A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone

 ,
,  , , ,
, , , 
Abstract
:1. Introduction
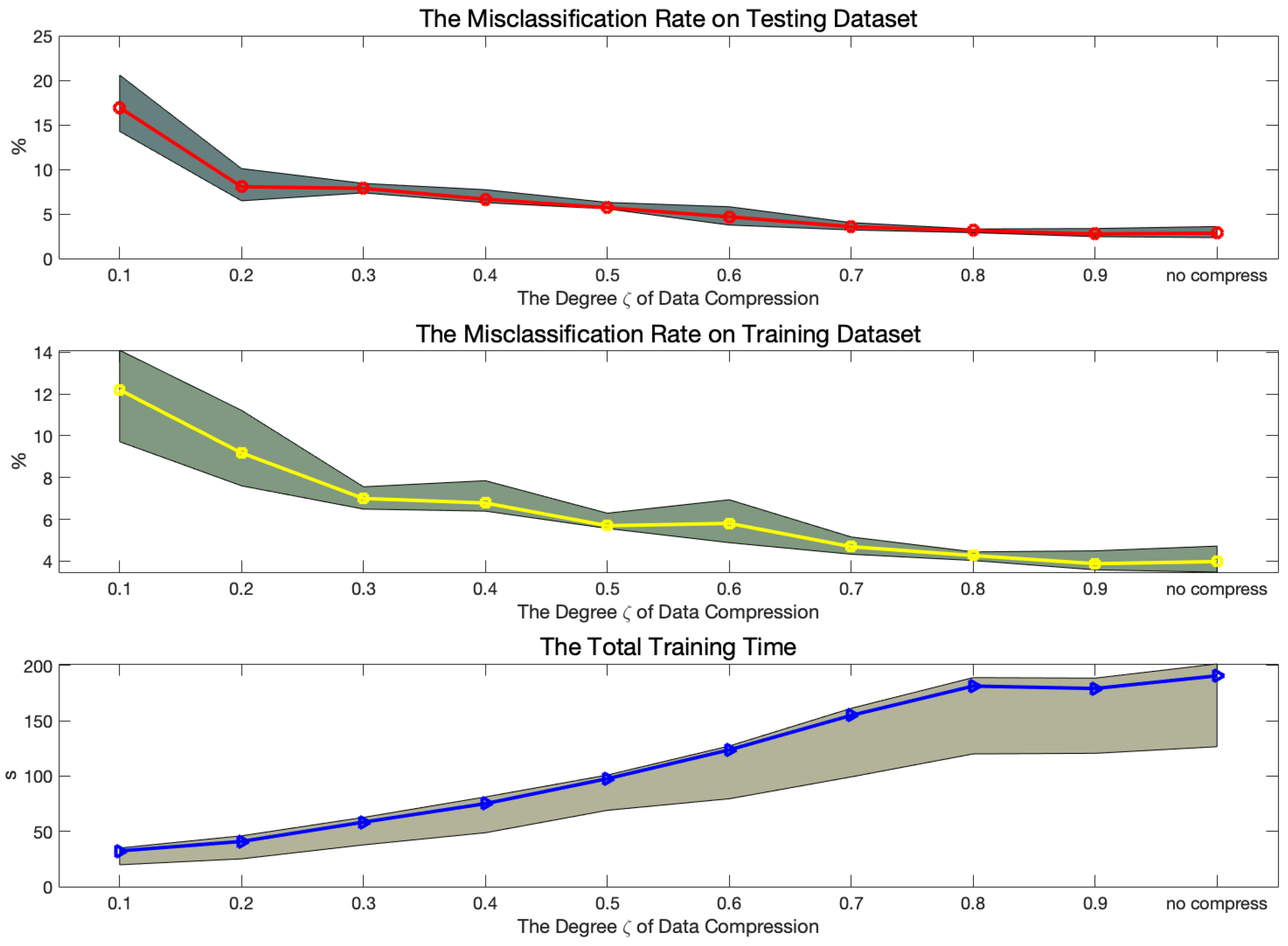
- Although it can reduce the computational complexity of data storage and transfer for the onboard implementation of DL algorithms on smartphone and wearable devices, this technique is hampered by data acquisition and memory constrained. Therefore, exploring optimal compression methods and adopting mobile phone enabled GPU to minimize computation time is highly needed.
- The signals processing and dimensionality reduction are two significant aspects of HAR process for enhancing the recognition rate. The acquired new signals with low dimensional data minimize computational complexity, especially in mobile devices with limited computation powers and memory.
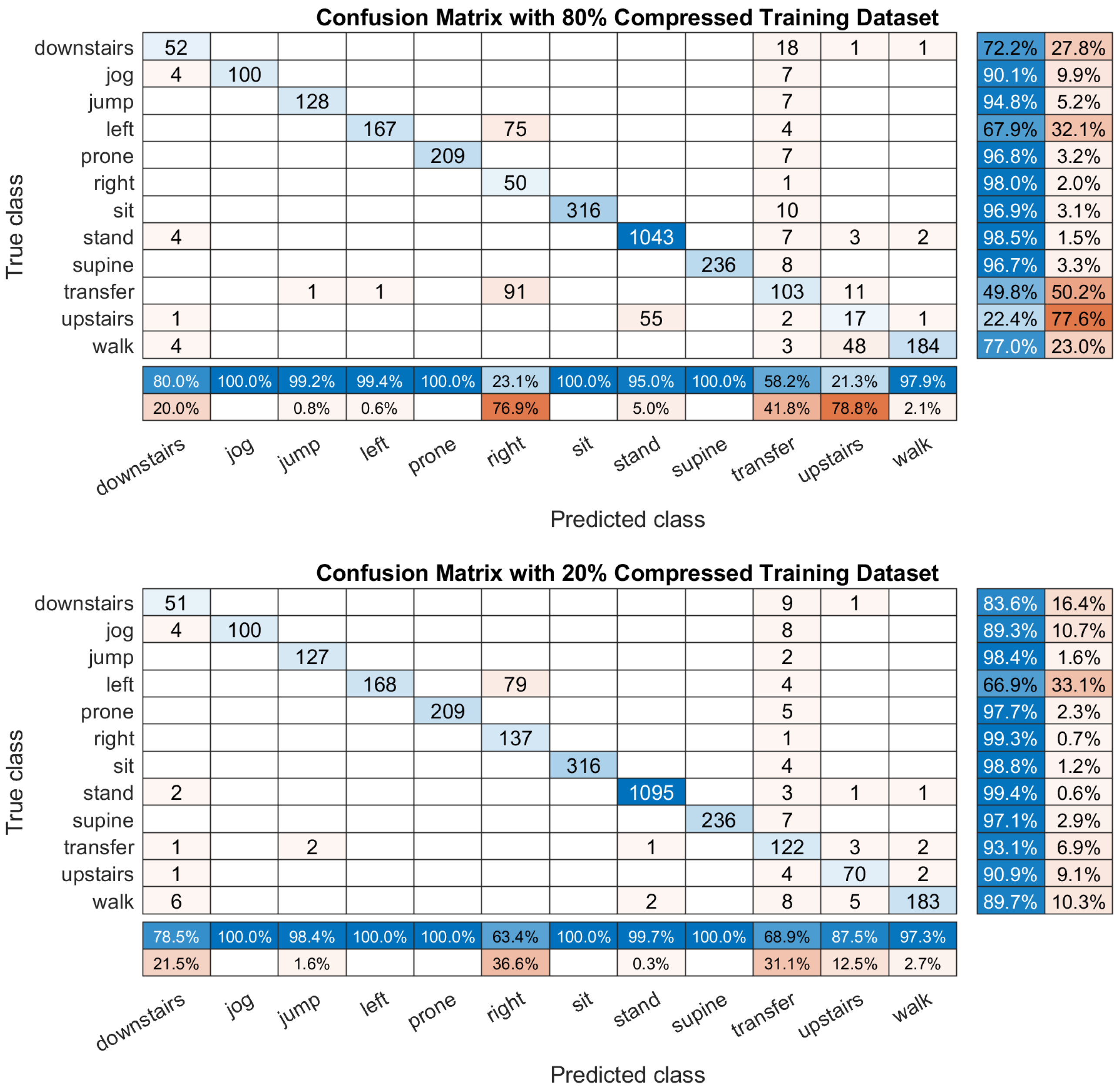
- Human activity is too complex to be recognized because it is easy to be affected by the user’s habit, age, physical status, and even wearable devices. For example, there are many transitions between two activities, such as from sitting to standing [53]. Thus, to explore an algorithm to identify the transfer motions and other complex activities becomes more popular.
2. Materials and Methods
2.1. Data Preparation
2.2. The Proposed Method
2.2.1. Signal Processing
2.2.2. Data Compression
2.2.3. Deep Convolutional Neural Networks
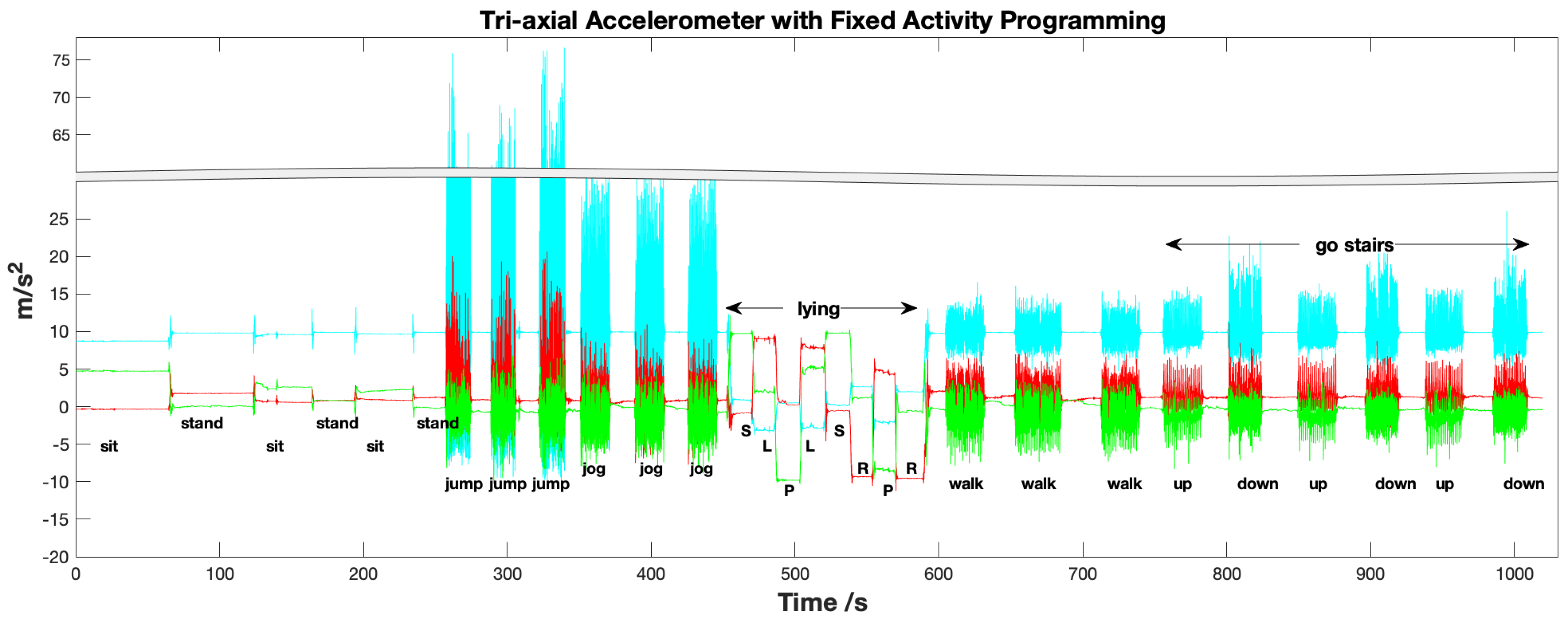
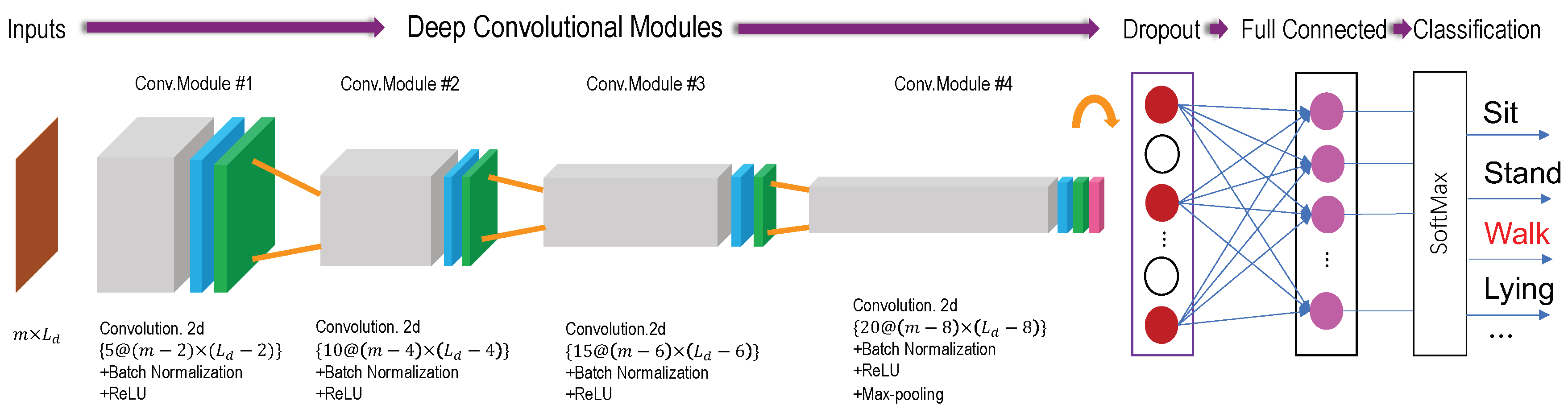
- Inputs: A matrix with m dimensions and fixed time-length, namely . Specifically, we constructed four kinds of inputs for comparison experiments, i.e., , , and . Where represent the Y and Z axis of orientation signals. Figure 4 ’inputs’ shows the 3 s input vector of a given training data size, namely with 50 Hz sample frequency.
- Deep Convolution Modules: Four deep convolutional modules are designed in DCNN model. The first three modules (Conv.Module #1 to Conv.Module #3), consist of a 2D CNN layers, a batch normalization (BN) layer and a Rectified Linear Unit (ReLU) activation function. The last convolution module Conv.Module #4 add a max-pooling layer. The convolution operations were performed using the four window sizes, 5, 10, 15 and 20. The size of yielded feature map are , , , and . The convolution operations were performed using the window size . The BN layer is adopted for allowing each layer of the CNN network to learn by itself a little bit more independently of other layers. The ReLU layer aims to solve the vanishing gradient and exploding gradient problems [73].
- Max-pooling: The max-pooling was performed to select the largest feature value finally. The max-pooled result acquired from the last layer of Conv.Module #4 reshape to create a feature vector for the input matrix.
- Dropout: The convolved and max-pooled feature vectors usually too large to cause overfitting problem. This phenomenon will decrease the classification accuracy. The dropout layer is applied for avoiding overfitting and reducing the training time. The percentage of the dropout is set to 0.5 in our evaluation experiment to be explained later.
- Output: The SoftMax layer was placed as an output layer of the fully-connected layer as shown in Figure 4. It classify the activities by computing the probability of each input of the node in the softmax layer, like sitting, standing, walking and lying. The highest probability is then determined as the predicted (or recognized) activity. Finally, the activity label is outputted to the final node (in red).
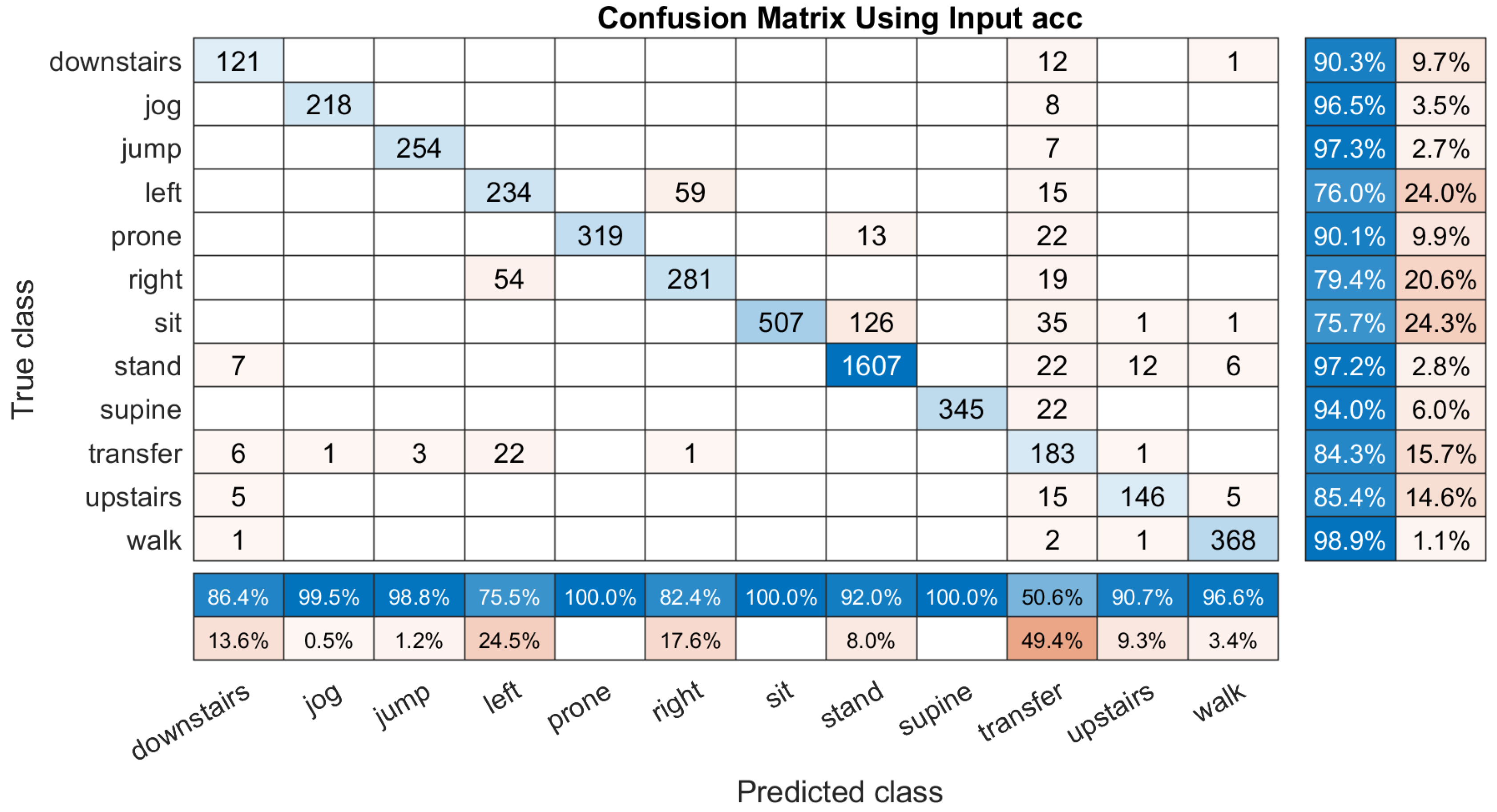
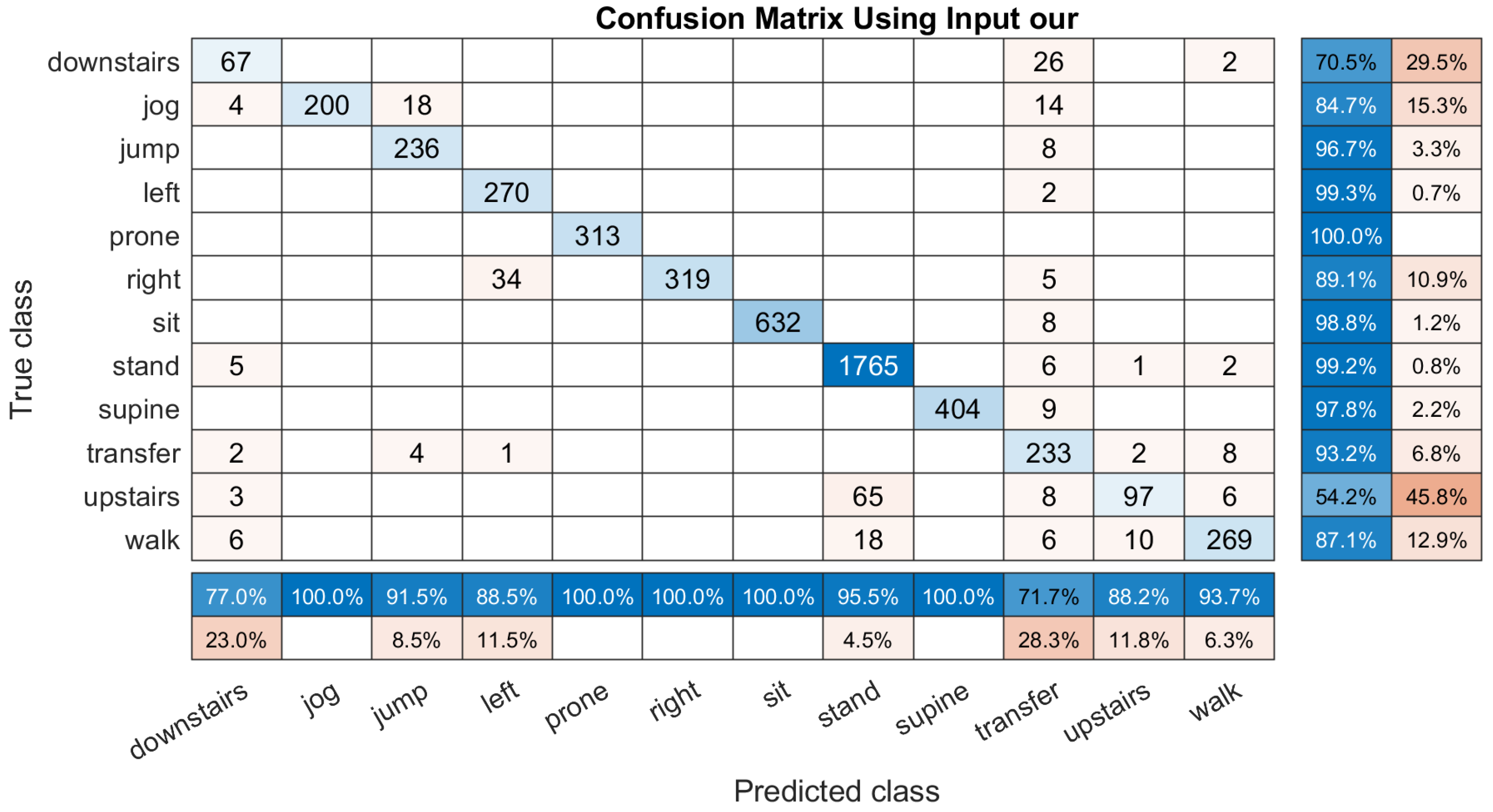
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Capela, N.; Lemaire, E.; Baddour, N.; Rudolf, M.; Goljar, N.; Burger, H. Evaluation of a smartphone human activity recognition application with able-bodied and stroke participants. J. Neuroeng. Rehabil. 2016, 13, 5. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.Y. A comparative study on human activity recognition using inertial sensors in a smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Saeedi, R.; Norgaard, S.; Gebremedhin, A.H. A closed-loop deep learning architecture for robust activity recognition using wearable sensors. In Proceedings of the 2017 IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 473–479. [Google Scholar]
- Fang, S.H.; Liao, H.H.; Fei, Y.X.; Chen, K.H.; Huang, J.W.; Lu, Y.D.; Tsao, Y. Transportation modes classification using sensors on smartphones. Sensors 2016, 16, 1324. [Google Scholar] [CrossRef] [PubMed]
- Khemchandani, R.; Sharma, S. Robust least squares twin support vector machine for human activity recognition. Appl. Soft Comput. 2016, 47, 33–46. [Google Scholar] [CrossRef]
- Meyer, D.; Wien, F.T. Support vector machines. In The Interface to Libsvm in Package e1071; Imprint Chapman and Hall/CRC: New York, NY, USA, 2015; p. 28. [Google Scholar]
- Tran, D.N.; Phan, D.D. Human activities recognition in android smartphone using support vector machine. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 64–68. [Google Scholar]
- Vermeulen, J.L.; Hillebrand, A.; Geraerts, R. A comparative study of k-nearest neighbour techniques in crowd simulation. Comput. Animat. Virtual Worlds 2017, 28, e1775. [Google Scholar] [CrossRef]
- Ignatov, A.D.; Strijov, V.V. Human activity recognition using quasiperiodic time series collected from a single triaxial accelerometer. Multimed. Tools Appl. 2016, 75, 7257–7270. [Google Scholar] [CrossRef]
- Su, H.; Yang, C.; Mdeihly, H.; Rizzo, A.; Ferrigno, G.; De Momi, E. Neural Network Enhanced Robot Tool Identification and Calibration for Bilateral Teleoperation. 2019. Available online: https://ieeexplore.ieee.org/abstract/document/8805341 (accessed on 19 August 2019).
- Li, Z.; Yang, C.; Fan, L. Advanced Control of Wheeled Inverted Pendulum Systems; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Mekruksavanich, S.; Hnoohom, N.; Jitpattanakul, A. Smartwatch-based sitting detection with human activity recognition for office workers syndrome. In Proceedings of the 2018 International ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI-NCON), Muang Chiang Rai, Thailand, 25–28 February 2018; pp. 160–164. [Google Scholar]
- Fullerton, E.; Heller, B.; Munoz-Organero, M. Recognizing human activity in free-living using multiple body-worn accelerometers. IEEE Sens. J. 2017, 17, 5290–5297. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Tharwat, A.; Mahdi, H.; Elhoseny, M.; Hassanien, A.E. Recognizing human activity in mobile crowdsensing environment using optimized k-NN algorithm. Expert Syst. Appl. 2018, 107, 32–44. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Complex human activity recognition using smartphone and wrist-worn motion sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef]
- Hu, Y.; Li, Z.; Li, G.; Yuan, P.; Yang, C.; Song, R. Development of sensory-motor fusion-based manipulation and grasping control for a robotic hand-eye system. IEEE Trans. Syst. Ma, Cybern. Syst. 2016, 47, 1169–1180. [Google Scholar] [CrossRef]
- Paul, P.; George, T. An effective approach for human activity recognition on smartphone. In Proceedings of the 2015 IEEE International Conference on Engineering and Technology (Icetech), Coimbatore, India, 20 March 2015; pp. 1–3. [Google Scholar]
- Scheurer, S.; Tedesco, S.; Brown, K.N.; O’Flynn, B. Human activity recognition for emergency first responders via body-worn inertial sensors. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Eindhoven, The Netherlands, 9–12 May 2017; pp. 5–8. [Google Scholar]
- Su, H.; Li, Z.; Li, G.; Yang, C. EMG-Based neural network control of an upper-limb power-assist exoskeleton robot. In International Symposium on Neural Networks; Springer: Dalian, China, 2013; pp. 204–211. [Google Scholar]
- Mehr, H.D.; Polat, H.; Cetin, A. Resident activity recognition in smart homes by using artificial neural networks. In Proceedings of the 2016 4th International Istanbul Smart Grid Congress and Fair (ICSG), Istanbul, Turkey, 20–21 April 2016; pp. 1–5. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar]
- Su, H.; Enayati, N.; Vantadori, L.; Spinoglio, A.; Ferrigno, G.; De Momi, E. Online human-like redundancy optimization for tele-operated anthropomorphic manipulators. Int. J. Adv. Robot. Syst. 2018, 15. [Google Scholar] [CrossRef]
- Plötz, T.; Guan, Y. Deep learning for human activity recognition in mobile computing. Computer 2018, 51, 50–59. [Google Scholar] [CrossRef]
- Hasan, M.; Roy-Chowdhury, A.K. Continuous learning of human activity models using deep nets. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 705–720. [Google Scholar]
- Lane, N.D.; Georgiev, P. Can deep learning revolutionize mobile sensing? In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 117–122. [Google Scholar]
- Wang, Y.; Wei, L.; Vasilakos, A.V.; Jin, Q. Device-to-Device based mobile social networking in proximity (MSNP) on smartphones: Framework, challenges and prototype. Future Gener. Comput. Syst. 2017, 74, 241–253. [Google Scholar] [CrossRef]
- Wang, Y.; Jia, X.; Jin, Q.; Ma, J. QuaCentive: A quality-aware incentive mechanism in mobile crowdsourced sensing (MCS). J. Supercomput. 2016, 72, 2924–2941. [Google Scholar] [CrossRef]
- Cao, L.; Wang, Y.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient Group-based Context—Aware human activity recognition on smartphone. J. Parallel Distrib. Comput. 2018, 118, 67–80. [Google Scholar] [CrossRef]
- Hu, Y.; Su, H.; Zhang, L.; Miao, S.; Chen, G.; Knoll, A. Nonlinear Model Predictive Control for Mobile Robot Using Varying-Parameter Convergent Differential Neural Network. Robotics 2019, 8, 64. [Google Scholar] [CrossRef]
- Su, H.; Li, S.; Manivannan, J.; Bascetta, L.; Ferrigno, G.; Momi, E.D. Manipulability Optimization Control of a Serial Redundant Robot for Robot-assisted Minimally Invasive Surgery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1323–1328. [Google Scholar]
- Li, Z.; Su, C.Y.; Li, G.; Su, H. Fuzzy approximation-based adaptive backstepping control of an exoskeleton for human upper limbs. IEEE Trans. Fuzzy Syst. 2014, 23, 555–566. [Google Scholar] [CrossRef]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Structural-RNN: Deep learning on spatio-temporal graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5308–5317. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Chen, Y.; Xue, Y. A deep learning approach to human activity recognition based on single accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep activity recognition models with triaxial accelerometers. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016. [Google Scholar]
- Yu, S.; Qin, L. Human activity recognition with smartphone inertial sensors using bidir-lstm networks. In Proceedings of the 2018 3rd International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Huhhot, China, 14–16 September 2018; pp. 219–224. [Google Scholar]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef]
- Su, H.; Qi, W.; Hu, Y.; Sandoval, J.; Zhang, L.; Schmirander, Y.; Chen, G.; Aliverti, A.; Knoll, A.; Ferrigno, G.; et al. Towards Model-Free Tool Dynamic Identification and Calibration Using Multi-Layer Neural Network. Sensors 2019, 19, 3636. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Ordóñez, F.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.A.H.; Roy, N.; Misra, A. Scaling human activity recognition via deep learning-based domain adaptation. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19 March 2018; pp. 1–9. [Google Scholar]
- Lu, Y.; Wei, Y.; Liu, L.; Zhong, J.; Sun, L.; Liu, Y. Towards unsupervised physical activity recognition using smartphone accelerometers. Multimed. Tools Appl. 2017, 76, 10701–10719. [Google Scholar] [CrossRef]
- Reynolds, D. Gaussian mixture models. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2015; pp. 827–832. [Google Scholar]
- Bouguettaya, A.; Yu, Q.; Liu, X.; Zhou, X.; Song, A. Efficient agglomerative hierarchical clustering. Expert Syst. Appl. 2015, 42, 2785–2797. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Jin, X.; Han, J. K-medoids clustering. Encyclopedia of Machine Learning and Data Mining; Springer US: New York, NY, USA, 2017; pp. 697–700. [Google Scholar]
- Nie, F.; Wang, X.; Jordan, M.I.; Huang, H. The constrained laplacian rank algorithm for graph-based clustering. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Li, Z.; Xia, Y.; Su, C.Y. Intelligent Networked Teleoperation Control; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Su, H.; Sandoval, J.; Vieyres, P.; Poisson, G.; Ferrigno, G.; De Momi, E. Safety-enhanced collaborative framework for tele-operated minimally invasive surgery using a 7-DoF torque-controlled robot. Int. J. Control Autom. Syst. 2018, 16, 2915–2923. [Google Scholar] [CrossRef]
- Su, H.; Sandoval, J.; Makhdoomi, M.; Ferrigno, G.; De Momi, E. Safety-enhanced human-robot interaction control of redundant robot for teleoperated minimally invasive surgery. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6611–6616. [Google Scholar]
- Su, H.; Yang, C.; Ferrigno, G.; De Momi, E. Improved Human–Robot Collaborative Control of Redundant Robot for Teleoperated Minimally Invasive Surgery. IEEE Robot. Autom. Lett. 2019, 4, 1447–1453. [Google Scholar] [CrossRef]
- Sandhu, M.; Kaur, S.; Kaur, J. A study on design and implementation of Butterworth, Chebyshev and elliptic filter with Matlab. Int. J. Emerg. Technol. Eng. Res. 2016, 4, 111–114. [Google Scholar]
- Lutovac, M.D.; Tošić, D.V.; Evans, B.L. Filter Design for Signal Processing Using MATLAB and Mathematica; Prentice Hall: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Roetenberg, D.; Luinge, H.J.; Baten, C.T.; Veltink, P.H. Compensation of magnetic disturbances improves inertial and magnetic sensing of human body segment orientation. IEEE Trans. Neural Syst. Rehabil. Eng. 2005, 13, 395–405. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, L.; Wang, M.; Cheng, H. Research of adaptive index based on slide window for spatial-textual query. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Casson, A.J.; Galvez, A.V.; Jarchi, D. Gyroscope vs. accelerometer measurements of motion from wrist PPG during physical exercise. ICT Express 2016, 2, 175–179. [Google Scholar] [CrossRef]
- Biagetti, G.; Crippa, P.; Falaschetti, L.; Orcioni, S.; Turchetti, C. Human activity recognition using accelerometer and photoplethysmographic signals. In International Conference on Intelligent Decision Technologies; Springer: Cham, Switzerland, 2017; pp. 53–62. [Google Scholar]
- Dernbach, S.; Das, B.; Krishnan, N.C.; Thomas, B.L.; Cook, D.J. Simple and complex activity recognition through smart phones. In Proceedings of the 2012 Eighth International Conference on Intelligent Environments, Guanajuato, Mexico, 26–29 June 2012; pp. 214–221. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Energy Efficient Smartphone-Based Activity Recognition using Fixed-Point Arithmetic. J. UCS 2013, 19, 1295–1314. [Google Scholar]
- Biagetti, G.; Crippa, P.; Falaschetti, L.; Orcioni, S.; Turchetti, C. An efficient technique for real-time human activity classification using accelerometer data. In International Conference on Intelligent Decision Technologies; Springer: Cham, Switzerland, 2016; pp. 425–434. [Google Scholar]
- Ye, J. Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
- Achille, A.; Soatto, S. Information dropout: Learning optimal representations through noisy computation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef] [PubMed]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2217–2225. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Pedamonti, D. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv 2018, arXiv:1804.02763. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Accuracy | Computational Time | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| FR-DCNN | 94.09% ± 0.0070 | 94.18% ± 0.0170 | 88.00 s ± 15.57 | 0.0028 s ± 0.0007 |
| 3 Modules DCNN | 93.92% ± 0.0075 | 93.04% ± 0.0170 | 71.75 s ± 13.32 | 0.0022 s ± 0.0006 |
| 5 Modules DCNN | 93.23% ± 0.0317 | 93.06% ± 0.0308 | 118.32 s ± 18.32 | 0.0036 s ± 0.0009 |
| LSTM | 93.59% ± 0.0103 | 95.39% ± 0.0178 | 226.29 s ± 3.92 | 0.0118 s ± 0.0004 |
| Bi-LSTM | 93.65% ± 0.0065 | 95.35% ± 0.0157 | 266.28 s ± 6.61 | 0.0142 s ± 0.0004 |
| Algorithms | Accuracy | Computational Time | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| FR-DCNN | 96.88% ± 0.0050 | 95.27% ± 0.0160 | 179.38 s ± 36.41 | 0.0029 s ± 0.0008 |
| 3 Modules DCNN | 96.06% ± 0.0055 | 93.61% ± 0.0163 | 135.28 s ± 26.45 | 0.0022 s ± 0.0006 |
| 5 Modules DCNN | 95.60% ± 0.0090 | 94.26% ± 0.0166 | 226.24 s ± 36.62 | 0.0038 s ± 0.0008 |
| LSTM | 94.55% ± 0.0088 | 96.43% ± 0.0077 | 406.28 s ± 4.53 | 0.0115 s ± 0.0001 |
| Bi-LSTM | 94.52% ± 0.0080 | 96.42% ± 0.0107 | 515.76 s ± 28.35 | 0.0143 s ± 0.0007 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors 2019, 19, 3731. https://doi.org/10.3390/s19173731
Qi W, Su H, Yang C, Ferrigno G, De Momi E, Aliverti A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors. 2019; 19(17):3731. https://doi.org/10.3390/s19173731
Chicago/Turabian StyleQi, Wen, Hang Su, Chenguang Yang, Giancarlo Ferrigno, Elena De Momi, and Andrea Aliverti. 2019. "A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone" Sensors 19, no. 17: 3731. https://doi.org/10.3390/s19173731