1. Introduction
Today, seasonal time series forecasting represents a crucial activity in many fields such as macroeconomics, finance and marketing, and weather and climate analysis. In particular, predicting the evolution of weather parameters as climate change effects represents a crucial activity for the purpose of planning and designing resilient actions to safeguard landscape, biodiversity, and the health of citizens. One of the processes for the evolution of the climate of an area of study is to analyze continuously measured data from weather stations and to capture and monitor changes in seasonal values of climate parameters. In this analysis, a significant role is played by seasonal time series forecasting algorithms applied to weather data.
Time series forecasting techniques are applied to time-measured data in order to predict future trends of a variable. A characteristic detectable in many time series is seasonality, consisting in a regularly repeating pattern of highs and lows related to specific time periods such as seasons, months, weeks, and so on.
A seasonal behavior is present, generally, in time series of weather variables: it consists of variations that are found with similar intensity in the same periods. For example, the warmest daily temperature is recorded periodically in the summer season.
A cyclical behavior, on the other hand, can drift over time because the time between periods is not precise. For example, the wettest day in a geographical area can often be recorded in autumn, but sometimes, it occurs also in other seasons of the year.
An irregular behavior is observed in time series which present short-term oscillations. Normally, they are caused by a stationary stochastic process.
Many algorithms were proposed in the literature to analyze seasonal and cyclical time series. Treatments of this approaches are in References [
1,
2,
3,
4]. The most famous time series forecasting statistical method is the Box–Jenkins approach that applied Autoregressive Integrated Moving Average (ARIMA) models [
1,
2,
3,
4]. A specific model, called Seasonal ARIMA or SARIMA [
5], is used when the time series exhibits seasonality.
ARIMA models cannot capture nonlinear tendencies generally present in a time series: some soft computing approaches have been presented in the literature for capturing nonlinear characteristics in seasonal time series.
Artificial Neural Networks (ANN) can be applied as nonlinear auto-regression models to capture nonlinear characteristics in the data. Some authors propose a multilayer Feed Forward Network (FNN) method [
6,
7] in which the output value
yt of a parameter
y at time
t is given by a function of the values
yt−1,
yt−2, …,
yt−ND of the measured values at time
t − 1,
t − 2, …,
t − ND, where ND is the number of input nodes. Other authors propose seasonal time series forecasting methods based on Time Lagged Neural Networks (TLNN) architecture [
8,
9,
10,
11]. In a TLNN, the input nodes are the time series values at some particular lags. For example, in a time series with monthly seasonal periods, the neural network used for forecasting the parameter value at time
t can contain input nodes corresponding to the lagged values at the time
t − 1,
t − 2, ...,
t − 12.
The main problem of the ANN-based forecasting method is the choice of appropriate values for the network parameters on which the accuracy of the results depends heavily.
Also, Support Vector Machine-based (SVM) approaches are used to capture nonlinear characteristics in time series forecasting. SVM uses a kernel function to transform the input variables into a multidimensional feature space; then, the Lagrange multipliers are used for finding the best hyperplane to model the data in the feature space [
12]. Some authors propose seasonal forecasting methods based on Least Squares Support Vector Machine models [
13,
14,
15]. LSSVM [
16] is a variation of SVM that involves least square optimization solutions in a kernel-based SVM regression model.
The main advantage of SVM-based methods is that that the solution is unique and there is no risk to move towards local minima, but some problems remain as the choice of the kernel parameters influences the structure of the feature space, affecting the final solution.
In order to overcome these difficulties in Reference [
17], a hybrid adaptive ANN method, called ADANN (Automatic Design of Artificial Neural Networks), is proposed by applying a genetic algorithm for evolution of the ANN topology and the back-propagation parameter. The authors compare this algorithm with SARIMA- and SVM-based algorithms on various time series, showing that the best results in terms of accuracy are obtained by using the ADANN algorithm, even if it requires more computational effort than the previous ones.
The Fuzzy Transform (F-transform) technique [
18] was applied by some authors in times series forecasting. In Reference [
19], the authors use the multidimensional inverse F-transform as a regression function in a time series analysis. In Reference [
20], a hybrid method integrating fuzzy transform, pattern recognition, and fuzzy natural logic techniques is proposed in order to predict the trend and the seasonal behavior of seasonal time series.
In References [
21,
22], a novel forecasting algorithm is proposed by using the direct and inverse F-transform, called the Time Series Seasonal F-transform (TFSS). In the TFSS, a polynomial fitting is applied to evaluate the trend of the time series. Then, the dataset is de-treated by subtracting the trend from it and the de-treated dataset is partitioned in s seasonal subsets. Finally, the inverse F-transform is calculated on each seasonal subset. The authors test the TFSS algorithm on whether the time series shows that it improves the performances of the seasonal ARIMA and F-Transform forecasting methods.
The aim of our research is to improve the performance of the TFSS algorithm. In this work, we apply the inverse F
1-transform [
23] as a regression function to manage seasonal time series: the F
1-transform represents a refinement of the F-transform for approximating a function. We have implemented a variation of the TFSS method in which we used the F
1-transform to forecast seasonal time series. We test our method to forecast seasonal time series of the climatic Heat Index (HI) parameter calculated by the daily weather data measured from a set of weather stations. In our experiments, we compare the performances of our method with the ones obtained by using the TSSF, Seasonal Arima, and ADANN methods. In Reference [
23], the authors show that SVM and ADANN have the same performances. For this reason, in our experiments carried out in this research, we do not use the SVM method but only the ADANN method
In
Section 2, we introduce the F
1-transform concept; in
Section 3, we present our seasonal time series forecasting methods. In
Section 4, we show the results of the tests; conclusions and future prospects are contained in
Section 5.
2. F1-Transform
2.1. Direct and Inverse Fuzzy Transform
Let [
a,
b] be a closed interval of real numbers, and
x1,
x2, …,
xn (
n ≥ 2) be points of [
a,
b], called nodes, such that
x1 =
a <
x2 < … <
xn =
b. The family of fuzzy sets
A1, …,
An: [
a,
b] → [0,1], called basic functions [
18], is a fuzzy partition of [
a,
b] if the following holds:
- (1)
Ai(xi) = 1 for every i = 1, 2, …, n;
- (2)
Ai(x) = 0 if x is in [xi−1,xi+1] for i = 2, …, n − 1;
- (3)
Ai(x) is a continuous function on [a,b];
- (4)
Ai(x) strictly increases on [xi−1, xi] for i = 2, …, n and strictly decreases on [xi,xi+1] for i = 1,…, n − 1;
- (5)
A1(x) + … + An(x) = 1 for every x in [a,b].
The fuzzy sets {A1(x), …, An(x)} form an h-uniform fuzzy partition of [a,b] if
- (6)
n ≥ 3 and xi = a + h∙(i − 1), where h = (b − a)/(n − 1) and i = 1, 2, …, n (that is, the nodes are equidistant);
- (7)
Ai(xi − x) = Ai(xi + x) for every x in [0,h] and i = 2, …, n − 1;
- (8)
Ai+1(x) = Ai(x − h) for every x in [xi, xi+1] and i = 1, 2, …, n − 1.
Let f(x) be a function defined in [a,b]. Here, we are only interested in the discrete case, that is, in functions f, assuming determined values in the set P of points p1, ..., pm of [a,b]. The set P is called sufficiently dense with respect to the fixed partition {A1, A2, …, An} if, for any index i in {1, …, n}, there exists at least an index j in {1, …, m} such that Ai(pj) > 0
If
P is sufficiently dense with respect to the fixed fuzzy partition {
A1,
A2, …,
An}, we can define the n-tuple {
F1,
F2, …,
Fn} as the discrete direct F-transform of
f with respect to the basic functions {
A1,
A2, …,
An} [
18], with the following components:
for
k = 1, …,
n. Similarly, we define the discrete inverse F-transform of
f with respect to the basic functions {
A1,
A2, …,
An} by setting
The following theorem holds (Reference [
18]):
Theorem 1. Let f(x) be a function assigned on the set of points P = {p1, ..., pm} of [a,b]. Then, for every ε > 0, there exists an integer n(ε) and a related fuzzy partition {A1, A2, …, An(ε)} such that for any j = 1, …, m 2.2. F1-Fuzzy Transform
Let {
A1(
x), …,
An(
x)} be an uniform fuzzy partition of [
a,
b] and
, where
denotes the Hilbert space of square integrable functions on [
a,
b]. We consider the linear subspace
of
with orthogonal basis given by the following polynomials:
where the coefficients
and
are given by
and
The following theorem holds (Reference [
23], Theorem 3).
Theorem 2. Letand {Ak(x) k = 1, ..., n} be a h-uniform fuzzy partition of [a,b]. Moreover, let f and A1, A2, …, An be functions four times continuously differentiable on [a,b]. Then, the following approximation holds true:whereis the derivative of the function f in the point xk. From Theorem 2 descends the following corollary (Reference [
23], Corollary 1).
Corollary 1. Letand {Ak(x) k = 1, ..., n} be a generalized fuzzy partition of [a,b]. Moreover, letand Ak be four times continuously differentiable on [a,b]. Then, for each k = 1, …, n, we have the following:
where
is the kth component of the F1-transform of f with respect to Ak, k = 1, ..., n.
Let {Ak(x) k = 1, ..., n} be an h-uniform fuzzy partition of [a,b] and (x1, f(x1)),…, (xn, f(xn)) be a discrete set of n points of the function f. Equations (2) and (3) can approximate f in the discrete case asandrespectively. The discrete approximation ofandwith Equations (10) and (11) are used to calculate the discrete F1-transform components in Equation (8) and to approximate the function f(x) in Equation (7). The parameteris given by the kth component of the discrete direct F-transform (Equation (1)).
We define the discrete inverse F1-transform of f: The following theorem holds:
Theorem 3. Let {Ak(x) k = 1, ..., n} be an h-uniform generalized fuzzy partition of [a,b], and letbe the inverse F1-transform of f given by Equation (12). Moreover, let f, A1, A2, …, An be functions four times differentiable on [a,b]. Then, for any x ∊ [a,b], the following holds: Proof of Theorem 3. By Theorem 3, we can use the inverse F1-transform to approximate the function f in a point x ∊ [a,b]. □
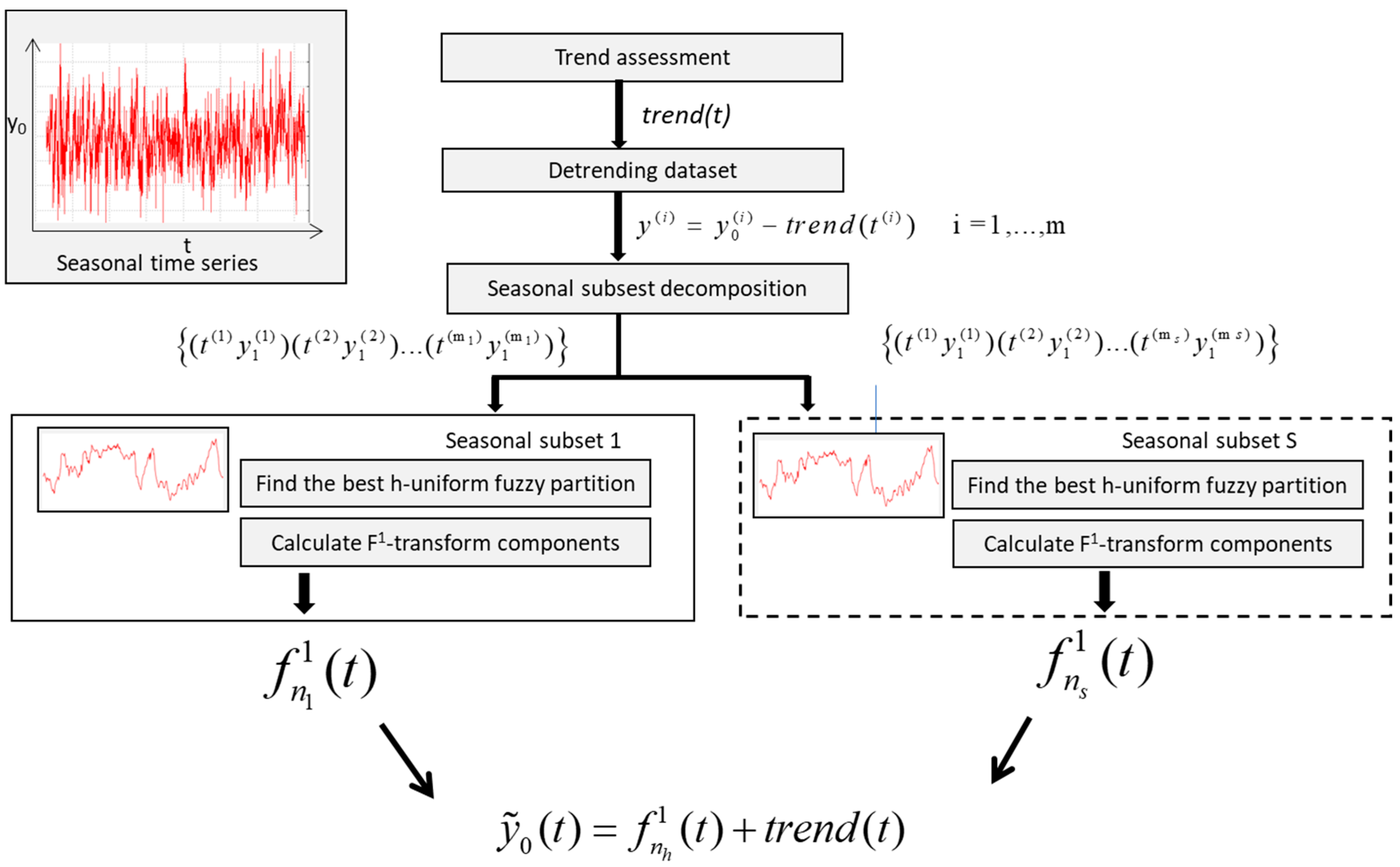
3. The Time Series Seasonal Forecasting F1 Fuzzy Transform Method (TSSF1)
Let {(t(1), y0(1)), (t(2), y0(2)) ... (t(m), y0(m))} be a time series formed by a set of M measures of a parameter y0 at different times; we suppose that this time series shows seasonality.
As in TFSS, we apply a polynomial fitting to approximate the trend of the time series; then, we partition the time series in s seasonal subsets.
To approximate the seasonality, we calculated the direct F1-transform of each subset and approximate the seasonal functionality with the inverse F1-transform.
After assessing the functional trend of the phenomenon in time, we subtract the trend from the data, obtaining the de-treated dataset:
It is partitioned in S subsets, with S as the seasonal period. Each subset represents the seasonal fluctuations with respect to the trend.
Let {(t(1) , y(1)), (t(2) , y(2)) ... (t(ms) , y(ms))}, s = 1, 2, …, S be the sth subset given by ms couples of de-treated data where t(1), t(2), … t(ms) are defined in a domain . Let {A1, A2, …, Ans} be an h-uniform generalized fuzzy partition sufficiently dense with respect to this subset, where A1, A2, …, Ans are four times differentiable in the domain .
We calculate the direct F
1-transform components (Equation (9)),
, where
where
We approximate the seasonal fluctuation at time
t with the following inverse F
1-transform:
To forecast the value of the parameter
y0 at time
t in the
hth season, we apply the following formula:
where
is the approximation of the parameter
y0 at time
t,
is the
sth seasonal fluctuation at time
t, and
trend(
t) is the trend of
y0 at time
t.
For creating the h-uniform fuzzy partition of the
sth subset, we take the following basic functions:
where
t1 =
,
t2, …
tns =
are the nodes,
, and
k = 1, …,
ns.
To obtain the optimal number of nodes
ns, we implement the process applied in Reference [
17]: the value of
ns is initially set to 3. Then, we calculate the direct F
1-transform components via Equations (15) and (16) and the Mean Absolute Deviation Mean (MAD-MEAN) index, given by
where the value
i = 1, 2, …,
ms is calculated by Equation (17). The MAD-MEAN index represents a good accuracy metric in time series analyses, as proved in Reference [
24].
If the MAD-MEAN index is greater than a specified threshold, the algorithm stops and Equation (18) is used to assess the value of y0 at time t; otherwise, the process is iterated by creating an h-uniform fuzzy partition, where ns = ns + 1. At any iteration, if the subset is not sufficiently dense with respect to the fuzzy partition, the algorithm stops; else, the values of and , k = 1, 2, …, ns by Equations (15) and (16) are calculated.
Table 1 shows the algorithm in pseudocode. The output of the algorithm are the polynomial coefficients to be used to obtain the trend at time
t and the F
1-transform components
and
, so to calculate the assess of the value
at time
t via Equation (18).
Figure 1 is a schematized TSSF1 algorithm.
4. Experimental Results
We test the TSSF1 algorithm on a dataset of daily weather data collected from weather stations. The dataset is composed by daily weather data collected from the weather stations managed by the Italian Air Force located in the Campania Region: they are the weather stations of Capo Palinuro, Capri, Grazzanise, Napoli Capodichino, Salerno Pontecagnano, and Trevico.
Our aim is to analyze the seasonality of the Heat Index (HI) [
25], an index function of the maximum daily air temperature and of the daily relative humidity. HI index measures the physiological discomfort caused by the presence of high temperatures and high humidity levels.
The HI takes into account several factors, such as vapor pressure, actual wind speed, sample size, internal body temperature, and sweating rate, represented by numerical coefficients. The calculation of HI is based on the following formula obtained by multiple regression analysis carried out in Reference [
26] (NWS-NOAA, 2):
with
T = air temperature and
RH = relative humidity (%). The values of the coefficients
c1, ...,
c9 are shown in
Appendix A.
This formula applies only in the case of temperatures above 27 °C and relative humidities above 40%, conditions often verified during the summer. For temperatures below 25 °C, with low humidity (<30%), it can be assumed that the heat index coincides with the actual temperature, without significant effects due to humidity.
The table in
Appendix A shows the classification of the heat wave health hazard levels based on HI values carried out by the United States National Weather Service-National Oceanic Atmospheric Administration (NWS-NOAA, 2).
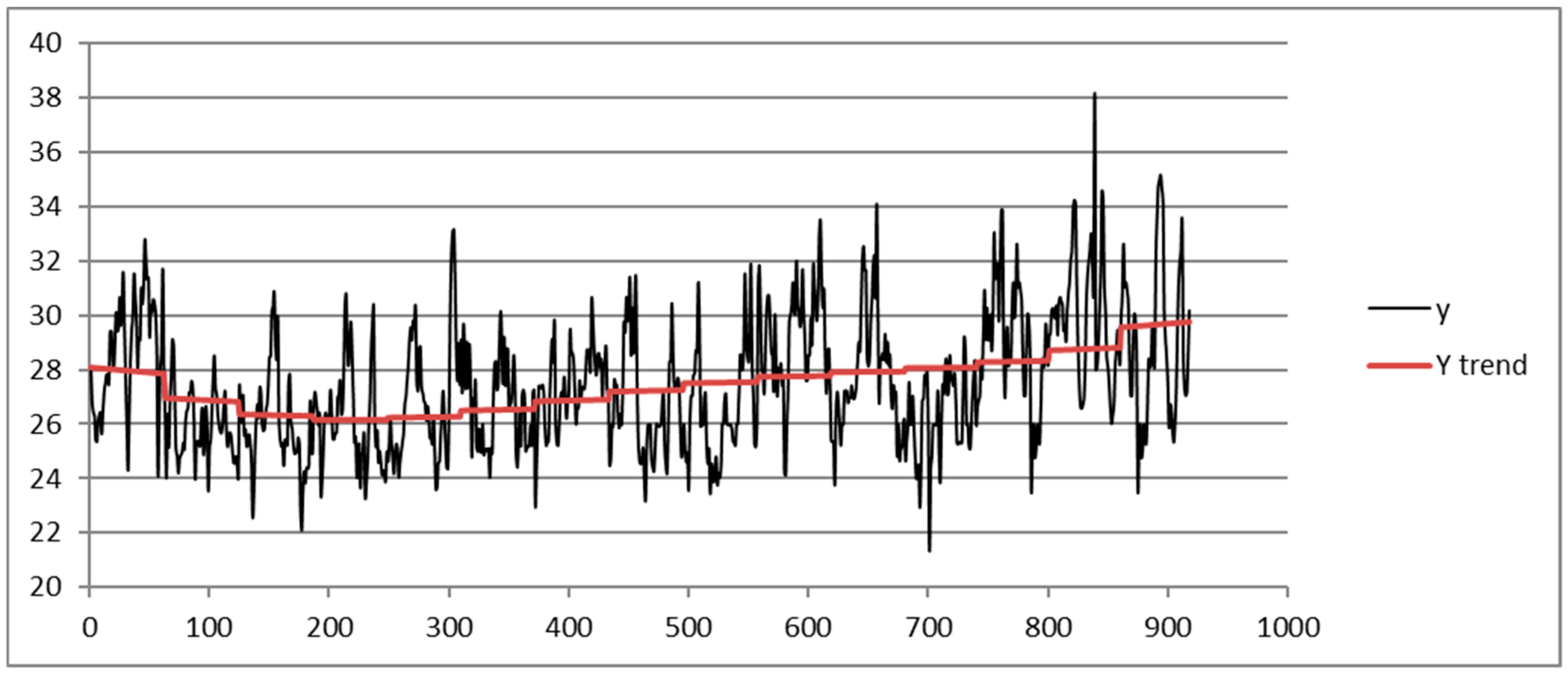
The training datasets are given by HI values measured in degrees Celsius and calculated by the daily max temperature and the relative humidity recorded in the months July and August from 1 July 2003 to 31 August 2017, comprising a period of 918 days. The season is given by the number of weeks, so we partition each dataset in k = 9 subsets.
Following the TSSF algorithm, we calculate the trend fitting the data with a polynomial of 9th degree ; then, a threshold value of 5 for the MAD-MEAN index is set.
Figure 2 shows the trend obtained from the dataset of the station of Capodichino. The day is represented on the abscissa using the corresponding progressive identifier.
We compare the results obtained via SARIMA, ADANN, TSSF, and TSSF1. We use the Forecast Pro tool [
27] to apply the SARIMA algorithm. The ADANN method is applied by implementing the ADANN algorithm in References [
17,
28,
29]; based on the experimental tests we have carried out, we apply a GA algorithm with a stopping criterion of 200 generations to search the optimal number of the input and hidden layer nodes. The TSSF method is applied implementing the TSSF algorithm in Reference [
22].
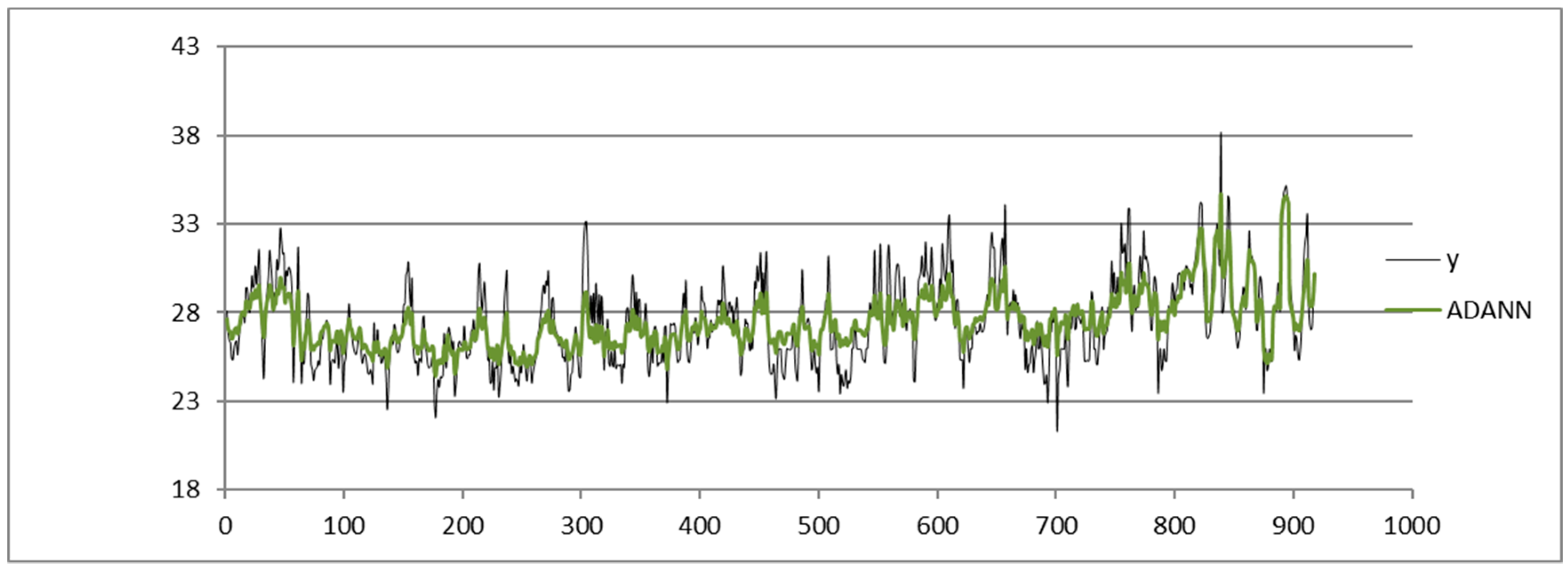
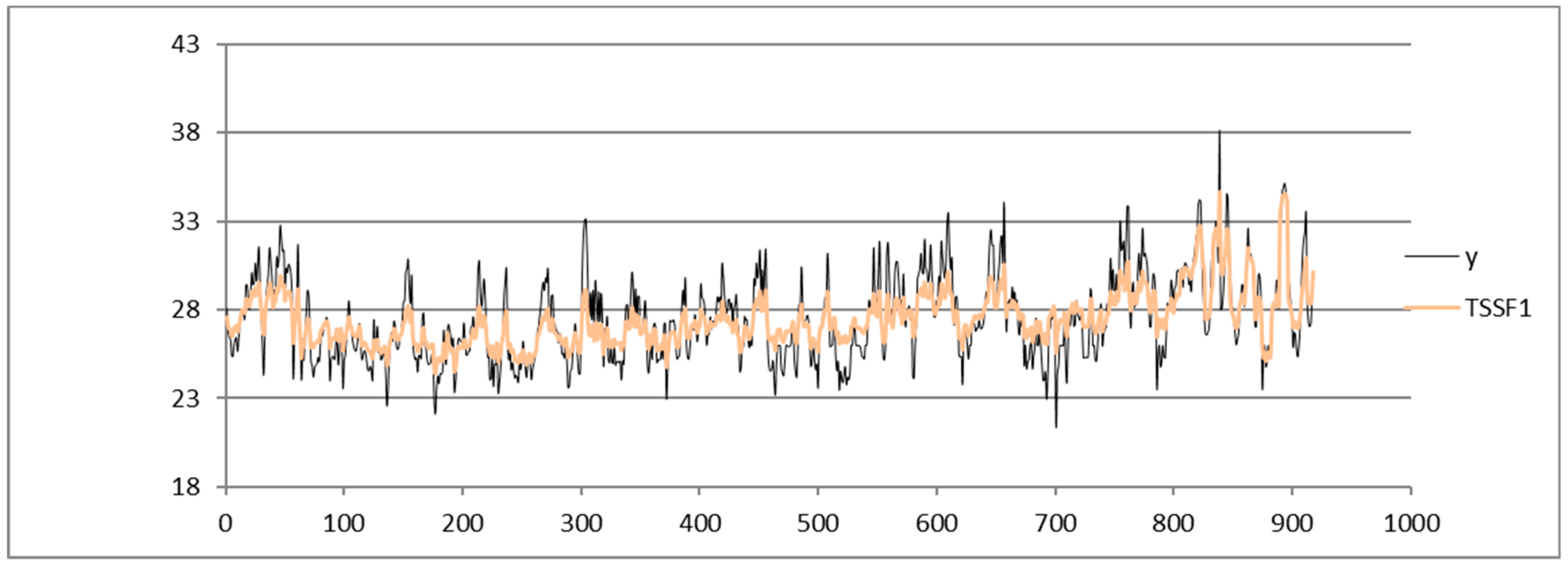
Shown below is the HI index time series from the dataset of the Napoli Capodichino station obtained by applying the SARIMA (
Figure 3), ADANN (
Figure 4), TSSF (
Figure 5), and TSSF1 (
Figure 6) algorithms.
We compare the results obtained via SARIMA (
Figure 3).
To measure the performances of the algorithms in addition to the MAD-MEAN index, we calculate also the well-known time series accuracy indexes: Root Mean Square Error (RMSE), Mean Absolute Percentage Error (MAPE), and Mean Absolute Deviation (MAD).
In
Table 2, the measures of the four accuracy indexes obtained from all the datasets of the weather stations are shown. For each dataset, the ARIMA, ADANN, TSSF, and TSSF1 algorithms are applied as well.
The results in
Table 2 show that, for all the datasets, the performance of the TSSF1 algorithm are better than that of the Spatial ARIMA and TSSF algorithms and comparable with that of the ADANN algorithm. In fact, both the measured values of the MAD-MEAN index and those of the RMSE, MAD, and MAPE indices obtained by using the TSSF1 method are very similar to the values obtained using the ADANN method; on the other hand, the ADANN method has a higher computational complexity with respect to the TSSF1 algorithm due to the use of the GA algorithm necessary for determine the optimal number of nodes of the input layer and the hidden layer.
In order to measure the forecasting performances of the results for any weather station, we create a test dataset given HI values related to the period 1 July 2018–31 August 2018; then, we calculate the RMSE of the forecasted values obtained by using the SARIMA, ADANN, TSSF, and TSSF1 algorithms. In
Table 3, we show the RMSE measured in the 9 methods for each parameter.
As well as the results in
Table 2, the results in
Table 3 show that the forecasting performances of the TSSF1 algorithm are comparable with that of the ADANN algorithm and better than that of the SARIMA and TSSF algorithms. This trend is confirmed for all six datasets used in this comparison test.
5. Conclusions
We propose a novel seasonal time series forecasting algorithm based on the direct and inverse F1-transform. The aim of this research is to improve the performance of the TSSF algorithm, a seasonal time series forecasting method based on direct and inverse F-transform. As in TSSF, we apply a polynomial fitting to extract the trend and partition the training dataset in S subsets, where S is the number of seasons. For each subset, the direct F1-transform components are calculated and the inverse F1-transform is used to predict the value of an assigned output as well.
We test our algorithm on datasets of the daily heat index in the months of July and August calculated by using the daily max temperature and humidity values measured from the six Italian weather stations of Capo Palinuro, Capri, Grazzanise, Napoli Capodichino, Salerno Pontecagnano, and Trevico starting from 1 July 2003 and up to 31 August 2017. We compare the accuracy and the forecasting performances of our method with the ones obtained by using the Seasonal ARIMA ADANN and TSSF methods; the results show that the proposed method has better performances than those obtained using Seasonal-ARIMA and TSSF and performances comparable with those obtained by using the ADANN algorithm, with the advantage of being more efficient than ADANN in terms of computational complexity; in fact, compared to the TSSF1 algorithm, which has a quadratic dependence on the size of the dataset, ADANN has longer execution times, since in ADANN, two hundred generations are needed to obtain the optimal number of input and hidden layer nodes.
In the future, we intend to optimize the performance of the TFSS1 algorithm, parallelizing the calculation processes of the direct F-transform components on each seasonal subset and implementing an efficient algorithm for optimizing the MAD-MEAN index threshold.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





