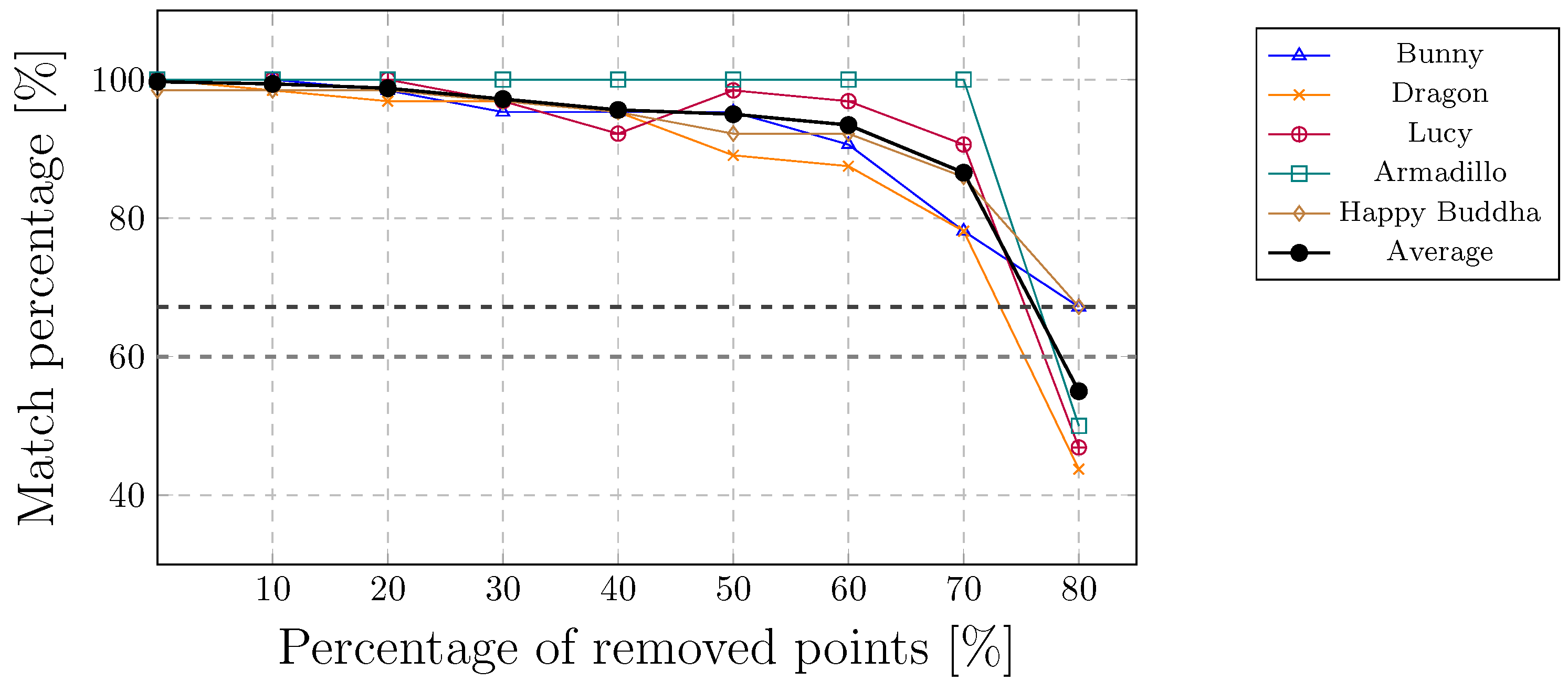
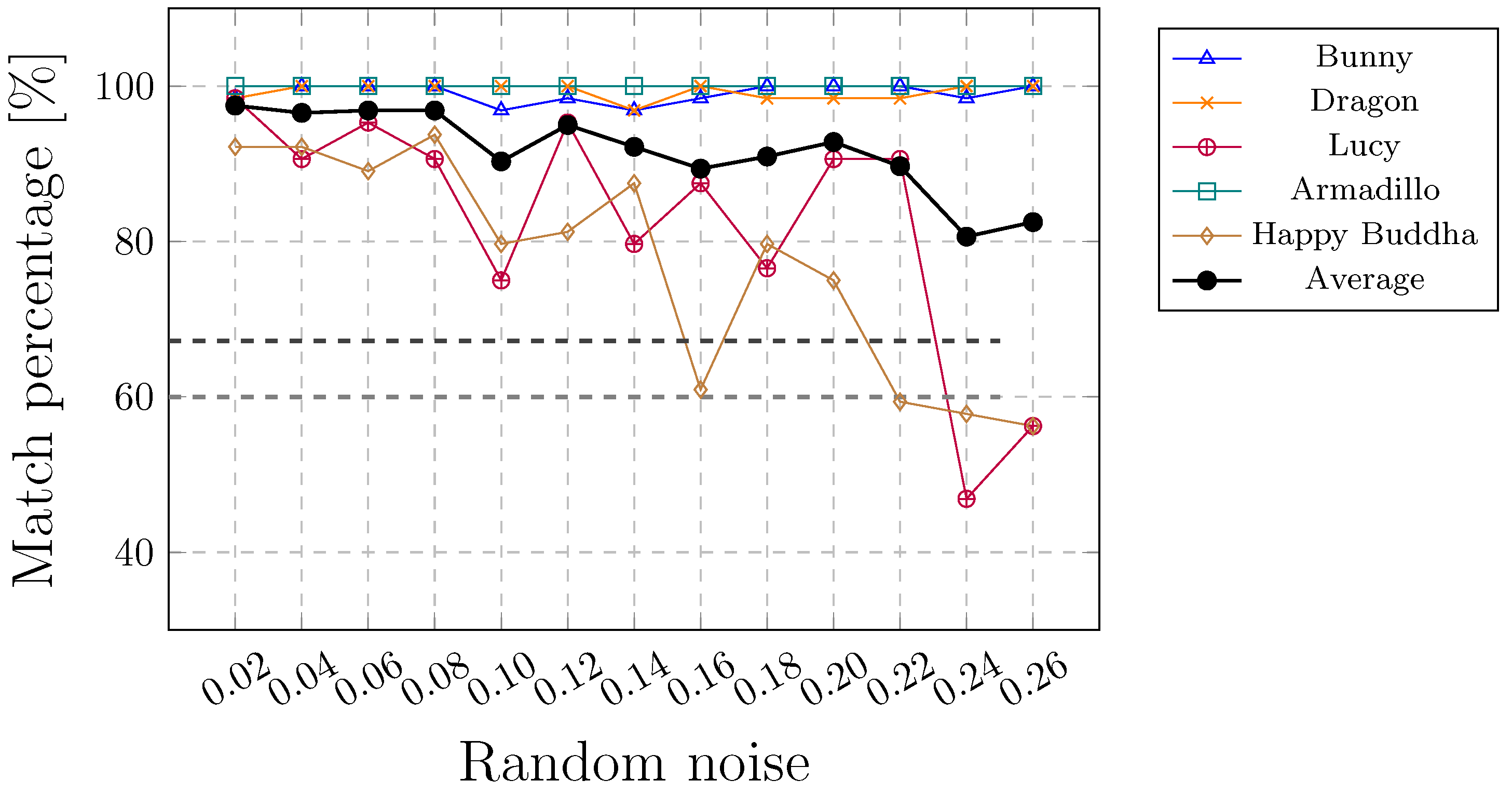
The main contribution of this paper is a new registration method for a relative scale estimation using a 3D convex hull in the process of the watermark extraction from a point cloud [
46,
47]. The main motivation was to overcome the main disadvantage of methods using the RANSAC algorithm and its variants. Namely, RANSAC is an iterative algorithm, operating on all points from the point cloud. The points are unstructured and, therefore, difficult for the registration. The number of geometric entities were reduced and the structured entity (i.e., the 3D convex hull) is obtained, which is more suitable for the registration. The proposed approach is an extension of our method for watermarking of georeferenced airborne LiDAR data [
48], which does not consider the affine transformation attacks, because these types of attacks are meaningless for LiDAR data. On the contrary, the presented extension works on point clouds in general, and can handle affine transformation, cropping, and random removal attacks. In the continuation, a brief overview of the method for watermarking georeferenced airborne LiDAR data is given in the next subsection [
48]. After that, the new registration method for watermark extraction from the point cloud is explained in detail.
3.2. Point Cloud Watermarking
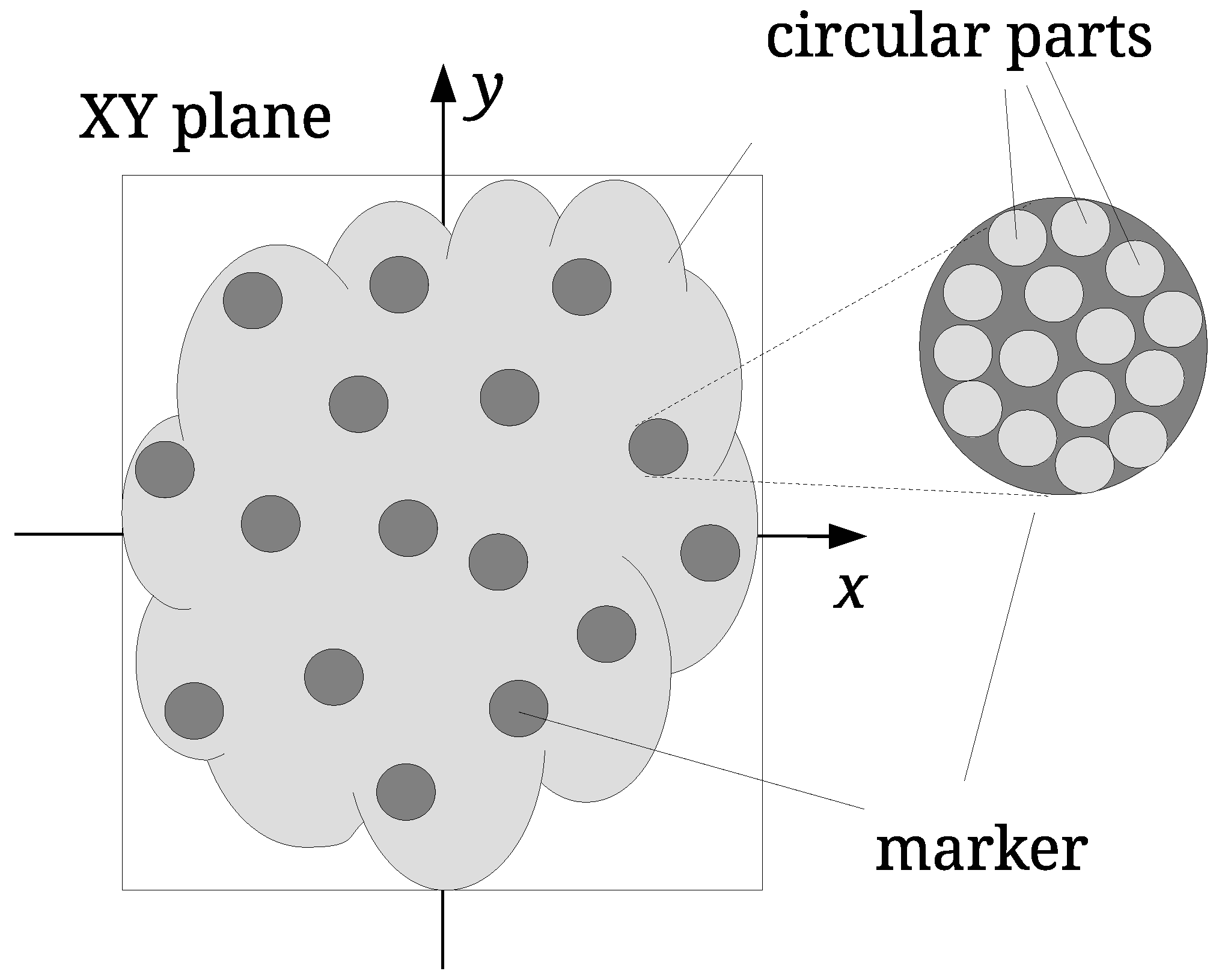
Contrary to the georeferenced LiDAR points, point clouds, consisting of points scanned from the surfaces of 3D models, can be positioned, scaled, and oriented in many different ways. This is the reason watermarking of such point clouds differs from the LiDAR point clouds’ watermarking. In the continuation of the paper, the original point cloud is denoted as I, while the possibly attacked point cloud as .
Watermark Embedding
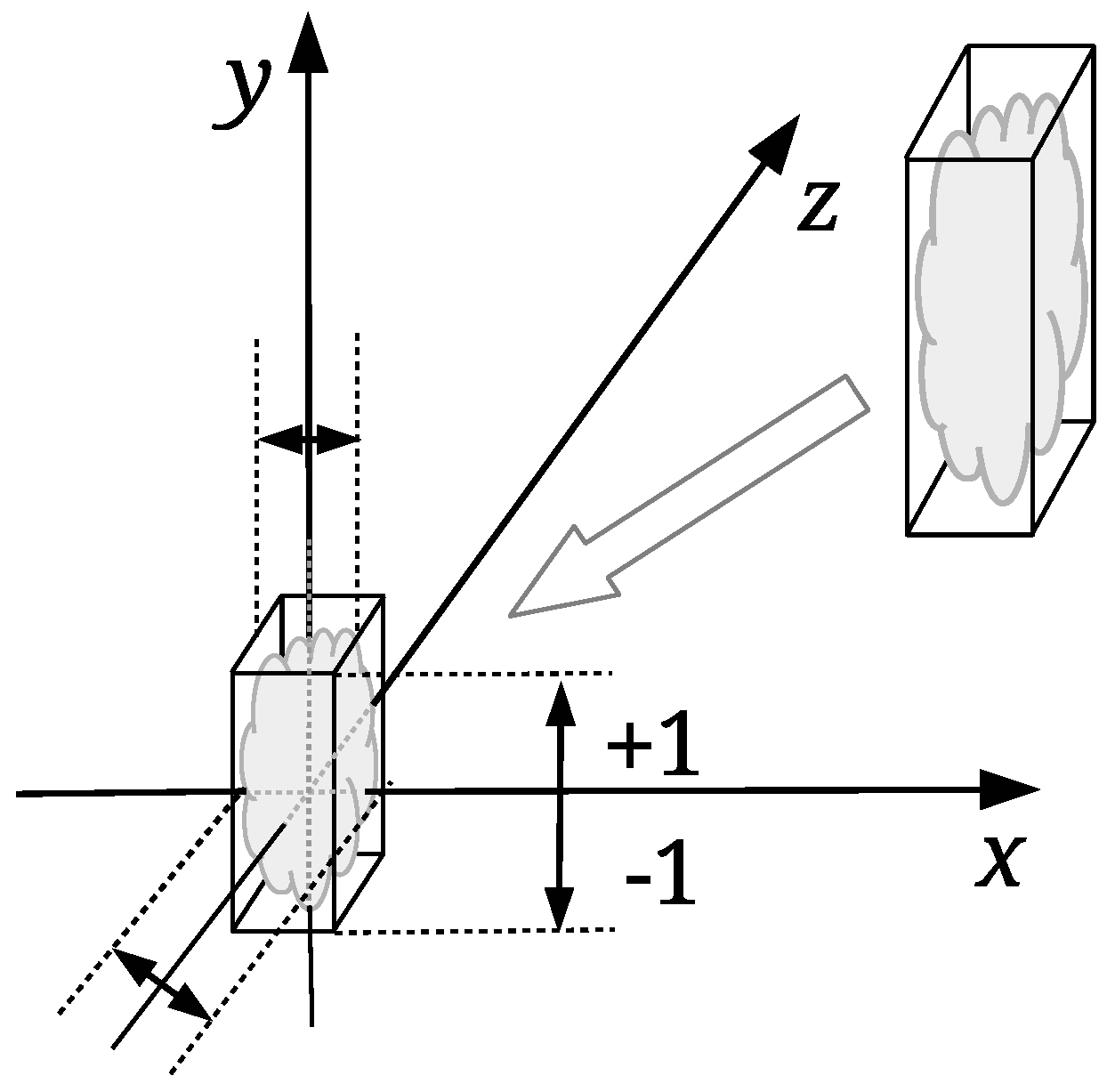
The watermark embedding process should change the coordinates of the points by the same amount regardless of the point cloud size. The input point cloud is normalised first; it is scaled proportionally to map its height between the values
and
(see
Figure 2). The so-called normalised point cloud
is obtained from
I in such a way. The bounding box of
I is needed only in this step. The normalization of the watermarked, and possible attacked point cloud, is not needed in the process of the point cloud registration. The proposed registration approach is based on the scale ratios between identified triangles of the source and target convex-hulls, as explained in the continuation. The same watermark embedding process is then performed, as described briefly in
Section 3.1.
Watermark Extraction
The first step of the watermark extraction from
is its registration. However, before the registration,
is cleaned of possible outliers. In our case, the statistical outlier removal algorithm was applied from the Point Cloud Library (PCL) [
49,
50].
3.3. Convex Hull Point Cloud Registration
The convex hull of a set
I of points in Euclidean space is the smallest convex set that contains
I [
51]. There are various algorithms for constructing convex hulls. In our approach, the Quickhull [
46] has been used for
I and
. Let
(the source convex-hull) and
(the target convex-hull) be convex hulls of
and
, correspondingly. The surface of a 3D convex hull consists of triangles and, therefore,
denotes a set of triangles of
, and
a set of triangles of
. The registration algorithm attempts to find the pairs of corresponding triangles from
and
, i.e.,
. If a matching pair of triangles is found, the appropriate scale factor (i.e., the needed affine transformation) can be calculated easily. Unfortunately, various attacks can change
considerably. Consequently, the number of triangles in both sets can be different, i.e.,
, and the best matching triangles are difficult to identify. Even worse, as explained later, a triangle from
can have multiple matches with triangles from
. However, if
and
are similar to some extent, there should be enough corresponding triangles among
and
that the scale and the rigid affine transformation can be estimated. These are then applied to
for its alignment with
. An Iterative Closest Point algorithm (ICP) was applied for this task [
33,
34,
35].
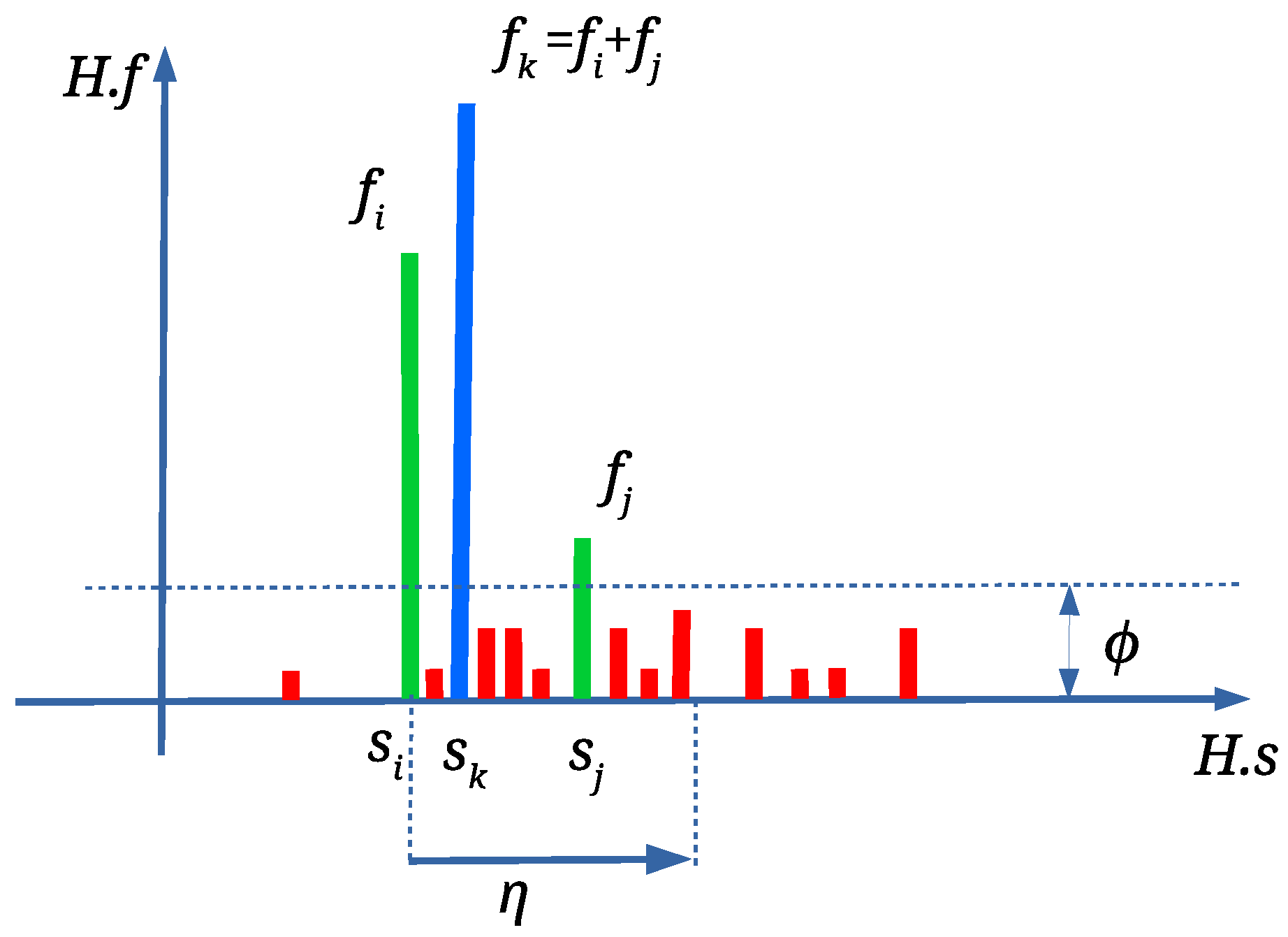
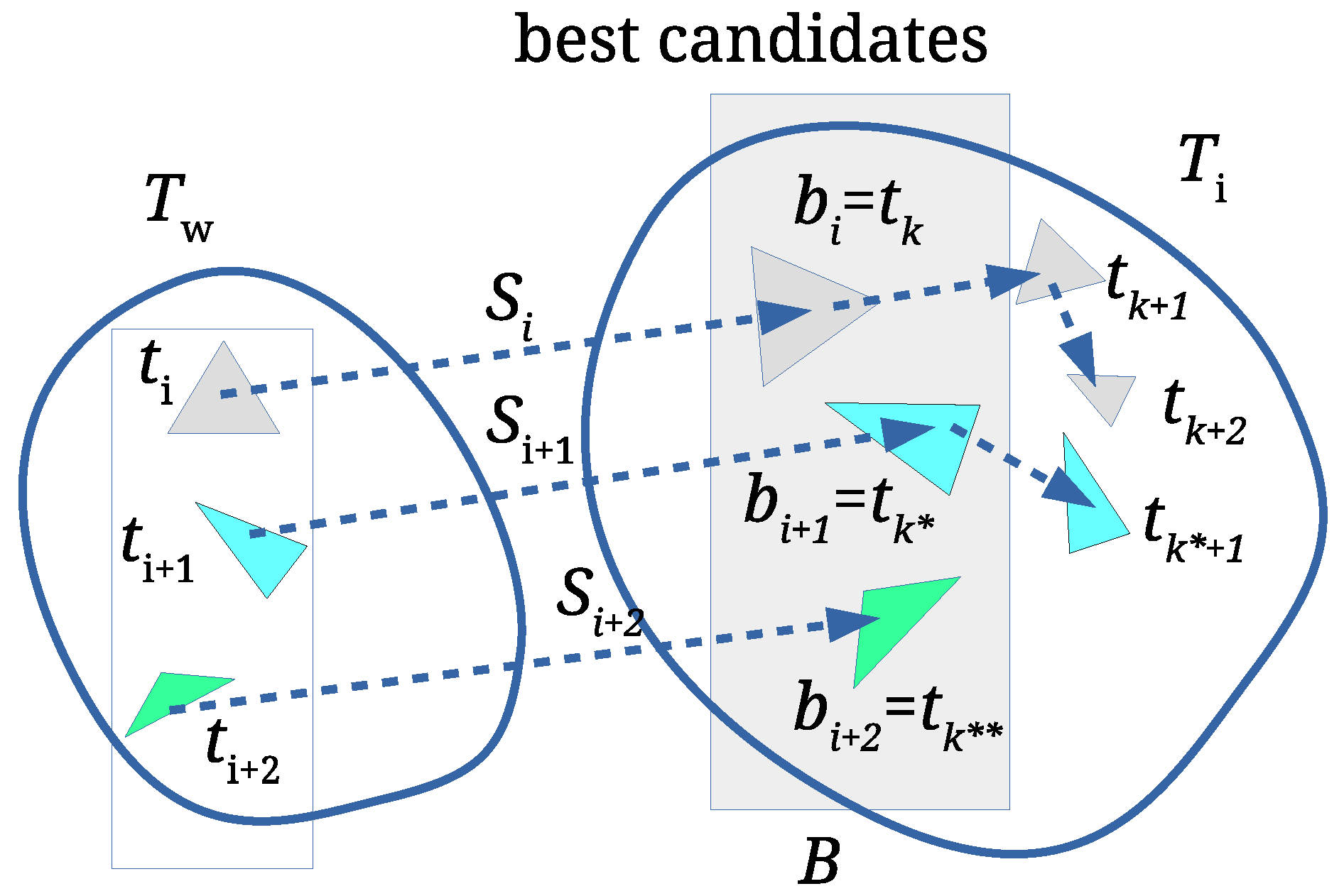
Relative Scale Estimation
The areas
and
of each triangle
and
are calculated first. The triangles of each convex hull are then sorted separately in decreasing order of their areas, and, after that, compared by examining the edge ratios. However, small triangles are not convenient for the comparison, because even the slightest additive noise can change their edge ratios significantly. Thus, 40% of the smallest triangles from
and 20% of the tiniest triangles from
are discarded (these percentages were determined experimentally). Next, the lengths of each triangle edges (
, and
) are calculated, and arranged in increasing order, i.e.,
. The edges are used to calculate the edge ratios
and
according to Equation (
1):
The similarity ratios
and
are then calculated as follows:
Triangle
is considered to be similar enough to triangle
, if
, where
is a given threshold. Arrays of scale factors
are formed for each
and matching similar triangles candidates
by applying Equation (
3):
All arrays
are then sorted in decreasing order. The first elements of each
are the best matching triangles and the candidates for the final scale factor estimation (see
Figure 3). An array
is formed, where
is the first element of
(the one with the best scale factor), while
and
are indices of corresponding similar triangles
and
, respectively. Array
B is then sorted in decreasing order according to the
. If
is obtained by scaling
with some scale factor
s and no other attacks occur, then the largest triangles from
with the similarity ratios
and
match with the largest triangles from
with the same similarity ratios. In such cases, the scale factor
s would be equal to
, i.e.,
.
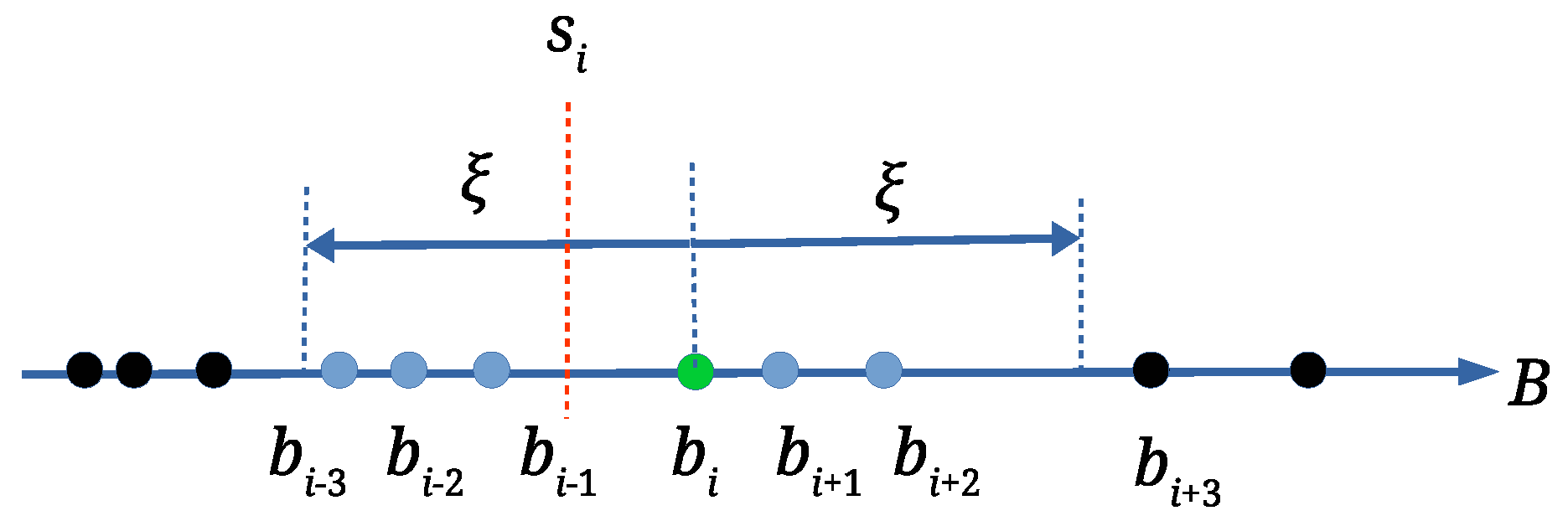
Unfortunately, attacks cause that
may have different values. Thus, array
B is processed in order to determine the most frequent value of the scale factor. An array
is established, which is populated by applying Algorithm 1. The scale factor
is calculated as an average of scale factors within the range
(
is the range threshold, defined experimentally),
is an array of matching triangle pairs, and
is the number of scale factors
within the considered range (see
Figure 4). If only a scale attack has occurred, or if there are no attacks at all, at most one scale factor
with the highest value
exists. On the other hand, the attacks can cause that the scale factors are dispersed. The wrong scale factors should be isolated, and the correct scale factor should be determined as precisely as possible. Thus, the relatively small range threshold tolerance (
) is used. As the scale factors
, that are within range
, are already handled, the next element for processing from
B is the first scale factor that is outside the range
(the scale factor
in
Figure 4).
| Algorithm 1 Find Most Frequent Scale. |
Require:B—an array of best scale factors, —the range threshold (default: ), n—the length of the array B- 1:
- 2:
whiledo - 3:
- 4:
- 5:
- 6:
- 7:
while do - 8:
- 9:
- 10:
- 11:
- 12:
end while - 13:
- 14:
while do - 15:
- 16:
- 17:
- 18:
- 19:
end while - 20:
- 21:
end while
|
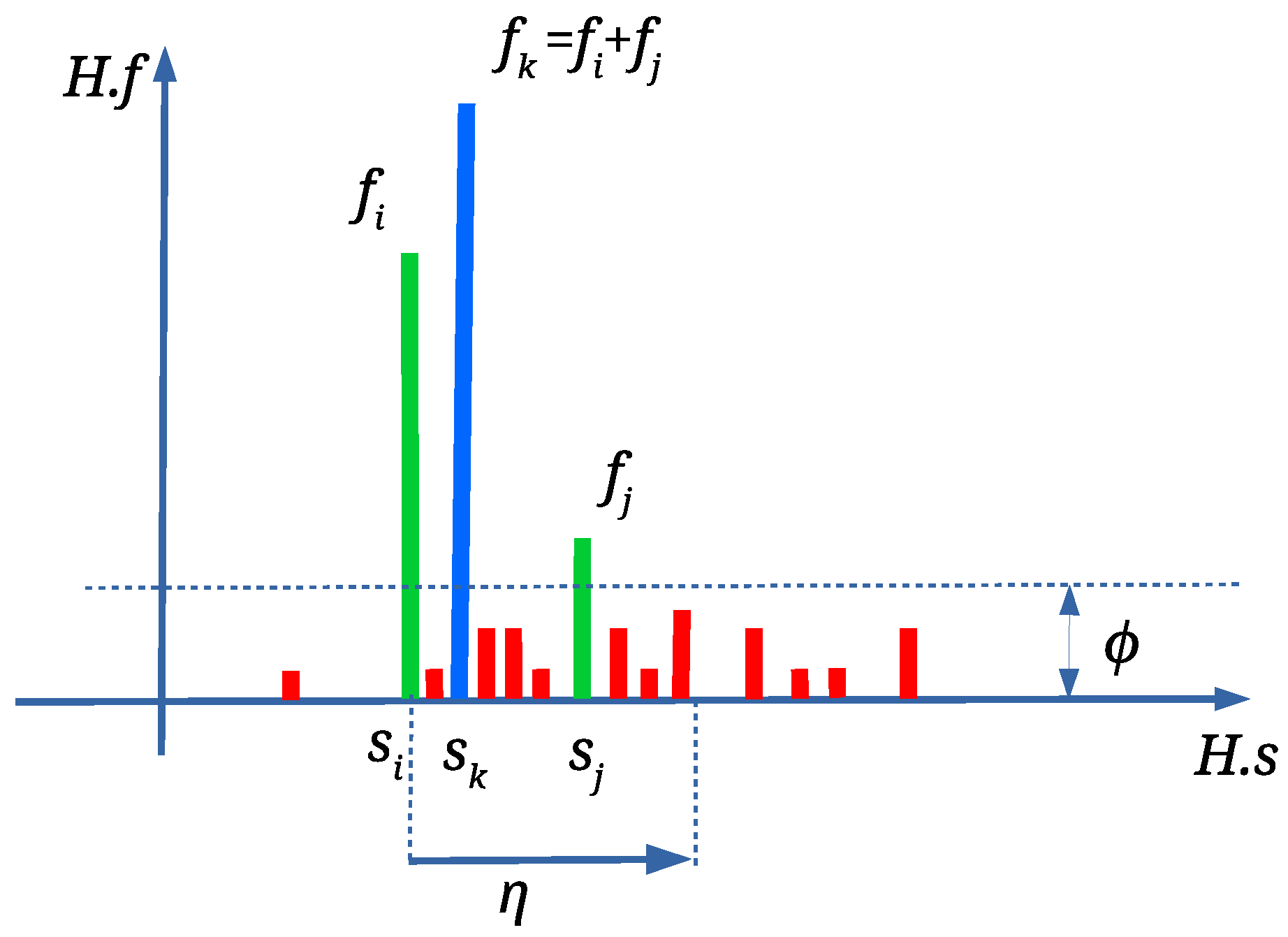
Any scale factor
with
is discarded in the continuation applying Algorithm 2.
is an occurrence threshold, which was set experimentally to
(see
Figure 5). The isolated wrong scale factors are discarded in this way. Depending on the attacks, there can be more than one
with
. In such case, scale factors are joined, calculating weighted average
(see
Figure 5) with Equation (
4). This is performed only if
(see
Figure 5) (the range threshold
was defined experimentally).
Triangle pairs and are joined, too. Finally, H is sorted according to and the first with the highest is the best scale estimation.
| Algorithm 2 Scale Factor Discarding And Joining. |
Require:H—the output from Algorithm 1, —the range threshold (default: , —the frequency threshold (default: ), n—is the length of the array H)- 1:
fordo - 2:
if then - 3:
- 4:
- 5:
- 6:
for do - 7:
if then - 8:
- 9:
- 10:
- 11:
- 12:
end if - 13:
end for - 14:
- 15:
- 16:
- 17:
end if - 18:
end for
|
Rotation and Translation Estimation
The first
with the highest
in the array
H also contains an array of matching triangles
. They are used for estimation of rotation and translation. Two auxiliary point clouds are built, from the first and the second matching pair of triangles
and
. The centres of the triangles are used as the points of these clouds. The source triangles are scaled by
. Because the auxiliary cloud contains considerably fewer points, rotation and translation is performed fast. The rigid transformation matrix (i.e.,rotation and translation) is determined between newly created point clouds by applying the Single Value Decomposition-based alignment estimation [
52]. Because the correspondences of the points between these point clouds have been already obtained from the scale estimation process, applying this algorithm is the most efficient solution. The scaling and the rigid transformation are then applied to the watermarked point cloud
. In this way, a better initial alignment hint is assured for the ICP algorithm. The ICP algorithm is applied at the end for the fine alignment of
to
. As a good initial alignment of the source cloud is achieved, only a few iterations of the ICP are needed.
Extraction of the Watermark Bits
The same steps are performed as in the process of watermark embedding after aligning
to
(see Watermark Embedding in
Section 3.2 and [
48]), except for the last step. The markers are determined; the distances are calculated, and a vector of the DCT coefficients is built. The last DCT coefficient is checked to determine the value of the embedded watermark bit. This process is repeated for all marker locations to reconstruct the whole watermark.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}