Signal Processing for Time Domain Wavelengths of Ultra-Weak FBGs Array in Perimeter Security Monitoring Based on Spark Streaming


Abstract
:1. Introduction
2. Materials and Methods
2.1. T-DBSCAN
2.2. AP-DBSCAN Algorithm
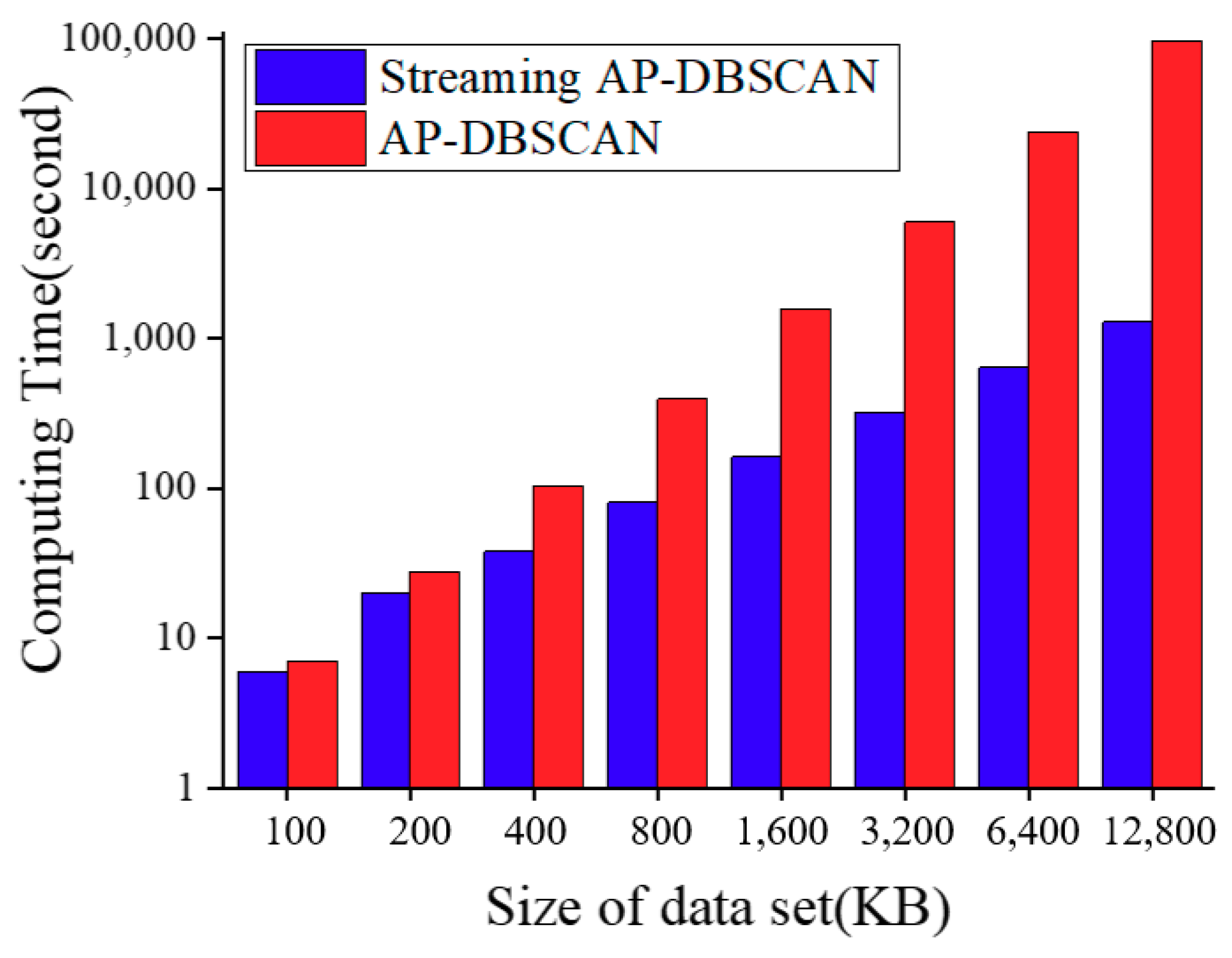
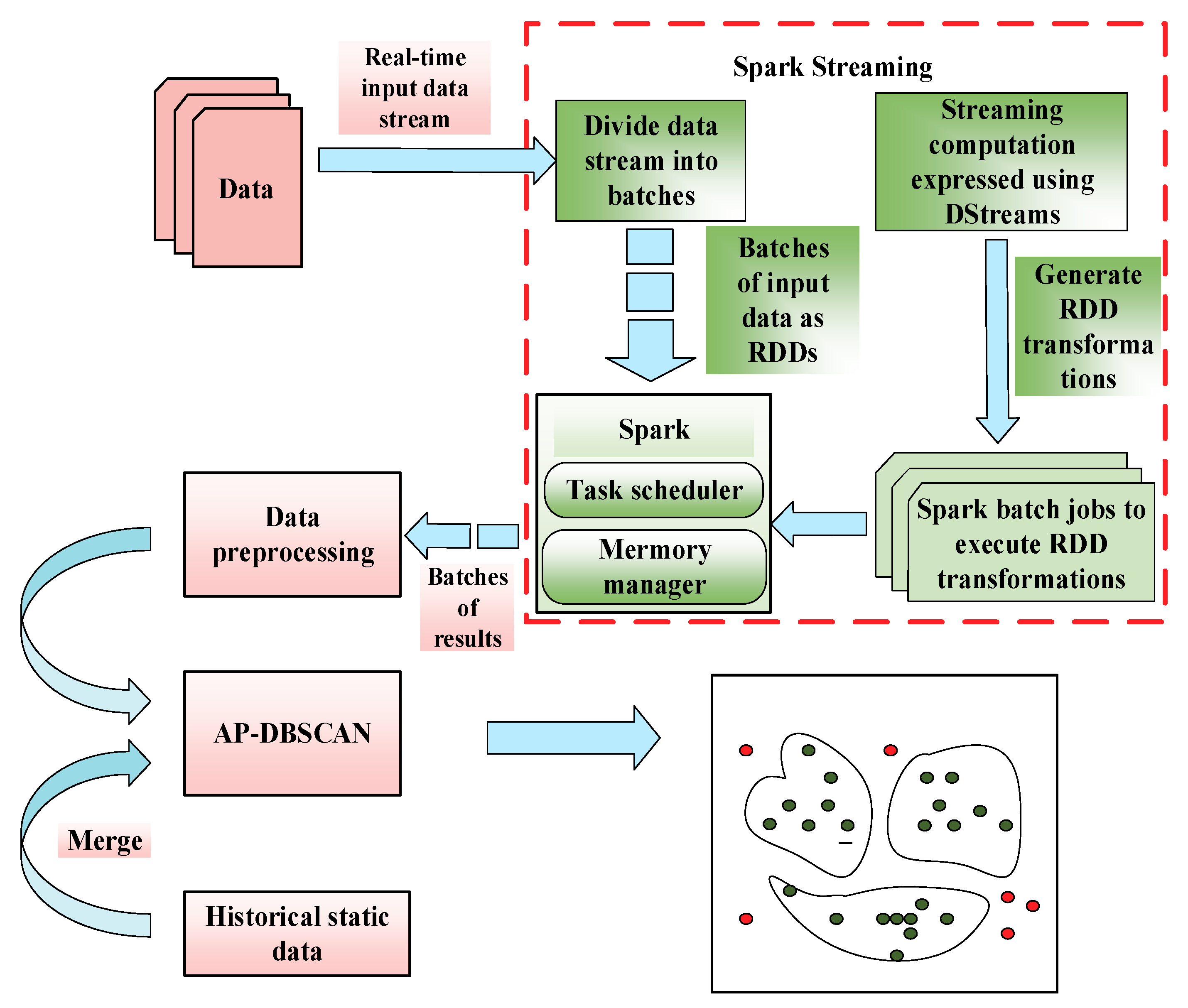
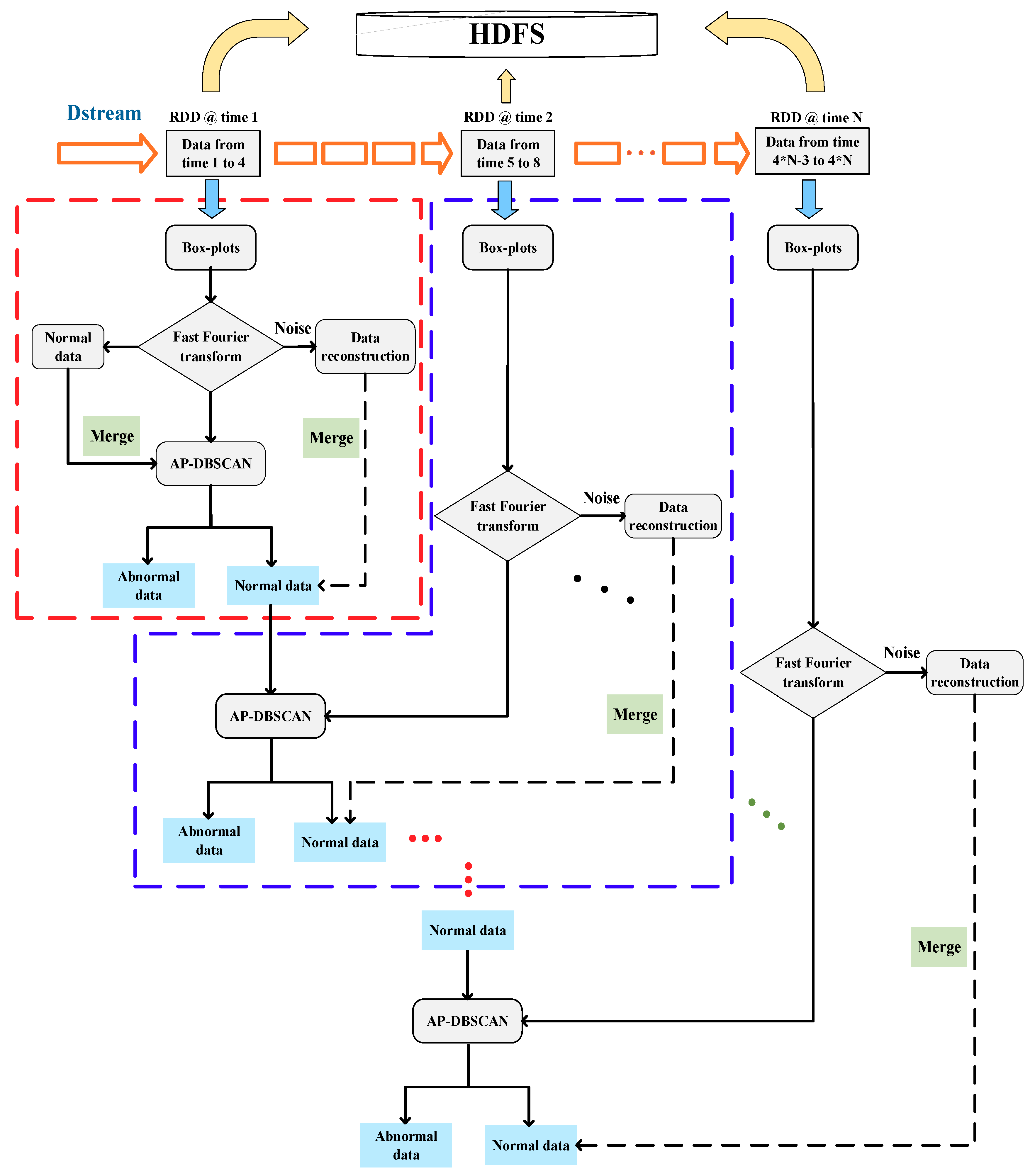
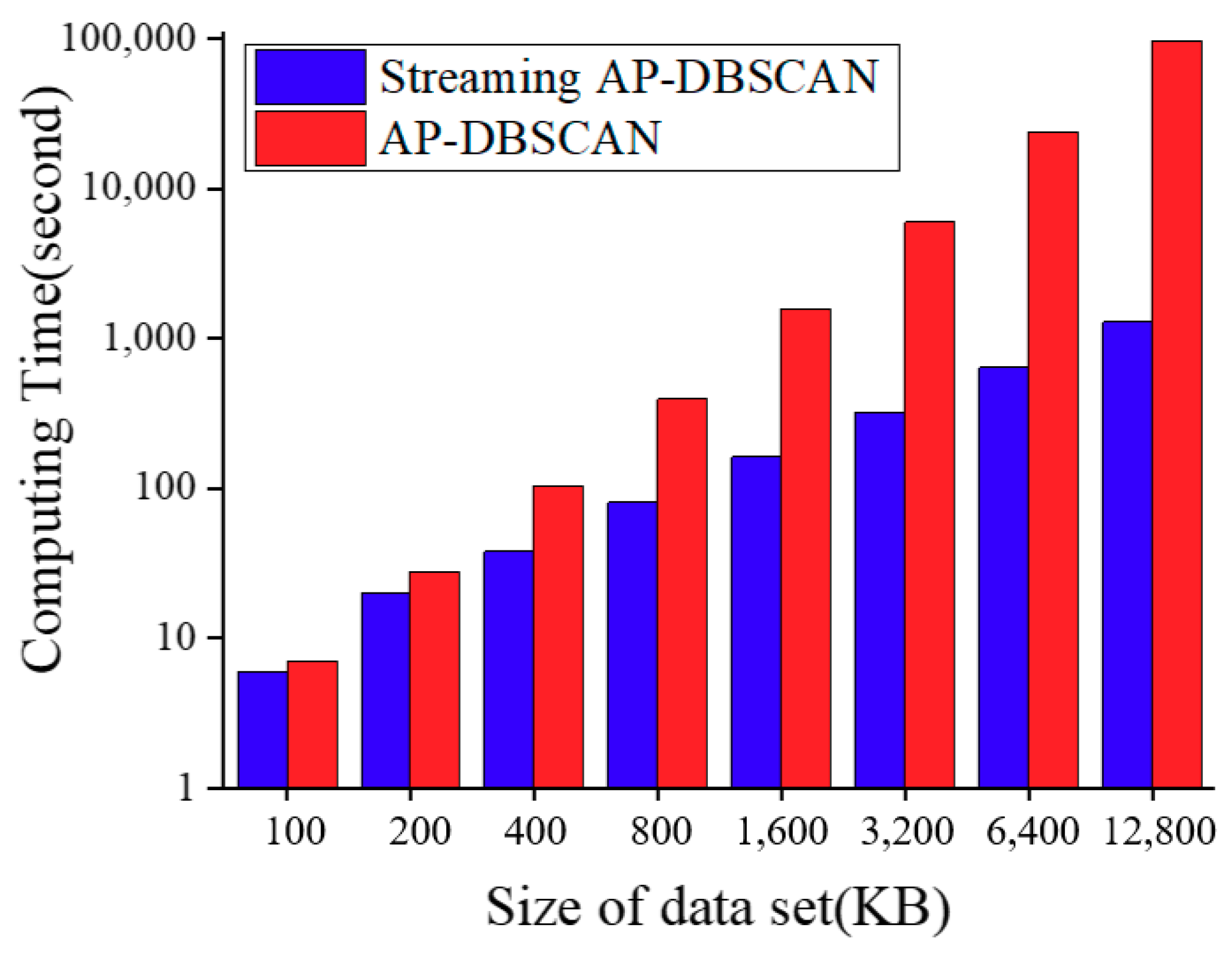
2.3. AP-DBSCAN on Spark Streaming
| Algorithm 1. Main steps in AP-DBSCAN on Spark Streaming. |
| 1: Input: The training sets of n workers: Normal data: |
| 2: Step1: Create a local streaming context with two working thread and a batch interval of 4 s. |
| 3: Step2: Create an input in DStream. |
| 4: Step3: Operate DStream: Convert segment data and normal data to RDD, perform the first AP-DBSCAN to get the result of the clustering: →first RDD→AP-DBSCAN→the first clustering result While input DStream = true Abnormal data is separated from the first result, normal data is retained and mixed into the next data; Perform AP-DBSCAN to get the result of clustering. |
| 5: Step4: Start Spark Streaming. |
| 6: Output: The results of clustering on each RDD. |
3. Results and Analysis
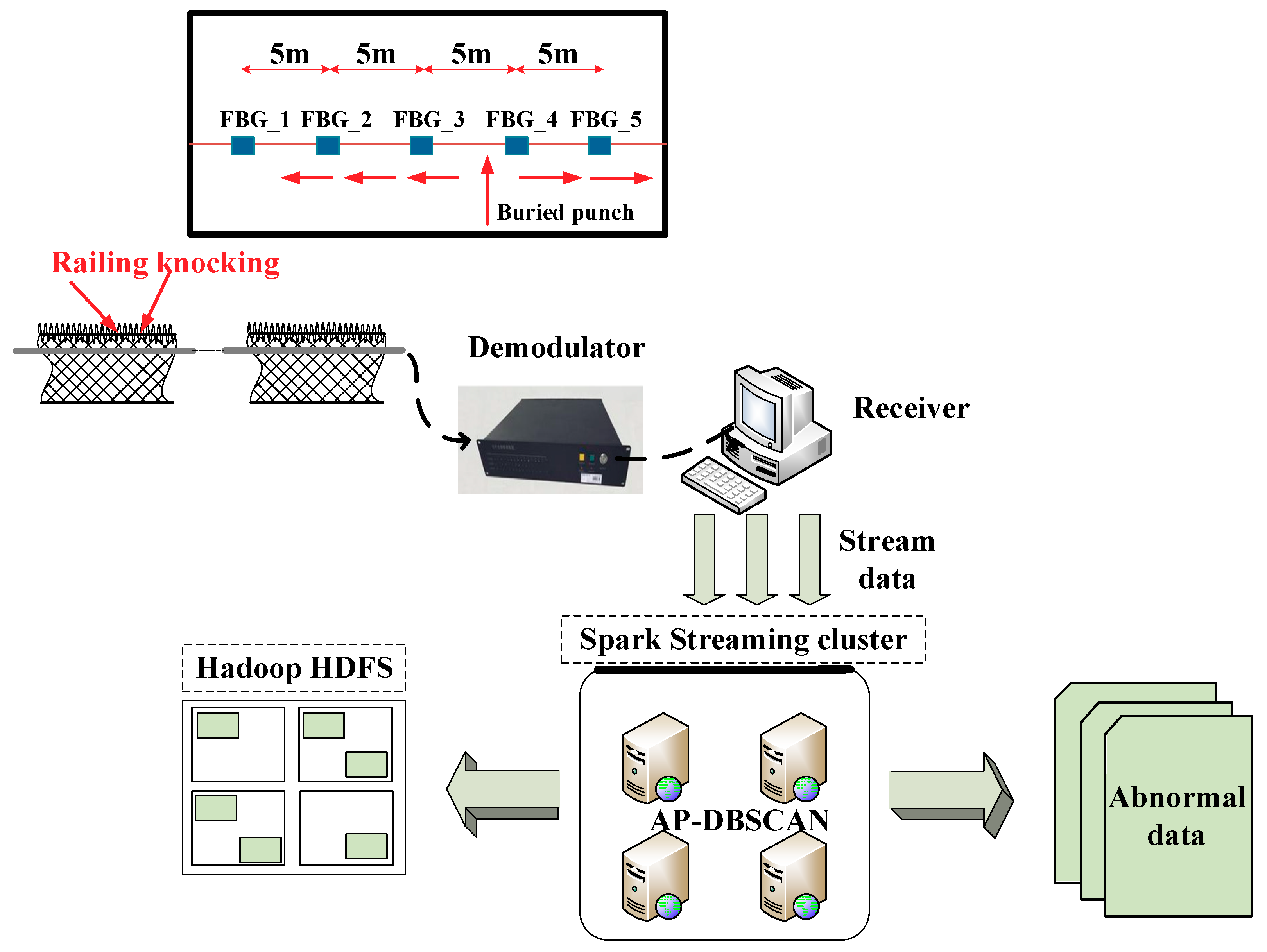
3.1. Monitoring System Based on the UWFBG Array
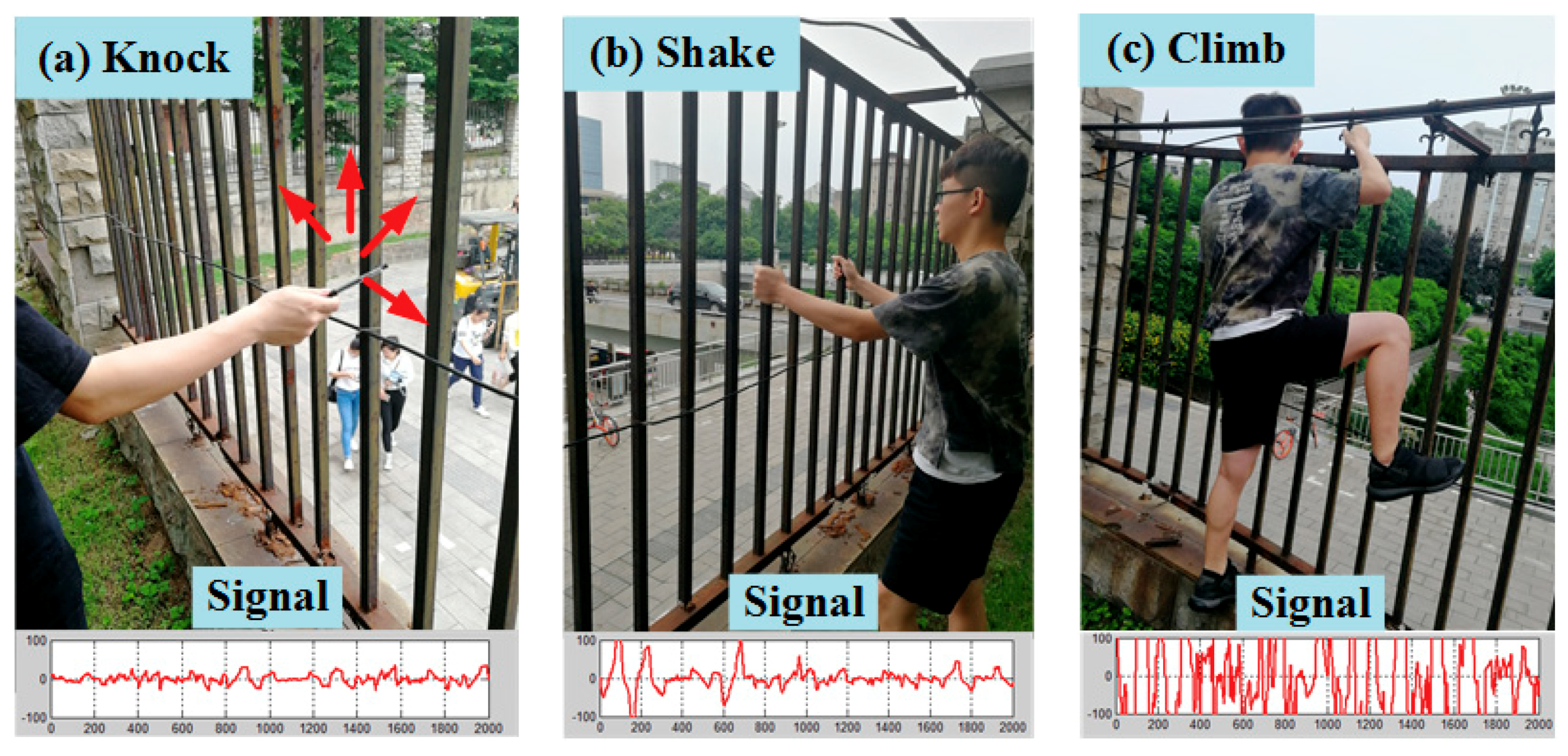
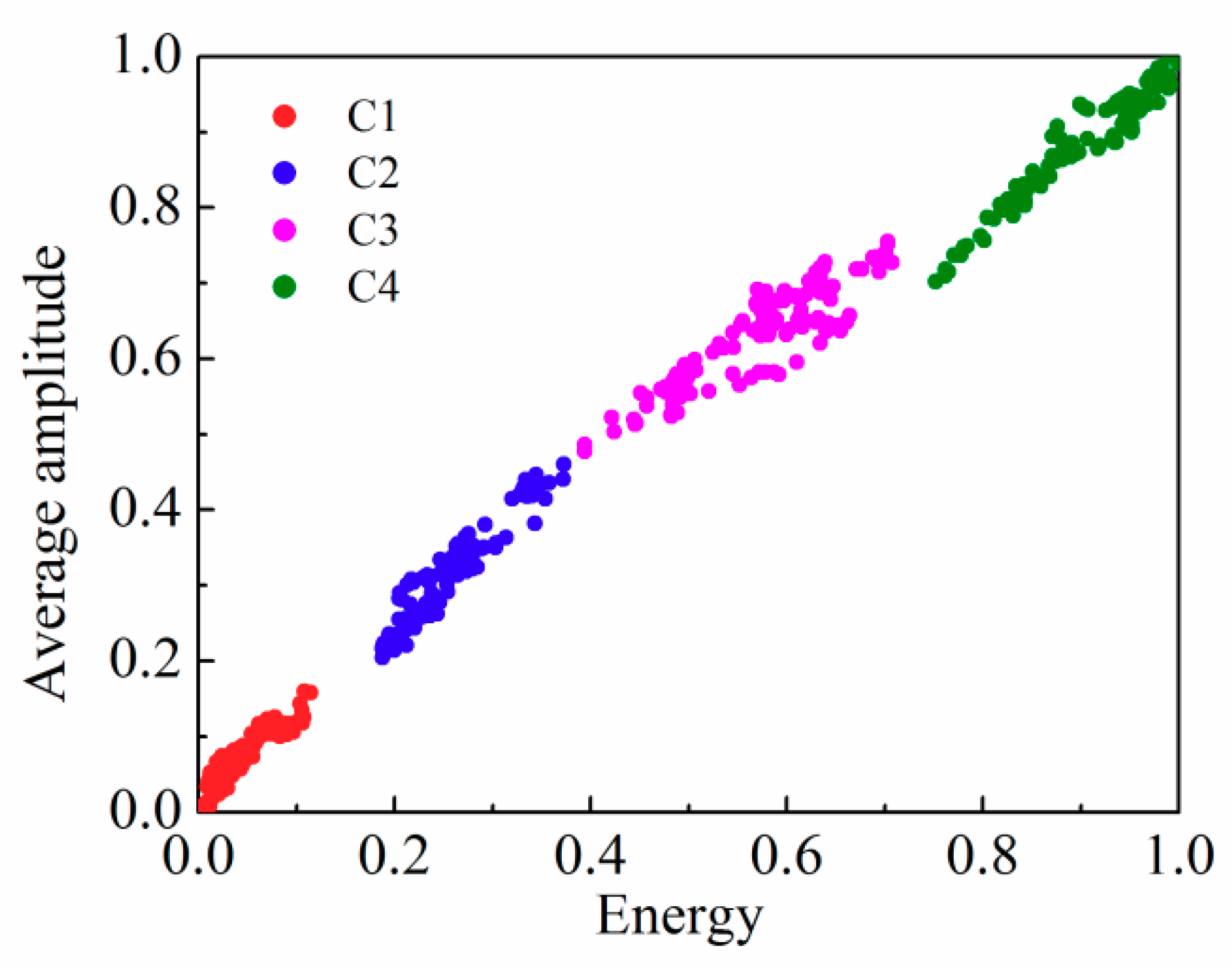
3.2. Signal Processing for Railing Sensors
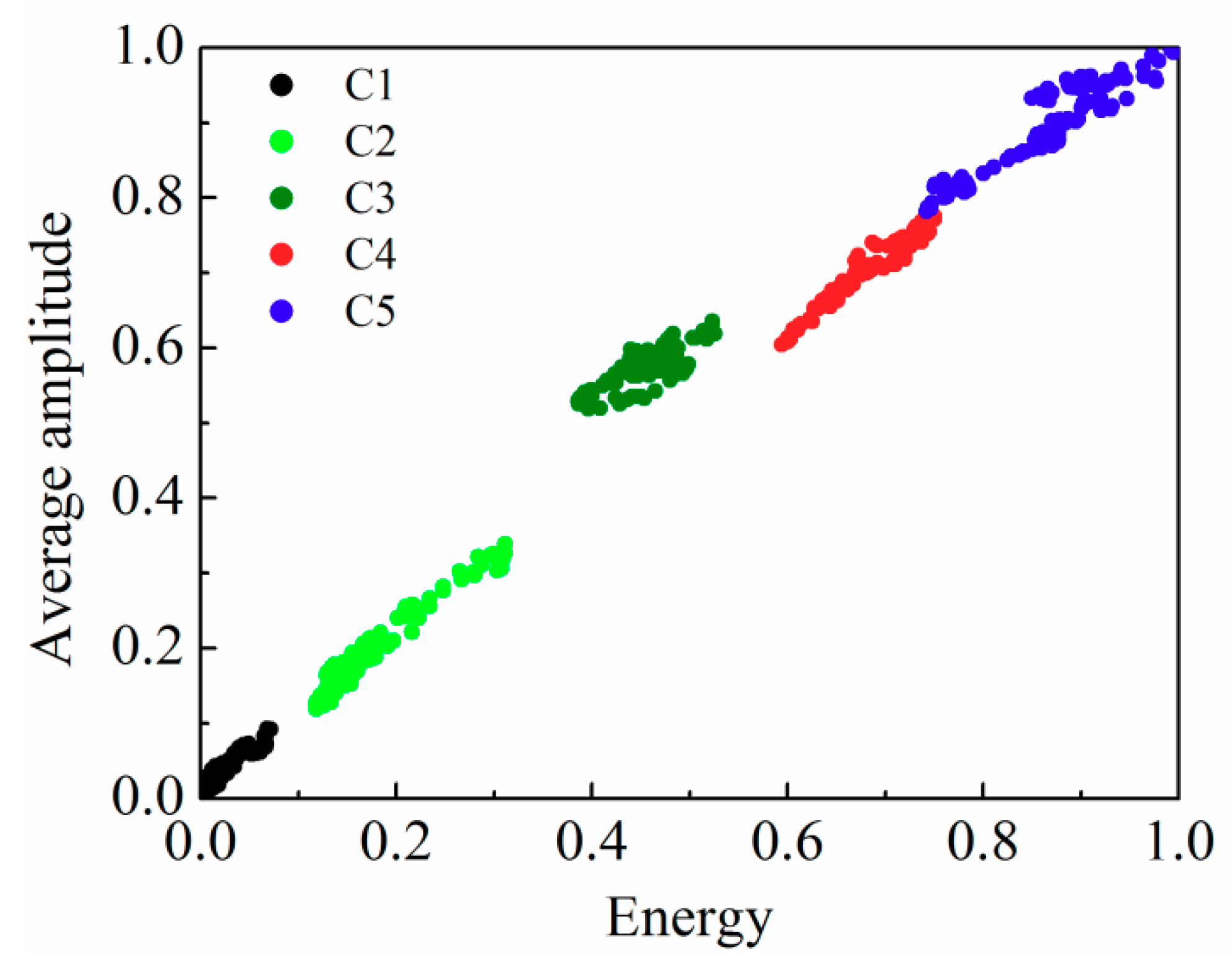
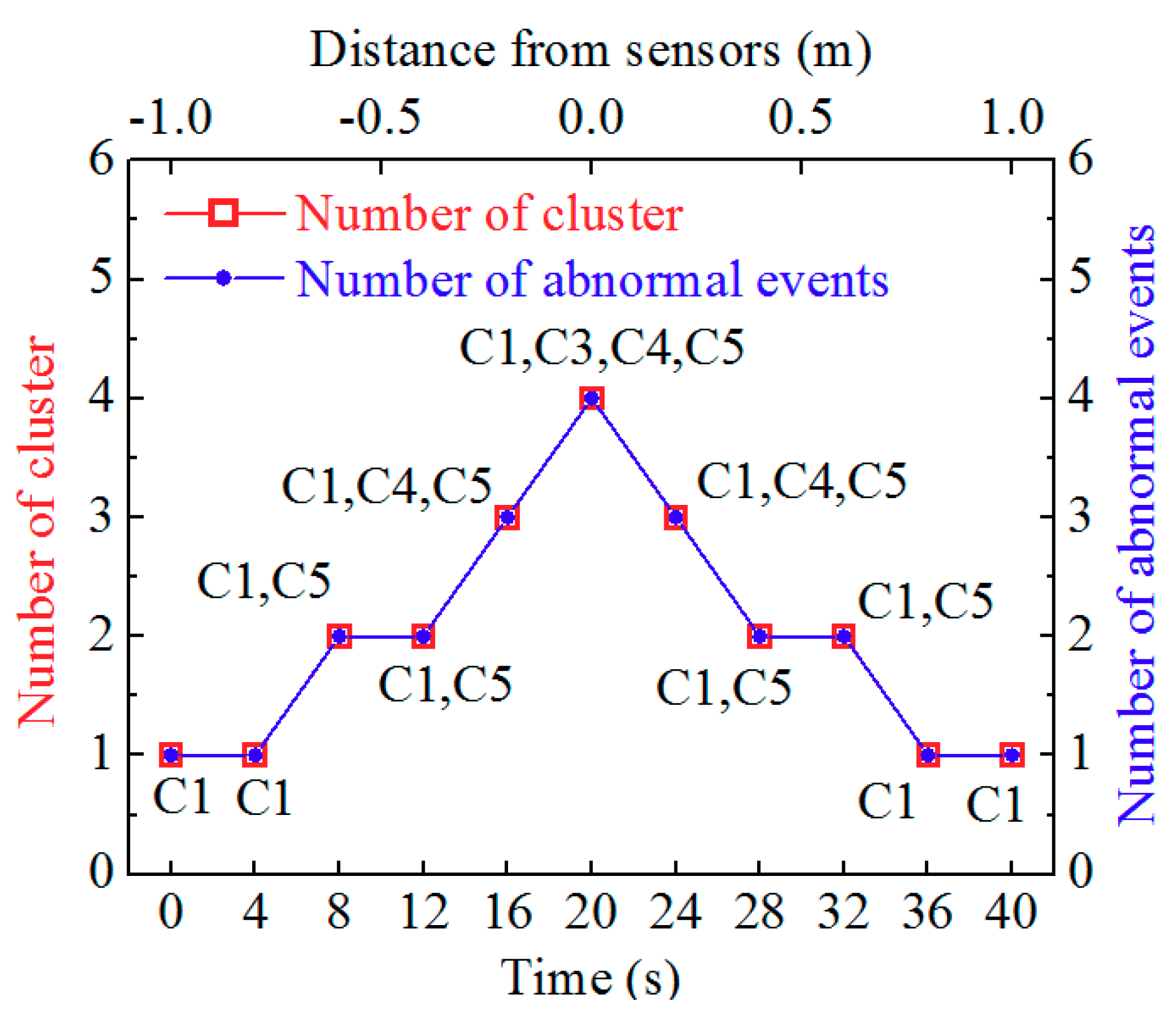
3.3. Signal Processing for Buried Sensors
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yu, H.H.; Zheng, Y.; Guo, H.Y. Research progress in online preparation techniques of fiber Bragg gratings on optical fiber drawing tower. J. Funct. Mater. 2014, 45, 12001–12005. [Google Scholar]
- Allwood, G.; Hinckley, S.; Wild, G. Optical Fiber Bragg grating based intrusion detection systems for homeland security. In Proceedings of the IEEE Sensors Applications Symposium (SAS), Galveston, TX, USA, 19–21 February 2013; pp. 66–70. [Google Scholar]
- Catalano, A.; Bruno, F.A.; Pisco, M. An Intrusion Detection System for the Protection of Railway Assets Using Fiber Bragg Grating Sensors. Sensors 2014, 14, 18268–18285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zaharia, M.; Xin, R.S.; Wendell, P. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Stai, E.; Karyotis, V.; Papavassiliou, S. A Hyperbolic Space Analytics Framework for Big Network Data and their Applications. IEEE Netw. 2016, 30, 11–17. [Google Scholar] [CrossRef]
- Jia, Z.; Xue, C.; Chen, G.; Zhan, J.; Zhang, L.; Lin, Y.; Hofstee, P. Auto-tuning Spark big data workloads on POWER8: Prediction-based dynamic SMT threading. In Proceedings of the 2016 International Conference on Parallel Architectures and Compilation, Haifa, Israel, 11–15 September 2016; pp. 387–400. [Google Scholar]
- Robert, C. Machine learning, a probabilistic perspective. Chance 2014, 27, 62–63. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 2951–2959. [Google Scholar]
- O’Callaghan, L.; Mishra, N.; Meyerson, A.; Guha, S. Streaming-data algorithms for high-quality clustering. In Proceedings of the IEEE International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 685–694. [Google Scholar] [Green Version]
- Fenandez-Rodriguez, J.Y.; Alvarez-Garcia, J.A.; Fisteus, J.A.; Luaces, M.R.; Magana, V.C. Benchmarking real-time vehicle data streaming models for a Smart City. Inf. Syst. 2017, 72, 62–76. [Google Scholar] [CrossRef]
- Lee, K.; Lee, C.G. Lazy Approaches for Interval Timing Correlation of Sensor Data Streams. Sensors 2010, 10, 5329–5345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, H.; Liu, F.; Yuan, Y.; Yu, H.; Yang, M. Ultra-weak FBG and its refractive index distribution in the drawing optical fiber. Opt. Express 2015, 23, 1094–4087. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gong, J.; Dong, B.; Wang, D.; Shilig, T.J.; Wang, A. A large serial time-division multiplexed fiber Bragg grating sensor network. J. Lightw. Technol. 2012, 40, 2751–2756. [Google Scholar] [CrossRef]
- Zhang, M.L.; Sun, Q.Z.; Wang, Z.; Li, X.; Liu, H.; Liu, D. A large capacity sensing network with identical weak fiber Bragg gratings multiplexing. Opt. Commun. 2012, 285, 3082–3087. [Google Scholar] [CrossRef]
- Zaharia, M.; Das, T.; Li, H. Discretized streams: Fault-tolerant streaming computation at scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farmington, PL, USA, 3–6 November 2013; pp. 423–438. [Google Scholar]
- Ghesmoune, M.; Lebbah, M.; Azzag, H. Micro-batching growing neural gas for clustering data streams using spark streaming. Procedia Comput. Sci. 2015, 53, 158–166. [Google Scholar] [CrossRef]
- Lu, Y.; Cao, B.; Rego, C.; Glover, F. A tabu search based clustering algorithm and its parallel implementation on spark. Appl. Soft Comput. 2018, 63, 97–109. [Google Scholar] [CrossRef]
- Miller, Z.; Dickinson, B.; Deitrick, W.; Hu, W.; Wang, A.H. Twitter spammer detection using data stream clustering. Inf. Sci. 2014, 260, 64–73. [Google Scholar] [CrossRef]
- Yue, S.H.; Li, P.; Guo, J.D. A statistical information based clustering approach in distance space. J. Zhejiang Univ. Sci. 2005, 6, 71–78. [Google Scholar] [CrossRef]
- Peng, C.; Guoyou, S.; Shuang, L.; Jian, Y. An incremental density based spatial clustering of application with noise algorithm based on partition index. J. Comput. Theor. Nanosci. 2016, 13, 10273–10280. [Google Scholar] [CrossRef]
- Cao, F.; Ester, M.; Qian, W.; Zhou, A. Density-based clustering over an evolving data stream with noise. In Proceedings of the 2006 SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 328–339. [Google Scholar]
- Li, B.; Wang, Q.; Barney, E.; Hart, L.; Wall, C.; Chawarska, K.; de Urabain, I.S.; Smith, T.J.; Shic, F. Modified DBSCAN algorithm on oculomotor fixation identification. In Proceedings of the 2016 Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 337–338. [Google Scholar]
- Edla, D.R.; Jana, P.K. A prototype-based modified DBSCAN for gene clustering. Procedia Technol. 2012, 6, 485–492. [Google Scholar] [CrossRef]
- Cai, Y. An improved DBSCAN algorithm which is insensitive to input parameters. Acta Sci. Nat. Univ. Pekinesis 2004, 40, 480–486. [Google Scholar]
- Feng, P.; Ge, L. Adaptive DBSCAN-based algorithm for constellation reconstruction and modulation identification. In Proceedings of the IEEE Asia-Pacific Radio Science Conference, Qingdao, China, 24–27 August 2004; pp. 177–180. [Google Scholar]
- Spitzer, M.; Wildenhain, J.; Rappsilber, J.; Tyers, M. BoxPlotR: A web tool for generation of box plots. Nat. Methods 2014, 11, 121–122. [Google Scholar] [CrossRef] [PubMed]
- Haji-Hashemi, H.; Norouzi, P.; Safarnejad, M.R.; Larijani, B.; Habibi, M.M.; Raeisi, H. Sensitive electrochemical immunosensor for citrus bacterial canker disease detection using fast fourier transformation square-wave voltammetry method. J. Electroanal. Chem. 2018, 820, 111–117. [Google Scholar] [CrossRef]
- Khan, S.S.; Ahmad, A. Cluster centre initialization algorithm for K-means clustering. Pattern Recognit. Lett. 2004, 25, 1293–1302. [Google Scholar] [CrossRef]
- Yang, J.; Ke, Y.S.; Wang, M.Z. An adaptive clustering segmentation algorithm based on FCM. Turk. J. Electr. Eng. Comput. Sci. 2017, 25, 4533–4544. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Clustering Algorithm | |
|---|---|---|
| T-DBSCAN | AP-DBSCAN | |
| C1 | 119 | 119 |
| C2 | 113 | 113 |
| C3 | 111 | 111 |
| C4 | 121 | 121 |
| Number of clusters | 4 | 4 |
| Data Size (kB) | Misclassified Patterns (kB) | Computation Time (s) | ER (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | A | B | C | A | B | C | |
| 150 | 12 | 3 | 3 | 10 | 10 | 11 | 8.0 | 2.0 | 2.0 |
| 185 | 15 | 4 | 5 | 27 | 29 | 25 | 8.1 | 2.1 | 3.0 |
| 286 | 26 | 10 | 9 | 43 | 44 | 41 | 9.1 | 3.5 | 3.1 |
| 768 | 59 | 24 | 21 | 391 | 401 | 379 | 7.7 | 3.1 | 2.8 |
| 1024 | 93 | 32 | 33 | 578 | 593 | 533 | 9.1 | 3.2 | 3.3 |
| 1625 | 131 | 49 | 47 | 1601 | 1701 | 1567 | 8.1 | 3.0 | 3.0 |
| Data Set | Clustering Algorithm | |
|---|---|---|
| T-DBSCAN | AP-DBSCAN | |
| C1 | 116 | 116 |
| C2 | 115 | 115 |
| C3 | 115 | 115 |
| C4 | 115 | 115 |
| C5 | 114 | 114 |
| Number of clusters | 5 | 5 |
| Data Size (kB) | Misclassified Patterns (kB) | Computation Time (s) | ER (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | A | B | C | A | B | C | |
| 131 | 10 | 5 | 2 | 9 | 9 | 10 | 7.6 | 3.8 | 1.5 |
| 254 | 23 | 15 | 7 | 40 | 42 | 37 | 9.1 | 5.9 | 2.8 |
| 552 | 46 | 27 | 13 | 287 | 301 | 266 | 8.3 | 4.9 | 2.4 |
| 783 | 62 | 34 | 23 | 399 | 420 | 391 | 7.9 | 4.3 | 2.9 |
| 1131 | 101 | 81 | 39 | 583 | 606 | 542 | 8.9 | 7.1 | 3.4 |
| 1721 | 140 | 121 | 51 | 1721 | 1835 | 1643 | 8.1 | 7.0 | 3.0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Z.; Liu, F.; Yuan, Y.; Li, S.; Li, Z. Signal Processing for Time Domain Wavelengths of Ultra-Weak FBGs Array in Perimeter Security Monitoring Based on Spark Streaming. Sensors 2018, 18, 2937. https://doi.org/10.3390/s18092937
Yu Z, Liu F, Yuan Y, Li S, Li Z. Signal Processing for Time Domain Wavelengths of Ultra-Weak FBGs Array in Perimeter Security Monitoring Based on Spark Streaming. Sensors. 2018; 18(9):2937. https://doi.org/10.3390/s18092937
Chicago/Turabian StyleYu, Zhenhao, Fang Liu, Yinquan Yuan, Sihan Li, and Zhengying Li. 2018. "Signal Processing for Time Domain Wavelengths of Ultra-Weak FBGs Array in Perimeter Security Monitoring Based on Spark Streaming" Sensors 18, no. 9: 2937. https://doi.org/10.3390/s18092937
APA StyleYu, Z., Liu, F., Yuan, Y., Li, S., & Li, Z. (2018). Signal Processing for Time Domain Wavelengths of Ultra-Weak FBGs Array in Perimeter Security Monitoring Based on Spark Streaming. Sensors, 18(9), 2937. https://doi.org/10.3390/s18092937