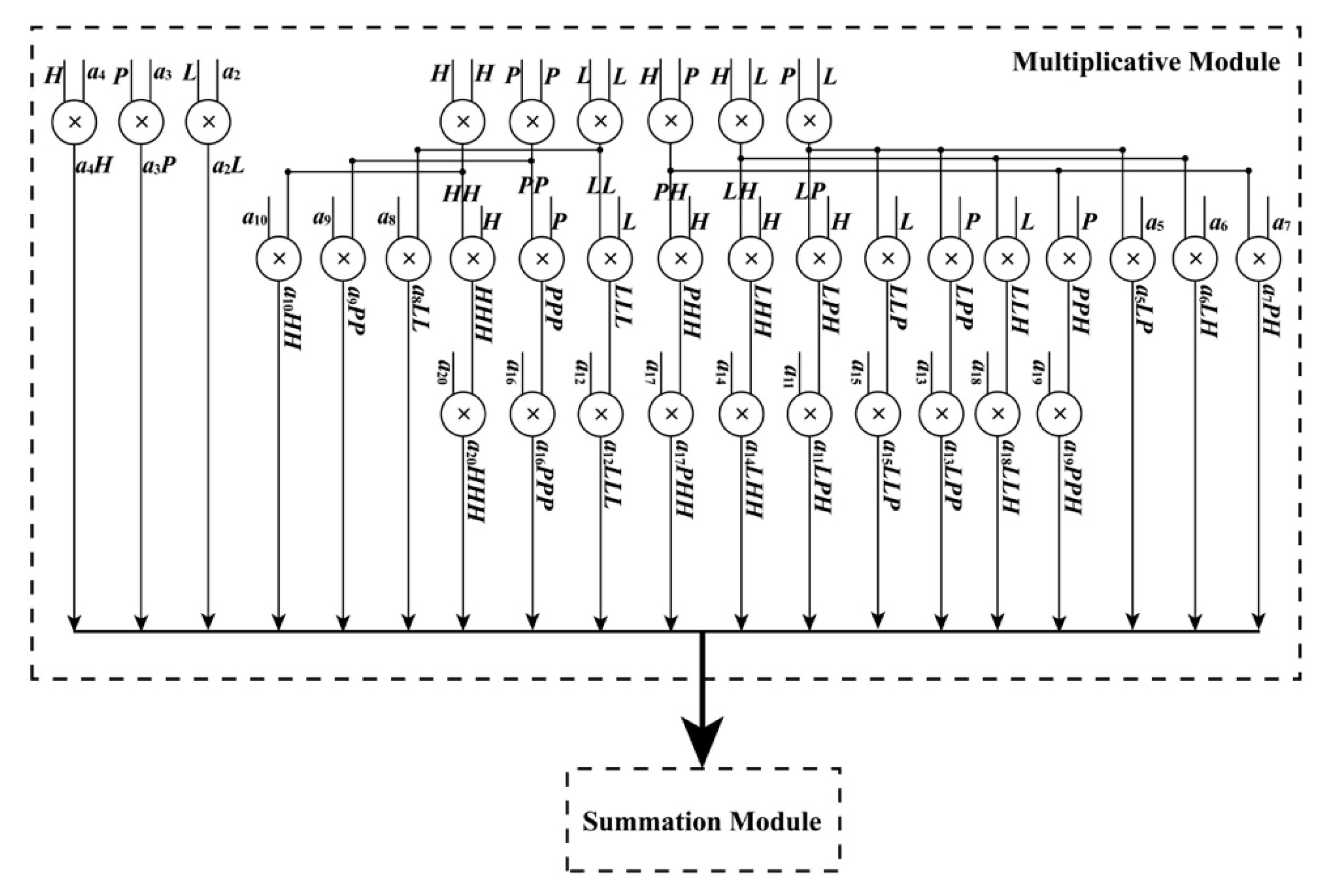
• Polynomial Module
When the ReM_Done_Sig and (
L,
P,
H) are being received by the PM module, the PM module starts to work. As shown in Equations (4) and (5), these polynomials have a uniform form, which are suitable for the implementation of an FPGA chip in parallel. In these equations, variables such as
LH,
LP, and
PH are shared. To implement these polynomials in parallel using an FPGA chip, a parallel computation architecture is proposed in
Figure 5 and
Figure 6. As shown in those figures, the PM module is divided into two parts: one is used to perform multiplication and the other is applied to manipulate addition. When performing addition, some special operations about the positive and negative sets of data should be considered. Thus, for the additions in
Figure 6, each of them is extended to a similar form, as shown in
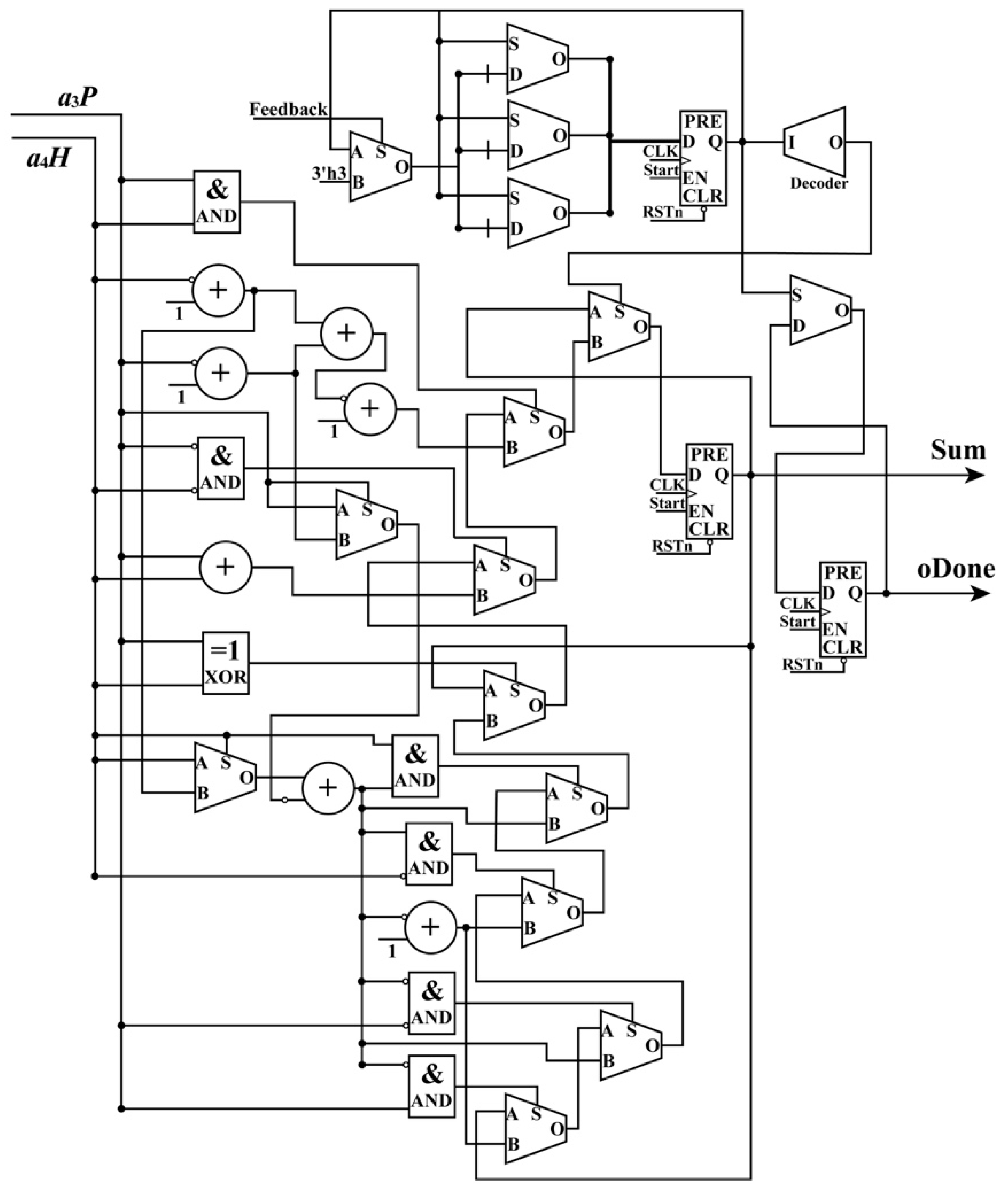
Figure 7, taking the addition between
a3P and
a4H as an example. In the example, three situations are considered: (i)
a3P and
a4H are both positive; (ii)
a3P and
a4H are both negative; and (iii)
a3P and
a4H have opposite signs. The details for an extended addition are shown in
Figure 7.
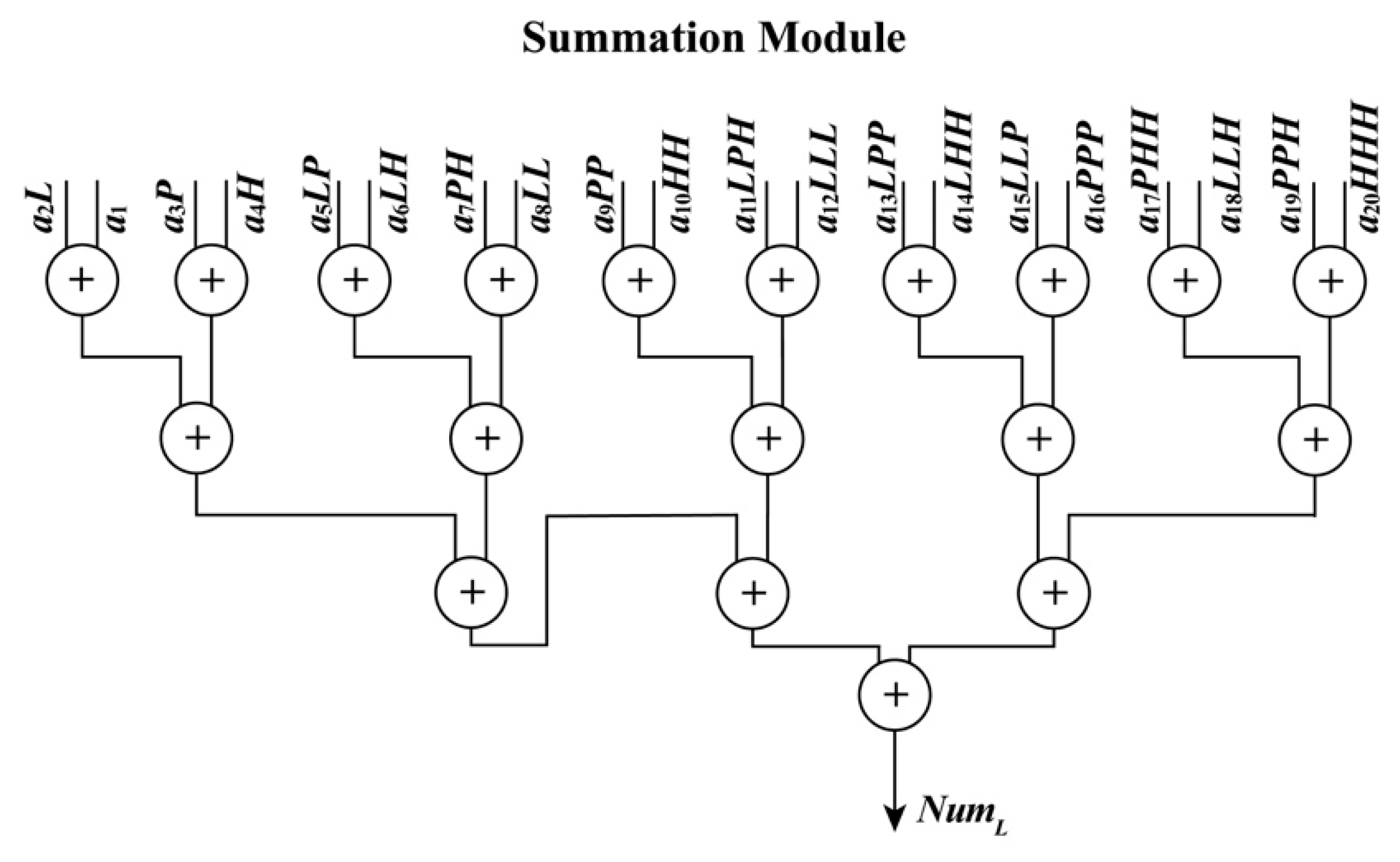
To implement each polynomial, 35 multipliers are utilized in the multiplication, and 19 extended additions are used. In each extended addition, three flipflops, four selectors, seven adders, and eleven multiplexers are applied. After processing the PM module, four sums, i.e., NumL, NumS, DenL, and DenS, are obtained with the done signal of the PM module, PM_Done_Sig, in the same clock cycle.
• Ratio Module
When the PM_Done_Sig,
NumL,
NumS,
DenL and
DenS are being received, the RaM module starts to calculate the normalized coordinates (
X,
Y) of image coordinates. As shown in Equation (6), the forms for the two equations are the same. It is convenient to calculate
X and
Y in parallel using an FPGA chip. In
Figure 8, a parallel-computing architecture that is used to calculate
X is presented. In the same way, the
Y coordinate can be obtained.
To obtain the X (or Y) coordinate, one divider, three adders, six multiplexers, six flipflops (two flipflops are public), and 32 selectors are applied. After the processing of the RaM module, the X coordinate and Y coordinate are acquired with the done signal, RaM_Done_Sig, in the same clock cycle.
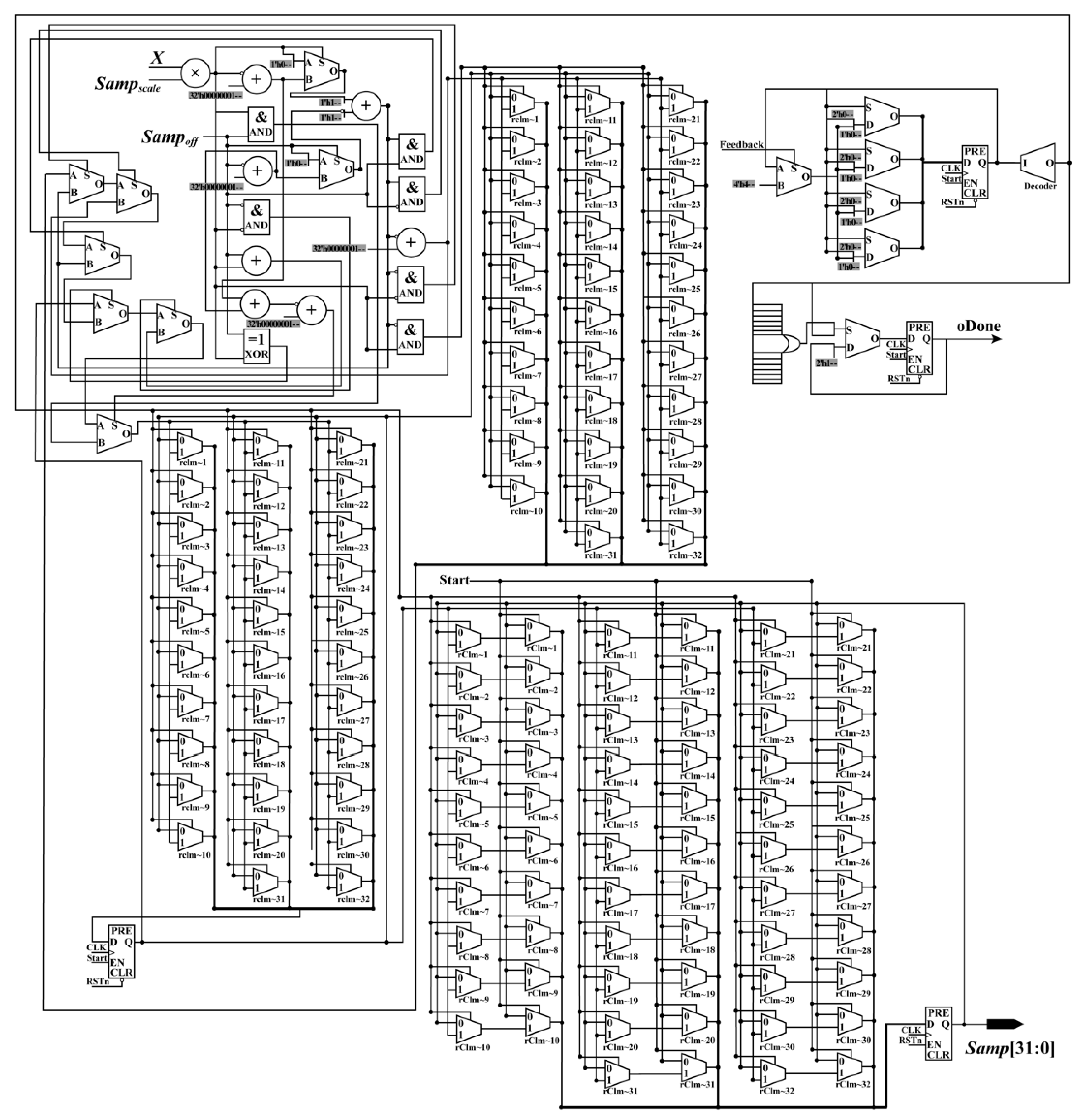
• Image Coordinate Calculation Module
When the RaM_Done_Sig, X, and Y coordinates are being detected, the RCM module starts to calculate the image coordinates (Samp, Line), i.e., column and row indexes. As shown in Equation (9), the equations give the relationship between the normalized coordinates (X, Y) and image coordinates (Samp, Line).
As shown in Equation (9), the equations have a uniform form, which is helpful for implementation using an FPGA. To calculate the image coordinates (
Samp,
Line) in parallel, a parallel-computing hardware architecture is designed. Because the forms of the equations in Equation (9) are similar, only the schematic diagram used for calculating the
Samp coordinate is given. As shown in
Figure 9, there are one multiplier, four flipflops (two of them are shared when calculating
Line coordinate), five selectors (MUX) shared when calculating
Line coordinate, seven adders, and 136 multiplexers (MUX21).
After the processing of the RCM module, the image coordinates, that is, the column and row indexes (Samp, Line), and the done signal (RCM_Done_Sig) are obtained in the same clock cycle. Up to this point, the whole processing of the coordinate transformation is done. The obtained image coordinates are sent to the interpolation module to interpolate the grayscale.
2.2.3. Interpolation Module
Because the obtained column and row indexes may not exist only at the center of a pixel, it is necessary to use the interpolation method to obtain the grayscale in the obtained column and row indexes. Considering the interpolation effect, the complexity of an interpolation algorithm, and the resources of an FPGA, the bilinear interpolation method is selected to implement the interpolation for grayscale. Mathematically, the bilinear interpolation algorithm can be expressed by the following equation:
where
i and
j are nonnegative integers; the intermediates
p = |
i − int(
i)| and
q = |
j − int(
j)| are within the range of (0, 1); and
g(
i,
j) represents gray values.
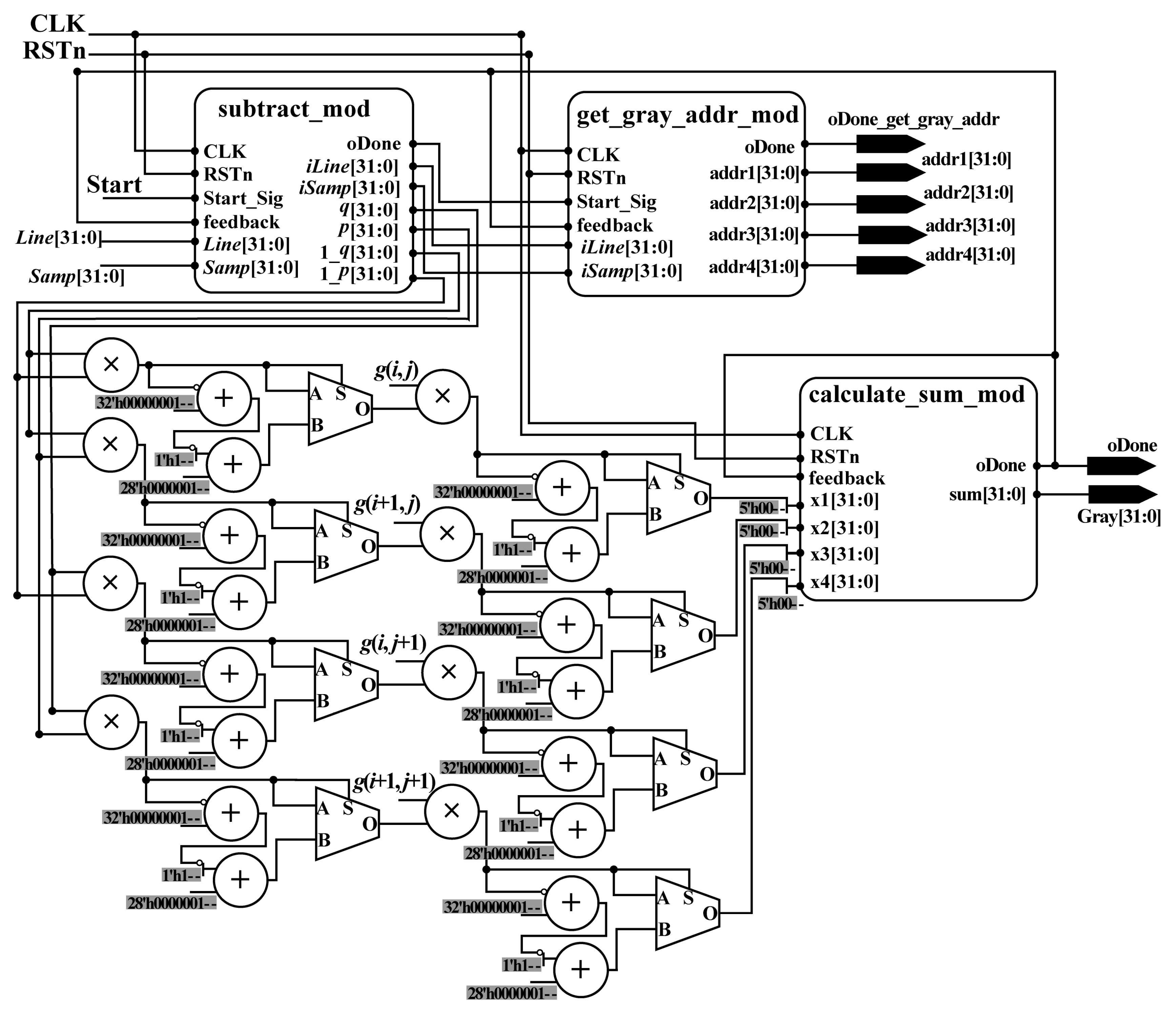
To implement the bilinear interpolation algorithm in parallel using an FPGA chip, a parallel computation architecture was designed (see
Figure 10). The designed hardware architecture contains four submodules/parts: (i) the subtract_mod, which is used to obtain the integer part (
iLine and
iSamp) and fractional part (
p and
q) of
Line and
Samp indexes, and to calculate the subtraction (1_
p and 1_
q) in Equation (18); (ii) the get_gray_addr_mod, which is applied to obtain the address of gray in RAM; (iii) the multiplication part, which is utilized to calculate the multiplications in Equation (18); and (iv) the calculate_sum_mod, which is used to compute the sum in Equation (18). After the processing of the calculate_sum_mod, the results of interpolation in (
Samp,
Line) are obtained. The details of subtract_mod, get_gray_addr_mod, and calculate_sum_mod are described as follows.
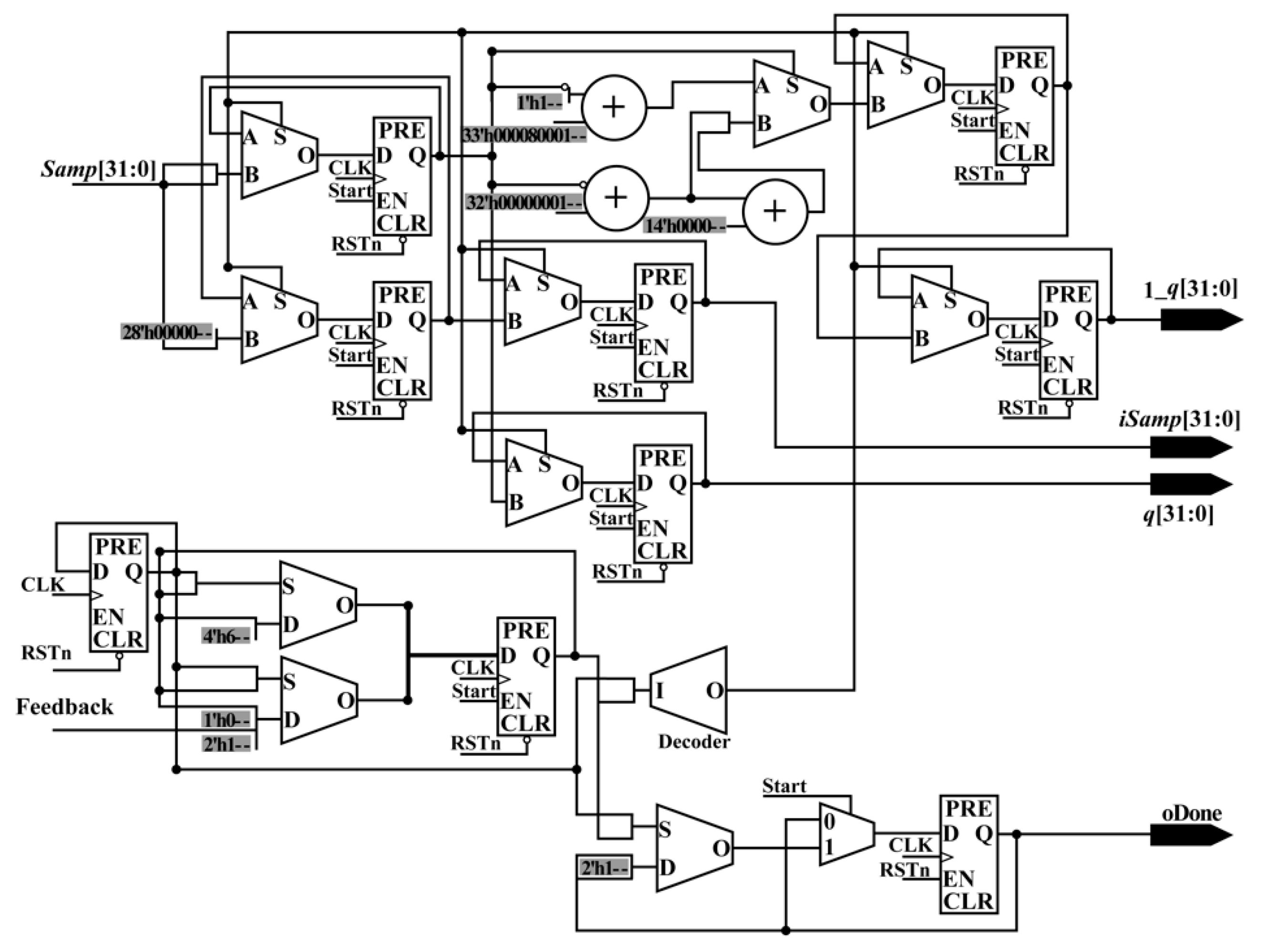
• subtract_mod
As shown in Equation (18), to perform the bilinear interpolation method, the gray values of four neighbors around the acquired column and row indexes are required. Thus, the acquired column and row indexes should be pre-processed to obtained the integer part and fractional part, which are used to calculate (1 −
q) and (1 −
p). To implement the function using an FPGA chip, a parallel-computing architecture is proposed, named subtract_mod. In subtract_mod, the methods used to acquire
iSamp,
q and 1
_q are similar to those for obtaining
iLine,
p and 1
_p, respectively. Thus, in this section, only the schematic diagram for obtaining
iSamp,
q and 1
_q is given (see
Figure 11).
As shown in
Figure 11, to obtain
iSamp,
q and 1
_q, three adders, seven multiplexers (MUX21), and nine flipflops (three of which are shared when
iLine),
p and 1
_p are used. In addition, three MUXs are public. After the processing of the whole subtract_mod,
iSamp,
q, 1
_q,
iLine,
p, and 1
_p are acquired with the done signal in the same clock cycle. When obtaining these variables,
iSamp and
iLine are sent to the next submodule to retrieve the address of gray for four neighbors in RAM. Meanwhile,
q, 1
_q,
iLine,
p, and 1
_p are sent to another part to perform multiplication.
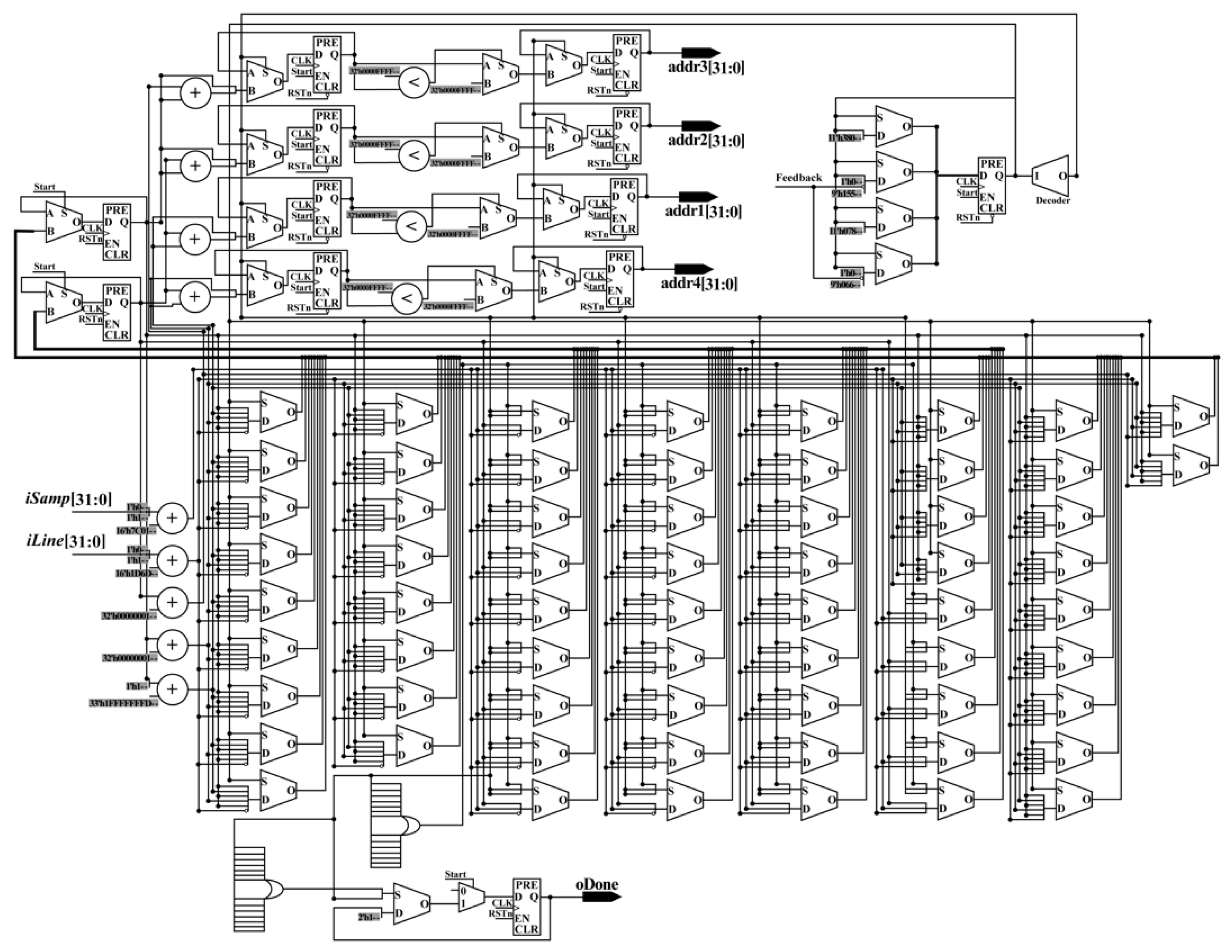
• get_gray_addr_mod
The grayscale of a pixel can be obtained according to the corresponding address. To obtain the gray values of four neighbors around the obtained column and row indexes in parallel, a parallel-computing hardware architecture is proposed (see
Figure 12), called get_gray_addr_mod. In the get_gray_addr_mod, 3 LESS-THAN comparators, 9 adders, 10 MUX21, 12 flipflops, and 70 MUX are applied. After the processing of the get_gray_addr_mod, four addresses are obtained with the done signal in the same clock cycle. According to the obtained addresses, the gray values can be acquired from RAM. Then, they are sent to the multiplication part to perform the multiplication.
• calculate_sum_mod
As shown in
Figure 10, after the multiplication process, four variables,
x1,
x2,
x3, and
x4, are obtained in the same clock cycle. To implement the addition for four variables, two levels of additions are needed. Each addition corresponds to an extended addition that has an architecture that is similar to
Figure 7. The details can be found in
Section 2.2.2 and
Figure 7. After the processing of the calculate_sum_mod, the result of interpolation in (
Samp,
Line) can be obtained.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}