1. Introduction
With the boom of connected vehicles and other mobile devices [
1,
2,
3], users generate ever-increasing demands on cellular networks, like 5G and LTE. However, long delays exist when accessing the Internet through wireless mobile networks [
4,
5,
6,
7]. One of the main reasons is unnecessarily large-sized buffers at intermediate routers and end hosts due to the low price of memory.
Owing to the excessive buffer space, the widely deployed transmission control protocol (TCP) implementations, which are loss-based congestion control algorithms, such as NewReno [
8] and CUBIC [
9], will rarely suffer a loss even if they fully utilize the bandwidth. Thus, the TCP sender will keep increasing the amount of in-flight data. This results in up to several seconds of round trip delay [
10,
11,
12,
13]. However, the phenomenon does not cause critical problems when only one flow utilizes the buffer, as short flows will not build up queue and throughput matters with long flows.
However, smart phones are becoming more and more powerful and are usually equipped with several core processors. Thus, users expect them to perform multitasking simultaneously. If both long flows and short flows are coexisting, the short flows can experience huge flow completion time (FCT) when the buffers are filled with the packets belonging to the long flows [
14].
To tackle this problem, researchers have proposed some algorithms. The sender-oriented approaches [
7] proposed to utilize the round trip time (RTT), e.g., TCP Vegas [
15], or the bandwidth-delay product (BDP), rather than the packet loss event, to control the congestion window (cwnd) in this buffer bloat cellular networks. However, the delay-based approaches may suffer from bandwidth starvation when they coexist with loss-based approaches. In addition, some researchers focus on the AQM (AQM) at intermediate routers to throttle the number of packets that stay in the buffer, such as Codel [
16], PIE [
17] and fq_Codel [
18]. However, few intermediate routers enable AQM in practice [
6], and it still remains unclear how quickly these AQM schemes will be deployed in practice including cellular networks, e.g., 5G and LTE networks.
Other works focus on the receiver side and the receiver-oriented approaches work with flow control which adjust their advertised receive window (rwnd) to limit the amount of in-flight data, like Dynamic Receiver Window Adjustment (DRWA) [
4,
5] and Receiver-side TCP Adaptive queue Control (RTAC) [
6]. In cellular networks, base stations typically have a separate buffer space for each user. Thus, one of the main advantages of the receiver-oriented approach is that the receiver based mechanism will not influence the performance of other users. In addition, it can be implemented without the intervention of service providers and can quickly and easily be deployed by updating the firmware of the user’s device.
Although existing receiver-oriented mechanisms can alleviate the problem, the short flows can also show poor performance with the existing algorithms when they are competing with long-lived flows, i.e., a user playing an online game and, at the same time, downloading a song in the background, because there is no service differentiation between TCP flows. However, most of the TCP sessions in today’s Internet is constituted by short flows (e.g., web requests) [
19]. Thus, it becomes of critical importance to enhance the performance of TCP in mobile networks to improve the quality of experience.
To this end, we proposed a novel receiver-oriented approach, named a Delay-based Flow Control algorithm with Service Differentiation (DFCSD), to mitigate the problem described above and improve the performance of both short flows and long flows in cellular networks. In DFCSD, the receiver controls the rwnd in a TCP-friendly manner and is automatically suitable for a certain application based on the TCP fluid model to achieve both performance improvement and latency reduction.
Note that DFCSD limits the sending rate through rwnd, which is calculated irrelevant to the congestion control algorithms at the sender side. Furthermore, it works effectively only when rwnd is smaller than cwnd, thus avoiding throughput degradation. We show that DFCSD successfully prevents long delays and achieves good performance under resource competing environments. The main contributions of this paper are as follows:
To improve the FCT of short flows, we developed a DFCSD algorithm, which can effectively alleviate the long delays caused by the oversized buffer, is compatible with existing TCP variants, and can fairly share resource with conventional receivers.
A key challenge in the proposed DFCSD algorithm was the calculation of the advertised window for each competing flow to maximize the network utility, as well as guaranteed completion time of short flows. To this end, this paper advises different rwnd for different flows, utilizes the idea of TCP fluid model, and takes into account flow characteristics, i.e, the flow size.
2. Related Works
Server-oriented end-to-end congestion control protocols: Since a large part of mobile traffic is constituted by TCP flows, TCP congestion control is always one of the hottest research topics, and its performance is critically important [
7,
20]. So far, numeric TCP variants have been proposed, which fall into three categories, namely, loss-based, delay-based, and combined loss- and delay-based. TCP Taho [
21], TCP Reno, and TCP NewReno [
8] are among the early approaches and are loss-based congestion control algorithms. Highspeed TCP (HSTCP) [
22] and CUBIC [
9] modify the window growth mode to quickly achieve high network utilization. Among them, CUBIC is the default congestion control algorithm in the current Linux kernel.
Delay-based protocols (e.g., TCP Vegas and FAST TCP [
23]) detect the network congestion and adjust the cwnd based on RTT. The delay-based variants can react to the network congestion more quickly compared to the loss-based mechanisms [
24] and are capable of limiting the standing queue size and decreasing the amount of packets that are dropped in the eNodeB. However, the delay-based approaches will suffer from significant throughput degradation when competing with loss-based algorithms, e.g., TCP-Reno [
25].
In addition, Compound TCP (CTCP) [
26] incorporates the delay-based component into the loss-based TCP congestion avoidance algorithm. TCP Bottleneck Bandwidth and RTT (TCP BBR) [
27] estimates both bottleneck bandwidth and RTT delay and uses a distributed control loop to try to verge on the optimum to fully utilize the network while maintaining a small queue. Recently, a number of new algorithms have also been proposed, like Low Extra Delay Background Transport (LEDBAT) [
28] and TCP Binary Increase Congestion control (BIC) [
29]. However, these mechanisms are mainly designed for the wired network and are not suitable for highly variable cellular networks.
Meanwhile, some TCP variants offering differentiation among flows have been proposed. TCP Nice [
30] aims to reduce the interference inflicted by background flows on foreground flows by modifying TCP congestion control to be more sensitive to congestion than traditional protocols by detecting congestion earlier, reacting to it more aggressively, and allowing much smaller effective minimum cwnds. TCP TS-Prio [
31] describes a simple method to differentiate services based on the congestion control parameter configuration, i.e., the sliding window configuration of a TCP server and a simple priority marker. This algorithm requires that the TCP server recognizes these priorities, and the queue management policy should be RED (Random Early Detection) or similar. The authors in Reference [
32] proposed an approach which automatically prioritizes short (interactive) transfers by basing the priority of packets on the TCP connection window to achieve the goal of reducing congestion-induced delays for interactive applications using service differentiation mechanisms. However, this needs the support of the intermediate router.
Fortunately, several congestion control algorithms have been proposed aiming to improve the TCP performance in cellular networks. C2TCP [
7] classifies the network into “good-condition” and “bad-condition” based on the idea of Codel [
16]. It increases the cwnd when the network is in the “good-condition” and sets cwnd to one when the network is in the “bad-condition”. Sprout [
10] adjusts its cwnd by predicting the bandwidth of the mobile network while Verus [
11] calculates the cwnd based on the current network delay.
Active queue management (AQM) schemes: These algorithms aim to throttle the number of packets those stay in the buffer at intermediate routers. The main idea behind these AQM schemes is dropping packets at the router of bottleneck links so that the sender can slow down its sending rate. Traditional AQM algorithms, like RED [
33], BLUE [
34], and AVQ [
35], have many tuning parameters, making them hard to implement [
10,
36]. To solve this problem, Codel [
16], PIE [
17], and fq_Codel [
18] have recently been proposed. However, these improved AQM schemes still have an important issue when applied to cellular networks. On one hand, these schemes have the same setting for all applications, which is not the case in the real network where every application may have different delay or throughput requirements. On the other hand, it still remains unclear how quickly these AQM schemes will be deployed in practice included in cellular networks, e.g., 5G and LTE networks.
Receiver-oriented protocols: The receiver-oriented approaches work with flow control, which control the sending rate by the advertised rwnd. Until now, serveral algorithms have been proposed. In DRWA [
4,
5], the receiver increases rwnd when the current RTT is close to the minimum RTT and decreases it when RTT becomes larger, aiming to keep RTT close to its minimum RTT. RTAC [
6] integrates the AQM into the loss-based congestion algorithms and is implemented at the receiver side. However, neither of the schemes provides service differentiation. In cellular networks, base stations typically have a separate buffer space for each user. Thus, one of the main advantages of the receiver-oriented approach is that the receiver based mechanism will not influence the performance of other users. In addition, it can be implemented without the intervention of service providers and can quickly and easily be deployed by updating the firmware of the user’s device. Based on the above analysis, we proposed a receiver-oriented approach named DFCSD, which employs the TCP fluid model and service differentiation to maintain the network throughput while improving the FCT. We compare DFCSD with both DRWA and RTAC in
Section 5.
3. Motivation
In this section, we demonstrate the conducted empirical studies based on ns-2 (version 2.35) patched with LTE-Module to analyze the root reason why current TCP algorithms fail to provide satisfactory performance and present the design objectives.
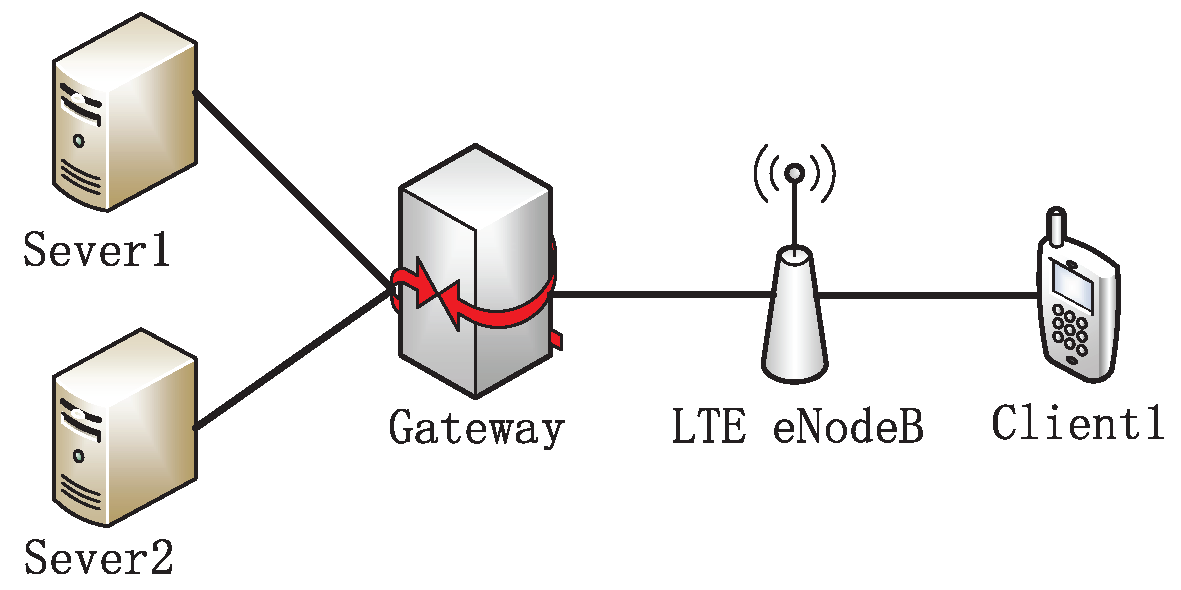
The topology is shown in
Figure 1, where the UE (User Equipment) is connected to the eNodeB, and the eNodeB is attached to a gateway node through the Ethernet with 125 Mbps bandwidth and a 2 ms delay, ensuring it is not the bottleneck of the testbed. The UE downloads files from the server located in the wired side through FTP. The default buffer size of the base station is 50 packets. The size of the long flow and short flow is 10 MB and 128 KB, respectively.
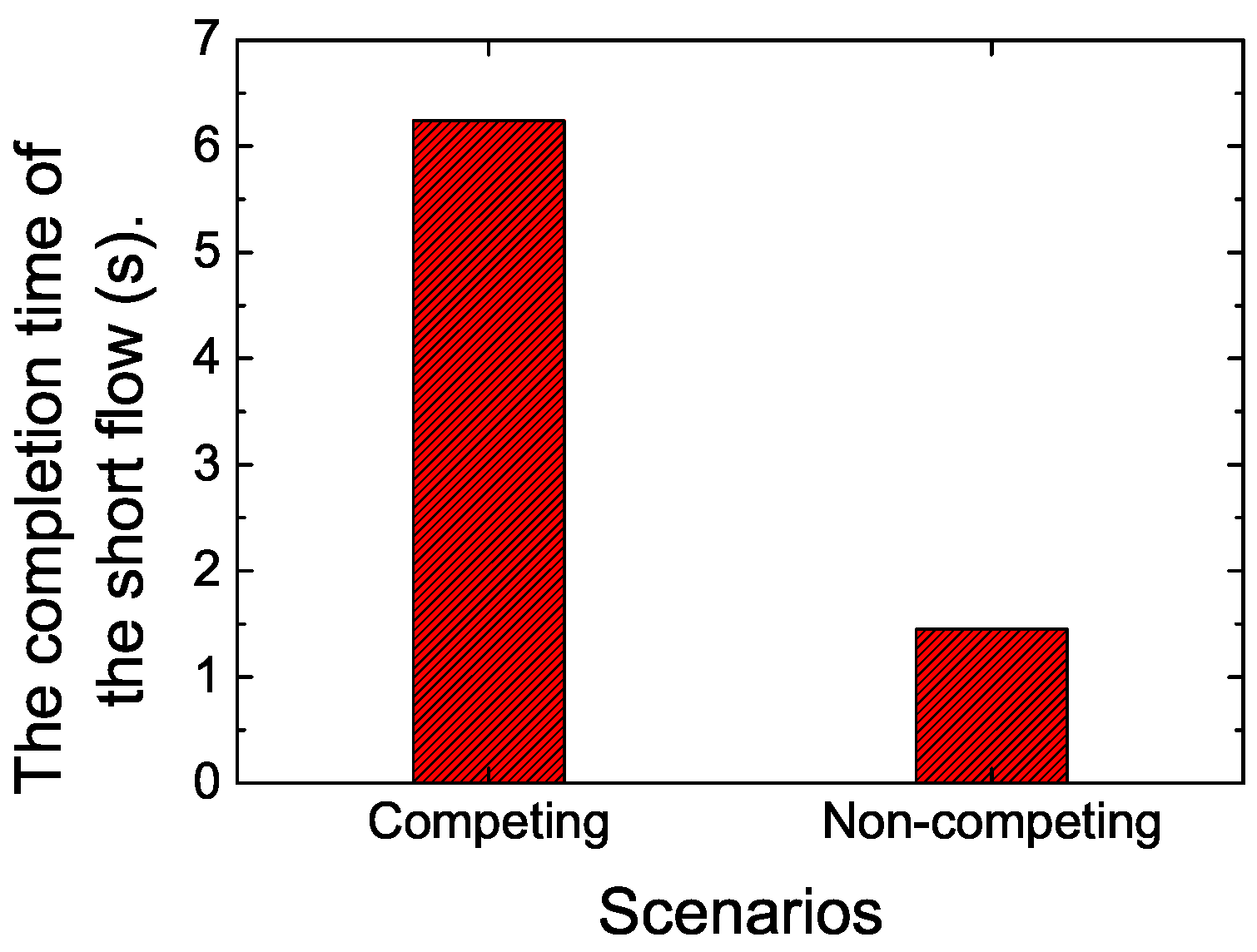
To validate whether the large buffer size in cellular networks would impact the performance of short flows or not, we calculated the FCT of the short flow in the network scenarios where there were competing long flows or where there were not. The results are shown in
Figure 2. In the competing network scenario, a short flow competes with a long flow. The long flow starts at 0 s, and the short flow starts at 30 s.
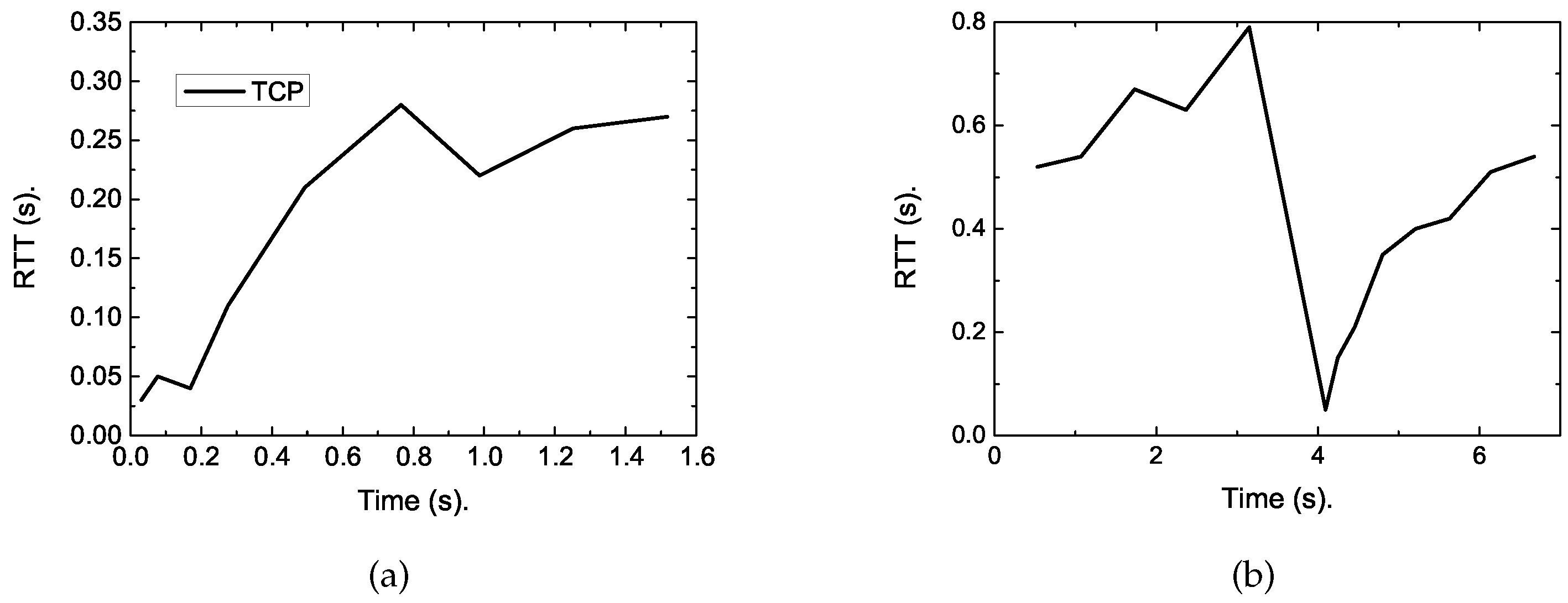
According to the results, the completion time of the short flow increased sharply when the long flow joins. To reveal the reasons, we traced the RTT varying with time and conducted statistics on the packet drop rate. According to
Figure 3, the RTT can be up to 800 ms when the long flow exists. The reason lies in that the buffers in cellular networks are oversized, which can absorb a large amount of packets, causing large queuing delay, thus long RTT. This leads to a large FCT of short flows.
What is worse is that the default congestion control algorithm is loss-based, which will not slow down its sending rate until the buffer is full. When the buffer cannot accommodate all the in-flight packets, packet loss occurs. According to our statistics, when there is only one short flow with size of 128 KB, there is no packet lost event. However, when a 10 MB long flow competes with this short flow, the drop rate is up to 2.75%. This will further increase the short flow’s completion time. On the other hand, these lost packets have to be retransmitted, causing wasting of network resource. As validated in
Section 5, the obtained network goodput of regular TCP is smaller than the improved algorithms.
Based on the above analysis, we concluded that the oversized buffer in the cellular networks may lead to extremely long delays, causing performance degradation for both short flows and long flows, especially when they are competing for the same wireless access network. The observation motivated us to design a novel approach to effectively control the delay.
4. The Proposed DFCSD Algorithm
The goal of the proposed DFCSD algorithm was to control the delay caused by the persistent queueing to improve the TCP performance for both short flows and long flows, especially when both long flows and short flows compete for the same mobile access network. In this section, we first describe the TCP model where users receive data packets through wireless access links, such as 5G and LTE networks. Then, we present DFCSD.
4.1. Problem Formulation
We considered a network shared by a set of flows. The path of each flow consists of a set of links . Every flow s maintains its own cwnd and transmission rate . Each flow s is associated with utility function that is assumed to be concave and differentiable. Each link has capacity . We denote the set of flows that pass through link l by . Let be the total packet arrival rate at link l.
The objective of TCP and its variants is to determine appropriate rates for the flows in order to maximize the total utility subject to link capacity constraints. Thus, we have:
There exists a unique optimal solution for
, since the objective function is strictly concave and the feasible region is compact [
6].
Consider the standard dual problem of Equation (
1) and obtain the Lagrangian function as:
where the multiplier
p can be interpreted as the price or the congestion signal, such as queue length and loss probability associated with link
l, and:
is the aggregate price of the links constituting the path of flow
s. Thus, we call
the path price.
From the Karush–Kuhn–Tucker conditions (KKT) [
37], the optimal
is achieved when
, i.e.,
where
.
The proposed DFCSD algorithm is a receive-oriented approach, and one of its core ideas is to control the number of packets backlogged at the routers, thus reducing the queueing delay, which is similar with TCP Vegas [
15]. In TCP Vegas, a source calculates the difference
between its expected rate
/
and its actual rate
/
, as shown in Equation (
5) where
is the cwnd,
is the average RTT in the last round, and
is the minimal RTT that has been measured so far.
If
, the cwnd is increased by one packet. If
, the cwnd is decreased by one packet. If the difference is equal to
, the window size is unchanged. Its utility function is [
38,
39]:
When the algorithm converges the equilibrium windows
and the associated equilibrium RTTs
satisfy:
From Equation (
7), by multiplying
and replacing
with
, we can obtain that:
which means that the window size
minus the BDP
equals
, the total backlog buffered in the path of
s. In other words, we see that a source increments or decrements its window according to whether the total backlog
is smaller or larger than
.
In addition, according to Equations (
4) and (
6), we can also obtain that:
By substituting
into Equation (
9), we have:
which denotes the transmission rate that maximizes the network utility.
4.2. The Calculation of the Receive Window
We now focus on typical wireless access network scenarios, where users are connected through 5G and LTE networks. In this case, wireless links often become a bottleneck due to their limited bandwidth. Hence, in wireless access networks, we approximate the sum price as the price of an access link, i.e.,
Thus, we can assume that all the flows belonging to the same user in mobile networks have the same price as the base stations typically have a separate buffer space for each user [
4,
5].
DFCSD is similar to Vegas in the way it adjusts the sending rate to control the number of packets stayed in the buffer, which applies the RTT based flow control at the receiver side. More specifically, the rwnd is incremented or decremented by one packet in the next period by comparing the current rate
with the target rate
, as shown in Equation (
10), and achieves equilibrium when the rate is
.
Moreover, it aims to improve the performance of short flows in mobile networks where the buffer is oversized and long delay exists, especially when short flows coexist with long flows. To this end, we should also give short flows higher priority when competing with long flows. Thus, DFCSD provides service differentiation for these flows by setting different
based on the data amount that has been transmitted. According to Equation (
8), a smaller
means that a smaller number of data amount of flow
s can be buffered. DFCSD aims to improve the FCT of short flows when they are competing with long flows as they pile up packets at BSs, APs, and end hosts with oversized buffers. Thus, larger flows should have the smaller
so that short flows can still inject data into the buffer when large flows start to slow down its sending rate.
In addition, the backlog buffered in the path of flow
s should be no larger than the default maximum value, i.e.,
. Thus, the
is in the range
and should have a significant correlation with the flow size, which ranges from 0 to infinity. Based on the above considerations, we define the exponential function as shown in Equation (
12) to achieve these goals.
where
is the transmitted data amount of flow
s, and
and
are the minimum and maximum value of the competing flow sizes.
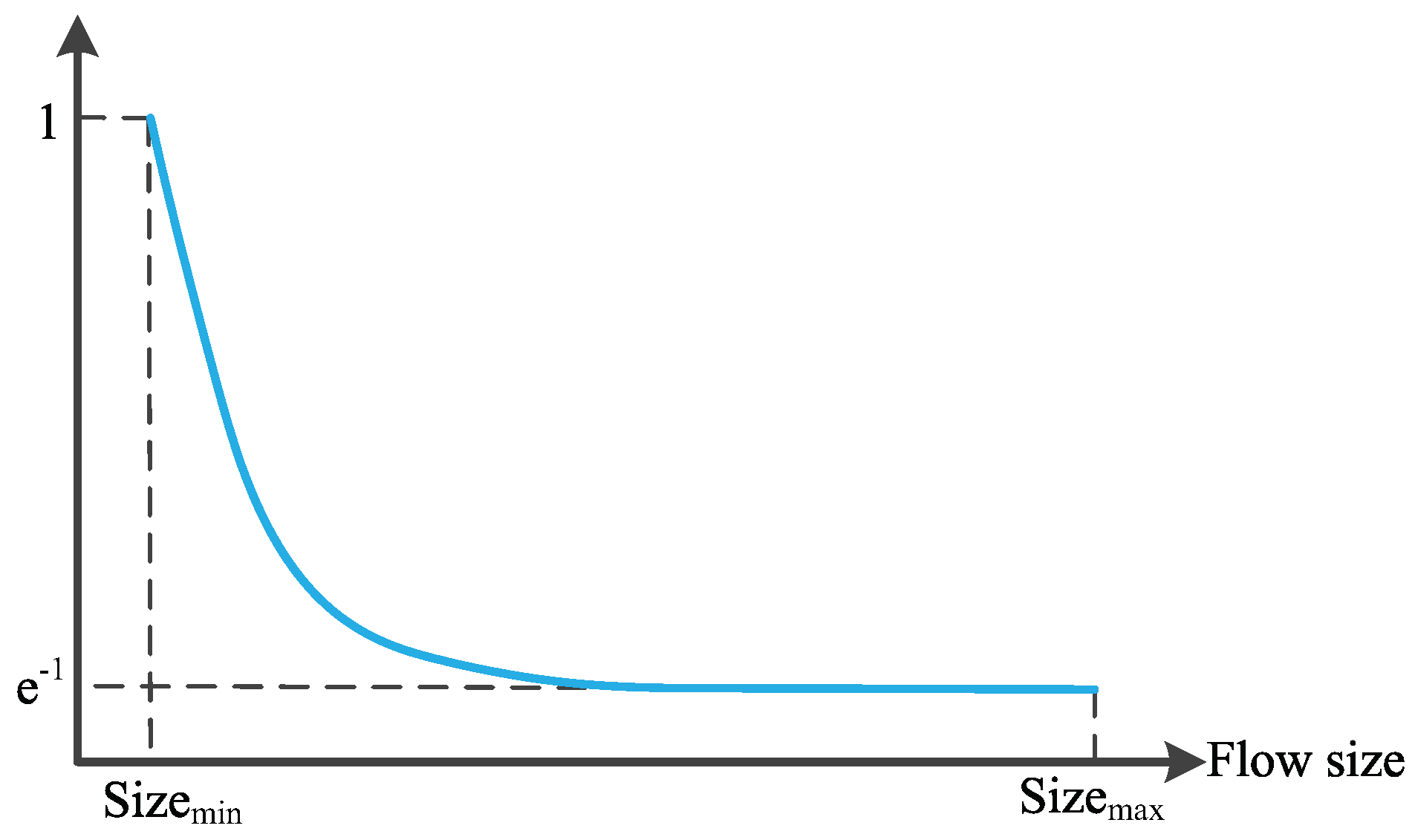
According to
Figure 4, which draws the curve of
,
is in the range of [
,
] and decreases with the increase of competing flow size. As
denotes the number of packets buffered in the path of flow
s, we can get that the smaller the flow is, the more packets that it can be backlogged in the shared buffer. This gives the short flows more opportunities for transmission as long flows start to decrease its data rate when it detects the number of the packets buffered reaches its
. However, the value of
belonging to the short flow is larger than that of the long flow, as analyzed above. The short flow will continue to increase its sending rate until the the backlogged packets reaches its
. On the other hand, we know that the buffer is mainly occupied by long flows, which carry a large amount of data. Limiting the backlogged packets of the long flow can effectively avoid the high RTT and packet loss caused by buffer overflow, thus increasing the transmission efficiency.
It is important to note that for the flow s with the largest size when multiple flows are competing on the network, its is minimum and the value is rather than 0. This setting guarantees that the flow with the largest size can still inject a small number of data in the buffer, with the aim of maintaining the throughput of long flows while controlling the queuing delay.
Above all, according to Equations (
10) and (
12), the receiver with DFCSD advertises rwnd as:
4.3. The DFCSD Algorithm
Algorithm 1 shows the details of the DFCSD. According to Equation (
13), the receiver should obtain the current RTT, namely,
, to calculate the rwnd. If the TCP timestamp option [
5] is available, DFCSD can use it to obtain a more accurate estimation of the RTT (Line 10–12). Fortunately, both Windows Server and Linux support the TCP timestamp option, as long as the client requests it in the initial SYN segment [
4,
5]. If the timestamp option is available, DFCSD uses the same technique as DRS [
40] and DRWA [
4,
5] to measure RTT on the receiver side (Line 8).
After knowing the RTT, DFCSD records the
, which is the minimum RTT ever seen in this connection and counts the amount of data,
, that flow s has been received. Then, DFCSD sets the rwnd according to Equation (
13).
The ideas stem from delay-based congestion control algorithms but work better than they do for two reasons. First, in cellular networks, a base station typically has a separate buffer space for each user [
4,
5], and it is always the bottleneck. In this condition, DFCSD will not be affected by the flows belonging to other users. Furthermore, DFCSD only guides the TCP cwnd by advertising an adaptive rwnd, and the bandwidth probing responsibility still lies with the TCP congestion control algorithm at the sender. Therefore, typical throughput degradation seen in delay-based TCP will not appear.
| Algorithm 1: The DFCSD Algorithm |
 |
5. Evaluation
In this section, we validate our proposed DFCSD algorithm by comparing its performance to regular TCP, the DRWA algorithm [
4,
5], and the RTAC [
6] scheme. The version of TCP is TCP Reno, which is the default value of ns2 and is a loss-based congestion control algorithm.
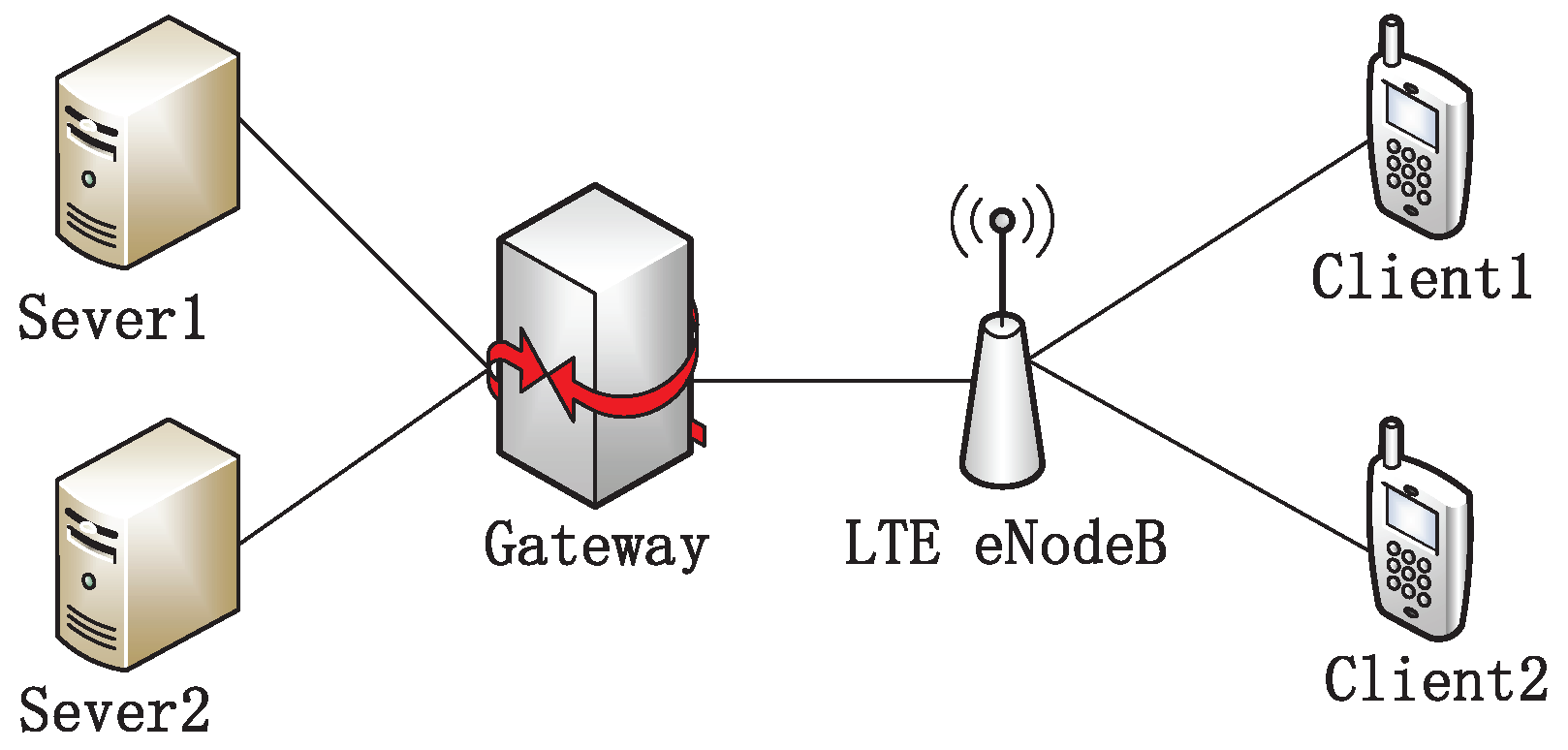
Our experiments were conducted on the ns-2 (version 2.35). We used the TCP algorithm embedded in this simulation testbed and implemented the proposed DFCSD and DRWA, as well as RTAC. The topology is shown in
Figure 5. Two client devices are associated with the same LTE eNodeB, and download data from the server which is located in the wired side. The eNodeB is attached to a gateway node through the Ethernet with 125 Mbps bandwidth and a 2 ms delay, ensuring it is not the bottleneck of the testbed. The buffer size at the eNodeB is set as the default value of 50 packets in the LTE. The default value of the wireless transmission rate in ns2 is 1 Mpbs. In the last part of the experiment, we conducted the performance of each algorithm with varying wirless transmission rates which vary from 1 Mbps to 54 Mbps.
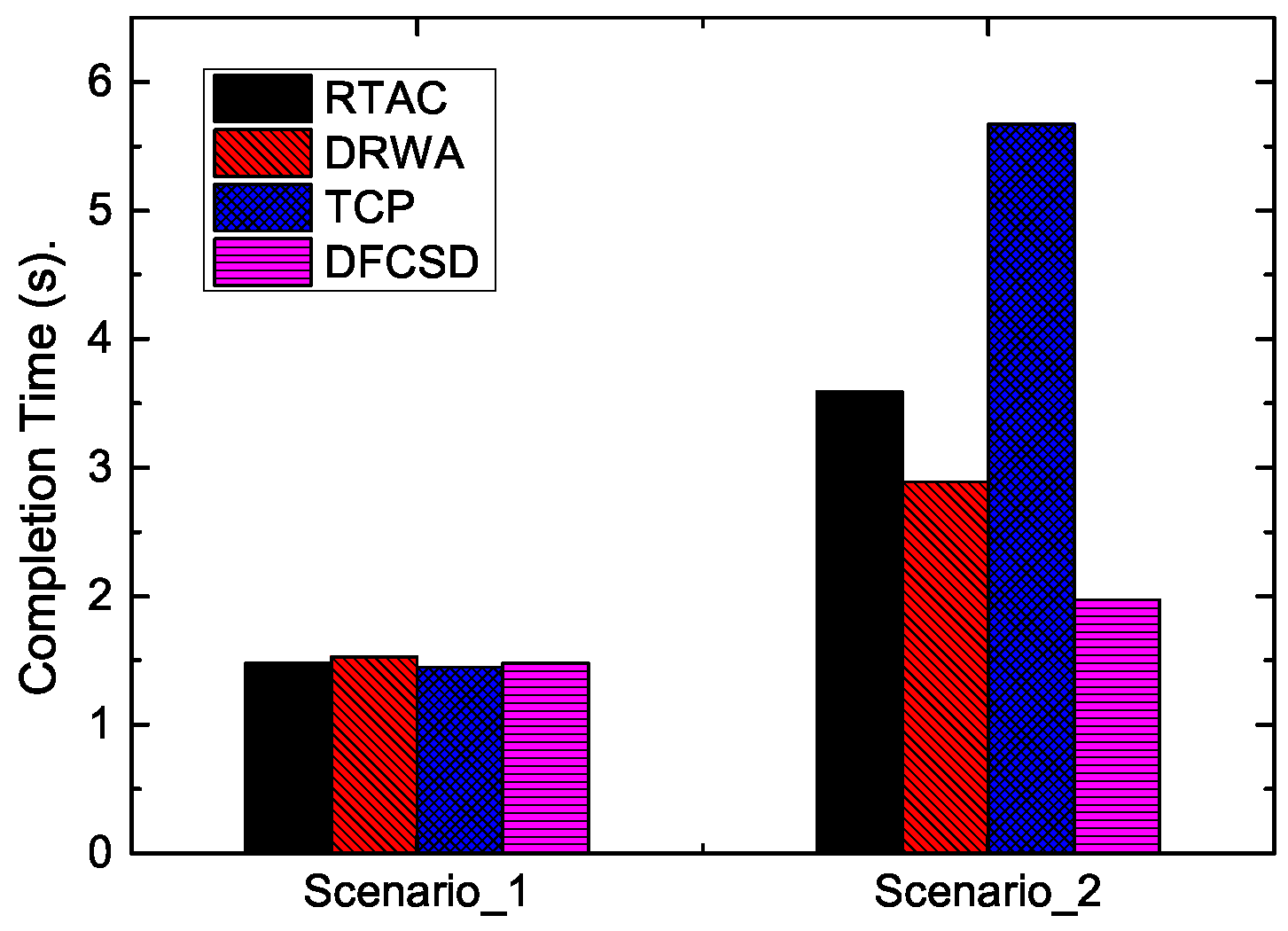
To illustrate the performance impairments for short flows caused by the large buffer size in LTE networks, we first evaluated the completion time of a short flow when there was a concurrent long flow (Scenario_2) or not (Scenario_1) over a mobile device. The size of the long flow and short flow is 10 MB and 128 KB, respectively. The long flow starts at 0 s, and the short flow starts at 30 s. The results are shown in
Figure 6.
According to
Figure 6, when there was only one short flow (Scenario_1), the completion time of the four algorithms were nearly the same, with the value of about 1.48 ms, and the RTT of each algorithm differentiated a little with the maximum value of about 300 ms, as shown in
Figure 7. However, when the long flow competed with the short flow, the completion time of the short flow increased sharply with default TCP. All the improved algorithms, namely, DRWA, RTAC, and the proposed DFCSD can alleviate this phenomenon, where DFCSD performed best, followed by RTAC.
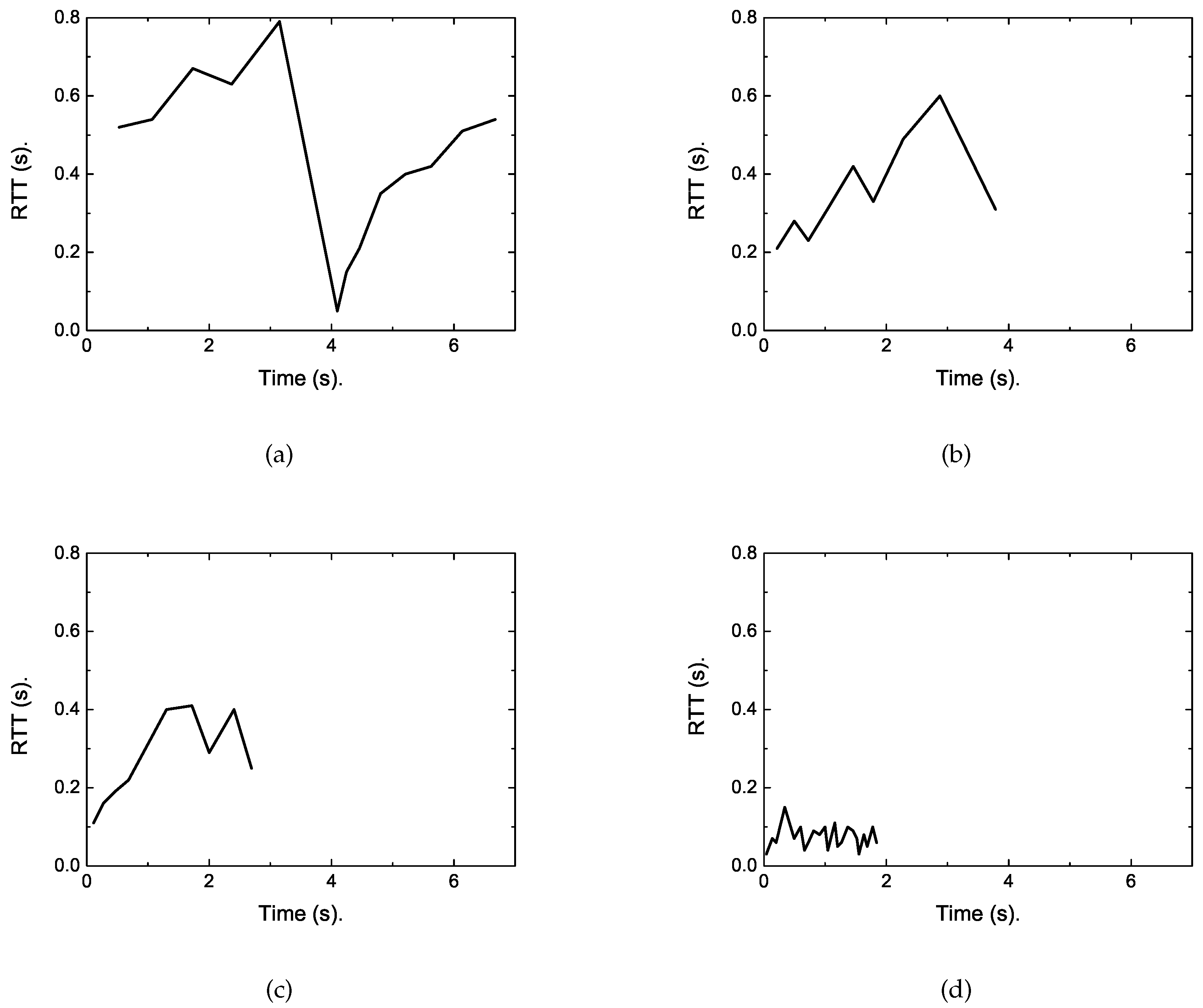
To reveal the reasons, we traced the RTT of the short flow under each algorithm. The results are shown in
Figure 8. As presented in these figures, we can obtain the reason lies in that regular TCP is loss-based, whose cwnd will continue to grow until the buffer size is full, thus packet loss occurs. This can fully utilize the network resource in common network scenarios. However, the buffers of eNodeB in LTE are heavily provisioned to accommodate the dynamic cellular link. This will result in up to 800 ms of round trip delay [
4,
5], as shown in
Figure 8, which is far larger than that depicted in
Figure 7 when no competing long flow exists. This causes a large completion time for short flows. However, for the proposed DFCSD algorithm, the sending rate is slowed down when the measured RTT exceeds a certain threshold value, which can control the backlogged packets in the buffer, and thus the RTT.
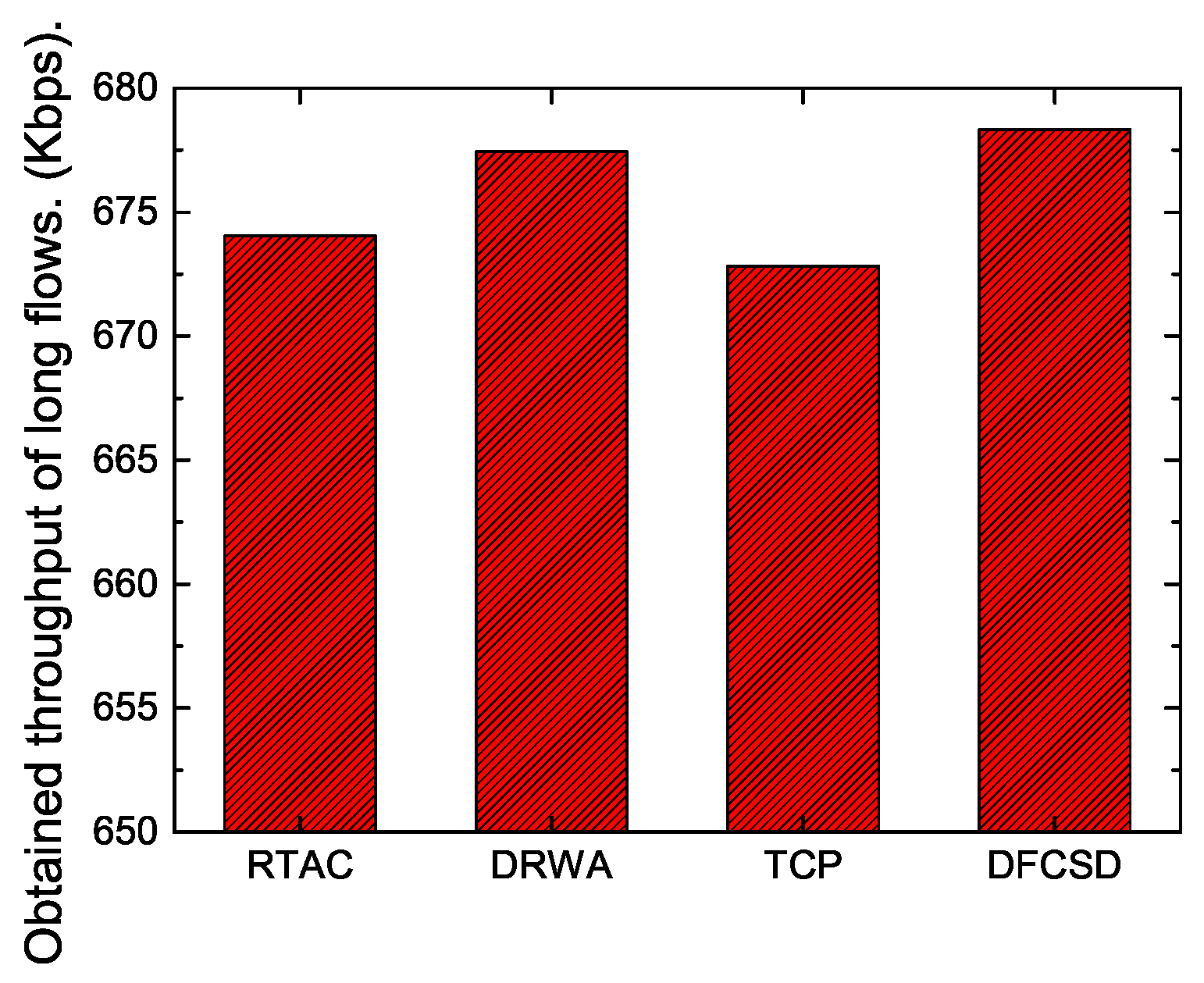
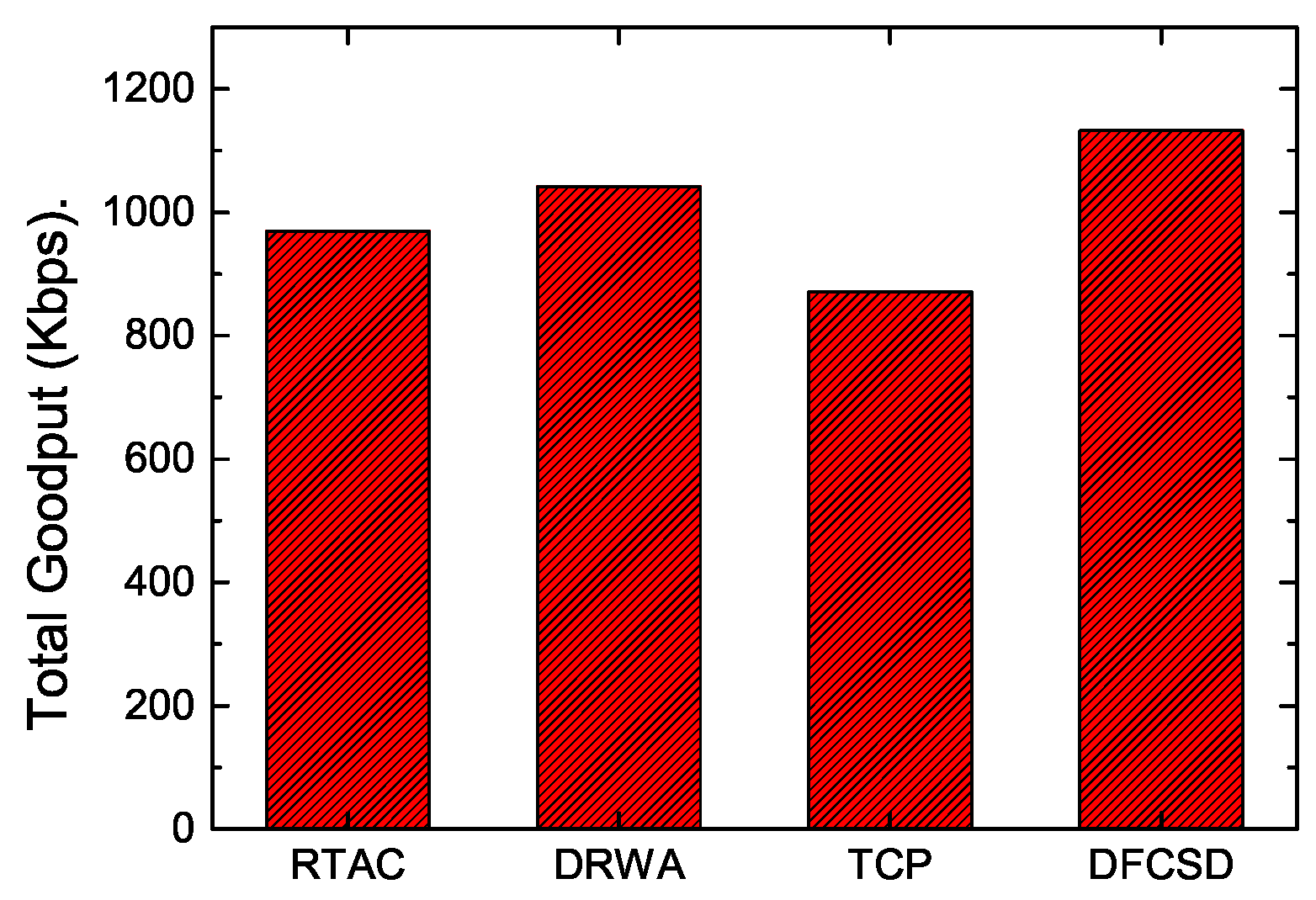
In addition, we also calculated the throughput of long flows and the obtained goodput of the networks to investigate how the algorithms influence them. The results are depicted in
Figure 9 and
Figure 10. According to
Figure 9, there is very little difference (about 5 Kbps) between the throughput of long flows with each algorithm, which validates that the performance improvement of DFCSD for short flows depends on the utilization of the untapped resource rather than suppressing long flows, as the main idea of DFCSD is to alleviate the large queueing delay caused by the oversized buffer size to improve the FCT of the short flows and to avoid buffer overflow which brings retransmissions and even RTOs. The loss-based algorithms, trying to find the limit for a given connection by forcing a router buffer somewhere to overflow, cause packets to be dropped occasionally. The retransmissions caused by the packet loss of each algorithm are shown in
Table 1. For DFCSD, the phenomenon does not exist as it slows down its sending rate before the buffer is full, achieving higher network utilization. As a result, the obtained network goodput, shown in
Figure 10, reveals that DFCSD outperformed other algorithms, followed by DRWA.
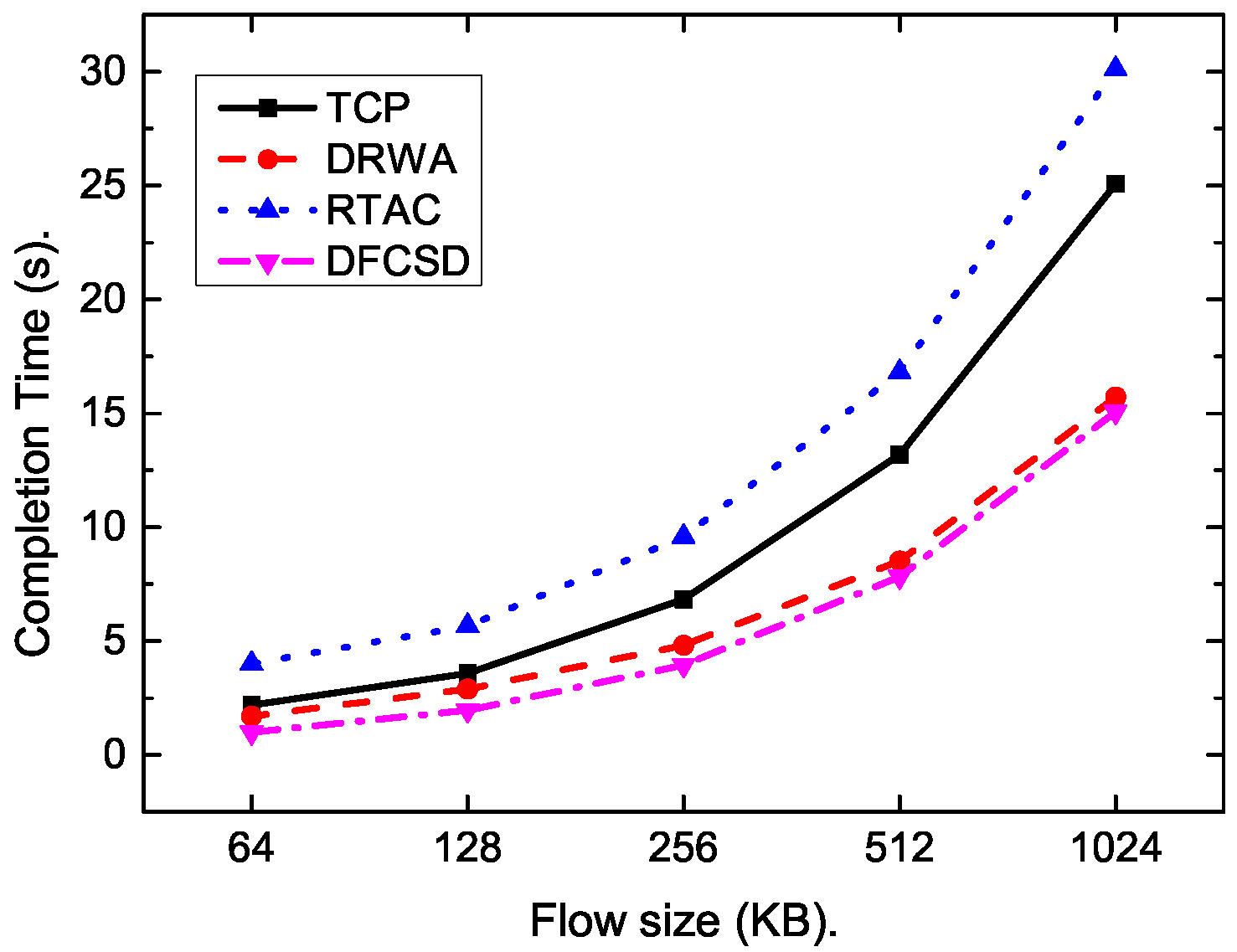
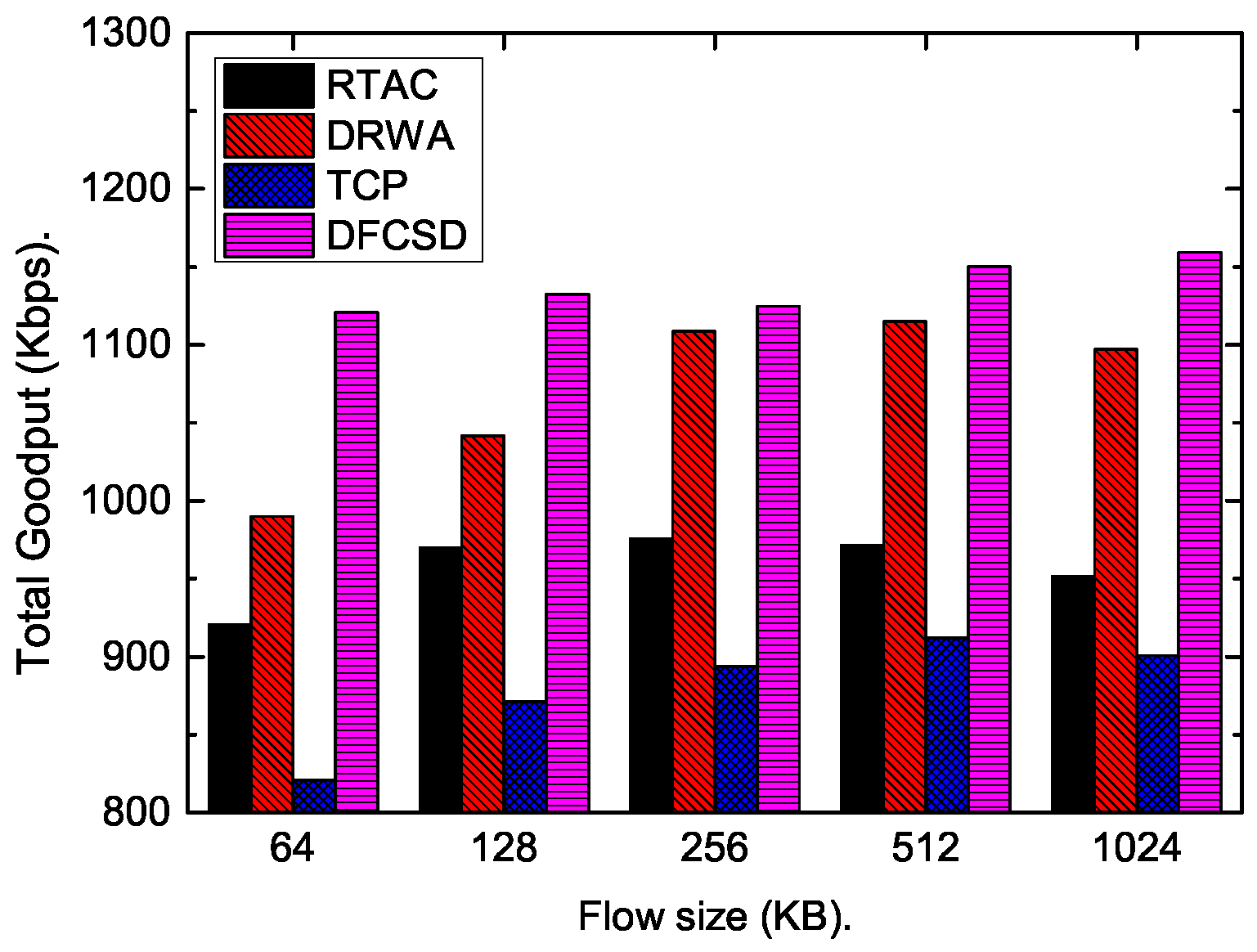
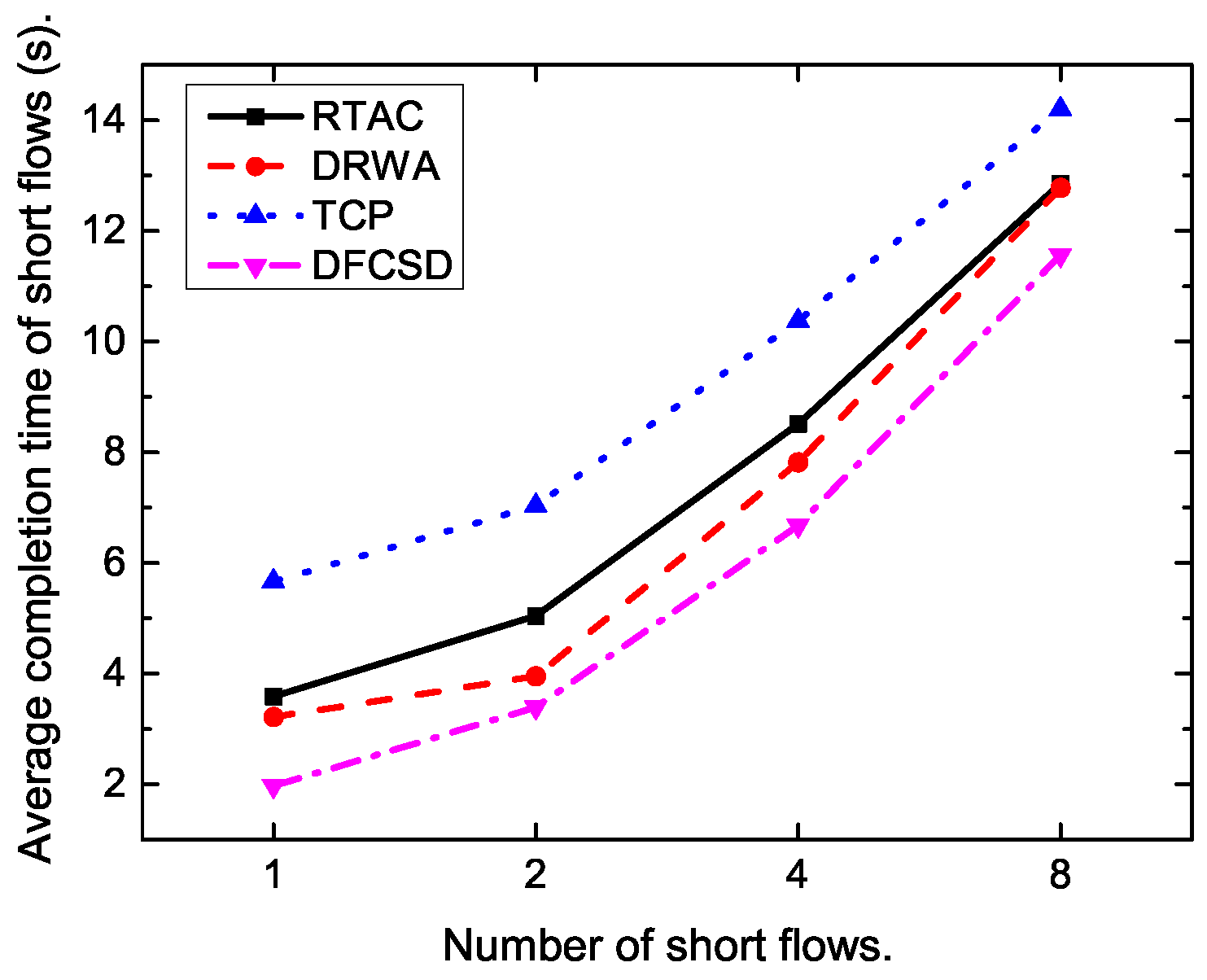
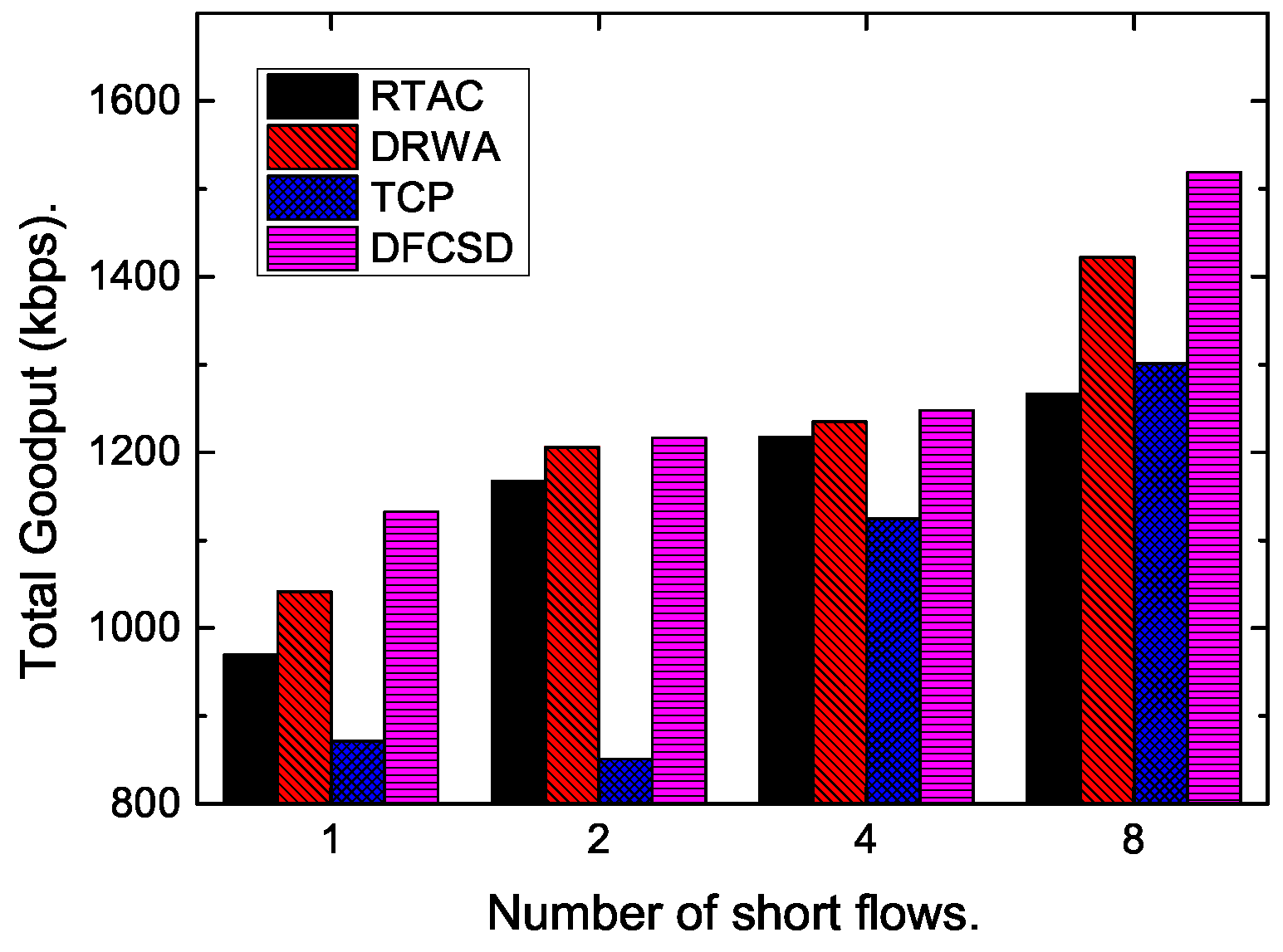
Then, we further conducted experiments by varying the size, as well as the number, of the short flows.
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the results. The results are consistent with those when only one short flow competing with long flows. More specifically, the average FCT increased with the size of short flows, as well as the number of concurrent short flows. The proposed DFCSD performed best, followed by DRWA, and TCP performed worst. The gains benefit from the controlled queuing delay as analyzed above. On the other hand, for the obtained goodput of each algorithm, TCP also performed worse compared to other algorithms, due to the buffer overflow and the retransmitted packets, wasting the network resource.
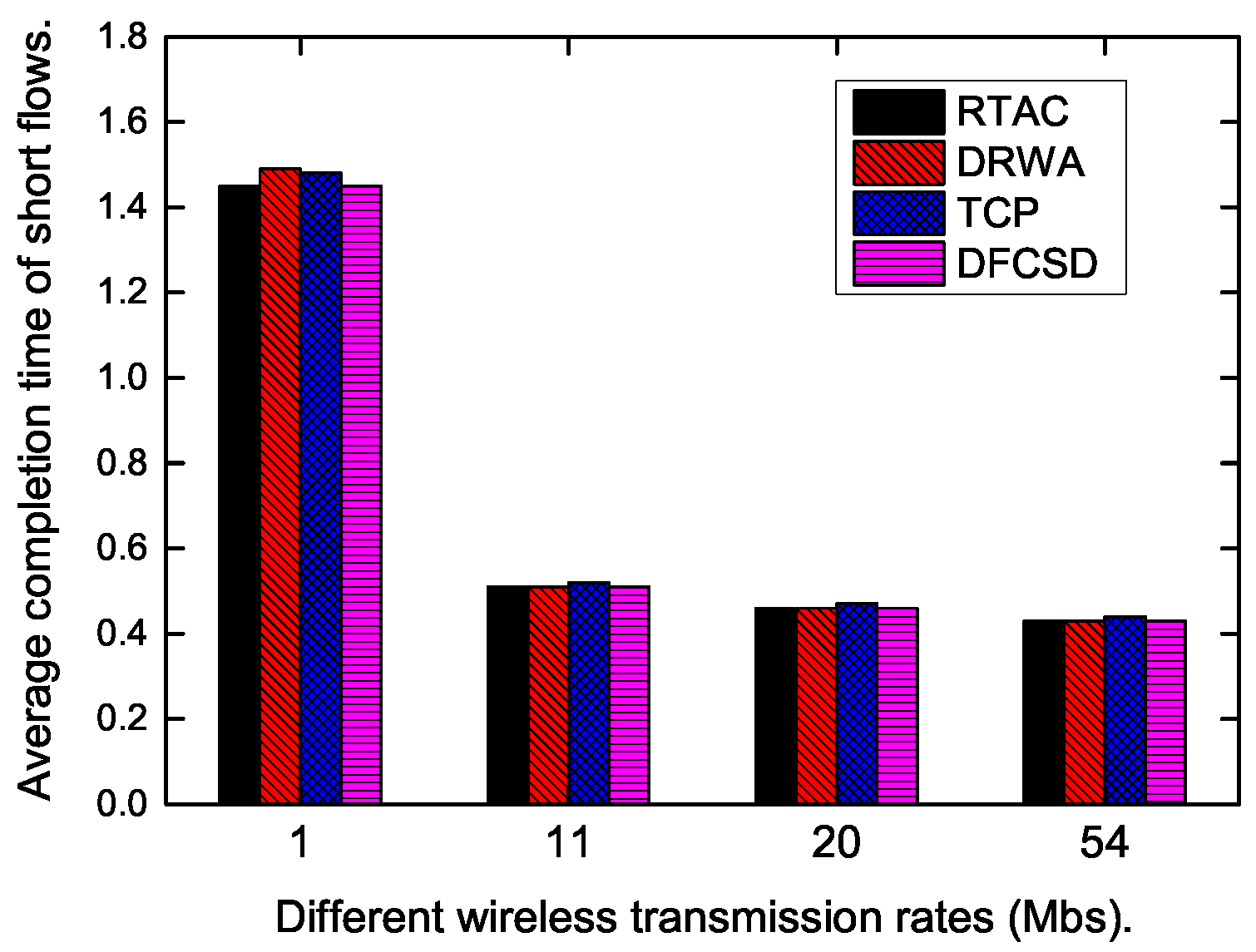
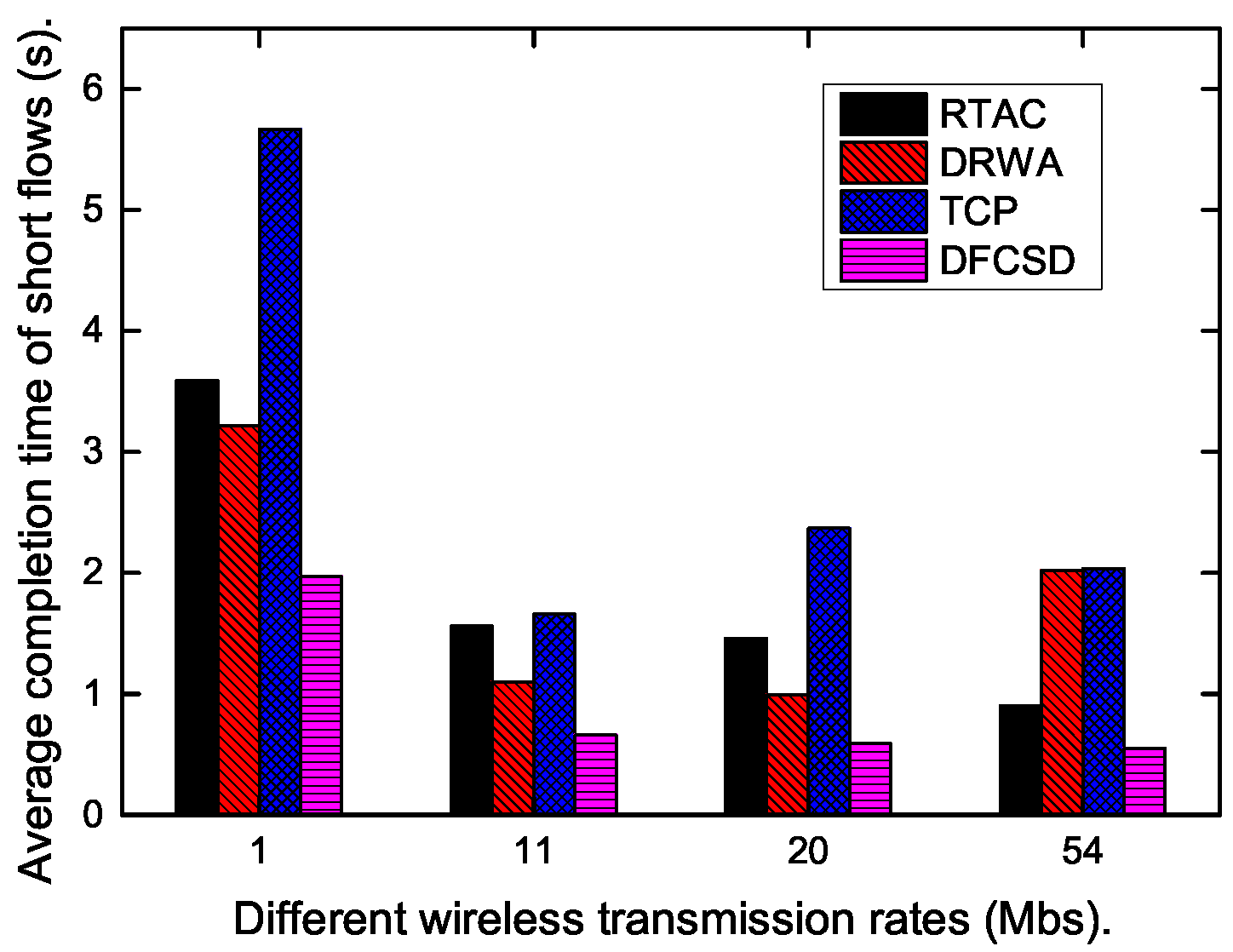
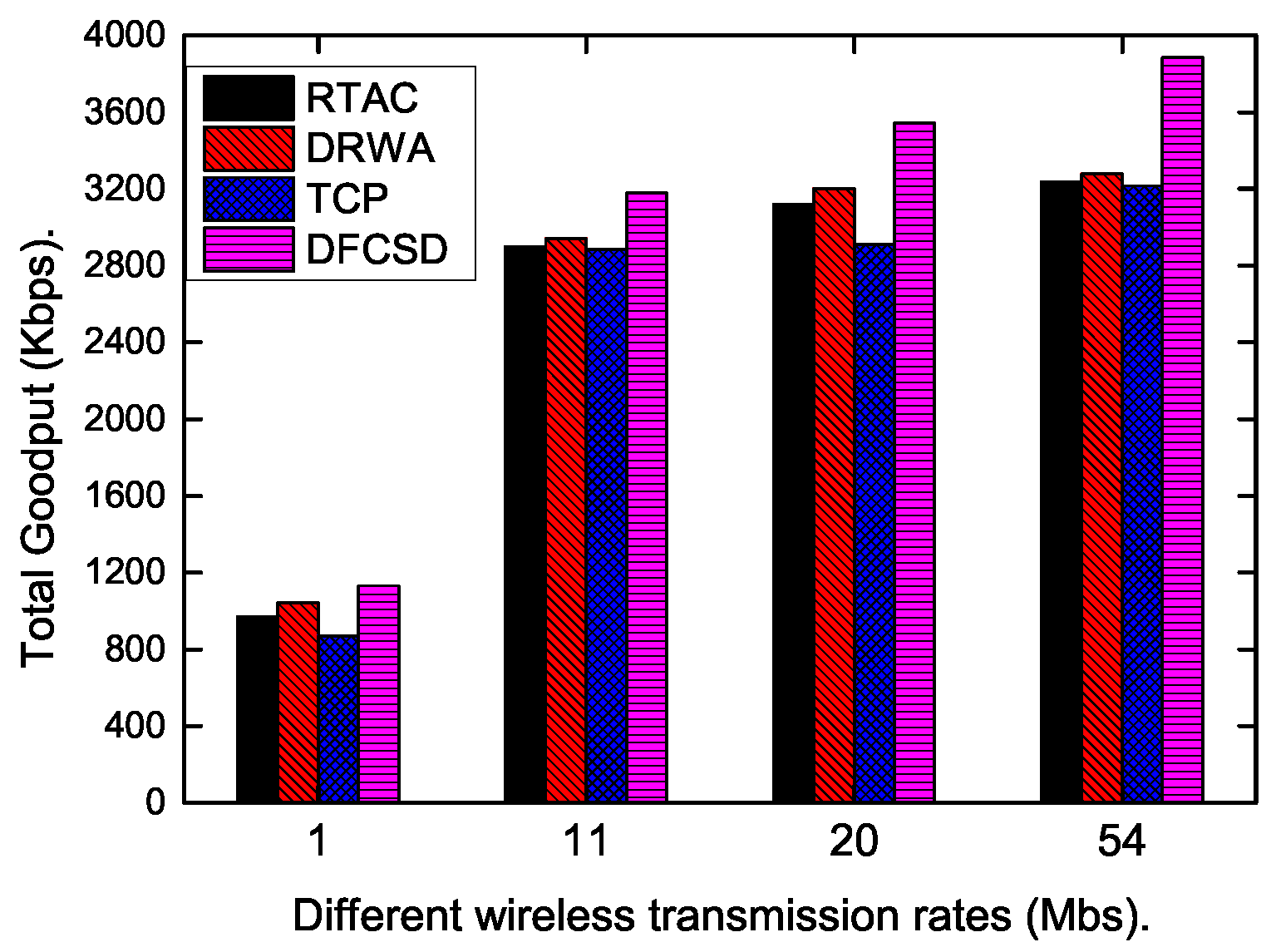
Finally, we did experiments when the wireless rate varied from 1 Mbps to 54 Mpbs to investigate the impact of the wireless rate on each algorithm. The results are shown in
Figure 15,
Figure 16 and
Figure 17. According to these figures, the completion time of the short flow decreases with increasing wireless rate and increases sharply when long flow exists. The results are consistent with our conclusion that long flows have a significant impact on the performance of the competing short flows. In addition, we also calculated the obtained goodput of the networks in this varying wireless transmit scenarios, which is depicted in
Figure 17. DFCSD also outperformed other algorithms, followed by DRWA. As analyzed above, this is a benefit of the reduced retransmissions. The retranmissions are caused by the packet loss and packet retransmission may lead to the waste of the network resource, thus lower network goodput.


 and
and 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
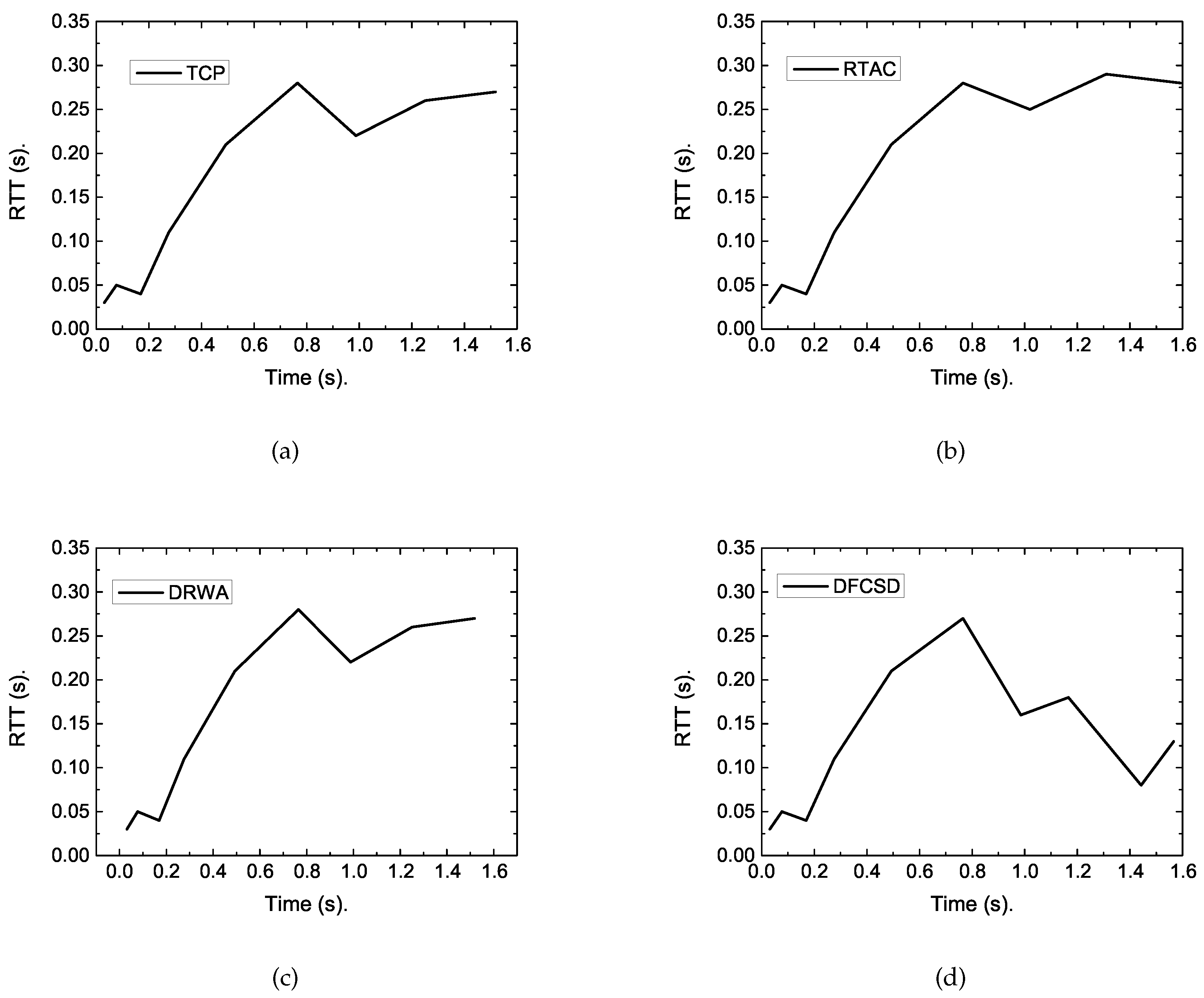{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}