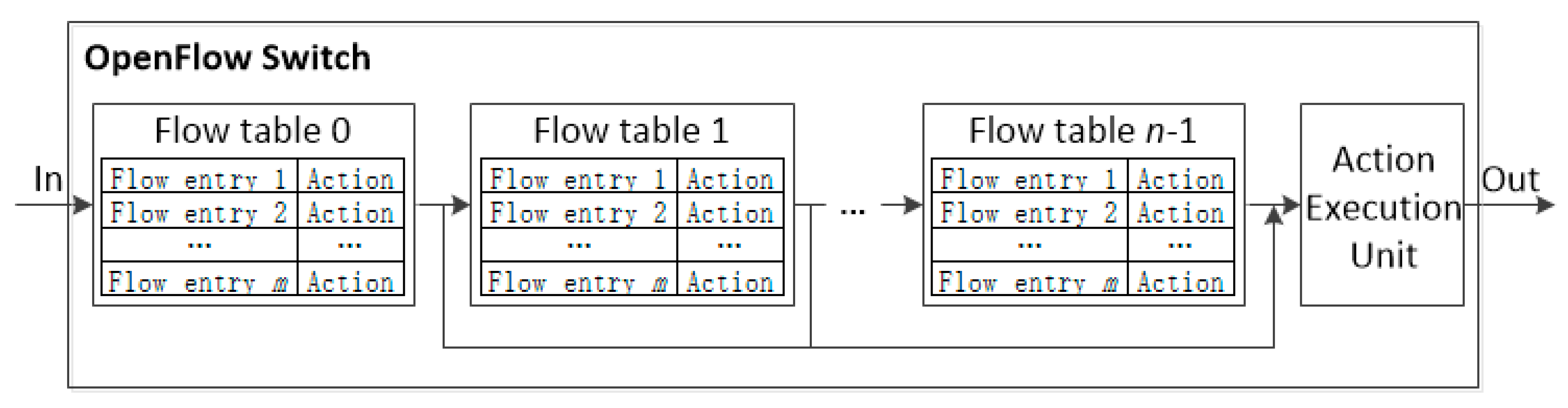
3.2. Aggregation of Entry
The number of possible flow paths in a flow table is typically small because only a limited number of interface cards can fit into the switch chassis. In contrast, the number of forwarding entries is quite large, in the range of several thousands. Considering this disparity, a scheme reducing the size of flow table is developed which involves two techniques presented below.
3.2.1. Pruning of Redundant Entries
Pruning is a technique eliminating some redundant entries [
20]. To facilitate the discussion, some terms are defined as follows. Notice that the match fields of a flow entry may have different lengths.
Assume that entry_P is the parent of entry_Q, Lp is the length of entry_P, and P(i) is the ith bit of entry_P. Then the following three conditions hold: (a) LP < LQ; (b) For all i(1 < i < LP), P(i) = Q(i); (c) There is no Q’ such that LP < LQ’ < LQ; and Q’(i) = Q(i) for all i(1 < i < LP).
Entry_P is identical to entry_Q if same actions are executed for the matched packet.
If P is identical to Q, Q is a redundant flow entry. Assume that Q matches a flow. Then the flow will match P as well by the definition. If Q is removed from the flow table, P becomes the matched entry. As P and Q have the same actions, removing Q makes no difference. Note that the technique is general enough that it can be used with any entry lookup algorithm regardless of the type of the flow table.
3.2.2. QM-Based Mask Extension
The second technique exploits the flexibility offered by the TCAM hardware. TCAM allows arbitrary mask, in other words, the bits of 1s or 0s do not require to be continuous.
Table 2 shows an example of mask extension.
E1 and
E2 both have the same action of ‘Forward to 1’. It is possible to combine
E1 and
E2 into one single entry with the prefix of 1100 and mask of 1101. The 0 at bit 3 in the mask allows combining
E1 and
E2 into a same entry. The aggregated version of the original flow table with the mask extension technique is shown in the right-hand side. The table size has been reduced to 3 from 5.
Note that the mask extension is equivalent to the logic minimization problem [
20]. The problem is that ‘given a set of entries with the same action, find a set of minimal covers.’ Such logic minimization problem [
33] is a non-deterministic polynomial (NP) complete problem, and there exist mainly three kinds of methods used for its solution.
Karnaugh mapping [
34]: It is simple but when the number of variables is larger than six, it becomes very complex.
Quine–McCluskey (QM) algorithm [
23,
24,
25]: It is functionally identical to Karnaugh mapping, but the tabular form makes it more efficient to be used with a computer algorithm, supporting any number of variables. It also provides a deterministic method checking if the logical function is minimal.
Espresso logic minimizer [
35,
36]: It can produce a solution fast but cannot guarantee optimal result.
Here the QM algorithm is employed for mask extension. Algorithm 1 shows the proposed entry aggregation scheme with the QM algorithm-based mask extension. Here, E(l,a) is the set of original entries having the same length of l and action of a. A(l,a) is the result of QM algorithm.
| Algorithm 1. Entry aggregation with mask extension |
| //n is the number of original entries |
| //m is the number of entries having the same length and action |
| 1: Begin |
| 2: Input entry[i] |
| 3: for i from 0 to n |
| 4: if have same entry[i].l and entry[i].a |
| 5: move to E(l,a) |
| 6: End for |
| 7: for i from 0 to m |
| 8: A(l,a) = QMminimize(E(l,a)) |
| 9: end for |
| 10: remove E(l,a) |
| 11: install A(l,a) |
| 12: end |
An example of the proposed mask extension scheme is shown below. In
Table 3, there are 11 entries with different actions. After selecting the entries having the same action, the entry aggregation problem is simplified into the following minimization function:
Step 1: find prime implicants (
Pi). Here all minterms are placed in the minterm table as shown in
Table 4, and Stage I is to combine the minterms. If two terms vary by only a single bit, that bit is replaced with a dash (-). Stage II is the result of Stage I, and Stage III is the result of combining the minterms in Stage II. ‘/’ indicates if the entry is combined in the next stage.
According to
Table 4, all the prime implicants are shown as follows:
Step 2: find essential prime implicants (Pe).
From
Table 4, none of the minterms can be combined any further. At this point, the table of essential prime implicant is constructed as in
Table 5.
In order to find the essential prime implicants, each column needs to be checked whether there exists only one ‘*’. If a column has only one ‘*’, the minterm can be covered by only one prime implicant. Then this prime implicant is essential. According to
Table 5,
P1 is the only essential prime implicant.
As
P2 can be covered by
P1 and
P3, same as
P3,
P4,
P5,
P6, and
P7, they are not essential. In this example, the essential prime implicants cannot handle all the minterms (only
E0,
E3,
E5, and
E9 are covered). Therefore, other prime implicants are combined with
P1 to get the final result as:
At last the final
Table 6 is obtained as follows:
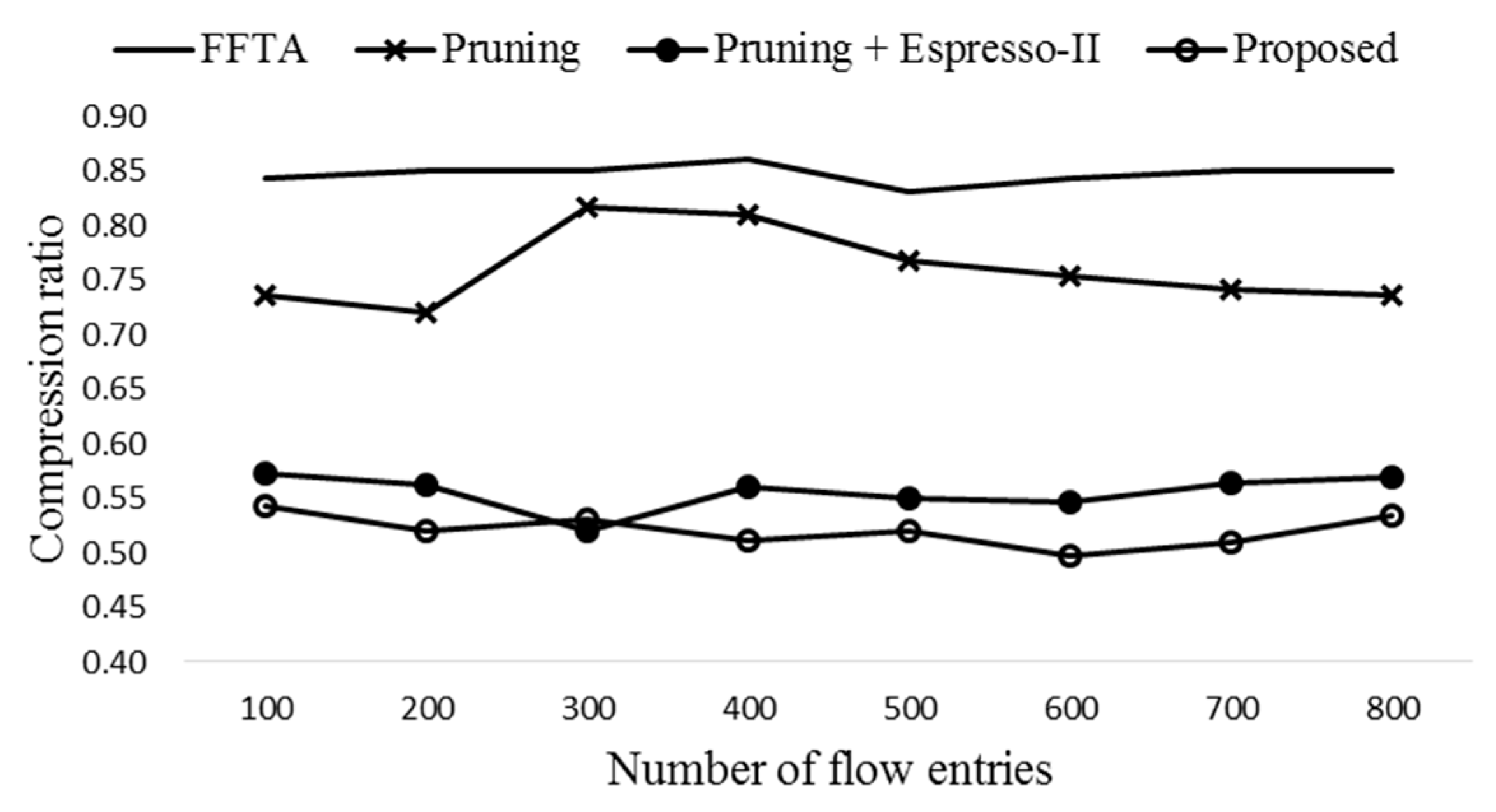
The number of entries is aggregated from 11 to 6, and the compression ratio is 6/11 = 0.545.
3.3. Hidden Markov Model-Based Prediction
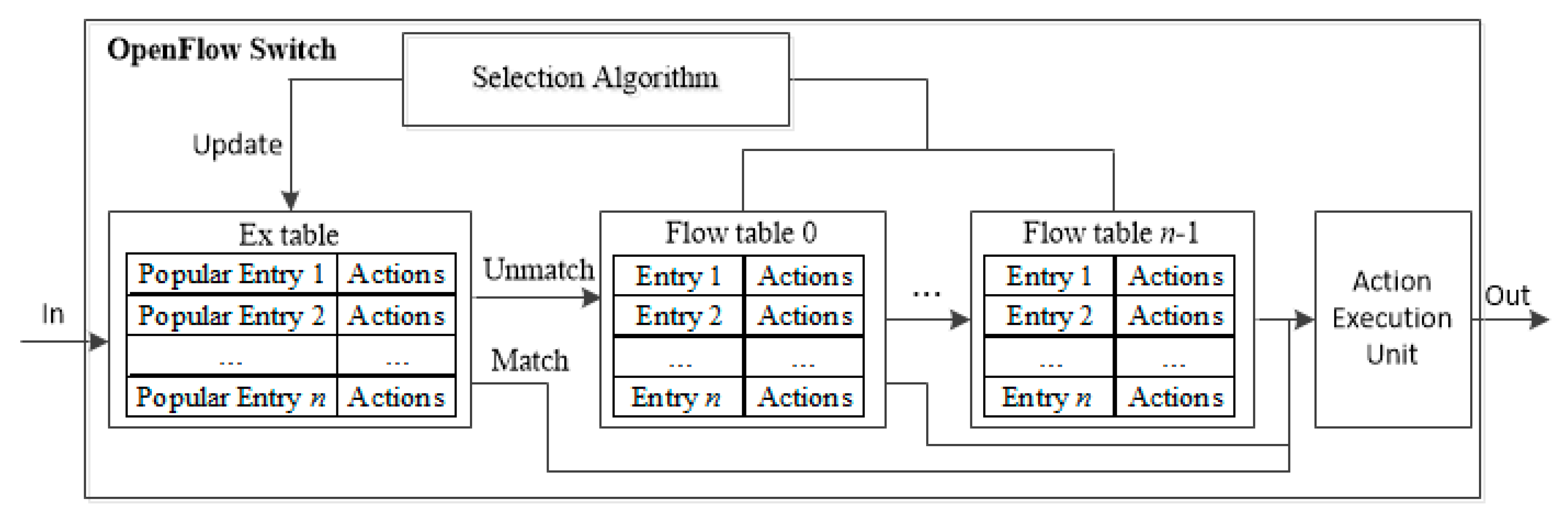
The goal of the proposed scheme based on HMM is to dynamically predict the popularity of the flow entries as accurately as possible and update the ExTable accordingly. After the flow entries are aggregated, the popularity of the flow entries are estimated periodically and the entries deemed to be popular are moved to ExTable. Note that the size of ExTable, np, is smaller than (1 − C)∙NMFT where C and NMFT are the TCAM compression ratio and the size of entire MFT, respectively.
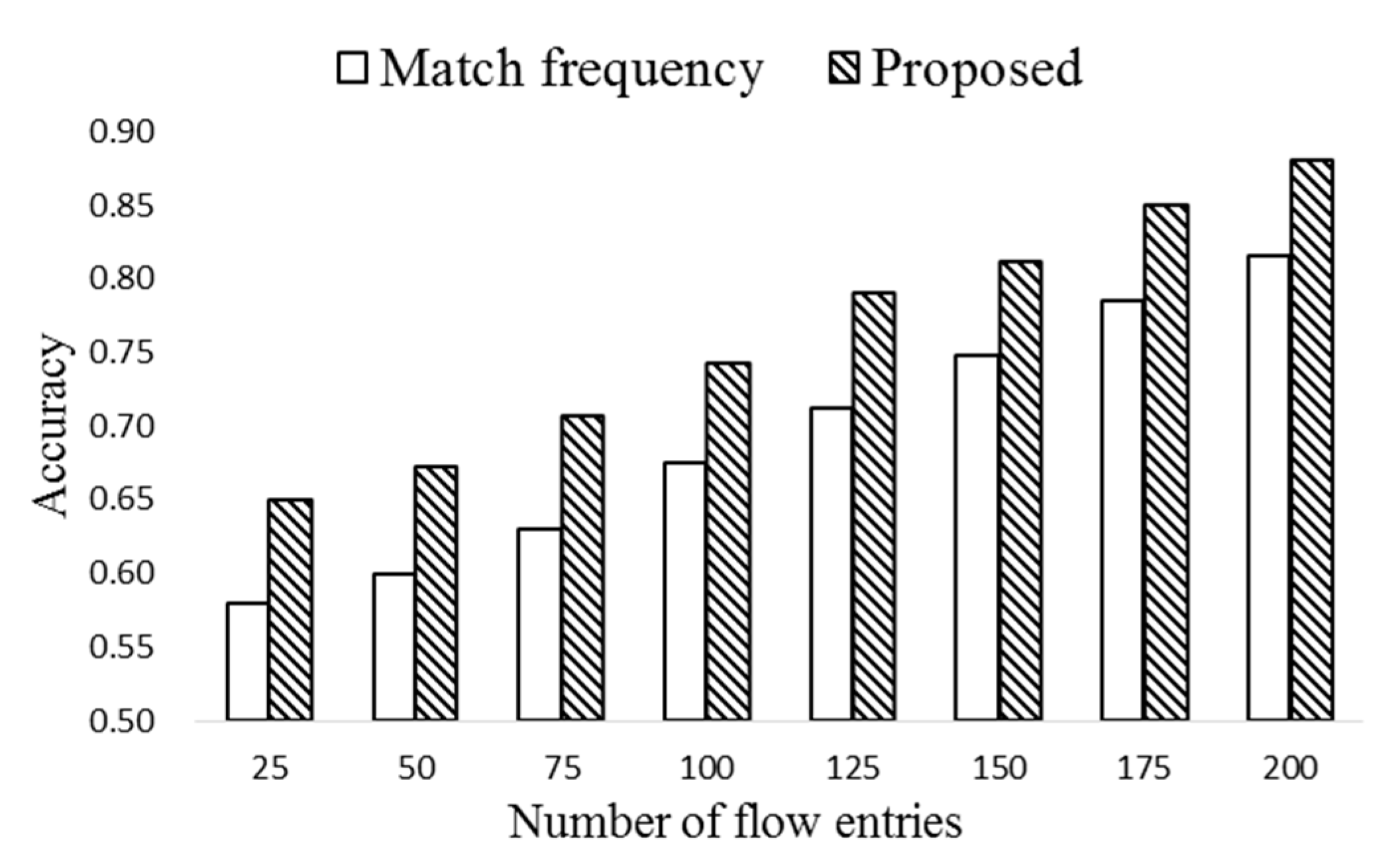
The match frequency of an entry indicates the popularity. For this, a counter, M, is associated to each flow entry, which is activated when the entry is installed in the flow table. M is the number of matches before the prediction occurs. Note that M may not be the only indicator of the popularity, and thus HMM is employed to estimate the probability of the flow entries to be matched in the near future.
The interarrival time of the flow is assumed to follow exponential distribution, and therefore the number of arrivals can be modeled using Poisson distribution. The probability of a flow arriving in a given interval of time of Δ
t is predicted as follows. Assume that flow arrival occurs at any time. The probability of
k arrivals in Δ
t is given by:
The probability of at least one arrival in the interval Δ
t is given as:
The probability of a flow arriving in the next interval is computed as the mean value of the entire period from the beginning. It is:
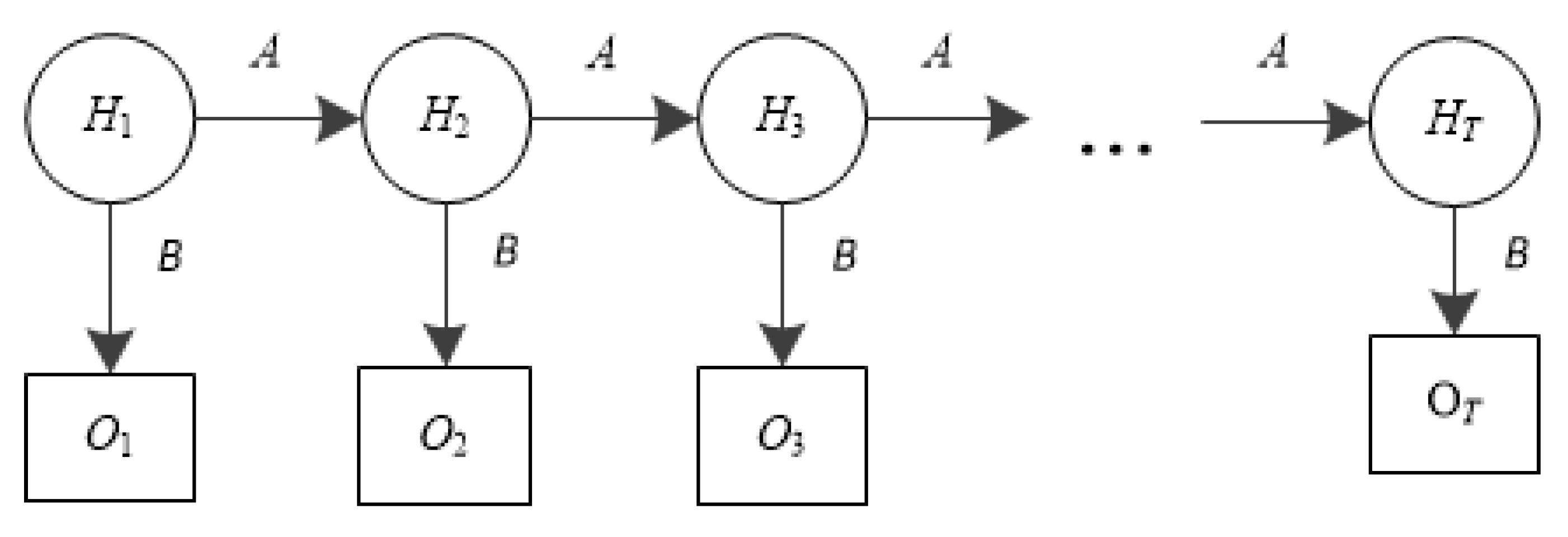
HMM is effective to predict the probability of an observed sequence with the given triple
λ = (
π,
A,
B). Let
H = {
H0,
H1, …,
Hn} be a set of hidden states, where
Hi is defined as the number of time segments (Δ
t seconds per segment) a flow entry has not been matched from the initial state. For example, if there was no match for last 3Δ
t seconds,
H3 = 3Δ
t. If there was a match,
H3 = 0. Note that the hard timeout period (
TH) is preset, and an entry is forced to be evicted if no match occurs during
TH. Therefore, there will be
n (=
TH/Δ
t) segments before an entry is finally evicted, and
Hn is the last state. Since
O = {
O0,
O1, …,
On} is a set of observable states of any entry,
Oi indicates if the entry is matched in
ith segment. It has two values; ‘1’ for a successful match, ‘0’ no match.
Figure 4 shows the structure of the HMM of the proposed scheme.
With the HMM the probability of an observed sequence is found with the given parameters,
A,
B, and
π. For a flow entry, there exist
N (=
n + 1) hidden states in its life time. Assume that there exist
m time segments before the prediction occurs. Then the (
n −
m) × (
n −
m) hidden state transition probability matrix,
A, and the (
n −
m) × 2 emission probability matrix,
B, are obtained as follows:
In order to compute the likelihood probability, P(O|λ) of O = {O0, O1, …, O(n−m)}, the forward algorithm is adopted. Note that the probability of the observation sequence is obtained in which the value of Oi is 1 and the predicted last observable state is O(n−m). Then P(O|λ) is calculated as follows.
Through the forward algorithm, the P(O|λ) of each observed state can be computed. In order to decide the popularity of each entry, the value of Oi is set to 1 to record the probability of successful match.
Large
P(
O|
λ) means that the entry has high match probability. The number of popular flow entries selected in each flow table is denoted as
k. Periodic ExTable update occurs in every Δ
T. Here the popularity,
ω, is decided based on the match frequency,
M, and match probability,
P(
O|
λ), as follows:
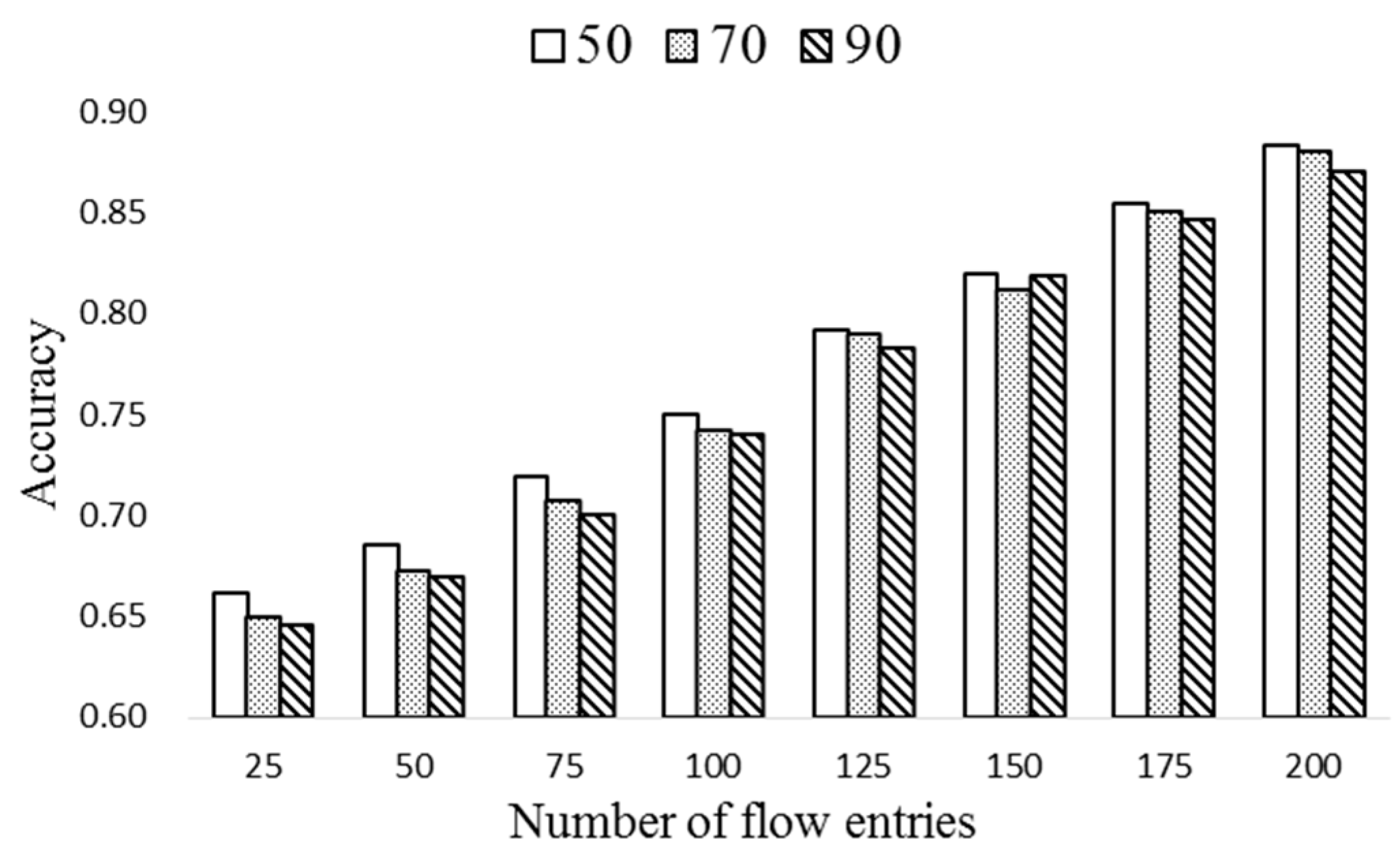
After calculating the popularity, the flow entries of k largest popularity are moved to the ExTable. The number of flow entries in ExTable is nt∙k if there exist nt flow tables (nt∙k ≤ np). If there exist several flow entries of the same value, the one of the longest remaining life time is selected. The proposed periodic entry selection scheme is depicted in Algorithm 2.
| Algorithm 2. Selection operation of popular entry |
| 1: Begin |
| 2: create ExTable using the saved memory |
| 3: set ΔT, k |
| 4: flowEntry.M[i][j] = 0 |
| 5: flowEntry.P[i][j] = 0 |
| 6: flowEntry.ω[i][j] = 0 |
| 7: while 0 < Δt < ΔT |
| 8: for i from 0 to nt −1 |
| 9: for j from 0 to nf −1 |
| 10: input O, λ = (π,A,B) |
| 11: initial α0(j) by Equation (17), π by Equations (18) and (19) |
| 12: compute αt(j) by Equation (24) |
| 13: calculate flowEntry.P[i][j] by Equation (25) |
| 14: count flowEntry.M[i][j] |
| 15: calculate flowEntry.ω[i][j] by Equation (26) |
| 16: end for |
| 17: end for |
| 18:end while |
| 19: if (Δt == ΔT) |
| 20: fori from 0 to nt − 1 |
| 21: sort flowEntry. ω[i][j] from large to small |
| 22: forj from 0 to k |
| 23: select flowEntry[i][j] |
| 24: end for |
| 25: end for |
| 26: end if |
| 27: update flowEntry[i][j] into ExTable |
| 28: end |
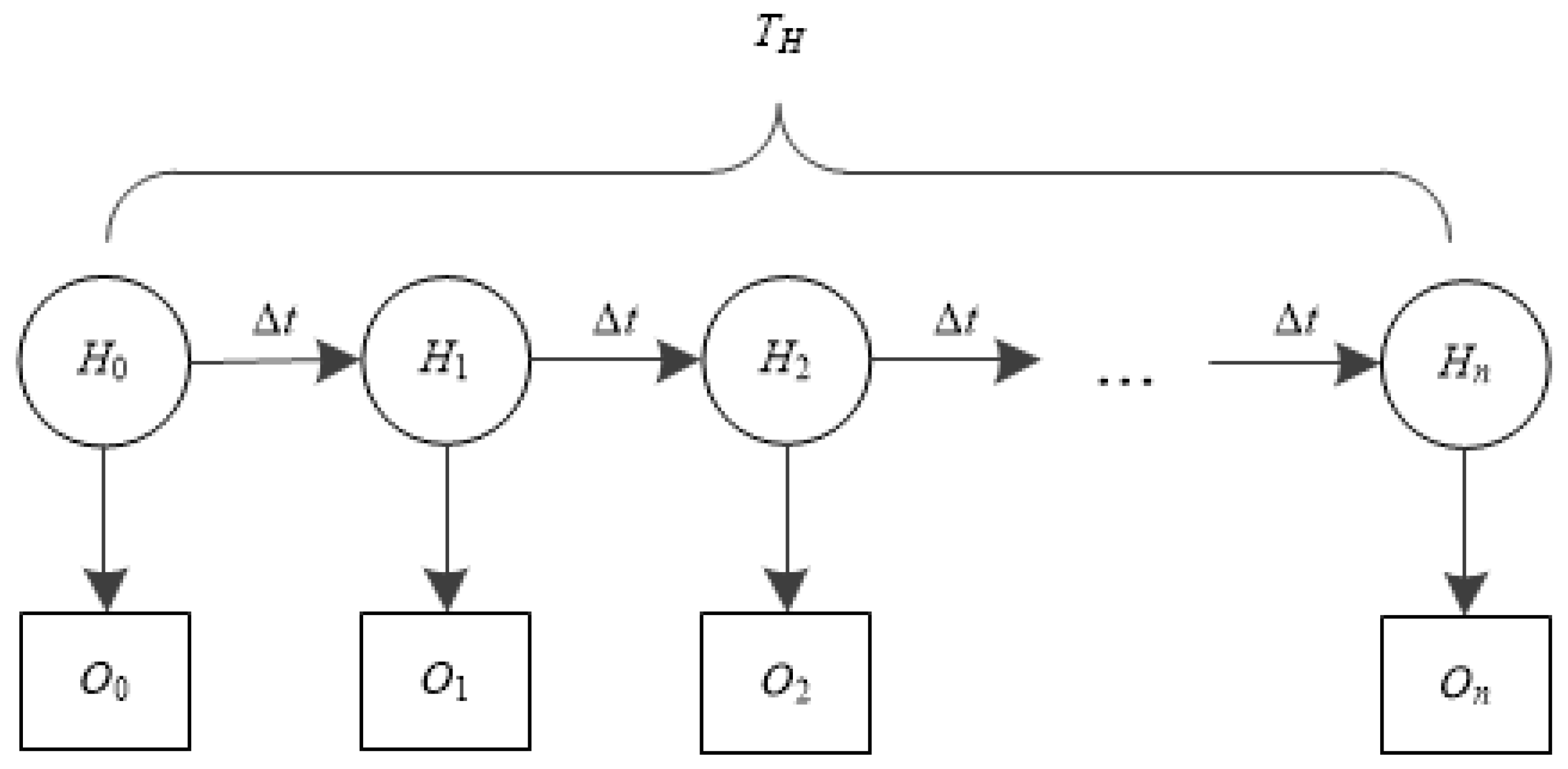
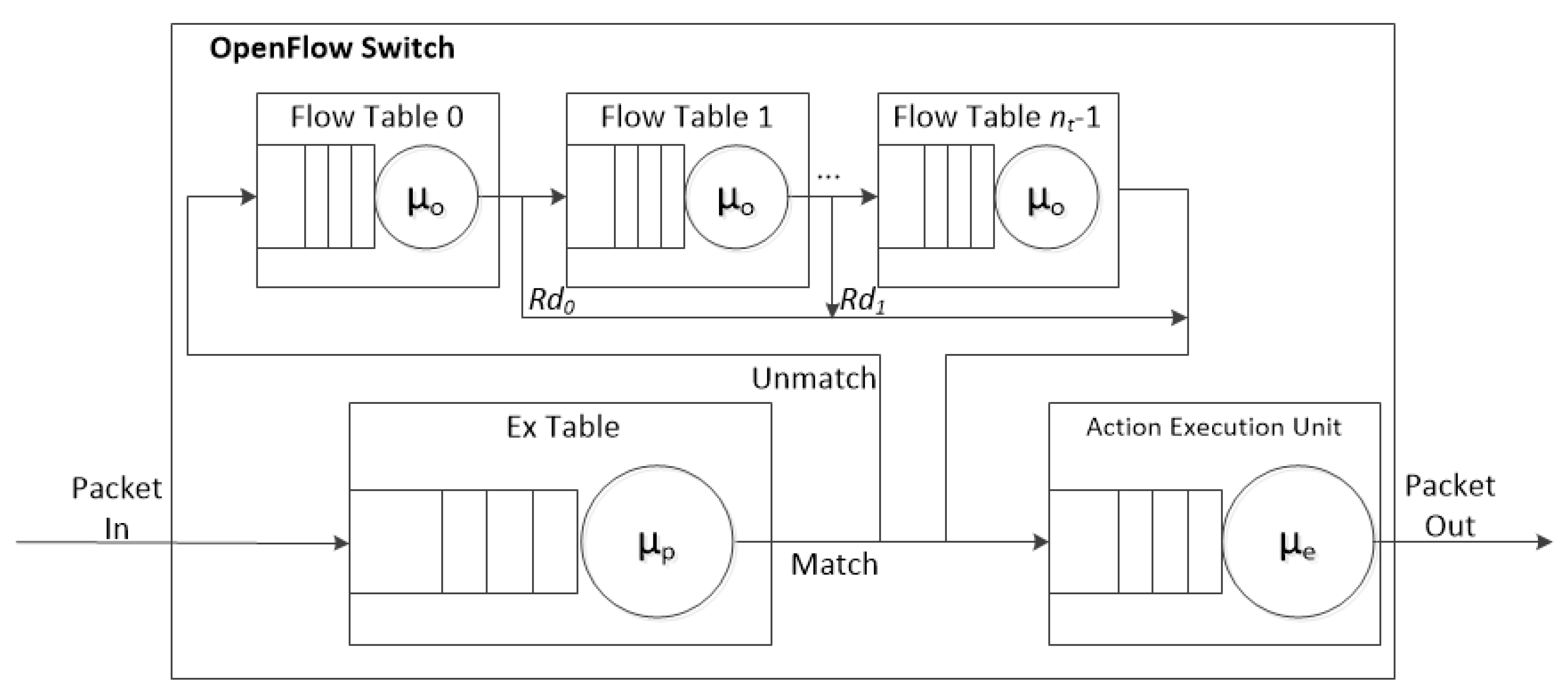
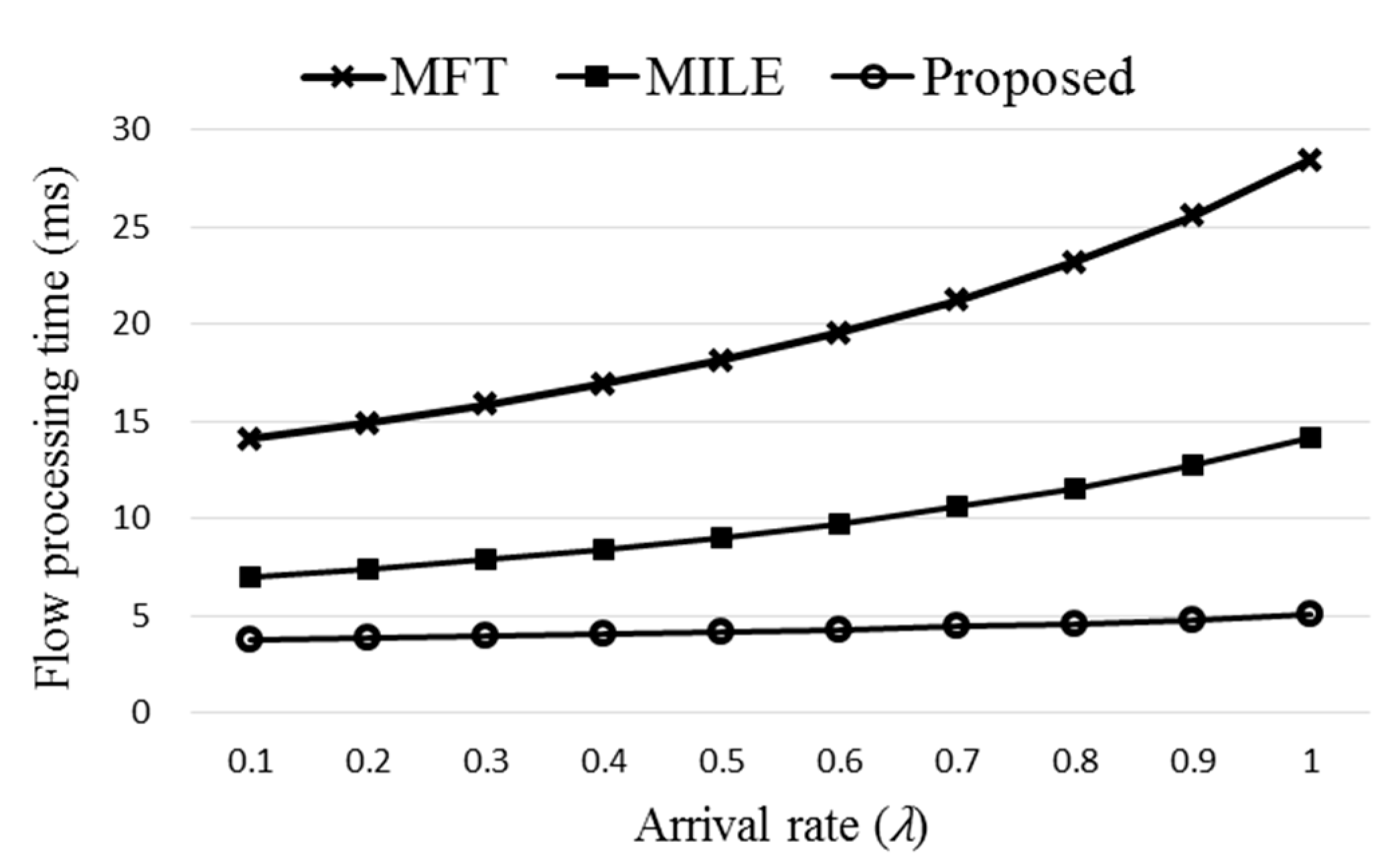
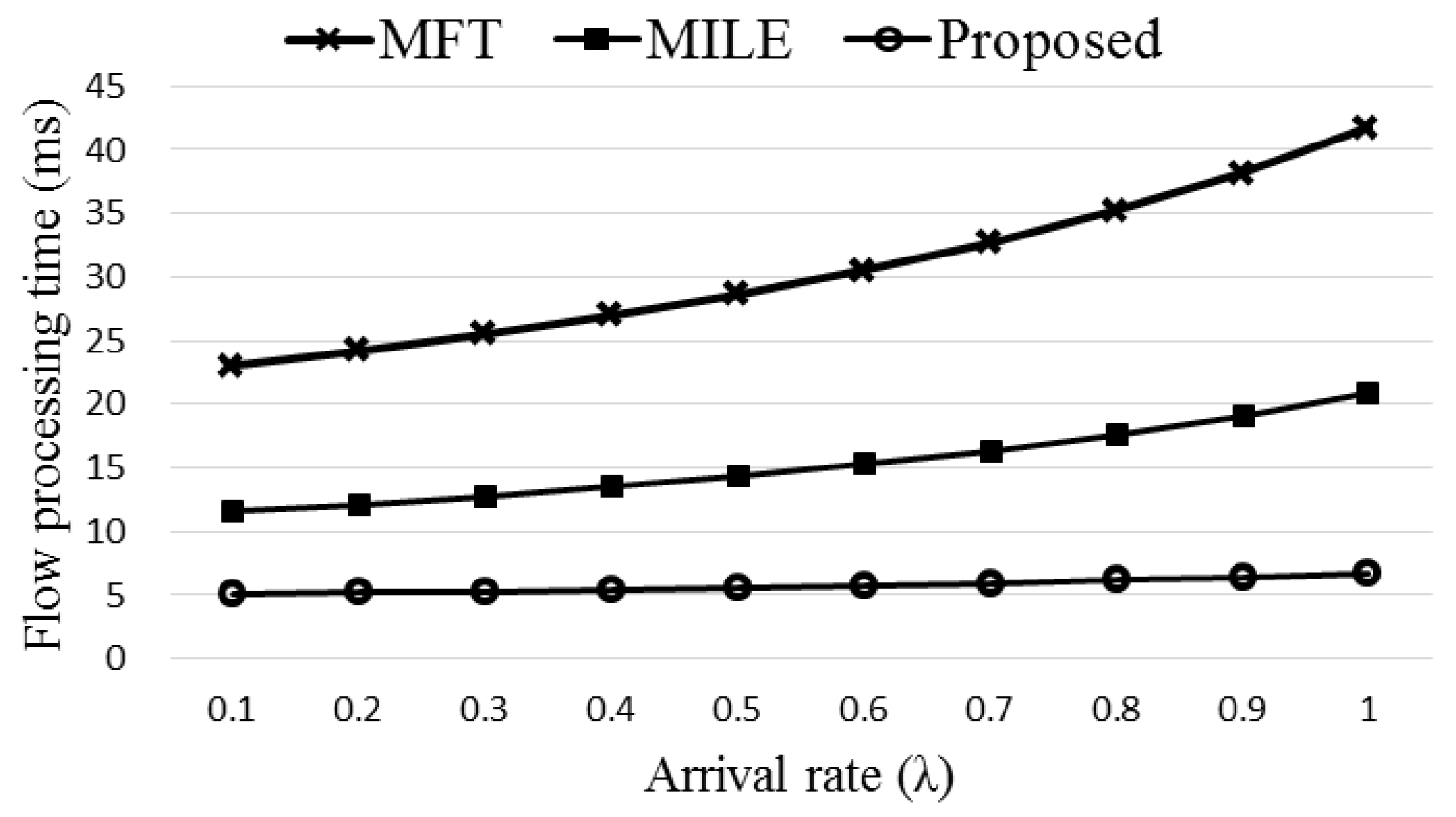
3.4. Flow Processing Time
The queuing model [
19,
37] of the proposed ExTable scheme is shown in
Figure 5 where each of the nodes is considered as an M/M/1 queue.
Table 7 is the list of variables used in the model.
According to Little’s Law [
37], the flow processing time in the system can be calculated as
T =
N/
λ, where
N is the average number of flows in the system and
λ is the arrival rate of the flows. For obtaining the flow processing time of the proposed scheme,
TF, firstly the average number of flows in the system,
NF, needs to be obtained. In the following formula
Rm is the match rate of the ExTable, and
ρp, ρf, and
ρe are the utilization of ExTable, flow table, and AEU, respectively. Note that there exists a direct path from each flow table to AEU. The rate of sending packets directly to AEU from the flow tables are {
Rd0,
Rd1, …,
Rdnt−2}, where
nt ≥ 2. In order to calculate
NF, the average number of flows in ExTable, flow table 0, flow table 1, flow table (
nt−1) and AEU,
Np,
Nf0,
Nf1,
Nf(nt−1), and
Ne, should be estimated. They are calculated as follows:
The average number of flows in the system,
NF, is as follows:
Note that there exist one ExTable,
nt flow tables and one AEU. As a result, the flow processing time,
TF, is obtained as follows:
The queueing model of the flow processing time for ExTable is used later in computer simulation. The proposed scheme is simulated and compared with the existing schemes in the following section.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
