FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks

 , ,
, ,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- We present a novel system to classify the friendship strength between nodes using machine learning classifiers. We also present a new metric to depict the node’s acquaintanceships.
- We design the FSF algorithm by also taking into account the resources of the relay device on the routing decisions.
- We propose a watchdog and a reputation system to detect the nodes’ selfishness behaviour.
- We evaluate and compare the proposed algorithm with respect to other well-known routing algorithms, and show its performance improvements in realistic scenarios.
2. Related Works
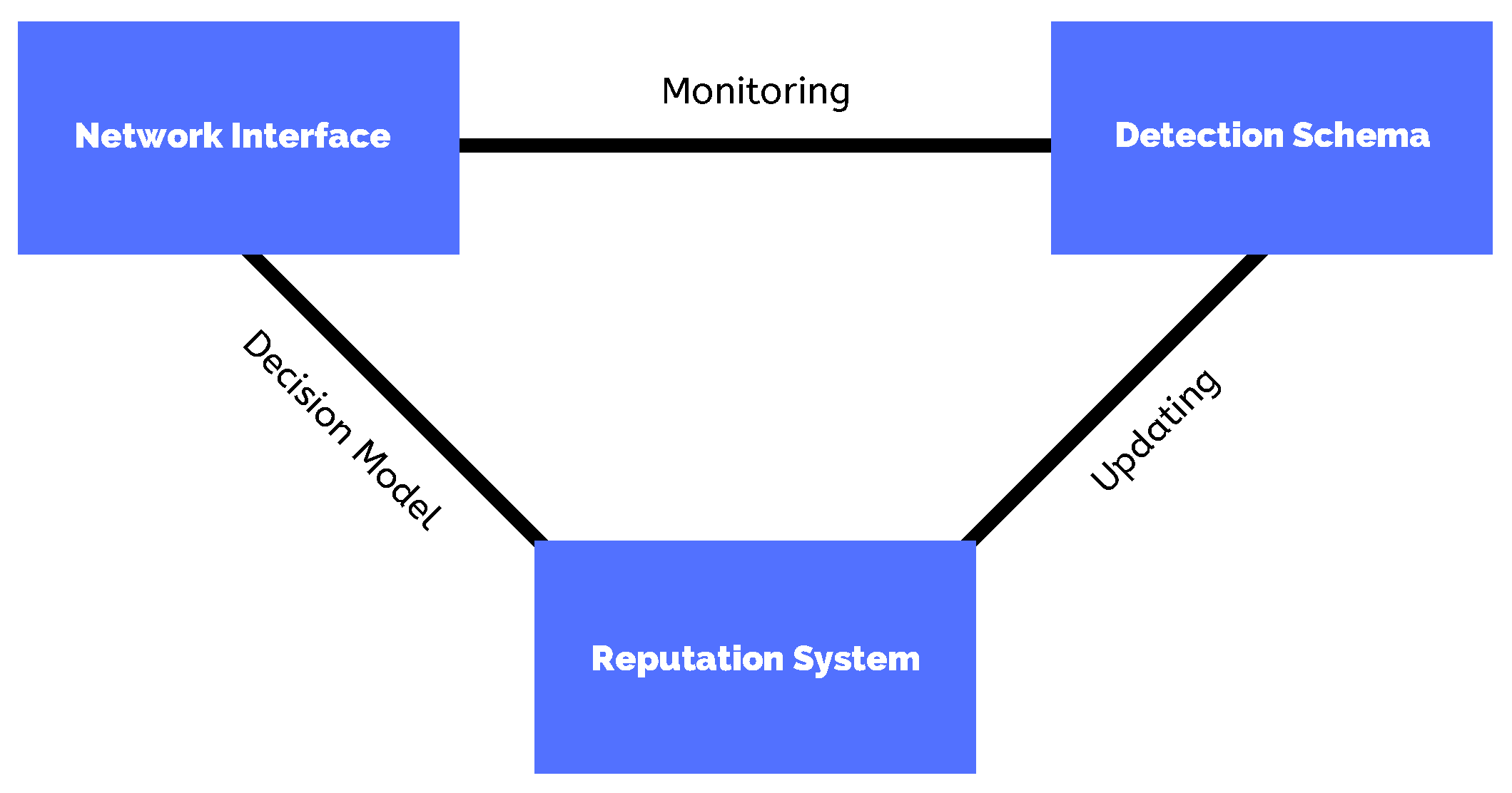
3. Architecture Overview
- The social tie classifier system. The main goal of this system is to update information related to the social ties between each pair of nodes in the network. The social ties can be classified into friends, acquaintances, and unknown. A node stores information about its social ties in two different lists: my social ties, which stores the own node’s social ties, and global social ties which stores the social ties from the other network nodes.With the aim of updating my social ties list, every node has a database containing information about their meetings with other nodes in the network. The database belonging to the node is divided into rows, where the row stores data related to the history of meetings between nodes and . Initially, this database is empty. Upon each contact opportunity, both the nodes in contact update the information related to the meetings between themselves in their own databases. Based on this information, they can classify the social tie with every other node participating in the network (as friends, acquaintances, or unknown). Such classification is performed periodically every T seconds.The global social ties list is updated at every contact opportunity taking place after the first T seconds. In a contact opportunity between the nodes and , they share information about their own social ties (my social ties list) with each other, and then they include this information in the corresponding entry in their global social ties list. More details about these two lists will be provided in Section 4.1.2.
- Selfishness assessment system—The main goal of this system is to update the node’s reputation in terms of selfishness behaviour. In this work, a node can be classified as individually selfish, socially selfish, and non-selfish. Initially, the nodes have the same reputation and no information about the network. The node’s reputation is updated according to their behaviour when they were selected as a relay node in the past. In such a situation, a node can behave in three ways: (i) it always accepts receiving the message, (ii) never accept the message, (iii) it accepts receiving the message only if it is not experiencing resource constraints. Upon each decision, nodes update their own reputation. The selfishness assessment system is divided into two main systems: a detection scheme, which is implemented as a collaborative watchdog system based on [37], and a reputation system, which is based on a logistic function. More details about these components will be provided in Section 4.2.
3.1. Network Model
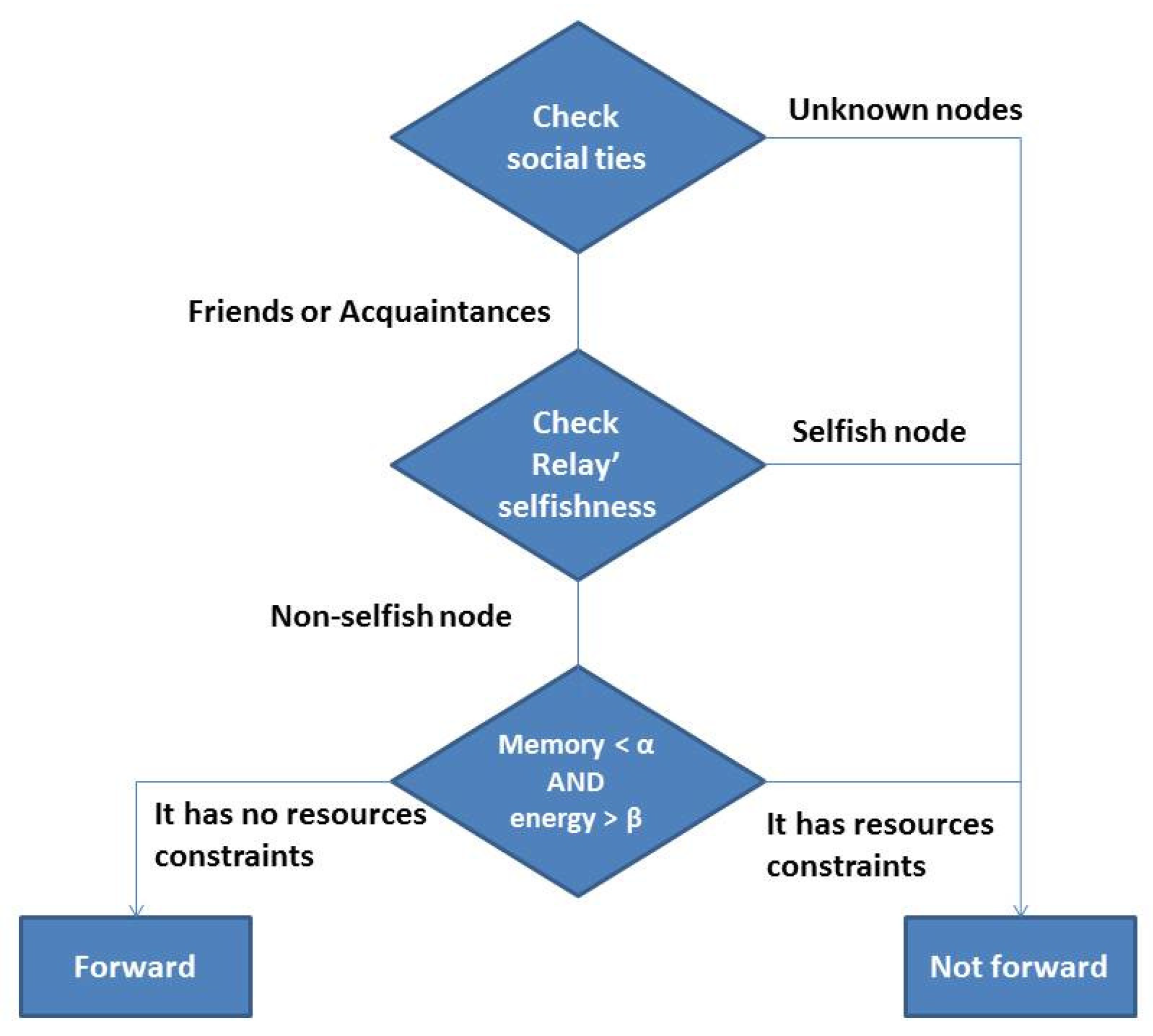
3.2. FSF Forwarding Strategy
4. Detailed Design
4.1. Social Tie Classifier System
- Nodes’ acquaintance mechanism—it is a mechanism responsible for discovering the nodes’ acquaintances group. To achieve this aim, we propose a new metric to depict the node’s acquaintanceship.
- Nodes’ friend mechanism—it is the mechanism responsible for discover the nodes’ friends group. This mechanism takes into account two scenarios: (i) the information about the friendship strength between the nodes is available (self-reported friendship), and (ii) the self-reported information is not available.
- my social ties—This list is divided into rows, one for each other node in the network. The rows have the format , where can be friends (1), acquaintances (0), and unknown (−1). At every contact opportunity, both the nodes in contact update the row corresponding to each other in my social ties list.
- global social ties—This is a matrix containing N rows and N columns with 0’s in the diagonal, where the value stored at the position [i, j] represents the social tie between nodes i and j (1, 0, or −1). Every node uses this structure to store the already known information about the social ties between the other nodes in the network. At each contact opportunity, after updating the information, the nodes involved exchange their my social ties lists. Then, based on this information, they also update their global social ties matrix. Finally, based on this matrix, the nodes are able to build the first part of their own routing table.
4.1.1. Nodes’ Acquaintances Mechanism
- Calculate =
- Calculate =
- Calculate =
- Calculate according to Equation (4) =
4.1.2. Nodes’ Friends Discovering Mechanism
- Number of meetings (NM)—Represents how many times two nodes were within the radio range of each other. Possible values: low, average, and high.
- Average Contact duration (ACD)—Represents the average time that two nodes remain within each other’s coverage area. Possible values: low, average, and high.
- Average Time Between Contacts (ATBC)—Represents the average time between the last contact and the new contact. Possible values: low, average, and high.
- Meetings outside the university (MOU)—Represents the information about the meetings between a pair of nodes outside the university. Possible values: yes (they meet outside the university), no (they do not meet outside the university).
- Common Acquaintances (CA)—Represents information about the common acquaintances between nodes. Possible values: yes (they have common acquaintances), no (they do not have common acquaintances).
- Friendship strength (FS)—Represents the self-reported friendship between a pair of nodes participating in the experiment. From a machine learning perspective, it is the class. Possible values: strong (they are friends), and weak (they are not friends).
4.1.3. Example of Naive Bayes Classification
4.2. Selfishness Assessment System
- individually selfish—according to the selfishness classification made in [7], individual selfishness can be defined as “the unwillingness of a single node to relay the messages of all other nodes to conserve its limited resources”. These nodes do not accept to relay messages.
- socially selfish—it can be defined as a type of selfishness in which a node belongs to a community, and it is willing to relay messages to the nodes within the same community, but it refuses to relay messages to the nodes outside its community [7]. Thus, these nodes will only relay messages for nodes with whom they have some social tie (friends or acquaintances).
- non-selfish—those nodes accepting to relay messages to any other node.
- (i)
- Selfish Contact:Node A, using its monitoring mechanism during a contact, detects that a neighbour node B is selfish.
- (ii)
- Non-Selfish Contact:Both nodes A and B are non-selfish. Thus, they may share with each other information about the selfishness of their neighbours.
- (i)
- Average ReputationAt every contact, the node calculates its average reputation using Equation (9), that is, the arithmetic mean of the reputation of the neighbours at the moment of contact with node B:
- (ii)
- Node UpdateWhen a selfish node is detected, a node updates its reputation by using Equation (10), where assumes 0 when B is detected as selfish, and 1 otherwise. is the weight assigned to each new observation:
5. Experimental Setup
5.1. Extensions to the ONE Simulator
5.2. Nodes’ Mobility
- Cambridge [8]—In the Cambridge trace, the devices were distributed to students from the University of Cambridge, mainly to students attending the Computer Laboratory, specifically Ph.D. and Master students and undergraduates.
- Reality [9]—In Reality, mobile phones were distributed to 97 students from the MIT and used over the course of six months.
- NCCU [10]—By using an Android application installed on smart handheld devices, it represents 115 students’ moving on a typical school day at the National Chengchi University over a period of 15 days.
- Sassy [11]—In this experiment, the authors distributed 27 devices to students at the University of St. Andrews over a period of 79 days.
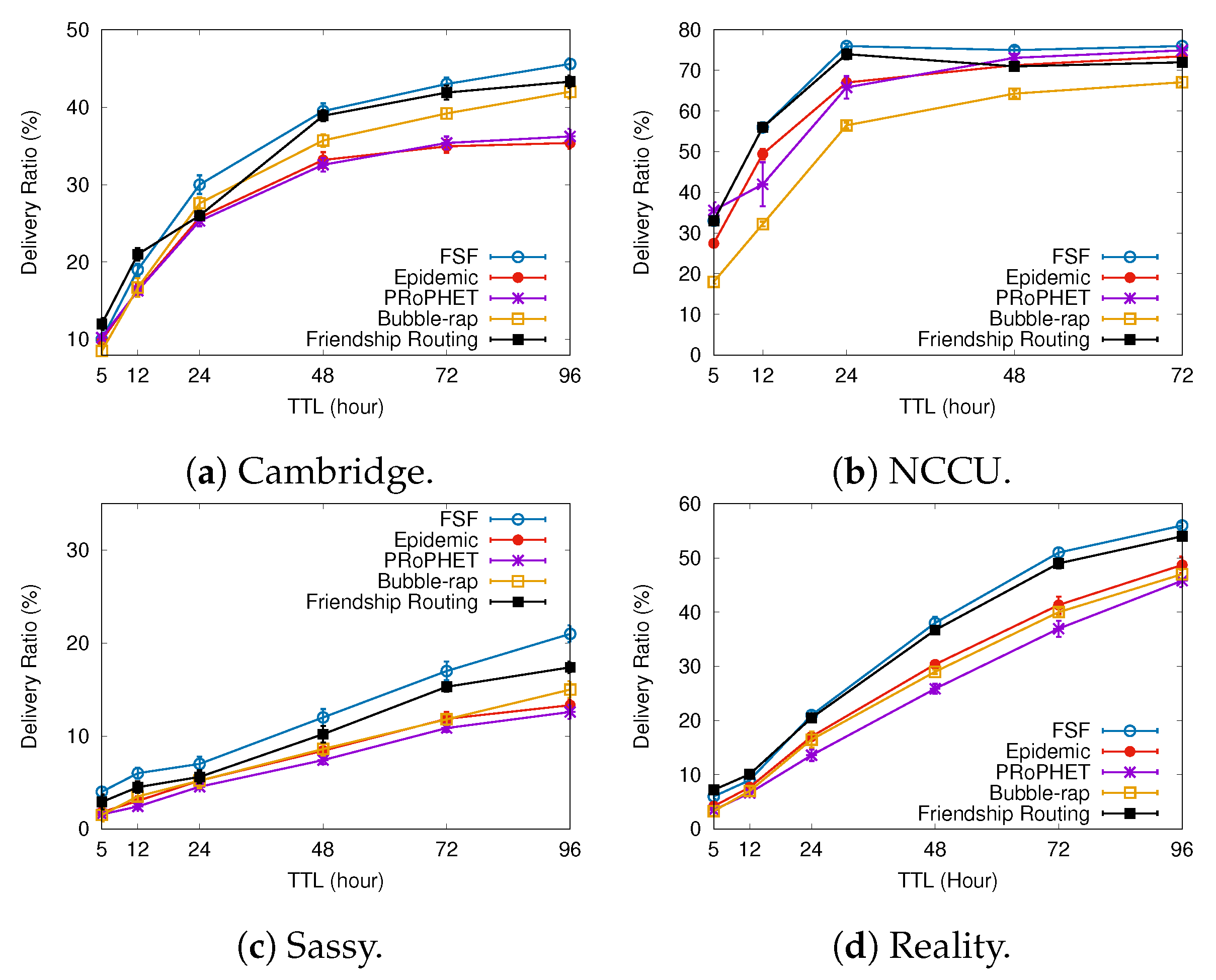
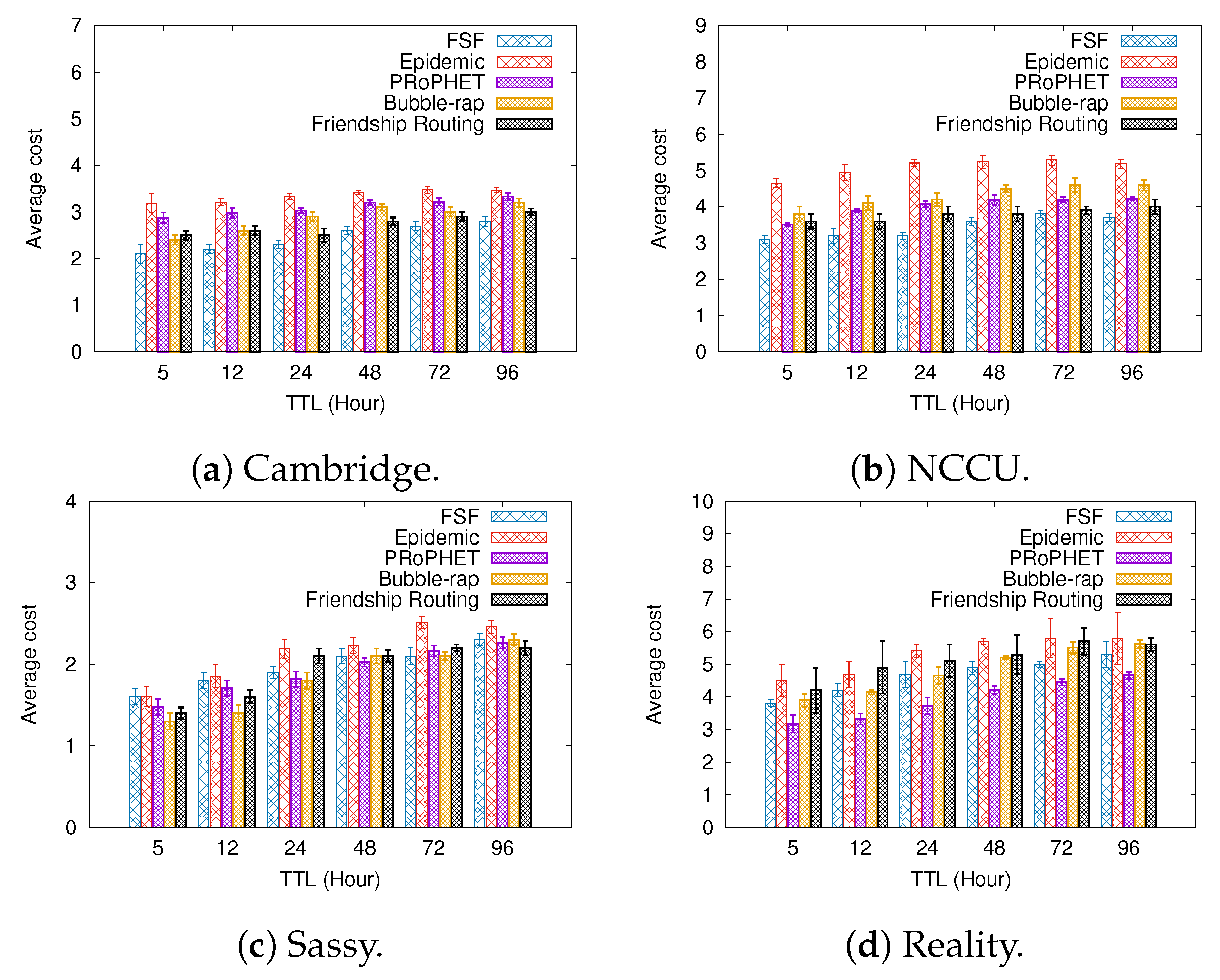
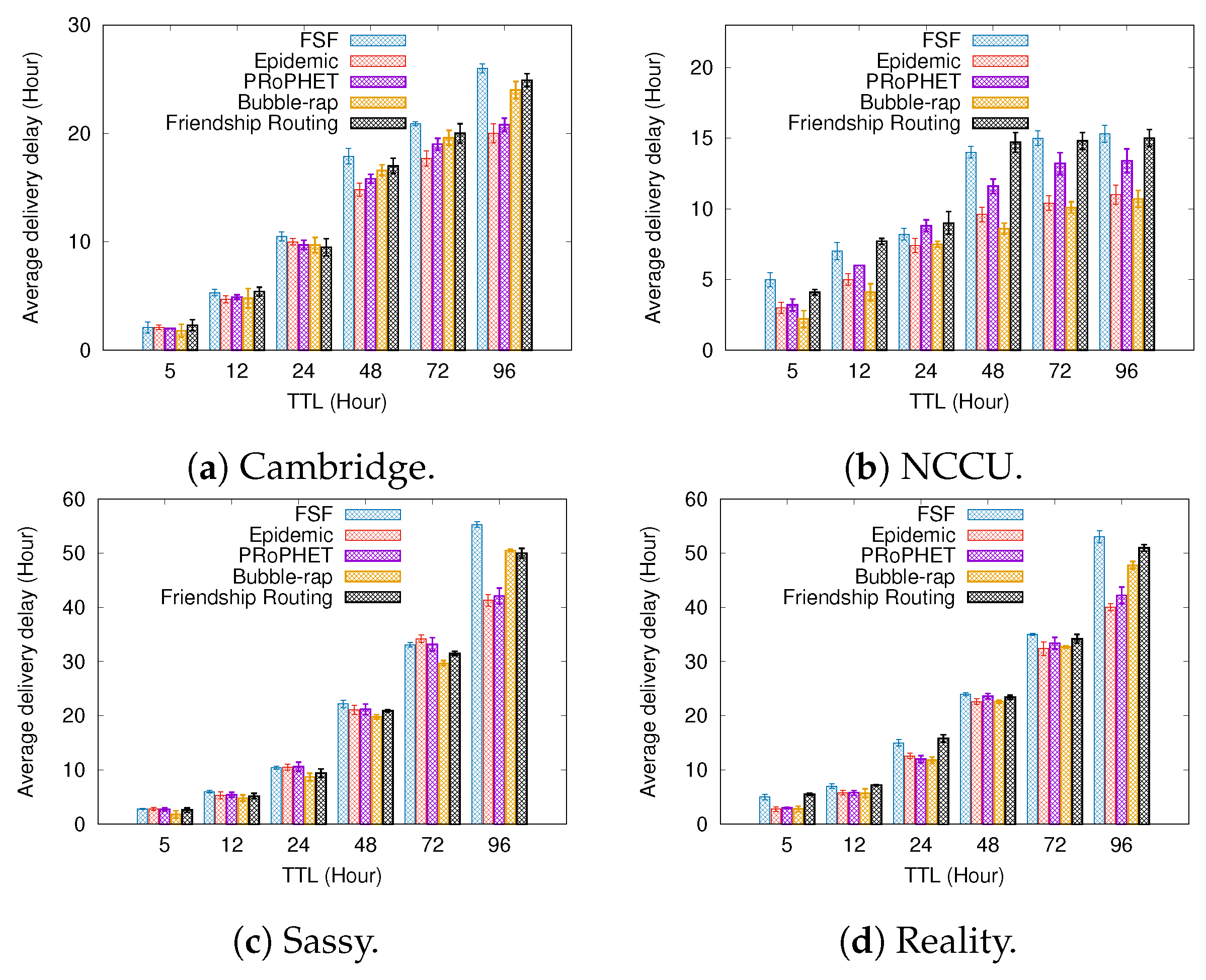
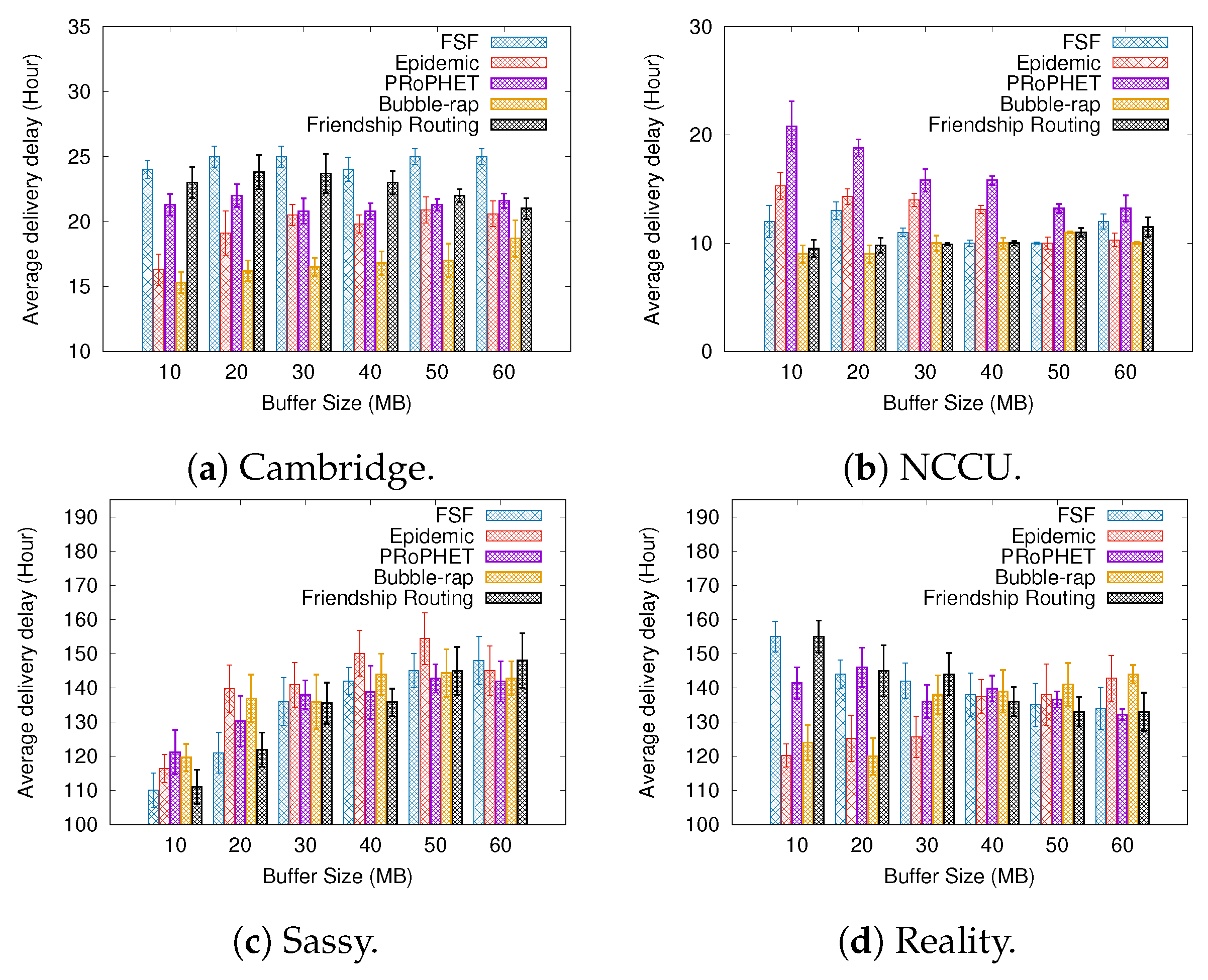
5.3. Routing Algorithms Used for Comparison
- Epidemic [15]—For this algorithm, every contact is an opportunity for the nodes to exchange all the messages stored in their buffers with each other. It is worth mentioning that, despite it achieving good performance, its routing strategy consumes many network resources. However, it is an interesting benchmark for comparison.
- PROPhET [14]—This algorithm is based on determining the probability of meeting with the message destination. A node carrying a message will send it to another node if the delivery predictability of the destination of the message is higher at the other node. For every contact oportunity, this algorithm compares the probability of each node meeting the message destination node in the future. The node carrying a message will forward it to the other node if the latter has a higher meeting probability.
- BUBBLE-RAP [12]—This algorithm takes into account the concepts of nodes’ popularity and centrality in the routing decisions. It selects high centrality nodes and community members related to the message destination node.
- Friendship routing [13]—This is the first algorithm that takes into account the friendship strength between the nodes in the routing decisions. It forwards messages to relay nodes having a greater friendship with the message destination.
5.4. Metrics of Interest
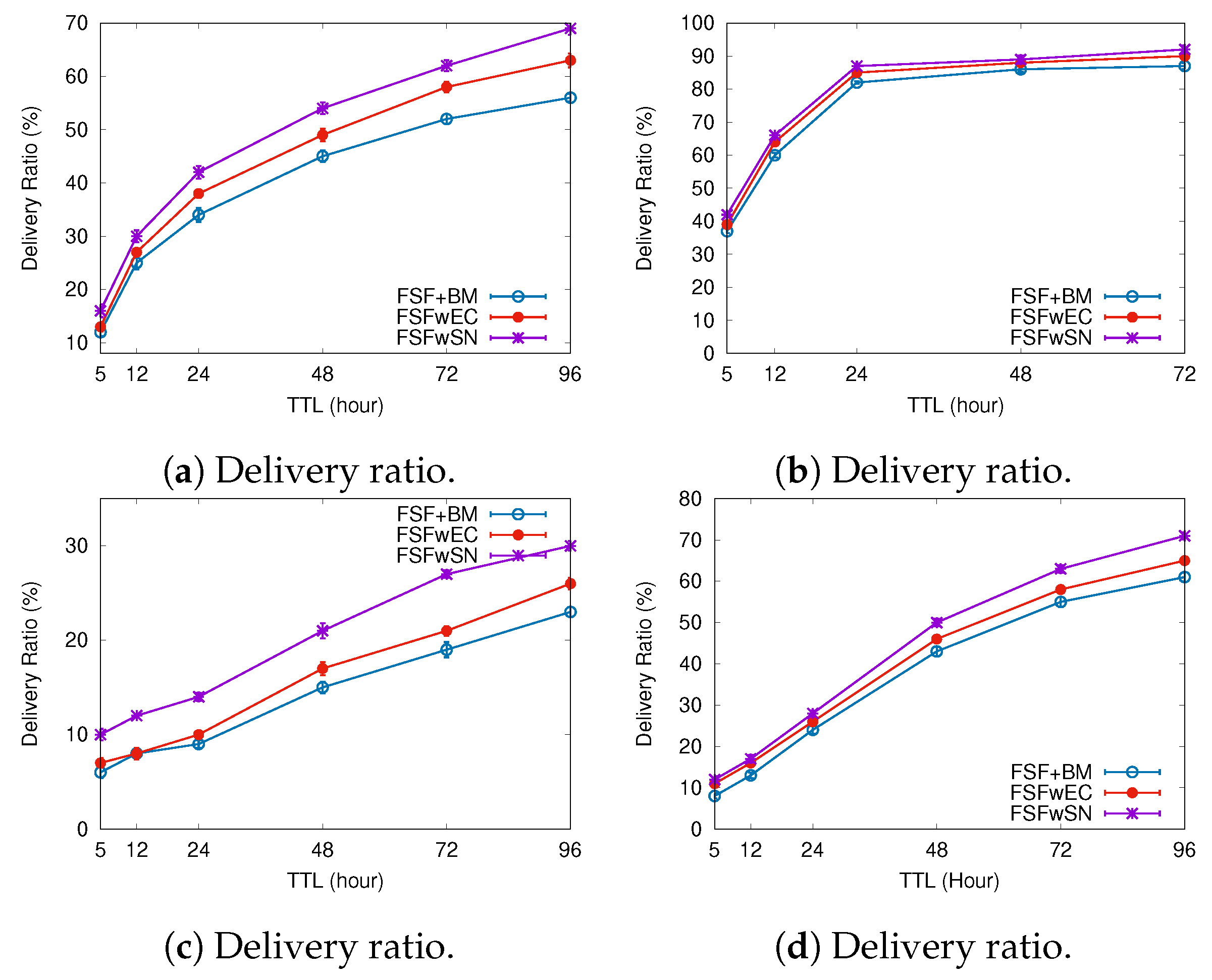
- Delivery ratio—it can be defined as the ratio of messages received by the destination nodes to those generated by the source nodes.
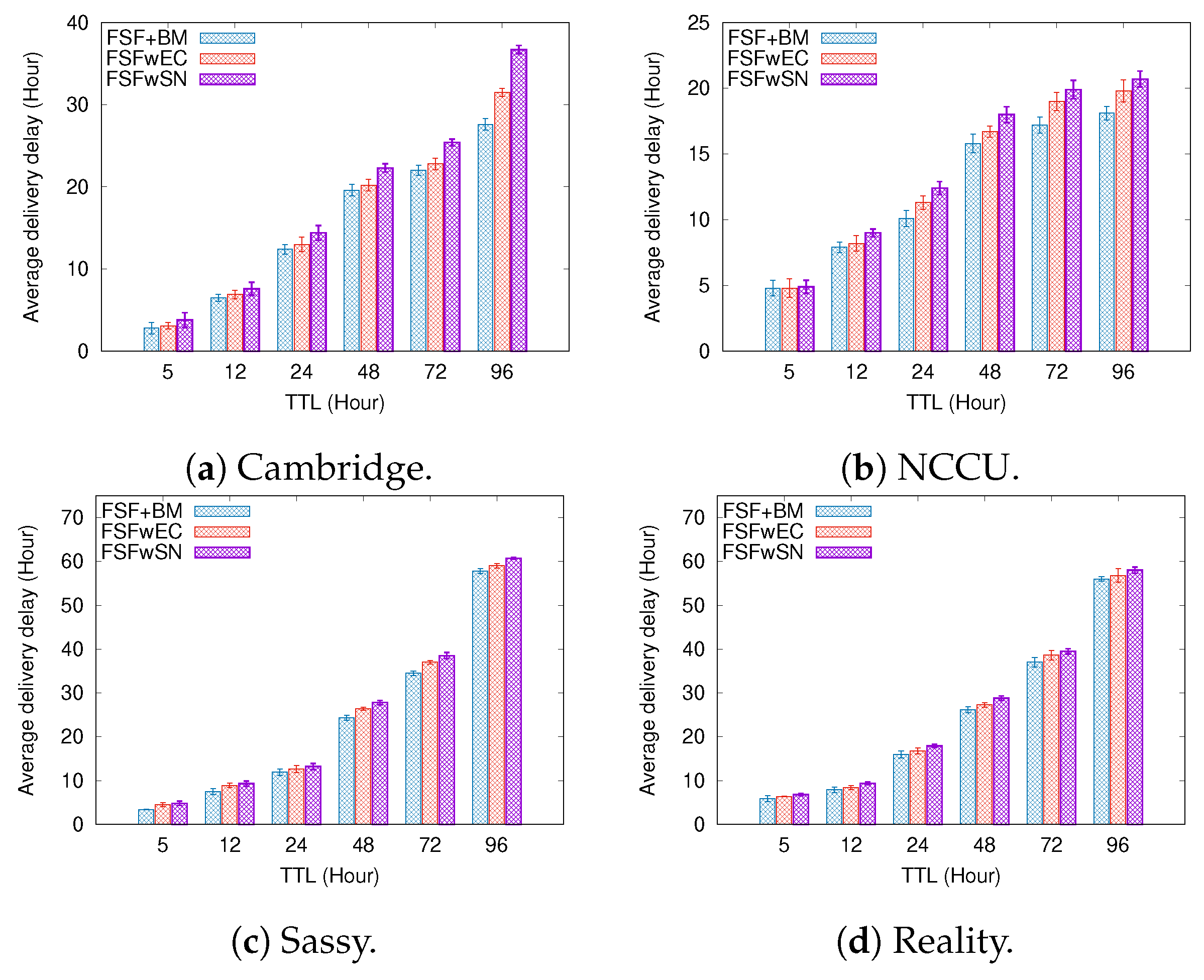
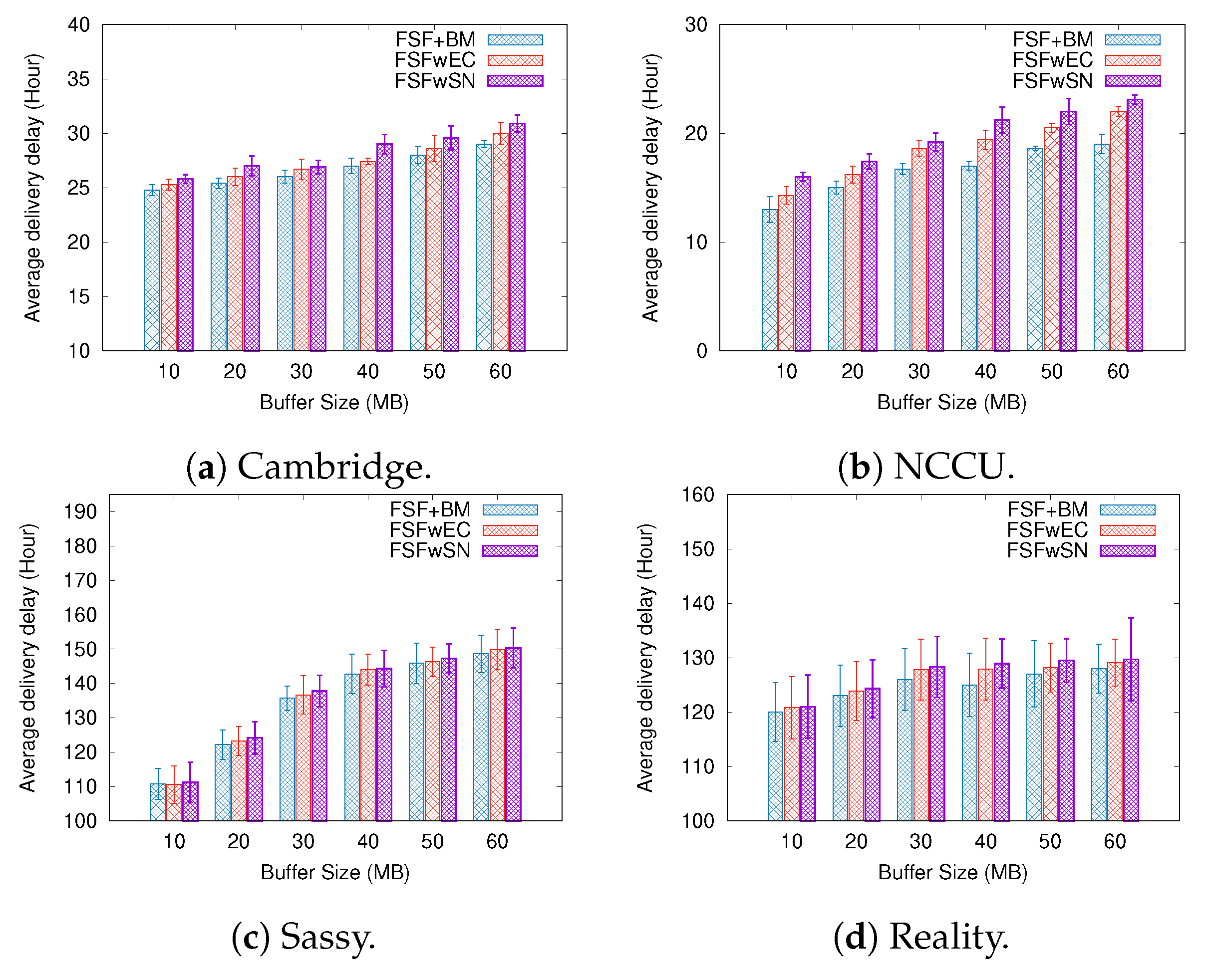
- Average delivery delay—it can be defined as the average time interval between the sending and receiving events for messages travelling along the network.
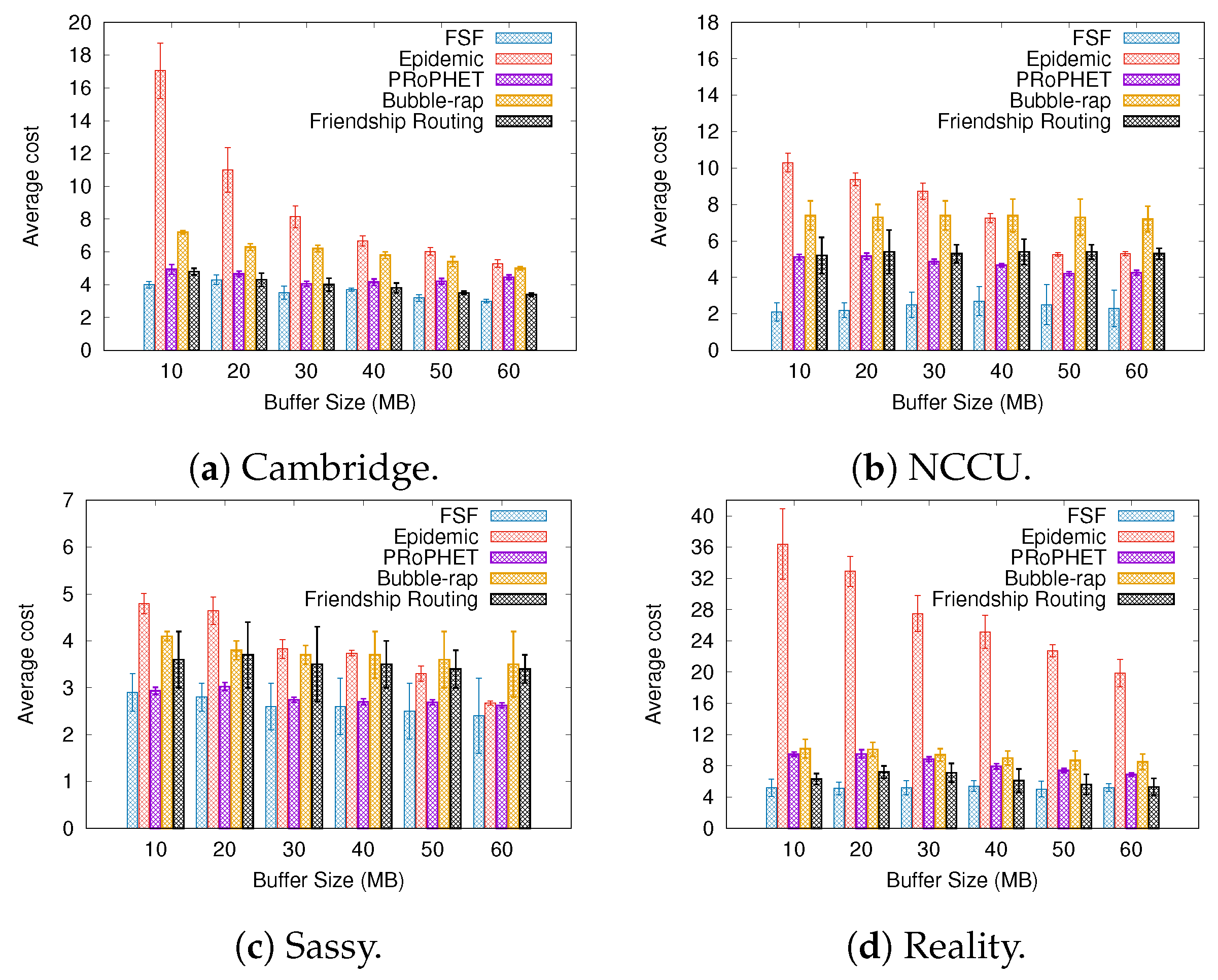
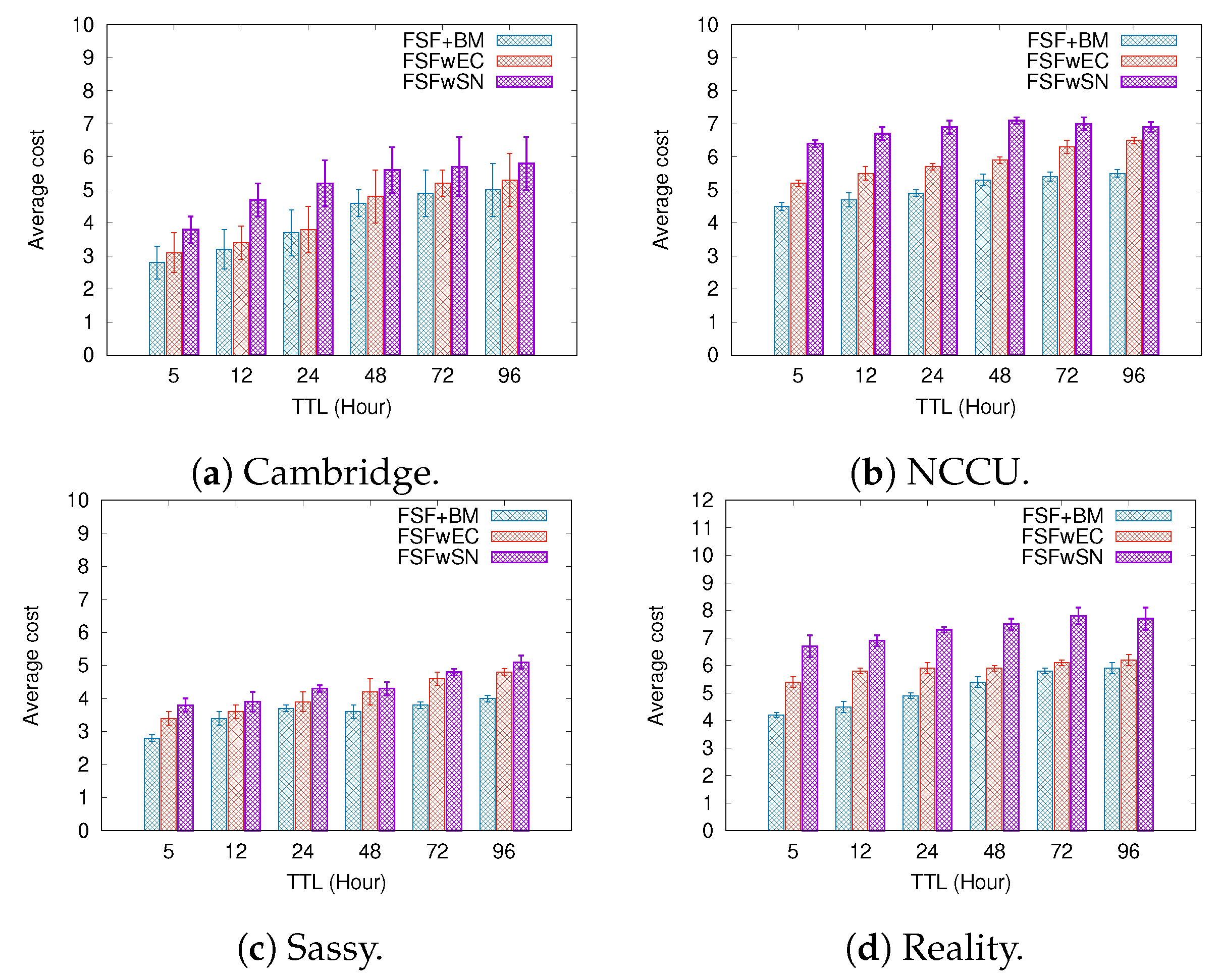
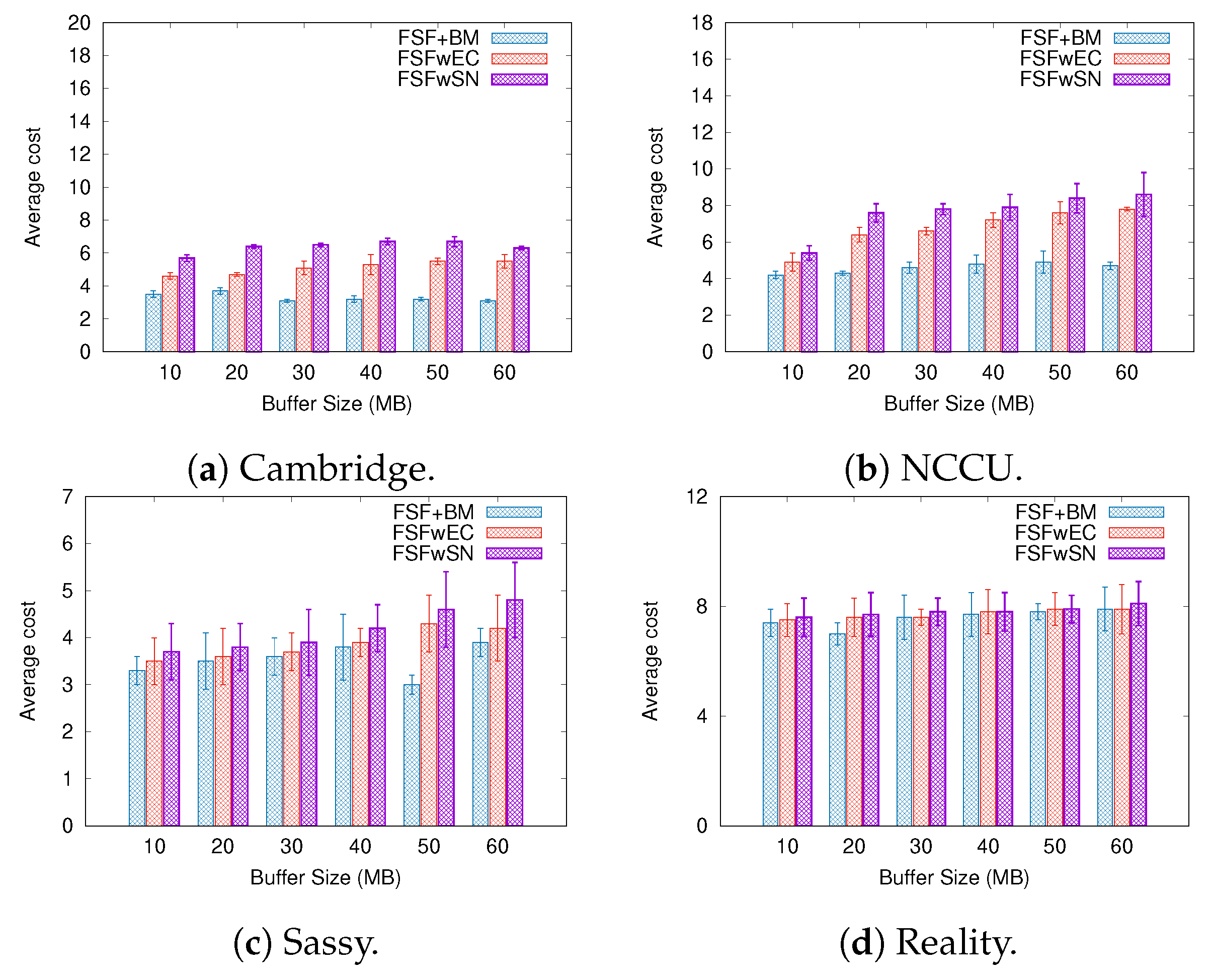
- Average cost—it can be defined as the average number of forwarding events per message delivered to the destination.
5.5. Nodes’ Power Consumption
- Off—no power consumption as the network node interface is turned off.
- Inactive—reduced power consumption as the network node interface is idle.
- Scan—the node consumes power while the network node interface detects neighbours.
- Transmission—the node consumes power while sending a message.
- Reception—the node consumes power because it is receiving a message.
6. Results and Discussion
6.1. Results Depending on the Message TTL
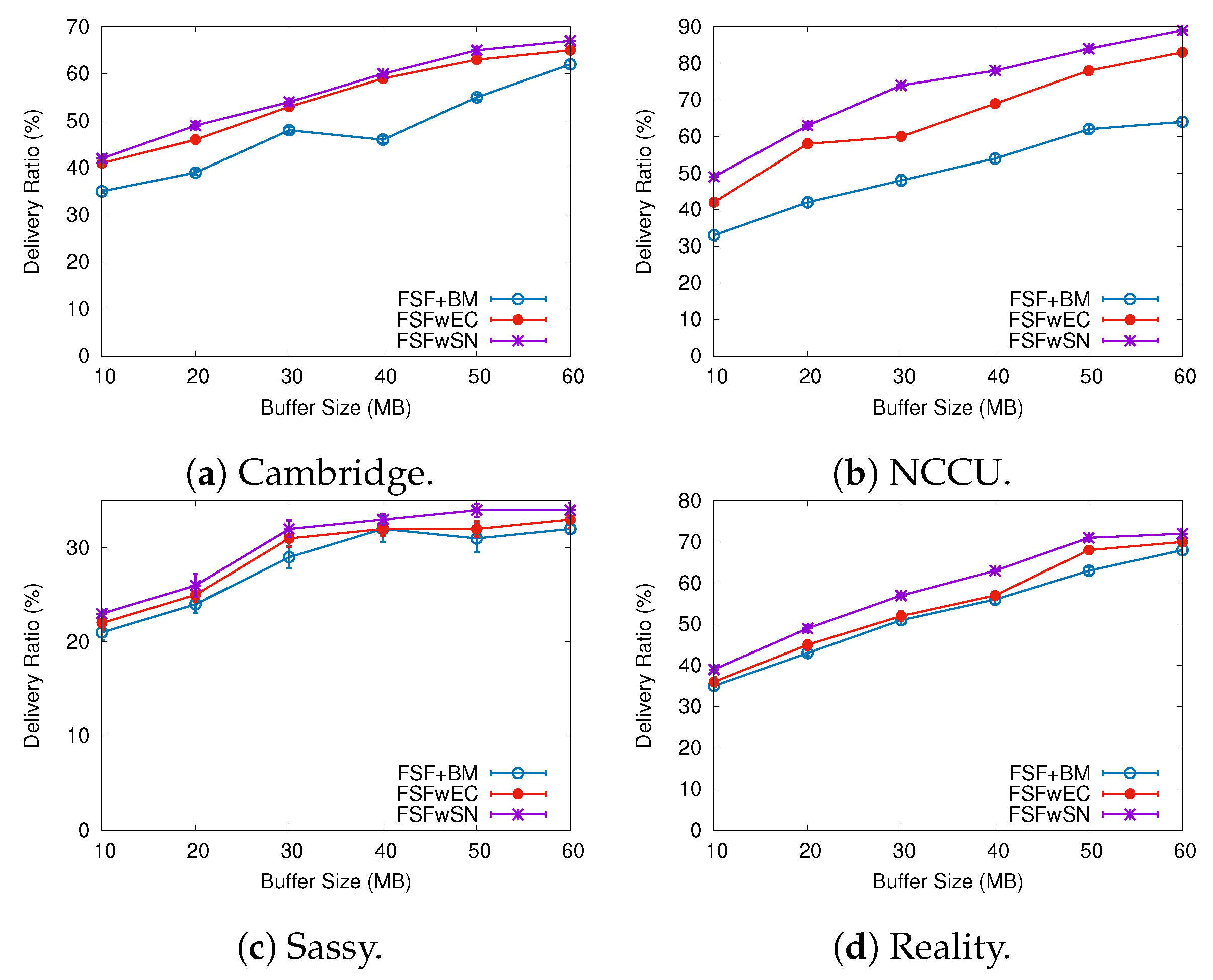
6.2. Results Depending on the Buffer Size
6.3. Understanding the FSF Performance
- FSF with social-based Buffer Management (FSF+BM)—We want to evaluate the impact of using a buffer management algorithm to favour the FSF forwarding. According to [49], the message scheduling and discarding strategy can strongly impact the routing performance in OppNets. When the nodes buffers are limited, nodes can soon operate close to their maximum storage capacity. When node A tries to forward a message, but there is no space in the receiving buffer of node B, B should drop one or more stored messages. The best choice is to preserve the messages with a high probability of being forwarded in future contact opportunities. Moreover, during a contact opportunity, every node must decide which messages it should forward. This is a crucial issue since the contact duration cannot be long enough to the exchange of all messages they would like to. Thus, we selected the social-based algorithm called Friendly-Drop [50] as the buffer management algorithm.
- FSF without Energy Constraint (FSFwEC)—We want to evaluate the impact of power constrained nodes over the FSF performance. In forwarding events, nodes consume more energy, and thus their energy level is not enough to take part in the network. In this scenario, we selected the Drop Oldest as the buffer management algorithm.
- FSF without Selfish Nodes (FSFwSN)—We want to evaluate the impact over the FSF performance when there are no selfish nodes. The nodes may refuse to accept messages if they are under resource constraints. In this scenario, we selected the Drop Oldest as the buffer management algorithm.
6.4. Additional Discussions
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Trifunovic, S.; Kouyoumdjieva, S.T.; Distl, B.; Pajevic, L.; Karlsson, G.; Plattner, B. A Decade of Research in Opportunistic Networks: Challenges, Relevance, and Future Directions. IEEE Commun. Mag. 2017, 55, 168–173. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhao, L.; Liu, Z.; Liu, Q. N-Drop: Congestion control strategy under epidemic routing in DTN. In Proceedings of the 2009 International Conference on Wireless Communications and Mobile Computing: Connecting the World Wirelessly, Leipzig, Germany, 21–24 June 2009; pp. 457–460. [Google Scholar]
- Lu, X.; Lio, P.; Hui, P. Distance-based opportunistic mobile data offloading. Sensors 2016, 16, 878. [Google Scholar] [CrossRef] [PubMed]
- Zeng, F.; Zhao, N.; Li, W. Effective Social Relationship Measurement and Cluster Based Routing in Mobile Opportunistic Networks. Sensors 2017, 17, 1109. [Google Scholar] [CrossRef] [PubMed]
- de Oliveira, C.T.; Moreira, M.D.; Rubinstein, M.G.; Costa, L.H.M.; Duarte, O.C.M. Uma análise da probabilidade de entrega de mensagens em redes tolerantes a atrasos e desconexoes. SBRC Simpósio Brasileiro de Redes de Computadores e Sistemas Distribuídos 2007, 293, 305. [Google Scholar]
- Khabbaz, M.J.; Assi, C.M.; Fawaz, W.F. Disruption-tolerant networking: A comprehensive survey on recent developments and persisting challenges. IEEE Commun. Surv. Tutor. 2012, 14, 607–640. [Google Scholar] [CrossRef]
- Miao, J.; Hasan, O.; Mokhtar, S.B.; Brunie, L.; Yim, K. An investigation on the unwillingness of nodes to participate in mobile delay tolerant network routing. Int. J. Inf. Manag. 2013, 33, 252–262. [Google Scholar] [CrossRef] [Green Version]
- Akestoridis, D.G. CRAWDAD Dataset Uoi/Haggle (v. 2016-08-28): Derived from Cambridge/Haggle (v. 2009-05-29). 2016. Available online: https://crawdad.org/uoi/haggle/20160828 (accessed on 29 May 2009).
- Pentland, A.; Eagle, N.; Lazer, D. Inferring social network structure using mobile phone data. Proc. Natl. Acad. Sci. USA 2009, 106, 15274–15278. [Google Scholar]
- Tsai, T.C.; Chan, H.H. NCCU Trace: Social-network-aware mobility trace. IEEE Commun. Mag. 2015, 53, 144–149. [Google Scholar] [CrossRef]
- Bigwood, G.; Abdesslem, F.B.; Henderson, T. Predicting location-sharing privacy preferences in social network applications. Proc. Aware Cast 2012, 12, 1–12. [Google Scholar]
- Hui, P.; Crowcroft, J.; Yoneki, E. Bubble rap: Social-based forwarding in delay-tolerant networks. IEEE Trans. Mob. Comput. 2011, 10, 1576–1589. [Google Scholar] [CrossRef]
- Bulut, E.; Szymanski, B.K. Friendship based routing in delay tolerant mobile social networks. In Proceedings of the 2010 IEEE Global Telecommunications Conference (GLOBECOM 2010), Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Lindgren, A.; Doria, A.; Schelén, O. Probabilistic routing in intermittently connected networks. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2003, 7, 19–20. [Google Scholar] [CrossRef]
- Cao, Y.; Sun, Z. Routing in delay/disruption tolerant networks: A taxonomy, survey and challenges. IEEE Commun. Surv. Tutor. 2013, 15, 654–677. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, B.; Shi, X.; Wang, Y. A survey of social-based routing in delay tolerant networks: Positive and negative social effects. IEEE Commun. Surv. Tutor. 2013, 15, 387–401. [Google Scholar] [CrossRef]
- Shah, R.C.; Roy, S.; Jain, S.; Brunette, W. Data mules: Modeling and analysis of a three-tier architecture for sparse sensor networks. Ad Hoc Netw. 2003, 1, 215–233. [Google Scholar] [CrossRef]
- Zhao, W.; Ammar, M.; Zegura, E. A message ferrying approach for data delivery in sparse mobile ad hoc networks. In Proceedings of the 5th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Tokyo, Japan, 24–26 May 2004; pp. 187–198. [Google Scholar]
- Zhao, W.; Ammar, M.; Zegura, E. Controlling the mobility of multiple data transport ferries in a delay-tolerant network. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 1407–1418. [Google Scholar]
- Zhao, W.; Ammar, M.H. Message ferrying: Proactive routing in highly-partitioned wireless ad hoc networks. In Proceedings of the Ninth IEEE Workshop on Future Trends of Distributed Computing Systems (FTDCS 2003), San Juan, PR, USA, 30 May 2003; pp. 308–314. [Google Scholar]
- Burns, B.; Brock, O.; Levine, B.N. MORA routing and capacity building in disruption-tolerant networks. Ad Hoc Netw. 2008, 6, 600–620. [Google Scholar] [CrossRef]
- Vahdat, A.; Becker, D. Epidemic Routing for Partially Connected Ad Hoc Networks; Technical Report, Technical Report CS-200006; Duke University: Durham, NC, USA, 2000. [Google Scholar]
- Shaghaghian, S.; Coates, M. Optimal Forwarding in Opportunistic Delay Tolerant Networks with Meeting Rate Estimations. IEEE Trans. Signal Inf. Process. Netw. 2015, 1, 104–116. [Google Scholar] [CrossRef]
- Li, L.; Qin, Y.; Zhong, X. A Novel Routing Scheme for Resource-Constraint Opportunistic Networks: A Cooperative Multiplayer Bargaining Game Approach. IEEE Trans. Veh. Technol. 2016, 65, 6547–6561. [Google Scholar] [CrossRef]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and wait: An efficient routing scheme for intermittently connected mobile networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, Philadelphia, PA, USA, 26 August 2005; pp. 252–259. [Google Scholar]
- Juang, P.; Oki, H.; Wang, Y.; Martonosi, M.; Peh, L.S.; Rubenstein, D. Energy-efficient computing for wildlife tracking: Design tradeoffs and early experiences with ZebraNet. ACM Sigplan Not. 2002, 37, 96–107. [Google Scholar] [CrossRef]
- Burgess, J.; Gallagher, B.; Jensen, D.; Levine, B.N. Maxprop: Routing for vehicle-based disruption-tolerant networks. In Proceedings of the 25TH IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006; Volume 6, pp. 1–11. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Efficient routing in intermittently connected mobile networks: The single-copy case. IEEE/ACM Trans. Netw. ToN 2008, 16, 63–76. [Google Scholar] [CrossRef]
- Liu, C.; Wu, J. An optimal probabilistic forwarding protocolin delay tolerant networks. In Proceedings of the Tenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, New Orleans, LA, USA, 18–21 May 2009; pp. 105–114. [Google Scholar]
- Nguyen, H.A.; Giordano, S.; Puiatti, A. Probabilistic routing protocol for intermittently connected mobile ad hoc network (propicman). In Proceedings of the 2007 IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, Espoo, Finland, 18–21 June 2007; pp. 1–6. [Google Scholar]
- Oliveira, E.C.; de Albuquerque, C.V. NECTAR: A DTN routing protocol based on neighborhood contact history. In Proceedings of the 2009 ACM symposium on Applied Computing, Honolulu, HI, USA, 8–12 March 2009; pp. 40–46. [Google Scholar]
- Zhang, L.; Wang, X.; Lu, J.; Ren, M.; Duan, Z.; Cai, Z. A novel contact prediction-based routing scheme for DTNs. Trans. Emerg. Telecommun. Technol. 2014. [Google Scholar] [CrossRef]
- Okasha, S. Altruism, group selection and correlated interaction. Br. J. Philos. Sci. 2005, 56, 703–725. [Google Scholar] [CrossRef]
- Qin, Y.; Li, L.; Zhang, X.; Zhong, X. NFCU: A New Friendship-based Routing with Buffer Management in Opportunistic Networks. arXiv 2015, arXiv:1501.07754. [Google Scholar]
- Souza, C.; Mota, E.; Galvao, L.; Manzoni, P.; Cano, J.C.; Calafate, C.T. Fsf: Friendship and selfishness forwarding for delay tolerant networks. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 1200–1207. [Google Scholar]
- Li, Q.; Zhu, S.; Cao, G. Routing in socially selfish delay tolerant networks. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Hernandez-Orallo, E.; Olmos, M.D.S.; Cano, J.C.; Calafate, C.T.; Manzoni, P. CoCoWa: A collaborative contact-based watchdog for detecting selfish nodes. IEEE Trans. Mob. Comput. 2015, 14, 1162–1175. [Google Scholar] [CrossRef]
- Li, F.; Wu, J. LocalCom: A community-based epidemic forwarding scheme in disruption-tolerant networks. In Proceedings of the SECON’09. 6th Annual IEEE Communications Society Conference onSensor, Mesh and Ad Hoc Communications and Networks, Rome, Italy, 22–26 June 2009; pp. 1–9. [Google Scholar]
- Park, M.; Min, S.; Thus, S.; Oh, D.; Kim, B.; Lee, J. Mobility pattern based routing algorithm for delay/disruption tolerant networks. In Smart Spaces and Next Generation Wired/Wireless Networking; Springer: Berlin/Heidelberg, Germany, 2010; pp. 275–286. [Google Scholar]
- Hui, P.; Chaintreau, A.; Scott, J.; Gass, R.; Crowcroft, J.; Diot, C. Pocket switched networks and human mobility in conference environments. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, Philadelphia, PA, USA, 26 August 2005; pp. 244–251. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence; IBM: New York, NY, USA, 2001; Volume 3, pp. 41–46. [Google Scholar]
- Souza, C.; Mota, E.; Manzoni, P.; Cano, J.C.; Calafate, C.T. Improving delivery delay in social-based message forwarding in Delay Tolerant Networks. In Proceedings of the 2016 workshop on Fostering Latin-American Research in Data Communication Networks, Florianopolis, Brazil, 22–26 August 2016; pp. 52–54. [Google Scholar]
- Marti, S.; Giuli, T.J.; Lai, K.; Baker, M. Mitigating routing misbehavior in mobile ad hoc networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 255–265. [Google Scholar]
- Li, W.; Joshi, A. Outlier detection in ad hoc networks using dempster-shafer theory. In Proceedings of the Tenth International Conference on Mobile Data Management: Systems, Services and Middleware, MDM’09, Taipei, Taiwan, 18–20 May 2009; pp. 112–121. [Google Scholar]
- Soares, D.; Mota, E.; Souza, C.; Manzoni, P.; Cano, J.C.; Calafate, C. A statistical learning reputation system for opportunistic networks. In Proceedings of the 2014 IFIP Wireless Days (WD), Rio de Janeiro, Brazil, 12–14 November 2014; pp. 1–6. [Google Scholar]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The ONE Simulator for DTN Protocol Evaluation. In Proceedings of the 2nd International Conference on Simulation Tools and Techniques, SIMUTools ’09, Rome, Italy, 2–6 March 2009; ICST: New York, NY, USA, 2009. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Silva, D.R.; Costa, A.; Macedo, J. Energy impact analysis on DTN routing protocols. In Proceedings of the ExtremeCom 2012, Zurich, Switzerland, 10–14 March 2012; pp. 1–6. [Google Scholar]
- Tang, L.; Chai, Y.; Li, Y.; Weng, B. Buffer Management Policies in Opportunistic Networks. J. Comput. Inf. Syst. 2012, 8, 5149–5159. [Google Scholar]
- Souza, C.; Mota, E.; Manzoni, P.; Cano, J.C.; Calafate, C.T.; Hernandez-Orallo, E.; Tapia, J.H. Friendly-drop: A social-based buffer management algorithm for opportunistic networks. In Proceedings of the Wireless Days (WD), Dubai, UAE, 3–5 April 2018; pp. 172–177. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trace | Cambridge | Reality | NCCU | Sassy |
|---|---|---|---|---|
| Device | iMotes | Phone | Smart Handheld | T-mote |
| Network Interface | Bluetooth | Bluetooth | Wi-fi/Bluetooth | Sensor |
| Nodes | 54 | 97 | 115 | 27 |
| Trace Duration (days) | 11 | 246 | 15 | 79 |
| Number of contacts (aprox.) | 10.873 | 54.667 | 81.115 | 35.274 |
| T value (days) | 3 | 7 | 3 | 7 |
| NM | ACD | ATBC | MOU | CA | FS |
|---|---|---|---|---|---|
| low | high | average | yes | no | weak |
| low | high | high | no | yes | weak |
| average | average | average | no | yes | weak |
| high | average | low | yes | yes | weak |
| high | low | low | no | no | strong |
| high | low | average | no | yes | strong |
| average | high | low | yes | no | weak |
| low | average | low | yes | no | weak |
| high | average | average | no | yes | strong |
| average | low | high | no | no | weak |
| average | high | high | no | yes | strong |
| high | high | high | yes | yes | weak |
| low | high | average | yes | no | strong |
| average | average | low | no | no | weak |
| low | low | low | no | yes | weak |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souza, C.; Mota, E.; Soares, D.; Manzoni, P.; Cano, J.-C.; Calafate, C.T.; Hernández-Orallo, E. FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks. Sensors 2019, 19, 2374. https://doi.org/10.3390/s19102374
Souza C, Mota E, Soares D, Manzoni P, Cano J-C, Calafate CT, Hernández-Orallo E. FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks. Sensors. 2019; 19(10):2374. https://doi.org/10.3390/s19102374
Chicago/Turabian StyleSouza, Camilo, Edjair Mota, Diogo Soares, Pietro Manzoni, Juan-Carlos Cano, Carlos T. Calafate, and Enrique Hernández-Orallo. 2019. "FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks" Sensors 19, no. 10: 2374. https://doi.org/10.3390/s19102374
APA StyleSouza, C., Mota, E., Soares, D., Manzoni, P., Cano, J.-C., Calafate, C. T., & Hernández-Orallo, E. (2019). FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks. Sensors, 19(10), 2374. https://doi.org/10.3390/s19102374