TLTD: A Testing Framework for Learning-Based IoT Traffic Detection Systems


Abstract
1. Introduction
- We migrate the application scenarios of adversarial samples from the image recognition domain to the IoT malicious traffic detection field. This migration cannot be achieved simply by replacing the model’s training data from pictures to traffic. We need to do specific technical processing on the traffic data to ensure the validity of the adversarial sample.
- We introduce the genetic algorithm into the method of generating the adversarial sample and realize the black-box attack against the machine learning model.
- Our approach is equally valid for networks that have difficulty computing gradients or expressing mathematically.
2. Related Work
2.1. Fast Gradient Sign
2.2. One Pixel Attack
2.3. Application of Adversarial Samples in Malware Detection
- (1)
- The input samples in the image are all pixels and the values of the pixels are continuous. However, in the field of network security, input characteristics are usually discrete and the range of values of different features is usually different.
- (2)
- The pixels in the image can be freely changed within the value range. The restrictions on the modification of traffic or software are much more demanding. Arbitrary modifications may result in traffic or software not working properly.
3. Methodology
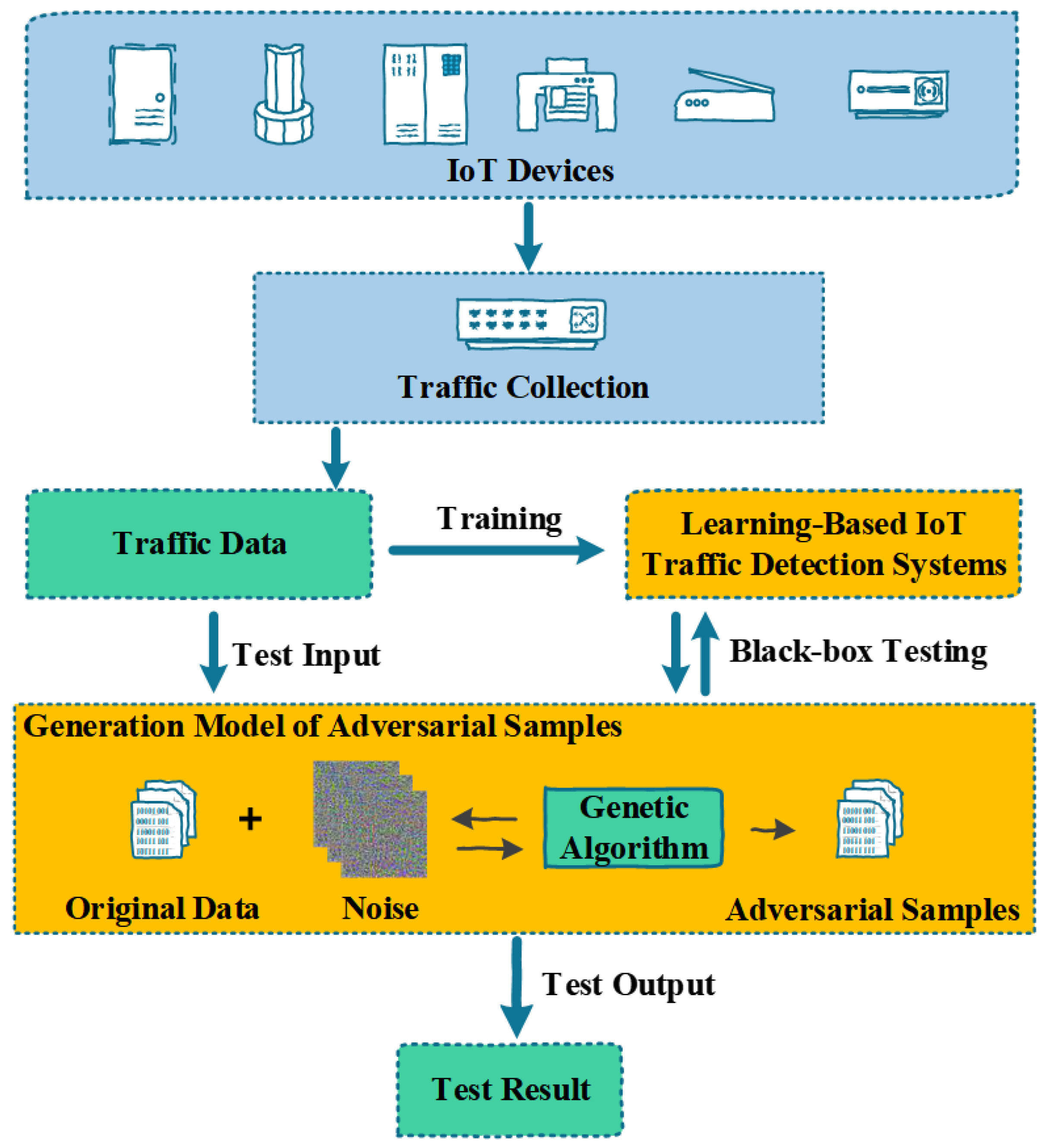
3.1. Framework
3.2. Algorithm
| Algorithm 1 Generating an adversarial sample. |
| Require: Population Size , Number of features , Original sample |
| for do |
| for do |
| if then |
| Compute |
| else |
| Compute |
| end if |
| end for |
| Compute |
| if then |
| Continue |
| else |
| Output |
| end if |
| end for |
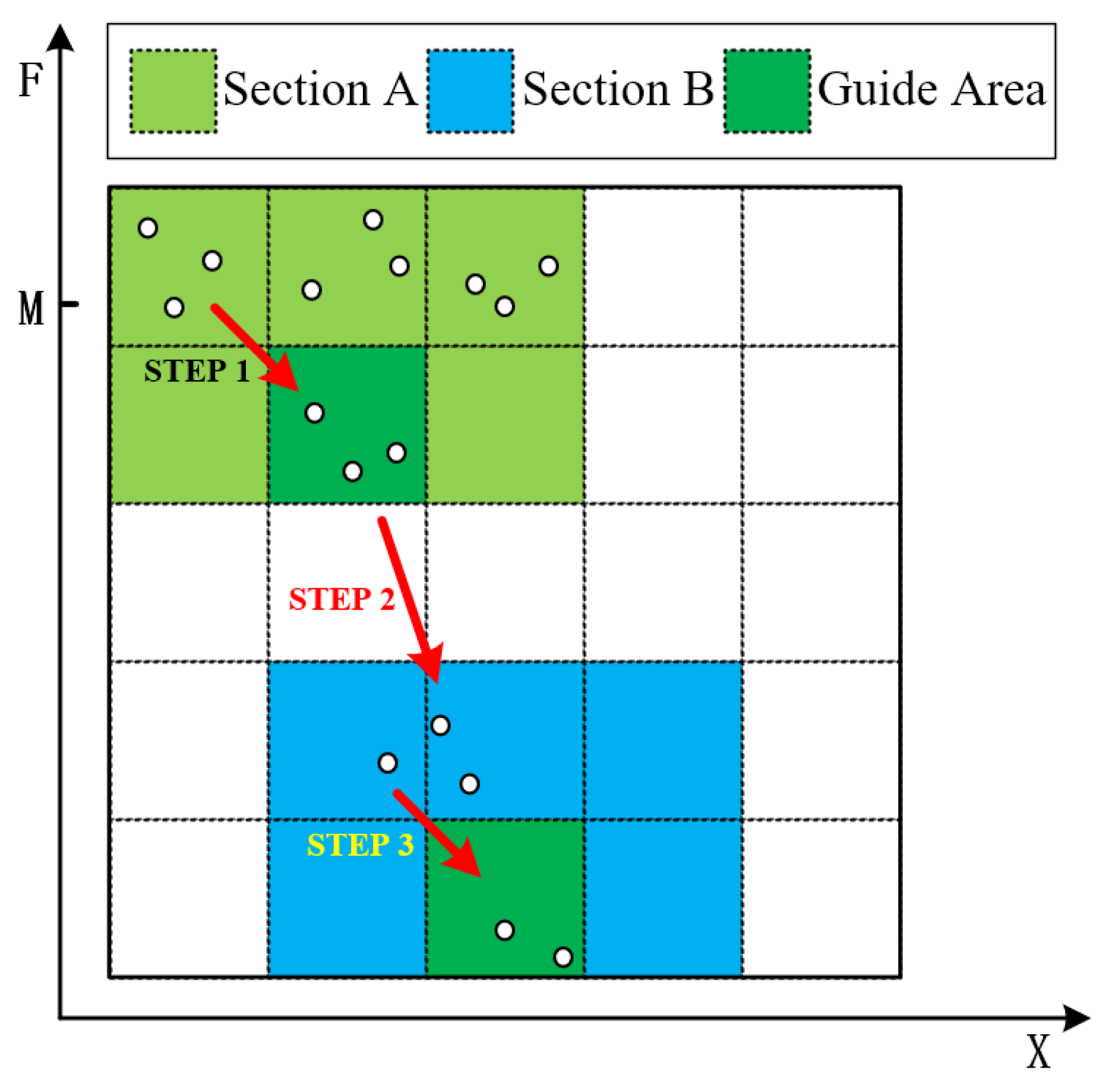
- Step 1.
- At this time, the adversarial sample cannot successfully mislead the classifier. Individuals at the top of section A gradually approach the bottom through crossover and mutation operators.
- Step 2.
- The individuals move from Section A to Section B, indicating that , i.e., the adversarial samples generated at this time can successfully mislead the classifier.
- Step 3.
- Individuals at the top of Section B gradually approach the bottom, indicating the improvement of the similarity between the adversarial traffic and the original traffic.
4. Experiments
4.1. Data Set and Environment
- Basic features of individual TCP connections;
- Content features within a connection suggested by domain knowledge;
- Traffic features computed using a two-second time window.
4.2. IoT Traffic Detection Model
4.3. Simulation Experiments
- STEP 1.
- Determine the number of individuals selected each time;
- STEP 2.
- Choose individuals randomly from the population and select the individuals with the best fitness values to enter the offspring population;
- STEP 3.
- Repeat STEP 2 for several times and the resulting individuals constitute a new generation of the population.
4.3.1. TLTD-I
4.3.2. TLTD-II
4.3.3. TLTD-III
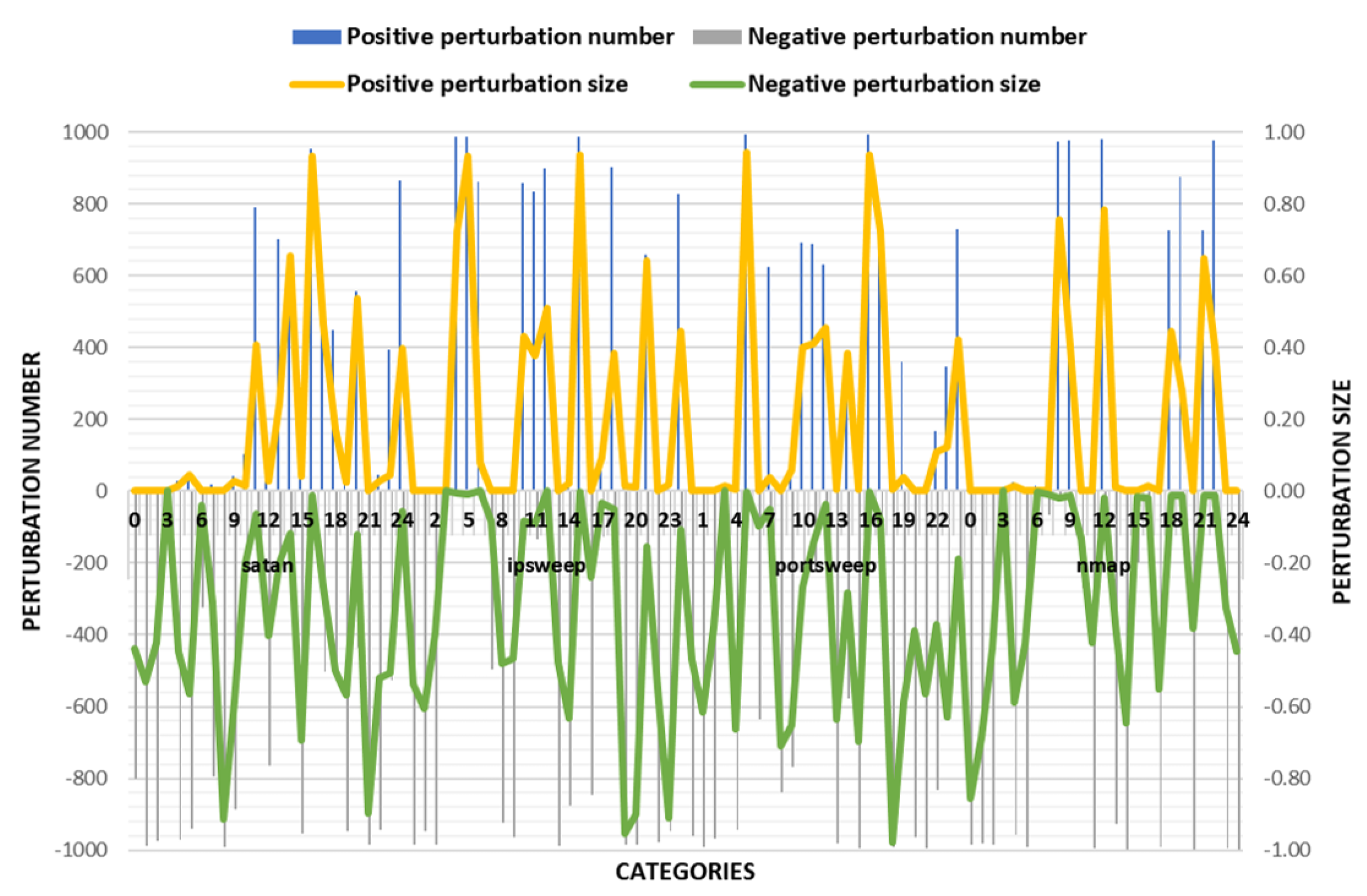
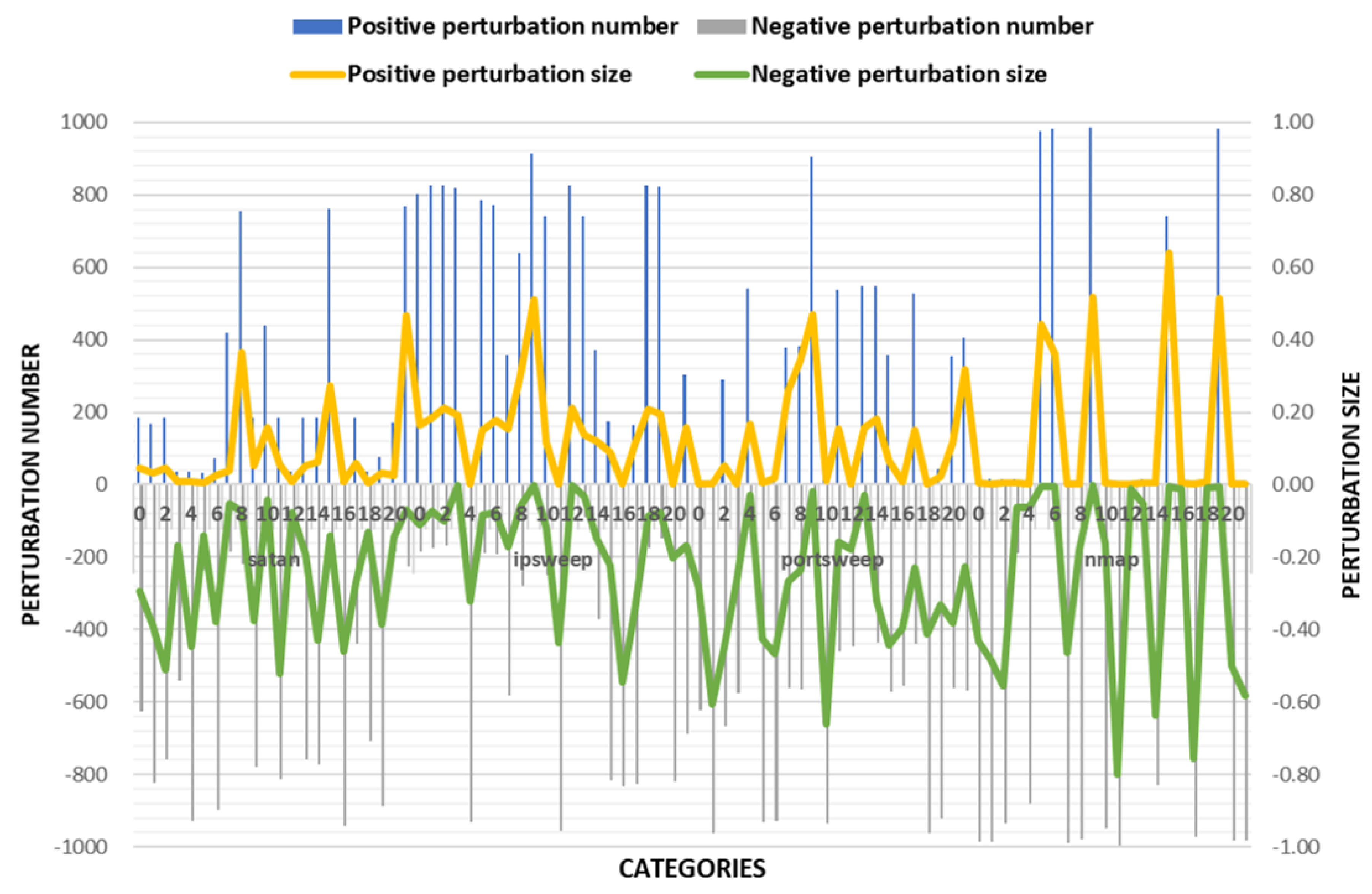
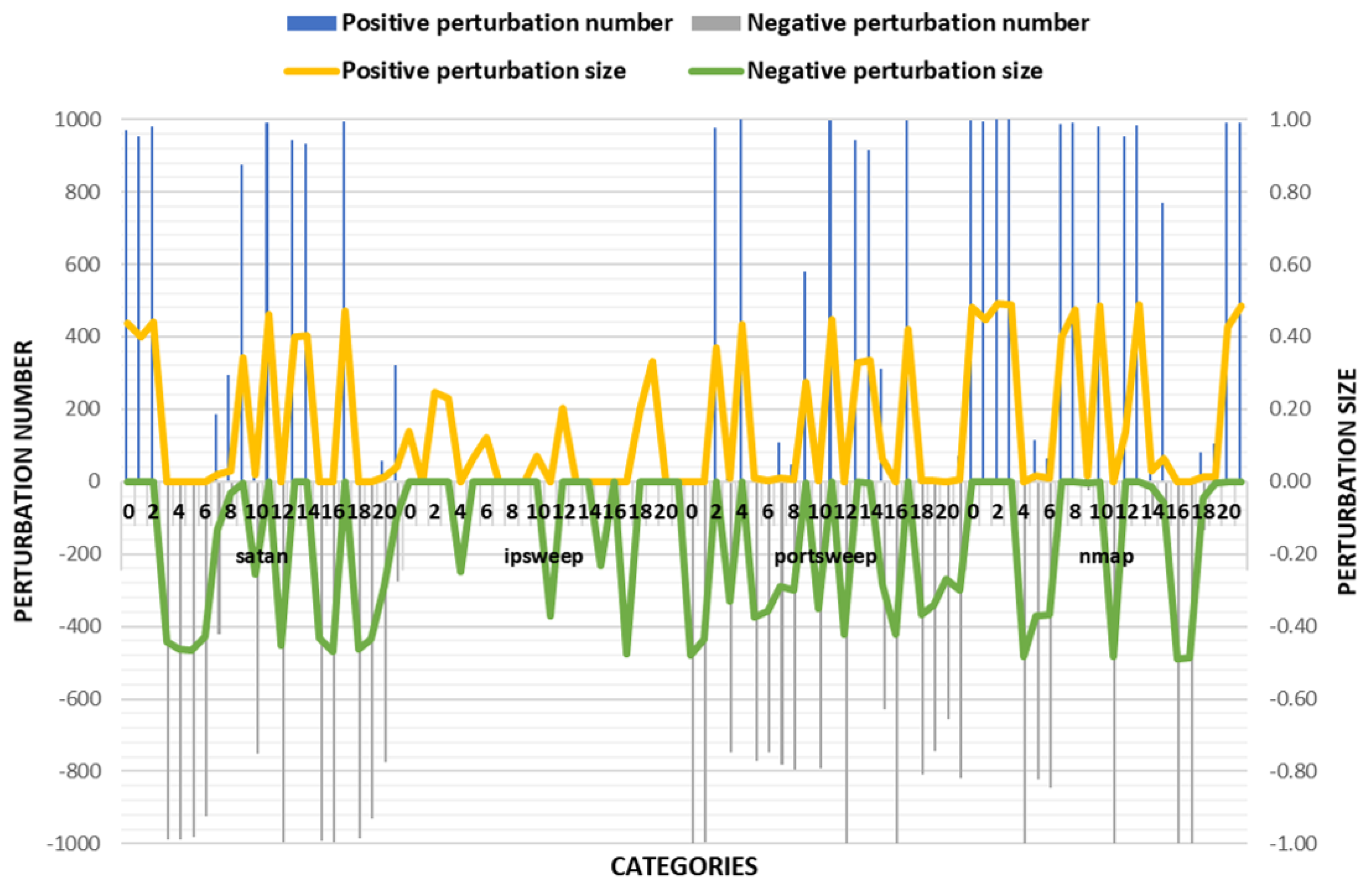
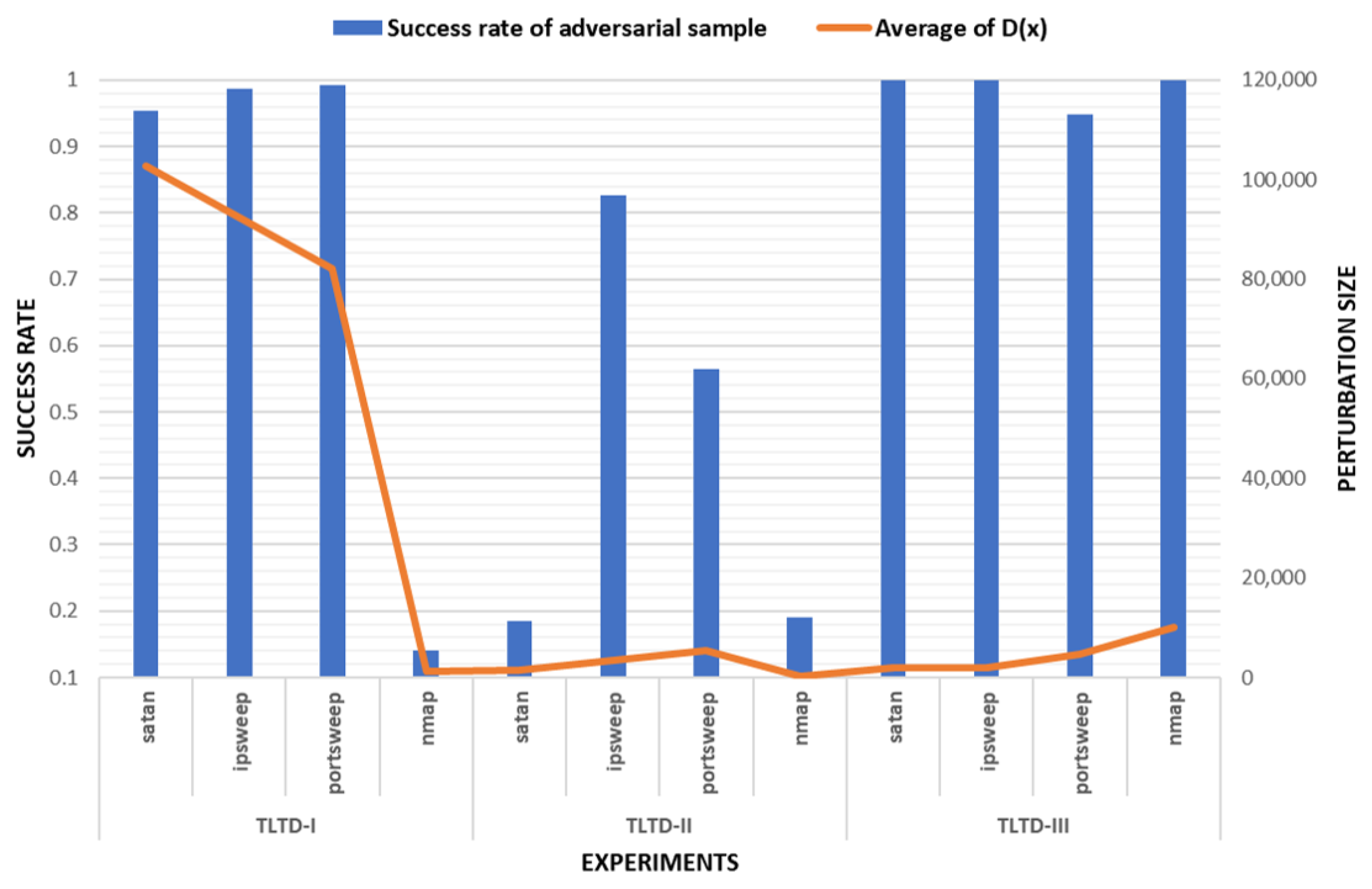
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Doshi, R.; Apthorpe, N.; Feamster, N. Machine Learning DDoS Detection for Consumer Internet of Things Devices. arXiv 2018, arXiv:1804.04159. [Google Scholar]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Dubouilh, P.L.; Iorkyase, E.; Tachtatzis, C.; Atkinson, R. Threat analysis of IoT networks using artificial neural network intrusion detection system. In Proceedings of the 2016 International Symposium on Networks, Computers and Communications (ISNCC), Yasmine Hammamet, Tunisiam, 11–13 May 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Bull, P.; Austin, R.; Popov, E.; Sharma, M.; Watson, R. Flow based security for IoT devices using an SDN gateway. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud (FiCloud), Vienna, Austria, 22–24 August 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Nobakht, M.; Sivaraman, V.; Boreli, R. A host-based intrusion detection and mitigation framework for smart home IoT using OpenFlow. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Du, X.J.; Yang, X.; Mohsen, G.Z.; Chen, H.H. An effective key management scheme for heterogeneous sensor networks. Ad Hoc Netw. 2007, 5, 24–34. [Google Scholar] [CrossRef]
- Du, X.J.; Mohsen, G.Z.; Yang, X.; Chen, H.H. A routing-driven elliptic curve cryptography based key management scheme for heterogeneous sensor networks. IEEE Trans. Wireless Commun. 2009, 8, 1223–1229. [Google Scholar] [CrossRef]
- Barreno, M.; Nelson, B.; Joseph, A.D.; Tygar, J. The security of machine learning. Mach. Learn. 2010, 81, 121–148. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Dezfooli, S.M.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. Number EPFL-CONF-226156. [Google Scholar]
- Fawzi, A.; Dezfooli, S.M.M.; Frossard, P. A Geometric Perspective on the Robustness of Deep Networks; Technical Report; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2017. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 372–387. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv 2016, arXiv:1606.04435. [Google Scholar]
- Hu, W.; Ying, T. Generating adversarial malware examples for black-box attacks based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Yang, W.; Kong, D.; Xie, T.; Gunter, C.A. Malware detection in adversarial settings: Exploiting feature evolutions and confusions in android apps. In Proceedings of the 33rd Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Demontis, A.; Melis, M.; Biggio, B.; Maiorca, D.; Arp, D.; Rieck, K.; Corona, I.; Giacinto, G.; Roli, F. Yes, machine learning can be more secure! A case study on Android malware detection. IEEE Trans. Dependable Secur. Comput. 2017. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Su, J.; Vargas, D.V.; Kouichi, S. One pixel attack for fooling deep neural networks. arXiv 2017, arXiv:1710.08864. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU (Central Processing Unit) | Inter(R) Core(TM) i507400 CPU @ 3.00 GHz |
| Memory | 8 GB |
| Video Card | Inter(R) HD Graphics 630 |
| Operating System | Windows 10 |
| Programming Language | Python 3.6 |
| Development Platform | Jupyter Notebook |
| Dependence | Tensorflow, numpy etc. |
| Category | Satan | Ipsweep | Portsweep | Nmap |
|---|---|---|---|---|
| Amount | 15,892 | 12,381 | 10,413 | 2316 |
| Category | Satan | Ipsweep | Portsweep | Nmap |
|---|---|---|---|---|
| Detection Rate | 0.9940 | 0.9805 | 0.9931 | 0.9330 |
| Population | Cross Probability | Mutation Probability | Selection | Iterations | ||
|---|---|---|---|---|---|---|
| 300 | 0.5 | 0.3 | Tournament | 200 | 1000 | 150 |
| Category | Success Rate | Average of | Average of | The Number of Modified Features |
|---|---|---|---|---|
| satan | 0.953 | −0.139 | 102,729.98 | 21.493 |
| ipsweep | 0.986 | 0.352 | 92,384.84 | 21.975 |
| portsweep | 0.993 | −0.117 | 82,101.05 | 22.459 |
| nmap | 0.140 | −0.072 | 1337.47 | 18.918 |
| Category | Success Rate | Average of | Average of | The Number of Modified Features |
|---|---|---|---|---|
| satan | 0.185 | −0.177 | 1479.37 | 17.441 |
| ipsweep | 0.826 | 0.309 | 3322.13 | 20.431 |
| portsweep | 0.564 | −0.197 | 5341.48 | 18.841 |
| nmap | 0.190 | −0.148 | 186.95 | 16.807 |
| Category | Success Rate | Average of | Average of | The Number of Modified Features |
|---|---|---|---|---|
| satan | 1 | −0.062 | 1888.23 | 19.765 |
| ipsweep | 1 | 0.379 | 1868.63 | 19.943 |
| portsweep | 0.949 | −0.118 | 4622.63 | 19.554 |
| nmap | 1 | 0.098 | 3010.94 | 18.276 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Zhang, X.; Guizani, N.; Lu, J.; Zhu, Q.; Du, X. TLTD: A Testing Framework for Learning-Based IoT Traffic Detection Systems. Sensors 2018, 18, 2630. https://doi.org/10.3390/s18082630
Liu X, Zhang X, Guizani N, Lu J, Zhu Q, Du X. TLTD: A Testing Framework for Learning-Based IoT Traffic Detection Systems. Sensors. 2018; 18(8):2630. https://doi.org/10.3390/s18082630
Chicago/Turabian StyleLiu, Xiaolei, Xiaosong Zhang, Nadra Guizani, Jiazhong Lu, Qingxin Zhu, and Xiaojiang Du. 2018. "TLTD: A Testing Framework for Learning-Based IoT Traffic Detection Systems" Sensors 18, no. 8: 2630. https://doi.org/10.3390/s18082630
APA StyleLiu, X., Zhang, X., Guizani, N., Lu, J., Zhu, Q., & Du, X. (2018). TLTD: A Testing Framework for Learning-Based IoT Traffic Detection Systems. Sensors, 18(8), 2630. https://doi.org/10.3390/s18082630