Abstract
In traditional fault diagnosis strategies, massive and disordered data cannot be utilized effectively. Furthermore, just a single parameter is used for fault diagnosis of a weapons fire control system, which might lead to uncertainty in the results. This paper proposes an information fusion method in which rough set theory (RST) is combined with an improved Dempster–Shafer (DS) evidence theory to identify various system operation states. First, the feature information of different faults is extracted from the original data, then this information is used as the evidence of the state for a diagnosis object. By introducing RST, the extracted fault information is reduced in terms of the number of attributes, and the basic probability value of the reduced fault information is obtained. Based on an analysis of conflicts in the existing DS evidence theory, an improved conflict evidence synthesis method is proposed, which combines the improved synthesis rule and the conflict evidence weight allocation methods. Then, an intelligent evaluation model for the fire control system operation state is established, which is based on the improved evidence theory and RST. The case of a power supply module in a fire control computer is analyzed. In this case, the state grade of the power supply module is evaluated by the proposed method, and the conclusion verifies the effectiveness of the proposed method in evaluating the operation state of a fire control system.
1. Introduction
Since the start of the 21st century, industrial manufacturing has gradually tended to become automated, large-scale, and systematic. In unmanned factories, the composition of industrial machinery and equipment is increasingly complex and functions increasingly well. Due to this, people are gradually paying more attention to the safety of equipment. The most commonly used method for traditional industrial equipment maintenance includes acquisition operation signal feature extraction and fault diagnosis. However, traditional fault diagnosis methods have been unable to adapt to the increasing tendency of industrial equipment to be: (1) modular; (2) generalized; (3) intelligent; and (4) modernized.
A fire control system is a kind of complex electronic system which is responsible for controlling the aiming and firing of weaponry. Such systems play an important role in modern warfare, and their development is becoming more and more intelligent and modernized. If the system fails, it will greatly reduce the combat capability of weaponry. A general-purpose fire control system has the characteristics of randomness, susceptibility, concurrency, and communication. Traditional fault diagnosis methods cannot meet the demand of fault diagnosis for a fire control system. For example, the state evaluation of the fire control computer and sensor subsystem is massive [1]. The state values from different levels reflect the running state of the fire control computer and sensor subsystem. However, due to the inaccurate measurement process and unified evaluation standards, the operational state evaluation of fire control computers and sensor subsystems has great ambiguity and uncertainty.
Since rough set theory (RST) contains a mechanism to deal with imprecise or uncertain problems, no prior information is needed to deal with uncertain information [2]. RST can objectively describe or deal with uncertain problems, avoid certain subjectivity, conduct attribute and value reduction for fault features, and use the reduced data for equipment fault prediction. Furthermore, Dempster–Shafer (DS) evidence theory has a strong ability to process uncertain information and thus one can employ the DS synthesis rule and diagnostic decision rule to perform decision analysis on the fusion reliability interval and obtain a final diagnosis result [3]. Additionally, there is evidence conflict in the evidence synthesis process of DS evidence theory, where the traditional approach’s synthesis method often abandons the conflict and proposes a multi-sensor data fusion method based on evidence reliability and entropy [4]. For the methods described above, there are still the following shortcomings: (1) the reasoning ability of RST is weak; (2) human factors often interfere with the evidence acquisition of DS evidence theory, which plays a crucial role in the decision-making results; and (3) the practice of abandoning the conflict part greatly reduces the reliability of the decision results. A multi-sensor data fusion method based on evidence reliability and entropy was proposed [5]; however, it is possible for the evidence combination to explode.
Based on the above research, this paper aims to tackle the problems in fault detection: the inability to synthesize conflicting evidence with the traditional synthesis rules and the combination explosion caused by excessive evidence dimensions. In this paper, a fire control system state evaluation method based on RST and improved evidence is proposed to solve the following problems: (1) the combination explosion; (2) the largely subjective nature of evidence acquisition; and (3) the inconsistency between the decision-making result and the actual result due to evidence conflicts.
In this paper, RST is first introduced to preprocess and discretize the collected fire control system data. In order to retain the core attributes, attribute reduction is carried out and the basic probability assignment is determined [6]. For the basic probability, based on the analysis of the existing DS rule improvement method and the conflict evidence weight allocation method, an improved conflict evidence synthesis method is proposed to effectively resolve the adverse impact of conflicting evidence on composite results. Thus, an intelligent operation state evaluation model of a fire control system based on the improved evidence theory is established. The data evaluation results based on the fire control computer power supply module show that the obtained evaluation results are consistent with prior knowledge. The results show that the model can more accurately evaluate the running state of the fire control system. Additionally, our approach can effectively reduce the adverse impact of uncertainty on the evaluation of the operation state of the fire control system. The power supply module of the fire control computer is taken as a case study to verify the effectiveness of the proposed method. The main results of our approach: (1) Obtain the set of simplest attributes by using RST; (2) the improvement of the DS evidence guarantees a low conflict evidence weight distribution, improves the degree of determining the weight distribution for high consistency and good conflict evidence, and ensures the consistency degree is high by assigning poor weight allocation to conflicting evidence; (3) The status evaluation results are consistent with the prior knowledge through the proposed information fusion method.
In Section 2, we describe the concept and principle of RST, including the attribute reduction algorithm based on the discernibility matrix; in Section 3, we describe the concept and principle of DS evidence, including the deficiencies of traditional evidence; in Section 4, we describe the improvement of the evidence; and in Section 5, we verify the validity of the proposed RST combined with the improvements to the traditional DS evidence theory method.
2. Rough Set Theory
The Polish scholar Z. Pawlak proposed RST in 1982. RST is an effective tool for dealing with incomplete information. It does not require any prior information except for the set being processed. By analyzing the relationship between the studied objects, the potential rules for the set are obtained [7].
2.1. The Basic concept of Rough Set Theory
2.1.1. Information System and Decision Table
The information system is the primary structure in RST. The information system , where is the universe of discourse; is the set of attributes for all of the research objects [8]; where is the set of conditional attributes and is the set of decision attributes; V is the set of attribute values of the studied objects , where is the value range for [9,10]; and f: is the information function and is a single mapping, i.e., [11] specifies the value of the xth attribute for each object in U.
For , if the research object attribute set consists of a conditional attribute and a decision attribute D, that is, , then the information system S is called the decision table [12].
2.1.2. Indistinguishable Relation
Let be an information system; defines the indistinguishable relation Ind(B) about B as:
The indistinguishable relation divides U into equivalence classes, where all objects in an equivalence class are indistinguishable from each other [13].
2.1.3. Approximate Weight
The information system ; Ind(A) is the equivalence relation over U; , the approximate quality of set X with respect to attribute set B, is defined as:
where denotes the largest set of all subsets that must exist in the X set. The definition of approximate mass represents the probability that can be accurately divided under the attribute set B.
2.2. Attribute Reduction
Attribute reduction is performed to maintain the expressiveness of the information system and delete redundant attributes. Let be an equivalence relation family. When Ind(R) = Ind(R − {r}), then can be omitted from , otherwise, cannot be omitted from . If cannot be omitted for any , then the family is said to be independent. Obviously, when R is independent, and , then P is independent [14]. The set of all the necessary relationships in R is called the core of R. The equivalence relation family is defined via: If the discretized values of each sample under any n attributes correspond to the same value, then the value of these n attributes in the decision table is equal and they are referred to as equivalent attributes.
2.2.1. Discernibility Matrix
The discernibility matrix, also known as the discernible matrix or the distinct matrix, is a method of knowledge representation proposed by Skowron in 1991.
Let be a decision table; for any , is the value of the object on the attribute C is the decision attribute value corresponding to sample . Then the discernibility matrix of is [15,16]:
It is obvious that the discernibility matrix is a symmetric matrix. Thus, in the calculation, it is only necessary to calculate its lower triangular matrix.
The above definition indicates that the differential elements of the ith row and jth column of are sets or values of conditional attributes. When the decision attribute values of and are different, then all of the conditional attributes that make and have different values constitute the difference element . The relation of these conditional attributes is the disjunction relation “”, meaning that any conditional attribute can distinguish from . If there is no conditional attribute that makes the and values different, that is, all of the conditional attribute values of and are the same, and the decision attribute values are different, then the difference element is an empty set.
Individuals with the same decision attribute value, whether or not the conditional attribute values are the same, cannot be distinguished. Therefore, when the decision attributes of individuals and are the same, the value of distinct elements is 0 instead of an empty set, indicating that there is no need to take it into consideration. Additionally, for the differential elements on the main diagonal of the discernibility matrix, for i = j and this = , the difference elements are also represented by 0 instead of the empty set .
2.2.2. Discernibility Function
The discernibility function of the decision table S can be formally expressed as [17]:
where is the disjunction of the matrix term .
2.2.3. Attribute Reduction Algorithm Based on the Discernibility Matrix
In order to avoid a large number of redundant attributes in the actual system which affect the speed of operation and accuracy of decision-making, this paper simplifies the decision table. An instance in the decision table can be considered as a rule, which may contain redundant attribute values, so the reduction of instance attribute values is the reduction of the decision rule [18]. The reduction of decision rules is the unnecessary condition of eliminating each rule separately. It is not the reduction of the attributes for the entire system, but the reduction of redundant attribute values for each decision rule. The formalization of the discernibility matrix is shown in Table 1.

Table 1.
Schematic diagram of the discernibility matrix.
Where is the element of sample, and the off diagonal values are the by applying the above Equation (3); the process for attribute reduction algorithm based on the discernibility matrix involves the following steps:
- Calculate the discernibility matrix M(S) for the decision table S according to the above Equation (3);
- Calculate the discernibility function fM(S) based on the discernibility matrix M(S);
- Calculate the minimum disjunctive normal form of discernibility function fM(S), where each disjunctive component is a reduction.
3. DS Evidence Theory
DS evidence theory is an uncertain reasoning method which can integrate the evidence provided by multiple evidence sources [19,20] and constantly reduces the hypothesis set based on the accumulation of evidence. It has strong decision-processing ability and is widely used in data fusion and target recognition [21].
3.1. Acquisition Method for the Basic Probability Value
is a nonempty finite set; let be the identification framework, if the functions satisfies the two conditions:
(1) (where is the empty set), and (2) ,
then, m is called the basic credibility distribution of the framework. Note, , m(A) is the basic credibility distribution of A and is the power set of . Essentially, is the probability of the occurrence of the statement A.
Assuming that A is any subset on the identification framework , then the belief function satisfies [22,23]:
If , then A is called the focal element of the belief function Bel. The relationship between the belief function Bel(A) and the basic credibility allocation function is [24,25,26]:
Based on Equation (6), it can be seen that the total trust degree of A—the sum of basic credibility—is expressed by Bel(A).
In the decision table , where C is the conditional attribute set and D is the decision attribute set [27,28], define . Thus, for , the corresponding equation to calculate the basic credibility assignment is
where .
3.2. Synthesis Method of Traditional Evidence Theory
DS evidence synthesis is based on the evidence decision coefficient. The general form of the evidence combination rule in DS evidence theory is [29]:
where and are the basic credibility functions of X and Y, respectively, and is the combined basic credibility function. The value of K indicates the degree to which the combined evidences conflict with each other. When , it means that the two evidences are completely consistent (completely compatible); and when , it means that the two evidences are in complete conflict. For , the two evidences are partially compatible.
3.3. Deficiencies of Evidence Theory
When applying evidence theory to practical situations, information with different degrees of conflict is often encountered. When dealing with different evidence bodies with low confidence and high conflict, the results are often not ideal and sometimes even contrary to common sense [30].
3.3.1. Causes of Conflict
The main reasons why evidence theory produces phenomena that are inconsistent with common sense when dealing with contradictory evidence [31,32,33] are as follows. In order to maintain the normalization of the basic probability distribution function between evidences, the rule of evidence theory synthesis introduces the conflict factor K, which changes the basic probability distribution of the common focal element between the two evidences to of the original probability distribution. However, conflicts are not generated by all focal elements together, and conflicts generated by common focal elements with large distribution functions are not necessarily large. Therefore, if the conflict information is completely abandoned without analysis, it will inevitably lead to the loss of important information.
3.3.2. Classification of Conflict Problems
● Conventional Conflict Problem
High Conflict: Take the identification framework and the following evidence:
Using the traditional evidence theory synthesis rule, Equation (8), the synthesis results are shown in Table 2.
Table 2.
Synthesis results of the traditional evidence theory from the example above.
The conflict factor for this example is thus, K = 0.0099 + 0.9801 + 0.0099 = 0.09999, and .
The support degree for the two pieces of evidence is extremely small for B; however, the synthesis result suggests that B is fully supported. Obviously, this is inconsistent with the actual situation.
Total Conflict: assume the identification framework and the evidence as follows [34]:
The conflict factor is , the denominator of Equation (8) becomes 0, so the synthesis rule of evidence theory cannot be used [35].
● Less Robustness
High Conflict: Take the identification framework and the following evidence:
After the synthesis of the two pieces of evidence, the result was obtained, which was almost opposite to the synthesis result of . Therefore, when slight changes were found in the BPA of the focal element, the fusion result would be greatly different, which indicated that the synthesis rules of the evidence theory were very sensitive to the BPA of the focal element.
● One Vote Veto
Suppose the support degree of n pieces of evidence for A is as follows:
The above n pieces of evidence are fused using the rule of evidence theory synthesis, and m(A) = 0. It can be seen from this example that, when one piece of evidence is inconsistent with or in complete conflict with multiple pieces of evidence, one negative vote will be obtained after the synthesis of the evidence, indicating that other evidence has no influence on the synthesis result.
4. Improvements to the Traditional Evidence Theory
Synthesis problems, in view of evidence theory, have been analyzed by many scholars, who have presented a series of effective solutions. Some of these approaches adopt a view that does not tally with the actual result for the synthesis rule. Holders of this viewpoint attempt to improve the evidence combination rules by using modified conflict information. Another view holds that the inaccuracy of the synthesis results derives from the evidence source rather than the synthesis rules of traditional evidence theory [36,37,38]. Additionally, there is a new view that the error of the result comes from an incomplete identification framework [39]. In this paper, evidence theory can be improved by modifying combination rules and evidence bodies [40].
4.1. Weight Distribution of Conflicting Evidence
At present, the weight distribution of conflicting evidence mainly adopts the conflict weight distribution method based on the distance between two pieces of evidence [41] or the similarity coefficient [42]. These commonly used methods usually only consider the mutual support degree between evidence and do not consider the role of evidence itself in decision making [43,44]. When the uncertainty degree of the evidence itself is high and the conflict caused by the evidence is low, the impact of the evidence on decision making is also low. Therefore, under the premise of good consistency between evidence and the decision-making, the less uncertain the evidence is, the more effective the decision will be. When the weight of conflict is allocated, the weight of the evidence should be higher, so as to make better decisions.
Let there be an identification frame . The basic probability distribution of any event in the identification framework, which is presented in Equation (9), is converted into fuzzy membership :
Then, the distance between any two evidences is defined as:
where represents intersection (smaller value) and represents union set (larger value). In order to avoid the scenario that the denominator of the fraction in the equation is 0, it is required to identify focal elements in the framework. The gap between two evidence bodies is represented by the evidence distance, which is another way of expressing evidence conflict. When the distance between evidences is 0, it means that there is no conflict between the two pieces of evidence, and they are completely consistent. That is, the degree of consistency between the two evidences is 1. When the distance between the evidences is 1, it means that there is complete conflict between the two evidences and there is no similarity, that is, the degree of consistency between the two evidences is 0.
Thus, the similarity coefficient of the two pieces of evidence is
Assuming that the number of evidences obtained by the system is m, the evidence similarity number can be calculated by using the above formula, and the similarity matrix is thus:
The degree of consistency between two evidences reflects the degree of mutual support between the two pieces of evidence [45,46]; therefore, the support degree of each piece of evidence for can be obtained by adding the rows or columns of the similarity matrix as follows [47]:
Obviously, the greater the degree to which a piece of evidence is supported by other evidence, the higher its credibility will be, and vice versa. Therefore, inter-evidence support is often used to represent the credibility of a single piece of evidence. Equation (14) is normalized to calculate the credibility of the evidence, as shown in
In recent decades, various uncertainty measures have been proposed, e.g., Yager’s dissonance measure, Shannon entropy, and others derived from the Boltzmann–Gibbs (BG) entropy in thermodynamics and statistical mechanics, which have been used as an indicator to measure uncertainty associated with a probability density function (PDF). In this paper, a new entropy, called the Deng entropy, is proposed to handle the uncertain measure of Basic Probability Assignment (BPA). Deng entropy can be seen as a generalized Shannon entropy [48]. When the BPA is degenerate with the probability distribution, the Deng entropy is degenerate with the Shannon entropy. Benefiting from the above research, the uncertainty measure of probability has a widely accepted solution [49]; assuming that the recognition framework contains n pieces of evidence, which yields the corresponding basic probability assignment, the Deng entropy of the ith piece of evidence is defined as follows:
where m is a mass function defined on the frame of discernment , is a focal element of m, and is the cardinality of . As shown in the above definition, Deng entropy is formally similar to the classical Shannon entropy, however, the belief for each focal element is divided by a term , which represents the potential number of states in (of course, the empty set is not included). Through a simple transformation, it is found that Deng entropy is actually a type of composite measure, as follows:
where the term is interpreted as a measure of the total non-specificity in the mass function m, and the term is a measure of the discord of the mass function among various focal elements.
Deng entropy can measure the uncertainty degree of some information. The higher the Deng entropy, the higher the degree of uncertainty. In a decision-making system, the more uncertain the information is (high Deng entropy), the lower its influence on decision making should be. Conversely, the more certain the information is (low Deng entropy), the higher the impact on decision making should be. Evidence consistency is used to reflect this idea in the overall decision-making process, as well as the degree of conflict with other evidence. The higher the consistency of evidence, the lower the degree of conflict with other evidence, and the more likely it will be to yield correct decisions. In the decision system, the average basic probability assignment of each subset (decision attribute) in the identification framework can reflect the correct trend of decision making in the evidence set. If there is a large distance between the basic probability assignment [50] of a subset in the identification framework and the average basic probability assignment, the evidence consistency is low. Conversely, if there is a small distance between the two, the evidence consistency is higher.
For an identification framework with n pieces of evidence, the recognition framework is , and is the corresponding basic probability assignment. Thus, the evidence consistency is defined as [51]:
where represents the average basic probability assignment of each subset within the recognition framework.
Evidence validity shows the influence of evidence on making correct decisions, which can be comprehensively measured by the consistency of evidence and the certainty of evidence. When the degree and consistency of evidence are high, it indicates that the evidence is of great help to make correct decisions and has high effectiveness. When the degree of evidence confirmation is high and the consistency is low, although the evidence has a high role in decision making, its effectiveness should be low, so as to avoid the adverse impact of increasing evidence on making correct decisions. The evidence validity can be defined as:
Since evidence validity reflects the influence of the evidence itself on correct decision making, and the credibility is based on the similarity between one piece of evidence other evidence, this paper redefines the weight distribution of conflicting evidence by using both evidence validity and evidence credibility as follows:
The weight distribution method of conflicting evidence increases the weight of conflicting evidence that can help make correct decisions and reduces the weight of conflicting evidence that may make wrong decisions, so as to achieve better convergence results.
4.2. Steps to Improve the Method
According to the new conflict evidence weights, an improved conflict evidence synthesis method can be obtained. The specific steps of this method are as follows:
Step 1: For the n pieces of evidence within the recognition framework, the similarity coefficients between every two pieces of evidence are calculated, and the similarity matrix is obtained.
Step 2: Calculate the support degree of the ith piece of evidence according to the similarity matrix. After normalization of the support degree, obtain the credibility for each evidence.
Step 3: Calculate the information entropy and consistency of each evidence and obtain the evidence validity according to Equation (18).
Step 4: Considering the influence of evidence credibility and evidence validity on conflicting evidence, the weight of the piece of evidence is calculated according to Equation (19).
Step 5: According to this new weight distribution for the conflict evidence, redefine the conflict distribution function f(A) to obtain a new conformity rule, via:
where .
4.3. The Performance of Our Proposed Synthesis Method Compared to Other Methods
In order to verify the effectiveness of the new conflict evidence synthesis rule designed in this paper, a comparative analysis was conducted with the basic probability assignment given by the high conflict evidence in Table 3, as an example. As the conflict factor , the classical DS synthesis method cannot be used. We compare our proposed approach to several other methods briefly introduced below.
Table 3.
The basic probability assignment for high conflict evidence.
Yager’s formula [52] removes the normalization factor and assigns the conflict information generated by the evidence to the identification framework . The rules of composition are as follows:
where . This method has the problem of “one vote no”, and the result is not ideal when multiple evidence bodies are synthesized.
By defining the concept of evidence credibility, Sun Quan et al. [53] set the evidence conflict parameter K, average support degree , and credibility parameter . They further used the credibility to allocate the parts of the conflict information assigned to unknown items. Suppose that the evidence corresponding to is as follows [54]:
With and .
The smaller the conflict parameter K, the less the conflict between pieces of evidence will be. The fusion result is mainly determined by . When the evidence conflict is larger or there is complete conflict, K is closer to 1, and the results of the approach average the credibility and the support degree Furthermore, the conflict between the distribution of the information is related to the evidence on the degree of the average support . Thus, the probability of the unknowns dominates the distribution results against our judgment and analysis, and this method is not reasonable to effectively deal with conflict problems.
In Li Bicheng’s opinion [55], conflicting evidence can all be used, and an average distribution of evidence is defined. However, the average idea proposed by this method is not consistent with reality.
In the literature [56], conflicts caused by evidence are allocated to conflicting focal points according to the BPA proportional relation of conflicting focal points [56]. The commutativity of the rules of evidence theory synthesis cannot be satisfied. When the order of synthesis is different, the results of synthesis are different, which limits the application of the rules of evidence theory synthesis.
In this paper, the above synthesis method is adopted. To compare and illustrate the effectiveness of the evidence synthesis method and the rationality of the fusion result, we take four samples , , , and the basic probability assignment of high conflict evidence as an example for comparative analysis, as shown in Table 3. The results are shown in Table 4. m(A), m(B), m(C) respectively represents the basic probability distribution function of A, B, C. Where is the support for target A after synthesis of evidence , , , , is the fundamental probability of the unknown.
Table 4.
Comparison of synthesis results for the example in Table 4.
As can be seen from the results in Table 4, both Yager’s method and the method from Reference [54] assign the conflict probability to unknown terms, and the fusion result cannot make a correct decision. The methods in References [55] and [56] modify the composition rules, assign the conflict to the basic probability of the conflict focal element, improve the rationality of the composition results, and can thus help one make a correct decision. By introducing the weight of evidence for effectiveness, the method in this paper improves on the other methods. Our approach guarantees a low conflict evidence weight distribution, improves the degree of determining the weight distribution for high consistency and good conflict evidence, and ensures the consistency degree is high by assigning poor weight allocation to conflicting evidence. Thus, our approach has better convergence effects, is more accurate, and can be used to make correct decisions.
5. Case Analysis
5.1. Establishment of a Diagnosis Model
For the state assessment and fault diagnosis of a weapon fire control system, rough set and DS evidence theory are introduced. The rough set restores the information system formed by the original data and extracts the classification rules so that the evidence theory can obtain the basic credibility. Then by allocating and using the synthesis rules, the final decision result is determined. The basic structure of the data fusion method based on rough set and evidence theory is shown in Figure 1.
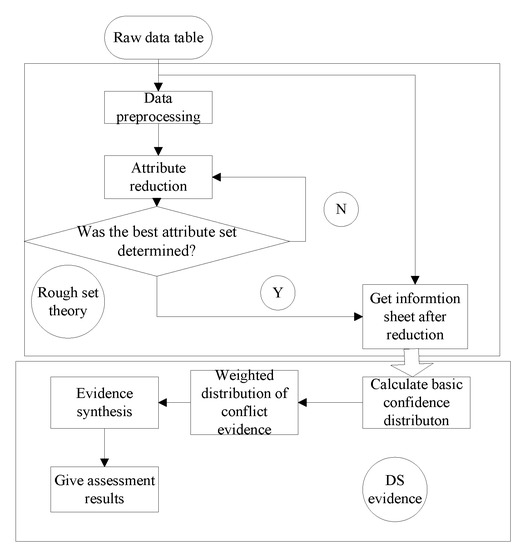
Figure 1.
Structure of data fusion based on rough set and evidence theory.
5.2. Diagnostic Examples
Take the power supply module for the core subsystem of a certain type of tank fire control, fire control computer, and sensor subsystem as an example. The power supply module primarily shows a 26 V main signal that is powered by an external 5 A fuse and is used for the fire control computer through a filter. The 26 V power supply(01) on the power board and the 26 V power supply(02) to the sighting system generate a ±15 V power signal on the power board. The application of a letter-following fusion method is used to construct and analyze the power supply module, and the validity and practicability of the algorithm are verified.
5.2.1. Modeling
This article has five training sample objects, 13 conditional attributes , and one decision attribute D. Table 5 shows the set of state evaluations for the decision attribute, , where the normal state code is 1, the power supply state of ±15 V is denoted 2, the failure state of the 26 V power supply 01 is denoted 3, the failure state of the 26 V power supply 02 is denoted 4, and the failure of the main 26 V power supply is denoted 5. Where 26 V (01) power supplies the power panel of fire control computer; and 26 V (02) power supplies the laser power counter, sight control box, and sight mirror body.
Table 5.
Decision attribute codes for various states (D).
The set of conditional attribute codes is and is shown in Table 6.
Table 6.
Conditional attribute codes (C).
Where the corresponding pin is the aviation plug port number, where Power 15 V (a) and Power 15 V (b) are used to power supply ADA-5a board, Power-15V (a) and Power-15V (b) are used to power supply ADA-5b board.
Set the research sample object as . The original data is shown in Table 7. The raw voltages data is measured by connecting the upper computer with the power module through the test cable.
Table 7.
Raw voltages measured in various states of the fire control system.
The conditions of the discretization according to the experience of experts are shown in Table 8.
Table 8.
Discretization standards.
Discretization of data is completed; the process of discretization involves the following equation:
and the generated discretized decision table can be used to handle attribute reduction using rough set theory; the results are shown in Table 9.
Table 9.
Discretized decision table.
5.2.2. Redundant Attribute Reduction
From the original data table, we find all the equivalent attributes in the decision table and perform reduction based on the defined equivalent attributes. The discovered equivalent attributes are as follows:
After removing the redundant attributes, the conditional attribute set becomes .
According to the approximate mass equation by applying the above Equation (2), we next find the approximate quality of the conditional attributes in C:
After further attribute reduction, the reduction set is and the 13 conditional attributes are reduced to only three remaining important attributes. This fully demonstrates the reduction ability of rough set theory, and thus, the processing efficiency of the subsequent DS evidence theory is improved [57]. Attribute reduction should be maintained in principle. Before and after the reduction, the integrity of the content of the decision table must be ensured.
5.2.3. Allocation of the Fundamental Credibility
Based on Table 10, by applying the above Equation (7), the basic credibility for all of the evidence is assigned, as shown in Table 11. Table 10 is also the beginning of the combination of DS evidence theory and rough set theory.
Table 10.
Reduced decision table.
Table 11.
Basic trust allocation.
According to Equation (21), for the conflict factor, a value of is obtained. The synthesis results are summarized in Table 12 and Table 13, which adopt the classical DS theoretical synthesis method.
Table 12.
Results of the fusion of and into .
Table 13.
Results of the fusion of , , and into .
Thus, from Table 13, we find , , , , . From these results, the diagnosis result is ; however, the actual operation level is ; the actual operation level is not obtained and the diagnosis result is invalid. Therefore, the classical DS synthesis method is unable to evaluate the reliability of the power module under the conditions of high conflict. Additionally, Yager’s method and the method from Reference [52] will assign the probability of conflict to unknown terms, and the synthetic results cannot accurately give the evaluation results of the running state.
Thus, the improved conflict evidence synthesis method presented in this paper is adopted to synthesize such high conflict evidence. The synthesis steps are as follows:
Step 1: Calculate the similarity matrix by applying the above Equation (12):
Step 2: Calculate the support degree between pieces of evidence by applying the above Equation (13):
Step 3: Calculate the credibility of the evidence by applying the above Equation (14):
Step 4: Calculate the Deng entropy of the evidence by applying the above Equation (15):
calculate the consistency of evidence by applying the above Equation (17):
and calculate the validity of evidence by applying the above Equation (18):
Step 5: Calculate the weights of the conflict evidence by applying the above Equation (19):
and calculate by applying the above Equation (20):
Thus, according to Equation (20), the following result is obtained:
Since is the largest value, the corresponding operation level is . That is, the 26 V main power failure hidden state is the predicted operating state, and the diagnostic result of test sample is consistent with the actual processing result. The method designed in this paper is used to evaluate the operation state of the monitoring data (fault unknown) of the power supply module of a certain type of fire control computer.
6. Conclusions
This article first introduced rough set theory and the related concepts of DS evidence theory. Then, we studied how the combination of rough set theory and DS evidence theory could play to the advantages of the two algorithms and avoid their disadvantages. An analysis of the classical theory of evidence conflict and evidence synthesis rules was performed. On the basis of an evidence weight allocation method, this paper proposed an evidence similarity calculation method using the fuzzy membership degree of reliability and the validity of the evidence. Furthermore, an improved conflict evidence synthesis method was proposed and studied with a comparative analysis. Finally, the improved method was applied to the intelligent evaluation model of a power supply module of a fire control computer. An example shows that this model can solve the paradoxical problem caused by the conflict of evidence theory synthesis rules to some extent and can accurately evaluate the running state.
There is a large amount of running state data for a fire control computer. In the future, we suggest establishing an overall running state evaluation system according to the classification of incoming and outgoing signals. By gradually improving the study of state evaluation, one can meet the required standards for state evaluation of a fire control system and provide a favorable basis for the realization of situational maintenance.
Author Contributions
Y.L.: Supervision; Formal analysis; Writing review & editing; A.W.: Data curation; Methodology; Software; Writing original draft; X.Y.: Formal analysis; Funding acquisition; Project administration; Writing review & editing.
Funding
This paper is supported by National Natural Science Foundation (71801196); China Postdoctoral Science Foundation (2018M631606).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Su, J.; Chen, Y.; Yang, G.; Zhang, L. Fault diagnosis of certain type of tank fire control system based on BP neural network. In Proceedings of the IEEE International Conference on Electronic Measurement & Instruments, Harbin, China, 16–19 August 2014. [Google Scholar]
- Chen, J.; Li, Y.; Ye, F. Uncertain information fusion for gearbox fault diagnosis based on BP neural network and D-S evidence theory. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016. [Google Scholar]
- Li, Z.; Chen, L. A novel evidential FMEA method by integrating fuzzy belief structure and grey relational projection method. Eng. Appl. Artif. Intell. 2019, 77, 136–147. [Google Scholar] [CrossRef]
- Yuan, K.; Xiao, F.; Fei, L.; Kang, B.; Deng, Y. Conflict management based on belief function entropy in sensor fusion. SpringerPlus 2016, 5, 638. [Google Scholar] [CrossRef]
- Xiao, J.; Tong, M.; Feng, W.; Guo, X. Improvement Research of Evidence Theory in Mine Water Inrush Prediction. In Proceedings of the IEEE International Workshop on Education Technology & Computer Science, Wuhan, China, 6–7 March 2010. [Google Scholar]
- Feng, D.; Dias Pereira, J.M. Study on Information Fusion Based on Wavelet Neural Network and Evidence Theory in Fault Diagnosis. In Proceedings of the 2007 8thInternational Conference on Electronic Measurement and Instruments, Xi’an, China, 16–18 August 2007. [Google Scholar]
- Lingras, J.; Szczuka, W.; Dominikslezak, N. Rough Sets and Knowledge Technology; Springer Nature, Inc.: New York, NY, USA, 2013. [Google Scholar]
- Meng, H.N.; Qi, Y.; Hou, D.; Chen, Y. A Rough Wavelet Network Model with Genetic Algorithm and its Application to Aging Forecasting of Application Server. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007. [Google Scholar]
- Vorobeychik, Y.; Reeves, D.M. Equilibrium analysis of dynamic bidding in sponsored search auctions. Int. J. Electron. Bus. 2008, 6, 172–193. [Google Scholar] [CrossRef]
- Gong, Z.T.; Sun, B.Z.; Xu, Z.M.; Zhang, Z.Q. The rough set analysis approach to water resources allocation decisions in the inland river basin of arid regions. In Proceedings of the IEEE 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005. [Google Scholar]
- Liu, G.; Yu, W. The Application of Rough Set Theory in Worsted Roving Procedure. In Innovations and Advanced Techniques in Systems, Computing Sciences and Software Engineering; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Yin, S.; Huang, Z.; Chen, L.; Qiu, Y. A Approach for Text Classification Feature Dimensionality Reduction and Rule Generation on Rough Set. In Proceedings of the IEEE International Conference on Innovative Computing Information & Control, Dalian, China, 18–20 June 2008. [Google Scholar]
- Tao, S.; Yukari, N.; Chan, G. Design of building construction safety prediction model based on optimized BP neural network algorithm. Soft Comput. 2019. [Google Scholar] [CrossRef]
- Qi, X.J.; Xu, X.D.; Sun, H. Selection and Application of Suburban Residential Evaluation Based on Rough Set. Appl. Mech. Mater. 2013, 368, 83–91. [Google Scholar] [CrossRef]
- Yang, Y.B. Research on Data Mining Algorithm Based on Rough Set. Adv. Mater. Res. 2012, 433, 3340–3346. [Google Scholar] [CrossRef]
- Huang, W.; Wang, W.; Meng, Q. Fault Diagnosis Method for Power Transformers Based on Rough Set Theory. In Proceedings of the IEEE Control & Decision Conference, Yantai, China, 2–4 July 2008. [Google Scholar]
- Wang, T.; Li, Y.Q.; Zhao, S.F. Application of SVM Based on Rough Set in Real Estate Prices Prediction. In Proceedings of the International Conference on Wireless Communications, Dalian, China, 12–14 October 2008. [Google Scholar]
- Shi, Z. Advanced Artificial Intelligence; World Scientific: Singapore, 2011. [Google Scholar]
- Yusoff, M.; Ariffin, J.; Mohamed, A. Advances in Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Zhang, H.; Deng, Y. Engine fault diagnosis based on sensor data fusion considering information quality and evidence theory. Adv. Mech. Eng. 2018, 10. [Google Scholar] [CrossRef]
- Tong, Y.; Zhao, R.; Ye, W.; Li, D. Research on energy efficiency evaluation for overhead crane. Kybernetes 2016, 45, 788–797. [Google Scholar] [CrossRef]
- Miao, Z.; Gandelin, M.H.; Yuan, B. An OOPR-based rose variety recognition system. Eng. Appl. Artif. Intell. 2006, 19, 79–101. [Google Scholar]
- Xu, B.; Tao, C.; Xia, H. A Method for Dam Safety Evaluation Based on Dempster-Shafer Theory. In Proceedings of the International Conference on Advanced Intelligent Computing Theories & Applications with Aspects of Artificial Intelligence, Changsha, China, 18–21 August 2010. [Google Scholar]
- Srivastava, R.P.; Shafer, G.R. Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer Nature, Inc.: New York, NY, USA, 2008. [Google Scholar]
- Skersys, T.; Butleris, R.; Butkiene, R. Communications in Computer and Information Science. Commun. Comput. Inf. Sci. 2012, 252, 551–557. [Google Scholar]
- Destercke, S.; Burger, T. Toward an Axiomatic Definition of Conflict Between Belief Functions. IEEE Trans. Cybern. 2013, 43, 585–596. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Lu, P. Electricity Load Forecasting Using Rough Set Attribute Reduction Algorithm Based on Immune Genetic Algorithm and Support Vector Machines. In Proceedings of the IEEE International Conference on Risk Management & Engineering Management, Beijing, China, 4–6 November 2008. [Google Scholar]
- Bi, Y.; Wu, S.; Guo, G. Combining Prioritized Decisions in Classification[C]// Modeling Decisions for Artificial Intelligence. In Proceedings of the 4th International Conference, MDAI 2007, Kitakyushu, Japan, 16–18 August 2007; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Chen, L.; Deng, X. A Modified Method for Evaluating Sustainable Transport Solutions Based on AHP and Dempster–Shafer Evidence Theory. Appl. Sci. 2018, 8, 563. [Google Scholar] [CrossRef]
- Su, X.; Li, L.; Shi, F.; Qian, H. Research on the Fusion of Dependent Evidence Based on Mutual Information. IEEE Access 2018, 6, 71839–71845. [Google Scholar] [CrossRef]
- Smets, P. Analyzing the combination of conflicting belief functions. Inf. Fusion 2007, 8, 387–412. [Google Scholar] [CrossRef]
- Lefevre, E.; Colot, O.; Vannoorenberghe, P. Belief function combination and conflict management. Inf. Fusion 2002, 3, 149–162. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Xie, C.; Zhou, D. An evidential sensor fusion method in fault diagnosis. Adv. Mech. Eng. 2016, 3, 8–15. [Google Scholar] [CrossRef]
- Zadeh, L.A. A Simple View of the Dempster-Shafer Theory of Evidence and Its Implication for the Rule of Combination. AI Mag. 1986, 7, 85–90. [Google Scholar]
- Pichon, F.; Destercke, S.; Burger, T. A Consistency-Specificity Trade-Off to Select Source Behavior in Information Fusion. IEEE Trans. Cybern. 2015, 45, 598–609. [Google Scholar] [CrossRef]
- Zhang, Z. Research on the Problem of Ignorant Evidence Fusion Based on D-S Evidence Theory Trust Model in P2P Network. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006. [Google Scholar]
- Zhang, W.; Deng, Y. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Dubois, D.; Liu, W.; Ma, J.; Prade, H. The basic principles of uncertain information fusion. An organised review of merging rules in different representation frameworks. Inf. Fusion 2016, 32, 12–39. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, K.; Deng, Y. Base belief function: An efficient method of conflict management. J. Ambient Intell. Humaniz. Comput. 2018. [Google Scholar] [CrossRef]
- Li, J.W.; Cheng, Y.M.; Zhang, S.W.; Liang, Y. Research of combination rule based on evidence distance and local conflict distribution. In Proceedings of the China Control & Decision Conference, Xuzhou, China, 26–28 May 2010. [Google Scholar]
- Liang, L.; Shen, Y.; Cai, Q.; Gu, Y. A reliability data fusion method based on improved D-S evidence theory. In Proceedings of the IEEE 2016 11th International Conference on Reliability, Maintainability and Safety (ICRMS), Hangzhou, China, 26–28 October 2016. [Google Scholar]
- Pal, N.R.; Bezdek, J.C.; Hemasinha, R. Hemasinha: Uncertainty measures for evidential reasoning I: A review. Int. J. Approx. Reason. 1992, 7, 165–183. [Google Scholar] [CrossRef]
- Pal, N.R.; Bezdek, J.C.; Hemasinha, R. Hemasinha: Uncertainty measures for evidential reasoning II: A new measure of total uncertainty. Int. J. Approx. Reason. 1993, 8, 1–16. [Google Scholar] [CrossRef]
- Miao, Y.; Ma, X.; Zhang, J. Research on the combination rules of the D-S evidence theory and improvement of extension to fuzzy sets. In Proceedings of the 2010 Chinese Control and Decision Conference, Xuzhou, China, 26–28 May 2010. [Google Scholar]
- Liang, X.; Feng, J.; Liu, A. A modified D-S decision-making algorithm for multi-sensor target identification. In Proceedings of the International Conference on Advances in Swarm Intelligence, Beijing, China, 12–15 June 2010; Springer: Berlin, Germany, 2010. [Google Scholar]
- Jiang, W.; Zhang, A.; Yang, Q. A New Method to Determine Evidence Discounting Coefficient. In Proceedings of the International Conference on Intelligent Computing, Shanghai, China, 15–18 September 2008; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Li, Y.; Deng, Y. Generalized ordered propositions fusion based on belief entropy. Int. J. Comput. Commun. Control 2018, 13, 792–807. [Google Scholar] [CrossRef]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Xu, W.X.; Tan, J.W.; Zhan, H. Research and Application of the Improved DST New Method Based on Fuzzy Consistent Matrix and the Weighted Average. Adv. Mater. Res. 2014, 1030–1032, 1764–1768. [Google Scholar] [CrossRef]
- Patterson, M.A.; Rao, A. Exploiting Sparsity in Direct Collocation Pseudospectral Methods for Solving Optimal Control Problems. J. Spacecr. Rocket. 2012, 49, 354–377. [Google Scholar] [CrossRef]
- Yager, R. On the Dempster Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Sun, Q.; Ye, X.Q.; Gu, W.K. A New Synthetic Formula Based on Evidence Theory. Acta Electron. Sin. 2000, 28, 117–119. [Google Scholar]
- Wang, F.; Wang, D. Application of mechanical fault diagnosis of circuit breaker on evidence theory method. In Proceedings of the IEEE International Conference on Computer Science and Service System (CSSS), Nanjing, China, 27–29 June 2011. [Google Scholar]
- Li, B.; Wang, B.; Wei, J.; Huang, Y. Department of Information Science. Efficient Combination Rule of Evidence Theory. J. Data Acquis. Process. 2002. [Google Scholar] [CrossRef]
- Qi, W.; Ding, J.; Liu, Y.; Zhao, Z. An Improved Method of Evidence Synthesis and Its Application in Fuzzy Evaluation. Fire Control Command Control 2018, 43, 67–71. [Google Scholar]
- Fan, X.; Zuo, M.J. Fault diagnosis of machines based on D-S evidence theory. Part 1: D-S Evidence Theory and Its Improvement. Pattern Recognit. Lett. 2006, 27, 366–376. [Google Scholar] [CrossRef]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).