1. Introduction
Recent innovations in electronics and wearable technologies facilitate interactive communication between human beings and machines, including computers. This human–machine interface (HMI) system will become more important for the Internet of Things (IoT) and ubiquitous computing [
1]. Typically, communication starts when an object (i.e., a machine) receives and interprets a human’s (i.e., the user’s) intention. Thus, for the HMI, an input device that can capture the user’s intention is crucial.
Human gestures enable an ergonomic approach to input for the HMI. Human body language is an important communication tool that is intuitively used to convey, exchange, interpret, and understand people’s thoughts, intentions, or even emotions. Thus, body language not only supports or conveys emphasis in spoken language but also is a complete language in itself; it is natural to consider human gestures, such as hand gestures, for HMI input [
2]. However, so that they can be widely accepted as a HMI input, recognition of human gestures still has several hurdles to overcome.
One critical challenge is that human hand gestures are significantly less diverse than the functions needed by the HMI. HMI functions are more diversified and complicated. This trend of diversification is observable in the smartphone example. Only a decade ago, several handheld electronic devices co-existed to cover diverse human needs, including cell phones, personal digital assistants (PDAs), mp3 players or CD players, digital cameras or digital camcorders, gaming devices, and calculators, whereas, now, almost all the functions of these devices converge into a single mobile device: A smartphone. In contrast, in a smartphone, all human intentions are expressed only by swiping or tapping fingers on the touch screen.
Hand gesture-based interaction is one common approach being considered as HMI inputs [
3]. Hand gestures are recognized by two major methods: Vision image processing [
4] or wearable electronics [
5]. Vision sensors are popularly used, especially in specific applications, such as smart televisions [
6] or multimedia applications [
7]. Though, in the last decade, dramatic advances have been made in semiconductor sensors (e.g., micro electro mechanical systems sensors). These advances provide precise, small-sized, light-weighted, and low-priced sensor solutions that are “wearable” by human beings.
Wearable sensors include electromyography (EMG), touch sensors, strain gauges, flex sensors, inertial sensors, and ultrasonic sensors [
8]. Among wearable sensors, wearable inertial sensors may be the most widely employed for human-motion recognition [
9,
10]. In general, inertial sensors refer to sensor systems consisting of accelerometers and gyroscopes, and magnetometers.
It is common to co-use multiple wearable sensors by sensor-fusion algorithms. For example, a glove with multiple wearable sensors is reported to monitor hand gestures [
11]. A 3D printer is used to manufacture the glove housing, which contains flex sensors (on fingers), pressure sensors (at fingertips), and an inertial sensor (on the back of one’s hand).
In many sensor-fusion algorithms, inertial sensors are typically used to track hand motions, while other sensors (e.g., EMG sensors) detect additional hand information, such as finger snapping, hand gripping, or fingerspelling [
12,
13]. One prominent combination may be inertial and EMG sensors [
12,
13,
14,
15,
16,
17]. The hand position is determined by the inertial sensor and the EMG sensors provide supportive information to fully understand complicated finger or hand gestures. It is also possible to adopt strain gauges, tilt sensors, or even vision sensors, instead of the EMG sensors.
These recognition methods of complex gestures consequently increase the amount of sensor data. To handle the increased data, machine learning is drawing attention. Various machine learning techniques are introduced for wearable sensors. Data from a wristband device having EMG sensors are processed by either a linear discriminant analysis (LDA) classifier [
13] or a support vector machine classifier [
18]. In another study, signals generated from a MEMS accelerometer are digitized, coded, and analyzed using a feedforward neural network (FNN) [
19].
Meanwhile, there have been approaches using only wearable inertial sensors. This inertial-sensor-only approach potentially increases portability and mobility with a reduced computation load, compared to the cases using multiple wearable sensors or heavy algorithms. A research team asked users to write words using a smartphone as a pen [
20] and reconstruct the handwritings using a gyroscope and accelerometer embedded in the phone. The handwriting included English and Chinese characters and emoticons. Other studies utilized kinematics based on inertial sensor signals to monitor hands or arms [
21,
22,
23]. Recognizing the motions of a head or feet are also reported [
24,
25] but they are not adapted in hand gesture recognition.
As input devices for a HMI, it cannot be doubted that wearable inertial sensors should be accurate and rapid. However, these dual goals are contradictory, because improved accuracy frequently increases the computation load, resulting in slow speed. In addition, user hand gestures should be simple and straightforward. Moreover, inertial-sensor-based gesture-recognition systems additionally have fundamental limitations. One limitation is the inertial sensor noise, which continues to be accumulated, resulting in bias or drift in the system output [
26]. The second limitation is that signals from MEMS gyroscopes may be confused with accelerometer signals [
27].
To resolve these problems, the signal processing of inertial sensor outputs has actively been investigated, from simple outputs (such as moving average filters) to the recently developed outputs (such as machine learning). Recent approaches include digitizing the sensor signals to generate codes and calculating statistical measures of the signals to represent their patterns. One system distinguished seven hand gestures using a three-axis MEMS accelerometer [
28]. Accelerometer signals are digitized by labelling positive and negative signals and are restored by a Hopfield network.
These accelerometer-only approaches effectively capture linear gestures (e.g., up/down or left/right patterns), but are not easily applicable for detecting circular motions (e.g., clockwise rotation or hand waving). To recognize both linear and rotational gestures, methods that rely on both accelerometers and gyroscopes were proposed. A research applied the Markov chain algorithm to monitor the movement of the arms using accelerometer and gyroscope sensors worn on the forearms [
29]. In another recent work paper, a real-time gesture recognition technique, named Continuous Hand Gestures (CHG), was reported [
30]. The technique first defines six basic gestures, then finds their statistical measures, including means and standard deviations (STDs), and finally produces a database for the measures of each gesture.
These accelerometer-gyroscope combinations exhibit an excellent accuracy, but still require solutions providing multiple functions with a limited number of hand gestures. To address these challenges, the objective of this study was to develop a unified multi-modal HMI input device conveying the user’s intention rapidly and precisely. A comparison with published works with other using sensors is summarized in
Table 1.
Table 1 summarizes recent activities reporting the use of various wearable sensors as the HMI input, using the accelerometer, gyroscope, accelerometer-gyroscope fusion, ultrasonic, and fusion accelerometer-gyroscope with electromyography approaches. The accelerometer-only approach cannot detect rotational motions, and some computation loads should be allowed for the sensor fusion (depending on logics) or machine learning algorithms (during training). Thus, this paper selects a gyroscope-only system, expecting better rotation-sensing capability (than the accelerometer-only systems), reduced sensor cost and computation load (than the sensor fusion), and decreased computational load during model training (than the machine learning). Of course, these comparisons are only qualitative explanations and should acknowledge that the performance of each method can be improved by algorithm/system optimization. Trajectory tracking is also considered because it is the functionality equipped in laser pointers or computer mice. In addition, most recognition methods hold the gesture-signal data for a certain time, which is defined as the steady gesture state [
23] in the table, to improve detection accuracy. However, for real-time HMI inputs, a continuous recognition is preferred. As all references in
Table 1 report excellent recognition rates exceeding 90%, it is reasonable to target a recognition rate larger than 90%. Though, this work tries to enable multifunctional capabilities with less numbers of hand gestures, which are not seriously considered in all the references. This uniqueness is crucial for multi-modal HMI input devices, we think, and is expressed by the number of demonstrated applications in the table.
2. Design of the Wearable System
Our proposed system is configured to implement several important key features. First, our system relies on selected simple hand gestures (denoted as “unit gestures”), whose functions are redefined for different application programs. A machine (utilizing our wearable system) already acknowledges the currently running application. Therefore, the function executed by each gesture can differ by application, facilitating multifunction capabilities with less gesture complexity to realize a unified multi-modal input device for HMI.
The second feature is that the sensor used is simplified to use only one three-axis gyroscope which is, however, providing both gesture recognition and trajectory tracking functions. In addition, this approach miniaturizes the wearable devices and reduces required cost, compared to the accelerometer-gyroscope combination.
The third feature is continuous hand-gesture recognition in real time. To minimize the delay caused by computation load, we reduced the computational complexity by employing a simple algorithm that calculates the normalized covariance between the pattern signal of the user’s hand gesture and the reference signal pattern. Signal waveforms (generated during experiments) and their characteristics were stored in an in-built database with an appropriate window size.
The last feature is the system accuracy. Despite the fact that the complexity is reduced and multiple input devices converge into a single miniature device, sufficient accuracy should be guaranteed. To avoid errors caused by a hand tremor or unintentional hand gestures, we co-considered pattern similarity and signal magnitudes, and, through experiments, deduced the recognition threshold values that correctly identify the hand. In addition, a learning mode was included for user customization.
Our multi-modal input device is anticipated to be employed in various consumer electronics. Possible major applications include input devices to (1) computers, such as personal computers, laptops, or tablet PCs, (2) portable multimedia players like mp3 players or smartphones, (3) wireless remote controllers for presentation programs, home electronics, or video game consoles, and (4) a head mounted display (HMD) typically used in virtual reality modules. As an example, a user connects our multi-modal input device to a laptop and gives a presentation to audiences. After finishing the meeting, the user wants to read an article that he/she stopped reading for the meeting. While the user is waiting for a bus, he/she goes back to the previously viewed website and scrolls up to refresh news feeds. In the bus, the user watches a movie chip using a smartphone or HMD, and, after coming back home, the user wants to turn on an air conditioner and a robot vacuum cleaner.
Even in this simple scenario, we require many input devices, such as a laser presentation remote, a computer mouse and keyboard, and several remote controllers. However, all of these can be replaced by a single multi-modal input device, which is the main target of our approach. To demonstrate the concept, we selected three example cases (giving a presentation, playing a video, and surfing a website) and conducted experiments using one input device. Details are described in
Section 4.
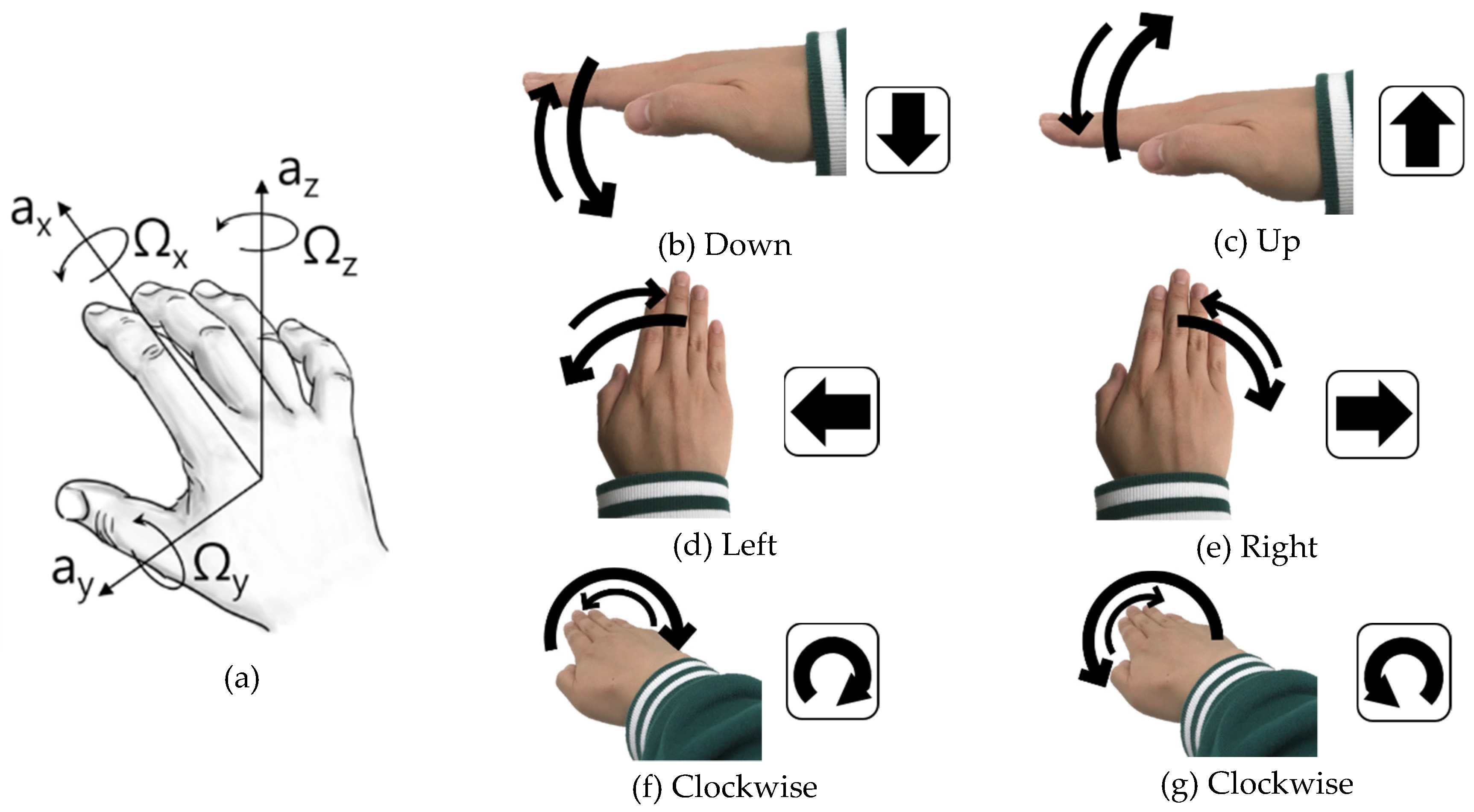
An overview of the designed system with algorithms is shown in
Figure 1. The gyroscope generates angular velocity data from hand gestures and feeds the data to the machine (e.g., a personal computer) interfaced with the three-axis gyroscope. The machine processes the raw sensor data using a custom-moving average filter to reduce sensor noise, produced either by the sensor limitations or unwanted gestures, such as hand tremors. In addition, initially, a learning mode is conducted so that the machine “learns” the preferences and habits of users. The reference signal pattern is updated and fitted according to the user’s gesture.
We analyzed the characteristics of the data, including their average, standard deviation (STD), variance, and covariance values. The values were used to calculate a normalized covariance (ρ), which was the key determinant of gesture recognition in this study. To derive the analyzed values, the filtered data were windowed to select a set of data samples selected from the most recent data samples.
The normalized covariance was calculated for the unit gestures, respectively, and the gesture maximizing the ρ value was determined to be that which the user intended. The machine selected a gesture that maximized ρ. The signals of the six gestures were already learned by the machine in the learning mode, which is initiated when a user turns on the machine. Then, the sensor signal was compared with two thresholds (related to the signal vector magnitude (SVM) and ρ) to enhance recognition accuracy with a low computation load. The machine validated a gesture as an intended gesture through comparing the threshold values and the magnitude of the input signal. The details are described in the following sections.
4. Experimental Demonstration of Multimodal Capability
Previously, we described several key techniques, including normalized covariance for pattern recognition, two thresholds (ρth and Mth) for enhanced accuracy, and the learning mode for user-customized interaction. These techniques were used together to realize a multi-modal input device for the HMI, facilitating simple, real-time, accurate, user-friendly, and multi-functional features. These advantages were demonstrated by follow-up experiments.
Our experimental setup is depicted in
Figure 5. The sensor system was an inertial sensor system made of a micro controller unit, 2.4 GHz band chipsets, and a nine-axis inertial sensor. The inertial sensor included an accelerometer, a gyroscope, and a magnetometer, but this study only relied on the three-axis gyroscope. The gyroscope sampling rate was 20 Hz. The sensor system was assembled in a plastic box and communicated with the receiver.
4.1. Verification Using Three Different Application Programs
To verify the proposed concept, the developed input device was employed in three application programs, which were in general controlled by different input devices. The programs were the presentation program (the typical input device of which is a laser presentation pointer), a media player for playing video/movie files (the typical input device of which is a remote controller), and a web browser for surfing (the typical input device of which is a computer mouse).
Each experiment followed a predefined sequence. First, we ran the target application program and determined its core functions. Then, the functions were matched with the six hand gestures in
Figure 2 and, if needed, simple combinations of the six gestures (e.g., two times “Right” gestures) were also used. When the initial setup had been completed, the first participant in the experiment operated the learning mode and then conducted a scenario comprising successive hand gestures executing all core functions. After the participant finished the scenario, the next participant followed the learning mode, which re-adjusted the input device according to his/her preferences, and conducted the scenario again. Five participants took part in this experiment.
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
4.2. Application Program #1: Presentation
When giving a presentation, a user usually brings a presentation laser pointer and needs three major features. The first feature advances the presentation to the next slide or returns it to the previous slide. Sometimes, the user wants to return to the first slide or skip to the last slide to save slide-changing time. The second feature selects and runs objects embedded in a slide. The objects include movie clips, audio files, animations, etc. The final feature is used to draw the audience’s attention; it turns on a laser used for pointing at intended locations on a slide. This feature is called the focus mode and is exemplified by the laser-pointer option used in the slide-show mode. Based on this analysis, we selected seven key functions and matched them with the six hand gestures. The function-gesture matching results are listed in
Table 5.
These functions were experimented with, as shown in
Figure 6. The arrow signs in the figure indicate the executed hand gestures. The number shown on the screen is the slide number. First, a participant was asked to conduct a “Left” gesture and the slide returned to the previous slide and the slide number changed from 5 to 4 (
Figure 6a). When the participant was asked to execute a “Right” gesture, the slide number increased from slide 5 to 6 (
Figure 6b). For faster transition, the participant rapidly conducted two “Left” or two “Right” gestures. This one-time “Double-Left” or “Double-Right” action resulted in the presentation going to the first slide (
Figure 6c) or jumping to the final (20th) slide (
Figure 6d). Then, the participant was asked to play a video clip embedded in slid 3. After conducting two slow “Left” gestures to go to slid 3, he/she performed an “Up” gesture to select the chip and sequentially made a “Down” gesture to play it (
Figure 6e). While the video played, the participant rested his/her hand. Finally, the participant was asked to emphasize some contents in slide number 5. He/she conducted two slow “Right” gestures to go to the fifth slide and either a “CW” or a “CCW” gesture to activate the focus mode. As illustrated in
Figure 6f, he/she then freely moved the mouse cursor (the white cursor movement is highlighted by the red circles). When the participant no longer needed the focus mode, he/she performed a “CW” or “CCW” gesture one more time and deactivated the mode.
Table 5 summarizes the success/error rates after five participants completed the sequence in
Figure 6, 50 times. The error sources were individually analyzed by non-recognition (when a gesture is not recognized) and incorrect recognition (when it is recognized as a different gesture). The table shows that, regardless of the user, high success rates are demonstrated in the range of 92% to 96%. Thus, our single-device concept successfully incorporates all the needed functions of a presentation laser pointer and is suitable for use with a presentation.
4.3. Application Program #2: Playing Video/Music Files Using a Multimedia Player
Multimedia contents are mostly controlled by a remote controller. Multimedia controllers require four major features. The first feature is playing and pausing the currently playing file. The second feature is time shifting, such as fast-forwarding and rewinding, while the third is changing files in a playlist, such as playing the previous or next file. The final feature is volume control.
Table 6 shows the function-gesture matching results of a multimedia player.
Figure 7 depicts an experimental sequence of playing a horizon-landscape video file. The red-circled symbol in each figure is generated by the used multimedia software and confirms which function is currently executed. A participant conducts a “Down” gesture to play the video and a second “Down” to pause it (
Figure 7a). Then, he/she makes a “Left” gesture to rewind the video clip, the time of which goes back to dawn, and then performs a “Right” gesture to fast-forward the video so that its time rapidly goes to sunset (
Figure 7b).
Figure 7c illustrates the results of the “Double-Left” and “Double-Right” gestures: The video changes to the previous clip and the next video clips, respectively. Finally, in
Figure 7d, the participant turns his/her hand counterclockwise and the video-sound volume decreases and eventually is muted. Then, he/she rotates the hand clockwise and increases the sound volume.
Table 6 reveals that the success rates span from 90% to 96%. The double-gestures (“Double-Right” or “Double-Left”) show the lowest success rate, because their non-recognition rate is relatively high. However, regardless of the participant or function, all gestures show superior success rates higher than or equal to 90%, which satisfies all the needed functions of multimedia players.
4.4. Application Program #3: Web-Surfing Using Web-Browser
As compared with the two application programs discussed in the previous sections, surfing web browsers requires different input characteristics, which are usually provided by a computer mouse and, if needed, the support of a computer keyboard. A conventional computer mouse provides two major features. One feature is selection functions provided by left or right clicks. The other is positioning the mouse cursor by moving the mouse. Keyboard functions may include going to the previous page (backspace key) and to the next page (alt-right-arrow keys) or refreshing the current page (F5 key).
Table 7 is the gesture-function matching results of web-surfing.
Figure 8 illustrates an experiment sequence using the web browser. A participant first uses a default mode and locates the cursor on an intended website hyperlink. If the cursor does not move for a certain time (set as 0.7 s in this application), it freezes at the cursor-pointing location and allows the user to select certain activities. Then, the user conducts an “Up” gesture in
Figure 8a. Now, the participant can move the cursor, meaning that the function changes to the cursor-positioning mode, and place it on the pop-up menu. He/she selects the function by making a “Down” gesture. In this step, he/she opens a page in the same tab. When the (selected) page is displayed, the participant makes a “Left” gesture to return to the previous page (here, the search page) and then performs a “Right” gesture to move to the forward page, as depicted in
Figure 8b. When a user no longer wants to use left/right clicking or forward/backward functions, he/she can rotate his/her hand in either the clockwise or counterclockwise direction to return to the cursor-positioning mode (
Figure 8c).
The experimental results are summarized in
Table 7, showing that a high success rate is achieved in all functions, from 93% to 99%. Therefore, it is demonstrated that our concept can cover not only all the functions of a computer mouse but also some functions that require a computer keyboard.
4.5. Summary of the Verification Experiments
As noted, threshold values of normalized covariance (ρth) and averaged SVM (Mth) were adjusted by applications. For the presentation, ρth is 0.8 and Mth is 50. Both of them were relatively large, because a user typically used large gestures (large Mth) during presentation and willingly accepted a lack of recognition but strongly wanted to avoid any wrong actions (large ρth). Whereas, when a person listens to music or watches a video, hand gestures are typically large but a user is less concerned with incorrect recognition, which is easily corrected by quickly executing the right gesture one more time. Thus, the Mth was maintained at 50, while the ρth was decreased to 0.5. When a user surfs the web, the user’s hand movements show a wide speed range. Thus, the Mth was decreased to 30. The normalized covariance threshold was increased to 0.7.
Figure 9 summarizes the experimental results on gesture recognition rate in each program. All the recognition rates were higher than 90% and generally 92–96%. Moreover, the success rate increased as a user became more familiar with the input device. One accidental observation was that a user became more familiar with using our wearable input device and began to adapt himself/herself. This observation offered a hint for achieving a 100% success as the number of repetitions increased.
The computation load of this system was represented by a recognition delay time, which is experimentally evaluated herein. The delay time was defined as the time elapsed until a computer executed a specific function (matched to a specific gesture) since a user completed the corresponding hand gesture. The elapsed time was repeatedly measured for 100 times using a stopwatch. The measured delay-time values were 0.21 ± 0.05 s, and dominantly observed from 0.22 to 0.23 s. These values were not significantly long and were within the time scale of the cognitive band (0.1 to 10 s), which is the time required for a computer mediated HMI system [
35]. Thus, we consider our system to be able to operate in real time.
5. Conclusions
This paper proposes a method providing a wearable electronics system providing a unified multi-modal input device for HMI systems. Six unit gestures are employed and resynchronized for three different application programs. The resynchronization is feasible because a machine in an HMI system already recognizes which program is currently running, and the required functions differ according to application programs. The resynchronization-by-program approach reduces the number of required functions to a great extent and (sequentially) the diversity in HMI input devices, realizing a unified (multi-modal) input device for HMI systems with less complex hand gestures.
For fast and reliable recognition, two determinants are used: Normalized covariance and averaged SVM. The normalized covariance determines the gesture pattern similarity, and the SVM distinguishes errors caused by small hand gestures. In addition, the machine initially learns user preferences and habits by means of a learning mode. Thus, a highly successful gesture-recognition algorithm is achieved.
The developed algorithm was applied to three application programs: Presentations, a multimedia player (for playing video/music files), and a web browser. The three programs are usually controlled by a laser pointer, remote controller, and computer mouse, respectively. Our single wearable sensor exhibits high success rates for the different functions of the three programs. Therefore, the developed sensor has high potential as a multi-modal wearable input device for HMI systems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}