Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection



Abstract
:1. Introduction
- (1)
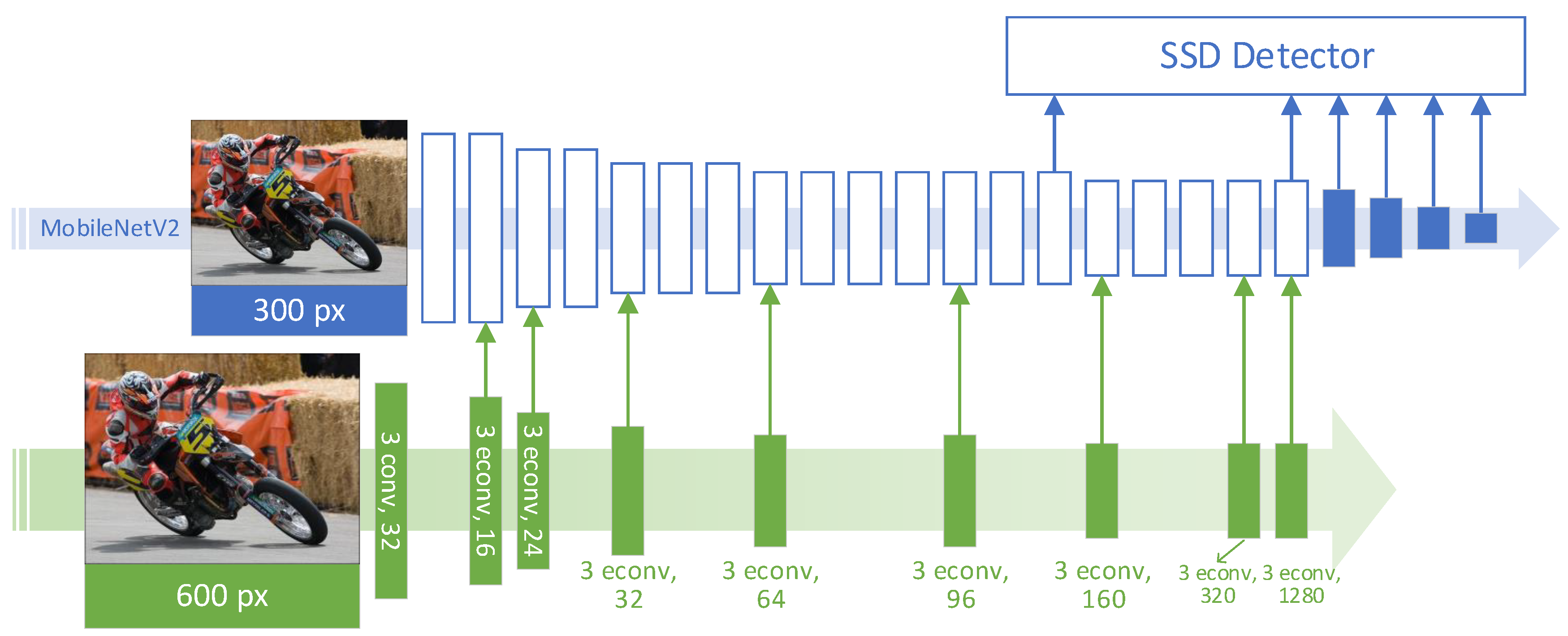
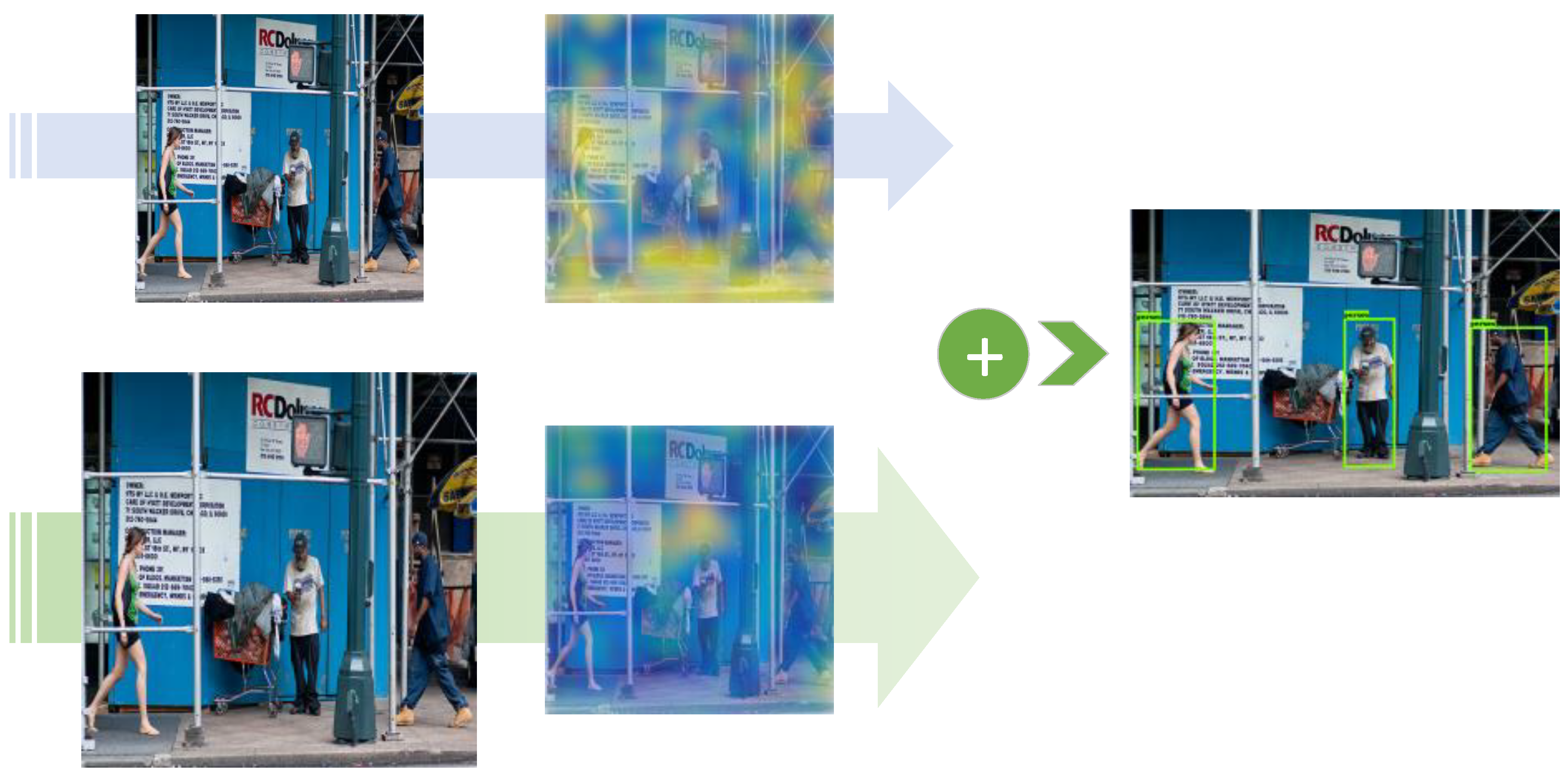
- A novel dual-resolution dual-path framework, DualNets, was designed to enhance CNN-based object-detection applications that are sensitive to computational payloads. DualNets consist of dual CNN paths taking different input resolutions and holding complementary features, resulting in strengthened capability for visual-feature representation.
- (2)
- The auxiliary paths in DualNets were designed to accept larger inputs to enrich visual features for object detection. The auxiliary feature maps were then rapidly downsampled to lower overall computation payloads. With such design patterns, computational cost can be flexibly controlled.
- (3)
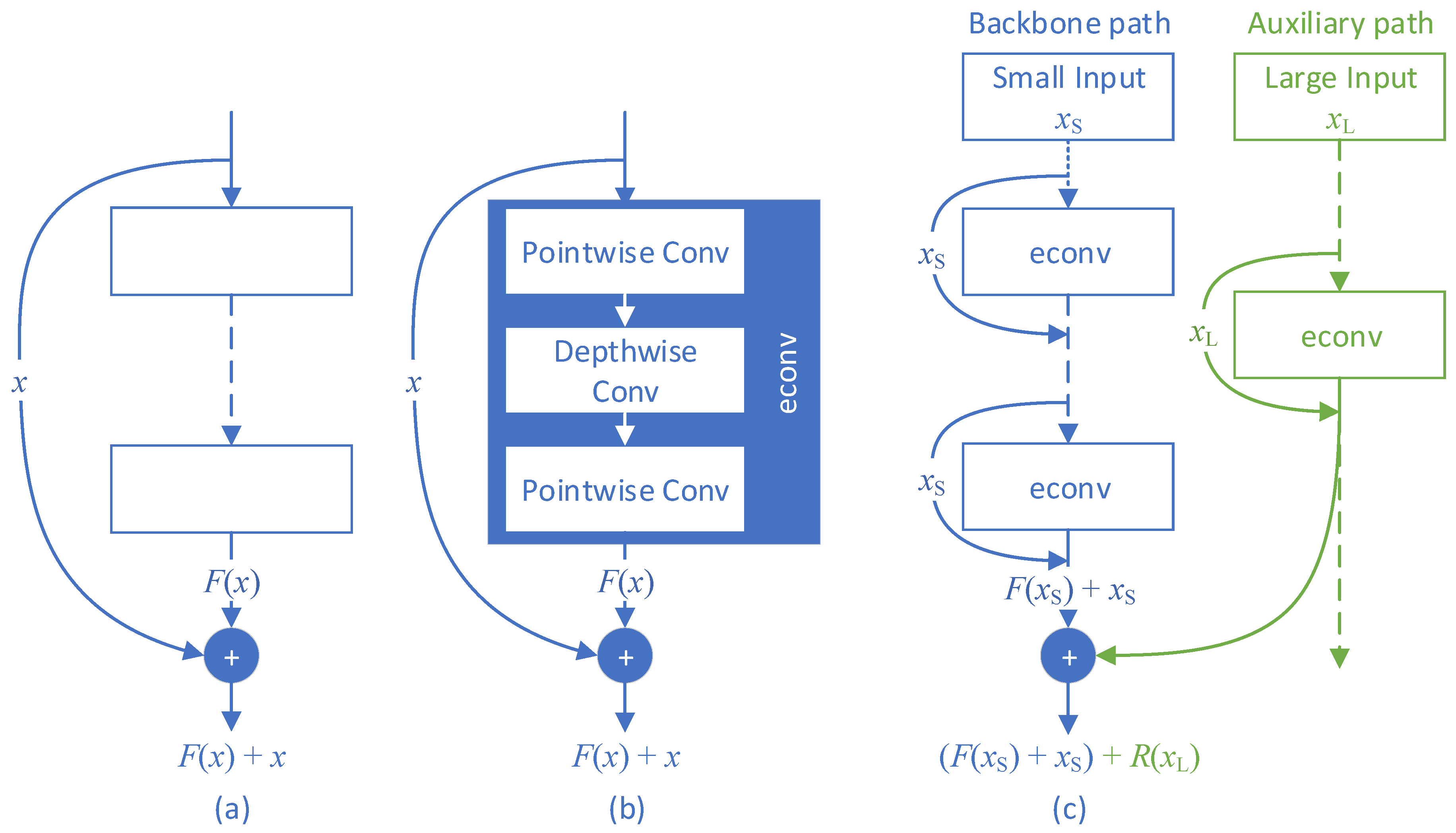
- Feature maps extracted by auxiliary paths are progressively fused into the backbone CNN streamline. We developed a novel form of residual learning [14], which is the core of the proposed progressive fusion strategy. Applying the fusion strategy on complementary features extracted by the dual paths, DualNets can raise the accuracy of mobile-oriented CNN detectors.
2. Related Work
2.1. CNN-Based Object Detection
2.2. Fast Inference Using Small CNN Models
2.3. Dual-Path Models
3. DualNets: Dual-Input Dual-Path CNNs
3.1. Brief Review of MobileNets and SSD
3.2. Dual Inputs and Dual Paths
3.3. Progressive Residual Fusion
4. Experiments
4.1. Ablation Study on Dualnet-300
4.1.1. Weight Sharing
4.1.2. Initializing from a Pretrained Model
4.1.3. Fusion Strategy
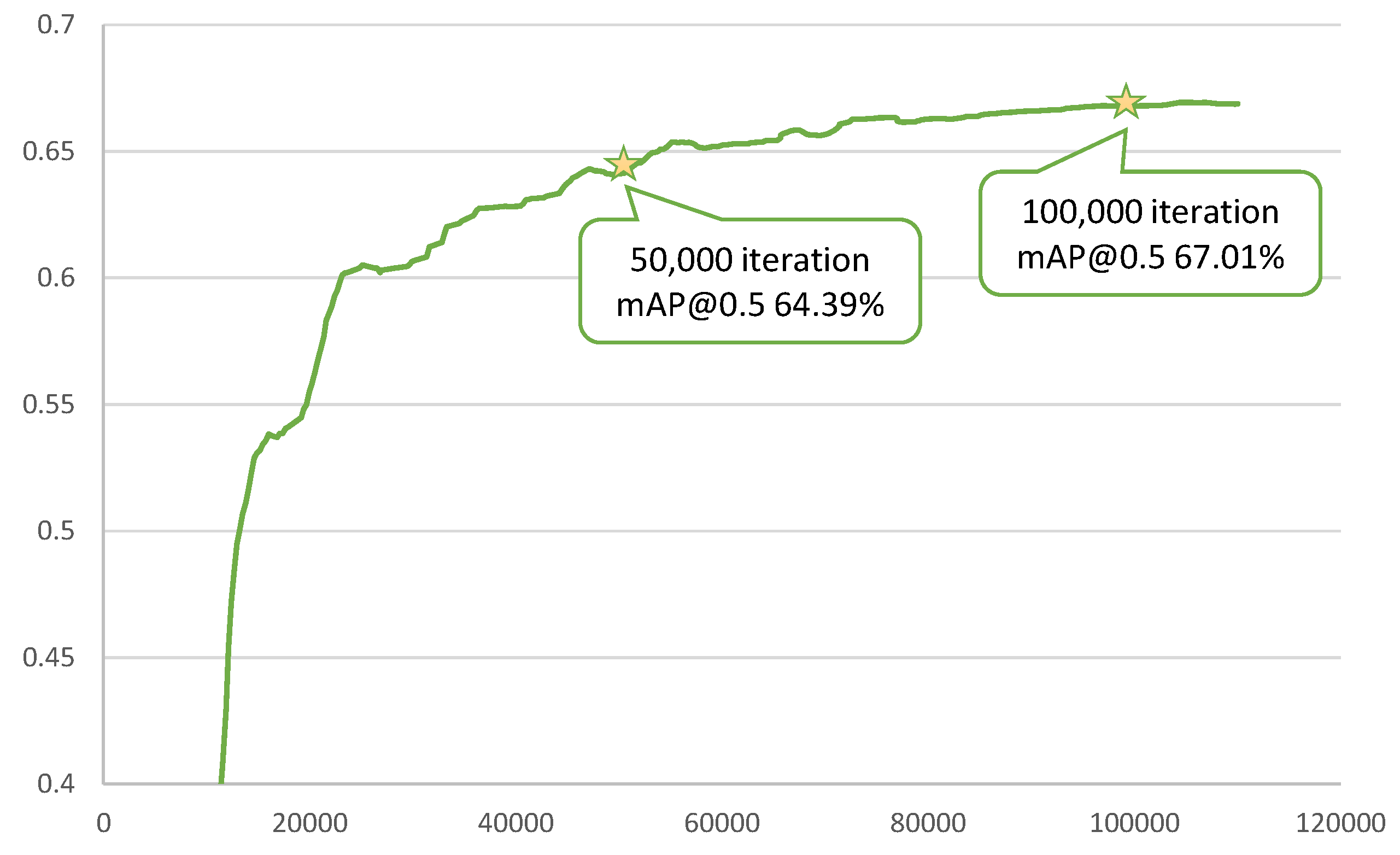
4.2. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, T.Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Pang, Y.; Cao, J.; Li, X. Learning sampling distributions for efficient object detection. IEEE Trans. Cybern. 2017, 47, 117–129. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Ye, L.; Li, X.; Pan, J. Incremental Learning with Saliency Map for Moving Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 640–651. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Neural Information Processing Systems Conference, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Li, X. Exploring Multi-Branch and High-Level Semantic Networks for Improving Pedestrian Detection. arXiv 2018, arXiv:1804.00872. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In Defense of Two-Stage Object Detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. RON: Reverse Connection With Objectness Prior Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, J.; Pang, Y.; Li, X. Learning Multilayer Channel Features for Pedestrian Detection. IEEE Trans. Image Process. 2017, 26, 3210–3220. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Pang, Y. GlanceNets—Efficient convolutional neural networks with adaptive hard example mining. Sci.-China-Inf. Sci. 2018, 61, 109101. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, Q.; Jin, S.; Yan, J. Mimicking Very Efficient Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Wang, J.; Wang, W.; Gao, W. Beyond Knowledge Distillation: Collaborative Learning for Bidirectional Model Assistance. IEEE Access 2018, 6, 39490–39500. [Google Scholar] [CrossRef]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Mazzini, D. Guided Upsampling Network for Real-Time Semantic Segmentation. arXiv 2018, arXiv:1807.07466. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. arXiv 2017, arXiv:1704.08545v2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, G.; Han, J.; Guo, Y.; Liu, L.; Ding, G.; Ni, Q.; Shao, L. Unsupervised Deep Video Hashing via Balanced Code for Large-scale Video Retrieval. IEEE Trans. Image Process. 2019, 28, 1993–2007. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Han, J.; Lin, Z.; Ding, G.; Zhang, B.; Ni, Q. Joint Image-Text Hashing for Fast Large-Scale Cross-Media Retrieval Using Self-Supervised Deep Learning. IEEE Trans. Ind. Electron. 2019. [Google Scholar] [CrossRef]
- Han, J.; Pauwels, E.; de Zeeuw, P.; de With, P. Employing a RGB-D sensor for real-time tracking of humans across multiple re-entries in a smart environment. IEEE Trans. Consum. Electron. 2012, 58, 255–263. [Google Scholar]
- Ding, G.; Guo, Y.; Chen, K.; Chu, C.; Han, J.; Dai, Q. DECODE: Deep Confidence Network for Robust Image Classification. IEEE Trans. Image Process. 2019. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DualNets | |||||||
|---|---|---|---|---|---|---|---|
| MobileNetV2 | |||||||
| # | op. ker. | str. | ch. | # | op. ker. | str. | ch. |
| input 300px | - | 3 | input 600px | - | 3 | ||
| 1 | conv.3 | 2 | 32 | 1 | conv.3 | 2 | 32 |
| 2 | econv.3 | 1 | 16 | 2 | econv.3 | 2 | 16 |
| 3 | econv.3 | 2 | 24 | 3 | econv.3 | 2 | 24 |
| 4 | econv.3 | 1 | 24 | ||||
| 5 | econv.3 | 2 | 32 | 4 | econv.3 | 2 | 32 |
| 6 | econv.3 | 1 | 32 | ||||
| 7 | econv.3 | 1 | 32 | ||||
| 8 | econv.3 | 2 | 64 | 5 | econv.3 | 2 | 64 |
| 9 | econv.3 | 1 | 64 | ||||
| 10 | econv.3 | 1 | 64 | ||||
| 11 | econv.3 | 1 | 64 | ||||
| 12 | econv.3 | 1 | 96 | 6 | econv.3 | 1 | 96 |
| 13 | econv.3 | 1 | 96 | ||||
| 14 | econv.3 | 1 | 96 | ||||
| 15 | econv.3 | 2 | 160 | 7 | econv.3 | 2 | 160 |
| 16 | econv.3 | 1 | 160 | ||||
| 17 | econv.3 | 1 | 160 | ||||
| 18 | econv.3 | 1 | 320 | 8 | econv.3 | 1 | 320 |
| 19 | conv.1 | 1 | 1280 | 9 | econv.3 | 1 | 1280 |
| Initializer | mAP | mAP (Medium Scale) | mAP (Large Scale) |
|---|---|---|---|
| Weight-sharing | 50.07% | 7.88% | 36.20% |
| Pre-trained | 63.43% | 10.93% | 45.72% |
| Random | 64.39% | 10.93% | 46.45% |
| Timing | Method | mAP | mAP (Medium Scale) | mAP (Large Scale) |
|---|---|---|---|---|
| Det. | concat. | 58.51% | 9.51% | 41.32% |
| Det. | res. | 59.39% | 9.56% | 42.35% |
| Prog. late | res. | 61.45% | 9.99% | 45.44% |
| Prog. early | res. | 64.39% | 10.93% | 46.45% |
| mAP@IoU0.5 100 k iter. | mAP (Medium Scale) | mAP (Large Scale) | Time (ms) | |
|---|---|---|---|---|
| MobileNetV2–SSD-300 | 66.48% | 12.16% | 48.91% | 6.18 |
| DualNet-300 | 67.01% | 12.45% | 49.09% | 10.7 |
| Faster R-CNN (VGG, 600 px) | 70.40% | – | – | 110 |
| mAP@IoU.5:.05:.95 | mAP (Medium Scale) | mAP (Large Scale) | |
|---|---|---|---|
| MobileNetV2–SSD-300 | 13.7% | 10.5% | 27.0% |
| DualNet-300 | 14.1% | 10.8% | 28.4% |
| MobileNetV2–SSD-512 | 15.2% | 12.1% | 28.4% |
| DualNet-512 | 15.6% | 12.5% | 29.5% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.; Sun, H.; Song, Z.; Han, J. Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sensors 2019, 19, 3111. https://doi.org/10.3390/s19143111
Pan J, Sun H, Song Z, Han J. Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sensors. 2019; 19(14):3111. https://doi.org/10.3390/s19143111
Chicago/Turabian StylePan, Jing, Hanqing Sun, Zhanjie Song, and Jungong Han. 2019. "Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection" Sensors 19, no. 14: 3111. https://doi.org/10.3390/s19143111
APA StylePan, J., Sun, H., Song, Z., & Han, J. (2019). Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sensors, 19(14), 3111. https://doi.org/10.3390/s19143111