1. Introduction
The sensor control problem is often considered under the umbrella of “Sensor Management”, which often deals with a wide range of management issues related to sensors in applications such as sensor scheduling, communication protocols, and sensor kinematics. Sensor control in multi-object tracking systems, on the other hand, presents a very specific domain which pays exclusive attention to the applications that need sensor control implementation, where all deployed sensors are efficiently utilized to gain a comprehensive understanding of the tracking scenario.
The term ‘Sensor Control’, in the context of this paper, refers to the dynamic deployment of one or more sensors in various multi-object tracking scenarios, by seeking the best control command for achieving optimum tracking results. The control command refers to the control of the freedom of movement of mobile sensors in a sensing system, to efficiently track the objects within the operational constraints of the system. The sensor control strategies are devised using stochastic methods, given the highly probabilistic scenario posed by the unpredictability of the noise, clutter and the object behaviors.
This review focuses on stochastic control solutions for sensor movements in multi-object systems that are modeled in the Random Finite Set (RFS) framework. Such solutions are usually formulated based on the widely followed Partially Observable Markov Decision Process (POMDP) [
1] approach for Bayesian multi-object filtering, in which each action is perceived as a result of the previous measurement.
Although the broader area of sensor management has seen a tremendous growth in the past decade and has been reviewed in several papers in the literature [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16], there seems to be no comprehensive review of the specific area of stochastic sensor control that provides detailed insight into the contributions and progress made in this domain. As such, in this work, we present the general sensor control problem and the key components of typical solutions introduced in the literature. This is followed by a categorization of the existing methods that include a new generation of solutions called selective sensor control.
The broader area of sensor management has seen tremendous growth in the past few decades, and the solutions developed for conventional multi-object filters have been reviewed in several papers in the literature [
1,
2,
3,
5,
17,
18,
19,
20,
21,
22,
23]. Therefore, although we consider those methods in our categorization, we do not include a a review of them in this article, and concentrate on the more recent literature that is focused on sensor control for RFS-based filters.
The paper is organized as follows.
Section 2 presents an overview of the sensor control problem formulation and the key concepts.
Section 3 provides a categorization of sensor control approaches. This is followed by
Section 4 in which a review of the major contributions in each category is provided. Some comparative simulation experiments and their results are presented and discussed in
Section 5, followed by concluding remarks and future directions presented in
Section 7.
2. Sensor Control Problem
The multi-object sensor control is a nonlinear stochastic control problem that aims to assign sensors the right sensor state at the right time [
3]. The control problem is particularly challenging due to the high complexity and uncertainties involved in multi-object systems. The uncertainty is introduced into the system by the unperceived variations in the number of objects and also the false alarms and misdetections inherent to the system dynamics.
The sensor control decision is made in the presence of uncertainties in the object state and measurement spaces, usually with the assumption that the previous observation is available when making the next decision. Such stochastic control problems can be effectively handled in the POMDP framework [
1] where the multi-object state is modeled as a Markov process, with knowledge on the posterior probability density function (pdf) of the multi-object state conditioned on the past measurements and the true state being unknown. The solution to sensor control problems generally depends on the definition of a measure of goodness that is usually quantified in terms of either the accuracy of the resulting multi-object state estimation, or the information content of the resulting multi-object posterior distribution. The decision-making is performed based on optimizing an
objective function.
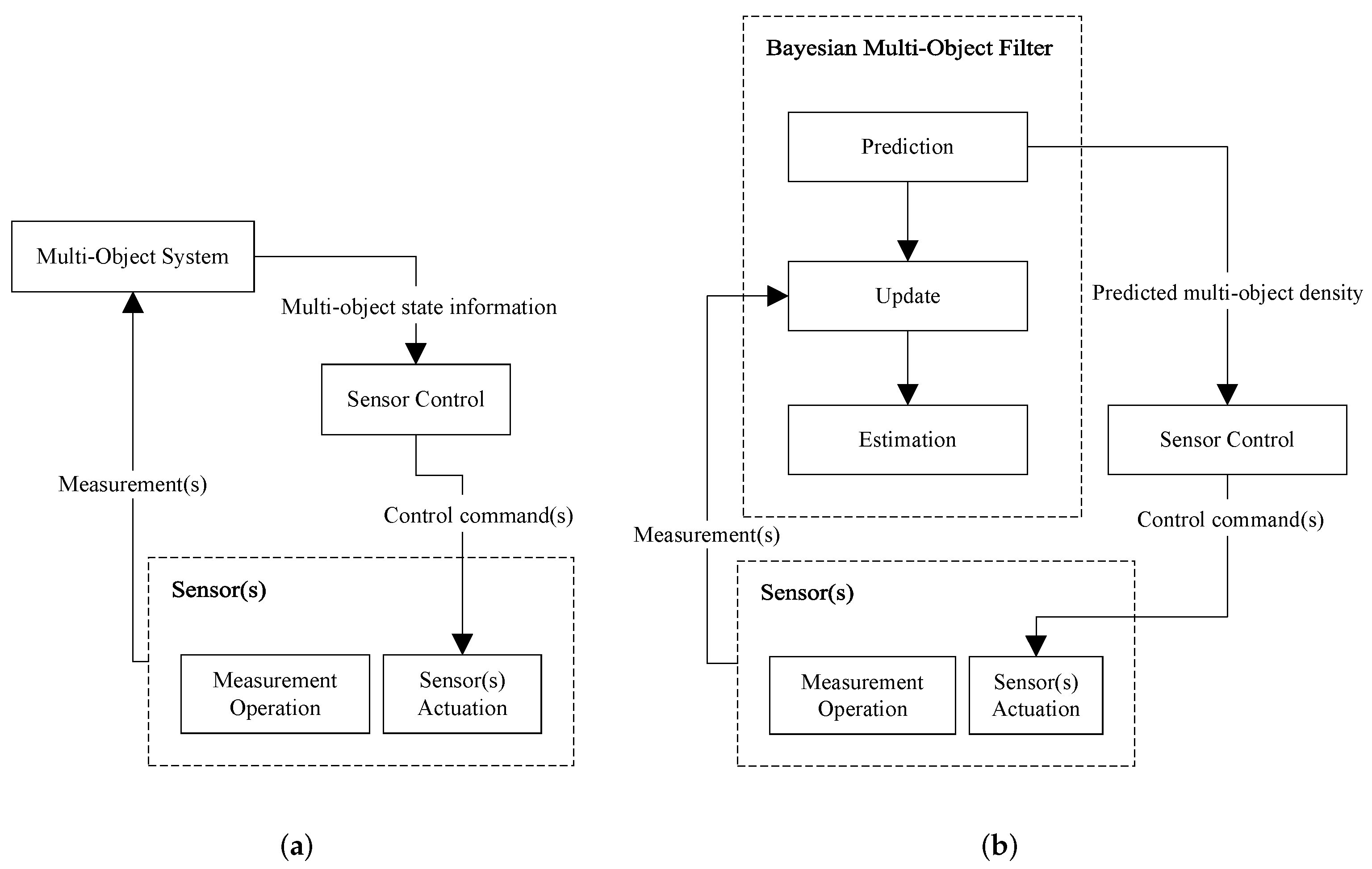
Consider a general multi-object system. As shown in the schematic diagram of
Figure 1a, it receives measurements from sensor(s) and outputs’ multi-object state information at any time. The sensor control solution inputs that information and outputs control command(s) for the sensor(s) that are then actuated accordingly, before the next measurements are acquired and sent to the multi-object system for processing at the next iteration.
In many applications, the multi-object system is implemented as a Bayesian multi-object filter that is mainly comprised of three steps: prediction, update, and estimation. In such scenarios, the sensor control problem turns into a stochastic control solution.
Figure 1b shows a schematic diagram of the complete closed-loop system, exhibiting the usual approach in which the sensor control module constructs the control commands from the predicted multi-object density.
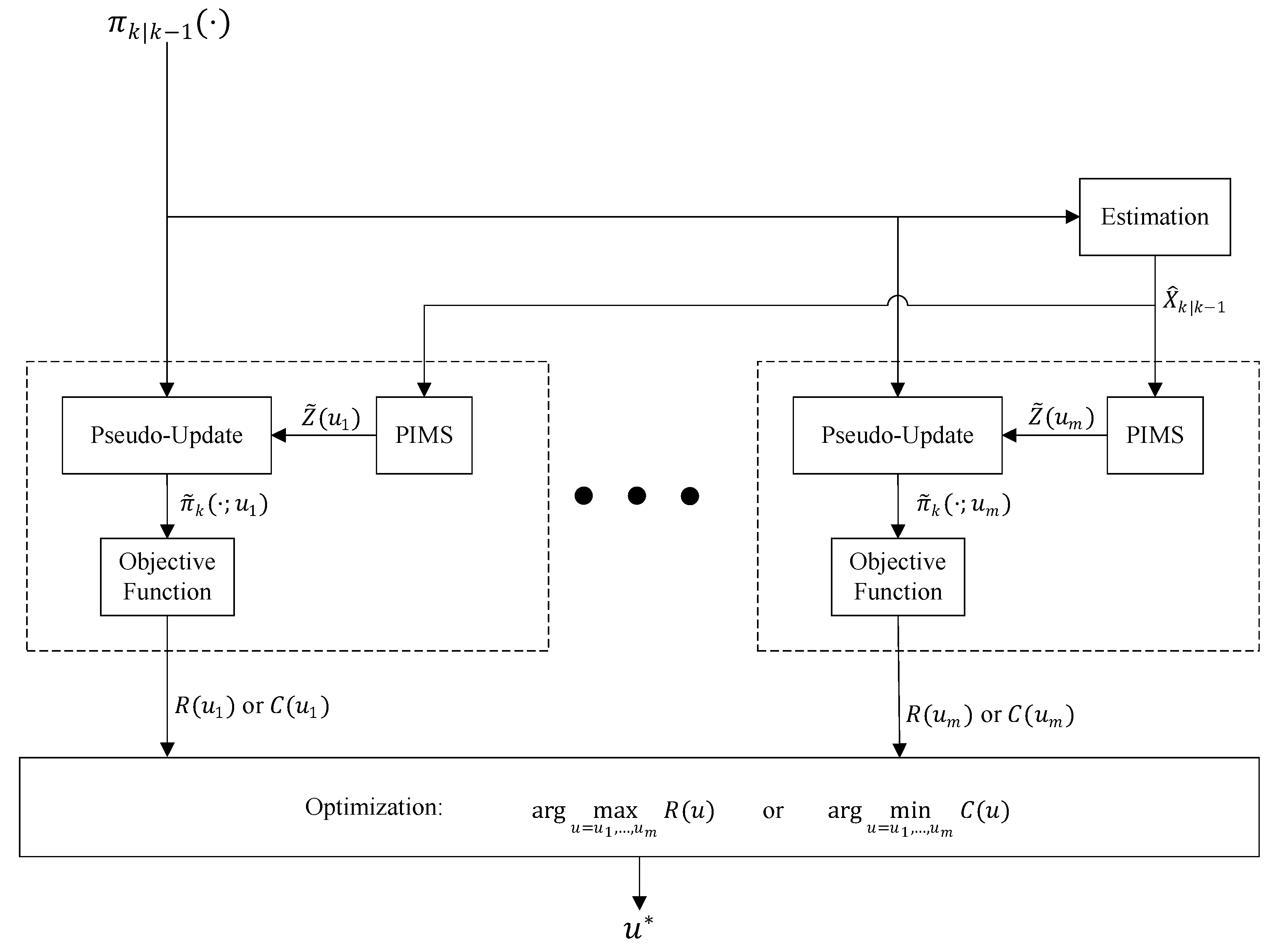
Figure 2 presents how this information is processed inside a generic sensor control algorithm to generate a control command decision in the single-sensor case. Note that the outputs of the “estimation block” are only determined after the sensor control commands are determined and sensors are actuated accordingly then measurements are acquired using which the update step is executed. Importantly, the outputs of the “Estimation” block cannot be directly used for sensor control. However, the prediction step does not need the sensor measurements and can occur before any determination occurs on the sensor control commands. Hence, the most informative (and most recently updated) input that can be given to the sensor control block in
Figure 1b is the “Predicted multi-object density”. Let us denote the predicted multi-object density at time
k by
and the set of all admissible sensor control commands by
. The predicted density is used first to extract a predicted set of object state estimates, denoted by
. For each possible control command
, the following steps are taken:
First, a set of ideal noise-free and clutter-free measurements called the predicted ideal measurement set (PIMS) [
6], denoted by
is constructed as follows:
in which
is the single-object likelihood function (sensor model) which varies with the control command
.
Example 1. Consider a multi-object tracking application in 2D space, where each single-object state contains the object location coordinates (e.g., its x and y if the object is moving in a 2D space) and may include other components such as velocity, acceleration, and bearing angle. We also consider a sensor that its location is controllable, i.e., the control command is the sensor location vector. The sensor measures range. That is, if it detects the object, it returns:where and the measurement noise n is a zero-mean Gaussian random variable with a range dependent variance . The single-object likelihood function is then given by: Hence, for a given sensor location and object location , the PIMS measurement is given by:which achieves the maximum likelihood value of After the PIMS is calculated, the update step of the multi-object filter is run. Since this update step utilizes the PIMS as a measurement set, we call it
pseudo-update and its output is called a
pseudo-posterior denoted by
(as shown in
Figure 2). An essential component of the algorithm is an objective function that inputs this pseudo-posterior and outputs a cost value,
, or a reward
. An optimization search over all the cost or rewards for various admissible control commands returns the
best control command
. This command can be one of various actions such as spinning in positive or negative directions or making a step displacement in different directions.
4. Survey of Recent Literature
In this section, we explore some of the significant methods that have been recently proposed in the signal processing literature for single and multi-sensor control for multi-target tracking in a stochastic POMDP framework.
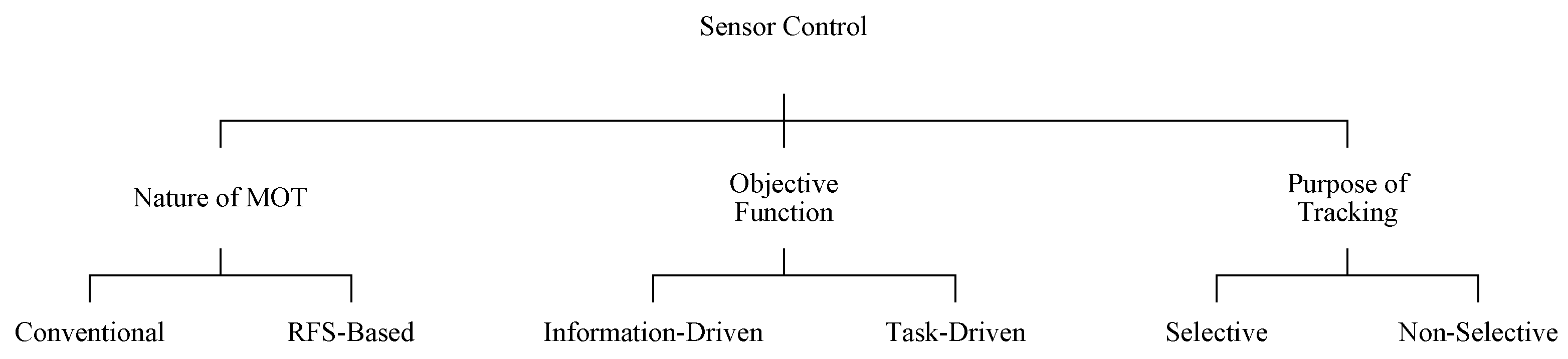
Table 1 lists how each of the methods that are reviewed in this article, are classified. In all these methods, the sensor control solution is primarily proposed to be used with RFS-based multi-target tracking filters. However, Mahler’s method called Posterior Expected Number of Targets (PENT) [
5] can be simply used with both the RFS-based multi-target filters (such as the probability hypothesis density—PHD—filter) and the conventional ones (such as the MHT filter). This section would provide the reader with a snapshot of the significant steps in the evolution of sensor control methods to the current state-of-the-art.
4.1. Information-Driven Sensor Control
The purpose of sensor control is to effectively use the sensor/s, by allowing them to interact with the tracking environment to gain useful information that reduce uncertainty. Every movement of the sensor is aimed at an information gain on the targets’ states and cardinality i.e., information on the accuracy of state/location of the target that is being tracked; and/or information on the presence or absence of targets. The amount of information gain is usually measured by the change in entropy between the probability densities prior and post sensor measurements. It was in the work of Hintz and McVey [
46] that we find the earliest reference to the application of information-driven control for sensor management and state estimation, or, more precisely, the measures for information gain, where they employed Shannon entropy with Kalman filters for target tracking.
A number of information theoretic divergence measures followed that, for sensor control in single and multi-target tracking scenarios. These included divergence methods like the Kullback–Leibler (KL) divergence [
17] and Rényi divergence [
47] between the prior and posterior target densities. The expected divergence or information gain (that measures the difference between information content of random variables) is thus used as the basis for selecting the optimal control action. Similarity between random variables can also be measured using the distance between their probability distributions, as in methods like total variation, Bhattacharyya, Hellinger-Matusita, Wasserstein, etc. These measures cannot be computed analytically and hence require expensive approximations like Monte Carlo, except for some special cases. In this section, we endeavor to briefly touch upon information-driven sensor control methods due to their popular usage.
4.1.1. Rényi Divergence-Based Sensor Control
The Rényi or alpha divergence is a commonly used objective function in information-driven sensor control. It is defined as a measure of information gain from a prior to a posterior multi-target density. Referring to
Figure 2, let us assume that, at time
k, for a given sensor control command,
u, the predicted multi-object density
evolves to a pseudo-posterior
after going through a pseudo-update step using the PIMS
. The information gain from the prior to the pseudo posterior (which is the information gained from PIMS measurements) is quantified by the Rényi divergence between the two densities, defined as follows:
where
is an adjustable parameter. The Rényi divergence turns into the Kullback–Leibler divergence when
or the Hellinger affinity with
. Set integration is generally defined as follows: [
42]
Rényi Divergence-Based Sensor Control with a General RFS Filter
In 2010, Ristic and Vo [
11] proposed an information-driven sensor control method to propagate the multi-object posterior of the particle implementation of Bayes multi-object filter using random finite sets. They employed Rényi divergence as reward function in their implementation. As there is no general closed-from solution to Rényi divergence, a numerical approximation using a Sequential Monte Carlo (SMC) method is provided in the paper. Assume that the prior distribution is approximated by
N particles:
where each pair
represents a multi-object set particle and its weight. Through application of Bayes’ rule (which is related the posterior to the prior through the multi-object likelihood function), the Rényi divergence is proven to be approximated by:
where
is the multi-object likelihood function (sensor model). The optimal control vector is chosen by:
Rényi Divergence-Based Sensor Control with a PHD/CPHD Filter
Approximating a multi-object density by particle sets is evidently very expensive in terms of computation. Indeed, the original method proposed in [
11] involved sampling in the measurement set as well, which can be simplified using the PIMS instead. However, the computational cost can be too heavy to implement in the presence of more than five objects in the scene. Later in 2011, Ristic and Vo [
12] proposed the Poisson and i.i.d. cluster approximation of Rényi divergence for sensor control with multi-object tracking using PHD and Cardinalized PHD (CPHD) filters.
Assume that both the predicted and updated multi-object densities are of i.i.d. cluster types given by:
where
and
are the cardinality distribution and the spatial single-object density, respectively. The Rényi divergence for i.i.d. cluster pdfs applicable to the CPHD filter recursions is derived as [
12]
In PHD filter recursion where both the multi-object densities are Poisson RFS densities, the Rényi divergence becomes simpler as follows:
where
is the average number of objects in the Poisson RFS and
is the spatial single-object density. In their works, Ristic and Vo [
11,
12] examine the reward function in a scenario involving multiple moving objects and a controllable moving range-only sensor. The sensor’s detection accuracy (misdetection, noise and false alarm rate) improves for shorter sensor-object distance. Hence, in this case, the sensor control algorithm is expected to drive the sensor as close as possible to all objects. The Rényi divergence in this case is seen to be rapidly controlling the sensor to move towards the objects. Consequently, the optimal sub-pattern assignment (OSPA) metric, which is used as for performance evaluation, decreases when the sensor control algorithm is in place.
Though several solutions for sensor control using Rényi divergence have been proposed, the obvious problem with all these is the computational expense associated with them, primarily due to the absence of a robust analytical solution to Rényi divergence.
4.1.2. Cauchy–Schwarz Divergence
Another information theoretic reward function that has attracted attention recently is the Cauchy–Schwarz (CS) divergence. The CS divergence is based on the Cauchy–Schwarz inequality for inner products, and, for two random vectors with probability densities
f and
g, it is defined as [
29]
where
is the inner product of the two functions, and
. The CS divergence is a measure of the distance between the two densities. It is to be noted that, when
,
; otherwise, it is positive and a symmetric function. The argument of the logarithm in Equation (
15) does not exceed one (according to Cauchy–Schwarz inequality) and is positive, as probability densities are non-negative. Geometrically, in CS divergence, the logarithm argument is the cosine of the angle between the two densities in the space of density functions, hence representing the “difference” in information content of the two densities. The Cauchy–Schwarz divergence can also be interpreted as an approximation to the Kullback–Leibler divergence [
17].
CS Divergence-Based Sensor Control with a PHD Filter
Consider the predicted and pseudo-posterior multi-object RFS densities,
and
. Hoang et al. [
31] showed that the CS divergence between the two RFS densities is given by:
where
K is the unit of hyper-volume in the single-object state space.
Hoang et al. [
31] derived a closed-form solution for the CS divergence between two Poisson RFS densities and proposed how it could be used for sensor control with the PHD filter [
4,
7]. Assume that the predicted prior and pseudo posterior densities are Poisson densities in a PHD filter, with their intensity functions denoted by
and
. Note that with the intensity function
given, the average cardinality
and spatial single-object density
can be computed as follows:
Honag et al. [
31] proved that the CS divergence between the two Poisson RFS densities is simply given by:
where
K is the unit of hyper-volume measurement in the single-object state space. In simple terms, the Cauchy–Schwarz divergence between any two Poisson point processes is half the squared distance between their intensity functions. Sensor control takes place by choosing the control command that maximizes the above divergence as the reward function:
Calculation of the reward function depends on how the PHD filter is implemented. In an SMC implementation, suppose that the two intensity functions are approximated by the same particles but different weights. Note that this assumption is based on what actually happens in the filter because, through the update step, only particle weights are changed, not the location of the particles. Then we can assume:
Then, the sensor control policy (
19) is implemented as below:
For applications that require target tracks, this approach does not seem to fit, as the PHD filters do not provide tracks. In addition, the drawback with the PHD filter for sensor control is that it involves a poor approximation to the multi-target posterior, leading to highly uncertain cardinality estimates [
8,
9].
CS Divergence-Based Sensor Control with a Multi-Bernoulli Filter
Later in 2016, based on (
18), Gostar et al. [
35] derived an approximation for the CS divergence between two multi-Bernoulli densities and used it for sensor control in a cardinality-balanced multi-Bernoulli filter (CB-MeMBer). Consider the multi-Bernoulli (MB) predicted multi-object prior and pseudo posterior being parameterized as
where each
denotes a possible object (a Bernoulli component) with its probability of existence being
, and its state density function conditioned on existence being
. Gostar et al. [
35] approximate each MB density with its closest Poisson RFS density, which is the Poisson with matching intensity function. The intensity function of an RFS density is its first moment, and, for the above two MB densities, they are given by:
Substituting the intensity functions in Equation (
22) results in the following sensor control policy:
Again, to calculate the integral, in an SMC implementation, suppose that single-object density of each Bernoulli component is approximated by particles:
Then, the sensor control policy (
27) is implemented as below:
It is important to note that, through the process of computing the PIMS and running the pseudo-update step, each Bernoulli component is assigned a measurement, i.e., data association is known. Hence, for each particle weight
, finding its associated weight in the updated MB,
, is straightforward. See [
35] for more details.
CS Divergence-Based Sensor Control with a Labeled Multi-Bernoulli Filter
The above investigation was followed by another approximate solution for the CS divergence between Poisson approximations of the predicted and updated Sequential Monte Carlo (SMC) Labeled Multi-Bernoulli (LMB) posteriors [
45]. Consider the LMB predicted multi-object prior and pseudo posterior being parameterized as
where each
denotes a possible target track (with label
ℓ) with its probability of existence denoted by
, and its state density function conditioned on existence denoted by
. Note the change of density symbols to boldface, which is customary in the literature when denoting
labeled densities. Similarly, labeled single-object and multi-object states are denoted by bold-face symbols
and
, respectively.
In a similar fashion to their previous work [
35], Gostar et al. [
45] showed that, with the above assumptions, the sensor control policy is derived as follows:
where
and
are the weights of
j-th particle which approximate the densities
and
in an SMC implementation of the LMB filter, respectively.
CS Divergence-Based Sensor Control with a Generalized Labeled Multi-Bernoulli Filter
Beard et al. [
33] derived the exact closed-form solution for CS divergence between two generalized labeled multi-Bernoulli (GLMB) densities for sensor control in applications where a GLMB filter [
37,
41], also known as the Vo–Vo filter is being used to track multiple targets. Let
be a labeled single-object state and
be a projection from the labeled state space to the label space, a function that takes the labeled state and returns the label part only. Denoting a labeled set by
, its label set is similarly defined as
. For a labeled RFS, each element must have a distinct label, i.e., the cardinality of the set itself must equal the cardinality of its label set:
The function
is called the
distinct label indicator. A GLMB is a labeled RFS with a density of the form:
where
denotes a discrete and finite index set, each
is a density in the single-object state space, i.e.,
, and the label set weights
are normalized over the space of labels and indexes, i.e.,
The above GLMB density is completely characterized by the set:
For detailed description of prediction and update steps of the GLMB filter and its particular form called delta-GLMB, refer to [
37,
41].
Assume that the predicted GLMB prior is characterized as:
and the pseudo-posterior associated with control command
u is a GLMB characterized by:
Beard et al. [
33] showed that the CS divergence between the above GLMB densities is given by:
where
SMC implementation of the above is straightforward. If each density is approximated with the same particles but different weights, each inner product of the densities is calculated by summing all the products of corresponding weights in the two sets of particles.
CS Divergence-Based Sensor Control with Constraints
An important consideration that has been taken into account by Beard et al. [
33] and Gostar et al. [
45] is the practical constraints that may be applicable when choosing the optimal sensor control command
. Imagine an application in which there is a region in the state space that the sensor cannot be controlled to end up there. For instance, in a defense application, if the objects are enemy targets, the sensors cannot end up up close to any of the targets. For each control command
u, such a region can be denoted by
. In such a constrained sensor control problem, we want the region to be void (empty of any objects) with a very high probability called the “void probability”. For a given multi-object density
, the void probability for a region
S is defined as
For the purpose of sensor control, the void probability is computed with the pseudo-posterior density in mind. The work in [
45] suggests that, in multi-target tracking with LMB filters, implementation of sensor control with void probability constraint enables the control of sensors to be moved in desirable directions for maximizing the information gain, while keeping a safe distance from the targets. When the pseudo-posterior is of LMB form with parameters
, and each density
is approximated with particles and weights
, the void probability is derived as follows [
45]:
where
Taking the void probability constraint into account, the sensor control policy is turned into:
where
and
is the minimum void probability, a user-defined threshold that is very close to 1.
When a GLMB filter is being used for multi-object tracking, the void probability is formulated differently. Consider the pseudo-posterior associated with control command
u in which GLMB is characterized by:
Beard et al. [
33] show that the void probability in this case is given by:
In case of SMC implementation where each density
is approximated by particles and weights
, the above expression is simplified to:
In this case, the control policy is:
where
is given by Equation (
34) and
is the set of all control commands
for which the void probability calculated by (
41) is more than the user-defined minimum threshold
.
4.2. Task-Driven Sensor Control
The RFS-based sensor control methods, in general and task-driven sensor control approaches specifically, saw their beginnings in the works published by Mahler in 2003 [
3] and 2004 [
5], which provided the early investigations to devise a foundational basis for sensor management based on the RFS filtering framework. In the task-driven approach, the objective function is formulated as a cost function that directly depends on the tracking performance of the system, quantified by metrics such as error and cardinality variance.
4.2.1. Posterior Expected Number of Targets (PENT)
In 2003, Mahler [
3] showed that the Csiszár information-theoretic objective function and geometric functionals lead to tractable sensor management algorithms when used in conjunction with the multi-hypothesis correlator (MHC) filtering algorithms. In 2004, Mahler et al. [
5] proposed a “probabilistically natural” sensor management objective function called the posterior expected number of targets (PENT), constructed using an optimization strategy called “maxi-PIMS”. PENT was introduced for the control of sensors with a finite field-of-view (FoV), for the purpose of selecting the action that will maximize the posterior expected number of objects (cardinality) returned after updating the multi-object density. Hence, in the general sensor control framework shown in
Figure 2, PENT is implemented by maximizing the reward function:
Note that the term
is indeed the Expected A Posteriori (EAP) estimate of posterior cardinality, and could be replaced with the Maximum A Posterior (MAP) estimate, turning the sensor control policy into the general form of:
Although PENT was originally introduced and its objective function was further formulated for PHD and MHC filters [
3,
5], the above general control policy is applicable with any multi-object filter in place, including the JPDA, MHT, MB, LMB and GLMB filters. Here are some examples:
When a PHD filter with SMC implementation is used as the multi-object system, the above control policy is given by:
Assuming that a multi-Bernoulli filter or an LMB filter with SMC is in place, we have:
4.2.2. Cardinality Variance-Based Sensor Control
The PENT method is particularly useful when sensors have limited FoV. An alternative task-driven approach towards sensor control is to prioritize the accuracy of the resulting cardinality estimate rather than its mean. In this approach, the objective function is the following cost to be minimized:
Gostar et al. [
14,
15] derived this cost function for the applications where a multi-Bernoulli filter is used for multi-object tracking, as follows:
Similarly, with an LMB filter, the cost function is given by:
Hoang et al. [
13] proposed to use the maximum a posteriori (MAP) estimate of cardinality for variance calculations, i.e., to the following cost function:
where
is the MAP estimate of cardinality. With an LMB filter, they showed the cost function is given by:
where the MAP cardinality estimate is calculated as follows:
4.2.3. Posterior Expected Error of Cardinality and States (PEECS)
In 2015, Gostar et al. [
26] proposed a new cost function called Posterior Expected Error of Cardinality and States (PEECS) [
26] in which a linear combination of the normalized errors of the number of objects and their estimated states is considered as the cost function for sensor control,
where
and
denote the normalized variances of the cardinality and state estimates, respectively, and
is a user-defined constant to determine emphasis on accuracy of cardinality estimates versus the state estimates. The normalized variance is given by (
50) but divided by
, which is the maximum variance corresponding to the worst case where all probabilities of existence are 0.5,
The normalized variance of state estimates depends on the application and the variables included in the single-object state. Consider an application where the principal interest is in localization error in a 2D space. Let us assume that the state vector includes the
x- and
y-coordinates of the object, denoted by
and
, respectively. Consider a multi-Bernoulli filter being used as the MOT, and implemented using the SMC method in which the
-th Bernoulli component of the pseudo posterior
is parameterized by its probability of existence
and its density approximated by particles and weights
where the location components of the particle
are denoted by
and
. Then, the error variance associated with the
-th Bernoulli component is given by:
where
and
are the variances of
x-coordinate and
y-coordinate estimates of the possible object associated with the
-the Bernoulli component, and are given by:
The maximum of the above variances occur when all particle weights are equal to
, which leads to:
and the normalized state variance for the
-th Bernoulli component is calculated by:
The total state variance (which is still normalized) is given by:
4.3. Selective Sensor Control
All the methods discussed so far deal with the sensor control problem for multi-target tracking of a group of targets or a target ensemble. The labeled random finite set filters such as LMB and GLMB filters allow for tracking the target trajectories along with estimating the number of targets and their states within the stochastic filtering scheme. Therefore, with such filters used, such as the MOT, one can control the sensor(s) towards acquiring most useful measurements for the purpose of tracking the targets of interest (ToIs), which are those with specific labels of interest.
4.3.1. Maximum Confidence in Existence
Panicker et al. [
16] investigated how the target label information returned by an LMB filter can be effectively used for sensor control focused on some ToIs. An intuitive solution is also proposed in [
16] for scenarios in which one or more of the ToIs temporarily disappear from the tracking scene. Their method is a task-driven sensor control routine with a cost function that is dependent on the pseudo-updated states of only the ToIs.
This approach is based on maximizing the expected confidence of the filter’s inference on the existence of the ToIs. After the pseudo-update of the LMB density, the filter returns an estimate of the total number of existing ToIs, given by the cardinality mean
where
is the set of labels of interest and
is the pseudo-updated probability of existence for the object with label
ℓ. The confidence in this estimate is inversely related to the variance of cardinality. Therefore, to maximize the confidence, the following cost function is minimized:
4.3.2. Selective-PEECS
As an alternative selective sensor control solution, the Selective-PEECS approach [
16] employs the PEECS cost function [
26]. The selective-PEECS cost function is similar to PEECS in Equation (
55) with the difference that the normalized variances of cardinality and state terms are computed by summing over the labels of interest. More specifically, we have:
4.4. Extension to Multi-Sensor Control
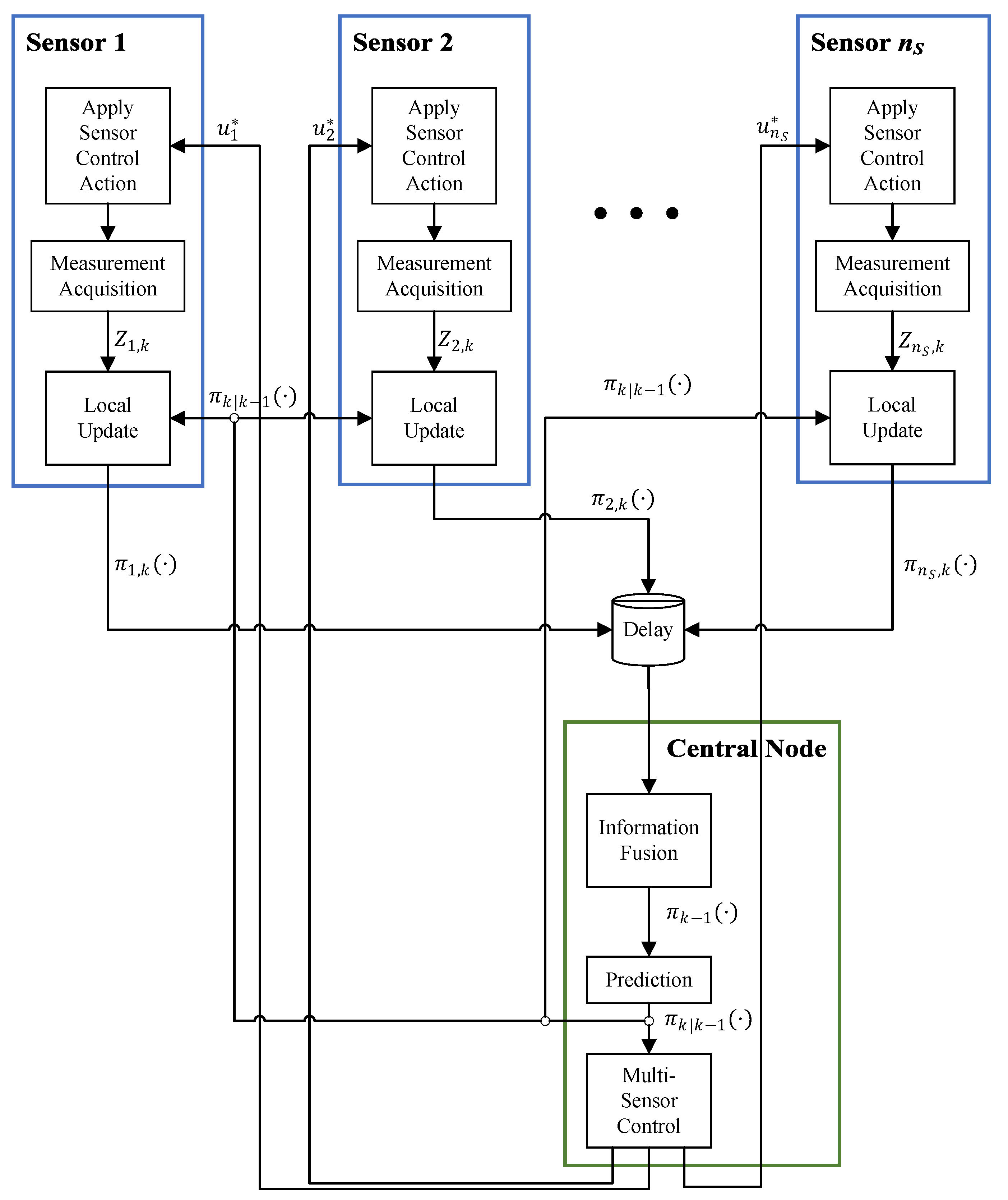
Most of the work discussed earlier uses a single sensor control strategy for tracking multiple targets. In a multi-sensor scenario, the control solution is straightforward if the sensors form a centralized network. Consider
sensor nodes that are all connected to a central node as shown in
Figure 4. At each time
k, in each node
, the sensor receives a command
from the central node and changes its state (e.g., moves, spins, changes its gain and so on) accordingly. Then, it generates a measurement set of detections
that is locally used to run the update step of a multi-object filter. All of the local posteriors,
are then communicated back to the central node.
In the central node, the received local posteriors are fused and the resulting multi-object density is used to run the prediction step of the multi-object filter centrally. The predicted prior is then used for two purposes: (i) it is communicated back to each sensor node for the local update to run in the next time, and (ii) it is input to a multi-sensor control routine that generates an -tuple multi-sensor control command and sends each control command to the corresponding sensor node.
Algorithm 1 shows the most straightforward process that can be implemented for the “Multi-Sensor Control” block in
Figure 4. In the first step, a multi-object estimate
is computed from the prior. It is then used to calculate PIMS for each sensor node after being hypothetically actuated based on each possible control command. The PIMS is then used to run a pseudo-update step in the central node, which results in a pseudo-posterior for each node and each control command.
After all the possible pseudo-posteriors are computed for all sensor nodes and all control commands, for each -tuple multi-sensor control command all the corresponding pseudo-posteriors at different sensor nodes are fused, and the resulting pseudo-posterior is used to compute the objective function. In Algorithm 1, it is a reward function that is maximized to return the optimal multi-sensor control command .
Note: The reward (or cost) function used in line 11 of Algorithm 1 can be any of the functions discussed in this section, divergence-based or task-driven or selective.
It is also important to note that the information fusion operation used in line 10 of Algorithm 1 must be the same operation that is used for fusion of real posteriors in the central node (the “Information Fusion” block in
Figure 4). One of the widely used methods for fusion of multiple posteriors is the Generalized Covariance Intersection (GCI) rule that is employed for consensus-based fusion of multiple multi-object densities of various forms. It has been used for fusion of Poisson multi-object posteriors of multiple local PHD filters [
48], multi-Bernoulli densities of local multi-Bernoulli filters [
49], i.d.d. clusters densities of several CPHD filters [
50] and GLMB densities of several local Vo–Vo filters or LMB densities of several LMB filters [
51].
| Algorithm 1 Step-by-step operations that run inside the multi-sensor control block in Figure 4. |
- 1:
functionMulti_Sensor_Control() - 2:
Estimate() - 3:
for do - 4:
for do - 5:
PIMS() - 6:
Update() - 7:
end for - 8:
end for - 9:
for do - 10:
Fuse() - 11:
Reward() - 12:
end for - 13:
- 14:
return - 15:
end function
|
ARAPP (Accelerated Ratio of Absence to Presence Probability) Method
As a multi-sensor extension to the selective sensor control solution discussed earlier, the ARAPP approach [
52] employs the RAPP (Ratio of Absence to Presence Probability) cost function [
52]. This method optimizes a closed-form objective function called RAPP which can be calculated directly after the prediction step in the central node of the sensor network. The new cost function is computed before the pseudo-update operations, and hence a large amount of computation is saved. The simulation results in the paper suggest that the proposed methods lead to significant improvements in terms of tracking accuracy of objects of interest, compared to using the non-selective sensor control methods. Numerical experiments indicate that the proposed method significantly outperforms the common non-selective sensor control methods. When compared to selective-PEECS, the state-of-the-art method for selective sensor control, it is seen to perform similarly in terms of the mean-square-error (MSE) of tracking of the targets of interest, but is significantly (eight times) faster than the selective-PEECS method, which suggests a substantial reduction in the computational overhead.
5. Comparative Simulation Results
This section presents a few samples of recent works in which the performance of various sensor control algorithms are compared through simulations that involve multiple manoeuvring targets. In all the simulations, the single target state includes the location coordinates and speeds of the target, i.e.,
Each target randomly moves from time
to
k according to
where
and
and we have:
in which
T is the sampling time, and
is the noise power.
A controllable sensor is used to detect the targets and return their range and bearing angles in a surveillance area. The probability of the sensor detecting an object depends on the distance between the sensor and the object,
where
and
are the object and sensor locations, respectively. Conditional on detection, the measurement returned by the sensor is noisy, formulated by:
where
and
are range and bearing measurement noise, and both normally distributed with zero mean but different and varying variances,
Similar to the probability of detection, the noise power terms are also dependent on the sensor-object distance:
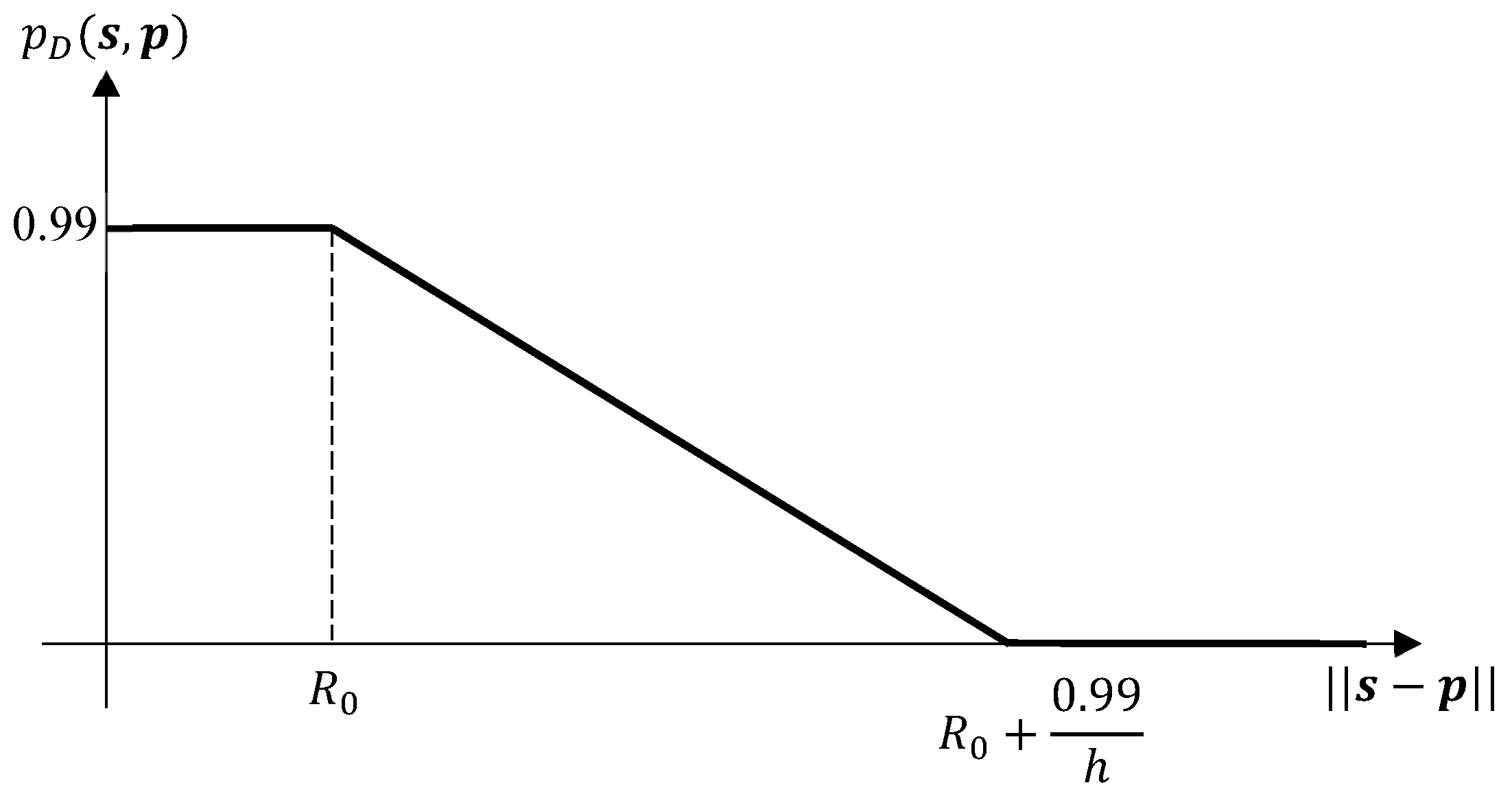
The target position is a function of the pulse transit time between the sensor and target and is proportional to the distance between them. In addition, the delay of received echo is proportional to the distance to target. In a recent work, Yong et al. [
53] state that, although the radar system errors are impacted by various factors such as the altitude of the sensor (radar), range and elevation between the sensor and target, the main factors of influence are the range and elevation. Importantly, the probability of detection decreases with the sensor-object distance (see
Figure 5), and the power of measurement noise increases with the sensor-object distance. Hence, in this case, the sensor is generally expected to return more accurate measurements (that include less noise and misdetections) and the sensor control solution is expected to drive the sensor towards the centre of all objects as they manoeuvre.
The above scenario and models for target motion and measurement uncertainties is one of the most common scenarios considered for performance evaluation in the sensor control literature.
Table 2 shows a list of such methods and the scenarios considered in them.
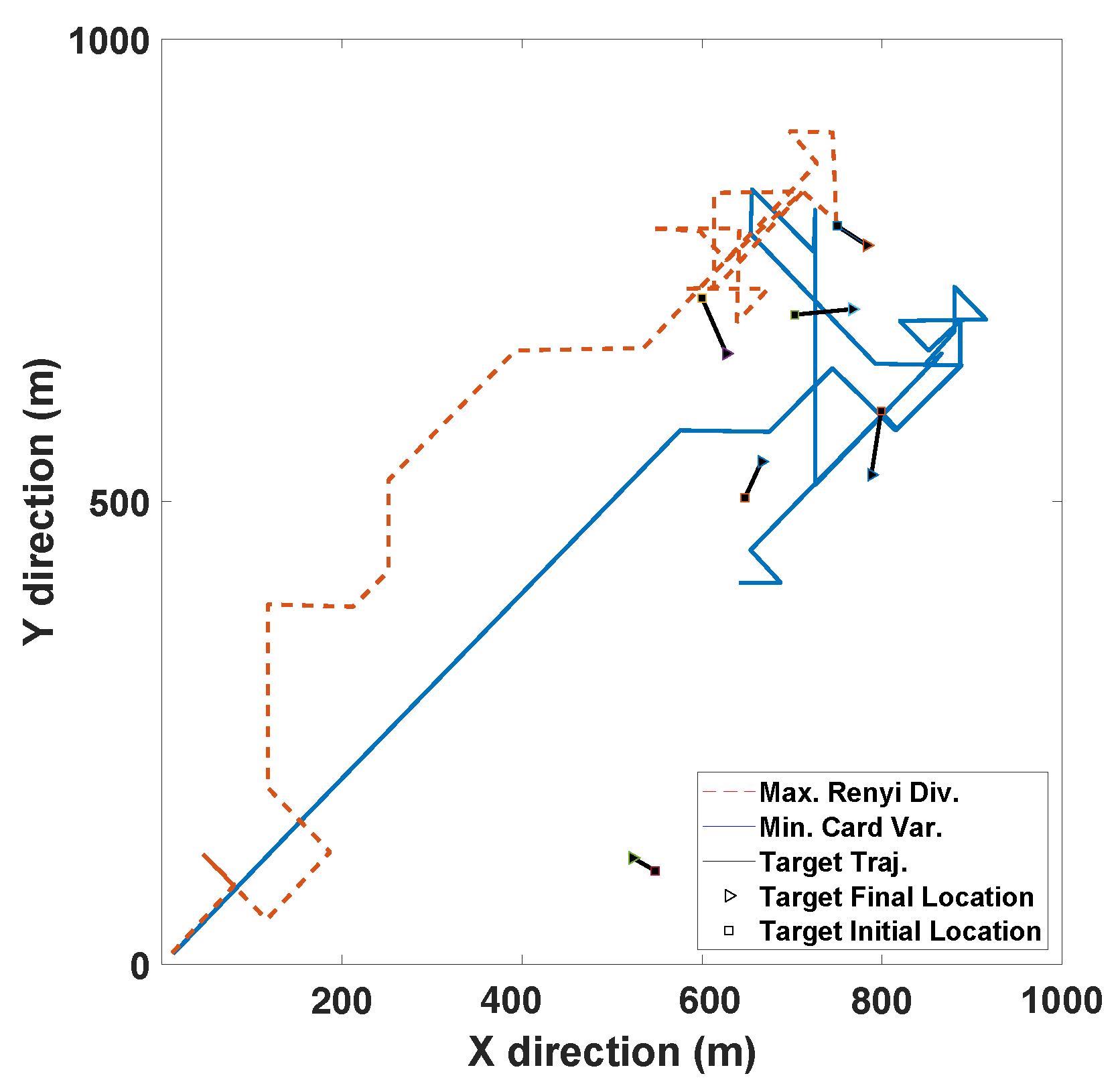
Figure 6 illustrates the typical resultant sensor trajectories for Rényi divergence-based and the MAP cardinality variance-based sensor control strategies as reported by Hoang et al. [
32]. In their simulation, five targets manoeuvre in a 1000 m×1000 m surveillance area. The sensor starts from the origin, and at each time
k, its previous location
varies to one of the admissible locations in the following control command space:
In the experiment shown in
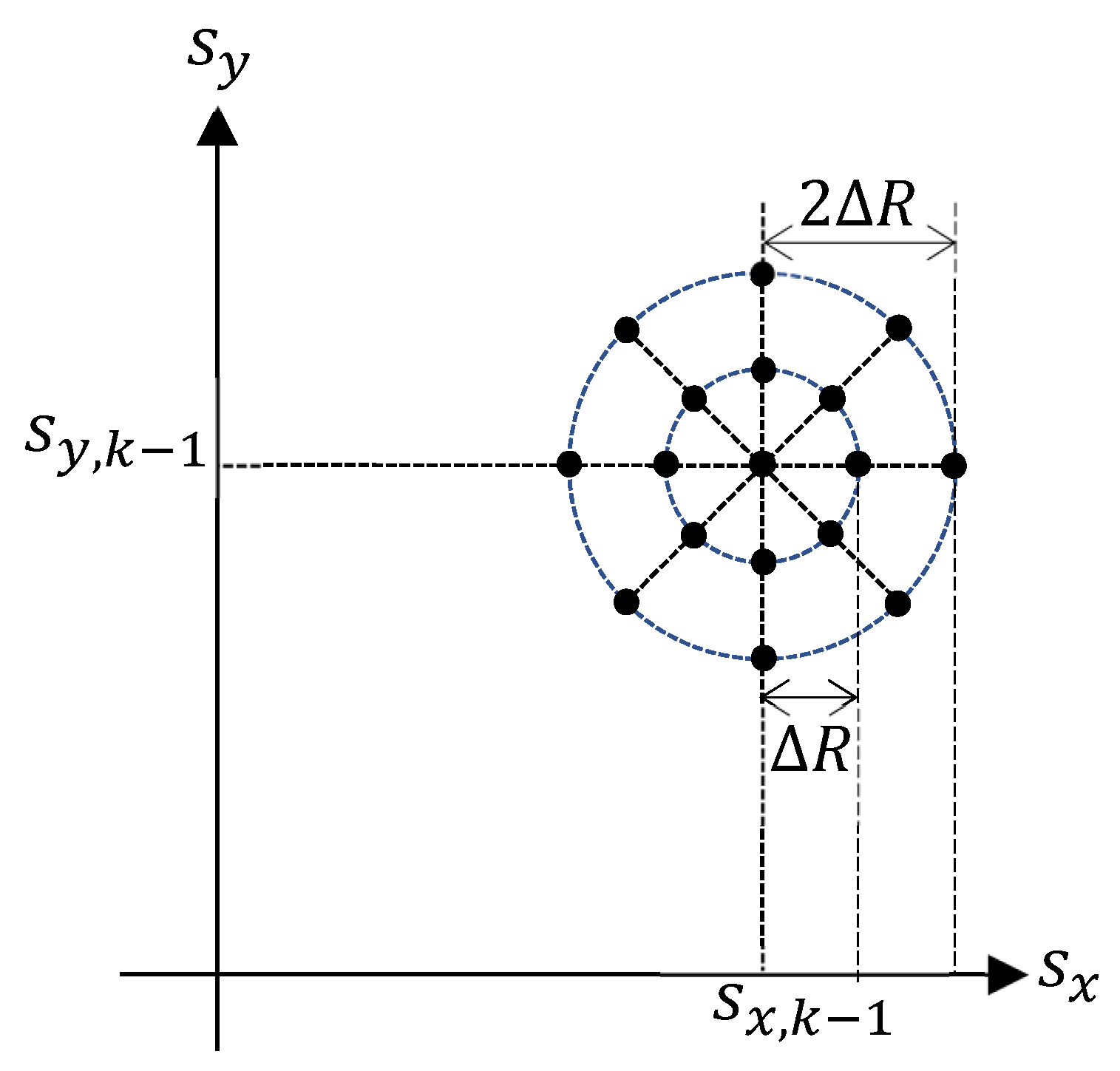
Figure 6, we have borrowed the parameters
m,
and
. All the admissible sensor movements from the location
are shown as solid black circles in
Figure 7. The parameters of the detection profile in Equation (
67) and measurement noise are chosen as:
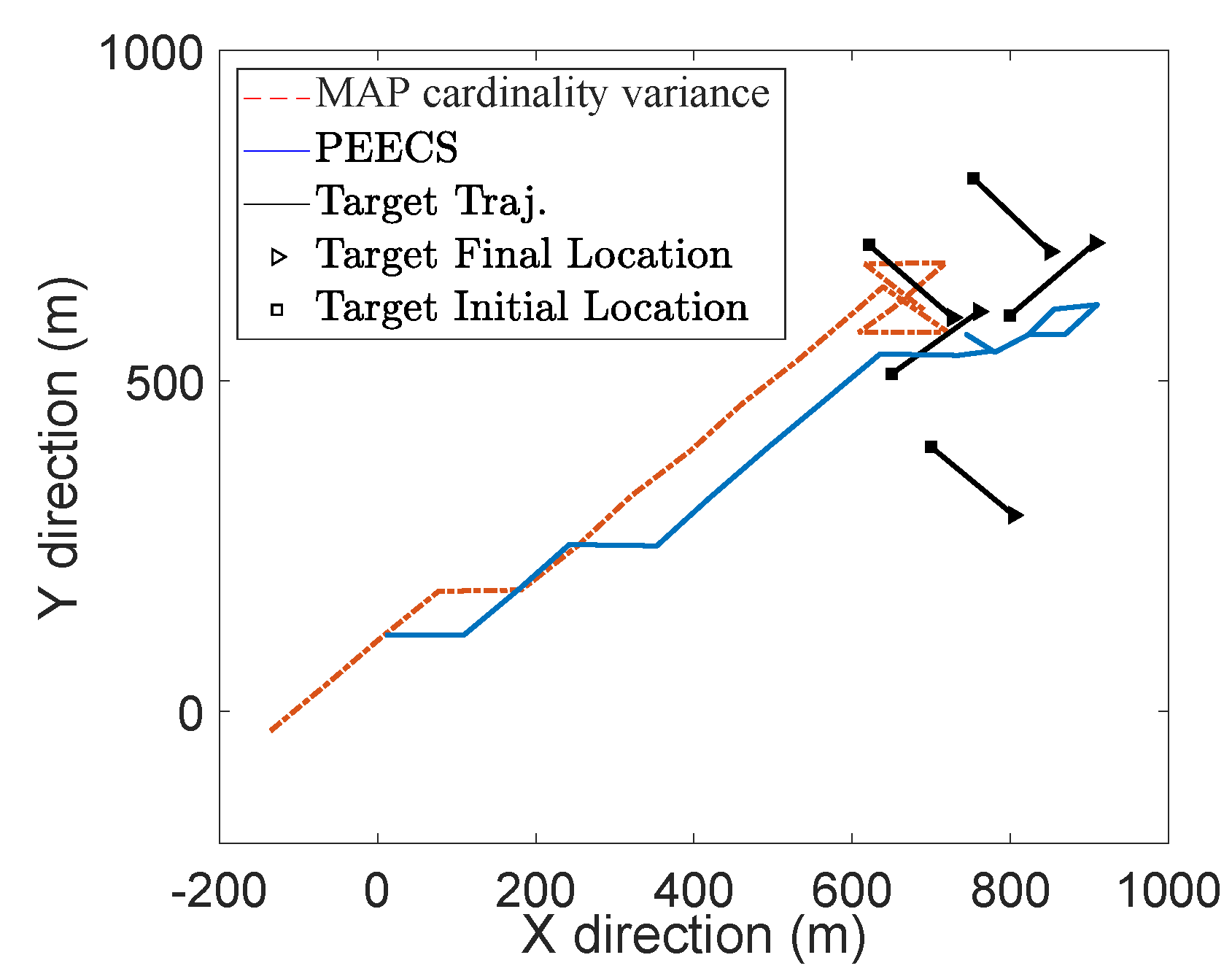
The task-driven PEECS method [
26] is compared with the MAP cardinality variance method [
32] and the resulting sensor locations are shown in
Figure 8.
Figure 9 compares the OSPA errors of PEECS and the Rényi divergence-based method suggested in [
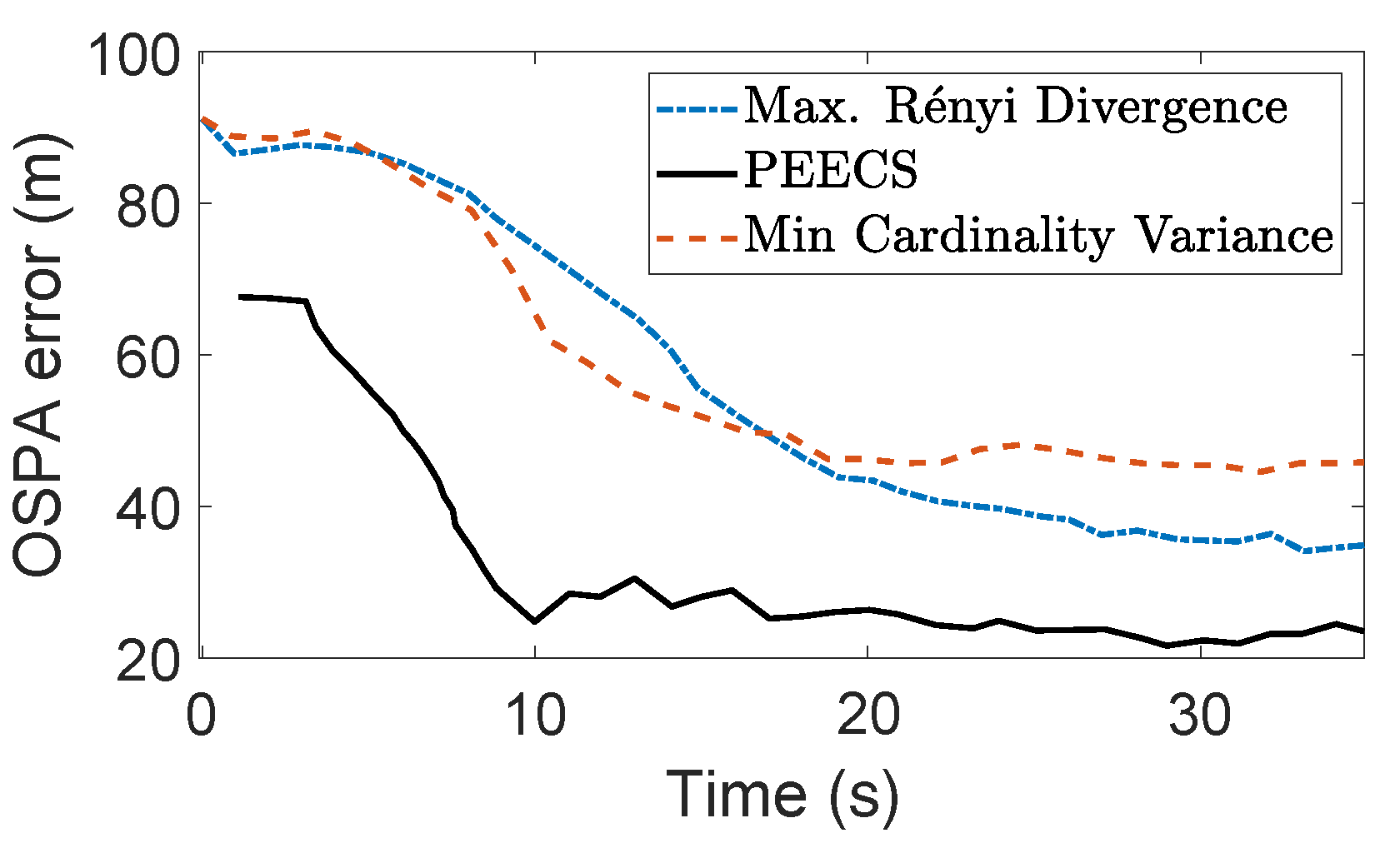
32]. As both cardinality and localization errors are considered in the cost function of PEECS, this method improves the sensor control performance for multi-target scenarios with high clutter. In
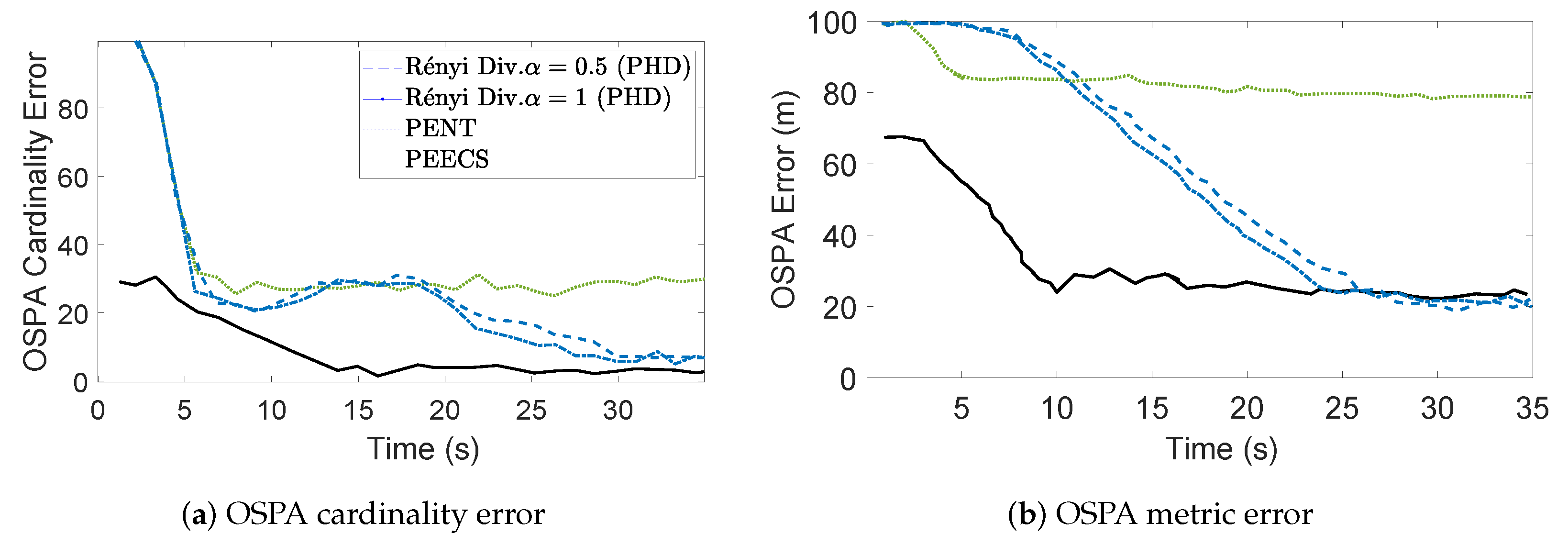
Figure 10, the estimation errors of PEECS sensor control method are compared to the PHD-based methods [
26]. Similarly, the OSPA errors returned by the sensor control method based on Cauchy–Schwarz divergence [
35] are compared to Rényi divergence-based sensor control [
11] as presented in
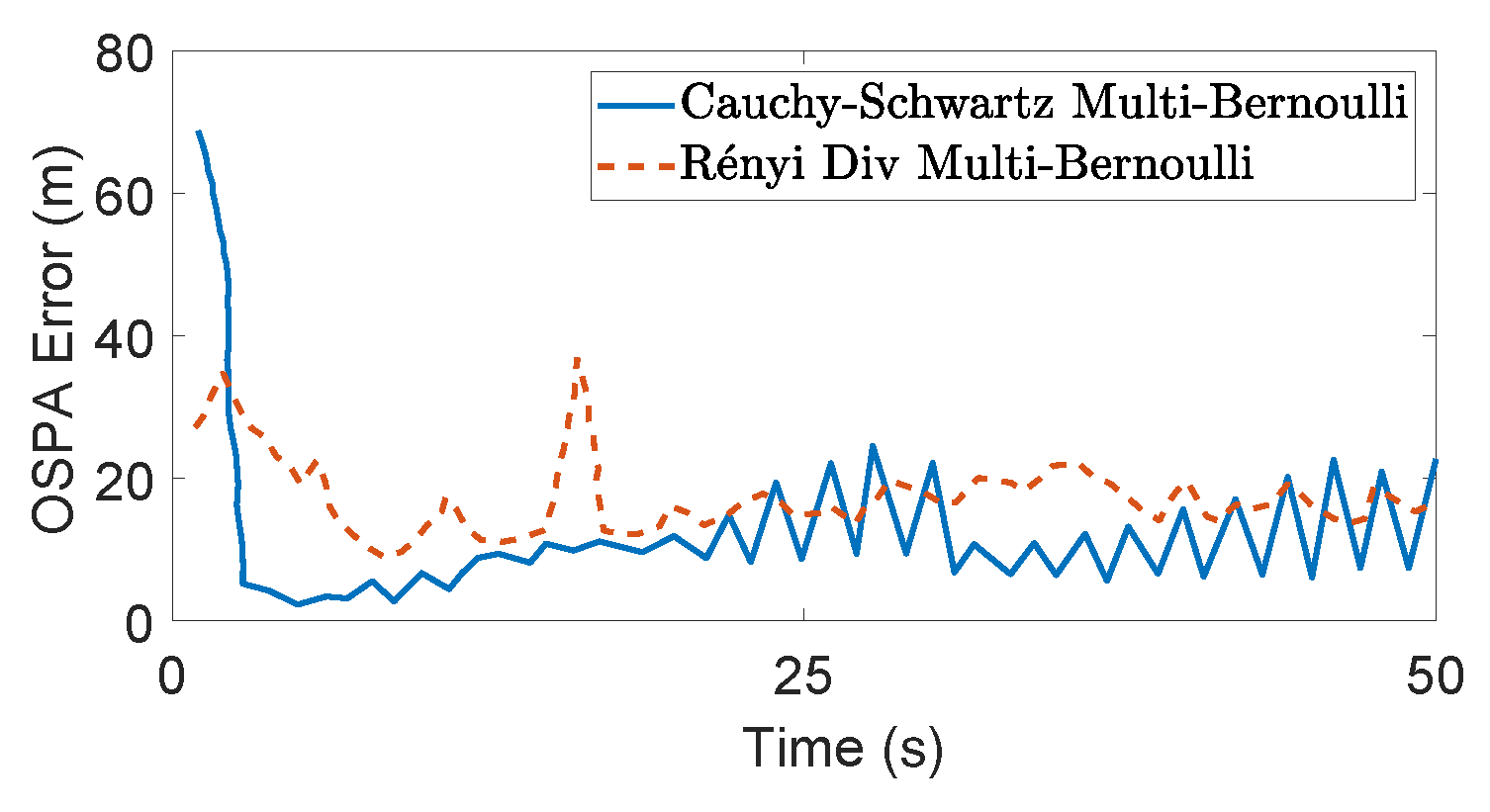
Figure 11.
Figure 12 and
Figure 13 show the simulation results borrowed from [
16] for a selective single-sensor multi-target scenario. While
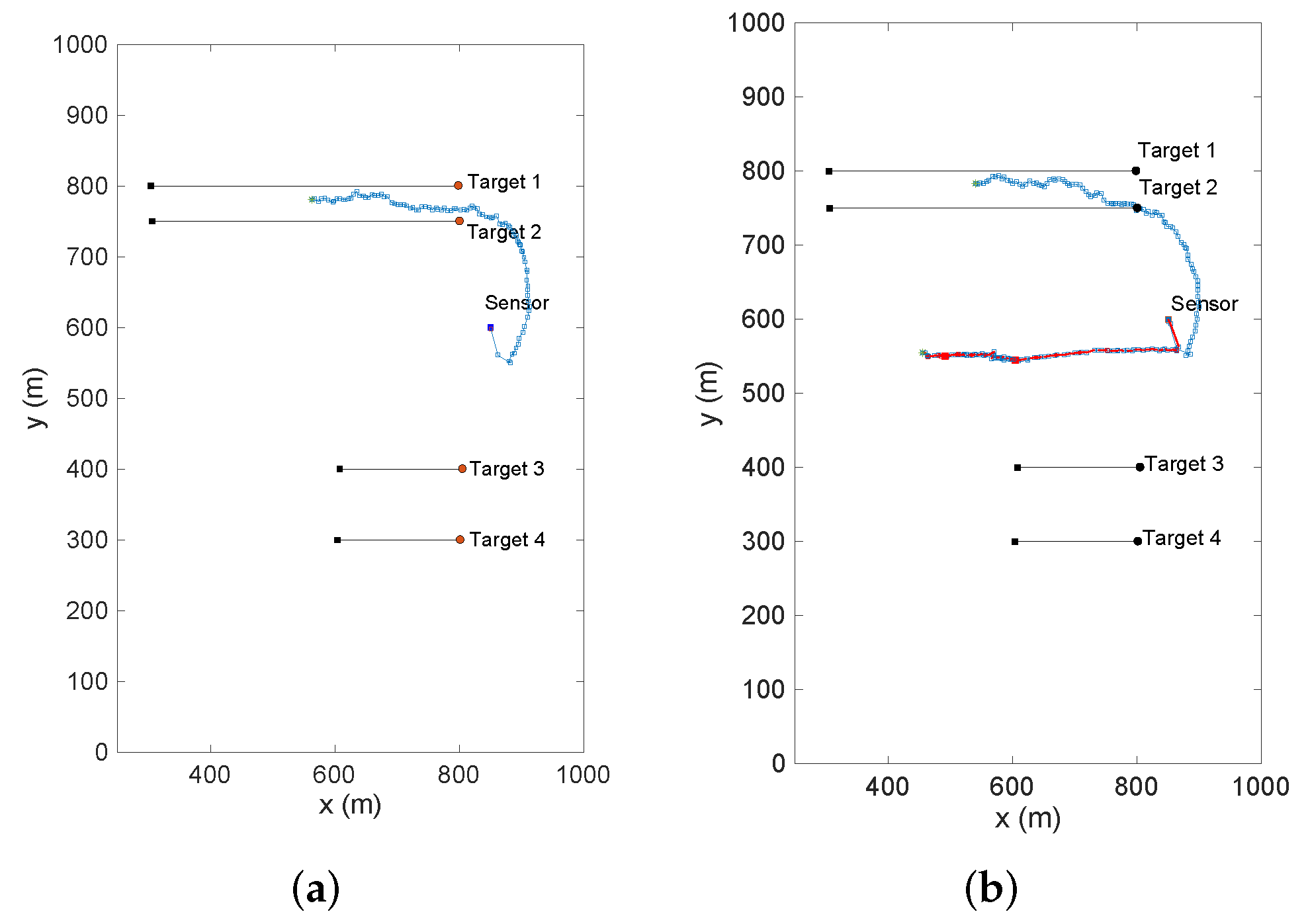
Figure 12a demonstrates the sensor path returned by the maximum confidence method,
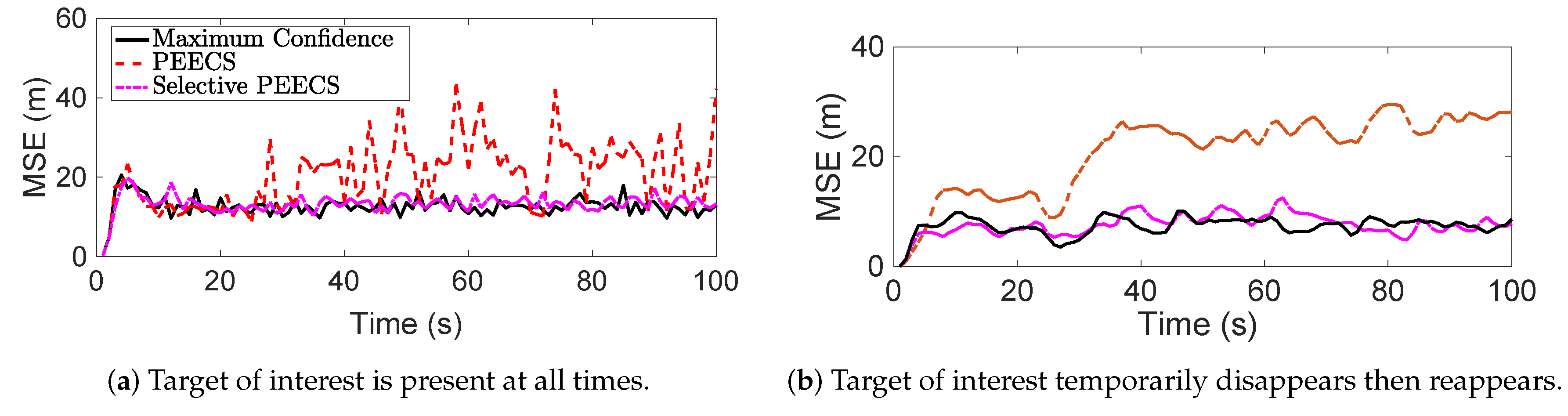
Figure 12b provides the sensor trajectories returned by the selective and non-selective PEECS sensor control methods. Comparing the trajectories, it is inferred that the selective sensor control methods definitely serve selective tracking applications better than the traditional non-selective methods.
Figure 13a provides the mean squared error (MSE) returned on tracking the ToIs in order to compare the performance of selective method with PEECS [
26], the non-selective sensor control routine.
Figure 13b demonstrates the results obtained for the case of disappearing target. It is shown in [
16] that tracking error for the ToIs is reduced and speed of computation is considerably increased, when selective sensor control is included.
6. Discussion on Performance Comparison
In this section, we provide a performance comparison for various methods considering the contributions made towards the sensor control. In the sensor control literature, performance enhancement is usually demonstrated in terms of reduction in tracking errors. The computational speed has not been a major focus for performance and comparison in the recent literature. Hence, this review covers the performance comparisons in terms of tracking accuracy in a comprehensive manner. However, acknowledging the importance of computation, we also provide a table for comparison of computational speed (
Table 3), as presented in the recent literature on selective sensor control methods [
52]. It compares the labelled RFS-based selective sensor control methods with a state-of-the-art non-selective sensor control method.
A comparative study of the Rényi divergence (information theoretic) and cardinality variance (task driven) approaches discussed by Hoang and Vo [
32] imply that, although both the control methods perform well in cases with high target observability, in specific cases where the observability is low, their performance degrades. In such scenarios, Rényi divergence performs better than the other, but the Cardinality variance method results in a smoother sensor trajectory, as observed from
Figure 6. On comparing the OSPA performance of these methods with PEECS sensor control, as discussed in [
26] and observed from
Figure 9, it is evident that PEECS exhibits better performance, primarily due to its structural emphasis on taking error terms into account that are similar to the terms that form the OSPA metric. PEECS performs similarly to the MAP cardinality variance cost function, differing in its use of variance of cardinality around the mean (statistical variance) instead of variance around the MAP estimate. In addition, errors in both the cardinality and state estimates impact the PEECS cost.
Figure 10a,b indicate that the OSPA errors of PEECS converge to a minimum faster than PENT and PHD-based Rényi divergence methods.
Performance evaluation of these non-selective sensor control methods compared to selective control methods returns promising results for the tracking accuracy in terms of computational speed and performance metric (mean-squared error (MSE) of the state estimates of targets of interest). This is evident from
Figure 13, which clearly shows significant improvements in state estimation errors for the ToIs with the selective methods such as Maximum confidence and selective-PEECS compared to the non-selective PEECS method.
Considering computational speed, due to lack of a generic closed-form solution, Rényi divergence-based sensor control is usually implemented with
set particle approximations and hence is substantially more computationally expensive than task driven solutions such as PEECS whose cost functions are computationally effective. Indeed, PEECS sensor control is shown to be at least four times faster than the PHD-based sensor control methods [
12]. The closed form solution for Cauchy–Schwarz divergence proposed by Gostar et al. [
35] (in a multi-Bernoulli filtering scheme) seems to outperform the computational speed of the information-theoretic sensor control methods, while maintaining comparable tracking accuracy. In
Figure 11, the OSPA errors returned by the sensor control method based on Cauchy–Schwarz divergence [
35] is shown in comparison to the Rényi divergence-based sensor control [
11], as reported in [
35]. It can be inferred from
Table 3 that, in a multi-sensor scenario, the ARAPP sensor control method is very efficient, making it 36 times faster than the non-selective PEECS, and eight times faster than the selective-PEECS method.
7. Conclusions and Future Directions
One of the most significant challenges with multi-sensor control is its computational cost due to the need for search in the multi-dimensional sensor command space . Indeed, looking at lines 9–12 of Algorithm 1, for each -tuple , a fusion operation step followed by a reward calculation step need to be conducted. Algorithm 1 presents the most straightforward approach which involves an excessive search for the optimal multi-sensor control command. For practical feasibility, especially in real-time applications, there is a significant interest in alternative accelerated search routines.
Wang et al. [
36] have recently introduced a guided search method to solve the multi-dimensional optimization problem inherent to multi-sensor control using an accelerated scheme inspired by the Coordinate Descent Method (CDM) [
36]. This results in significant improvement in the runtime of the algorithm and also its real-time feasibility in the presence of multiple sensors. However, there is still a large room for improvement, as the CDM does not exploit the multi-object density and PIMS information at its core and is merely an accelerated search over the multi-dimensional space.
The computational cost can also be improved by devising new ways to calculate the objective function without the need to go through the pseudo-update steps of the filter, which can be very expensive. The main point of sensor control is due to the sensor’s detection profile being dependent on the sensor state. Therefore, this dependency might be formulated directly in a closed-form approximate derivation for the objective function, so that we can calculate it without the need to run the pseudo-update step for each admissible (multi-)sensor control command.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}